mirror of
https://github.com/ByteByteGoHq/system-design-101.git
synced 2026-06-14 21:31:17 -04:00
Adds ByteByteGo guides and links (#106)
This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
This commit is contained in:
{kind=link}
|
Before Width: | Height: | Size: 984 KiB After Width: | Height: | Size: 984 KiB |
@@ -2,6 +2,7 @@
|
|||||||
*.epub
|
*.epub
|
||||||
__pycache__/
|
__pycache__/
|
||||||
*.py[cod]
|
*.py[cod]
|
||||||
|
.idea
|
||||||
|
|
||||||
# C extensions
|
# C extensions
|
||||||
*.so
|
*.so
|
||||||
@@ -41,6 +42,8 @@ htmlcov/
|
|||||||
nosetests.xml
|
nosetests.xml
|
||||||
coverage.xml
|
coverage.xml
|
||||||
|
|
||||||
|
node_modules
|
||||||
|
|
||||||
# Translations
|
# Translations
|
||||||
*.mo
|
*.mo
|
||||||
*.pot
|
*.pot
|
||||||
|
|||||||
@@ -13,7 +13,3 @@ Thank you for your interest in contributing! Here are some guidelines to follow
|
|||||||
### GitHub Pull Requests Docs
|
### GitHub Pull Requests Docs
|
||||||
|
|
||||||
If you are not familiar with pull requests, review the [pull request docs](https://help.github.com/articles/using-pull-requests/).
|
If you are not familiar with pull requests, review the [pull request docs](https://help.github.com/articles/using-pull-requests/).
|
||||||
|
|
||||||
## Translations
|
|
||||||
|
|
||||||
Refer to [TRANSLATIONS.md](translations/TRANSLATIONS.md)
|
|
||||||
|
|||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'AI and Machine Learning'
|
||||||
|
description: 'Learn the basics of AI and Machine Learning, how they work, and some real-world applications with visual illustrations.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/brain.png'
|
||||||
|
sort: 120
|
||||||
|
---
|
||||||
|
|
||||||
|
AI and Machine Learning are two of the most popular technologies in the tech industry. They are used in various applications such as recommendation systems, image recognition, natural language processing, and more. In this guide, we will explore the basics of AI and Machine Learning, how they work, and some real-world applications.
|
||||||
@@ -0,0 +1,11 @@
|
|||||||
|
---
|
||||||
|
title: 'API and Web Development'
|
||||||
|
description: 'Learn how APIs enable web development by providing standardized protocols for data exchange between different parts of web applications.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/api.png'
|
||||||
|
sort: 100
|
||||||
|
---
|
||||||
|
|
||||||
|
Web development involves building websites and applications by combining frontend UI, backend logic, and databases. APIs are the fundamental building blocks that enable these components to communicate effectively.
|
||||||
|
|
||||||
|
APIs provide standardized protocols for data exchange between different parts of web applications. Using technologies like REST and GraphQL, APIs allow integration of services, database operations, and interactive features while keeping system components cleanly separated.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Caching & Performance'
|
||||||
|
description: 'Learn to improve the performance of your system by caching data with these visual guides.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/order.png'
|
||||||
|
sort: 150
|
||||||
|
---
|
||||||
|
|
||||||
|
Caching is a technique that stores a copy of a given resource and serves it back when requested. When a web server renders a web page, it stores the result of the page rendering in a cache. The next time the web page is requested, the server serves the cached page without re-rendering the page. This process reduces the time needed to generate the web page and reduces the load on the server.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Cloud & Distributed Systems'
|
||||||
|
description: 'Learn the fundamental concepts, best practices, and real-world examples of cloud computing and distributed systems.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/cloud.png'
|
||||||
|
sort: 180
|
||||||
|
---
|
||||||
|
|
||||||
|
Cloud computing and distributed systems are the backbone of modern software architecture. They enable us to build scalable, reliable, and high-performance systems. This category covers the fundamental concepts, best practices, and real-world examples of cloud computing and distributed systems.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Computer Fundamentals'
|
||||||
|
description: 'Understanding computer fundamentals is essential for software engineers. These guides cover the topics that are fundamental to computer science and software engineering and will help you understand certain system design aspects better.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/laptop.png'
|
||||||
|
sort: 220
|
||||||
|
---
|
||||||
|
|
||||||
|
Understanding computer fundamentals is essential for software engineers. These guides cover the topics that are fundamental to computer science and software engineering and will help you understand certain system design aspects better.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Database and Storage'
|
||||||
|
description: 'Understand the different types of databases and storage solutions and how to choose the right one for your application.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/database.png'
|
||||||
|
sort: 130
|
||||||
|
---
|
||||||
|
|
||||||
|
Databases are the backbone of most modern applications since they store and manage the data that powers the application. There are many types of databases, including relational databases, NoSQL databases, in-memory databases, and key-value stores. Each type of database has its own strengths and weaknesses, and the best choice depends on the specific requirements of the application.
|
||||||
@@ -0,0 +1,11 @@
|
|||||||
|
---
|
||||||
|
title: 'DevOps and CI/CD'
|
||||||
|
description: 'Learn all about DevOps, CI/CD, and how they can help you deliver software faster and more reliably. Understand the best practices and tools to implement DevOps and CI/CD in your organization.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/refresh.png'
|
||||||
|
sort: 200
|
||||||
|
---
|
||||||
|
|
||||||
|
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops). It aims to shorten the systems development life cycle and provide continuous delivery with high software quality. DevOps is complementary with Agile software development; several DevOps aspects came from Agile methodology.
|
||||||
|
|
||||||
|
CI/CD stands for Continuous Integration and Continuous Delivery. CI/CD is a method to frequently deliver apps to customers by introducing automation into the stages of app development. The main concepts attributed to CI/CD are continuous integration, continuous delivery, and continuous deployment.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'DevTools & Productivity'
|
||||||
|
description: 'Guides on developer tools and productivity techniques to help you become more efficient in your daily work.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/supplement-bottle.png'
|
||||||
|
sort: 170
|
||||||
|
---
|
||||||
|
|
||||||
|
Developer and productivity tools are essential for software engineers to build, test, and deploy software. This collection of guides covers a wide range of tools and techniques to help you become more productive and efficient in your daily work.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'How it Works?'
|
||||||
|
description: 'Go deep into the internals of how things work with these visual guides ranging from OAuth2 to how the internet works.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/question-mark.png'
|
||||||
|
sort: 190
|
||||||
|
---
|
||||||
|
|
||||||
|
Learning how things work is a great way to understand the world around us. This collection of guides will help you understand how things work in the world of system design.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Payment and Fintech'
|
||||||
|
description: 'Explore the architecture of a payment system and a fintech system. Look at the real-world examples of payment systems like PayPal, Stripe, and Square.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/medal.png'
|
||||||
|
sort: 160
|
||||||
|
---
|
||||||
|
|
||||||
|
Payment and Fintech are two of the most popular categories in system design interviews. In these guides, we will explore the architecture of a payment system and a fintech system.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Real World Case Studies'
|
||||||
|
description: 'Understand how popular tech companies have evolved over the years. Dive into case studies of companies like Twitter, Netflix, Uber and more.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/earth-planet.png'
|
||||||
|
sort: 110
|
||||||
|
---
|
||||||
|
|
||||||
|
Real-world case studies are a great way to learn about the architecture, design, and scalability of popular tech companies. Dive into these case studies to understand how companies like Twitter, Netflix, Uber and more have evolved over the years.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Security'
|
||||||
|
description: 'Guides on security concepts and best practices for system design. Learn how to protect your system from unauthorized access, data breaches, and other security threats.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/lock.png'
|
||||||
|
sort: 210
|
||||||
|
---
|
||||||
|
|
||||||
|
Security is a critical aspect of system design. It is essential to protect the system from unauthorized access, data breaches, and other security threats. In this set of guides, we will explore some of the key security concepts and best practices that you should consider when designing a system.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Software Architecture'
|
||||||
|
description: 'Learn about software architecture, the process of converting software characteristics such as flexibility, scalability, feasibility, reusability, and security into a structured solution that meets the technical and the business expectations.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/image.png'
|
||||||
|
sort: 160
|
||||||
|
---
|
||||||
|
|
||||||
|
Software architecture is the process of converting software characteristics such as flexibility, scalability, feasibility, reusability, and security into a structured solution that meets the technical and the business expectations. It is the process of defining a structured solution that meets all the technical and operational requirements, while optimizing common quality attributes such as performance, security, and manageability.
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Software Development'
|
||||||
|
description: 'Visual guides to help you understand different aspects of software development including but not limited to software architecture, design patterns, and software development methodologies.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/code.png'
|
||||||
|
sort: 170
|
||||||
|
---
|
||||||
|
|
||||||
|
Software Development is the process of designing, coding, testing, and maintaining software. It is a systematic approach to developing software. Software development is a broad field that includes many different disciplines. Some of the most common disciplines in software development include:
|
||||||
@@ -0,0 +1,9 @@
|
|||||||
|
---
|
||||||
|
title: 'Technical Interviews'
|
||||||
|
description: 'Learn to ace technical interviews with coding challenges, system design questions, and interview tips.'
|
||||||
|
image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
|
||||||
|
icon: '/icons/tower.png'
|
||||||
|
sort: 140
|
||||||
|
---
|
||||||
|
|
||||||
|
Technical interviews are a critical part of the hiring process for software engineers. They are designed to test your problem-solving skills, coding abilities, and technical knowledge. In this category, you will find resources to help you prepare for technical interviews, including coding challenges, system design questions, and tips for acing the interview.
|
||||||
@@ -0,0 +1,44 @@
|
|||||||
|
---
|
||||||
|
title: "10 Books for Software Developers"
|
||||||
|
description: "A curated list of must-read books for software developers."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0023-10-books-every-software-engineer-should-read.png"
|
||||||
|
createdAt: "2024-02-28"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- "Software Development"
|
||||||
|
- "Books"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## General Advice
|
||||||
|
|
||||||
|
* **The Pragmatic Programmer** by Andrew Hunt and David Thomas
|
||||||
|
|
||||||
|
* **Code Complete** by Steve McConnell: Often considered a bible for software developers, this comprehensive book covers all aspects of software development, from design and coding to testing and maintenance.
|
||||||
|
|
||||||
|
## Coding
|
||||||
|
|
||||||
|
* **Clean Code** by Robert C. Martin
|
||||||
|
|
||||||
|
* **Refactoring** by Martin Fowler
|
||||||
|
|
||||||
|
## Software Architecture
|
||||||
|
|
||||||
|
* **Designing Data-Intensive Applications** by Martin Kleppmann
|
||||||
|
|
||||||
|
* **System Design Interview** (our own book :))
|
||||||
|
|
||||||
|
## Design Patterns
|
||||||
|
|
||||||
|
* **Design Patterns** by Eric Gamma and Others
|
||||||
|
|
||||||
|
* **Domain-Driven Design** by Eric Evans
|
||||||
|
|
||||||
|
## Data Structures and Algorithms
|
||||||
|
|
||||||
|
* **Introduction to Algorithms** by Cormen, Leiserson, Rivest, and Stein
|
||||||
|
|
||||||
|
* **Cracking the Coding Interview** by Gayle Laakmann McDowell
|
||||||
@@ -0,0 +1,25 @@
|
|||||||
|
---
|
||||||
|
title: '10 Essential Components of a Production Web Application'
|
||||||
|
description: 'Explore 10 key components for building robust web applications.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0395-typical-architecture-of-a-web-application.png'
|
||||||
|
createdAt: '2024-02-20'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- Web Architecture
|
||||||
|
- System Design
|
||||||
|
---
|
||||||
|
|
||||||
|
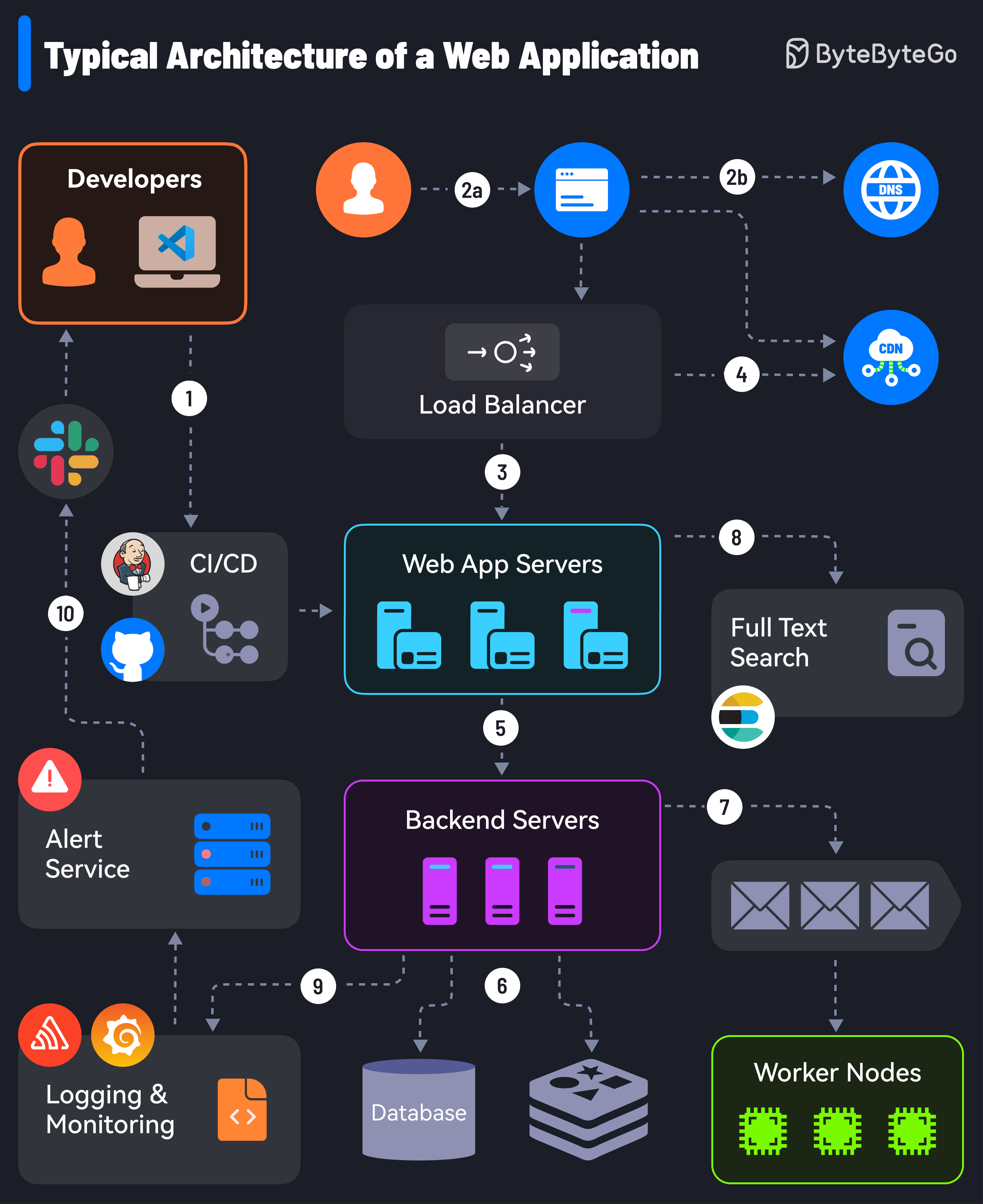
|
||||||
|
|
||||||
|
1. It all starts with CI/CD pipelines that deploy code to the server instances. Tools like Jenkins and GitHub help over here.
|
||||||
|
2. The user requests originate from the web browser. After DNS resolution, the requests reach the app servers.
|
||||||
|
3. Load balancers and reverse proxies (such as Nginx & HAProxy) distribute user requests evenly across the web application servers.
|
||||||
|
4. The requests can also be served by a Content Delivery Network (CDN).
|
||||||
|
5. The web app communicates with backend services via APIs.
|
||||||
|
6. The backend services interact with database servers or distributed caches to provide the data.
|
||||||
|
7. Resource-intensive and long-running tasks are sent to job workers using a job queue.
|
||||||
|
8. The full-text search service supports the search functionality. Tools like Elasticsearch and Apache Solr can help here.
|
||||||
|
9. Monitoring tools (such as Sentry, Grafana, and Prometheus) store logs and help analyze data to ensure everything works fine.
|
||||||
|
10. In case of issues, alerting services notify developers through platforms like Slack for quick resolution.
|
||||||
@@ -0,0 +1,56 @@
|
|||||||
|
---
|
||||||
|
title: "10 Good Coding Principles to Improve Code Quality"
|
||||||
|
description: "Improve code quality with these 10 essential coding principles."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0051-10-good-coding-principles.png"
|
||||||
|
createdAt: "2024-03-15"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- "coding practices"
|
||||||
|
- "software quality"
|
||||||
|
---
|
||||||
|
|
||||||
|
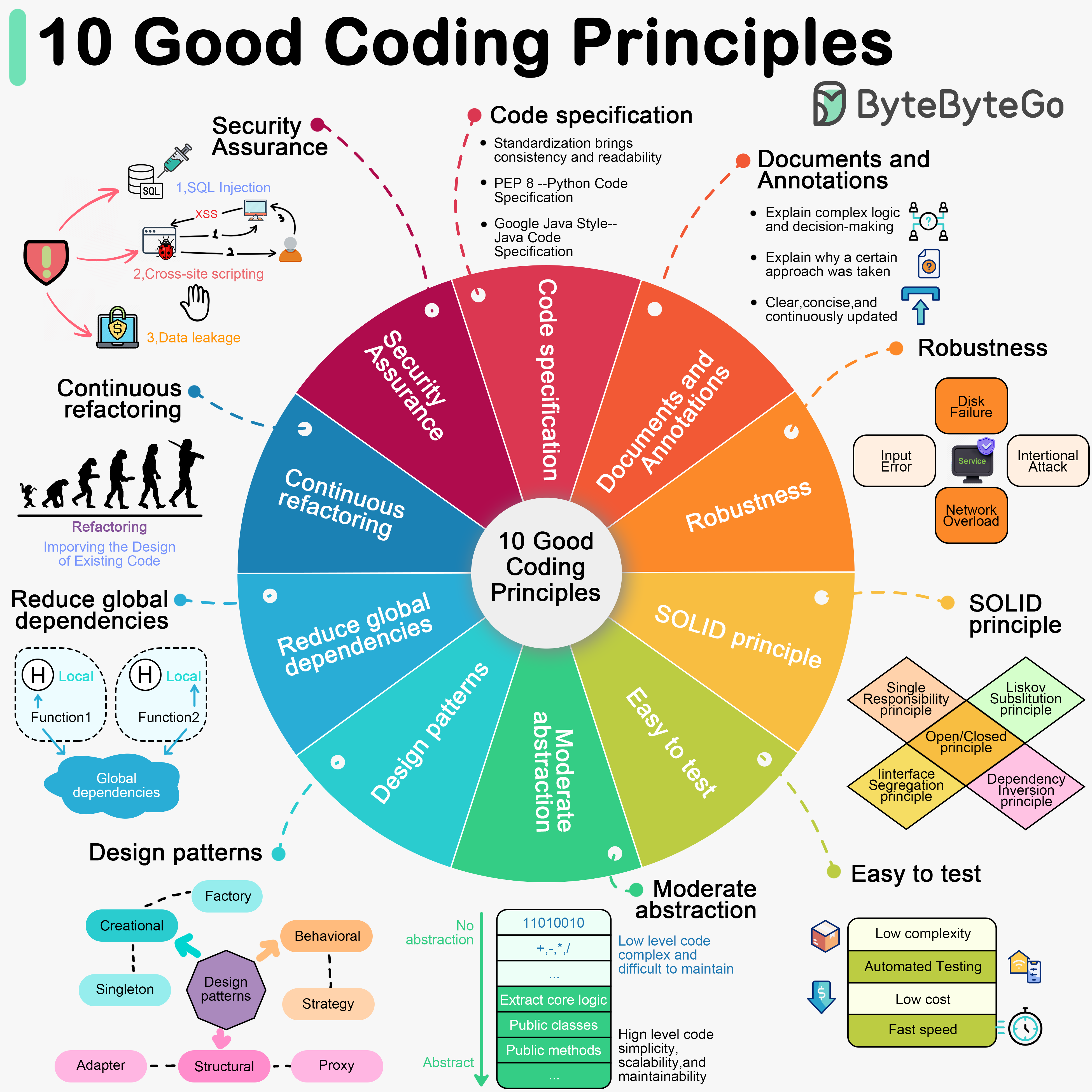
|
||||||
|
|
||||||
|
Software development requires good system designs and coding standards. We list 10 good coding principles in the diagram below.
|
||||||
|
|
||||||
|
## 1. Follow Code Specifications
|
||||||
|
|
||||||
|
When we write code, it is important to follow the industry's well-established norms, like “PEP 8”, “Google Java Style”. Adhering to a set of agreed-upon code specifications ensures that the quality of the code is consistent and readable.
|
||||||
|
|
||||||
|
## 2. Documentation and Comments
|
||||||
|
|
||||||
|
Good code should be clearly documented and commented to explain complex logic and decisions. Comments should explain why a certain approach was taken (“Why”) rather than what exactly is being done (“What”). Documentation and comments should be clear, concise, and continuously updated.
|
||||||
|
|
||||||
|
## 3. Robustness
|
||||||
|
|
||||||
|
Good code should be able to handle a variety of unexpected situations and inputs without crashing or producing unpredictable results. Most common approach is to catch and handle exceptions.
|
||||||
|
|
||||||
|
## 4. Follow the SOLID principle
|
||||||
|
|
||||||
|
“Single Responsibility”, “Open/Closed”, “Liskov Substitution”, “Interface Segregation”, and “Dependency Inversion” - these five principles (SOLID for short) are the cornerstones of writing code that scales and is easy to maintain.
|
||||||
|
|
||||||
|
## 5. Make Testing Easy
|
||||||
|
|
||||||
|
Testability of software is particularly important. Good code should be easy to test, both by trying to reduce the complexity of each component, and by supporting automated testing to ensure that it behaves as expected.
|
||||||
|
|
||||||
|
## 6. Abstraction
|
||||||
|
|
||||||
|
Abstraction requires us to extract the core logic and hide the complexity, thus making the code more flexible and generic. Good code should have a moderate level of abstraction, neither over-designed nor neglecting long-term expandability and maintainability.
|
||||||
|
|
||||||
|
## 7. Utilize Design Patterns, but don't over-design
|
||||||
|
|
||||||
|
Design patterns can help us solve some common problems. However, every pattern has its applicable scenarios. Overusing or misusing design patterns may make your code more complex and difficult to understand.
|
||||||
|
|
||||||
|
## 8. Reduce Global Dependencies
|
||||||
|
|
||||||
|
We can get bogged down in dependencies and confusing state management if we use global variables and instances. Good code should rely on localized state and parameter passing. Functions should be side-effect free.
|
||||||
|
|
||||||
|
## 9. Continuous Refactoring
|
||||||
|
|
||||||
|
Good code is maintainable and extensible. Continuous refactoring reduces technical debt by identifying and fixing problems as early as possible.
|
||||||
|
|
||||||
|
## 10. Security is a Top Priority
|
||||||
|
|
||||||
|
Good code should avoid common security vulnerabilities.
|
||||||
@@ -0,0 +1,38 @@
|
|||||||
|
---
|
||||||
|
title: "10 Key Data Structures We Use Every Day"
|
||||||
|
description: "Explore 10 essential data structures used daily in software development."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0024-10-data-structures-used-in-daily-life.png"
|
||||||
|
createdAt: "2024-03-03"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- "Data Structures"
|
||||||
|
- "Algorithms"
|
||||||
|
---
|
||||||
|
|
||||||
|
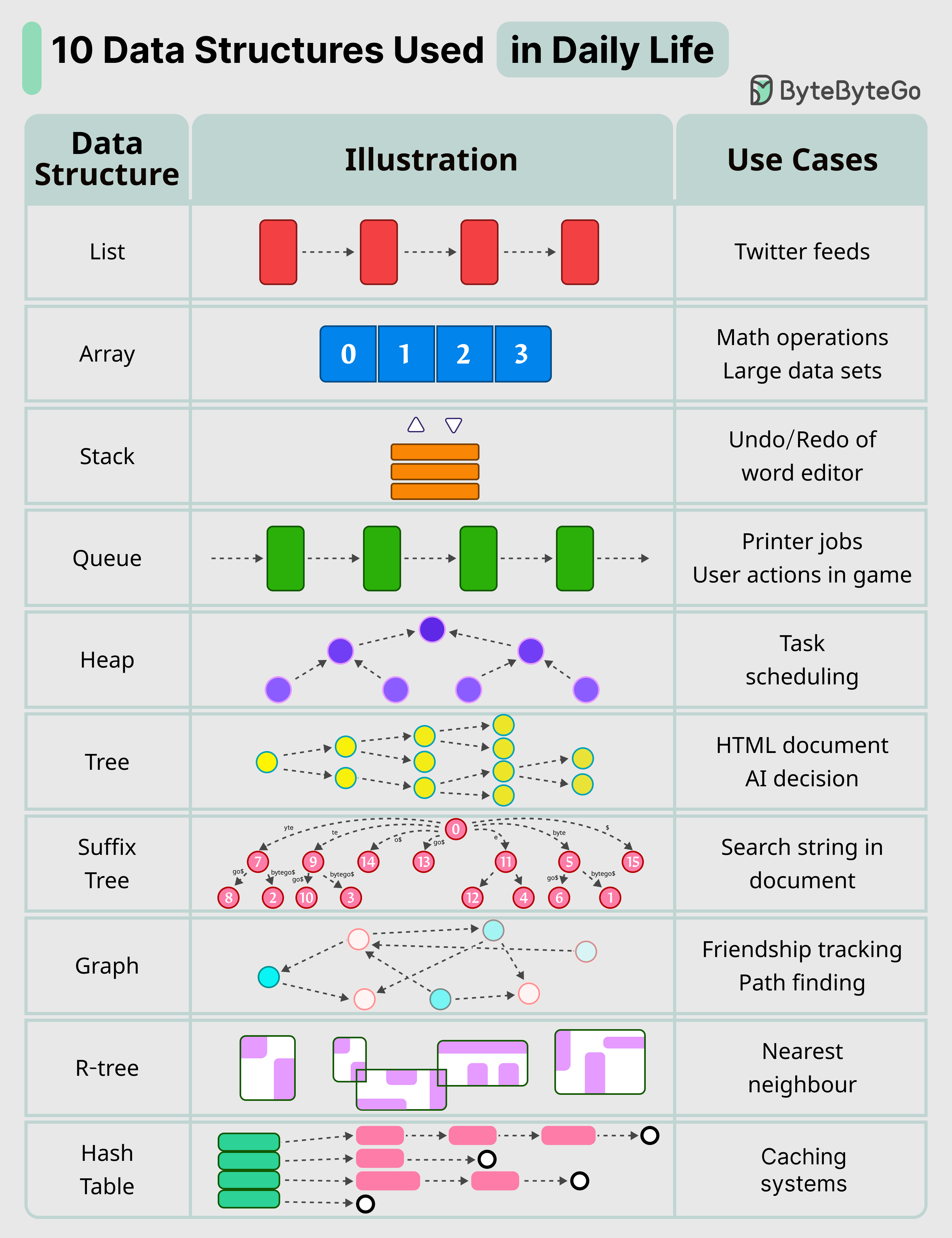
|
||||||
|
|
||||||
|
Here are 10 key data structures we use every day:
|
||||||
|
|
||||||
|
* **List**: Keep your Twitter feeds
|
||||||
|
|
||||||
|
* **Stack**: Support undo/redo of the word editor
|
||||||
|
|
||||||
|
* **Queue**: Keep printer jobs, or send user actions in-game
|
||||||
|
|
||||||
|
* **Hash Table**: Caching systems
|
||||||
|
|
||||||
|
* **Array**: Math operations
|
||||||
|
|
||||||
|
* **Heap**: Task scheduling
|
||||||
|
|
||||||
|
* **Tree**: Keep the HTML document, or for AI decision
|
||||||
|
|
||||||
|
* **Suffix Tree**: For searching string in a document
|
||||||
|
|
||||||
|
* **Graph**: For tracking friendship, or path finding
|
||||||
|
|
||||||
|
* **R-Tree**: For finding the nearest neighbor
|
||||||
|
|
||||||
|
* **Vertex Buffer**: For sending data to GPU for rendering
|
||||||
@@ -0,0 +1,56 @@
|
|||||||
|
---
|
||||||
|
title: '10 Principles for Building Resilient Payment Systems'
|
||||||
|
description: '10 principles for building resilient payment systems based on Shopify.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0336-shopify.png'
|
||||||
|
createdAt: '2024-03-07'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- real-world-case-studies
|
||||||
|
tags:
|
||||||
|
- payment systems
|
||||||
|
- resilience
|
||||||
|
---
|
||||||
|
|
||||||
|
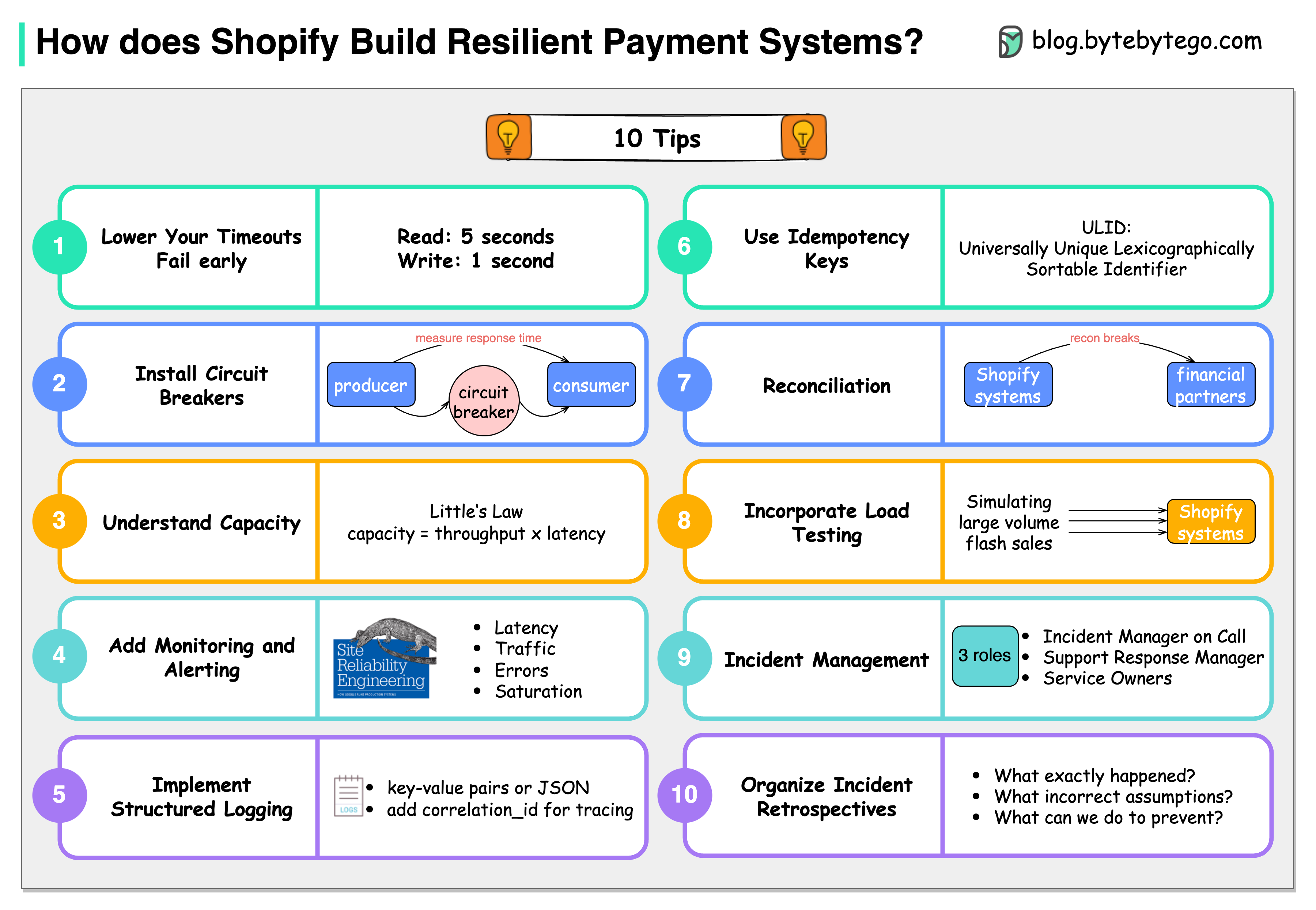
|
||||||
|
|
||||||
|
Shopify has some precious tips for building resilient payment systems.
|
||||||
|
|
||||||
|
### Lower the timeouts, and let the service fail early
|
||||||
|
|
||||||
|
The default timeout is 60 seconds. Based on Shopify’s experiences, read timeout of 5 seconds and write timeout of 1 second are decent setups.
|
||||||
|
|
||||||
|
### Install circuit breaks
|
||||||
|
|
||||||
|
Shopify developed Semian to protect Net::HTTP, MySQL, Redis, and gRPC services with a circuit breaker in Ruby.
|
||||||
|
|
||||||
|
### Capacity management
|
||||||
|
|
||||||
|
If we have 50 requests arrive in our queue and it takes an average of 100 milliseconds to process a request, our throughput is 500 requests per second.
|
||||||
|
|
||||||
|
### Add monitoring and alerting
|
||||||
|
|
||||||
|
Google’s site reliability engineering (SRE) book lists four golden signals a user-facing system should be monitored for: latency, traffic, errors, and saturation.
|
||||||
|
|
||||||
|
### Implement structured logging
|
||||||
|
|
||||||
|
We store logs in a centralized place and make them easily searchable.
|
||||||
|
|
||||||
|
### Use idempotency keys
|
||||||
|
|
||||||
|
Use the Universally Unique Lexicographically Sortable Identifier (ULID) for these idempotency keys instead of a random version 4 UUID.
|
||||||
|
|
||||||
|
### Be consistent with reconciliation
|
||||||
|
|
||||||
|
Store the reconciliation breaks with Shopify’s financial partners in the database.
|
||||||
|
|
||||||
|
### Incorporate load testing
|
||||||
|
|
||||||
|
Shopify regularly simulates the large volume flash sales to get the benchmark results.
|
||||||
|
|
||||||
|
### Get on top of incident management
|
||||||
|
|
||||||
|
Each incident channel has 3 roles: Incident Manager on Call (IMOC), Support Response Manager (SRM), and service owners.
|
||||||
|
|
||||||
|
### Organize incident retrospectives
|
||||||
|
|
||||||
|
For each incident, 3 questions are asked at Shopify: What exactly happened? What incorrect assumptions did we hold about our systems? What we can do to prevent this from happening?
|
||||||
@@ -0,0 +1,76 @@
|
|||||||
|
---
|
||||||
|
title: "10 System Design Tradeoffs You Cannot Ignore"
|
||||||
|
description: "Explore 10 crucial system design tradeoffs for robust architecture."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0026-10-system-design-trade-offs-you-cannot-ignore.png"
|
||||||
|
createdAt: "2024-03-03"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- System Design
|
||||||
|
- Tradeoffs
|
||||||
|
---
|
||||||
|
|
||||||
|
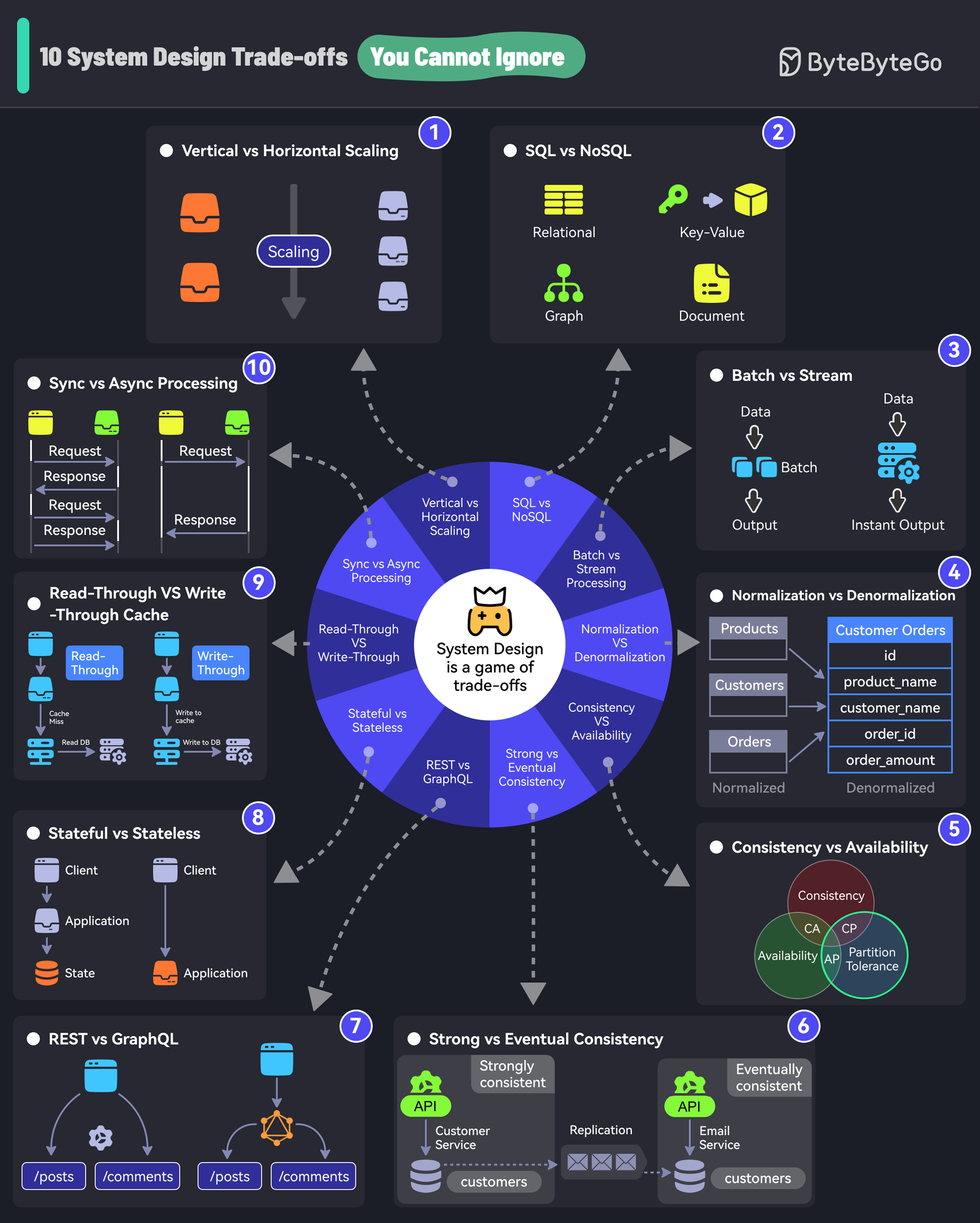
|
||||||
|
|
||||||
|
If you don’t know trade-offs, you DON'T KNOW system design.
|
||||||
|
|
||||||
|
## 1. Vertical vs Horizontal Scaling
|
||||||
|
|
||||||
|
Vertical scaling is adding more resources (CPU, RAM) to an existing server.
|
||||||
|
|
||||||
|
Horizontal scaling means adding more servers to the pool.
|
||||||
|
|
||||||
|
## 2. SQL vs NoSQL
|
||||||
|
|
||||||
|
SQL databases organize data into tables of rows and columns.
|
||||||
|
|
||||||
|
NoSQL is ideal for applications that need a flexible schema.
|
||||||
|
|
||||||
|
## 3. Batch vs Stream Processing
|
||||||
|
|
||||||
|
Batch processing involves collecting data and processing it all at once. For example, daily billing processes.
|
||||||
|
|
||||||
|
Stream processing processes data in real time. For example, fraud detection processes.
|
||||||
|
|
||||||
|
## 4. Normalization vs Denormalization
|
||||||
|
|
||||||
|
Normalization splits data into related tables to ensure that each piece of information is stored only once.
|
||||||
|
|
||||||
|
Denormalization combines data into fewer tables for better query performance.
|
||||||
|
|
||||||
|
## 5. Consistency vs Availability
|
||||||
|
|
||||||
|
Consistency is the assurance of getting the most recent data every single time.
|
||||||
|
|
||||||
|
Availability is about ensuring that the system is always up and running, even if some parts are having problems.
|
||||||
|
|
||||||
|
## 6. Strong vs Eventual Consistency
|
||||||
|
|
||||||
|
Strong consistency is when data updates are immediately reflected.
|
||||||
|
|
||||||
|
Eventual consistency is when data updates are delayed before being available across nodes.
|
||||||
|
|
||||||
|
## 7. REST vs GraphQL
|
||||||
|
|
||||||
|
With REST endpoints, you gather data by accessing multiple endpoints.
|
||||||
|
|
||||||
|
With GraphQL, you get more efficient data fetching with specific queries but the design cost is higher.
|
||||||
|
|
||||||
|
## 8. Stateful vs Stateless
|
||||||
|
|
||||||
|
A stateful system remembers past interactions.
|
||||||
|
|
||||||
|
A stateless system does not keep track of past interactions.
|
||||||
|
|
||||||
|
## 9. Read-Through vs Write-Through Cache
|
||||||
|
|
||||||
|
A read-through cache loads data from the database in case of a cache miss.
|
||||||
|
|
||||||
|
A write-through cache simultaneously writes data updates to the cache and storage.
|
||||||
|
|
||||||
|
## 10. Sync vs Async Processing
|
||||||
|
|
||||||
|
In synchronous processing, tasks are performed one after another.
|
||||||
|
|
||||||
|
In asynchronous processing, tasks can run in the background. New tasks can be started without waiting for a new task.
|
||||||
@@ -0,0 +1,44 @@
|
|||||||
|
---
|
||||||
|
title: '100X Postgres Scaling at Figma'
|
||||||
|
description: 'Learn how Figma scaled its Postgres database by 100x.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0048-100x-postgres-scaling-at-figma.png'
|
||||||
|
createdAt: '2024-02-12'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- real-world-case-studies
|
||||||
|
tags:
|
||||||
|
- Postgres
|
||||||
|
- Scaling
|
||||||
|
---
|
||||||
|
|
||||||
|
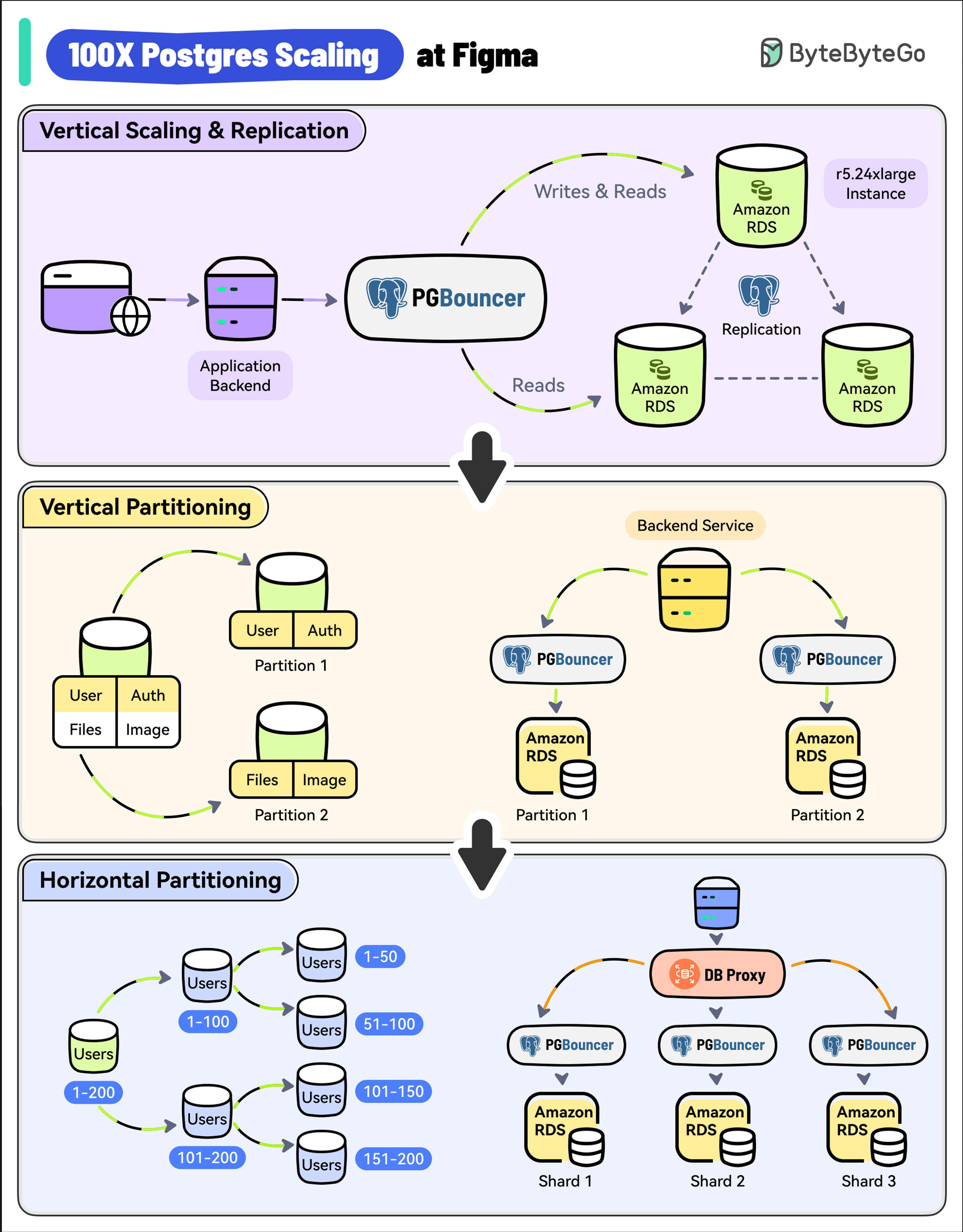
|
||||||
|
|
||||||
|
With 3 million monthly users, Figma’s user base has increased by 200% since 2018.
|
||||||
|
|
||||||
|
As a result, its Postgres database witnessed a whopping 100X growth.
|
||||||
|
|
||||||
|
* **Vertical Scaling and Replication**
|
||||||
|
|
||||||
|
Figma used a single, large Amazon RDS database.
|
||||||
|
|
||||||
|
As a first step, they upgraded to the largest instance available (from r5.12xlarge to r5.24xlarge).
|
||||||
|
|
||||||
|
They also created multiple read replicas to scale read traffic and added PgBouncer as a connection pooler to limit the impact of a growing number of connections.
|
||||||
|
|
||||||
|
* **Vertical Partitioning**
|
||||||
|
|
||||||
|
The next step was vertical partitioning.
|
||||||
|
|
||||||
|
They migrated high-traffic tables like “Figma Files” and “Organizations” into their separate databases.
|
||||||
|
|
||||||
|
Multiple PgBouncer instances were used to manage the connections for these separate databases.
|
||||||
|
|
||||||
|
* **Horizontal Partitioning**
|
||||||
|
|
||||||
|
Over time, some tables crossed several terabytes of data and billions of rows.
|
||||||
|
|
||||||
|
Postgres Vacuum became an issue and max IOPS exceeded the limits of Amazon RDS at the time.
|
||||||
|
|
||||||
|
To solve this, Figma implemented horizontal partitioning by splitting large tables across multiple physical databases.
|
||||||
|
|
||||||
|
A new DBProxy service was built to handle routing and query execution.
|
||||||
@@ -0,0 +1,58 @@
|
|||||||
|
---
|
||||||
|
title: "11 Steps to Go From Junior to Senior Developer"
|
||||||
|
description: "Roadmap with steps to transition from junior to senior developer."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0243-junior-to-senior-developer-roadmap.png"
|
||||||
|
createdAt: "2024-03-13"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- career-growth
|
||||||
|
- software-engineering
|
||||||
|
---
|
||||||
|
|
||||||
|
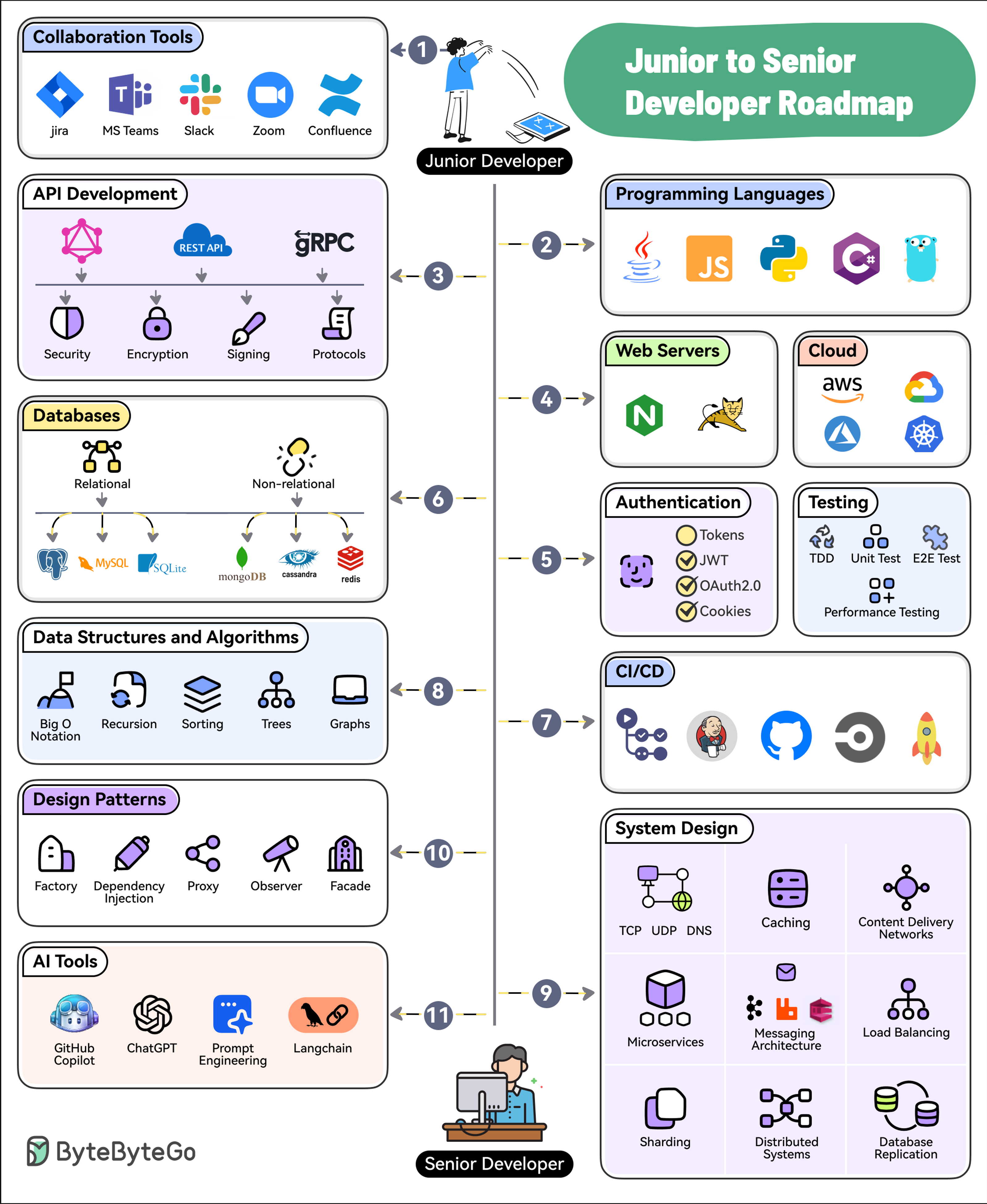
|
||||||
|
|
||||||
|
## 1. Collaboration Tools
|
||||||
|
|
||||||
|
Software development is a social activity. Learn to use collaboration tools like Jira, Confluence, Slack, MS Teams, Zoom, etc.
|
||||||
|
|
||||||
|
## 2. Programming Languages
|
||||||
|
|
||||||
|
Pick and master one or two programming languages. Choose from options like Java, Python, JavaScript, C#, Go, etc.
|
||||||
|
|
||||||
|
## 3. API Development
|
||||||
|
|
||||||
|
Learn the ins and outs of API Development approaches such as REST, GraphQL, and gRPC.
|
||||||
|
|
||||||
|
## 4. Web Servers and Hosting
|
||||||
|
|
||||||
|
Know about web servers as well as cloud platforms like AWS, Azure, GCP, and Kubernetes
|
||||||
|
|
||||||
|
## 5. Authentication and Testing
|
||||||
|
|
||||||
|
Learn how to secure your applications with authentication techniques such as JWTs, OAuth2, etc. Also, master testing techniques like TDD, E2E Testing, and Performance Testing
|
||||||
|
|
||||||
|
## 6. Databases
|
||||||
|
|
||||||
|
Learn to work with relational (Postgres, MySQL, and SQLite) and non-relational databases (MongoDB, Cassandra, and Redis).
|
||||||
|
|
||||||
|
## 7. CI/CD
|
||||||
|
|
||||||
|
Pick tools like GitHub Actions, Jenkins, or CircleCI to learn about continuous integration and continuous delivery.
|
||||||
|
|
||||||
|
## 8. Data Structures and Algorithms
|
||||||
|
|
||||||
|
Master the basics of DSA with topics like Big O Notation, Sorting, Trees, and Graphs.
|
||||||
|
|
||||||
|
## 9. System Design
|
||||||
|
|
||||||
|
Learn System Design concepts such as Networking, Caching, CDNs, Microservices, Messaging, Load Balancing, Replication, Distributed Systems, etc.
|
||||||
|
|
||||||
|
## 10. Design patterns
|
||||||
|
|
||||||
|
Master the application of design patterns such as dependency injection, factory, proxy, observers, and facade.
|
||||||
|
|
||||||
|
## 11. AI Tools
|
||||||
|
|
||||||
|
To future-proof your career, learn to leverage AI tools like GitHub Copilot, ChatGPT, Langchain, and Prompt Engineering.
|
||||||
@@ -0,0 +1,56 @@
|
|||||||
|
---
|
||||||
|
title: "15 Open-Source Projects That Changed the World"
|
||||||
|
description: "Explore 15 open-source projects that revolutionized software development."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0029-15-open-source-projects-that-changed-the-world.png"
|
||||||
|
createdAt: "2024-03-10"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devtools-productivity
|
||||||
|
tags:
|
||||||
|
- "Open Source"
|
||||||
|
- "Software Development"
|
||||||
|
---
|
||||||
|
|
||||||
|
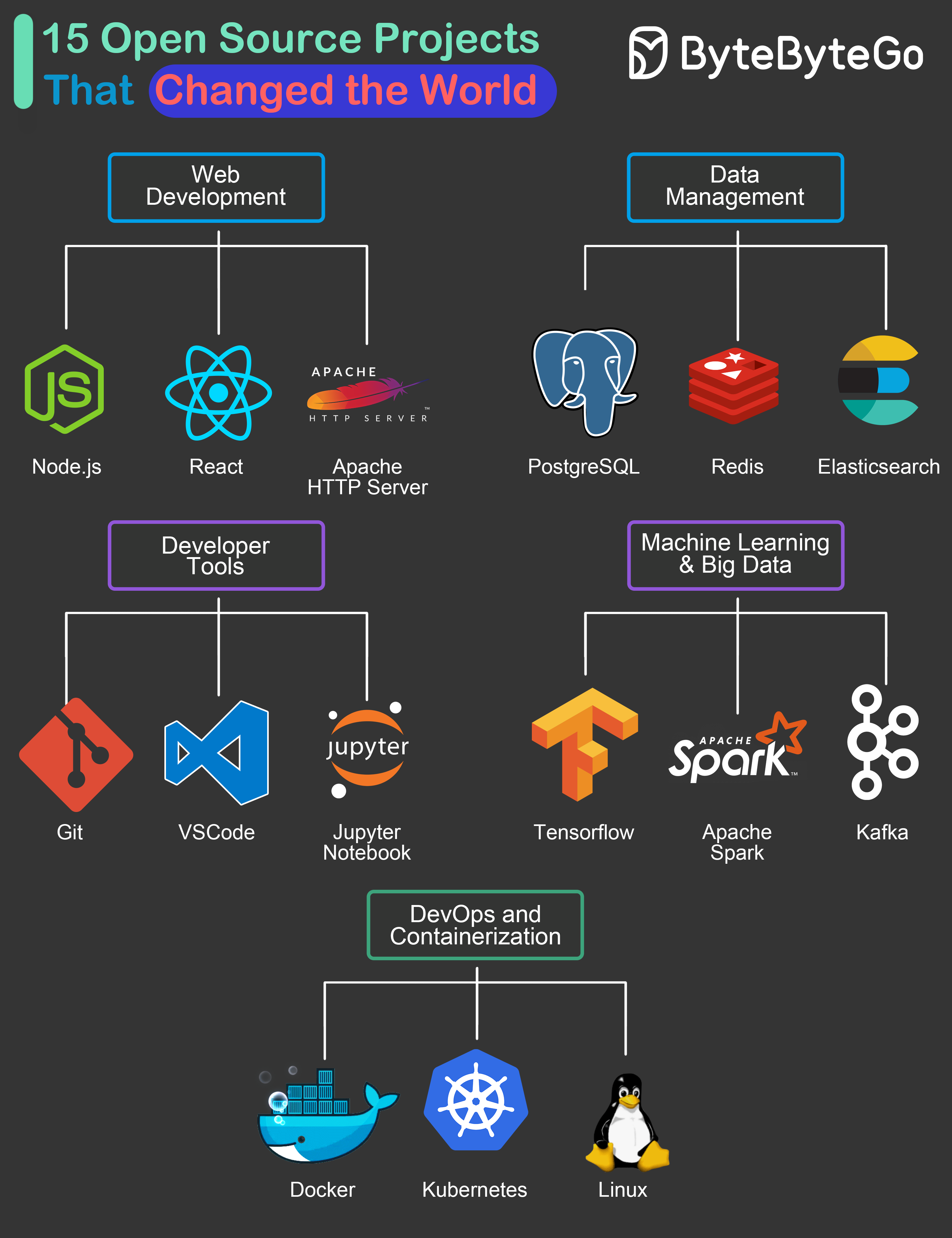
|
||||||
|
|
||||||
|
To come up with the list, we tried to look at the overall impact these projects have created on the industry and related technologies. Also, we’ve focused on projects that have led to a big change in the day-to-day lives of many software developers across the world.
|
||||||
|
|
||||||
|
## Web Development
|
||||||
|
|
||||||
|
* **Node.js:** The cross-platform server-side Javascript runtime that brought JS to server-side development
|
||||||
|
|
||||||
|
* **React:** The library that became the foundation of many web development frameworks.
|
||||||
|
|
||||||
|
* **Apache HTTP Server:** The highly versatile web server loved by enterprises and startups alike. Served as inspiration for many other web servers over the years.
|
||||||
|
|
||||||
|
## Data Management
|
||||||
|
|
||||||
|
* **PostgreSQL:** An open-source relational database management system that provided a high-quality alternative to costly systems
|
||||||
|
|
||||||
|
* **Redis:** The super versatile data store that can be used a cache, message broker and even general-purpose storage
|
||||||
|
|
||||||
|
* **Elasticsearch:** A scale solution to search, analyze and visualize large volumes of data
|
||||||
|
|
||||||
|
## Developer Tools
|
||||||
|
|
||||||
|
* **Git:** Free and open-source version control tool that allows developer collaboration across the globe.
|
||||||
|
|
||||||
|
* **VSCode:** One of the most popular source code editors in the world
|
||||||
|
|
||||||
|
* **Jupyter Notebook:** The web application that lets developers share live code, equations, visualizations and narrative text.
|
||||||
|
|
||||||
|
## Machine Learning & Big Data
|
||||||
|
|
||||||
|
* **Tensorflow:** The leading choice to leverage machine learning techniques
|
||||||
|
|
||||||
|
* **Apache Spark:** Standard tool for big data processing and analytics platforms
|
||||||
|
|
||||||
|
* **Kafka:** Standard platform for building real-time data pipelines and applications.
|
||||||
|
|
||||||
|
## DevOps & Containerization
|
||||||
|
|
||||||
|
* **Docker:** The open source solution that allows developers to package and deploy applications in a consistent and portable way.
|
||||||
|
|
||||||
|
* **Kubernetes:** The heart of Cloud-Native architecture and a platform to manage multiple containers
|
||||||
|
|
||||||
|
* **Linux:** The OS that democratized the world of software development.
|
||||||
@@ -0,0 +1,33 @@
|
|||||||
|
---
|
||||||
|
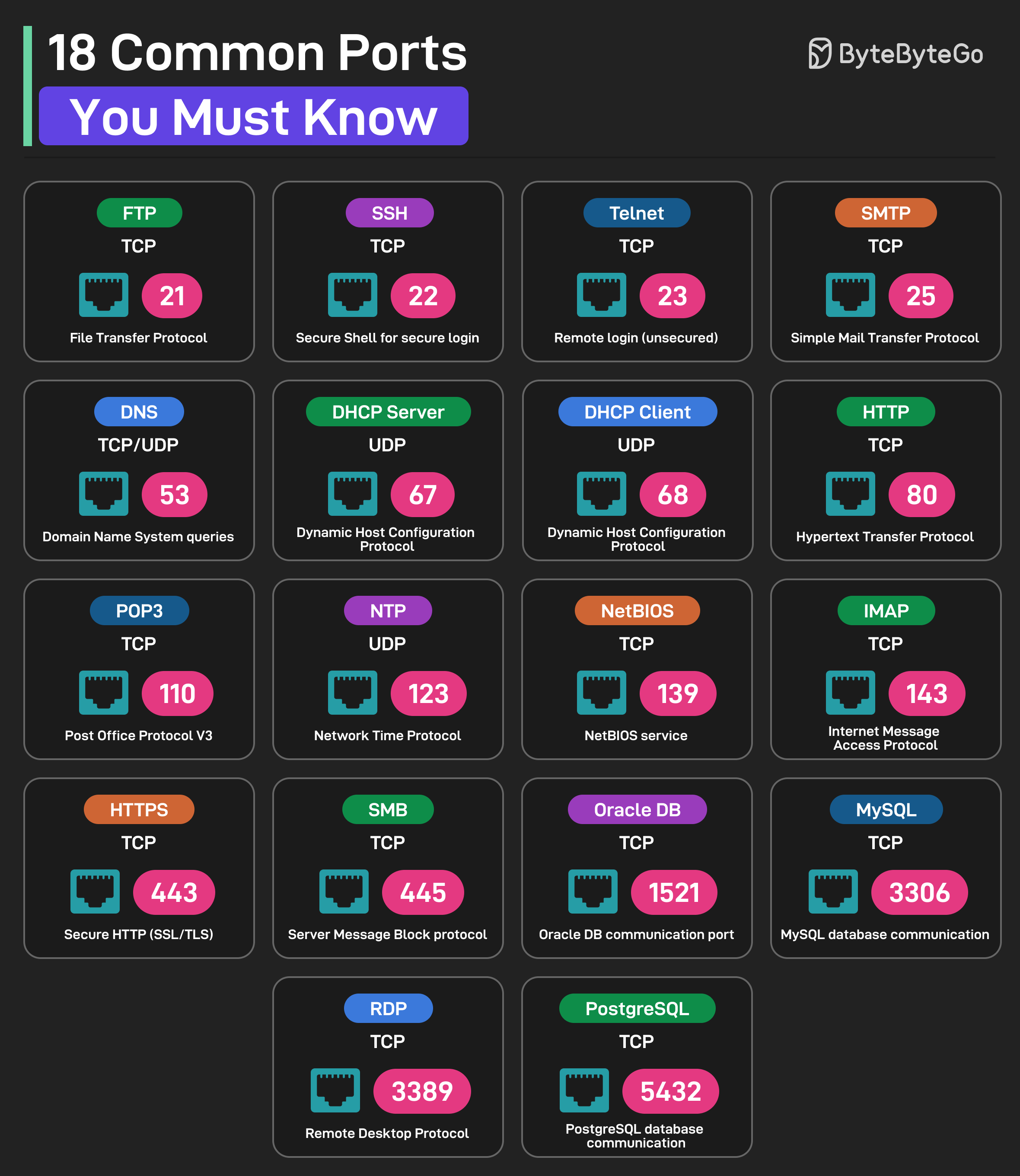
title: 18 Common Ports Worth Knowing
|
||||||
|
description: Learn about 18 common network ports and their uses.
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0030-18-common-ports-you-must-know.png'
|
||||||
|
createdAt: '2024-02-05'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- Networking
|
||||||
|
- Ports
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* **FTP (File Transfer Protocol):** Uses TCP Port 21
|
||||||
|
* **SSH (Secure Shell for Login):** Uses TCP Port 22
|
||||||
|
* **Telnet:** Uses TCP Port 23 for remote login
|
||||||
|
* **SMTP (Simple Mail Transfer Protocol):** Uses TCP Port 25
|
||||||
|
* **DNS:** Uses UDP or TCP on Port 53 for DNS queries
|
||||||
|
* **DHCP Server:** Uses UDP Port 67
|
||||||
|
* **DHCP Client:** Uses UDP Port 68
|
||||||
|
* **HTTP (Hypertext Transfer Protocol):** Uses TCP Port 80
|
||||||
|
* **POP3 (Post Office Protocol V3):** Uses TCP Port 110
|
||||||
|
* **NTP (Network Time Protocol):** Uses UDP Port 123
|
||||||
|
* **NetBIOS:** Uses TCP Port 139 for NetBIOS service
|
||||||
|
* **IMAP (Internet Message Access Protocol):** Uses TCP Port 143
|
||||||
|
* **HTTPS (Secure HTTP):** Uses TCP Port 443
|
||||||
|
* **SMB (Server Message Block):** Uses TCP Port 445
|
||||||
|
* **Oracle DB:** Uses TCP Port 1521 for Oracle database communication port
|
||||||
|
* **MySQL:** Uses TCP Port 3306 for MySQL database communication port
|
||||||
|
* **RDP:** Uses TCP Port 3389 for Remote Desktop Protocol
|
||||||
|
* **PostgreSQL:** Uses TCP Port 5432 for PostgreSQL database communication
|
||||||
@@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
title: "18 Key Design Patterns Every Developer Should Know"
|
||||||
|
description: "Explore 18 essential design patterns for efficient software development."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0032-oo-patterns-you-should-know.png"
|
||||||
|
createdAt: "2024-03-02"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- "design patterns"
|
||||||
|
- "software development"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Patterns are reusable solutions to common design problems, resulting in a smoother, more efficient development process. They serve as blueprints for building better software structures. These are some of the most popular patterns:
|
||||||
|
|
||||||
|
* **Abstract Factory:** Family Creator - Makes groups of related items.
|
||||||
|
|
||||||
|
* **Builder:** Lego Master - Builds objects step by step, keeping creation and appearance separate.
|
||||||
|
|
||||||
|
* **Prototype:** Clone Maker - Creates copies of fully prepared examples.
|
||||||
|
|
||||||
|
* **Singleton:** One and Only - A special class with just one instance.
|
||||||
|
|
||||||
|
* **Adapter:** Universal Plug - Connects things with different interfaces.
|
||||||
|
|
||||||
|
* **Bridge:** Function Connector - Links how an object works to what it does.
|
||||||
|
|
||||||
|
* **Composite:** Tree Builder - Forms tree-like structures of simple and complex parts.
|
||||||
|
|
||||||
|
* **Decorator:** Customizer - Adds features to objects without changing their core.
|
||||||
|
|
||||||
|
* **Facade:** One-Stop-Shop - Represents a whole system with a single, simplified interface.
|
||||||
|
|
||||||
|
* **Flyweight:** Space Saver - Shares small, reusable items efficiently.
|
||||||
|
|
||||||
|
* **Proxy:** Stand-In Actor - Represents another object, controlling access or actions.
|
||||||
|
|
||||||
|
* **Chain of Responsibility:** Request Relay - Passes a request through a chain of objects until handled.
|
||||||
|
|
||||||
|
* **Command:** Task Wrapper - Turns a request into an object, ready for action.
|
||||||
|
|
||||||
|
* **Iterator:** Collection Explorer - Accesses elements in a collection one by one.
|
||||||
|
|
||||||
|
* **Mediator:** Communication Hub - Simplifies interactions between different classes.
|
||||||
|
|
||||||
|
* **Memento:** Time Capsule - Captures and restores an object's state.
|
||||||
|
|
||||||
|
* **Observer:** News Broadcaster - Notifies classes about changes in other objects.
|
||||||
|
|
||||||
|
* **Visitor:** Skillful Guest - Adds new operations to a class without altering it.
|
||||||
@@ -0,0 +1,32 @@
|
|||||||
|
---
|
||||||
|
title: "2 Decades of Cloud Evolution"
|
||||||
|
description: "Explore the evolution of cloud computing over the past two decades."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0147-cloud-evolution.png"
|
||||||
|
createdAt: "2024-03-02"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Cloud Computing"
|
||||||
|
- "Cloud Evolution"
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
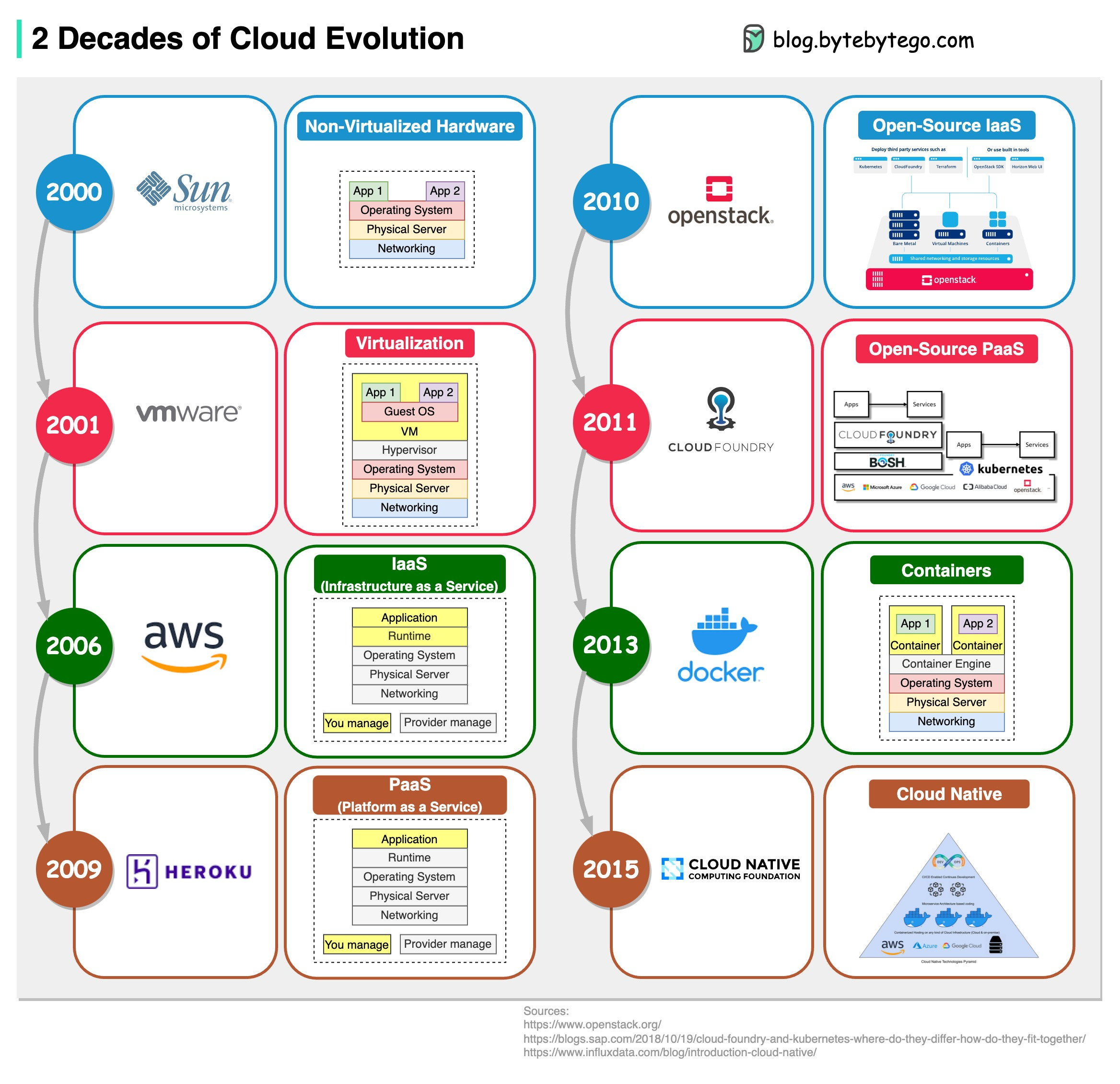
IaaS, PaaS, Cloud Native… How do we get here? The diagram below shows two decades of cloud evolution.
|
||||||
|
|
||||||
|
## Cloud Evolution Timeline
|
||||||
|
|
||||||
|
* 2001 - VMWare - Virtualization via hypervisor
|
||||||
|
|
||||||
|
* 2006 - AWS - IaaS (Infrastructure as a Service)
|
||||||
|
|
||||||
|
* 2009 - Heroku - PaaS (Platform as a Service)
|
||||||
|
|
||||||
|
* 2010 - OpenStack - Open-source IaaS
|
||||||
|
|
||||||
|
* 2011 - CloudFoundry - Open-source PaaS
|
||||||
|
|
||||||
|
* 2013 - Docker - Containers
|
||||||
|
|
||||||
|
* 2015 - CNCF (Cloud Native Computing Foundation) - Cloud Native
|
||||||
@@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
title: "20 Popular Open Source Projects Started by Big Companies"
|
||||||
|
description: "Explore 20 popular open source projects backed by major tech companies."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0034-20-popular-open-source-projects-by-big-tech.png"
|
||||||
|
createdAt: "2024-03-11"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devtools-productivity
|
||||||
|
tags:
|
||||||
|
- "Open Source"
|
||||||
|
- "Technology"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 1. Google
|
||||||
|
|
||||||
|
* Kubernetes
|
||||||
|
* TensorFlow
|
||||||
|
* Go
|
||||||
|
* Angular
|
||||||
|
|
||||||
|
## 2. Meta
|
||||||
|
|
||||||
|
* React
|
||||||
|
* PyTorch
|
||||||
|
* GraphQL
|
||||||
|
* Cassandra
|
||||||
|
|
||||||
|
## 3. Microsoft
|
||||||
|
|
||||||
|
* VSCode
|
||||||
|
* TypeScript
|
||||||
|
* Playwright
|
||||||
|
|
||||||
|
## 4. Netflix
|
||||||
|
|
||||||
|
* Chaos Monkey
|
||||||
|
* Hystrix
|
||||||
|
* Zuul
|
||||||
|
|
||||||
|
## 5. LinkedIn
|
||||||
|
|
||||||
|
* Kafka
|
||||||
|
* Samza
|
||||||
|
* Pinot
|
||||||
|
|
||||||
|
## 6. RedHat
|
||||||
|
|
||||||
|
* Ansible
|
||||||
|
* OpenShift
|
||||||
|
* Ceph Storage
|
||||||
@@ -0,0 +1,66 @@
|
|||||||
|
---
|
||||||
|
title: "25 Papers That Completely Transformed the Computer World"
|
||||||
|
description: "A curated list of influential papers that shaped the computer world."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0419-25-papers-that-completely-transformed-the-computer-world.png"
|
||||||
|
createdAt: "2024-02-09"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Distributed Systems"
|
||||||
|
- "Computer Science"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Here are 25 papers that have significantly impacted the field of computer science:
|
||||||
|
|
||||||
|
* [Dynamo - Amazon’s Highly Available Key Value Store](https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)
|
||||||
|
|
||||||
|
* [Google File System](https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf): Insights into a highly scalable file system
|
||||||
|
|
||||||
|
* [Scaling Memcached at Facebook](https://research.facebook.com/file/839620310074473/scaling-memcache-at-facebook.pdf): A look at the complexities of Caching
|
||||||
|
|
||||||
|
* [BigTable](https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf): The design principles behind a distributed storage system
|
||||||
|
|
||||||
|
* [Borg - Large Scale Cluster Management at Google](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43438.pdf)
|
||||||
|
|
||||||
|
* [Cassandra](https://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf): A look at the design and architecture of a distributed NoSQL database
|
||||||
|
|
||||||
|
* [Attention Is All You Need](https://arxiv.org/abs/1706.03762): Into a new deep learning architecture known as the transformer
|
||||||
|
|
||||||
|
* [Kafka](https://www.microsoft.com/en-us/research/wp-content/uploads/2017/09/Kafka.pdf): Internals of the distributed messaging platform
|
||||||
|
|
||||||
|
* [FoundationDB](https://www.foundationdb.org/files/fdb-paper.pdf): A look at how a distributed database
|
||||||
|
|
||||||
|
* [Amazon Aurora](https://web.stanford.edu/class/cs245/readings/aurora.pdf): To learn how Amazon provides high-availability and performance
|
||||||
|
|
||||||
|
* [Spanner](https://static.googleusercontent.com/media/research.google.com/en//archive/spanner-osdi2012.pdf): Design and architecture of Google’s globally distributed database
|
||||||
|
|
||||||
|
* [MapReduce](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/16cb30b4b92fd4989b8619a61752a2387c6dd474.pdf): A detailed look at how MapReduce enables parallel processing of massive volumes of data
|
||||||
|
|
||||||
|
* [Shard Manager](https://dl.acm.org/doi/pdf/10.1145/3477132.3483546): Understanding the generic shard management framework
|
||||||
|
|
||||||
|
* [Dapper](https://static.googleusercontent.com/media/research.google.com/en//archive/papers/dapper-2010-1.pdf): Insights into Google’s distributed systems tracing infrastructure
|
||||||
|
|
||||||
|
* [Flink](https://www.researchgate.net/publication/308993790_Apache_Flink_Stream_and_Batch_Processing_in_a_Single_Engine): A detailed look at the unified architecture of stream and batch processing
|
||||||
|
|
||||||
|
* [A Comprehensive Survey on Vector Databases](https://arxiv.org/pdf/2310.11703.pdf)
|
||||||
|
|
||||||
|
* [Zanzibar](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/10683a8987dbf0c6d4edcafb9b4f05cc9de5974a.pdf): A look at the design, implementation and deployment of a global system for managing access control lists at Google
|
||||||
|
|
||||||
|
* [Monarch](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/d84ab6c93881af998de877d0070a706de7bec6d8.pdf): Architecture of Google’s in-memory time series database
|
||||||
|
|
||||||
|
* [Thrift](https://thrift.apache.org/static/files/thrift-20070401.pdf): Explore the design choices behind Facebook’s code-generation tool
|
||||||
|
|
||||||
|
* [Bitcoin](https://bitcoin.org/bitcoin.pdf): The ground-breaking introduction to the peer-to-peer electronic cash system
|
||||||
|
|
||||||
|
* [WTF - Who to Follow Service at Twitter](https://web.stanford.edu/~rezab/papers/wtf_overview.pdf): Twitter’s (now X) user recommendation system
|
||||||
|
|
||||||
|
* [MyRocks: LSM-Tree Database Storage Engine](https://www.vldb.org/pvldb/vol13/p3217-matsunobu.pdf)
|
||||||
|
|
||||||
|
* [GoTo Considered Harmful](https://homepages.cwi.nl/~storm/teaching/reader/Dijkstra68.pdf)
|
||||||
|
|
||||||
|
* [Raft Consensus Algorithm](https://raft.github.io/raft.pdf): To learn about the more understandable consensus algorithm
|
||||||
|
|
||||||
|
* [Time Clocks and Ordering of Events](https://lamport.azurewebsites.net/pubs/time-clocks.pdf): The extremely important paper that explains the concept of time and event ordering in a distributed system
|
||||||
@@ -0,0 +1,64 @@
|
|||||||
|
---
|
||||||
|
title: "30 Useful AI Apps That Can Help You in 2025"
|
||||||
|
description: "Discover 30 AI apps to boost productivity, creativity, and more in 2025."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0039-30-useful-ai-apps-that-can-help-you-in-2025.png"
|
||||||
|
createdAt: "2024-03-01"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devtools-productivity
|
||||||
|
tags:
|
||||||
|
- "AI Tools"
|
||||||
|
- "Productivity"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
AI apps are taking over the world. There’s an AI app for every conceivable use case. Here are some AI apps for different categories:
|
||||||
|
|
||||||
|
## General Purpose
|
||||||
|
|
||||||
|
* Perplexity
|
||||||
|
* Anthropic Claude
|
||||||
|
* Grok
|
||||||
|
* ChatGPT
|
||||||
|
* Gemini
|
||||||
|
|
||||||
|
## Writing Code
|
||||||
|
|
||||||
|
* Cursor
|
||||||
|
* Replit
|
||||||
|
* Windsurf AI
|
||||||
|
* Github Copilot
|
||||||
|
* Tabnine
|
||||||
|
|
||||||
|
## Productivity
|
||||||
|
|
||||||
|
* Adobe (PDF Chat)
|
||||||
|
* Gemini for Gmail
|
||||||
|
* Gamma (AI slide deck)
|
||||||
|
* WisprFlow (AI voice dictation)
|
||||||
|
* Granola (AI notetaker)
|
||||||
|
|
||||||
|
## Audience Building
|
||||||
|
|
||||||
|
* Delphi (AI text, voice)
|
||||||
|
* HeyGen (video translation)
|
||||||
|
* Persona (AI agent builder)
|
||||||
|
* Captions (AI video editing)
|
||||||
|
* OpusClips (Video repurposing)
|
||||||
|
|
||||||
|
## Creativity
|
||||||
|
|
||||||
|
* ElevenLabs (realistic AI voices)
|
||||||
|
* Midjourney
|
||||||
|
* Suno AI (music generation)
|
||||||
|
* Krea (enhance images)
|
||||||
|
* Photoroom (AI image editing)
|
||||||
|
|
||||||
|
## Learning and Growth
|
||||||
|
|
||||||
|
* Particle News App
|
||||||
|
* Rosebud (AI journal app)
|
||||||
|
* NotebookLM
|
||||||
|
* GoodInside (parenting co-pilot)
|
||||||
|
* Ash (AI counselor)
|
||||||
@@ -0,0 +1,44 @@
|
|||||||
|
---
|
||||||
|
title: '4 Ways Netflix Uses Caching'
|
||||||
|
description: 'Explore how Netflix uses caching to maintain user engagement.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0007-4-ways-netflix-uses-caching.png'
|
||||||
|
createdAt: '2024-02-25'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- real-world-case-studies
|
||||||
|
tags:
|
||||||
|
- Caching
|
||||||
|
- Netflix
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
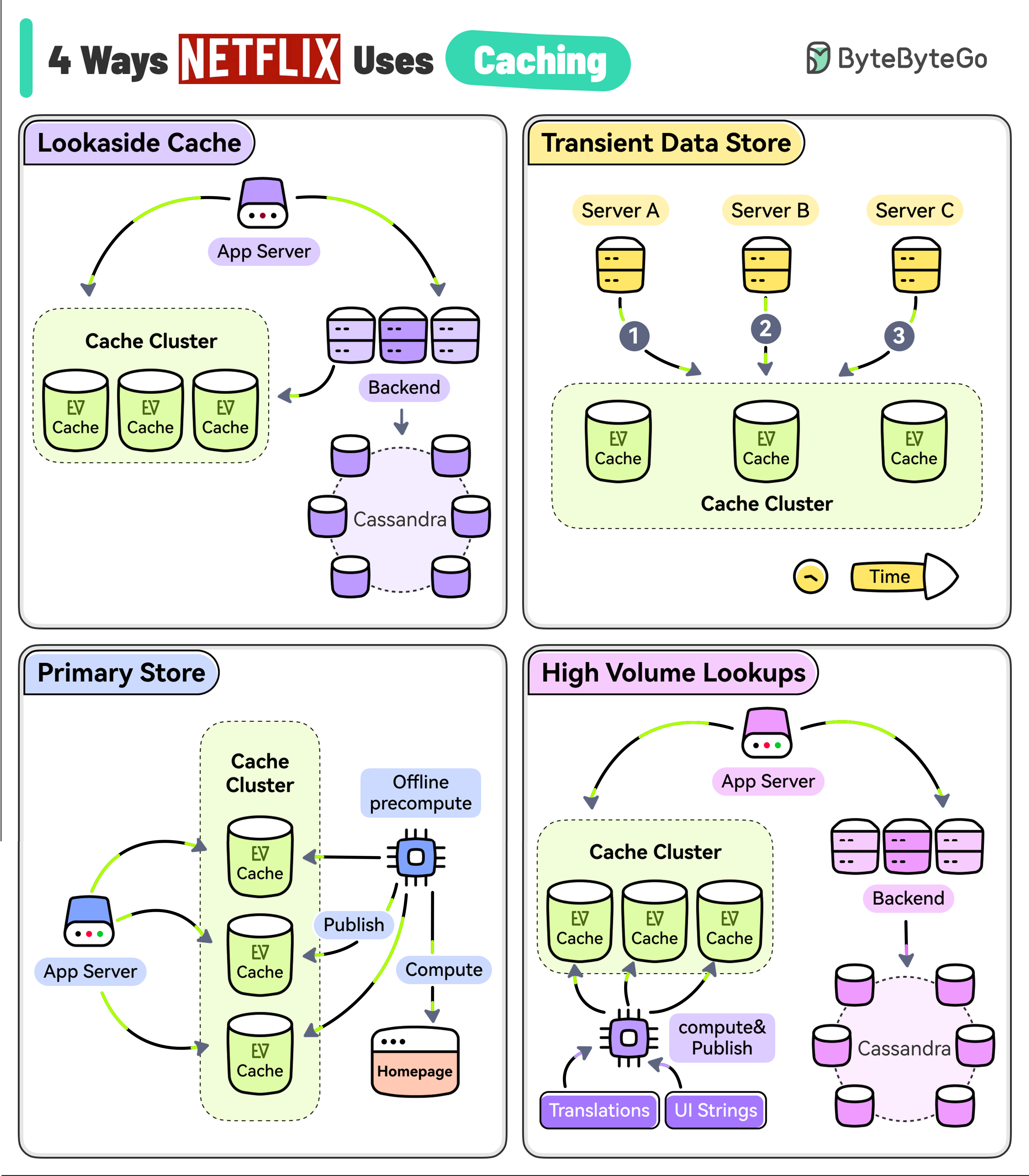
The goal of Netflix is to keep you streaming for as long as possible. But a user’s typical attention span is just 90 seconds.
|
||||||
|
|
||||||
|
They use EVCache (a distributed key-value store) to reduce latency so that the users don’t lose interest.
|
||||||
|
|
||||||
|
However, EVCache has multiple use cases at Netflix.
|
||||||
|
|
||||||
|
* **Lookaside Cache**
|
||||||
|
|
||||||
|
When the application needs some data, it first tries the EVCache client and if the data is not in the cache, it goes to the backend service and the Cassandra database to fetch the data.
|
||||||
|
|
||||||
|
The service also keeps the cache updated for future requests.
|
||||||
|
|
||||||
|
* **Transient Data Store**
|
||||||
|
|
||||||
|
Netflix uses EVCache to keep track of transient data such as playback session information.
|
||||||
|
|
||||||
|
One application service might start the session while the other may update the session followed by a session closure at the very end.
|
||||||
|
|
||||||
|
* **Primary Store**
|
||||||
|
|
||||||
|
Netflix runs large-scale pre-compute systems every night to compute a brand-new home page for every profile of every user based on watch history and recommendations.
|
||||||
|
|
||||||
|
All of that data is written into the EVCache cluster from where the online services read the data and build the homepage.
|
||||||
|
|
||||||
|
* **High Volume Data**
|
||||||
|
|
||||||
|
Netflix has data that has a high volume of access and also needs to be highly available. For example, UI strings and translations that are shown on the Netflix home page.
|
||||||
|
|
||||||
|
A separate process asynchronously computes and publishes the UI string to EVCache from where the application can read it with low latency and high availability.
|
||||||
@@ -0,0 +1,37 @@
|
|||||||
|
---
|
||||||
|
title: "4 Ways of QR Code Payment"
|
||||||
|
description: "Explore the 4 different methods of QR code payments."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0310-qr-code.jpg"
|
||||||
|
createdAt: "2024-03-01"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- payment-and-fintech
|
||||||
|
tags:
|
||||||
|
- QR Codes
|
||||||
|
- Payments
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
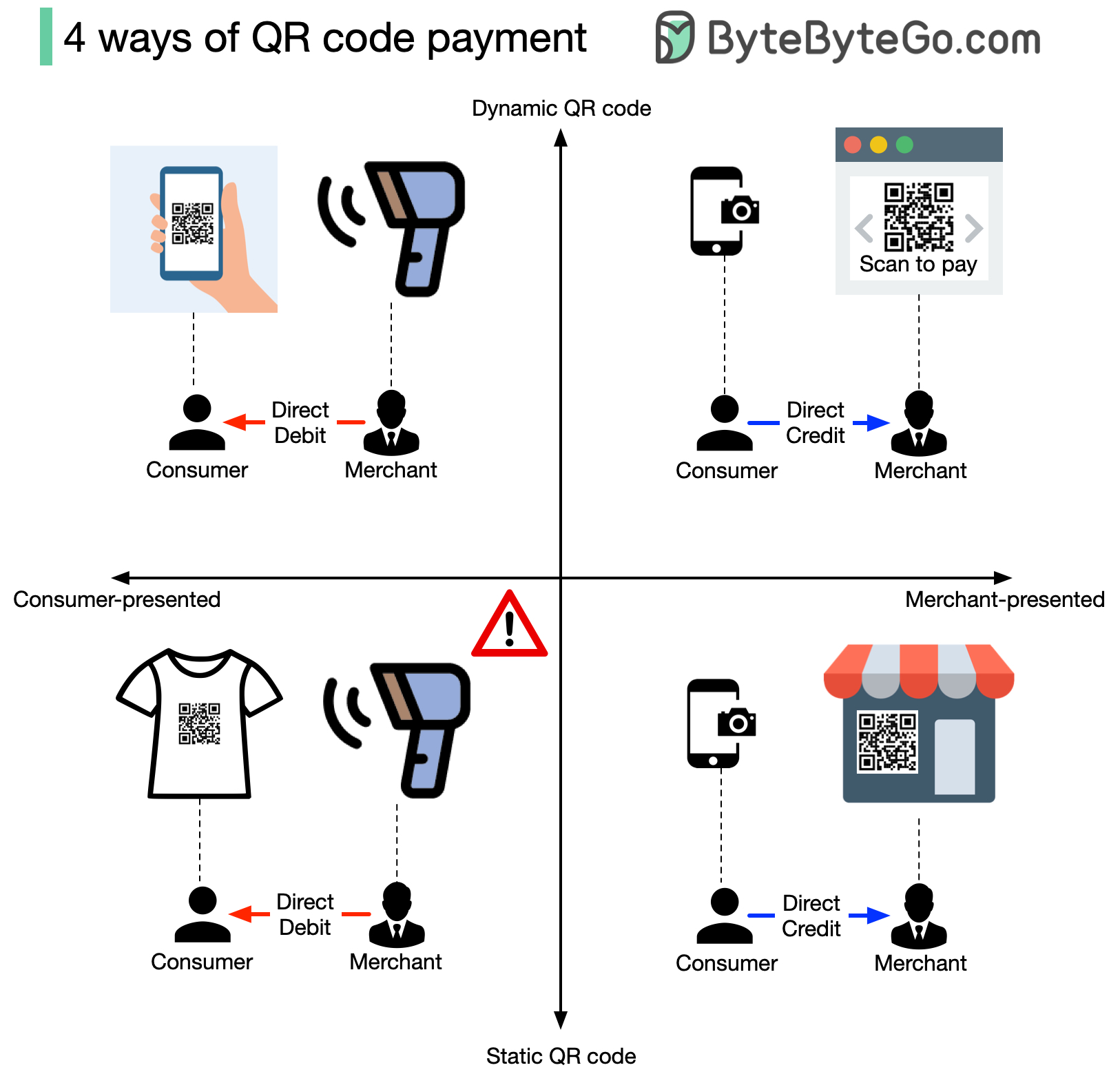
Payment through scanning QR code is very common, but do you know how many ways there are to do it?
|
||||||
|
|
||||||
|
There are 4 ways, no matter whether you’re using PayPal, Stripe, Paytm, WeChat, or Alipay. Is this surprising to you? To understand this, we will answer two questions.
|
||||||
|
|
||||||
|
## Who Presents the QR Code?
|
||||||
|
|
||||||
|
1. You can present the QR code, and the merchant scans the code for payment. This is called ‘consumer-presented mode,’ and what the merchant does is direct debit your account.
|
||||||
|
|
||||||
|
2. Obviously, the other way is that the merchant presents the QR code for you to scan to pay the due amount. This is called ‘merchant-presented mode,’ and you grant the direct credit from your account.
|
||||||
|
|
||||||
|
## Is the QR Code Dynamic or Static?
|
||||||
|
|
||||||
|
1. A dynamic QR code means the QR code will be generated when you present it, or it will automatically regenerate every few seconds. Because it is dynamically generated, it may contain rich information, such as the amount due, transaction type, etc.
|
||||||
|
|
||||||
|
2. A static QR code is generated once and used everywhere. Usually, it only contains the account information.
|
||||||
|
|
||||||
|
So there are 2*2=4 ways to scan a QR code, which are:
|
||||||
|
|
||||||
|
* Consumer-presented mode + static QR code
|
||||||
|
* Consumer-presented mode + dynamic QR code
|
||||||
|
* Merchant-presented mode + static QR code
|
||||||
|
* Merchant-presented mode + dynamic QR code
|
||||||
@@ -0,0 +1,24 @@
|
|||||||
|
---
|
||||||
|
title: '5 Functions to Merge Data with Pandas'
|
||||||
|
description: 'Explore 5 Pandas functions for efficient data merging and analysis.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0192-five-pandas.jpg'
|
||||||
|
createdAt: '2024-03-08'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- ai-machine-learning
|
||||||
|
tags:
|
||||||
|
- Pandas
|
||||||
|
- Data Manipulation
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
How do we quickly merge data without Microsoft Excel?
|
||||||
|
|
||||||
|
Here are 5 useful pandas functions for production data analysis.
|
||||||
|
|
||||||
|
- **Concat:** this function supports the vertical and horizontal combination of two tables. Concat can quickly combine the data from different shards.
|
||||||
|
- **Append:** this function supports the adding of data to an existing table. Append can be used in web crawlers. The new data can be appended to the table when it is crawled.
|
||||||
|
- **Merge:** this function supports horizontal combination on keys. It works similarly to database joins. Merge can be used to combine data from different domains with the same keys.
|
||||||
|
- **Join:** this function works similarly to database outer joins.
|
||||||
|
- **Combine:** this function can apply calculations while combining two tables. The example below chooses the smaller value for the cell. Combine is useful for a data cleansing process.
|
||||||
@@ -0,0 +1,20 @@
|
|||||||
|
---
|
||||||
|
title: '5 HTTP Status Codes That Should Never Have Been Created'
|
||||||
|
description: 'Explore 5 HTTP status codes that are quirky, humorous, or problematic.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0232-http-status-code-shouldnt-exist.png'
|
||||||
|
createdAt: '2024-01-27'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- HTTP Status Codes
|
||||||
|
- Web Development
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
* **451 Unavailable for Legal Reasons:** Access denied due to legal issues.
|
||||||
|
* **218 This is Fine:** Inspired by the meme, bypasses server error overrides.
|
||||||
|
* **420 Enhance Your Calm:** Twitter’s old code for exceeding rate limits. Now changed to 429.
|
||||||
|
* **530 Site Frozen:** Used by Pantheon for locked sites, often unpaid bills.
|
||||||
|
* **418 I'm a Teapot:** A classic April Fool's joke indicating a server's limitations.
|
||||||
@@ -0,0 +1,36 @@
|
|||||||
|
---
|
||||||
|
title: "5 Important Components of Linux"
|
||||||
|
description: "Explore the core components of the Linux operating system."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0253-learn-linux.png"
|
||||||
|
createdAt: "2024-03-09"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devtools-productivity
|
||||||
|
tags:
|
||||||
|
- "linux"
|
||||||
|
- "operating-systems"
|
||||||
|
---
|
||||||
|
|
||||||
|
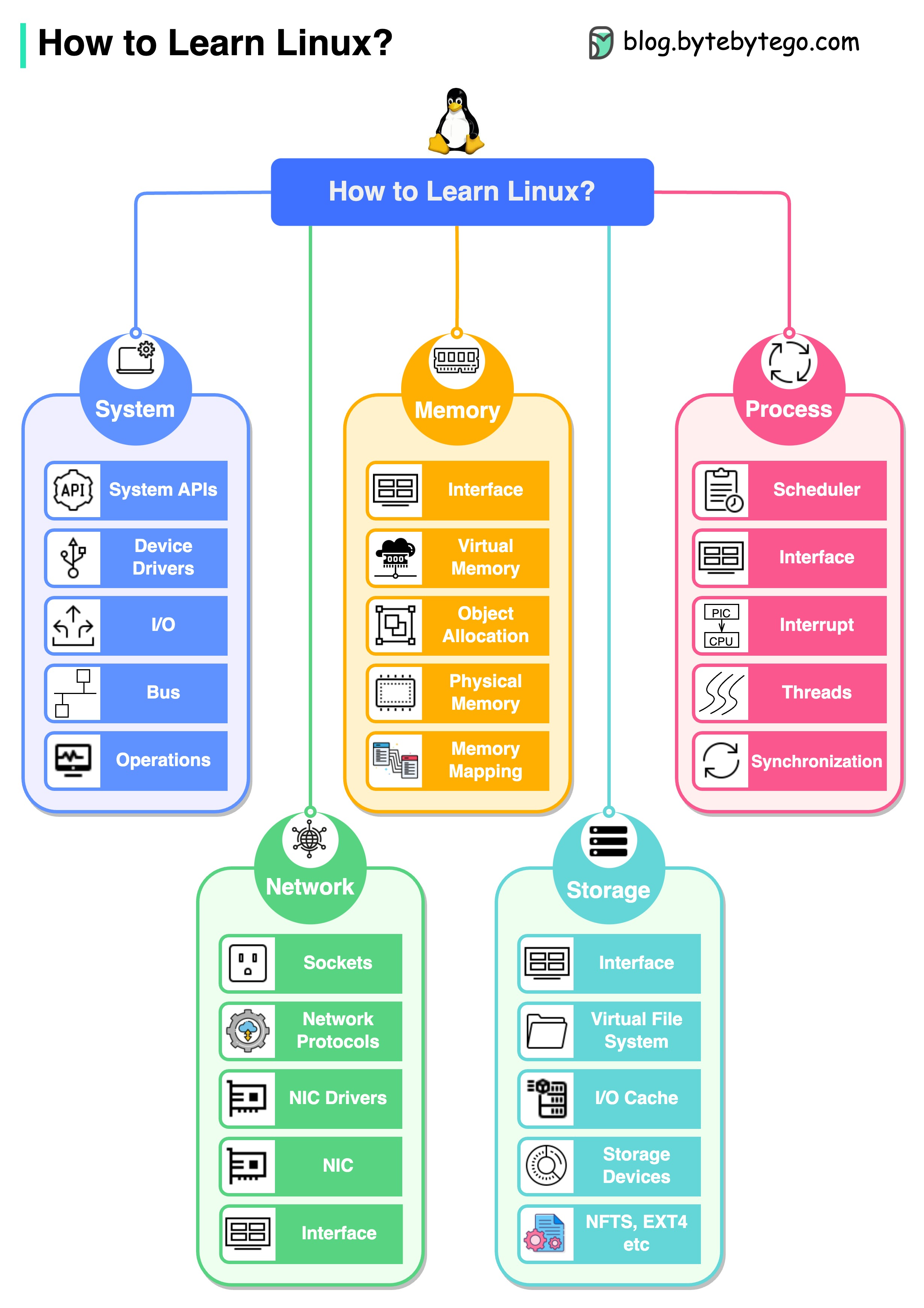
|
||||||
|
|
||||||
|
Here are the five important components of Linux:
|
||||||
|
|
||||||
|
* **System**
|
||||||
|
|
||||||
|
In the system component, we need to learn modules like system APIs, device drivers, I/O, buses, etc.
|
||||||
|
|
||||||
|
* **Memory**
|
||||||
|
|
||||||
|
In memory management, we need to learn modules like physical memory, virtual memory, memory mappings, object allocation, etc.
|
||||||
|
|
||||||
|
* **Process**
|
||||||
|
|
||||||
|
In process management, we need to learn modules like process scheduling, interrupts, threads, synchronization, etc.
|
||||||
|
|
||||||
|
* **Network**
|
||||||
|
|
||||||
|
In the network component, we need to learn important modules like network protocols, sockets, NIC drivers, etc.
|
||||||
|
|
||||||
|
* **Storage**
|
||||||
|
|
||||||
|
In system storage management, we need to learn modules like file systems, I/O caches, different storage devices, file system implementations, etc.
|
||||||
@@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
title: "6 Software Architectural Patterns You Must Know"
|
||||||
|
description: "Explore 6 key software architectural patterns for efficient problem-solving."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0008-6-software-architectural-patterns-you-must-know.png"
|
||||||
|
createdAt: "2024-03-08"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- "Architecture"
|
||||||
|
- "Design Patterns"
|
||||||
|
---
|
||||||
|
|
||||||
|
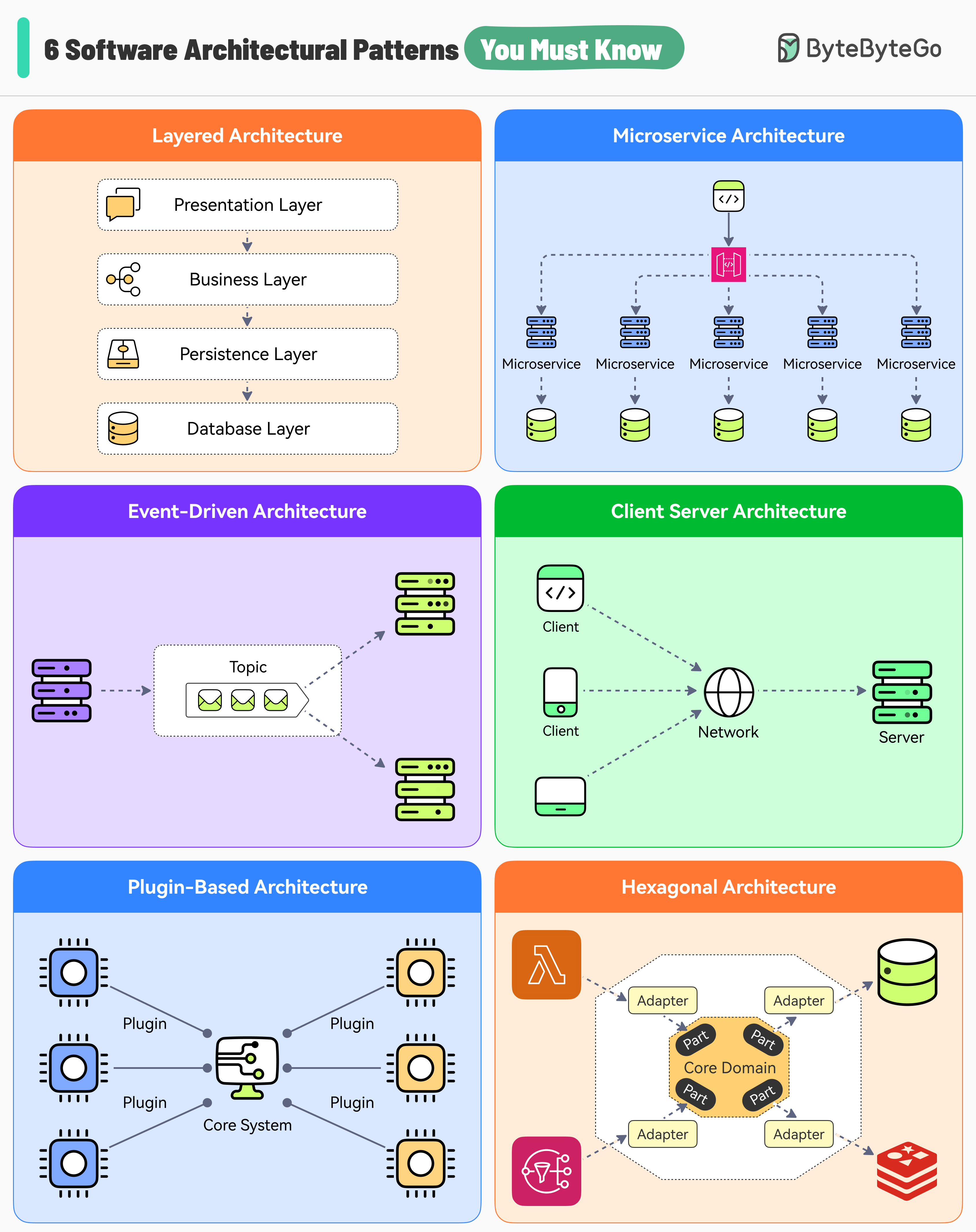
|
||||||
|
|
||||||
|
Choosing the right software architecture pattern is essential for solving problems efficiently.
|
||||||
|
|
||||||
|
## 1. Layered Architecture
|
||||||
|
|
||||||
|
Each layer plays a distinct and clear role within the application context.
|
||||||
|
|
||||||
|
Great for applications that need to be built quickly. On the downside, source code can become unorganized if proper rules aren’t followed.
|
||||||
|
|
||||||
|
## 2. Microservices Architecture
|
||||||
|
|
||||||
|
Break down a large system into smaller and more manageable components.
|
||||||
|
|
||||||
|
Systems built with microservices architecture are fault tolerant. Also, each component can be scaled individually. On the downside, it might increase the complexity of the application.
|
||||||
|
|
||||||
|
## 3. Event-Driven Architecture
|
||||||
|
|
||||||
|
Services talk to each other by emitting events that other services may or may not consume.
|
||||||
|
|
||||||
|
This style promotes loose coupling between components. However, testing individual components becomes challenging.
|
||||||
|
|
||||||
|
## 4. Client-Server Architecture
|
||||||
|
|
||||||
|
It comprises two main components - clients and servers communicating over a network.
|
||||||
|
|
||||||
|
Great for real-time services. However, servers can become a single point of failure.
|
||||||
|
|
||||||
|
## 5. Plugin-based Architecture
|
||||||
|
|
||||||
|
This pattern consists of two types of components - a core system and plugins. The plugin modules are independent components providing a specialized functionality.
|
||||||
|
|
||||||
|
Great for applications that have to be expanded over time like IDEs. However, changing the core is difficult.
|
||||||
|
|
||||||
|
## 6. Hexagonal Architecture
|
||||||
|
|
||||||
|
This pattern creates an abstraction layer that protects the core of an application and isolates it from external integrations for better modularity. Also known as ports and adapters architecture.
|
||||||
|
|
||||||
|
On the downside, this pattern can lead to increased development time and learning curve.
|
||||||
@@ -0,0 +1,42 @@
|
|||||||
|
---
|
||||||
|
title: "7 Must-Know Strategies to Scale Your Database"
|
||||||
|
description: "Explore 7 key strategies to effectively scale your database."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0161-database-scaling-cheatsheet.png"
|
||||||
|
createdAt: "2024-03-15"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "database scaling"
|
||||||
|
- "database optimization"
|
||||||
|
---
|
||||||
|
|
||||||
|
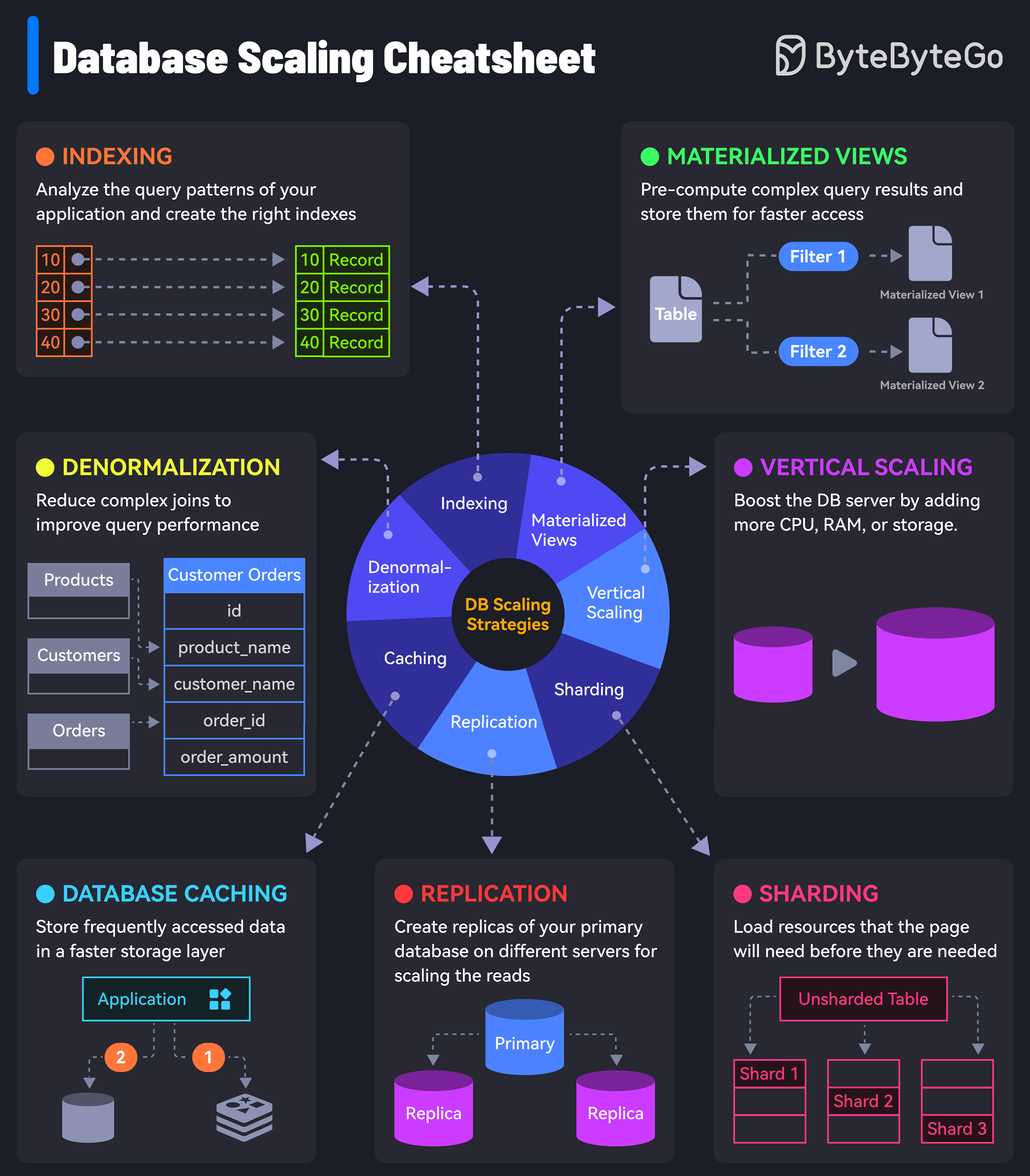
|
||||||
|
|
||||||
|
## 1. Indexing
|
||||||
|
|
||||||
|
Check the query patterns of your application and create the right indexes.
|
||||||
|
|
||||||
|
## 2. Materialized Views
|
||||||
|
|
||||||
|
Pre-compute complex query results and store them for faster access.
|
||||||
|
|
||||||
|
## 3. Denormalization
|
||||||
|
|
||||||
|
Reduce complex joins to improve query performance.
|
||||||
|
|
||||||
|
## 4. Vertical Scaling
|
||||||
|
|
||||||
|
Boost your database server by adding more CPU, RAM, or storage.
|
||||||
|
|
||||||
|
## 5. Caching
|
||||||
|
|
||||||
|
Store frequently accessed data in a faster storage layer to reduce database load.
|
||||||
|
|
||||||
|
## 6. Replication
|
||||||
|
|
||||||
|
Create replicas of your primary database on different servers for scaling the reads.
|
||||||
|
|
||||||
|
## 7. Sharding
|
||||||
|
|
||||||
|
Split your database tables into smaller pieces and spread them across servers. Used for scaling the writes as well as the reads.
|
||||||
@@ -0,0 +1,54 @@
|
|||||||
|
---
|
||||||
|
title: "8 Common System Design Problems and Solutions"
|
||||||
|
description: "Explore 8 common system design problems and their effective solutions."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0010-common-system-design-problems-and-solutions.png"
|
||||||
|
createdAt: "2024-03-07"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- System Design
|
||||||
|
- Scalability
|
||||||
|
---
|
||||||
|
|
||||||
|
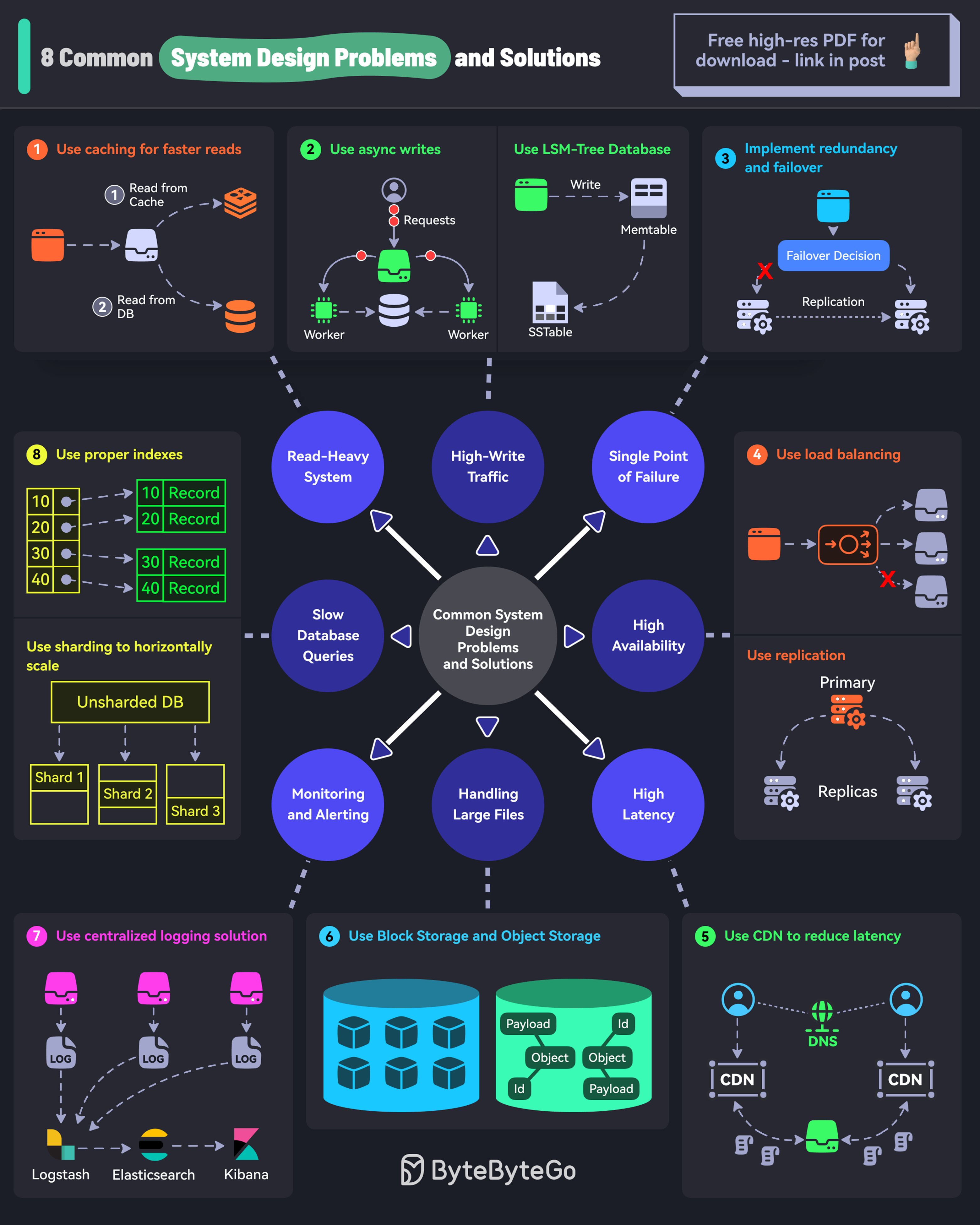
|
||||||
|
|
||||||
|
Do you know those 8 common problems in large-scale production systems and their solutions? Time to test your skills!!
|
||||||
|
|
||||||
|
## 1. Read-Heavy System
|
||||||
|
|
||||||
|
Use caching to make the reads faster.
|
||||||
|
|
||||||
|
## 2. High-Write Traffic
|
||||||
|
|
||||||
|
* Use async workers to process the writes
|
||||||
|
|
||||||
|
* Use databases powered by LSM-Trees
|
||||||
|
|
||||||
|
## 3. Single Point of Failure
|
||||||
|
|
||||||
|
Implement redundancy and failover mechanisms for critical components like databases.
|
||||||
|
|
||||||
|
## 4. High Availability
|
||||||
|
|
||||||
|
* Use load balancing to ensure that requests go to healthy server instances.
|
||||||
|
|
||||||
|
* Use database replication to improve durability and availability.
|
||||||
|
|
||||||
|
## 5. High Latency
|
||||||
|
|
||||||
|
Use a content delivery network to reduce latency.
|
||||||
|
|
||||||
|
## 6. Handling Large Files
|
||||||
|
|
||||||
|
Use block storage and object storage to handle large files and complex data.
|
||||||
|
|
||||||
|
## 7. Monitoring and Alerting
|
||||||
|
|
||||||
|
Use a centralized logging system using something like the ELK stack.
|
||||||
|
|
||||||
|
## 8. Slower Database Queries
|
||||||
|
|
||||||
|
* Use proper indexes to optimize queries.
|
||||||
|
|
||||||
|
* Use sharding to scale the database horizontally.
|
||||||
@@ -0,0 +1,36 @@
|
|||||||
|
---
|
||||||
|
title: "8 Data Structures That Power Your Databases"
|
||||||
|
description: "Explore 8 key data structures that drive database efficiency."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0181-eight-ds-db.jpg"
|
||||||
|
createdAt: "2024-03-02"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- Data Structures
|
||||||
|
- Databases
|
||||||
|
---
|
||||||
|
|
||||||
|
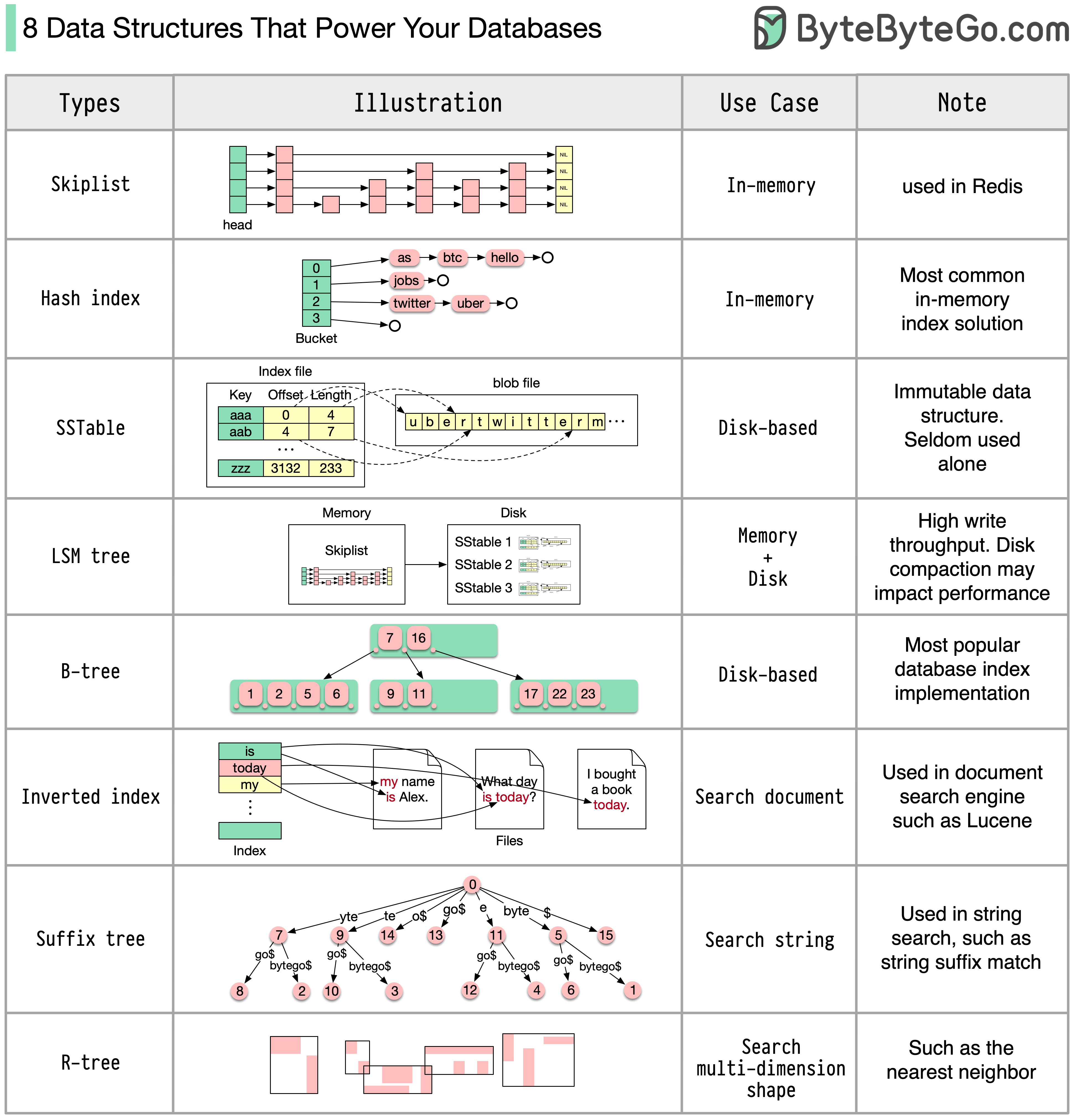
|
||||||
|
|
||||||
|
The answer will vary depending on your use case. Data can be indexed in memory or on disk. Similarly, data formats vary, such as numbers, strings, geographic coordinates, etc. The system might be write-heavy or read-heavy. All of these factors affect your choice of database index format.
|
||||||
|
|
||||||
|
The following are some of the most popular data structures used for indexing data:
|
||||||
|
|
||||||
|
* **Skiplist:** a common in-memory index type. Used in Redis
|
||||||
|
|
||||||
|
* **Hash index:** a very common implementation of the “Map” data structure (or “Collection”)
|
||||||
|
|
||||||
|
* **SSTable:** immutable on-disk “Map” implementation
|
||||||
|
|
||||||
|
* **LSM tree:** Skiplist + SSTable. High write throughput
|
||||||
|
|
||||||
|
* **B-tree:** disk-based solution. Consistent read/write performance
|
||||||
|
|
||||||
|
* **Inverted index:** used for document indexing. Used in Lucene
|
||||||
|
|
||||||
|
* **Suffix tree:** for string pattern search
|
||||||
|
|
||||||
|
* **R-tree:** multi-dimension search, such as finding the nearest neighbor
|
||||||
|
|
||||||
|
This is not an exhaustive list of all database index types.
|
||||||
@@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
title: "8 Key Concepts in Domain-Driven Design"
|
||||||
|
description: "Explore 8 key concepts in Domain-Driven Design for better software."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0011-8-key-concepts-in-ddd.png"
|
||||||
|
createdAt: "2024-03-06"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- DDD
|
||||||
|
- Software Design
|
||||||
|
---
|
||||||
|
|
||||||
|
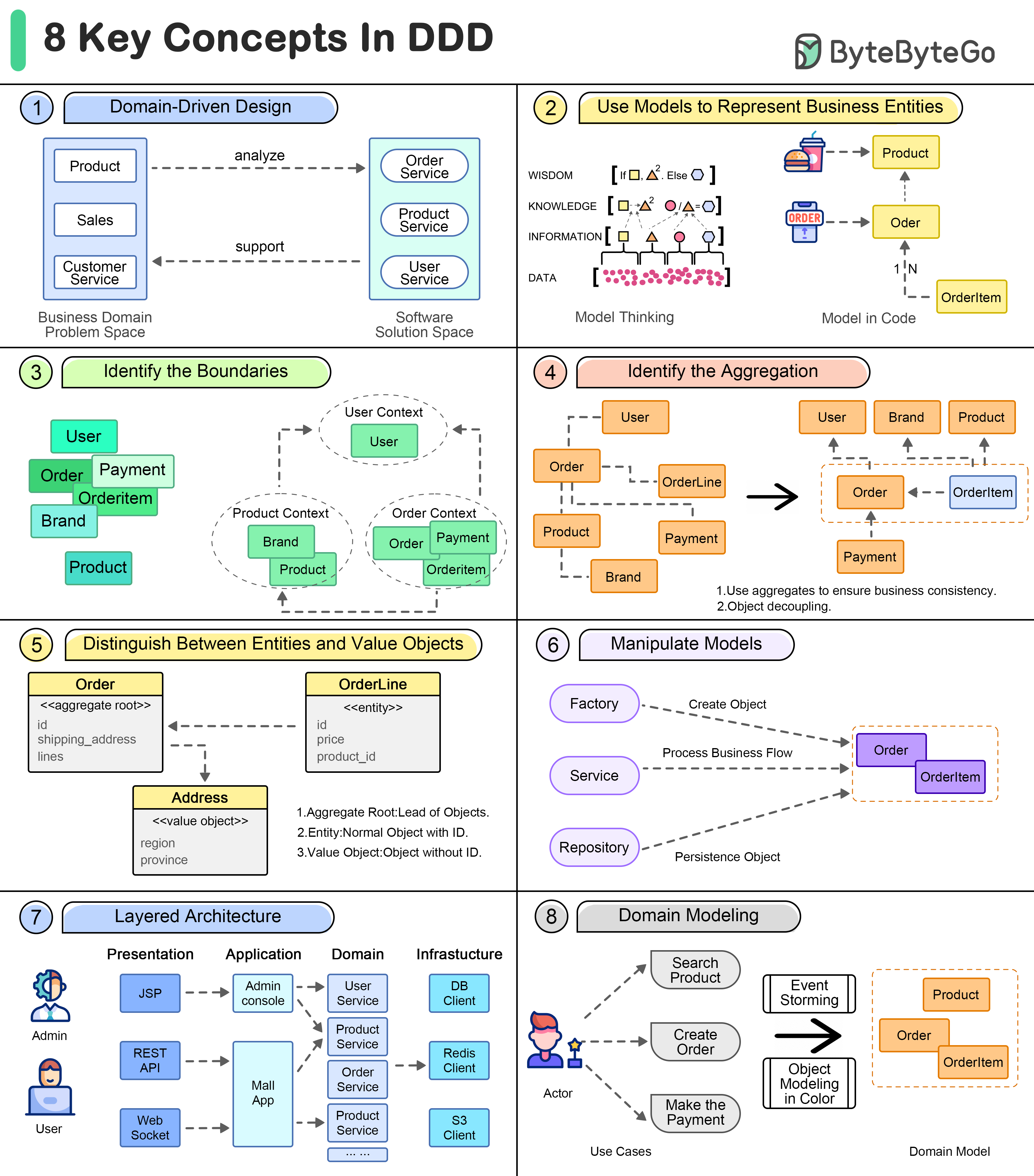
|
||||||
|
|
||||||
|
Domain-driven design advocates driving the design of software through domain modeling.
|
||||||
|
|
||||||
|
Unified language is one of the key concepts of domain-driven design. A domain model is a bridge across the business domains.
|
||||||
|
|
||||||
|
## Domain Driven Design
|
||||||
|
|
||||||
|
Domain-driven design advocates driving the design of software through domain modeling.
|
||||||
|
|
||||||
|
Unified language is one of the key concepts of domain-driven design. A domain model is a bridge across the business domains.
|
||||||
|
|
||||||
|
## Business Entities
|
||||||
|
|
||||||
|
The use of models can assist in expressing business concepts and knowledge and in guiding further development of software, such as databases, APIs, etc.
|
||||||
|
|
||||||
|
## Model Boundaries
|
||||||
|
|
||||||
|
Loose boundaries among sets of domain models are used to model business correlations.
|
||||||
|
|
||||||
|
## Aggregation
|
||||||
|
|
||||||
|
An Aggregate is a cluster of related objects (entities and value objects) that are treated as a single unit for the purpose of data changes.
|
||||||
|
|
||||||
|
## Entities vs. Value Objects
|
||||||
|
|
||||||
|
In addition to aggregate roots and entities, there are some models that look like disposable, they don't have their own ID to identify them, but are more as part of some entity that expresses a collection of several fields.
|
||||||
|
|
||||||
|
## Operational Modeling
|
||||||
|
|
||||||
|
In domain-driven design, in order to manipulate these models, there are a number of objects that act as "operators".
|
||||||
|
|
||||||
|
## Layering the architecture
|
||||||
|
|
||||||
|
In order to better organize the various objects in a project, we need to simplify the complexity of complex projects by layering them like a computer network.
|
||||||
|
|
||||||
|
## Build the domain model
|
||||||
|
|
||||||
|
Many methods have been invented to extract domain models from business knowledge.
|
||||||
@@ -0,0 +1,22 @@
|
|||||||
|
---
|
||||||
|
title: "8 Key OOP Concepts Every Developer Should Know"
|
||||||
|
description: "Learn the 8 key OOP concepts every developer should know."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0294-oo-concepts.png"
|
||||||
|
createdAt: "2024-03-01"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- "OOP"
|
||||||
|
- "Programming"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Object-Oriented Programming (OOP) has been around since the 1960s, but it really took off in the 1990s with languages like Java and C++.
|
||||||
|
|
||||||
|
Why is OOP Important? OOP allows you to create blueprints (called classes) for digital objects, and these objects know how to communicate with one another to make amazing things happen in your software. Having a well-organized toolbox rather than a jumbled drawer of tools makes your code tidier and easier to change.
|
||||||
|
|
||||||
|
In order to get to grips with OOP, think of it as creating digital Lego blocks that can be combined in countless ways. Take a book or watch some tutorials, and then practice writing code - there's no better way to learn than to practice!
|
||||||
|
|
||||||
|
Don't be afraid of OOP - it's a powerful tool in your coder's toolbox, and with some practice, you'll be able to develop everything from nifty apps to digital skyscrapers!
|
||||||
@@ -0,0 +1,50 @@
|
|||||||
|
---
|
||||||
|
title: "8 Must-Know Scalability Strategies"
|
||||||
|
description: "Explore 8 essential strategies to effectively scale your system."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0013-8-must-know-strategies-to-scale-your-system.png"
|
||||||
|
createdAt: "2024-01-27"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Scalability"
|
||||||
|
- "System Design"
|
||||||
|
---
|
||||||
|
|
||||||
|
What do Amazon, Netflix, and Uber have in common? They are extremely good at scaling their system whenever needed.
|
||||||
|
|
||||||
|
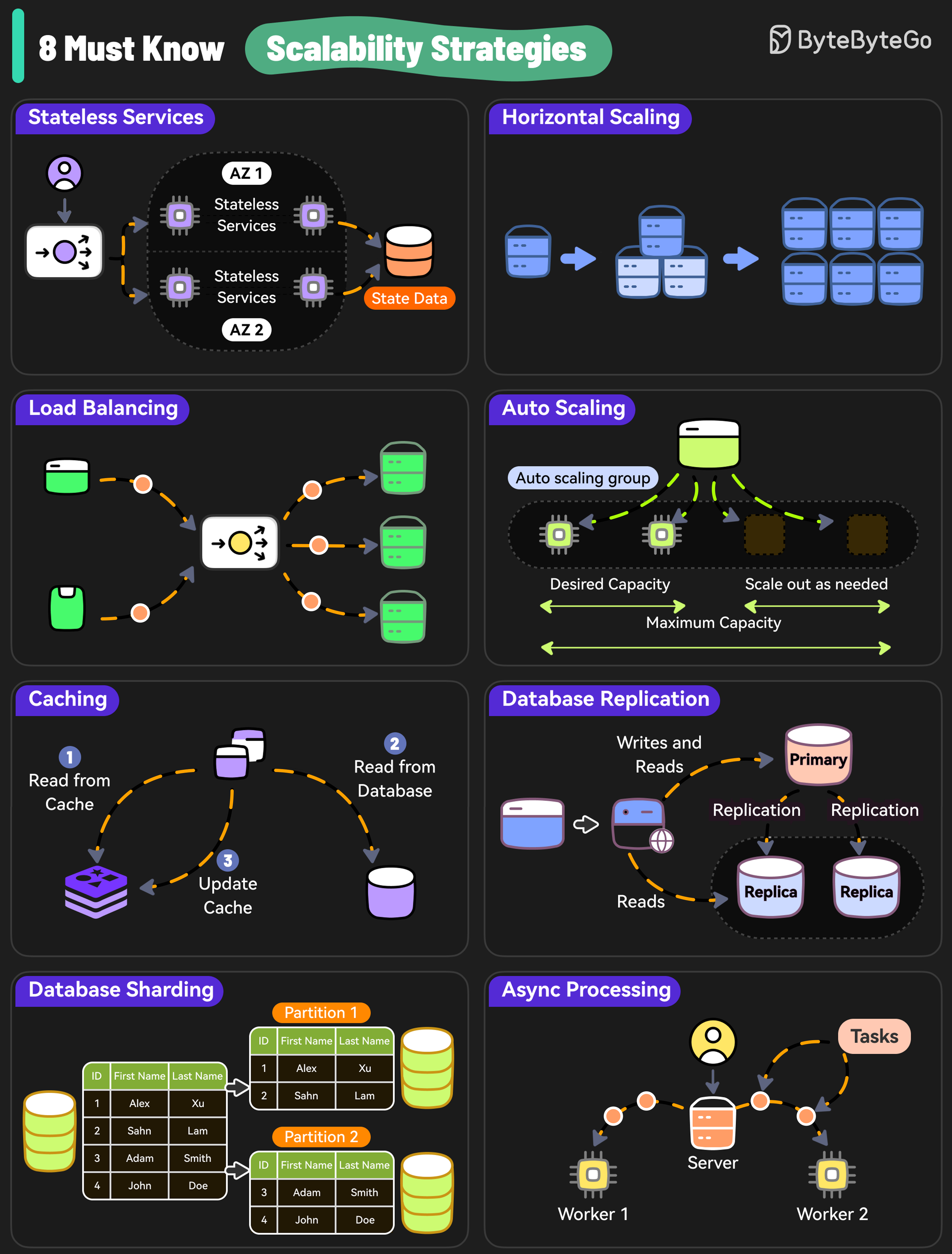
|
||||||
|
|
||||||
|
Here are 8 must-know strategies to scale your system.
|
||||||
|
|
||||||
|
* Stateless Services
|
||||||
|
|
||||||
|
Design stateless services because they don’t rely on server-specific data and are easier to scale.
|
||||||
|
|
||||||
|
* Horizontal Scaling
|
||||||
|
|
||||||
|
Add more servers so that the workload can be shared.
|
||||||
|
|
||||||
|
* Load Balancing
|
||||||
|
|
||||||
|
Use a load balancer to distribute incoming requests evenly across multiple servers.
|
||||||
|
|
||||||
|
* Auto Scaling
|
||||||
|
|
||||||
|
Implement auto-scaling policies to adjust resources based on real-time traffic.
|
||||||
|
|
||||||
|
* Caching
|
||||||
|
|
||||||
|
Use caching to reduce the load on the database and handle repetitive requests at scale.
|
||||||
|
|
||||||
|
* Database Replication
|
||||||
|
|
||||||
|
Replicate data across multiple nodes to scale the read operations while improving redundancy.
|
||||||
|
|
||||||
|
* Database Sharding
|
||||||
|
|
||||||
|
Distribute data across multiple instances to scale the writes as well as reads.
|
||||||
|
|
||||||
|
* Async Processing
|
||||||
|
|
||||||
|
Move time-consuming and resource-intensive tasks to background workers using async processing to scale out new requests.
|
||||||
@@ -0,0 +1,31 @@
|
|||||||
|
---
|
||||||
|
title: '8 Tips for Efficient API Design'
|
||||||
|
description: 'Improve your API design with these 8 essential tips for efficiency.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0385-top-8-tips-for-restful-api-design.png'
|
||||||
|
createdAt: '2024-02-08'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- API Design
|
||||||
|
- Best Practices
|
||||||
|
---
|
||||||
|
|
||||||
|
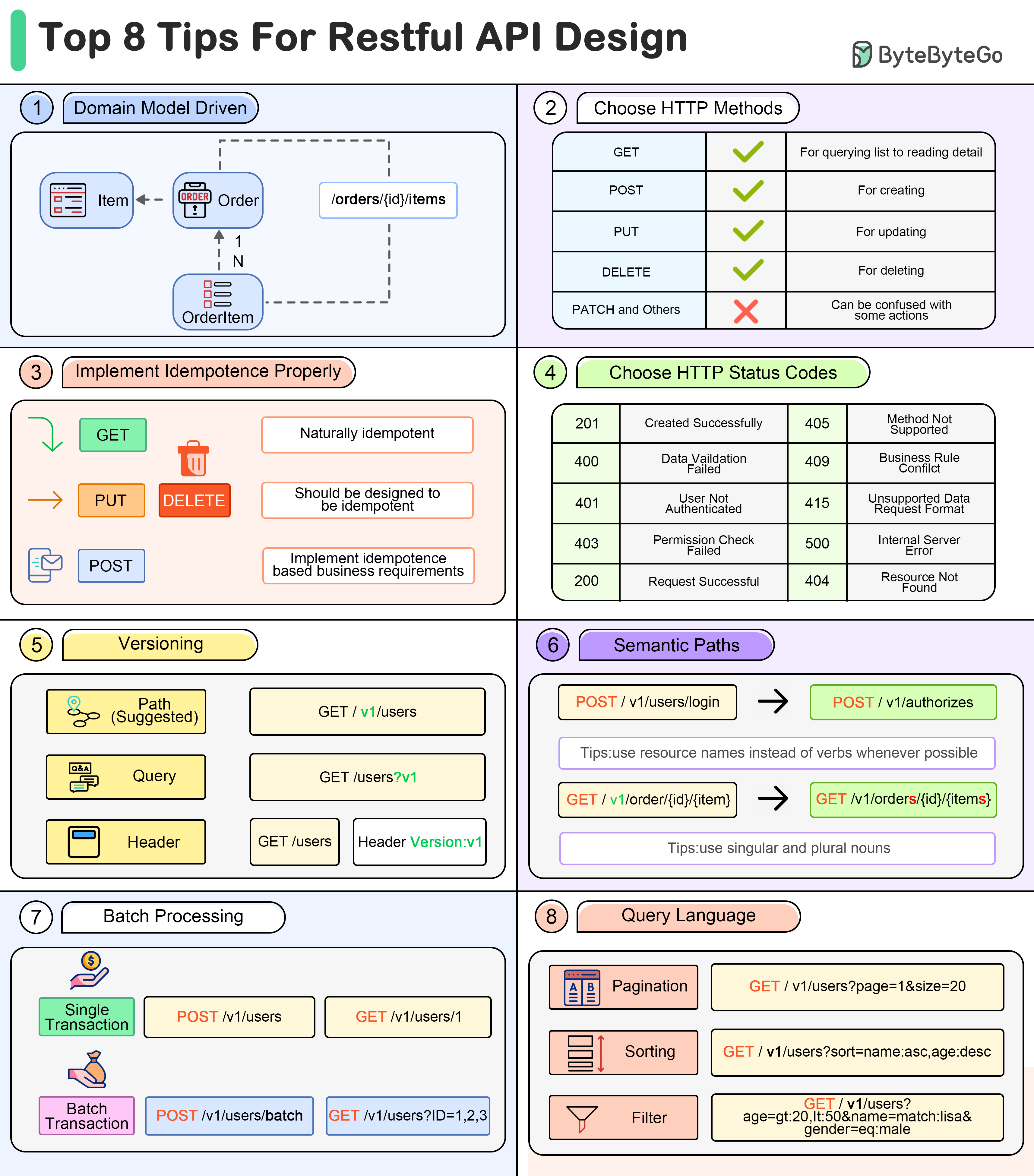
|
||||||
|
|
||||||
|
* **Domain Model Driven**
|
||||||
|
When designing the path structure of a RESTful API, we can refer to the domain model.
|
||||||
|
* **Choose Proper HTTP Methods**
|
||||||
|
Defining a few basic HTTP Methods can simplify the API design. For example, PATCH can often be a problem for teams.
|
||||||
|
* **Implement Idempotence Properly**
|
||||||
|
Designing for idempotence in advance can improve the robustness of an API. GET method is idempotent, but POST needs to be designed properly to be idempotent.
|
||||||
|
* **Choose Proper HTTP Status Codes**
|
||||||
|
Define a limited number of HTTP status codes to use to simplify application development.
|
||||||
|
* **Versioning**
|
||||||
|
Designing the version number for the API in advance can simplify upgrade work.
|
||||||
|
* **Semantic Paths**
|
||||||
|
Using semantic paths makes APIs easier to understand, so that users can find the correct APIs in the documentation.
|
||||||
|
* **Batch Processing**
|
||||||
|
Use batch/bulk as a keyword and place it at the end of the path.
|
||||||
|
* **Query Language**
|
||||||
|
Designing a set of query rules makes the API more flexible. For example, pagination, sorting, filtering etc.
|
||||||
@@ -0,0 +1,66 @@
|
|||||||
|
---
|
||||||
|
title: "9 Best Practices for Building Microservices"
|
||||||
|
description: "Best practices for building robust and scalable microservices systems."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0019-9-best-practices-for-building-microservices.png"
|
||||||
|
createdAt: '2024-03-05'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- "Microservices"
|
||||||
|
- "Architecture"
|
||||||
|
---
|
||||||
|
|
||||||
|
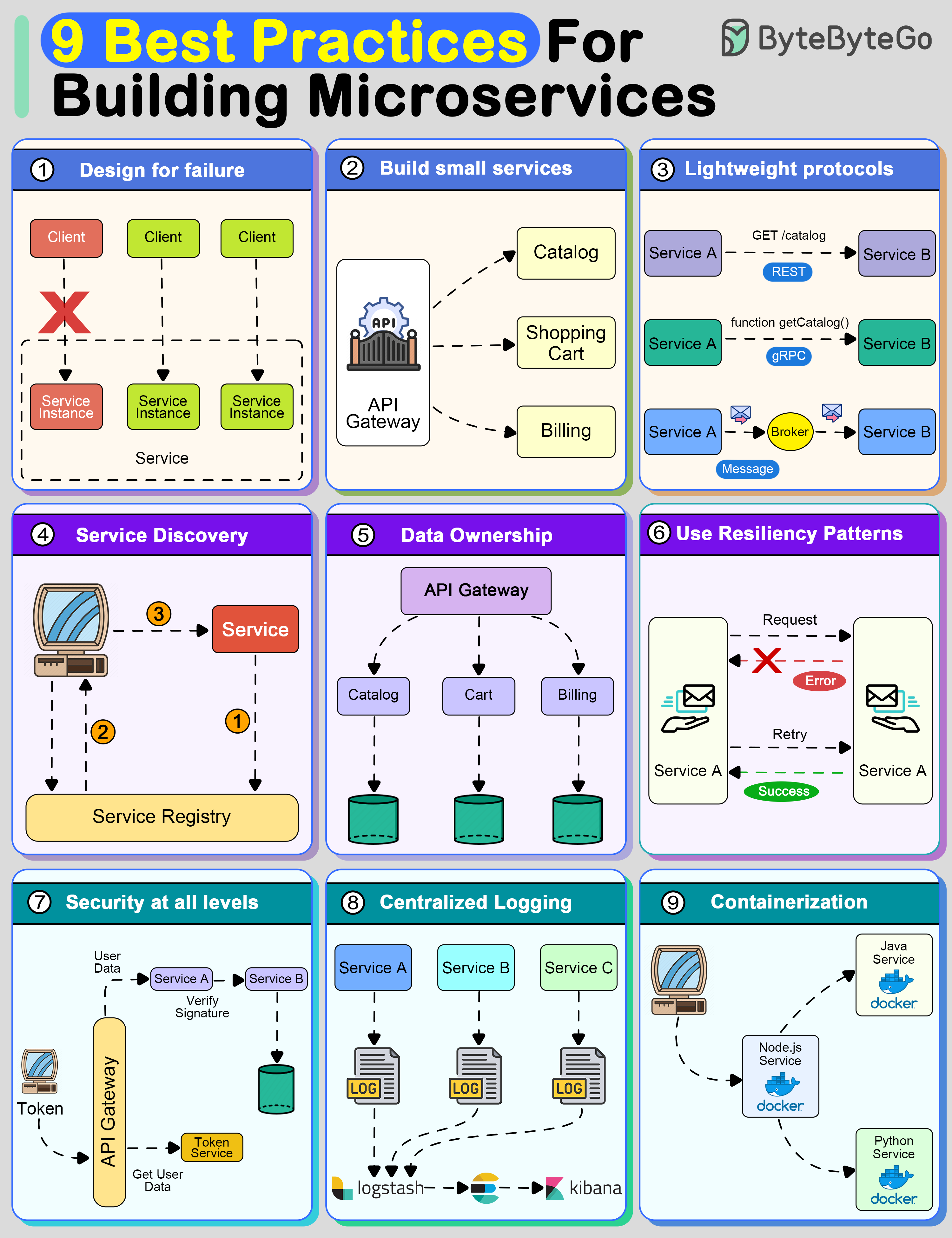
|
||||||
|
|
||||||
|
Creating a system using microservices is extremely difficult unless you follow some strong principles.
|
||||||
|
|
||||||
|
## 1. Design For Failure
|
||||||
|
|
||||||
|
A distributed system with microservices is going to fail.
|
||||||
|
|
||||||
|
You must design the system to tolerate failure at multiple levels such as infrastructure, database, and individual services. Use circuit breakers, bulkheads, or graceful degradation methods to deal with failures.
|
||||||
|
|
||||||
|
## 2. Build Small Services
|
||||||
|
|
||||||
|
A microservice should not do multiple things at once.
|
||||||
|
|
||||||
|
A good microservice is designed to do one thing well.
|
||||||
|
|
||||||
|
## 3. Use lightweight protocols for communication
|
||||||
|
|
||||||
|
Communication is the core of a distributed system.
|
||||||
|
|
||||||
|
Microservices must talk to each other using lightweight protocols. Options include REST, gRPC, or message brokers.
|
||||||
|
|
||||||
|
## 4. Implement service discovery
|
||||||
|
|
||||||
|
To communicate with each other, microservices need to discover each other over the network.
|
||||||
|
|
||||||
|
Implement service discovery using tools such as Consul, Eureka, or Kubernetes Services
|
||||||
|
|
||||||
|
## 5. Data Ownership
|
||||||
|
|
||||||
|
In microservices, data should be owned and managed by the individual services.
|
||||||
|
|
||||||
|
The goal should be to reduce coupling between services so that they can evolve independently.
|
||||||
|
|
||||||
|
## 6. Use resiliency patterns
|
||||||
|
|
||||||
|
Implement specific resiliency patterns to improve the availability of the services.
|
||||||
|
|
||||||
|
Examples: retry policies, caching, and rate limiting.
|
||||||
|
|
||||||
|
## 7. Security at all levels
|
||||||
|
|
||||||
|
In a microservices-based system, the attack surface is quite large. You must implement security at every level of the service communication path.
|
||||||
|
|
||||||
|
## 8. Centralized logging
|
||||||
|
|
||||||
|
Logs are important to finding issues in a system. With multiple services, they become critical.
|
||||||
|
|
||||||
|
## 9. Use containerization techniques
|
||||||
|
|
||||||
|
To deploy microservices in an isolated manner, use containerization techniques.
|
||||||
|
|
||||||
|
Tools like Docker and Kubernetes can help with this as they are meant to simplify the scaling and deployment of a microservice.
|
||||||
@@ -0,0 +1,36 @@
|
|||||||
|
---
|
||||||
|
title: "9 Best Practices for Developing Microservices"
|
||||||
|
description: "Explore 9 key practices for effective microservices development."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0275-micro-best-practices.png"
|
||||||
|
createdAt: "2024-02-26"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- "microservices"
|
||||||
|
- "best practices"
|
||||||
|
---
|
||||||
|
|
||||||
|
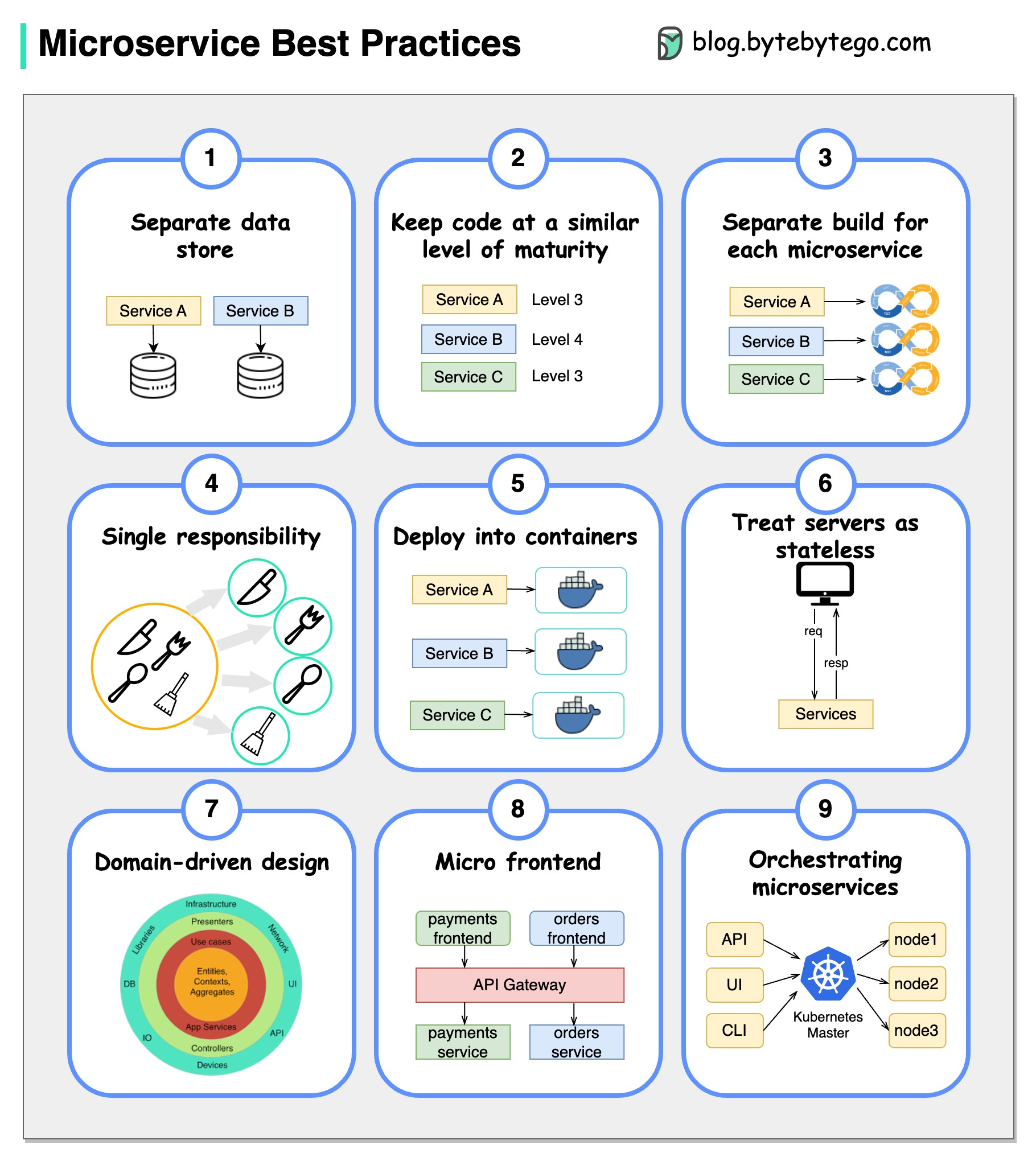
|
||||||
|
|
||||||
|
When developing microservices, it's crucial to follow these best practices:
|
||||||
|
|
||||||
|
## Best Practices
|
||||||
|
|
||||||
|
* **Use separate data storage for each microservice**
|
||||||
|
|
||||||
|
* **Keep code at a similar level of maturity**
|
||||||
|
|
||||||
|
* **Separate build for each microservice**
|
||||||
|
|
||||||
|
* **Assign each microservice with a single responsibility**
|
||||||
|
|
||||||
|
* **Deploy into containers**
|
||||||
|
|
||||||
|
* **Design stateless services**
|
||||||
|
|
||||||
|
* **Adopt domain-driven design**
|
||||||
|
|
||||||
|
* **Design micro frontend**
|
||||||
|
|
||||||
|
* **Orchestrating microservices**
|
||||||
@@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
title: "9 Docker Best Practices You Must Know"
|
||||||
|
description: "Learn 9 essential Docker best practices for efficient containerization."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0016-9-docker-best-practices-you-must-know.png"
|
||||||
|
createdAt: "2024-03-02"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devops-cicd
|
||||||
|
tags:
|
||||||
|
- Docker
|
||||||
|
- Containerization
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 1. Use official images
|
||||||
|
|
||||||
|
This ensures security, reliability, and regular updates.
|
||||||
|
|
||||||
|
## 2. Use a specific image version
|
||||||
|
|
||||||
|
The default latest tag is unpredictable and causes unexpected behavior.
|
||||||
|
|
||||||
|
## 3. Multi-Stage builds
|
||||||
|
|
||||||
|
Reduces final image size by excluding build tools and dependencies.
|
||||||
|
|
||||||
|
## 4. Use .dockerignore
|
||||||
|
|
||||||
|
Excludes unnecessary files, speeds up builds, and reduces image size.
|
||||||
|
|
||||||
|
## 5. Use the least privileged user
|
||||||
|
|
||||||
|
Enhances security by limiting container privileges.
|
||||||
|
|
||||||
|
## 6. Use environment variables
|
||||||
|
|
||||||
|
Increases flexibility and portability across different environments.
|
||||||
|
|
||||||
|
## 7. Order matters for caching
|
||||||
|
|
||||||
|
Order your steps from least to most frequently changing to optimize caching.
|
||||||
|
|
||||||
|
## 8. Label your images
|
||||||
|
|
||||||
|
It improves organization and helps with image management.
|
||||||
|
|
||||||
|
## 9. Scan images
|
||||||
|
|
||||||
|
Find security vulnerabilities before they become bigger problems.
|
||||||
|
|
||||||
|
Over to you: Which other Docker best practices will you add to the list?
|
||||||
@@ -0,0 +1,50 @@
|
|||||||
|
---
|
||||||
|
title: "9 Essential Components of a Production Microservice Application"
|
||||||
|
description: "Explore 9 key components for building robust microservice applications."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0020-9-essential-components-of-production-microservice-app.png"
|
||||||
|
createdAt: "2024-03-04"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- Microservices
|
||||||
|
- Architecture
|
||||||
|
---
|
||||||
|
|
||||||
|
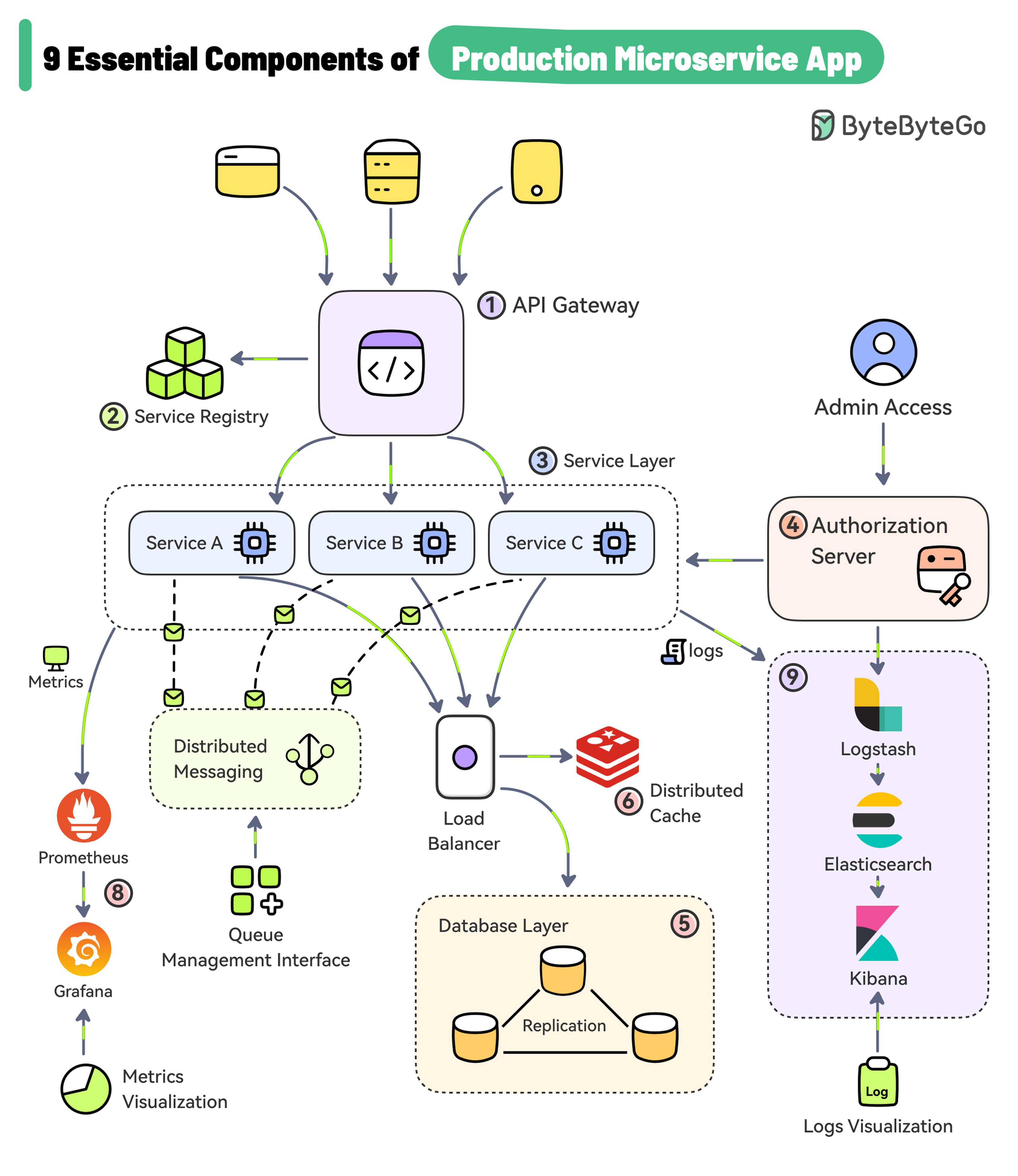
|
||||||
|
|
||||||
|
## 1. API Gateway
|
||||||
|
|
||||||
|
The gateway provides a unified entry point for client applications. It handles routing, filtering, and load balancing.
|
||||||
|
|
||||||
|
## 2. Service Registry
|
||||||
|
|
||||||
|
The service registry contains the details of all the services. The gateway discovers the service using the registry. For example, Consul, Eureka, Zookeeper, etc.
|
||||||
|
|
||||||
|
## 3. Service Layer
|
||||||
|
|
||||||
|
Each microservice serves a specific business function and can run on multiple instances. These services can be built using frameworks like Spring Boot, NestJS, etc.
|
||||||
|
|
||||||
|
## 4. Authorization Server
|
||||||
|
|
||||||
|
Used to secure the microservices and manage identity and access control. Tools like Keycloak, Azure AD, and Okta can help over here.
|
||||||
|
|
||||||
|
## 5. Data Storage
|
||||||
|
|
||||||
|
Databases like PostgreSQL and MySQL can store application data generated by the services.
|
||||||
|
|
||||||
|
## 6. Distributed Caching
|
||||||
|
|
||||||
|
Caching is a great approach for boosting the application performance. Options include caching solutions like Redis, Couchbase, Memcached, etc.
|
||||||
|
|
||||||
|
## 7. Async Microservices Communication
|
||||||
|
|
||||||
|
Use platforms such as Kafka and RabbitMQ to support async communication between microservices.
|
||||||
|
|
||||||
|
## 8. Metrics Visualization
|
||||||
|
|
||||||
|
Microservices can be configured to publish metrics to Prometheus and tools like Grafana can help visualize the metrics.
|
||||||
|
|
||||||
|
## 9. Log Aggregation and Visualization
|
||||||
|
|
||||||
|
Logs generated by the services are aggregated using Logstash, stored in Elasticsearch, and visualized with Kibana.
|
||||||
@@ -0,0 +1,28 @@
|
|||||||
|
---
|
||||||
|
title: "A Beginner's Guide to CDN"
|
||||||
|
description: "Learn about CDNs: improve performance, reliability, and security."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0025-a-beginner-s-guide-to-cdn.png"
|
||||||
|
createdAt: "2024-02-18"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- caching-performance
|
||||||
|
tags:
|
||||||
|
- "CDN"
|
||||||
|
- "Networking"
|
||||||
|
---
|
||||||
|
|
||||||
|
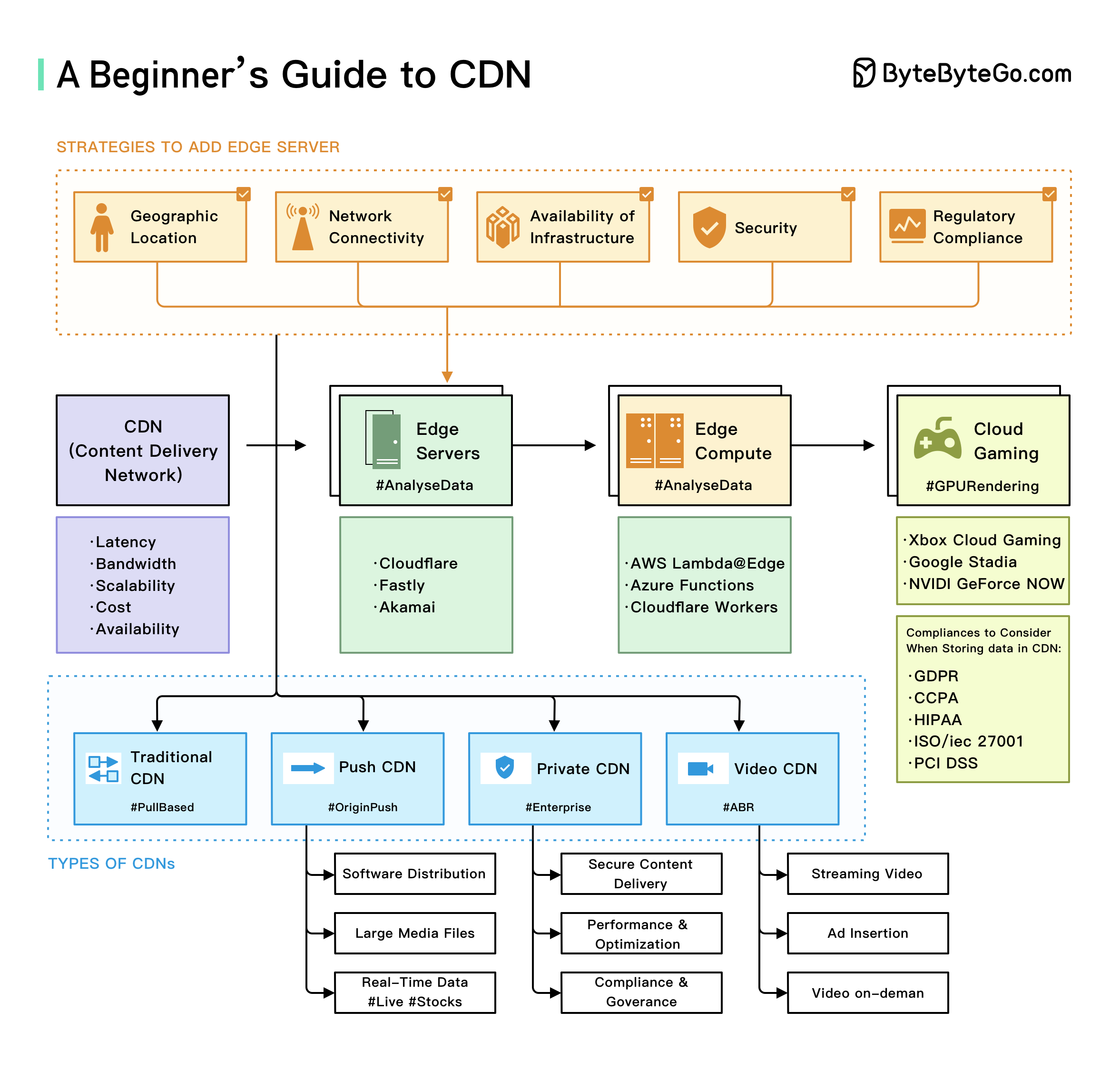
|
||||||
|
|
||||||
|
A guest post by Love Sharma. You can read the full article [here](https://blog.devgenius.io/a-beginners-guide-to-cdn-what-it-is-and-how-it-works-f06946288fbb).
|
||||||
|
|
||||||
|
CDNs are distributed server networks that help improve the performance, reliability, and security of content delivery on the internet.
|
||||||
|
|
||||||
|
## The Overall CDN Diagram explains:
|
||||||
|
|
||||||
|
* Edge servers are located closer to the end user than traditional servers, which helps reduce latency and improve website performance.
|
||||||
|
|
||||||
|
* Edge computing is a type of computing that processes data closer to the end user rather than in a centralized data center. This helps to reduce latency and improve the performance of applications that require real-time processing, such as video streaming or online gaming.
|
||||||
|
|
||||||
|
* Cloud gaming is online gaming that uses cloud computing to provide users with high-quality, low-latency gaming experiences.
|
||||||
|
|
||||||
|
Together, these technologies are transforming how we access and consume digital content. By providing faster, more reliable, and more immersive experiences for users, they are helping to drive the growth of the digital economy and create new opportunities for businesses and consumers alike.
|
||||||
@@ -0,0 +1,30 @@
|
|||||||
|
---
|
||||||
|
title: "A Brief History of Programming Languages"
|
||||||
|
description: "Explore the evolution of programming languages over the past 70 years."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0305-programming-languages.png"
|
||||||
|
createdAt: "2024-03-04"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- programming-languages
|
||||||
|
- history
|
||||||
|
---
|
||||||
|
|
||||||
|
C, C++, Java, Javascript, Typescript, Golang, Rust, how do programming languages evolve for the past 70 years?
|
||||||
|
|
||||||
|
<img src="https://assets.bytebytego.com/diagrams/0305-programming-languages.png" alt="Programming Languages History">
|
||||||
|
|
||||||
|
* Perforated cards were the first generation of programming languages. Assembly languages, which are machine-oriented, are the second generation of programming language. Third-generation languages, which are human-oriented, have been around since 1957.
|
||||||
|
|
||||||
|
* Early languages like Fortran and LISP proposed garbage collection, recursion, exceptions. These features still exist in modern programming languages.
|
||||||
|
|
||||||
|
* In 1972, two influential languages were born: Smalltalk and C. Smalltalk greatly influenced scripting languages and client-side languages. C language was developed for unix programming.
|
||||||
|
|
||||||
|
* In the 1980s, object-oriented languages became popular because of its advantage in graphic user interfaces. Object-C and C++ are two famous ones.
|
||||||
|
|
||||||
|
* In the 1990s, the PCs became cheaper. The programming languages at this stage emphasized on security and simplicity. Python was born in this decade. It was easy to learn and extend and it quickly gained popularity. In 1995, Java, Javascript, PHP and Ruby were born.
|
||||||
|
|
||||||
|
* In 2000, C# was released by Microsoft. Although it was bundled with .NET framework, this language carried a lot of advanced features.
|
||||||
|
|
||||||
|
* A number of languages were developed in the 2010s to improve C++ or Java. In the C++ family, we have D, Rust, Zig and most recently Carbon. In the Java family, we have Golang and Kotlin. The use of Flutter made Dart popular, and Typescript was developed to be fully compatible with Javascript. Also, Apple finally released Swift to replace Object-C.
|
||||||
@@ -0,0 +1,40 @@
|
|||||||
|
---
|
||||||
|
title: 'A cheat sheet for API designs'
|
||||||
|
description: 'A handy cheat sheet for designing secure and efficient APIs.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0137-cheat-sheet-for-api-design.png'
|
||||||
|
createdAt: '2024-02-14'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- API Design
|
||||||
|
- Security
|
||||||
|
---
|
||||||
|
|
||||||
|
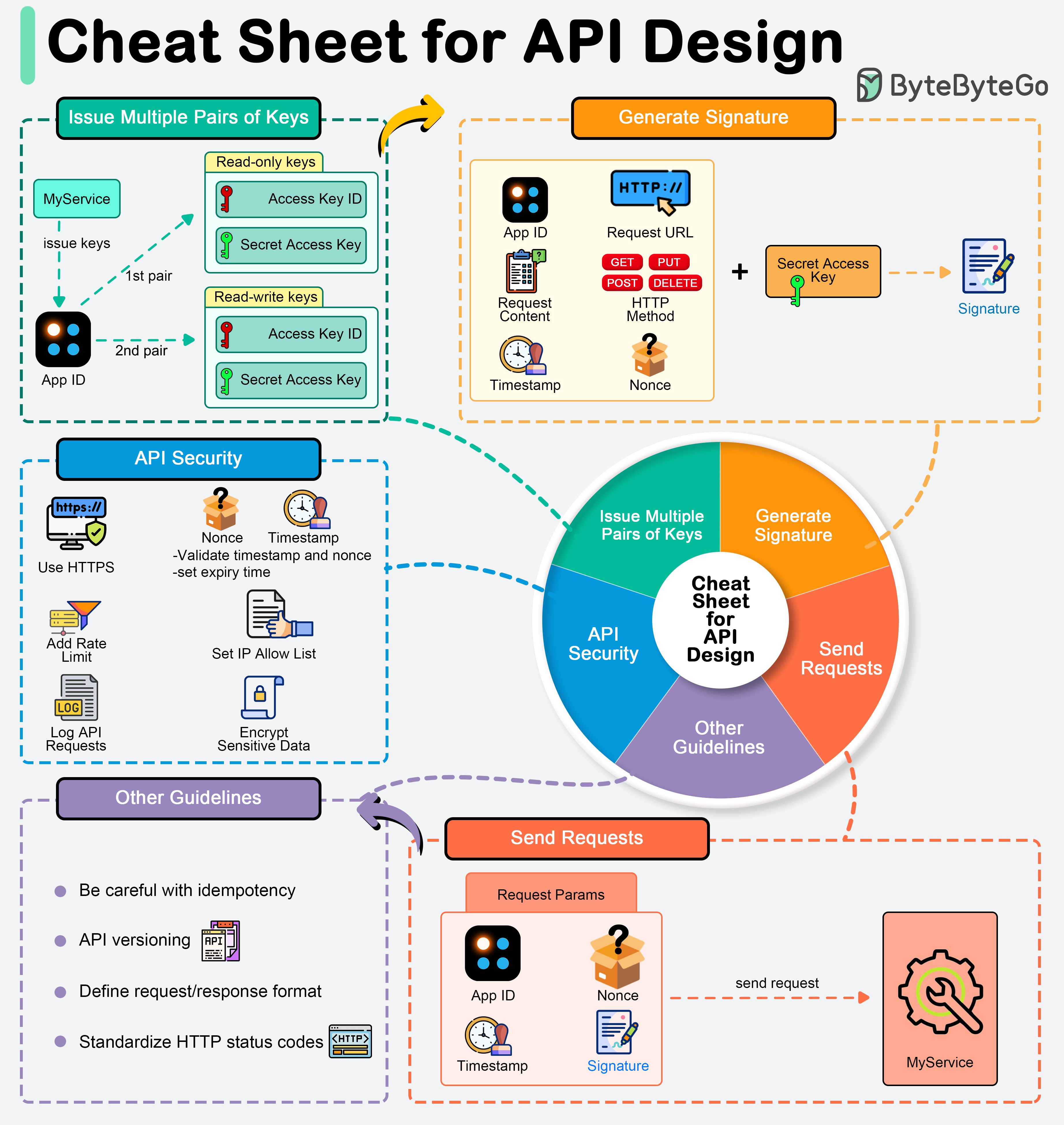
|
||||||
|
|
||||||
|
APIs expose business logic and data to external systems, so designing them securely and efficiently is important.
|
||||||
|
|
||||||
|
## API key generation
|
||||||
|
|
||||||
|
We normally generate one unique app ID for each client and generate different pairs of public key (access key) and private key (secret key) to cater to different authorizations. For example, we can generate one pair of keys for read-only access and another pair for read-write access.
|
||||||
|
|
||||||
|
## Signature generation
|
||||||
|
|
||||||
|
Signatures are used to verify the authenticity and integrity of API requests. They are generated using the secret key and typically involve the following steps:
|
||||||
|
|
||||||
|
* Collect parameters
|
||||||
|
* Create a string to sign
|
||||||
|
* Hash the string: Use a cryptographic hash function, like HMAC (Hash-based Message Authentication Code) in combination with SHA-256, to hash the string using the secret key.
|
||||||
|
* Send the requests
|
||||||
|
|
||||||
|
When designing an API, deciding what should be included in HTTP request parameters is crucial. Include the following in the request parameters:
|
||||||
|
|
||||||
|
* Authentication Credentials
|
||||||
|
* Timestamp: To prevent replay attacks.
|
||||||
|
* Request-specific Data: Necessary to process the request, such as user IDs, transaction details, or search queries.
|
||||||
|
* Nonces: Randomly generated strings included in each request to ensure that each request is unique and to prevent replay attacks.
|
||||||
|
|
||||||
|
## Security guidelines
|
||||||
|
|
||||||
|
To safeguard APIs against common vulnerabilities and threats, adhere to these security guidelines.
|
||||||
@@ -0,0 +1,40 @@
|
|||||||
|
---
|
||||||
|
title: "A Cheat Sheet for Designing Fault-Tolerant Systems"
|
||||||
|
description: "Top principles for designing robust, fault-tolerant systems."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0139-cheat-sheet-for-fault-tolerant-systems.png"
|
||||||
|
createdAt: "2024-02-14"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Fault Tolerance"
|
||||||
|
- "System Design"
|
||||||
|
---
|
||||||
|
|
||||||
|
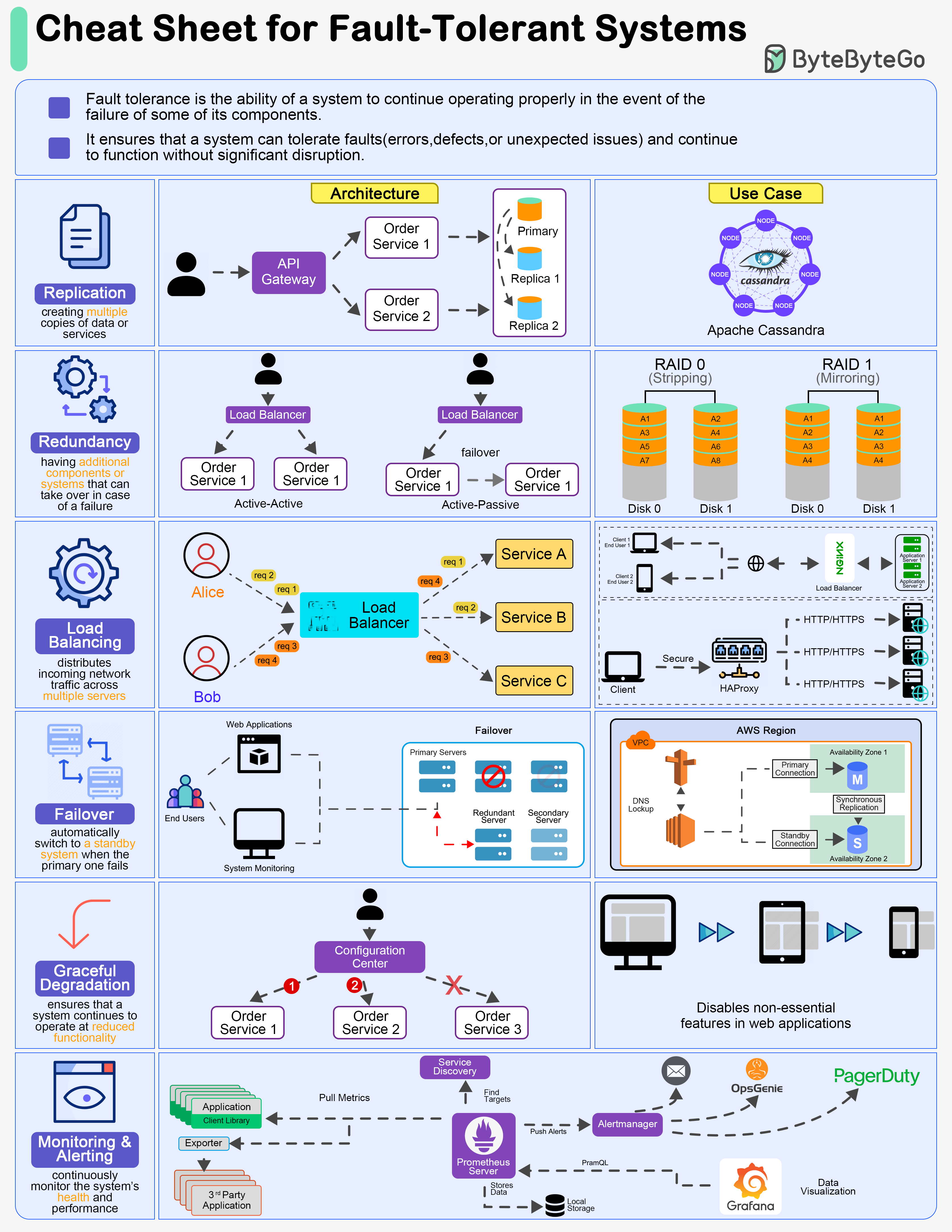
|
||||||
|
|
||||||
|
Designing fault-tolerant systems is crucial for ensuring high availability and reliability in various applications. Here are six top principles of designing fault-tolerant systems:
|
||||||
|
|
||||||
|
## Replication
|
||||||
|
|
||||||
|
Replication involves creating multiple copies of data or services across different nodes or locations.
|
||||||
|
|
||||||
|
## Redundancy
|
||||||
|
|
||||||
|
Redundancy refers to having additional components or systems that can take over in case of a failure.
|
||||||
|
|
||||||
|
## Load Balancing
|
||||||
|
|
||||||
|
Load balancing distributes incoming network traffic across multiple servers to ensure no single server becomes a point of failure.
|
||||||
|
|
||||||
|
## Failover Mechanisms
|
||||||
|
|
||||||
|
Failover mechanisms automatically switch to a standby system or component when the primary one fails.
|
||||||
|
|
||||||
|
## Graceful Degradation
|
||||||
|
|
||||||
|
Graceful degradation ensures that a system continues to operate at reduced functionality rather than completely failing when some components fail.
|
||||||
|
|
||||||
|
## Monitoring and Alerting
|
||||||
|
|
||||||
|
Continuously monitor the system's health and performance, and set up alerts for any anomalies or failures.
|
||||||
@@ -0,0 +1,32 @@
|
|||||||
|
---
|
||||||
|
title: "A cheat sheet for system designs"
|
||||||
|
description: "15 core concepts for system design in a handy cheat sheet."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0352-a-cheat-sheet-for-system-designs.png"
|
||||||
|
createdAt: "2024-03-08"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "system design"
|
||||||
|
- "architecture"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
The diagram below lists 15 core concepts when we design systems. The cheat sheet is straightforward to go through one by one. Save it for future reference!
|
||||||
|
|
||||||
|
* Requirement gathering
|
||||||
|
* System architecture
|
||||||
|
* Data design
|
||||||
|
* Domain design
|
||||||
|
* Scalability
|
||||||
|
* Reliability
|
||||||
|
* Availability
|
||||||
|
* Performance
|
||||||
|
* Security
|
||||||
|
* Maintainability
|
||||||
|
* Testing
|
||||||
|
* User experience design
|
||||||
|
* Cost estimation
|
||||||
|
* Documentation
|
||||||
|
* Migration plan
|
||||||
@@ -0,0 +1,48 @@
|
|||||||
|
---
|
||||||
|
title: "UML Class Diagrams Cheatsheet"
|
||||||
|
description: "A quick reference guide to UML class diagrams and their components."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0399-a-cheatsheet-for-uml-class-diagrams.png"
|
||||||
|
createdAt: "2024-02-22"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- UML
|
||||||
|
- Design Patterns
|
||||||
|
---
|
||||||
|
|
||||||
|
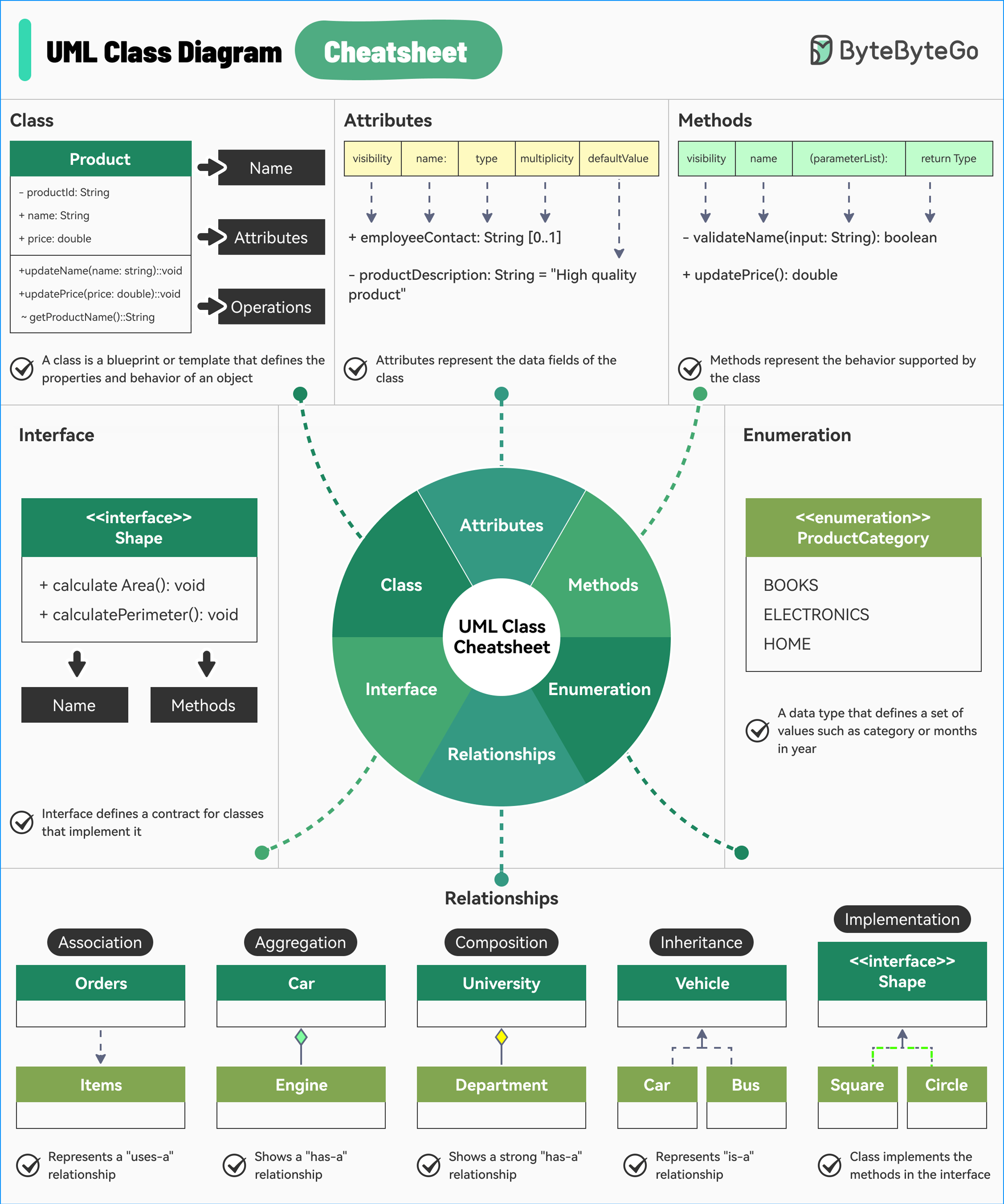
|
||||||
|
|
||||||
|
UML is a standard way to visualize the design of your system and class diagrams are used across the industry.
|
||||||
|
|
||||||
|
They consist of:
|
||||||
|
|
||||||
|
* **Class**
|
||||||
|
|
||||||
|
Acts as the blueprint that defines the properties and behavior of an object.
|
||||||
|
|
||||||
|
* **Attributes**
|
||||||
|
|
||||||
|
Attributes in a UML class diagram represent the data fields of the class.
|
||||||
|
|
||||||
|
* **Methods**
|
||||||
|
|
||||||
|
Methods in a UML class diagram represent the behavior that a class can perform.
|
||||||
|
|
||||||
|
* **Interfaces**
|
||||||
|
|
||||||
|
Defines a contract for classes that implement it. Includes a set of methods that the implementing classes must provide.
|
||||||
|
|
||||||
|
* **Enumeration**
|
||||||
|
|
||||||
|
A special data type that defines a set of named values such as product category or months in a year.
|
||||||
|
|
||||||
|
* **Relationships**
|
||||||
|
|
||||||
|
Determines how one class is related to another. Some common relationships are as follows:
|
||||||
|
|
||||||
|
* Association
|
||||||
|
* Aggregation
|
||||||
|
* Composition
|
||||||
|
* Inheritance
|
||||||
|
* Implementation
|
||||||
@@ -0,0 +1,23 @@
|
|||||||
|
---
|
||||||
|
title: 'A Cheatsheet on Comparing API Architectural Styles'
|
||||||
|
description: 'A quick reference guide comparing popular API architectural styles.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0092-cheatsheet-on-comparing-api-architectural-styles.png'
|
||||||
|
createdAt: '2024-02-26'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- API
|
||||||
|
- Architecture
|
||||||
|
---
|
||||||
|
|
||||||
|
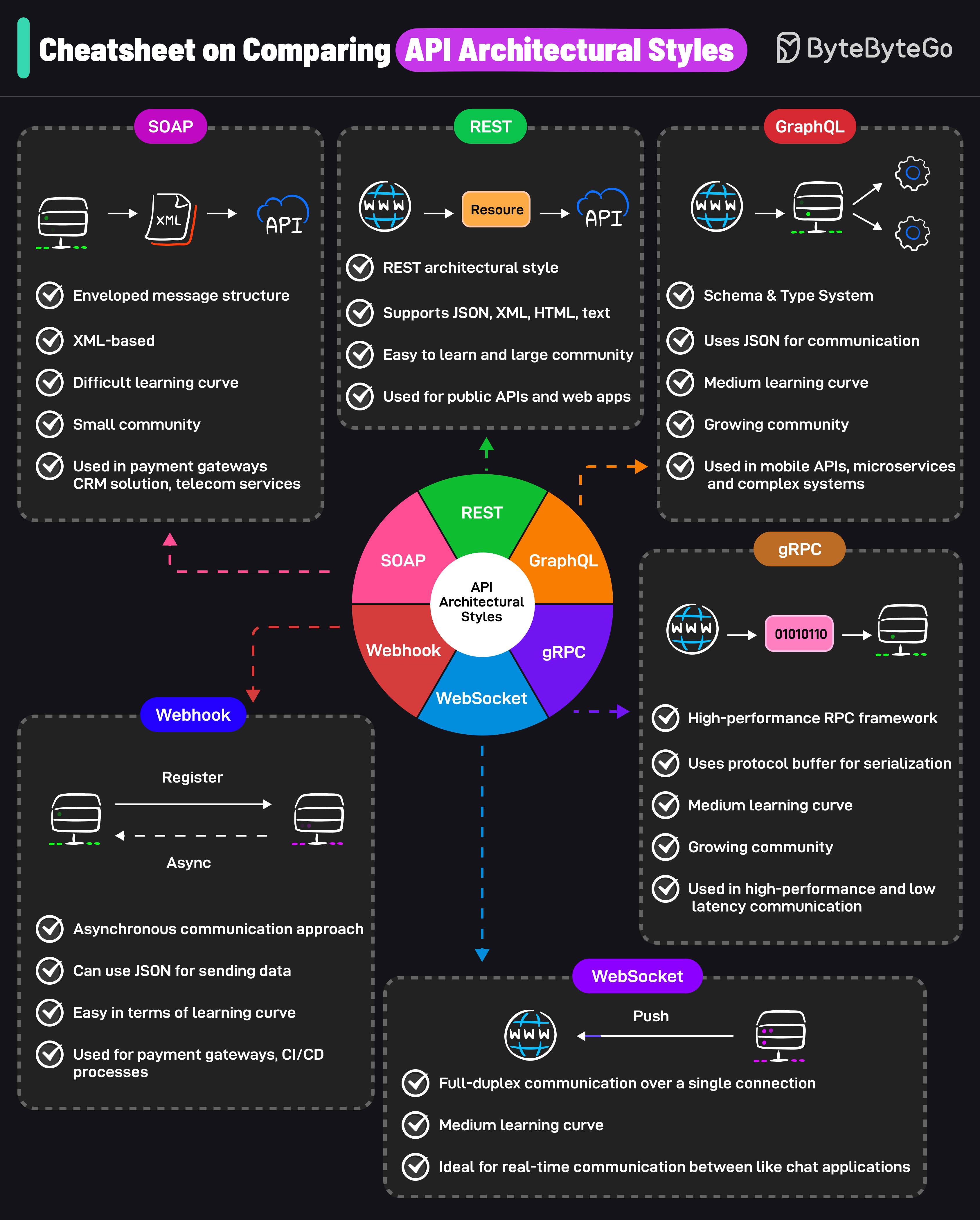
|
||||||
|
|
||||||
|
It covers the 6 most popular API architectural styles:
|
||||||
|
|
||||||
|
* SOAP
|
||||||
|
* REST
|
||||||
|
* GraphQL
|
||||||
|
* gRPC
|
||||||
|
* WebSocket
|
||||||
|
* Webhook
|
||||||
@@ -0,0 +1,88 @@
|
|||||||
|
---
|
||||||
|
title: "A Cheatsheet on Database Performance"
|
||||||
|
description: "Concise guide to optimize database performance with key strategies."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0062-a-cheatsheet-on-database-performance.png"
|
||||||
|
createdAt: "2024-03-11"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "database"
|
||||||
|
- "performance"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Database Performance Cheatsheet
|
||||||
|
|
||||||
|
Here's a cheatsheet on database performance:
|
||||||
|
|
||||||
|
### **1. Indexing**
|
||||||
|
|
||||||
|
* **Purpose**: Speed up data retrieval.
|
||||||
|
* **Considerations**:
|
||||||
|
* Over-indexing can slow down writes.
|
||||||
|
* Regularly review and optimize indexes.
|
||||||
|
|
||||||
|
### **2. Query Optimization**
|
||||||
|
|
||||||
|
* **Techniques**:
|
||||||
|
* Use `EXPLAIN` to analyze query plans.
|
||||||
|
* Avoid `SELECT *`.
|
||||||
|
* Write efficient `WHERE` clauses.
|
||||||
|
|
||||||
|
### **3. Connection Pooling**
|
||||||
|
|
||||||
|
* **Benefits**:
|
||||||
|
* Reduces overhead of establishing new connections.
|
||||||
|
* Improves response times.
|
||||||
|
|
||||||
|
### **4. Caching**
|
||||||
|
|
||||||
|
* **Levels**:
|
||||||
|
* Application-level (e.g., Memcached, Redis).
|
||||||
|
* Database-level (query cache).
|
||||||
|
|
||||||
|
### **5. Sharding**
|
||||||
|
|
||||||
|
* **Definition**: Distribute data across multiple databases.
|
||||||
|
* **Use Cases**:
|
||||||
|
* Handling large datasets.
|
||||||
|
* Improving write performance.
|
||||||
|
|
||||||
|
### **6. Replication**
|
||||||
|
|
||||||
|
* **Types**:
|
||||||
|
* Master-slave.
|
||||||
|
* Master-master.
|
||||||
|
* **Purpose**:
|
||||||
|
* Read scaling.
|
||||||
|
* High availability.
|
||||||
|
|
||||||
|
### **7. Hardware**
|
||||||
|
|
||||||
|
* **Considerations**:
|
||||||
|
* Sufficient RAM.
|
||||||
|
* Fast storage (SSD).
|
||||||
|
* Adequate CPU.
|
||||||
|
|
||||||
|
### **8. Monitoring**
|
||||||
|
|
||||||
|
* **Metrics**:
|
||||||
|
* Query response times.
|
||||||
|
* CPU usage.
|
||||||
|
* Disk I/O.
|
||||||
|
|
||||||
|
### **9. Normalization/Denormalization**
|
||||||
|
|
||||||
|
* **Normalization**: Reduces redundancy.
|
||||||
|
* **Denormalization**: Improves read performance (trade-off with redundancy).
|
||||||
|
|
||||||
|
### **10. Partitioning**
|
||||||
|
|
||||||
|
* **Types**:
|
||||||
|
* Horizontal.
|
||||||
|
* Vertical.
|
||||||
|
* **Purpose**:
|
||||||
|
* Improve query performance.
|
||||||
|
* Easier data management.
|
||||||
@@ -0,0 +1,30 @@
|
|||||||
|
---
|
||||||
|
title: "Infrastructure as Code Landscape Cheatsheet"
|
||||||
|
description: "A quick reference guide to the Infrastructure as Code landscape."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0063-a-cheatsheet-on-infrastructure-as-code-landscape.png"
|
||||||
|
createdAt: "2024-02-18"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Infrastructure as Code"
|
||||||
|
- "DevOps"
|
||||||
|
---
|
||||||
|
|
||||||
|
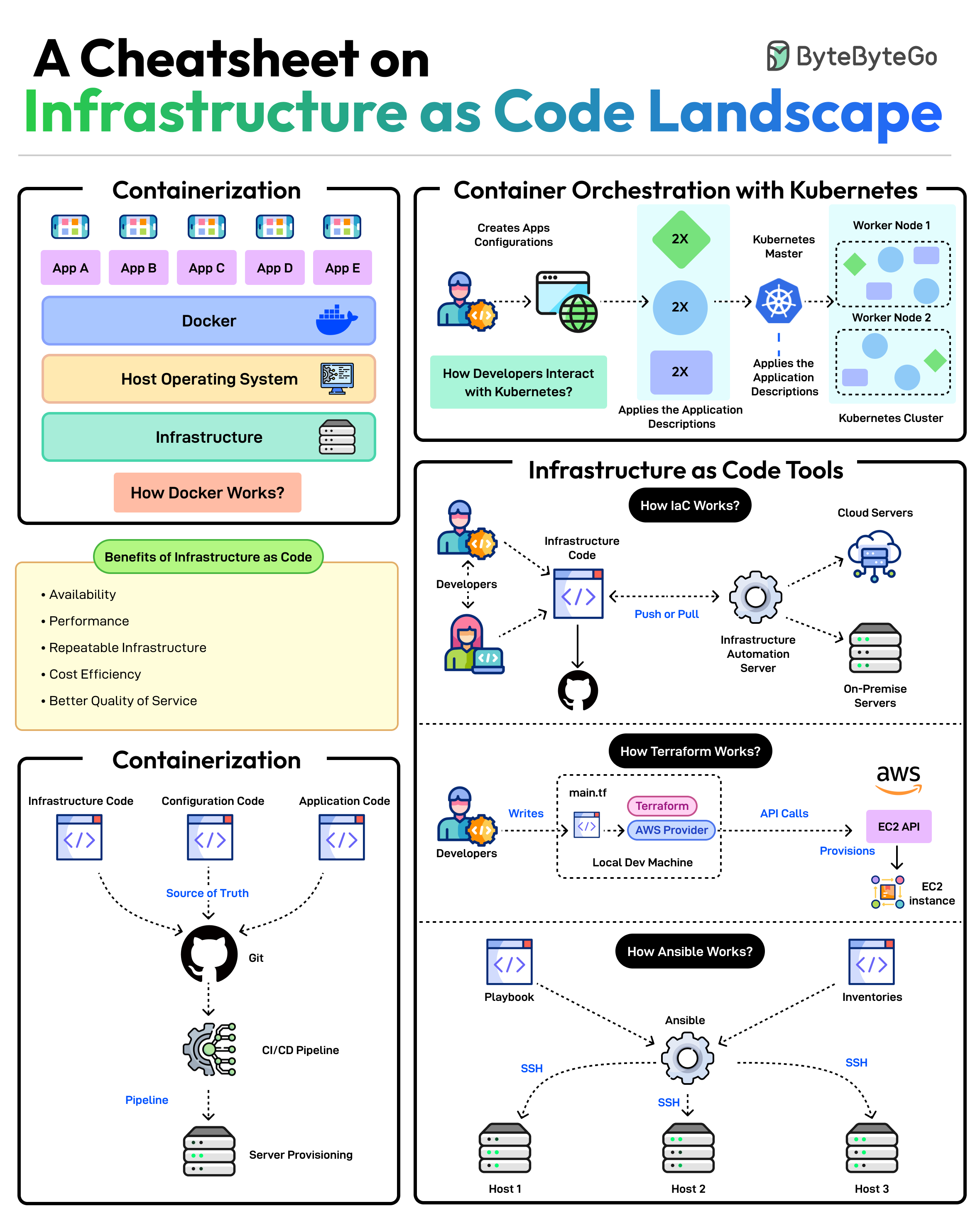
|
||||||
|
|
||||||
|
Scalable infrastructure provisioning provides several benefits related to availability, scalability, repeatability, and cost-effectiveness.
|
||||||
|
|
||||||
|
But how do you achieve this?
|
||||||
|
|
||||||
|
Provisioning infrastructure using code is the key to scalable infra management.
|
||||||
|
|
||||||
|
There are multiple strategies that can help:
|
||||||
|
|
||||||
|
* Containerization is one of the first strategies to make application deployments based on code. Docker is one of the most popular ways to containerize the application.
|
||||||
|
|
||||||
|
* Next, container orchestration becomes a necessity when dealing with multiple containers in an application. This is where container orchestration tools like Kubernetes become important.
|
||||||
|
|
||||||
|
* IaC treats infrastructure provisioning and configuration as code, allowing developers to define the application infrastructure in files that can be versioned, tested, and reused. Popular tools such as Terraform, AWS CloudFormation, and Ansible can be used. Ansible is more of a configuration tool.
|
||||||
|
|
||||||
|
* GitOps leverages a Git workflow combined with CI/CD to automate infrastructure and configuration updates.
|
||||||
@@ -0,0 +1,45 @@
|
|||||||
|
---
|
||||||
|
title: A Cheatsheet to Build Secure APIs
|
||||||
|
description: Concise strategies for building secure APIs to protect your application.
|
||||||
|
image: https://assets.bytebytego.com/diagrams/0064-a-cheatsheet-to-build-secure-apis.png
|
||||||
|
createdAt: '2024-02-23'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- API Security
|
||||||
|
- Security
|
||||||
|
---
|
||||||
|
|
||||||
|
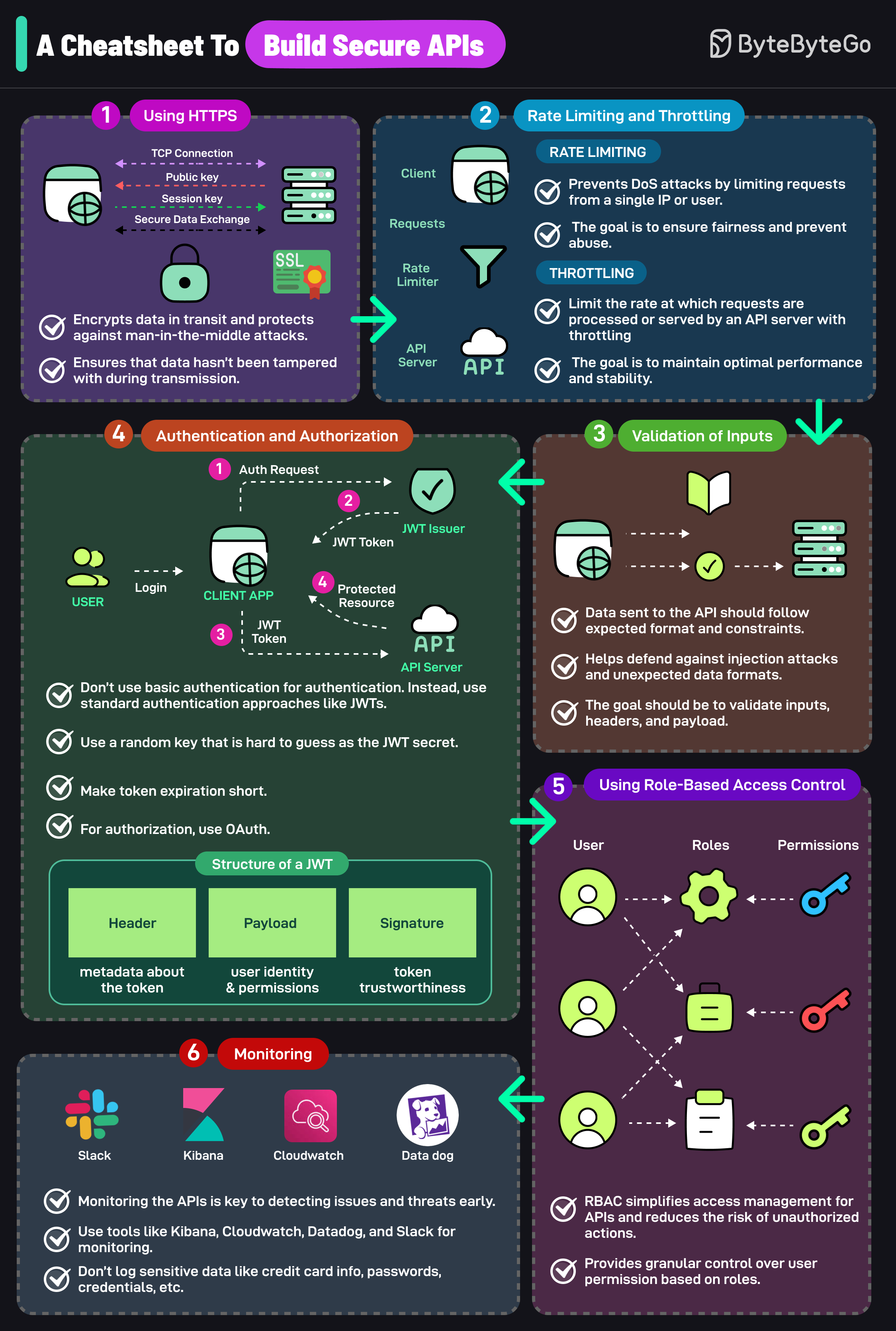
|
||||||
|
|
||||||
|
An insecure API can compromise your entire application. Follow these strategies to mitigate the risk:
|
||||||
|
|
||||||
|
## Using HTTPS
|
||||||
|
|
||||||
|
- Encrypts data in transit and protects against man-in-the-middle attacks.
|
||||||
|
- This ensures that data hasn’t been tampered with during transmission.
|
||||||
|
|
||||||
|
## Rate Limiting and Throttling
|
||||||
|
- Rate limiting prevents DoS attacks by limiting requests from a single IP or user.
|
||||||
|
- The goal is to ensure fairness and prevent abuse.
|
||||||
|
|
||||||
|
## Validation of Inputs
|
||||||
|
- Defends against injection attacks and unexpected data format.
|
||||||
|
- Validate headers, inputs, and payload.
|
||||||
|
|
||||||
|
## Authentication and Authorization
|
||||||
|
- Don’t use basic auth for authentication.
|
||||||
|
- Instead, use a standard authentication approach like JWTs
|
||||||
|
* Use a random key that is hard to guess as the JWT secret
|
||||||
|
* Make token expiration short
|
||||||
|
-For authorization, use OAuth
|
||||||
|
|
||||||
|
## Using Role-based Access Control
|
||||||
|
- RBAC simplifies access management for APIs and reduces the risk of unauthorized actions.
|
||||||
|
- Granular control over user permission based on roles.
|
||||||
|
|
||||||
|
## Monitoring
|
||||||
|
- Monitoring the APIs is the key to detecting issues and threats early.
|
||||||
|
- Use tools like Kibana, Cloudwatch, Datadog, and Slack for monitoring
|
||||||
|
- Don’t log sensitive data like credit card info, passwords, credentials, etc.
|
||||||
@@ -0,0 +1,68 @@
|
|||||||
|
---
|
||||||
|
title: "A Crash Course on Database Sharding"
|
||||||
|
description: "Learn database sharding: concepts, techniques, and implementation."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0065-a-crash-course-on-database-sharding.png"
|
||||||
|
createdAt: "2024-03-04"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "database"
|
||||||
|
- "sharding"
|
||||||
|
---
|
||||||
|
|
||||||
|
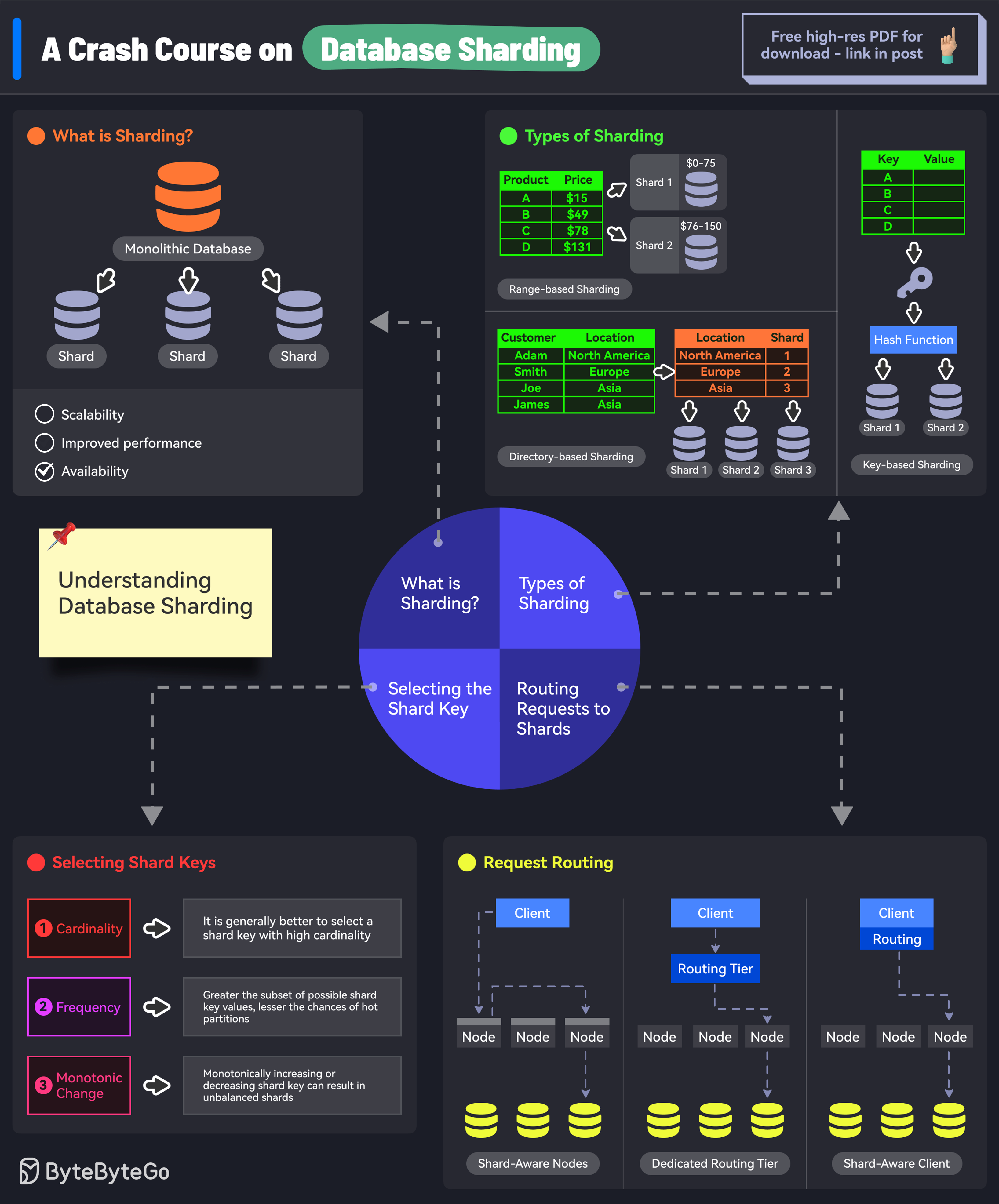
|
||||||
|
|
||||||
|
## What is Database Sharding?
|
||||||
|
|
||||||
|
Database sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards. The word shard means a small piece of something bigger.
|
||||||
|
|
||||||
|
Sharding is also known as horizontal partitioning. Each shard contains a portion of the data, and all shards together contain all of the data.
|
||||||
|
|
||||||
|
## Why Sharding?
|
||||||
|
|
||||||
|
Sharding is implemented to solve these problems:
|
||||||
|
|
||||||
|
* **Too much data on one machine**: A single database server can only handle so much data.
|
||||||
|
|
||||||
|
* **Too many requests on one machine**: A single database server can only handle so many requests.
|
||||||
|
|
||||||
|
* **High Latency**: As data grows, query latency increases.
|
||||||
|
|
||||||
|
## How Sharding Works
|
||||||
|
|
||||||
|
Sharding involves splitting a database into multiple, independent parts (shards) and distributing them across different servers or machines. Each shard contains a subset of the data, and all shards collectively hold the entire dataset.
|
||||||
|
|
||||||
|
### Sharding Key
|
||||||
|
|
||||||
|
A sharding key is a column in the database table that determines how the data is distributed across the shards. The sharding key is used by the sharding algorithm to determine which shard a particular row of data should be stored in.
|
||||||
|
|
||||||
|
### Sharding Algorithm
|
||||||
|
|
||||||
|
The sharding algorithm is the logic that determines which shard a particular row of data should be stored in. The sharding algorithm uses the sharding key to make this determination.
|
||||||
|
|
||||||
|
Here are some common sharding algorithms:
|
||||||
|
|
||||||
|
* **Range-based sharding**: Data is divided into ranges based on the sharding key. For example, users with IDs from 1 to 1000 might be stored in shard 1, users with IDs from 1001 to 2000 in shard 2, and so on.
|
||||||
|
|
||||||
|
* **Hash-based sharding**: A hash function is applied to the sharding key to determine the shard. For example, `shard_id = hash(user_id) % num_shards`.
|
||||||
|
|
||||||
|
* **Directory-based sharding**: A lookup table (or directory) is used to map sharding keys to shard locations.
|
||||||
|
|
||||||
|
## Sharding Approaches
|
||||||
|
|
||||||
|
* **Application-level sharding**: The application is responsible for determining which shard to use for each query.
|
||||||
|
|
||||||
|
* **Middleware sharding**: A middleware layer sits between the application and the database and handles the sharding logic.
|
||||||
|
|
||||||
|
* **Database-native sharding**: The database system itself provides sharding capabilities.
|
||||||
|
|
||||||
|
## Sharding Challenges
|
||||||
|
|
||||||
|
* **Increased Complexity**: Sharding adds complexity to the database infrastructure and application code.
|
||||||
|
|
||||||
|
* **Data Distribution**: Choosing the right sharding key and algorithm is crucial for even data distribution and performance.
|
||||||
|
|
||||||
|
* **Joins and Transactions**: Performing joins and transactions across shards can be challenging and may require distributed transaction management.
|
||||||
|
|
||||||
|
* **Resharding**: Changing the sharding scheme after the database has been sharded can be a complex and time-consuming process.
|
||||||
@@ -0,0 +1,35 @@
|
|||||||
|
---
|
||||||
|
title: "A Crash Course on Architectural Scalability"
|
||||||
|
description: "Learn about architectural scalability, bottlenecks, and key techniques."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0293-a-crash-course-on-architectural-scalability.png"
|
||||||
|
createdAt: "2024-02-10"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Scalability"
|
||||||
|
- "Architecture"
|
||||||
|
---
|
||||||
|
|
||||||
|
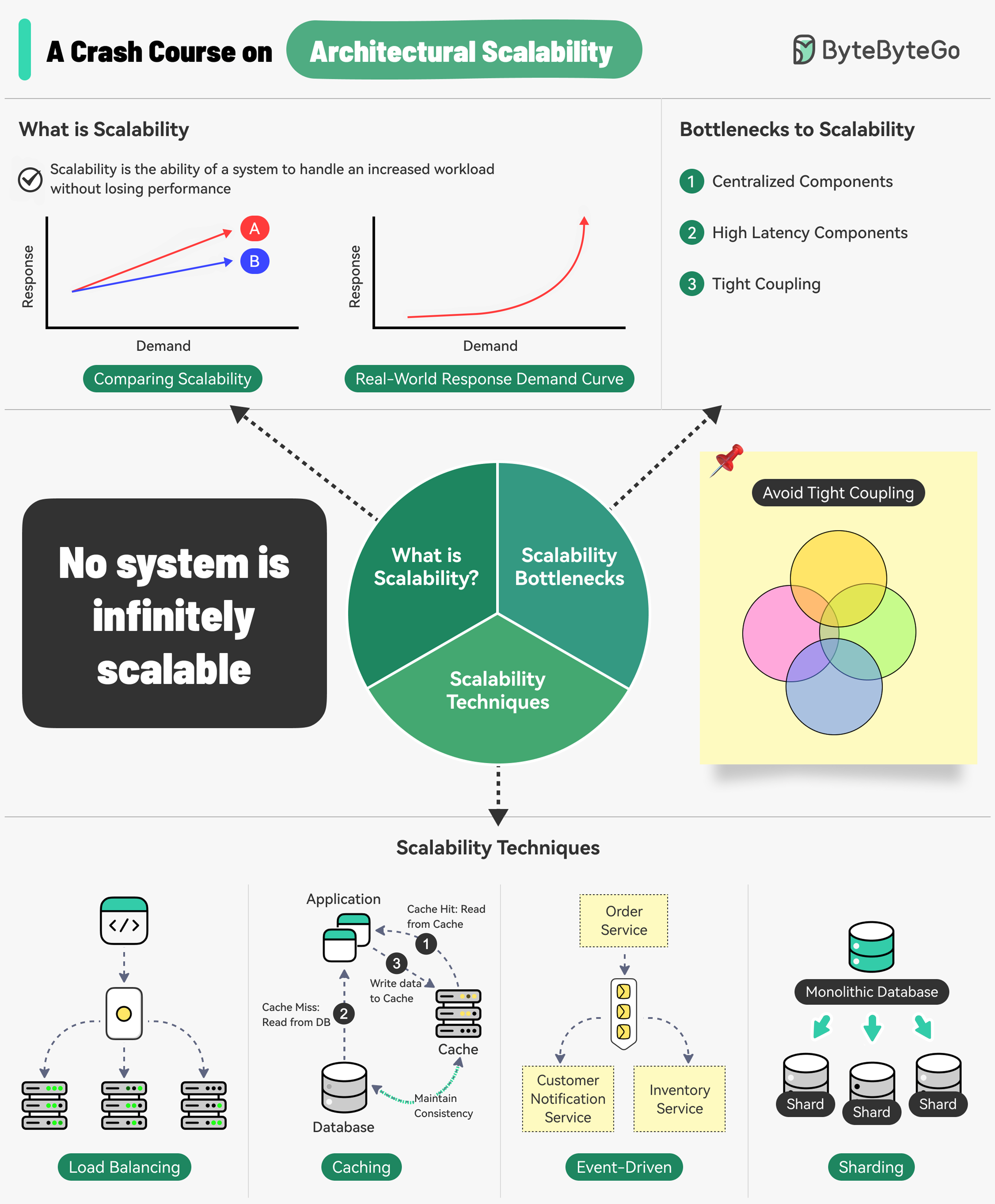
|
||||||
|
|
||||||
|
Scalability is the ability of a system to handle an increased workload without losing performance.
|
||||||
|
|
||||||
|
However, we can also look at scalability in terms of the scaling strategy.
|
||||||
|
|
||||||
|
Scalability is the system’s ability to handle an increased workload by repeatedly applying a cost-effective strategy. This means it can be difficult to scale a system beyond a certain point if the scaling strategy is not financially viable.
|
||||||
|
|
||||||
|
Three main bottlenecks to scalability are:
|
||||||
|
|
||||||
|
1. Centralized components: This can become a single point of failure
|
||||||
|
2. High Latency Components: These are components that perform time-consuming operations.
|
||||||
|
3. Tight Coupling: Makes the components difficult to scale
|
||||||
|
|
||||||
|
Therefore, to build a scalable system, we should follow the principles of statelessness, loose coupling, and asynchronous processing.
|
||||||
|
|
||||||
|
Some common techniques for improving scalability are as follows:
|
||||||
|
|
||||||
|
* Load Balancing: Spread requests across multiple servers to prevent a single server from becoming a bottleneck.
|
||||||
|
* Caching: Store the most commonly request information in memory.
|
||||||
|
* Event-Driven Processing: Use an async processing approach to process long-running tasks.
|
||||||
|
* Sharding: Split a large dataset into smaller subsets called shards for horizontal scalability.
|
||||||
@@ -0,0 +1,46 @@
|
|||||||
|
---
|
||||||
|
title: "A Roadmap for Full-Stack Development"
|
||||||
|
description: "A guide to the technologies and skills needed for full-stack development."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0199-full-stack-developer-roadmap.png"
|
||||||
|
createdAt: "2024-02-18"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- "Full-Stack Development"
|
||||||
|
- "Software Development"
|
||||||
|
---
|
||||||
|
|
||||||
|
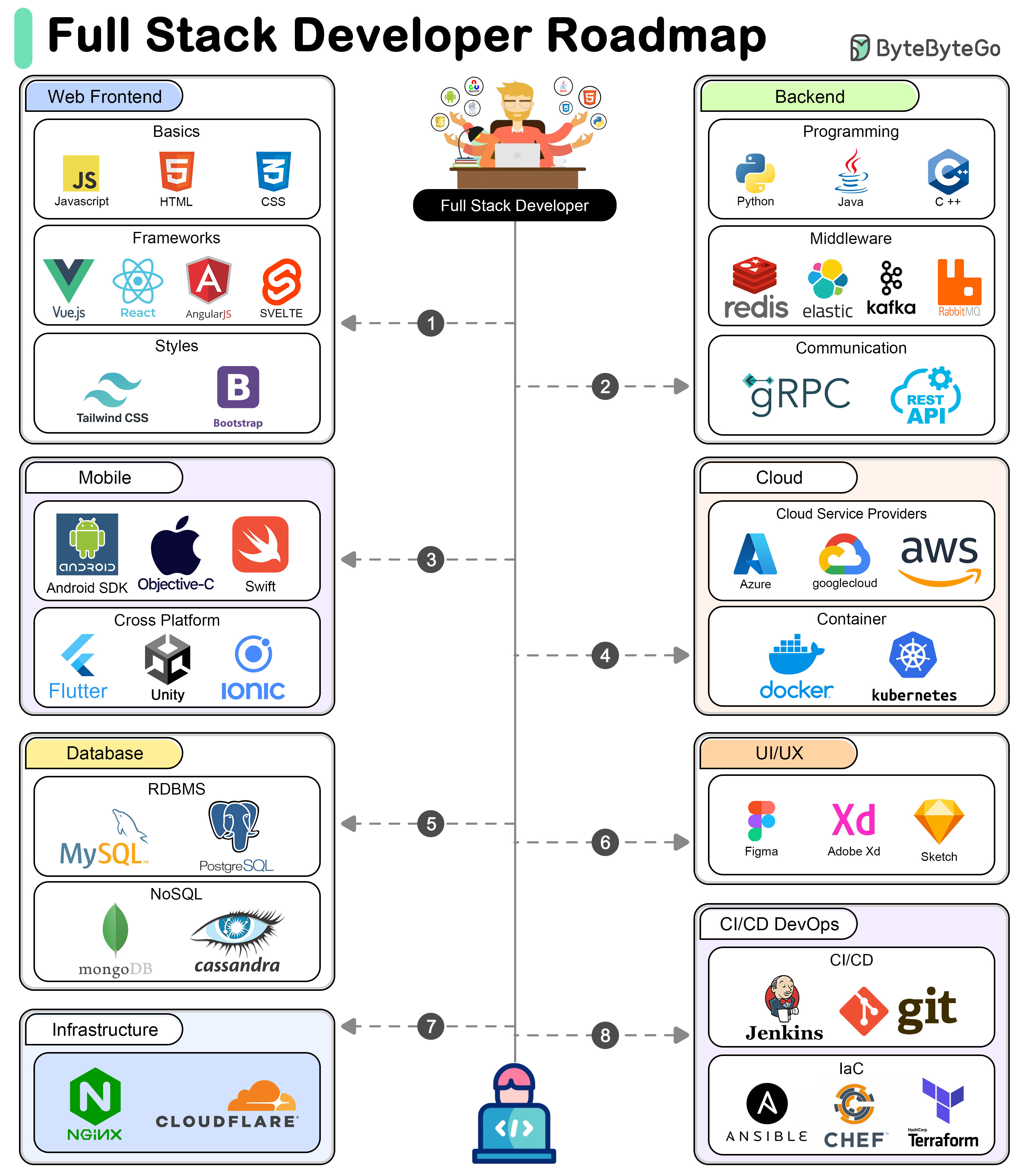
|
||||||
|
|
||||||
|
A full-stack developer needs to be proficient in a wide range of technologies and tools across different areas of software development. Here’s a comprehensive look at the technical stacks required for a full-stack developer.
|
||||||
|
|
||||||
|
## Technical Stacks for Full-Stack Development
|
||||||
|
|
||||||
|
* **Frontend Development**
|
||||||
|
|
||||||
|
Frontend development involves creating the user interface and user experience of a web application.
|
||||||
|
|
||||||
|
* **Backend Development**
|
||||||
|
|
||||||
|
Backend development involves managing the server-side logic, databases, and integration of various services.
|
||||||
|
|
||||||
|
* **Database Development**
|
||||||
|
|
||||||
|
Database development involves managing data storage, retrieval, and manipulation.
|
||||||
|
|
||||||
|
* **Mobile Development**
|
||||||
|
|
||||||
|
Mobile development involves creating applications for mobile devices.
|
||||||
|
|
||||||
|
* **Cloud Computing**
|
||||||
|
|
||||||
|
Cloud computing involves deploying and managing applications on cloud platforms.
|
||||||
|
|
||||||
|
* **UI/UX Design**
|
||||||
|
|
||||||
|
UI/UX design involves designing the user interface and experience of applications.
|
||||||
|
|
||||||
|
* **Infrastructure and DevOps**
|
||||||
|
|
||||||
|
Infrastructure and DevOps involve managing the infrastructure, deployment, and continuous integration/continuous delivery (CI/CD) of applications.
|
||||||
@@ -0,0 +1,35 @@
|
|||||||
|
---
|
||||||
|
title: "0 to 1.5 Billion Guests: Airbnb's Architectural Evolution"
|
||||||
|
description: "Explore Airbnb's architectural evolution to support 1.5 billion guests."
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0427-zero-to-1-5-billion-guests-airbnb-s-architectural-evolution.png'
|
||||||
|
createdAt: '2024-02-27'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- real-world-case-studies
|
||||||
|
tags:
|
||||||
|
- Architecture
|
||||||
|
- Microservices
|
||||||
|
---
|
||||||
|
|
||||||
|
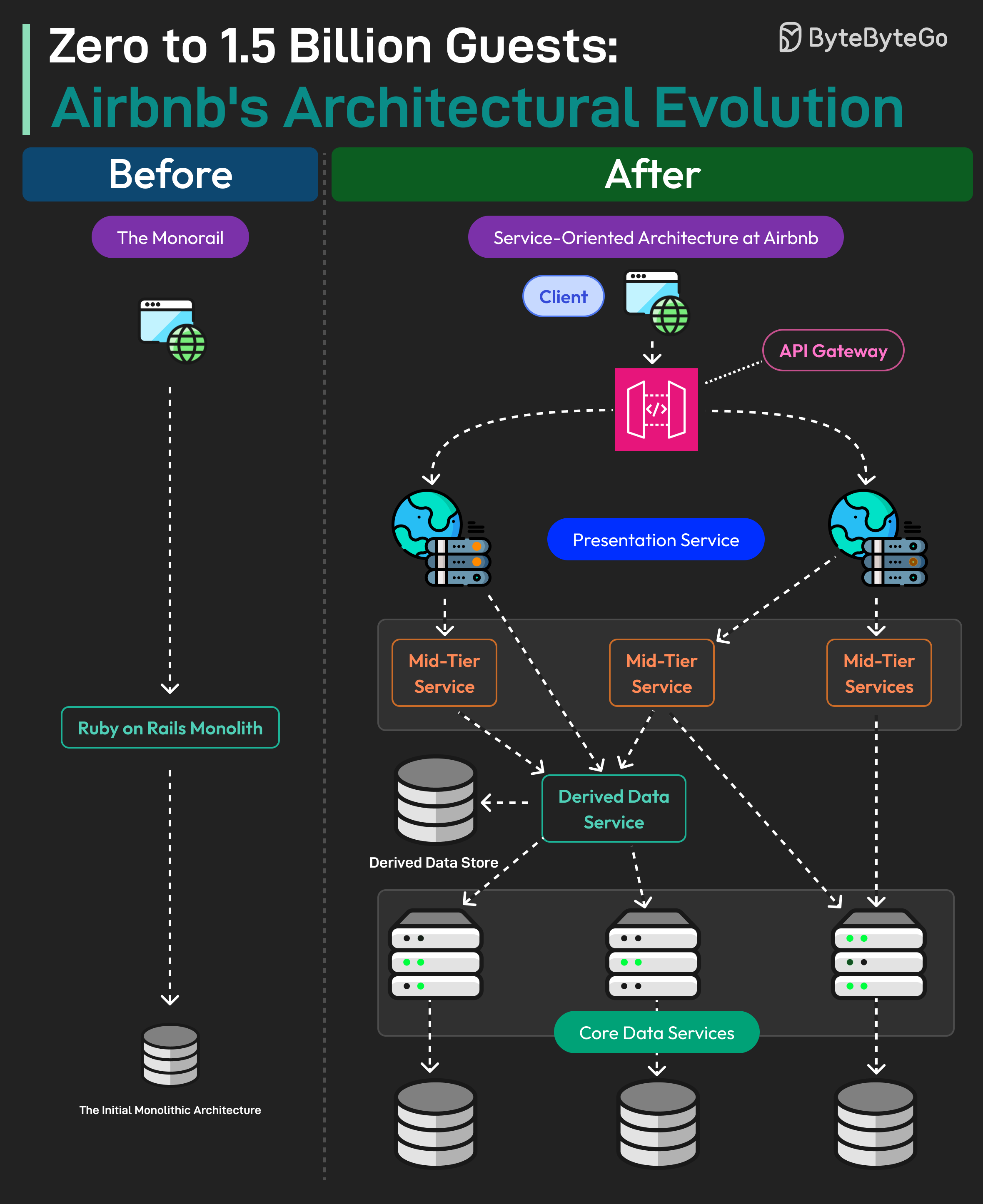
|
||||||
|
|
||||||
|
Airbnb operates in 200+ countries and has helped 4 million hosts welcome over 1.5 billion guests across the world.
|
||||||
|
|
||||||
|
What powers Airbnb technically?
|
||||||
|
|
||||||
|
Airbnb started as a monolithic application. It was built using Ruby-on-Rails and was internally known as the Monorail.
|
||||||
|
|
||||||
|
The monolith was a single-tier unit responsible for both client and server-side functionality.
|
||||||
|
|
||||||
|
However, as Airbnb went into hypergrowth, the Monorail started facing issues. This is when they began a migration journey to move from monolithic to Service-Oriented Architecture.
|
||||||
|
|
||||||
|
For Airbnb, SOA is a network of loosely coupled services where clients make their requests to a gateway and the gateway routes these requests to multiple services and databases.
|
||||||
|
|
||||||
|
Various types of services were built such as:
|
||||||
|
|
||||||
|
* **Data Service:** This is the bottom layer and acts as the entry point for all read and write operations on the data entities.
|
||||||
|
* **Derived Data Service:** These services read from data services and apply basic business logic.
|
||||||
|
* **Middle Tier Service:** They manage important business logic that doesn’t fit at the data service level or derived data service level.
|
||||||
|
* **Presentation Service:** They aggregate data from all other services and also apply some frontend-specific business logic.
|
||||||
|
|
||||||
|
After the migration, the Monorail was eliminated and all reads/writes were migrated to the new services.
|
||||||
@@ -0,0 +1,30 @@
|
|||||||
|
---
|
||||||
|
title: "Algorithms for System Design Interviews"
|
||||||
|
description: "Essential algorithms for system design interviews and software engineers."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0068-algorithms-geo-hash-linkedin.jpg"
|
||||||
|
createdAt: "2024-03-08"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- System Design
|
||||||
|
- Algorithms
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
What are some of the algorithms you should know before taking system design interviews?
|
||||||
|
|
||||||
|
I put together a list and explained why they are important. Those algorithms are not only useful for interviews but good to understand for any software engineer.
|
||||||
|
|
||||||
|
One thing to keep in mind is that understanding “how those algorithms are used in real-world systems” is generally more important than the implementation details in a system design interview.
|
||||||
|
|
||||||
|
What do the stars mean in the diagram?
|
||||||
|
|
||||||
|
It’s very difficult to rank algorithms by importance objectively. I’m open to suggestions and making adjustments.
|
||||||
|
|
||||||
|
Five-star: Very important. Try to understand how it works and why.
|
||||||
|
|
||||||
|
Three-star: Important to some extent. You may not need to know the implementation details.
|
||||||
|
|
||||||
|
One-star: Advanced. Good to know for senior candidates.
|
||||||
@@ -0,0 +1,44 @@
|
|||||||
|
---
|
||||||
|
title: "Amazon Prime Video Monitoring Service"
|
||||||
|
description: "Learn how Amazon Prime Video monitoring saved 90% cost by moving to monolith."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0328-serverless-to-monolithic.jpeg"
|
||||||
|
createdAt: "2024-02-23"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-architecture
|
||||||
|
tags:
|
||||||
|
- "Microservices"
|
||||||
|
- "System Design"
|
||||||
|
---
|
||||||
|
|
||||||
|
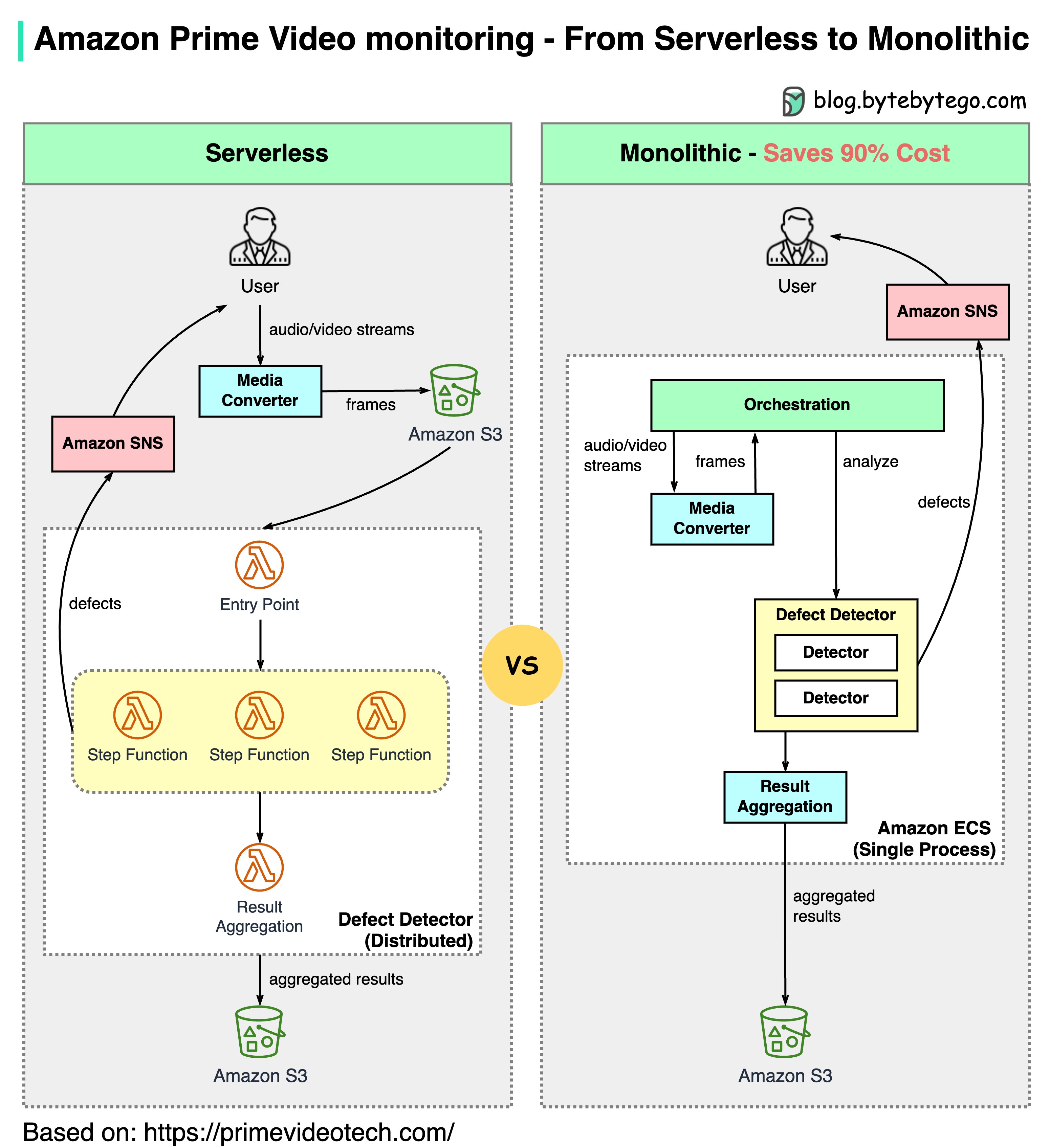
|
||||||
|
|
||||||
|
Why did Amazon Prime Video monitoring move **from serverless to monolithic**? How can it save 90% cost?
|
||||||
|
|
||||||
|
The diagram above shows the architecture comparison before and after the migration.
|
||||||
|
|
||||||
|
## What is Amazon Prime Video Monitoring Service?
|
||||||
|
|
||||||
|
Prime Video service needs to monitor the quality of thousands of live streams. The monitoring tool automatically analyzes the streams in real time and identifies quality issues like block corruption, video freeze, and sync problems. This is an important process for customer satisfaction.
|
||||||
|
|
||||||
|
There are 3 steps: media converter, defect detector, and real-time notification.
|
||||||
|
|
||||||
|
* What is the problem with the old architecture?
|
||||||
|
|
||||||
|
The old architecture was based on Amazon Lambda, which was good for building services quickly. However, it was not cost-effective when running the architecture at a high scale. The two most expensive operations are:
|
||||||
|
|
||||||
|
1. The orchestration workflow - AWS step functions charge users by state transitions and the orchestration performs multiple state transitions every second.
|
||||||
|
|
||||||
|
2. Data passing between distributed components - the intermediate data is stored in Amazon S3 so that the next stage can download. The download can be costly when the volume is high.
|
||||||
|
|
||||||
|
* Monolithic architecture saves 90% cost
|
||||||
|
|
||||||
|
A monolithic architecture is designed to address the cost issues. There are still 3 components, but the media converter and defect detector are deployed in the same process, saving the cost of passing data over the network. Surprisingly, this approach to deployment architecture change led to 90% cost savings!
|
||||||
|
|
||||||
|
This is an interesting and unique case study because microservices have become a go-to and fashionable choice in the tech industry. It's good to see that we are having more discussions about evolving the architecture and having more honest discussions about its pros and cons. Decomposing components into distributed microservices comes with a cost.
|
||||||
|
|
||||||
|
* What did Amazon leaders say about this?
|
||||||
|
|
||||||
|
Amazon CTO Werner Vogels: “Building **evolvable software systems** is a strategy, not a religion. And revisiting your architectures with an open mind is a must.”
|
||||||
|
|
||||||
|
Ex Amazon VP Sustainability Adrian Cockcroft: “The Prime Video team had followed a path I call **Serverless First**…I don’t advocate **Serverless Only**”.
|
||||||
@@ -0,0 +1,27 @@
|
|||||||
|
---
|
||||||
|
title: 'API Gateway 101'
|
||||||
|
description: 'Learn the fundamentals of API Gateways: functions, benefits, and more.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0074-api-gateway-101.png'
|
||||||
|
createdAt: '2024-02-15'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- API Gateway
|
||||||
|
- Microservices
|
||||||
|
---
|
||||||
|
|
||||||
|
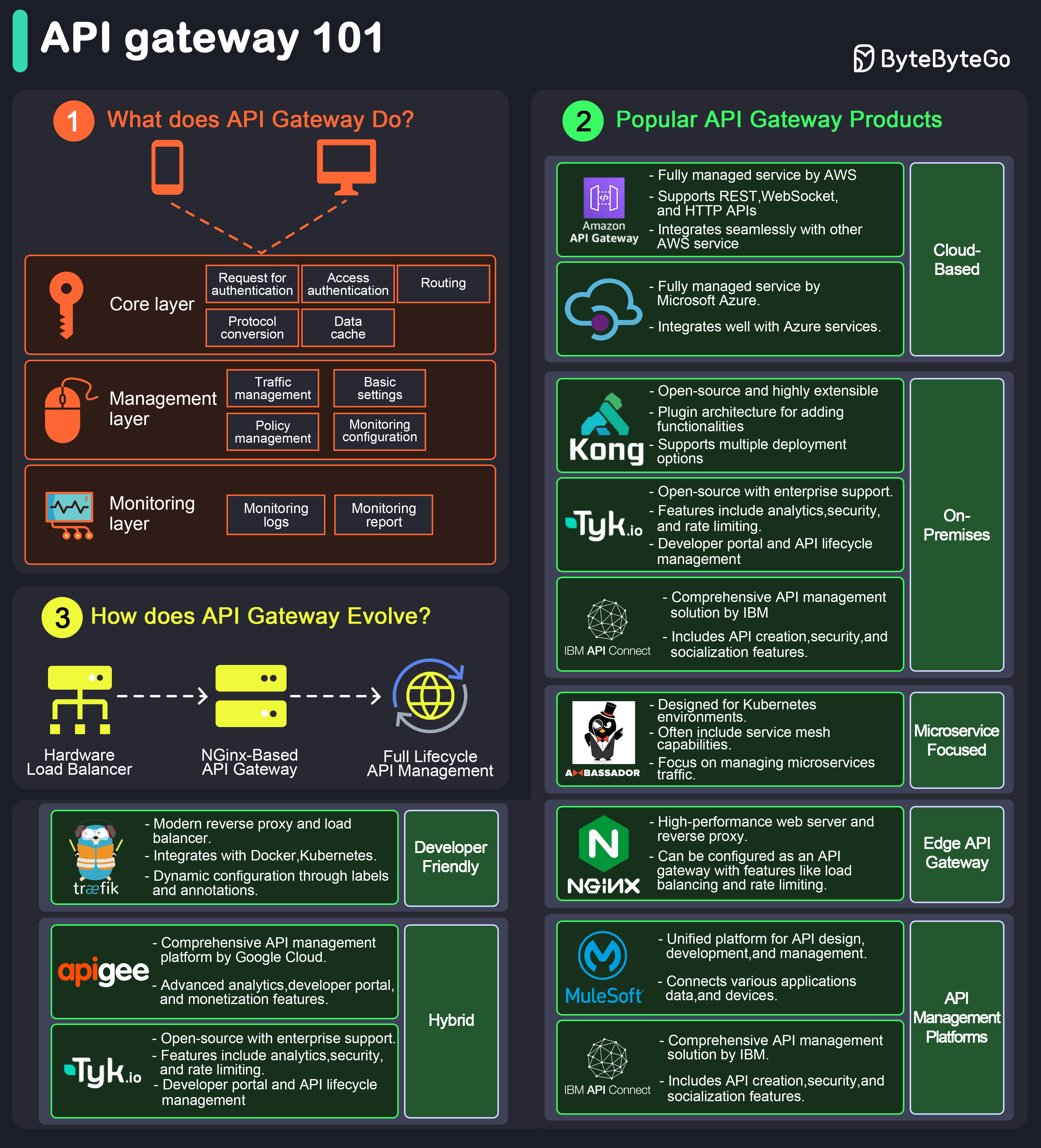
|
||||||
|
|
||||||
|
An API gateway is a server that acts as an API front-end, receiving API requests, enforcing throttling and security policies, passing requests to the back-end service, and then returning the appropriate result to the client.
|
||||||
|
|
||||||
|
It is essentially a middleman between the client and the server, managing and optimizing API traffic.
|
||||||
|
|
||||||
|
**Key Functions of an API Gateway**
|
||||||
|
|
||||||
|
* **Request Routing:** Directs incoming API requests to the appropriate backend service.
|
||||||
|
* **Load Balancing:** Distributes requests across multiple servers to ensure no single server is overwhelmed.
|
||||||
|
* **Security:** Implements security measures like authentication, authorization, and data encryption.
|
||||||
|
* **Rate Limiting and Throttling:** Controls the number of requests a client can make within a certain period.
|
||||||
|
* **API Composition:** Combines multiple backend API requests into a single frontend request to optimize performance.
|
||||||
|
* **Caching:** Stores responses temporarily to reduce the need for repeated processing.
|
||||||
@@ -0,0 +1,20 @@
|
|||||||
|
---
|
||||||
|
title: 'API of APIs - App Integrations'
|
||||||
|
description: 'Explore API of APIs and app integrations in this detailed guide.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0426-api-of-apis-app-integrations.png'
|
||||||
|
createdAt: '2024-02-13'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- real-world-case-studies
|
||||||
|
tags:
|
||||||
|
- API Integration
|
||||||
|
- No-Code
|
||||||
|
---
|
||||||
|
|
||||||
|
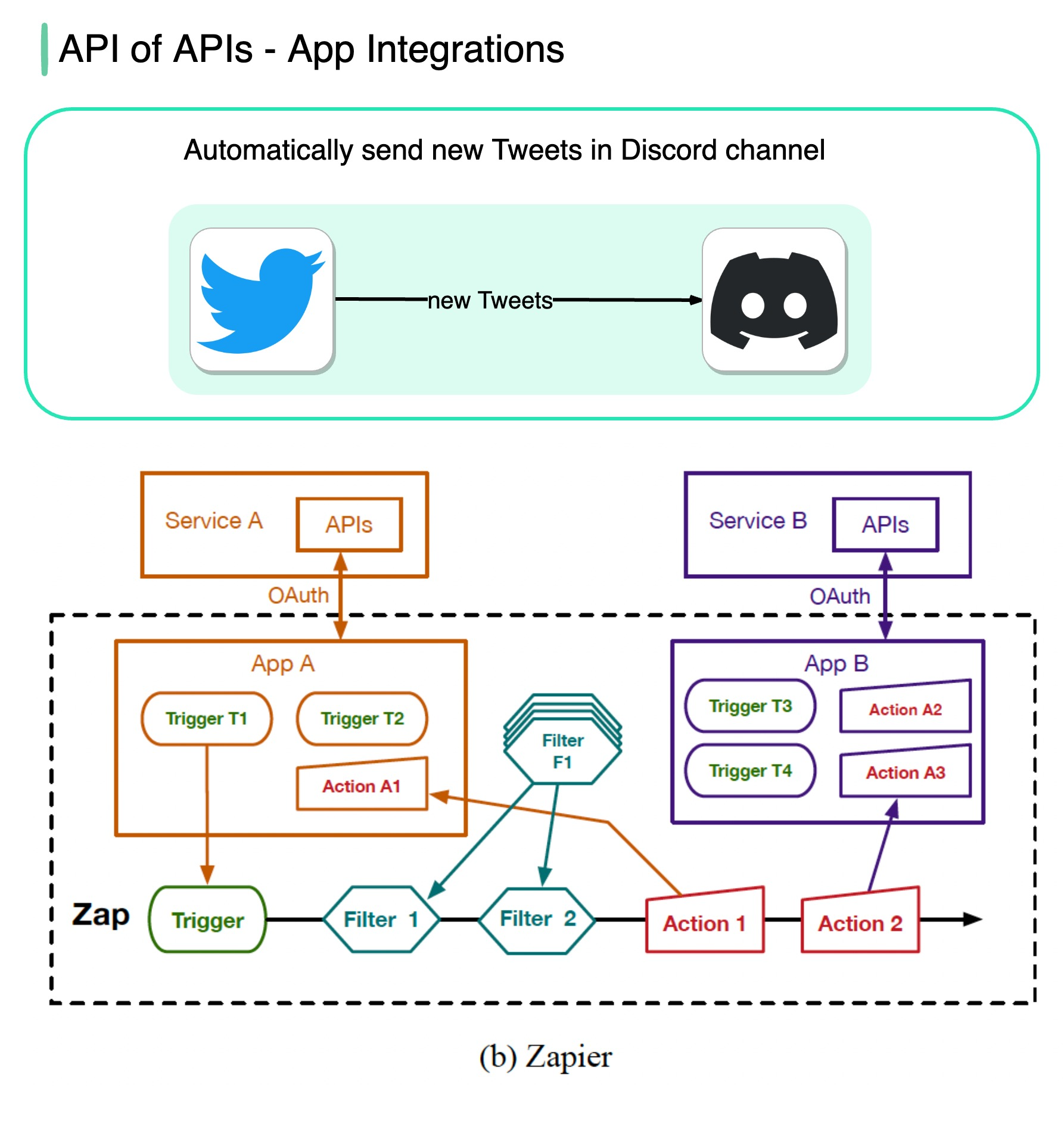
|
||||||
|
|
||||||
|
No-code tools such as Zapier, IFTTT, etc., allow anyone to build apps and automate workflows using a visual interface.
|
||||||
|
|
||||||
|
The flowchart below shows how it works.
|
||||||
|
|
||||||
|
Image source: Paper: IFTTT vs. Zapier: A Comparative Study of Trigger-Action Programming Frameworks
|
||||||
@@ -0,0 +1,34 @@
|
|||||||
|
---
|
||||||
|
title: 'API vs SDK'
|
||||||
|
description: 'Understand the key differences between APIs and SDKs in software development.'
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0071-api-vs-sdk.png'
|
||||||
|
createdAt: '2024-02-22'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- api-web-development
|
||||||
|
tags:
|
||||||
|
- API
|
||||||
|
- SDK
|
||||||
|
---
|
||||||
|
|
||||||
|
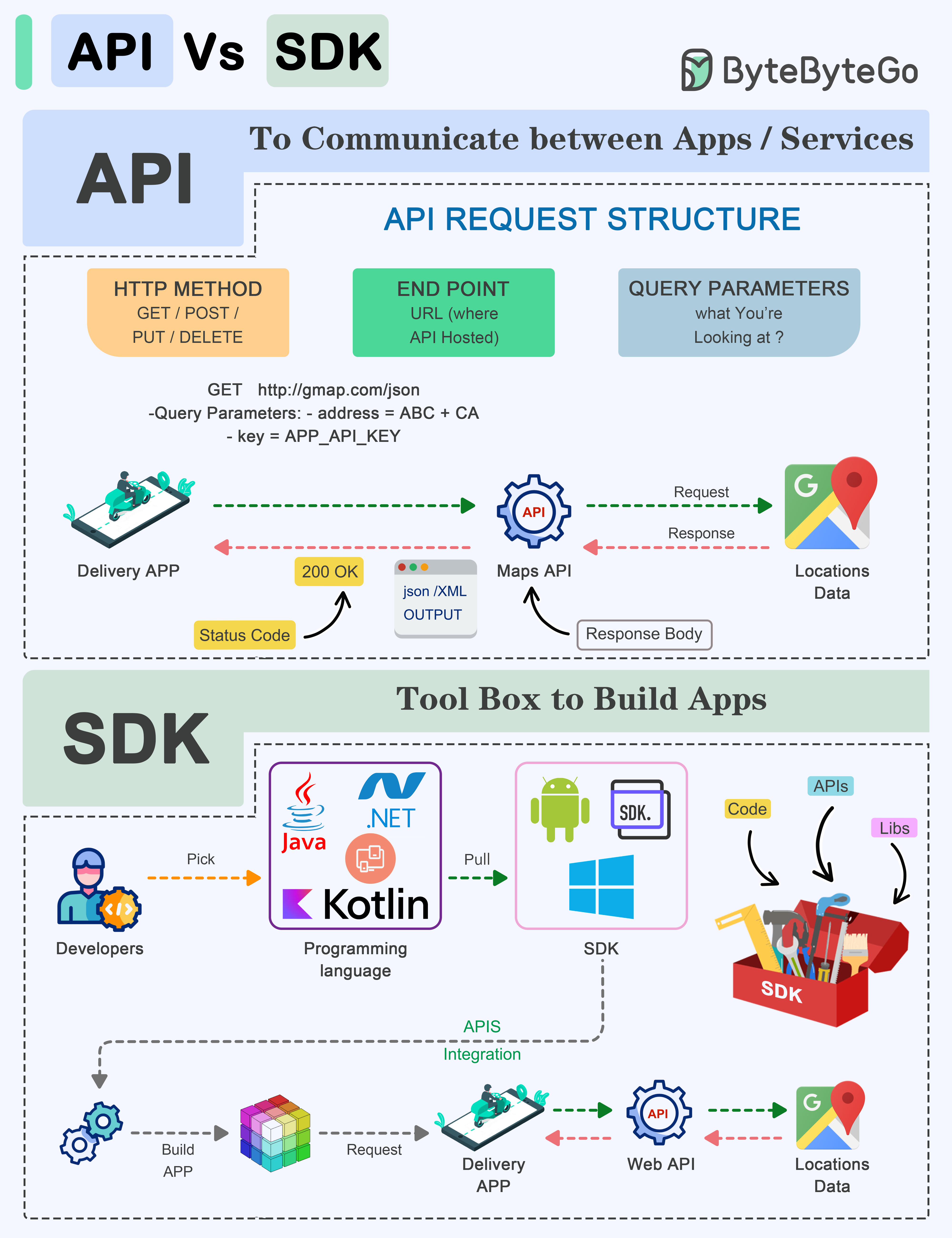
|
||||||
|
|
||||||
|
API (Application Programming Interface) and SDK (Software Development Kit) are essential tools in the software development world, but they serve distinct purposes:
|
||||||
|
|
||||||
|
**API:**
|
||||||
|
|
||||||
|
An API is a set of rules and protocols that allows different software applications and services to communicate with each other.
|
||||||
|
|
||||||
|
* It defines how software components should interact.
|
||||||
|
* Facilitates data exchange and functionality access between software components.
|
||||||
|
* Typically consists of endpoints, requests, and responses.
|
||||||
|
|
||||||
|
**SDK:**
|
||||||
|
|
||||||
|
An SDK is a comprehensive package of tools, libraries, sample code, and documentation that assists developers in building applications for a particular platform, framework, or hardware.
|
||||||
|
|
||||||
|
* Offers higher-level abstractions, simplifying development for a specific platform.
|
||||||
|
* Tailored to specific platforms or frameworks, ensuring compatibility and optimal performance on that platform.
|
||||||
|
* Offer access to advanced features and capabilities specific to the platform, which might be otherwise challenging to implement from scratch.
|
||||||
|
|
||||||
|
The choice between APIs and SDKs depends on the development goals and requirements of the project.
|
||||||
@@ -0,0 +1,22 @@
|
|||||||
|
---
|
||||||
|
title: "AWS Services Cheat Sheet"
|
||||||
|
description: "A visual guide to navigate AWS expansive landscape of cloud services."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0082-aws-cloud-services-cheat-sheet.png"
|
||||||
|
createdAt: "2024-03-15"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "AWS"
|
||||||
|
- "Cloud Computing"
|
||||||
|
---
|
||||||
|
|
||||||
|
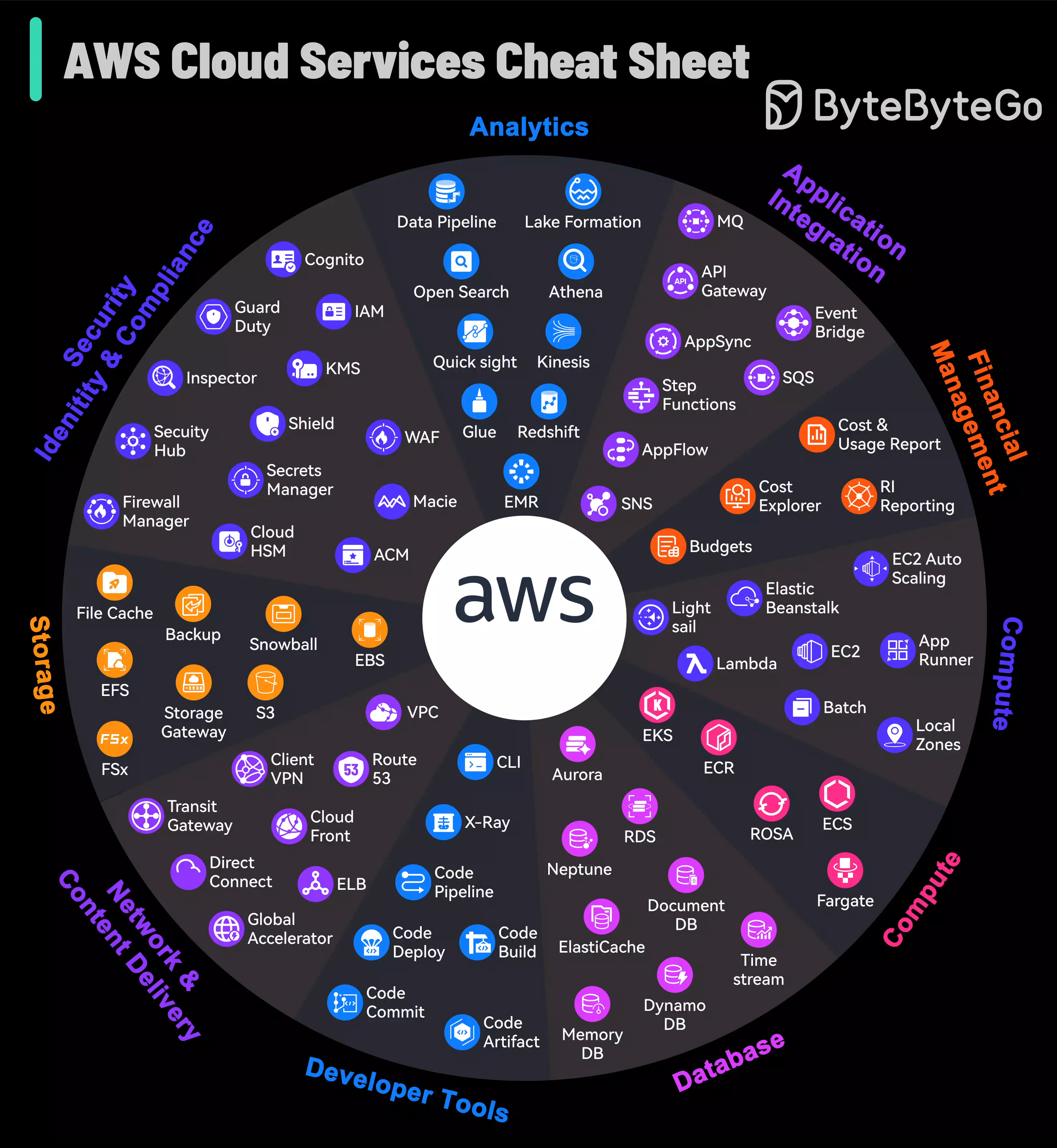
|
||||||
|
|
||||||
|
AWS grew from an in-house project to the market leader in cloud services, offering so many different services that even experts can find it a lot to take in.
|
||||||
|
|
||||||
|
The platform not only caters to foundational cloud needs but also stays at the forefront of emerging technologies such as machine learning and IoT, establishing itself as a bedrock for cutting-edge innovation. AWS continuously refines its array of services, ensuring advanced capabilities for security, scalability, and operational efficiency are available.
|
||||||
|
|
||||||
|
For those navigating the complex array of options, this AWS Services Guide is a helpful visual aid.
|
||||||
|
|
||||||
|
It simplifies the exploration of AWS's expansive landscape, making it accessible for users to identify and leverage the right tools for their cloud-based endeavors.
|
||||||
@@ -0,0 +1,30 @@
|
|||||||
|
---
|
||||||
|
title: "AWS Services Evolution"
|
||||||
|
description: "Explore the evolution of AWS from its early days to a comprehensive cloud platform."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0081-aws-services-evolution.png"
|
||||||
|
createdAt: "2024-03-06"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Cloud Computing"
|
||||||
|
- "AWS"
|
||||||
|
---
|
||||||
|
|
||||||
|
[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fbb384f75-2fbb-4c5b-9d5e-b97557d02f33_1572x1894.png)
|
||||||
|
|
||||||
|
How did AWS grow from just a few services in 2006 to over 200 fully-featured services? Let's take a look.
|
||||||
|
|
||||||
|
Since 2006, it has become a cloud computing leader, offering foundational infrastructure, platforms, and advanced capabilities like serverless computing and AI.
|
||||||
|
|
||||||
|
This expansion empowered innovation, allowing complex applications without extensive hardware management. AWS also explored edge and quantum computing, staying at tech's forefront.
|
||||||
|
|
||||||
|
This evolution mirrors cloud computing's shift from niche to essential, benefiting global businesses with efficiency and scalability.
|
||||||
|
|
||||||
|
Happy to present the curated list of AWS services introduced over the years below.
|
||||||
|
|
||||||
|
Note:
|
||||||
|
|
||||||
|
* The announcement or preview year differs from the public release year for certain services. In these cases, we've noted the service under the release year
|
||||||
|
|
||||||
|
* Unreleased services noted in announcement years
|
||||||
@@ -0,0 +1,22 @@
|
|||||||
|
---
|
||||||
|
title: "Azure Services Cheat Sheet"
|
||||||
|
description: "A concise guide to Microsoft Azure services and their applications."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0083-azure-cloud-services-cheat-sheet.png"
|
||||||
|
createdAt: "2024-03-07"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Azure"
|
||||||
|
- "Cloud Computing"
|
||||||
|
---
|
||||||
|
|
||||||
|
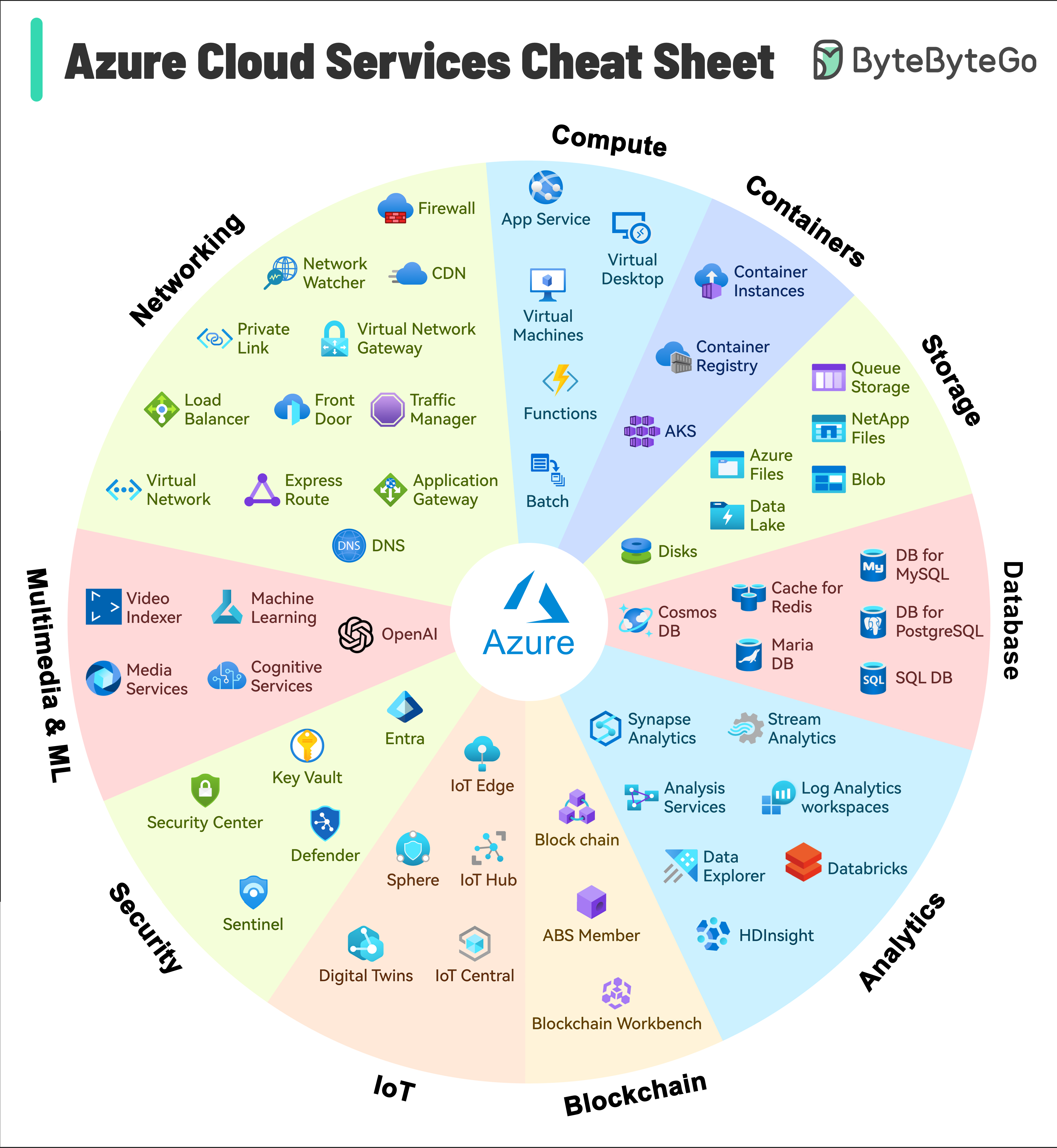
|
||||||
|
|
||||||
|
Launched in 2010, Microsoft Azure has quickly grown to hold the No. 2 position in market share by evolving from basic offerings to a comprehensive, flexible cloud ecosystem.
|
||||||
|
|
||||||
|
Today, Azure not only supports traditional cloud applications but also caters to emerging technologies such as AI, IoT, and blockchain, making it a crucial platform for innovation and development.
|
||||||
|
|
||||||
|
As it evolves, Azure continues to enhance its capabilities to provide advanced solutions for security, scalability, and efficiency, meeting the demands of modern enterprises and startups alike. This expansion allows organizations to adapt and thrive in a rapidly changing digital landscape.
|
||||||
|
|
||||||
|
The attached illustration can serve as both an introduction and a quick reference for anyone aiming to understand Azure.
|
||||||
@@ -0,0 +1,34 @@
|
|||||||
|
---
|
||||||
|
title: "B-Tree vs. LSM-Tree"
|
||||||
|
description: "Explore the differences between B-Tree and LSM-Tree data structures."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0091-btree-lsm.png"
|
||||||
|
createdAt: "2024-02-16"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "Data Structures"
|
||||||
|
- "Databases"
|
||||||
|
---
|
||||||
|
|
||||||
|
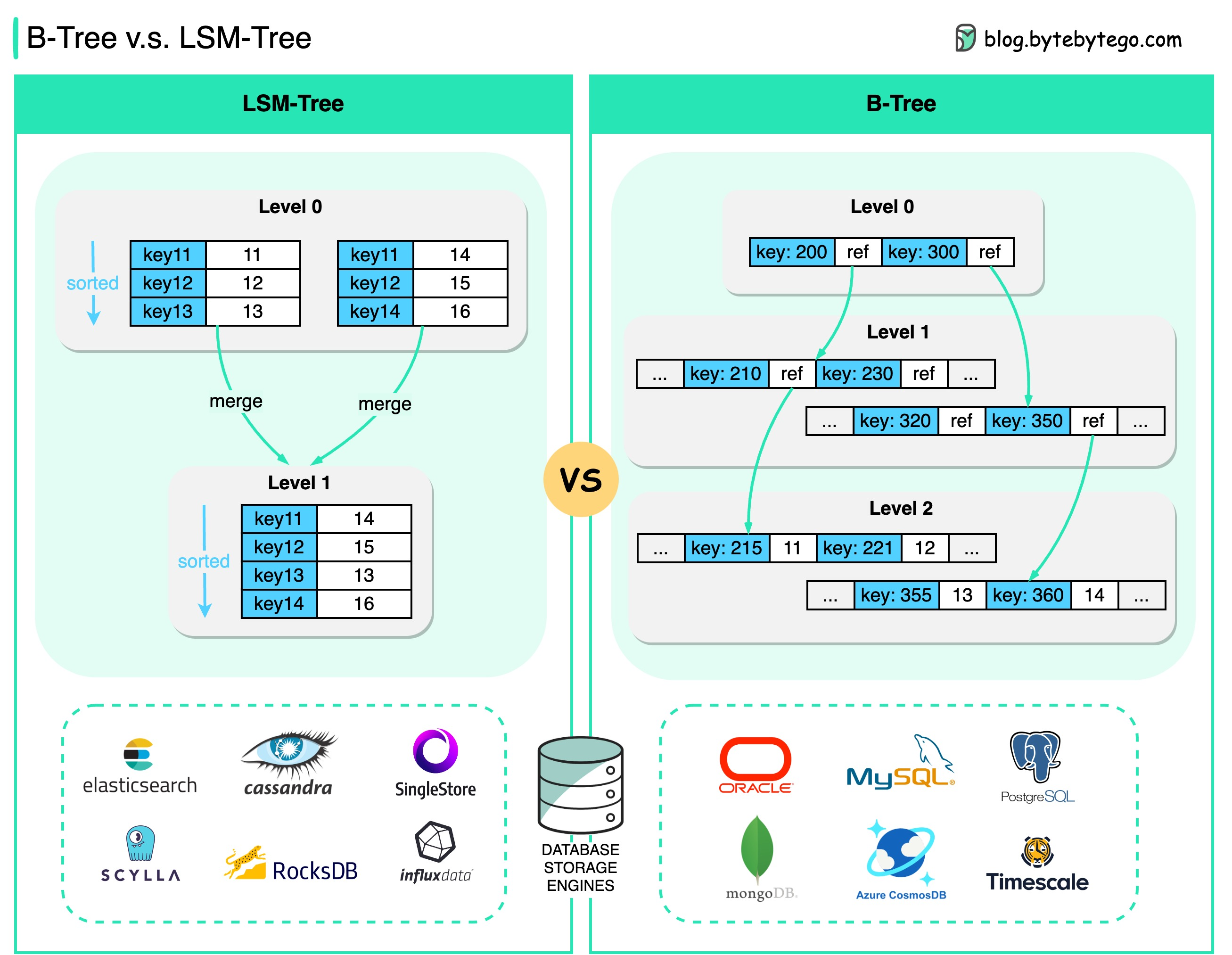
|
||||||
|
|
||||||
|
## B-Tree
|
||||||
|
|
||||||
|
B-Tree is the most widely used indexing data structure in almost all relational databases.
|
||||||
|
|
||||||
|
The basic unit of information storage in B-Tree is usually called a “page”. Looking up a key traces down the range of keys until the actual value is found.
|
||||||
|
|
||||||
|
## LSM-Tree
|
||||||
|
|
||||||
|
LSM-Tree (Log-Structured Merge Tree) is widely used by many NoSQL databases, such as Cassandra, LevelDB, and RocksDB.
|
||||||
|
|
||||||
|
LSM-trees maintain key-value pairs and are persisted to disk using a Sorted Strings Table (SSTable), in which the keys are sorted.
|
||||||
|
|
||||||
|
Level 0 segments are periodically merged into Level 1 segments. This process is called **compaction.**
|
||||||
|
|
||||||
|
The biggest difference is probably this:
|
||||||
|
|
||||||
|
* B-Tree enables faster reads
|
||||||
|
|
||||||
|
* LSM-Tree enables fast writes
|
||||||
@@ -0,0 +1,32 @@
|
|||||||
|
---
|
||||||
|
title: "Big Data Pipeline Cheatsheet for AWS, Azure, and Google Cloud"
|
||||||
|
description: "Big data pipeline cheatsheet for AWS, Azure, and Google Cloud."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0086-big-data-pipeline-cheatsheet-for-aws-azure-and-gcp.png"
|
||||||
|
createdAt: "2024-03-14"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Big Data"
|
||||||
|
- "Cloud Computing"
|
||||||
|
---
|
||||||
|
|
||||||
|
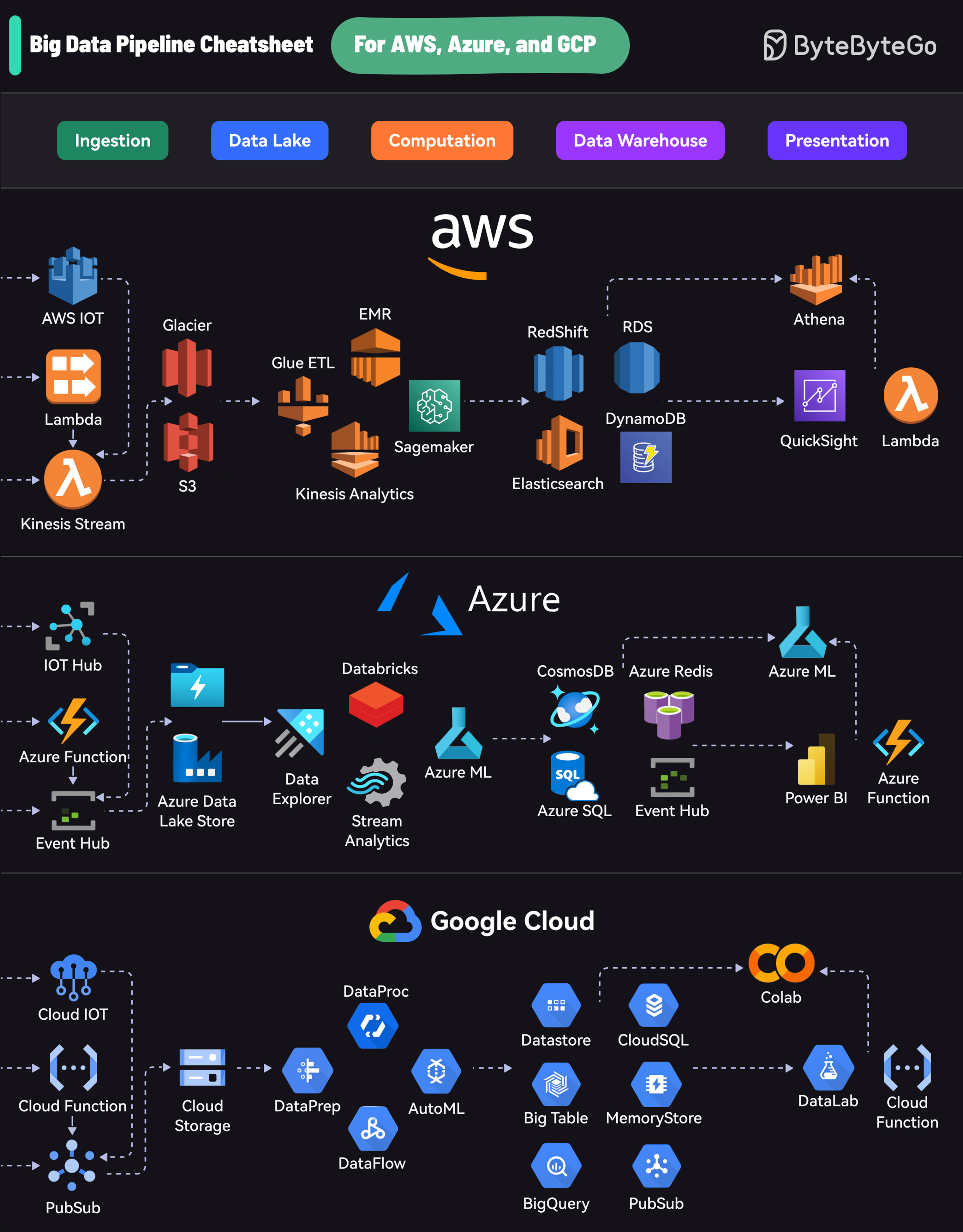
|
||||||
|
|
||||||
|
Each platform offers a comprehensive suite of services that cover the entire lifecycle:
|
||||||
|
|
||||||
|
* Ingestion: Collecting data from various sources
|
||||||
|
|
||||||
|
* Data Lake: Storing raw data
|
||||||
|
|
||||||
|
* Computation: Processing and analyzing data
|
||||||
|
|
||||||
|
* Data Warehouse: Storing structured data
|
||||||
|
|
||||||
|
* Presentation: Visualizing and reporting insights
|
||||||
|
|
||||||
|
AWS uses services like Kinesis for data streaming, S3 for storage, EMR for processing, RedShift for warehousing, and QuickSight for visualization.
|
||||||
|
|
||||||
|
Azure’s pipeline includes Event Hubs for ingestion, Data Lake Store for storage, Databricks for processing, Cosmos DB for warehousing, and Power BI for presentation.
|
||||||
|
|
||||||
|
GCP offers PubSub for data streaming, Cloud Storage for data lakes, DataProc and DataFlow for processing, BigQuery for warehousing, and Data Studio for visualization.
|
||||||
@@ -0,0 +1,26 @@
|
|||||||
|
---
|
||||||
|
title: "Big Endian vs Little Endian"
|
||||||
|
description: "Explore big endian vs little endian byte ordering in computer architecture."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0084-big-endian-vs-little-endian.png"
|
||||||
|
createdAt: "2024-02-26"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- "Computer Architecture"
|
||||||
|
- "Data Representation"
|
||||||
|
---
|
||||||
|
|
||||||
|
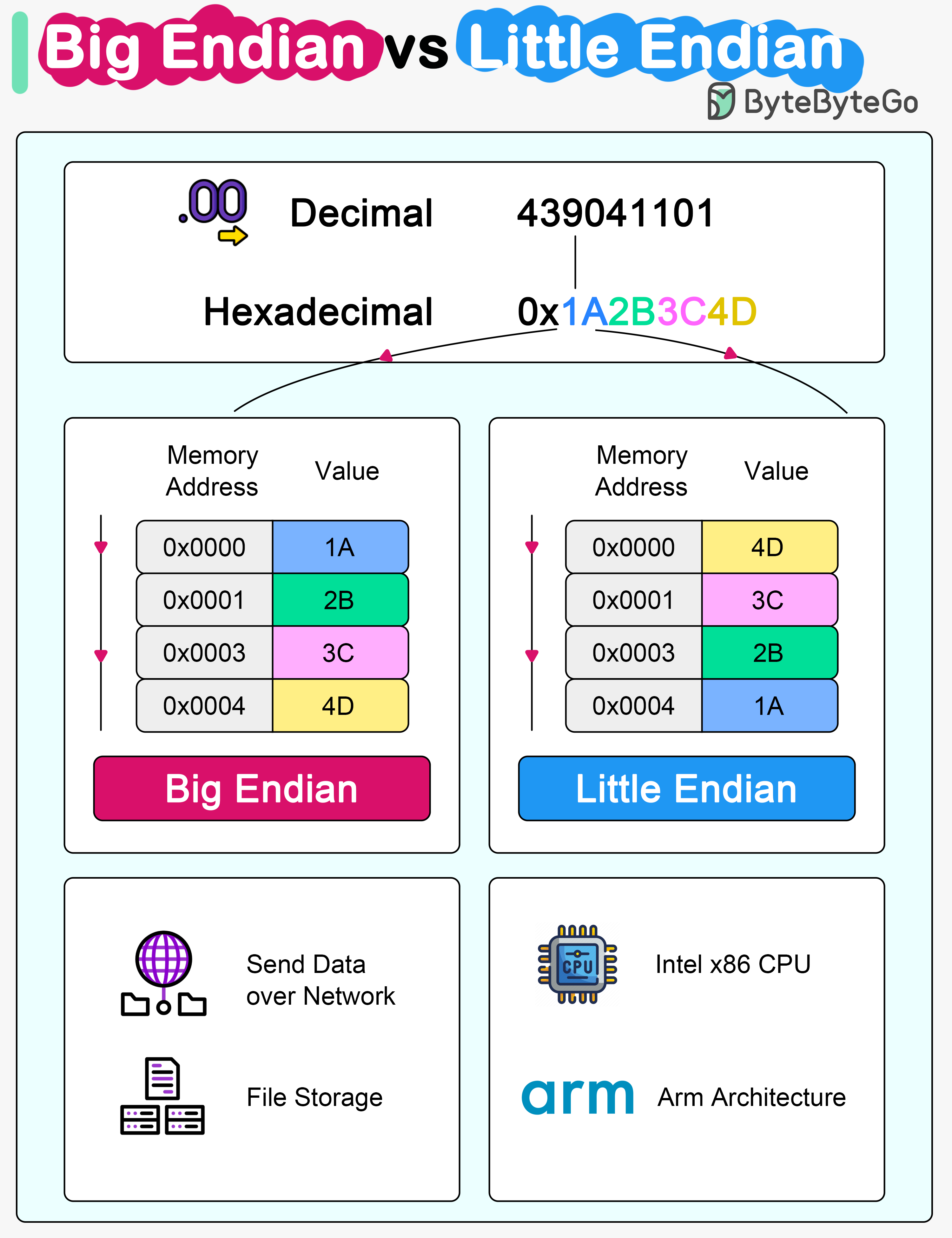
|
||||||
|
|
||||||
|
Microprocessor architectures commonly use two different methods to store the individual bytes in memory. This difference is referred to as “byte ordering” or “endian nature”.
|
||||||
|
|
||||||
|
## Little Endian
|
||||||
|
|
||||||
|
Intel x86 processors store a two-byte integer with the least significant byte first, followed by the most significant byte. This is called little-endian byte ordering.
|
||||||
|
|
||||||
|
## Big Endian
|
||||||
|
|
||||||
|
In big endian byte order, the most significant byte is stored at the lowest memory address, and the least significant byte is stored at the highest memory address. Older PowerPC and Motorola 68k architectures often use big endian. In network communications and file storage, we also use big endian.
|
||||||
|
|
||||||
|
The byte ordering becomes significant when data is transferred between systems or processed by systems with different endianness. It's important to handle byte order correctly to interpret data consistently across diverse systems.
|
||||||
@@ -0,0 +1,50 @@
|
|||||||
|
---
|
||||||
|
title: "Blocking vs Non-Blocking Queue"
|
||||||
|
description: "Explore blocking vs non-blocking queues, differences, and implementation."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0088-blocking-noblocking-queue.jpeg"
|
||||||
|
createdAt: "2024-02-25"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- Concurrency
|
||||||
|
- Data Structures
|
||||||
|
---
|
||||||
|
|
||||||
|
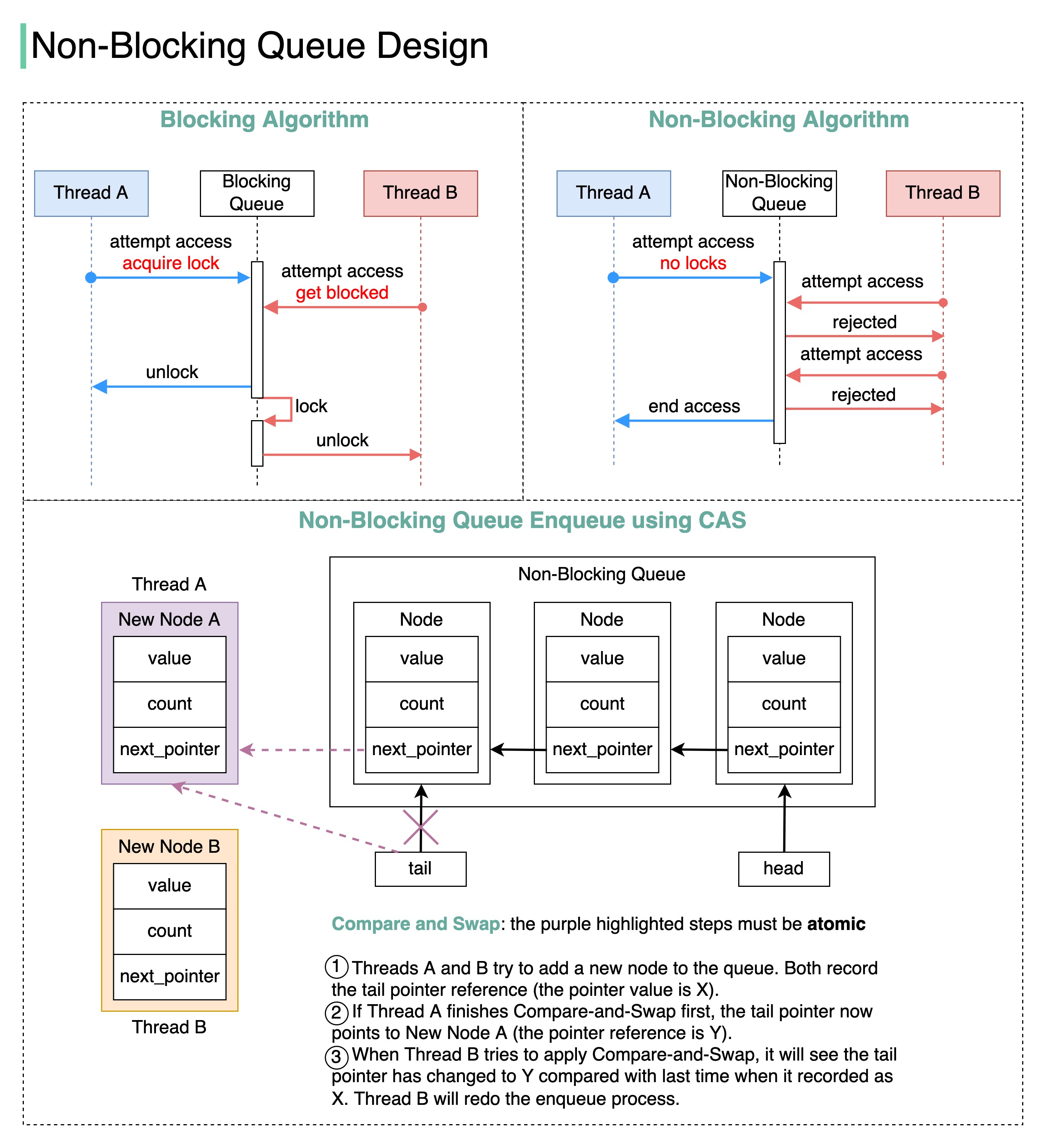
|
||||||
|
|
||||||
|
How do we implement a **non-blocking** queue? What are the differences between blocking and non-blocking algorithms?
|
||||||
|
|
||||||
|
The terms we use when discussing blocking and non-blocking algorithms can be confusing, so let’s start by reviewing the terminology in the concurrency area with a diagram.
|
||||||
|
|
||||||
|
## Blocking vs Non-Blocking Algorithms
|
||||||
|
|
||||||
|
* **Blocking**
|
||||||
|
|
||||||
|
The blocking algorithm uses locks. Thread A acquires the lock first, and Thread B might wait for arbitrary lengthy periods if Thread A gets suspended while holding the lock. This algorithm may cause Thread B to starve.
|
||||||
|
|
||||||
|
* **Non-blocking**
|
||||||
|
|
||||||
|
The non-blocking algorithm allows Thread A to access the queue, but Thread A must complete a task in a certain number of steps. Other threads like Thread B may still starve due to the rejections.
|
||||||
|
|
||||||
|
This is the main **difference** between blocking and non-blocking algorithms: The blocking algorithm blocks Thread B until the lock is released. A non-blocking algorithm notifies Thread B that access is rejected.
|
||||||
|
|
||||||
|
* **Starvation-free**
|
||||||
|
|
||||||
|
Thread Starvation means a thread cannot acquire access to certain shared resources and cannot proceed. Starvation-free means this situation does not occur.
|
||||||
|
|
||||||
|
* **Wait-free**
|
||||||
|
|
||||||
|
All threads can complete the tasks within a finite number of steps.
|
||||||
|
|
||||||
|
𝘞𝘢𝘪𝘵-𝘧𝘳𝘦𝘦 = 𝘕𝘰𝘯-𝘉𝘭𝘰𝘤𝘬𝘪𝘯𝘨 + 𝘚𝘵𝘢𝘳𝘷𝘢𝘵𝘪𝘰𝘯-𝘧𝘳𝘦𝘦
|
||||||
|
|
||||||
|
## Non-Blocking Queue Implementation
|
||||||
|
|
||||||
|
We can use Compare and Swap (CAS) to implement a non-blocking queue. The diagram below illustrates the algorithm.
|
||||||
|
|
||||||
|
## Benefits
|
||||||
|
|
||||||
|
1. No thread suspension. Thread B can get a response immediately and then decide what to do next. In this way, the thread latency is greatly reduced.
|
||||||
|
|
||||||
|
2. No deadlocks. Threads A and B do not wait for the lock to release, meaning that there is no possibility of a deadlock occurring.
|
||||||
@@ -0,0 +1,36 @@
|
|||||||
|
---
|
||||||
|
title: "Build a Simple Chat Application with Redis"
|
||||||
|
description: "Learn to build a simple chat application using Redis pub/sub."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0314-redis-chat.jpg"
|
||||||
|
createdAt: "2024-03-04"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- how-it-works
|
||||||
|
tags:
|
||||||
|
- Redis
|
||||||
|
- Chat Application
|
||||||
|
---
|
||||||
|
|
||||||
|
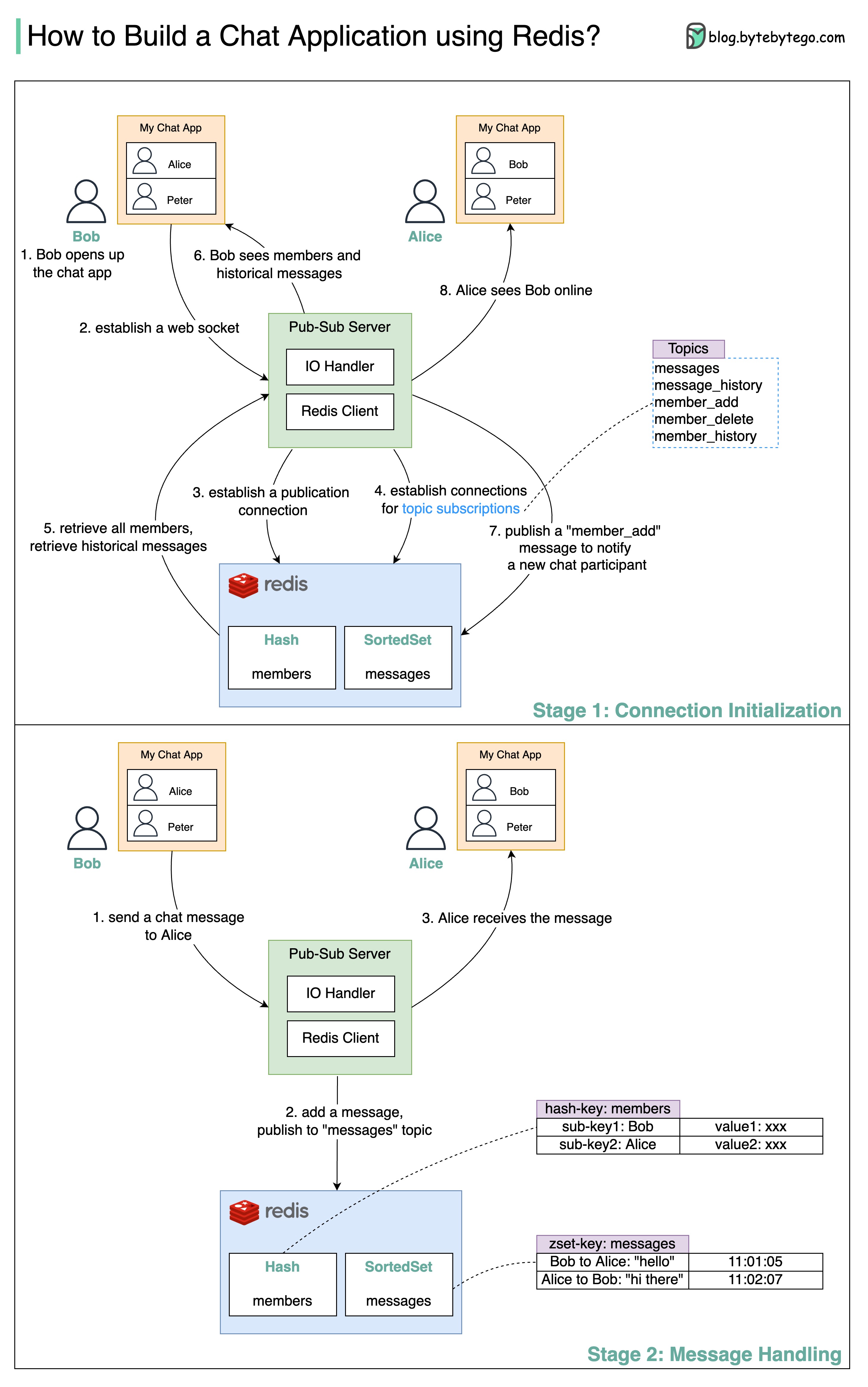
|
||||||
|
|
||||||
|
How do we build a simple chat application using Redis?
|
||||||
|
|
||||||
|
The diagram below shows how we can leverage the pub-sub functionality of Redis to develop a chat application.
|
||||||
|
|
||||||
|
## Stage 1: Connection Initialization
|
||||||
|
|
||||||
|
* Steps 1 and 2: Bob opens the chat application. A web socket is established between the client and the server.
|
||||||
|
|
||||||
|
* Steps 3 and 4: The pub-sub server establishes several connections to Redis. One connection is used to update the Redis data models and publish messages to a topic. Other connections are used to subscribe and listen to updates for topics.
|
||||||
|
|
||||||
|
* Steps 5 and 6: Bob’s client application requires the chat member list and the historical message list. The information is retrieved from Redis and sent to the client application.
|
||||||
|
|
||||||
|
* Steps 7 and 8: Since Bob is a new member joining the chat application, a message is published to the “member\_add” topic, and as a result, other participants of the chat application can see Bob.
|
||||||
|
|
||||||
|
## Stage 2: Message Handling
|
||||||
|
|
||||||
|
* Step 1: Bob sends a message to Alice in the chat application.
|
||||||
|
|
||||||
|
* Step 2: The new chat message is added to Redis SortedSet by calling ‘zadd.’ The chat messages are sorted based on arrival time. The pub-sub server then publishes the chat message to the “messages” topic so subscribers can pick it up.
|
||||||
|
|
||||||
|
* Step 3: Alice’s client application receives the chat message from Bob.
|
||||||
@@ -0,0 +1,28 @@
|
|||||||
|
---
|
||||||
|
title: "Cache Miss Attack"
|
||||||
|
description: "Explore cache miss attacks, their impact, and mitigation strategies."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0128-cache-miss-attack.png"
|
||||||
|
createdAt: "2024-02-27"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- caching-performance
|
||||||
|
tags:
|
||||||
|
- "Caching"
|
||||||
|
- "Security"
|
||||||
|
---
|
||||||
|
|
||||||
|
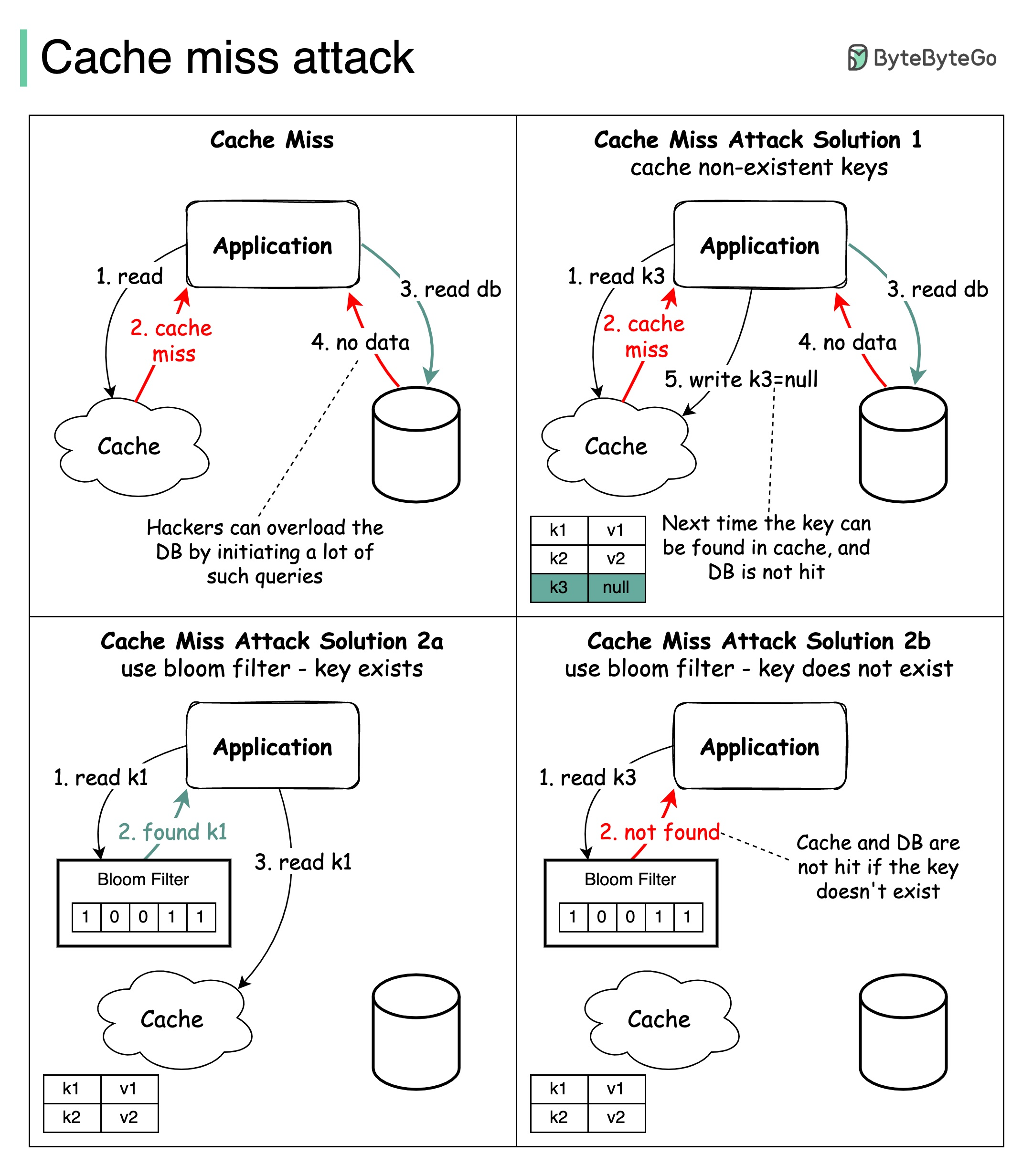
|
||||||
|
|
||||||
|
Caching is awesome but it doesn’t come without a cost, just like many things in life.
|
||||||
|
|
||||||
|
One of the issues is 𝐂𝐚𝐜𝐡𝐞 𝐌𝐢𝐬𝐬 𝐀𝐭𝐭𝐚𝐜𝐤. Please correct me if this is not the right term. It refers to the scenario where data to fetch doesn't exist in the database and the data isn’t cached either. So every request hits the database eventually, defeating the purpose of using a cache. If a malicious user initiates lots of queries with such keys, the database can easily be overloaded.
|
||||||
|
|
||||||
|
The diagram above illustrates the process.
|
||||||
|
|
||||||
|
## Solutions
|
||||||
|
|
||||||
|
Two approaches are commonly used to solve this problem:
|
||||||
|
|
||||||
|
* **Cache keys with null value.** Set a short TTL (Time to Live) for keys with null value.
|
||||||
|
|
||||||
|
* **Using Bloom filter.** A Bloom filter is a data structure that can rapidly tell us whether an element is present in a set or not. If the key exists, the request first goes to the cache and then queries the database if needed. If the key doesn't exist in the data set, it means the key doesn’t exist in the cache/database. In this case, the query will not hit the cache or database layer.
|
||||||
@@ -0,0 +1,40 @@
|
|||||||
|
---
|
||||||
|
title: "Cache Systems Every Developer Should Know"
|
||||||
|
description: "Explore essential caching layers for developers to optimize performance."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0418-cache-systems-every-developer-should-know.jpeg"
|
||||||
|
createdAt: "2024-02-20"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- caching-performance
|
||||||
|
tags:
|
||||||
|
- Caching
|
||||||
|
- Performance
|
||||||
|
---
|
||||||
|
|
||||||
|
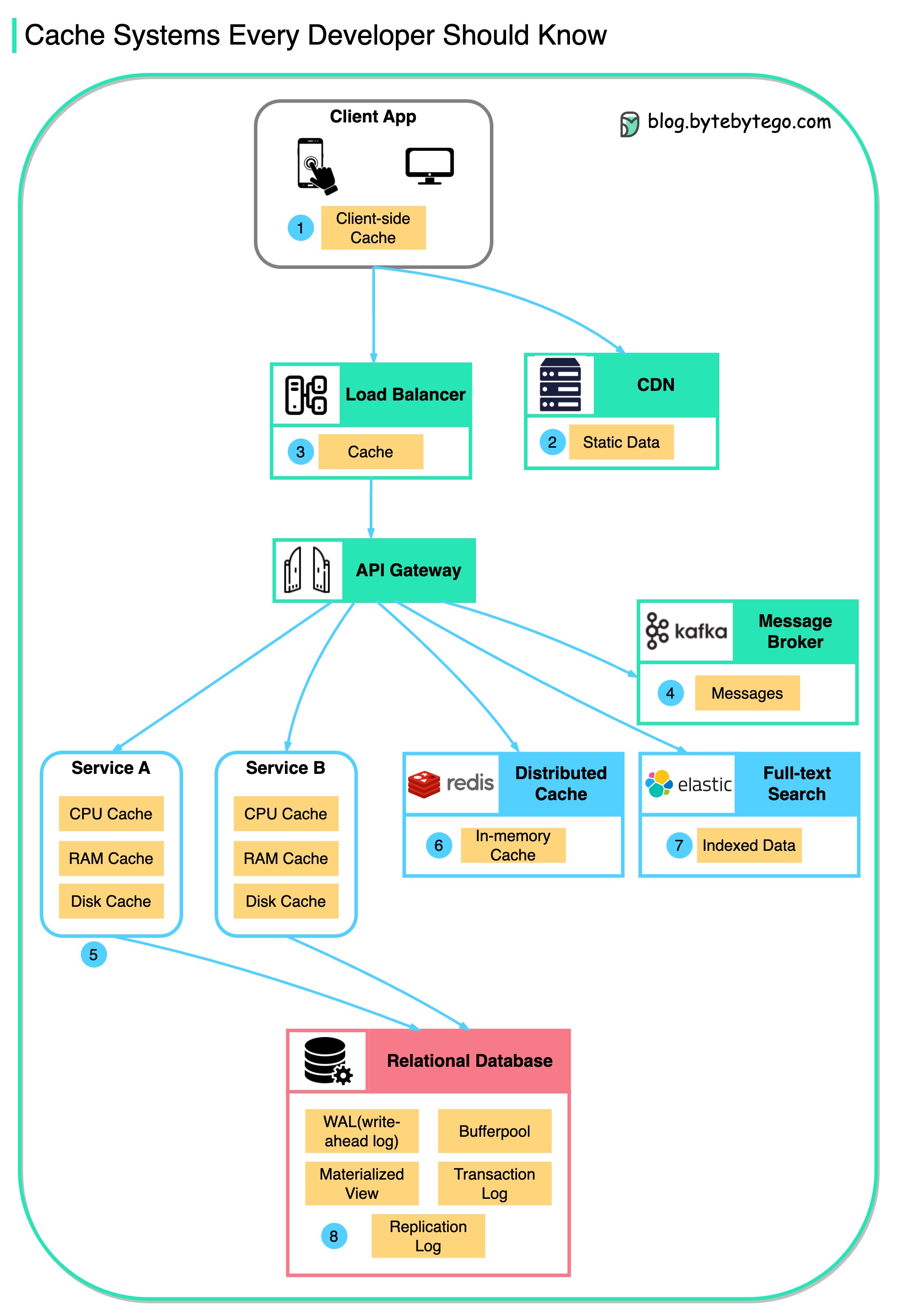
|
||||||
|
|
||||||
|
Data is cached everywhere, from the client-facing side to backend systems. Let's look at the many caching layers:
|
||||||
|
|
||||||
|
## Caching Layers
|
||||||
|
|
||||||
|
1. Client Apps: Browsers cache HTTP responses. Server responses include caching directives in headers. Upon subsequent requests, browsers may serve cached data if still fresh.
|
||||||
|
|
||||||
|
2. Content Delivery Networks: CDNs cache static content like images, stylesheets, and JavaScript files. They serve cached content from locations closer to users, reducing latency and load times.
|
||||||
|
|
||||||
|
3. Load Balancers: Some load balancers cache frequently requested data. This allows serving responses without engaging backend servers, reducing load and response times.
|
||||||
|
|
||||||
|
4. Message Brokers: Systems like Kafka can cache messages on disk per a retention policy. Consumers then pull messages according to their own schedule.
|
||||||
|
|
||||||
|
5. Services: Individual services often employ caching to improve data retrieval speeds, first checking in-memory caches before querying databases. Services may also utilize disk caching for larger datasets.
|
||||||
|
|
||||||
|
6. Distributed Caches: Systems like Redis cache key-value pairs across services, providing faster read/write capabilities compared to traditional databases.
|
||||||
|
|
||||||
|
7. Full-text Search Engines: Platforms like Elasticsearch index data for efficient text search. This index is effectively a form of cache, optimized for quick text search retrieval.
|
||||||
|
|
||||||
|
8. Databases: There are specialized mechanisms to enhance performance, some of which include caching concepts:
|
||||||
|
|
||||||
|
### Database Caching Mechanisms
|
||||||
|
|
||||||
|
* **Bufferpool:** This is a cache within the database that holds copies of data pages. It allows for quick reads and writes to temporary storage in memory, reducing the need to access data from disk.
|
||||||
|
|
||||||
|
* **Materialized Views:** They are similar to caches in that they store the results of computationally expensive queries. The database can return these precomputed results quickly, rather than recalculating them.
|
||||||
@@ -0,0 +1,46 @@
|
|||||||
|
---
|
||||||
|
title: "Can Kafka Lose Messages?"
|
||||||
|
description: "Explore Kafka's message loss scenarios and prevention strategies."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0130-can-kafka-lose-messages.png"
|
||||||
|
createdAt: "2024-02-12"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- "database-and-storage"
|
||||||
|
tags:
|
||||||
|
- "Kafka"
|
||||||
|
- "Message Loss"
|
||||||
|
---
|
||||||
|
|
||||||
|
Error handling is one of the most important aspects of building reliable systems.
|
||||||
|
|
||||||
|
Today, we will discuss an important topic: Can Kafka lose messages?
|
||||||
|
|
||||||
|
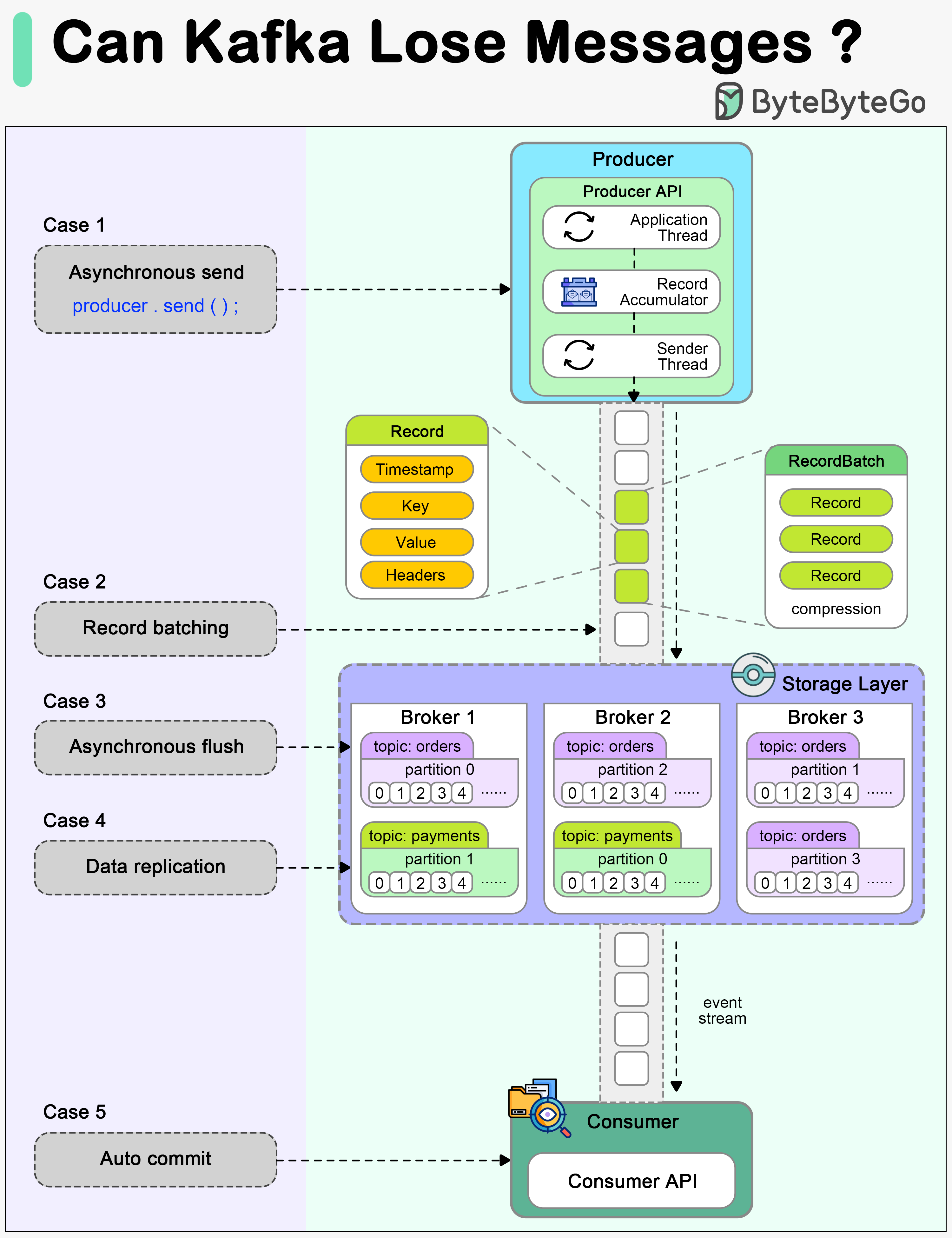
|
||||||
|
|
||||||
|
A common belief among many developers is that Kafka, by its very design, guarantees no message loss. However, understanding the nuances of Kafka's architecture and configuration is essential to truly grasp how and when it might lose messages, and more importantly, how to prevent such scenarios.
|
||||||
|
|
||||||
|
The diagram above shows how a message can be lost during its lifecycle in Kafka.
|
||||||
|
|
||||||
|
## Producer
|
||||||
|
|
||||||
|
When we call producer.send() to send a message, it doesn't get sent to the broker directly. There are two threads and a queue involved in the message-sending process:
|
||||||
|
|
||||||
|
* Application thread
|
||||||
|
* Record accumulator
|
||||||
|
* Sender thread (I/O thread)
|
||||||
|
|
||||||
|
We need to configure proper ‘acks’ and ‘retries’ for the producer to make sure messages are sent to the broker.
|
||||||
|
|
||||||
|
## Broker
|
||||||
|
|
||||||
|
A broker cluster should not lose messages when it is functioning normally. However, we need to understand which extreme situations might lead to message loss:
|
||||||
|
|
||||||
|
* The messages are usually flushed to the disk asynchronously for higher I/O throughput, so if the instance is down before the flush happens, the messages are lost.
|
||||||
|
|
||||||
|
* The replicas in the Kafka cluster need to be properly configured to hold a valid copy of the data. The determinism in data synchronization is important.
|
||||||
|
|
||||||
|
## Consumer
|
||||||
|
|
||||||
|
Kafka offers different ways to commit messages. Auto-committing might acknowledge the processing of records before they are actually processed. When the consumer is down in the middle of processing, some records may never be processed.
|
||||||
|
|
||||||
|
A good practice is to combine both synchronous and asynchronous commits, where we use asynchronous commits in the processing loop for higher throughput and synchronous commits in exception handling to make sure the last offset is always committed.
|
||||||
@@ -0,0 +1,55 @@
|
|||||||
|
---
|
||||||
|
title: "CAP, BASE, SOLID, KISS, What do these acronyms mean?"
|
||||||
|
description: "Understanding common acronyms in system design: CAP, BASE, SOLID, and KISS."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0350-cap-base-solid-kiss.png"
|
||||||
|
createdAt: "2024-03-09"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "System Design"
|
||||||
|
- "Software Engineering"
|
||||||
|
---
|
||||||
|
|
||||||
|
The diagram below explains the common acronyms in system designs.
|
||||||
|
|
||||||
|
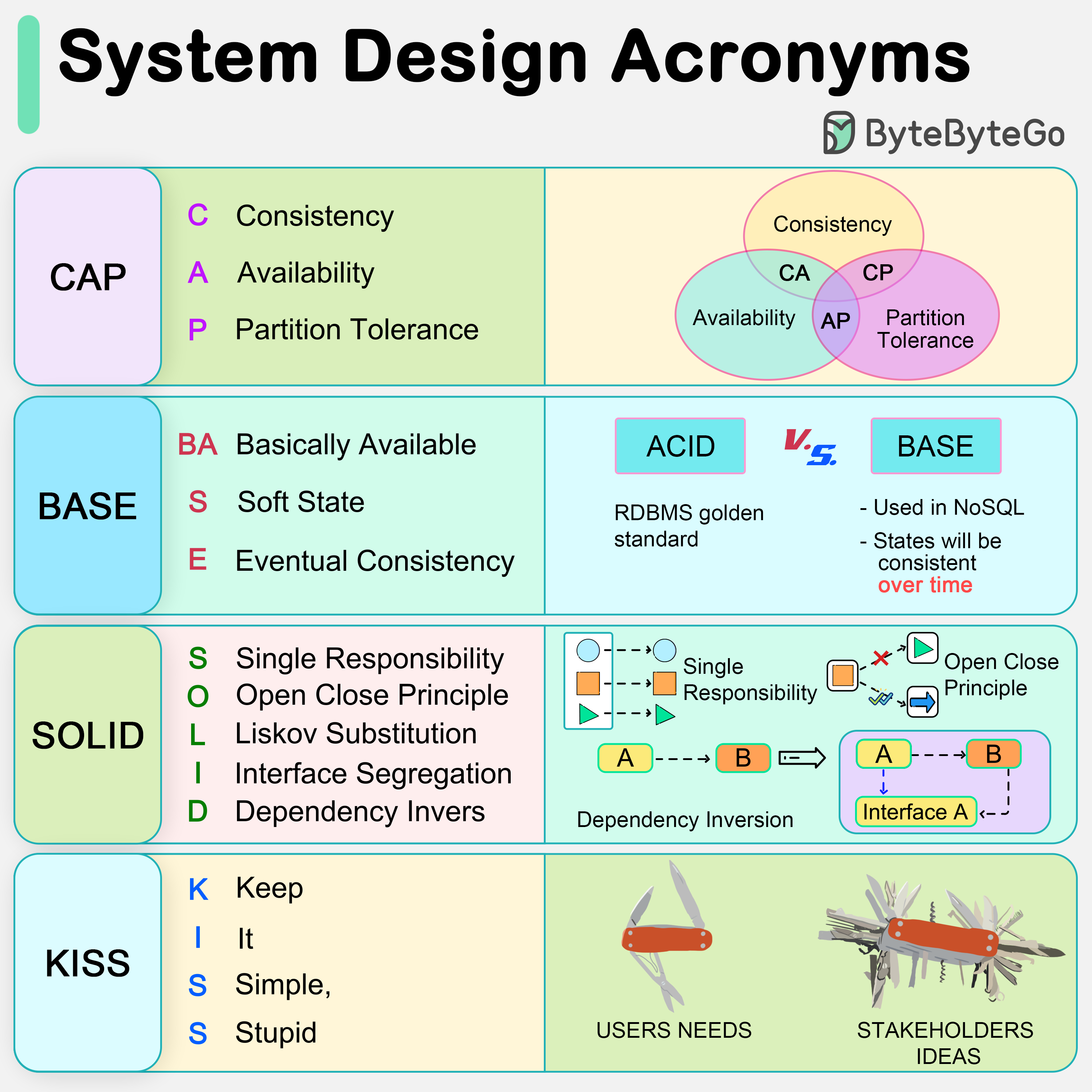
|
||||||
|
|
||||||
|
* **CAP**
|
||||||
|
|
||||||
|
CAP theorem states that any distributed data store can only provide two of the following three guarantees:
|
||||||
|
|
||||||
|
1. Consistency - Every read receives the most recent write or an error.
|
||||||
|
2. Availability - Every request receives a response.
|
||||||
|
3. Partition tolerance - The system continues to operate in network faults.
|
||||||
|
|
||||||
|
However, this theorem was criticized for being too narrow for distributed systems, and we shouldn’t use it to categorize the databases. Network faults are guaranteed to happen in distributed systems, and we must deal with this in any distributed systems.
|
||||||
|
|
||||||
|
You can read more on this in “Please stop calling databases CP or AP” by Martin Kleppmann.
|
||||||
|
|
||||||
|
* **BASE**
|
||||||
|
|
||||||
|
The ACID (Atomicity-Consistency-Isolation-Durability) model used in relational databases is too strict for NoSQL databases. The BASE principle offers more flexibility, choosing availability over consistency. It states that the states will eventually be consistent.
|
||||||
|
|
||||||
|
* **SOLID**
|
||||||
|
|
||||||
|
SOLID principle is quite famous in OOP. There are 5 components to it.
|
||||||
|
|
||||||
|
1. SRP (Single Responsibility Principle)
|
||||||
|
Each unit of code should have one responsibility.
|
||||||
|
|
||||||
|
2. OCP (Open Close Principle)
|
||||||
|
Units of code should be open for extension but closed for modification.
|
||||||
|
|
||||||
|
3. LSP (Liskov Substitution Principle)
|
||||||
|
A subclass should be able to be substituted by its base class.
|
||||||
|
|
||||||
|
4. ISP (Interface Segregation Principle)
|
||||||
|
Expose multiple interfaces with specific responsibilities.
|
||||||
|
|
||||||
|
5. DIP (Dependency Inversion Principle)
|
||||||
|
Use abstractions to decouple dependencies in the system.
|
||||||
|
|
||||||
|
* **KISS**
|
||||||
|
|
||||||
|
"Keep it simple, stupid!" is a design principle first noted by the U.S. Navy in 1960. It states that most systems work best if they are kept simple.
|
||||||
@@ -0,0 +1,42 @@
|
|||||||
|
---
|
||||||
|
title: "CAP Theorem: One of the Most Misunderstood Terms"
|
||||||
|
description: "Explore the CAP theorem, its implications, and common misunderstandings."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0131-cap-theorem.jpeg"
|
||||||
|
createdAt: "2024-03-06"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "distributed systems"
|
||||||
|
- "cap theorem"
|
||||||
|
---
|
||||||
|
|
||||||
|
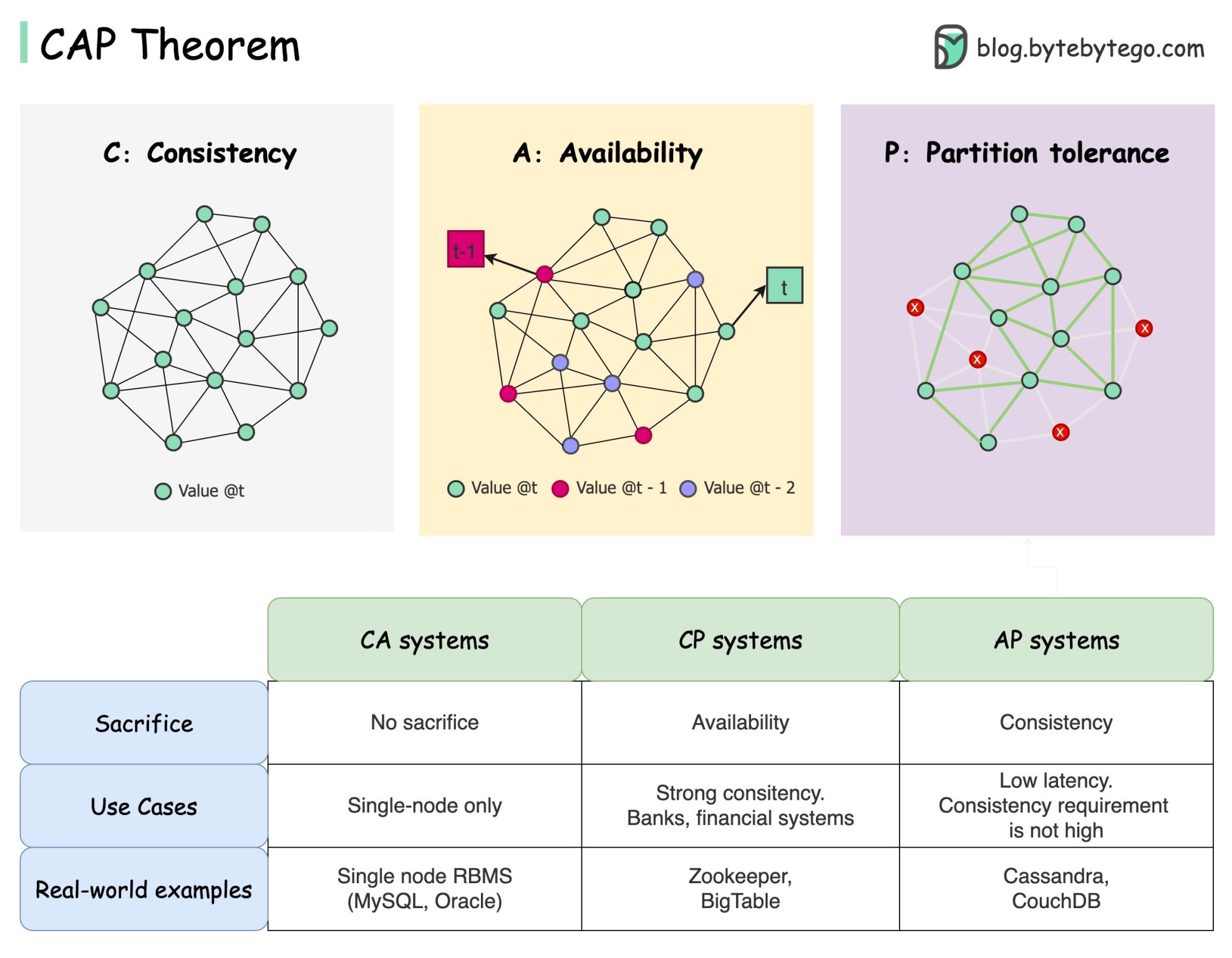
|
||||||
|
|
||||||
|
The CAP theorem is one of the most famous terms in computer science, but I bet different developers have different understandings. Let’s examine what it is and why it can be confusing.
|
||||||
|
|
||||||
|
CAP theorem states that a distributed system can't provide more than two of these three guarantees simultaneously.
|
||||||
|
|
||||||
|
## Consistency
|
||||||
|
|
||||||
|
Consistency means all clients see the same data at the same time no matter which node they connect to.
|
||||||
|
|
||||||
|
## Availability
|
||||||
|
|
||||||
|
Availability means any client which requests data gets a response even if some of the nodes are down.
|
||||||
|
|
||||||
|
## Partition Tolerance
|
||||||
|
|
||||||
|
Partition tolerance means the system continues to operate despite network partitions.
|
||||||
|
|
||||||
|
The “2 of 3” formulation can be useful, but this simplification could be misleading.
|
||||||
|
|
||||||
|
* Picking a database is not easy. Justifying our choice purely based on the CAP theorem is not enough. For example, companies don't choose Cassandra for chat applications simply because it is an AP system. There is a list of good characteristics that make Cassandra a desirable option for storing chat messages. We need to dig deeper.
|
||||||
|
|
||||||
|
* “CAP prohibits only a tiny part of the design space: perfect availability and consistency in the presence of partitions, which are rare”. Quoted from the paper: CAP Twelve Years Later: How the “Rules” Have Changed.
|
||||||
|
|
||||||
|
* The theorem is about 100% availability and consistency. A more realistic discussion would be the trade-offs between latency and consistency when there is no network partition. See PACELC theorem for more details.
|
||||||
|
|
||||||
|
## Is the CAP theorem really useful?
|
||||||
|
|
||||||
|
I think it is still useful as it opens our minds to a set of tradeoff discussions, but it is only part of the story. We need to dig deeper when picking the right database.
|
||||||
@@ -0,0 +1,40 @@
|
|||||||
|
---
|
||||||
|
title: "Change Data Capture: Key to Leverage Real-time Data"
|
||||||
|
description: "Learn how Change Data Capture (CDC) helps leverage real-time data."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0133-change-data-capture-key-to-leverage-real-time-data.png"
|
||||||
|
createdAt: "2024-02-11"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "Data Streaming"
|
||||||
|
- "Data Synchronization"
|
||||||
|
---
|
||||||
|
|
||||||
|
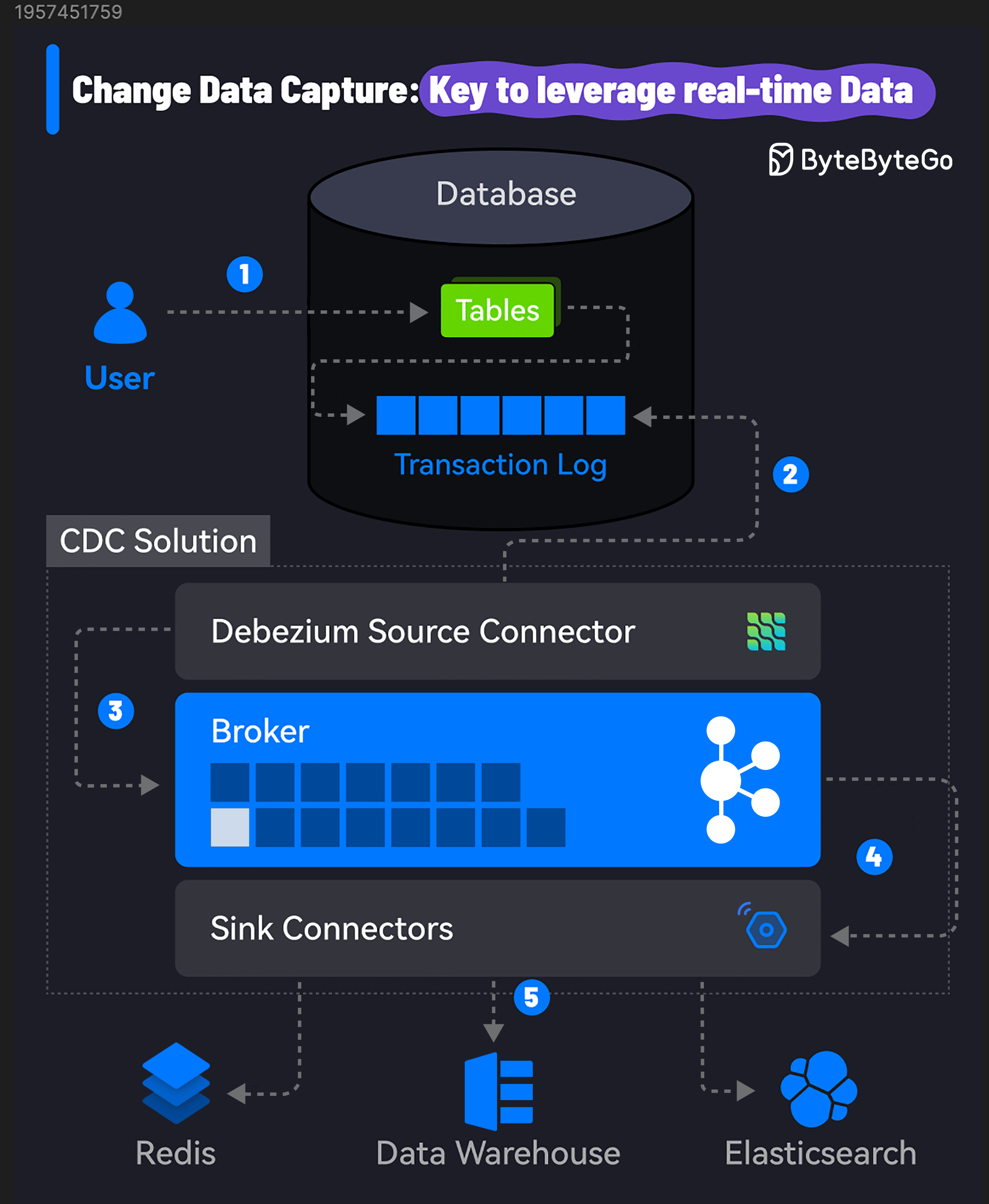
|
||||||
|
|
||||||
|
90% of the world’s data was created in the last two years and this growth will only get faster.
|
||||||
|
|
||||||
|
However, the biggest challenge is to leverage this data in real-time. Constant data changes make databases, data lakes, and data warehouses out of sync.
|
||||||
|
|
||||||
|
CDC or Change Data Capture can help you overcome this challenge.
|
||||||
|
|
||||||
|
CDC identifies and captures changes made to the data in a database, allowing you to replicate and sync data across multiple systems.
|
||||||
|
|
||||||
|
## How Change Data Capture Works
|
||||||
|
|
||||||
|
So, how does Change Data Capture work? Here's a step-by-step breakdown:
|
||||||
|
|
||||||
|
1. Data Modification: A change is made to the data in the source database. It could be an insert, update, or delete operation on a table.
|
||||||
|
|
||||||
|
2. Change Capture: A CDC tool monitors the database transaction logs to capture the modifications. It uses the source connector to connect to the database and read the logs.
|
||||||
|
|
||||||
|
3. Change Processing: The captured changes are processed and transformed into a format suitable for the downstream systems.
|
||||||
|
|
||||||
|
4. Change Propagation: The processed changes are published to a message queue and propagated to the target systems, such as data warehouses, analytics platforms, distributed caches like Redis, and so on.
|
||||||
|
|
||||||
|
5. Real-Time Integration: The CDC tool uses its sink connector to consume the log and update the target systems. The changes are received in real time, allowing for conflict-free data analysis and decision-making.
|
||||||
|
|
||||||
|
Users only need to take care of step 1 while all other steps are transparent.
|
||||||
|
|
||||||
|
A popular CDC solution uses Debezium with Kafka Connect to stream data changes from the source to target systems using Kafka as the broker. Debezium has connectors for most databases such as MySQL, PostgreSQL, Oracle, etc.
|
||||||
@@ -0,0 +1,42 @@
|
|||||||
|
---
|
||||||
|
title: ChatGPT Timeline
|
||||||
|
description: A visual guide to the evolution of ChatGPT and its underlying tech.
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0136-chatgpt-how-we-get-here.png'
|
||||||
|
createdAt: '2024-03-10'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- ai-machine-learning
|
||||||
|
tags:
|
||||||
|
- AI History
|
||||||
|
- NLP
|
||||||
|
---
|
||||||
|
|
||||||
|
A picture is worth a thousand words. ChatGPT seems to come out of nowhere. Little did we know that it was built on top of decades of research.
|
||||||
|
|
||||||
|
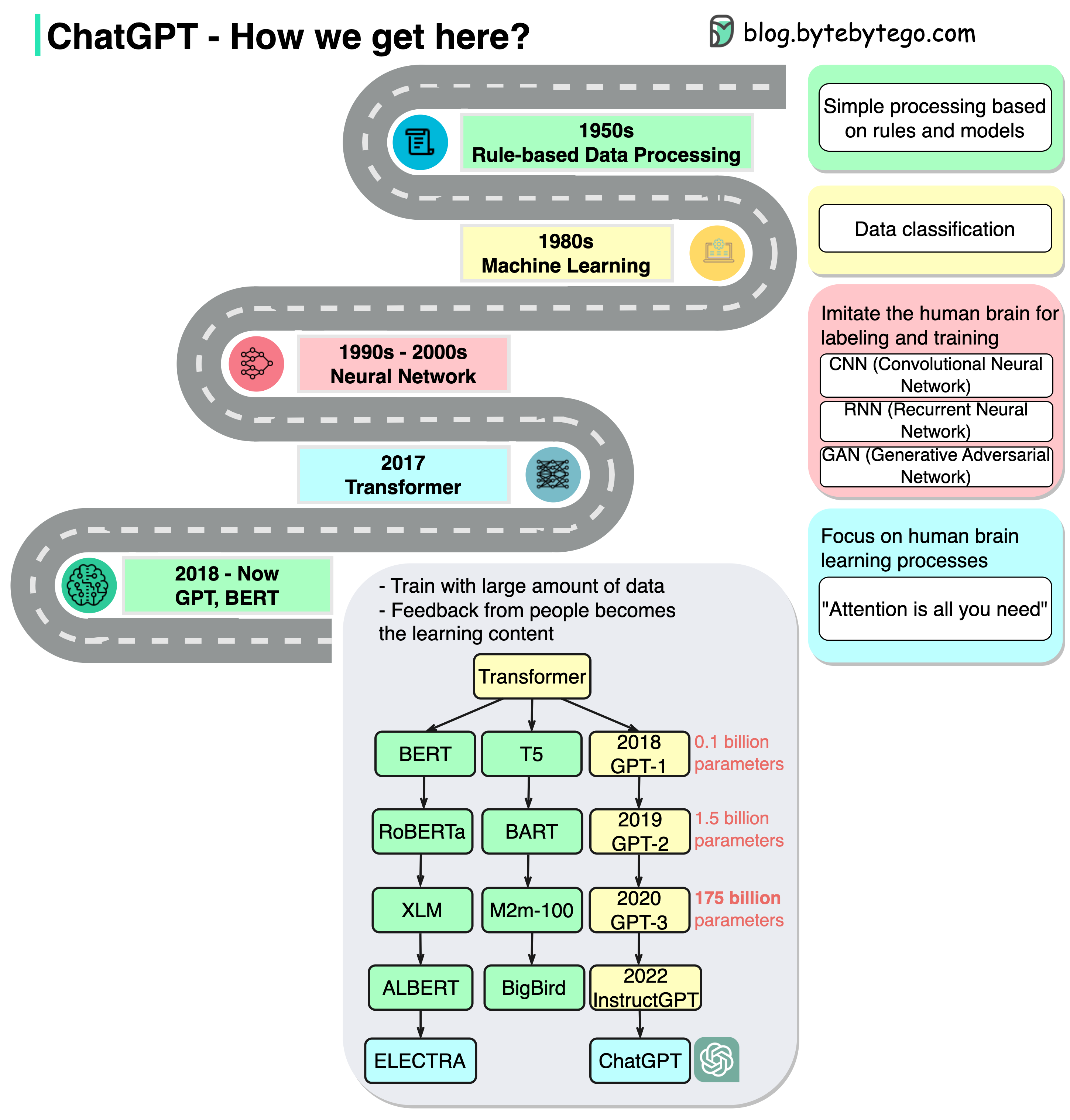
|
||||||
|
|
||||||
|
The diagram above shows how we get here.
|
||||||
|
|
||||||
|
## 1950s
|
||||||
|
|
||||||
|
In this stage, people still used primitive models that are based on rules.
|
||||||
|
|
||||||
|
## 1980s
|
||||||
|
|
||||||
|
Since the 1980s, machine learning started to pick up and was used for classification. The training was conducted on a small range of data.
|
||||||
|
|
||||||
|
## 1990s - 2000s
|
||||||
|
|
||||||
|
Since the 1990s, neural networks started to imitate human brains for labeling and training. There are generally 3 types:
|
||||||
|
|
||||||
|
- CNN (Convolutional Neural Network): often used in visual-related tasks.
|
||||||
|
- RNN (Recurrent Neural Network): useful in natural language tasks
|
||||||
|
- GAN (Generative Adversarial Network): comprised of two networks(Generative and Discriminative). This is a generative model that can generate novel images that look alike.
|
||||||
|
|
||||||
|
## 2017
|
||||||
|
|
||||||
|
“Attention is all you need” represents the foundation of generative AI. The transformer model greatly shortens the training time by parallelism.
|
||||||
|
|
||||||
|
## 2018 - Now
|
||||||
|
|
||||||
|
In this stage, due to the major progress of the transformer model, we see various models train on a massive amount of data. Human demonstration becomes the learning content of the model. We’ve seen many AI writers that can write articles, news, technical docs, and even code. This has great commercial value as well and sets off a global whirlwind.
|
||||||
@@ -0,0 +1,32 @@
|
|||||||
|
---
|
||||||
|
title: "Choose the Right Database for Metric Collection"
|
||||||
|
description: "A guide to choosing the right database for a metric collecting system."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0273-metrics-access-pattern.jpg"
|
||||||
|
createdAt: "2024-02-23"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devops-cicd
|
||||||
|
tags:
|
||||||
|
- "databases"
|
||||||
|
- "metrics"
|
||||||
|
---
|
||||||
|
|
||||||
|
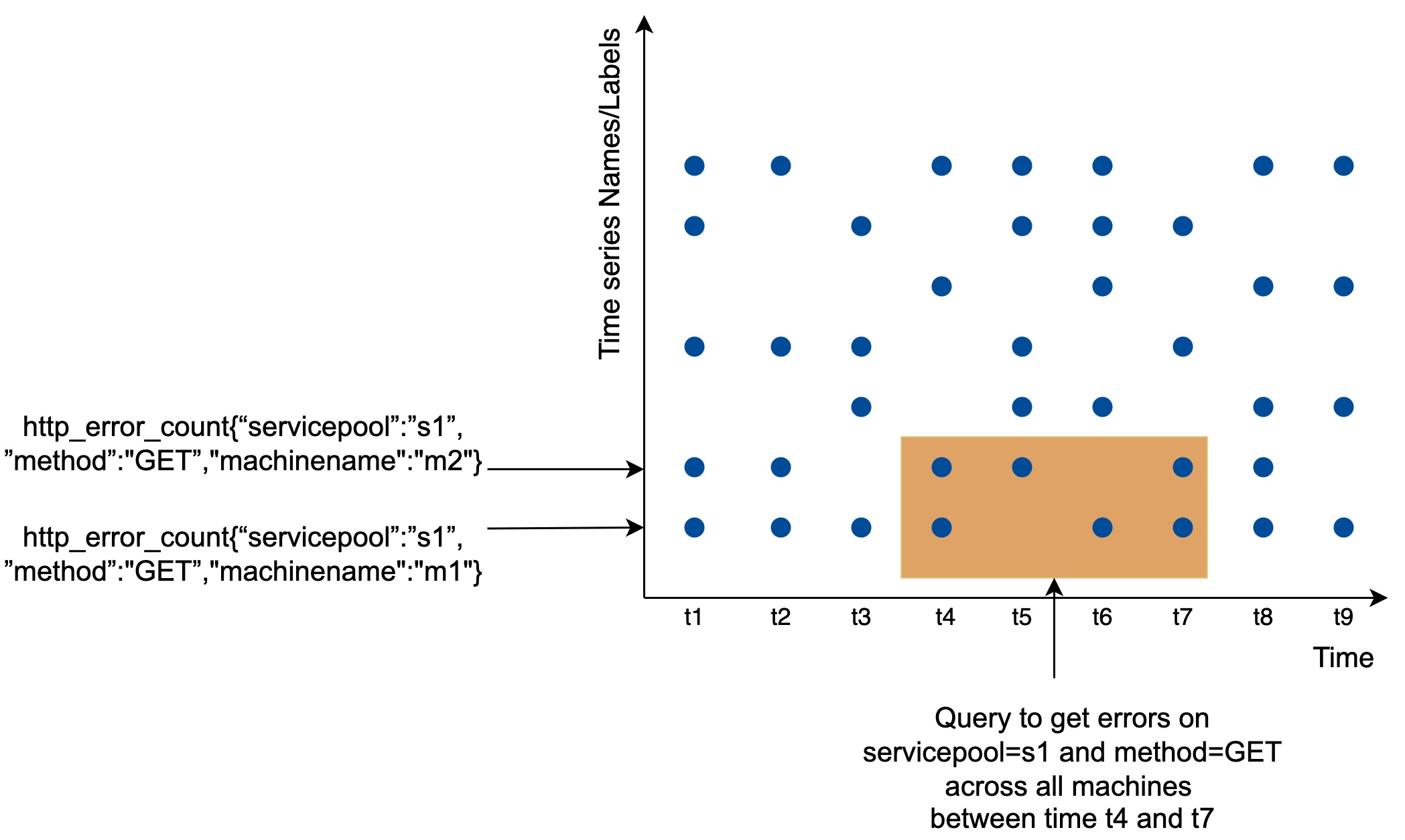
|
||||||
|
|
||||||
|
Which database shall I use for the **metric collecting system**? This is one of the most important questions we need to address in a system design interview.
|
||||||
|
|
||||||
|
## Data access pattern
|
||||||
|
|
||||||
|
As shown in the diagram, each label on the y-axis represents a time series (uniquely identified by the names and labels) while the x-axis represents time.
|
||||||
|
|
||||||
|
The write load is heavy. As you can see, there can be many time-series data points written at any moment. There are millions of operational metrics written per day, and many metrics are collected at high frequency, so the traffic is undoubtedly write-heavy.
|
||||||
|
|
||||||
|
At the same time, the read load is spiky. Both visualization and alert services send queries to the database and depending on the access patterns of the graphs and alerts, the read volume could be bursty.
|
||||||
|
|
||||||
|
## Choose the right database
|
||||||
|
|
||||||
|
The data storage system is the heart of the design. It’s not recommended to build your own storage system or use a general-purpose storage system (MySQL) for this job.
|
||||||
|
|
||||||
|
A general-purpose database, in theory, could support time-series data, but it would require expert-level tuning to make it work at our scale. Specifically, a relational database is not optimized for operations you would commonly perform against time-series data. For example, computing the moving average in a rolling time window requires complicated SQL that is difficult to read (there is an example of this in the deep dive section). Besides, to support tagging/labeling data, we need to add an index for each tag. Moreover, a general-purpose relational database does not perform well under constant heavy write load. At our scale, we would need to expend significant effort in tuning the database, and even then, it might not perform well.
|
||||||
|
|
||||||
|
How about NoSQL? In theory, a few NoSQL databases on the market could handle time-series data effectively. For example, Cassandra and Bigtable can both be used for time series data. However, this would require deep knowledge of the internal workings of each NoSQL to devise a scalable schema for effectively storing and querying time-series data. With industrial-scale time-series databases readily available, using a general-purpose NoSQL database is not appealing.
|
||||||
@@ -0,0 +1,44 @@
|
|||||||
|
---
|
||||||
|
title: "CI/CD Pipeline Explained in Simple Terms"
|
||||||
|
description: "Learn about CI/CD pipelines, their stages, and benefits in software delivery."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0140-ci-cd-pipeline.png"
|
||||||
|
createdAt: "2024-03-16"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devops-cicd
|
||||||
|
tags:
|
||||||
|
- "CI/CD"
|
||||||
|
- "DevOps"
|
||||||
|
---
|
||||||
|
|
||||||
|
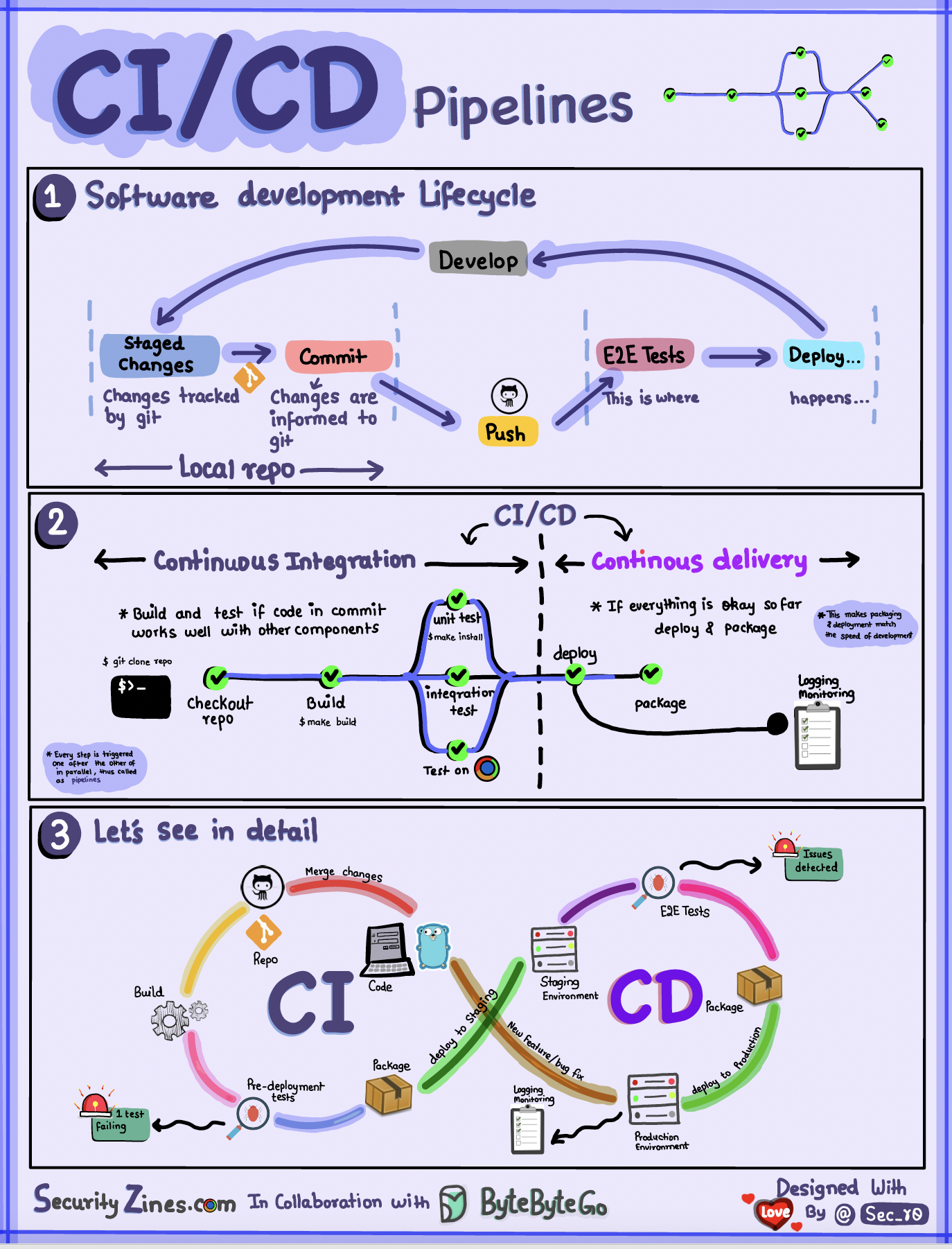
|
||||||
|
|
||||||
|
## SDLC with CI/CD
|
||||||
|
|
||||||
|
The software development life cycle (SDLC) consists of several key stages: development, testing, deployment, and maintenance. CI/CD automates and integrates these stages to enable faster, more reliable releases.
|
||||||
|
|
||||||
|
When code is pushed to a git repository, it triggers an automated build and test process. End-to-end (e2e) test cases are run to validate the code. If tests pass, the code can be automatically deployed to staging/production. If issues are found, the code is sent back to development for bug fixing. This automation provides fast feedback to developers and reduces risk of bugs in production.
|
||||||
|
|
||||||
|
## Difference between CI and CD
|
||||||
|
|
||||||
|
Continuous Integration (CI) automates the build, test, and merge process. It runs tests whenever code is committed to detect integration issues early. This encourages frequent code commits and rapid feedback.
|
||||||
|
|
||||||
|
Continuous Delivery (CD) automates release processes like infrastructure changes and deployment. It ensures software can be released reliably at any time through automated workflows. CD may also automate the manual testing and approval steps required before production deployment.
|
||||||
|
|
||||||
|
## CI/CD Pipeline
|
||||||
|
|
||||||
|
A typical CI/CD pipeline has several connected stages:
|
||||||
|
|
||||||
|
* Developer commits code changes to source control
|
||||||
|
|
||||||
|
* CI server detects changes and triggers build
|
||||||
|
|
||||||
|
* Code is compiled, tested (unit, integration tests)
|
||||||
|
|
||||||
|
* Test results reported to developer
|
||||||
|
|
||||||
|
* On success, artifacts are deployed to staging environments
|
||||||
|
|
||||||
|
* Further testing may be done on staging before release
|
||||||
|
|
||||||
|
* CD system deploys approved changes to production
|
||||||
@@ -0,0 +1,26 @@
|
|||||||
|
---
|
||||||
|
title: "CI/CD Simplified Visual Guide"
|
||||||
|
description: "A visual guide to understanding and improving CI/CD pipelines."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0141-ci-cd-workflow.png"
|
||||||
|
createdAt: "2024-03-04"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devops-cicd
|
||||||
|
tags:
|
||||||
|
- "CI/CD"
|
||||||
|
- "DevOps"
|
||||||
|
---
|
||||||
|
|
||||||
|
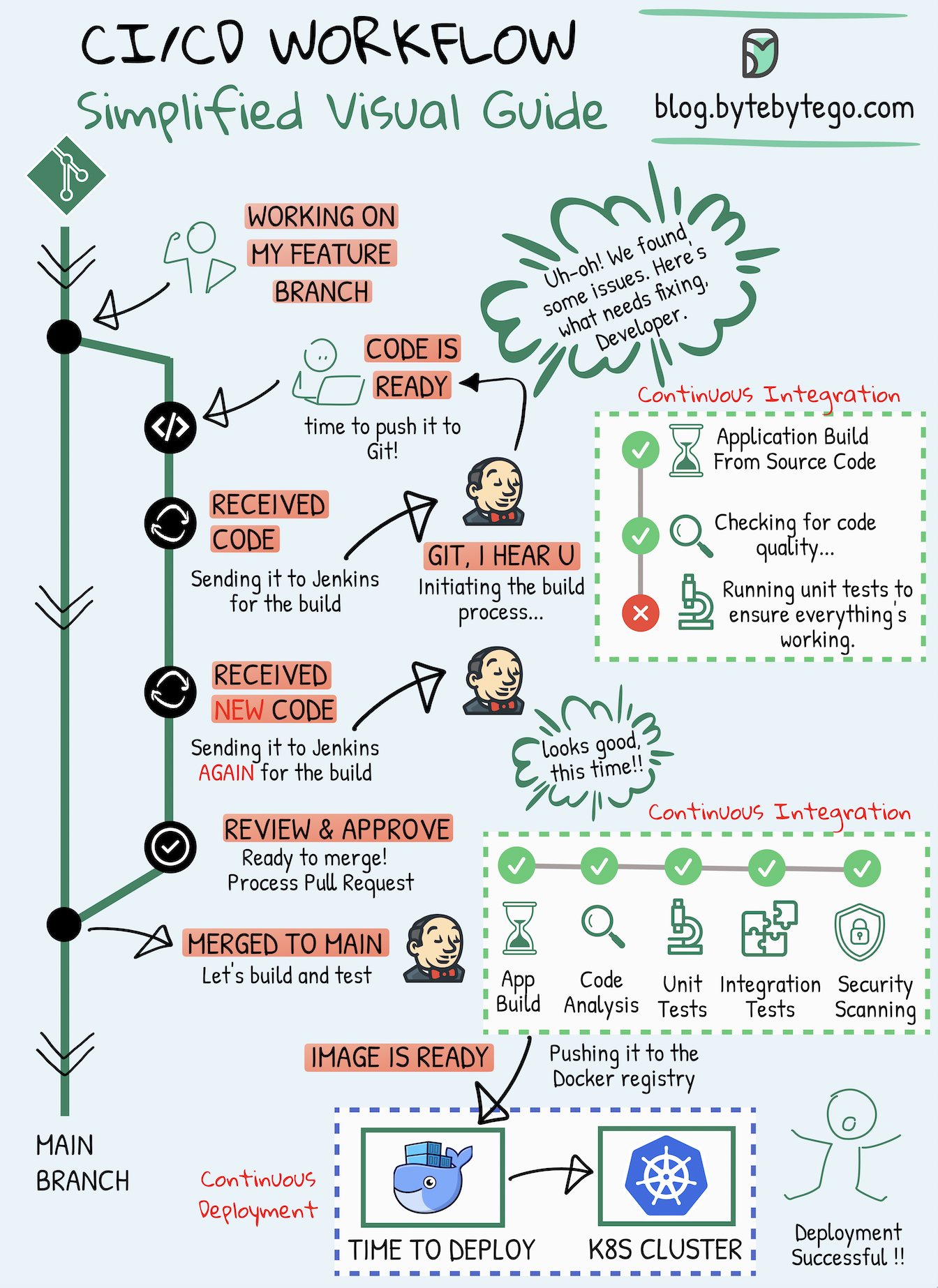
|
||||||
|
|
||||||
|
Whether you're a developer, a DevOps specialist, a tester, or involved in any modern IT role, CI/CD pipelines have become an integral part of the software development process.
|
||||||
|
|
||||||
|
## Continuous Integration (CI)
|
||||||
|
|
||||||
|
Continuous Integration (CI) is a practice where code changes are frequently combined into a shared repository. This process includes automatic checks to ensure the new code works well with the existing code.
|
||||||
|
|
||||||
|
## Continuous Deployment (CD)
|
||||||
|
|
||||||
|
Continuous Deployment (CD) takes care of automatically putting these code changes into real-world use. It makes sure that the process of moving new code to production is smooth and reliable.
|
||||||
|
|
||||||
|
This visual guide is designed to help you grasp and enhance your methods for creating and delivering software more effectively.
|
||||||
@@ -0,0 +1,20 @@
|
|||||||
|
---
|
||||||
|
title: "Cloud Comparison Cheat Sheet"
|
||||||
|
description: "A handy cheat sheet comparing different cloud services."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0093-cloud-comparison-cheat-sheet.png"
|
||||||
|
createdAt: "2024-03-13"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- Cloud Computing
|
||||||
|
- Comparison
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Cloud comparison Cheat Sheet
|
||||||
|
|
||||||
|
A nice cheat sheet of different cloud services (2023 edition)!
|
||||||
|
|
||||||
|
Guest post by [Govardhana Miriyala Kannaiah](https://www.linkedin.com/in/govardhana-miriyala-kannaiah/).
|
||||||
@@ -0,0 +1,33 @@
|
|||||||
|
---
|
||||||
|
title: "Cloud Cost Reduction Techniques"
|
||||||
|
description: "Learn effective strategies to minimize cloud spending and optimize resources."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0145-cloud-cost-reduction-techniques.png"
|
||||||
|
createdAt: "2024-03-03"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- Cloud Cost Optimization
|
||||||
|
- Resource Management
|
||||||
|
---
|
||||||
|
|
||||||
|
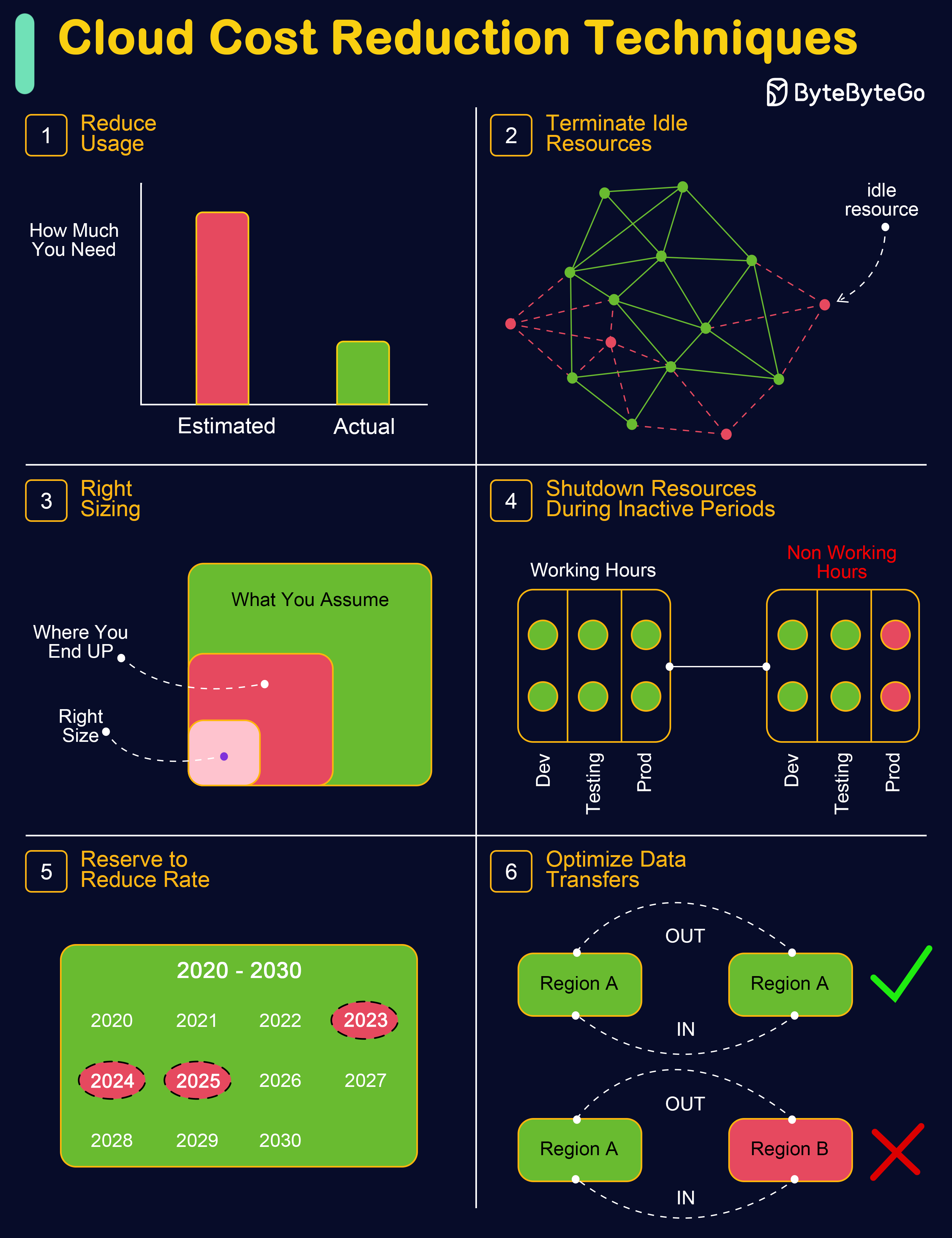
|
||||||
|
|
||||||
|
Irrational Cloud Cost is the biggest challenge many organizations are battling as they navigate the complexities of cloud computing.
|
||||||
|
Efficiently managing these costs is crucial for optimizing cloud usage and maintaining financial health.
|
||||||
|
|
||||||
|
The following techniques can help businesses effectively control and minimize their cloud expenses.
|
||||||
|
|
||||||
|
* **Reduce Usage:** Fine-tune the volume and scale of resources to ensure efficiency without compromising on the performance of applications (e.g., downsizing instances, minimizing storage space, consolidating services).
|
||||||
|
|
||||||
|
* **Terminate Idle Resources:** Locate and eliminate resources that are not in active use, such as dormant instances, databases, or storage units.
|
||||||
|
|
||||||
|
* **Right Sizing:** Adjust instance sizes to adequately meet the demands of your applications, ensuring neither underuse nor overuse.
|
||||||
|
|
||||||
|
* **Shutdown Resources During Off-Peak Times:** Set up automatic mechanisms or schedules for turning off non-essential resources when they are not in use, especially during low-activity periods.
|
||||||
|
|
||||||
|
* **Reserve to Reduce Rate:** Adopt cost-effective pricing models like Reserved Instances or Savings Plans that align with your specific workload needs.
|
||||||
|
|
||||||
|
Bonus Tip: Consider using Spot Instances and lower-tier storage options for additional cost savings.
|
||||||
|
|
||||||
|
* **Optimize Data Transfers:** Utilize methods such as data compression and Content Delivery Networks (CDNs) to cut down on bandwidth expenses, and strategically position resources to reduce data transfer costs, focusing on intra-region transfers.
|
||||||
@@ -0,0 +1,22 @@
|
|||||||
|
---
|
||||||
|
title: "Cloud Database Cheat Sheet"
|
||||||
|
description: "A handy guide to cloud databases and their open-source alternatives."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0146-cloud-dbs2.png"
|
||||||
|
createdAt: "2024-02-18"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "Cloud Computing"
|
||||||
|
- "Databases"
|
||||||
|
---
|
||||||
|
|
||||||
|
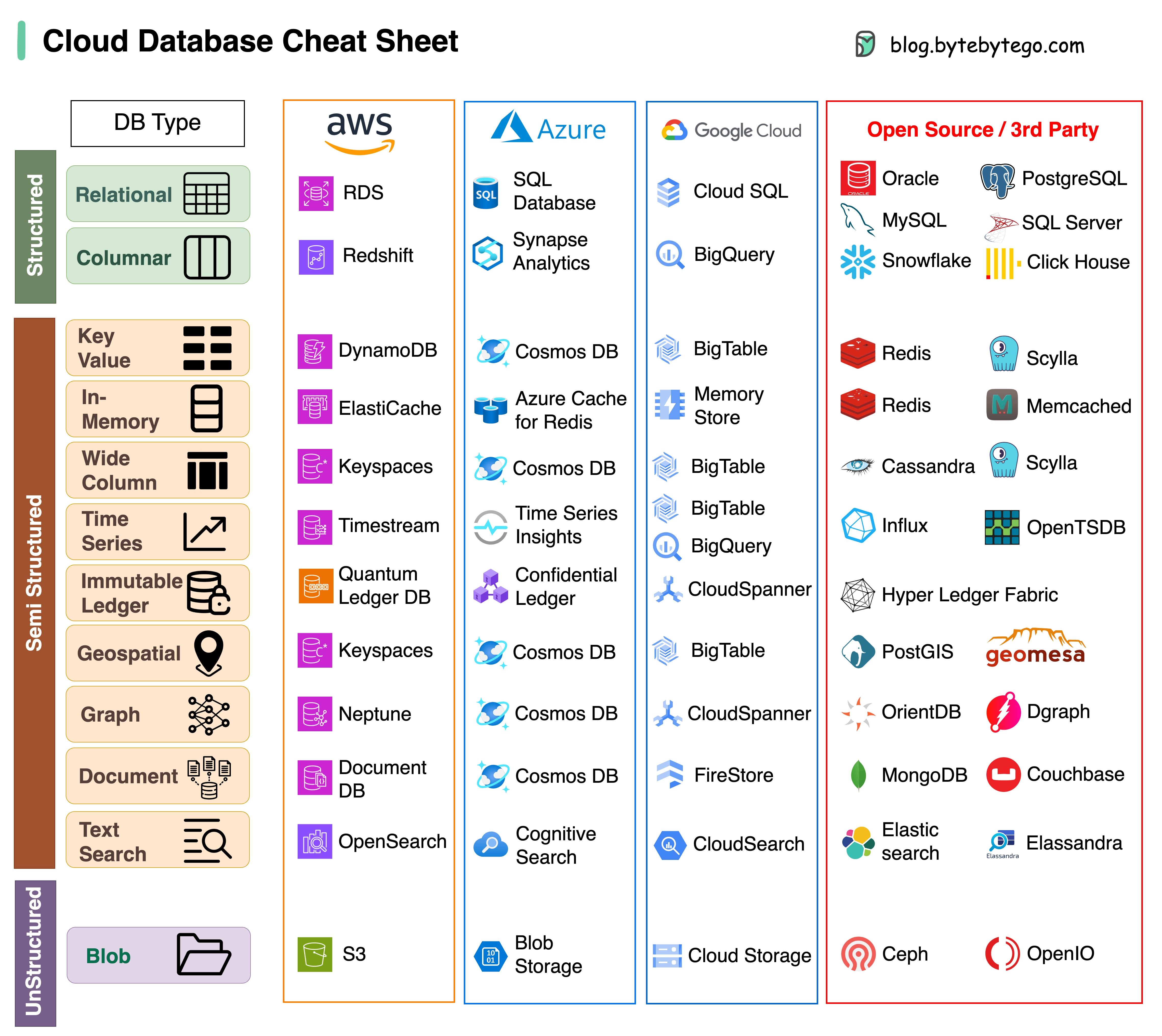
|
||||||
|
|
||||||
|
A cheat sheet of various databases in cloud services, along with their corresponding open-source/3rd-party options.
|
||||||
|
|
||||||
|
Choosing the right database for your project is a complex task. The multitude of database options, each suited to distinct use cases, can quickly lead to decision fatigue.
|
||||||
|
|
||||||
|
We hope this cheat sheet provides the high level direction to pinpoint the right service that aligns with your project's needs and avoid potential pitfalls.
|
||||||
|
|
||||||
|
Note: Google has limited documentation for their database use cases. Even though we did our best to look at what was available and arrived at the best option, some of the entries may be not accurate.
|
||||||
@@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
title: "Cloud Disaster Recovery Strategies"
|
||||||
|
description: "Explore cloud disaster recovery strategies: RTO, RPO, and key approaches."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0050-cloud-disaster-recovery-strategies.png"
|
||||||
|
createdAt: "2024-01-29"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Cloud Computing"
|
||||||
|
- "Disaster Recovery"
|
||||||
|
---
|
||||||
|
|
||||||
|
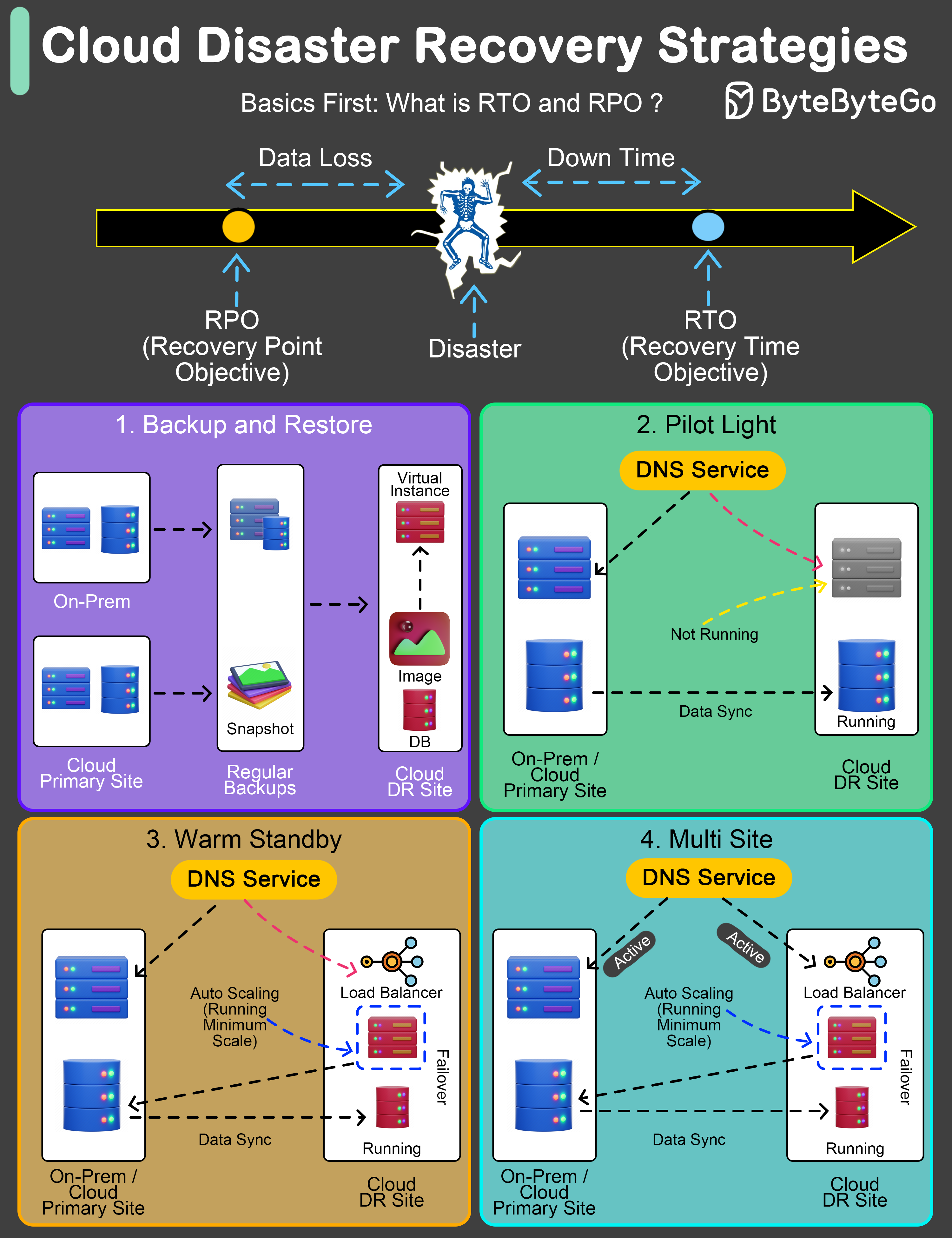
|
||||||
|
|
||||||
|
An effective Disaster Recovery (DR) plan is not just a precaution; it's a necessity.
|
||||||
|
|
||||||
|
The key to any robust DR strategy lies in understanding and setting two pivotal benchmarks: Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
|
||||||
|
|
||||||
|
* **Recovery Time Objective (RTO)** refers to the maximum acceptable length of time that your application or network can be offline after a disaster.
|
||||||
|
|
||||||
|
* **Recovery Point Objective (RPO)**, on the other hand, indicates the maximum acceptable amount of data loss measured in time.
|
||||||
|
|
||||||
|
Let's explore four widely adopted DR strategies:
|
||||||
|
|
||||||
|
## Backup and Restore Strategy:
|
||||||
|
|
||||||
|
This method involves regular backups of data and systems to facilitate post-disaster recovery.
|
||||||
|
|
||||||
|
* **Typical RTO:** From several hours to a few days.
|
||||||
|
* **Typical RPO:** From a few hours up to the time of the last successful backup.
|
||||||
|
|
||||||
|
## Pilot Light Approach:
|
||||||
|
|
||||||
|
Maintains crucial components in a ready-to-activate mode, enabling rapid scaling in response to a disaster.
|
||||||
|
|
||||||
|
* **Typical RTO:** From a few minutes to several hours.
|
||||||
|
* **Typical RPO:** Depends on how often data is synchronized.
|
||||||
|
|
||||||
|
## Warm Standby Solution:
|
||||||
|
|
||||||
|
Establishes a semi-active environment with current data to reduce recovery time.
|
||||||
|
|
||||||
|
* **Typical RTO:** Generally within a few minutes to hours.
|
||||||
|
* **Typical RPO:** Up to the last few minutes or hours.
|
||||||
|
|
||||||
|
## Hot Site / Multi-Site Configuration:
|
||||||
|
|
||||||
|
Ensures a fully operational, duplicate environment that runs parallel to the primary system.
|
||||||
|
|
||||||
|
* **Typical RTO:** Almost immediate, often just a few minutes.
|
||||||
|
* **Typical RPO:** Extremely minimal, usually only a few seconds old.
|
||||||
@@ -0,0 +1,20 @@
|
|||||||
|
---
|
||||||
|
title: "Cloud Load Balancer Cheat Sheet"
|
||||||
|
description: "A concise guide to cloud load balancers and their optimal use cases."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0094-cloud-load-balancer-cheatsheet.gif"
|
||||||
|
createdAt: "2024-03-05"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Cloud Computing"
|
||||||
|
- "Load Balancing"
|
||||||
|
---
|
||||||
|
|
||||||
|
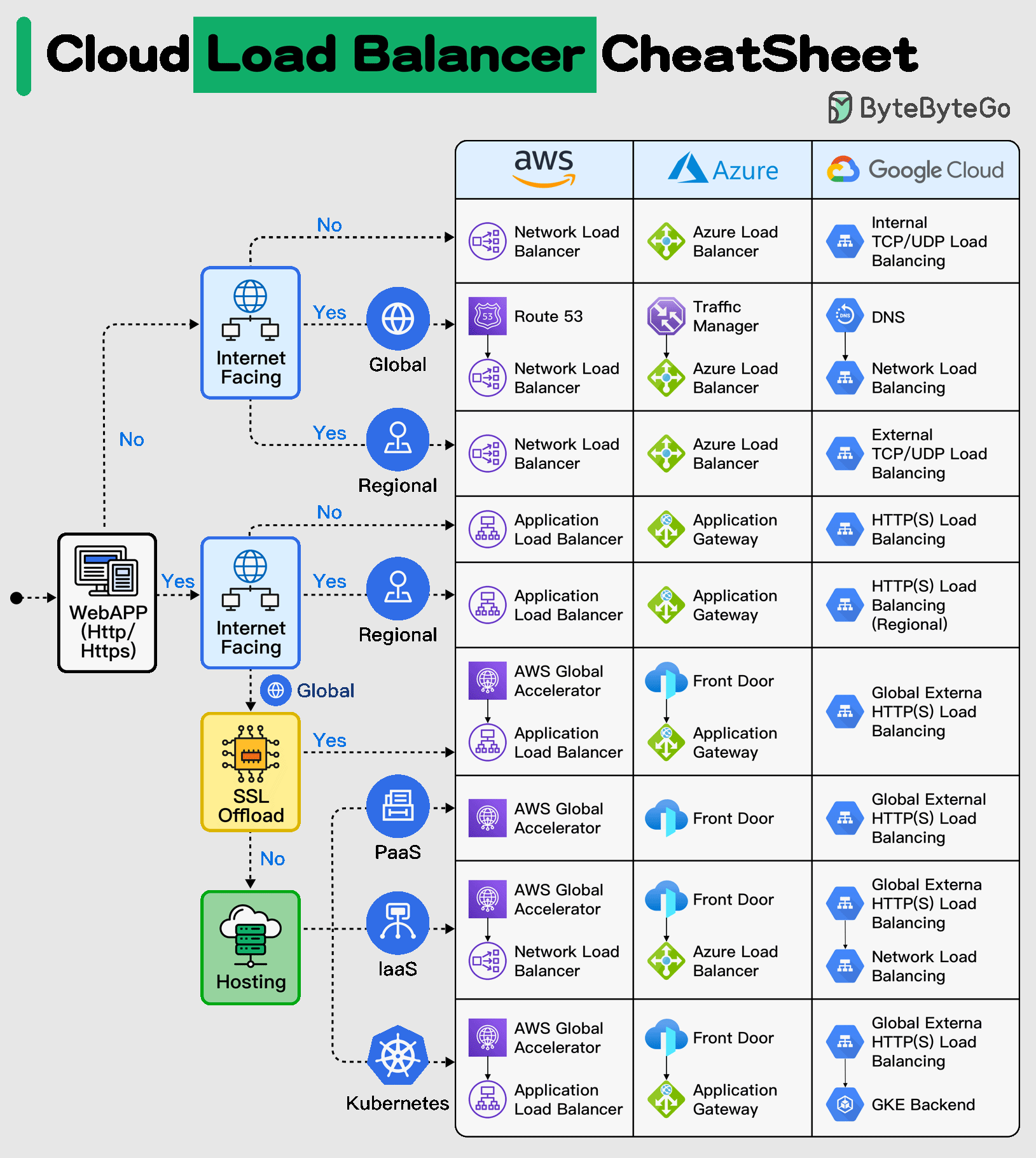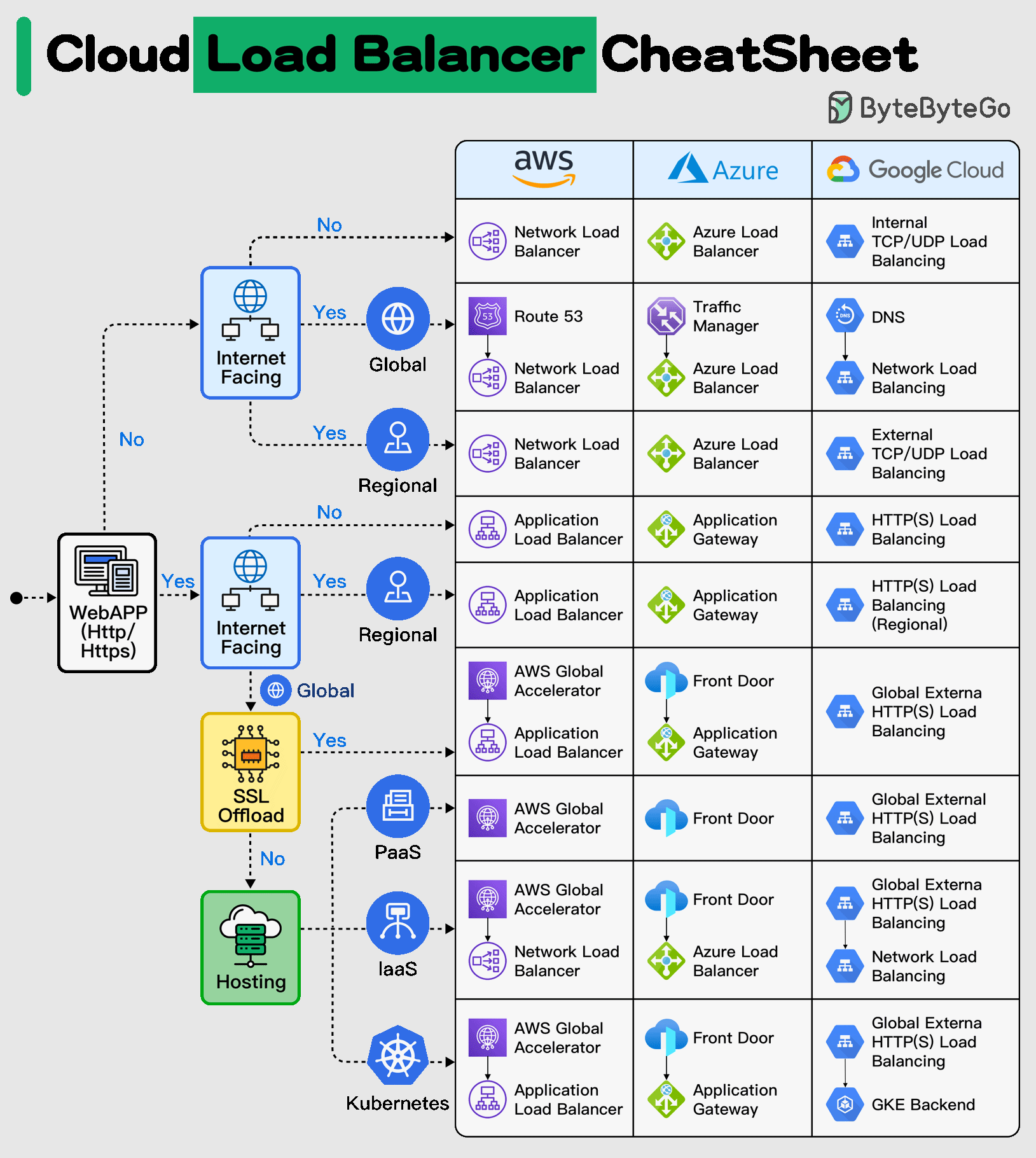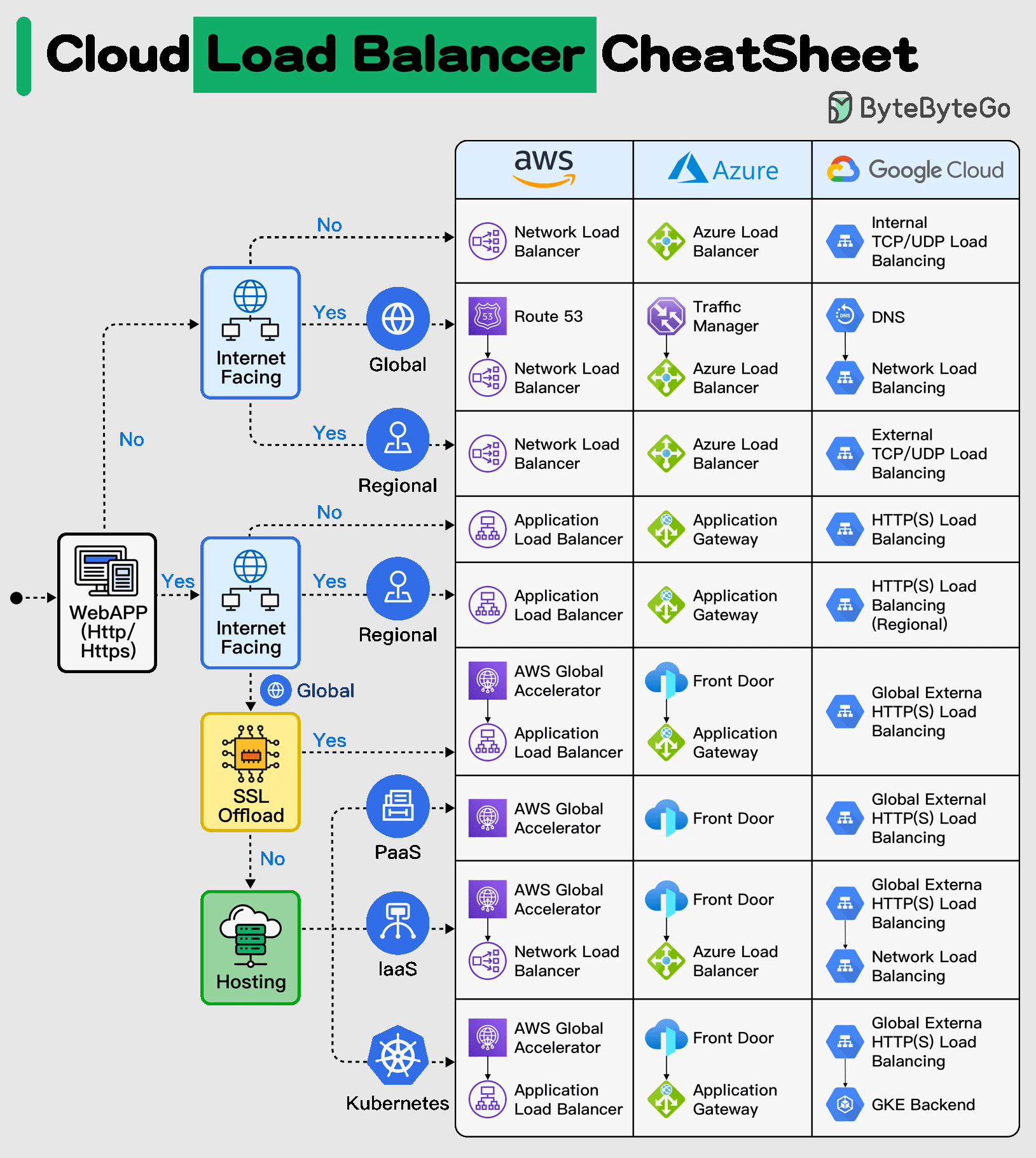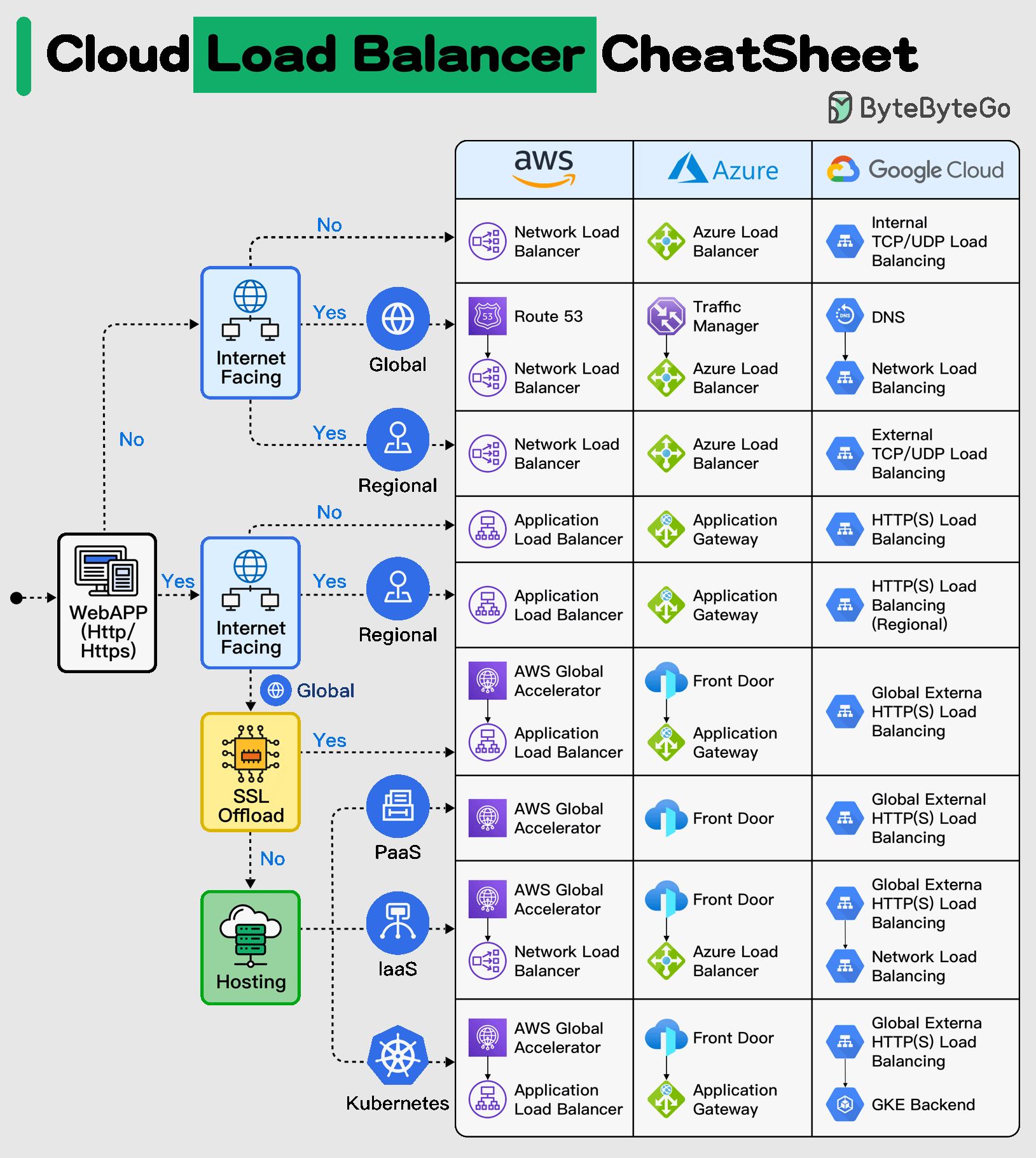
|
||||||
|
|
||||||
|
In today's multi-cloud landscape, mastering load balancing is essential to ensure seamless user experiences and maximize resource utilization, especially when orchestrating applications across multiple cloud providers. Having the right knowledge is key to overcoming these challenges and achieving consistent, reliable application delivery.
|
||||||
|
|
||||||
|
In selecting the appropriate load balancer type, it's essential to consider factors such as application traffic patterns, scalability requirements, and security considerations. By carefully evaluating your specific use case, you can make informed decisions that enhance your cloud infrastructure's efficiency and reliability.
|
||||||
|
|
||||||
|
This Cloud Load Balancer cheat sheet would help you in simplifying the decision-making process and helping you implement the most effective load balancing strategy for your cloud-based applications.
|
||||||
@@ -0,0 +1,38 @@
|
|||||||
|
---
|
||||||
|
title: "Cloud Monitoring Cheat Sheet"
|
||||||
|
description: "A handy guide to cloud monitoring across major providers and tools."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0095-cloud-monitoring-cheat-sheet.png"
|
||||||
|
createdAt: "2024-02-24"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- cloud-distributed-systems
|
||||||
|
tags:
|
||||||
|
- "Cloud Computing"
|
||||||
|
- "Monitoring"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
A nice cheat sheet of different monitoring infrastructure in cloud services.
|
||||||
|
|
||||||
|
This cheat sheet offers a concise yet comprehensive comparison of key monitoring elements across the three major cloud providers and open-source / 3rd party tools.
|
||||||
|
|
||||||
|
Let's delve into the essential monitoring aspects covered:
|
||||||
|
|
||||||
|
* **Data Collection:** Gather information from diverse sources to enhance decision-making.
|
||||||
|
|
||||||
|
* **Data Storage:** Safely store and manage data for future analysis and reference.
|
||||||
|
|
||||||
|
* **Data Analysis:** Extract valuable insights from data to drive informed actions.
|
||||||
|
|
||||||
|
* **Alerting:** Receive real-time notifications about critical events or anomalies.
|
||||||
|
|
||||||
|
* **Visualization:** Present data in a visually comprehensible format for better understanding.
|
||||||
|
|
||||||
|
* **Reporting and Compliance:** Generate reports and ensure adherence to regulatory standards.
|
||||||
|
|
||||||
|
* **Automation:** Streamline processes and tasks through automated workflows.
|
||||||
|
|
||||||
|
* **Integration:** Seamlessly connect and exchange data between different systems or tools.
|
||||||
|
|
||||||
|
* **Feedback Loops:** Continuously refine strategies based on feedback and performance analysis.
|
||||||
@@ -0,0 +1,54 @@
|
|||||||
|
---
|
||||||
|
title: "Cloud Native Anti-Patterns"
|
||||||
|
description: "Avoid common pitfalls in cloud-native development for robust applications."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0070-cloud-native-anti-patterns.png"
|
||||||
|
createdAt: "2024-02-25"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- devops-cicd
|
||||||
|
tags:
|
||||||
|
- "Cloud Native"
|
||||||
|
- "Anti-Patterns"
|
||||||
|
---
|
||||||
|
|
||||||
|
By being aware of these anti-patterns and following cloud-native best practices, you can design, build, and operate more robust, scalable, and cost-efficient cloud-native applications.
|
||||||
|
|
||||||
|
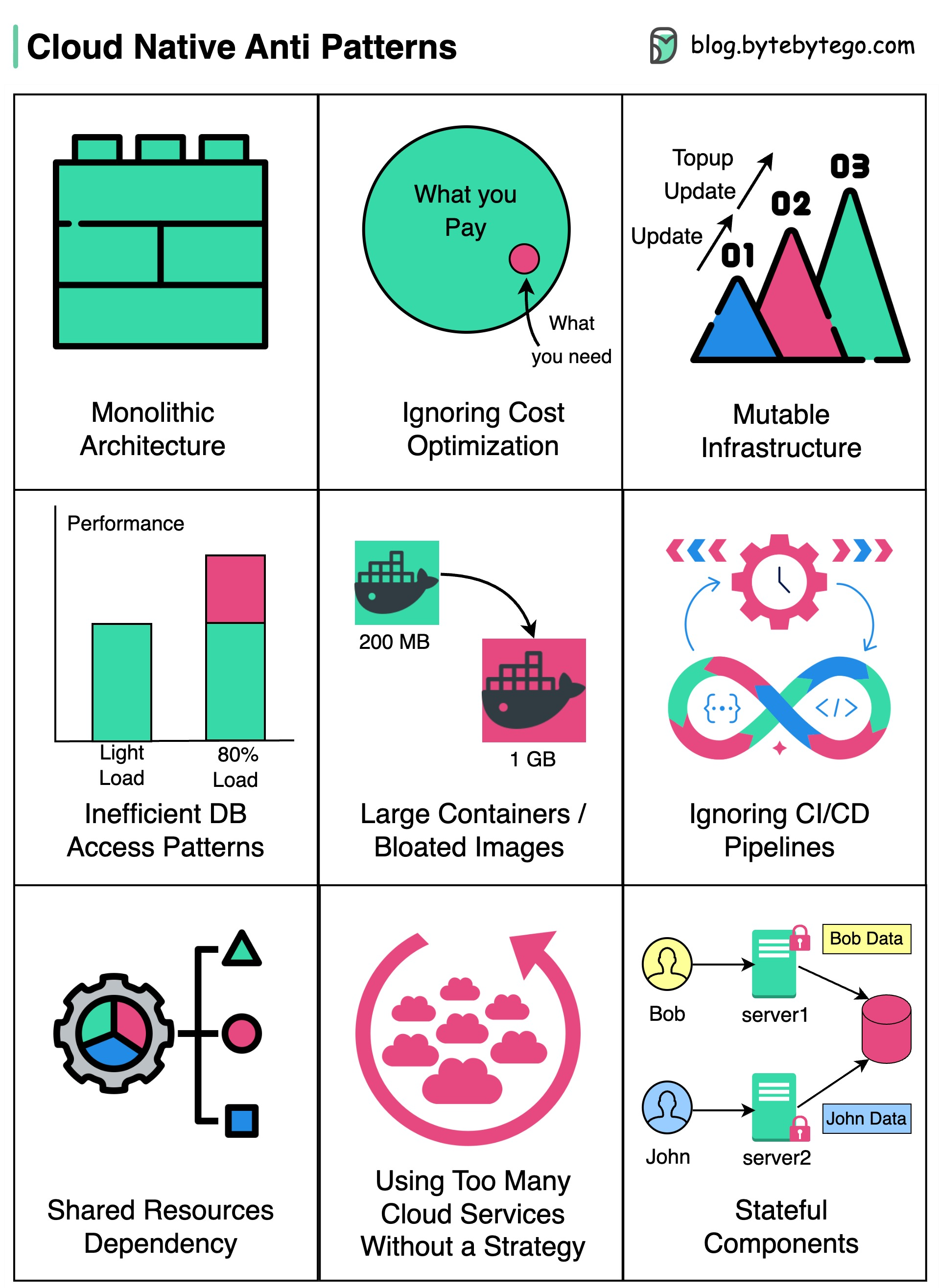
|
||||||
|
|
||||||
|
## Monolithic Architecture
|
||||||
|
|
||||||
|
One large, tightly coupled application running on the cloud, hindering scalability and agility.
|
||||||
|
|
||||||
|
## Ignoring Cost Optimization
|
||||||
|
|
||||||
|
Cloud services can be expensive, and not optimizing costs can result in budget overruns.
|
||||||
|
|
||||||
|
## Mutable Infrastructure
|
||||||
|
|
||||||
|
* Infrastructure components are to be treated as disposable and are never modified in place.
|
||||||
|
|
||||||
|
* Failing to embrace this approach can lead to configuration drift, increased maintenance, and decreased reliability.
|
||||||
|
|
||||||
|
## Inefficient DB Access Patterns
|
||||||
|
|
||||||
|
Use of overly complex queries or lacking database indexing, can lead to performance degradation and database bottlenecks.
|
||||||
|
|
||||||
|
## Large Containers or Bloated Images
|
||||||
|
|
||||||
|
Creating large containers or using bloated images can increase deployment times, consume more resources, and slow down application scaling.
|
||||||
|
|
||||||
|
## Ignoring CI/CD Pipelines
|
||||||
|
|
||||||
|
Deployments become manual and error-prone, impeding the speed and frequency of software releases.
|
||||||
|
|
||||||
|
## Shared Resources Dependency
|
||||||
|
|
||||||
|
Applications relying on shared resources like databases can create contention and bottlenecks, affecting overall performance.
|
||||||
|
|
||||||
|
## Using Too Many Cloud Services Without a Strategy
|
||||||
|
|
||||||
|
While cloud providers offer a vast array of services, using too many of them without a clear strategy can create complexity and make it harder to manage the application.
|
||||||
|
|
||||||
|
## Stateful Components
|
||||||
|
|
||||||
|
Relying on persistent state in applications can introduce complexity, hinder scalability, and limit fault tolerance.
|
||||||
@@ -0,0 +1,28 @@
|
|||||||
|
---
|
||||||
|
title: "Concurrency vs Parallelism"
|
||||||
|
description: "Understand the difference between concurrency and parallelism in system design."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0150-concurrency-is-not-parallelism.png"
|
||||||
|
createdAt: "2024-03-11"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- software-development
|
||||||
|
tags:
|
||||||
|
- "Concurrency"
|
||||||
|
- "Parallelism"
|
||||||
|
---
|
||||||
|
|
||||||
|
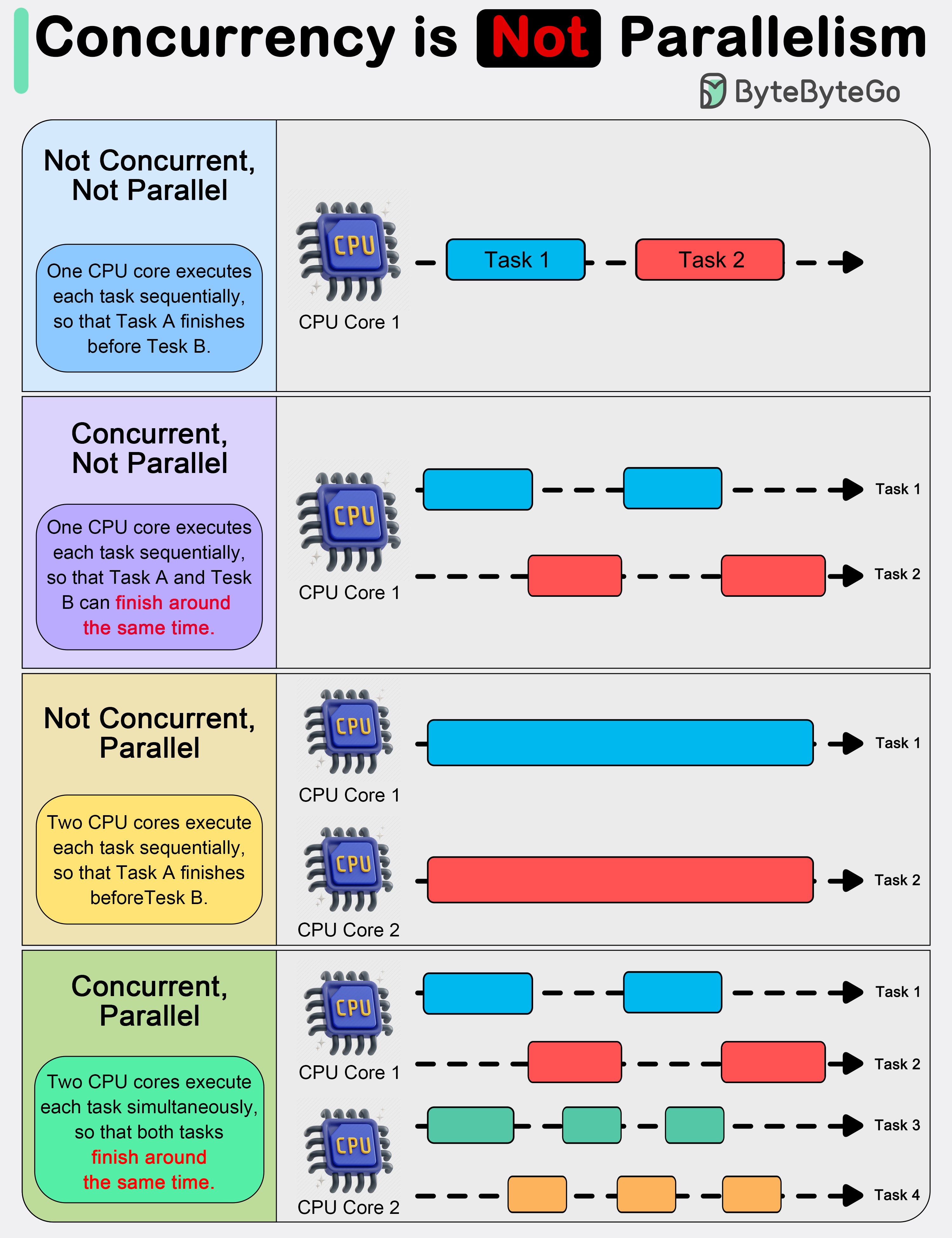
|
||||||
|
|
||||||
|
In system design, it is important to understand the difference between concurrency and parallelism.
|
||||||
|
|
||||||
|
As Rob Pyke(one of the creators of GoLang) stated:“ Concurrency is about **dealing with** lots of things at once. Parallelism is about **doing** lots of things at once." This distinction emphasizes that concurrency is more about the **design** of a program, while parallelism is about the **execution**.
|
||||||
|
|
||||||
|
Concurrency is about dealing with multiple things at once. It involves structuring a program to handle multiple tasks simultaneously, where the tasks can start, run, and complete in overlapping time periods, but not necessarily at the same instant.
|
||||||
|
|
||||||
|
Concurrency is about the composition of independently executing processes and describes a program's ability to manage multiple tasks by making progress on them without necessarily completing one before it starts another.
|
||||||
|
|
||||||
|
Parallelism, on the other hand, refers to the simultaneous execution of multiple computations. It is the technique of running two or more tasks or computations at the same time, utilizing multiple processors or cores within a computer to perform several operations concurrently. Parallelism requires hardware with multiple processing units, and its primary goal is to increase the throughput and computational speed of a system.
|
||||||
|
|
||||||
|
In practical terms, concurrency enables a program to remain responsive to input, perform background tasks, and handle multiple operations in a seemingly simultaneous manner, even on a single-core processor. It's particularly useful in I/O-bound and high-latency operations where programs need to wait for external events, such as file, network, or user interactions.
|
||||||
|
|
||||||
|
Parallelism, with its ability to perform multiple operations at the same time, is crucial in CPU-bound tasks where computational speed and throughput are the bottlenecks. Applications that require heavy mathematical computations, data analysis, image processing, and real-time processing can significantly benefit from parallel execution.
|
||||||
@@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
title: "Consistent Hashing Explained"
|
||||||
|
description: "Explore consistent hashing: its benefits, and real-world applications."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0151-consistent-hashing.png"
|
||||||
|
createdAt: "2024-03-07"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- database-and-storage
|
||||||
|
tags:
|
||||||
|
- "Consistent Hashing"
|
||||||
|
- "Distributed Systems"
|
||||||
|
---
|
||||||
|
|
||||||
|
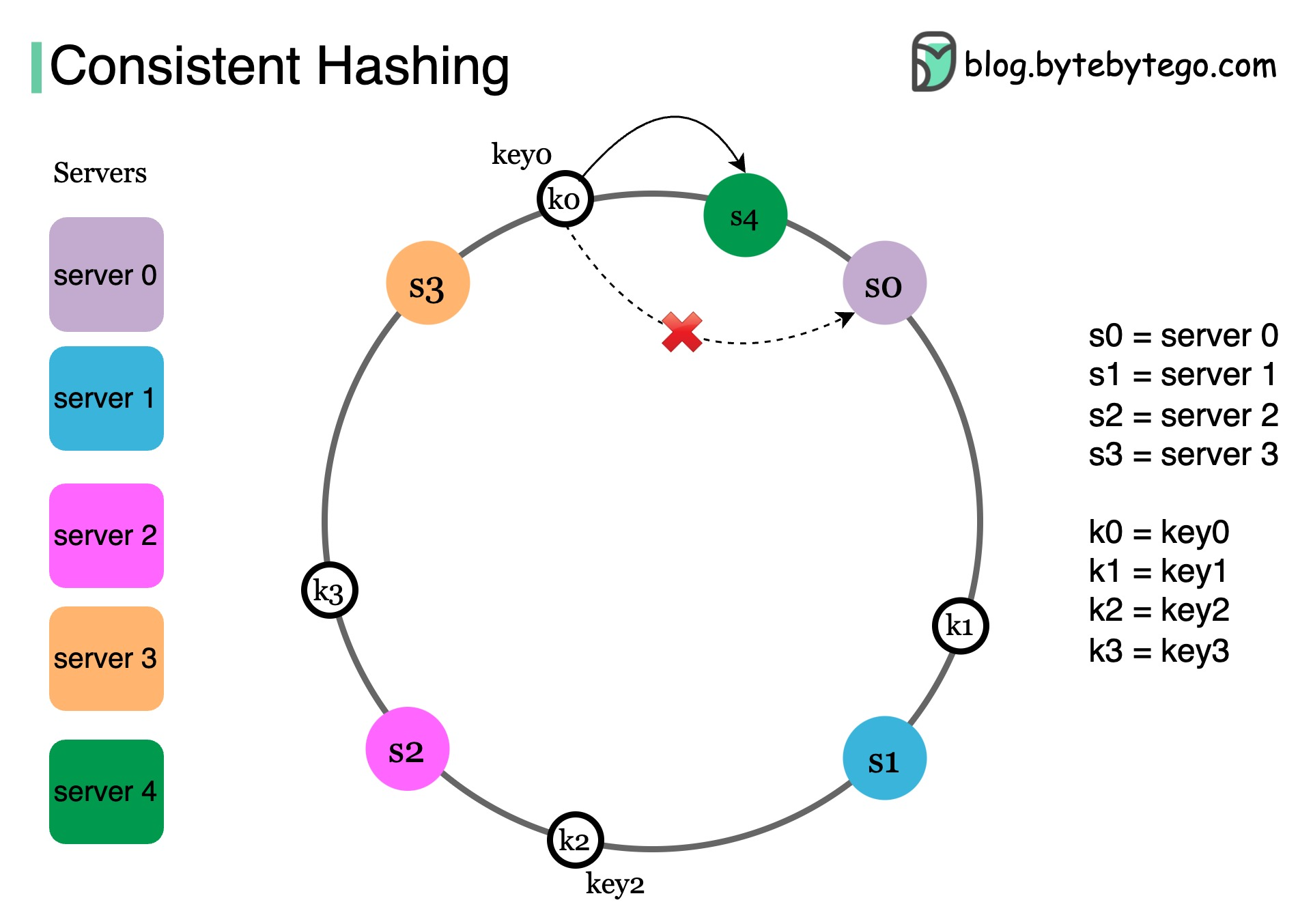
|
||||||
|
|
||||||
|
## Algorithm 1: Consistent Hashing
|
||||||
|
|
||||||
|
What do Amazon DynamoDB, Apache Cassandra, Discord, and Akamai CDN have in common?
|
||||||
|
|
||||||
|
They all use consistent hashing. Let’s dive right in.
|
||||||
|
|
||||||
|
## What’s the issue with simple hashing?
|
||||||
|
|
||||||
|
In a large-scale distributed system, data does not fit on a single server. They are “distributed” across many machines. This is called horizontal scaling.
|
||||||
|
|
||||||
|
To build such a system with predictable performance, it is important to distribute the data evenly across those servers.
|
||||||
|
|
||||||
|
Simple hashing: serverIndex = hash(key) % N, where N is the size of the server pool
|
||||||
|
|
||||||
|
This approach works well when the size of the cluster is fixed, and the data distribution is even. But when new servers get added to meet new demand, or when existing servers get removed, it triggers a storm of misses and a lot of objects to be moved.
|
||||||
|
|
||||||
|
## Consistent hashing
|
||||||
|
|
||||||
|
Consistent hashing is an effective technique to mitigate this issue.
|
||||||
|
|
||||||
|
The goal of consistent hashing is simple. We want almost all objects to stay assigned to the same server even as the number of servers changes.
|
||||||
|
|
||||||
|
As shown in the diagram, using a hash function, we hash each server by its name or IP address, and place the server onto the ring. Next, we hash each object by its key with the same hashing function.
|
||||||
|
|
||||||
|
To locate the server for a particular object, we go clockwise from the location of the object key on the ring until a server is found. Continue with our example, key 0 is on server 0, key 1 is on server 1.
|
||||||
|
|
||||||
|
Now let’s take a look at what happens when we add a server.
|
||||||
|
|
||||||
|
Here we insert a new server s4 to the left of s0 on the ring. Note that only k0 needs to be moved from s0 to s4. This is because s4 is the first server k0 encounters by going clockwise from k0’s position on the ring. Keys k1, k2, and k3 are not affected.
|
||||||
|
|
||||||
|
## How consistent hashing is used in the real world
|
||||||
|
|
||||||
|
* **Amazon DynamoDB and Apache Cassandra:** minimize data movement during rebalancing
|
||||||
|
|
||||||
|
* **Content delivery networks like Akamai:** distribute web contents evenly among the edge servers
|
||||||
|
|
||||||
|
* **Load balancers like Google Network Load Balancer:** distribute persistent connections evenly across backend servers
|
||||||
@@ -0,0 +1,36 @@
|
|||||||
|
---
|
||||||
|
title: "Cookies vs Sessions vs JWT vs PASETO"
|
||||||
|
description: "Explore cookies, sessions, JWT, and PASETO for modern authentication."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0155-cookies-vs-sessions-vs-jwt-vs-paseto.png"
|
||||||
|
createdAt: "2024-03-04"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- security
|
||||||
|
tags:
|
||||||
|
- "Authentication"
|
||||||
|
- "Security"
|
||||||
|
---
|
||||||
|
|
||||||
|
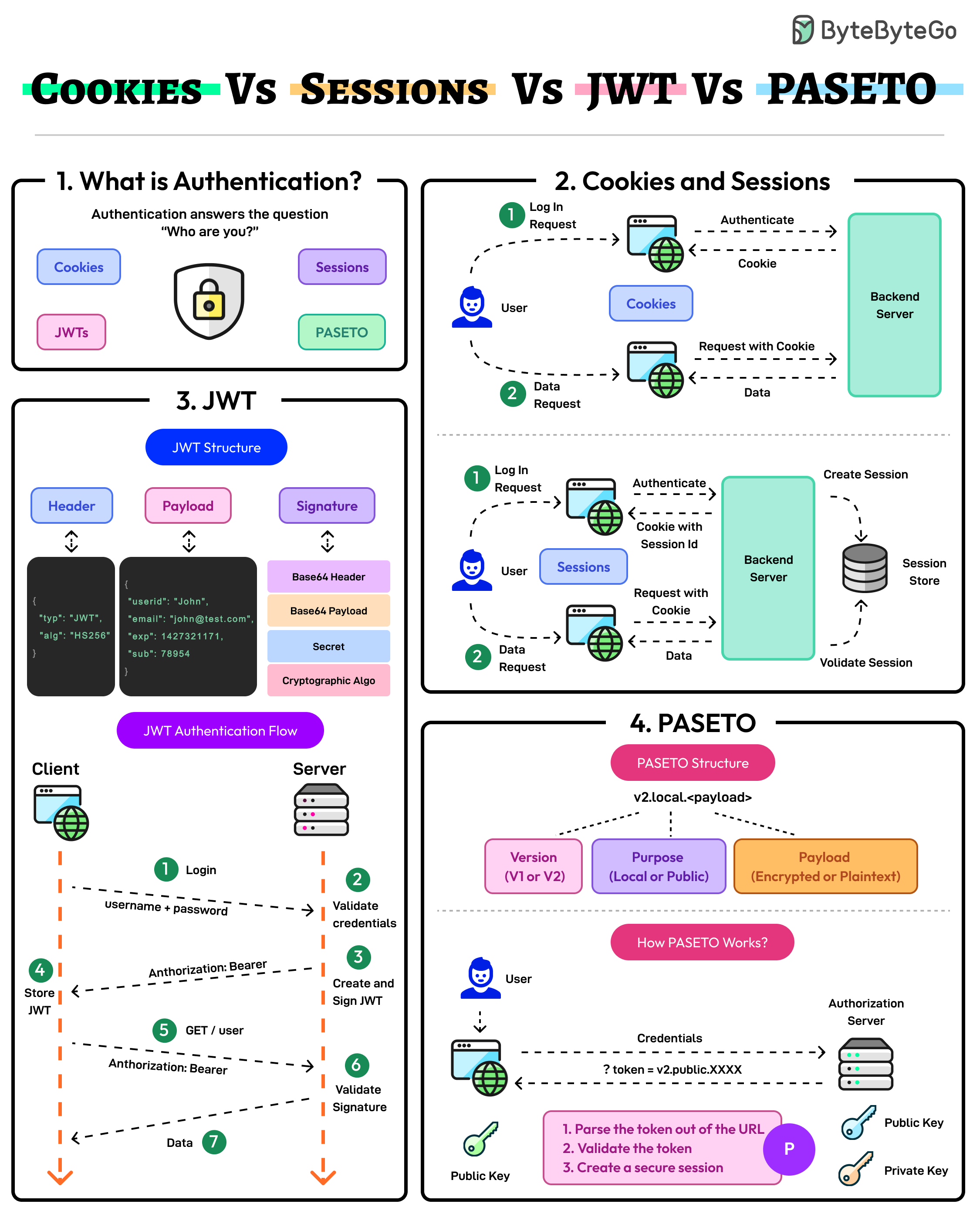
|
||||||
|
|
||||||
|
Authentication ensures that only authorized users gain access to an application’s resources. It answers the question of the user’s identity i.e. “Who are you?”
|
||||||
|
|
||||||
|
The modern authentication landscape has multiple approaches: Cookies, Sessions, JWTs, and PASETO. Here’s what they mean:
|
||||||
|
|
||||||
|
## Cookies and Sessions
|
||||||
|
|
||||||
|
Cookies and sessions are authentication mechanisms where session data is stored on the server and referenced via a client-side cookie.
|
||||||
|
|
||||||
|
Sessions are ideal for applications requiring strict server-side control over user data. On the downside, sessions may face scalability challenges in distributed systems.
|
||||||
|
|
||||||
|
## JWT
|
||||||
|
|
||||||
|
JSON Web Token (JWT) is a stateless, self-contained authentication method that stores all user data within the token.
|
||||||
|
|
||||||
|
JWTs are highly scalable but require careful handling to mitigate the chances of token theft and manage token expiration.
|
||||||
|
|
||||||
|
## PASETO
|
||||||
|
|
||||||
|
Platform-Agnostic Security Tokens or PASETO improve upon JWT by enforcing stronger cryptographic defaults and eliminating algorithmic vulnerabilities.
|
||||||
|
|
||||||
|
PASETO simplifies token implementation by avoiding the risks associated with misconfiguration.
|
||||||
@@ -0,0 +1,32 @@
|
|||||||
|
---
|
||||||
|
title: "Cybersecurity 101"
|
||||||
|
description: "A concise overview of cybersecurity fundamentals and key concepts."
|
||||||
|
image: "https://assets.bytebytego.com/diagrams/0156-cybersecurity-101-in-one-picture.png"
|
||||||
|
createdAt: "2024-03-03"
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- security
|
||||||
|
tags:
|
||||||
|
- "Cybersecurity"
|
||||||
|
- "Fundamentals"
|
||||||
|
---
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Introduction to Cybersecurity
|
||||||
|
|
||||||
|
## The CIA Triad
|
||||||
|
|
||||||
|
## Common Cybersecurity Threats
|
||||||
|
|
||||||
|
## Basic Defense Mechanisms
|
||||||
|
|
||||||
|
To combat these threats, several basic defense mechanisms are employed:
|
||||||
|
|
||||||
|
* **Firewalls:** Network security devices that monitor and control incoming and outgoing network traffic.
|
||||||
|
|
||||||
|
* **Antivirus Software:** Programs designed to detect and remove malware.
|
||||||
|
|
||||||
|
* **Encryption:** The process of converting information into a code to prevent unauthorized access.
|
||||||
|
|
||||||
|
## Cybersecurity Frameworks
|
||||||
@@ -0,0 +1,38 @@
|
|||||||
|
---
|
||||||
|
title: Data Pipelines Overview
|
||||||
|
description: Learn about the essential phases of data pipelines.
|
||||||
|
image: 'https://assets.bytebytego.com/diagrams/0157-data-pipeline-overview.png'
|
||||||
|
createdAt: '2024-03-14'
|
||||||
|
draft: false
|
||||||
|
categories:
|
||||||
|
- ai-machine-learning
|
||||||
|
tags:
|
||||||
|
- data-pipelines
|
||||||
|
- data-processing
|
||||||
|
---
|
||||||
|
|
||||||
|
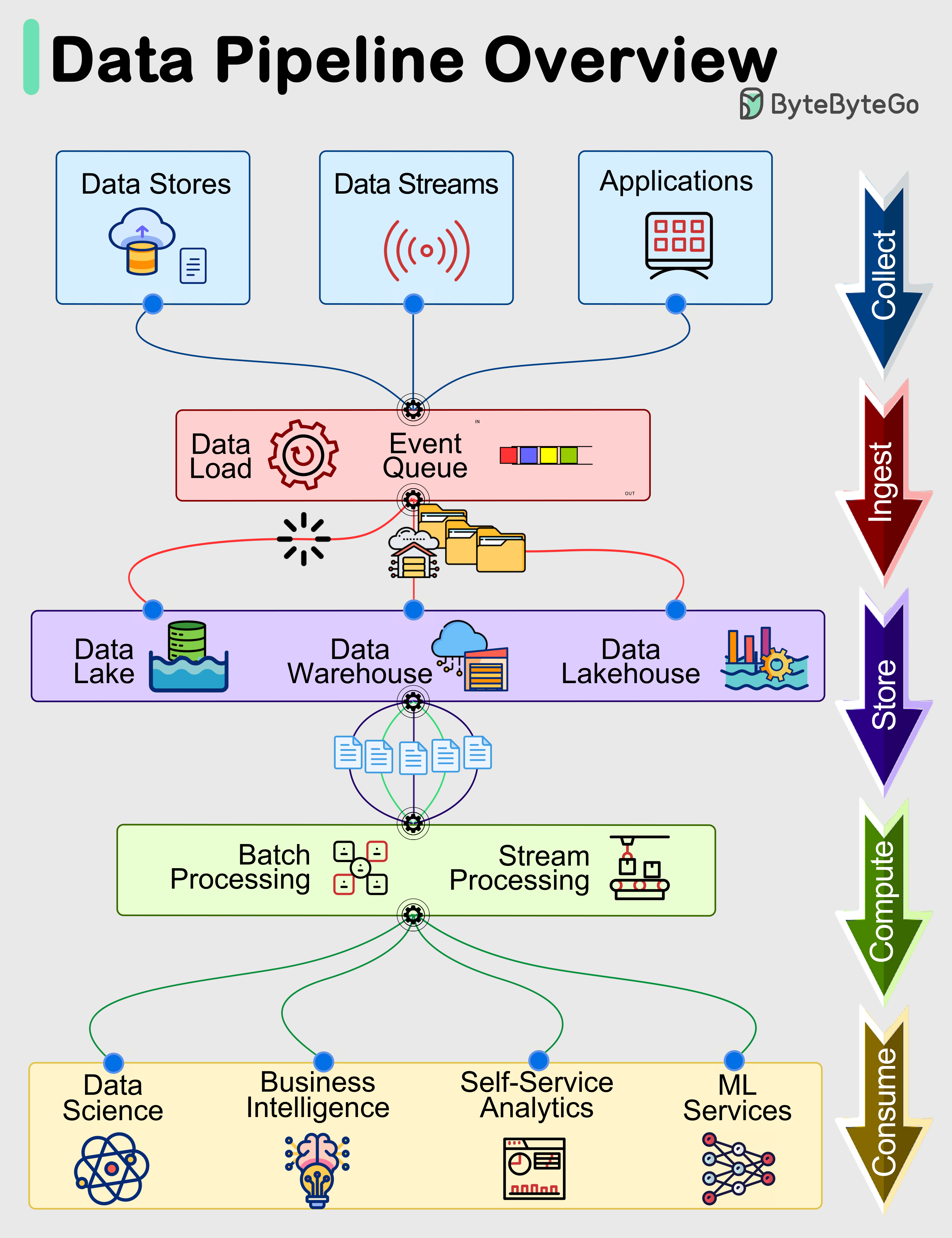
|
||||||
|
|
||||||
|
Data pipelines are a fundamental component of managing and processing data efficiently within modern systems. These pipelines typically encompass 5 predominant phases: Collect, Ingest, Store, Compute, and Consume.
|
||||||
|
|
||||||
|
## Collect:
|
||||||
|
|
||||||
|
Data is acquired from data stores, data streams, and applications, sourced remotely from devices, applications, or business systems.
|
||||||
|
|
||||||
|
## Ingest:
|
||||||
|
|
||||||
|
During the ingestion process, data is loaded into systems and organized within event queues.
|
||||||
|
|
||||||
|
## Store:
|
||||||
|
|
||||||
|
Post ingestion, organized data is stored in data warehouses, data lakes, and data lakehouses, along with various systems like databases, ensuring post-ingestion storage.
|
||||||
|
|
||||||
|
## Compute:
|
||||||
|
|
||||||
|
Data undergoes aggregation, cleansing, and manipulation to conform to company standards, including tasks such as format conversion, data compression, and partitioning. This phase employs both batch and stream processing techniques.
|
||||||
|
|
||||||
|
## Consume:
|
||||||
|
|
||||||
|
Processed data is made available for consumption through analytics and visualization tools, operational data stores, decision engines, user-facing applications, dashboards, data science, machine learning services, business intelligence, and self-service analytics.
|
||||||
|
|
||||||
|
The efficiency and effectiveness of each phase contribute to the overall success of data-driven operations within an organization.
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user