diff --git a/images/banner.jpg b/.github/banner.jpg
similarity index 100%
rename from images/banner.jpg
rename to .github/banner.jpg
diff --git a/.gitignore b/.gitignore
index 5ca2fa2..c9fe04b 100644
--- a/.gitignore
+++ b/.gitignore
@@ -2,6 +2,7 @@
*.epub
__pycache__/
*.py[cod]
+.idea
# C extensions
*.so
@@ -41,6 +42,8 @@ htmlcov/
nosetests.xml
coverage.xml
+node_modules
+
# Translations
*.mo
*.pot
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 22177a5..da16ad6 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -13,7 +13,3 @@ Thank you for your interest in contributing! Here are some guidelines to follow
### GitHub Pull Requests Docs
If you are not familiar with pull requests, review the [pull request docs](https://help.github.com/articles/using-pull-requests/).
-
-## Translations
-
-Refer to [TRANSLATIONS.md](translations/TRANSLATIONS.md)
diff --git a/README.md b/README.md
index f7c801a..0a75df3 100644
--- a/README.md
+++ b/README.md
@@ -1,5 +1,5 @@
-  +
+ 
@@ -22,1718 +22,431 @@ Whether you're preparing for a System Design Interview or you simply want to und
# Table of Contents
-
+
+
+* [API and Web Development](https://bytebytego.com/guides/api-web-development)
+ * [Short/long polling, SSE, WebSocket](https://bytebytego.com/guides/shortlong-polling-sse-websocket)
+ * [Load Balancer Realistic Use Cases](https://bytebytego.com/guides/load-balancer-realistic-use-cases-you-may-not-know)
+ * [5 HTTP Status Codes That Should Never Have Been Created](https://bytebytego.com/guides/5-http-status-codes-that-should-never-have-been-created)
+ * [How does gRPC work?](https://bytebytego.com/guides/how-does-grpc-work)
+ * [How NAT Enabled the Internet](https://bytebytego.com/guides/how-nat-made-the-growth-of-the-internet-possible)
+ * [Important Things About HTTP Headers](https://bytebytego.com/guides/important-things-about-http-headers-you-may-not-know)
+ * [Internet Traffic Routing Policies](https://bytebytego.com/guides/internet-traffic-routing-policies)
+ * [How Browsers Render Web Pages](https://bytebytego.com/guides/how-does-the-browser-render-a-web-page)
+ * [What makes HTTP2 faster than HTTP1?](https://bytebytego.com/guides/what-makes-http2-faster-than-http1)
+ * [What is CSS (Cascading Style Sheets)?](https://bytebytego.com/guides/what-is-css-cascading-style-sheets)
+ * [Key Use Cases for Load Balancers](https://bytebytego.com/guides/key-use-cases-for-load-balancers)
+ * [18 Common Ports Worth Knowing](https://bytebytego.com/guides/18-common-ports-worth-knowing)
+ * [What are the differences between WAN, LAN, PAN and MAN?](https://bytebytego.com/guides/what-are-the-differences-between-wan-lan-pan-and-man)
+ * [How does Javascript Work?](https://bytebytego.com/guides/how-does-javascript-work)
+ * [8 Tips for Efficient API Design](https://bytebytego.com/guides/8-tips-for-efficient-api-design)
+ * [Reverse Proxy vs. API Gateway vs. Load Balancer](https://bytebytego.com/guides/reverse-proxy-vs-api-gateway-vs-load-balancer)
+ * [How does REST API work?](https://bytebytego.com/guides/how-does-rest-api-work)
+ * [Load Balancer vs. API Gateway](https://bytebytego.com/guides/what-are-the-differences-between-a-load-balancer-and-an-api-gateway)
+ * [How GraphQL Works at LinkedIn](https://bytebytego.com/guides/how-does-graphql-work-in-the-real-world)
+ * [GraphQL Adoption Patterns](https://bytebytego.com/guides/graphql-adoption-patterns)
+ * [A cheat sheet for API designs](https://bytebytego.com/guides/a-cheat-sheet-for-api-designs)
+ * [API Gateway 101](https://bytebytego.com/guides/api-gateway-101)
+ * [Top 3 API Gateway Use Cases](https://bytebytego.com/guides/top-3-api-gateway-use-cases)
+ * [What do version numbers mean?](https://bytebytego.com/guides/what-do-version-numbers-mean)
+ * [Do you know all the components of a URL?](https://bytebytego.com/guides/do-you-know-all-the-components-of-a-url)
+ * [Unicast vs Broadcast vs Multicast vs Anycast](https://bytebytego.com/guides/unicast-vs-broadcast-vs-multicast-vs-anycast)
+ * [10 Essential Components of a Production Web Application](https://bytebytego.com/guides/10-essential-components-of-a-production-web-application)
+ * [URL, URI, URN - Differences Explained](https://bytebytego.com/guides/url-uri-urn-do-you-know-the-differences)
+ * [API vs SDK](https://bytebytego.com/guides/api-vs-sdk)
+ * [A Cheatsheet to Build Secure APIs](https://bytebytego.com/guides/a-cheatsheet-to-build-secure-apis)
+ * [HTTP Status Codes You Should Know](https://bytebytego.com/guides/http-status-code-you-should-know)
+ * [SOAP vs REST vs GraphQL vs RPC](https://bytebytego.com/guides/soap-vs-rest-vs-graphql-vs-rpc)
+ * [A Cheatsheet on Comparing API Architectural Styles](https://bytebytego.com/guides/a-cheatsheet-on-comparing-api-architectural-styles)
+ * [Top 9 HTTP Request Methods](https://bytebytego.com/guides/top-9-http-request-methods)
+ * [What is a Load Balancer?](https://bytebytego.com/guides/what-is-a-load-balancer)
+ * [Proxy vs Reverse Proxy](https://bytebytego.com/guides/proxy-vs-reverse-proxy)
+ * [HTTP/1 -> HTTP/2 -> HTTP/3](https://bytebytego.com/guides/http1-http2-http3)
+ * [Polling vs Webhooks](https://bytebytego.com/guides/polling-vs-webhooks)
+ * [How do we Perform Pagination in API Design?](https://bytebytego.com/guides/how-do-we-perform-pagination-in-api-design)
+ * [How to Design Effective and Safe APIs](https://bytebytego.com/guides/how-do-we-design-effective-and-safe-apis)
+ * [How to Design Secure Web API Access](https://bytebytego.com/guides/how-to-design-secure-web-api-access-for-your-website)
+ * [What Does an API Gateway Do?](https://bytebytego.com/guides/what-does-api-gateway-do)
+ * [What is gRPC?](https://bytebytego.com/guides/what-is-grpc)
+ * [Top 12 Tips for API Security](https://bytebytego.com/guides/top-12-tips-for-api-security)
+ * [Explaining 9 Types of API Testing](https://bytebytego.com/guides/explaining-9-types-of-api-testing)
+ * [REST API vs. GraphQL](https://bytebytego.com/guides/rest-api-vs-graphql)
+ * [What is GraphQL?](https://bytebytego.com/guides/what-is-graphql)
+ * [REST API Cheatsheet](https://bytebytego.com/guides/rest-api-cheatsheet)
+ * [The Ultimate API Learning Roadmap](https://bytebytego.com/guides/the-ultimate-api-learning-roadmap)
+ * [The Evolving Landscape of API Protocols in 2023](https://bytebytego.com/guides/the-evolving-landscape-of-api-protocols-in-2023)
+* [Real World Case Studies](https://bytebytego.com/guides/real-world-case-studies)
+ * [100X Postgres Scaling at Figma](https://bytebytego.com/guides/100x-postgres-scaling-at-figma)
+ * [API of APIs - App Integrations](https://bytebytego.com/guides/api-of-apis-app-integrations)
+ * [The one-line change that reduced clone times by 99% at Pinterest](https://bytebytego.com/guides/the-one-line-change-that-reduced-clone-times-by-a-whopping-99-says-pinterest)
+ * [Is Telegram Secure?](https://bytebytego.com/guides/is-telegram-secure)
+ * [Fixing Bugs Automatically at Meta Scale](https://bytebytego.com/guides/fixing-bugs-automatically-at-meta-scale)
+ * [How Levelsfyi Scaled to Millions of Users with Google Sheets](https://bytebytego.com/guides/how-levelsfyi-scaled-to-millions-of-users-with-google-sheets)
+ * [McDonald’s Event-Driven Architecture](https://bytebytego.com/guides/mcdonald's-event-driven-architecture)
+ * [Uber Tech Stack - CI/CD](https://bytebytego.com/guides/uber-tech-stack-cicd)
+ * [How to Design Stack Overflow](https://bytebytego.com/guides/how-will-you-design-the-stack-overflow-website)
+ * [Twitter 1.0 Tech Stack](https://bytebytego.com/guides/twitter-10-tech-stack)
+ * [How does Twitter recommend “For You” Timeline in 1.5 seconds?](https://bytebytego.com/guides/how-does-twitter-recommend-tweets)
+ * [How YouTube Handles Massive Video Uploads](https://bytebytego.com/guides/how-does-youtube-handle-massive-video-content-upload)
+ * [How Does a Typical Push Notification System Work?](https://bytebytego.com/guides/how-does-a-typical-push-notification-system-work)
+ * [4 Ways Netflix Uses Caching](https://bytebytego.com/guides/4-ways-netflix-uses-caching-to-hold-user-attention)
+ * [Netflix Tech Stack - Databases](https://bytebytego.com/guides/netflix-tech-stack-databases)
+ * [0 to 1.5 Billion Guests: Airbnb's Architectural Evolution](https://bytebytego.com/guides/airbnb-artchitectural-evolution)
+ * [How Netflix Scales Push Messaging](https://bytebytego.com/guides/how-does-netflix-scale-push-messaging-for-millions-of-devices)
+ * [Netflix's Overall Architecture](https://bytebytego.com/guides/netflixs-overall-architecture)
+ * [Netflix Tech Stack - CI/CD Pipeline](https://bytebytego.com/guides/netflix-tech-stack-cicd-pipeline)
+ * [How TikTok Manages a 200K File Frontend MonoRepo](https://bytebytego.com/guides/how-tiktok-manages-a-200k-file-frontend-monorepo)
+ * [How Netflix Really Uses Java](https://bytebytego.com/guides/how-netflix-really-uses-java)
+ * [Evolution of Airbnb’s Microservice Architecture](https://bytebytego.com/guides/evolution-of-airbnb's-microservice)
+ * [Reddit's Core Architecture](https://bytebytego.com/guides/reddit's-core-architecture)
+ * [10 Principles for Building Resilient Payment Systems](https://bytebytego.com/guides/10-principles-for-building-resilient-payment-systems-by-shopify)
+ * [What is the Journey of a Slack Message?](https://bytebytego.com/guides/what-is-the-journey-of-a-slack-message)
+ * [Top 9 Engineering Blogs](https://bytebytego.com/guides/top-9-engineering-blog-favorites)
+ * [Uber Tech Stack](https://bytebytego.com/guides/uber-tech-stack)
+ * [Evolution of the Netflix API Architecture](https://bytebytego.com/guides/evolution-of-the-netflix-api-architecture)
+ * [How Discord Stores Trillions of Messages](https://bytebytego.com/guides/how-discord-stores-trillions-of-messages)
+ * [Twitter Architecture 2022 vs. 2012](https://bytebytego.com/guides/twitter-architecture-2022-vs-2012)
+ * [Evolution of Uber's API Layer](https://bytebytego.com/guides/evolution-of-uber's-api-layer)
+ * [Netflix's Tech Stack](https://bytebytego.com/guides/netflixs-tech-stack)
+* [AI and Machine Learning](https://bytebytego.com/guides/ai-machine-learning)
+ * [5 Functions to Merge Data with Pandas](https://bytebytego.com/guides/5-functions-to-merge-data-with-pandas)
+ * [Key Data Terms](https://bytebytego.com/guides/key-data-terms)
+ * [ChatGPT Timeline](https://bytebytego.com/guides/chatgpt-timeline)
+ * [DeepSeek 1-Pager](https://bytebytego.com/guides/deepseek-1-pager)
+ * [The Open Source AI Stack](https://bytebytego.com/guides/the-open-source-ai-stack)
+ * [What is an AI Agent?](https://bytebytego.com/guides/what-is-an-ai-agent)
+ * [Data Pipelines Overview](https://bytebytego.com/guides/data-pipelines-overview)
+ * [How does ChatGPT work?](https://bytebytego.com/guides/how-does-chatgpt-work)
+* [Database and Storage](https://bytebytego.com/guides/database-and-storage)
+ * [Read Replica Pattern](https://bytebytego.com/guides/read-replica-pattern)
+ * [Pessimistic vs Optimistic Locking](https://bytebytego.com/guides/pessimistic-vs-optimistic-locking)
+ * [How to Upload a Large File to S3](https://bytebytego.com/guides/how-to-upload-a-large-file-to-s3)
+ * [Types of Message Queues](https://bytebytego.com/guides/types-of-message-queue)
+ * [Smooth Data Migration with Avro](https://bytebytego.com/guides/smooth-data-migration-with-avro)
+ * [The Ultimate Kafka 101 You Cannot Miss](https://bytebytego.com/guides/the-ultimate-kafka-101-you-cannot-miss)
+ * [Database Isolation Levels](https://bytebytego.com/guides/what-are-database-isolation-levels)
+ * [Top 6 Data Management Patterns](https://bytebytego.com/guides/how-do-we-manage-data)
+ * [Why is Kafka Fast?](https://bytebytego.com/guides/why-is-kafka-fast)
+ * [Explaining the 4 Most Commonly Used Types of Queues](https://bytebytego.com/guides/explaining-the-4-most-commonly-used-types-of-queues-in-a-single-diagram)
+ * [Time Series DB (TSDB) in 20 Lines](https://bytebytego.com/guides/time-series-db-tsdb-in-20-lines)
+ * [Differences in Event Sourcing System Design](https://bytebytego.com/guides/differences-in-event-sourcing-system-design)
+ * [Erasure Coding](https://bytebytego.com/guides/erasure-coding)
+ * [Delivery Semantics](https://bytebytego.com/guides/delivery-semantics)
+ * [Change Data Capture: Key to Leverage Real-time Data](https://bytebytego.com/guides/change-data-capture-key-to-leverage-real-time-data)
+ * [Can Kafka Lose Messages?](https://bytebytego.com/guides/can-kafka-lose-messages)
+ * [Storage Systems Overview](https://bytebytego.com/guides/storage-systems-overview)
+ * [Explain the Top 6 Use Cases of Object Stores](https://bytebytego.com/guides/explain-the-top-6-use-cases-of-object-stores)
+ * [Top Eventual Consistency Patterns You Must Know](https://bytebytego.com/guides/top-eventual-consistency-patterns-you-must-know)
+ * [B-Tree vs. LSM-Tree](https://bytebytego.com/guides/b-tree-vs)
+ * [How to Decide Which Type of Database to Use](https://bytebytego.com/guides/how-do-you-decide-which-type-of-database-to-use)
+ * [Cloud Database Cheat Sheet](https://bytebytego.com/guides/cloud-database-cheat-sheet)
+ * [Types of Memory](https://bytebytego.com/guides/types-of-memory)
+ * [Understanding Database Types](https://bytebytego.com/guides/understanding-database-types)
+ * [Top 4 Data Sharding Algorithms Explained](https://bytebytego.com/guides/top-4-data-sharding-algorithms-explained)
+ * [Top 6 Database Models](https://bytebytego.com/guides/top-6-database-models)
+ * [SQL Statement Execution in Database](https://bytebytego.com/guides/how-is-a-sql-statement-executed-in-the-database)
+ * [What is Serverless DB?](https://bytebytego.com/guides/what-is-serverless-db)
+ * [Why PostgreSQL is the Most Loved Database](https://bytebytego.com/guides/why-is-postgresql-voted-as-the-most-loved-database-by-stackoverflow-2022-developer-survey)
+ * [Top 10 Most Popular Open-Source Databases](https://bytebytego.com/guides/top-10-most-popular-open-source-databases)
+ * [Is PostgreSQL Eating the Database World?](https://bytebytego.com/guides/is-postgresql-eating-the-database-world)
+ * [How to Choose the Right Database](https://bytebytego.com/guides/how-to-choose-the-right-database)
+ * [iQIYI Database Selection Trees](https://bytebytego.com/guides/iqiyi-database-selection-trees)
+ * [8 Data Structures That Power Your Databases](https://bytebytego.com/guides/8-data-structures-that-power-your-databases)
+ * [How to Implement Read Replica Pattern](https://bytebytego.com/guides/how-to-implement-read-replica-pattern)
+ * [A Crash Course on Database Sharding](https://bytebytego.com/guides/a-crash-course-in-database-sharding)
+ * [IBM MQ -> RabbitMQ -> Kafka -> Pulsar: Message Queue Evolution](https://bytebytego.com/guides/how-do-message-queue-architectures-evolve)
+ * [CAP Theorem: One of the Most Misunderstood Terms](https://bytebytego.com/guides/cap-theorem-one-of-the-most-misunderstood-terms)
+ * [Consistent Hashing Explained](https://bytebytego.com/guides/consistent-hashing)
+ * [Types of Databases](https://bytebytego.com/guides/types-of-databases)
+ * [Key Concepts to Understand Database Sharding](https://bytebytego.com/guides/key-concepts-to-understand-database-sharding)
+ * [Database Locks Explained](https://bytebytego.com/guides/what-are-the-differences-among-database-locks)
+ * [A Cheatsheet on Database Performance](https://bytebytego.com/guides/a-cheatsheet-on-database-performance)
+ * [What does ACID mean?](https://bytebytego.com/guides/what-does-acid-mean)
+ * [Top 5 Kafka Use Cases](https://bytebytego.com/guides/top-5-kafka-use-cases)
+ * [Types of Memory and Storage](https://bytebytego.com/guides/types-of-memory-and-storage)
+ * [7 Must-Know Strategies to Scale Your Database](https://bytebytego.com/guides/7-must-know-strategies-to-scale-your-database)
+* [Technical Interviews](https://bytebytego.com/guides/technical-interviews)
+ * [How do SQL Joins Work?](https://bytebytego.com/guides/how-do-sql-joins-work)
+ * [What Happens When You Type google.com Into a Browser?](https://bytebytego.com/guides/what-happens-when-you-type-google)
+ * [What Happens When You Type a URL Into Your Browser?](https://bytebytego.com/guides/what-happens-when-you-type-a-url-into-your-browser)
+ * [How to Ace System Design Interviews](https://bytebytego.com/guides/how-to-ace-system-design-interviews-like-a-boss)
+ * [Recommended Materials for Technical Interviews](https://bytebytego.com/guides/my-recommended-materials-for-cracking-your-next-technical-interview)
+* [Caching & Performance](https://bytebytego.com/guides/caching-performance)
+ * [What is ELK Stack and Why is it Popular?](https://bytebytego.com/guides/what-is-elk-stack-and-why-is-it-so-popular-for-log-management)
+ * [Why are Content Delivery Networks (CDN) so Popular?](https://bytebytego.com/guides/why-are-content-delivery-networks-cdn-so-popular)
+ * [How Big Keys Impact Redis Persistence](https://bytebytego.com/guides/how-do-big-keys-impact-redis-persistence)
+ * [A Beginner's Guide to CDN](https://bytebytego.com/guides/a-beginner's-guide-to-cdn-content-delivery-network)
+ * [The Ultimate Redis 101](https://bytebytego.com/guides/the-ultimate-redis-101)
+ * [Cache Systems Every Developer Should Know](https://bytebytego.com/guides/cache-systems-every-developer-should-know)
+ * [Top 5 Strategies to Reduce Latency](https://bytebytego.com/guides/top-5-strategies-to-reduce-latency)
+ * [Top 5 Caching Strategies](https://bytebytego.com/guides/top-5-caching-strategies)
+ * [Things to Consider When Using Cache](https://bytebytego.com/guides/things-to-consider-when-using-cache)
+ * [Cache Eviction Policies](https://bytebytego.com/guides/most-popular-cache-eviction)
+ * [Memcached vs Redis](https://bytebytego.com/guides/memcached-vs-redis)
+ * [Low Latency Stock Exchange](https://bytebytego.com/guides/low-latency-stock-exchange)
+ * [Cache Miss Attack](https://bytebytego.com/guides/cache-miss-attack)
+ * [Top 8 Cache Eviction Strategies](https://bytebytego.com/guides/top-8-cache-eviction-strategies)
+ * [How Can Cache Systems Go Wrong?](https://bytebytego.com/guides/how-can-cache-systems-go-wrong)
+ * [Top 6 Elasticsearch Use Cases](https://bytebytego.com/guides/top-6-elasticsearch-use-cases)
+ * [How Does CDN Work?](https://bytebytego.com/guides/how-does-cnd-work)
+ * [How Redis Architecture Evolved](https://bytebytego.com/guides/how-redis-architecture-evolve)
+ * [How Does Redis Persist Data?](https://bytebytego.com/guides/how-does-redis-persist-data)
+ * [How can Redis be used?](https://bytebytego.com/guides/how-can-redis-be-used)
+ * [Why is Redis so Fast?](https://bytebytego.com/guides/why-is-redis-so-fast)
+ * [How to Learn Elasticsearch](https://bytebytego.com/guides/how-do-we-learn-elasticsearch)
+ * [What is CDN (Content Delivery Network)?](https://bytebytego.com/guides/what-is-cdn-content-delivery-network)
+ * [Frontend Performance Optimization](https://bytebytego.com/guides/how-to-load-your-websites-at-lightning-speed)
+ * [Which Latency Numbers Should You Know?](https://bytebytego.com/guides/which-latency-numbers-should-you-know)
+ * [Top Caching Strategies](https://bytebytego.com/guides/what-are-the-top-caching-strategies)
+ * [Top 9 Website Performance Metrics You Cannot Ignore](https://bytebytego.com/guides/top-9-website-performance-metrics-you-cannot-ignore)
+ * [Top 5 Common Ways to Improve API Performance](https://bytebytego.com/guides/top-5-common-ways-to-improve-api-performance)
+ * [Learn Cache](https://bytebytego.com/guides/learn-cache)
+* [Payment and Fintech](https://bytebytego.com/guides/payment-and-fintech)
+ * [E-commerce Workflow](https://bytebytego.com/guides/e-commerce-workflow)
+ * [Digital Wallets: Banks vs. Blockchain](https://bytebytego.com/guides/digital-wallet-in-traditional-banks-vs-wallet-in-blockchain)
+ * [What is a Stop-Loss Order and How Does it Work?](https://bytebytego.com/guides/what-is-a-stop-loss-order-and-how-does-it-work)
+ * [What is Web 3.0? Why doesn't it have ads?](https://bytebytego.com/guides/what-is-web-3)
+ * [SWIFT Payment Messaging System](https://bytebytego.com/guides/swift-payment-messaging-system)
+ * [4 Ways of QR Code Payment](https://bytebytego.com/guides/4-ways-of-qr-code-payment)
+ * [Handling Hotspot Accounts](https://bytebytego.com/guides/handling-hotspot-accounts)
+ * [Reconciliation in Payment](https://bytebytego.com/guides/reconciliation-in-payment)
+ * [Unified Payments Interface (UPI)](https://bytebytego.com/guides/unified-payments-interface-upi-in-india)
+ * [How Scan to Pay Works](https://bytebytego.com/guides/how-does-scan-to-pay-work)
+ * [Money Movement](https://bytebytego.com/guides/money-movement)
+ * [Payment System](https://bytebytego.com/guides/payment-system)
+ * [How to Learn Payments](https://bytebytego.com/guides/how-to-learn-payments)
+ * [The Payments Ecosystem](https://bytebytego.com/guides/the-payments-ecosystem)
+ * [Foreign Exchange Payments](https://bytebytego.com/guides/foreign-exchange-payments)
+ * [How to Avoid Double Payment](https://bytebytego.com/guides/how-to-avoid-double-payment)
+ * [How do Apple Pay and Google Pay work?](https://bytebytego.com/guides/how-applegoogle-pay-works)
+ * [How VISA Works When Swiping a Credit Card](https://bytebytego.com/guides/how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchant's-shop)
+ * [How ACH Payment Works](https://bytebytego.com/guides/how-does-ach-payment-work)
+ * [How does Visa make money?](https://bytebytego.com/guides/how-does-visa-make-money)
+* [Software Architecture](https://bytebytego.com/guides/software-architecture)
+ * [Inter-Process Communication on Linux](https://bytebytego.com/guides/how-do-processes-talk-to-each-other-on-linux)
+ * [Orchestration vs. Choreography in Microservices](https://bytebytego.com/guides/orchestration-vs-choreography-microservices)
+ * [UML Class Diagrams Cheatsheet](https://bytebytego.com/guides/a-cheatsheet-for-uml-class-diagrams)
+ * [Amazon Prime Video Monitoring Service](https://bytebytego.com/guides/amazon-prime-video-monitoring-service)
+ * [Is Microservice Architecture the Silver Bullet?](https://bytebytego.com/guides/is-microservice-architecture-the-silver-bullet)
+ * [Database Middleware](https://bytebytego.com/guides/database-middleware)
+ * [9 Best Practices for Developing Microservices](https://bytebytego.com/guides/9-best-practices-for-developing-microservices)
+ * [Design Patterns Cheat Sheet](https://bytebytego.com/guides/design-patterns-cheat-sheet-part-1-and-part-2)
+ * [Key Terms in Domain-Driven Design](https://bytebytego.com/guides/key-terms-in-domain-driven-design)
+ * [8 Key OOP Concepts Every Developer Should Know](https://bytebytego.com/guides/8-key-oop-concepts-every-developer-should-know)
+ * [18 Key Design Patterns Every Developer Should Know](https://bytebytego.com/guides/18-key-design-patterns-every-developer-should-know)
+ * [10 System Design Tradeoffs You Cannot Ignore](https://bytebytego.com/guides/10-system-design-tradeoffs-you-cannot-ignore)
+ * [9 Essential Components of a Production Microservice Application](https://bytebytego.com/guides/9-essential-components-of-a-production-microservice-application)
+ * [9 Best Practices for Building Microservices](https://bytebytego.com/guides/9-best-practices-for-building-microservices)
+ * [8 Key Concepts in Domain-Driven Design](https://bytebytego.com/guides/8-key-concepts-in-ddd)
+ * [8 Common System Design Problems and Solutions](https://bytebytego.com/guides/8-common-system-design-problems-and-solutions)
+ * [6 Software Architectural Patterns You Must Know](https://bytebytego.com/guides/6-software-architectural-patterns-you-must-know)
+ * [How To Release A Mobile App](https://bytebytego.com/guides/how-to-release-a-mobile-app)
+ * [How Do Computer Programs Run?](https://bytebytego.com/guides/how-do-computer-programs-run)
+ * [Linux Boot Process Explained](https://bytebytego.com/guides/linux-boot-process-explained)
+ * [MVC, MVP, MVVM, VIPER Patterns](https://bytebytego.com/guides/mvc-mvp-mvvm-viper-patterns)
+ * [The Ultimate Software Architect Knowledge Map](https://bytebytego.com/guides/the-ultimate-software-architect-knowledge-map)
+ * [Typical Microservice Architecture](https://bytebytego.com/guides/what-does-a-typical-microservice-architecture-look-like)
+ * [Top 5 Software Architectural Patterns](https://bytebytego.com/guides/top-5-software-architectural-patterns)
+* [DevTools & Productivity](https://bytebytego.com/guides/devtools-productivity)
+ * [Git Commands Cheat Sheet](https://bytebytego.com/guides/git-commands-cheat-sheet)
+ * [How does Git Work?](https://bytebytego.com/guides/git-workflow)
+ * [JSON Crack: Visualize JSON Files](https://bytebytego.com/guides/json-files)
+ * [Git vs GitHub](https://bytebytego.com/guides/git-vs-github)
+ * [Git Merge vs. Git Rebase](https://bytebytego.com/guides/git-merge-vs-git-rebate)
+ * [30 Useful AI Apps That Can Help You in 2025](https://bytebytego.com/guides/30-useful-ai-apps-that-can-help-you-in-2025)
+ * [Diagram as Code](https://bytebytego.com/guides/diagram-as-code)
+ * [Top 9 Causes of 100% CPU Usage](https://bytebytego.com/guides/top-9-cases-behind-100-cpu-usage)
+ * [Top 6 Tools to Turn Code into Beautiful Diagrams](https://bytebytego.com/guides/top-6-tools-to-turn-code-into-beautiful-diagrams)
+ * [Tools for Shipping Code to Production](https://bytebytego.com/guides/what-tools-does-your-team-use-to-ship-code-to-production-and-ensure-code-quality)
+ * [Making Sense of Search Engine Optimization](https://bytebytego.com/guides/making-sense-of-search-engine-optimization)
+ * [Most Used Linux Commands Map](https://bytebytego.com/guides/most-used-linux-commands-map)
+ * [Linux File Permissions Illustrated](https://bytebytego.com/guides/linux-file-permission-illustrated)
+ * [5 Important Components of Linux](https://bytebytego.com/guides/5-important-components-of-linux)
+ * [15 Open-Source Projects That Changed the World](https://bytebytego.com/guides/15-open-source-projects-that-changed-the-world)
+ * [20 Popular Open Source Projects Started by Big Companies](https://bytebytego.com/guides/20-popular-open-source-projects-started-or-supported-by-big-companies)
+ * [Linux File System Explained](https://bytebytego.com/guides/linux-file-system-explained)
+ * [Life is Short, Use Dev Tools](https://bytebytego.com/guides/life-is-short-use-dev-tools)
+ * [How Git Works](https://bytebytego.com/guides/how-does-git-work)
+ * [How do Companies Ship Code to Production?](https://bytebytego.com/guides/how-do-companies-ship-code-to-production)
+* [Software Development](https://bytebytego.com/guides/software-development)
+ * [Top 6 Most Commonly Used Server Types](https://bytebytego.com/guides/top-6-most-commonly-used-server-types)
+ * [How does Garbage Collection work?](https://bytebytego.com/guides/how-does-garbage-collection-work)
+ * [A Roadmap for Full-Stack Development](https://bytebytego.com/guides/a-roadmap-for-full-stack-development)
+ * [What Are the Greenest Programming Languages?](https://bytebytego.com/guides/what-are-the-greenest-programming-languages)
+ * [Java Collection Hierarchy](https://bytebytego.com/guides/java-collection-hierarchy)
+ * [Running C, C++, or Rust in a Web Browser](https://bytebytego.com/guides/is-it-possible-to-run-c-c++-or-rust-on-a-web-browser)
+ * [Top 8 C++ Use Cases](https://bytebytego.com/guides/top-8-c++-use-cases)
+ * [Top 6 Multithreading Design Patterns You Must Know](https://bytebytego.com/guides/top-6-multithreading-design-patterns-you-must-know)
+ * [Data Transmission Between Applications](https://bytebytego.com/guides/how-is-data-transmitted-between-applications)
+ * [Blocking vs Non-Blocking Queue](https://bytebytego.com/guides/blocking-vs-non-blocking-queue)
+ * [Big Endian vs Little Endian](https://bytebytego.com/guides/big-endian-vs-little-endian)
+ * [How to Avoid Crawling Duplicate URLs at Google Scale?](https://bytebytego.com/guides/how-to-avoid-crawling-duplicate-urls-at-google-scale)
+ * [10 Books for Software Developers](https://bytebytego.com/guides/10-books-for-software-developers)
+ * [Top 8 Standards Every Developer Should Know](https://bytebytego.com/guides/top-8-standards-every-developer-should-know)
+ * [How Do C++, Java, Python Work?](https://bytebytego.com/guides/how-do-c++-java-python-work)
+ * [10 Key Data Structures We Use Every Day](https://bytebytego.com/guides/10-key-data-structures-we-use-every-day)
+ * [A Brief History of Programming Languages](https://bytebytego.com/guides/a-brief-history-og-programming-languages)
+ * [Top 6 Load Balancing Algorithms](https://bytebytego.com/guides/top-6-load-balancing-algorithms)
+ * [The Fundamental Pillars of Object-Oriented Programming](https://bytebytego.com/guides/the-fundamental-pillars-of-object-oriented-programming)
+ * [Top 8 Programming Paradigms](https://bytebytego.com/guides/top-8-programming-paradigms)
+ * [Algorithms for System Design Interviews](https://bytebytego.com/guides/algorithms-you-should-know-before-taking-system-design-interviews)
+ * [Imperative vs Functional vs Object-oriented Programming](https://bytebytego.com/guides/imperative-vs-functional-vs-object-oriented-programming)
+ * [Explaining 9 Types of API Testing](https://bytebytego.com/guides/explaining-9-types-of-api-testing)
+ * [The 9 Algorithms That Dominate Our World](https://bytebytego.com/guides/the-9-algorithms-that-dominate-our-world)
+ * [Concurrency vs Parallelism](https://bytebytego.com/guides/concurrency-is-not-parallelism)
+ * [Linux Boot Process Explained](https://bytebytego.com/guides/linux-boot-process-explained)
+ * [11 Steps to Go From Junior to Senior Developer](https://bytebytego.com/guides/11-steps-to-go-from-junior-to-senior-developer)
+ * [10 Good Coding Principles to Improve Code Quality](https://bytebytego.com/guides/10-good-coding-principles-to-improve-code-quality)
+* [Cloud & Distributed Systems](https://bytebytego.com/guides/cloud-distributed-systems)
+ * [How AWS Lambda Works Behind the Scenes](https://bytebytego.com/guides/how-does-aws-lambda-work-behind-the-scenes)
+ * [8 Must-Know Scalability Strategies](https://bytebytego.com/guides/8-must-know-scalability-strategies)
+ * [System Design Cheat Sheet](https://bytebytego.com/guides/system-design-cheat-sheet)
+ * [Cloud Disaster Recovery Strategies](https://bytebytego.com/guides/cloud-disaster-recovery-strategies)
+ * [Vertical vs Horizontal Partitioning](https://bytebytego.com/guides/vertical-partitioning-vs-horizontal-partitioning)
+ * [Top 9 Architectural Patterns for Data and Communication Flow](https://bytebytego.com/guides/top-9-architectural-patterns-for-data-and-communication-flow)
+ * [Top 6 Cases to Apply Idempotency](https://bytebytego.com/guides/top-6-cases-to-apply-idempotency)
+ * [Top 5 Trade-offs in System Designs](https://bytebytego.com/guides/top-5-trade-offs-in-system-designs)
+ * [How to Detect Node Failures in Distributed Systems](https://bytebytego.com/guides/how-do-we-detect-node-failures-in-distributed-systems)
+ * [Why Meta, Google, and Amazon Stop Using Leap Seconds](https://bytebytego.com/guides/do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds)
+ * [The Fantastic Four of System Design](https://bytebytego.com/guides/who-are-the-fantastic-four-of-system-design)
+ * [What makes AWS Lambda so fast?](https://bytebytego.com/guides/what-makes-aws-lambda-so-fast)
+ * [Scaling Websites for Millions of Users](https://bytebytego.com/guides/how-to-scale-a-website-to-support-millions-of-users)
+ * [Resiliency Patterns](https://bytebytego.com/guides/resiliency-patterns)
+ * [25 Papers That Completely Transformed the Computer World](https://bytebytego.com/guides/25-papers-that-completely-transformed-the-computer-world)
+ * [A Crash Course on Architectural Scalability](https://bytebytego.com/guides/a-crash-course-on-architectural-scalability)
+ * [Must Know System Design Building Blocks](https://bytebytego.com/guides/must-know-system-design-building-blocks)
+ * [Monorepo vs. Microrepo: Which is Best?](https://bytebytego.com/guides/monorepo-vs)
+ * [How to Handle Web Request Errors](https://bytebytego.com/guides/how-to-handle-web-request-error)
+ * [A Cheat Sheet for Designing Fault-Tolerant Systems](https://bytebytego.com/guides/a-cheat-sheet-for-designing-fault-tolerant-systems)
+ * [Typical AWS Network Architecture](https://bytebytego.com/guides/typical-aws-network-architecture-in-one-diagram)
+ * [Unique ID Generator](https://bytebytego.com/guides/unique-id-generator)
+ * [Amazon's Build System: Brazil](https://bytebytego.com/guides/how-does-amazon-build-system-work)
+ * [Infrastructure as Code Landscape Cheatsheet](https://bytebytego.com/guides/a-cheatsheet-on-infrastructure-as-code-landscape)
+ * [How do we manage configurations in a system?](https://bytebytego.com/guides/how-do-we-manage-configurations-in-a-system)
+ * [How do we incorporate Event Sourcing into systems?](https://bytebytego.com/guides/how-do-we-incorporate-event-sourcing-into-the-systems)
+ * [The 12-Factor App](https://bytebytego.com/guides/the-12-factor-app)
+ * [Explaining 5 Unique ID Generators](https://bytebytego.com/guides/explaining-5-unique-id-generators-in-distributed-systems)
+ * [Retry Strategies for System Failures](https://bytebytego.com/guides/how-do-we-retry-on-failures)
+ * [Cloud Monitoring Cheat Sheet](https://bytebytego.com/guides/cloud-monitoring-cheat-sheet)
+ * [Why Use a Distributed Lock?](https://bytebytego.com/guides/why-do-we-need-to-use-a-distributed-lock)
+ * [Top 6 Cloud Messaging Patterns](https://bytebytego.com/guides/top-6-cloud-messaging-patterns)
+ * [Most Important AWS Services to Learn](https://bytebytego.com/guides/what-are-the-most-important-aws-services-to-learn)
+ * [How to Transform a System to be Cloud Native](https://bytebytego.com/guides/how-do-we-transform-a-system-to-be-cloud-native)
+ * [Hidden Costs of the Cloud](https://bytebytego.com/guides/hidden-costs-of-the-cloud)
+ * [2 Decades of Cloud Evolution](https://bytebytego.com/guides/2-decades-of-cloud-evolution)
+ * [Cloud Cost Reduction Techniques](https://bytebytego.com/guides/cloud-cost-reduction-techniques)
+ * [Top 7 Most-Used Distributed System Patterns](https://bytebytego.com/guides/top-7-most-used-distributed-system-patterns)
+ * [Cloud Load Balancer Cheat Sheet](https://bytebytego.com/guides/cloud-load-balancer-cheat-sheet)
+ * [AWS Services Evolution](https://bytebytego.com/guides/aws-services-evolution)
+ * [Azure Services Cheat Sheet](https://bytebytego.com/guides/azure-services-cheat-sheet)
+ * [A cheat sheet for system designs](https://bytebytego.com/guides/a-cheat-sheet-for-system-designs)
+ * [CAP, BASE, SOLID, KISS, What do these acronyms mean?](https://bytebytego.com/guides/cap-base-solid-kiss-what-do-these-acronyms-mean)
+ * [System Design Blueprint: The Ultimate Guide](https://bytebytego.com/guides/system-design-blueprint-the-ultimate-guide)
+ * [How to Design for High Availability](https://bytebytego.com/guides/how-do-we-design-for-high-availability)
+ * [What is Cloud Native?](https://bytebytego.com/guides/what-is-cloud-native)
+ * [Cloud Comparison Cheat Sheet](https://bytebytego.com/guides/cloud-comparison-cheat-sheet)
+ * [Big Data Pipeline Cheatsheet for AWS, Azure, and Google Cloud](https://bytebytego.com/guides/big-data-pipeline-cheatsheet-for-aws-azure-and-google-cloud)
+ * [AWS Services Cheat Sheet](https://bytebytego.com/guides/aws-services-cheat-sheet)
+* [How it Works?](https://bytebytego.com/guides/how-it-works)
+ * [How do AirTags work?](https://bytebytego.com/guides/how-do-airtags-work)
+ * [How is Email Delivered?](https://bytebytego.com/guides/how-is-email-delivered)
+ * [Design Gmail](https://bytebytego.com/guides/design-gmail)
+ * [How Google/Apple Maps Blur License Plates and Faces](https://bytebytego.com/guides/how-do-googleapple-maps-blur-license-plates-and-human-faces-on-street-view)
+ * [Quadtree](https://bytebytego.com/guides/quadtree)
+ * [Build a Simple Chat Application with Redis](https://bytebytego.com/guides/build-a-simple-chat-application)
+ * [Live Streaming Explained](https://bytebytego.com/guides/live-streaming-explained)
+ * [How to Design a System for Internationalization](https://bytebytego.com/guides/how-do-we-design-a-system-for-internationalization)
+ * [How to Design Google Docs](https://bytebytego.com/guides/how-to-design-google-docs)
+ * [Payment System](https://bytebytego.com/guides/payment-system)
+ * [Experiment Platform Architecture](https://bytebytego.com/guides/possible-experiment-platform-architecture)
+ * [Design Google Maps](https://bytebytego.com/guides/design-google-maps)
+ * [Designing a Chat Application](https://bytebytego.com/guides/how-do-we-design-a-chat-application-like-whatsapp-facebook-messenger-or-discord)
+ * [Design Stock Exchange](https://bytebytego.com/guides/design-stock-exchange)
+ * [How are Notifications Pushed to Our Phones or PCs?](https://bytebytego.com/guides/how-are-notifications-pushed-to-our-phones-or-pcs)
+ * [What Happens When You Upload a File to Amazon S3?](https://bytebytego.com/guides/what-happens-when-you-upload-a-file-to-amazon-s3)
+ * [Proximity Service](https://bytebytego.com/guides/proximity-service)
+ * [How Do Search Engines Work?](https://bytebytego.com/guides/how-do-search-engines-work)
+* [DevOps and CI/CD](https://bytebytego.com/guides/devops-cicd)
+ * [Top 10 Kubernetes Design Patterns](https://bytebytego.com/guides/top-10-k8s-design-patterns)
+ * [Some DevOps Books I Find Enlightening](https://bytebytego.com/guides/some-devops-books-i-find-enlightening)
+ * [Paradigm Shift: Developer to Tester Ratio](https://bytebytego.com/guides/paradigm-shift-how-developer-to-tester-ratio-changed-from-11-to-1001)
+ * [Push vs Pull in Metrics Collection Systems](https://bytebytego.com/guides/push-vs-pull-in-metrics-collecting-systems)
+ * [Choose the Right Database for Metric Collection](https://bytebytego.com/guides/choose-the-right-database-for-metric-collecting-system)
+ * [Top 4 Kubernetes Service Types](https://bytebytego.com/guides/top-4-kubernetes-service-types-in-one-diagram)
+ * [Cloud Native Anti-Patterns](https://bytebytego.com/guides/cloud-native-anti-patterns)
+ * [Kubernetes Tools Stack Wheel](https://bytebytego.com/guides/kubernetes-tools-stack-wheel)
+ * [Kubernetes Tools Ecosystem](https://bytebytego.com/guides/kubernetes-tools-ecosystem)
+ * [Kubernetes Periodic Table](https://bytebytego.com/guides/kubernetes-periodic-table)
+ * [9 Docker Best Practices You Must Know](https://bytebytego.com/guides/9-docker-best-practices-you-must-know)
+ * [Netflix Tech Stack - CI/CD Pipeline](https://bytebytego.com/guides/netflix-tech-stack-cicd-pipeline)
+ * [Top 8 Must-Know Docker Concepts](https://bytebytego.com/guides/top-8-must-know-docker-concepts)
+ * [CI/CD Simplified Visual Guide](https://bytebytego.com/guides/cicd-simplified-visual-guide)
+ * [Top 5 Most-Used Deployment Strategies](https://bytebytego.com/guides/top-5-most-used-deployment-strategies)
+ * [Kubernetes Command Cheatsheet](https://bytebytego.com/guides/the-ultimate-kubernetes-command-cheatsheet)
+ * [Kubernetes Deployment Strategies](https://bytebytego.com/guides/kubernetes-deployment-strategies)
+ * [How does Terraform turn Code into Cloud?](https://bytebytego.com/guides/how-does-terraform-turn-code-into-cloud)
+ * [DevOps vs. SRE vs. Platform Engineering](https://bytebytego.com/guides/devops-vs-sre-vs-paltform-engg)
+ * [Deployment Strategies](https://bytebytego.com/guides/how-to-deploy-services)
+ * [Logging, Tracing, and Metrics](https://bytebytego.com/guides/logging-tracing-metrics)
+ * [Log Parsing Cheat Sheet](https://bytebytego.com/guides/log-parsing-cheat-sheet)
+ * [DevOps vs NoOps: What's the Difference?](https://bytebytego.com/guides/devops-vs-noops)
+ * [Why is Nginx so Popular?](https://bytebytego.com/guides/why-is-nginx-so-popular)
+ * [What is Kubernetes (k8s)?](https://bytebytego.com/guides/what-is-k8s-kubernetes)
+ * [How does Docker work?](https://bytebytego.com/guides/how-does-docker-work)
+ * [CI/CD Pipeline Explained in Simple Terms](https://bytebytego.com/guides/cicd-pipeline-explained-in-simple-terms)
+* [Security](https://bytebytego.com/guides/security)
+ * [What is DevSecOps?](https://bytebytego.com/guides/what-is-devsecops)
+ * [Encoding vs Encryption vs Tokenization](https://bytebytego.com/guides/encoding-vs-encryption-vs-tokenization)
+ * [Storing Passwords Safely: A Comprehensive Guide](https://bytebytego.com/guides/how-to-store-passwords-in-the-database)
+ * [Designing a Permission System](https://bytebytego.com/guides/how-do-we-design-a-permission-system)
+ * [How Password Managers Work](https://bytebytego.com/guides/how-does-a-password-manager-such-as-1password-or-lastpass-work)
+ * [Is PassKey Shaping a Passwordless Future?](https://bytebytego.com/guides/is-passkey-shaping-a-passwordless-future)
+ * [Firewall Explained to Kids and Adults](https://bytebytego.com/guides/firewall-explained-to-kids-and-adults)
+ * [Cookies vs Sessions](https://bytebytego.com/guides/what-are-the-differences-between-cookies-and-sessions)
+ * [HTTP Cookies Explained With a Simple Diagram](https://bytebytego.com/guides/http-cookies-explained-with-a-simple-diagram)
+ * [Token, Cookie, Session](https://bytebytego.com/guides/token-cookie-session)
+ * [Sessions, Tokens, JWT, SSO, and OAuth Explained](https://bytebytego.com/guides/explaining-sessions-tokens-jwt-sso-and-oauth-in-one-diagram)
+ * [How to Design a Secure System](https://bytebytego.com/guides/how-do-we-design-a-secure-system)
+ * [Top 6 Firewall Use Cases](https://bytebytego.com/guides/top-6-firewall-use-cases)
+ * [Top 4 Authentication Mechanisms](https://bytebytego.com/guides/top-4-forms-of-authentication-mechanisms)
+ * [How Digital Signatures Work](https://bytebytego.com/guides/how-digital-signatures-work)
+ * [How do we manage sensitive data in a system?](https://bytebytego.com/guides/how-do-we-manage-sensitive-data-in-a-system)
+ * [HTTPS, SSL Handshake, and Data Encryption Explained](https://bytebytego.com/guides/https-ssl-handshake-and-data-encryption-explained-to-kids)
+ * [Symmetric vs Asymmetric Encryption](https://bytebytego.com/guides/symmetric-encryption-vs-asymmetric-encryption)
+ * [Session-based Authentication vs. JWT](https://bytebytego.com/guides/what's-the-difference-between-session-based-authentication-and-jwts)
+ * [JWT 101: Key to Stateless Authentication](https://bytebytego.com/guides/jwt-101-key-to-stateless-authentication)
+ * [Is HTTPS Safe?](https://bytebytego.com/guides/is-https-safe)
+ * [Cybersecurity 101](https://bytebytego.com/guides/cybersecurity-101-in-one-picture)
+ * [Cookies vs Sessions vs JWT vs PASETO](https://bytebytego.com/guides/cookies-vs-sessions-vs-jwt-vs-paseto)
+ * [How does SSH work?](https://bytebytego.com/guides/how-does-ssh-work)
+ * [How Does a VPN Work?](https://bytebytego.com/guides/how-does-a-vpn-work)
+ * [How Google Authenticator Works](https://bytebytego.com/guides/how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work)
+ * [Types of VPNs](https://bytebytego.com/guides/types-of-vpns)
+ * [What is a Cookie?](https://bytebytego.com/guides/what-is-a-cookie)
+ * [OAuth 2.0 Flows](https://bytebytego.com/guides/oauth-20-flows)
+ * [Top Network Security Cheatsheet](https://bytebytego.com/guides/top-network-security-cheatsheet)
+ * [What is SSO (Single Sign-On)?](https://bytebytego.com/guides/v1what-is-sso-single-sign-on)
+ * [How does HTTPS work?](https://bytebytego.com/guides/how-does-https-work)
+ * [Session, Cookie, JWT, Token, SSO, and OAuth 2.0 Explained](https://bytebytego.com/guides/session-cookie-jwt-token-sso-and-oauth-2)
+ * [Explaining JSON Web Token (JWT) to a 10 Year Old Kid](https://bytebytego.com/guides/explaining-json-web-token-jwt-to-a-10-year-old-kid)
+ * [OAuth 2.0 Explained With Simple Terms](https://bytebytego.com/guides/oauth-2-explained-with-siple-terms)
+* [Computer Fundamentals](https://bytebytego.com/guides/computer-fundamentals)
+ * [Paging vs Segmentation](https://bytebytego.com/guides/what-are-the-differences-between-paging-and-segmentation)
+ * [IPv4 vs. IPv6: Differences](https://bytebytego.com/guides/ipv4-vs-ipv6)
+ * [Top 4 Most Popular Use Cases for UDP](https://bytebytego.com/guides/top-4-most-popular-use-cases-for-udp)
+ * [How Does the Domain Name System (DNS) Lookup Work?](https://bytebytego.com/guides/how-does-the-domain-name-system-dns-lookup-work)
+ * [DNS Record Types You Should Know](https://bytebytego.com/guides/dns-record-types-you-should-know)
+ * [TCP vs UDP for Online Gaming](https://bytebytego.com/guides/what-protocol-does-online-gaming-use-to-transmit-data)
+ * [What is a Deadlock?](https://bytebytego.com/guides/what-is-a-deadlock)
+ * [Process vs Thread: Key Differences](https://bytebytego.com/guides/what-is-the-difference-between-process-and-thread)
+ * [OSI Model Explained](https://bytebytego.com/guides/what-is-osi-model)
+ * [Visualizing a SQL Query](https://bytebytego.com/guides/visualizing-a-sql-query)
+ * [Explaining 8 Popular Network Protocols in 1 Diagram](https://bytebytego.com/guides/explaining-8-popular-network-protocols-in-1-diagram)
+ * [What is the Best Way to Learn SQL?](https://bytebytego.com/guides/what-is-the-best-way-to-learn-sql)
-- [Communication protocols](#communication-protocols)
- - [REST API vs. GraphQL](#rest-api-vs-graphql)
- - [How does gRPC work?](#how-does-grpc-work)
- - [What is a webhook?](#what-is-a-webhook)
- - [How to improve API performance?](#how-to-improve-api-performance)
- - [HTTP 1.0 -\> HTTP 1.1 -\> HTTP 2.0 -\> HTTP 3.0 (QUIC)](#http-10---http-11---http-20---http-30-quic)
- - [SOAP vs REST vs GraphQL vs RPC](#soap-vs-rest-vs-graphql-vs-rpc)
- - [Code First vs. API First](#code-first-vs-api-first)
- - [HTTP status codes](#http-status-codes)
- - [What does API gateway do?](#what-does-api-gateway-do)
- - [How do we design effective and safe APIs?](#how-do-we-design-effective-and-safe-apis)
- - [TCP/IP encapsulation](#tcpip-encapsulation)
- - [Why is Nginx called a “reverse” proxy?](#why-is-nginx-called-a-reverse-proxy)
- - [What are the common load-balancing algorithms?](#what-are-the-common-load-balancing-algorithms)
- - [URL, URI, URN - Do you know the differences?](#url-uri-urn---do-you-know-the-differences)
-- [CI/CD](#cicd)
- - [CI/CD Pipeline Explained in Simple Terms](#cicd-pipeline-explained-in-simple-terms)
- - [Netflix Tech Stack (CI/CD Pipeline)](#netflix-tech-stack-cicd-pipeline)
-- [Architecture patterns](#architecture-patterns)
- - [MVC, MVP, MVVM, MVVM-C, and VIPER](#mvc-mvp-mvvm-mvvm-c-and-viper)
- - [18 Key Design Patterns Every Developer Should Know](#18-key-design-patterns-every-developer-should-know)
-- [Database](#database)
- - [A nice cheat sheet of different databases in cloud services](#a-nice-cheat-sheet-of-different-databases-in-cloud-services)
- - [8 Data Structures That Power Your Databases](#8-data-structures-that-power-your-databases)
- - [How is an SQL statement executed in the database?](#how-is-an-sql-statement-executed-in-the-database)
- - [CAP theorem](#cap-theorem)
- - [Types of Memory and Storage](#types-of-memory-and-storage)
- - [Visualizing a SQL query](#visualizing-a-sql-query)
- - [SQL language](#sql-language)
-- [Cache](#cache)
- - [Data is cached everywhere](#data-is-cached-everywhere)
- - [Why is Redis so fast?](#why-is-redis-so-fast)
- - [How can Redis be used?](#how-can-redis-be-used)
- - [Top caching strategies](#top-caching-strategies)
-- [Microservice architecture](#microservice-architecture)
- - [What does a typical microservice architecture look like?](#what-does-a-typical-microservice-architecture-look-like)
- - [Microservice Best Practices](#microservice-best-practices)
- - [What tech stack is commonly used for microservices?](#what-tech-stack-is-commonly-used-for-microservices)
- - [Why is Kafka fast](#why-is-kafka-fast)
-- [Payment systems](#payment-systems)
- - [How to learn payment systems?](#how-to-learn-payment-systems)
- - [Why is the credit card called “the most profitable product in banks”? How does VISA/Mastercard make money?](#why-is-the-credit-card-called-the-most-profitable-product-in-banks-how-does-visamastercard-make-money)
- - [How does VISA work when we swipe a credit card at a merchant’s shop?](#how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchants-shop)
- - [Payment Systems Around The World Series (Part 1): Unified Payments Interface (UPI) in India](#payment-systems-around-the-world-series-part-1-unified-payments-interface-upi-in-india)
-- [DevOps](#devops)
- - [DevOps vs. SRE vs. Platform Engineering. What is the difference?](#devops-vs-sre-vs-platform-engineering-what-is-the-difference)
- - [What is k8s (Kubernetes)?](#what-is-k8s-kubernetes)
- - [Docker vs. Kubernetes. Which one should we use?](#docker-vs-kubernetes-which-one-should-we-use)
- - [How does Docker work?](#how-does-docker-work)
-- [GIT](#git)
- - [How Git Commands work](#how-git-commands-work)
- - [How does Git Work?](#how-does-git-work)
- - [Git merge vs. Git rebase](#git-merge-vs-git-rebase)
-- [Cloud Services](#cloud-services)
- - [A nice cheat sheet of different cloud services (2023 edition)](#a-nice-cheat-sheet-of-different-cloud-services-2023-edition)
- - [What is cloud native?](#what-is-cloud-native)
-- [Developer productivity tools](#developer-productivity-tools)
- - [Visualize JSON files](#visualize-json-files)
- - [Automatically turn code into architecture diagrams](#automatically-turn-code-into-architecture-diagrams)
-- [Linux](#linux)
- - [Linux file system explained](#linux-file-system-explained)
- - [18 Most-used Linux Commands You Should Know](#18-most-used-linux-commands-you-should-know)
-- [Security](#security)
- - [How does HTTPS work?](#how-does-https-work)
- - [Oauth 2.0 Explained With Simple Terms.](#oauth-20-explained-with-simple-terms)
- - [Top 4 Forms of Authentication Mechanisms](#top-4-forms-of-authentication-mechanisms)
- - [Session, cookie, JWT, token, SSO, and OAuth 2.0 - what are they?](#session-cookie-jwt-token-sso-and-oauth-20---what-are-they)
- - [How to store passwords safely in the database and how to validate a password?](#how-to-store-passwords-safely-in-the-database-and-how-to-validate-a-password)
- - [Explaining JSON Web Token (JWT) to a 10 year old Kid](#explaining-json-web-token-jwt-to-a-10-year-old-kid)
- - [How does Google Authenticator (or other types of 2-factor authenticators) work?](#how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work)
-- [Real World Case Studies](#real-world-case-studies)
- - [Netflix's Tech Stack](#netflixs-tech-stack)
- - [Twitter Architecture 2022](#twitter-architecture-2022)
- - [Evolution of Airbnb’s microservice architecture over the past 15 years](#evolution-of-airbnbs-microservice-architecture-over-the-past-15-years)
- - [Monorepo vs. Microrepo.](#monorepo-vs-microrepo)
- - [How will you design the Stack Overflow website?](#how-will-you-design-the-stack-overflow-website)
- - [Why did Amazon Prime Video monitoring move from serverless to monolithic? How can it save 90% cost?](#why-did-amazon-prime-video-monitoring-move-from-serverless-to-monolithic-how-can-it-save-90-cost)
- - [How does Disney Hotstar capture 5 Billion Emojis during a tournament?](#how-does-disney-hotstar-capture-5-billion-emojis-during-a-tournament)
- - [How Discord Stores Trillions Of Messages](#how-discord-stores-trillions-of-messages)
- - [How do video live streamings work on YouTube, TikTok live, or Twitch?](#how-do-video-live-streamings-work-on-youtube-tiktok-live-or-twitch)
-## Communication protocols
-
-Architecture styles define how different components of an application programming interface (API) interact with one another. As a result, they ensure efficiency, reliability, and ease of integration with other systems by providing a standard approach to designing and building APIs. Here are the most used styles:
-
-
-  -
-
-
-- SOAP:
-
- Mature, comprehensive, XML-based
-
- Best for enterprise applications
-
-- RESTful:
-
- Popular, easy-to-implement, HTTP methods
-
- Ideal for web services
-
-- GraphQL:
-
- Query language, request specific data
-
- Reduces network overhead, faster responses
-
-- gRPC:
-
- Modern, high-performance, Protocol Buffers
-
- Suitable for microservices architectures
-
-- WebSocket:
-
- Real-time, bidirectional, persistent connections
-
- Perfect for low-latency data exchange
-
-- Webhook:
-
- Event-driven, HTTP callbacks, asynchronous
-
- Notifies systems when events occur
-
-
-### REST API vs. GraphQL
-
-When it comes to API design, REST and GraphQL each have their own strengths and weaknesses.
-
-The diagram below shows a quick comparison between REST and GraphQL.
-
-
-  -
-
-
-REST
-
-- Uses standard HTTP methods like GET, POST, PUT, DELETE for CRUD operations.
-- Works well when you need simple, uniform interfaces between separate services/applications.
-- Caching strategies are straightforward to implement.
-- The downside is it may require multiple roundtrips to assemble related data from separate endpoints.
-
-GraphQL
-
-- Provides a single endpoint for clients to query for precisely the data they need.
-- Clients specify the exact fields required in nested queries, and the server returns optimized payloads containing just those fields.
-- Supports Mutations for modifying data and Subscriptions for real-time notifications.
-- Great for aggregating data from multiple sources and works well with rapidly evolving frontend requirements.
-- However, it shifts complexity to the client side and can allow abusive queries if not properly safeguarded
-- Caching strategies can be more complicated than REST.
-
-The best choice between REST and GraphQL depends on the specific requirements of the application and development team. GraphQL is a good fit for complex or frequently changing frontend needs, while REST suits applications where simple and consistent contracts are preferred.
-
-Neither API approach is a silver bullet. Carefully evaluating requirements and tradeoffs is important to pick the right style. Both REST and GraphQL are valid options for exposing data and powering modern applications.
-
-
-### How does gRPC work?
-
-RPC (Remote Procedure Call) is called “**remote**” because it enables communications between remote services when services are deployed to different servers under microservice architecture. From the user’s point of view, it acts like a local function call.
-
-The diagram below illustrates the overall data flow for **gRPC**.
-
-
-  -
-
-
-Step 1: A REST call is made from the client. The request body is usually in JSON format.
-
-Steps 2 - 4: The order service (gRPC client) receives the REST call, transforms it, and makes an RPC call to the payment service. gRPC encodes the **client stub** into a binary format and sends it to the low-level transport layer.
-
-Step 5: gRPC sends the packets over the network via HTTP2. Because of binary encoding and network optimizations, gRPC is said to be 5X faster than JSON.
-
-Steps 6 - 8: The payment service (gRPC server) receives the packets from the network, decodes them, and invokes the server application.
-
-Steps 9 - 11: The result is returned from the server application, and gets encoded and sent to the transport layer.
-
-Steps 12 - 14: The order service receives the packets, decodes them, and sends the result to the client application.
-
-### What is a webhook?
-
-The diagram below shows a comparison between polling and Webhook.
-
-
-  -
-
-
-Assume we run an eCommerce website. The clients send orders to the order service via the API gateway, which goes to the payment service for payment transactions. The payment service then talks to an external payment service provider (PSP) to complete the transactions.
-
-There are two ways to handle communications with the external PSP.
-
-**1. Short polling**
-
-After sending the payment request to the PSP, the payment service keeps asking the PSP about the payment status. After several rounds, the PSP finally returns with the status.
-
-Short polling has two drawbacks:
-* Constant polling of the status requires resources from the payment service.
-* The External service communicates directly with the payment service, creating security vulnerabilities.
-
-**2. Webhook**
-
-We can register a webhook with the external service. It means: call me back at a certain URL when you have updates on the request. When the PSP has completed the processing, it will invoke the HTTP request to update the payment status.
-
-In this way, the programming paradigm is changed, and the payment service doesn’t need to waste resources to poll the payment status anymore.
-
-What if the PSP never calls back? We can set up a housekeeping job to check payment status every hour.
-
-Webhooks are often referred to as reverse APIs or push APIs because the server sends HTTP requests to the client. We need to pay attention to 3 things when using a webhook:
-
-1. We need to design a proper API for the external service to call.
-2. We need to set up proper rules in the API gateway for security reasons.
-3. We need to register the correct URL at the external service.
-
-### How to improve API performance?
-
-The diagram below shows 5 common tricks to improve API performance.
-
-
-  -
-
-
-Pagination
-
-This is a common optimization when the size of the result is large. The results are streaming back to the client to improve the service responsiveness.
-
-Asynchronous Logging
-
-Synchronous logging deals with the disk for every call and can slow down the system. Asynchronous logging sends logs to a lock-free buffer first and immediately returns. The logs will be flushed to the disk periodically. This significantly reduces the I/O overhead.
-
-Caching
-
-We can store frequently accessed data into a cache. The client can query the cache first instead of visiting the database directly. If there is a cache miss, the client can query from the database. Caches like Redis store data in memory, so the data access is much faster than the database.
-
-Payload Compression
-
-The requests and responses can be compressed using gzip etc so that the transmitted data size is much smaller. This speeds up the upload and download.
-
-Connection Pool
-
-When accessing resources, we often need to load data from the database. Opening the closing db connections adds significant overhead. So we should connect to the db via a pool of open connections. The connection pool is responsible for managing the connection lifecycle.
-
-### HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC)
-
-What problem does each generation of HTTP solve?
-
-The diagram below illustrates the key features.
-
-
-  -
-
-
-- HTTP 1.0 was finalized and fully documented in 1996. Every request to the same server requires a separate TCP connection.
-
-- HTTP 1.1 was published in 1997. A TCP connection can be left open for reuse (persistent connection), but it doesn’t solve the HOL (head-of-line) blocking issue.
-
- HOL blocking - when the number of allowed parallel requests in the browser is used up, subsequent requests need to wait for the former ones to complete.
-
-- HTTP 2.0 was published in 2015. It addresses HOL issue through request multiplexing, which eliminates HOL blocking at the application layer, but HOL still exists at the transport (TCP) layer.
-
- As you can see in the diagram, HTTP 2.0 introduced the concept of HTTP “streams”: an abstraction that allows multiplexing different HTTP exchanges onto the same TCP connection. Each stream doesn’t need to be sent in order.
-
-- HTTP 3.0 first draft was published in 2020. It is the proposed successor to HTTP 2.0. It uses QUIC instead of TCP for the underlying transport protocol, thus removing HOL blocking in the transport layer.
-
-QUIC is based on UDP. It introduces streams as first-class citizens at the transport layer. QUIC streams share the same QUIC connection, so no additional handshakes and slow starts are required to create new ones, but QUIC streams are delivered independently such that in most cases packet loss affecting one stream doesn't affect others.
-
-### SOAP vs REST vs GraphQL vs RPC
-
-The diagram below illustrates the API timeline and API styles comparison.
-
-Over time, different API architectural styles are released. Each of them has its own patterns of standardizing data exchange.
-
-You can check out the use cases of each style in the diagram.
-
-
-  -
-
-
-
-### Code First vs. API First
-
-The diagram below shows the differences between code-first development and API-first development. Why do we want to consider API first design?
-
-
-  -
-
-
-
-- Microservices increase system complexity and we have separate services to serve different functions of the system. While this kind of architecture facilitates decoupling and segregation of duty, we need to handle the various communications among services.
-
-It is better to think through the system's complexity before writing the code and carefully defining the boundaries of the services.
-
-- Separate functional teams need to speak the same language and the dedicated functional teams are only responsible for their own components and services. It is recommended that the organization speak the same language via API design.
-
-We can mock requests and responses to validate the API design before writing code.
-
-- Improve software quality and developer productivity Since we have ironed out most of the uncertainties when the project starts, the overall development process is smoother, and the software quality is greatly improved.
-
-Developers are happy about the process as well because they can focus on functional development instead of negotiating sudden changes.
-
-The possibility of having surprises toward the end of the project lifecycle is reduced.
-
-Because we have designed the API first, the tests can be designed while the code is being developed. In a way, we also have TDD (Test Driven Design) when using API first development.
-
-### HTTP status codes
-
-
-  -
-
-
-
-The response codes for HTTP are divided into five categories:
-
-Informational (100-199)
-Success (200-299)
-Redirection (300-399)
-Client Error (400-499)
-Server Error (500-599)
-
-### What does API gateway do?
-
-The diagram below shows the details.
-
-
-  -
-
-
-Step 1 - The client sends an HTTP request to the API gateway.
-
-Step 2 - The API gateway parses and validates the attributes in the HTTP request.
-
-Step 3 - The API gateway performs allow-list/deny-list checks.
-
-Step 4 - The API gateway talks to an identity provider for authentication and authorization.
-
-Step 5 - The rate limiting rules are applied to the request. If it is over the limit, the request is rejected.
-
-Steps 6 and 7 - Now that the request has passed basic checks, the API gateway finds the relevant service to route to by path matching.
-
-Step 8 - The API gateway transforms the request into the appropriate protocol and sends it to backend microservices.
-
-Steps 9-12: The API gateway can handle errors properly, and deals with faults if the error takes a longer time to recover (circuit break). It can also leverage ELK (Elastic-Logstash-Kibana) stack for logging and monitoring. We sometimes cache data in the API gateway.
-
-### How do we design effective and safe APIs?
-
-The diagram below shows typical API designs with a shopping cart example.
-
-
-  -
-
-
-
-Note that API design is not just URL path design. Most of the time, we need to choose the proper resource names, identifiers, and path patterns. It is equally important to design proper HTTP header fields or to design effective rate-limiting rules within the API gateway.
-
-### TCP/IP encapsulation
-
-How is data sent over the network? Why do we need so many layers in the OSI model?
-
-The diagram below shows how data is encapsulated and de-encapsulated when transmitting over the network.
-
-
-  -
-
-
-Step 1: When Device A sends data to Device B over the network via the HTTP protocol, it is first added an HTTP header at the application layer.
-
-Step 2: Then a TCP or a UDP header is added to the data. It is encapsulated into TCP segments at the transport layer. The header contains the source port, destination port, and sequence number.
-
-Step 3: The segments are then encapsulated with an IP header at the network layer. The IP header contains the source/destination IP addresses.
-
-Step 4: The IP datagram is added a MAC header at the data link layer, with source/destination MAC addresses.
-
-Step 5: The encapsulated frames are sent to the physical layer and sent over the network in binary bits.
-
-Steps 6-10: When Device B receives the bits from the network, it performs the de-encapsulation process, which is a reverse processing of the encapsulation process. The headers are removed layer by layer, and eventually, Device B can read the data.
-
-We need layers in the network model because each layer focuses on its own responsibilities. Each layer can rely on the headers for processing instructions and does not need to know the meaning of the data from the last layer.
-
-### Why is Nginx called a “reverse” proxy?
-
-The diagram below shows the differences between a 𝐟𝐨𝐫𝐰𝐚𝐫𝐝 𝐩𝐫𝐨𝐱𝐲 and a 𝐫𝐞𝐯𝐞𝐫𝐬𝐞 𝐩𝐫𝐨𝐱𝐲.
-
-
-  -
-
-
-A forward proxy is a server that sits between user devices and the internet.
-
-A forward proxy is commonly used for:
-
-1. Protecting clients
-2. Circumventing browsing restrictions
-3. Blocking access to certain content
-
-A reverse proxy is a server that accepts a request from the client, forwards the request to web servers, and returns the results to the client as if the proxy server had processed the request.
-
-A reverse proxy is good for:
-
-1. Protecting servers
-2. Load balancing
-3. Caching static contents
-4. Encrypting and decrypting SSL communications
-
-### What are the common load-balancing algorithms?
-
-The diagram below shows 6 common algorithms.
-
-
-  -
-
-
-- Static Algorithms
-
-1. Round robin
-
- The client requests are sent to different service instances in sequential order. The services are usually required to be stateless.
-
-3. Sticky round-robin
-
- This is an improvement of the round-robin algorithm. If Alice’s first request goes to service A, the following requests go to service A as well.
-
-4. Weighted round-robin
-
- The admin can specify the weight for each service. The ones with a higher weight handle more requests than others.
-
-6. Hash
-
- This algorithm applies a hash function on the incoming requests’ IP or URL. The requests are routed to relevant instances based on the hash function result.
-
-- Dynamic Algorithms
-
-5. Least connections
-
- A new request is sent to the service instance with the least concurrent connections.
-
-7. Least response time
-
- A new request is sent to the service instance with the fastest response time.
-
-### URL, URI, URN - Do you know the differences?
-
-The diagram below shows a comparison of URL, URI, and URN.
-
-
-  -
-
-
-- URI
-
-URI stands for Uniform Resource Identifier. It identifies a logical or physical resource on the web. URL and URN are subtypes of URI. URL locates a resource, while URN names a resource.
-
-A URI is composed of the following parts:
-scheme:[//authority]path[?query][#fragment]
-
-- URL
-
-URL stands for Uniform Resource Locator, the key concept of HTTP. It is the address of a unique resource on the web. It can be used with other protocols like FTP and JDBC.
-
-- URN
-
-URN stands for Uniform Resource Name. It uses the urn scheme. URNs cannot be used to locate a resource. A simple example given in the diagram is composed of a namespace and a namespace-specific string.
-
-If you would like to learn more detail on the subject, I would recommend [W3C’s clarification](https://www.w3.org/TR/uri-clarification/).
-
-## CI/CD
-
-### CI/CD Pipeline Explained in Simple Terms
-
-
-  -
-
-
-Section 1 - SDLC with CI/CD
-
-The software development life cycle (SDLC) consists of several key stages: development, testing, deployment, and maintenance. CI/CD automates and integrates these stages to enable faster and more reliable releases.
-
-When code is pushed to a git repository, it triggers an automated build and test process. End-to-end (e2e) test cases are run to validate the code. If tests pass, the code can be automatically deployed to staging/production. If issues are found, the code is sent back to development for bug fixing. This automation provides fast feedback to developers and reduces the risk of bugs in production.
-
-Section 2 - Difference between CI and CD
-
-Continuous Integration (CI) automates the build, test, and merge process. It runs tests whenever code is committed to detect integration issues early. This encourages frequent code commits and rapid feedback.
-
-Continuous Delivery (CD) automates release processes like infrastructure changes and deployment. It ensures software can be released reliably at any time through automated workflows. CD may also automate the manual testing and approval steps required before production deployment.
-
-Section 3 - CI/CD Pipeline
-
-A typical CI/CD pipeline has several connected stages:
-- The developer commits code changes to the source control
-- CI server detects changes and triggers the build
-- Code is compiled, and tested (unit, integration tests)
-- Test results reported to the developer
-- On success, artifacts are deployed to staging environments
-- Further testing may be done on staging before release
-- CD system deploys approved changes to production
-
-### Netflix Tech Stack (CI/CD Pipeline)
-
-
-  -
-
-
-Planning: Netflix Engineering uses JIRA for planning and Confluence for documentation.
-
-Coding: Java is the primary programming language for the backend service, while other languages are used for different use cases.
-
-Build: Gradle is mainly used for building, and Gradle plugins are built to support various use cases.
-
-Packaging: Package and dependencies are packed into an Amazon Machine Image (AMI) for release.
-
-Testing: Testing emphasizes the production culture's focus on building chaos tools.
-
-Deployment: Netflix uses its self-built Spinnaker for canary rollout deployment.
-
-Monitoring: The monitoring metrics are centralized in Atlas, and Kayenta is used to detect anomalies.
-
-Incident report: Incidents are dispatched according to priority, and PagerDuty is used for incident handling.
-
-## Architecture patterns
-
-### MVC, MVP, MVVM, MVVM-C, and VIPER
-These architecture patterns are among the most commonly used in app development, whether on iOS or Android platforms. Developers have introduced them to overcome the limitations of earlier patterns. So, how do they differ?
-
-
-  -
-
-
-- MVC, the oldest pattern, dates back almost 50 years
-- Every pattern has a "view" (V) responsible for displaying content and receiving user input
-- Most patterns include a "model" (M) to manage business data
-- "Controller," "presenter," and "view-model" are translators that mediate between the view and the model ("entity" in the VIPER pattern)
-
-### 18 Key Design Patterns Every Developer Should Know
-
-Patterns are reusable solutions to common design problems, resulting in a smoother, more efficient development process. They serve as blueprints for building better software structures. These are some of the most popular patterns:
-
-
-  -
-
-
-- Abstract Factory: Family Creator - Makes groups of related items.
-- Builder: Lego Master - Builds objects step by step, keeping creation and appearance separate.
-- Prototype: Clone Maker - Creates copies of fully prepared examples.
-- Singleton: One and Only - A special class with just one instance.
-- Adapter: Universal Plug - Connects things with different interfaces.
-- Bridge: Function Connector - Links how an object works to what it does.
-- Composite: Tree Builder - Forms tree-like structures of simple and complex parts.
-- Decorator: Customizer - Adds features to objects without changing their core.
-- Facade: One-Stop-Shop - Represents a whole system with a single, simplified interface.
-- Flyweight: Space Saver - Shares small, reusable items efficiently.
-- Proxy: Stand-In Actor - Represents another object, controlling access or actions.
-- Chain of Responsibility: Request Relay - Passes a request through a chain of objects until handled.
-- Command: Task Wrapper - Turns a request into an object, ready for action.
-- Iterator: Collection Explorer - Accesses elements in a collection one by one.
-- Mediator: Communication Hub - Simplifies interactions between different classes.
-- Memento: Time Capsule - Captures and restores an object's state.
-- Observer: News Broadcaster - Notifies classes about changes in other objects.
-- Visitor: Skillful Guest - Adds new operations to a class without altering it.
-
-## Database
-
-### A nice cheat sheet of different databases in cloud services
-
-
-  -
-
-
-Choosing the right database for your project is a complex task. Many database options, each suited to distinct use cases, can quickly lead to decision fatigue.
-
-We hope this cheat sheet provides high-level direction to pinpoint the right service that aligns with your project's needs and avoid potential pitfalls.
-
-Note: Google has limited documentation for their database use cases. Even though we did our best to look at what was available and arrived at the best option, some of the entries may need to be more accurate.
-
-### 8 Data Structures That Power Your Databases
-
-The answer will vary depending on your use case. Data can be indexed in memory or on disk. Similarly, data formats vary, such as numbers, strings, geographic coordinates, etc. The system might be write-heavy or read-heavy. All of these factors affect your choice of database index format.
-
-
-  -
-
-
-The following are some of the most popular data structures used for indexing data:
-
-- Skiplist: a common in-memory index type. Used in Redis
-- Hash index: a very common implementation of the “Map” data structure (or “Collection”)
-- SSTable: immutable on-disk “Map” implementation
-- LSM tree: Skiplist + SSTable. High write throughput
-- B-tree: disk-based solution. Consistent read/write performance
-- Inverted index: used for document indexing. Used in Lucene
-- Suffix tree: for string pattern search
-- R-tree: multi-dimension search, such as finding the nearest neighbor
-
-### How is an SQL statement executed in the database?
-
-The diagram below shows the process. Note that the architectures for different databases are different, the diagram demonstrates some common designs.
-
-
-  -
-
-
-
-Step 1 - A SQL statement is sent to the database via a transport layer protocol (e.g.TCP).
-
-Step 2 - The SQL statement is sent to the command parser, where it goes through syntactic and semantic analysis, and a query tree is generated afterward.
-
-Step 3 - The query tree is sent to the optimizer. The optimizer creates an execution plan.
-
-Step 4 - The execution plan is sent to the executor. The executor retrieves data from the execution.
-
-Step 5 - Access methods provide the data fetching logic required for execution, retrieving data from the storage engine.
-
-Step 6 - Access methods decide whether the SQL statement is read-only. If the query is read-only (SELECT statement), it is passed to the buffer manager for further processing. The buffer manager looks for the data in the cache or data files.
-
-Step 7 - If the statement is an UPDATE or INSERT, it is passed to the transaction manager for further processing.
-
-Step 8 - During a transaction, the data is in lock mode. This is guaranteed by the lock manager. It also ensures the transaction’s ACID properties.
-
-### CAP theorem
-
-The CAP theorem is one of the most famous terms in computer science, but I bet different developers have different understandings. Let’s examine what it is and why it can be confusing.
-
-
-  -
-
-
-CAP theorem states that a distributed system can't provide more than two of these three guarantees simultaneously.
-
-**Consistency**: consistency means all clients see the same data at the same time no matter which node they connect to.
-
-**Availability**: availability means any client that requests data gets a response even if some of the nodes are down.
-
-**Partition Tolerance**: a partition indicates a communication break between two nodes. Partition tolerance means the system continues to operate despite network partitions.
-
-The “2 of 3” formulation can be useful, **but this simplification could be misleading**.
-
-1. Picking a database is not easy. Justifying our choice purely based on the CAP theorem is not enough. For example, companies don't choose Cassandra for chat applications simply because it is an AP system. There is a list of good characteristics that make Cassandra a desirable option for storing chat messages. We need to dig deeper.
-
-2. “CAP prohibits only a tiny part of the design space: perfect availability and consistency in the presence of partitions, which are rare”. Quoted from the paper: CAP Twelve Years Later: How the “Rules” Have Changed.
-
-3. The theorem is about 100% availability and consistency. A more realistic discussion would be the trade-offs between latency and consistency when there is no network partition. See PACELC theorem for more details.
-
-**Is the CAP theorem actually useful?**
-
-I think it is still useful as it opens our minds to a set of tradeoff discussions, but it is only part of the story. We need to dig deeper when picking the right database.
-
-### Types of Memory and Storage
-
-
-  -
-
-
-
-### Visualizing a SQL query
-
-
-  -
-
-
-SQL statements are executed by the database system in several steps, including:
-
-- Parsing the SQL statement and checking its validity
-- Transforming the SQL into an internal representation, such as relational algebra
-- Optimizing the internal representation and creating an execution plan that utilizes index information
-- Executing the plan and returning the results
-
-The execution of SQL is highly complex and involves many considerations, such as:
-
-- The use of indexes and caches
-- The order of table joins
-- Concurrency control
-- Transaction management
-
-### SQL language
-
-In 1986, SQL (Structured Query Language) became a standard. Over the next 40 years, it became the dominant language for relational database management systems. Reading the latest standard (ANSI SQL 2016) can be time-consuming. How can I learn it?
-
-
-  -
-
-
-There are 5 components of the SQL language:
-
-- DDL: data definition language, such as CREATE, ALTER, DROP
-- DQL: data query language, such as SELECT
-- DML: data manipulation language, such as INSERT, UPDATE, DELETE
-- DCL: data control language, such as GRANT, REVOKE
-- TCL: transaction control language, such as COMMIT, ROLLBACK
-
-For a backend engineer, you may need to know most of it. As a data analyst, you may need to have a good understanding of DQL. Select the topics that are most relevant to you.
-
-## Cache
-
-### Data is cached everywhere
-
-This diagram illustrates where we cache data in a typical architecture.
-
-
-  -
-
-
-
-There are **multiple layers** along the flow.
-
-1. Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time, and it is returned with an expiry policy in the HTTP header; we request data again, and the client app tries to retrieve the data from the browser cache first.
-2. CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
-3. Load Balancer: The load Balancer can cache resources as well.
-4. Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
-5. Services: There are multiple layers of cache in a service. If the data is not cached in the CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
-6. Distributed Cache: Distributed cache like Redis holds key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
-7. Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
-8. Database: Even in the database, we have different levels of caches:
-- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
-- Bufferpool: A memory area allocated to cache query results
-- Materialized View: Pre-compute query results and store them in the database tables for better query performance
-- Transaction log: record all the transactions and database updates
-- Replication Log: used to record the replication state in a database cluster
-
-### Why is Redis so fast?
-
-There are 3 main reasons as shown in the diagram below.
-
-
-  -
-
-
-
-1. Redis is a RAM-based data store. RAM access is at least 1000 times faster than random disk access.
-2. Redis leverages IO multiplexing and single-threaded execution loop for execution efficiency.
-3. Redis leverages several efficient lower-level data structures.
-
-Question: Another popular in-memory store is Memcached. Do you know the differences between Redis and Memcached?
-
-You might have noticed the style of this diagram is different from my previous posts. Please let me know which one you prefer.
-
-### How can Redis be used?
-
-
-  -
-
-
-
-There is more to Redis than just caching.
-
-Redis can be used in a variety of scenarios as shown in the diagram.
-
-- Session
-
- We can use Redis to share user session data among different services.
-
-- Cache
-
- We can use Redis to cache objects or pages, especially for hotspot data.
-
-- Distributed lock
-
- We can use a Redis string to acquire locks among distributed services.
-
-- Counter
-
- We can count how many likes or how many reads for articles.
-
-- Rate limiter
-
- We can apply a rate limiter for certain user IPs.
-
-- Global ID generator
-
- We can use Redis Int for global ID.
-
-- Shopping cart
-
- We can use Redis Hash to represent key-value pairs in a shopping cart.
-
-- Calculate user retention
-
- We can use Bitmap to represent the user login daily and calculate user retention.
-
-- Message queue
-
- We can use List for a message queue.
-
-- Ranking
-
- We can use ZSet to sort the articles.
-
-### Top caching strategies
-
-Designing large-scale systems usually requires careful consideration of caching.
-Below are five caching strategies that are frequently utilized.
-
-
-  -
-
-
-
-
-## Microservice architecture
-
-### What does a typical microservice architecture look like?
-
-
-  -
-
-
-
-The diagram below shows a typical microservice architecture.
-
-- Load Balancer: This distributes incoming traffic across multiple backend services.
-- CDN (Content Delivery Network): CDN is a group of geographically distributed servers that hold static content for faster delivery. The clients look for content in CDN first, then progress to backend services.
-- API Gateway: This handles incoming requests and routes them to the relevant services. It talks to the identity provider and service discovery.
-- Identity Provider: This handles authentication and authorization for users.
-- Service Registry & Discovery: Microservice registration and discovery happen in this component, and the API gateway looks for relevant services in this component to talk to.
-- Management: This component is responsible for monitoring the services.
-- Microservices: Microservices are designed and deployed in different domains. Each domain has its own database. The API gateway talks to the microservices via REST API or other protocols, and the microservices within the same domain talk to each other using RPC (Remote Procedure Call).
-
-Benefits of microservices:
-
-- They can be quickly designed, deployed, and horizontally scaled.
-- Each domain can be independently maintained by a dedicated team.
-- Business requirements can be customized in each domain and better supported, as a result.
-
-### Microservice Best Practices
-
-A picture is worth a thousand words: 9 best practices for developing microservices.
-
-
-  -
-
-
-
-When we develop microservices, we need to follow the following best practices:
-
-1. Use separate data storage for each microservice
-2. Keep code at a similar level of maturity
-3. Separate build for each microservice
-4. Assign each microservice with a single responsibility
-5. Deploy into containers
-6. Design stateless services
-7. Adopt domain-driven design
-8. Design micro frontend
-9. Orchestrating microservices
-
-### What tech stack is commonly used for microservices?
-
-Below you will find a diagram showing the microservice tech stack, both for the development phase and for production.
-
-
-  -
-
-
-
-▶️ 𝐏𝐫𝐞-𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧
-
-- Define API - This establishes a contract between frontend and backend. We can use Postman or OpenAPI for this.
-- Development - Node.js or react is popular for frontend development, and java/python/go for backend development. Also, we need to change the configurations in the API gateway according to API definitions.
-- Continuous Integration - JUnit and Jenkins for automated testing. The code is packaged into a Docker image and deployed as microservices.
-
-▶️ 𝐏𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧
-
-- NGinx is a common choice for load balancers. Cloudflare provides CDN (Content Delivery Network).
-- API Gateway - We can use spring boot for the gateway, and use Eureka/Zookeeper for service discovery.
-- The microservices are deployed on clouds. We have options among AWS, Microsoft Azure, or Google GCP.
-Cache and Full-text Search - Redis is a common choice for caching key-value pairs. Elasticsearch is used for full-text search.
-- Communications - For services to talk to each other, we can use messaging infra Kafka or RPC.
-- Persistence - We can use MySQL or PostgreSQL for a relational database, and Amazon S3 for object store. We can also use Cassandra for the wide-column store if necessary.
-- Management & Monitoring - To manage so many microservices, the common Ops tools include Prometheus, Elastic Stack, and Kubernetes.
-
-### Why is Kafka fast
-
-There are many design decisions that contributed to Kafka’s performance. In this post, we’ll focus on two. We think these two carried the most weight.
-
-
-  -
-
-
-1. The first one is Kafka’s reliance on Sequential I/O.
-2. The second design choice that gives Kafka its performance advantage is its focus on efficiency: zero copy principle.
-
-The diagram illustrates how the data is transmitted between producer and consumer, and what zero-copy means.
-
-- Step 1.1 - 1.3: Producer writes data to the disk
-- Step 2: Consumer reads data without zero-copy
-
-2.1 The data is loaded from disk to OS cache
-
-2.2 The data is copied from OS cache to Kafka application
-
-2.3 Kafka application copies the data into the socket buffer
-
-2.4 The data is copied from socket buffer to network card
-
-2.5 The network card sends data out to the consumer
-
-
-- Step 3: Consumer reads data with zero-copy
-
-3.1: The data is loaded from disk to OS cache
-3.2 OS cache directly copies the data to the network card via sendfile() command
-3.3 The network card sends data out to the consumer
-
-Zero copy is a shortcut to save the multiple data copies between application context and kernel context.
-
-## Payment systems
-
-### How to learn payment systems?
-
-
-  -
-
-
-### Why is the credit card called “the most profitable product in banks”? How does VISA/Mastercard make money?
-
-The diagram below shows the economics of the credit card payment flow.
-
-
-  -
-
-
-1. The cardholder pays a merchant $100 to buy a product.
-
-2. The merchant benefits from the use of the credit card with higher sales volume and needs to compensate the issuer and the card network for providing the payment service. The acquiring bank sets a fee with the merchant, called the “merchant discount fee.”
-
-3 - 4. The acquiring bank keeps $0.25 as the acquiring markup, and $1.75 is paid to the issuing bank as the interchange fee. The merchant discount fee should cover the interchange fee.
-
- The interchange fee is set by the card network because it is less efficient for each issuing bank to negotiate fees with each merchant.
-
-5. The card network sets up the network assessments and fees with each bank, which pays the card network for its services every month. For example, VISA charges a 0.11% assessment, plus a $0.0195 usage fee, for every swipe.
-
-6. The cardholder pays the issuing bank for its services.
-
-Why should the issuing bank be compensated?
-
-- The issuer pays the merchant even if the cardholder fails to pay the issuer.
-- The issuer pays the merchant before the cardholder pays the issuer.
-- The issuer has other operating costs, including managing customer accounts, providing statements, fraud detection, risk management, clearing & settlement, etc.
-
-### How does VISA work when we swipe a credit card at a merchant’s shop?
-
-
-  -
-
-
-
-VISA, Mastercard, and American Express act as card networks for the clearing and settling of funds. The card acquiring bank and the card issuing bank can be – and often are – different. If banks were to settle transactions one by one without an intermediary, each bank would have to settle the transactions with all the other banks. This is quite inefficient.
-
-The diagram below shows VISA’s role in the credit card payment process. There are two flows involved. Authorization flow happens when the customer swipes the credit card. Capture and settlement flow happens when the merchant wants to get the money at the end of the day.
-
-- Authorization Flow
-
-Step 0: The card issuing bank issues credit cards to its customers.
-
-Step 1: The cardholder wants to buy a product and swipes the credit card at the Point of Sale (POS) terminal in the merchant’s shop.
-
-Step 2: The POS terminal sends the transaction to the acquiring bank, which has provided the POS terminal.
-
-Steps 3 and 4: The acquiring bank sends the transaction to the card network, also called the card scheme. The card network sends the transaction to the issuing bank for approval.
-
-Steps 4.1, 4.2 and 4.3: The issuing bank freezes the money if the transaction is approved. The approval or rejection is sent back to the acquirer, as well as the POS terminal.
-
-- Capture and Settlement Flow
-
-Steps 1 and 2: The merchant wants to collect the money at the end of the day, so they hit ”capture” on the POS terminal. The transactions are sent to the acquirer in batch. The acquirer sends the batch file with transactions to the card network.
-
-Step 3: The card network performs clearing for the transactions collected from different acquirers, and sends the clearing files to different issuing banks.
-
-Step 4: The issuing banks confirm the correctness of the clearing files, and transfer money to the relevant acquiring banks.
-
-Step 5: The acquiring bank then transfers money to the merchant’s bank.
-
-Step 4: The card network clears up the transactions from different acquiring banks. Clearing is a process in which mutual offset transactions are netted, so the number of total transactions is reduced.
-
-In the process, the card network takes on the burden of talking to each bank and receives service fees in return.
-
-### Payment Systems Around The World Series (Part 1): Unified Payments Interface (UPI) in India
-
-
-What’s UPI? UPI is an instant real-time payment system developed by the National Payments Corporation of India.
-
-It accounts for 60% of digital retail transactions in India today.
-
-UPI = payment markup language + standard for interoperable payments
-
-
-
-  -
-
-
-
-## DevOps
-
-### DevOps vs. SRE vs. Platform Engineering. What is the difference?
-
-The concepts of DevOps, SRE, and Platform Engineering have emerged at different times and have been developed by various individuals and organizations.
-
-
-  -
-
-
-DevOps as a concept was introduced in 2009 by Patrick Debois and Andrew Shafer at the Agile conference. They sought to bridge the gap between software development and operations by promoting a collaborative culture and shared responsibility for the entire software development lifecycle.
-
-SRE, or Site Reliability Engineering, was pioneered by Google in the early 2000s to address operational challenges in managing large-scale, complex systems. Google developed SRE practices and tools, such as the Borg cluster management system and the Monarch monitoring system, to improve the reliability and efficiency of their services.
-
-Platform Engineering is a more recent concept, building on the foundation of SRE engineering. The precise origins of Platform Engineering are less clear, but it is generally understood to be an extension of the DevOps and SRE practices, with a focus on delivering a comprehensive platform for product development that supports the entire business perspective.
-
-It's worth noting that while these concepts emerged at different times. They are all related to the broader trend of improving collaboration, automation, and efficiency in software development and operations.
-
-### What is k8s (Kubernetes)?
-
-K8s is a container orchestration system. It is used for container deployment and management. Its design is greatly impacted by Google’s internal system Borg.
-
-
-  -
-
-
-A k8s cluster consists of a set of worker machines, called nodes, that run containerized applications. Every cluster has at least one worker node.
-
-The worker node(s) host the Pods that are the components of the application workload. The control plane manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers, and a cluster usually runs multiple nodes, providing fault tolerance and high availability.
-
-- Control Plane Components
-
-1. API Server
-
- The API server talks to all the components in the k8s cluster. All the operations on pods are executed by talking to the API server.
-
-2. Scheduler
-
- The scheduler watches pod workloads and assigns loads on newly created pods.
-
-3. Controller Manager
-
- The controller manager runs the controllers, including Node Controller, Job Controller, EndpointSlice Controller, and ServiceAccount Controller.
-
-4. Etcd
-
- etcd is a key-value store used as Kubernetes' backing store for all cluster data.
-
-- Nodes
-
-1. Pods
-
- A pod is a group of containers and is the smallest unit that k8s administers. Pods have a single IP address applied to every container within the pod.
-
-2. Kubelet
-
- An agent that runs on each node in the cluster. It ensures containers are running in a Pod.
-
-3. Kube Proxy
-
- Kube-proxy is a network proxy that runs on each node in your cluster. It routes traffic coming into a node from the service. It forwards requests for work to the correct containers.
-
-### Docker vs. Kubernetes. Which one should we use?
-
-
-  -
-
-
-
-What is Docker ?
-
-Docker is an open-source platform that allows you to package, distribute, and run applications in isolated containers. It focuses on containerization, providing lightweight environments that encapsulate applications and their dependencies.
-
-What is Kubernetes ?
-
-Kubernetes, often referred to as K8s, is an open-source container orchestration platform. It provides a framework for automating the deployment, scaling, and management of containerized applications across a cluster of nodes.
-
-How are both different from each other ?
-
-Docker: Docker operates at the individual container level on a single operating system host.
-
-You must manually manage each host and setting up networks, security policies, and storage for multiple related containers can be complex.
-
-Kubernetes: Kubernetes operates at the cluster level. It manages multiple containerized applications across multiple hosts, providing automation for tasks like load balancing, scaling, and ensuring the desired state of applications.
-
-In short, Docker focuses on containerization and running containers on individual hosts, while Kubernetes specializes in managing and orchestrating containers at scale across a cluster of hosts.
-
-### How does Docker work?
-
-The diagram below shows the architecture of Docker and how it works when we run “docker build”, “docker pull”
-and “docker run”.
-
-
-  -
-
-
-There are 3 components in Docker architecture:
-
-- Docker client
-
- The docker client talks to the Docker daemon.
-
-- Docker host
-
- The Docker daemon listens for Docker API requests and manages Docker objects such as images, containers, networks, and volumes.
-
-- Docker registry
-
- A Docker registry stores Docker images. Docker Hub is a public registry that anyone can use.
-
-Let’s take the “docker run” command as an example.
-
- 1. Docker pulls the image from the registry.
- 1. Docker creates a new container.
- 1. Docker allocates a read-write filesystem to the container.
- 1. Docker creates a network interface to connect the container to the default network.
- 1. Docker starts the container.
-
-## GIT
-
-### How Git Commands work
-
-To begin with, it's essential to identify where our code is stored. The common assumption is that there are only two locations - one on a remote server like Github and the other on our local machine. However, this isn't entirely accurate. Git maintains three local storages on our machine, which means that our code can be found in four places:
-
-
-  -
-
-
-
-- Working directory: where we edit files
-- Staging area: a temporary location where files are kept for the next commit
-- Local repository: contains the code that has been committed
-- Remote repository: the remote server that stores the code
-
-Most Git commands primarily move files between these four locations.
-
-### How does Git Work?
-
-The diagram below shows the Git workflow.
-
-
-  -
-
-
-
-Git is a distributed version control system.
-
-Every developer maintains a local copy of the main repository and edits and commits to the local copy.
-
-The commit is very fast because the operation doesn’t interact with the remote repository.
-
-If the remote repository crashes, the files can be recovered from the local repositories.
-
-### Git merge vs. Git rebase
-
-What are the differences?
-
-
-  -
-
-
-
-When we **merge changes** from one Git branch to another, we can use ‘git merge’ or ‘git rebase’. The diagram below shows how the two commands work.
-
-**Git merge**
-
-This creates a new commit G’ in the main branch. G’ ties the histories of both main and feature branches.
-
-Git merge is **non-destructive**. Neither the main nor the feature branch is changed.
-
-**Git rebase**
-
-Git rebase moves the feature branch histories to the head of the main branch. It creates new commits E’, F’, and G’ for each commit in the feature branch.
-
-The benefit of rebase is that it has a linear **commit history**.
-
-Rebase can be dangerous if “the golden rule of git rebase” is not followed.
-
-**The Golden Rule of Git Rebase**
-
-Never use it on public branches!
-
-## Cloud Services
-
-### A nice cheat sheet of different cloud services (2023 edition)
-
-
-  -
-
-
-
-### What is cloud native?
-
-Below is a diagram showing the evolution of architecture and processes since the 1980s.
-
-
-  -
-
-
-Organizations can build and run scalable applications on public, private, and hybrid clouds using cloud native technologies.
-
-This means the applications are designed to leverage cloud features, so they are resilient to load and easy to scale.
-
-Cloud native includes 4 aspects:
-
-1. Development process
-
- This has progressed from waterfall to agile to DevOps.
-
-2. Application Architecture
-
- The architecture has gone from monolithic to microservices. Each service is designed to be small, adaptive to the limited resources in cloud containers.
-
-3. Deployment & packaging
-
- The applications used to be deployed on physical servers. Then around 2000, the applications that were not sensitive to latency were usually deployed on virtual servers. With cloud native applications, they are packaged into docker images and deployed in containers.
-
-4. Application infrastructure
-
- The applications are massively deployed on cloud infrastructure instead of self-hosted servers.
-
-## Developer productivity tools
-
-### Visualize JSON files
-
-Nested JSON files are hard to read.
-
-**JsonCrack** generates graph diagrams from JSON files and makes them easy to read.
-
-Additionally, the generated diagrams can be downloaded as images.
-
-
-  -
-
-
-
-### Automatically turn code into architecture diagrams
-
-
-  -
-
-
-
-What does it do?
-
-- Draw the cloud system architecture in Python code.
-- Diagrams can also be rendered directly inside the Jupyter Notebooks.
-- No design tools are needed.
-- Supports the following providers: AWS, Azure, GCP, Kubernetes, Alibaba Cloud, Oracle Cloud, etc.
-
-[Github repo](https://github.com/mingrammer/diagrams)
-
-## Linux
-
-### Linux file system explained
-
-
-  -
-
-
-The Linux file system used to resemble an unorganized town where individuals constructed their houses wherever they pleased. However, in 1994, the Filesystem Hierarchy Standard (FHS) was introduced to bring order to the Linux file system.
-
-By implementing a standard like the FHS, software can ensure a consistent layout across various Linux distributions. Nonetheless, not all Linux distributions strictly adhere to this standard. They often incorporate their own unique elements or cater to specific requirements.
-To become proficient in this standard, you can begin by exploring. Utilize commands such as "cd" for navigation and "ls" for listing directory contents. Imagine the file system as a tree, starting from the root (/). With time, it will become second nature to you, transforming you into a skilled Linux administrator.
-
-### 18 Most-used Linux Commands You Should Know
-
-Linux commands are instructions for interacting with the operating system. They help manage files, directories, system processes, and many other aspects of the system. You need to become familiar with these commands in order to navigate and maintain Linux-based systems efficiently and effectively.
-
-This diagram below shows popular Linux commands:
-
-
-  -
-
-
-
-- ls - List files and directories
-- cd - Change the current directory
-- mkdir - Create a new directory
-- rm - Remove files or directories
-- cp - Copy files or directories
-- mv - Move or rename files or directories
-- chmod - Change file or directory permissions
-- grep - Search for a pattern in files
-- find - Search for files and directories
-- tar - manipulate tarball archive files
-- vi - Edit files using text editors
-- cat - display the content of files
-- top - Display processes and resource usage
-- ps - Display processes information
-- kill - Terminate a process by sending a signal
-- du - Estimate file space usage
-- ifconfig - Configure network interfaces
-- ping - Test network connectivity between hosts
-
-## Security
-
-### How does HTTPS work?
-
-Hypertext Transfer Protocol Secure (HTTPS) is an extension of the Hypertext Transfer Protocol (HTTP.) HTTPS transmits encrypted data using Transport Layer Security (TLS.) If the data is hijacked online, all the hijacker gets is binary code.
-
-
-  -
-
-
-
-How is the data encrypted and decrypted?
-
-Step 1 - The client (browser) and the server establish a TCP connection.
-
-Step 2 - The client sends a “client hello” to the server. The message contains a set of necessary encryption algorithms (cipher suites) and the latest TLS version it can support. The server responds with a “server hello” so the browser knows whether it can support the algorithms and TLS version.
-
-The server then sends the SSL certificate to the client. The certificate contains the public key, host name, expiry dates, etc. The client validates the certificate.
-
-Step 3 - After validating the SSL certificate, the client generates a session key and encrypts it using the public key. The server receives the encrypted session key and decrypts it with the private key.
-
-Step 4 - Now that both the client and the server hold the same session key (symmetric encryption), the encrypted data is transmitted in a secure bi-directional channel.
-
-Why does HTTPS switch to symmetric encryption during data transmission? There are two main reasons:
-
-1. Security: The asymmetric encryption goes only one way. This means that if the server tries to send the encrypted data back to the client, anyone can decrypt the data using the public key.
-
-2. Server resources: The asymmetric encryption adds quite a lot of mathematical overhead. It is not suitable for data transmissions in long sessions.
-
-### Oauth 2.0 Explained With Simple Terms.
-
-OAuth 2.0 is a powerful and secure framework that allows different applications to securely interact with each other on behalf of users without sharing sensitive credentials.
-
-
-  -
-
-
-The entities involved in OAuth are the User, the Server, and the Identity Provider (IDP).
-
-What Can an OAuth Token Do?
-
-When you use OAuth, you get an OAuth token that represents your identity and permissions. This token can do a few important things:
-
-Single Sign-On (SSO): With an OAuth token, you can log into multiple services or apps using just one login, making life easier and safer.
-
-Authorization Across Systems: The OAuth token allows you to share your authorization or access rights across various systems, so you don't have to log in separately everywhere.
-
-Accessing User Profile: Apps with an OAuth token can access certain parts of your user profile that you allow, but they won't see everything.
-
-Remember, OAuth 2.0 is all about keeping you and your data safe while making your online experiences seamless and hassle-free across different applications and services.
-
-### Top 4 Forms of Authentication Mechanisms
-
-
-  -
-
-
-1. SSH Keys:
-
- Cryptographic keys are used to access remote systems and servers securely
-
-1. OAuth Tokens:
-
- Tokens that provide limited access to user data on third-party applications
-
-1. SSL Certificates:
-
- Digital certificates ensure secure and encrypted communication between servers and clients
-
-1. Credentials:
-
- User authentication information is used to verify and grant access to various systems and services
-
-### Session, cookie, JWT, token, SSO, and OAuth 2.0 - what are they?
-
-These terms are all related to user identity management. When you log into a website, you declare who you are (identification). Your identity is verified (authentication), and you are granted the necessary permissions (authorization). Many solutions have been proposed in the past, and the list keeps growing.
-
-
-  -
-
-
-From simple to complex, here is my understanding of user identity management:
-
-- WWW-Authenticate is the most basic method. You are asked for the username and password by the browser. As a result of the inability to control the login life cycle, it is seldom used today.
-
-- A finer control over the login life cycle is session-cookie. The server maintains session storage, and the browser keeps the ID of the session. A cookie usually only works with browsers and is not mobile app friendly.
-
-- To address the compatibility issue, the token can be used. The client sends the token to the server, and the server validates the token. The downside is that the token needs to be encrypted and decrypted, which may be time-consuming.
-
-- JWT is a standard way of representing tokens. This information can be verified and trusted because it is digitally signed. Since JWT contains the signature, there is no need to save session information on the server side.
-
-- By using SSO (single sign-on), you can sign on only once and log in to multiple websites. It uses CAS (central authentication service) to maintain cross-site information.
-
-- By using OAuth 2.0, you can authorize one website to access your information on another website.
-
-### How to store passwords safely in the database and how to validate a password?
-
-
-  -
-
-
-
-**Things NOT to do**
-
-- Storing passwords in plain text is not a good idea because anyone with internal access can see them.
-
-- Storing password hashes directly is not sufficient because it is pruned to precomputation attacks, such as rainbow tables.
-
-- To mitigate precomputation attacks, we salt the passwords.
-
-**What is salt?**
-
-According to OWASP guidelines, “a salt is a unique, randomly generated string that is added to each password as part of the hashing process”.
-
-**How to store a password and salt?**
-
-1. the hash result is unique to each password.
-1. The password can be stored in the database using the following format: hash(password + salt).
-
-**How to validate a password?**
-
-To validate a password, it can go through the following process:
-
-1. A client enters the password.
-1. The system fetches the corresponding salt from the database.
-1. The system appends the salt to the password and hashes it. Let’s call the hashed value H1.
-1. The system compares H1 and H2, where H2 is the hash stored in the database. If they are the same, the password is valid.
-
-### Explaining JSON Web Token (JWT) to a 10 year old Kid
-
-
-  -
-
-
-Imagine you have a special box called a JWT. Inside this box, there are three parts: a header, a payload, and a signature.
-
-The header is like the label on the outside of the box. It tells us what type of box it is and how it's secured. It's usually written in a format called JSON, which is just a way to organize information using curly braces { } and colons : .
-
-The payload is like the actual message or information you want to send. It could be your name, age, or any other data you want to share. It's also written in JSON format, so it's easy to understand and work with.
-Now, the signature is what makes the JWT secure. It's like a special seal that only the sender knows how to create. The signature is created using a secret code, kind of like a password. This signature ensures that nobody can tamper with the contents of the JWT without the sender knowing about it.
-
-When you want to send the JWT to a server, you put the header, payload, and signature inside the box. Then you send it over to the server. The server can easily read the header and payload to understand who you are and what you want to do.
-
-### How does Google Authenticator (or other types of 2-factor authenticators) work?
-
-Google Authenticator is commonly used for logging into our accounts when 2-factor authentication is enabled. How does it guarantee security?
-
-Google Authenticator is a software-based authenticator that implements a two-step verification service. The diagram below provides detail.
-
-
-  -
-
-
-
-There are two stages involved:
-
-- Stage 1 - The user enables Google two-step verification.
-- Stage 2 - The user uses the authenticator for logging in, etc.
-
-Let’s look at these stages.
-
-**Stage 1**
-
-Steps 1 and 2: Bob opens the web page to enable two-step verification. The front end requests a secret key. The authentication service generates the secret key for Bob and stores it in the database.
-
-Step 3: The authentication service returns a URI to the front end. The URI is composed of a key issuer, username, and secret key. The URI is displayed in the form of a QR code on the web page.
-
-Step 4: Bob then uses Google Authenticator to scan the generated QR code. The secret key is stored in the authenticator.
-
-**Stage 2**
-Steps 1 and 2: Bob wants to log into a website with Google two-step verification. For this, he needs the password. Every 30 seconds, Google Authenticator generates a 6-digit password using TOTP (Time-based One Time Password) algorithm. Bob uses the password to enter the website.
-
-Steps 3 and 4: The frontend sends the password Bob enters to the backend for authentication. The authentication service reads the secret key from the database and generates a 6-digit password using the same TOTP algorithm as the client.
-
-Step 5: The authentication service compares the two passwords generated by the client and the server, and returns the comparison result to the frontend. Bob can proceed with the login process only if the two passwords match.
-
-Is this authentication mechanism safe?
-
-- Can the secret key be obtained by others?
-
- We need to make sure the secret key is transmitted using HTTPS. The authenticator client and the database store the secret key, and we need to make sure the secret keys are encrypted.
-
-- Can the 6-digit password be guessed by hackers?
-
- No. The password has 6 digits, so the generated password has 1 million potential combinations. Plus, the password changes every 30 seconds. If hackers want to guess the password in 30 seconds, they need to enter 30,000 combinations per second.
-
-
-## Real World Case Studies
-
-### Netflix's Tech Stack
-
-This post is based on research from many Netflix engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us.
-
-
-  -
-
-
-**Mobile and web**: Netflix has adopted Swift and Kotlin to build native mobile apps. For its web application, it uses React.
-
-**Frontend/server communication**: Netflix uses GraphQL.
-
-**Backend services**: Netflix relies on ZUUL, Eureka, the Spring Boot framework, and other technologies.
-
-**Databases**: Netflix utilizes EV cache, Cassandra, CockroachDB, and other databases.
-
-**Messaging/streaming**: Netflix employs Apache Kafka and Fink for messaging and streaming purposes.
-
-**Video storage**: Netflix uses S3 and Open Connect for video storage.
-
-**Data processing**: Netflix utilizes Flink and Spark for data processing, which is then visualized using Tableau. Redshift is used for processing structured data warehouse information.
-
-**CI/CD**: Netflix employs various tools such as JIRA, Confluence, PagerDuty, Jenkins, Gradle, Chaos Monkey, Spinnaker, Atlas, and more for CI/CD processes.
-
-### Twitter Architecture 2022
-
-Yes, this is the real Twitter architecture. It is posted by Elon Musk and redrawn by us for better readability.
-
-
-  -
-
-
-
-### Evolution of Airbnb’s microservice architecture over the past 15 years
-
-Airbnb’s microservice architecture went through 3 main stages.
-
-
-  -
-
-
-
-Monolith (2008 - 2017)
-
-Airbnb began as a simple marketplace for hosts and guests. This is built in a Ruby on Rails application - the monolith.
-
-What’s the challenge?
-
-- Confusing team ownership + unowned code
-- Slow deployment
-
-Microservices (2017 - 2020)
-
-Microservice aims to solve those challenges. In the microservice architecture, key services include:
-
-- Data fetching service
-- Business logic data service
-- Write workflow service
-- UI aggregation service
-- Each service had one owning team
-
-What’s the challenge?
-
-Hundreds of services and dependencies were difficult for humans to manage.
-
-Micro + macroservices (2020 - present)
-
-This is what Airbnb is working on now. The micro and macroservice hybrid model focuses on the unification of APIs.
-
-### Monorepo vs. Microrepo.
-
-Which is the best? Why do different companies choose different options?
-
-
-  -
-
-
-
-Monorepo isn't new; Linux and Windows were both created using Monorepo. To improve scalability and build speed, Google developed its internal dedicated toolchain to scale it faster and strict coding quality standards to keep it consistent.
-
-Amazon and Netflix are major ambassadors of the Microservice philosophy. This approach naturally separates the service code into separate repositories. It scales faster but can lead to governance pain points later on.
-
-Within Monorepo, each service is a folder, and every folder has a BUILD config and OWNERS permission control. Every service member is responsible for their own folder.
-
-On the other hand, in Microrepo, each service is responsible for its repository, with the build config and permissions typically set for the entire repository.
-
-In Monorepo, dependencies are shared across the entire codebase regardless of your business, so when there's a version upgrade, every codebase upgrades their version.
-
-In Microrepo, dependencies are controlled within each repository. Businesses choose when to upgrade their versions based on their own schedules.
-
-Monorepo has a standard for check-ins. Google's code review process is famously known for setting a high bar, ensuring a coherent quality standard for Monorepo, regardless of the business.
-
-Microrepo can either set its own standard or adopt a shared standard by incorporating the best practices. It can scale faster for business, but the code quality might be a bit different.
-Google engineers built Bazel, and Meta built Buck. There are other open-source tools available, including Nx, Lerna, and others.
-
-Over the years, Microrepo has had more supported tools, including Maven and Gradle for Java, NPM for NodeJS, and CMake for C/C++, among others.
-
-### How will you design the Stack Overflow website?
-
-If your answer is on-premise servers and monolith (on the bottom of the following image), you would likely fail the interview, but that's how it is built in reality!
-
-
-  -
-
-
-
-**What people think it should look like**
-
-The interviewer is probably expecting something like the top portion of the picture.
-
-- Microservice is used to decompose the system into small components.
-- Each service has its own database. Use cache heavily.
-- The service is sharded.
-- The services talk to each other asynchronously through message queues.
-- The service is implemented using Event Sourcing with CQRS.
-- Showing off knowledge in distributed systems such as eventual consistency, CAP theorem, etc.
-
-**What it actually is**
-
-Stack Overflow serves all the traffic with only 9 on-premise web servers, and it’s on monolith! It has its own servers and does not run on the cloud.
-
-This is contrary to all our popular beliefs these days.
-
-### Why did Amazon Prime Video monitoring move from serverless to monolithic? How can it save 90% cost?
-
-The diagram below shows the architecture comparison before and after the migration.
-
-
-  -
-
-
-
-What is Amazon Prime Video Monitoring Service?
-
-Prime Video service needs to monitor the quality of thousands of live streams. The monitoring tool automatically analyzes the streams in real time and identifies quality issues like block corruption, video freeze, and sync problems. This is an important process for customer satisfaction.
-
-There are 3 steps: media converter, defect detector, and real-time notification.
-
-- What is the problem with the old architecture?
-
- The old architecture was based on Amazon Lambda, which was good for building services quickly. However, it was not cost-effective when running the architecture at a high scale. The two most expensive operations are:
-
-1. The orchestration workflow - AWS step functions charge users by state transitions and the orchestration performs multiple state transitions every second.
-
-2. Data passing between distributed components - the intermediate data is stored in Amazon S3 so that the next stage can download. The download can be costly when the volume is high.
-
-- Monolithic architecture saves 90% cost
-
- A monolithic architecture is designed to address the cost issues. There are still 3 components, but the media converter and defect detector are deployed in the same process, saving the cost of passing data over the network. Surprisingly, this approach to deployment architecture change led to 90% cost savings!
-
-This is an interesting and unique case study because microservices have become a go-to and fashionable choice in the tech industry. It's good to see that we are having more discussions about evolving the architecture and having more honest discussions about its pros and cons. Decomposing components into distributed microservices comes with a cost.
-
-- What did Amazon leaders say about this?
-
- Amazon CTO Werner Vogels: “Building **evolvable software systems** is a strategy, not a religion. And revisiting your architecture with an open mind is a must.”
-
-Ex Amazon VP Sustainability Adrian Cockcroft: “The Prime Video team had followed a path I call **Serverless First**…I don’t advocate **Serverless Only**”.
-
-### How does Disney Hotstar capture 5 Billion Emojis during a tournament?
-
-
-  -
-
-
-
-1. Clients send emojis through standard HTTP requests. You can think of Golang Service as a typical Web Server. Golang is chosen because it supports concurrency well. Threads in Golang are lightweight.
-
-2. Since the write volume is very high, Kafka (message queue) is used as a buffer.
-
-3. Emoji data are aggregated by a streaming processing service called Spark. It aggregates data every 2 seconds, which is configurable. There is a trade-off to be made based on the interval. A shorter interval means emojis are delivered to other clients faster but it also means more computing resources are needed.
-
-4. Aggregated data is written to another Kafka.
-
-5. The PubSub consumers pull aggregated emoji data from Kafka.
-
-6. Emojis are delivered to other clients in real-time through the PubSub infrastructure. The PubSub infrastructure is interesting. Hotstar considered the following protocols: Socketio, NATS, MQTT, and gRPC, and settled with MQTT.
-
-A similar design is adopted by LinkedIn which streams a million likes/sec.
-
-### How Discord Stores Trillions Of Messages
-
-The diagram below shows the evolution of message storage at Discord:
-
-
-  -
-
-
-
-MongoDB ➡️ Cassandra ➡️ ScyllaDB
-
-In 2015, the first version of Discord was built on top of a single MongoDB replica. Around Nov 2015, MongoDB stored 100 million messages and the RAM couldn’t hold the data and index any longer. The latency became unpredictable. Message storage needs to be moved to another database. Cassandra was chosen.
-
-In 2017, Discord had 12 Cassandra nodes and stored billions of messages.
-
-At the beginning of 2022, it had 177 nodes with trillions of messages. At this point, latency was unpredictable, and maintenance operations became too expensive to run.
-
-There are several reasons for the issue:
-
-- Cassandra uses the LSM tree for the internal data structure. The reads are more expensive than the writes. There can be many concurrent reads on a server with hundreds of users, resulting in hotspots.
-- Maintaining clusters, such as compacting SSTables, impacts performance.
-- Garbage collection pauses would cause significant latency spikes
-
-ScyllaDB is Cassandra compatible database written in C++. Discord redesigned its architecture to have a monolithic API, a data service written in Rust, and ScyllaDB-based storage.
-
-The p99 read latency in ScyllaDB is 15ms compared to 40-125ms in Cassandra. The p99 write latency is 5ms compared to 5-70ms in Cassandra.
-
-### How do video live streamings work on YouTube, TikTok live, or Twitch?
-
-Live streaming differs from regular streaming because the video content is sent via the internet in real-time, usually with a latency of just a few seconds.
-
-The diagram below explains what happens behind the scenes to make this possible.
-
-
-  -
-
-
-
-Step 1: The raw video data is captured by a microphone and camera. The data is sent to the server side.
-
-Step 2: The video data is compressed and encoded. For example, the compressing algorithm separates the background and other video elements. After compression, the video is encoded to standards such as H.264. The size of the video data is much smaller after this step.
-
-Step 3: The encoded data is divided into smaller segments, usually seconds in length, so it takes much less time to download or stream.
-
-Step 4: The segmented data is sent to the streaming server. The streaming server needs to support different devices and network conditions. This is called ‘Adaptive Bitrate Streaming.’ This means we need to produce multiple files at different bitrates in steps 2 and 3.
-
-Step 5: The live streaming data is pushed to edge servers supported by CDN (Content Delivery Network.) Millions of viewers can watch the video from an edge server nearby. CDN significantly lowers data transmission latency.
-
-Step 6: The viewers’ devices decode and decompress the video data and play the video in a video player.
-
-Steps 7 and 8: If the video needs to be stored for replay, the encoded data is sent to a storage server, and viewers can request a replay from it later.
-
-Standard protocols for live streaming include:
-
-- RTMP (Real-Time Messaging Protocol): This was originally developed by Macromedia to transmit data between a Flash player and a server. Now it is used for streaming video data over the internet. Note that video conferencing applications like Skype use RTC (Real-Time Communication) protocol for lower latency.
-- HLS (HTTP Live Streaming): It requires the H.264 or H.265 encoding. Apple devices accept only HLS format.
-- DASH (Dynamic Adaptive Streaming over HTTP): DASH does not support Apple devices.
-- Both HLS and DASH support adaptive bitrate streaming.
-
## License
This work is licensed under CC BY-NC-ND 4.0



diff --git a/data/categories/ai-machine-learning.md b/data/categories/ai-machine-learning.md
new file mode 100644
index 0000000..debf70c
--- /dev/null
+++ b/data/categories/ai-machine-learning.md
@@ -0,0 +1,9 @@
+---
+title: 'AI and Machine Learning'
+description: 'Learn the basics of AI and Machine Learning, how they work, and some real-world applications with visual illustrations.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/brain.png'
+sort: 120
+---
+
+AI and Machine Learning are two of the most popular technologies in the tech industry. They are used in various applications such as recommendation systems, image recognition, natural language processing, and more. In this guide, we will explore the basics of AI and Machine Learning, how they work, and some real-world applications.
\ No newline at end of file
diff --git a/data/categories/api-web-development.md b/data/categories/api-web-development.md
new file mode 100644
index 0000000..4b0e3bc
--- /dev/null
+++ b/data/categories/api-web-development.md
@@ -0,0 +1,11 @@
+---
+title: 'API and Web Development'
+description: 'Learn how APIs enable web development by providing standardized protocols for data exchange between different parts of web applications.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/api.png'
+sort: 100
+---
+
+Web development involves building websites and applications by combining frontend UI, backend logic, and databases. APIs are the fundamental building blocks that enable these components to communicate effectively.
+
+APIs provide standardized protocols for data exchange between different parts of web applications. Using technologies like REST and GraphQL, APIs allow integration of services, database operations, and interactive features while keeping system components cleanly separated.
diff --git a/data/categories/caching-performance.md b/data/categories/caching-performance.md
new file mode 100644
index 0000000..a91157c
--- /dev/null
+++ b/data/categories/caching-performance.md
@@ -0,0 +1,9 @@
+---
+title: 'Caching & Performance'
+description: 'Learn to improve the performance of your system by caching data with these visual guides.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/order.png'
+sort: 150
+---
+
+Caching is a technique that stores a copy of a given resource and serves it back when requested. When a web server renders a web page, it stores the result of the page rendering in a cache. The next time the web page is requested, the server serves the cached page without re-rendering the page. This process reduces the time needed to generate the web page and reduces the load on the server.
\ No newline at end of file
diff --git a/data/categories/cloud-distributed-systems.md b/data/categories/cloud-distributed-systems.md
new file mode 100644
index 0000000..fccc2b1
--- /dev/null
+++ b/data/categories/cloud-distributed-systems.md
@@ -0,0 +1,9 @@
+---
+title: 'Cloud & Distributed Systems'
+description: 'Learn the fundamental concepts, best practices, and real-world examples of cloud computing and distributed systems.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/cloud.png'
+sort: 180
+---
+
+Cloud computing and distributed systems are the backbone of modern software architecture. They enable us to build scalable, reliable, and high-performance systems. This category covers the fundamental concepts, best practices, and real-world examples of cloud computing and distributed systems.
\ No newline at end of file
diff --git a/data/categories/computer-fundamentals.md b/data/categories/computer-fundamentals.md
new file mode 100644
index 0000000..eb5a75c
--- /dev/null
+++ b/data/categories/computer-fundamentals.md
@@ -0,0 +1,9 @@
+---
+title: 'Computer Fundamentals'
+description: 'Understanding computer fundamentals is essential for software engineers. These guides cover the topics that are fundamental to computer science and software engineering and will help you understand certain system design aspects better.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/laptop.png'
+sort: 220
+---
+
+Understanding computer fundamentals is essential for software engineers. These guides cover the topics that are fundamental to computer science and software engineering and will help you understand certain system design aspects better.
\ No newline at end of file
diff --git a/data/categories/database-and-storage.md b/data/categories/database-and-storage.md
new file mode 100644
index 0000000..d05a6c6
--- /dev/null
+++ b/data/categories/database-and-storage.md
@@ -0,0 +1,9 @@
+---
+title: 'Database and Storage'
+description: 'Understand the different types of databases and storage solutions and how to choose the right one for your application.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/database.png'
+sort: 130
+---
+
+Databases are the backbone of most modern applications since they store and manage the data that powers the application. There are many types of databases, including relational databases, NoSQL databases, in-memory databases, and key-value stores. Each type of database has its own strengths and weaknesses, and the best choice depends on the specific requirements of the application.
\ No newline at end of file
diff --git a/data/categories/devops-cicd.md b/data/categories/devops-cicd.md
new file mode 100644
index 0000000..680c63d
--- /dev/null
+++ b/data/categories/devops-cicd.md
@@ -0,0 +1,11 @@
+---
+title: 'DevOps and CI/CD'
+description: 'Learn all about DevOps, CI/CD, and how they can help you deliver software faster and more reliably. Understand the best practices and tools to implement DevOps and CI/CD in your organization.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/refresh.png'
+sort: 200
+---
+
+DevOps is a set of practices that combines software development (Dev) and IT operations (Ops). It aims to shorten the systems development life cycle and provide continuous delivery with high software quality. DevOps is complementary with Agile software development; several DevOps aspects came from Agile methodology.
+
+CI/CD stands for Continuous Integration and Continuous Delivery. CI/CD is a method to frequently deliver apps to customers by introducing automation into the stages of app development. The main concepts attributed to CI/CD are continuous integration, continuous delivery, and continuous deployment.
\ No newline at end of file
diff --git a/data/categories/devtools-productivity.md b/data/categories/devtools-productivity.md
new file mode 100644
index 0000000..09e11a2
--- /dev/null
+++ b/data/categories/devtools-productivity.md
@@ -0,0 +1,9 @@
+---
+title: 'DevTools & Productivity'
+description: 'Guides on developer tools and productivity techniques to help you become more efficient in your daily work.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/supplement-bottle.png'
+sort: 170
+---
+
+Developer and productivity tools are essential for software engineers to build, test, and deploy software. This collection of guides covers a wide range of tools and techniques to help you become more productive and efficient in your daily work.
\ No newline at end of file
diff --git a/data/categories/how-it-works.md b/data/categories/how-it-works.md
new file mode 100644
index 0000000..3da2ab6
--- /dev/null
+++ b/data/categories/how-it-works.md
@@ -0,0 +1,9 @@
+---
+title: 'How it Works?'
+description: 'Go deep into the internals of how things work with these visual guides ranging from OAuth2 to how the internet works.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/question-mark.png'
+sort: 190
+---
+
+Learning how things work is a great way to understand the world around us. This collection of guides will help you understand how things work in the world of system design.
diff --git a/data/categories/payment-and-fintech.md b/data/categories/payment-and-fintech.md
new file mode 100644
index 0000000..e3a73e0
--- /dev/null
+++ b/data/categories/payment-and-fintech.md
@@ -0,0 +1,9 @@
+---
+title: 'Payment and Fintech'
+description: 'Explore the architecture of a payment system and a fintech system. Look at the real-world examples of payment systems like PayPal, Stripe, and Square.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/medal.png'
+sort: 160
+---
+
+Payment and Fintech are two of the most popular categories in system design interviews. In these guides, we will explore the architecture of a payment system and a fintech system.
diff --git a/data/categories/real-world-case-studies.md b/data/categories/real-world-case-studies.md
new file mode 100644
index 0000000..b636ef7
--- /dev/null
+++ b/data/categories/real-world-case-studies.md
@@ -0,0 +1,9 @@
+---
+title: 'Real World Case Studies'
+description: 'Understand how popular tech companies have evolved over the years. Dive into case studies of companies like Twitter, Netflix, Uber and more.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/earth-planet.png'
+sort: 110
+---
+
+Real-world case studies are a great way to learn about the architecture, design, and scalability of popular tech companies. Dive into these case studies to understand how companies like Twitter, Netflix, Uber and more have evolved over the years.
\ No newline at end of file
diff --git a/data/categories/security.md b/data/categories/security.md
new file mode 100644
index 0000000..0d8b283
--- /dev/null
+++ b/data/categories/security.md
@@ -0,0 +1,9 @@
+---
+title: 'Security'
+description: 'Guides on security concepts and best practices for system design. Learn how to protect your system from unauthorized access, data breaches, and other security threats.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/lock.png'
+sort: 210
+---
+
+Security is a critical aspect of system design. It is essential to protect the system from unauthorized access, data breaches, and other security threats. In this set of guides, we will explore some of the key security concepts and best practices that you should consider when designing a system.
\ No newline at end of file
diff --git a/data/categories/software-architecture.md b/data/categories/software-architecture.md
new file mode 100644
index 0000000..3390e26
--- /dev/null
+++ b/data/categories/software-architecture.md
@@ -0,0 +1,9 @@
+---
+title: 'Software Architecture'
+description: 'Learn about software architecture, the process of converting software characteristics such as flexibility, scalability, feasibility, reusability, and security into a structured solution that meets the technical and the business expectations.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/image.png'
+sort: 160
+---
+
+Software architecture is the process of converting software characteristics such as flexibility, scalability, feasibility, reusability, and security into a structured solution that meets the technical and the business expectations. It is the process of defining a structured solution that meets all the technical and operational requirements, while optimizing common quality attributes such as performance, security, and manageability.
\ No newline at end of file
diff --git a/data/categories/software-development.md b/data/categories/software-development.md
new file mode 100644
index 0000000..b28ba6c
--- /dev/null
+++ b/data/categories/software-development.md
@@ -0,0 +1,9 @@
+---
+title: 'Software Development'
+description: 'Visual guides to help you understand different aspects of software development including but not limited to software architecture, design patterns, and software development methodologies.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/code.png'
+sort: 170
+---
+
+Software Development is the process of designing, coding, testing, and maintaining software. It is a systematic approach to developing software. Software development is a broad field that includes many different disciplines. Some of the most common disciplines in software development include:
\ No newline at end of file
diff --git a/data/categories/technical-interviews.md b/data/categories/technical-interviews.md
new file mode 100644
index 0000000..81d0a31
--- /dev/null
+++ b/data/categories/technical-interviews.md
@@ -0,0 +1,9 @@
+---
+title: 'Technical Interviews'
+description: 'Learn to ace technical interviews with coding challenges, system design questions, and interview tips.'
+image: 'https://github.com/ByteByteGoHq/system-design-101/raw/main/images/oAuth2.jpg'
+icon: '/icons/tower.png'
+sort: 140
+---
+
+Technical interviews are a critical part of the hiring process for software engineers. They are designed to test your problem-solving skills, coding abilities, and technical knowledge. In this category, you will find resources to help you prepare for technical interviews, including coding challenges, system design questions, and tips for acing the interview.
\ No newline at end of file
diff --git a/data/guides/10-books-for-software-developers.md b/data/guides/10-books-for-software-developers.md
new file mode 100644
index 0000000..e2c3231
--- /dev/null
+++ b/data/guides/10-books-for-software-developers.md
@@ -0,0 +1,44 @@
+---
+title: "10 Books for Software Developers"
+description: "A curated list of must-read books for software developers."
+image: "https://assets.bytebytego.com/diagrams/0023-10-books-every-software-engineer-should-read.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Software Development"
+ - "Books"
+---
+
+
+
+## General Advice
+
+* **The Pragmatic Programmer** by Andrew Hunt and David Thomas
+
+* **Code Complete** by Steve McConnell: Often considered a bible for software developers, this comprehensive book covers all aspects of software development, from design and coding to testing and maintenance.
+
+## Coding
+
+* **Clean Code** by Robert C. Martin
+
+* **Refactoring** by Martin Fowler
+
+## Software Architecture
+
+* **Designing Data-Intensive Applications** by Martin Kleppmann
+
+* **System Design Interview** (our own book :))
+
+## Design Patterns
+
+* **Design Patterns** by Eric Gamma and Others
+
+* **Domain-Driven Design** by Eric Evans
+
+## Data Structures and Algorithms
+
+* **Introduction to Algorithms** by Cormen, Leiserson, Rivest, and Stein
+
+* **Cracking the Coding Interview** by Gayle Laakmann McDowell
diff --git a/data/guides/10-essential-components-of-a-production-web-application.md b/data/guides/10-essential-components-of-a-production-web-application.md
new file mode 100644
index 0000000..0e1c067
--- /dev/null
+++ b/data/guides/10-essential-components-of-a-production-web-application.md
@@ -0,0 +1,25 @@
+---
+title: '10 Essential Components of a Production Web Application'
+description: 'Explore 10 key components for building robust web applications.'
+image: 'https://assets.bytebytego.com/diagrams/0395-typical-architecture-of-a-web-application.png'
+createdAt: '2024-02-20'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Web Architecture
+ - System Design
+---
+
+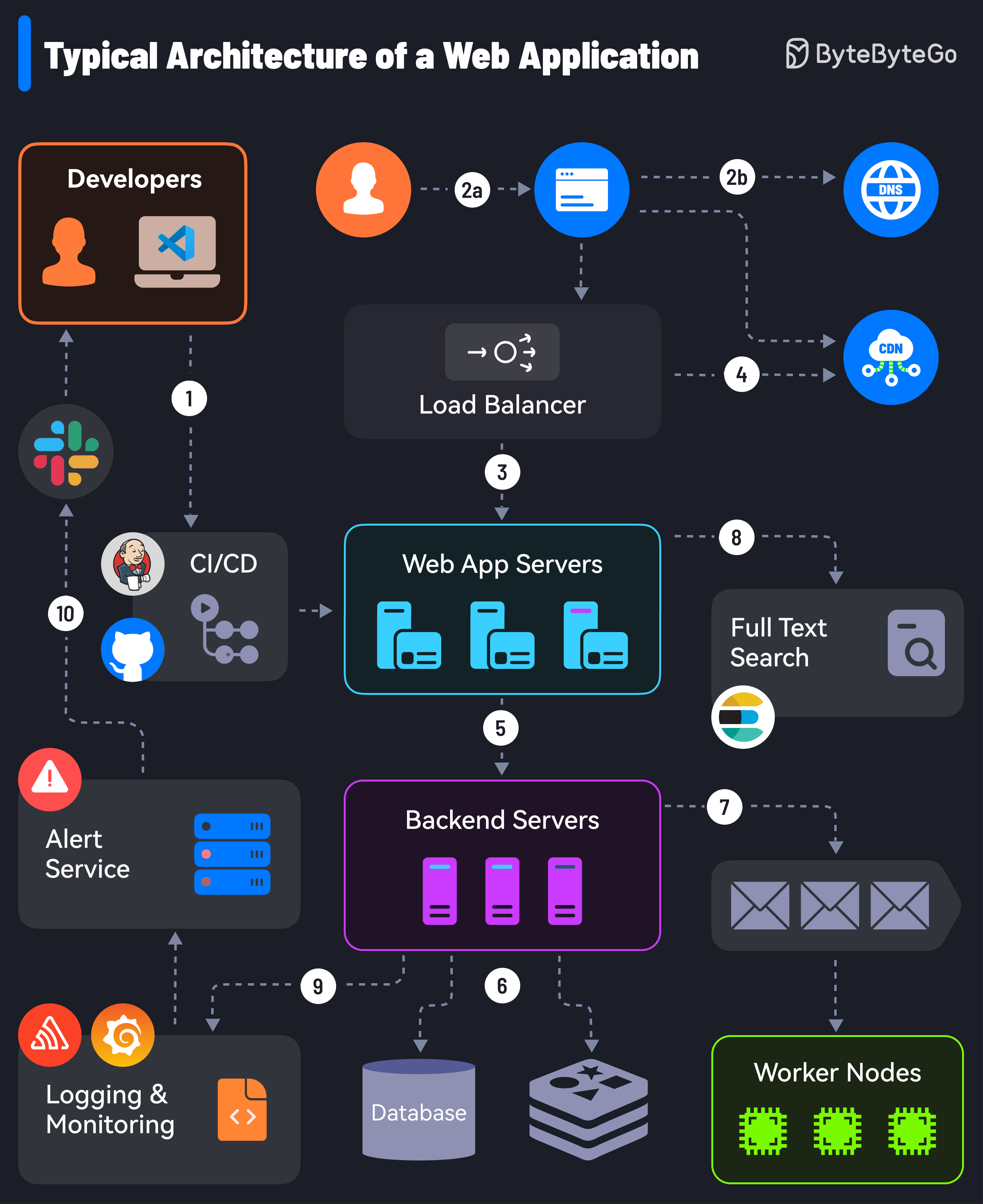
+
+1. It all starts with CI/CD pipelines that deploy code to the server instances. Tools like Jenkins and GitHub help over here.
+2. The user requests originate from the web browser. After DNS resolution, the requests reach the app servers.
+3. Load balancers and reverse proxies (such as Nginx & HAProxy) distribute user requests evenly across the web application servers.
+4. The requests can also be served by a Content Delivery Network (CDN).
+5. The web app communicates with backend services via APIs.
+6. The backend services interact with database servers or distributed caches to provide the data.
+7. Resource-intensive and long-running tasks are sent to job workers using a job queue.
+8. The full-text search service supports the search functionality. Tools like Elasticsearch and Apache Solr can help here.
+9. Monitoring tools (such as Sentry, Grafana, and Prometheus) store logs and help analyze data to ensure everything works fine.
+10. In case of issues, alerting services notify developers through platforms like Slack for quick resolution.
diff --git a/data/guides/10-good-coding-principles-to-improve-code-quality.md b/data/guides/10-good-coding-principles-to-improve-code-quality.md
new file mode 100644
index 0000000..74ea3f3
--- /dev/null
+++ b/data/guides/10-good-coding-principles-to-improve-code-quality.md
@@ -0,0 +1,56 @@
+---
+title: "10 Good Coding Principles to Improve Code Quality"
+description: "Improve code quality with these 10 essential coding principles."
+image: "https://assets.bytebytego.com/diagrams/0051-10-good-coding-principles.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - software-development
+tags:
+ - "coding practices"
+ - "software quality"
+---
+
+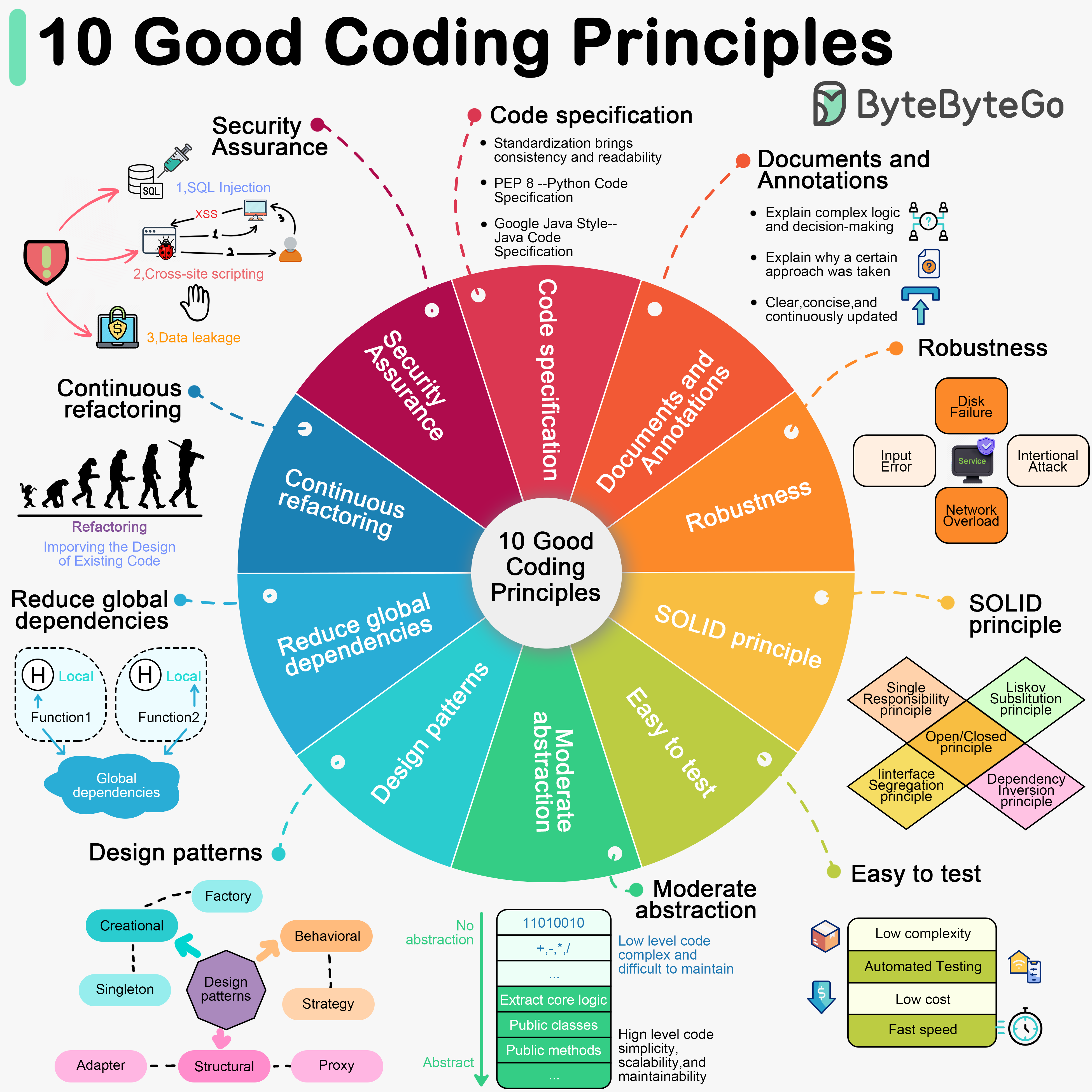
+
+Software development requires good system designs and coding standards. We list 10 good coding principles in the diagram below.
+
+## 1. Follow Code Specifications
+
+When we write code, it is important to follow the industry's well-established norms, like “PEP 8”, “Google Java Style”. Adhering to a set of agreed-upon code specifications ensures that the quality of the code is consistent and readable.
+
+## 2. Documentation and Comments
+
+Good code should be clearly documented and commented to explain complex logic and decisions. Comments should explain why a certain approach was taken (“Why”) rather than what exactly is being done (“What”). Documentation and comments should be clear, concise, and continuously updated.
+
+## 3. Robustness
+
+Good code should be able to handle a variety of unexpected situations and inputs without crashing or producing unpredictable results. Most common approach is to catch and handle exceptions.
+
+## 4. Follow the SOLID principle
+
+“Single Responsibility”, “Open/Closed”, “Liskov Substitution”, “Interface Segregation”, and “Dependency Inversion” - these five principles (SOLID for short) are the cornerstones of writing code that scales and is easy to maintain.
+
+## 5. Make Testing Easy
+
+Testability of software is particularly important. Good code should be easy to test, both by trying to reduce the complexity of each component, and by supporting automated testing to ensure that it behaves as expected.
+
+## 6. Abstraction
+
+Abstraction requires us to extract the core logic and hide the complexity, thus making the code more flexible and generic. Good code should have a moderate level of abstraction, neither over-designed nor neglecting long-term expandability and maintainability.
+
+## 7. Utilize Design Patterns, but don't over-design
+
+Design patterns can help us solve some common problems. However, every pattern has its applicable scenarios. Overusing or misusing design patterns may make your code more complex and difficult to understand.
+
+## 8. Reduce Global Dependencies
+
+We can get bogged down in dependencies and confusing state management if we use global variables and instances. Good code should rely on localized state and parameter passing. Functions should be side-effect free.
+
+## 9. Continuous Refactoring
+
+Good code is maintainable and extensible. Continuous refactoring reduces technical debt by identifying and fixing problems as early as possible.
+
+## 10. Security is a Top Priority
+
+Good code should avoid common security vulnerabilities.
diff --git a/data/guides/10-key-data-structures-we-use-every-day.md b/data/guides/10-key-data-structures-we-use-every-day.md
new file mode 100644
index 0000000..4407c10
--- /dev/null
+++ b/data/guides/10-key-data-structures-we-use-every-day.md
@@ -0,0 +1,38 @@
+---
+title: "10 Key Data Structures We Use Every Day"
+description: "Explore 10 essential data structures used daily in software development."
+image: "https://assets.bytebytego.com/diagrams/0024-10-data-structures-used-in-daily-life.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Data Structures"
+ - "Algorithms"
+---
+
+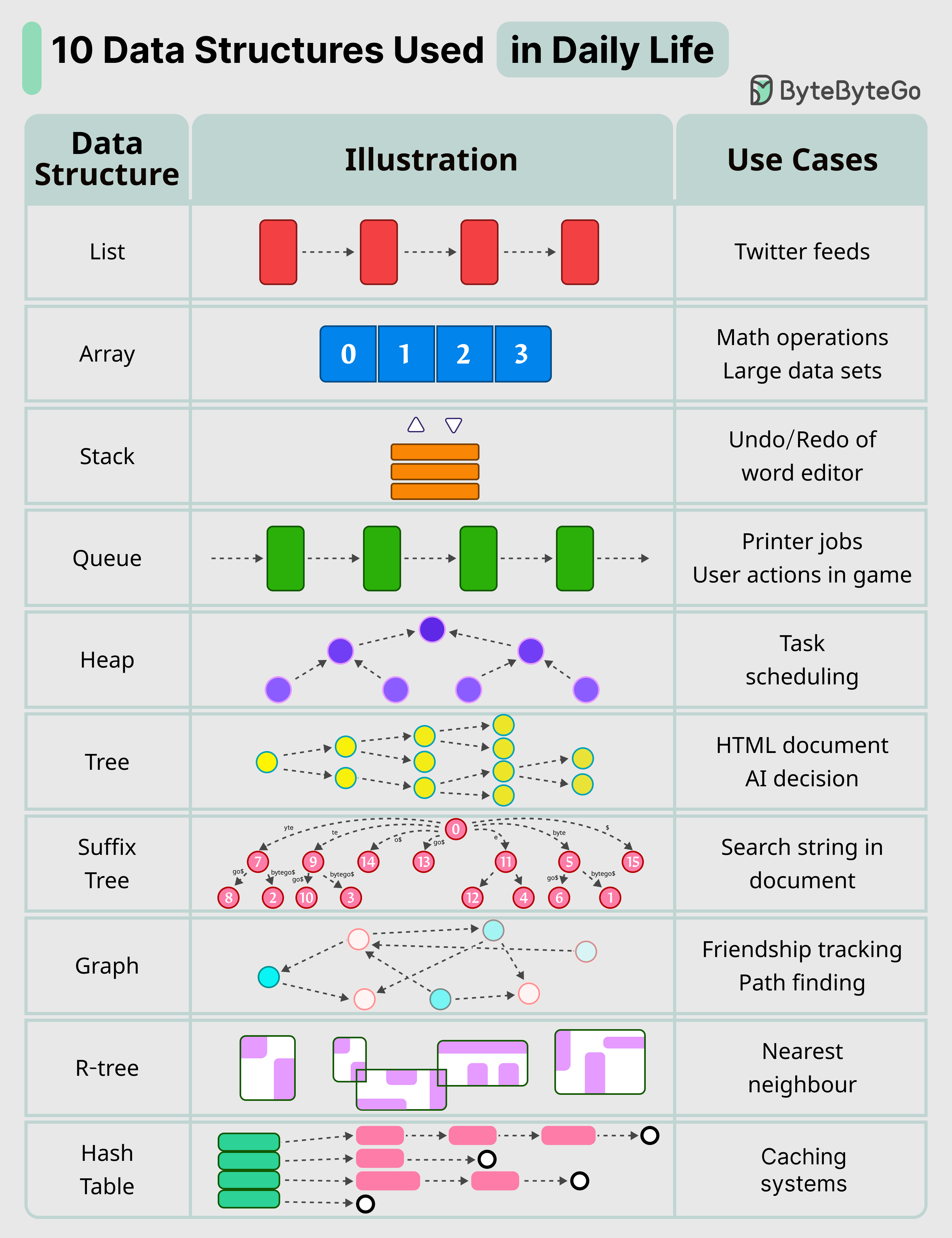
+
+Here are 10 key data structures we use every day:
+
+* **List**: Keep your Twitter feeds
+
+* **Stack**: Support undo/redo of the word editor
+
+* **Queue**: Keep printer jobs, or send user actions in-game
+
+* **Hash Table**: Caching systems
+
+* **Array**: Math operations
+
+* **Heap**: Task scheduling
+
+* **Tree**: Keep the HTML document, or for AI decision
+
+* **Suffix Tree**: For searching string in a document
+
+* **Graph**: For tracking friendship, or path finding
+
+* **R-Tree**: For finding the nearest neighbor
+
+* **Vertex Buffer**: For sending data to GPU for rendering
diff --git a/data/guides/10-principles-for-building-resilient-payment-systems-by-shopify.md b/data/guides/10-principles-for-building-resilient-payment-systems-by-shopify.md
new file mode 100644
index 0000000..6c7e81a
--- /dev/null
+++ b/data/guides/10-principles-for-building-resilient-payment-systems-by-shopify.md
@@ -0,0 +1,56 @@
+---
+title: '10 Principles for Building Resilient Payment Systems'
+description: '10 principles for building resilient payment systems based on Shopify.'
+image: 'https://assets.bytebytego.com/diagrams/0336-shopify.png'
+createdAt: '2024-03-07'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - payment systems
+ - resilience
+---
+
+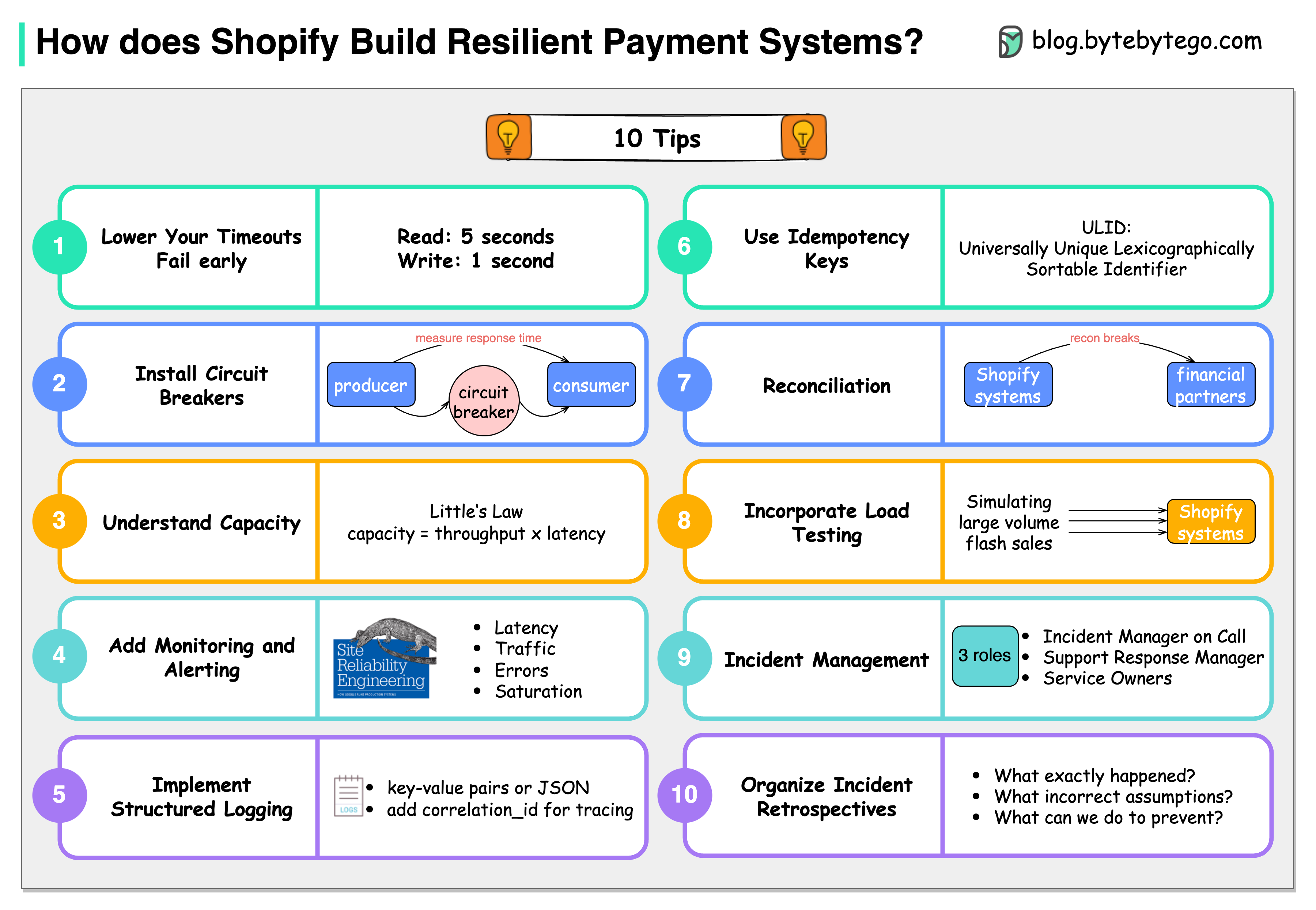
+
+Shopify has some precious tips for building resilient payment systems.
+
+### Lower the timeouts, and let the service fail early
+
+The default timeout is 60 seconds. Based on Shopify’s experiences, read timeout of 5 seconds and write timeout of 1 second are decent setups.
+
+### Install circuit breaks
+
+Shopify developed Semian to protect Net::HTTP, MySQL, Redis, and gRPC services with a circuit breaker in Ruby.
+
+### Capacity management
+
+If we have 50 requests arrive in our queue and it takes an average of 100 milliseconds to process a request, our throughput is 500 requests per second.
+
+### Add monitoring and alerting
+
+Google’s site reliability engineering (SRE) book lists four golden signals a user-facing system should be monitored for: latency, traffic, errors, and saturation.
+
+### Implement structured logging
+
+We store logs in a centralized place and make them easily searchable.
+
+### Use idempotency keys
+
+Use the Universally Unique Lexicographically Sortable Identifier (ULID) for these idempotency keys instead of a random version 4 UUID.
+
+### Be consistent with reconciliation
+
+Store the reconciliation breaks with Shopify’s financial partners in the database.
+
+### Incorporate load testing
+
+Shopify regularly simulates the large volume flash sales to get the benchmark results.
+
+### Get on top of incident management
+
+Each incident channel has 3 roles: Incident Manager on Call (IMOC), Support Response Manager (SRM), and service owners.
+
+### Organize incident retrospectives
+
+For each incident, 3 questions are asked at Shopify: What exactly happened? What incorrect assumptions did we hold about our systems? What we can do to prevent this from happening?
diff --git a/data/guides/10-system-design-tradeoffs-you-cannot-ignore.md b/data/guides/10-system-design-tradeoffs-you-cannot-ignore.md
new file mode 100644
index 0000000..b0a0384
--- /dev/null
+++ b/data/guides/10-system-design-tradeoffs-you-cannot-ignore.md
@@ -0,0 +1,76 @@
+---
+title: "10 System Design Tradeoffs You Cannot Ignore"
+description: "Explore 10 crucial system design tradeoffs for robust architecture."
+image: "https://assets.bytebytego.com/diagrams/0026-10-system-design-trade-offs-you-cannot-ignore.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - System Design
+ - Tradeoffs
+---
+
+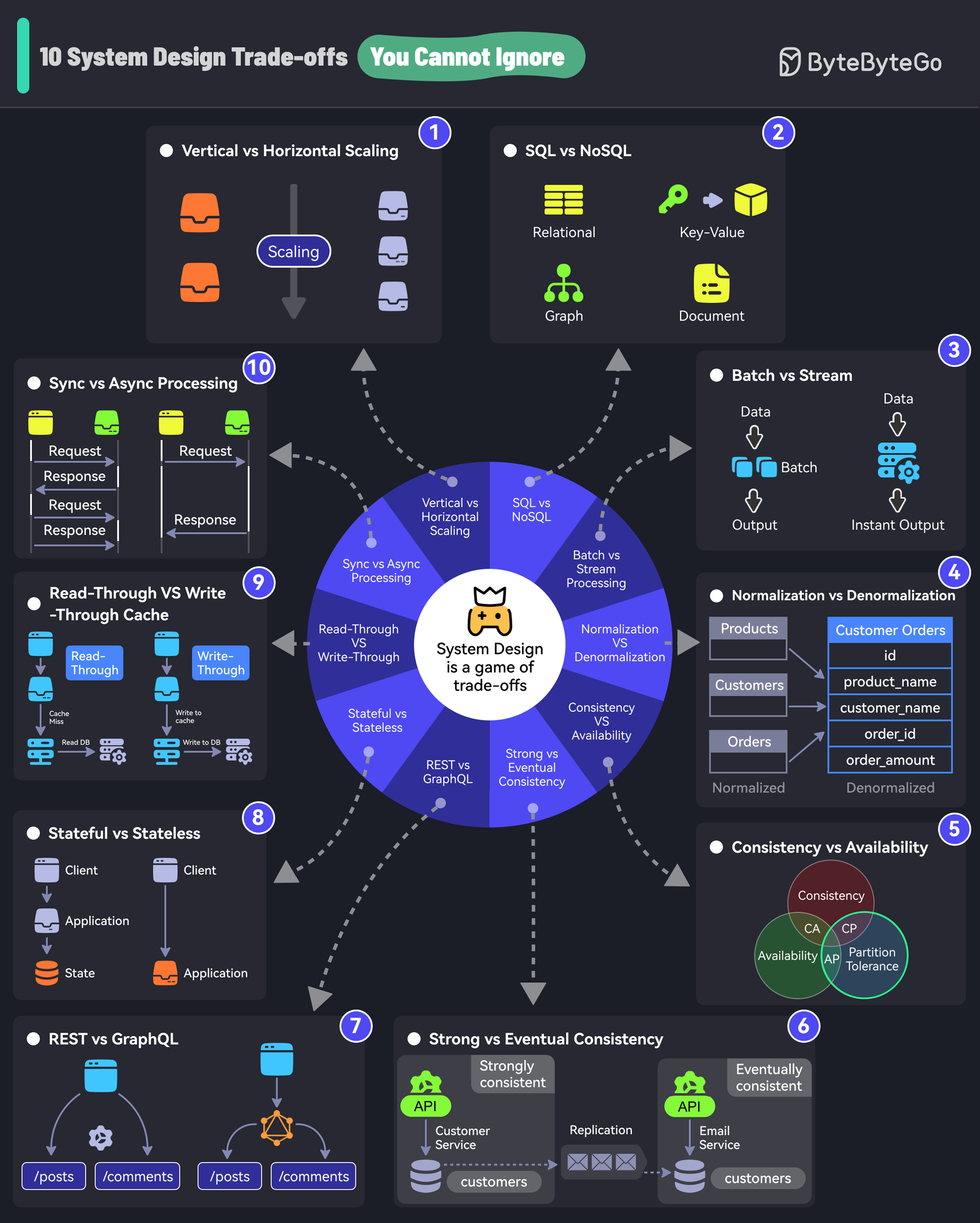
+
+If you don’t know trade-offs, you DON'T KNOW system design.
+
+## 1. Vertical vs Horizontal Scaling
+
+Vertical scaling is adding more resources (CPU, RAM) to an existing server.
+
+Horizontal scaling means adding more servers to the pool.
+
+## 2. SQL vs NoSQL
+
+SQL databases organize data into tables of rows and columns.
+
+NoSQL is ideal for applications that need a flexible schema.
+
+## 3. Batch vs Stream Processing
+
+Batch processing involves collecting data and processing it all at once. For example, daily billing processes.
+
+Stream processing processes data in real time. For example, fraud detection processes.
+
+## 4. Normalization vs Denormalization
+
+Normalization splits data into related tables to ensure that each piece of information is stored only once.
+
+Denormalization combines data into fewer tables for better query performance.
+
+## 5. Consistency vs Availability
+
+Consistency is the assurance of getting the most recent data every single time.
+
+Availability is about ensuring that the system is always up and running, even if some parts are having problems.
+
+## 6. Strong vs Eventual Consistency
+
+Strong consistency is when data updates are immediately reflected.
+
+Eventual consistency is when data updates are delayed before being available across nodes.
+
+## 7. REST vs GraphQL
+
+With REST endpoints, you gather data by accessing multiple endpoints.
+
+With GraphQL, you get more efficient data fetching with specific queries but the design cost is higher.
+
+## 8. Stateful vs Stateless
+
+A stateful system remembers past interactions.
+
+A stateless system does not keep track of past interactions.
+
+## 9. Read-Through vs Write-Through Cache
+
+A read-through cache loads data from the database in case of a cache miss.
+
+A write-through cache simultaneously writes data updates to the cache and storage.
+
+## 10. Sync vs Async Processing
+
+In synchronous processing, tasks are performed one after another.
+
+In asynchronous processing, tasks can run in the background. New tasks can be started without waiting for a new task.
diff --git a/data/guides/100x-postgres-scaling-at-figma.md b/data/guides/100x-postgres-scaling-at-figma.md
new file mode 100644
index 0000000..4f10f81
--- /dev/null
+++ b/data/guides/100x-postgres-scaling-at-figma.md
@@ -0,0 +1,44 @@
+---
+title: '100X Postgres Scaling at Figma'
+description: 'Learn how Figma scaled its Postgres database by 100x.'
+image: 'https://assets.bytebytego.com/diagrams/0048-100x-postgres-scaling-at-figma.png'
+createdAt: '2024-02-12'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Postgres
+ - Scaling
+---
+
+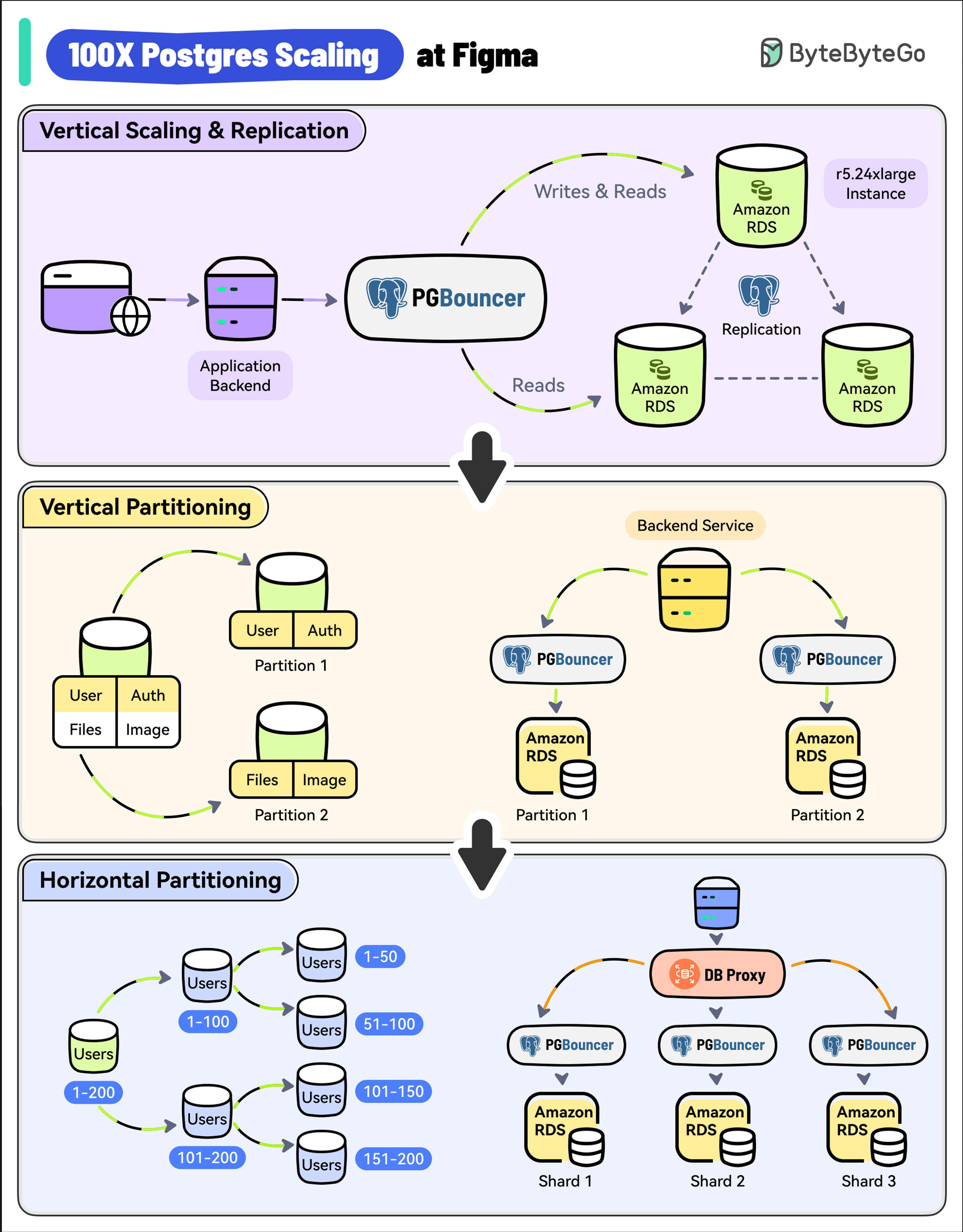
+
+With 3 million monthly users, Figma’s user base has increased by 200% since 2018.
+
+As a result, its Postgres database witnessed a whopping 100X growth.
+
+* **Vertical Scaling and Replication**
+
+ Figma used a single, large Amazon RDS database.
+
+ As a first step, they upgraded to the largest instance available (from r5.12xlarge to r5.24xlarge).
+
+ They also created multiple read replicas to scale read traffic and added PgBouncer as a connection pooler to limit the impact of a growing number of connections.
+
+* **Vertical Partitioning**
+
+ The next step was vertical partitioning.
+
+ They migrated high-traffic tables like “Figma Files” and “Organizations” into their separate databases.
+
+ Multiple PgBouncer instances were used to manage the connections for these separate databases.
+
+* **Horizontal Partitioning**
+
+ Over time, some tables crossed several terabytes of data and billions of rows.
+
+ Postgres Vacuum became an issue and max IOPS exceeded the limits of Amazon RDS at the time.
+
+ To solve this, Figma implemented horizontal partitioning by splitting large tables across multiple physical databases.
+
+ A new DBProxy service was built to handle routing and query execution.
diff --git a/data/guides/11-steps-to-go-from-junior-to-senior-developer.md b/data/guides/11-steps-to-go-from-junior-to-senior-developer.md
new file mode 100644
index 0000000..50ec32b
--- /dev/null
+++ b/data/guides/11-steps-to-go-from-junior-to-senior-developer.md
@@ -0,0 +1,58 @@
+---
+title: "11 Steps to Go From Junior to Senior Developer"
+description: "Roadmap with steps to transition from junior to senior developer."
+image: "https://assets.bytebytego.com/diagrams/0243-junior-to-senior-developer-roadmap.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - software-development
+tags:
+ - career-growth
+ - software-engineering
+---
+
+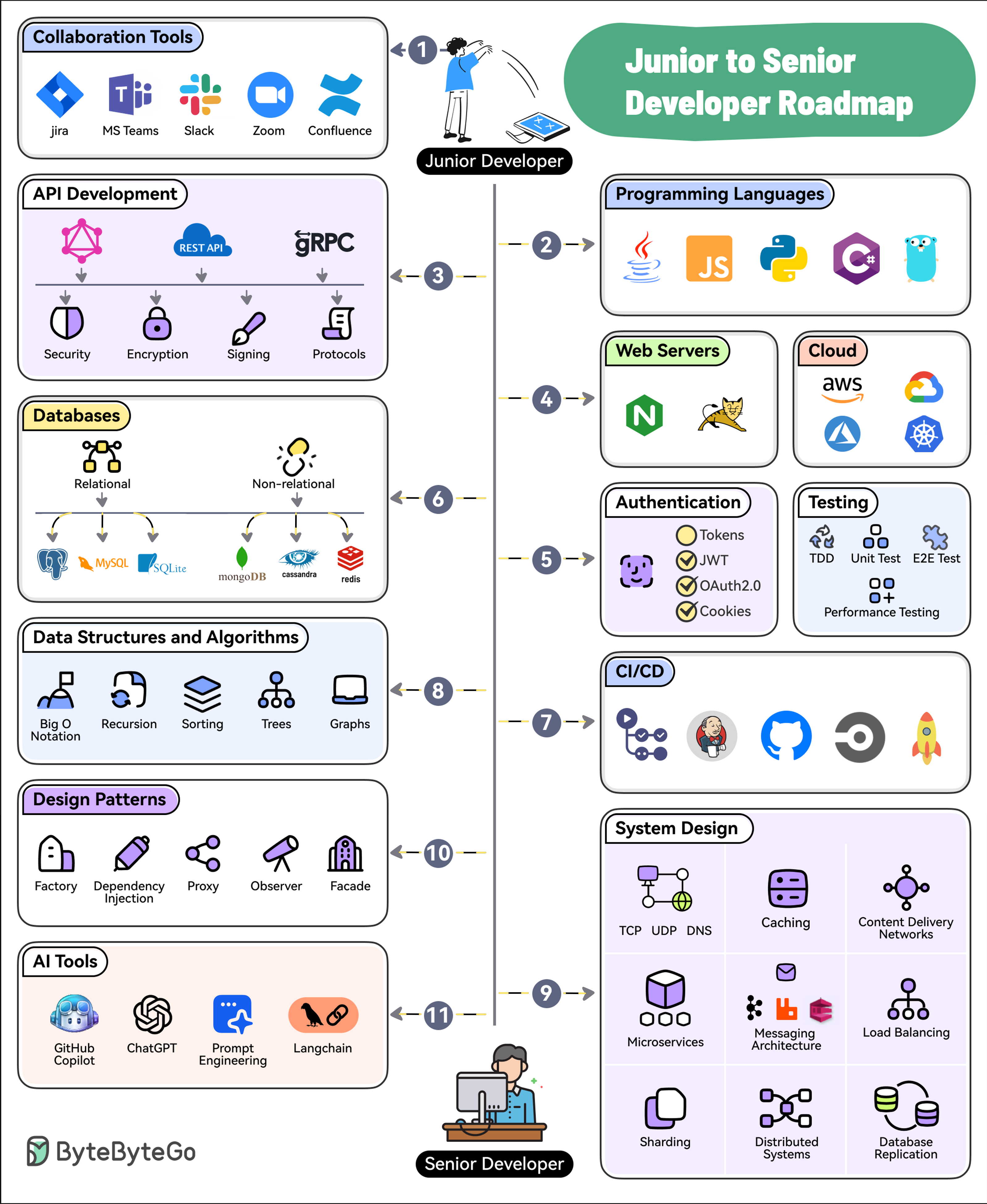
+
+## 1. Collaboration Tools
+
+Software development is a social activity. Learn to use collaboration tools like Jira, Confluence, Slack, MS Teams, Zoom, etc.
+
+## 2. Programming Languages
+
+Pick and master one or two programming languages. Choose from options like Java, Python, JavaScript, C#, Go, etc.
+
+## 3. API Development
+
+Learn the ins and outs of API Development approaches such as REST, GraphQL, and gRPC.
+
+## 4. Web Servers and Hosting
+
+Know about web servers as well as cloud platforms like AWS, Azure, GCP, and Kubernetes
+
+## 5. Authentication and Testing
+
+Learn how to secure your applications with authentication techniques such as JWTs, OAuth2, etc. Also, master testing techniques like TDD, E2E Testing, and Performance Testing
+
+## 6. Databases
+
+Learn to work with relational (Postgres, MySQL, and SQLite) and non-relational databases (MongoDB, Cassandra, and Redis).
+
+## 7. CI/CD
+
+Pick tools like GitHub Actions, Jenkins, or CircleCI to learn about continuous integration and continuous delivery.
+
+## 8. Data Structures and Algorithms
+
+Master the basics of DSA with topics like Big O Notation, Sorting, Trees, and Graphs.
+
+## 9. System Design
+
+Learn System Design concepts such as Networking, Caching, CDNs, Microservices, Messaging, Load Balancing, Replication, Distributed Systems, etc.
+
+## 10. Design patterns
+
+Master the application of design patterns such as dependency injection, factory, proxy, observers, and facade.
+
+## 11. AI Tools
+
+To future-proof your career, learn to leverage AI tools like GitHub Copilot, ChatGPT, Langchain, and Prompt Engineering.
diff --git a/data/guides/15-open-source-projects-that-changed-the-world.md b/data/guides/15-open-source-projects-that-changed-the-world.md
new file mode 100644
index 0000000..f3e6896
--- /dev/null
+++ b/data/guides/15-open-source-projects-that-changed-the-world.md
@@ -0,0 +1,56 @@
+---
+title: "15 Open-Source Projects That Changed the World"
+description: "Explore 15 open-source projects that revolutionized software development."
+image: "https://assets.bytebytego.com/diagrams/0029-15-open-source-projects-that-changed-the-world.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Open Source"
+ - "Software Development"
+---
+
+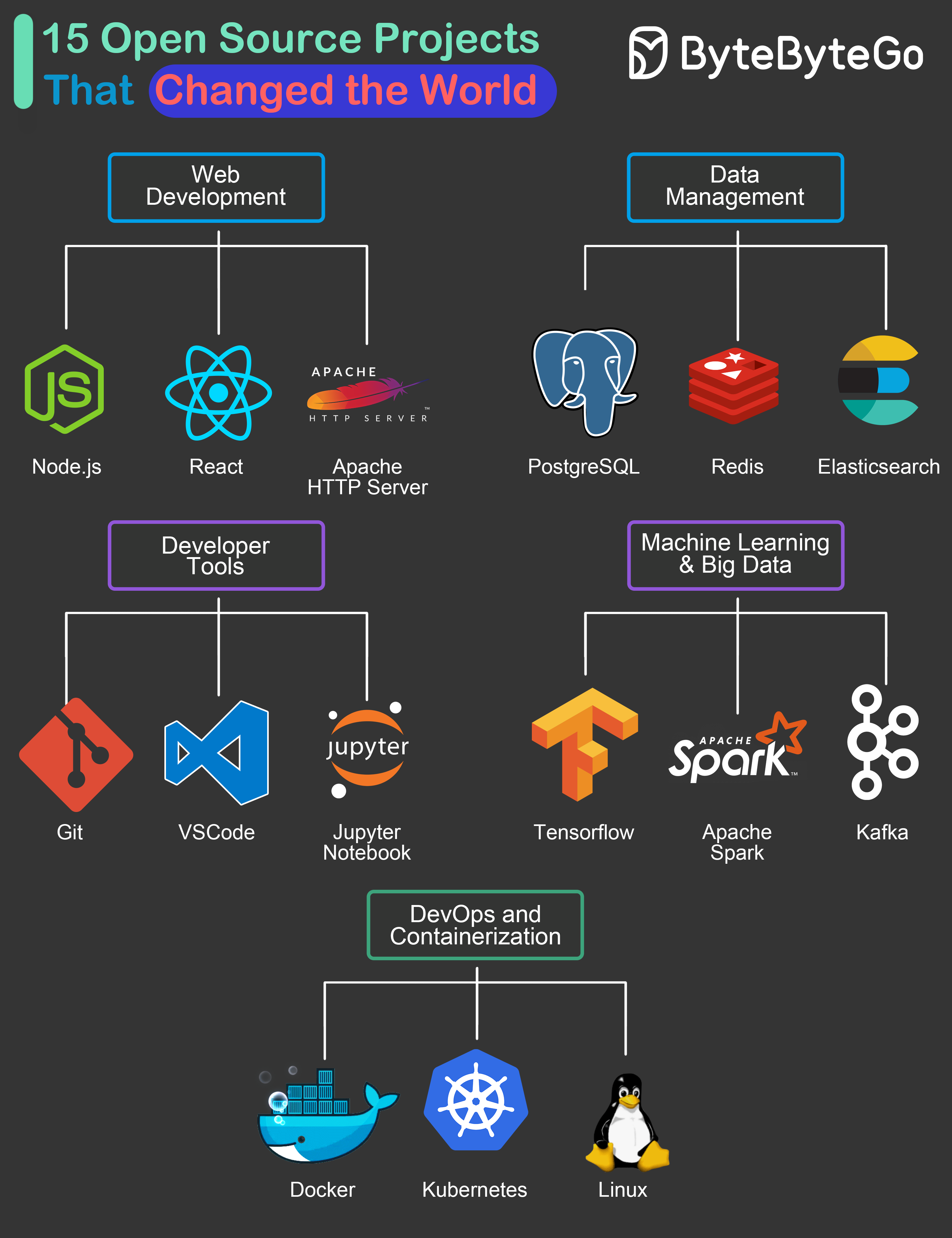
+
+To come up with the list, we tried to look at the overall impact these projects have created on the industry and related technologies. Also, we’ve focused on projects that have led to a big change in the day-to-day lives of many software developers across the world.
+
+## Web Development
+
+* **Node.js:** The cross-platform server-side Javascript runtime that brought JS to server-side development
+
+* **React:** The library that became the foundation of many web development frameworks.
+
+* **Apache HTTP Server:** The highly versatile web server loved by enterprises and startups alike. Served as inspiration for many other web servers over the years.
+
+## Data Management
+
+* **PostgreSQL:** An open-source relational database management system that provided a high-quality alternative to costly systems
+
+* **Redis:** The super versatile data store that can be used a cache, message broker and even general-purpose storage
+
+* **Elasticsearch:** A scale solution to search, analyze and visualize large volumes of data
+
+## Developer Tools
+
+* **Git:** Free and open-source version control tool that allows developer collaboration across the globe.
+
+* **VSCode:** One of the most popular source code editors in the world
+
+* **Jupyter Notebook:** The web application that lets developers share live code, equations, visualizations and narrative text.
+
+## Machine Learning & Big Data
+
+* **Tensorflow:** The leading choice to leverage machine learning techniques
+
+* **Apache Spark:** Standard tool for big data processing and analytics platforms
+
+* **Kafka:** Standard platform for building real-time data pipelines and applications.
+
+## DevOps & Containerization
+
+* **Docker:** The open source solution that allows developers to package and deploy applications in a consistent and portable way.
+
+* **Kubernetes:** The heart of Cloud-Native architecture and a platform to manage multiple containers
+
+* **Linux:** The OS that democratized the world of software development.
diff --git a/data/guides/18-common-ports-worth-knowing.md b/data/guides/18-common-ports-worth-knowing.md
new file mode 100644
index 0000000..7061915
--- /dev/null
+++ b/data/guides/18-common-ports-worth-knowing.md
@@ -0,0 +1,33 @@
+---
+title: 18 Common Ports Worth Knowing
+description: Learn about 18 common network ports and their uses.
+image: 'https://assets.bytebytego.com/diagrams/0030-18-common-ports-you-must-know.png'
+createdAt: '2024-02-05'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Networking
+ - Ports
+---
+
+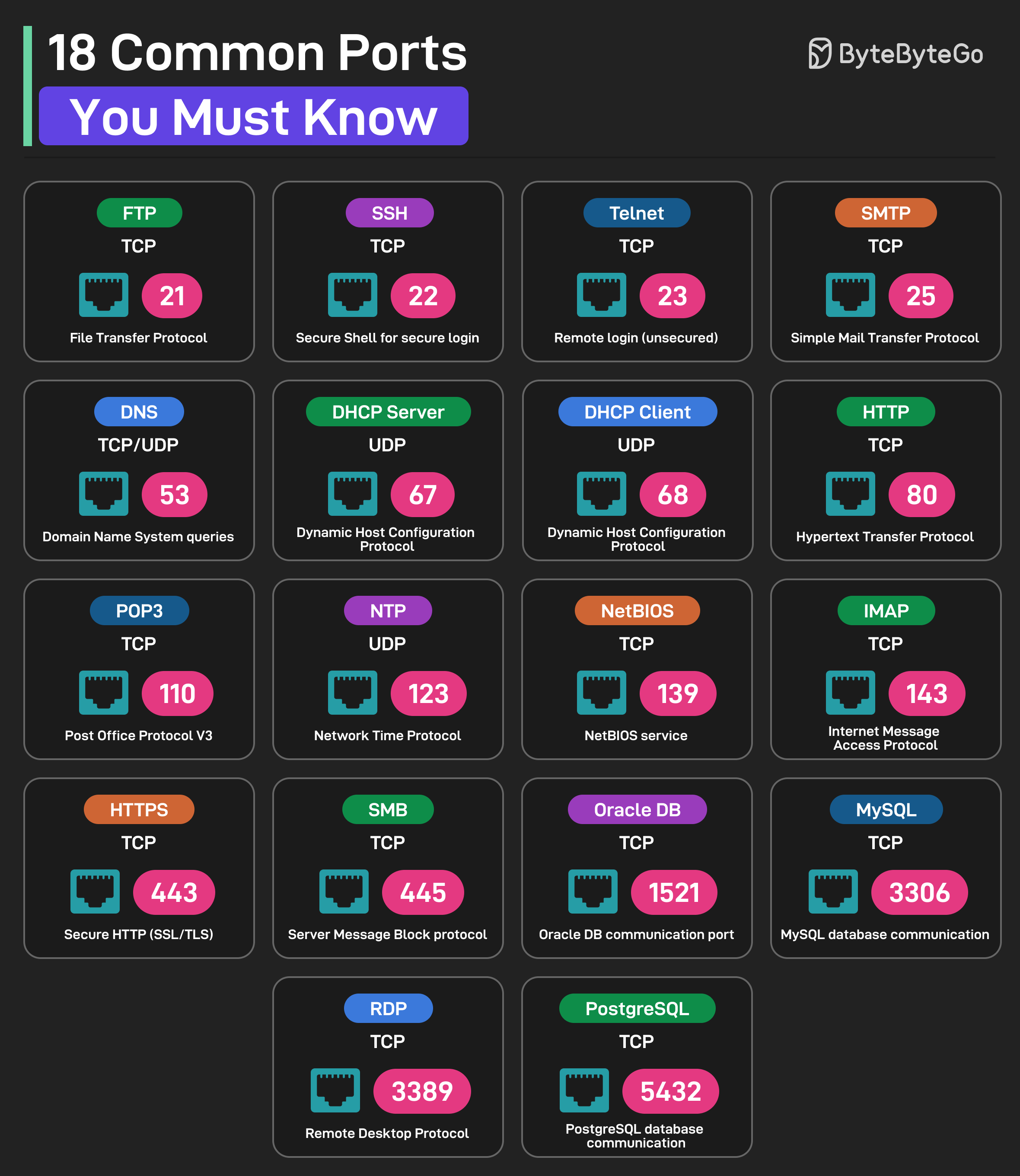
+
+* **FTP (File Transfer Protocol):** Uses TCP Port 21
+* **SSH (Secure Shell for Login):** Uses TCP Port 22
+* **Telnet:** Uses TCP Port 23 for remote login
+* **SMTP (Simple Mail Transfer Protocol):** Uses TCP Port 25
+* **DNS:** Uses UDP or TCP on Port 53 for DNS queries
+* **DHCP Server:** Uses UDP Port 67
+* **DHCP Client:** Uses UDP Port 68
+* **HTTP (Hypertext Transfer Protocol):** Uses TCP Port 80
+* **POP3 (Post Office Protocol V3):** Uses TCP Port 110
+* **NTP (Network Time Protocol):** Uses UDP Port 123
+* **NetBIOS:** Uses TCP Port 139 for NetBIOS service
+* **IMAP (Internet Message Access Protocol):** Uses TCP Port 143
+* **HTTPS (Secure HTTP):** Uses TCP Port 443
+* **SMB (Server Message Block):** Uses TCP Port 445
+* **Oracle DB:** Uses TCP Port 1521 for Oracle database communication port
+* **MySQL:** Uses TCP Port 3306 for MySQL database communication port
+* **RDP:** Uses TCP Port 3389 for Remote Desktop Protocol
+* **PostgreSQL:** Uses TCP Port 5432 for PostgreSQL database communication
diff --git a/data/guides/18-key-design-patterns-every-developer-should-know.md b/data/guides/18-key-design-patterns-every-developer-should-know.md
new file mode 100644
index 0000000..d9ef0c3
--- /dev/null
+++ b/data/guides/18-key-design-patterns-every-developer-should-know.md
@@ -0,0 +1,52 @@
+---
+title: "18 Key Design Patterns Every Developer Should Know"
+description: "Explore 18 essential design patterns for efficient software development."
+image: "https://assets.bytebytego.com/diagrams/0032-oo-patterns-you-should-know.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "design patterns"
+ - "software development"
+---
+
+
+
+Patterns are reusable solutions to common design problems, resulting in a smoother, more efficient development process. They serve as blueprints for building better software structures. These are some of the most popular patterns:
+
+* **Abstract Factory:** Family Creator - Makes groups of related items.
+
+* **Builder:** Lego Master - Builds objects step by step, keeping creation and appearance separate.
+
+* **Prototype:** Clone Maker - Creates copies of fully prepared examples.
+
+* **Singleton:** One and Only - A special class with just one instance.
+
+* **Adapter:** Universal Plug - Connects things with different interfaces.
+
+* **Bridge:** Function Connector - Links how an object works to what it does.
+
+* **Composite:** Tree Builder - Forms tree-like structures of simple and complex parts.
+
+* **Decorator:** Customizer - Adds features to objects without changing their core.
+
+* **Facade:** One-Stop-Shop - Represents a whole system with a single, simplified interface.
+
+* **Flyweight:** Space Saver - Shares small, reusable items efficiently.
+
+* **Proxy:** Stand-In Actor - Represents another object, controlling access or actions.
+
+* **Chain of Responsibility:** Request Relay - Passes a request through a chain of objects until handled.
+
+* **Command:** Task Wrapper - Turns a request into an object, ready for action.
+
+* **Iterator:** Collection Explorer - Accesses elements in a collection one by one.
+
+* **Mediator:** Communication Hub - Simplifies interactions between different classes.
+
+* **Memento:** Time Capsule - Captures and restores an object's state.
+
+* **Observer:** News Broadcaster - Notifies classes about changes in other objects.
+
+* **Visitor:** Skillful Guest - Adds new operations to a class without altering it.
diff --git a/data/guides/2-decades-of-cloud-evolution.md b/data/guides/2-decades-of-cloud-evolution.md
new file mode 100644
index 0000000..fda763e
--- /dev/null
+++ b/data/guides/2-decades-of-cloud-evolution.md
@@ -0,0 +1,32 @@
+---
+title: "2 Decades of Cloud Evolution"
+description: "Explore the evolution of cloud computing over the past two decades."
+image: "https://assets.bytebytego.com/diagrams/0147-cloud-evolution.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "Cloud Evolution"
+---
+
+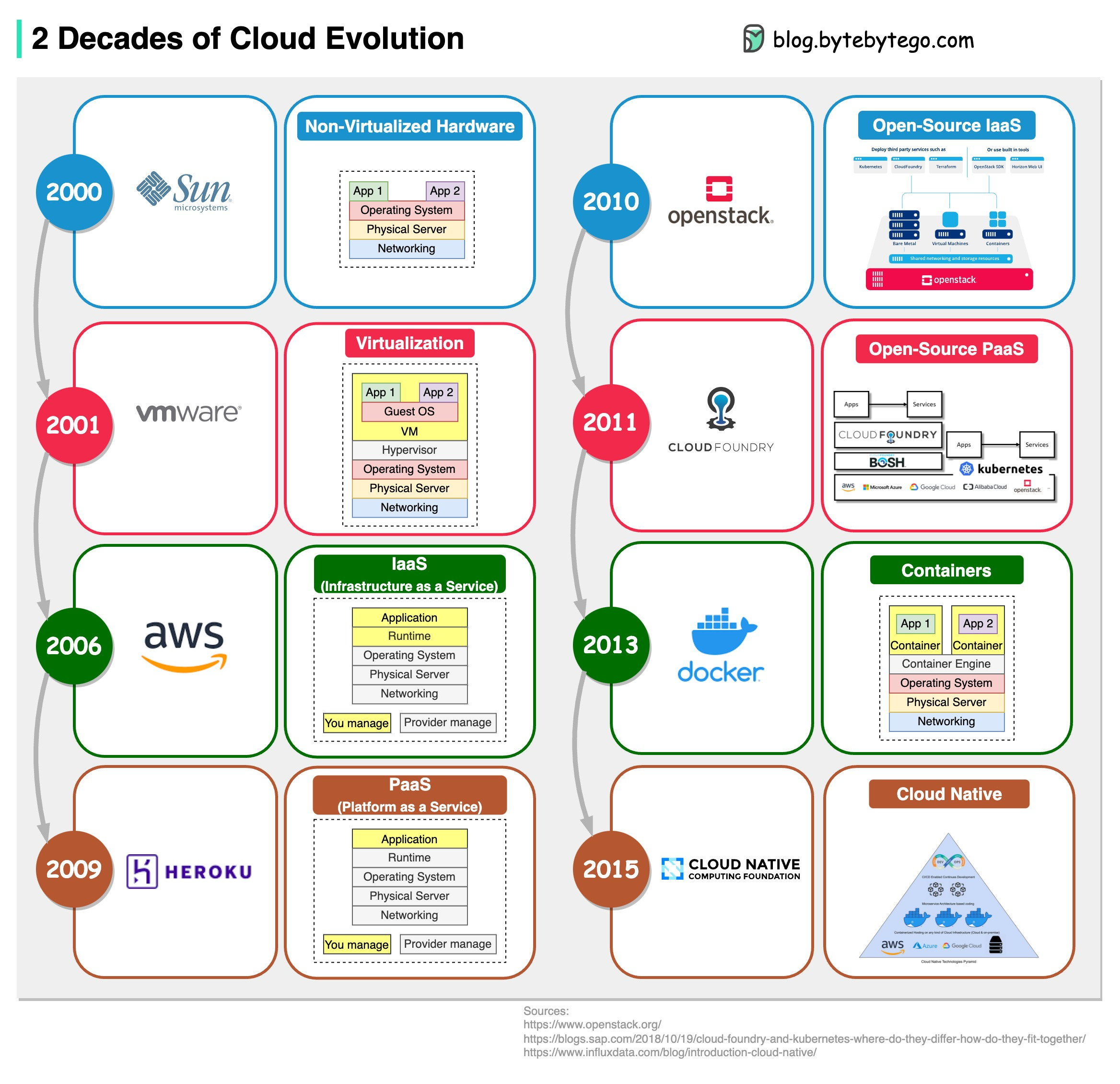
+
+IaaS, PaaS, Cloud Native… How do we get here? The diagram below shows two decades of cloud evolution.
+
+## Cloud Evolution Timeline
+
+* 2001 - VMWare - Virtualization via hypervisor
+
+* 2006 - AWS - IaaS (Infrastructure as a Service)
+
+* 2009 - Heroku - PaaS (Platform as a Service)
+
+* 2010 - OpenStack - Open-source IaaS
+
+* 2011 - CloudFoundry - Open-source PaaS
+
+* 2013 - Docker - Containers
+
+* 2015 - CNCF (Cloud Native Computing Foundation) - Cloud Native
diff --git a/data/guides/20-popular-open-source-projects-started-or-supported-by-big-companies.md b/data/guides/20-popular-open-source-projects-started-or-supported-by-big-companies.md
new file mode 100644
index 0000000..1dc5e57
--- /dev/null
+++ b/data/guides/20-popular-open-source-projects-started-or-supported-by-big-companies.md
@@ -0,0 +1,52 @@
+---
+title: "20 Popular Open Source Projects Started by Big Companies"
+description: "Explore 20 popular open source projects backed by major tech companies."
+image: "https://assets.bytebytego.com/diagrams/0034-20-popular-open-source-projects-by-big-tech.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Open Source"
+ - "Technology"
+---
+
+
+
+## 1. Google
+
+* Kubernetes
+* TensorFlow
+* Go
+* Angular
+
+## 2. Meta
+
+* React
+* PyTorch
+* GraphQL
+* Cassandra
+
+## 3. Microsoft
+
+* VSCode
+* TypeScript
+* Playwright
+
+## 4. Netflix
+
+* Chaos Monkey
+* Hystrix
+* Zuul
+
+## 5. LinkedIn
+
+* Kafka
+* Samza
+* Pinot
+
+## 6. RedHat
+
+* Ansible
+* OpenShift
+* Ceph Storage
diff --git a/data/guides/25-papers-that-completely-transformed-the-computer-world.md b/data/guides/25-papers-that-completely-transformed-the-computer-world.md
new file mode 100644
index 0000000..d02c7d0
--- /dev/null
+++ b/data/guides/25-papers-that-completely-transformed-the-computer-world.md
@@ -0,0 +1,66 @@
+---
+title: "25 Papers That Completely Transformed the Computer World"
+description: "A curated list of influential papers that shaped the computer world."
+image: "https://assets.bytebytego.com/diagrams/0419-25-papers-that-completely-transformed-the-computer-world.png"
+createdAt: "2024-02-09"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Distributed Systems"
+ - "Computer Science"
+---
+
+
+
+Here are 25 papers that have significantly impacted the field of computer science:
+
+* [Dynamo - Amazon’s Highly Available Key Value Store](https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)
+
+* [Google File System](https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf): Insights into a highly scalable file system
+
+* [Scaling Memcached at Facebook](https://research.facebook.com/file/839620310074473/scaling-memcache-at-facebook.pdf): A look at the complexities of Caching
+
+* [BigTable](https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf): The design principles behind a distributed storage system
+
+* [Borg - Large Scale Cluster Management at Google](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43438.pdf)
+
+* [Cassandra](https://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf): A look at the design and architecture of a distributed NoSQL database
+
+* [Attention Is All You Need](https://arxiv.org/abs/1706.03762): Into a new deep learning architecture known as the transformer
+
+* [Kafka](https://www.microsoft.com/en-us/research/wp-content/uploads/2017/09/Kafka.pdf): Internals of the distributed messaging platform
+
+* [FoundationDB](https://www.foundationdb.org/files/fdb-paper.pdf): A look at how a distributed database
+
+* [Amazon Aurora](https://web.stanford.edu/class/cs245/readings/aurora.pdf): To learn how Amazon provides high-availability and performance
+
+* [Spanner](https://static.googleusercontent.com/media/research.google.com/en//archive/spanner-osdi2012.pdf): Design and architecture of Google’s globally distributed database
+
+* [MapReduce](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/16cb30b4b92fd4989b8619a61752a2387c6dd474.pdf): A detailed look at how MapReduce enables parallel processing of massive volumes of data
+
+* [Shard Manager](https://dl.acm.org/doi/pdf/10.1145/3477132.3483546): Understanding the generic shard management framework
+
+* [Dapper](https://static.googleusercontent.com/media/research.google.com/en//archive/papers/dapper-2010-1.pdf): Insights into Google’s distributed systems tracing infrastructure
+
+* [Flink](https://www.researchgate.net/publication/308993790_Apache_Flink_Stream_and_Batch_Processing_in_a_Single_Engine): A detailed look at the unified architecture of stream and batch processing
+
+* [A Comprehensive Survey on Vector Databases](https://arxiv.org/pdf/2310.11703.pdf)
+
+* [Zanzibar](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/10683a8987dbf0c6d4edcafb9b4f05cc9de5974a.pdf): A look at the design, implementation and deployment of a global system for managing access control lists at Google
+
+* [Monarch](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/d84ab6c93881af998de877d0070a706de7bec6d8.pdf): Architecture of Google’s in-memory time series database
+
+* [Thrift](https://thrift.apache.org/static/files/thrift-20070401.pdf): Explore the design choices behind Facebook’s code-generation tool
+
+* [Bitcoin](https://bitcoin.org/bitcoin.pdf): The ground-breaking introduction to the peer-to-peer electronic cash system
+
+* [WTF - Who to Follow Service at Twitter](https://web.stanford.edu/~rezab/papers/wtf_overview.pdf): Twitter’s (now X) user recommendation system
+
+* [MyRocks: LSM-Tree Database Storage Engine](https://www.vldb.org/pvldb/vol13/p3217-matsunobu.pdf)
+
+* [GoTo Considered Harmful](https://homepages.cwi.nl/~storm/teaching/reader/Dijkstra68.pdf)
+
+* [Raft Consensus Algorithm](https://raft.github.io/raft.pdf): To learn about the more understandable consensus algorithm
+
+* [Time Clocks and Ordering of Events](https://lamport.azurewebsites.net/pubs/time-clocks.pdf): The extremely important paper that explains the concept of time and event ordering in a distributed system
diff --git a/data/guides/30-useful-ai-apps-that-can-help-you-in-2025.md b/data/guides/30-useful-ai-apps-that-can-help-you-in-2025.md
new file mode 100644
index 0000000..ed915b3
--- /dev/null
+++ b/data/guides/30-useful-ai-apps-that-can-help-you-in-2025.md
@@ -0,0 +1,64 @@
+---
+title: "30 Useful AI Apps That Can Help You in 2025"
+description: "Discover 30 AI apps to boost productivity, creativity, and more in 2025."
+image: "https://assets.bytebytego.com/diagrams/0039-30-useful-ai-apps-that-can-help-you-in-2025.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "AI Tools"
+ - "Productivity"
+---
+
+
+
+AI apps are taking over the world. There’s an AI app for every conceivable use case. Here are some AI apps for different categories:
+
+## General Purpose
+
+* Perplexity
+* Anthropic Claude
+* Grok
+* ChatGPT
+* Gemini
+
+## Writing Code
+
+* Cursor
+* Replit
+* Windsurf AI
+* Github Copilot
+* Tabnine
+
+## Productivity
+
+* Adobe (PDF Chat)
+* Gemini for Gmail
+* Gamma (AI slide deck)
+* WisprFlow (AI voice dictation)
+* Granola (AI notetaker)
+
+## Audience Building
+
+* Delphi (AI text, voice)
+* HeyGen (video translation)
+* Persona (AI agent builder)
+* Captions (AI video editing)
+* OpusClips (Video repurposing)
+
+## Creativity
+
+* ElevenLabs (realistic AI voices)
+* Midjourney
+* Suno AI (music generation)
+* Krea (enhance images)
+* Photoroom (AI image editing)
+
+## Learning and Growth
+
+* Particle News App
+* Rosebud (AI journal app)
+* NotebookLM
+* GoodInside (parenting co-pilot)
+* Ash (AI counselor)
diff --git a/data/guides/4-ways-netflix-uses-caching-to-hold-user-attention.md b/data/guides/4-ways-netflix-uses-caching-to-hold-user-attention.md
new file mode 100644
index 0000000..2f362da
--- /dev/null
+++ b/data/guides/4-ways-netflix-uses-caching-to-hold-user-attention.md
@@ -0,0 +1,44 @@
+---
+title: '4 Ways Netflix Uses Caching'
+description: 'Explore how Netflix uses caching to maintain user engagement.'
+image: 'https://assets.bytebytego.com/diagrams/0007-4-ways-netflix-uses-caching.png'
+createdAt: '2024-02-25'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Caching
+ - Netflix
+---
+
+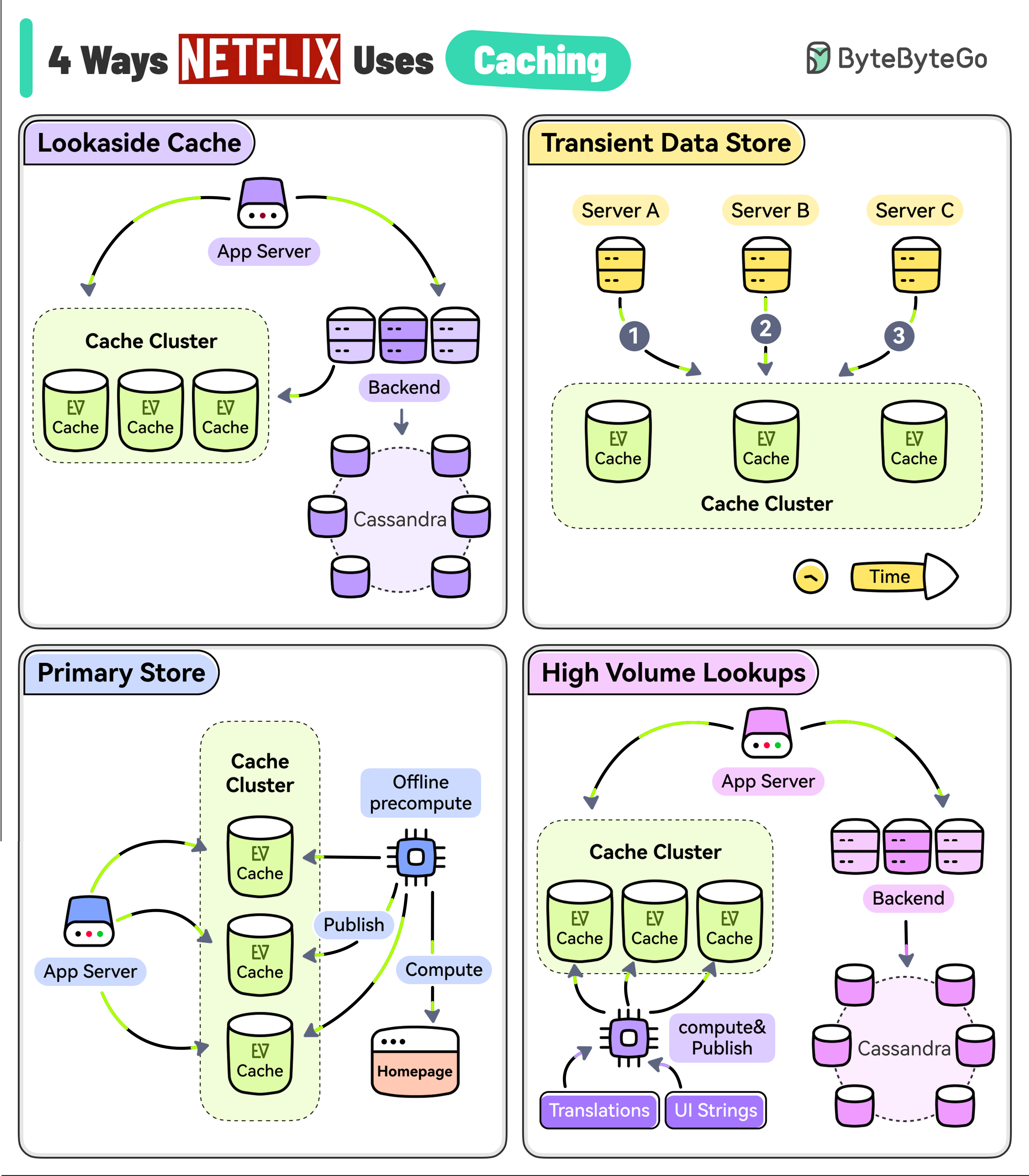
+
+The goal of Netflix is to keep you streaming for as long as possible. But a user’s typical attention span is just 90 seconds.
+
+They use EVCache (a distributed key-value store) to reduce latency so that the users don’t lose interest.
+
+However, EVCache has multiple use cases at Netflix.
+
+* **Lookaside Cache**
+
+ When the application needs some data, it first tries the EVCache client and if the data is not in the cache, it goes to the backend service and the Cassandra database to fetch the data.
+
+ The service also keeps the cache updated for future requests.
+
+* **Transient Data Store**
+
+ Netflix uses EVCache to keep track of transient data such as playback session information.
+
+ One application service might start the session while the other may update the session followed by a session closure at the very end.
+
+* **Primary Store**
+
+ Netflix runs large-scale pre-compute systems every night to compute a brand-new home page for every profile of every user based on watch history and recommendations.
+
+ All of that data is written into the EVCache cluster from where the online services read the data and build the homepage.
+
+* **High Volume Data**
+
+ Netflix has data that has a high volume of access and also needs to be highly available. For example, UI strings and translations that are shown on the Netflix home page.
+
+ A separate process asynchronously computes and publishes the UI string to EVCache from where the application can read it with low latency and high availability.
diff --git a/data/guides/4-ways-of-qr-code-payment.md b/data/guides/4-ways-of-qr-code-payment.md
new file mode 100644
index 0000000..8f894d1
--- /dev/null
+++ b/data/guides/4-ways-of-qr-code-payment.md
@@ -0,0 +1,37 @@
+---
+title: "4 Ways of QR Code Payment"
+description: "Explore the 4 different methods of QR code payments."
+image: "https://assets.bytebytego.com/diagrams/0310-qr-code.jpg"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - QR Codes
+ - Payments
+---
+
+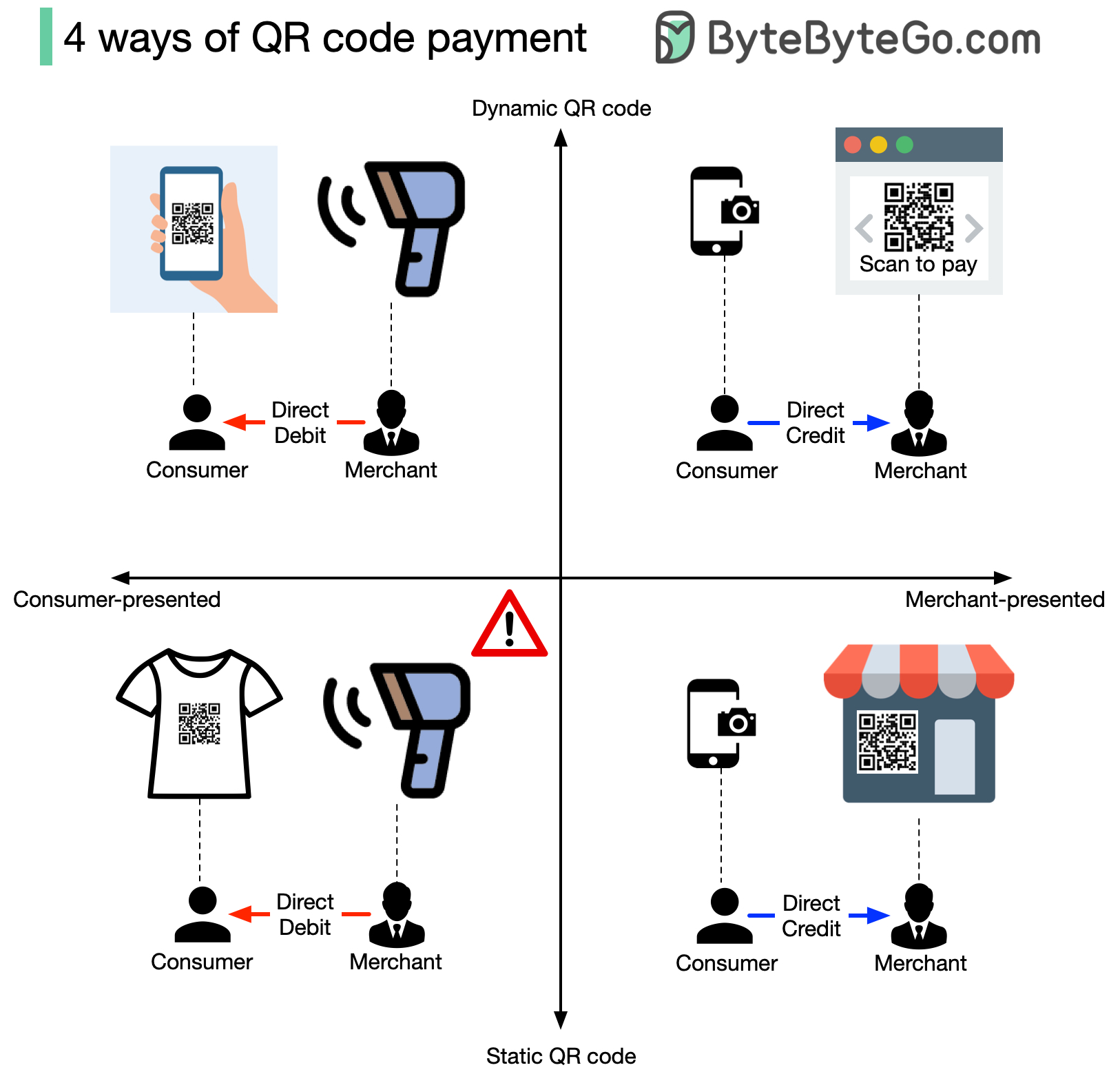
+
+Payment through scanning QR code is very common, but do you know how many ways there are to do it?
+
+There are 4 ways, no matter whether you’re using PayPal, Stripe, Paytm, WeChat, or Alipay. Is this surprising to you? To understand this, we will answer two questions.
+
+## Who Presents the QR Code?
+
+1. You can present the QR code, and the merchant scans the code for payment. This is called ‘consumer-presented mode,’ and what the merchant does is direct debit your account.
+
+2. Obviously, the other way is that the merchant presents the QR code for you to scan to pay the due amount. This is called ‘merchant-presented mode,’ and you grant the direct credit from your account.
+
+## Is the QR Code Dynamic or Static?
+
+1. A dynamic QR code means the QR code will be generated when you present it, or it will automatically regenerate every few seconds. Because it is dynamically generated, it may contain rich information, such as the amount due, transaction type, etc.
+
+2. A static QR code is generated once and used everywhere. Usually, it only contains the account information.
+
+So there are 2*2=4 ways to scan a QR code, which are:
+
+* Consumer-presented mode + static QR code
+* Consumer-presented mode + dynamic QR code
+* Merchant-presented mode + static QR code
+* Merchant-presented mode + dynamic QR code
diff --git a/data/guides/5-functions-to-merge-data-with-pandas.md b/data/guides/5-functions-to-merge-data-with-pandas.md
new file mode 100644
index 0000000..359698c
--- /dev/null
+++ b/data/guides/5-functions-to-merge-data-with-pandas.md
@@ -0,0 +1,24 @@
+---
+title: '5 Functions to Merge Data with Pandas'
+description: 'Explore 5 Pandas functions for efficient data merging and analysis.'
+image: 'https://assets.bytebytego.com/diagrams/0192-five-pandas.jpg'
+createdAt: '2024-03-08'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - Pandas
+ - Data Manipulation
+---
+
+
+
+How do we quickly merge data without Microsoft Excel?
+
+Here are 5 useful pandas functions for production data analysis.
+
+- **Concat:** this function supports the vertical and horizontal combination of two tables. Concat can quickly combine the data from different shards.
+- **Append:** this function supports the adding of data to an existing table. Append can be used in web crawlers. The new data can be appended to the table when it is crawled.
+- **Merge:** this function supports horizontal combination on keys. It works similarly to database joins. Merge can be used to combine data from different domains with the same keys.
+- **Join:** this function works similarly to database outer joins.
+- **Combine:** this function can apply calculations while combining two tables. The example below chooses the smaller value for the cell. Combine is useful for a data cleansing process.
diff --git a/data/guides/5-http-status-codes-that-should-never-have-been-created.md b/data/guides/5-http-status-codes-that-should-never-have-been-created.md
new file mode 100644
index 0000000..d63c050
--- /dev/null
+++ b/data/guides/5-http-status-codes-that-should-never-have-been-created.md
@@ -0,0 +1,20 @@
+---
+title: '5 HTTP Status Codes That Should Never Have Been Created'
+description: 'Explore 5 HTTP status codes that are quirky, humorous, or problematic.'
+image: 'https://assets.bytebytego.com/diagrams/0232-http-status-code-shouldnt-exist.png'
+createdAt: '2024-01-27'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP Status Codes
+ - Web Development
+---
+
+
+
+* **451 Unavailable for Legal Reasons:** Access denied due to legal issues.
+* **218 This is Fine:** Inspired by the meme, bypasses server error overrides.
+* **420 Enhance Your Calm:** Twitter’s old code for exceeding rate limits. Now changed to 429.
+* **530 Site Frozen:** Used by Pantheon for locked sites, often unpaid bills.
+* **418 I'm a Teapot:** A classic April Fool's joke indicating a server's limitations.
diff --git a/data/guides/5-important-components-of-linux.md b/data/guides/5-important-components-of-linux.md
new file mode 100644
index 0000000..470fd59
--- /dev/null
+++ b/data/guides/5-important-components-of-linux.md
@@ -0,0 +1,36 @@
+---
+title: "5 Important Components of Linux"
+description: "Explore the core components of the Linux operating system."
+image: "https://assets.bytebytego.com/diagrams/0253-learn-linux.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "linux"
+ - "operating-systems"
+---
+
+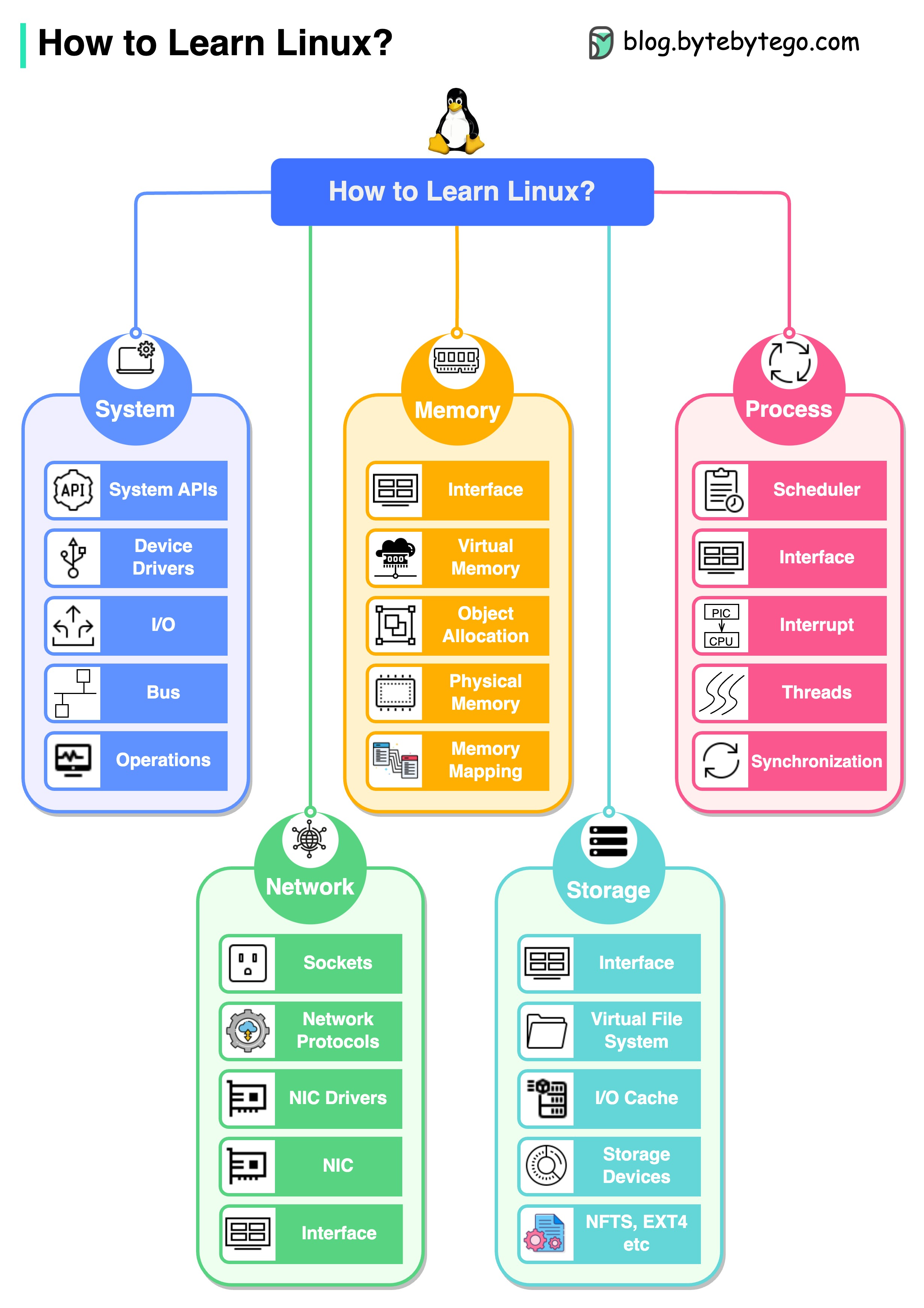
+
+Here are the five important components of Linux:
+
+* **System**
+
+ In the system component, we need to learn modules like system APIs, device drivers, I/O, buses, etc.
+
+* **Memory**
+
+ In memory management, we need to learn modules like physical memory, virtual memory, memory mappings, object allocation, etc.
+
+* **Process**
+
+ In process management, we need to learn modules like process scheduling, interrupts, threads, synchronization, etc.
+
+* **Network**
+
+ In the network component, we need to learn important modules like network protocols, sockets, NIC drivers, etc.
+
+* **Storage**
+
+ In system storage management, we need to learn modules like file systems, I/O caches, different storage devices, file system implementations, etc.
diff --git a/data/guides/6-software-architectural-patterns-you-must-know.md b/data/guides/6-software-architectural-patterns-you-must-know.md
new file mode 100644
index 0000000..48edd71
--- /dev/null
+++ b/data/guides/6-software-architectural-patterns-you-must-know.md
@@ -0,0 +1,52 @@
+---
+title: "6 Software Architectural Patterns You Must Know"
+description: "Explore 6 key software architectural patterns for efficient problem-solving."
+image: "https://assets.bytebytego.com/diagrams/0008-6-software-architectural-patterns-you-must-know.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Architecture"
+ - "Design Patterns"
+---
+
+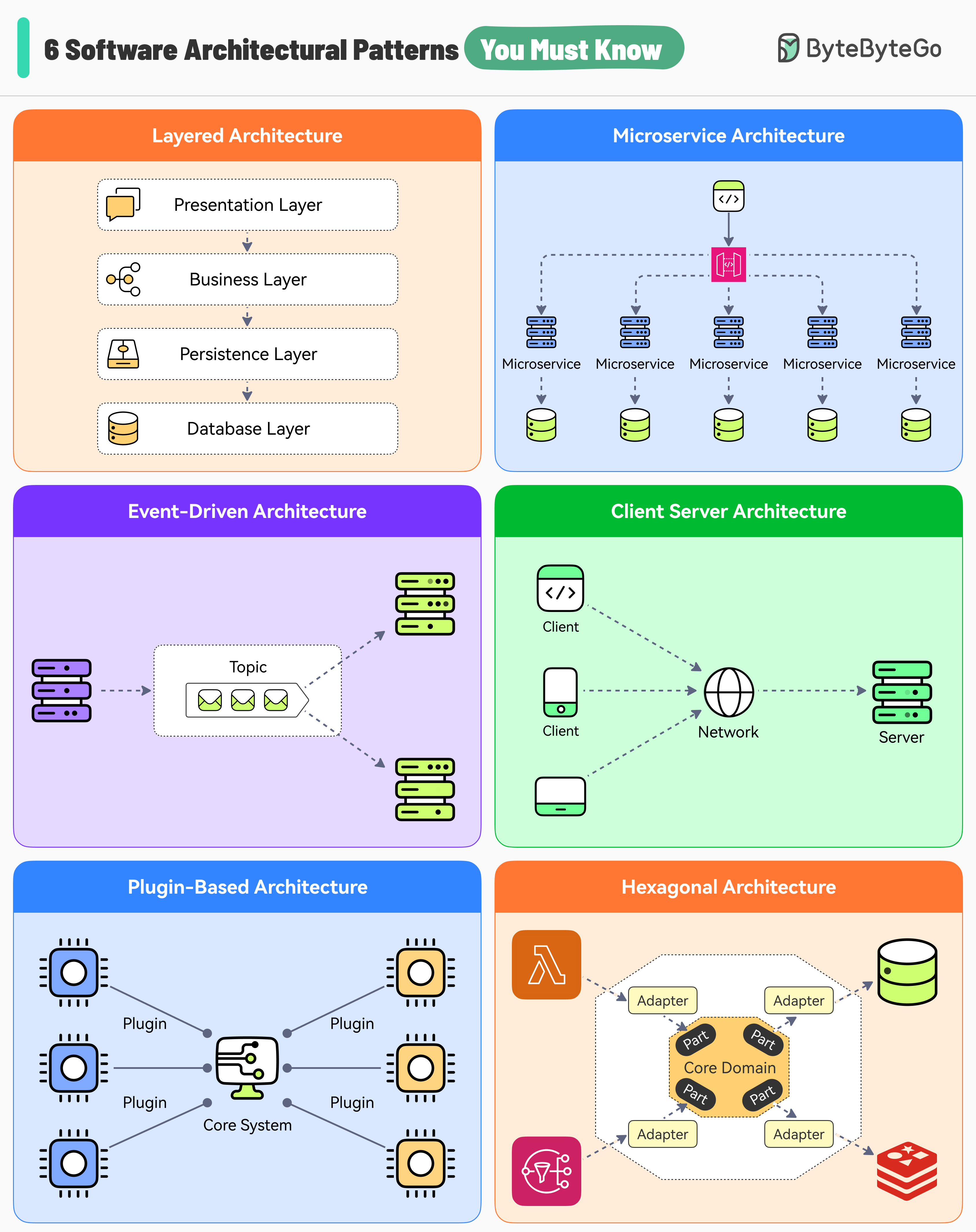
+
+Choosing the right software architecture pattern is essential for solving problems efficiently.
+
+## 1. Layered Architecture
+
+Each layer plays a distinct and clear role within the application context.
+
+Great for applications that need to be built quickly. On the downside, source code can become unorganized if proper rules aren’t followed.
+
+## 2. Microservices Architecture
+
+Break down a large system into smaller and more manageable components.
+
+Systems built with microservices architecture are fault tolerant. Also, each component can be scaled individually. On the downside, it might increase the complexity of the application.
+
+## 3. Event-Driven Architecture
+
+Services talk to each other by emitting events that other services may or may not consume.
+
+This style promotes loose coupling between components. However, testing individual components becomes challenging.
+
+## 4. Client-Server Architecture
+
+It comprises two main components - clients and servers communicating over a network.
+
+Great for real-time services. However, servers can become a single point of failure.
+
+## 5. Plugin-based Architecture
+
+This pattern consists of two types of components - a core system and plugins. The plugin modules are independent components providing a specialized functionality.
+
+Great for applications that have to be expanded over time like IDEs. However, changing the core is difficult.
+
+## 6. Hexagonal Architecture
+
+This pattern creates an abstraction layer that protects the core of an application and isolates it from external integrations for better modularity. Also known as ports and adapters architecture.
+
+On the downside, this pattern can lead to increased development time and learning curve.
diff --git a/data/guides/7-must-know-strategies-to-scale-your-database.md b/data/guides/7-must-know-strategies-to-scale-your-database.md
new file mode 100644
index 0000000..9b74b22
--- /dev/null
+++ b/data/guides/7-must-know-strategies-to-scale-your-database.md
@@ -0,0 +1,42 @@
+---
+title: "7 Must-Know Strategies to Scale Your Database"
+description: "Explore 7 key strategies to effectively scale your database."
+image: "https://assets.bytebytego.com/diagrams/0161-database-scaling-cheatsheet.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "database scaling"
+ - "database optimization"
+---
+
+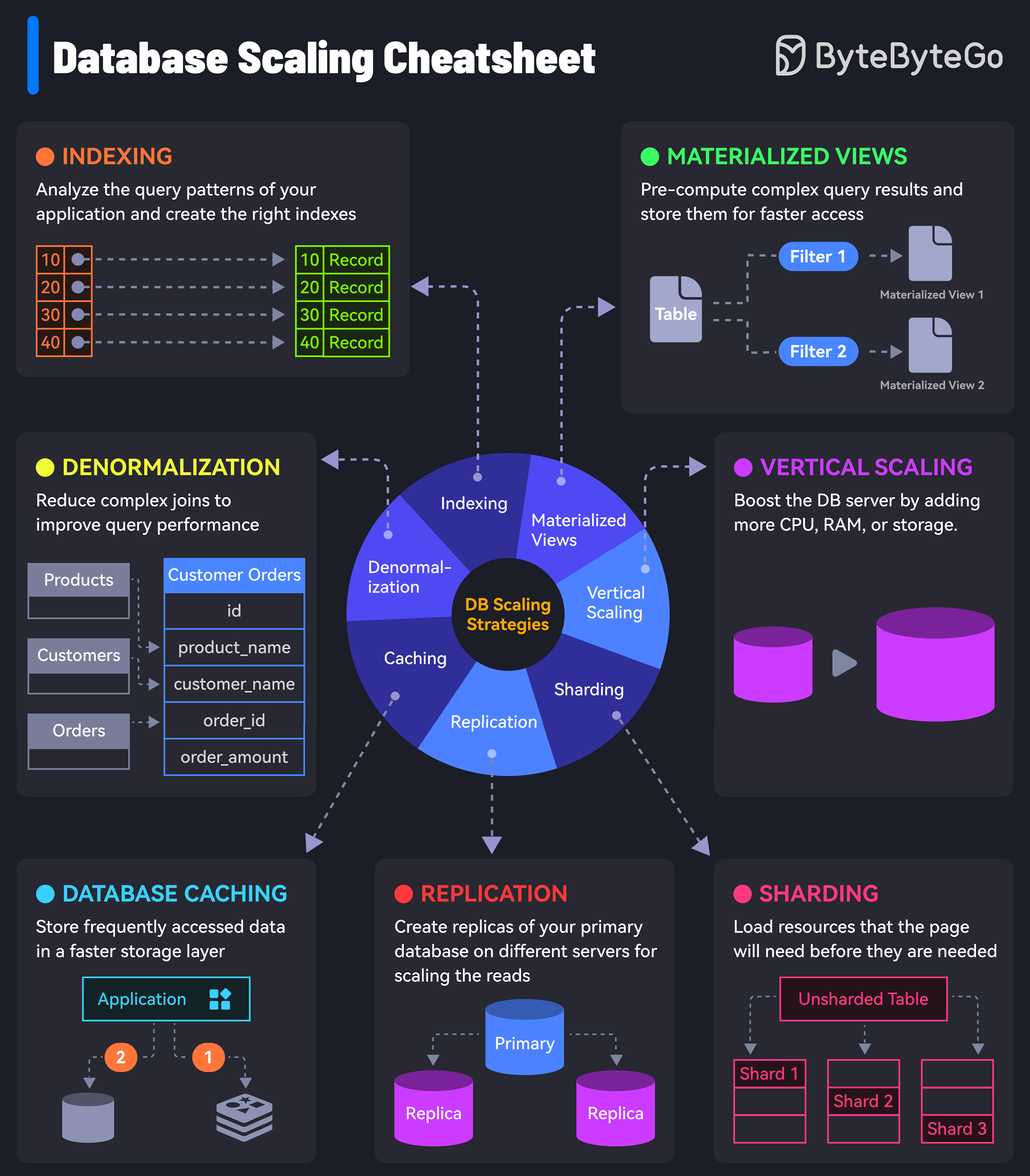
+
+## 1. Indexing
+
+Check the query patterns of your application and create the right indexes.
+
+## 2. Materialized Views
+
+Pre-compute complex query results and store them for faster access.
+
+## 3. Denormalization
+
+Reduce complex joins to improve query performance.
+
+## 4. Vertical Scaling
+
+Boost your database server by adding more CPU, RAM, or storage.
+
+## 5. Caching
+
+Store frequently accessed data in a faster storage layer to reduce database load.
+
+## 6. Replication
+
+Create replicas of your primary database on different servers for scaling the reads.
+
+## 7. Sharding
+
+Split your database tables into smaller pieces and spread them across servers. Used for scaling the writes as well as the reads.
diff --git a/data/guides/8-common-system-design-problems-and-solutions.md b/data/guides/8-common-system-design-problems-and-solutions.md
new file mode 100644
index 0000000..78e1f26
--- /dev/null
+++ b/data/guides/8-common-system-design-problems-and-solutions.md
@@ -0,0 +1,54 @@
+---
+title: "8 Common System Design Problems and Solutions"
+description: "Explore 8 common system design problems and their effective solutions."
+image: "https://assets.bytebytego.com/diagrams/0010-common-system-design-problems-and-solutions.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - System Design
+ - Scalability
+---
+
+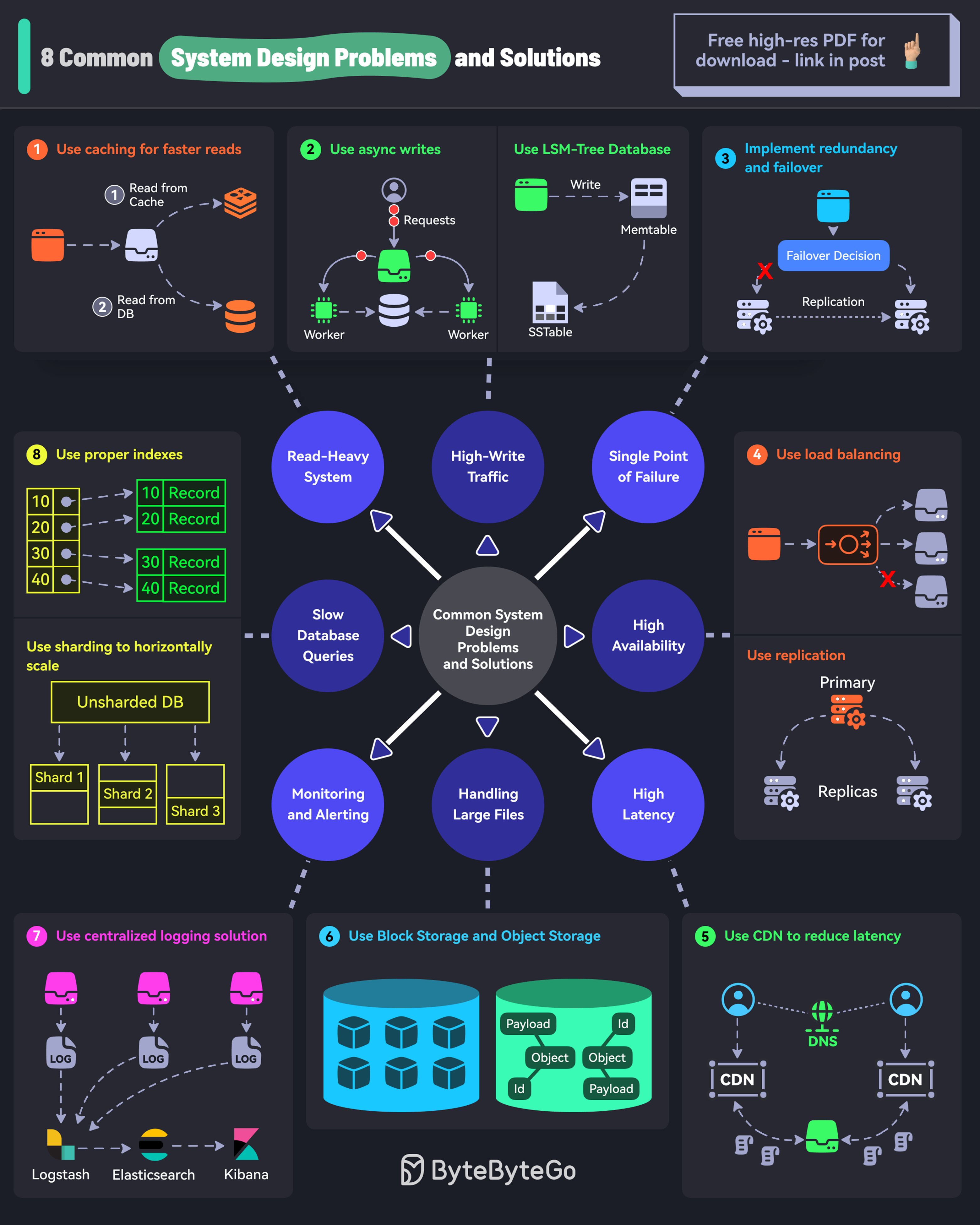
+
+Do you know those 8 common problems in large-scale production systems and their solutions? Time to test your skills!!
+
+## 1. Read-Heavy System
+
+Use caching to make the reads faster.
+
+## 2. High-Write Traffic
+
+* Use async workers to process the writes
+
+* Use databases powered by LSM-Trees
+
+## 3. Single Point of Failure
+
+Implement redundancy and failover mechanisms for critical components like databases.
+
+## 4. High Availability
+
+* Use load balancing to ensure that requests go to healthy server instances.
+
+* Use database replication to improve durability and availability.
+
+## 5. High Latency
+
+Use a content delivery network to reduce latency.
+
+## 6. Handling Large Files
+
+Use block storage and object storage to handle large files and complex data.
+
+## 7. Monitoring and Alerting
+
+Use a centralized logging system using something like the ELK stack.
+
+## 8. Slower Database Queries
+
+* Use proper indexes to optimize queries.
+
+* Use sharding to scale the database horizontally.
diff --git a/data/guides/8-data-structures-that-power-your-databases.md b/data/guides/8-data-structures-that-power-your-databases.md
new file mode 100644
index 0000000..2f83ea4
--- /dev/null
+++ b/data/guides/8-data-structures-that-power-your-databases.md
@@ -0,0 +1,36 @@
+---
+title: "8 Data Structures That Power Your Databases"
+description: "Explore 8 key data structures that drive database efficiency."
+image: "https://assets.bytebytego.com/diagrams/0181-eight-ds-db.jpg"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - Data Structures
+ - Databases
+---
+
+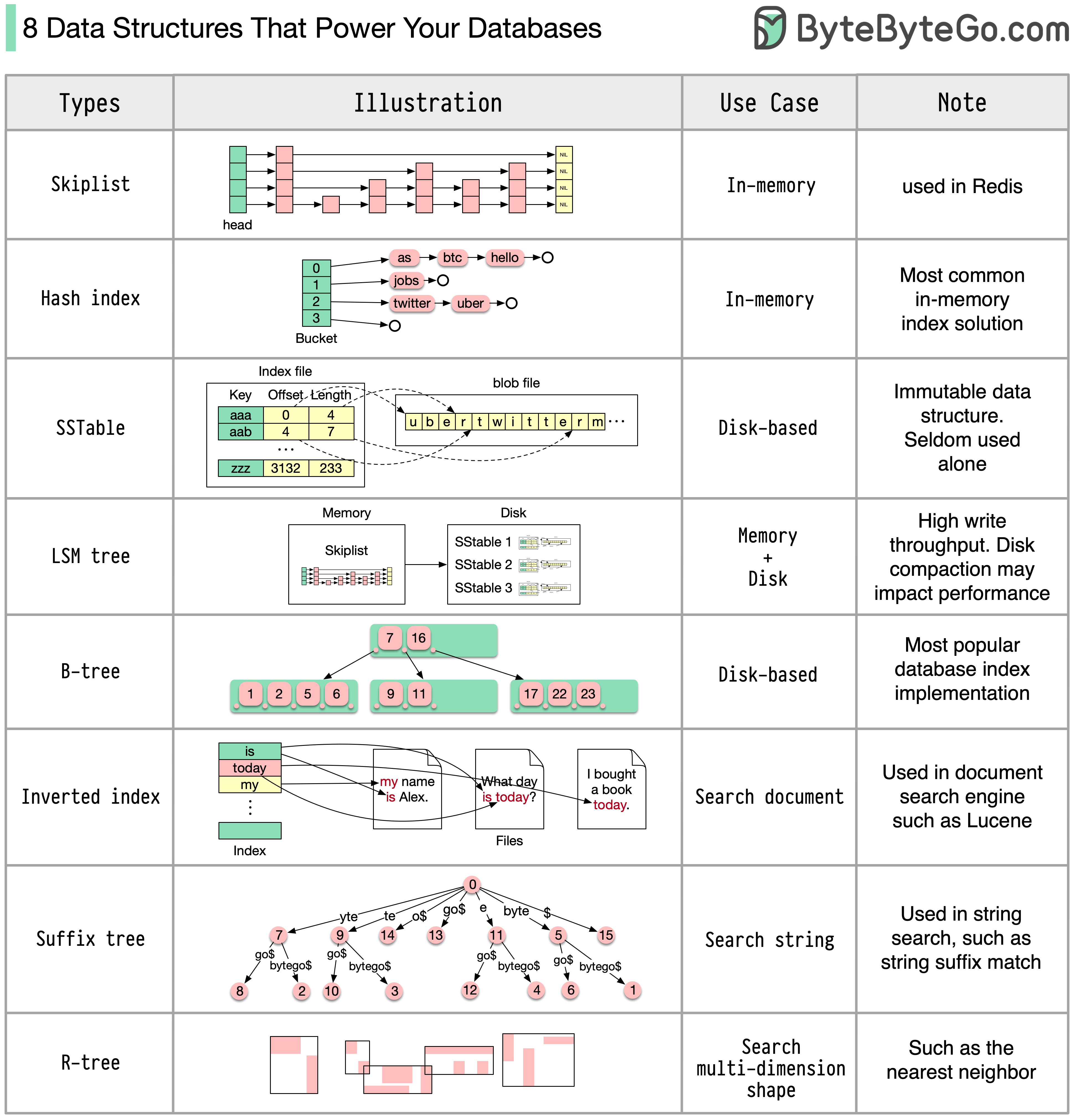
+
+The answer will vary depending on your use case. Data can be indexed in memory or on disk. Similarly, data formats vary, such as numbers, strings, geographic coordinates, etc. The system might be write-heavy or read-heavy. All of these factors affect your choice of database index format.
+
+The following are some of the most popular data structures used for indexing data:
+
+* **Skiplist:** a common in-memory index type. Used in Redis
+
+* **Hash index:** a very common implementation of the “Map” data structure (or “Collection”)
+
+* **SSTable:** immutable on-disk “Map” implementation
+
+* **LSM tree:** Skiplist + SSTable. High write throughput
+
+* **B-tree:** disk-based solution. Consistent read/write performance
+
+* **Inverted index:** used for document indexing. Used in Lucene
+
+* **Suffix tree:** for string pattern search
+
+* **R-tree:** multi-dimension search, such as finding the nearest neighbor
+
+This is not an exhaustive list of all database index types.
diff --git a/data/guides/8-key-concepts-in-ddd.md b/data/guides/8-key-concepts-in-ddd.md
new file mode 100644
index 0000000..e306a39
--- /dev/null
+++ b/data/guides/8-key-concepts-in-ddd.md
@@ -0,0 +1,52 @@
+---
+title: "8 Key Concepts in Domain-Driven Design"
+description: "Explore 8 key concepts in Domain-Driven Design for better software."
+image: "https://assets.bytebytego.com/diagrams/0011-8-key-concepts-in-ddd.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - DDD
+ - Software Design
+---
+
+
+
+Domain-driven design advocates driving the design of software through domain modeling.
+
+Unified language is one of the key concepts of domain-driven design. A domain model is a bridge across the business domains.
+
+## Domain Driven Design
+
+Domain-driven design advocates driving the design of software through domain modeling.
+
+Unified language is one of the key concepts of domain-driven design. A domain model is a bridge across the business domains.
+
+## Business Entities
+
+The use of models can assist in expressing business concepts and knowledge and in guiding further development of software, such as databases, APIs, etc.
+
+## Model Boundaries
+
+Loose boundaries among sets of domain models are used to model business correlations.
+
+## Aggregation
+
+An Aggregate is a cluster of related objects (entities and value objects) that are treated as a single unit for the purpose of data changes.
+
+## Entities vs. Value Objects
+
+In addition to aggregate roots and entities, there are some models that look like disposable, they don't have their own ID to identify them, but are more as part of some entity that expresses a collection of several fields.
+
+## Operational Modeling
+
+In domain-driven design, in order to manipulate these models, there are a number of objects that act as "operators".
+
+## Layering the architecture
+
+In order to better organize the various objects in a project, we need to simplify the complexity of complex projects by layering them like a computer network.
+
+## Build the domain model
+
+Many methods have been invented to extract domain models from business knowledge.
diff --git a/data/guides/8-key-oop-concepts-every-developer-should-know.md b/data/guides/8-key-oop-concepts-every-developer-should-know.md
new file mode 100644
index 0000000..e5f0a43
--- /dev/null
+++ b/data/guides/8-key-oop-concepts-every-developer-should-know.md
@@ -0,0 +1,22 @@
+---
+title: "8 Key OOP Concepts Every Developer Should Know"
+description: "Learn the 8 key OOP concepts every developer should know."
+image: "https://assets.bytebytego.com/diagrams/0294-oo-concepts.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "OOP"
+ - "Programming"
+---
+
+
+
+Object-Oriented Programming (OOP) has been around since the 1960s, but it really took off in the 1990s with languages like Java and C++.
+
+Why is OOP Important? OOP allows you to create blueprints (called classes) for digital objects, and these objects know how to communicate with one another to make amazing things happen in your software. Having a well-organized toolbox rather than a jumbled drawer of tools makes your code tidier and easier to change.
+
+In order to get to grips with OOP, think of it as creating digital Lego blocks that can be combined in countless ways. Take a book or watch some tutorials, and then practice writing code - there's no better way to learn than to practice!
+
+Don't be afraid of OOP - it's a powerful tool in your coder's toolbox, and with some practice, you'll be able to develop everything from nifty apps to digital skyscrapers!
diff --git a/data/guides/8-must-know-scalability-strategies.md b/data/guides/8-must-know-scalability-strategies.md
new file mode 100644
index 0000000..9dd5b45
--- /dev/null
+++ b/data/guides/8-must-know-scalability-strategies.md
@@ -0,0 +1,50 @@
+---
+title: "8 Must-Know Scalability Strategies"
+description: "Explore 8 essential strategies to effectively scale your system."
+image: "https://assets.bytebytego.com/diagrams/0013-8-must-know-strategies-to-scale-your-system.png"
+createdAt: "2024-01-27"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Scalability"
+ - "System Design"
+---
+
+What do Amazon, Netflix, and Uber have in common? They are extremely good at scaling their system whenever needed.
+
+
+
+Here are 8 must-know strategies to scale your system.
+
+* Stateless Services
+
+ Design stateless services because they don’t rely on server-specific data and are easier to scale.
+
+* Horizontal Scaling
+
+ Add more servers so that the workload can be shared.
+
+* Load Balancing
+
+ Use a load balancer to distribute incoming requests evenly across multiple servers.
+
+* Auto Scaling
+
+ Implement auto-scaling policies to adjust resources based on real-time traffic.
+
+* Caching
+
+ Use caching to reduce the load on the database and handle repetitive requests at scale.
+
+* Database Replication
+
+ Replicate data across multiple nodes to scale the read operations while improving redundancy.
+
+* Database Sharding
+
+ Distribute data across multiple instances to scale the writes as well as reads.
+
+* Async Processing
+
+ Move time-consuming and resource-intensive tasks to background workers using async processing to scale out new requests.
diff --git a/data/guides/8-tips-for-efficient-api-design.md b/data/guides/8-tips-for-efficient-api-design.md
new file mode 100644
index 0000000..96a8ec7
--- /dev/null
+++ b/data/guides/8-tips-for-efficient-api-design.md
@@ -0,0 +1,31 @@
+---
+title: '8 Tips for Efficient API Design'
+description: 'Improve your API design with these 8 essential tips for efficiency.'
+image: 'https://assets.bytebytego.com/diagrams/0385-top-8-tips-for-restful-api-design.png'
+createdAt: '2024-02-08'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Design
+ - Best Practices
+---
+
+
+
+* **Domain Model Driven**
+ When designing the path structure of a RESTful API, we can refer to the domain model.
+* **Choose Proper HTTP Methods**
+ Defining a few basic HTTP Methods can simplify the API design. For example, PATCH can often be a problem for teams.
+* **Implement Idempotence Properly**
+ Designing for idempotence in advance can improve the robustness of an API. GET method is idempotent, but POST needs to be designed properly to be idempotent.
+* **Choose Proper HTTP Status Codes**
+ Define a limited number of HTTP status codes to use to simplify application development.
+* **Versioning**
+ Designing the version number for the API in advance can simplify upgrade work.
+* **Semantic Paths**
+ Using semantic paths makes APIs easier to understand, so that users can find the correct APIs in the documentation.
+* **Batch Processing**
+ Use batch/bulk as a keyword and place it at the end of the path.
+* **Query Language**
+ Designing a set of query rules makes the API more flexible. For example, pagination, sorting, filtering etc.
diff --git a/data/guides/9-best-practices-for-building-microservices.md b/data/guides/9-best-practices-for-building-microservices.md
new file mode 100644
index 0000000..98b9672
--- /dev/null
+++ b/data/guides/9-best-practices-for-building-microservices.md
@@ -0,0 +1,66 @@
+---
+title: "9 Best Practices for Building Microservices"
+description: "Best practices for building robust and scalable microservices systems."
+image: "https://assets.bytebytego.com/diagrams/0019-9-best-practices-for-building-microservices.png"
+createdAt: '2024-03-05'
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Microservices"
+ - "Architecture"
+---
+
+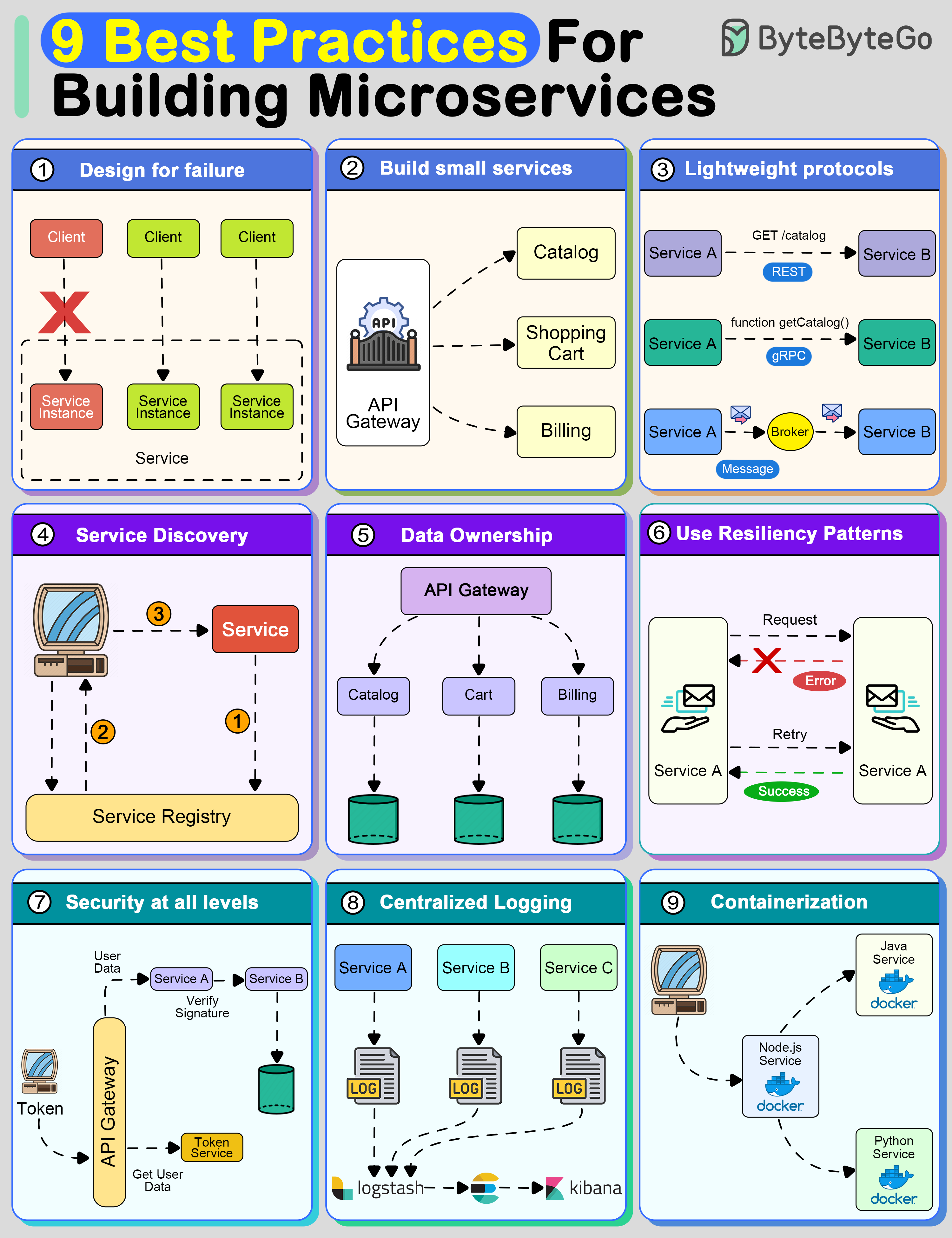
+
+Creating a system using microservices is extremely difficult unless you follow some strong principles.
+
+## 1. Design For Failure
+
+A distributed system with microservices is going to fail.
+
+You must design the system to tolerate failure at multiple levels such as infrastructure, database, and individual services. Use circuit breakers, bulkheads, or graceful degradation methods to deal with failures.
+
+## 2. Build Small Services
+
+A microservice should not do multiple things at once.
+
+A good microservice is designed to do one thing well.
+
+## 3. Use lightweight protocols for communication
+
+Communication is the core of a distributed system.
+
+Microservices must talk to each other using lightweight protocols. Options include REST, gRPC, or message brokers.
+
+## 4. Implement service discovery
+
+To communicate with each other, microservices need to discover each other over the network.
+
+Implement service discovery using tools such as Consul, Eureka, or Kubernetes Services
+
+## 5. Data Ownership
+
+In microservices, data should be owned and managed by the individual services.
+
+The goal should be to reduce coupling between services so that they can evolve independently.
+
+## 6. Use resiliency patterns
+
+Implement specific resiliency patterns to improve the availability of the services.
+
+Examples: retry policies, caching, and rate limiting.
+
+## 7. Security at all levels
+
+In a microservices-based system, the attack surface is quite large. You must implement security at every level of the service communication path.
+
+## 8. Centralized logging
+
+Logs are important to finding issues in a system. With multiple services, they become critical.
+
+## 9. Use containerization techniques
+
+To deploy microservices in an isolated manner, use containerization techniques.
+
+Tools like Docker and Kubernetes can help with this as they are meant to simplify the scaling and deployment of a microservice.
diff --git a/data/guides/9-best-practices-for-developing-microservices.md b/data/guides/9-best-practices-for-developing-microservices.md
new file mode 100644
index 0000000..f93c99a
--- /dev/null
+++ b/data/guides/9-best-practices-for-developing-microservices.md
@@ -0,0 +1,36 @@
+---
+title: "9 Best Practices for Developing Microservices"
+description: "Explore 9 key practices for effective microservices development."
+image: "https://assets.bytebytego.com/diagrams/0275-micro-best-practices.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "microservices"
+ - "best practices"
+---
+
+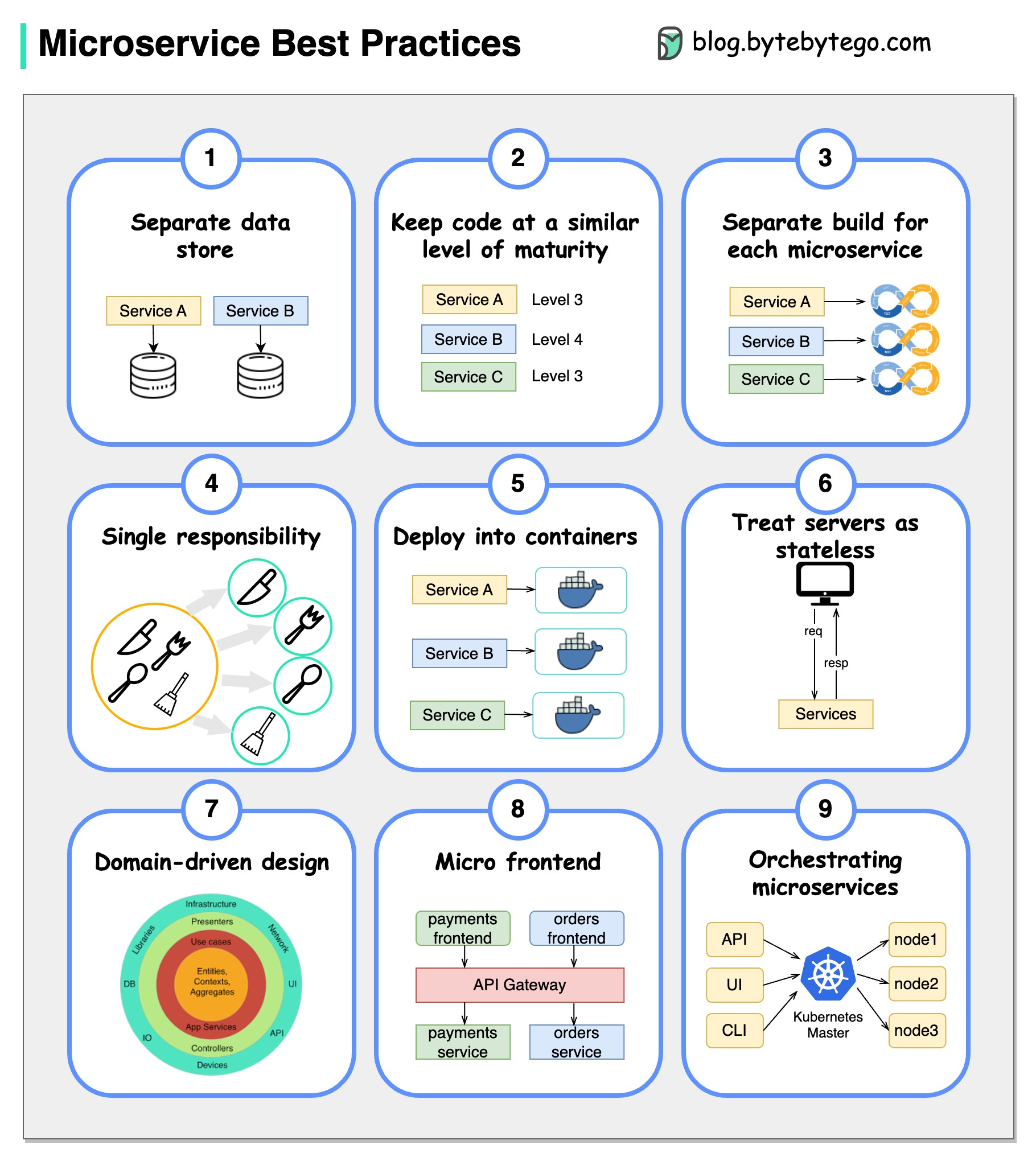
+
+When developing microservices, it's crucial to follow these best practices:
+
+## Best Practices
+
+* **Use separate data storage for each microservice**
+
+* **Keep code at a similar level of maturity**
+
+* **Separate build for each microservice**
+
+* **Assign each microservice with a single responsibility**
+
+* **Deploy into containers**
+
+* **Design stateless services**
+
+* **Adopt domain-driven design**
+
+* **Design micro frontend**
+
+* **Orchestrating microservices**
diff --git a/data/guides/9-docker-best-practices-you-must-know.md b/data/guides/9-docker-best-practices-you-must-know.md
new file mode 100644
index 0000000..664fa5a
--- /dev/null
+++ b/data/guides/9-docker-best-practices-you-must-know.md
@@ -0,0 +1,52 @@
+---
+title: "9 Docker Best Practices You Must Know"
+description: "Learn 9 essential Docker best practices for efficient containerization."
+image: "https://assets.bytebytego.com/diagrams/0016-9-docker-best-practices-you-must-know.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Docker
+ - Containerization
+---
+
+
+
+## 1. Use official images
+
+This ensures security, reliability, and regular updates.
+
+## 2. Use a specific image version
+
+The default latest tag is unpredictable and causes unexpected behavior.
+
+## 3. Multi-Stage builds
+
+Reduces final image size by excluding build tools and dependencies.
+
+## 4. Use .dockerignore
+
+Excludes unnecessary files, speeds up builds, and reduces image size.
+
+## 5. Use the least privileged user
+
+Enhances security by limiting container privileges.
+
+## 6. Use environment variables
+
+Increases flexibility and portability across different environments.
+
+## 7. Order matters for caching
+
+Order your steps from least to most frequently changing to optimize caching.
+
+## 8. Label your images
+
+It improves organization and helps with image management.
+
+## 9. Scan images
+
+Find security vulnerabilities before they become bigger problems.
+
+Over to you: Which other Docker best practices will you add to the list?
diff --git a/data/guides/9-essential-components-of-a-production-microservice-application.md b/data/guides/9-essential-components-of-a-production-microservice-application.md
new file mode 100644
index 0000000..30f8d6c
--- /dev/null
+++ b/data/guides/9-essential-components-of-a-production-microservice-application.md
@@ -0,0 +1,50 @@
+---
+title: "9 Essential Components of a Production Microservice Application"
+description: "Explore 9 key components for building robust microservice applications."
+image: "https://assets.bytebytego.com/diagrams/0020-9-essential-components-of-production-microservice-app.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Microservices
+ - Architecture
+---
+
+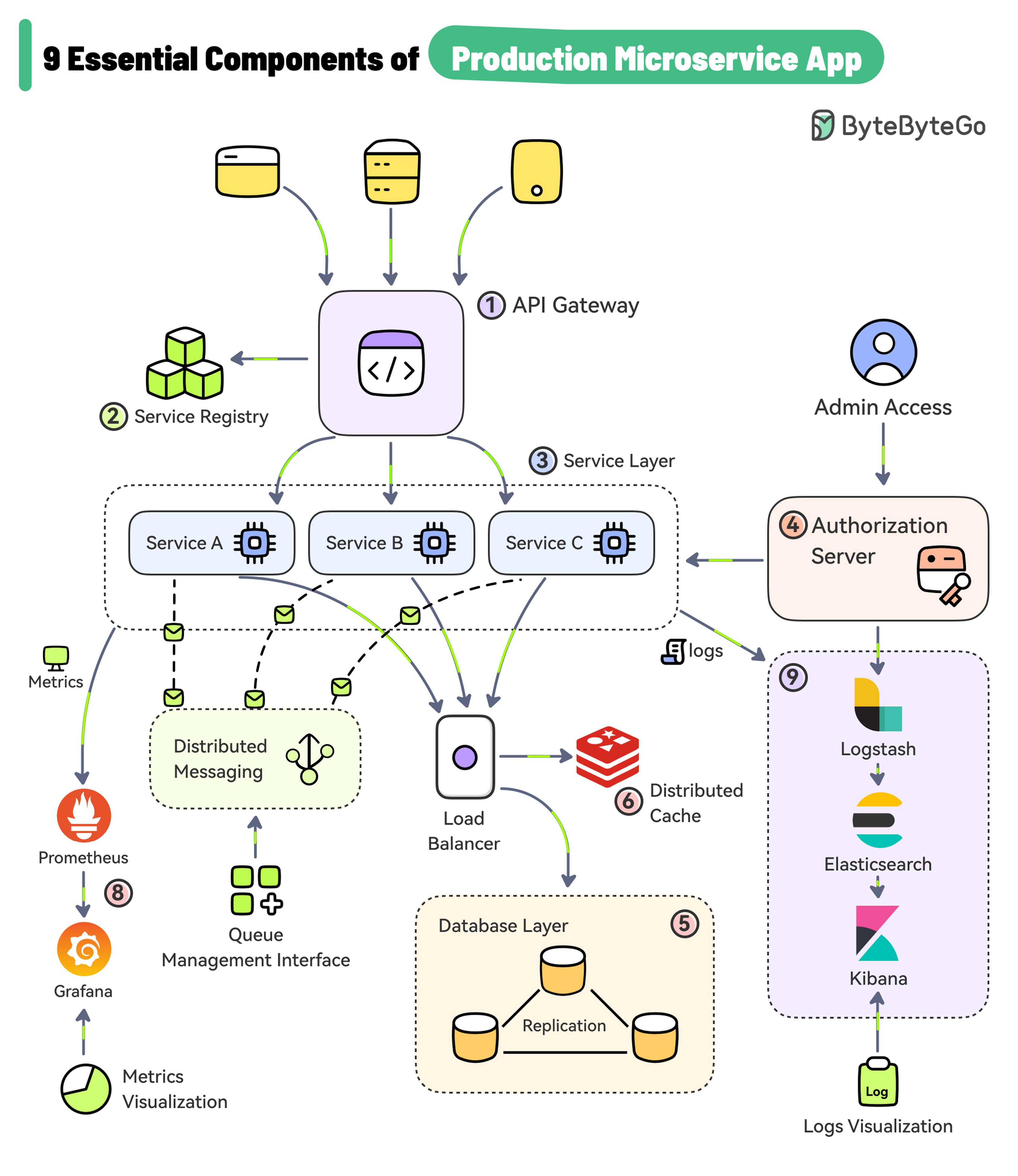
+
+## 1. API Gateway
+
+The gateway provides a unified entry point for client applications. It handles routing, filtering, and load balancing.
+
+## 2. Service Registry
+
+The service registry contains the details of all the services. The gateway discovers the service using the registry. For example, Consul, Eureka, Zookeeper, etc.
+
+## 3. Service Layer
+
+Each microservice serves a specific business function and can run on multiple instances. These services can be built using frameworks like Spring Boot, NestJS, etc.
+
+## 4. Authorization Server
+
+Used to secure the microservices and manage identity and access control. Tools like Keycloak, Azure AD, and Okta can help over here.
+
+## 5. Data Storage
+
+Databases like PostgreSQL and MySQL can store application data generated by the services.
+
+## 6. Distributed Caching
+
+Caching is a great approach for boosting the application performance. Options include caching solutions like Redis, Couchbase, Memcached, etc.
+
+## 7. Async Microservices Communication
+
+Use platforms such as Kafka and RabbitMQ to support async communication between microservices.
+
+## 8. Metrics Visualization
+
+Microservices can be configured to publish metrics to Prometheus and tools like Grafana can help visualize the metrics.
+
+## 9. Log Aggregation and Visualization
+
+Logs generated by the services are aggregated using Logstash, stored in Elasticsearch, and visualized with Kibana.
diff --git a/data/guides/a-beginner's-guide-to-cdn-content-delivery-network.md b/data/guides/a-beginner's-guide-to-cdn-content-delivery-network.md
new file mode 100644
index 0000000..95bc699
--- /dev/null
+++ b/data/guides/a-beginner's-guide-to-cdn-content-delivery-network.md
@@ -0,0 +1,28 @@
+---
+title: "A Beginner's Guide to CDN"
+description: "Learn about CDNs: improve performance, reliability, and security."
+image: "https://assets.bytebytego.com/diagrams/0025-a-beginner-s-guide-to-cdn.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "CDN"
+ - "Networking"
+---
+
+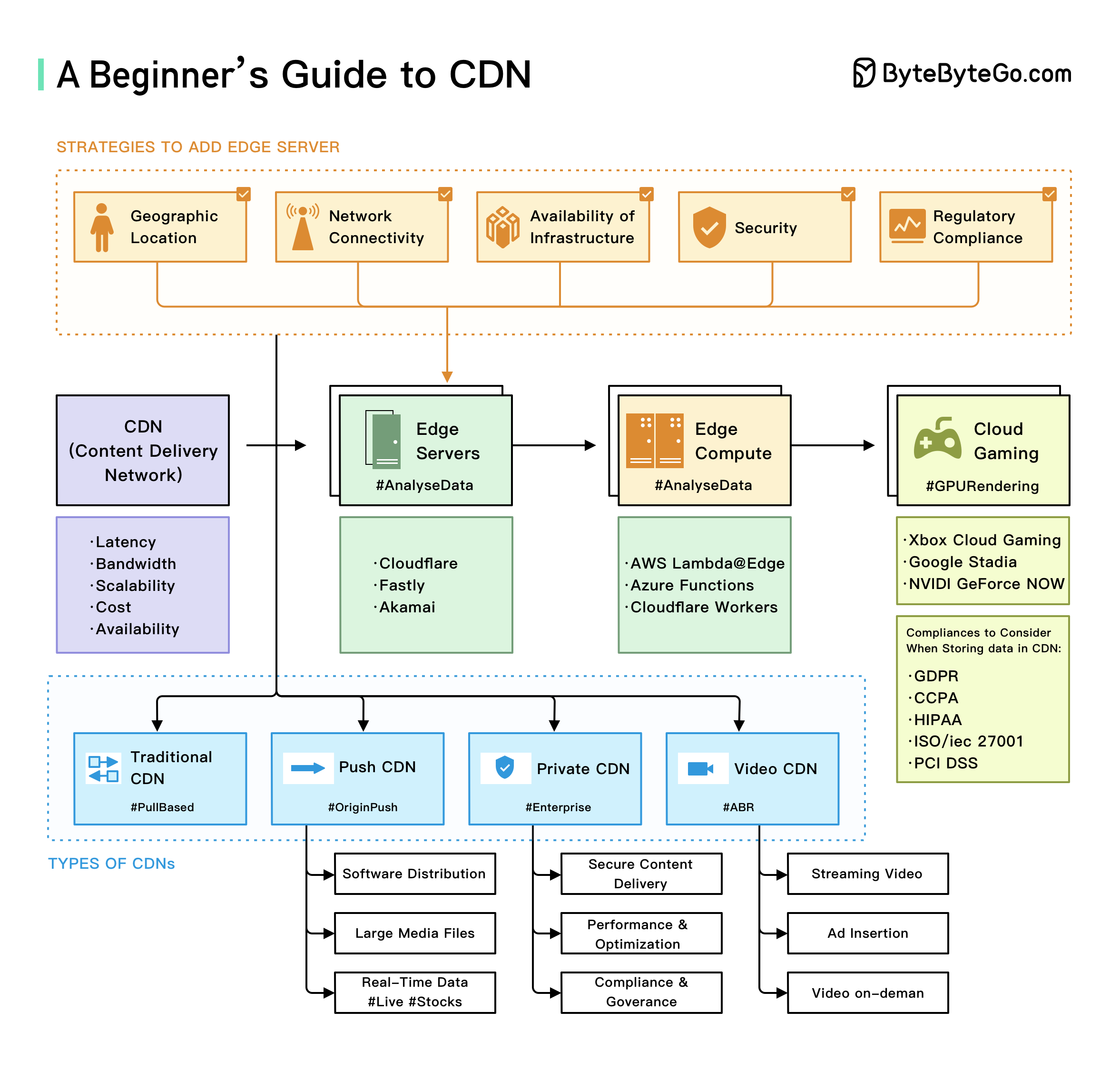
+
+A guest post by Love Sharma. You can read the full article [here](https://blog.devgenius.io/a-beginners-guide-to-cdn-what-it-is-and-how-it-works-f06946288fbb).
+
+CDNs are distributed server networks that help improve the performance, reliability, and security of content delivery on the internet.
+
+## The Overall CDN Diagram explains:
+
+* Edge servers are located closer to the end user than traditional servers, which helps reduce latency and improve website performance.
+
+* Edge computing is a type of computing that processes data closer to the end user rather than in a centralized data center. This helps to reduce latency and improve the performance of applications that require real-time processing, such as video streaming or online gaming.
+
+* Cloud gaming is online gaming that uses cloud computing to provide users with high-quality, low-latency gaming experiences.
+
+Together, these technologies are transforming how we access and consume digital content. By providing faster, more reliable, and more immersive experiences for users, they are helping to drive the growth of the digital economy and create new opportunities for businesses and consumers alike.
diff --git a/data/guides/a-brief-history-og-programming-languages.md b/data/guides/a-brief-history-og-programming-languages.md
new file mode 100644
index 0000000..eb62dcd
--- /dev/null
+++ b/data/guides/a-brief-history-og-programming-languages.md
@@ -0,0 +1,30 @@
+---
+title: "A Brief History of Programming Languages"
+description: "Explore the evolution of programming languages over the past 70 years."
+image: "https://assets.bytebytego.com/diagrams/0305-programming-languages.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - software-development
+tags:
+ - programming-languages
+ - history
+---
+
+C, C++, Java, Javascript, Typescript, Golang, Rust, how do programming languages evolve for the past 70 years?
+
+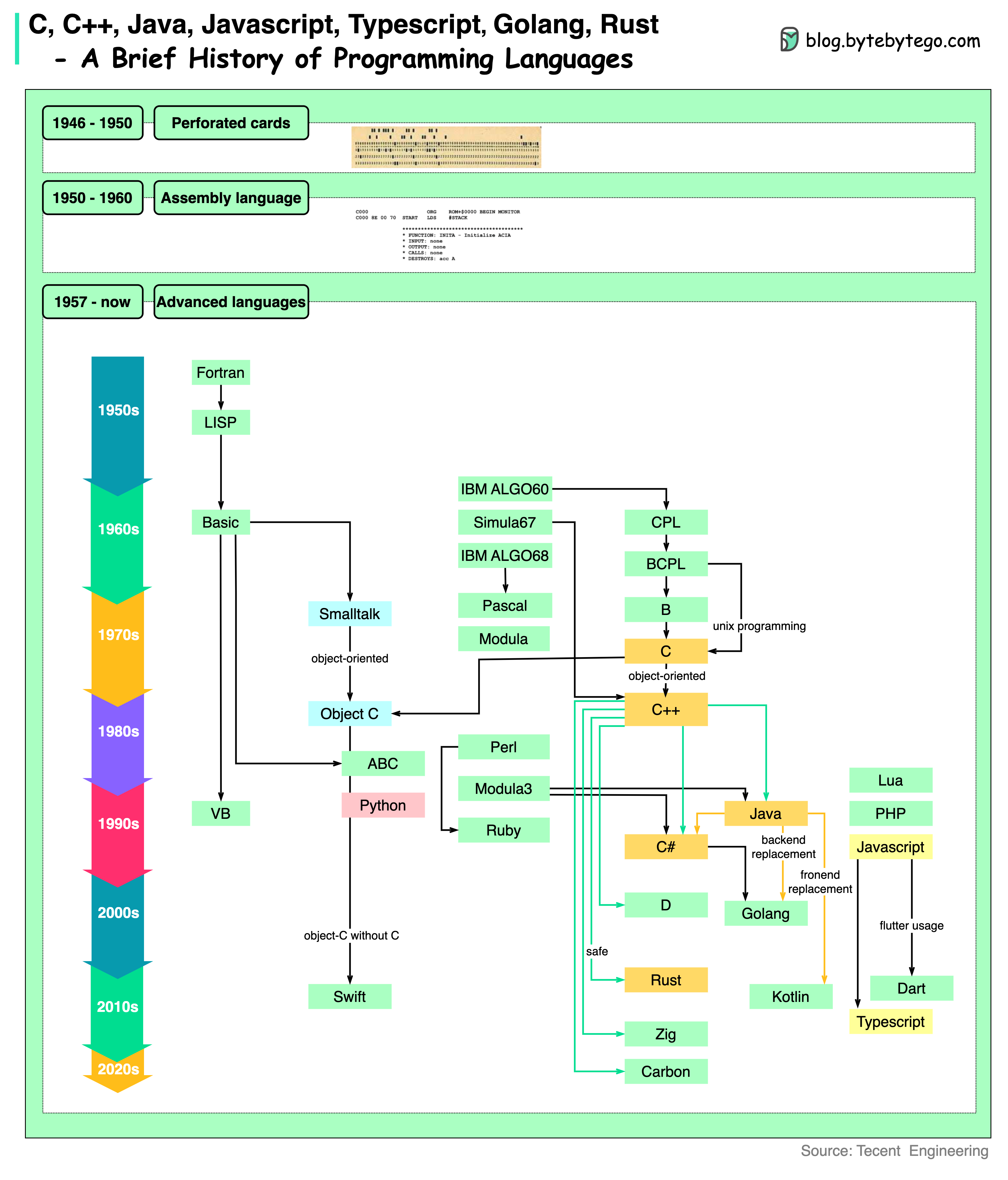 +
+* Perforated cards were the first generation of programming languages. Assembly languages, which are machine-oriented, are the second generation of programming language. Third-generation languages, which are human-oriented, have been around since 1957.
+
+* Early languages like Fortran and LISP proposed garbage collection, recursion, exceptions. These features still exist in modern programming languages.
+
+* In 1972, two influential languages were born: Smalltalk and C. Smalltalk greatly influenced scripting languages and client-side languages. C language was developed for unix programming.
+
+* In the 1980s, object-oriented languages became popular because of its advantage in graphic user interfaces. Object-C and C++ are two famous ones.
+
+* In the 1990s, the PCs became cheaper. The programming languages at this stage emphasized on security and simplicity. Python was born in this decade. It was easy to learn and extend and it quickly gained popularity. In 1995, Java, Javascript, PHP and Ruby were born.
+
+* In 2000, C# was released by Microsoft. Although it was bundled with .NET framework, this language carried a lot of advanced features.
+
+* A number of languages were developed in the 2010s to improve C++ or Java. In the C++ family, we have D, Rust, Zig and most recently Carbon. In the Java family, we have Golang and Kotlin. The use of Flutter made Dart popular, and Typescript was developed to be fully compatible with Javascript. Also, Apple finally released Swift to replace Object-C.
diff --git a/data/guides/a-cheat-sheet-for-api-designs.md b/data/guides/a-cheat-sheet-for-api-designs.md
new file mode 100644
index 0000000..1e51e00
--- /dev/null
+++ b/data/guides/a-cheat-sheet-for-api-designs.md
@@ -0,0 +1,40 @@
+---
+title: 'A cheat sheet for API designs'
+description: 'A handy cheat sheet for designing secure and efficient APIs.'
+image: 'https://assets.bytebytego.com/diagrams/0137-cheat-sheet-for-api-design.png'
+createdAt: '2024-02-14'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Design
+ - Security
+---
+
+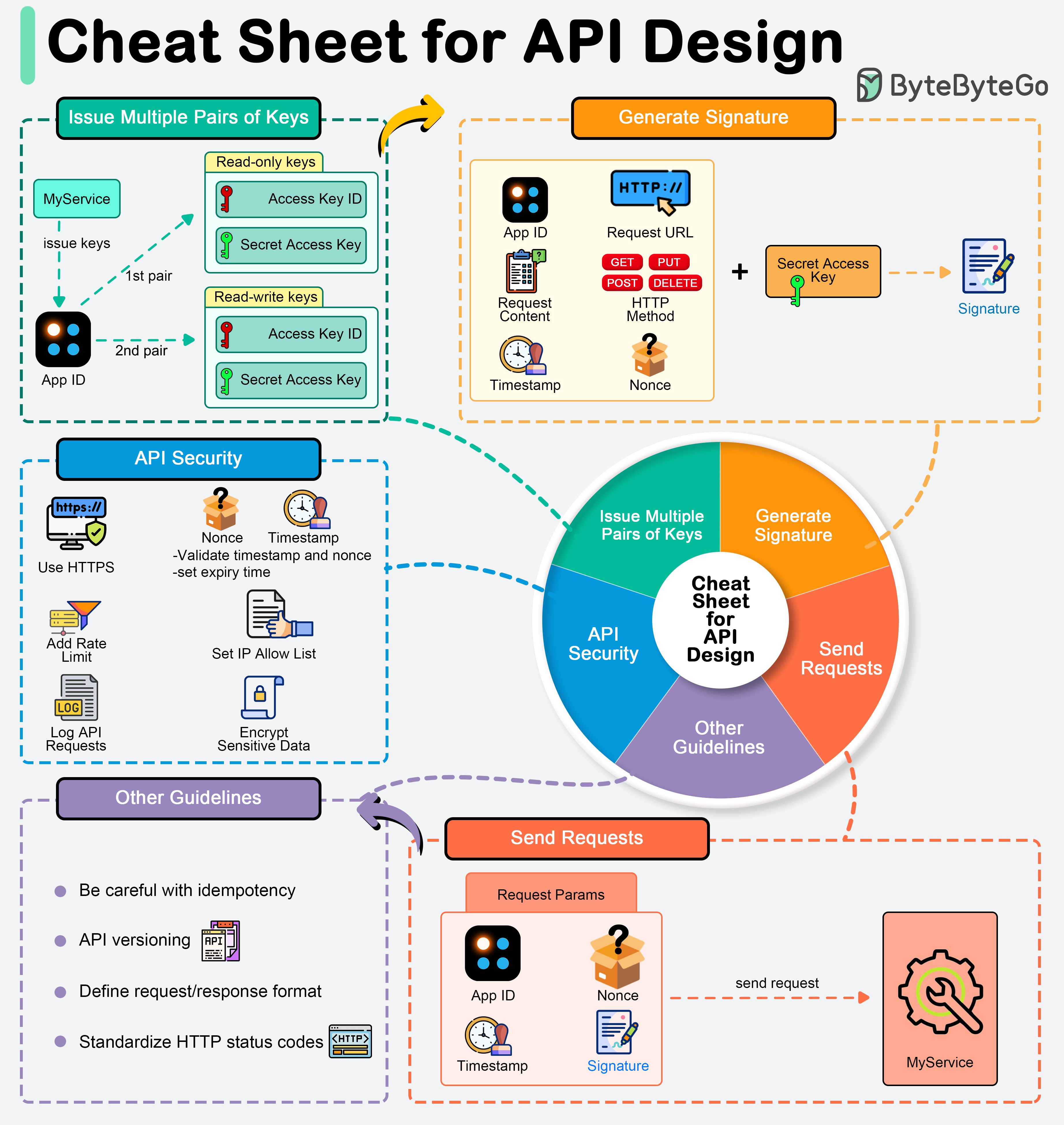
+
+APIs expose business logic and data to external systems, so designing them securely and efficiently is important.
+
+## API key generation
+
+We normally generate one unique app ID for each client and generate different pairs of public key (access key) and private key (secret key) to cater to different authorizations. For example, we can generate one pair of keys for read-only access and another pair for read-write access.
+
+## Signature generation
+
+Signatures are used to verify the authenticity and integrity of API requests. They are generated using the secret key and typically involve the following steps:
+
+* Collect parameters
+* Create a string to sign
+* Hash the string: Use a cryptographic hash function, like HMAC (Hash-based Message Authentication Code) in combination with SHA-256, to hash the string using the secret key.
+* Send the requests
+
+When designing an API, deciding what should be included in HTTP request parameters is crucial. Include the following in the request parameters:
+
+* Authentication Credentials
+* Timestamp: To prevent replay attacks.
+* Request-specific Data: Necessary to process the request, such as user IDs, transaction details, or search queries.
+* Nonces: Randomly generated strings included in each request to ensure that each request is unique and to prevent replay attacks.
+
+## Security guidelines
+
+To safeguard APIs against common vulnerabilities and threats, adhere to these security guidelines.
diff --git a/data/guides/a-cheat-sheet-for-designing-fault-tolerant-systems.md b/data/guides/a-cheat-sheet-for-designing-fault-tolerant-systems.md
new file mode 100644
index 0000000..d19fb06
--- /dev/null
+++ b/data/guides/a-cheat-sheet-for-designing-fault-tolerant-systems.md
@@ -0,0 +1,40 @@
+---
+title: "A Cheat Sheet for Designing Fault-Tolerant Systems"
+description: "Top principles for designing robust, fault-tolerant systems."
+image: "https://assets.bytebytego.com/diagrams/0139-cheat-sheet-for-fault-tolerant-systems.png"
+createdAt: "2024-02-14"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Fault Tolerance"
+ - "System Design"
+---
+
+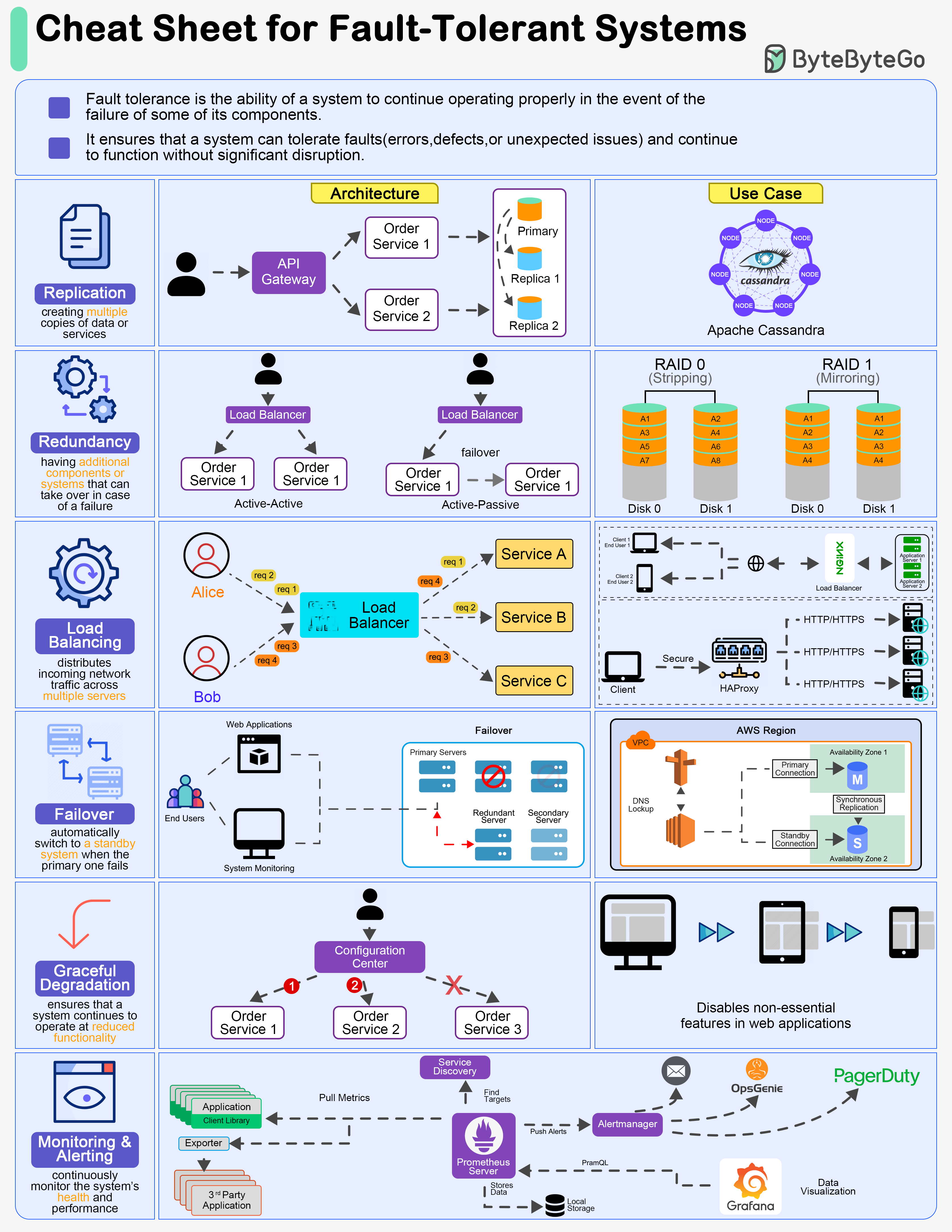
+
+Designing fault-tolerant systems is crucial for ensuring high availability and reliability in various applications. Here are six top principles of designing fault-tolerant systems:
+
+## Replication
+
+Replication involves creating multiple copies of data or services across different nodes or locations.
+
+## Redundancy
+
+Redundancy refers to having additional components or systems that can take over in case of a failure.
+
+## Load Balancing
+
+Load balancing distributes incoming network traffic across multiple servers to ensure no single server becomes a point of failure.
+
+## Failover Mechanisms
+
+Failover mechanisms automatically switch to a standby system or component when the primary one fails.
+
+## Graceful Degradation
+
+Graceful degradation ensures that a system continues to operate at reduced functionality rather than completely failing when some components fail.
+
+## Monitoring and Alerting
+
+Continuously monitor the system's health and performance, and set up alerts for any anomalies or failures.
diff --git a/data/guides/a-cheat-sheet-for-system-designs.md b/data/guides/a-cheat-sheet-for-system-designs.md
new file mode 100644
index 0000000..c2744c1
--- /dev/null
+++ b/data/guides/a-cheat-sheet-for-system-designs.md
@@ -0,0 +1,32 @@
+---
+title: "A cheat sheet for system designs"
+description: "15 core concepts for system design in a handy cheat sheet."
+image: "https://assets.bytebytego.com/diagrams/0352-a-cheat-sheet-for-system-designs.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "architecture"
+---
+
+
+
+The diagram below lists 15 core concepts when we design systems. The cheat sheet is straightforward to go through one by one. Save it for future reference!
+
+* Requirement gathering
+* System architecture
+* Data design
+* Domain design
+* Scalability
+* Reliability
+* Availability
+* Performance
+* Security
+* Maintainability
+* Testing
+* User experience design
+* Cost estimation
+* Documentation
+* Migration plan
diff --git a/data/guides/a-cheatsheet-for-uml-class-diagrams.md b/data/guides/a-cheatsheet-for-uml-class-diagrams.md
new file mode 100644
index 0000000..f7f3920
--- /dev/null
+++ b/data/guides/a-cheatsheet-for-uml-class-diagrams.md
@@ -0,0 +1,48 @@
+---
+title: "UML Class Diagrams Cheatsheet"
+description: "A quick reference guide to UML class diagrams and their components."
+image: "https://assets.bytebytego.com/diagrams/0399-a-cheatsheet-for-uml-class-diagrams.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - UML
+ - Design Patterns
+---
+
+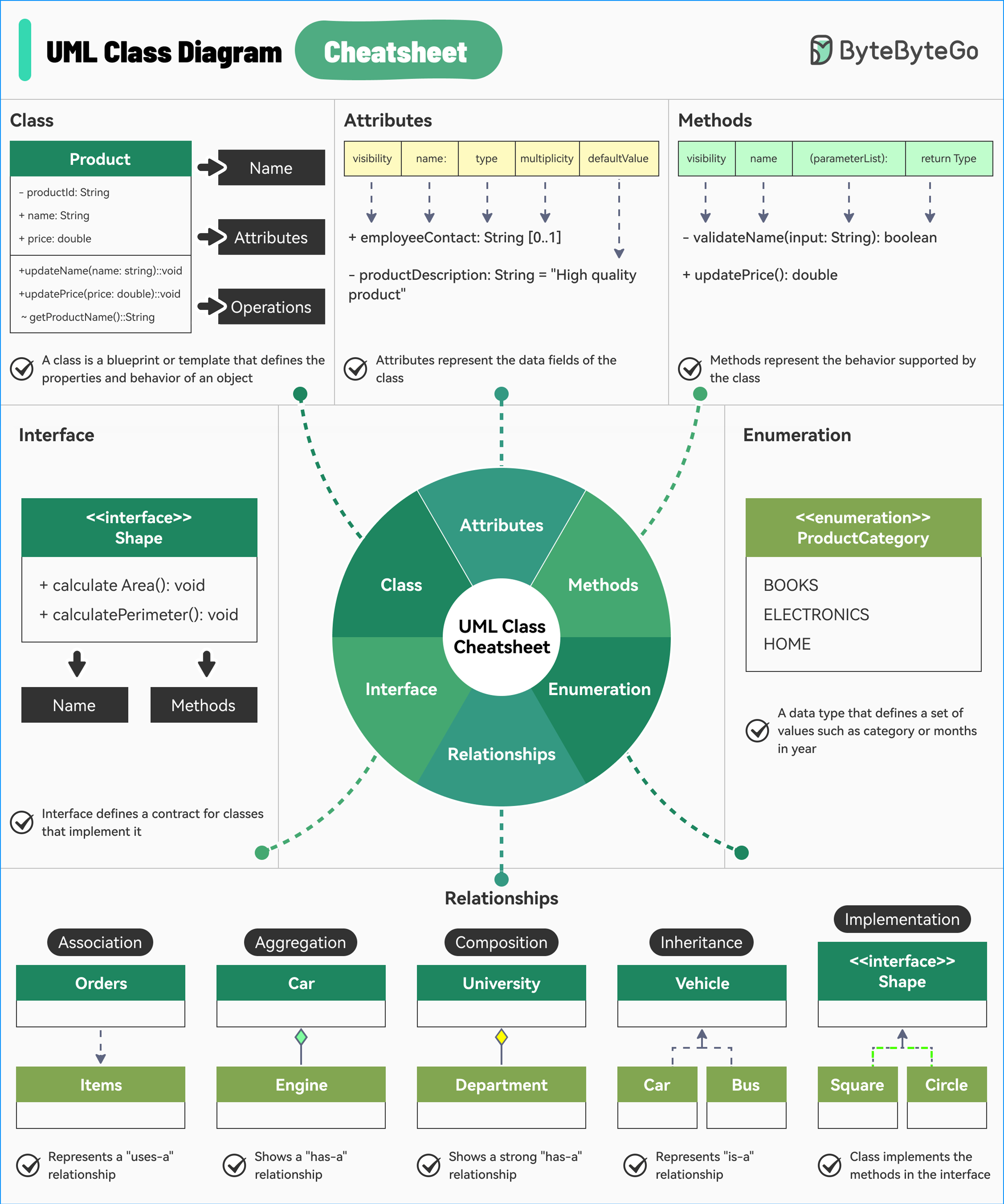
+
+UML is a standard way to visualize the design of your system and class diagrams are used across the industry.
+
+They consist of:
+
+* **Class**
+
+ Acts as the blueprint that defines the properties and behavior of an object.
+
+* **Attributes**
+
+ Attributes in a UML class diagram represent the data fields of the class.
+
+* **Methods**
+
+ Methods in a UML class diagram represent the behavior that a class can perform.
+
+* **Interfaces**
+
+ Defines a contract for classes that implement it. Includes a set of methods that the implementing classes must provide.
+
+* **Enumeration**
+
+ A special data type that defines a set of named values such as product category or months in a year.
+
+* **Relationships**
+
+ Determines how one class is related to another. Some common relationships are as follows:
+
+ * Association
+ * Aggregation
+ * Composition
+ * Inheritance
+ * Implementation
diff --git a/data/guides/a-cheatsheet-on-comparing-api-architectural-styles.md b/data/guides/a-cheatsheet-on-comparing-api-architectural-styles.md
new file mode 100644
index 0000000..0877a94
--- /dev/null
+++ b/data/guides/a-cheatsheet-on-comparing-api-architectural-styles.md
@@ -0,0 +1,23 @@
+---
+title: 'A Cheatsheet on Comparing API Architectural Styles'
+description: 'A quick reference guide comparing popular API architectural styles.'
+image: 'https://assets.bytebytego.com/diagrams/0092-cheatsheet-on-comparing-api-architectural-styles.png'
+createdAt: '2024-02-26'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Architecture
+---
+
+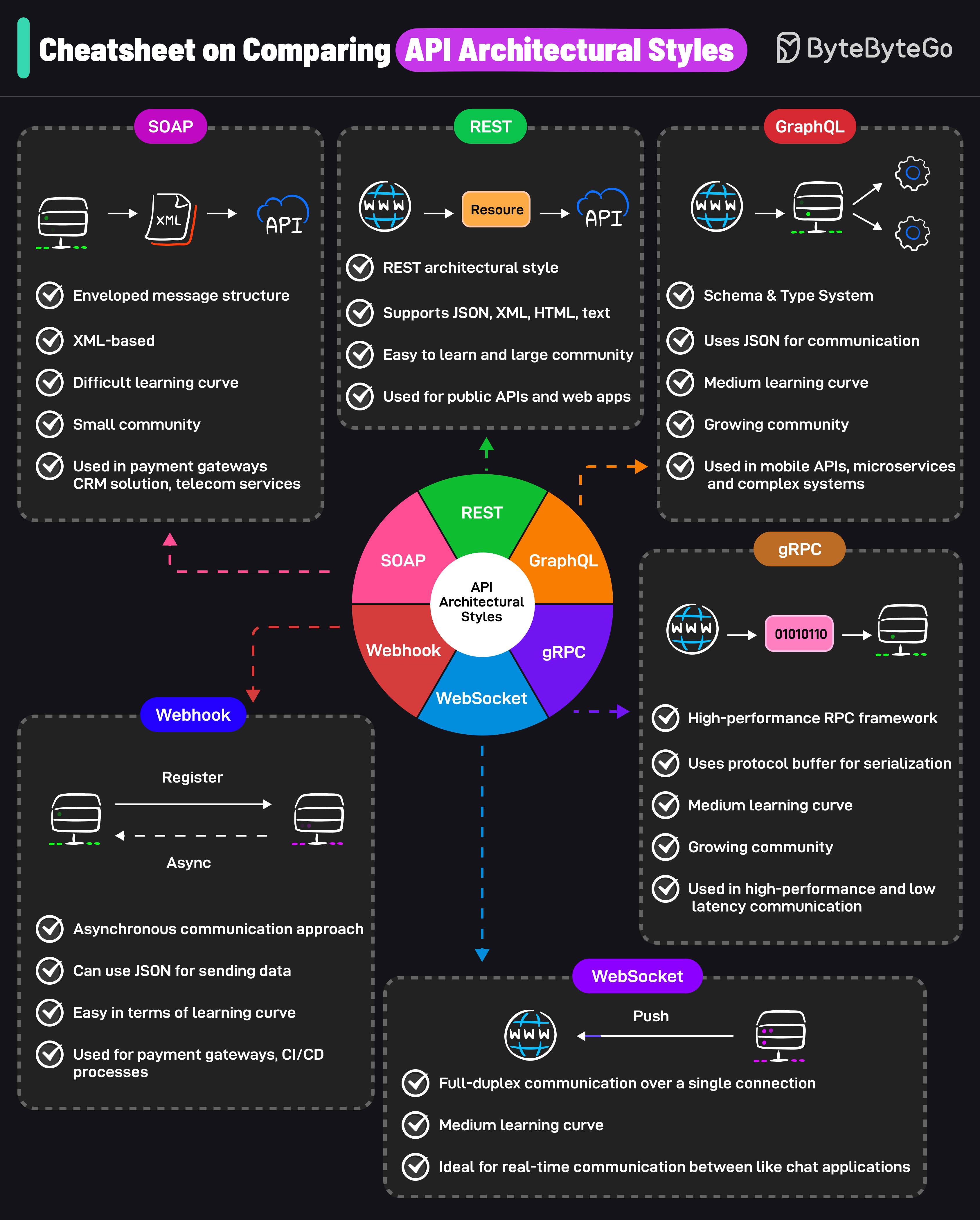
+
+It covers the 6 most popular API architectural styles:
+
+* SOAP
+* REST
+* GraphQL
+* gRPC
+* WebSocket
+* Webhook
diff --git a/data/guides/a-cheatsheet-on-database-performance.md b/data/guides/a-cheatsheet-on-database-performance.md
new file mode 100644
index 0000000..f9ce7e3
--- /dev/null
+++ b/data/guides/a-cheatsheet-on-database-performance.md
@@ -0,0 +1,88 @@
+---
+title: "A Cheatsheet on Database Performance"
+description: "Concise guide to optimize database performance with key strategies."
+image: "https://assets.bytebytego.com/diagrams/0062-a-cheatsheet-on-database-performance.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "database"
+ - "performance"
+---
+
+
+
+## Database Performance Cheatsheet
+
+Here's a cheatsheet on database performance:
+
+### **1. Indexing**
+
+* **Purpose**: Speed up data retrieval.
+* **Considerations**:
+ * Over-indexing can slow down writes.
+ * Regularly review and optimize indexes.
+
+### **2. Query Optimization**
+
+* **Techniques**:
+ * Use `EXPLAIN` to analyze query plans.
+ * Avoid `SELECT *`.
+ * Write efficient `WHERE` clauses.
+
+### **3. Connection Pooling**
+
+* **Benefits**:
+ * Reduces overhead of establishing new connections.
+ * Improves response times.
+
+### **4. Caching**
+
+* **Levels**:
+ * Application-level (e.g., Memcached, Redis).
+ * Database-level (query cache).
+
+### **5. Sharding**
+
+* **Definition**: Distribute data across multiple databases.
+* **Use Cases**:
+ * Handling large datasets.
+ * Improving write performance.
+
+### **6. Replication**
+
+* **Types**:
+ * Master-slave.
+ * Master-master.
+* **Purpose**:
+ * Read scaling.
+ * High availability.
+
+### **7. Hardware**
+
+* **Considerations**:
+ * Sufficient RAM.
+ * Fast storage (SSD).
+ * Adequate CPU.
+
+### **8. Monitoring**
+
+* **Metrics**:
+ * Query response times.
+ * CPU usage.
+ * Disk I/O.
+
+### **9. Normalization/Denormalization**
+
+* **Normalization**: Reduces redundancy.
+* **Denormalization**: Improves read performance (trade-off with redundancy).
+
+### **10. Partitioning**
+
+* **Types**:
+ * Horizontal.
+ * Vertical.
+* **Purpose**:
+ * Improve query performance.
+ * Easier data management.
diff --git a/data/guides/a-cheatsheet-on-infrastructure-as-code-landscape.md b/data/guides/a-cheatsheet-on-infrastructure-as-code-landscape.md
new file mode 100644
index 0000000..e1c68c0
--- /dev/null
+++ b/data/guides/a-cheatsheet-on-infrastructure-as-code-landscape.md
@@ -0,0 +1,30 @@
+---
+title: "Infrastructure as Code Landscape Cheatsheet"
+description: "A quick reference guide to the Infrastructure as Code landscape."
+image: "https://assets.bytebytego.com/diagrams/0063-a-cheatsheet-on-infrastructure-as-code-landscape.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Infrastructure as Code"
+ - "DevOps"
+---
+
+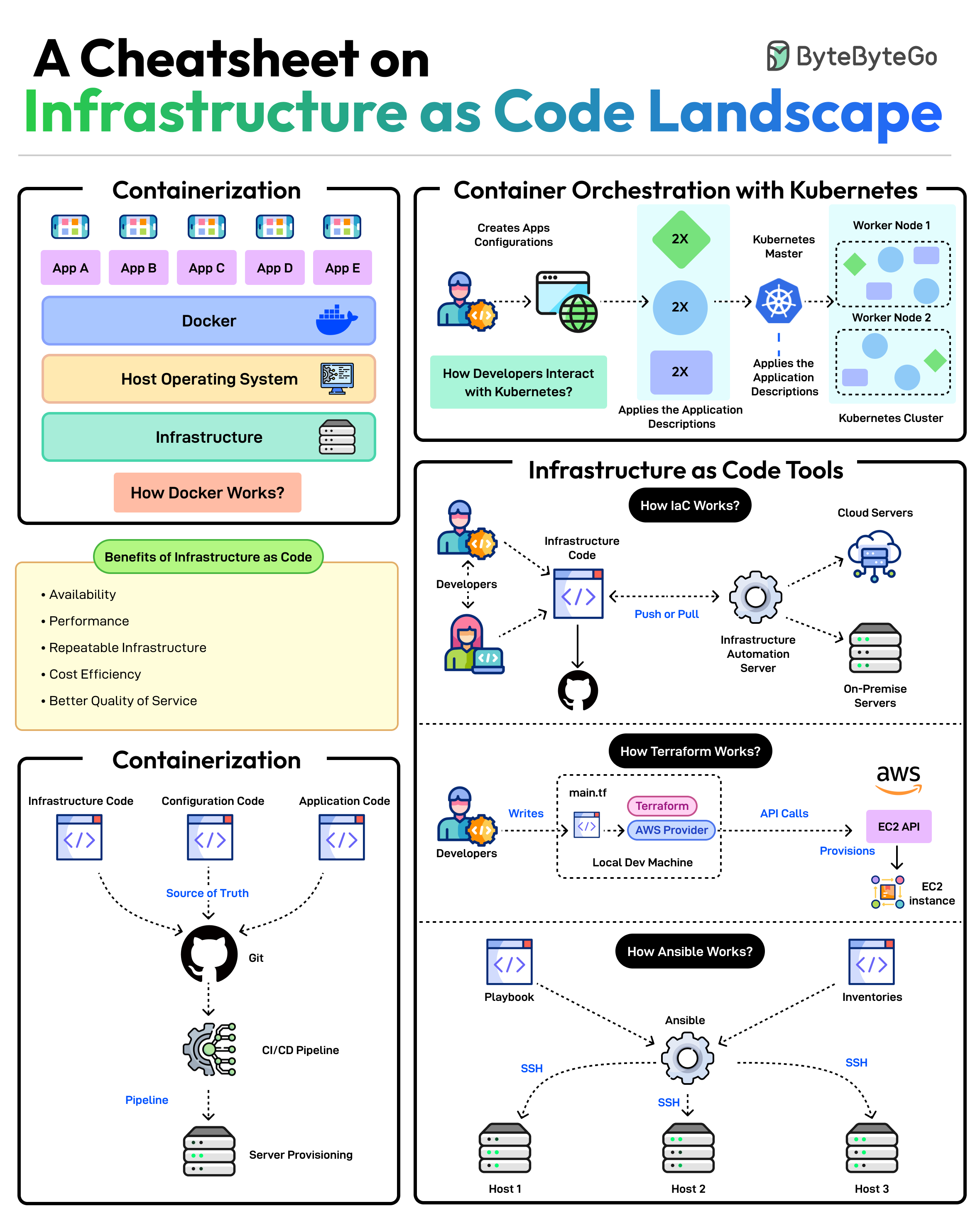
+
+Scalable infrastructure provisioning provides several benefits related to availability, scalability, repeatability, and cost-effectiveness.
+
+But how do you achieve this?
+
+Provisioning infrastructure using code is the key to scalable infra management.
+
+There are multiple strategies that can help:
+
+* Containerization is one of the first strategies to make application deployments based on code. Docker is one of the most popular ways to containerize the application.
+
+* Next, container orchestration becomes a necessity when dealing with multiple containers in an application. This is where container orchestration tools like Kubernetes become important.
+
+* IaC treats infrastructure provisioning and configuration as code, allowing developers to define the application infrastructure in files that can be versioned, tested, and reused. Popular tools such as Terraform, AWS CloudFormation, and Ansible can be used. Ansible is more of a configuration tool.
+
+* GitOps leverages a Git workflow combined with CI/CD to automate infrastructure and configuration updates.
diff --git a/data/guides/a-cheatsheet-to-build-secure-apis.md b/data/guides/a-cheatsheet-to-build-secure-apis.md
new file mode 100644
index 0000000..456be8c
--- /dev/null
+++ b/data/guides/a-cheatsheet-to-build-secure-apis.md
@@ -0,0 +1,45 @@
+---
+title: A Cheatsheet to Build Secure APIs
+description: Concise strategies for building secure APIs to protect your application.
+image: https://assets.bytebytego.com/diagrams/0064-a-cheatsheet-to-build-secure-apis.png
+createdAt: '2024-02-23'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Security
+ - Security
+---
+
+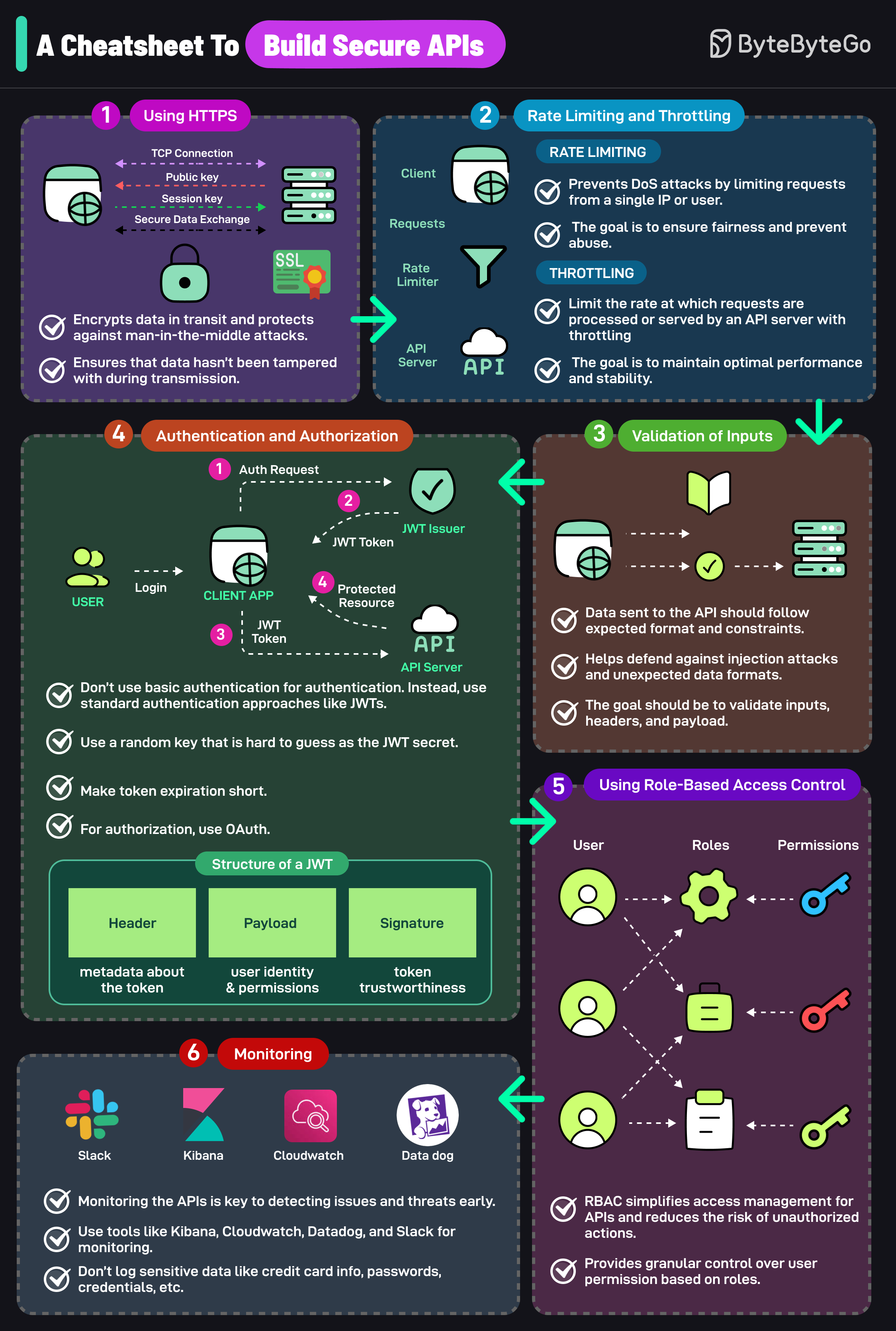
+
+An insecure API can compromise your entire application. Follow these strategies to mitigate the risk:
+
+## Using HTTPS
+
+- Encrypts data in transit and protects against man-in-the-middle attacks.
+- This ensures that data hasn’t been tampered with during transmission.
+
+## Rate Limiting and Throttling
+- Rate limiting prevents DoS attacks by limiting requests from a single IP or user.
+- The goal is to ensure fairness and prevent abuse.
+
+## Validation of Inputs
+- Defends against injection attacks and unexpected data format.
+- Validate headers, inputs, and payload.
+
+## Authentication and Authorization
+- Don’t use basic auth for authentication.
+- Instead, use a standard authentication approach like JWTs
+ * Use a random key that is hard to guess as the JWT secret
+ * Make token expiration short
+-For authorization, use OAuth
+
+## Using Role-based Access Control
+- RBAC simplifies access management for APIs and reduces the risk of unauthorized actions.
+- Granular control over user permission based on roles.
+
+## Monitoring
+- Monitoring the APIs is the key to detecting issues and threats early.
+ - Use tools like Kibana, Cloudwatch, Datadog, and Slack for monitoring
+ - Don’t log sensitive data like credit card info, passwords, credentials, etc.
diff --git a/data/guides/a-crash-course-in-database-sharding.md b/data/guides/a-crash-course-in-database-sharding.md
new file mode 100644
index 0000000..a2efa98
--- /dev/null
+++ b/data/guides/a-crash-course-in-database-sharding.md
@@ -0,0 +1,68 @@
+---
+title: "A Crash Course on Database Sharding"
+description: "Learn database sharding: concepts, techniques, and implementation."
+image: "https://assets.bytebytego.com/diagrams/0065-a-crash-course-on-database-sharding.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "database"
+ - "sharding"
+---
+
+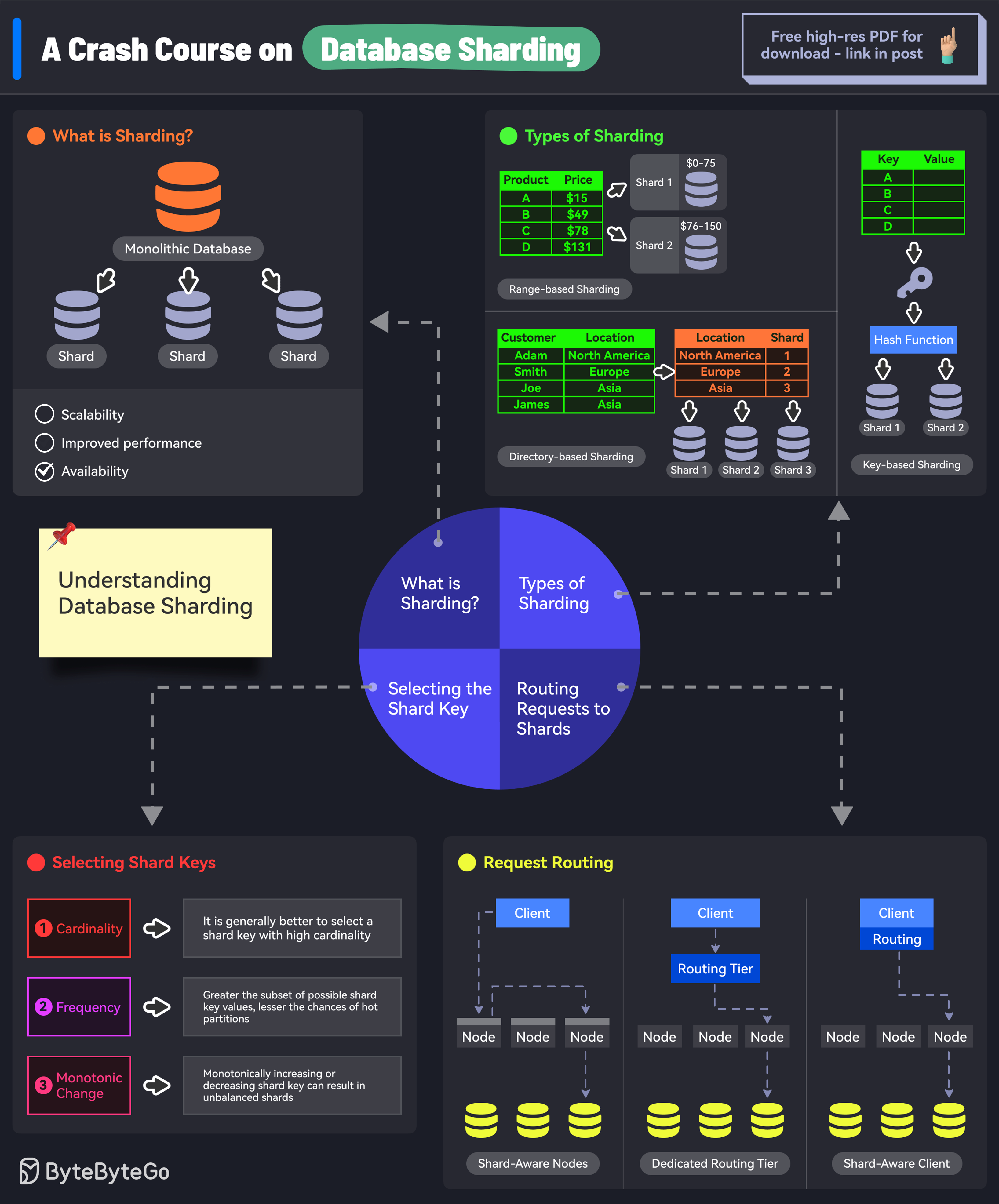
+
+## What is Database Sharding?
+
+Database sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards. The word shard means a small piece of something bigger.
+
+Sharding is also known as horizontal partitioning. Each shard contains a portion of the data, and all shards together contain all of the data.
+
+## Why Sharding?
+
+Sharding is implemented to solve these problems:
+
+* **Too much data on one machine**: A single database server can only handle so much data.
+
+* **Too many requests on one machine**: A single database server can only handle so many requests.
+
+* **High Latency**: As data grows, query latency increases.
+
+## How Sharding Works
+
+Sharding involves splitting a database into multiple, independent parts (shards) and distributing them across different servers or machines. Each shard contains a subset of the data, and all shards collectively hold the entire dataset.
+
+### Sharding Key
+
+A sharding key is a column in the database table that determines how the data is distributed across the shards. The sharding key is used by the sharding algorithm to determine which shard a particular row of data should be stored in.
+
+### Sharding Algorithm
+
+The sharding algorithm is the logic that determines which shard a particular row of data should be stored in. The sharding algorithm uses the sharding key to make this determination.
+
+Here are some common sharding algorithms:
+
+* **Range-based sharding**: Data is divided into ranges based on the sharding key. For example, users with IDs from 1 to 1000 might be stored in shard 1, users with IDs from 1001 to 2000 in shard 2, and so on.
+
+* **Hash-based sharding**: A hash function is applied to the sharding key to determine the shard. For example, `shard_id = hash(user_id) % num_shards`.
+
+* **Directory-based sharding**: A lookup table (or directory) is used to map sharding keys to shard locations.
+
+## Sharding Approaches
+
+* **Application-level sharding**: The application is responsible for determining which shard to use for each query.
+
+* **Middleware sharding**: A middleware layer sits between the application and the database and handles the sharding logic.
+
+* **Database-native sharding**: The database system itself provides sharding capabilities.
+
+## Sharding Challenges
+
+* **Increased Complexity**: Sharding adds complexity to the database infrastructure and application code.
+
+* **Data Distribution**: Choosing the right sharding key and algorithm is crucial for even data distribution and performance.
+
+* **Joins and Transactions**: Performing joins and transactions across shards can be challenging and may require distributed transaction management.
+
+* **Resharding**: Changing the sharding scheme after the database has been sharded can be a complex and time-consuming process.
diff --git a/data/guides/a-crash-course-on-architectural-scalability.md b/data/guides/a-crash-course-on-architectural-scalability.md
new file mode 100644
index 0000000..5f21792
--- /dev/null
+++ b/data/guides/a-crash-course-on-architectural-scalability.md
@@ -0,0 +1,35 @@
+---
+title: "A Crash Course on Architectural Scalability"
+description: "Learn about architectural scalability, bottlenecks, and key techniques."
+image: "https://assets.bytebytego.com/diagrams/0293-a-crash-course-on-architectural-scalability.png"
+createdAt: "2024-02-10"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Scalability"
+ - "Architecture"
+---
+
+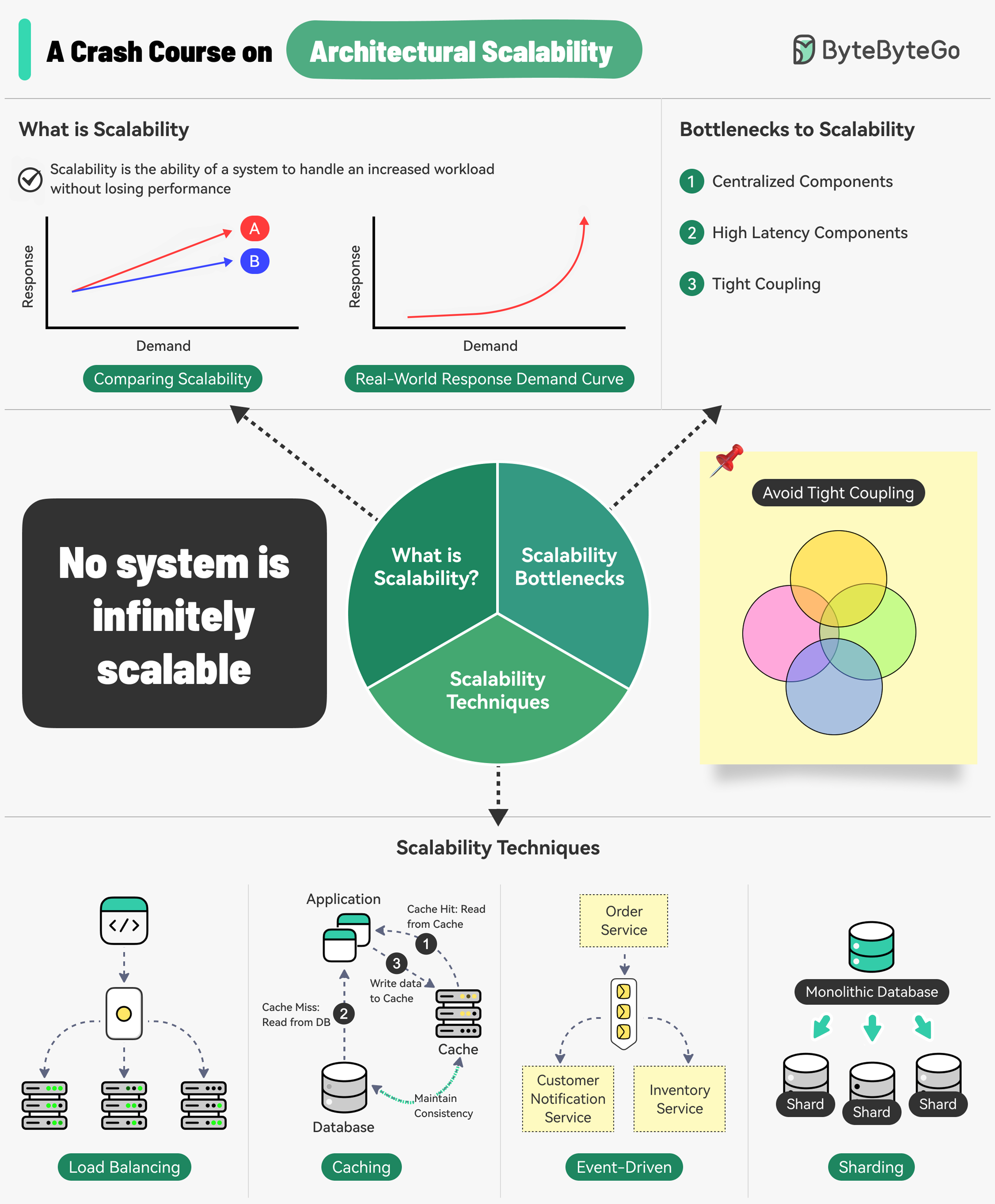
+
+Scalability is the ability of a system to handle an increased workload without losing performance.
+
+However, we can also look at scalability in terms of the scaling strategy.
+
+Scalability is the system’s ability to handle an increased workload by repeatedly applying a cost-effective strategy. This means it can be difficult to scale a system beyond a certain point if the scaling strategy is not financially viable.
+
+Three main bottlenecks to scalability are:
+
+1. Centralized components: This can become a single point of failure
+2. High Latency Components: These are components that perform time-consuming operations.
+3. Tight Coupling: Makes the components difficult to scale
+
+Therefore, to build a scalable system, we should follow the principles of statelessness, loose coupling, and asynchronous processing.
+
+Some common techniques for improving scalability are as follows:
+
+* Load Balancing: Spread requests across multiple servers to prevent a single server from becoming a bottleneck.
+* Caching: Store the most commonly request information in memory.
+* Event-Driven Processing: Use an async processing approach to process long-running tasks.
+* Sharding: Split a large dataset into smaller subsets called shards for horizontal scalability.
diff --git a/data/guides/a-roadmap-for-full-stack-development.md b/data/guides/a-roadmap-for-full-stack-development.md
new file mode 100644
index 0000000..03ee45d
--- /dev/null
+++ b/data/guides/a-roadmap-for-full-stack-development.md
@@ -0,0 +1,46 @@
+---
+title: "A Roadmap for Full-Stack Development"
+description: "A guide to the technologies and skills needed for full-stack development."
+image: "https://assets.bytebytego.com/diagrams/0199-full-stack-developer-roadmap.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Full-Stack Development"
+ - "Software Development"
+---
+
+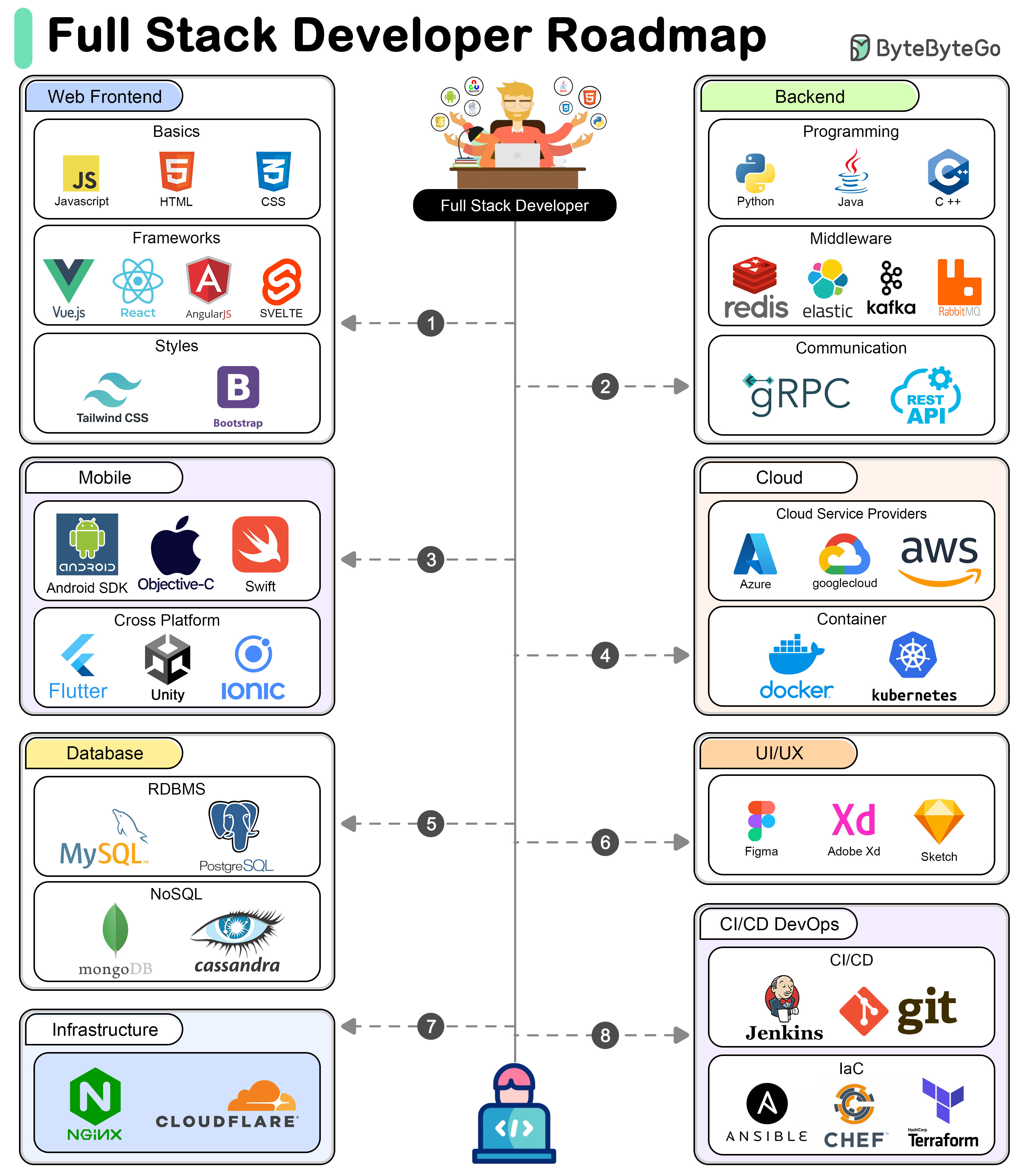
+
+A full-stack developer needs to be proficient in a wide range of technologies and tools across different areas of software development. Here’s a comprehensive look at the technical stacks required for a full-stack developer.
+
+## Technical Stacks for Full-Stack Development
+
+* **Frontend Development**
+
+ Frontend development involves creating the user interface and user experience of a web application.
+
+* **Backend Development**
+
+ Backend development involves managing the server-side logic, databases, and integration of various services.
+
+* **Database Development**
+
+ Database development involves managing data storage, retrieval, and manipulation.
+
+* **Mobile Development**
+
+ Mobile development involves creating applications for mobile devices.
+
+* **Cloud Computing**
+
+ Cloud computing involves deploying and managing applications on cloud platforms.
+
+* **UI/UX Design**
+
+ UI/UX design involves designing the user interface and experience of applications.
+
+* **Infrastructure and DevOps**
+
+ Infrastructure and DevOps involve managing the infrastructure, deployment, and continuous integration/continuous delivery (CI/CD) of applications.
diff --git a/data/guides/airbnb-artchitectural-evolution.md b/data/guides/airbnb-artchitectural-evolution.md
new file mode 100644
index 0000000..e462ec0
--- /dev/null
+++ b/data/guides/airbnb-artchitectural-evolution.md
@@ -0,0 +1,35 @@
+---
+title: "0 to 1.5 Billion Guests: Airbnb's Architectural Evolution"
+description: "Explore Airbnb's architectural evolution to support 1.5 billion guests."
+image: 'https://assets.bytebytego.com/diagrams/0427-zero-to-1-5-billion-guests-airbnb-s-architectural-evolution.png'
+createdAt: '2024-02-27'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Microservices
+---
+
+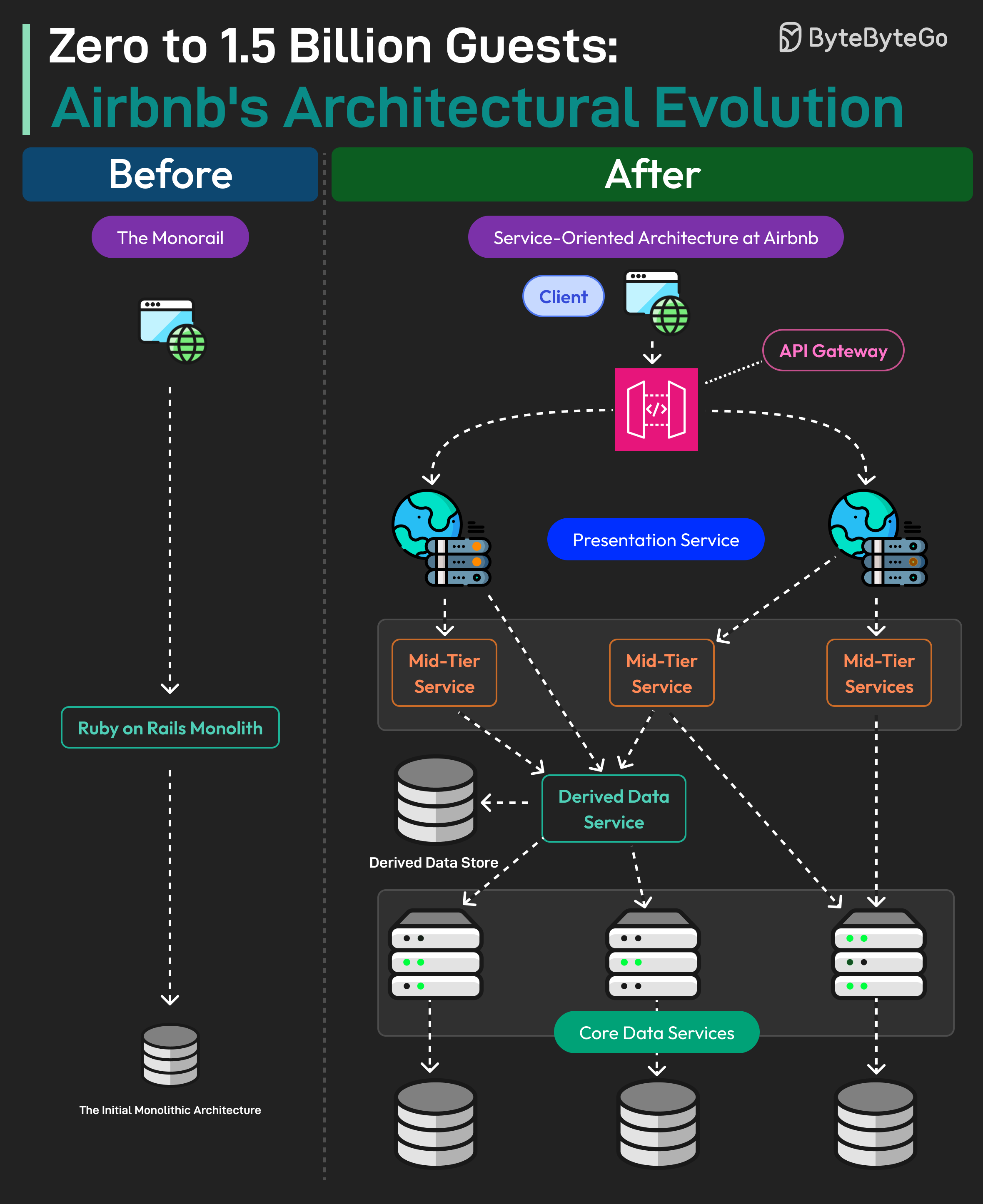
+
+Airbnb operates in 200+ countries and has helped 4 million hosts welcome over 1.5 billion guests across the world.
+
+What powers Airbnb technically?
+
+Airbnb started as a monolithic application. It was built using Ruby-on-Rails and was internally known as the Monorail.
+
+The monolith was a single-tier unit responsible for both client and server-side functionality.
+
+However, as Airbnb went into hypergrowth, the Monorail started facing issues. This is when they began a migration journey to move from monolithic to Service-Oriented Architecture.
+
+For Airbnb, SOA is a network of loosely coupled services where clients make their requests to a gateway and the gateway routes these requests to multiple services and databases.
+
+Various types of services were built such as:
+
+* **Data Service:** This is the bottom layer and acts as the entry point for all read and write operations on the data entities.
+* **Derived Data Service:** These services read from data services and apply basic business logic.
+* **Middle Tier Service:** They manage important business logic that doesn’t fit at the data service level or derived data service level.
+* **Presentation Service:** They aggregate data from all other services and also apply some frontend-specific business logic.
+
+After the migration, the Monorail was eliminated and all reads/writes were migrated to the new services.
diff --git a/data/guides/algorithms-you-should-know-before-taking-system-design-interviews.md b/data/guides/algorithms-you-should-know-before-taking-system-design-interviews.md
new file mode 100644
index 0000000..0ad544a
--- /dev/null
+++ b/data/guides/algorithms-you-should-know-before-taking-system-design-interviews.md
@@ -0,0 +1,30 @@
+---
+title: "Algorithms for System Design Interviews"
+description: "Essential algorithms for system design interviews and software engineers."
+image: "https://assets.bytebytego.com/diagrams/0068-algorithms-geo-hash-linkedin.jpg"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - software-development
+tags:
+ - System Design
+ - Algorithms
+---
+
+
+
+What are some of the algorithms you should know before taking system design interviews?
+
+I put together a list and explained why they are important. Those algorithms are not only useful for interviews but good to understand for any software engineer.
+
+One thing to keep in mind is that understanding “how those algorithms are used in real-world systems” is generally more important than the implementation details in a system design interview.
+
+What do the stars mean in the diagram?
+
+It’s very difficult to rank algorithms by importance objectively. I’m open to suggestions and making adjustments.
+
+Five-star: Very important. Try to understand how it works and why.
+
+Three-star: Important to some extent. You may not need to know the implementation details.
+
+One-star: Advanced. Good to know for senior candidates.
diff --git a/data/guides/amazon-prime-video-monitoring-service.md b/data/guides/amazon-prime-video-monitoring-service.md
new file mode 100644
index 0000000..05ea194
--- /dev/null
+++ b/data/guides/amazon-prime-video-monitoring-service.md
@@ -0,0 +1,44 @@
+---
+title: "Amazon Prime Video Monitoring Service"
+description: "Learn how Amazon Prime Video monitoring saved 90% cost by moving to monolith."
+image: "https://assets.bytebytego.com/diagrams/0328-serverless-to-monolithic.jpeg"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Microservices"
+ - "System Design"
+---
+
+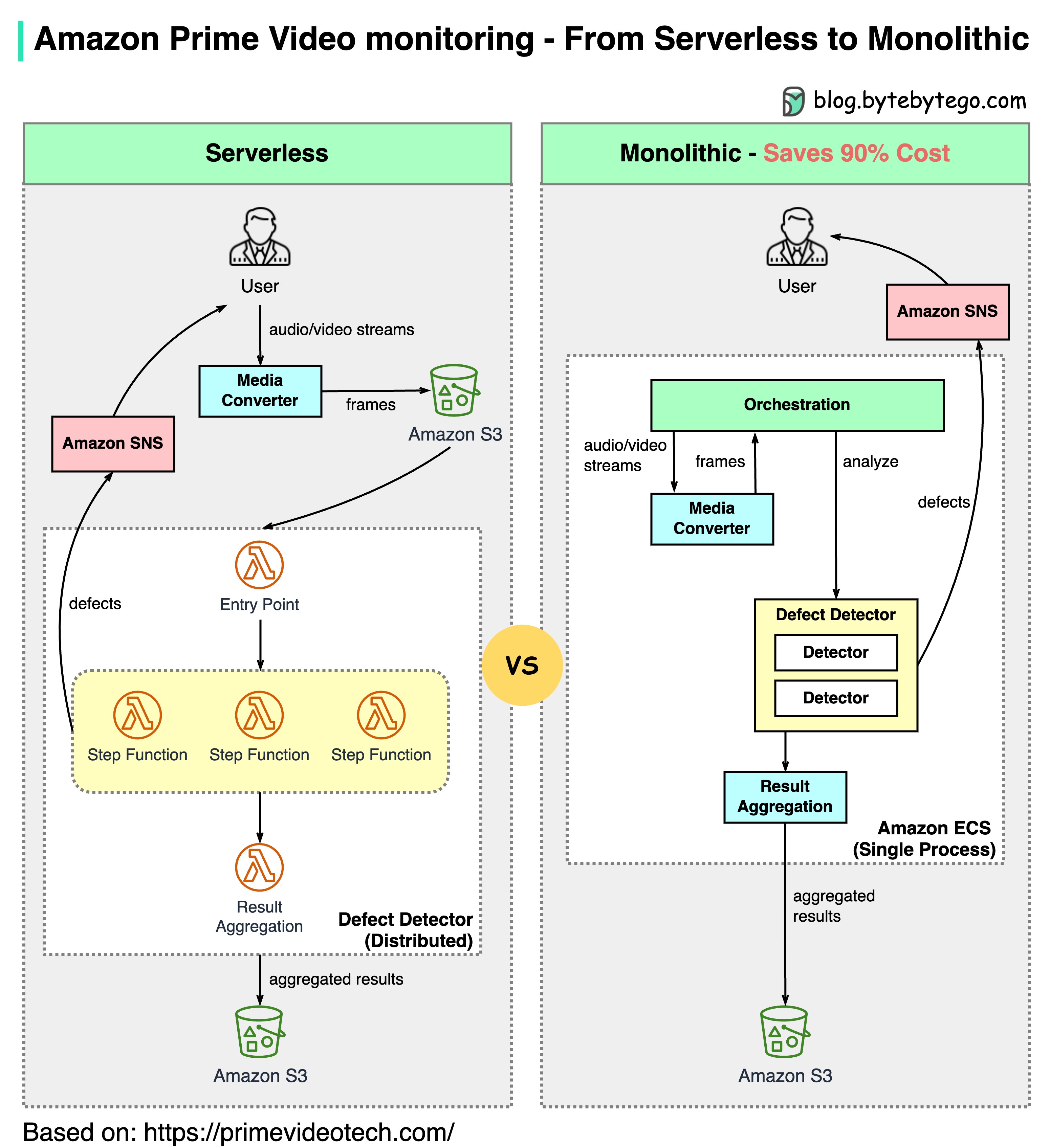
+
+Why did Amazon Prime Video monitoring move **from serverless to monolithic**? How can it save 90% cost?
+
+The diagram above shows the architecture comparison before and after the migration.
+
+## What is Amazon Prime Video Monitoring Service?
+
+Prime Video service needs to monitor the quality of thousands of live streams. The monitoring tool automatically analyzes the streams in real time and identifies quality issues like block corruption, video freeze, and sync problems. This is an important process for customer satisfaction.
+
+There are 3 steps: media converter, defect detector, and real-time notification.
+
+* What is the problem with the old architecture?
+
+ The old architecture was based on Amazon Lambda, which was good for building services quickly. However, it was not cost-effective when running the architecture at a high scale. The two most expensive operations are:
+
+ 1. The orchestration workflow - AWS step functions charge users by state transitions and the orchestration performs multiple state transitions every second.
+
+ 2. Data passing between distributed components - the intermediate data is stored in Amazon S3 so that the next stage can download. The download can be costly when the volume is high.
+
+* Monolithic architecture saves 90% cost
+
+ A monolithic architecture is designed to address the cost issues. There are still 3 components, but the media converter and defect detector are deployed in the same process, saving the cost of passing data over the network. Surprisingly, this approach to deployment architecture change led to 90% cost savings!
+
+ This is an interesting and unique case study because microservices have become a go-to and fashionable choice in the tech industry. It's good to see that we are having more discussions about evolving the architecture and having more honest discussions about its pros and cons. Decomposing components into distributed microservices comes with a cost.
+
+* What did Amazon leaders say about this?
+
+ Amazon CTO Werner Vogels: “Building **evolvable software systems** is a strategy, not a religion. And revisiting your architectures with an open mind is a must.”
+
+ Ex Amazon VP Sustainability Adrian Cockcroft: “The Prime Video team had followed a path I call **Serverless First**…I don’t advocate **Serverless Only**”.
diff --git a/data/guides/api-gateway-101.md b/data/guides/api-gateway-101.md
new file mode 100644
index 0000000..2eb6b08
--- /dev/null
+++ b/data/guides/api-gateway-101.md
@@ -0,0 +1,27 @@
+---
+title: 'API Gateway 101'
+description: 'Learn the fundamentals of API Gateways: functions, benefits, and more.'
+image: 'https://assets.bytebytego.com/diagrams/0074-api-gateway-101.png'
+createdAt: '2024-02-15'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Microservices
+---
+
+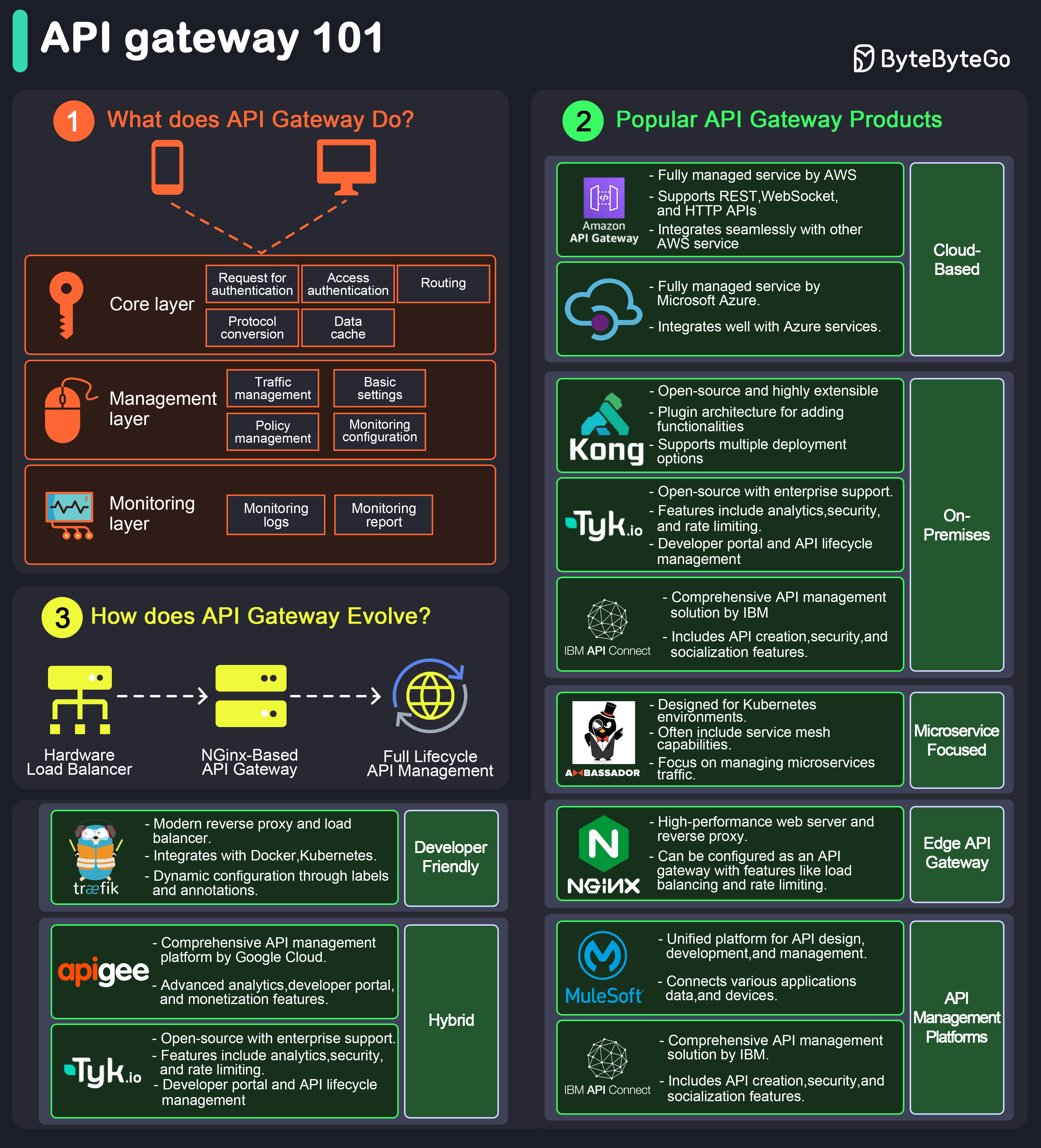
+
+An API gateway is a server that acts as an API front-end, receiving API requests, enforcing throttling and security policies, passing requests to the back-end service, and then returning the appropriate result to the client.
+
+It is essentially a middleman between the client and the server, managing and optimizing API traffic.
+
+**Key Functions of an API Gateway**
+
+* **Request Routing:** Directs incoming API requests to the appropriate backend service.
+* **Load Balancing:** Distributes requests across multiple servers to ensure no single server is overwhelmed.
+* **Security:** Implements security measures like authentication, authorization, and data encryption.
+* **Rate Limiting and Throttling:** Controls the number of requests a client can make within a certain period.
+* **API Composition:** Combines multiple backend API requests into a single frontend request to optimize performance.
+* **Caching:** Stores responses temporarily to reduce the need for repeated processing.
diff --git a/data/guides/api-of-apis-app-integrations.md b/data/guides/api-of-apis-app-integrations.md
new file mode 100644
index 0000000..38bf57d
--- /dev/null
+++ b/data/guides/api-of-apis-app-integrations.md
@@ -0,0 +1,20 @@
+---
+title: 'API of APIs - App Integrations'
+description: 'Explore API of APIs and app integrations in this detailed guide.'
+image: 'https://assets.bytebytego.com/diagrams/0426-api-of-apis-app-integrations.png'
+createdAt: '2024-02-13'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - API Integration
+ - No-Code
+---
+
+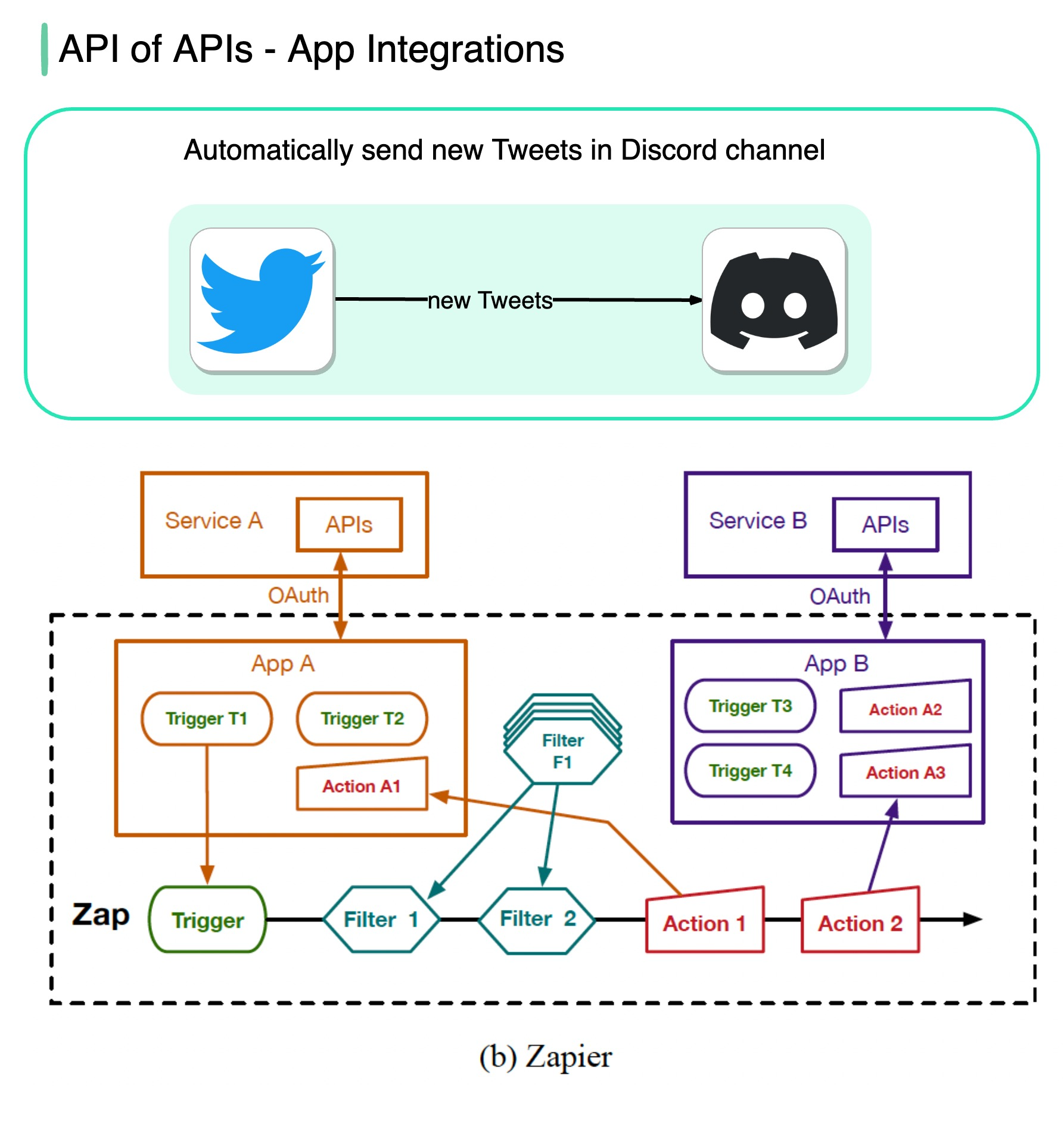
+
+No-code tools such as Zapier, IFTTT, etc., allow anyone to build apps and automate workflows using a visual interface.
+
+The flowchart below shows how it works.
+
+Image source: Paper: IFTTT vs. Zapier: A Comparative Study of Trigger-Action Programming Frameworks
diff --git a/data/guides/api-vs-sdk.md b/data/guides/api-vs-sdk.md
new file mode 100644
index 0000000..8189347
--- /dev/null
+++ b/data/guides/api-vs-sdk.md
@@ -0,0 +1,34 @@
+---
+title: 'API vs SDK'
+description: 'Understand the key differences between APIs and SDKs in software development.'
+image: 'https://assets.bytebytego.com/diagrams/0071-api-vs-sdk.png'
+createdAt: '2024-02-22'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - SDK
+---
+
+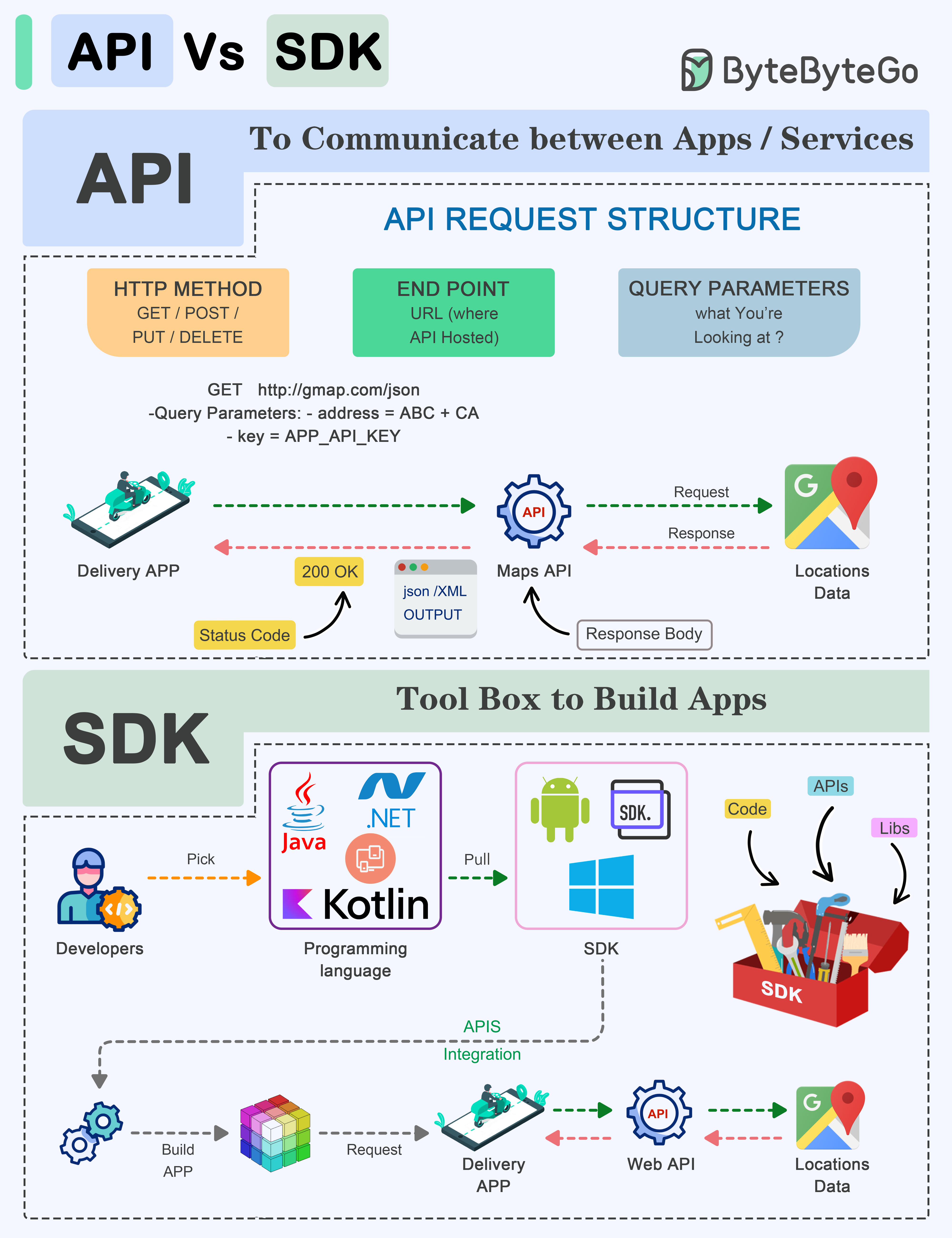
+
+API (Application Programming Interface) and SDK (Software Development Kit) are essential tools in the software development world, but they serve distinct purposes:
+
+**API:**
+
+An API is a set of rules and protocols that allows different software applications and services to communicate with each other.
+
+* It defines how software components should interact.
+* Facilitates data exchange and functionality access between software components.
+* Typically consists of endpoints, requests, and responses.
+
+**SDK:**
+
+An SDK is a comprehensive package of tools, libraries, sample code, and documentation that assists developers in building applications for a particular platform, framework, or hardware.
+
+* Offers higher-level abstractions, simplifying development for a specific platform.
+* Tailored to specific platforms or frameworks, ensuring compatibility and optimal performance on that platform.
+* Offer access to advanced features and capabilities specific to the platform, which might be otherwise challenging to implement from scratch.
+
+The choice between APIs and SDKs depends on the development goals and requirements of the project.
diff --git a/data/guides/aws-services-cheat-sheet.md b/data/guides/aws-services-cheat-sheet.md
new file mode 100644
index 0000000..8237559
--- /dev/null
+++ b/data/guides/aws-services-cheat-sheet.md
@@ -0,0 +1,22 @@
+---
+title: "AWS Services Cheat Sheet"
+description: "A visual guide to navigate AWS expansive landscape of cloud services."
+image: "https://assets.bytebytego.com/diagrams/0082-aws-cloud-services-cheat-sheet.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "AWS"
+ - "Cloud Computing"
+---
+
+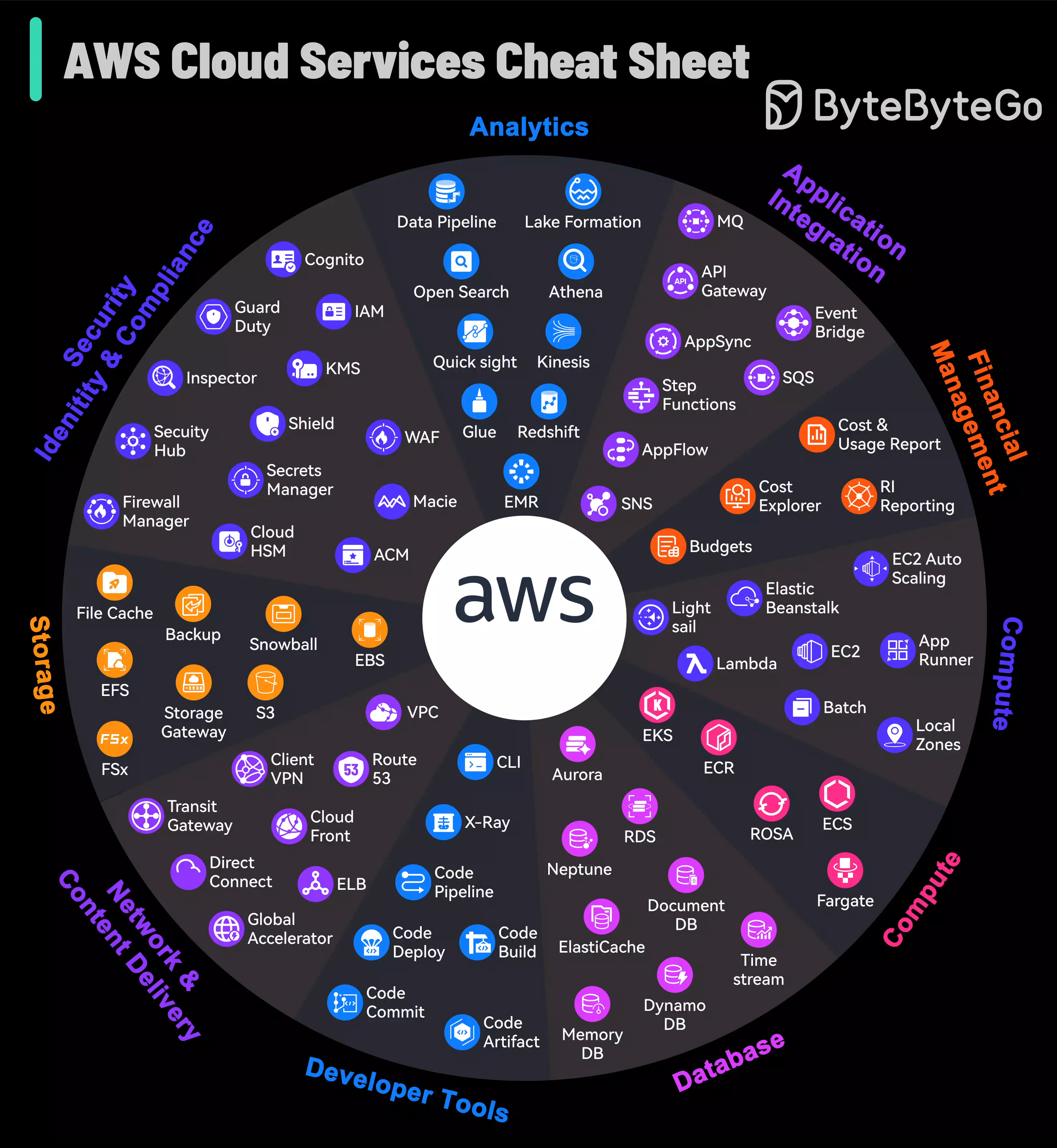
+
+AWS grew from an in-house project to the market leader in cloud services, offering so many different services that even experts can find it a lot to take in.
+
+The platform not only caters to foundational cloud needs but also stays at the forefront of emerging technologies such as machine learning and IoT, establishing itself as a bedrock for cutting-edge innovation. AWS continuously refines its array of services, ensuring advanced capabilities for security, scalability, and operational efficiency are available.
+
+For those navigating the complex array of options, this AWS Services Guide is a helpful visual aid.
+
+It simplifies the exploration of AWS's expansive landscape, making it accessible for users to identify and leverage the right tools for their cloud-based endeavors.
diff --git a/data/guides/aws-services-evolution.md b/data/guides/aws-services-evolution.md
new file mode 100644
index 0000000..5c25a47
--- /dev/null
+++ b/data/guides/aws-services-evolution.md
@@ -0,0 +1,30 @@
+---
+title: "AWS Services Evolution"
+description: "Explore the evolution of AWS from its early days to a comprehensive cloud platform."
+image: "https://assets.bytebytego.com/diagrams/0081-aws-services-evolution.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "AWS"
+---
+
+[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fbb384f75-2fbb-4c5b-9d5e-b97557d02f33_1572x1894.png)
+
+How did AWS grow from just a few services in 2006 to over 200 fully-featured services? Let's take a look.
+
+Since 2006, it has become a cloud computing leader, offering foundational infrastructure, platforms, and advanced capabilities like serverless computing and AI.
+
+This expansion empowered innovation, allowing complex applications without extensive hardware management. AWS also explored edge and quantum computing, staying at tech's forefront.
+
+This evolution mirrors cloud computing's shift from niche to essential, benefiting global businesses with efficiency and scalability.
+
+Happy to present the curated list of AWS services introduced over the years below.
+
+Note:
+
+* The announcement or preview year differs from the public release year for certain services. In these cases, we've noted the service under the release year
+
+* Unreleased services noted in announcement years
diff --git a/data/guides/azure-services-cheat-sheet.md b/data/guides/azure-services-cheat-sheet.md
new file mode 100644
index 0000000..1fd3d93
--- /dev/null
+++ b/data/guides/azure-services-cheat-sheet.md
@@ -0,0 +1,22 @@
+---
+title: "Azure Services Cheat Sheet"
+description: "A concise guide to Microsoft Azure services and their applications."
+image: "https://assets.bytebytego.com/diagrams/0083-azure-cloud-services-cheat-sheet.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Azure"
+ - "Cloud Computing"
+---
+
+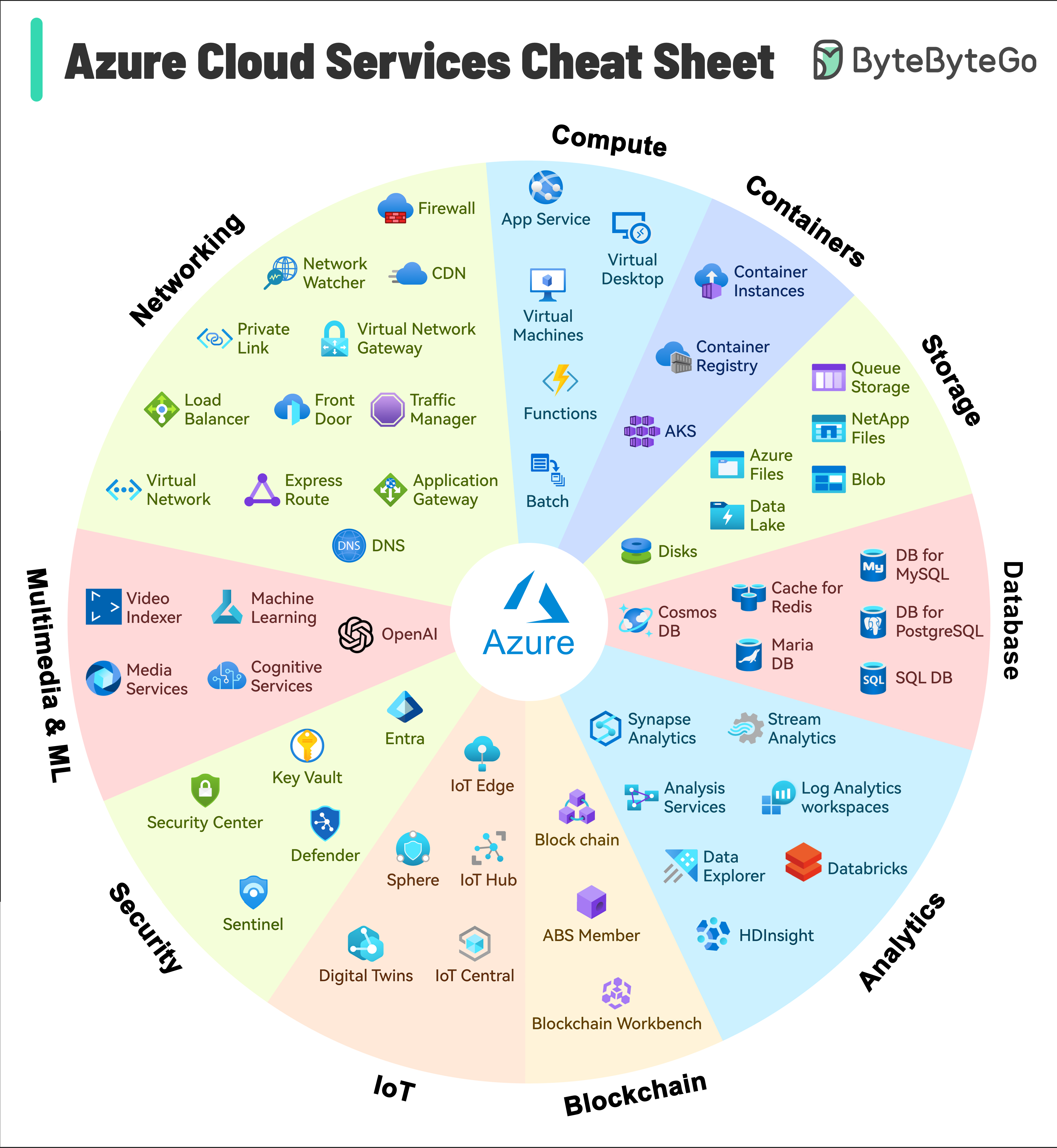
+
+Launched in 2010, Microsoft Azure has quickly grown to hold the No. 2 position in market share by evolving from basic offerings to a comprehensive, flexible cloud ecosystem.
+
+Today, Azure not only supports traditional cloud applications but also caters to emerging technologies such as AI, IoT, and blockchain, making it a crucial platform for innovation and development.
+
+As it evolves, Azure continues to enhance its capabilities to provide advanced solutions for security, scalability, and efficiency, meeting the demands of modern enterprises and startups alike. This expansion allows organizations to adapt and thrive in a rapidly changing digital landscape.
+
+The attached illustration can serve as both an introduction and a quick reference for anyone aiming to understand Azure.
diff --git a/data/guides/b-tree-vs.md b/data/guides/b-tree-vs.md
new file mode 100644
index 0000000..4798125
--- /dev/null
+++ b/data/guides/b-tree-vs.md
@@ -0,0 +1,34 @@
+---
+title: "B-Tree vs. LSM-Tree"
+description: "Explore the differences between B-Tree and LSM-Tree data structures."
+image: "https://assets.bytebytego.com/diagrams/0091-btree-lsm.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Structures"
+ - "Databases"
+---
+
+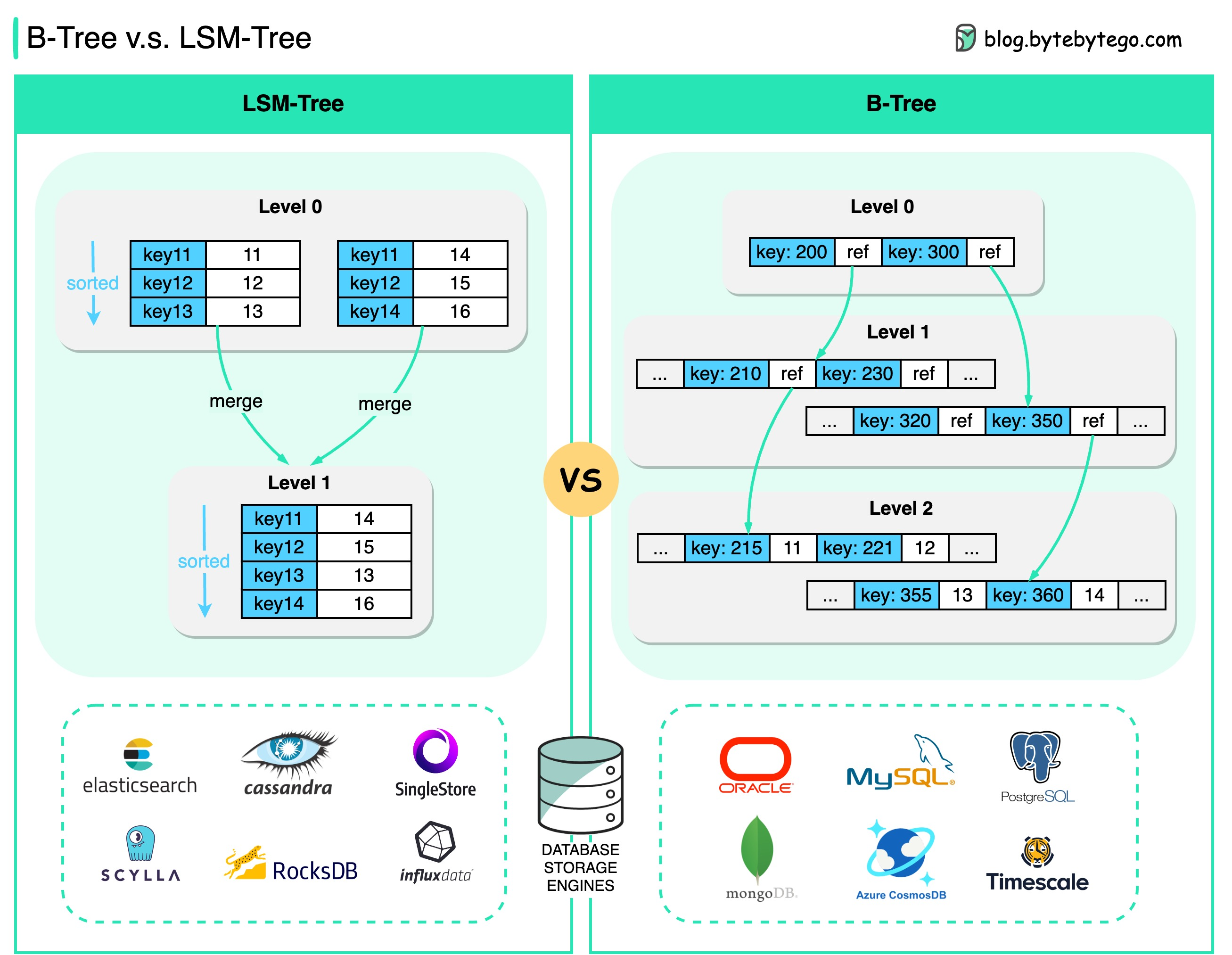
+
+## B-Tree
+
+B-Tree is the most widely used indexing data structure in almost all relational databases.
+
+The basic unit of information storage in B-Tree is usually called a “page”. Looking up a key traces down the range of keys until the actual value is found.
+
+## LSM-Tree
+
+LSM-Tree (Log-Structured Merge Tree) is widely used by many NoSQL databases, such as Cassandra, LevelDB, and RocksDB.
+
+LSM-trees maintain key-value pairs and are persisted to disk using a Sorted Strings Table (SSTable), in which the keys are sorted.
+
+Level 0 segments are periodically merged into Level 1 segments. This process is called **compaction.**
+
+The biggest difference is probably this:
+
+* B-Tree enables faster reads
+
+* LSM-Tree enables fast writes
diff --git a/data/guides/big-data-pipeline-cheatsheet-for-aws-azure-and-google-cloud.md b/data/guides/big-data-pipeline-cheatsheet-for-aws-azure-and-google-cloud.md
new file mode 100644
index 0000000..42de0cc
--- /dev/null
+++ b/data/guides/big-data-pipeline-cheatsheet-for-aws-azure-and-google-cloud.md
@@ -0,0 +1,32 @@
+---
+title: "Big Data Pipeline Cheatsheet for AWS, Azure, and Google Cloud"
+description: "Big data pipeline cheatsheet for AWS, Azure, and Google Cloud."
+image: "https://assets.bytebytego.com/diagrams/0086-big-data-pipeline-cheatsheet-for-aws-azure-and-gcp.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Big Data"
+ - "Cloud Computing"
+---
+
+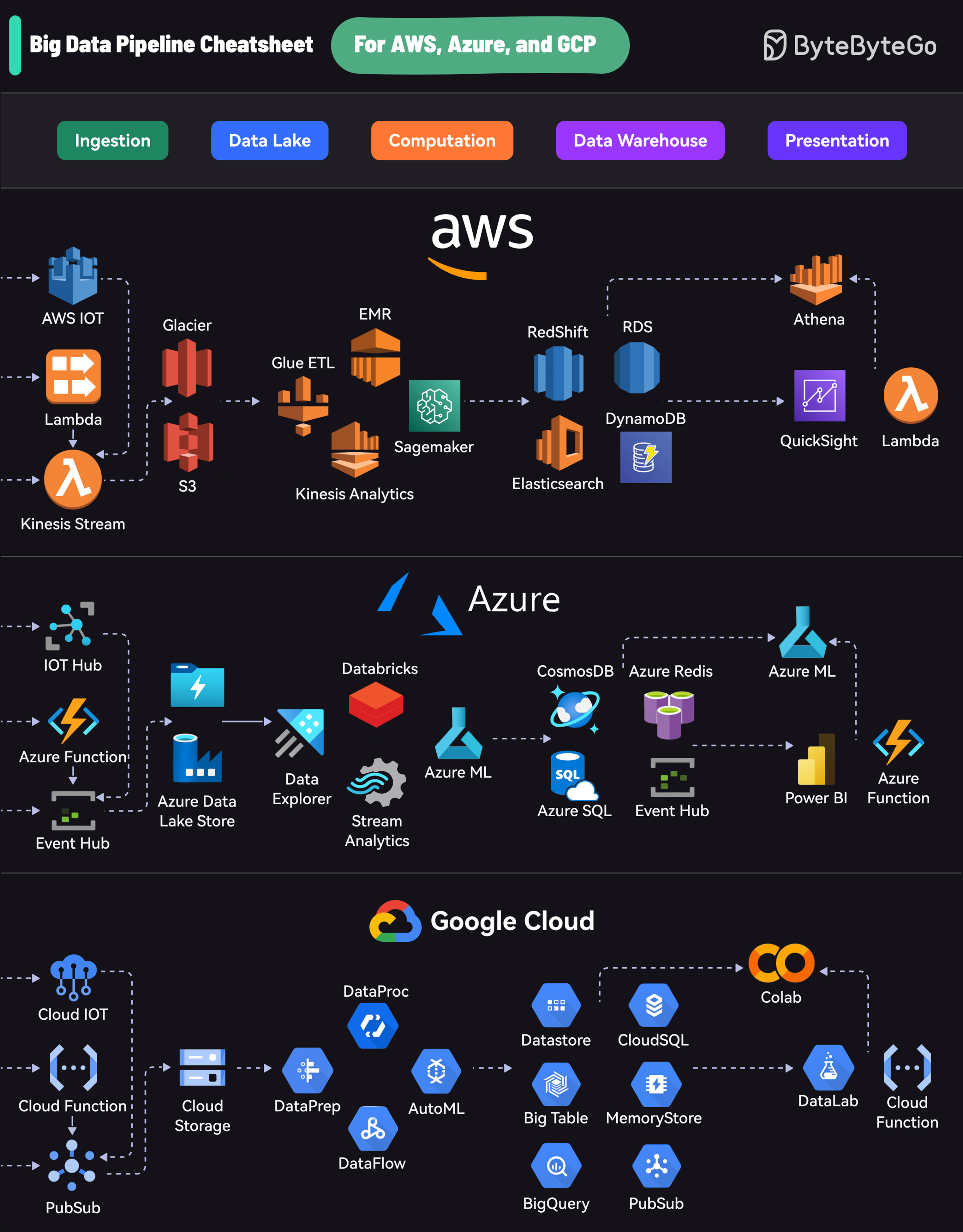
+
+Each platform offers a comprehensive suite of services that cover the entire lifecycle:
+
+* Ingestion: Collecting data from various sources
+
+* Data Lake: Storing raw data
+
+* Computation: Processing and analyzing data
+
+* Data Warehouse: Storing structured data
+
+* Presentation: Visualizing and reporting insights
+
+AWS uses services like Kinesis for data streaming, S3 for storage, EMR for processing, RedShift for warehousing, and QuickSight for visualization.
+
+Azure’s pipeline includes Event Hubs for ingestion, Data Lake Store for storage, Databricks for processing, Cosmos DB for warehousing, and Power BI for presentation.
+
+GCP offers PubSub for data streaming, Cloud Storage for data lakes, DataProc and DataFlow for processing, BigQuery for warehousing, and Data Studio for visualization.
diff --git a/data/guides/big-endian-vs-little-endian.md b/data/guides/big-endian-vs-little-endian.md
new file mode 100644
index 0000000..8347df4
--- /dev/null
+++ b/data/guides/big-endian-vs-little-endian.md
@@ -0,0 +1,26 @@
+---
+title: "Big Endian vs Little Endian"
+description: "Explore big endian vs little endian byte ordering in computer architecture."
+image: "https://assets.bytebytego.com/diagrams/0084-big-endian-vs-little-endian.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Computer Architecture"
+ - "Data Representation"
+---
+
+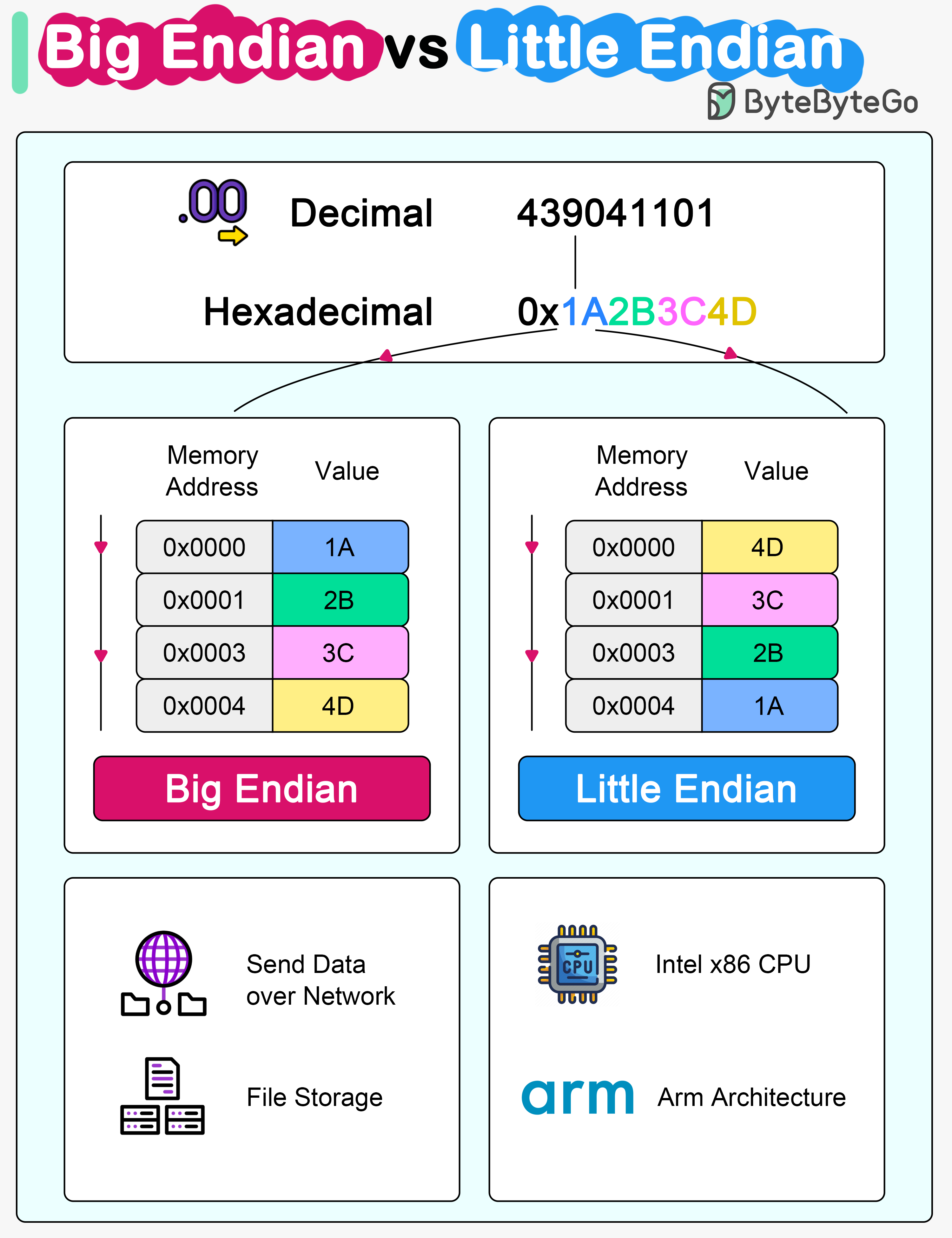
+
+Microprocessor architectures commonly use two different methods to store the individual bytes in memory. This difference is referred to as “byte ordering” or “endian nature”.
+
+## Little Endian
+
+Intel x86 processors store a two-byte integer with the least significant byte first, followed by the most significant byte. This is called little-endian byte ordering.
+
+## Big Endian
+
+In big endian byte order, the most significant byte is stored at the lowest memory address, and the least significant byte is stored at the highest memory address. Older PowerPC and Motorola 68k architectures often use big endian. In network communications and file storage, we also use big endian.
+
+The byte ordering becomes significant when data is transferred between systems or processed by systems with different endianness. It's important to handle byte order correctly to interpret data consistently across diverse systems.
diff --git a/data/guides/blocking-vs-non-blocking-queue.md b/data/guides/blocking-vs-non-blocking-queue.md
new file mode 100644
index 0000000..32d7c32
--- /dev/null
+++ b/data/guides/blocking-vs-non-blocking-queue.md
@@ -0,0 +1,50 @@
+---
+title: "Blocking vs Non-Blocking Queue"
+description: "Explore blocking vs non-blocking queues, differences, and implementation."
+image: "https://assets.bytebytego.com/diagrams/0088-blocking-noblocking-queue.jpeg"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - software-development
+tags:
+ - Concurrency
+ - Data Structures
+---
+
+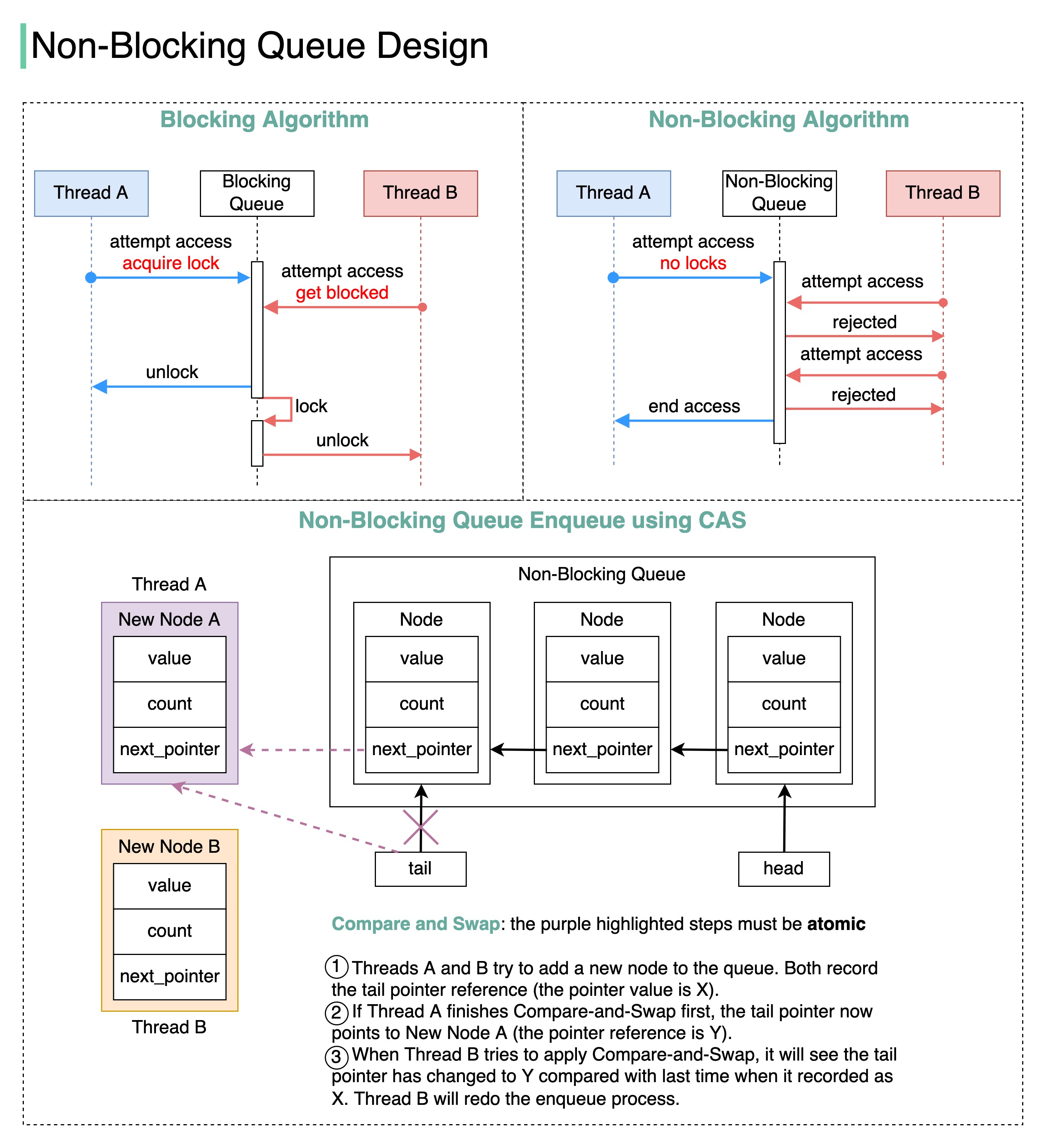
+
+How do we implement a **non-blocking** queue? What are the differences between blocking and non-blocking algorithms?
+
+The terms we use when discussing blocking and non-blocking algorithms can be confusing, so let’s start by reviewing the terminology in the concurrency area with a diagram.
+
+## Blocking vs Non-Blocking Algorithms
+
+* **Blocking**
+
+ The blocking algorithm uses locks. Thread A acquires the lock first, and Thread B might wait for arbitrary lengthy periods if Thread A gets suspended while holding the lock. This algorithm may cause Thread B to starve.
+
+* **Non-blocking**
+
+ The non-blocking algorithm allows Thread A to access the queue, but Thread A must complete a task in a certain number of steps. Other threads like Thread B may still starve due to the rejections.
+
+This is the main **difference** between blocking and non-blocking algorithms: The blocking algorithm blocks Thread B until the lock is released. A non-blocking algorithm notifies Thread B that access is rejected.
+
+* **Starvation-free**
+
+ Thread Starvation means a thread cannot acquire access to certain shared resources and cannot proceed. Starvation-free means this situation does not occur.
+
+* **Wait-free**
+
+ All threads can complete the tasks within a finite number of steps.
+
+𝘞𝘢𝘪𝘵-𝘧𝘳𝘦𝘦 = 𝘕𝘰𝘯-𝘉𝘭𝘰𝘤𝘬𝘪𝘯𝘨 + 𝘚𝘵𝘢𝘳𝘷𝘢𝘵𝘪𝘰𝘯-𝘧𝘳𝘦𝘦
+
+## Non-Blocking Queue Implementation
+
+We can use Compare and Swap (CAS) to implement a non-blocking queue. The diagram below illustrates the algorithm.
+
+## Benefits
+
+1. No thread suspension. Thread B can get a response immediately and then decide what to do next. In this way, the thread latency is greatly reduced.
+
+2. No deadlocks. Threads A and B do not wait for the lock to release, meaning that there is no possibility of a deadlock occurring.
diff --git a/data/guides/build-a-simple-chat-application.md b/data/guides/build-a-simple-chat-application.md
new file mode 100644
index 0000000..f459ac5
--- /dev/null
+++ b/data/guides/build-a-simple-chat-application.md
@@ -0,0 +1,36 @@
+---
+title: "Build a Simple Chat Application with Redis"
+description: "Learn to build a simple chat application using Redis pub/sub."
+image: "https://assets.bytebytego.com/diagrams/0314-redis-chat.jpg"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - Redis
+ - Chat Application
+---
+
+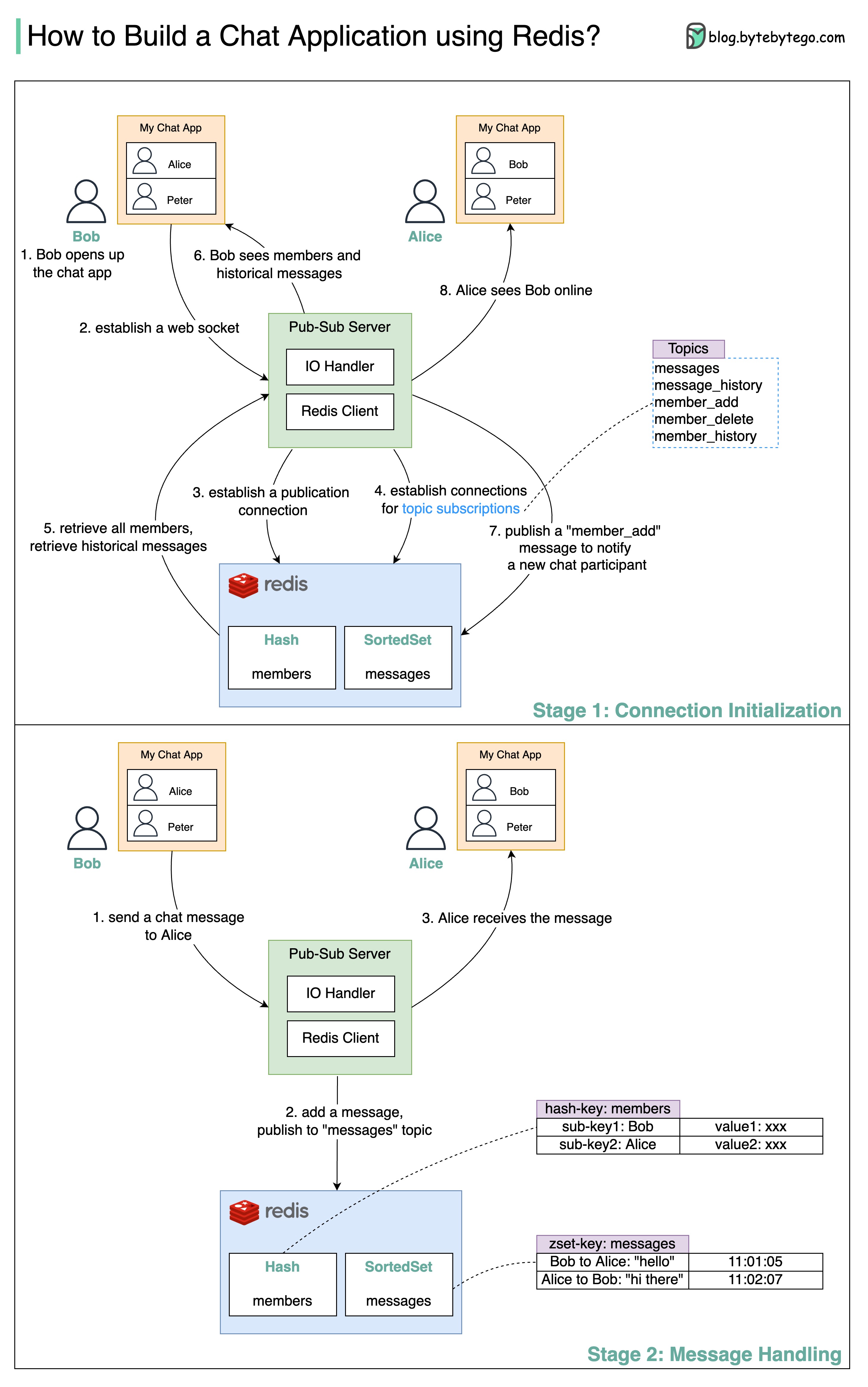
+
+How do we build a simple chat application using Redis?
+
+The diagram below shows how we can leverage the pub-sub functionality of Redis to develop a chat application.
+
+## Stage 1: Connection Initialization
+
+* Steps 1 and 2: Bob opens the chat application. A web socket is established between the client and the server.
+
+* Steps 3 and 4: The pub-sub server establishes several connections to Redis. One connection is used to update the Redis data models and publish messages to a topic. Other connections are used to subscribe and listen to updates for topics.
+
+* Steps 5 and 6: Bob’s client application requires the chat member list and the historical message list. The information is retrieved from Redis and sent to the client application.
+
+* Steps 7 and 8: Since Bob is a new member joining the chat application, a message is published to the “member\_add” topic, and as a result, other participants of the chat application can see Bob.
+
+## Stage 2: Message Handling
+
+* Step 1: Bob sends a message to Alice in the chat application.
+
+* Step 2: The new chat message is added to Redis SortedSet by calling ‘zadd.’ The chat messages are sorted based on arrival time. The pub-sub server then publishes the chat message to the “messages” topic so subscribers can pick it up.
+
+* Step 3: Alice’s client application receives the chat message from Bob.
diff --git a/data/guides/cache-miss-attack.md b/data/guides/cache-miss-attack.md
new file mode 100644
index 0000000..a884089
--- /dev/null
+++ b/data/guides/cache-miss-attack.md
@@ -0,0 +1,28 @@
+---
+title: "Cache Miss Attack"
+description: "Explore cache miss attacks, their impact, and mitigation strategies."
+image: "https://assets.bytebytego.com/diagrams/0128-cache-miss-attack.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Security"
+---
+
+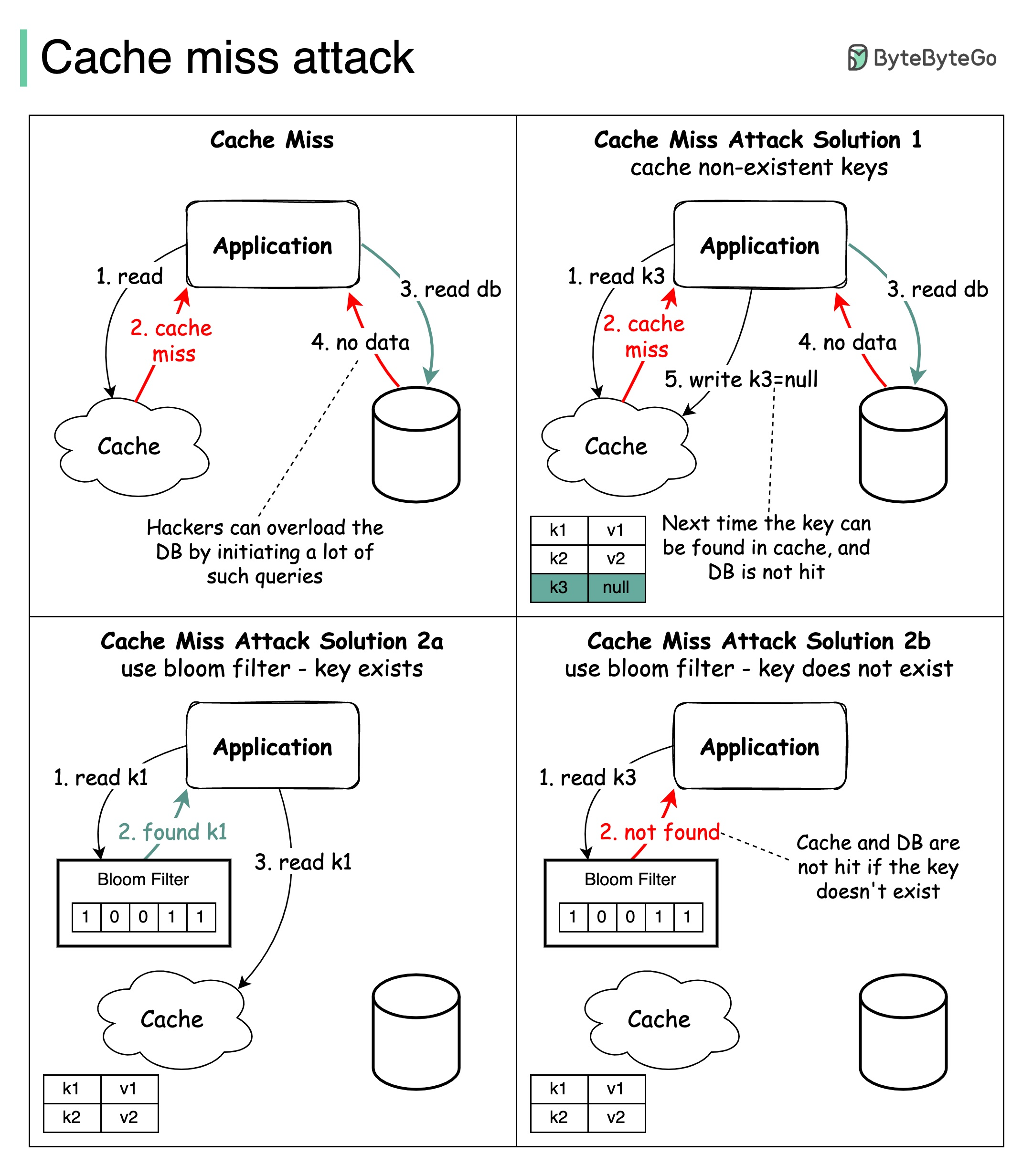
+
+Caching is awesome but it doesn’t come without a cost, just like many things in life.
+
+One of the issues is 𝐂𝐚𝐜𝐡𝐞 𝐌𝐢𝐬𝐬 𝐀𝐭𝐭𝐚𝐜𝐤. Please correct me if this is not the right term. It refers to the scenario where data to fetch doesn't exist in the database and the data isn’t cached either. So every request hits the database eventually, defeating the purpose of using a cache. If a malicious user initiates lots of queries with such keys, the database can easily be overloaded.
+
+The diagram above illustrates the process.
+
+## Solutions
+
+Two approaches are commonly used to solve this problem:
+
+* **Cache keys with null value.** Set a short TTL (Time to Live) for keys with null value.
+
+* **Using Bloom filter.** A Bloom filter is a data structure that can rapidly tell us whether an element is present in a set or not. If the key exists, the request first goes to the cache and then queries the database if needed. If the key doesn't exist in the data set, it means the key doesn’t exist in the cache/database. In this case, the query will not hit the cache or database layer.
diff --git a/data/guides/cache-systems-every-developer-should-know.md b/data/guides/cache-systems-every-developer-should-know.md
new file mode 100644
index 0000000..872c078
--- /dev/null
+++ b/data/guides/cache-systems-every-developer-should-know.md
@@ -0,0 +1,40 @@
+---
+title: "Cache Systems Every Developer Should Know"
+description: "Explore essential caching layers for developers to optimize performance."
+image: "https://assets.bytebytego.com/diagrams/0418-cache-systems-every-developer-should-know.jpeg"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Caching
+ - Performance
+---
+
+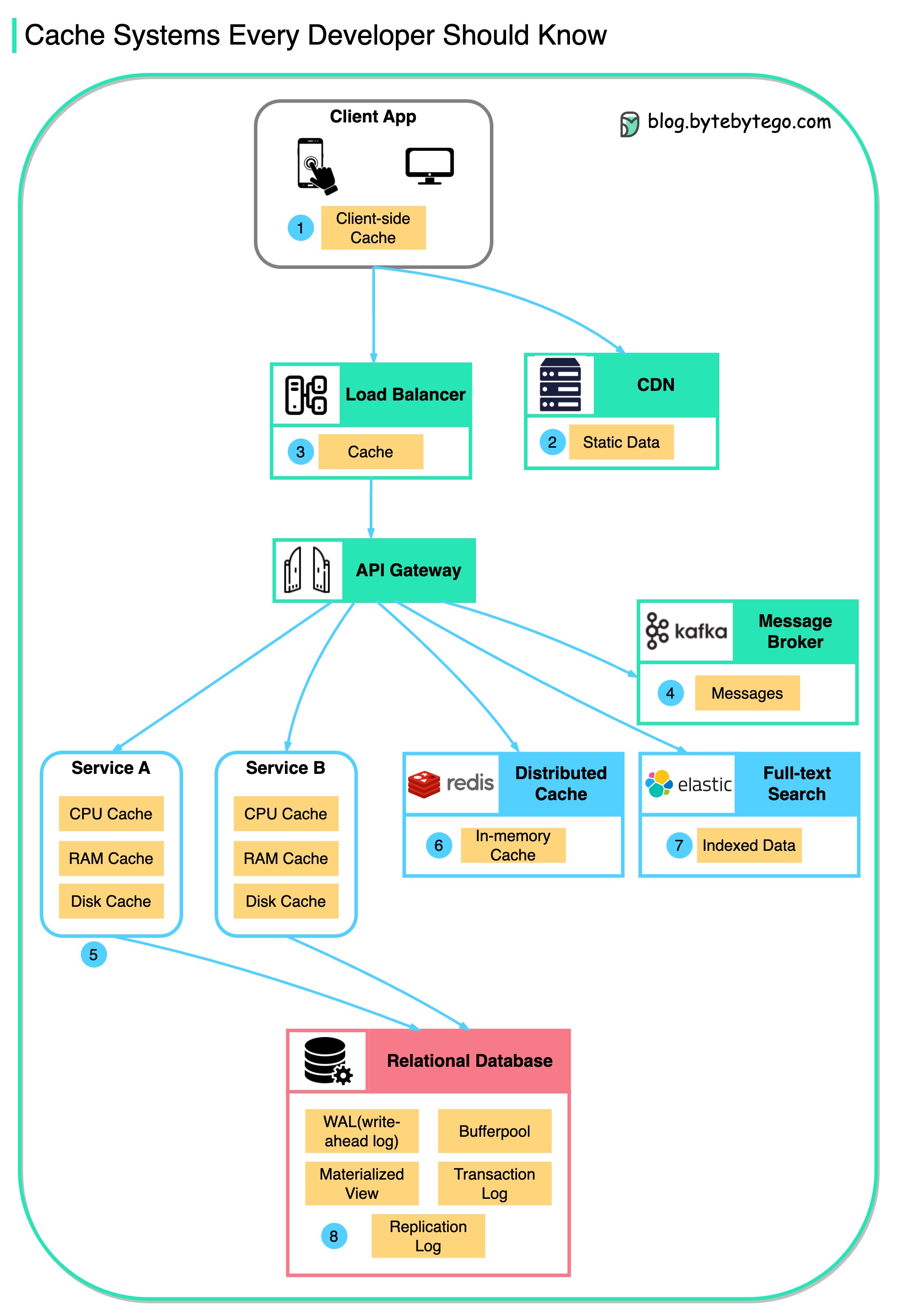
+
+Data is cached everywhere, from the client-facing side to backend systems. Let's look at the many caching layers:
+
+## Caching Layers
+
+1. Client Apps: Browsers cache HTTP responses. Server responses include caching directives in headers. Upon subsequent requests, browsers may serve cached data if still fresh.
+
+2. Content Delivery Networks: CDNs cache static content like images, stylesheets, and JavaScript files. They serve cached content from locations closer to users, reducing latency and load times.
+
+3. Load Balancers: Some load balancers cache frequently requested data. This allows serving responses without engaging backend servers, reducing load and response times.
+
+4. Message Brokers: Systems like Kafka can cache messages on disk per a retention policy. Consumers then pull messages according to their own schedule.
+
+5. Services: Individual services often employ caching to improve data retrieval speeds, first checking in-memory caches before querying databases. Services may also utilize disk caching for larger datasets.
+
+6. Distributed Caches: Systems like Redis cache key-value pairs across services, providing faster read/write capabilities compared to traditional databases.
+
+7. Full-text Search Engines: Platforms like Elasticsearch index data for efficient text search. This index is effectively a form of cache, optimized for quick text search retrieval.
+
+8. Databases: There are specialized mechanisms to enhance performance, some of which include caching concepts:
+
+### Database Caching Mechanisms
+
+* **Bufferpool:** This is a cache within the database that holds copies of data pages. It allows for quick reads and writes to temporary storage in memory, reducing the need to access data from disk.
+
+* **Materialized Views:** They are similar to caches in that they store the results of computationally expensive queries. The database can return these precomputed results quickly, rather than recalculating them.
diff --git a/data/guides/can-kafka-lose-messages.md b/data/guides/can-kafka-lose-messages.md
new file mode 100644
index 0000000..ecd210e
--- /dev/null
+++ b/data/guides/can-kafka-lose-messages.md
@@ -0,0 +1,46 @@
+---
+title: "Can Kafka Lose Messages?"
+description: "Explore Kafka's message loss scenarios and prevention strategies."
+image: "https://assets.bytebytego.com/diagrams/0130-can-kafka-lose-messages.png"
+createdAt: "2024-02-12"
+draft: false
+categories:
+ - "database-and-storage"
+tags:
+ - "Kafka"
+ - "Message Loss"
+---
+
+Error handling is one of the most important aspects of building reliable systems.
+
+Today, we will discuss an important topic: Can Kafka lose messages?
+
+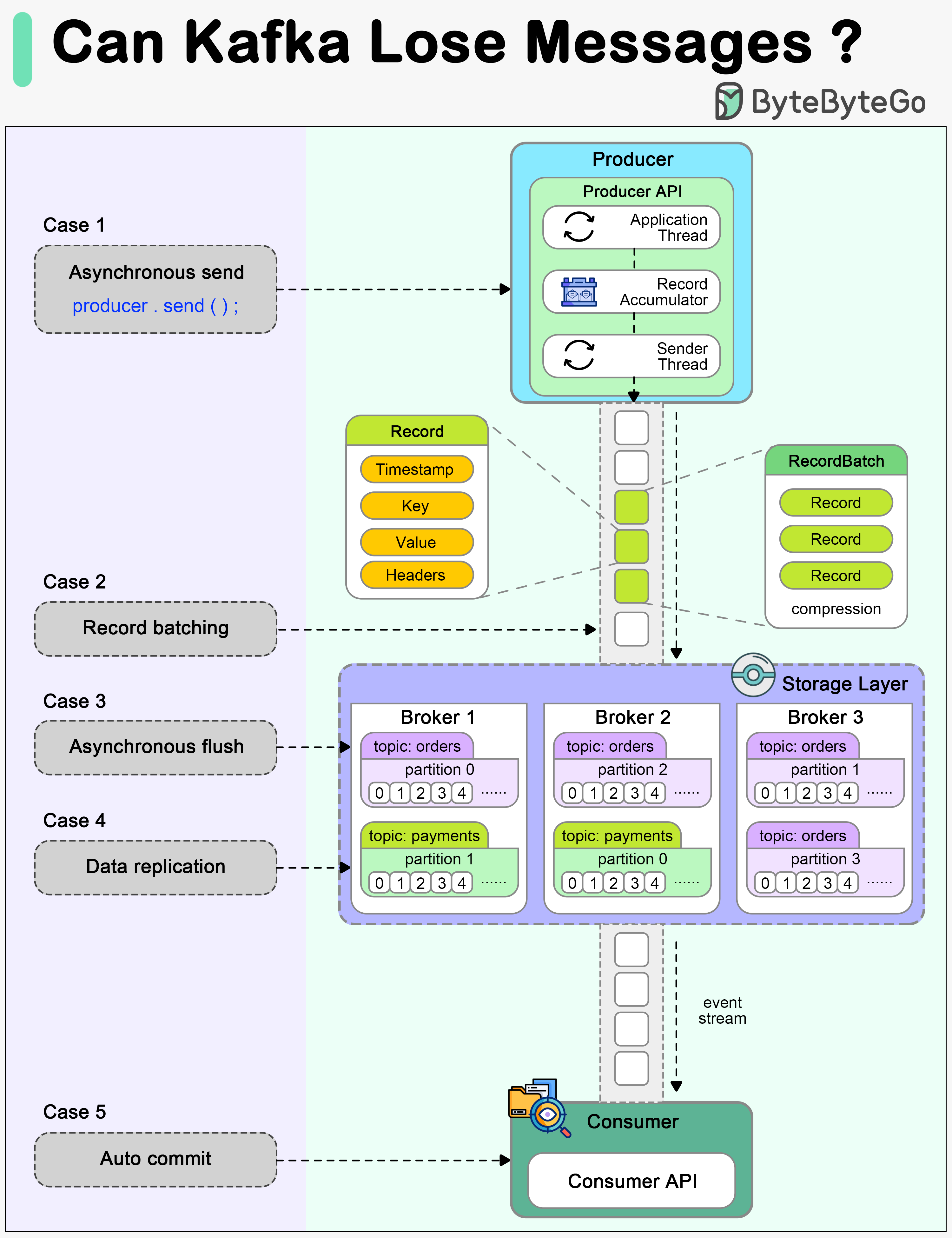
+
+A common belief among many developers is that Kafka, by its very design, guarantees no message loss. However, understanding the nuances of Kafka's architecture and configuration is essential to truly grasp how and when it might lose messages, and more importantly, how to prevent such scenarios.
+
+The diagram above shows how a message can be lost during its lifecycle in Kafka.
+
+## Producer
+
+When we call producer.send() to send a message, it doesn't get sent to the broker directly. There are two threads and a queue involved in the message-sending process:
+
+* Application thread
+* Record accumulator
+* Sender thread (I/O thread)
+
+We need to configure proper ‘acks’ and ‘retries’ for the producer to make sure messages are sent to the broker.
+
+## Broker
+
+A broker cluster should not lose messages when it is functioning normally. However, we need to understand which extreme situations might lead to message loss:
+
+* The messages are usually flushed to the disk asynchronously for higher I/O throughput, so if the instance is down before the flush happens, the messages are lost.
+
+* The replicas in the Kafka cluster need to be properly configured to hold a valid copy of the data. The determinism in data synchronization is important.
+
+## Consumer
+
+Kafka offers different ways to commit messages. Auto-committing might acknowledge the processing of records before they are actually processed. When the consumer is down in the middle of processing, some records may never be processed.
+
+A good practice is to combine both synchronous and asynchronous commits, where we use asynchronous commits in the processing loop for higher throughput and synchronous commits in exception handling to make sure the last offset is always committed.
diff --git a/data/guides/cap-base-solid-kiss-what-do-these-acronyms-mean.md b/data/guides/cap-base-solid-kiss-what-do-these-acronyms-mean.md
new file mode 100644
index 0000000..e31f002
--- /dev/null
+++ b/data/guides/cap-base-solid-kiss-what-do-these-acronyms-mean.md
@@ -0,0 +1,55 @@
+---
+title: "CAP, BASE, SOLID, KISS, What do these acronyms mean?"
+description: "Understanding common acronyms in system design: CAP, BASE, SOLID, and KISS."
+image: "https://assets.bytebytego.com/diagrams/0350-cap-base-solid-kiss.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "System Design"
+ - "Software Engineering"
+---
+
+The diagram below explains the common acronyms in system designs.
+
+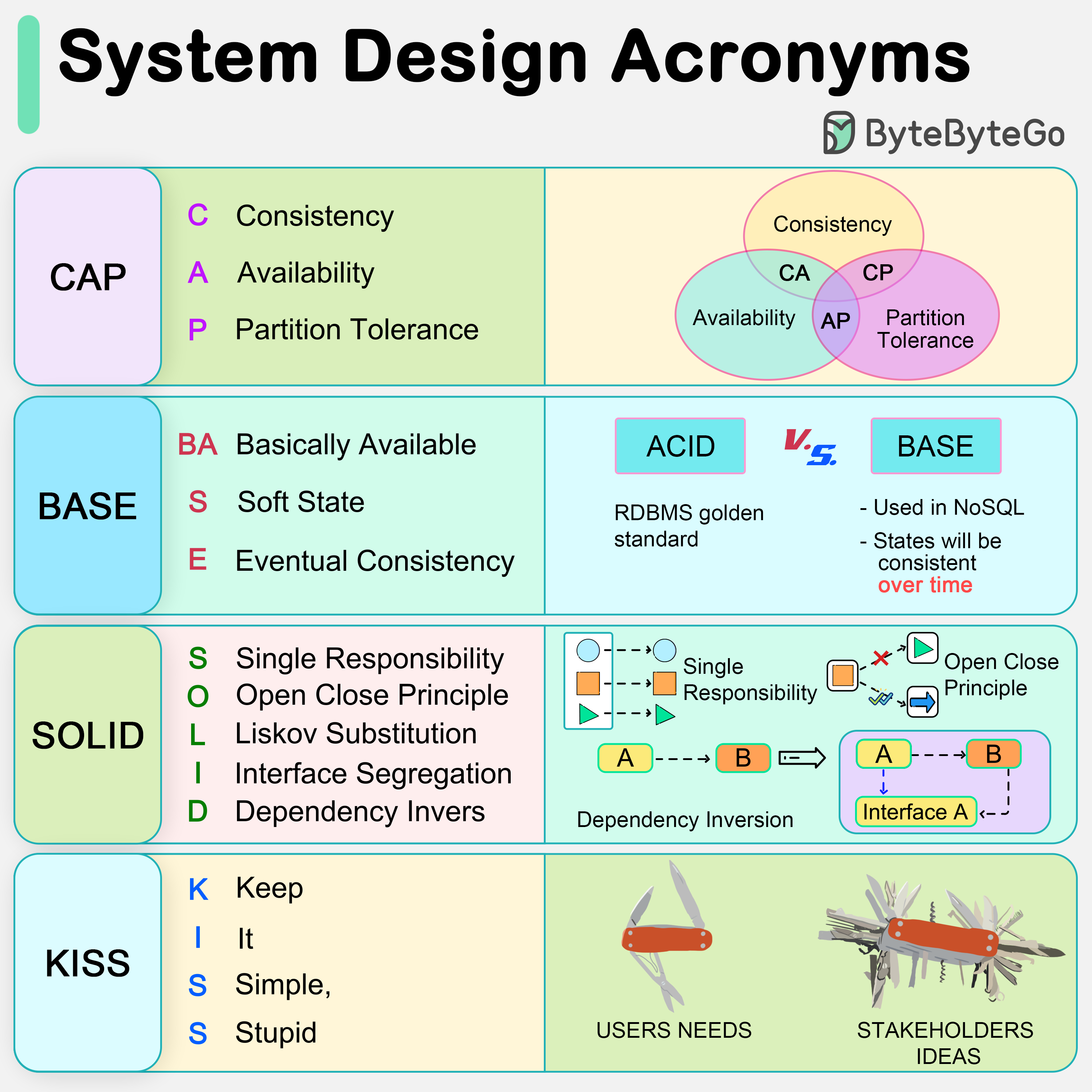
+
+* **CAP**
+
+ CAP theorem states that any distributed data store can only provide two of the following three guarantees:
+
+ 1. Consistency - Every read receives the most recent write or an error.
+ 2. Availability - Every request receives a response.
+ 3. Partition tolerance - The system continues to operate in network faults.
+
+ However, this theorem was criticized for being too narrow for distributed systems, and we shouldn’t use it to categorize the databases. Network faults are guaranteed to happen in distributed systems, and we must deal with this in any distributed systems.
+
+ You can read more on this in “Please stop calling databases CP or AP” by Martin Kleppmann.
+
+* **BASE**
+
+ The ACID (Atomicity-Consistency-Isolation-Durability) model used in relational databases is too strict for NoSQL databases. The BASE principle offers more flexibility, choosing availability over consistency. It states that the states will eventually be consistent.
+
+* **SOLID**
+
+ SOLID principle is quite famous in OOP. There are 5 components to it.
+
+ 1. SRP (Single Responsibility Principle)
+ Each unit of code should have one responsibility.
+
+ 2. OCP (Open Close Principle)
+ Units of code should be open for extension but closed for modification.
+
+ 3. LSP (Liskov Substitution Principle)
+ A subclass should be able to be substituted by its base class.
+
+ 4. ISP (Interface Segregation Principle)
+ Expose multiple interfaces with specific responsibilities.
+
+ 5. DIP (Dependency Inversion Principle)
+ Use abstractions to decouple dependencies in the system.
+
+* **KISS**
+
+ "Keep it simple, stupid!" is a design principle first noted by the U.S. Navy in 1960. It states that most systems work best if they are kept simple.
diff --git a/data/guides/cap-theorem-one-of-the-most-misunderstood-terms.md b/data/guides/cap-theorem-one-of-the-most-misunderstood-terms.md
new file mode 100644
index 0000000..5a101f9
--- /dev/null
+++ b/data/guides/cap-theorem-one-of-the-most-misunderstood-terms.md
@@ -0,0 +1,42 @@
+---
+title: "CAP Theorem: One of the Most Misunderstood Terms"
+description: "Explore the CAP theorem, its implications, and common misunderstandings."
+image: "https://assets.bytebytego.com/diagrams/0131-cap-theorem.jpeg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "distributed systems"
+ - "cap theorem"
+---
+
+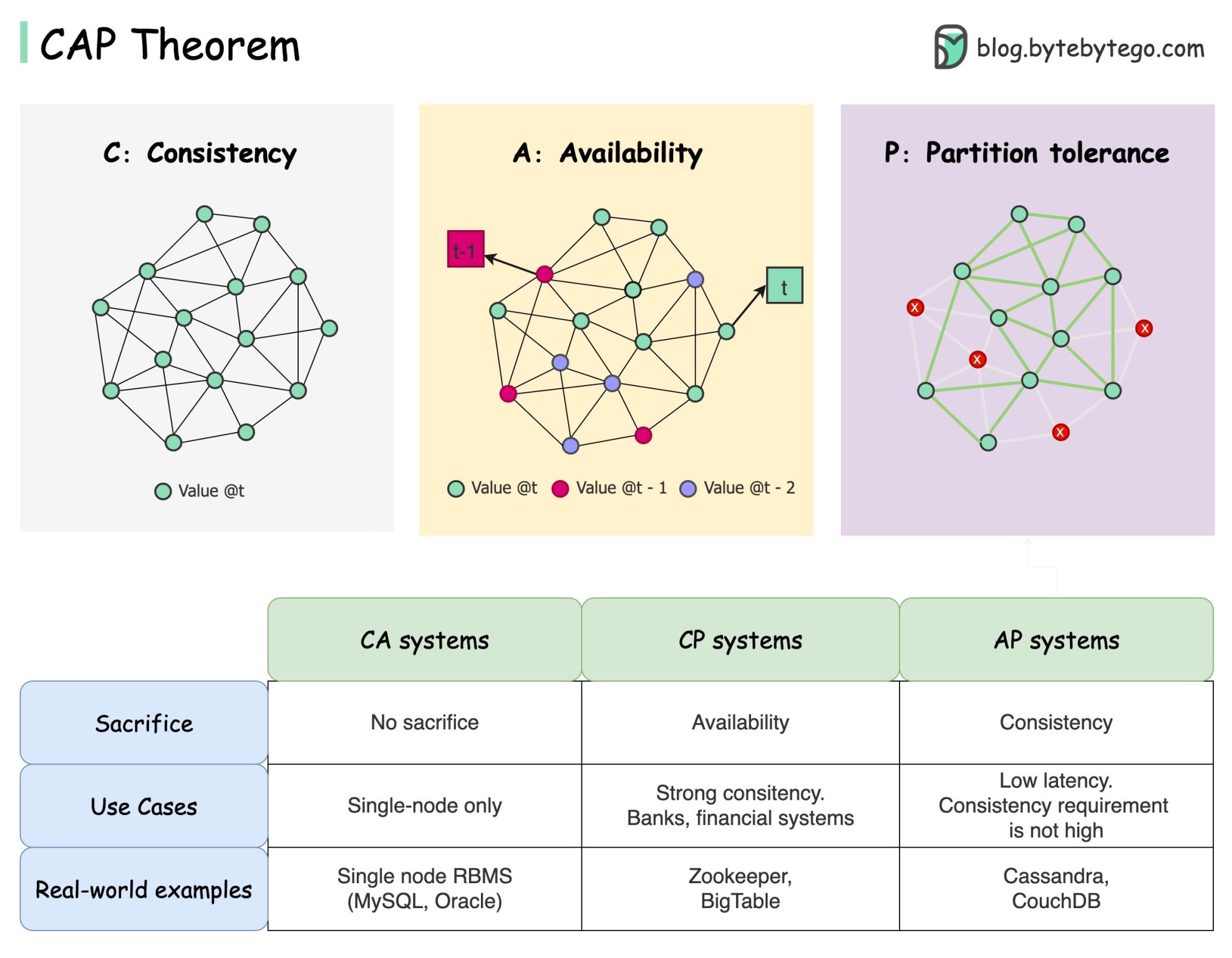
+
+The CAP theorem is one of the most famous terms in computer science, but I bet different developers have different understandings. Let’s examine what it is and why it can be confusing.
+
+CAP theorem states that a distributed system can't provide more than two of these three guarantees simultaneously.
+
+## Consistency
+
+Consistency means all clients see the same data at the same time no matter which node they connect to.
+
+## Availability
+
+Availability means any client which requests data gets a response even if some of the nodes are down.
+
+## Partition Tolerance
+
+Partition tolerance means the system continues to operate despite network partitions.
+
+The “2 of 3” formulation can be useful, but this simplification could be misleading.
+
+* Picking a database is not easy. Justifying our choice purely based on the CAP theorem is not enough. For example, companies don't choose Cassandra for chat applications simply because it is an AP system. There is a list of good characteristics that make Cassandra a desirable option for storing chat messages. We need to dig deeper.
+
+* “CAP prohibits only a tiny part of the design space: perfect availability and consistency in the presence of partitions, which are rare”. Quoted from the paper: CAP Twelve Years Later: How the “Rules” Have Changed.
+
+* The theorem is about 100% availability and consistency. A more realistic discussion would be the trade-offs between latency and consistency when there is no network partition. See PACELC theorem for more details.
+
+## Is the CAP theorem really useful?
+
+I think it is still useful as it opens our minds to a set of tradeoff discussions, but it is only part of the story. We need to dig deeper when picking the right database.
diff --git a/data/guides/change-data-capture-key-to-leverage-real-time-data.md b/data/guides/change-data-capture-key-to-leverage-real-time-data.md
new file mode 100644
index 0000000..9eaec49
--- /dev/null
+++ b/data/guides/change-data-capture-key-to-leverage-real-time-data.md
@@ -0,0 +1,40 @@
+---
+title: "Change Data Capture: Key to Leverage Real-time Data"
+description: "Learn how Change Data Capture (CDC) helps leverage real-time data."
+image: "https://assets.bytebytego.com/diagrams/0133-change-data-capture-key-to-leverage-real-time-data.png"
+createdAt: "2024-02-11"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Streaming"
+ - "Data Synchronization"
+---
+
+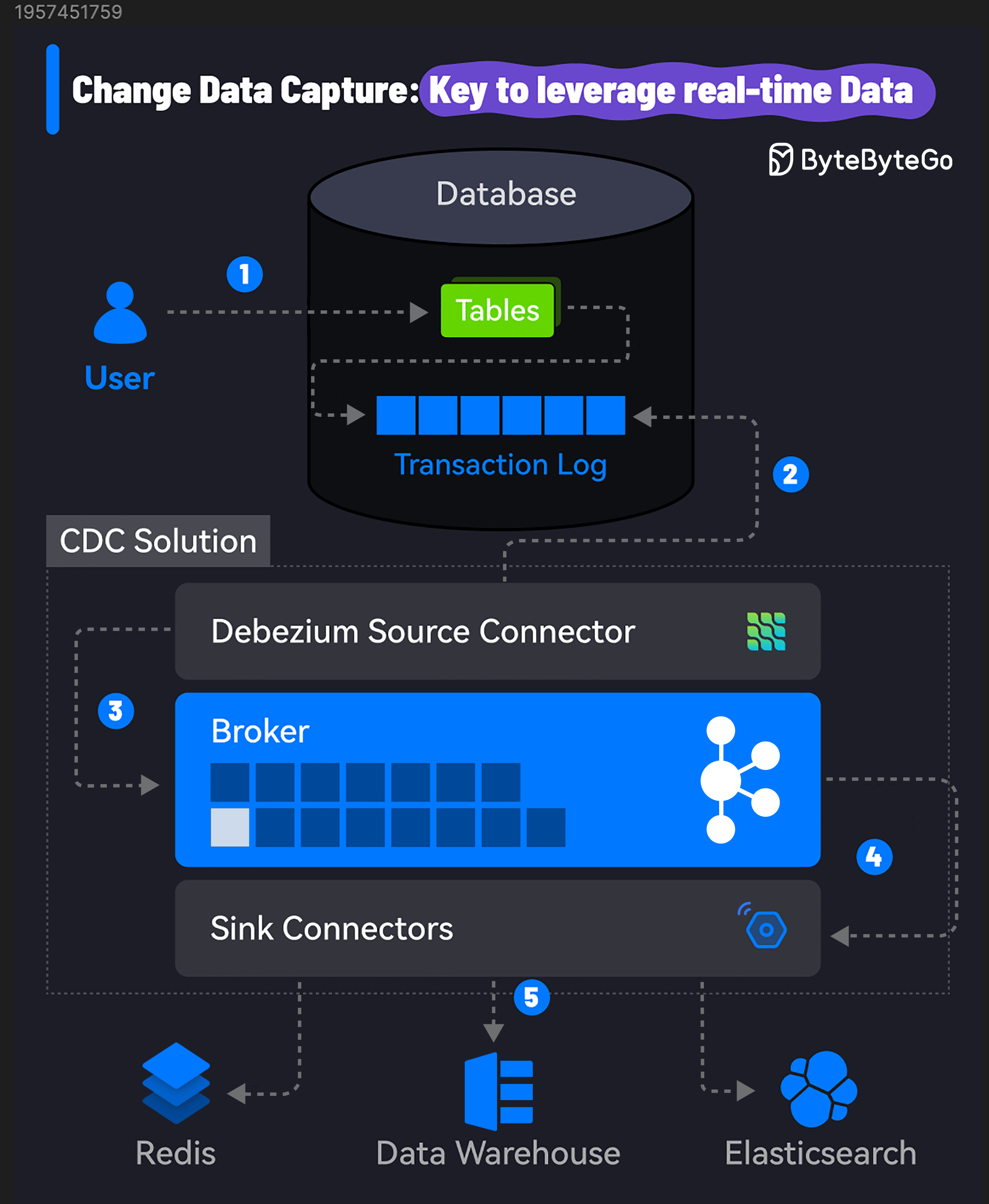
+
+90% of the world’s data was created in the last two years and this growth will only get faster.
+
+However, the biggest challenge is to leverage this data in real-time. Constant data changes make databases, data lakes, and data warehouses out of sync.
+
+CDC or Change Data Capture can help you overcome this challenge.
+
+CDC identifies and captures changes made to the data in a database, allowing you to replicate and sync data across multiple systems.
+
+## How Change Data Capture Works
+
+So, how does Change Data Capture work? Here's a step-by-step breakdown:
+
+1. Data Modification: A change is made to the data in the source database. It could be an insert, update, or delete operation on a table.
+
+2. Change Capture: A CDC tool monitors the database transaction logs to capture the modifications. It uses the source connector to connect to the database and read the logs.
+
+3. Change Processing: The captured changes are processed and transformed into a format suitable for the downstream systems.
+
+4. Change Propagation: The processed changes are published to a message queue and propagated to the target systems, such as data warehouses, analytics platforms, distributed caches like Redis, and so on.
+
+5. Real-Time Integration: The CDC tool uses its sink connector to consume the log and update the target systems. The changes are received in real time, allowing for conflict-free data analysis and decision-making.
+
+Users only need to take care of step 1 while all other steps are transparent.
+
+A popular CDC solution uses Debezium with Kafka Connect to stream data changes from the source to target systems using Kafka as the broker. Debezium has connectors for most databases such as MySQL, PostgreSQL, Oracle, etc.
diff --git a/data/guides/chatgpt-timeline.md b/data/guides/chatgpt-timeline.md
new file mode 100644
index 0000000..5306126
--- /dev/null
+++ b/data/guides/chatgpt-timeline.md
@@ -0,0 +1,42 @@
+---
+title: ChatGPT Timeline
+description: A visual guide to the evolution of ChatGPT and its underlying tech.
+image: 'https://assets.bytebytego.com/diagrams/0136-chatgpt-how-we-get-here.png'
+createdAt: '2024-03-10'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI History
+ - NLP
+---
+
+A picture is worth a thousand words. ChatGPT seems to come out of nowhere. Little did we know that it was built on top of decades of research.
+
+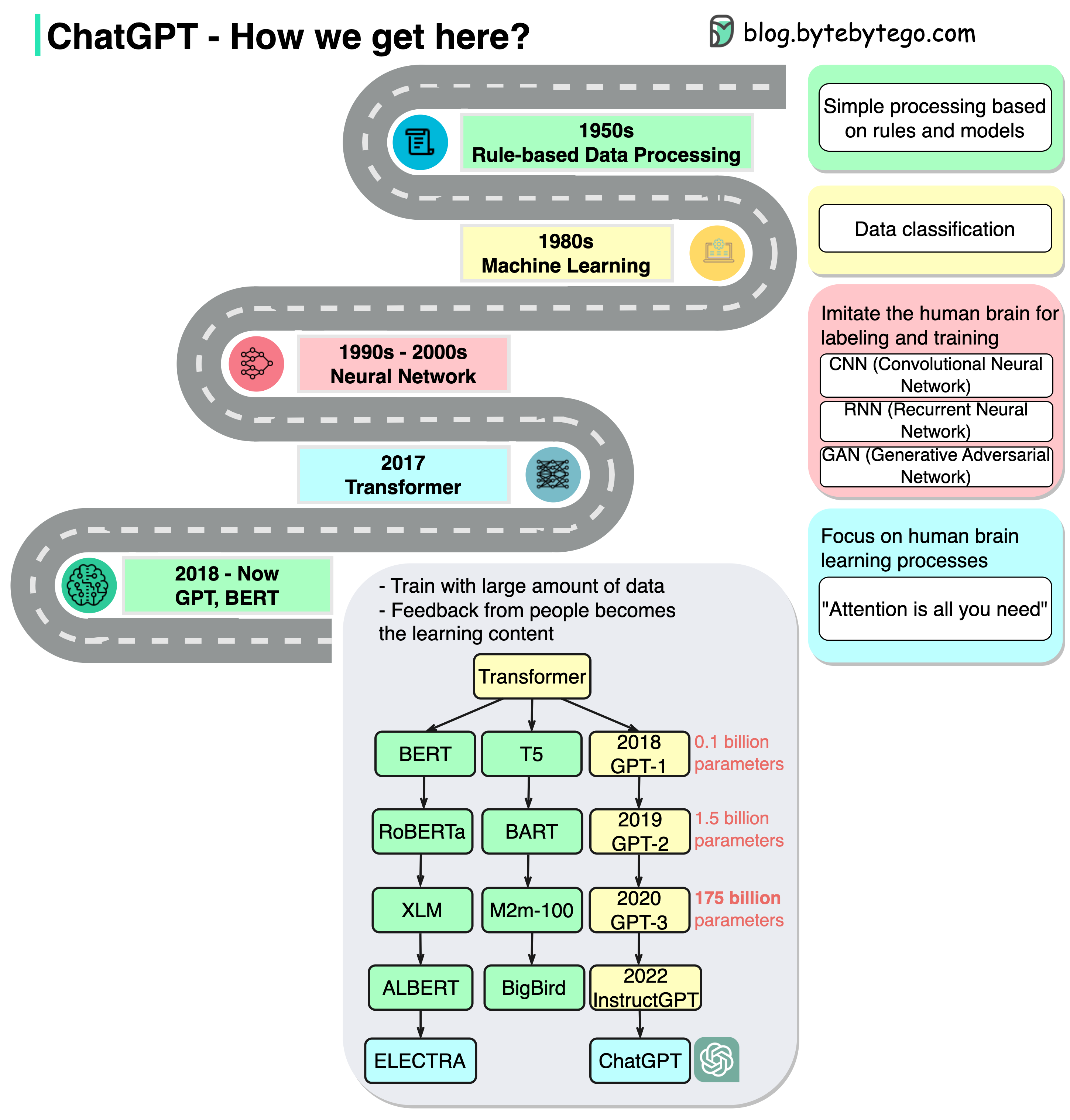
+
+The diagram above shows how we get here.
+
+## 1950s
+
+In this stage, people still used primitive models that are based on rules.
+
+## 1980s
+
+Since the 1980s, machine learning started to pick up and was used for classification. The training was conducted on a small range of data.
+
+## 1990s - 2000s
+
+Since the 1990s, neural networks started to imitate human brains for labeling and training. There are generally 3 types:
+
+- CNN (Convolutional Neural Network): often used in visual-related tasks.
+- RNN (Recurrent Neural Network): useful in natural language tasks
+- GAN (Generative Adversarial Network): comprised of two networks(Generative and Discriminative). This is a generative model that can generate novel images that look alike.
+
+## 2017
+
+“Attention is all you need” represents the foundation of generative AI. The transformer model greatly shortens the training time by parallelism.
+
+## 2018 - Now
+
+In this stage, due to the major progress of the transformer model, we see various models train on a massive amount of data. Human demonstration becomes the learning content of the model. We’ve seen many AI writers that can write articles, news, technical docs, and even code. This has great commercial value as well and sets off a global whirlwind.
diff --git a/data/guides/choose-the-right-database-for-metric-collecting-system.md b/data/guides/choose-the-right-database-for-metric-collecting-system.md
new file mode 100644
index 0000000..d80be54
--- /dev/null
+++ b/data/guides/choose-the-right-database-for-metric-collecting-system.md
@@ -0,0 +1,32 @@
+---
+title: "Choose the Right Database for Metric Collection"
+description: "A guide to choosing the right database for a metric collecting system."
+image: "https://assets.bytebytego.com/diagrams/0273-metrics-access-pattern.jpg"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "databases"
+ - "metrics"
+---
+
+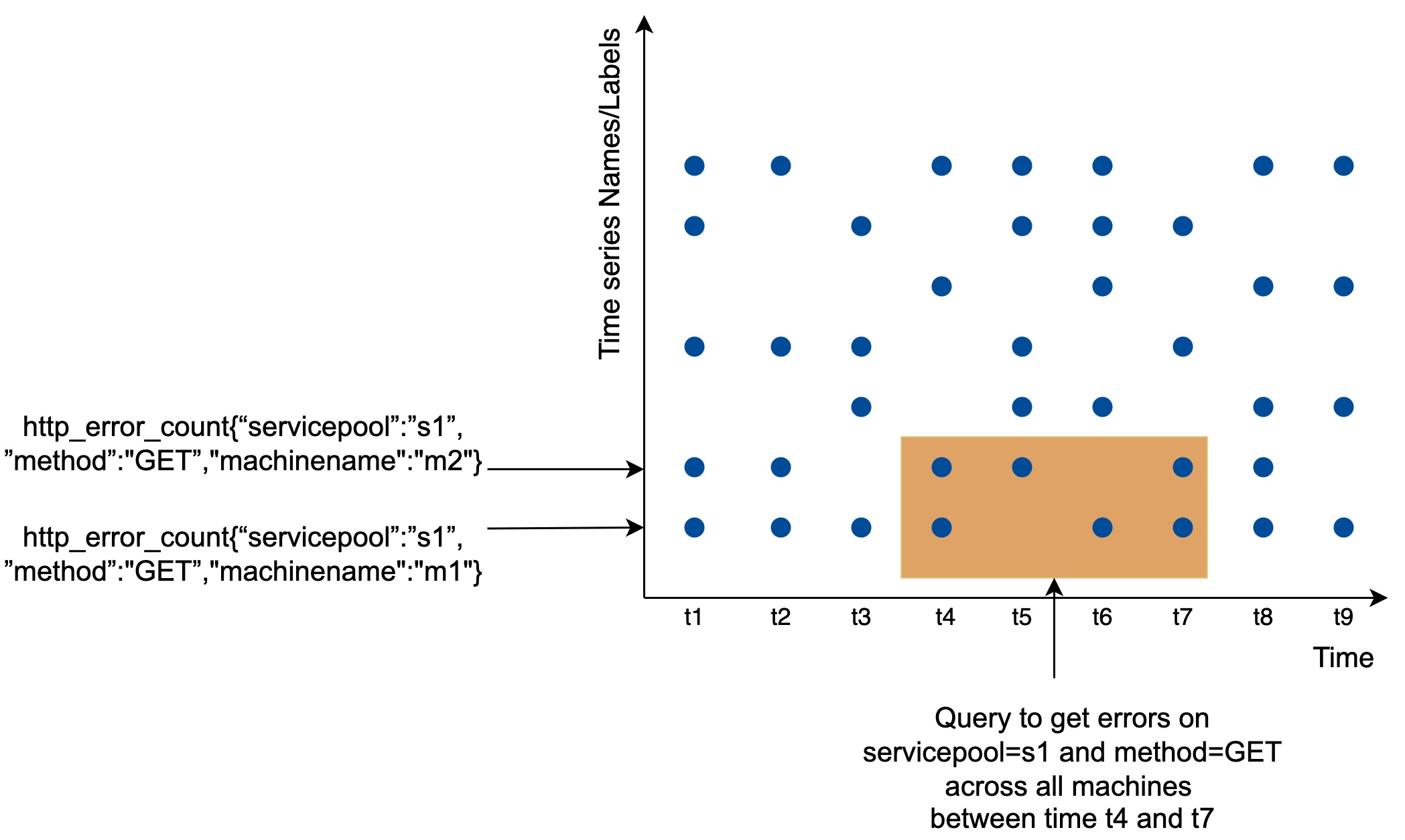
+
+Which database shall I use for the **metric collecting system**? This is one of the most important questions we need to address in a system design interview.
+
+## Data access pattern
+
+As shown in the diagram, each label on the y-axis represents a time series (uniquely identified by the names and labels) while the x-axis represents time.
+
+The write load is heavy. As you can see, there can be many time-series data points written at any moment. There are millions of operational metrics written per day, and many metrics are collected at high frequency, so the traffic is undoubtedly write-heavy.
+
+At the same time, the read load is spiky. Both visualization and alert services send queries to the database and depending on the access patterns of the graphs and alerts, the read volume could be bursty.
+
+## Choose the right database
+
+The data storage system is the heart of the design. It’s not recommended to build your own storage system or use a general-purpose storage system (MySQL) for this job.
+
+A general-purpose database, in theory, could support time-series data, but it would require expert-level tuning to make it work at our scale. Specifically, a relational database is not optimized for operations you would commonly perform against time-series data. For example, computing the moving average in a rolling time window requires complicated SQL that is difficult to read (there is an example of this in the deep dive section). Besides, to support tagging/labeling data, we need to add an index for each tag. Moreover, a general-purpose relational database does not perform well under constant heavy write load. At our scale, we would need to expend significant effort in tuning the database, and even then, it might not perform well.
+
+How about NoSQL? In theory, a few NoSQL databases on the market could handle time-series data effectively. For example, Cassandra and Bigtable can both be used for time series data. However, this would require deep knowledge of the internal workings of each NoSQL to devise a scalable schema for effectively storing and querying time-series data. With industrial-scale time-series databases readily available, using a general-purpose NoSQL database is not appealing.
diff --git a/data/guides/cicd-pipeline-explained-in-simple-terms.md b/data/guides/cicd-pipeline-explained-in-simple-terms.md
new file mode 100644
index 0000000..eb6936d
--- /dev/null
+++ b/data/guides/cicd-pipeline-explained-in-simple-terms.md
@@ -0,0 +1,44 @@
+---
+title: "CI/CD Pipeline Explained in Simple Terms"
+description: "Learn about CI/CD pipelines, their stages, and benefits in software delivery."
+image: "https://assets.bytebytego.com/diagrams/0140-ci-cd-pipeline.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "CI/CD"
+ - "DevOps"
+---
+
+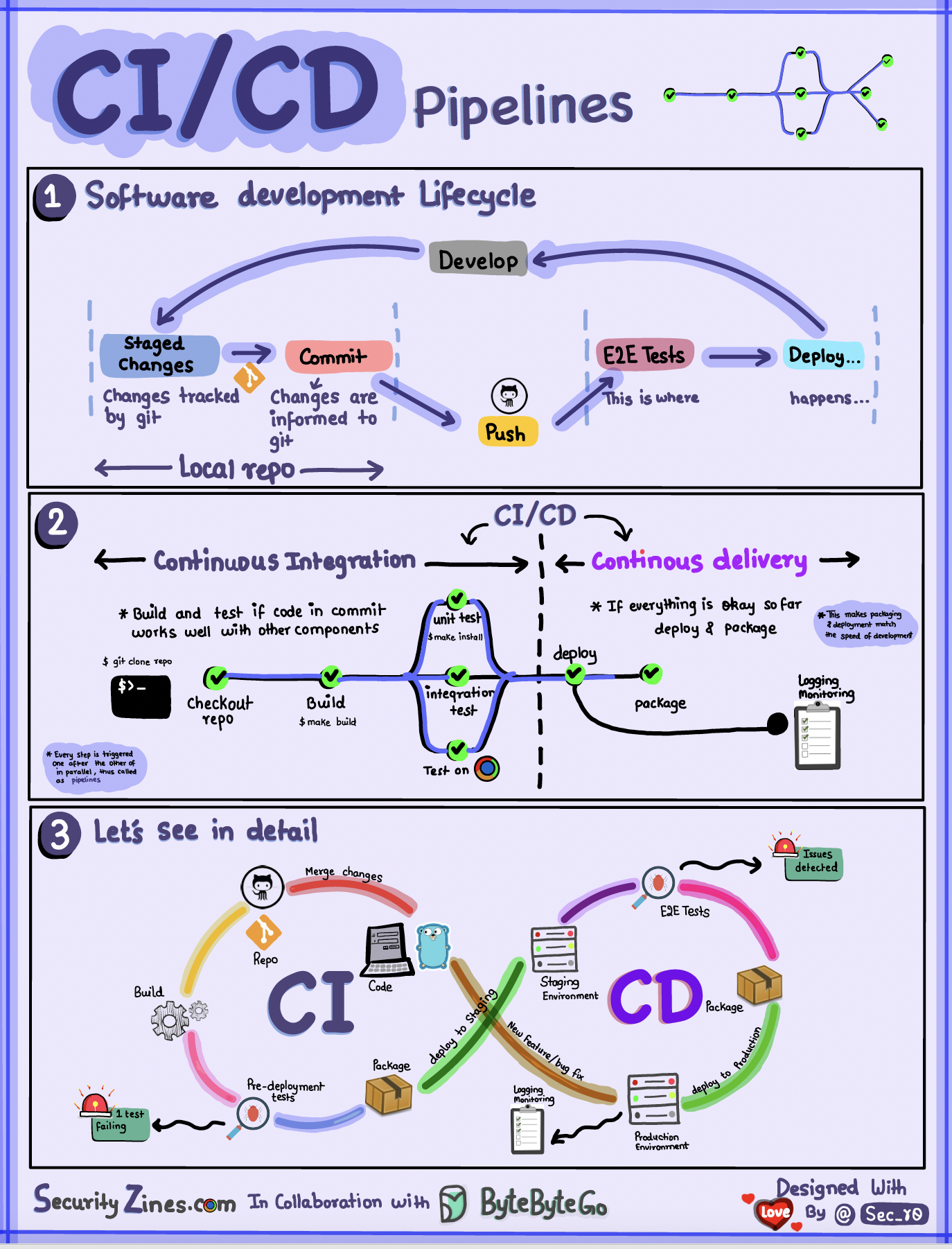
+
+## SDLC with CI/CD
+
+The software development life cycle (SDLC) consists of several key stages: development, testing, deployment, and maintenance. CI/CD automates and integrates these stages to enable faster, more reliable releases.
+
+When code is pushed to a git repository, it triggers an automated build and test process. End-to-end (e2e) test cases are run to validate the code. If tests pass, the code can be automatically deployed to staging/production. If issues are found, the code is sent back to development for bug fixing. This automation provides fast feedback to developers and reduces risk of bugs in production.
+
+## Difference between CI and CD
+
+Continuous Integration (CI) automates the build, test, and merge process. It runs tests whenever code is committed to detect integration issues early. This encourages frequent code commits and rapid feedback.
+
+Continuous Delivery (CD) automates release processes like infrastructure changes and deployment. It ensures software can be released reliably at any time through automated workflows. CD may also automate the manual testing and approval steps required before production deployment.
+
+## CI/CD Pipeline
+
+A typical CI/CD pipeline has several connected stages:
+
+* Developer commits code changes to source control
+
+* CI server detects changes and triggers build
+
+* Code is compiled, tested (unit, integration tests)
+
+* Test results reported to developer
+
+* On success, artifacts are deployed to staging environments
+
+* Further testing may be done on staging before release
+
+* CD system deploys approved changes to production
diff --git a/data/guides/cicd-simplified-visual-guide.md b/data/guides/cicd-simplified-visual-guide.md
new file mode 100644
index 0000000..9725717
--- /dev/null
+++ b/data/guides/cicd-simplified-visual-guide.md
@@ -0,0 +1,26 @@
+---
+title: "CI/CD Simplified Visual Guide"
+description: "A visual guide to understanding and improving CI/CD pipelines."
+image: "https://assets.bytebytego.com/diagrams/0141-ci-cd-workflow.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "CI/CD"
+ - "DevOps"
+---
+
+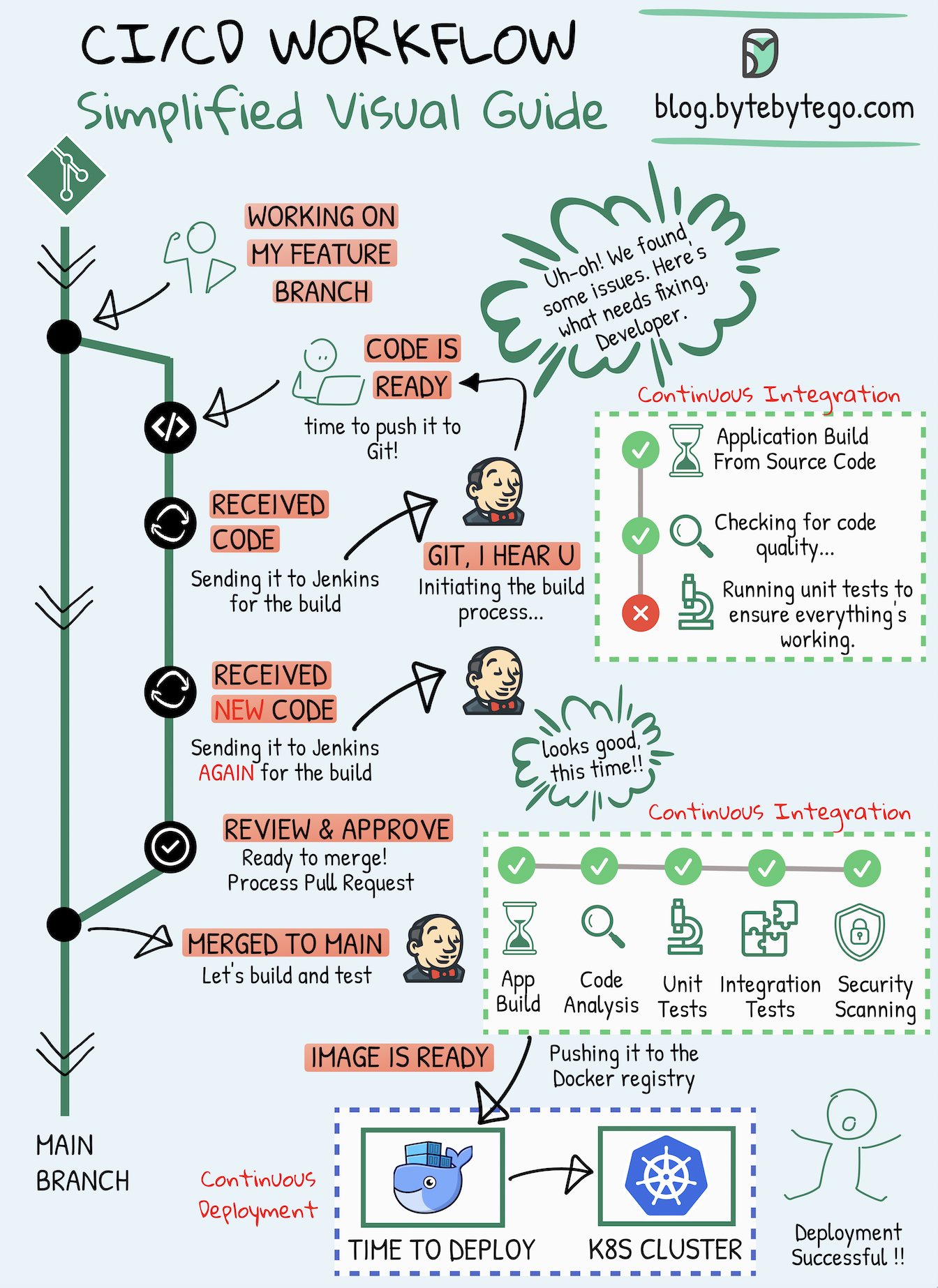
+
+Whether you're a developer, a DevOps specialist, a tester, or involved in any modern IT role, CI/CD pipelines have become an integral part of the software development process.
+
+## Continuous Integration (CI)
+
+Continuous Integration (CI) is a practice where code changes are frequently combined into a shared repository. This process includes automatic checks to ensure the new code works well with the existing code.
+
+## Continuous Deployment (CD)
+
+Continuous Deployment (CD) takes care of automatically putting these code changes into real-world use. It makes sure that the process of moving new code to production is smooth and reliable.
+
+This visual guide is designed to help you grasp and enhance your methods for creating and delivering software more effectively.
diff --git a/data/guides/cloud-comparison-cheat-sheet.md b/data/guides/cloud-comparison-cheat-sheet.md
new file mode 100644
index 0000000..54d5f44
--- /dev/null
+++ b/data/guides/cloud-comparison-cheat-sheet.md
@@ -0,0 +1,20 @@
+---
+title: "Cloud Comparison Cheat Sheet"
+description: "A handy cheat sheet comparing different cloud services."
+image: "https://assets.bytebytego.com/diagrams/0093-cloud-comparison-cheat-sheet.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Computing
+ - Comparison
+---
+
+
+
+## Cloud comparison Cheat Sheet
+
+A nice cheat sheet of different cloud services (2023 edition)!
+
+Guest post by [Govardhana Miriyala Kannaiah](https://www.linkedin.com/in/govardhana-miriyala-kannaiah/).
diff --git a/data/guides/cloud-cost-reduction-techniques.md b/data/guides/cloud-cost-reduction-techniques.md
new file mode 100644
index 0000000..3849349
--- /dev/null
+++ b/data/guides/cloud-cost-reduction-techniques.md
@@ -0,0 +1,33 @@
+---
+title: "Cloud Cost Reduction Techniques"
+description: "Learn effective strategies to minimize cloud spending and optimize resources."
+image: "https://assets.bytebytego.com/diagrams/0145-cloud-cost-reduction-techniques.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Cost Optimization
+ - Resource Management
+---
+
+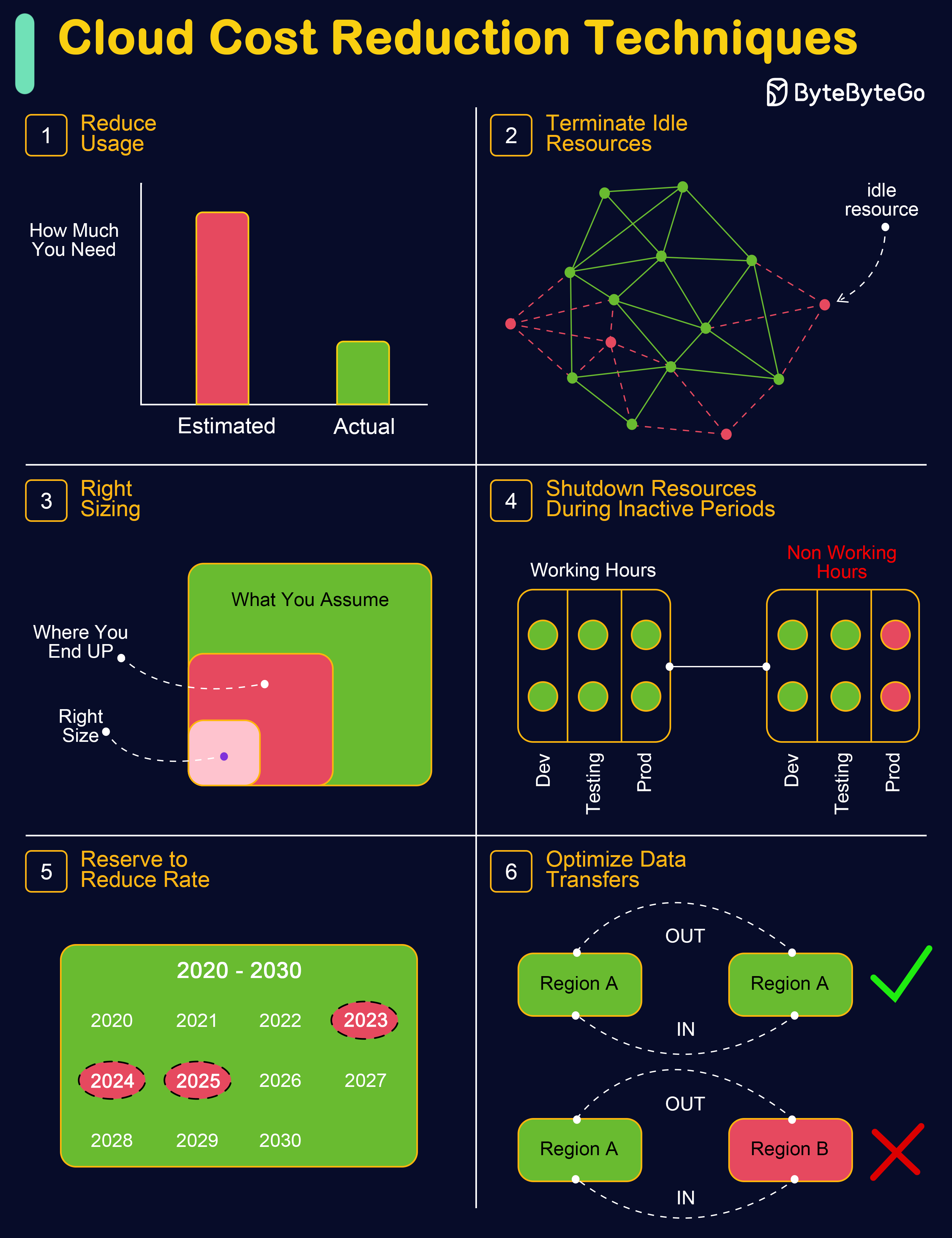
+
+Irrational Cloud Cost is the biggest challenge many organizations are battling as they navigate the complexities of cloud computing.
+Efficiently managing these costs is crucial for optimizing cloud usage and maintaining financial health.
+
+The following techniques can help businesses effectively control and minimize their cloud expenses.
+
+* **Reduce Usage:** Fine-tune the volume and scale of resources to ensure efficiency without compromising on the performance of applications (e.g., downsizing instances, minimizing storage space, consolidating services).
+
+* **Terminate Idle Resources:** Locate and eliminate resources that are not in active use, such as dormant instances, databases, or storage units.
+
+* **Right Sizing:** Adjust instance sizes to adequately meet the demands of your applications, ensuring neither underuse nor overuse.
+
+* **Shutdown Resources During Off-Peak Times:** Set up automatic mechanisms or schedules for turning off non-essential resources when they are not in use, especially during low-activity periods.
+
+* **Reserve to Reduce Rate:** Adopt cost-effective pricing models like Reserved Instances or Savings Plans that align with your specific workload needs.
+
+ Bonus Tip: Consider using Spot Instances and lower-tier storage options for additional cost savings.
+
+* **Optimize Data Transfers:** Utilize methods such as data compression and Content Delivery Networks (CDNs) to cut down on bandwidth expenses, and strategically position resources to reduce data transfer costs, focusing on intra-region transfers.
diff --git a/data/guides/cloud-database-cheat-sheet.md b/data/guides/cloud-database-cheat-sheet.md
new file mode 100644
index 0000000..9e7160c
--- /dev/null
+++ b/data/guides/cloud-database-cheat-sheet.md
@@ -0,0 +1,22 @@
+---
+title: "Cloud Database Cheat Sheet"
+description: "A handy guide to cloud databases and their open-source alternatives."
+image: "https://assets.bytebytego.com/diagrams/0146-cloud-dbs2.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Cloud Computing"
+ - "Databases"
+---
+
+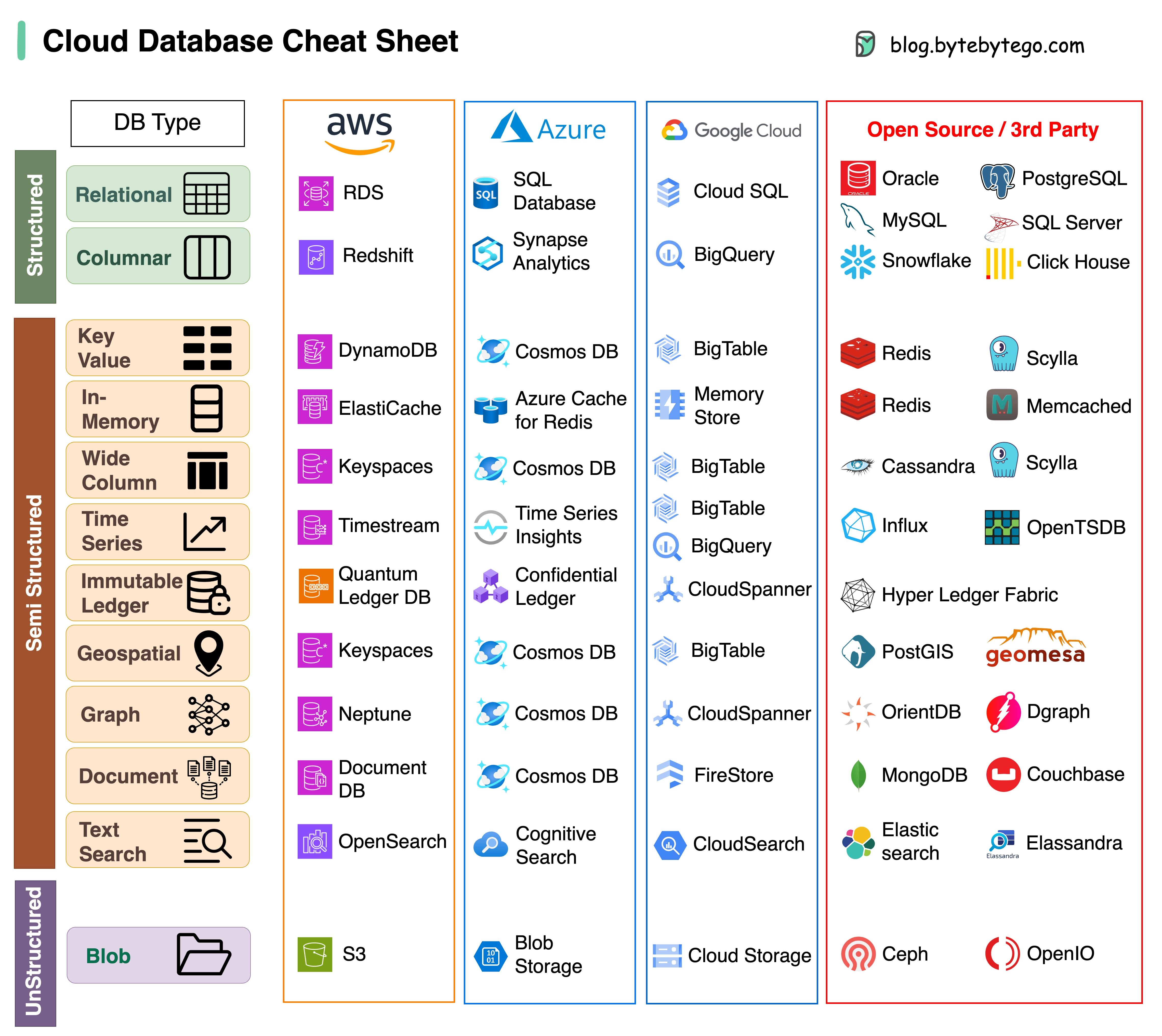
+
+A cheat sheet of various databases in cloud services, along with their corresponding open-source/3rd-party options.
+
+Choosing the right database for your project is a complex task. The multitude of database options, each suited to distinct use cases, can quickly lead to decision fatigue.
+
+We hope this cheat sheet provides the high level direction to pinpoint the right service that aligns with your project's needs and avoid potential pitfalls.
+
+Note: Google has limited documentation for their database use cases. Even though we did our best to look at what was available and arrived at the best option, some of the entries may be not accurate.
diff --git a/data/guides/cloud-disaster-recovery-strategies.md b/data/guides/cloud-disaster-recovery-strategies.md
new file mode 100644
index 0000000..69be567
--- /dev/null
+++ b/data/guides/cloud-disaster-recovery-strategies.md
@@ -0,0 +1,52 @@
+---
+title: "Cloud Disaster Recovery Strategies"
+description: "Explore cloud disaster recovery strategies: RTO, RPO, and key approaches."
+image: "https://assets.bytebytego.com/diagrams/0050-cloud-disaster-recovery-strategies.png"
+createdAt: "2024-01-29"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "Disaster Recovery"
+---
+
+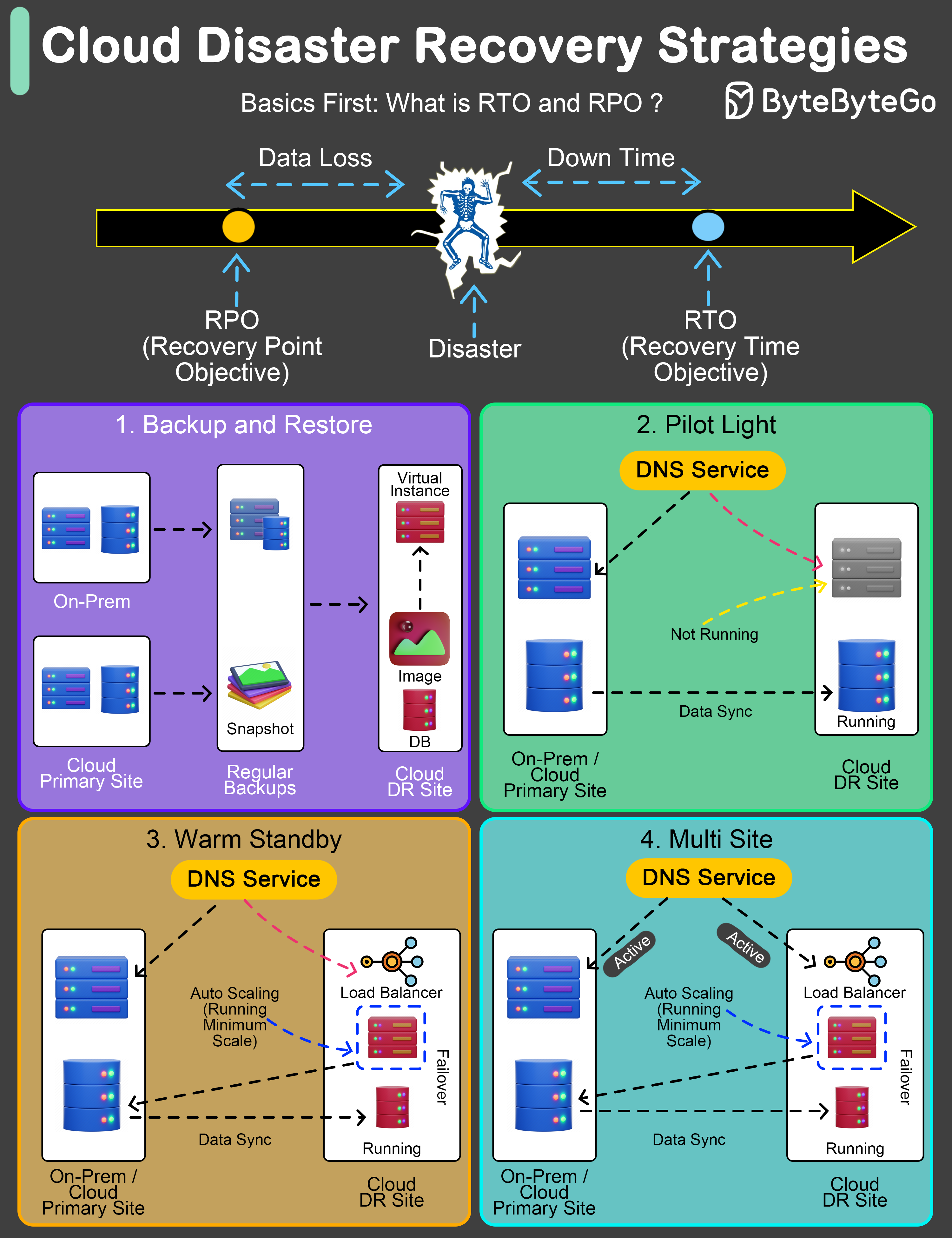
+
+An effective Disaster Recovery (DR) plan is not just a precaution; it's a necessity.
+
+The key to any robust DR strategy lies in understanding and setting two pivotal benchmarks: Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
+
+* **Recovery Time Objective (RTO)** refers to the maximum acceptable length of time that your application or network can be offline after a disaster.
+
+* **Recovery Point Objective (RPO)**, on the other hand, indicates the maximum acceptable amount of data loss measured in time.
+
+Let's explore four widely adopted DR strategies:
+
+## Backup and Restore Strategy:
+
+This method involves regular backups of data and systems to facilitate post-disaster recovery.
+
+* **Typical RTO:** From several hours to a few days.
+* **Typical RPO:** From a few hours up to the time of the last successful backup.
+
+## Pilot Light Approach:
+
+Maintains crucial components in a ready-to-activate mode, enabling rapid scaling in response to a disaster.
+
+* **Typical RTO:** From a few minutes to several hours.
+* **Typical RPO:** Depends on how often data is synchronized.
+
+## Warm Standby Solution:
+
+Establishes a semi-active environment with current data to reduce recovery time.
+
+* **Typical RTO:** Generally within a few minutes to hours.
+* **Typical RPO:** Up to the last few minutes or hours.
+
+## Hot Site / Multi-Site Configuration:
+
+Ensures a fully operational, duplicate environment that runs parallel to the primary system.
+
+* **Typical RTO:** Almost immediate, often just a few minutes.
+* **Typical RPO:** Extremely minimal, usually only a few seconds old.
diff --git a/data/guides/cloud-load-balancer-cheat-sheet.md b/data/guides/cloud-load-balancer-cheat-sheet.md
new file mode 100644
index 0000000..1009e11
--- /dev/null
+++ b/data/guides/cloud-load-balancer-cheat-sheet.md
@@ -0,0 +1,20 @@
+---
+title: "Cloud Load Balancer Cheat Sheet"
+description: "A concise guide to cloud load balancers and their optimal use cases."
+image: "https://assets.bytebytego.com/diagrams/0094-cloud-load-balancer-cheatsheet.gif"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "Load Balancing"
+---
+
+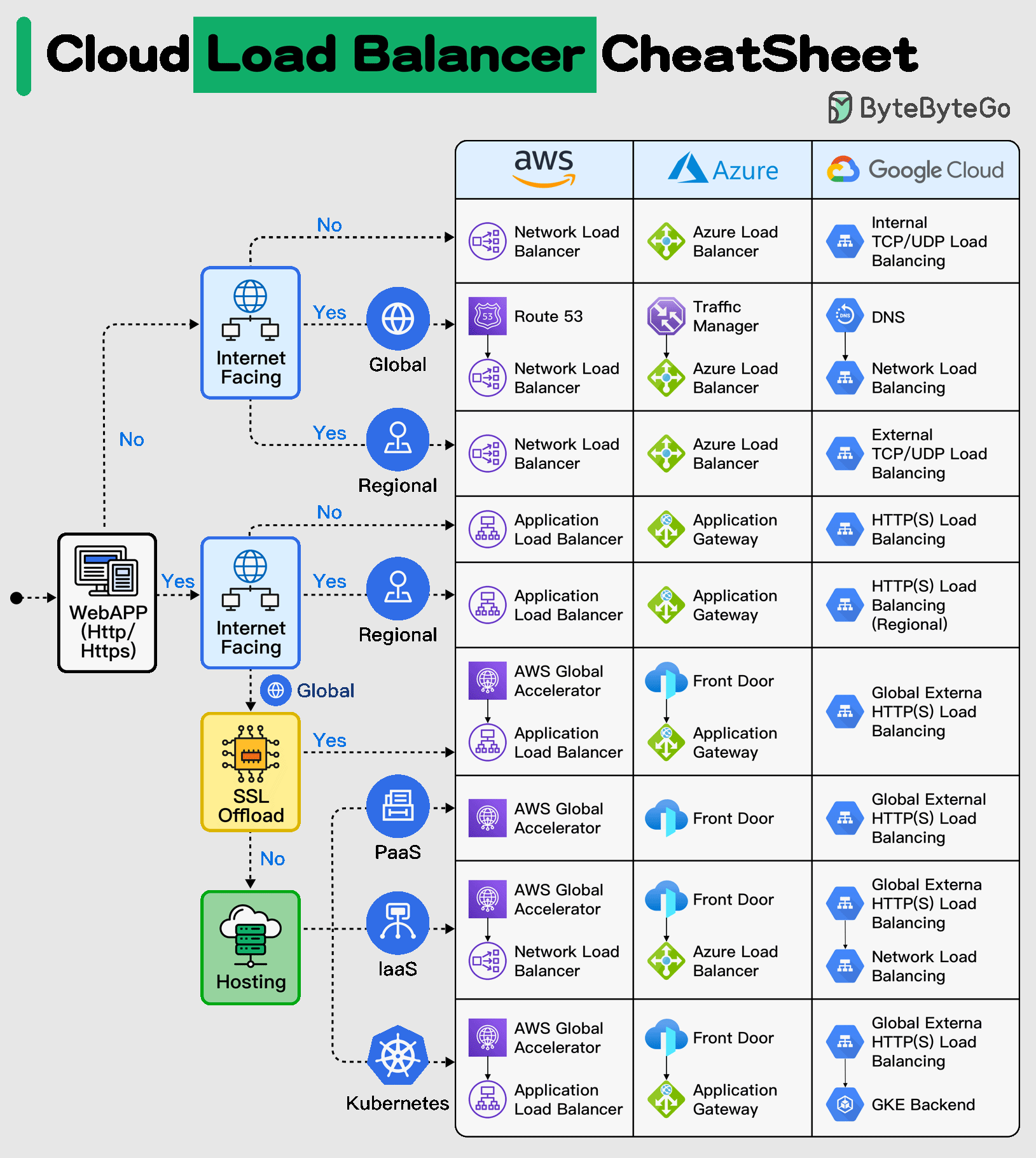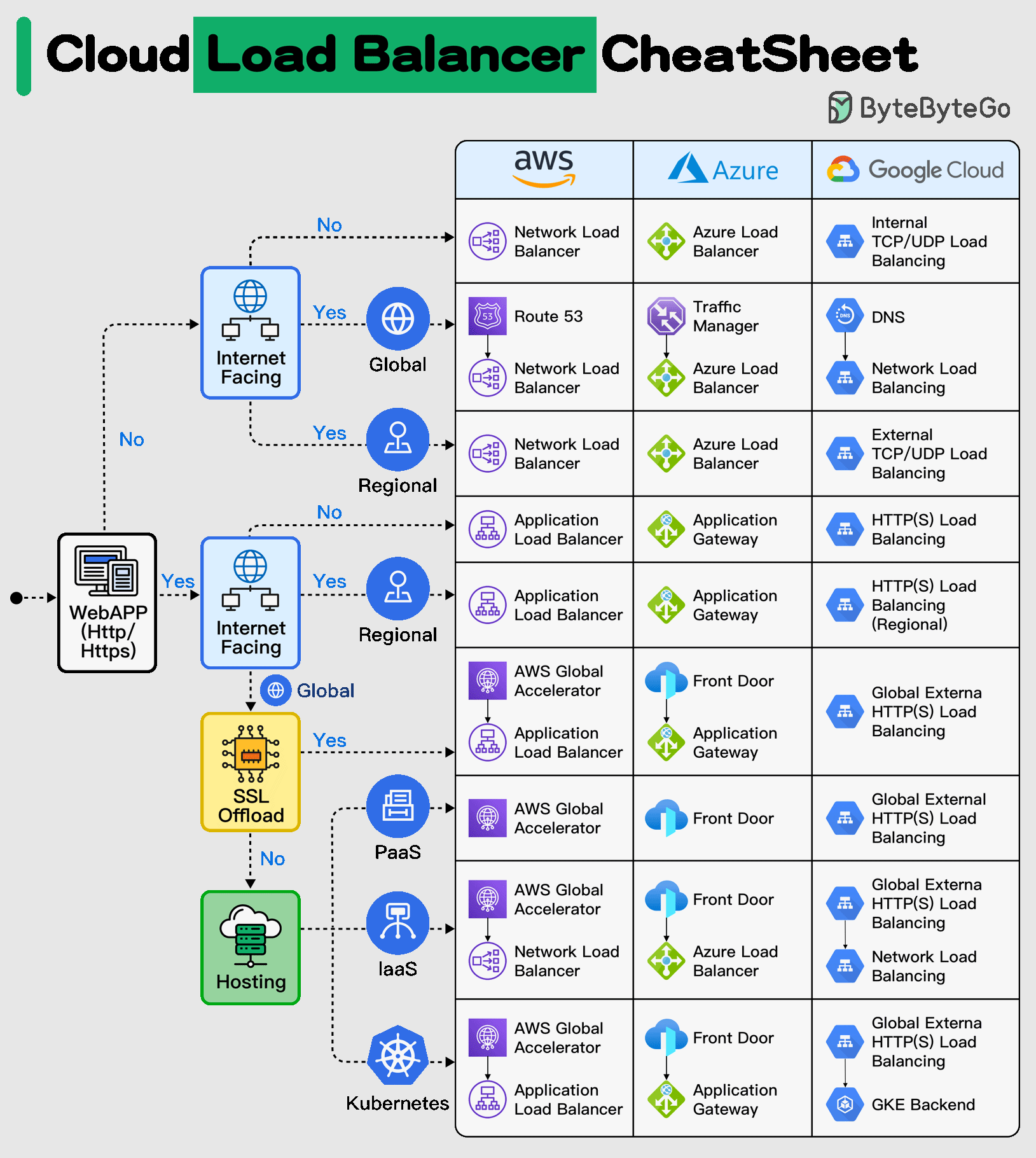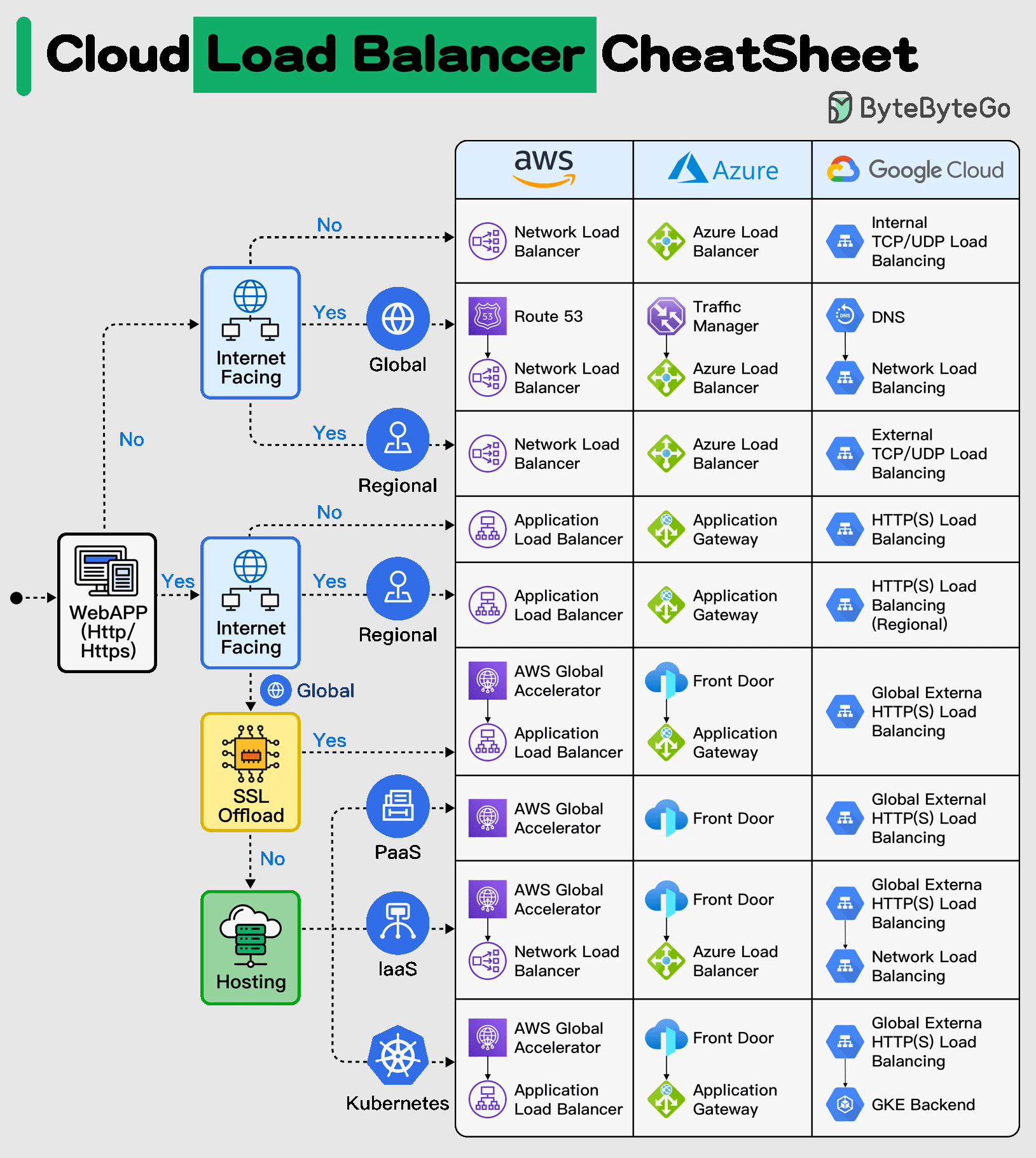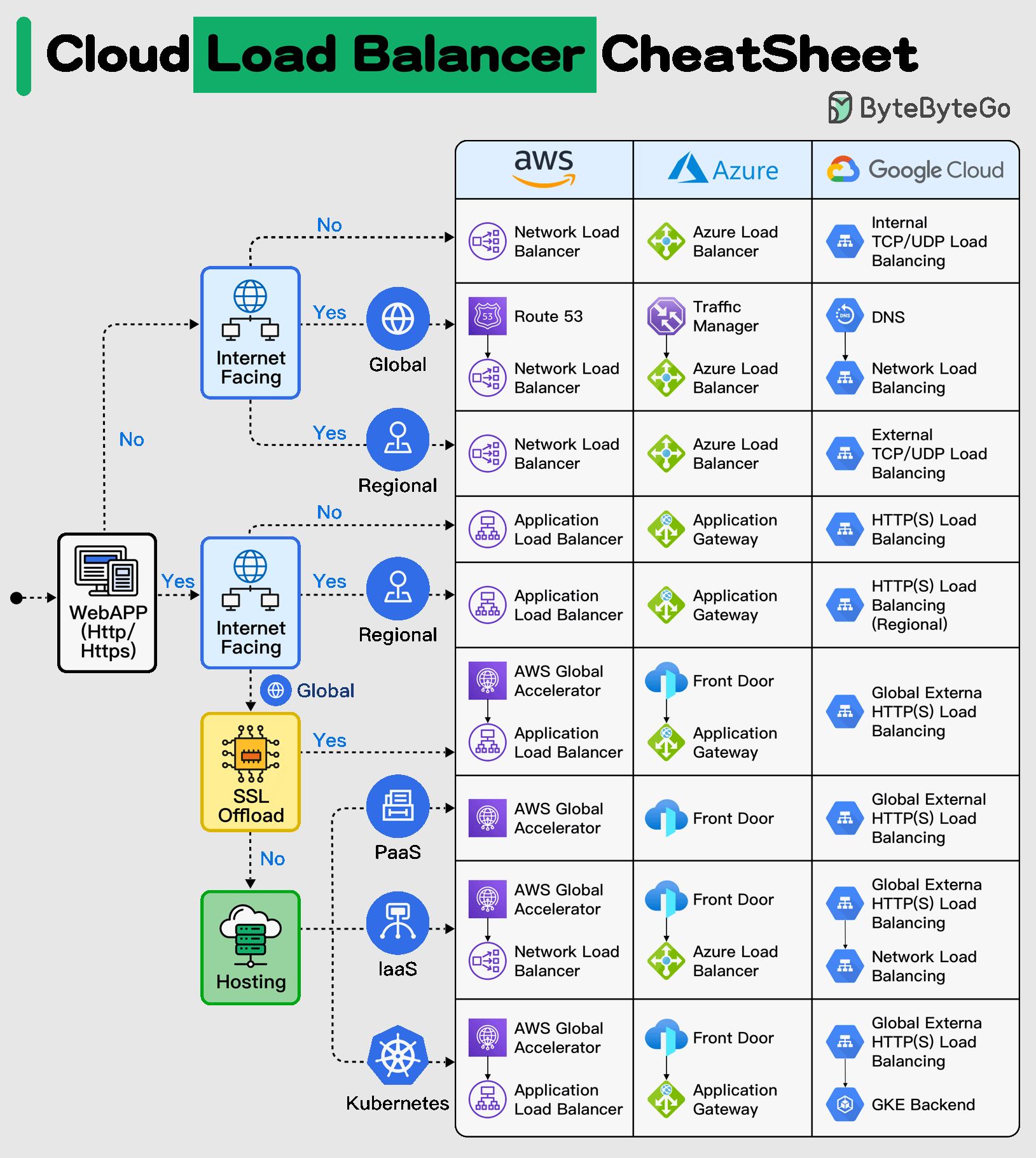
+
+In today's multi-cloud landscape, mastering load balancing is essential to ensure seamless user experiences and maximize resource utilization, especially when orchestrating applications across multiple cloud providers. Having the right knowledge is key to overcoming these challenges and achieving consistent, reliable application delivery.
+
+In selecting the appropriate load balancer type, it's essential to consider factors such as application traffic patterns, scalability requirements, and security considerations. By carefully evaluating your specific use case, you can make informed decisions that enhance your cloud infrastructure's efficiency and reliability.
+
+This Cloud Load Balancer cheat sheet would help you in simplifying the decision-making process and helping you implement the most effective load balancing strategy for your cloud-based applications.
diff --git a/data/guides/cloud-monitoring-cheat-sheet.md b/data/guides/cloud-monitoring-cheat-sheet.md
new file mode 100644
index 0000000..e3ba70b
--- /dev/null
+++ b/data/guides/cloud-monitoring-cheat-sheet.md
@@ -0,0 +1,38 @@
+---
+title: "Cloud Monitoring Cheat Sheet"
+description: "A handy guide to cloud monitoring across major providers and tools."
+image: "https://assets.bytebytego.com/diagrams/0095-cloud-monitoring-cheat-sheet.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "Monitoring"
+---
+
+
+
+A nice cheat sheet of different monitoring infrastructure in cloud services.
+
+This cheat sheet offers a concise yet comprehensive comparison of key monitoring elements across the three major cloud providers and open-source / 3rd party tools.
+
+Let's delve into the essential monitoring aspects covered:
+
+* **Data Collection:** Gather information from diverse sources to enhance decision-making.
+
+* **Data Storage:** Safely store and manage data for future analysis and reference.
+
+* **Data Analysis:** Extract valuable insights from data to drive informed actions.
+
+* **Alerting:** Receive real-time notifications about critical events or anomalies.
+
+* **Visualization:** Present data in a visually comprehensible format for better understanding.
+
+* **Reporting and Compliance:** Generate reports and ensure adherence to regulatory standards.
+
+* **Automation:** Streamline processes and tasks through automated workflows.
+
+* **Integration:** Seamlessly connect and exchange data between different systems or tools.
+
+* **Feedback Loops:** Continuously refine strategies based on feedback and performance analysis.
diff --git a/data/guides/cloud-native-anti-patterns.md b/data/guides/cloud-native-anti-patterns.md
new file mode 100644
index 0000000..0089c01
--- /dev/null
+++ b/data/guides/cloud-native-anti-patterns.md
@@ -0,0 +1,54 @@
+---
+title: "Cloud Native Anti-Patterns"
+description: "Avoid common pitfalls in cloud-native development for robust applications."
+image: "https://assets.bytebytego.com/diagrams/0070-cloud-native-anti-patterns.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Cloud Native"
+ - "Anti-Patterns"
+---
+
+By being aware of these anti-patterns and following cloud-native best practices, you can design, build, and operate more robust, scalable, and cost-efficient cloud-native applications.
+
+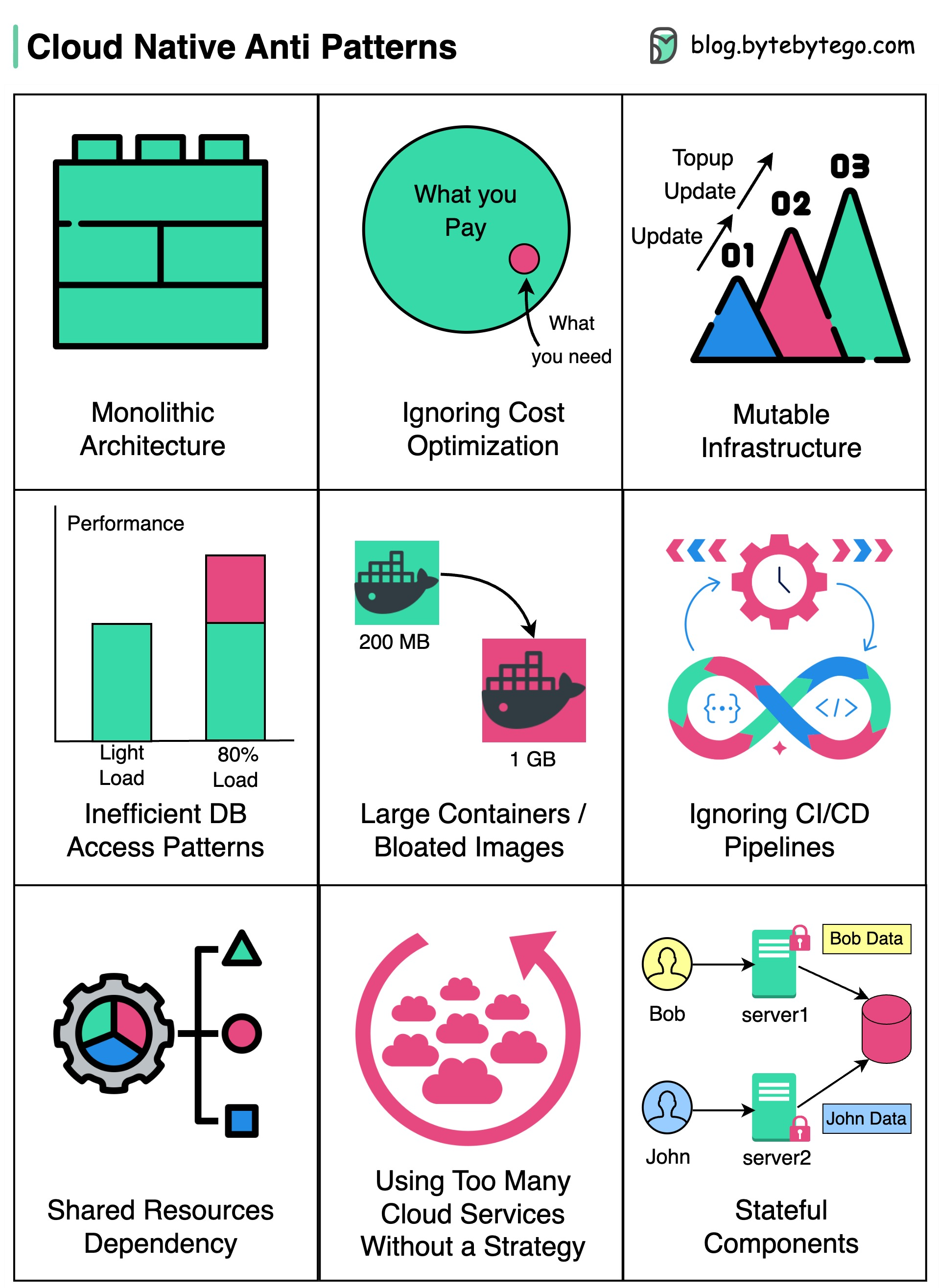
+
+## Monolithic Architecture
+
+One large, tightly coupled application running on the cloud, hindering scalability and agility.
+
+## Ignoring Cost Optimization
+
+Cloud services can be expensive, and not optimizing costs can result in budget overruns.
+
+## Mutable Infrastructure
+
+* Infrastructure components are to be treated as disposable and are never modified in place.
+
+* Failing to embrace this approach can lead to configuration drift, increased maintenance, and decreased reliability.
+
+## Inefficient DB Access Patterns
+
+Use of overly complex queries or lacking database indexing, can lead to performance degradation and database bottlenecks.
+
+## Large Containers or Bloated Images
+
+Creating large containers or using bloated images can increase deployment times, consume more resources, and slow down application scaling.
+
+## Ignoring CI/CD Pipelines
+
+Deployments become manual and error-prone, impeding the speed and frequency of software releases.
+
+## Shared Resources Dependency
+
+Applications relying on shared resources like databases can create contention and bottlenecks, affecting overall performance.
+
+## Using Too Many Cloud Services Without a Strategy
+
+While cloud providers offer a vast array of services, using too many of them without a clear strategy can create complexity and make it harder to manage the application.
+
+## Stateful Components
+
+Relying on persistent state in applications can introduce complexity, hinder scalability, and limit fault tolerance.
diff --git a/data/guides/concurrency-is-not-parallelism.md b/data/guides/concurrency-is-not-parallelism.md
new file mode 100644
index 0000000..cb12aaa
--- /dev/null
+++ b/data/guides/concurrency-is-not-parallelism.md
@@ -0,0 +1,28 @@
+---
+title: "Concurrency vs Parallelism"
+description: "Understand the difference between concurrency and parallelism in system design."
+image: "https://assets.bytebytego.com/diagrams/0150-concurrency-is-not-parallelism.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Concurrency"
+ - "Parallelism"
+---
+
+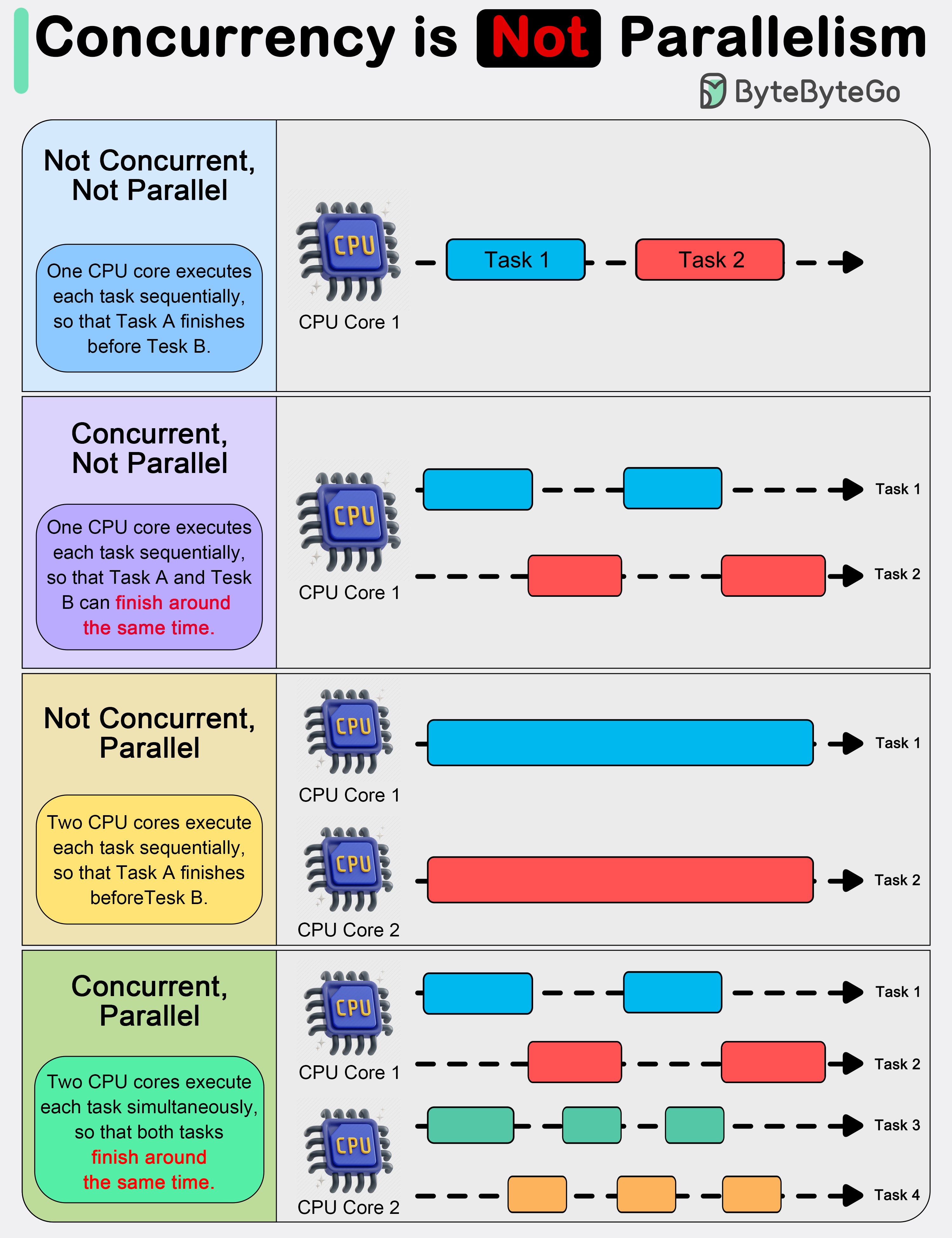
+
+In system design, it is important to understand the difference between concurrency and parallelism.
+
+As Rob Pyke(one of the creators of GoLang) stated:“ Concurrency is about **dealing with** lots of things at once. Parallelism is about **doing** lots of things at once." This distinction emphasizes that concurrency is more about the **design** of a program, while parallelism is about the **execution**.
+
+Concurrency is about dealing with multiple things at once. It involves structuring a program to handle multiple tasks simultaneously, where the tasks can start, run, and complete in overlapping time periods, but not necessarily at the same instant.
+
+Concurrency is about the composition of independently executing processes and describes a program's ability to manage multiple tasks by making progress on them without necessarily completing one before it starts another.
+
+Parallelism, on the other hand, refers to the simultaneous execution of multiple computations. It is the technique of running two or more tasks or computations at the same time, utilizing multiple processors or cores within a computer to perform several operations concurrently. Parallelism requires hardware with multiple processing units, and its primary goal is to increase the throughput and computational speed of a system.
+
+In practical terms, concurrency enables a program to remain responsive to input, perform background tasks, and handle multiple operations in a seemingly simultaneous manner, even on a single-core processor. It's particularly useful in I/O-bound and high-latency operations where programs need to wait for external events, such as file, network, or user interactions.
+
+Parallelism, with its ability to perform multiple operations at the same time, is crucial in CPU-bound tasks where computational speed and throughput are the bottlenecks. Applications that require heavy mathematical computations, data analysis, image processing, and real-time processing can significantly benefit from parallel execution.
diff --git a/data/guides/consistent-hashing.md b/data/guides/consistent-hashing.md
new file mode 100644
index 0000000..4e00758
--- /dev/null
+++ b/data/guides/consistent-hashing.md
@@ -0,0 +1,52 @@
+---
+title: "Consistent Hashing Explained"
+description: "Explore consistent hashing: its benefits, and real-world applications."
+image: "https://assets.bytebytego.com/diagrams/0151-consistent-hashing.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Consistent Hashing"
+ - "Distributed Systems"
+---
+
+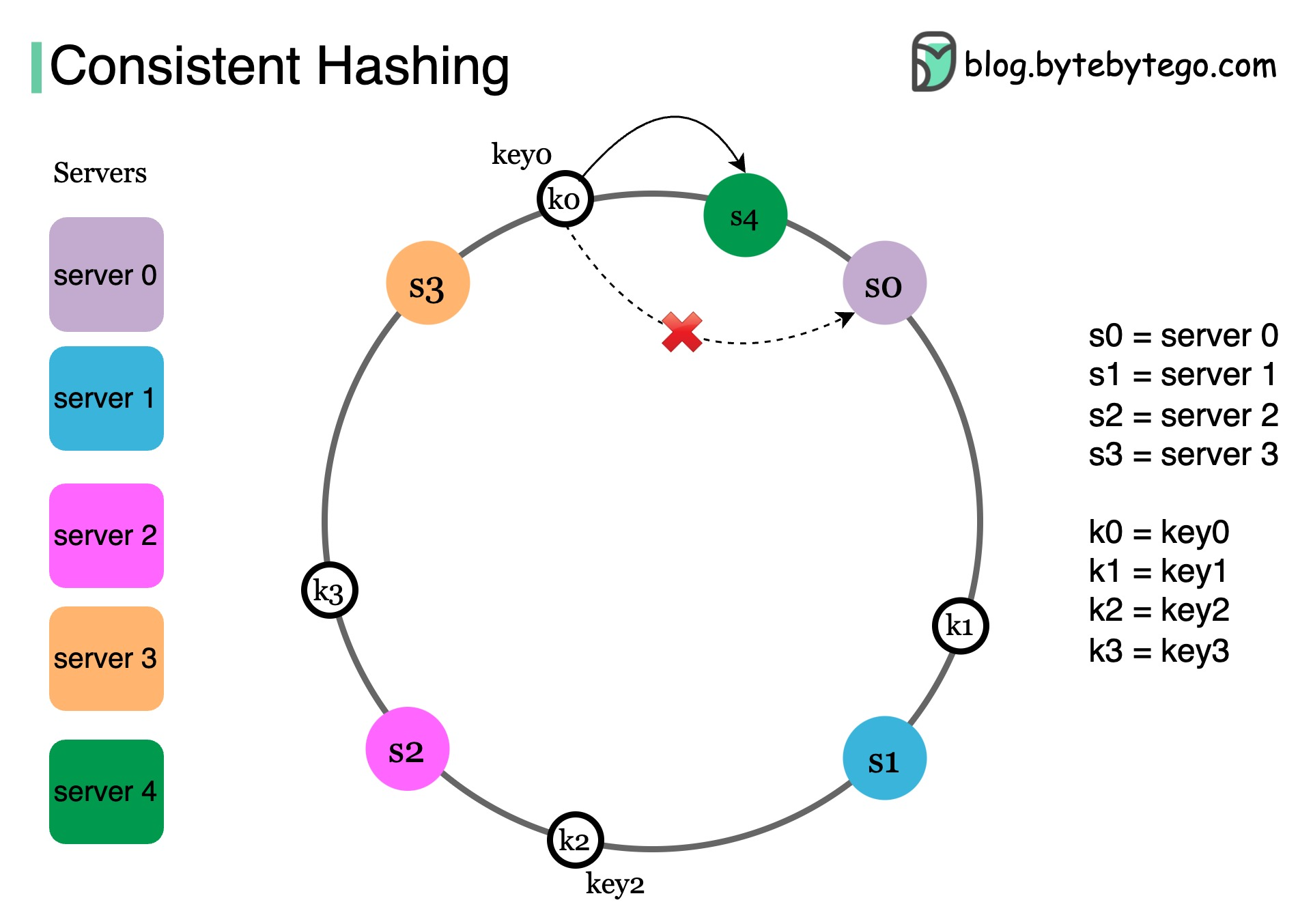
+
+## Algorithm 1: Consistent Hashing
+
+What do Amazon DynamoDB, Apache Cassandra, Discord, and Akamai CDN have in common?
+
+They all use consistent hashing. Let’s dive right in.
+
+## What’s the issue with simple hashing?
+
+In a large-scale distributed system, data does not fit on a single server. They are “distributed” across many machines. This is called horizontal scaling.
+
+To build such a system with predictable performance, it is important to distribute the data evenly across those servers.
+
+Simple hashing: serverIndex = hash(key) % N, where N is the size of the server pool
+
+This approach works well when the size of the cluster is fixed, and the data distribution is even. But when new servers get added to meet new demand, or when existing servers get removed, it triggers a storm of misses and a lot of objects to be moved.
+
+## Consistent hashing
+
+Consistent hashing is an effective technique to mitigate this issue.
+
+The goal of consistent hashing is simple. We want almost all objects to stay assigned to the same server even as the number of servers changes.
+
+As shown in the diagram, using a hash function, we hash each server by its name or IP address, and place the server onto the ring. Next, we hash each object by its key with the same hashing function.
+
+To locate the server for a particular object, we go clockwise from the location of the object key on the ring until a server is found. Continue with our example, key 0 is on server 0, key 1 is on server 1.
+
+Now let’s take a look at what happens when we add a server.
+
+Here we insert a new server s4 to the left of s0 on the ring. Note that only k0 needs to be moved from s0 to s4. This is because s4 is the first server k0 encounters by going clockwise from k0’s position on the ring. Keys k1, k2, and k3 are not affected.
+
+## How consistent hashing is used in the real world
+
+* **Amazon DynamoDB and Apache Cassandra:** minimize data movement during rebalancing
+
+* **Content delivery networks like Akamai:** distribute web contents evenly among the edge servers
+
+* **Load balancers like Google Network Load Balancer:** distribute persistent connections evenly across backend servers
diff --git a/data/guides/cookies-vs-sessions-vs-jwt-vs-paseto.md b/data/guides/cookies-vs-sessions-vs-jwt-vs-paseto.md
new file mode 100644
index 0000000..ba8d970
--- /dev/null
+++ b/data/guides/cookies-vs-sessions-vs-jwt-vs-paseto.md
@@ -0,0 +1,36 @@
+---
+title: "Cookies vs Sessions vs JWT vs PASETO"
+description: "Explore cookies, sessions, JWT, and PASETO for modern authentication."
+image: "https://assets.bytebytego.com/diagrams/0155-cookies-vs-sessions-vs-jwt-vs-paseto.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Security"
+---
+
+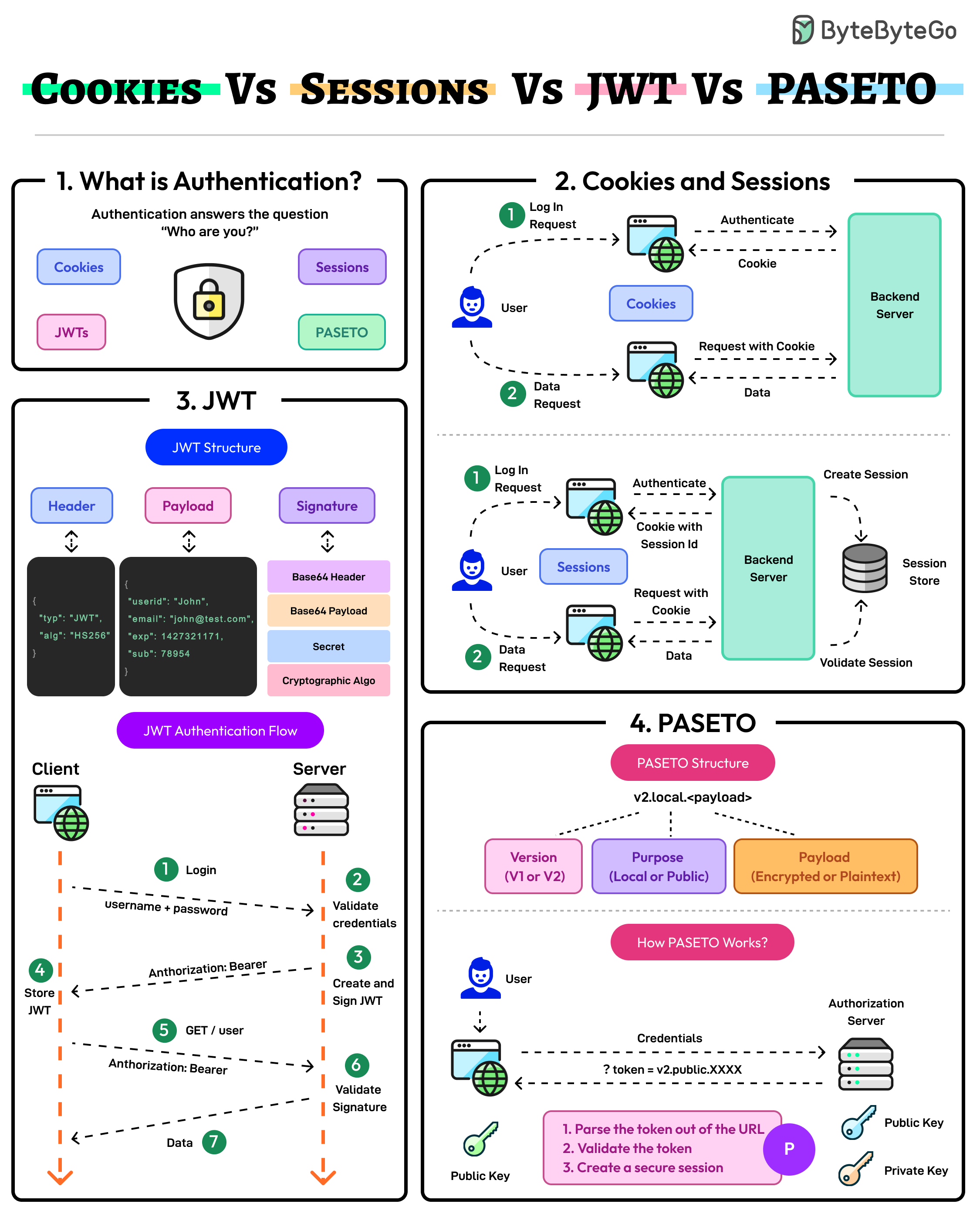
+
+Authentication ensures that only authorized users gain access to an application’s resources. It answers the question of the user’s identity i.e. “Who are you?”
+
+The modern authentication landscape has multiple approaches: Cookies, Sessions, JWTs, and PASETO. Here’s what they mean:
+
+## Cookies and Sessions
+
+Cookies and sessions are authentication mechanisms where session data is stored on the server and referenced via a client-side cookie.
+
+Sessions are ideal for applications requiring strict server-side control over user data. On the downside, sessions may face scalability challenges in distributed systems.
+
+## JWT
+
+JSON Web Token (JWT) is a stateless, self-contained authentication method that stores all user data within the token.
+
+JWTs are highly scalable but require careful handling to mitigate the chances of token theft and manage token expiration.
+
+## PASETO
+
+Platform-Agnostic Security Tokens or PASETO improve upon JWT by enforcing stronger cryptographic defaults and eliminating algorithmic vulnerabilities.
+
+PASETO simplifies token implementation by avoiding the risks associated with misconfiguration.
diff --git a/data/guides/cybersecurity-101-in-one-picture.md b/data/guides/cybersecurity-101-in-one-picture.md
new file mode 100644
index 0000000..a58691d
--- /dev/null
+++ b/data/guides/cybersecurity-101-in-one-picture.md
@@ -0,0 +1,32 @@
+---
+title: "Cybersecurity 101"
+description: "A concise overview of cybersecurity fundamentals and key concepts."
+image: "https://assets.bytebytego.com/diagrams/0156-cybersecurity-101-in-one-picture.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - security
+tags:
+ - "Cybersecurity"
+ - "Fundamentals"
+---
+
+
+
+## Introduction to Cybersecurity
+
+## The CIA Triad
+
+## Common Cybersecurity Threats
+
+## Basic Defense Mechanisms
+
+To combat these threats, several basic defense mechanisms are employed:
+
+* **Firewalls:** Network security devices that monitor and control incoming and outgoing network traffic.
+
+* **Antivirus Software:** Programs designed to detect and remove malware.
+
+* **Encryption:** The process of converting information into a code to prevent unauthorized access.
+
+## Cybersecurity Frameworks
diff --git a/data/guides/data-pipelines-overview.md b/data/guides/data-pipelines-overview.md
new file mode 100644
index 0000000..d110acb
--- /dev/null
+++ b/data/guides/data-pipelines-overview.md
@@ -0,0 +1,38 @@
+---
+title: Data Pipelines Overview
+description: Learn about the essential phases of data pipelines.
+image: 'https://assets.bytebytego.com/diagrams/0157-data-pipeline-overview.png'
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - data-pipelines
+ - data-processing
+---
+
+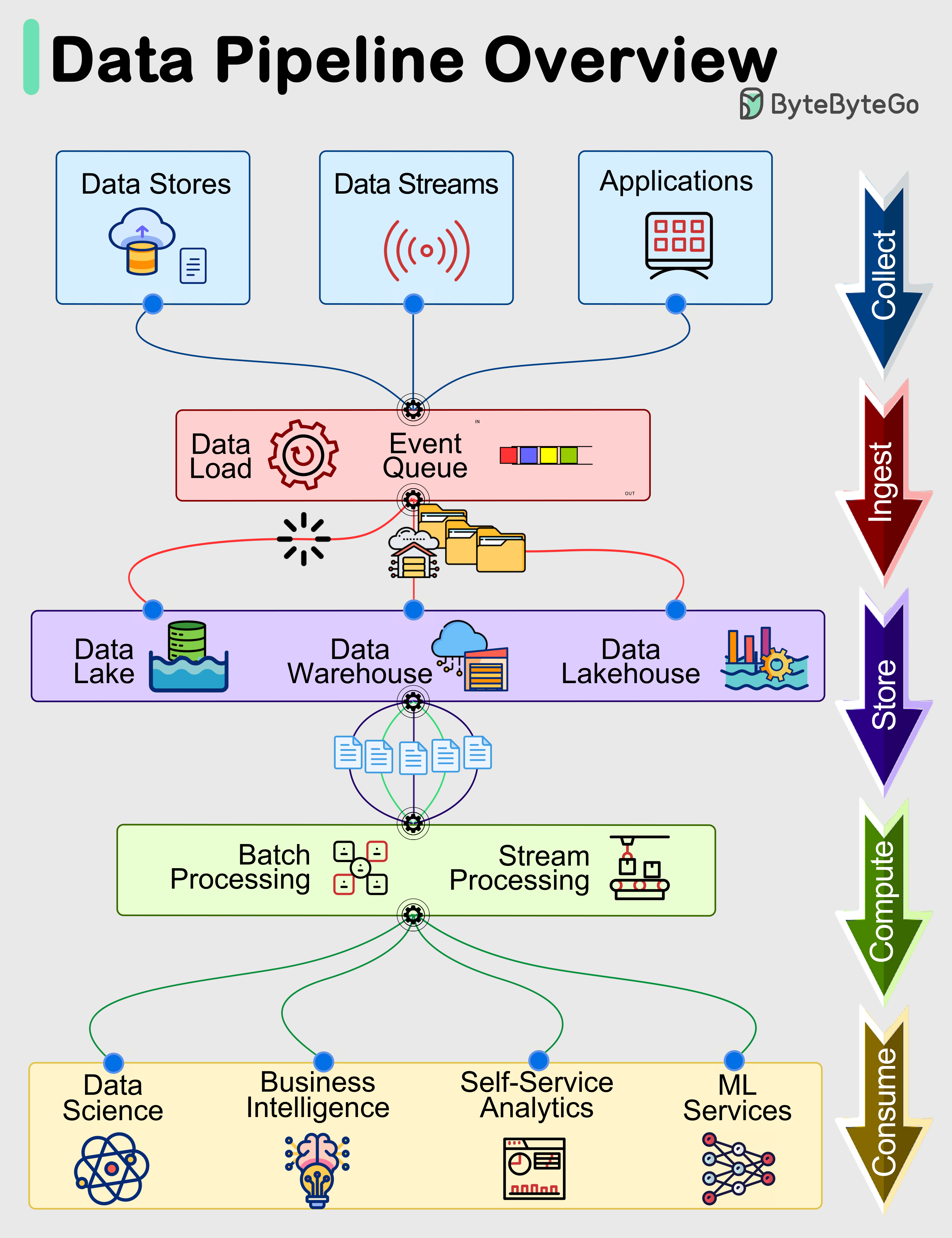
+
+Data pipelines are a fundamental component of managing and processing data efficiently within modern systems. These pipelines typically encompass 5 predominant phases: Collect, Ingest, Store, Compute, and Consume.
+
+## Collect:
+
+Data is acquired from data stores, data streams, and applications, sourced remotely from devices, applications, or business systems.
+
+## Ingest:
+
+During the ingestion process, data is loaded into systems and organized within event queues.
+
+## Store:
+
+Post ingestion, organized data is stored in data warehouses, data lakes, and data lakehouses, along with various systems like databases, ensuring post-ingestion storage.
+
+## Compute:
+
+Data undergoes aggregation, cleansing, and manipulation to conform to company standards, including tasks such as format conversion, data compression, and partitioning. This phase employs both batch and stream processing techniques.
+
+## Consume:
+
+Processed data is made available for consumption through analytics and visualization tools, operational data stores, decision engines, user-facing applications, dashboards, data science, machine learning services, business intelligence, and self-service analytics.
+
+The efficiency and effectiveness of each phase contribute to the overall success of data-driven operations within an organization.
diff --git a/data/guides/database-middleware.md b/data/guides/database-middleware.md
new file mode 100644
index 0000000..47a2ed0
--- /dev/null
+++ b/data/guides/database-middleware.md
@@ -0,0 +1,41 @@
+---
+title: "Database Middleware"
+description: "Explore database middleware for transparent routing and simplified code."
+image: "https://assets.bytebytego.com/diagrams/0276-middleware-png.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Database Routing
+ - Proxy
+---
+
+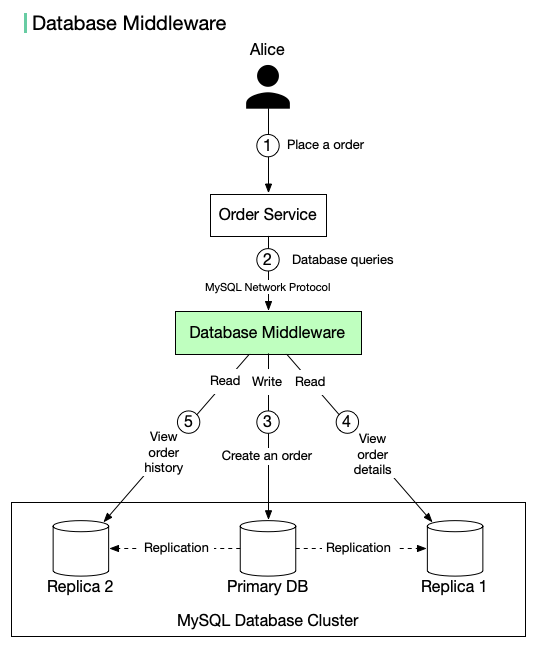
+
+There are two common ways to implement the read replica pattern:
+
+1. Embed the routing logic in the application code (explained in the last post).
+2. Use database middleware.
+
+We focus on option 2 here. The middleware provides transparent routing between the application and database servers. We can customize the routing logic based on difficult rules such as user, schema, statement, etc.
+
+The diagram above illustrates the setup:
+
+1. When Alice places an order on amazon, the request is sent to Order Service.
+2. Order Service does not directly interact with the database. Instead, it sends database queries to the database middleware.
+3. The database middleware routes writes to the primary database. Data is replicated to two replicas.
+4. Alice views the order details (read). The request is sent through the middleware.
+5. Alice views the recent order history (read). The request is sent through the middleware.
+
+The database middleware acts as a proxy between the application and databases. It uses standard MySQL network protocol for communication.
+
+## Pros
+
+* Simplified application code. The application doesn’t need to be aware of the database topology and manage access to the database directly.
+* Better compatibility. The middleware uses the MySQL network protocol. Any MySQL compatible client can connect to the middleware easily. This makes database migration easier.
+
+## Cons
+
+* Increased system complexity. A database middleware is a complex system. Since all database queries go through the middleware, it usually requires a high availability setup to avoid a single point of failure.
+* Additional middleware layer means additional network latency. Therefore, this layer requires excellent performance.
diff --git a/data/guides/deepseek-1-pager.md b/data/guides/deepseek-1-pager.md
new file mode 100644
index 0000000..45d4a5f
--- /dev/null
+++ b/data/guides/deepseek-1-pager.md
@@ -0,0 +1,32 @@
+---
+title: 'DeepSeek 1-Pager'
+description: "Explore DeepSeek's cost-effective AI model and its innovative R1 release."
+image: 'https://assets.bytebytego.com/diagrams/0164-deepseek.png'
+createdAt: '2024-03-11'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI Models
+ - DeepSeek
+---
+
+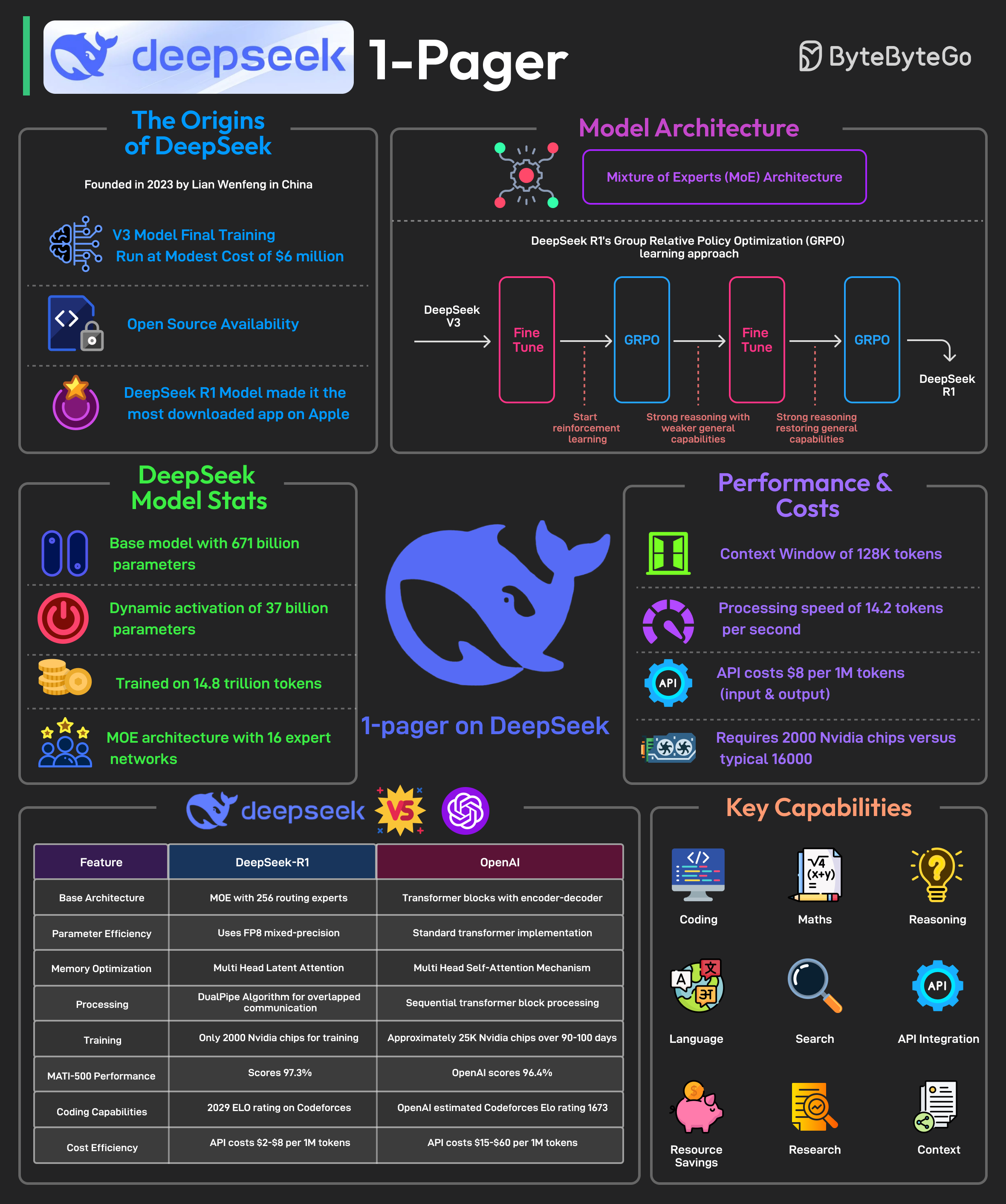
+
+It is said to have developed a powerful AI model at a remarkably low cost, approximately $6 million for the final training run. In January 2025, it is said to have released its latest reasoning-focused model known as DeepSeek R1.
+
+The release made it the No. 1 downloaded free app on the Apple Play Store.
+
+Most AI models are trained using supervised fine-tuning, meaning they learn by mimicking large datasets of human-annotated examples. This method has limitations.
+
+DeepSeek R1 overcomes these limitations by using Group Relative Policy Optimization (GRPO), a reinforcement learning technique that improves reasoning efficiency by comparing multiple possible answers within the same context.
+
+Some facts about DeepSeek’s R1 model are as follows:
+
+- DeepSeek-R1 uses a Mixture-of-Experts (MoE) architecture with 671 billion total parameters, activating only 37 billion parameters per task.
+- It employs selective parameter activation through MoE for resource optimization.
+- The model is pre-trained on 14.8 trillion tokens across 52 languages.
+- DeepSeek-R1 was trained using just 2000 Nvidia GPUs. By comparison, ChatGPT-4 needed approximately 25K Nvidia GPUs over 90-100 days.
+- The model is 85-90% more cost-effective than competitors.
+- It excels in mathematics, coding, and reasoning tasks.
+- Also, the model has been released as open-source under the MIT license.
diff --git a/data/guides/delivery-semantics.md b/data/guides/delivery-semantics.md
new file mode 100644
index 0000000..daef139
--- /dev/null
+++ b/data/guides/delivery-semantics.md
@@ -0,0 +1,41 @@
+---
+title: "Delivery Semantics"
+description: "Understand at-most once, at-least once, and exactly once delivery semantics."
+image: "https://assets.bytebytego.com/diagrams/0165-delivery-semantics.png"
+createdAt: "2024-02-10"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Message Queues"
+ - "Delivery Semantics"
+---
+
+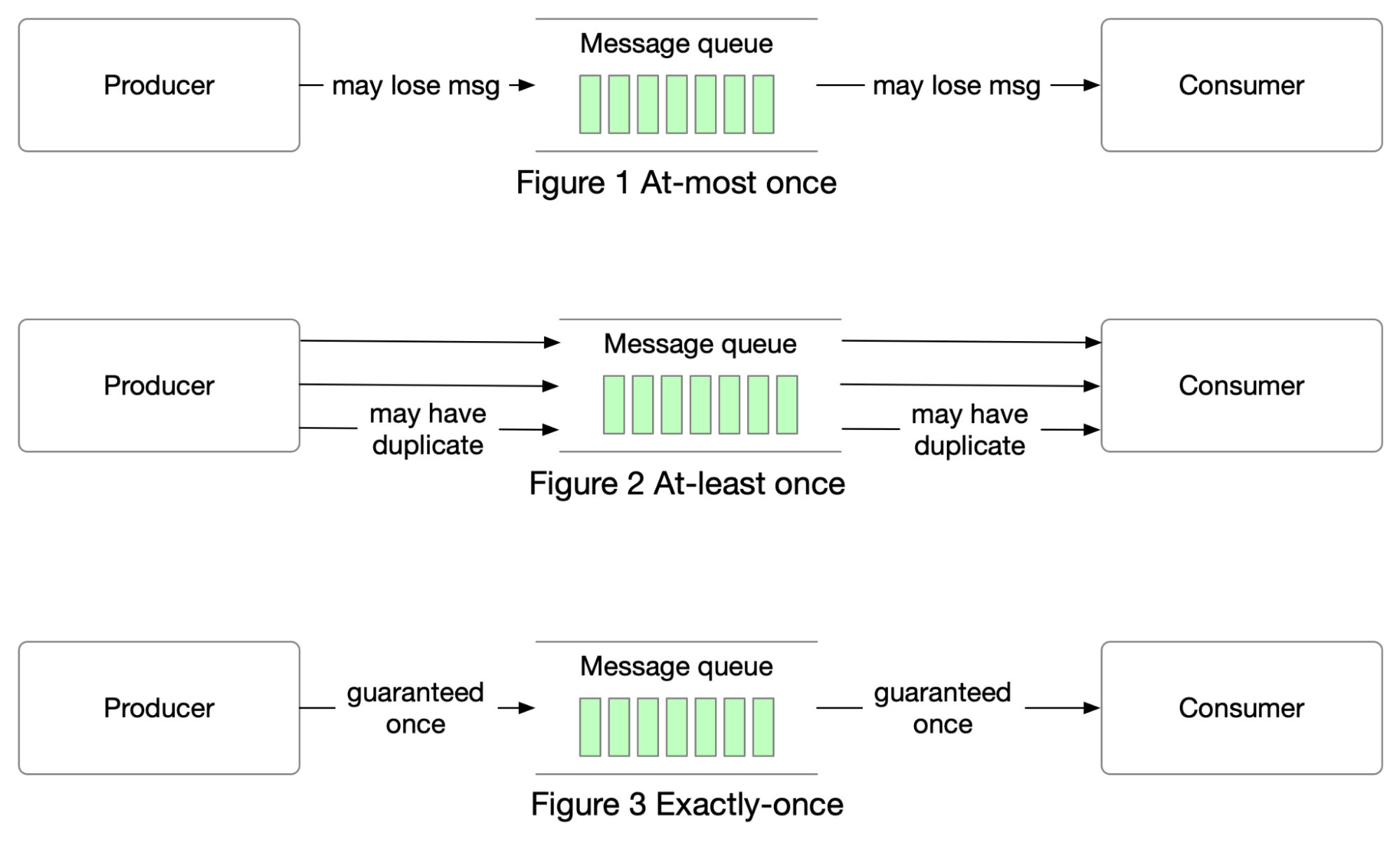
+
+In modern architecture, systems are broken up into small and independent building blocks with well-defined interfaces between them. Message queues provide communication and coordination for those building blocks. Today, let’s discuss different delivery semantics: at-most once, at-least once, and exactly once.
+
+## At-most once
+
+As the name suggests, at-most once means a message will be delivered not more than once. Messages may be lost but are not redelivered. This is how at-most once delivery works at the high level.
+
+### Use cases:
+
+* It is suitable for use cases like monitoring metrics, where a small amount of data loss is acceptable.
+
+## At-least once
+
+With this data delivery semantic, it’s acceptable to deliver a message more than once, but no message should be lost.
+
+### Use cases:
+
+* With at-least once, messages won’t be lost but the same message might be delivered multiple times. While not ideal from a user perspective, at-least once delivery semantics are usually good enough for use cases where data duplication is not a big issue or deduplication is possible on the consumer side.
+* For example, with a unique key in each message, a message can be rejected when writing duplicate data to the database.
+
+## Exactly once
+
+Exactly once is the most difficult delivery semantic to implement. It is friendly to users, but it has a high cost for the system’s performance and complexity.
+
+### Use cases:
+
+* Financial-related use cases (payment, trading, accounting, etc.). Exactly once is especially important when duplication is not acceptable and the downstream service or third party doesn’t support idempotency.
diff --git a/data/guides/design-gmail.md b/data/guides/design-gmail.md
new file mode 100644
index 0000000..13f66d9
--- /dev/null
+++ b/data/guides/design-gmail.md
@@ -0,0 +1,26 @@
+---
+title: "Design Gmail"
+description: "Explore the design of Gmail: from sending to receiving emails."
+image: "https://assets.bytebytego.com/diagrams/0184-email.jpg"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Email"
+ - "System Design"
+---
+
+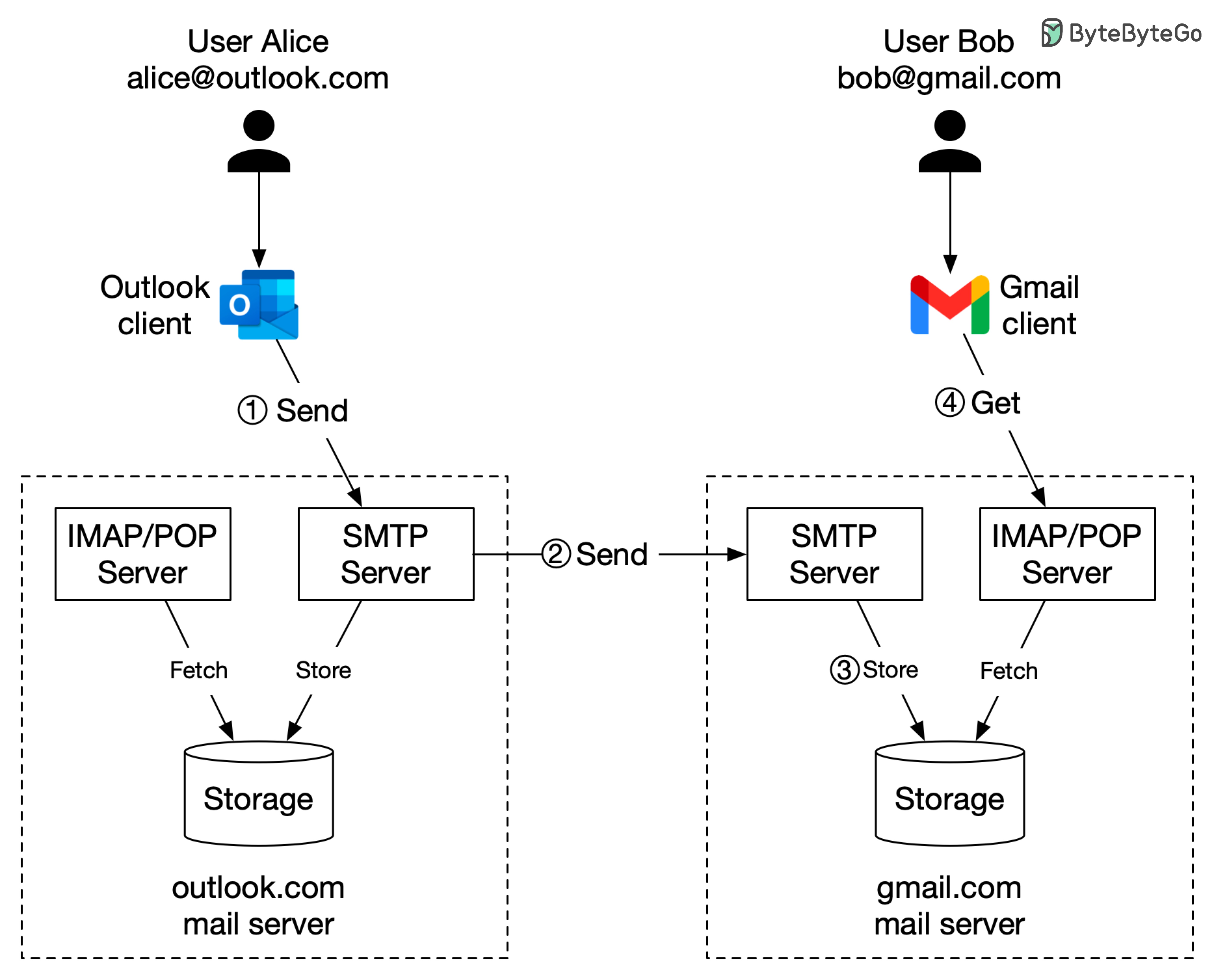
+
+One picture is worth more than a thousand words. In this post, we will take a look at what happens when Alice sends an email to Bob.
+
+## Sending an Email: A Step-by-Step Guide
+
+1. Alice logs in to her Outlook client, composes an email, and presses “send”. The email is sent to the Outlook mail server. The communication protocol between the Outlook client and mail server is SMTP.
+
+2. Outlook mail server queries the DNS (not shown in the diagram) to find the address of the recipient’s SMTP server. In this case, it is Gmail’s SMTP server. Next, it transfers the email to the Gmail mail server. The communication protocol between the mail servers is SMTP.
+
+3. The Gmail server stores the email and makes it available to Bob, the recipient.
+
+4. Gmail client fetches new emails through the IMAP/POP server when Bob logs in to Gmail.
diff --git a/data/guides/design-google-maps.md b/data/guides/design-google-maps.md
new file mode 100644
index 0000000..945282d
--- /dev/null
+++ b/data/guides/design-google-maps.md
@@ -0,0 +1,45 @@
+---
+title: "Design Google Maps"
+description: "Learn how to design a simplified version of Google Maps."
+image: "https://assets.bytebytego.com/diagrams/0207-google-maps.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "System Design"
+ - "Maps"
+---
+
+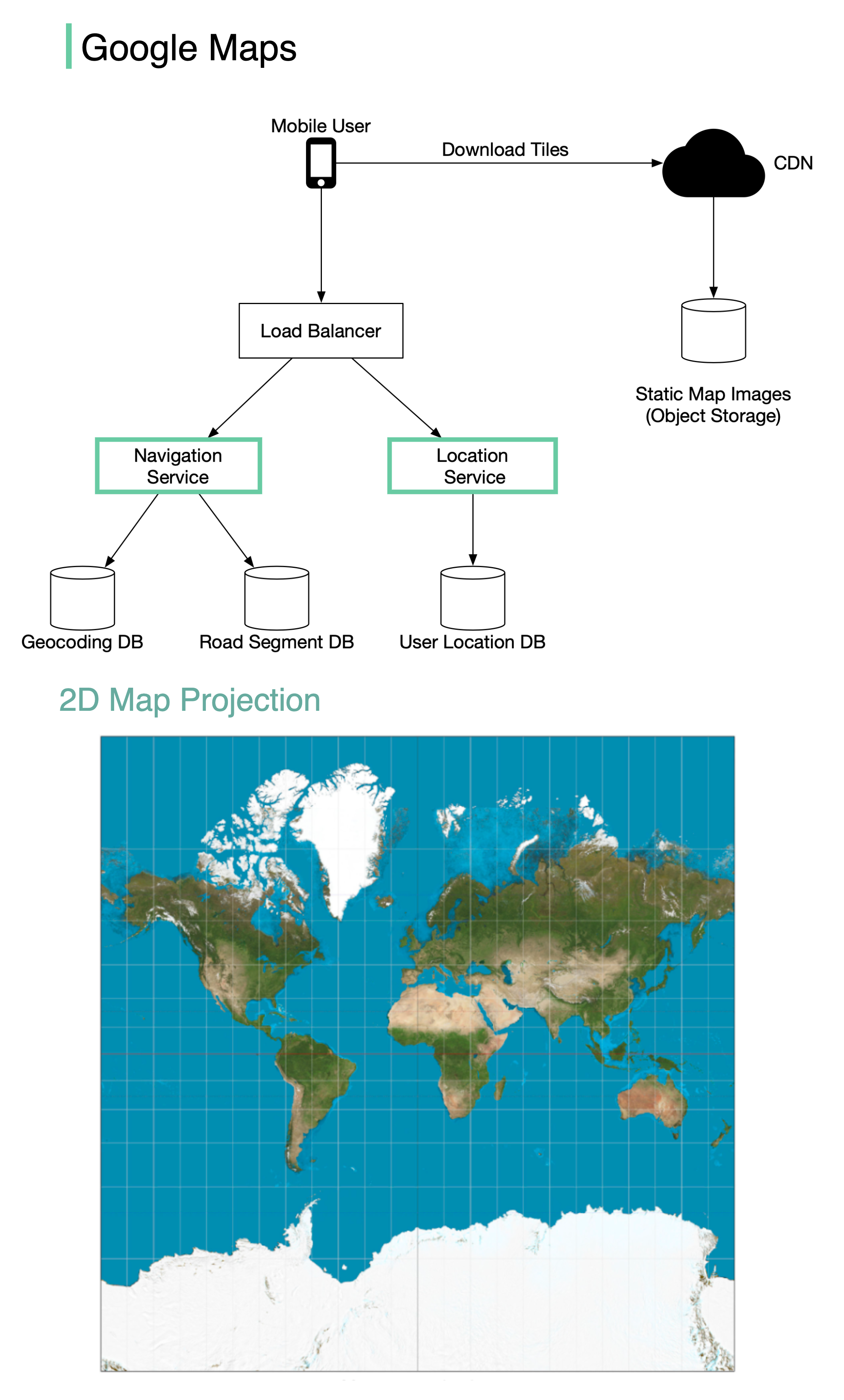
+
+Google started project **Google Maps** in 2005. As of March 2021, Google Maps had one billion daily active users, 99% coverage of the world.
+
+Although Google Maps is a very complex system, we can break it down into 3 high-level components. In this post, let’s take a look at how to design a simplified Google Maps.
+
+## Location Service
+
+The location service is responsible for recording a user’s location update. The Google Map clients send location updates every few seconds. The user location data is used in many cases:
+
+* detect new and recently closed roads.
+* improve the accuracy of the map over time.
+* used as an input for live traffic data.
+
+## Map Rendering
+
+The world’s map is projected into a huge 2D map image. It is broken down into small image blocks called “tiles” (see below). The tiles are static. They don’t change very often. An efficient way to serve static tile files is with a CDN backed by cloud storage like S3. The users can load the necessary tiles to compose a map from nearby CDN.
+
+What if a user is zooming and panning the map viewpoint on the client to explore their surroundings?
+
+An efficient way is to pre-calculate the map blocks with different zoom levels and load the images when needed.
+
+## Navigation Service
+
+This component is responsible for finding a reasonably fast route from point A to point B. It calls two services to help with the path calculation:
+
+1. Geocoding Service: resolve the given address to a latitude/longitude pair.
+2. Route Planner Service: this service does three things in sequence:
+
+ * Calculate top-K shortest paths between A and B
+ * Calculate the estimation of time for each path based on current traffic and historical data
+ * Rank the paths by time predictions and user filtering. For example, the user doesn’t want to avoid tolls.
diff --git a/data/guides/design-patterns-cheat-sheet-part-1-and-part-2.md b/data/guides/design-patterns-cheat-sheet-part-1-and-part-2.md
new file mode 100644
index 0000000..4c78a4f
--- /dev/null
+++ b/data/guides/design-patterns-cheat-sheet-part-1-and-part-2.md
@@ -0,0 +1,25 @@
+---
+title: "Design Patterns Cheat Sheet"
+description: "Concise guide to design patterns with examples and use cases."
+image: "https://assets.bytebytego.com/diagrams/0167-design-patterns-cheat-sheet-part-2.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "design patterns"
+ - "software design"
+---
+
+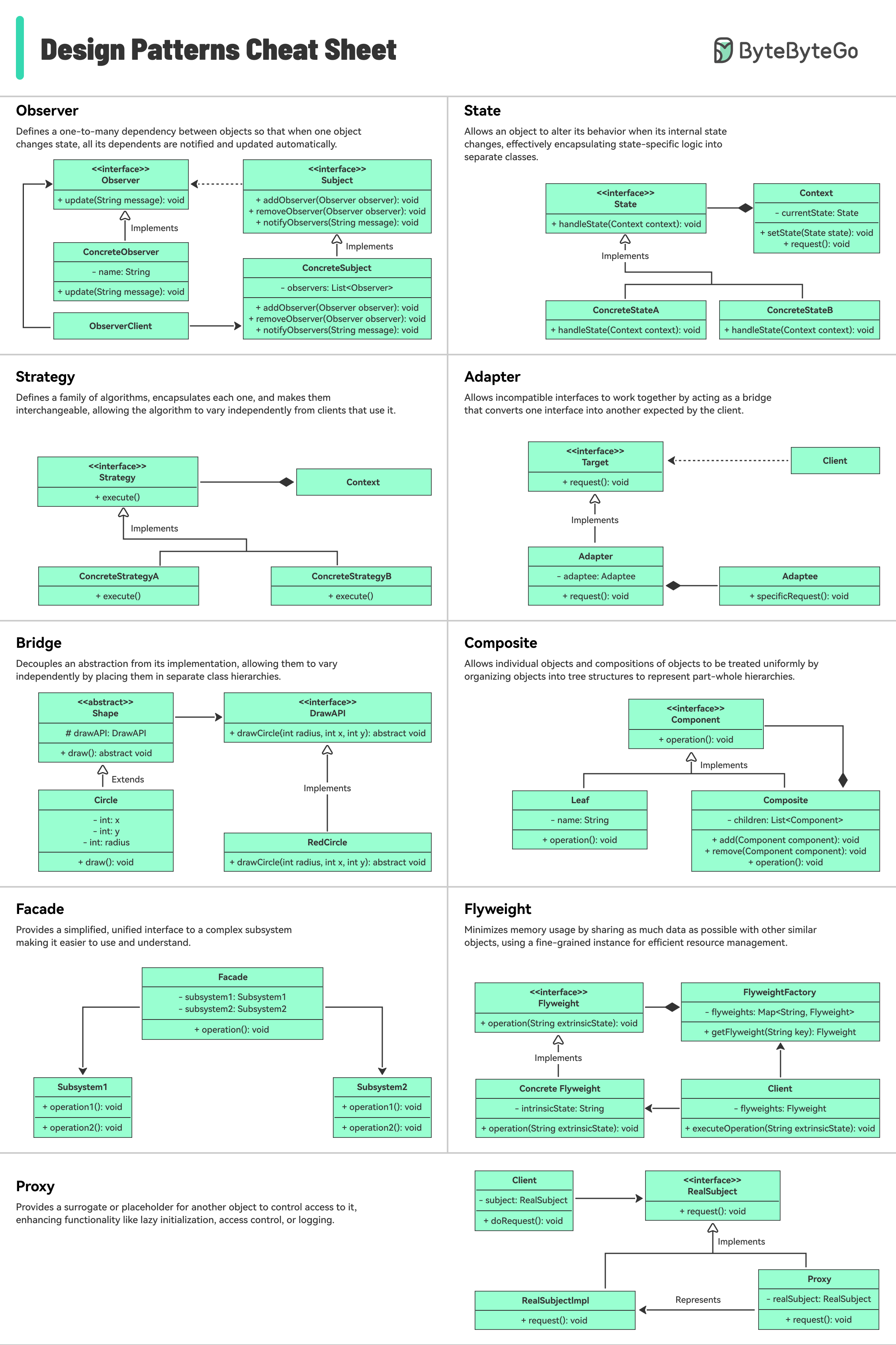
+
+The cheat sheet briefly explains each pattern and how to use it.
+
+What's included?
+
+* Factory
+* Builder
+* Prototype
+* Singleton
+* Chain of Responsibility
+* And many more!
diff --git a/data/guides/design-stock-exchange.md b/data/guides/design-stock-exchange.md
new file mode 100644
index 0000000..bf983f9
--- /dev/null
+++ b/data/guides/design-stock-exchange.md
@@ -0,0 +1,34 @@
+---
+title: "Design Stock Exchange"
+description: "Explore the design of a stock exchange and its key components."
+image: "https://assets.bytebytego.com/diagrams/0344-stock-exchange.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "System Design"
+ - "Trading Systems"
+---
+
+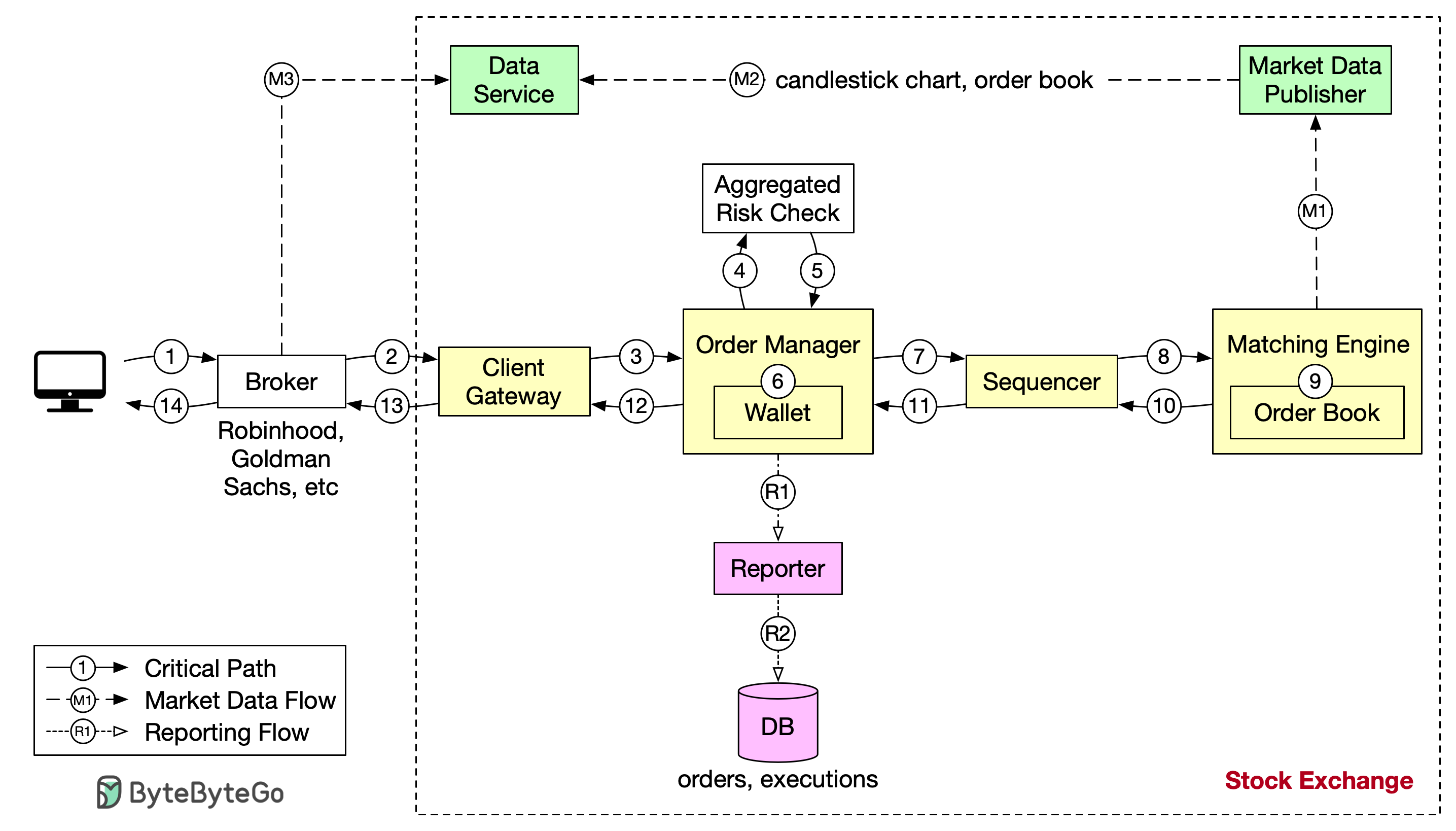
+
+Let’s trace the life of an order through various components in the diagram to see how the pieces fit together.
+
+First, we follow the order through the trading flow. This is the critical path with strict latency requirements. Everything has to happen fast in the flow:
+
+### Step 1: A client places an order via the broker’s web or mobile app.
+
+### Step 2: The broker sends the order to the exchange.
+
+### Step 3: The order enters the exchange through the client gateway. The client gateway performs basic gatekeeping functions such as input validation, rate limiting, authentication, normalization, etc. The client gateway then forwards the order to the order manager.
+
+### Step 4 - 5: The order manager performs risk checks based on rules set by the risk manager.
+
+### Step 6: After passing risk checks, the order manager verifies there are sufficient funds in the wallet for the order.
+
+### Step 7 - 9: The order is sent to the matching engine. When a match is found, the matching engine emits two executions, with one each for the buy and sell sides. To guarantee that matching results are deterministic when replayed, both orders and executions are sequenced.
+
+### Step 10 - 14: The executions are returned to the client.
+
+Note that the trading flow (steps 1 to 14) is on the critical path, while the market data flow and reporting flow are not. They have different latency requirements.
diff --git a/data/guides/devops-vs-noops.md b/data/guides/devops-vs-noops.md
new file mode 100644
index 0000000..9e856ee
--- /dev/null
+++ b/data/guides/devops-vs-noops.md
@@ -0,0 +1,24 @@
+---
+title: "DevOps vs NoOps: What's the Difference?"
+description: "How do DevOps, NoOps change the software development lifecycle (SDLC)?"
+image: "https://assets.bytebytego.com/diagrams/0099-devops-vs-noops.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Nginx"
+ - "Web Servers"
+---
+
+The diagram below compares traditional SDLC, DevOps and NoOps.
+
+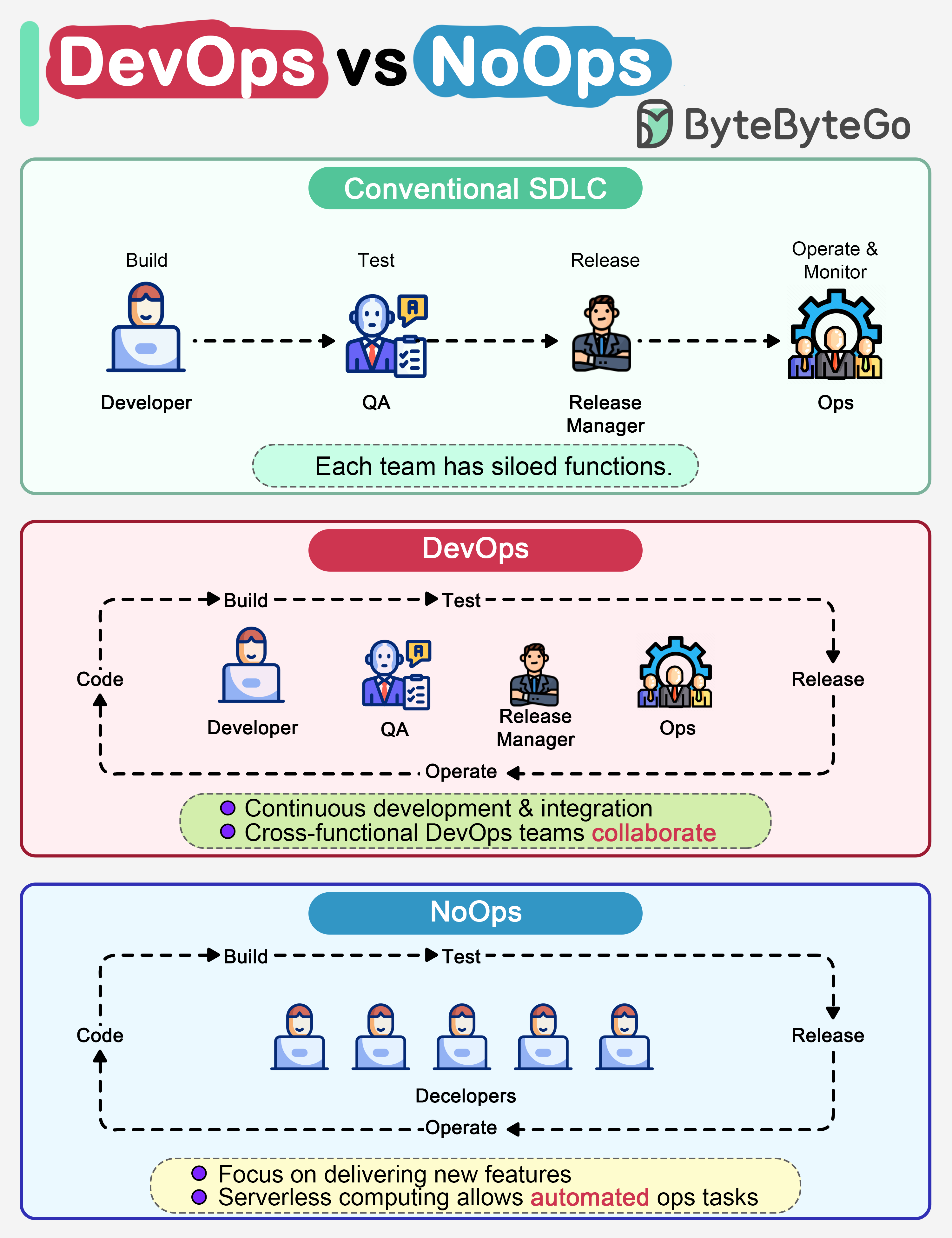
+
+In a traditional software development, code, build, test, release and monitoring are siloed functions. Each stage works independently and hands over to the next stage.
+
+DevOps, on the other hand, encourages continuous development and collaboration between developers and operations. This shortens the overall life cycle and provides continuous software delivery.
+
+NoOps is a newer concept with the development of serverless computing. Since we can architect the system using FaaS (Function-as-a-Service) and BaaS (Backend-as-a-Service), the cloud service providers can take care of most operations tasks. The developers can focus on feature development and automate operations tasks.
+
+NoOps is a pragmatic and effective methodology for startups or smaller-scale applications, which moves shortens the SDLC even more than DevOps.
diff --git a/data/guides/devops-vs-sre-vs-paltform-engg.md b/data/guides/devops-vs-sre-vs-paltform-engg.md
new file mode 100644
index 0000000..29f0169
--- /dev/null
+++ b/data/guides/devops-vs-sre-vs-paltform-engg.md
@@ -0,0 +1,28 @@
+---
+title: "DevOps vs. SRE vs. Platform Engineering"
+description: "Explore the differences between DevOps, SRE, and Platform Engineering."
+image: "https://assets.bytebytego.com/diagrams/0172-devops-sre-platform.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - DevOps
+ - SRE
+---
+
+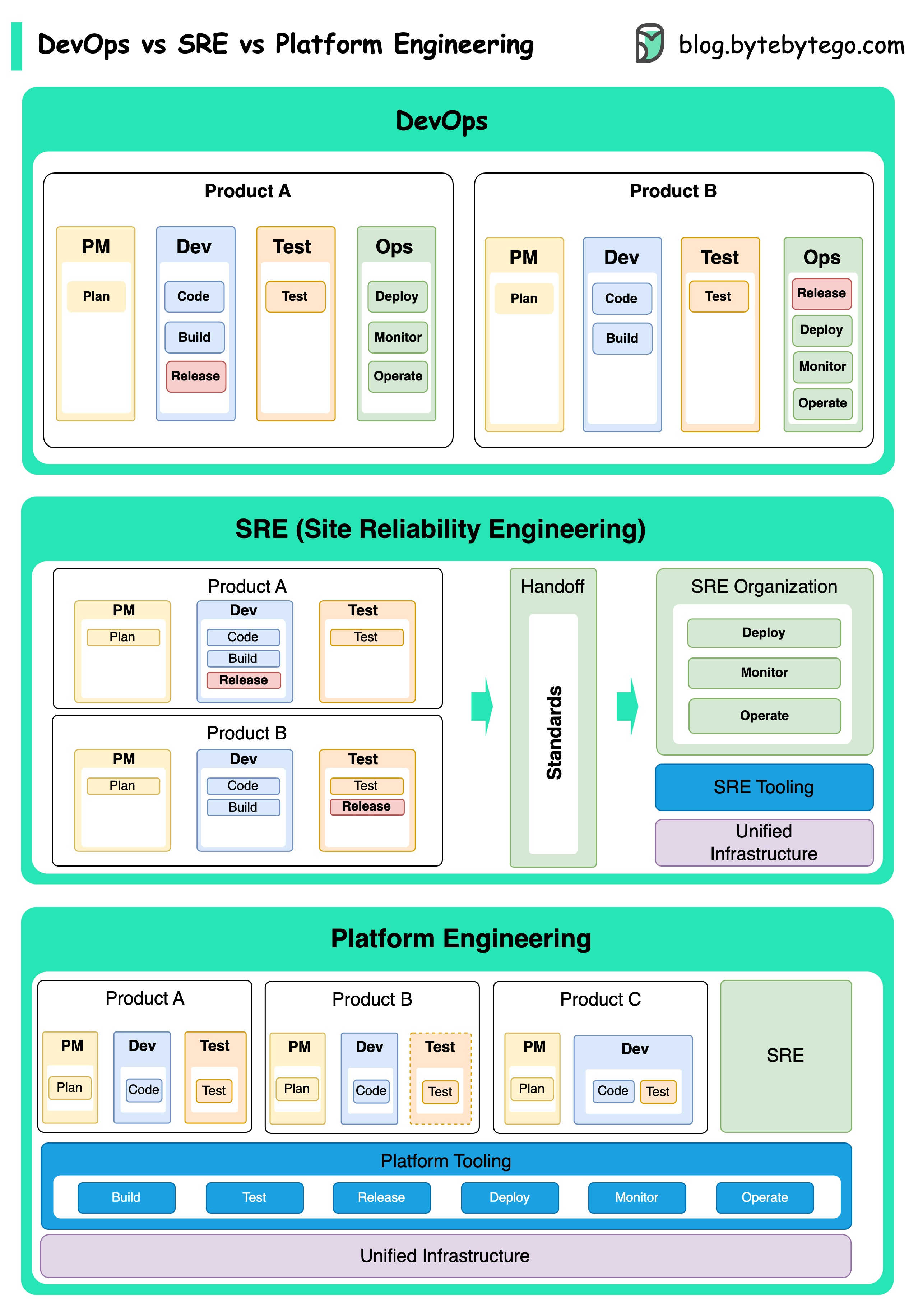
+
+The concepts of DevOps, SRE, and Platform Engineering have emerged at different times and have been developed by various individuals and organizations.
+
+By guest author [Xiong Wang](https://www.linkedin.com/in/wangxiong/)
+
+## Introduction
+
+DevOps as a concept was introduced in 2009 by Patrick Debois and Andrew Shafer at the Agile conference. They sought to bridge the gap between software development and operations by promoting a collaborative culture and shared responsibility for the entire software development lifecycle.
+
+SRE, or Site Reliability Engineering, was pioneered by Google in the early 2000s to address operational challenges in managing large-scale, complex systems. Google developed SRE practices and tools, such as the Borg cluster management system and the Monarch monitoring system, to improve the reliability and efficiency of their services.
+
+Platform Engineering is a more recent concept, building on the foundation of SRE engineering. The precise origins of Platform Engineering are less clear, but it is generally understood to be an extension of the DevOps and SRE practices, with a focus on delivering a comprehensive platform for product development that supports the entire business perspective.
+
+It's worth noting that while these concepts emerged at different times. They are all related to the broader trend of improving collaboration, automation, and efficiency in software development and operations.
diff --git a/data/guides/diagram-as-code.md b/data/guides/diagram-as-code.md
new file mode 100644
index 0000000..cedee97
--- /dev/null
+++ b/data/guides/diagram-as-code.md
@@ -0,0 +1,28 @@
+---
+title: "Diagram as Code"
+description: "Explore Diagram as Code for cloud system architecture prototyping."
+image: "https://assets.bytebytego.com/diagrams/0173-diagrams-as-code-twitter.jpeg"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "diagrams"
+ - "architecture"
+---
+
+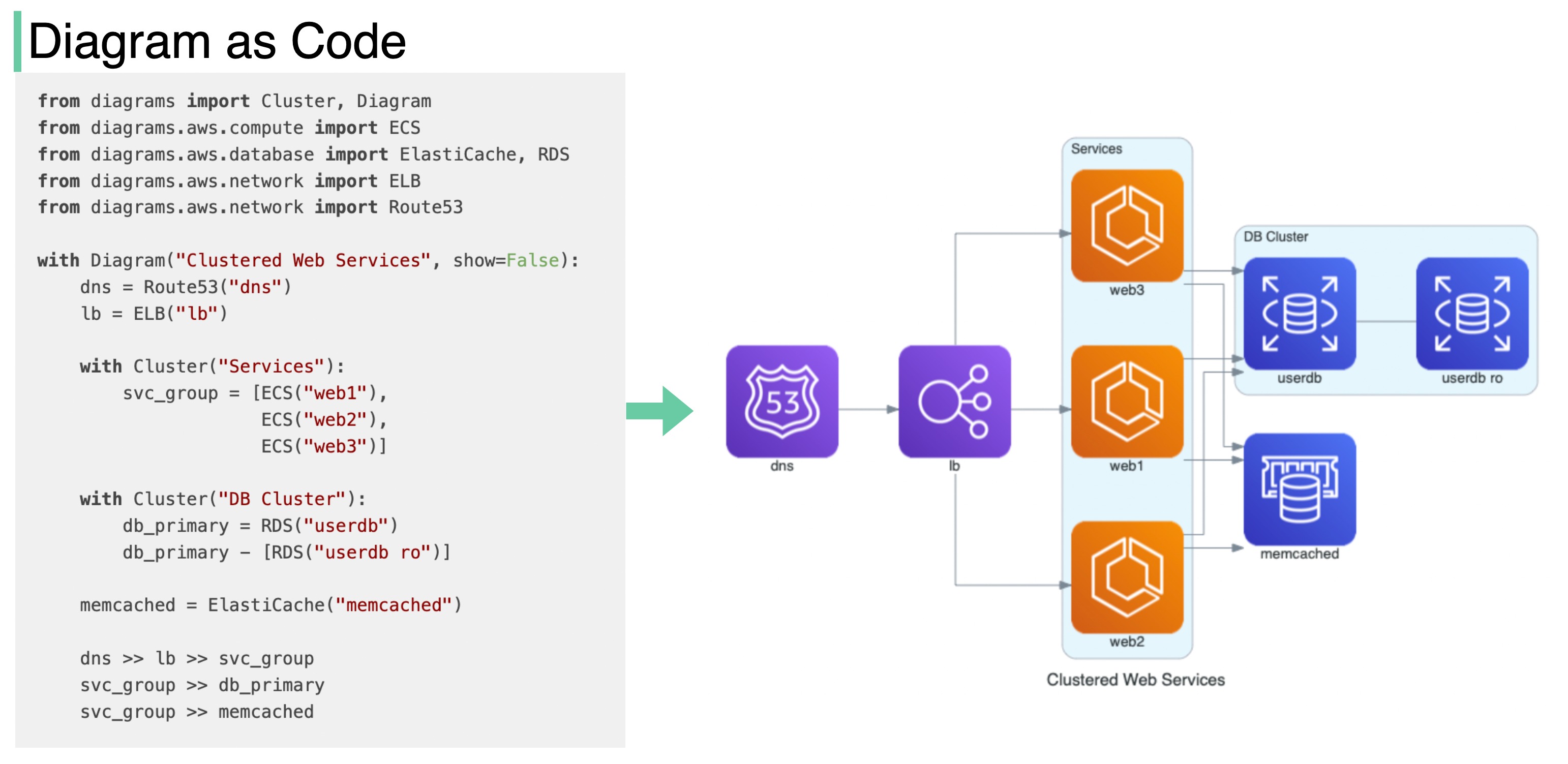
+
+Would it be nice if the code we wrote automatically turned into architecture diagrams?
+
+I recently discovered a Github repo that does exactly this: Diagram as Code for prototyping cloud system architectures.
+
+## What does it do?
+
+* Draw the cloud system architecture in Python code.
+
+* Diagrams can also be rendered directly inside the Jupyter Notebooks.
+
+* No design tools are needed.
+
+* Supports the following providers: AWS, Azure, GCP, Kubernetes, Alibaba Cloud, Oracle Cloud, etc.
diff --git a/data/guides/differences-in-event-sourcing-system-design.md b/data/guides/differences-in-event-sourcing-system-design.md
new file mode 100644
index 0000000..5855e41
--- /dev/null
+++ b/data/guides/differences-in-event-sourcing-system-design.md
@@ -0,0 +1,20 @@
+---
+title: "Differences in Event Sourcing System Design"
+description: "Explore the nuances of event sourcing system design and its benefits."
+image: "https://assets.bytebytego.com/diagrams/0188-event-sourcing.jpeg"
+createdAt: "2024-02-08"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "event sourcing"
+ - "system design"
+---
+
+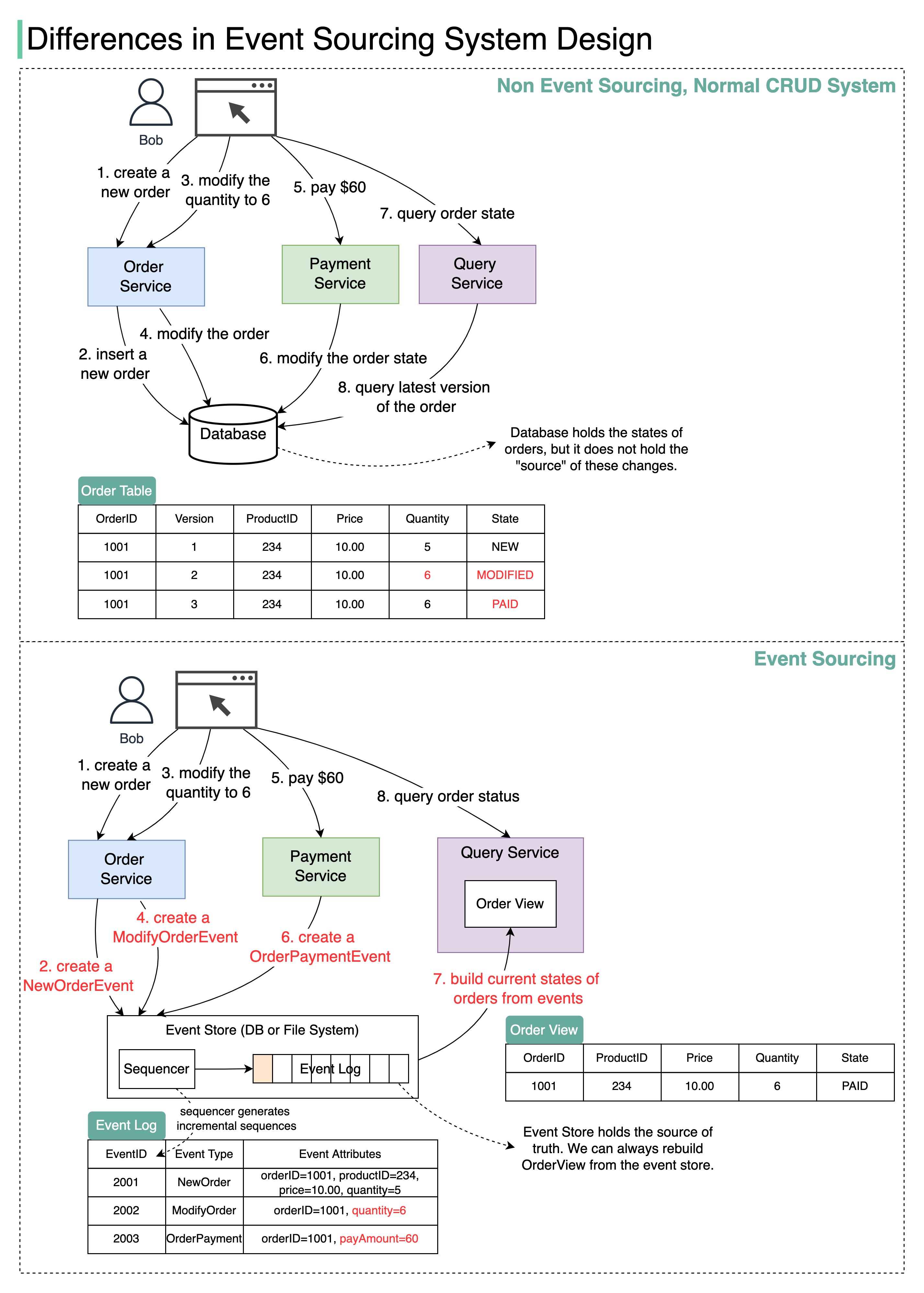
+
+How do we design a system using the event sourcing paradigm? How is it different from normal system design? What are the benefits? We will talk about it in this post.
+
+The diagram above shows the comparison of a normal CRUD system design with an event sourcing system design. We use an e-commerce system that can place orders and pay for the orders to demonstrate how event sourcing works.
+
+The event sourcing paradigm is used to design a system with determinism. This changes the philosophy of normal system designs.
diff --git a/data/guides/digital-wallet-in-traditional-banks-vs-wallet-in-blockchain.md b/data/guides/digital-wallet-in-traditional-banks-vs-wallet-in-blockchain.md
new file mode 100644
index 0000000..c985a08
--- /dev/null
+++ b/data/guides/digital-wallet-in-traditional-banks-vs-wallet-in-blockchain.md
@@ -0,0 +1,38 @@
+---
+title: "Digital Wallets: Banks vs. Blockchain"
+description: "Explore the differences between digital wallets in banks and blockchain."
+image: "https://assets.bytebytego.com/diagrams/0087-blockchains.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Blockchain"
+ - "Digital Wallets"
+---
+
+How does blockchain change the design of digital wallets? Why do VISA and PayPal invest in blockchains?
+
+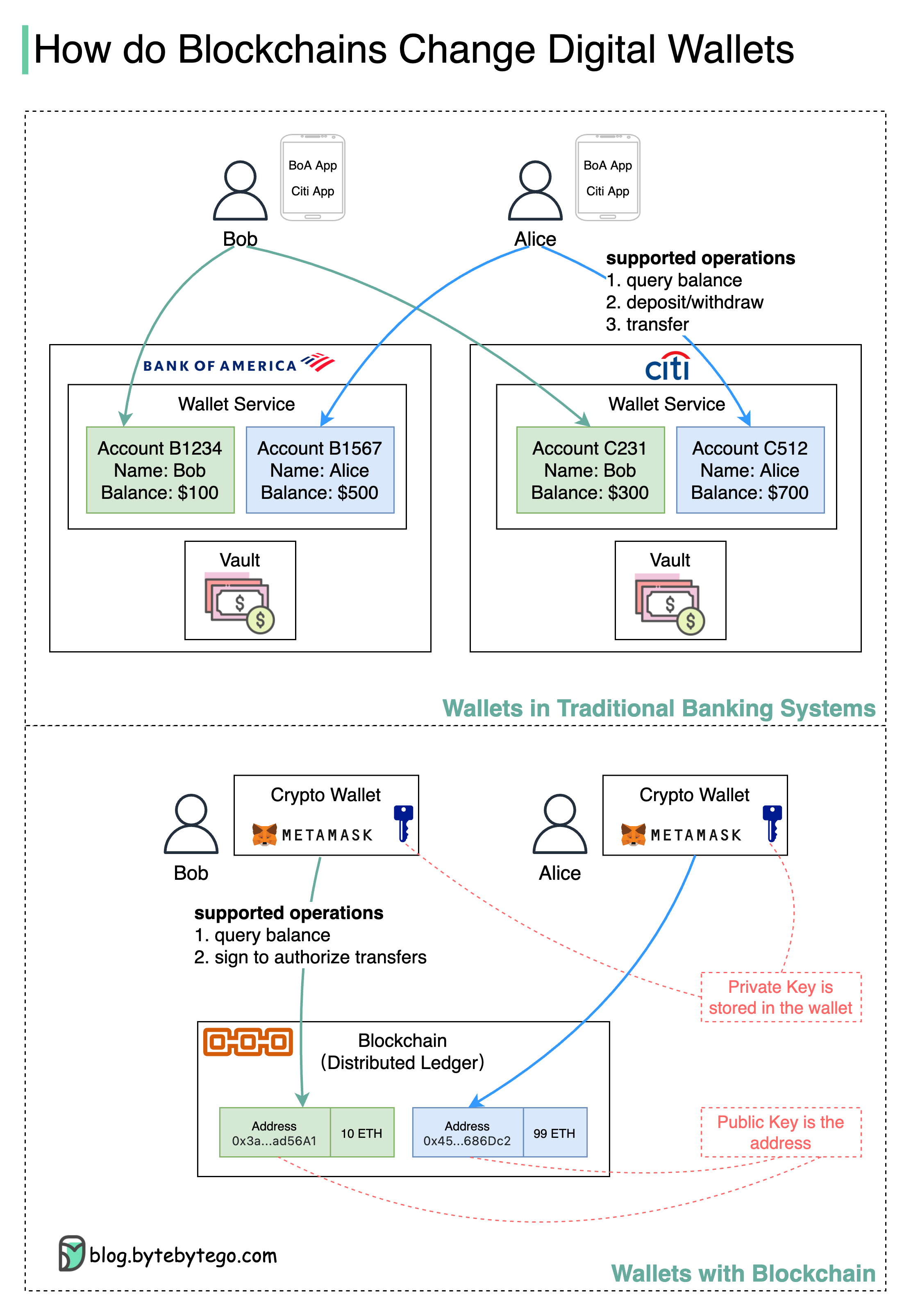
+
+## In banking systems
+
+* Deposit process: Bob goes to Bank of America (BoA) to open an account and deposit $100. A new account B1234 is created in the wallet system for Bob. The cash goes to the bank’s vault and Bob’s wallet now has $100. If Bob wants to use the banking services of Citibank (Citi,) he needs to go through the same process all over again.
+
+* Transfer process: Bob opens BoA’s App and transfers $50 to Alice’s account at Citi. The amount is deducted from Bob’s account B1234 and credited to Alice’s account C512. The actual movement of cash doesn’t happen instantly. It happens after BoA and Citi settle all transactions at end-of-day.
+
+* Withdrawal process: Bob withdraws his remaining $50 from account B1234. The amount is deducted from B1234, and Bob gets the cash.
+
+## With Blockchains
+
+* Deposit & Withdraw: Blockchains support cryptocurrencies, with no cash involved. Bob needs to generate an address as the transfer recipient and store the private key in a crypto wallet like Metamask. Then Bob can receive cryptocurrencies.
+
+* Transfer: Bob opens Metamask and enters Alice’s address, and sends it 2 ETHs. Then Bob signs the transaction to authorize the transfer with the private key. When this transaction is confirmed on blockchains, Bob’s address has 8 ETHs and Alice’s address has 101 ETHs.
+
+👉 Can you spot the differences?
+
+Blockchain is distributed ledger. It provides a unified interface to handle the common operations we perform on wallets. Instead of opening multiple accounts with different banks, we just need to open a single account on blockchains, which is the address.
+
+All transfers are confirmed on blockchains in pseudo real-time, saving us from waiting until end-of-day reconciliations.
+
+With blockchains, we can merge wallet services from different banks into one global service.
diff --git a/data/guides/dns-record-types-you-should-know.md b/data/guides/dns-record-types-you-should-know.md
new file mode 100644
index 0000000..5ace65b
--- /dev/null
+++ b/data/guides/dns-record-types-you-should-know.md
@@ -0,0 +1,48 @@
+---
+title: "DNS Record Types You Should Know"
+description: "Learn about the most common and important DNS record types."
+image: "https://assets.bytebytego.com/diagrams/0175-dns-record-types-you-should-know.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "DNS"
+ - "Networking"
+---
+
+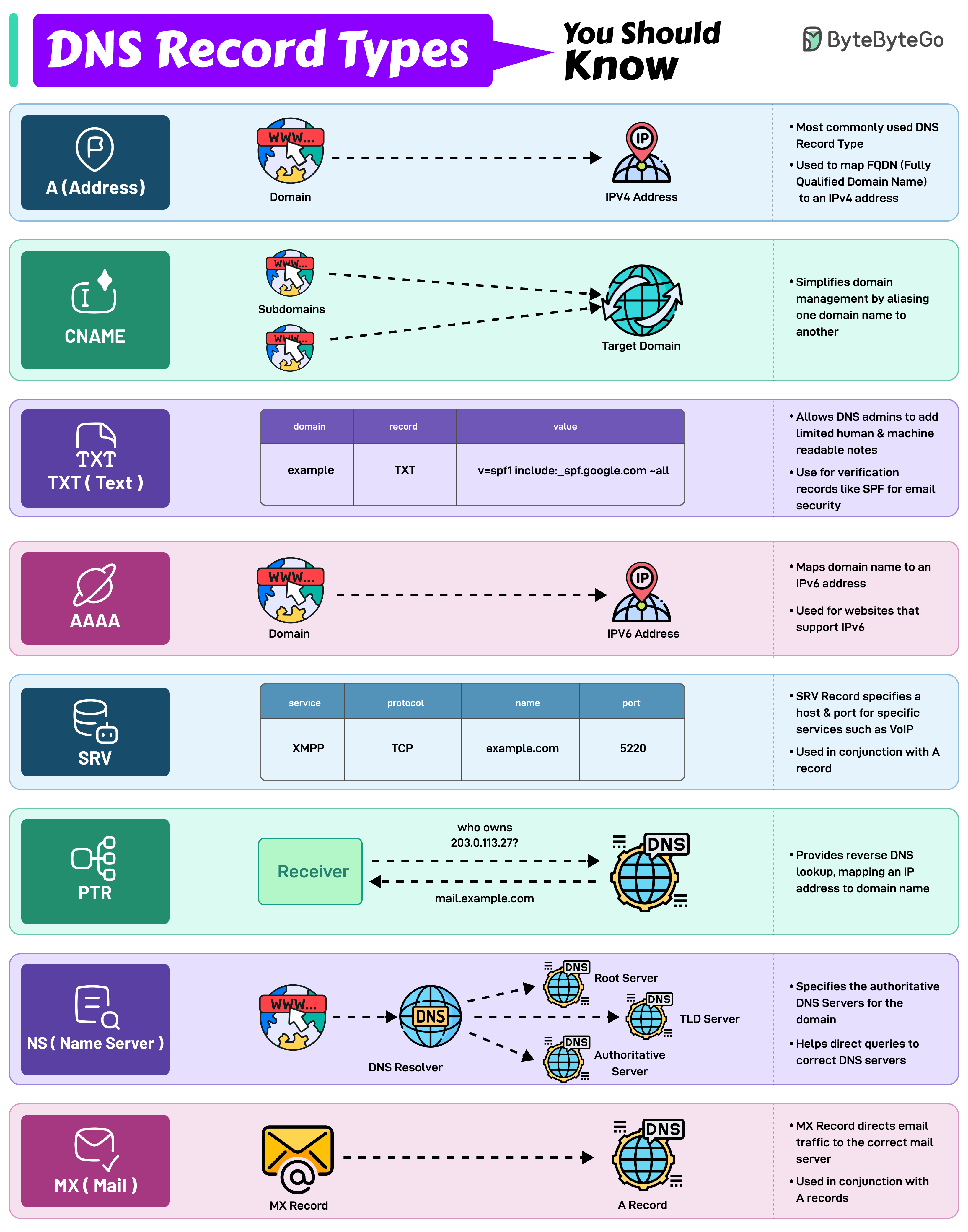
+
+Here are the 8 most commonly used DNS Record Types.
+
+## A (Address) Record
+
+Maps a domain name to an IPv4 address. It is one of the most essential records for translating human-readable domain names into IP addresses.
+
+## CNAME (Canonical Name) Record
+
+Used to alias one domain name to another. Often used for subdomains, pointing them to the main domain while keeping the actual domain name hidden.
+
+## AAAA Record
+
+Similar to an A record but maps a domain name to an IPv6 address. They are used for websites and services that support the IPv6 protocol.
+
+## PTR Record
+
+Provides reverse DNS lookup, mapping an IP address back to a domain name. It is commonly used in verifying the authenticity of a server.
+
+## MX Record
+
+Directs email traffic to the correct mail server.
+
+## NS (Name Server) Record
+
+Specifies the authoritative DNS servers for the domain. These records help direct queries to the correct DNS servers for further lookups.
+
+## SRV (Service) Record
+
+SRV record specifies a host and port for specific services such as VoIP. They are used in conjunction with A records.
+
+## TXT (Text) Record
+
+Allows the administrator to add human-readable text to the DNS records. It is used to include verification records, like SPF, for email security.
diff --git a/data/guides/do-you-know-all-the-components-of-a-url.md b/data/guides/do-you-know-all-the-components-of-a-url.md
new file mode 100644
index 0000000..ef790d9
--- /dev/null
+++ b/data/guides/do-you-know-all-the-components-of-a-url.md
@@ -0,0 +1,24 @@
+---
+title: 'Do you know all the components of a URL?'
+description: 'Learn about the different components that make up a URL.'
+image: 'https://assets.bytebytego.com/diagrams/0116-structure-of-url.png'
+createdAt: '2024-02-18'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - networking
+ - web-development
+---
+
+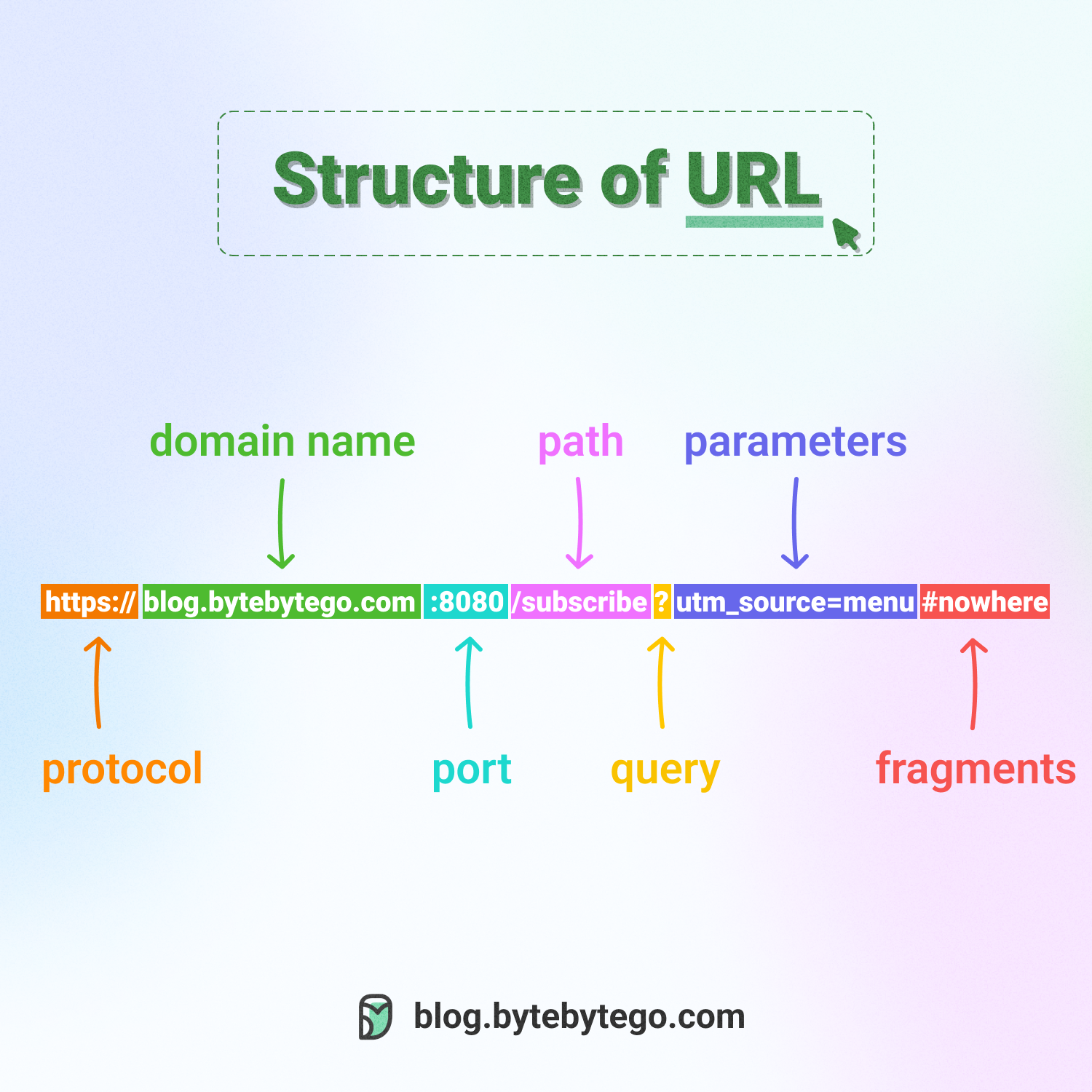
+
+Uniform Resource Locator (URL) is a term familiar to most people, as it is used to locate resources on the internet. When you type a URL into a web browser's address bar, you are accessing a "resource", not just a webpage.
+
+URLs comprise several components:
+
+* **The protocol or scheme**, such as http, https, and ftp.
+* **The domain name and port**, separated by a period (.)
+* **The path to the resource**, separated by a slash (/)
+* **The parameters**, which start with a question mark (?) and consist of key-value pairs, such as a=b&c=d.
+* **The fragment or anchor**, indicated by a pound sign (#), which is used to bookmark a specific section of the resource.
diff --git a/data/guides/do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.md b/data/guides/do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.md
new file mode 100644
index 0000000..1aca593
--- /dev/null
+++ b/data/guides/do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.md
@@ -0,0 +1,18 @@
+---
+title: "Why Meta, Google, and Amazon Stop Using Leap Seconds"
+description: "Explore why tech giants are moving away from leap seconds."
+image: "https://assets.bytebytego.com/diagrams/0363-do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.jpeg"
+createdAt: "2024-02-04"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Time Synchronization"
+ - "Leap Seconds"
+---
+
+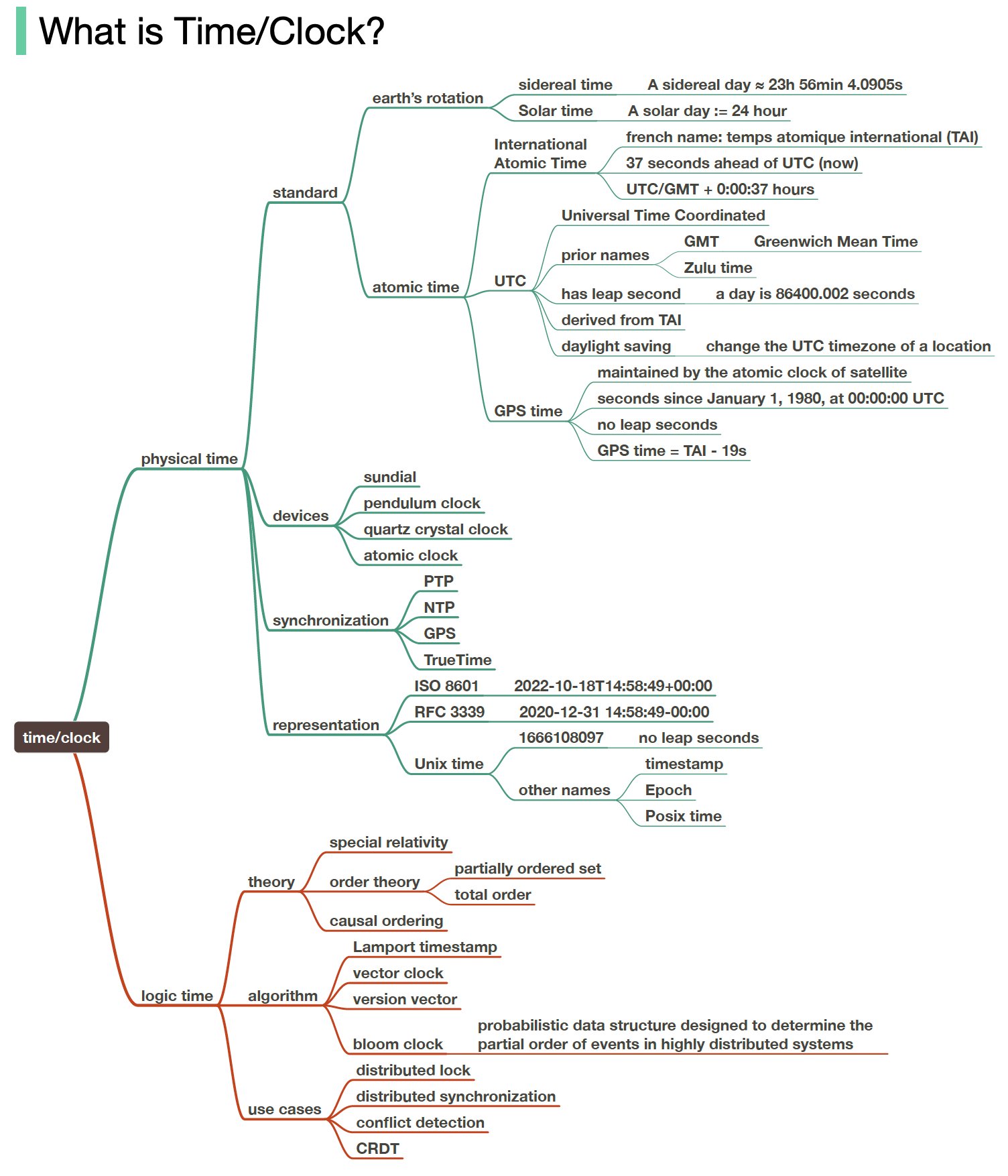
+
+Every few years, there is a special phenomenon that the second after “23:59:59” is not “00:00:00” but “23:59:60”. It is called leap second, which could easily cause time-processing bugs if not handled carefully.
+
+Do we always need to handle leap seconds? It depends on which time representation is used. Commonly used time representations include UTC, GMT, TAI, Unix Timestamp, Epoc time, TrueTime, and GPS time.
diff --git a/data/guides/e-commerce-workflow.md b/data/guides/e-commerce-workflow.md
new file mode 100644
index 0000000..bb5f798
--- /dev/null
+++ b/data/guides/e-commerce-workflow.md
@@ -0,0 +1,46 @@
+---
+title: "E-commerce Workflow"
+description: "Explore the behind-the-scenes of e-commerce: procurement to delivery."
+image: "https://assets.bytebytego.com/diagrams/0179-e-commerce-works.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - "payment-and-fintech"
+tags:
+ - "E-commerce"
+ - "Supply Chain"
+---
+
+What happens behind the scenes when we shop online?
+
+Disclaimer: I have limited knowledge of the eCommerce system. The diagram above is based on my research. Please suggest better names for the components or let me know if you spot an error.
+
+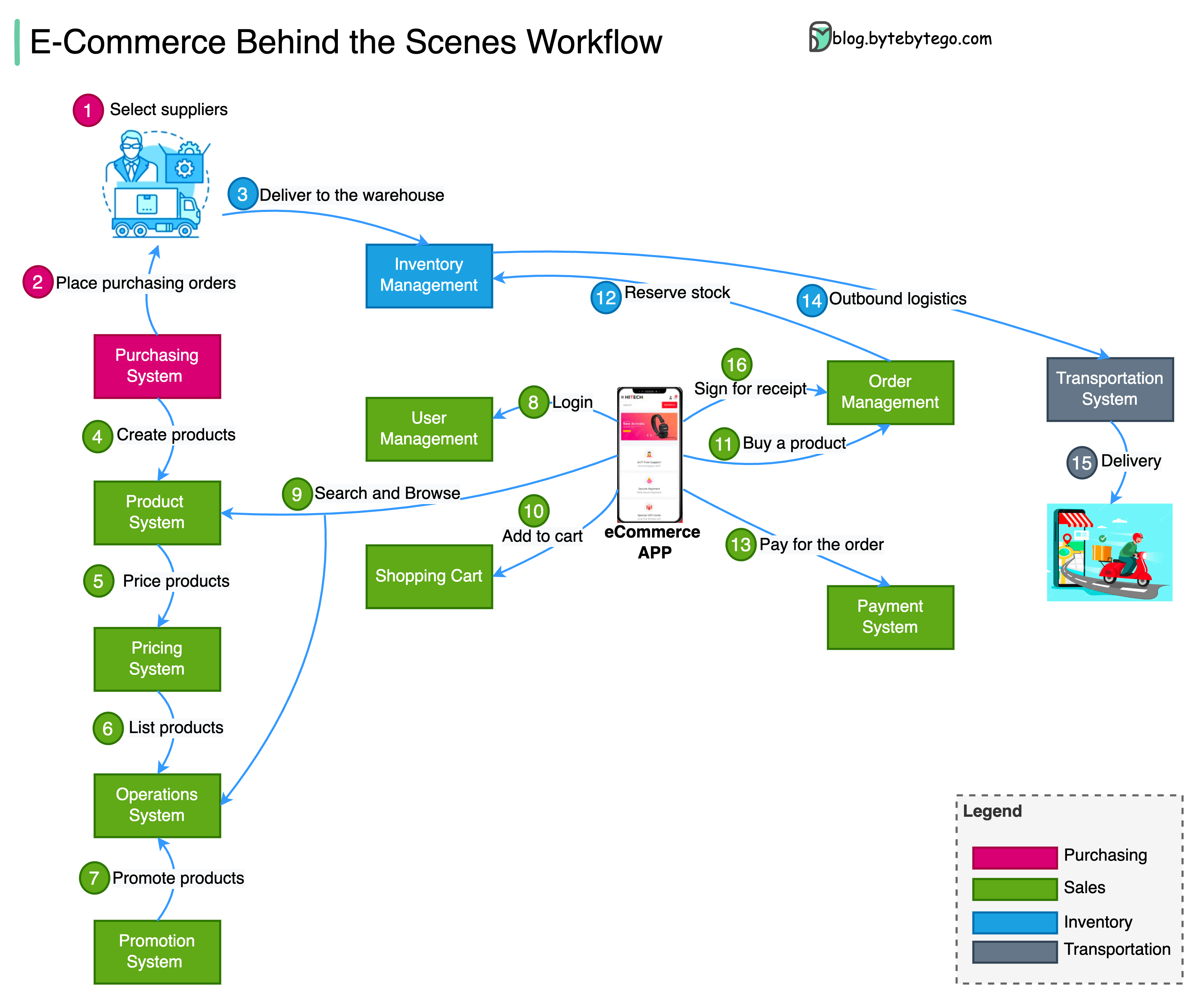
+
+The diagram above shows the 4 key business areas in a typical e-commerce company: procurement, inventory, eComm platform, and transportation.
+
+## Procurement
+
+* Step 1 - The procurement department selects suppliers and manages contracts with them.
+
+* Step 2 - The procurement department places orders with suppliers, manages the return of goods, and settles invoices with suppliers.
+
+## Inventory
+
+* Step 3 - The products or goods from suppliers are delivered to a storage facility. All products/goods are managed by inventory management systems.
+
+## EComm platform
+
+* Steps 4-7 - The “eComm platform - Product Management” system creates the product info managed by the product system. The pricing system prices the products. Then the products are ready to be listed for sale. The promotion system defines big sale activities, coupons, etc.
+
+* Step 8-11 - Consumers can now purchase products on the e-commerce APP. First, users register or log in to the APP. Next, users browse the product list and details, adding products to the shopping cart. They then place purchasing orders.
+
+* Steps 12,13 - The order management system reserves stock in the inventory management system. Then the users pay for the product.
+
+## Transportation
+
+* Steps 14,15 - The inventory system sends the outbound order to the transportation system, which manages the physical delivery of the goods.
+
+* Step 16 - Sign for item delivery (optional)
+
+Quick question: If a user buys many products, their big order might be divided into several small orders based on warehouse locations, product types, etc. Where would you place the “order splitting” system in the process outlined below?
diff --git a/data/guides/encoding-vs-encryption-vs-tokenization.md b/data/guides/encoding-vs-encryption-vs-tokenization.md
new file mode 100644
index 0000000..6e3b957
--- /dev/null
+++ b/data/guides/encoding-vs-encryption-vs-tokenization.md
@@ -0,0 +1,36 @@
+---
+title: "Encoding vs Encryption vs Tokenization"
+description: "Understand encoding, encryption, and tokenization for data handling."
+image: "https://assets.bytebytego.com/diagrams/0033-encoding-vs-encryption-vs-tokenization.png"
+createdAt: "2024-02-11"
+draft: false
+categories:
+ - security
+tags:
+ - "Data Security"
+ - "Data Handling"
+---
+
+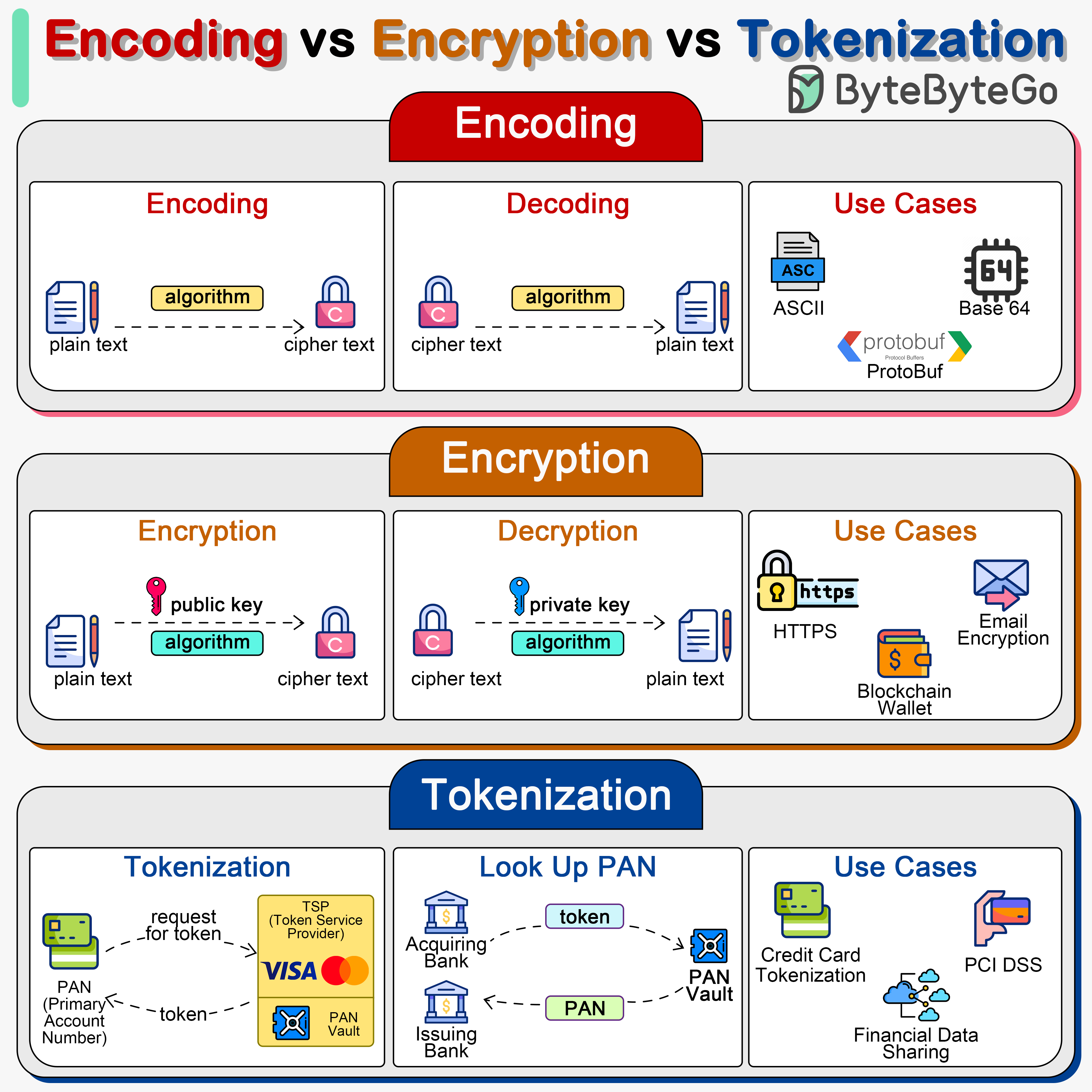
+
+Encoding, encryption, and tokenization are three distinct processes that handle data in different ways for various purposes, including data transmission, security, and compliance.
+
+In system designs, we need to select the right approach for handling sensitive information.
+
+## Encoding
+
+Encoding converts data into a different format using a scheme that can be easily reversed. Examples include Base64 encoding, which encodes binary data into ASCII characters, making it easier to transmit data over media that are designed to deal with textual data.
+
+Encoding is not meant for securing data. The encoded data can be easily decoded using the same scheme without the need for a key.
+
+## Encryption
+
+Encryption involves complex algorithms that use keys for transforming data. Encryption can be symmetric (using the same key for encryption and decryption) or asymmetric (using a public key for encryption and a private key for decryption).
+
+Encryption is designed to protect data confidentiality by transforming readable data (plaintext) into an unreadable format (ciphertext) using an algorithm and a secret key. Only those with the correct key can decrypt and access the original data.
+
+## Tokenization
+
+Tokenization is the process of substituting sensitive data with non-sensitive placeholders called tokens. The mapping between the original data and the token is stored securely in a token vault. These tokens can be used in various systems and processes without exposing the original data, reducing the risk of data breaches.
+
+Tokenization is often used for protecting credit card information, personal identification numbers, and other sensitive data. Tokenization is highly secure, as the tokens do not contain any part of the original data and thus cannot be reverse-engineered to reveal the original data. It is particularly useful for compliance with regulations like PCI DSS.
diff --git a/data/guides/erasure-coding.md b/data/guides/erasure-coding.md
new file mode 100644
index 0000000..ecb49c4
--- /dev/null
+++ b/data/guides/erasure-coding.md
@@ -0,0 +1,30 @@
+---
+title: "Erasure Coding"
+description: "Explore erasure coding: enhancing data durability in object storage."
+image: "https://assets.bytebytego.com/diagrams/0187-erasure-coding.png"
+createdAt: "2024-02-09"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Storage"
+ - "Data Redundancy"
+---
+
+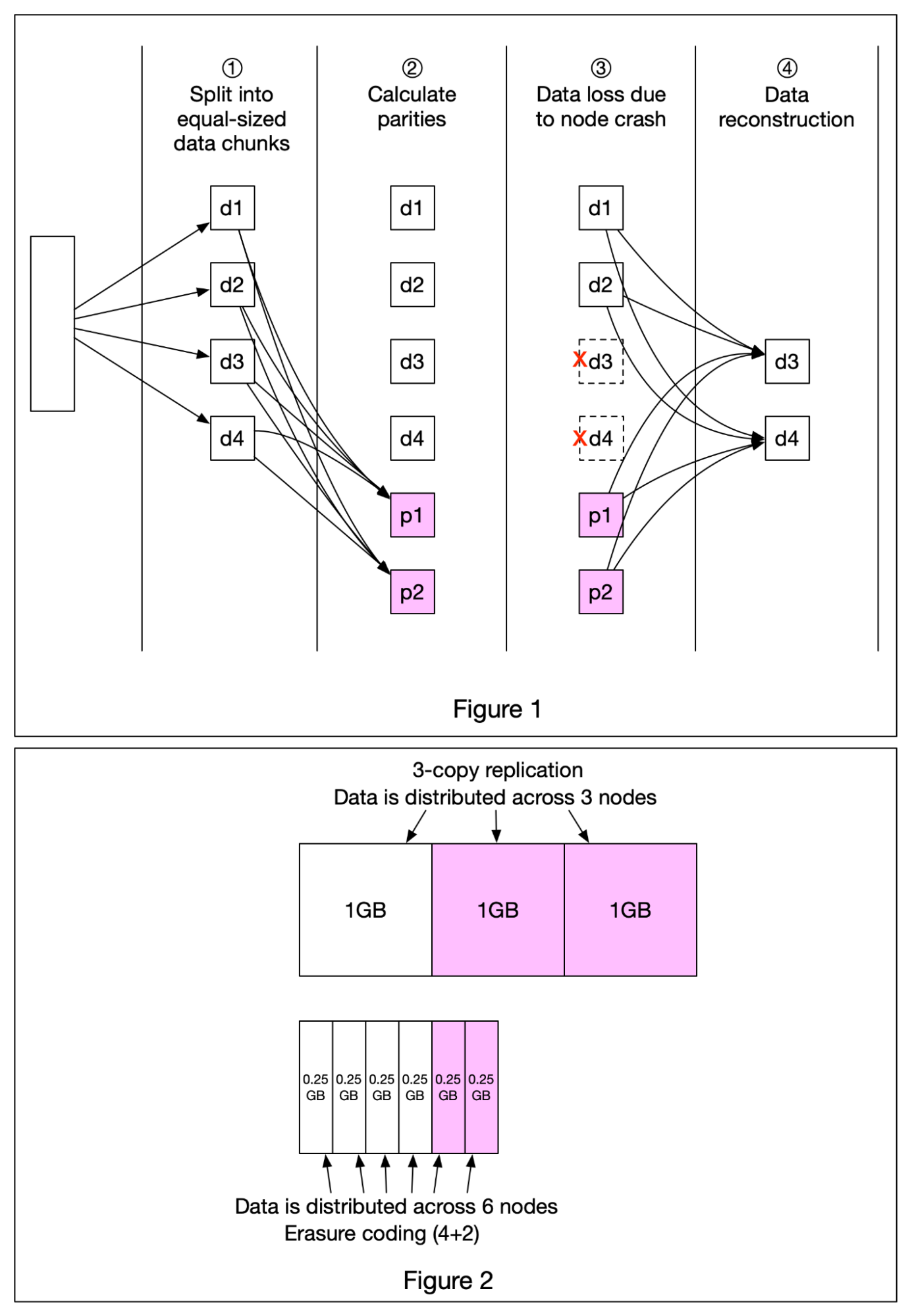
+
+A really cool technique that’s commonly used in object storage such as S3 to improve durability is called **Erasure Coding**. Let’s take a look at how it works.
+
+Erasure coding deals with data durability differently from replication. It chunks data into smaller pieces (placed on different servers) and creates parities for redundancy. In the event of failures, we can use chunk data and parities to reconstruct the data. Let’s take a look at a concrete example (4 + 2 erasure coding) as shown in Figure 1.
+
+* Data is broken up into four even-sized data chunks d1, d2, d3, and d4.
+
+* The mathematical formula is used to calculate the parities p1 and p2. To give a much simplified example, p1 = d1 + 2\*d2 - d3 + 4\*d4 and p2 = -d1 + 5\*d2 + d3 - 3\*d4.
+
+* Data d3 and d4 are lost due to node crashes.
+
+* The mathematical formula is used to reconstruct lost data d3 and d4, using the known values of d1, d2, p1, and p2.
+
+How much extra space does erasure coding need? For every two chunks of data, we need one parity block, so the storage overhead is 50% (Figure 2). While in 3-copy replication, the storage overhead is 200% (Figure 2).
+
+Does erasure coding increase data durability? Let’s assume a node has a 0.81% annual failure rate. According to the calculation done by Backblaze, erasure coding can achieve 11 nines durability vs 3-copy replication can achieve 6 nines durability.
diff --git a/data/guides/evolution-of-airbnb's-microservice.md b/data/guides/evolution-of-airbnb's-microservice.md
new file mode 100644
index 0000000..ad8af0a
--- /dev/null
+++ b/data/guides/evolution-of-airbnb's-microservice.md
@@ -0,0 +1,45 @@
+---
+title: 'Evolution of Airbnb’s Microservice Architecture'
+description: 'Explore the evolution of Airbnb’s microservice architecture in detail.'
+image: 'https://assets.bytebytego.com/diagrams/0014-airbnb-arch.jpg'
+createdAt: '2024-03-05'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Microservices
+ - Architecture
+---
+
+[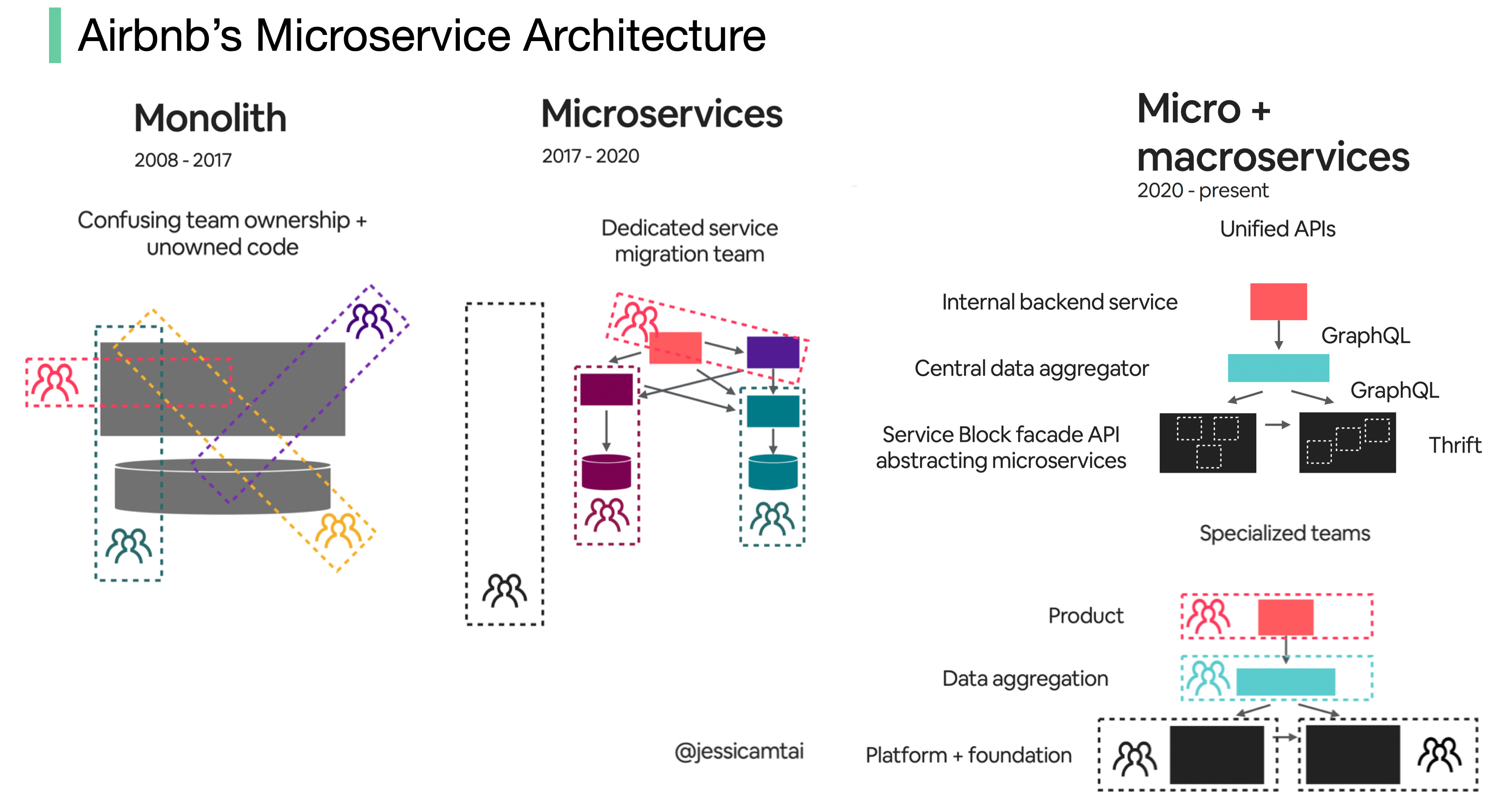](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F7c90c105-a6bf-46f4-b896-73390fcfe60b_3396x1839.jpeg)
+
+Airbnb’s microservice architecture went through 3 main stages. This post is based on the tech talk by Jessica Tai.
+
+**Monolith** (2008 - 2017)
+
+Airbnb began as a simple marketplace for hosts and guests. This is built in a Ruby on Rails application - the monolith.
+
+**What’s the challenge?**
+
+* Confusing team ownership + unowned code
+* Slow deployment
+
+**Microservices** (2017 - 2020)
+
+Microservice aims to solve those challenges. In the microservice architecture, key services include:
+
+* Data fetching service
+* Business logic data service
+* Write workflow service
+* UI aggregation service
+* Each service had one owning team
+
+**What’s the challenge?**
+
+Hundreds of services and dependencies were difficult for humans to manage.
+
+**Micro + macroservices** (2020 - present)
+
+This is what Airbnb is working on now. The micro and macroservice hybrid model focuses on the unification of APIs.
+
+Reference: [The Human Side of Airbnb’s Microservice Architecture](https://www.infoq.com/presentations/airbnb-culture-soa/)
diff --git a/data/guides/evolution-of-the-netflix-api-architecture.md b/data/guides/evolution-of-the-netflix-api-architecture.md
new file mode 100644
index 0000000..5e25858
--- /dev/null
+++ b/data/guides/evolution-of-the-netflix-api-architecture.md
@@ -0,0 +1,24 @@
+---
+title: 'Evolution of the Netflix API Architecture'
+description: 'Explore the evolution of Netflix API architecture through four stages.'
+image: 'https://assets.bytebytego.com/diagrams/0290-netflix-api.png'
+createdAt: '2024-03-11'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - API Architecture
+ - Netflix
+---
+
+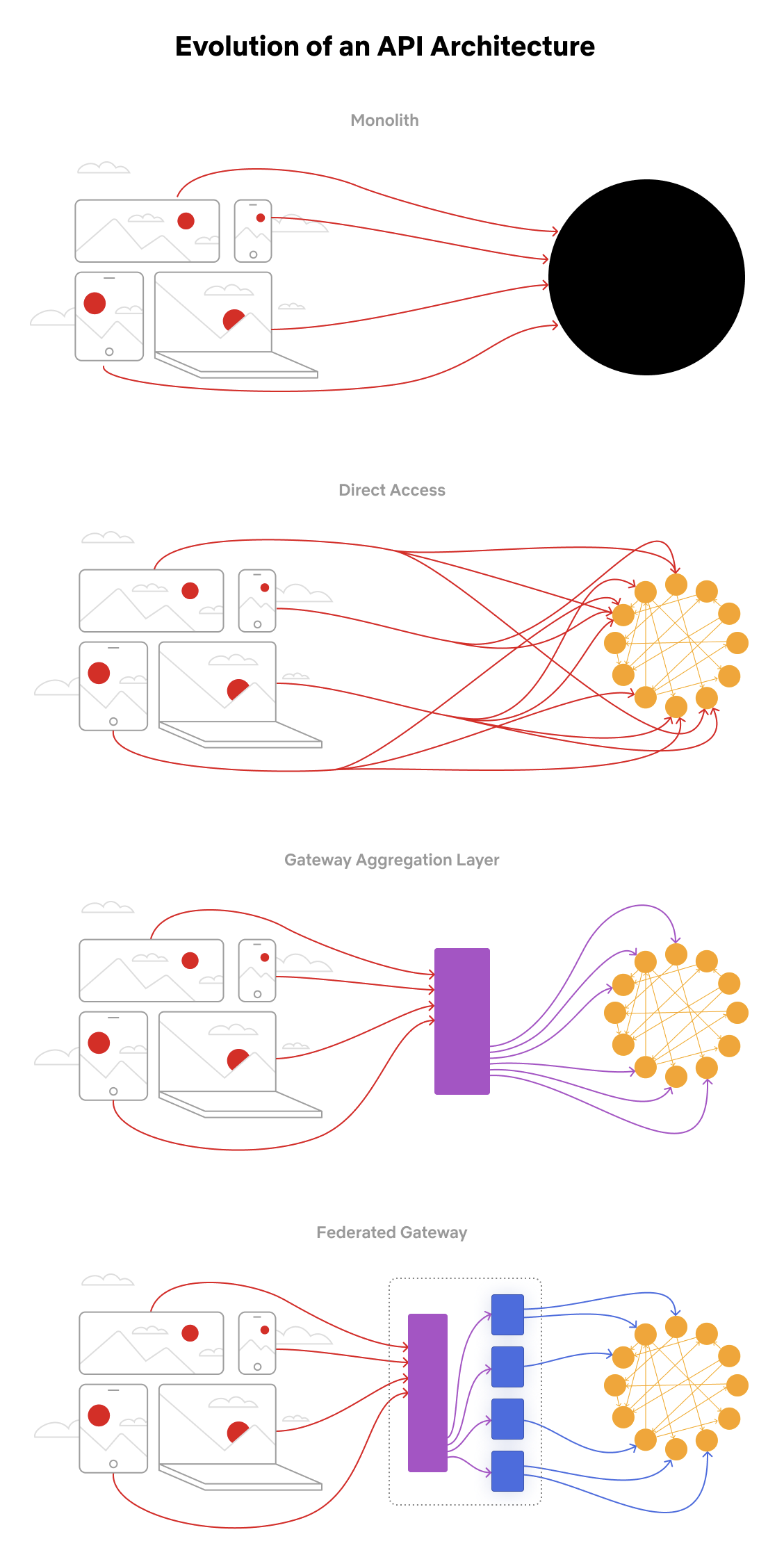
+
+The Netflix API architecture went through 4 main stages.
+
+**Monolith**. The application is packaged and deployed as a monolith, such as a single Java WAR file, Rails app, etc. Most startups begin with a monolith architecture.
+
+**Direct access**. In this architecture, a client app can make requests directly to the microservices. With hundreds or even thousands of microservices, exposing all of them to clients is not ideal.
+
+**Gateway aggregation layer**. Some use cases may span multiple services, we need a gateway aggregation layer. Imagine the Netflix app needs 3 APIs (movie, production, talent) to render the frontend. The gateway aggregation layer makes it possible.
+
+**Federated gateway**. As the number of developers grew and domain complexity increased, developing the API aggregation layer became increasingly harder. GraphQL federation allows Netflix to set up a single GraphQL gateway that fetches data from all the other APIs.
diff --git a/data/guides/evolution-of-uber's-api-layer.md b/data/guides/evolution-of-uber's-api-layer.md
new file mode 100644
index 0000000..08f8f46
--- /dev/null
+++ b/data/guides/evolution-of-uber's-api-layer.md
@@ -0,0 +1,22 @@
+---
+title: Evolution of Uber's API Layer
+description: Learn about the evolution of Uber's API layer.
+image: 'https://assets.bytebytego.com/diagrams/0397-uber-api-layer.png'
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - API Gateway
+ - Microservices
+---
+
+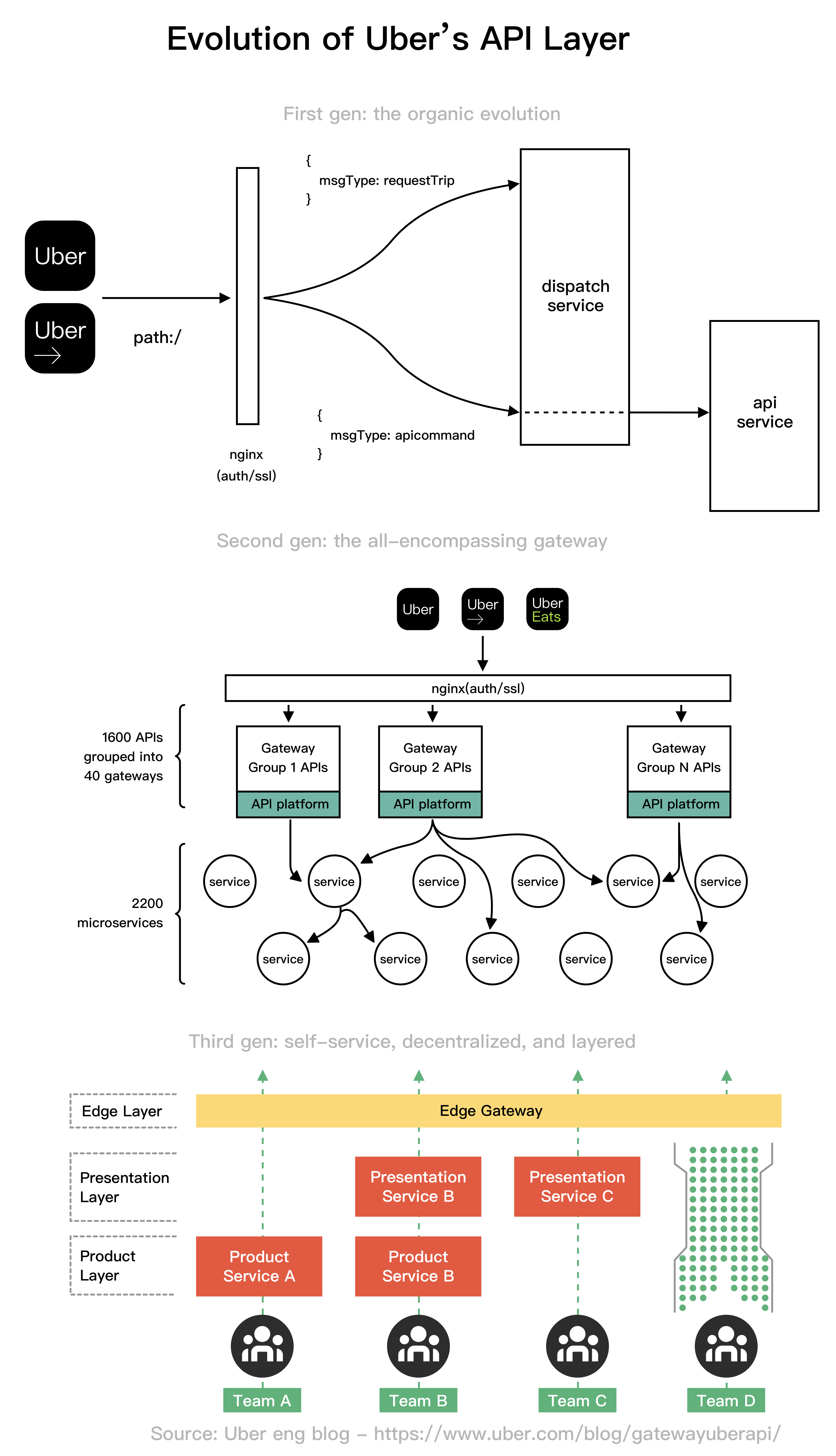
+
+Uber’s API gateway went through 3 main stages.
+
+First gen: the organic evolution. Uber's architecture in 2014 would have two key services: dispatch and API. A dispatch service connects a rider with a driver, while an API service stores the long-term data of users and trips.
+
+Second gen: the all-encompassing gateway. Uber adopted a microservice architecture very early on. By 2019, Uber's products were powered by 2,200+ microservices as a result of this architectural decision.
+
+Third gen: self-service, decentralized, and layered. As of early 2018, Uber had completely new business lines and numerous new applications. Freight, ATG, Elevate, groceries, and more are among the growing business lines. With a new set of goals comes the third generation.
diff --git a/data/guides/explain-the-top-6-use-cases-of-object-stores.md b/data/guides/explain-the-top-6-use-cases-of-object-stores.md
new file mode 100644
index 0000000..c9bf577
--- /dev/null
+++ b/data/guides/explain-the-top-6-use-cases-of-object-stores.md
@@ -0,0 +1,44 @@
+---
+title: "Explain the Top 6 Use Cases of Object Stores"
+description: "Explore the top 6 use cases of object stores in modern data management."
+image: "https://assets.bytebytego.com/diagrams/0117-explain-the-top-6-use-cases-of-object-stores.png"
+createdAt: "2024-02-14"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Object Storage"
+ - "Data Management"
+---
+
+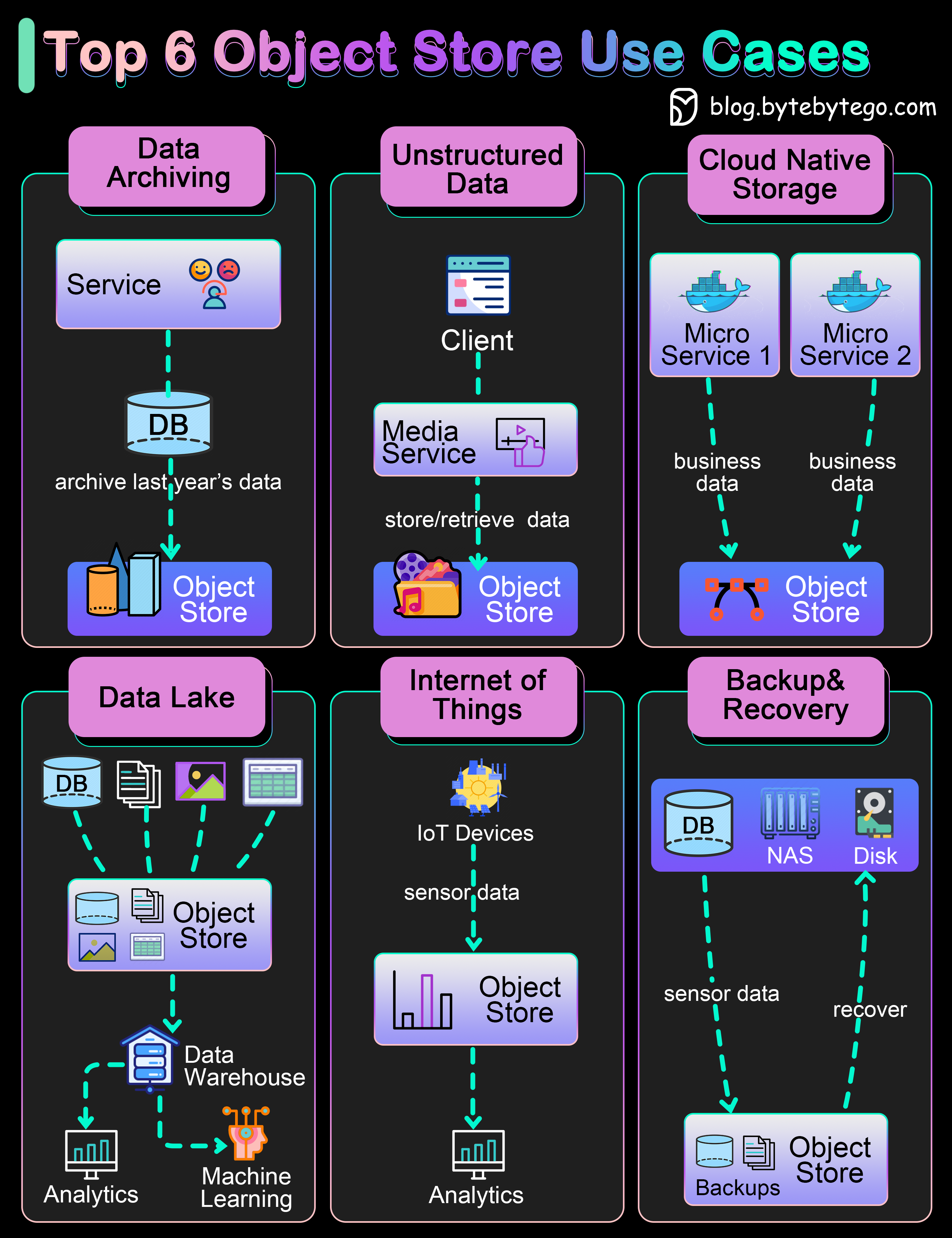
+
+What is an object store?
+
+Object store uses objects to store data. Compared with file storage which uses a hierarchical structure to store files, or block storage which divides files into equal block sizes, object storage stores metadata together with the objects. Typical products include AWS S3, Google Cloud Storage, and Azure Blob Storage.
+
+An object store provides flexibility in formats and scales easily.
+
+## Case 1: Data Archiving
+
+With the ever-growing amounts of business data, we cannot store all the data in core storage systems. We need to have layers of storage plan. An object store can be used to archive old data that exists for auditing or client statements. This is a cost-effective approach.
+
+## Case 2: Unstructured Data Storage
+
+We often need to deal with unstructured data or semi-structured data. In the past, they were usually stored as blobs in the relational database, which was quite inefficient. An object store is a good match for music, video files, and text documents. Companies like Spotify or Netflix uses object store to persist their media files.
+
+## Case 3: Cloud Native Storage
+
+For cloud-native applications, we need the data storage system to be flexible and scalable. Major public cloud providers have easy API access to their object store products and can be used for economical storage choices.
+
+## Case 4: Data Lake
+
+There are many types of data in a distributed system. An object store-backed data lake provides a good place for different business lines to dump their data for later analytics or machine learning. The efficient reads and writes of the object store facilitate more steps down the data processing pipeline, including ETL(Extract-Transform-Load) or constructing a data warehouse.
+
+## Case 5: Internet of Things (IoT)
+
+IoT sensors produce all kinds of data. An object store can store this type of time series and later run analytics or AI algorithms on them. Major public cloud providers provide pipelines to ingest raw IoT data into the object store.
+
+## Case 6: Backup and Recovery
+
+An object store can be used to store database or file system backups. Later, the backups can be loaded for fast recovery. This improves the system’s availability.
diff --git a/data/guides/explaining-5-unique-id-generators-in-distributed-systems.md b/data/guides/explaining-5-unique-id-generators-in-distributed-systems.md
new file mode 100644
index 0000000..70ff459
--- /dev/null
+++ b/data/guides/explaining-5-unique-id-generators-in-distributed-systems.md
@@ -0,0 +1,38 @@
+---
+title: "Explaining 5 Unique ID Generators"
+description: "Explore 5 unique ID generators and their pros and cons in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0006-explaining-5-unique-id-generators-in-distributed-systems.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Distributed Systems
+ - Unique IDs
+---
+
+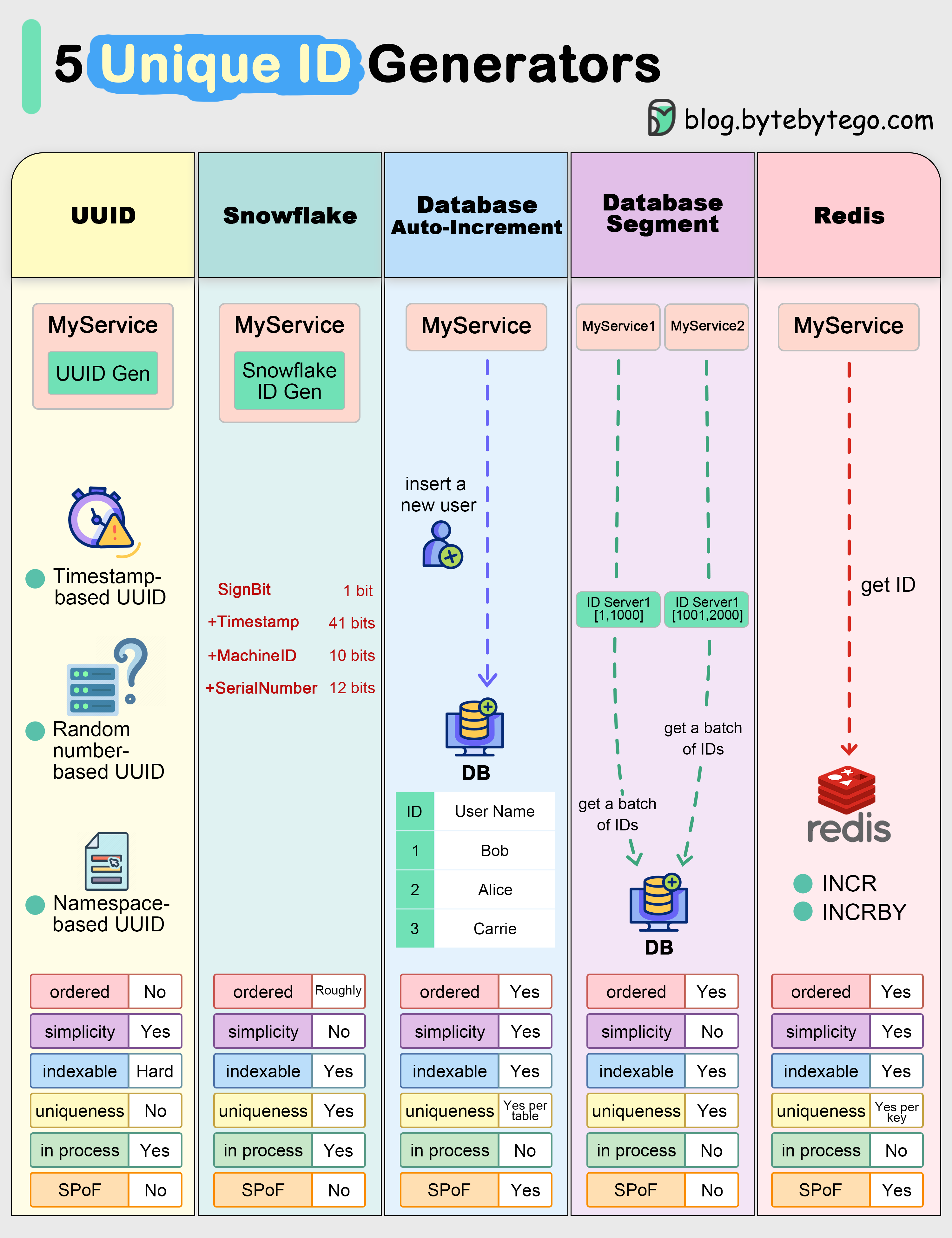
+
+The diagram below shows how they work. Each generator has its pros and cons.
+
+## UUID
+
+A UUID has 128 bits. It is simple to generate and no need to call another service. However, it is not sequential and inefficient for database indexing. Additionally, UUID doesn’t guarantee global uniqueness. We need to be careful with ID conflicts (although the chances are slim.)
+
+## Snowflake
+
+Snowflake’s ID generation process has multiple components: timestamp, machine ID, and serial number. The first bit is unused to ensure positive IDs. This generator doesn’t need to talk to an ID generator via the network, so is fast and scalable.
+
+Snowflake implementations vary. For example, data center ID can be added to the “MachineID” component to guarantee global uniqueness.
+
+## DB auto-increment
+
+Most database products offer auto-increment identity columns. Since this is supported in the database, we can leverage its transaction management to handle concurrent visits to the ID generator. This guarantees uniqueness in one table. However, this involves network communications and may expose sensitive business data to the outside. For example, if we use this as a user ID, our business competitors will have a rough idea of the total number of users registered on our website.
+
+## DB segment
+
+An alternative approach is to retrieve IDs from the database in batches and cache them in the ID servers, each ID server handling a segment of IDs. This greatly saves the I/O pressure on the database.
+
+## Redis
+
+We can also use Redis key-value pair to generate unique IDs. Redis stores data in memory, so this approach offers better performance than the database.
diff --git a/data/guides/explaining-8-popular-network-protocols-in-1-diagram.md b/data/guides/explaining-8-popular-network-protocols-in-1-diagram.md
new file mode 100644
index 0000000..079a6eb
--- /dev/null
+++ b/data/guides/explaining-8-popular-network-protocols-in-1-diagram.md
@@ -0,0 +1,48 @@
+---
+title: "Explaining 8 Popular Network Protocols in 1 Diagram"
+description: "A visual guide to understanding 8 common network protocols."
+image: "https://assets.bytebytego.com/diagrams/0292-explaining-8-popular-network-protocols-in-1-diagram.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Networking"
+ - "Protocols"
+---
+
+Network protocols are standard methods of transferring data between two computers in a network.
+
+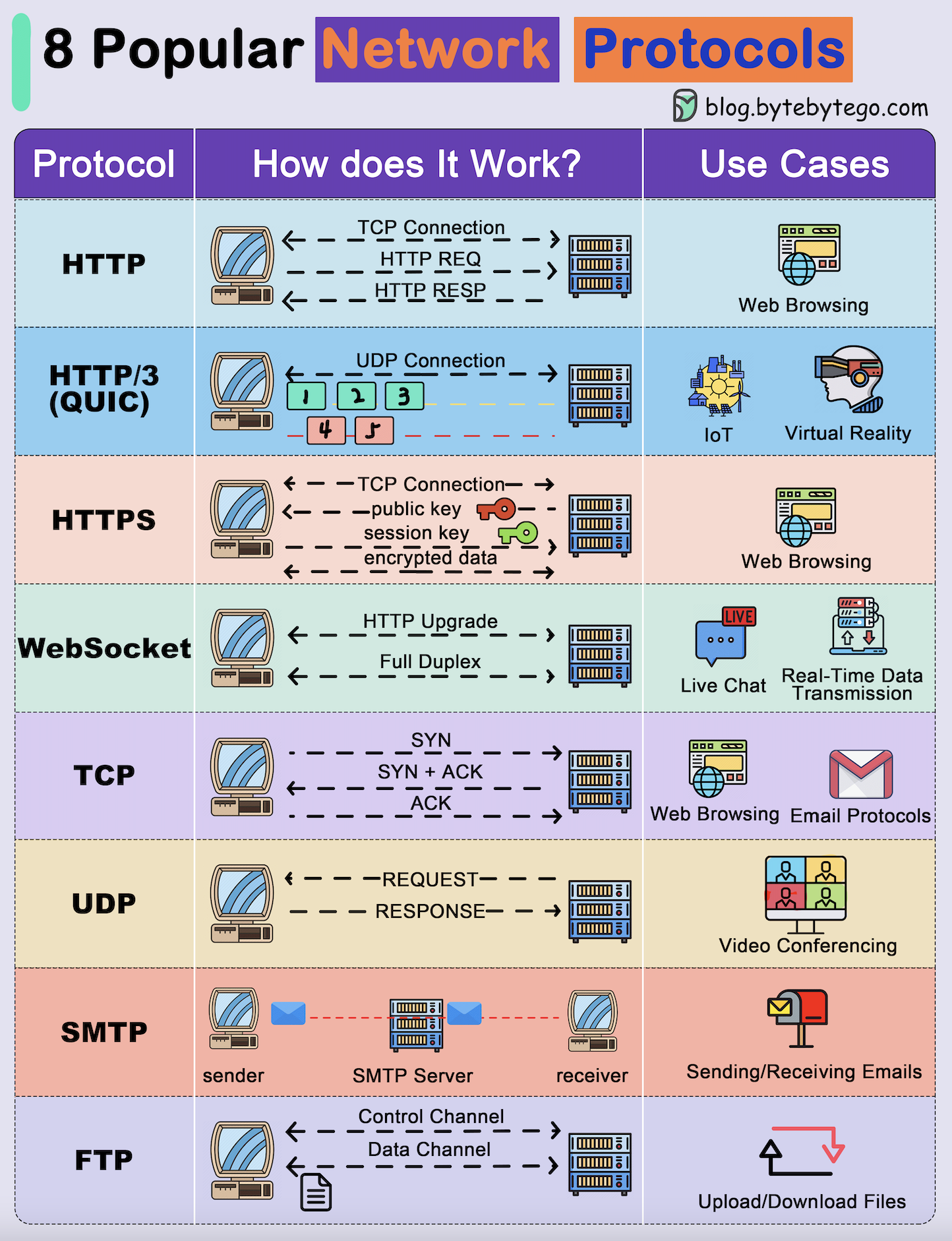
+
+## 1. HTTP (HyperText Transfer Protocol)
+
+HTTP is a protocol for fetching resources such as HTML documents. It is the foundation of any data exchange on the Web and it is a client-server protocol.
+
+## 2. HTTP/3
+
+HTTP/3 is the next major revision of the HTTP. It runs on QUIC, a new transport protocol designed for mobile-heavy internet usage. It relies on UDP instead of TCP, which enables faster web page responsiveness. VR applications demand more bandwidth to render intricate details of a virtual scene and will likely benefit from migrating to HTTP/3 powered by QUIC.
+
+## 3. HTTPS (HyperText Transfer Protocol Secure)
+
+HTTPS extends HTTP and uses encryption for secure communications.
+
+## 4. WebSocket
+
+WebSocket is a protocol that provides full-duplex communications over TCP. Clients establish WebSockets to receive real-time updates from the back-end services. Unlike REST, which always “pulls” data, WebSocket enables data to be “pushed”. Applications, like online gaming, stock trading, and messaging apps leverage WebSocket for real-time communication.
+
+## 5. TCP (Transmission Control Protocol)
+
+TCP is designed to send packets across the internet and ensure the successful delivery of data and messages over networks. Many application-layer protocols build on top of TCP.
+
+## 6. UDP (User Datagram Protocol)
+
+UDP sends packets directly to a target computer, without establishing a connection first. UDP is commonly used in time-sensitive communications where occasionally dropping packets is better than waiting. Voice and video traffic are often sent using this protocol.
+
+## 7. SMTP (Simple Mail Transfer Protocol)
+
+SMTP is a standard protocol to transfer electronic mail from one user to another.
+
+## 8. FTP (File Transfer Protocol)
+
+FTP is used to transfer computer files between client and server. It has separate connections for the control channel and data channel.
diff --git a/data/guides/explaining-9-types-of-api-testing.md b/data/guides/explaining-9-types-of-api-testing.md
new file mode 100644
index 0000000..dfb7630
--- /dev/null
+++ b/data/guides/explaining-9-types-of-api-testing.md
@@ -0,0 +1,34 @@
+---
+title: 'Explaining 9 Types of API Testing'
+description: 'Learn about 9 different types of API testing with detailed explanations.'
+image: 'https://assets.bytebytego.com/diagrams/0017-9-types-of-api-testing.png'
+createdAt: '2024-03-10'
+draft: false
+categories:
+ - api-web-development
+ - software-development
+tags:
+ - API Testing
+ - Software Testing
+---
+
+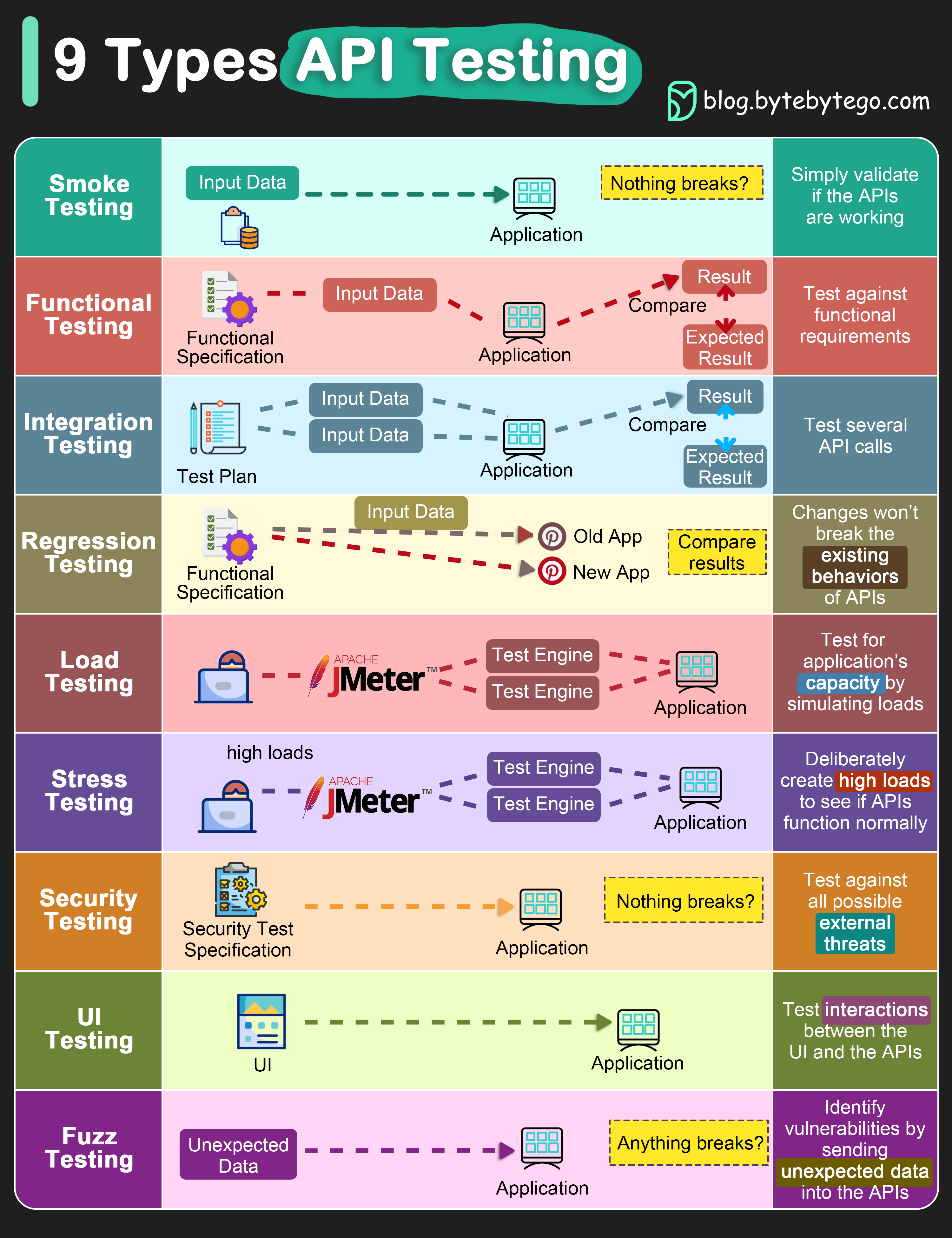
+
+* **Smoke Testing**
+ This is done after API development is complete. Simply validate if the APIs are working and nothing breaks.
+* **Functional Testing**
+ This creates a test plan based on the functional requirements and compares the results with the expected results.
+* **Integration Testing**
+ This test combines several API calls to perform end-to-end tests. The intra-service communications and data transmissions are tested.
+* **Regression Testing**
+ This test ensures that bug fixes or new features shouldn’t break the existing behaviors of APIs.
+* **Load Testing**
+ This tests applications’ performance by simulating different loads. Then we can calculate the capacity of the application.
+* **Stress Testing**
+ We deliberately create high loads to the APIs and test if the APIs are able to function normally.
+* **Security Testing**
+ This tests the APIs against all possible external threats.
+* **UI Testing**
+ This tests the UI interactions with the APIs to make sure the data can be displayed properly.
+* **Fuzz Testing**
+ This injects invalid or unexpected input data into the API and tries to crash the API. In this way, it identifies the API vulnerabilities.
diff --git a/data/guides/explaining-json-web-token-jwt-to-a-10-year-old-kid.md b/data/guides/explaining-json-web-token-jwt-to-a-10-year-old-kid.md
new file mode 100644
index 0000000..2e9fa9a
--- /dev/null
+++ b/data/guides/explaining-json-web-token-jwt-to-a-10-year-old-kid.md
@@ -0,0 +1,24 @@
+---
+title: "Explaining JSON Web Token (JWT) to a 10 Year Old Kid"
+description: "Explaining JSON Web Token (JWT) in simple terms for kids."
+image: "https://assets.bytebytego.com/diagrams/0107-explaining-json-web-token-jwt-to-a-10-year-old-kid.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - security
+tags:
+ - "JWT"
+ - "Security"
+---
+
+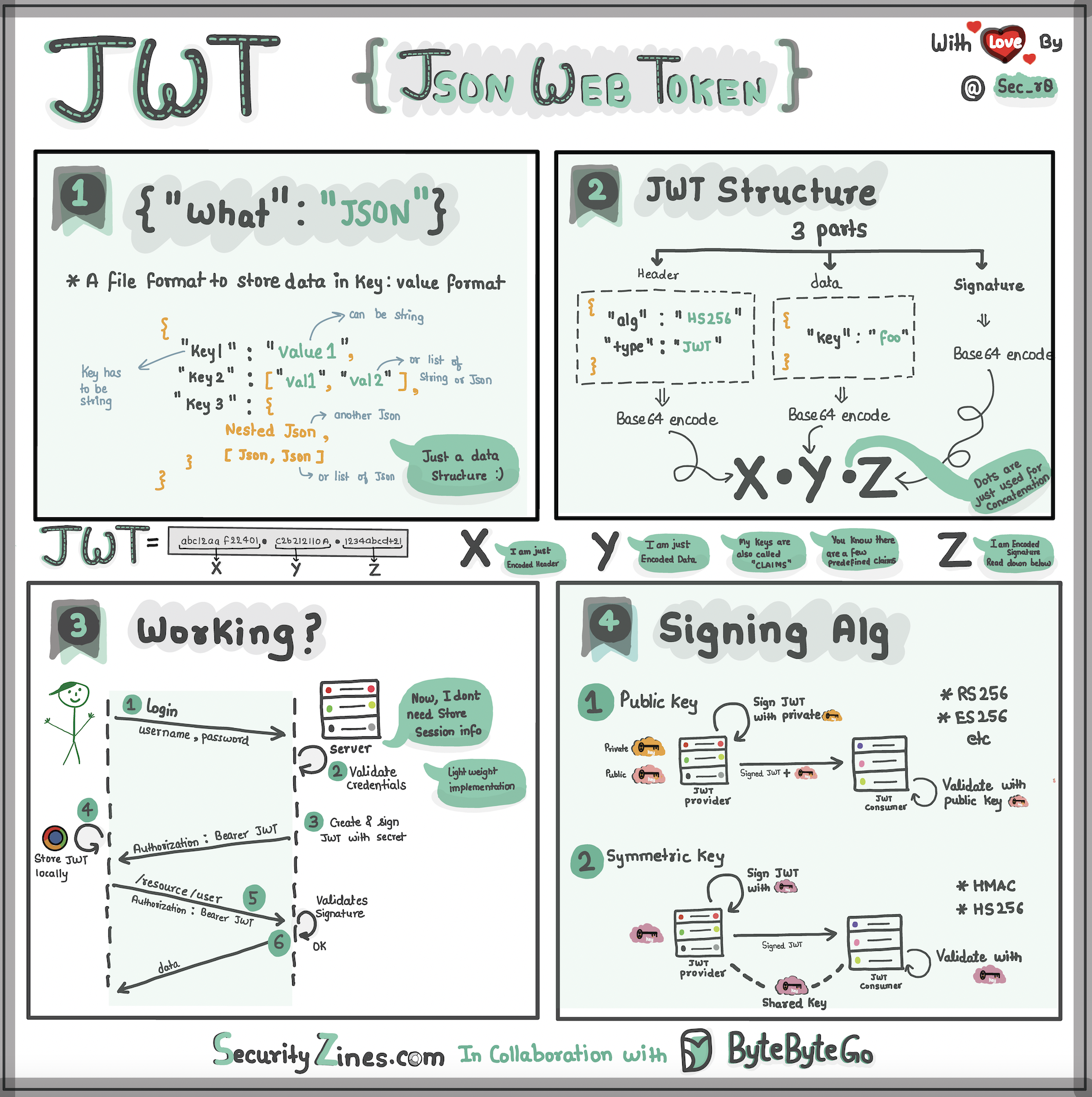
+
+Imagine you have a special box called a JWT. Inside this box, there are three parts: a header, a payload, and a signature.
+
+The header is like the label on the outside of the box. It tells us what type of box it is and how it's secured. It's usually written in a format called JSON, which is just a way to organize information using curly braces { } and colons :
+
+The payload is like the actual message or information you want to send. It could be your name, age, or any other data you want to share. It's also written in JSON format, so it's easy to understand and work with.
+
+Now, the signature is what makes the JWT secure. It's like a special seal that only the sender knows how to create. The signature is created using a secret code, kind of like a password. This signature ensures that nobody can tamper with the contents of the JWT without the sender knowing about it.
+
+When you want to send the JWT to a server, you put the header, payload, and signature inside the box. Then you send it over to the server. The server can easily read the header and payload to understand who you are and what you want to do.
diff --git a/data/guides/explaining-sessions-tokens-jwt-sso-and-oauth-in-one-diagram.md b/data/guides/explaining-sessions-tokens-jwt-sso-and-oauth-in-one-diagram.md
new file mode 100644
index 0000000..4f23b46
--- /dev/null
+++ b/data/guides/explaining-sessions-tokens-jwt-sso-and-oauth-in-one-diagram.md
@@ -0,0 +1,18 @@
+---
+title: "Sessions, Tokens, JWT, SSO, and OAuth Explained"
+description: "Understanding sessions, tokens, JWT, SSO, and OAuth concepts."
+image: "https://assets.bytebytego.com/diagrams/0330-session-square.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - security
+tags:
+ - Authentication
+ - Authorization
+---
+
+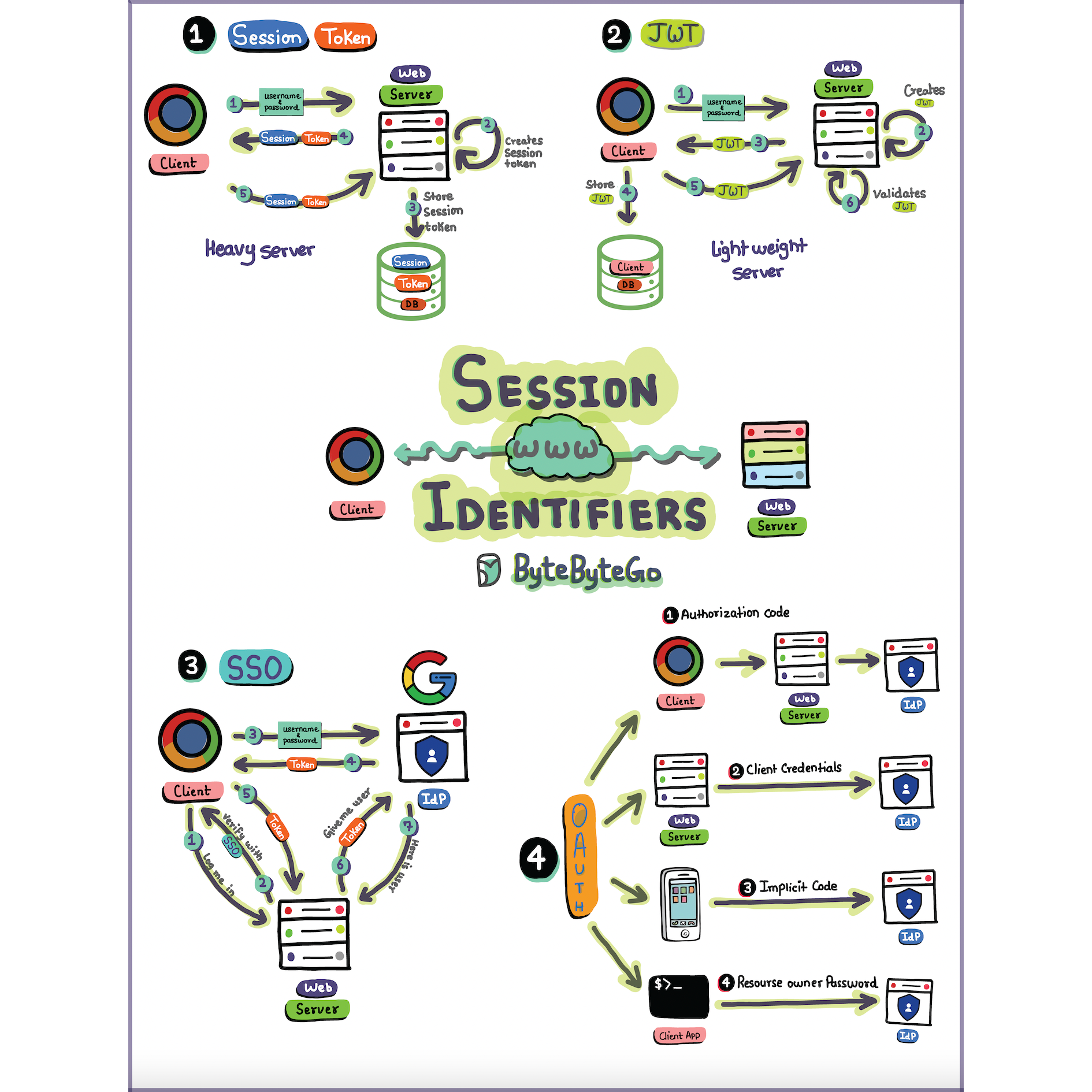
+
+Understanding these backstage maneuvers helps us build secure, seamless experiences.
+
+How do you see the evolution of web session management impacting the future of web applications and user experiences?
diff --git a/data/guides/explaining-the-4-most-commonly-used-types-of-queues-in-a-single-diagram.md b/data/guides/explaining-the-4-most-commonly-used-types-of-queues-in-a-single-diagram.md
new file mode 100644
index 0000000..9f5fab2
--- /dev/null
+++ b/data/guides/explaining-the-4-most-commonly-used-types-of-queues-in-a-single-diagram.md
@@ -0,0 +1,38 @@
+---
+title: "Explaining the 4 Most Commonly Used Types of Queues"
+description: "Learn about the 4 most commonly used types of queues in a single diagram"
+image: "https://assets.bytebytego.com/diagrams/0366-types-of-queues.png"
+createdAt: "2024-02-06"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Structures"
+ - "Queues"
+---
+
+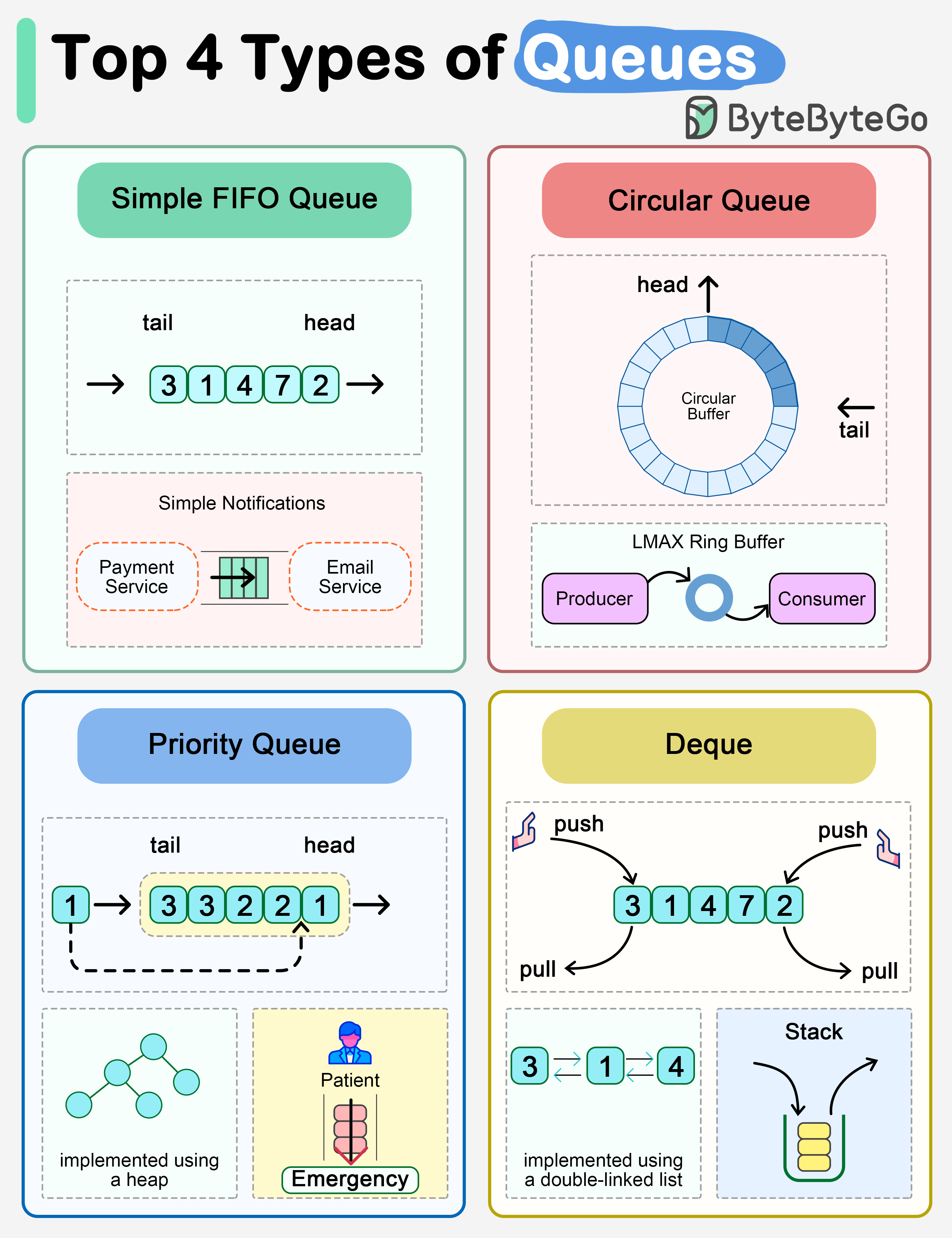
+
+Queues are popular data structures used widely in the system. The diagram above shows 4 different types of queues we often use.
+
+## Simple FIFO Queue
+
+A simple queue follows FIFO (First In First Out). A new element is inserted at the tail of the queue, and an element is removed from the head of the queue.
+
+If we would like to send out email notifications to the users whenever we receive a payment response, we can use a FIFO queue. The emails will be sent out in the same order as the payment responses.
+
+## Circular Queue
+
+A circular queue is also called a circular buffer or a ring buffer. Its last element is linked to the first element. Insertion takes place at the front of the queue and deletion at the end of the queue.
+
+A famous implementation is LMAX’s low-latency ring buffer. Trading components talk to each other via a ring buffer. This is implemented in memory and super fast.
+
+## Priority Queue
+
+The elements in a priority queue have predefined priorities. We take the element with the highest (or lowest) priority from the queue. Under the hood, it is implemented using a max heap or a min heap where the element with the largest or lowest priority is at the root of the heap.
+
+A typical use case is assigning patients with the highest severity to the emergency room while others to the regular rooms.
+
+## Deque
+
+Deque is also called double-ended queue. The insertion and deletion can happen at both the head and the tail. Deque supports both FIFO and LIFO (Last In First Out), so we can use it to implement a stack data structure.
diff --git a/data/guides/firewall-explained-to-kids-and-adults.md b/data/guides/firewall-explained-to-kids-and-adults.md
new file mode 100644
index 0000000..55c8d51
--- /dev/null
+++ b/data/guides/firewall-explained-to-kids-and-adults.md
@@ -0,0 +1,44 @@
+---
+title: "Firewall Explained to Kids and Adults"
+description: "Learn about firewalls: network security, types, and how they protect us."
+image: "https://assets.bytebytego.com/diagrams/0191-firewall.jpeg"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - security
+tags:
+ - "Network Security"
+ - "Firewall"
+---
+
+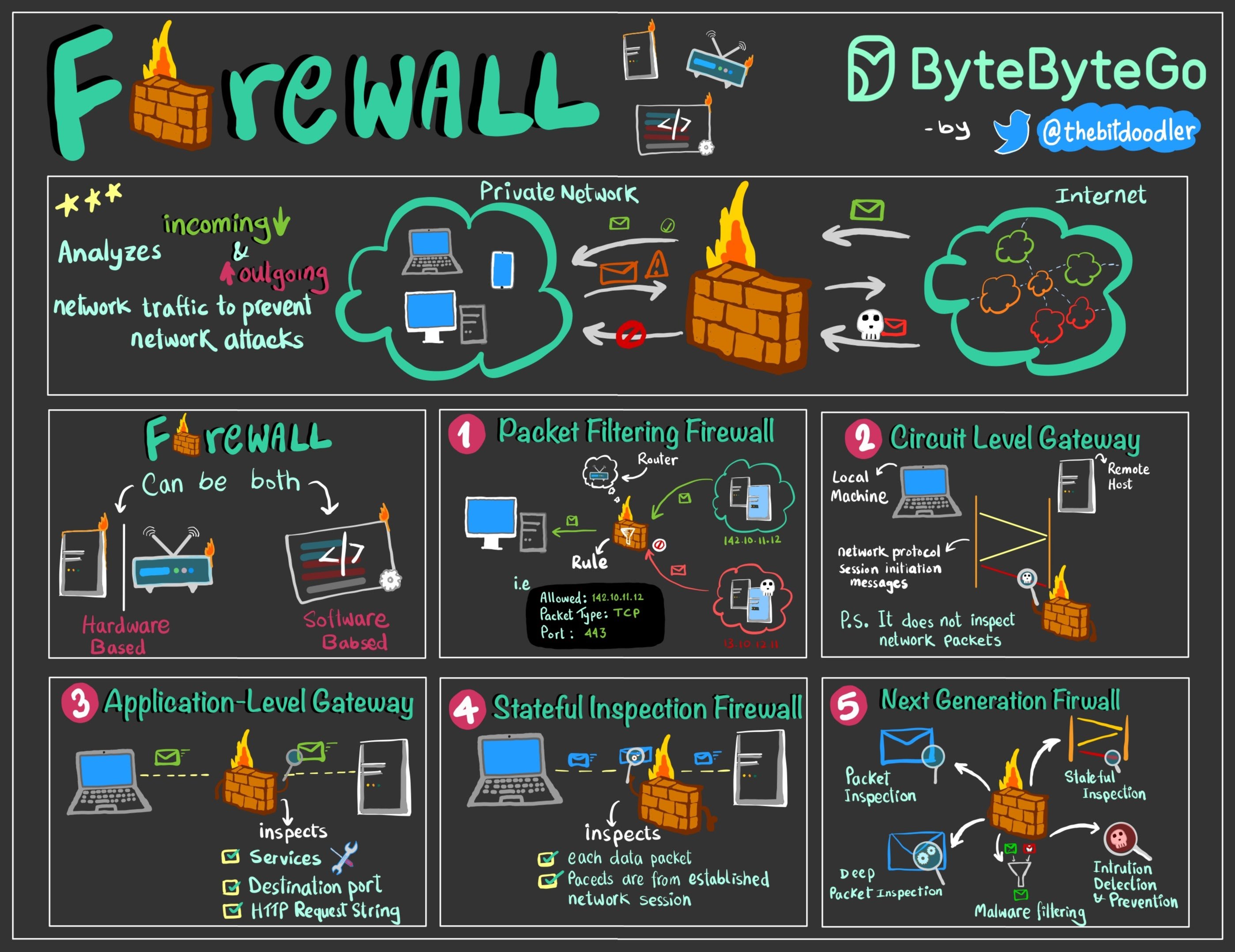
+
+A firewall is a network security system that controls and filters network traffic, acting as a watchman between a private network and the public Internet.
+
+They come in two broad categories:
+
+* Software-based: installed on individual devices for protection
+
+* Hardware-based: stand-alone devices that safeguard an entire network.
+
+Firewalls have several types, each designed for specific security needs:
+
+### Packet Filtering Firewalls
+
+Examines packets of data, accepting or rejecting based on source, destination, or protocols.
+
+### Circuit-level Gateways
+
+Monitors TCP handshake between packets to determine session legitimacy.
+
+### Application-level Gateways (Proxy Firewalls)
+
+Filters incoming traffic between your network and traffic source, offering a protective shield against untrusted networks.
+
+### Stateful Inspection Firewalls
+
+Tracks active connections to determine which packets to allow, analyzing in the context of their place in a data stream.
+
+### Next-Generation Firewalls (NGFWs)
+
+Advanced firewalls that integrate traditional methods with functionalities like intrusion prevention systems, deep packet analysis, and application awareness.
diff --git a/data/guides/fixing-bugs-automatically-at-meta-scale.md b/data/guides/fixing-bugs-automatically-at-meta-scale.md
new file mode 100644
index 0000000..1c93c47
--- /dev/null
+++ b/data/guides/fixing-bugs-automatically-at-meta-scale.md
@@ -0,0 +1,39 @@
+---
+title: Fixing Bugs Automatically at Meta Scale
+description: Meta's approach to automated bug fixing at scale using SapFix.
+image: 'https://assets.bytebytego.com/diagrams/0193-fixing-bugs-automatically-at-meta-scale.png'
+createdAt: '2024-02-16'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Automation
+ - Debugging
+---
+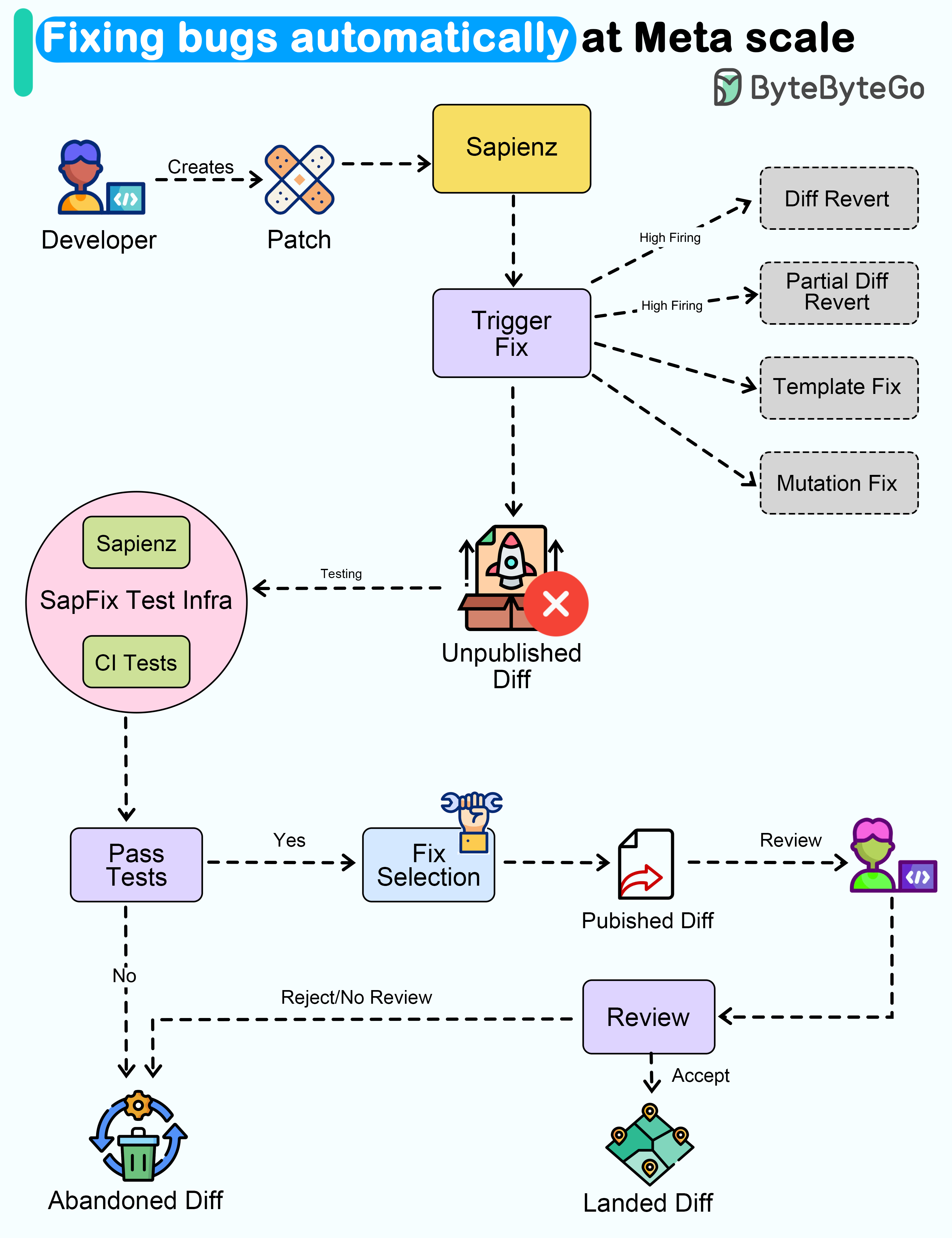
+
+Wouldn't it be nice if a system could automatically detect and fix bugs for us?
+
+Meta released a paper about how they automated end-to-end repair at the Facebook scale. Let's take a closer look.
+
+The goal of a tool called SapFix is to simplify debugging by automatically generating fixes for specific issues.
+
+How successful has SapFix been?
+
+Here are some details that have been made available:
+
+* Used on six key apps in the Facebook app family (Facebook, Messenger, Instagram, FBLite, Workplace and Workchat). Each app consists of tens of millions of lines of code
+
+* It generated 165 patches for 57 crashes in a 90-day pilot phase
+
+* The median time from fault detection to fix sent for human approval was 69 minutes.
+
+Here’s how SapFix actually works:
+
+1. Developers submit changes for review using Phabricator (Facebook’s CI system)
+2. SapFix selects appropriate test cases from Sapienz (Facebook’s automated test case design system) and executes them on the Diff submitted for review
+3. When SapFix detects a crash due to the Diff, it tries to generate potential fixes. There are 4 types of fixes - template, mutation, full revert and partial revert.
+4. For generating a fix, SapFix runs tests on the patched builds and checks what works. Think of it like solving a puzzle by trying out different pieces.
+5. Once the patches are tested, SapFix selects a candidate patch and sends it to a human reviewer for review through Phabricator.
+6. The primary reviewer is the developer who raised the change that caused the crash. This developer often has the best technical context. Other engineers are also subscribed to the proposed Diff.
+7. The developer can accept the patch proposed by SapFix. However, the developer can also reject the fix and discard it.
diff --git a/data/guides/foreign-exchange-payments.md b/data/guides/foreign-exchange-payments.md
new file mode 100644
index 0000000..6aac661
--- /dev/null
+++ b/data/guides/foreign-exchange-payments.md
@@ -0,0 +1,35 @@
+---
+title: "Foreign Exchange Payments"
+description: "Learn how foreign exchange payments work when buying/selling internationally."
+image: "https://assets.bytebytego.com/diagrams/0194-foreign-exchange.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Foreign Exchange"
+---
+
+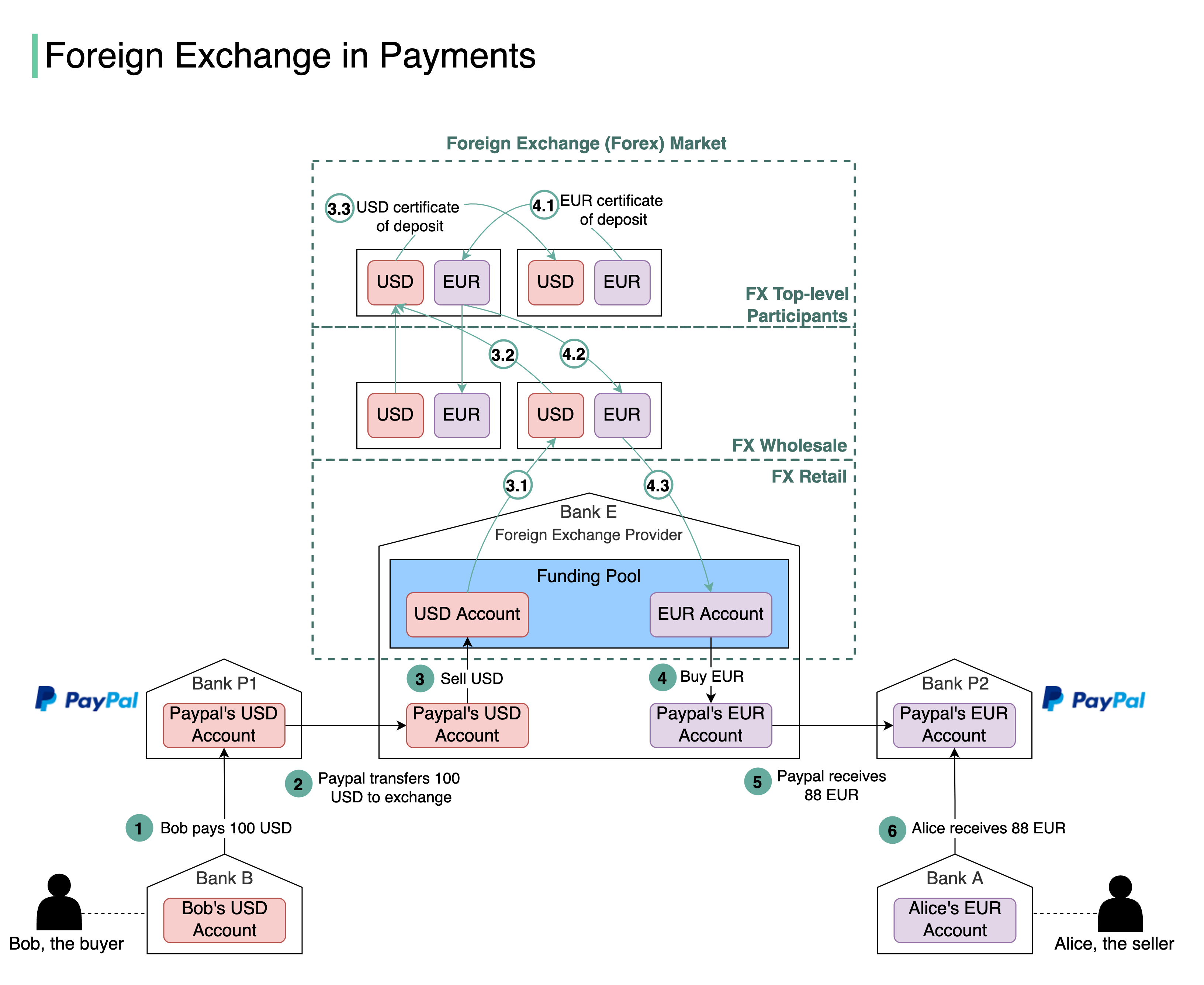
+
+The buyer pays in USD, and the European seller receives euros. How does this work?
+
+This process is called foreign exchange.
+
+Suppose Bob (the buyer) needs to pay 100 USD to Alice (the seller), and Alice can only receive EUR. The diagram above illustrates the process.
+
+1. Bob sends 100 USD via a third-party payment provider. In our example, it is Paypal. The money is transferred from Bob’s bank account (Bank B) to Paypal’s account in Bank P1.
+2. Paypal needs to convert USD to EUR. It leverages the foreign exchange provider (Bank E). Paypal sends 100 USD to its USD account in Bank E.
+3. 100 USD is sold to Bank E’s funding pool.
+4. Bank E’s funding pool provides 88 EUR in exchange for 100 USD. The money is put into Paypal’s EUR account in Bank E.
+5. Paypal’s EUR account in Bank P2 receives 88 EUR.
+6. 88 EUR is paid to Alice’s EUR account in Bank A.
+
+Now let’s take a close look at the foreign exchange (forex) market. It has 3 layers:
+
+* Retail market. Funding pools are parts of the retail market. To improve efficiency, Paypal usually buys a certain amount of foreign currencies in advance.
+* Wholesale market. The wholesale business is composed of investment banks, commercial banks, and foreign exchange providers. It usually handles accumulated orders from the retail market.
+* Top-level participants. They are multinational commercial banks that hold lots of money from different countries.
+
+When Bank E’s funding pool needs more EUR, it goes upward to the wholesale market to sell USD and buy EUR. When the wholesale market accumulates enough orders, it goes upward to top-level participants. Steps 3.1-3.3 and 4.1-4.3 explain how it works.
diff --git a/data/guides/git-commands-cheat-sheet.md b/data/guides/git-commands-cheat-sheet.md
new file mode 100644
index 0000000..73b46ff
--- /dev/null
+++ b/data/guides/git-commands-cheat-sheet.md
@@ -0,0 +1,60 @@
+---
+title: "Git Commands Cheat Sheet"
+description: "A handy guide to essential Git commands for developers."
+image: "https://assets.bytebytego.com/diagrams/0201-git-commands-cheat-sheet.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Git
+ - Version Control
+---
+
+
+
+## Getting Started
+
+* **git init**: Initializes a new Git repository.
+
+* **git clone [url]**: Clones a repository from a remote URL.
+
+## Making Changes
+
+* **git add [file]**: Adds a file to the staging area.
+
+* **git commit -m "[message]"**: Commits changes with a descriptive message.
+
+* **git status**: Shows the status of the working directory.
+
+* **git diff**: Shows the differences between the working directory and the staging area.
+
+## Branching and Merging
+
+* **git branch**: Lists all local branches.
+
+* **git branch [branch-name]**: Creates a new branch.
+
+* **git checkout [branch-name]**: Switches to the specified branch.
+
+* **git merge [branch-name]**: Merges the specified branch into the current branch.
+
+* **git branch -d [branch-name]**: Deletes the specified branch.
+
+## Remote Repositories
+
+* **git remote add origin [url]**: Adds a remote repository.
+
+* **git push origin [branch-name]**: Pushes changes to the remote repository.
+
+* **git pull origin [branch-name]**: Pulls changes from the remote repository.
+
+* **git fetch**: Fetches changes from the remote repository without merging.
+
+## Undoing Changes
+
+* **git reset [file]**: Unstages a file.
+
+* **git checkout -- [file]**: Discards changes to a file.
+
+* **git revert [commit]**: Creates a new commit that undoes the changes from the specified commit.
diff --git a/data/guides/git-merge-vs-git-rebate.md b/data/guides/git-merge-vs-git-rebate.md
new file mode 100644
index 0000000..ae20ed3
--- /dev/null
+++ b/data/guides/git-merge-vs-git-rebate.md
@@ -0,0 +1,36 @@
+---
+title: "Git Merge vs. Git Rebase"
+description: "Understand the difference between Git merge and Git rebase commands."
+image: "https://assets.bytebytego.com/diagrams/0203-git-merge-git-rebase.jpg"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Git
+ - Version Control
+---
+
+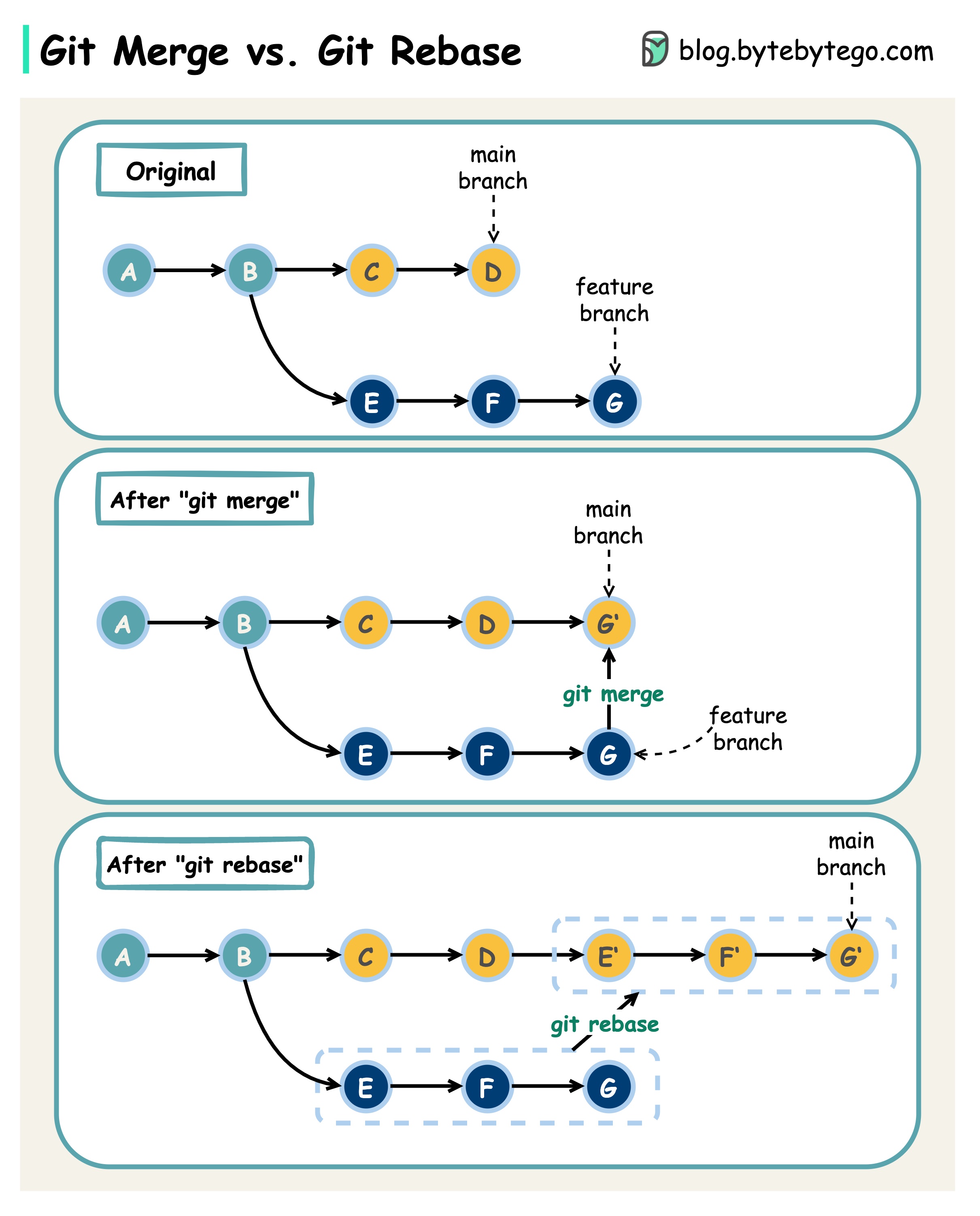
+
+What are the differences?
+
+When we 𝐦𝐞𝐫𝐠𝐞 𝐜𝐡𝐚𝐧𝐠𝐞𝐬 from one Git branch to another, we can use ‘git merge’ or ‘git rebase’. The diagram below shows how the two commands work.
+
+## Git Merge
+
+This creates a new commit G’ in the main branch. G’ ties the histories of both main and feature branches.
+
+Git merge is 𝐧𝐨𝐧-𝐝𝐞𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐯𝐞. Neither the main nor the feature branch is changed.
+
+## Git Rebase
+
+Git rebase moves the feature branch histories to the head of the main branch. It creates new commits E’, F’, and G’ for each commit in the feature branch.
+
+The benefit of rebase is that it has 𝐥𝐢𝐧𝐞𝐚𝐫 𝐜𝐨𝐦𝐦𝐢𝐭 𝐡𝐢𝐬𝐭𝐨𝐫𝐲.
+
+Rebase can be dangerous if “the golden rule of git rebase” is not followed.
+
+## The Golden Rule of Git Rebase
+
+Never use it on public branches!
diff --git a/data/guides/git-vs-github.md b/data/guides/git-vs-github.md
new file mode 100644
index 0000000..00c4028
--- /dev/null
+++ b/data/guides/git-vs-github.md
@@ -0,0 +1,36 @@
+---
+title: "Git vs GitHub"
+description: "Explore the differences between Git and GitHub for version control."
+image: "https://assets.bytebytego.com/diagrams/0204-git-vs-github.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Version Control
+ - Git
+---
+
+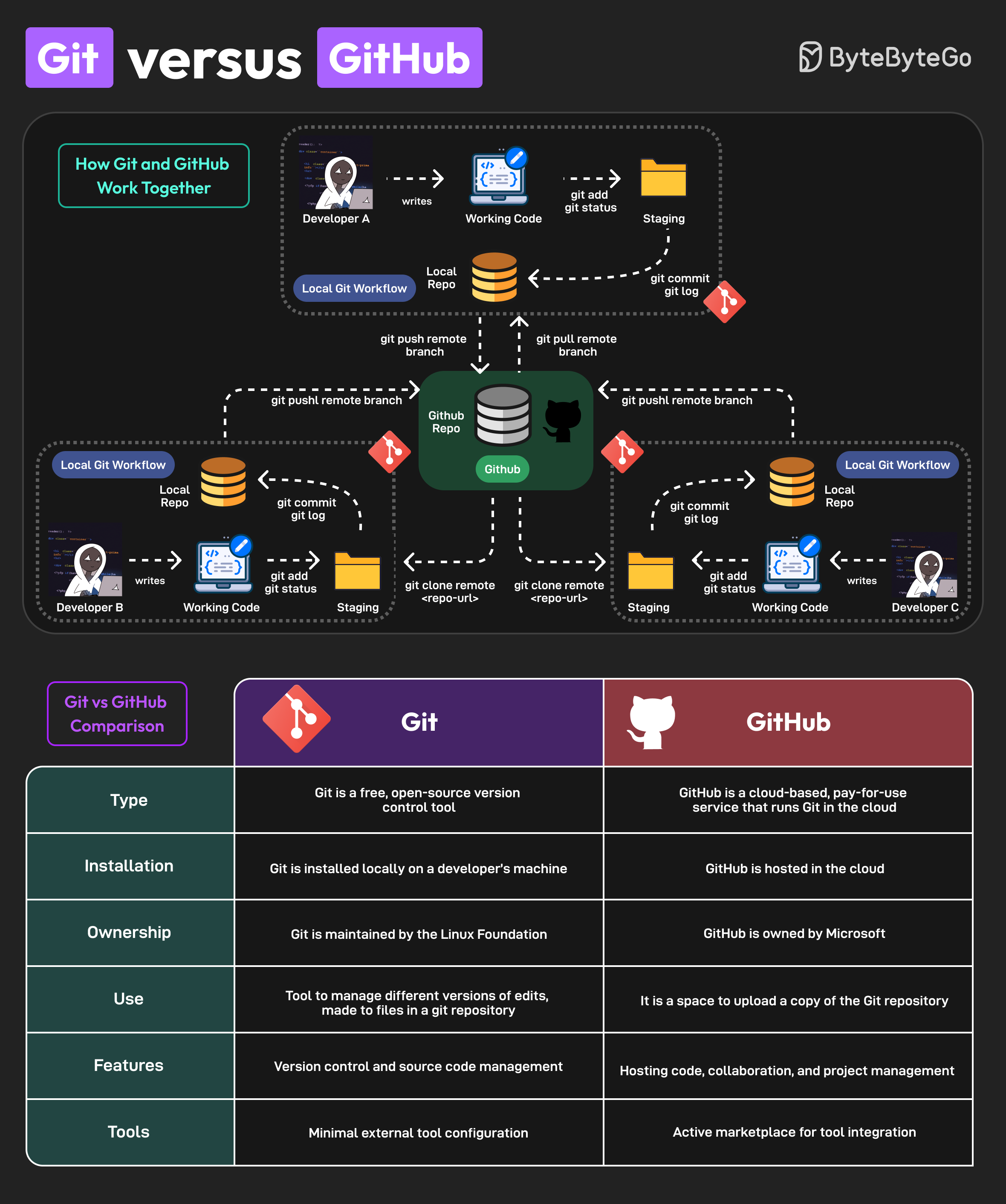
+
+Git and GitHub are popular tools for version control. They work together and complement each other to provide effective source control management.
+
+On a high level, Git is focused on version control and code sharing, whereas GitHub is focused on centralized source code hosting for sharing with other developers.
+
+However, they have some key differences
+
+## Key Differences
+
+* Git is a free, open-source version control tool. GitHub is a cloud-based, pay-for-use service that runs Git in the cloud.
+
+* Git is installed locally on a developer’s machine. GitHub is hosted in the cloud.
+
+* The Linux Foundation maintains Git. Microsoft owns GitHub.
+
+* Git can manage different versions of edits, made to files in a git repository. GitHub is a space to upload a copy of the Git repository.
+
+* Git supports version control and source code management. GitHub can be used for hosting code, collaboration, and project management.
+
+* Git has minimal external tool configuration. GitHub provides an active marketplace for tool integration.
+
+Lastly, you can use Git without GitHub but you cannot use GitHub without Git.
diff --git a/data/guides/git-workflow.md b/data/guides/git-workflow.md
new file mode 100644
index 0000000..e22db1c
--- /dev/null
+++ b/data/guides/git-workflow.md
@@ -0,0 +1,18 @@
+---
+title: "How does Git Work?"
+description: "A handy guide to learning how does Git work."
+image: "https://assets.bytebytego.com/diagrams/0205-git-workflow.jpg"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Git
+ - Version Control
+---
+
+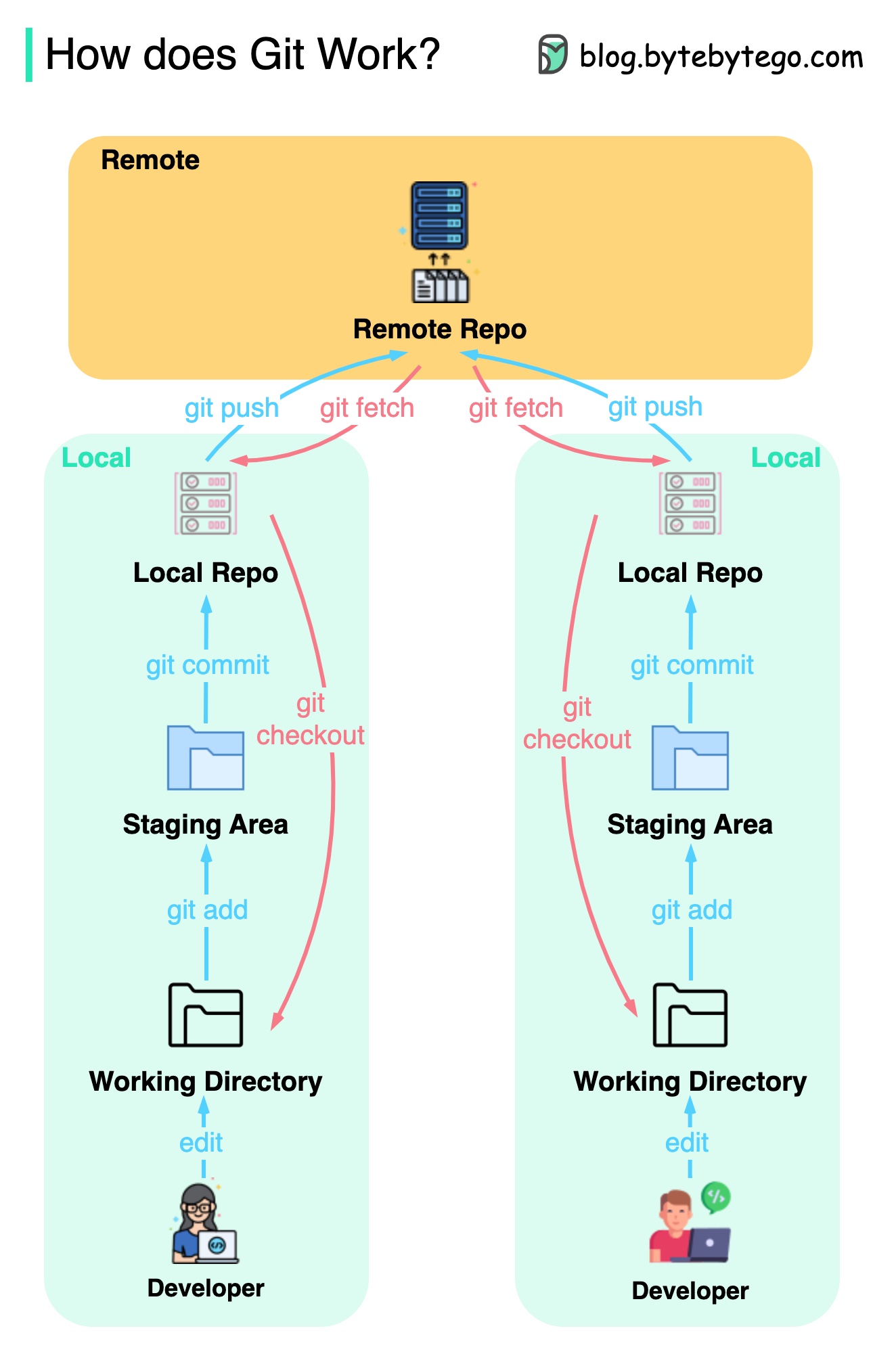
+
+Git is a distributed version control system that allows multiple developers to work on the same project simultaneously. It is widely used in software development to manage source code history.
+
+The diagram above shows the Git workflow with common commands.
\ No newline at end of file
diff --git a/data/guides/graphql-adoption-patterns.md b/data/guides/graphql-adoption-patterns.md
new file mode 100644
index 0000000..c6f5bf3
--- /dev/null
+++ b/data/guides/graphql-adoption-patterns.md
@@ -0,0 +1,39 @@
+---
+title: 'GraphQL Adoption Patterns'
+description: 'Explore 4 popular GraphQL adoption patterns for your team.'
+image: 'https://assets.bytebytego.com/diagrams/0208-graphql-adoption-patterns.png'
+createdAt: '2024-02-13'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - GraphQL
+ - API
+---
+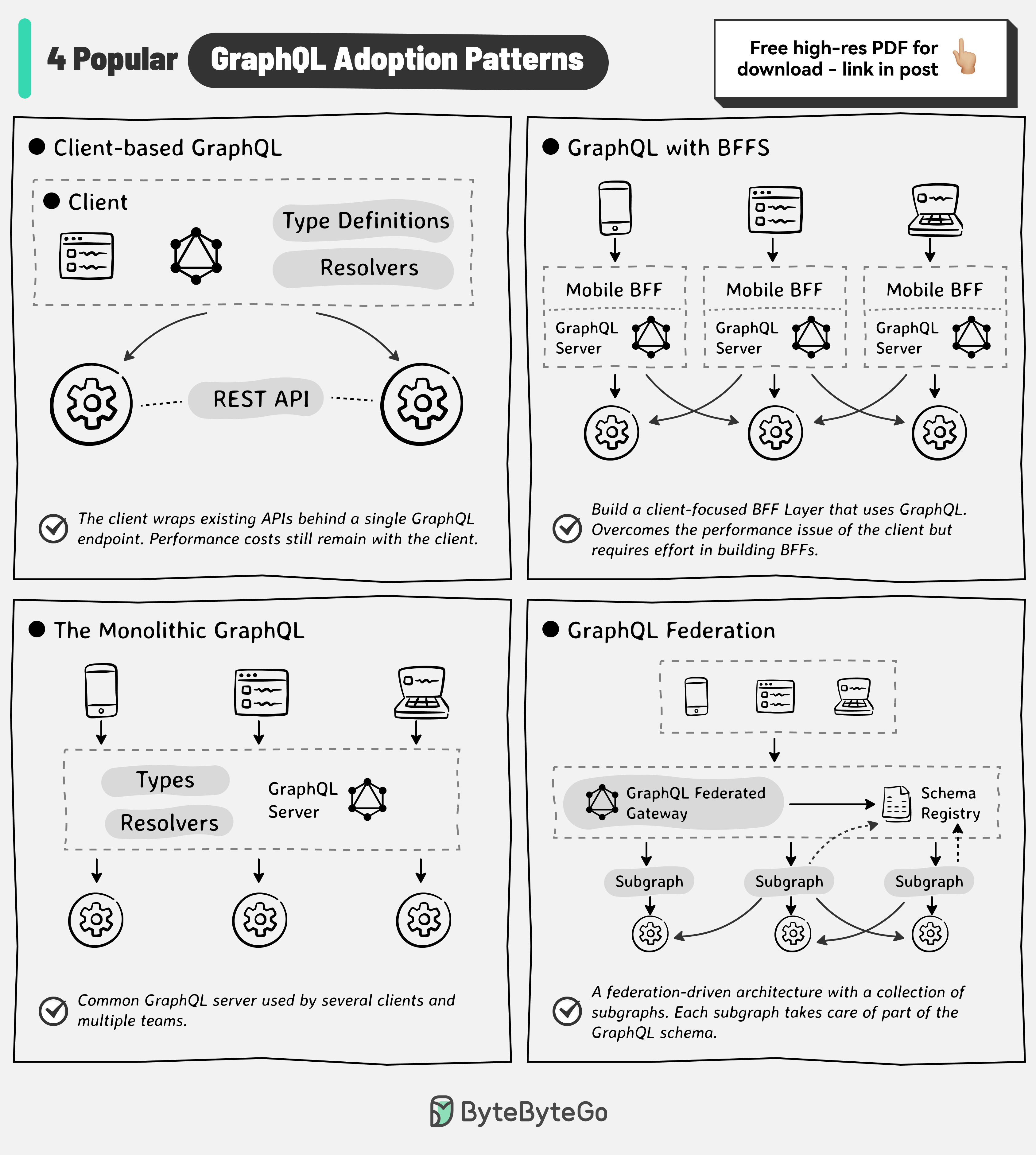
+
+Typically, teams begin their GraphQL journey with a basic architecture where a client application queries a single GraphQL server.
+
+However, multiple patterns are available:
+
+* **Client-based GraphQL**
+
+ The client wraps existing APIs behind a single GraphQL endpoint. This approach improves the developer experience but the client still bears the performance costs of aggregating data.
+
+* **GraphQL with BFFs**
+
+ BFF or Backend-for-Frontends adds a new layer where each client has a dedicated BFF service. GraphQL is a natural fit to build a client-focused intermediary layer.
+
+ Performance and developer experience for the clients is improved but there’s a tradeoff in building and maintaining BFFs.
+
+* **The Monolithic GraphQL**
+
+ Multiple teams share one codebase for a GraphQL server used by several clients. Also, a single team owns a GraphQL API that is accessed by multiple client teams.
+
+* **GraphQL Federation**
+
+ This involves consolidating multiple graphs into a supergraph.
+
+ GraphQL Federated Gateway takes care of routing the requests to the downstream subgraph services that take care of a specific part of the GraphQL schema. This approach maintains ownership of data with the domain team while avoiding duplication of effort.
+
+Over to you: Which GraphQL adoption approach have you seen or used?
diff --git a/data/guides/handling-hotspot-accounts.md b/data/guides/handling-hotspot-accounts.md
new file mode 100644
index 0000000..55794a6
--- /dev/null
+++ b/data/guides/handling-hotspot-accounts.md
@@ -0,0 +1,38 @@
+---
+title: "Handling Hotspot Accounts"
+description: "Learn how to handle hotspot accounts in payment systems effectively."
+image: "https://assets.bytebytego.com/diagrams/0212-hotspot-accounts.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "Scalability"
+---
+
+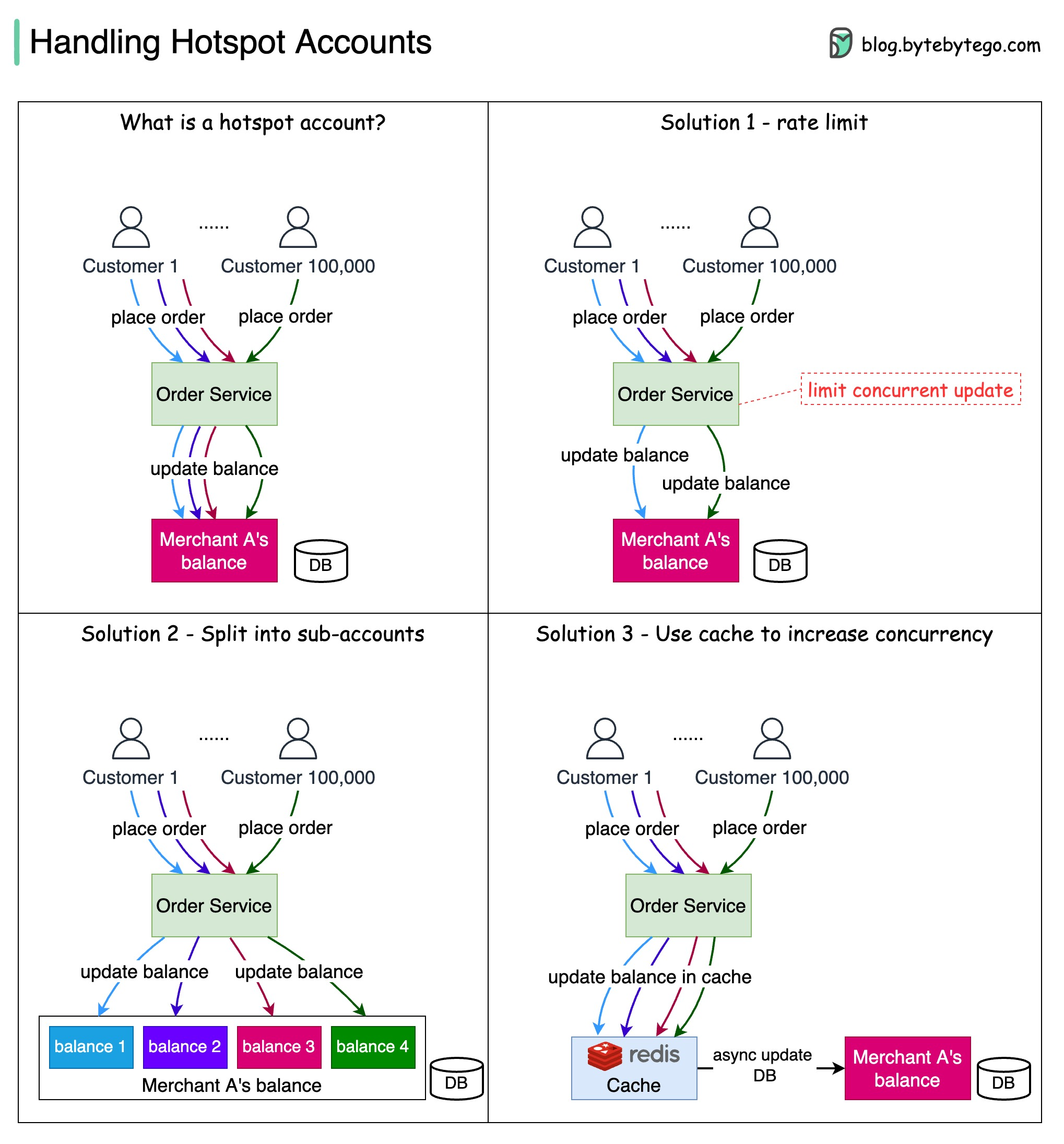
+
+Big accounts, such as Nike, Procter & Gamble & Nintendo, often cause hotspot issues for the payment system.
+
+A hotspot payment account is an account that has a large number of concurrent operations on it.
+
+For example, when merchant A starts a promotion on Amazon Prime day, it receives many concurrent purchasing orders. In this case, the merchant’s account in the database becomes a hotspot account due to frequent updates.
+
+In normal operations, we put a row lock on the merchant’s balance when it gets updated. However, this locking mechanism leads to low throughput and becomes a system bottleneck.
+
+The diagram above shows several optimizations.
+
+## Optimizations
+
+* **Rate limit**
+
+ We can limit the number of requests within a certain period. The remaining requests will be rejected or retried at a later time. It is a simple way to increase the system’s responsiveness for some users, but this can lead to a bad user experience.
+
+* **Split the balance account into sub-accounts**
+
+ We can set up sub-accounts for the merchant’s account. In this way, one update request only locks one sub-account, and the rest sub-accounts are still available.
+
+* **Use cache to update balance first**
+
+ We can set up a caching layer to update the merchant’s balance. The detailed statements and balances are updated in the database later asynchronously. The in-memory cache can deal with a much higher throughput than the database.
diff --git a/data/guides/hidden-costs-of-the-cloud.md b/data/guides/hidden-costs-of-the-cloud.md
new file mode 100644
index 0000000..58d8b04
--- /dev/null
+++ b/data/guides/hidden-costs-of-the-cloud.md
@@ -0,0 +1,38 @@
+---
+title: "Hidden Costs of the Cloud"
+description: "Uncover hidden cloud costs and learn how to avoid unexpected expenses."
+image: "https://assets.bytebytego.com/diagrams/0148-cloud-hidden-costs.png"
+createdAt: '2024-03-01'
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Cost
+ - Cost Optimization
+---
+
+While it may be inexpensive or even free to get started, the complexity often leads to hidden costs, resulting in large cloud bills.
+
+The purpose of this post is not to discourage using the cloud. I’m a big fan of the cloud. I simply want to raise awareness about this issue, as it's one of the critical topics that isn't often discussed.
+
+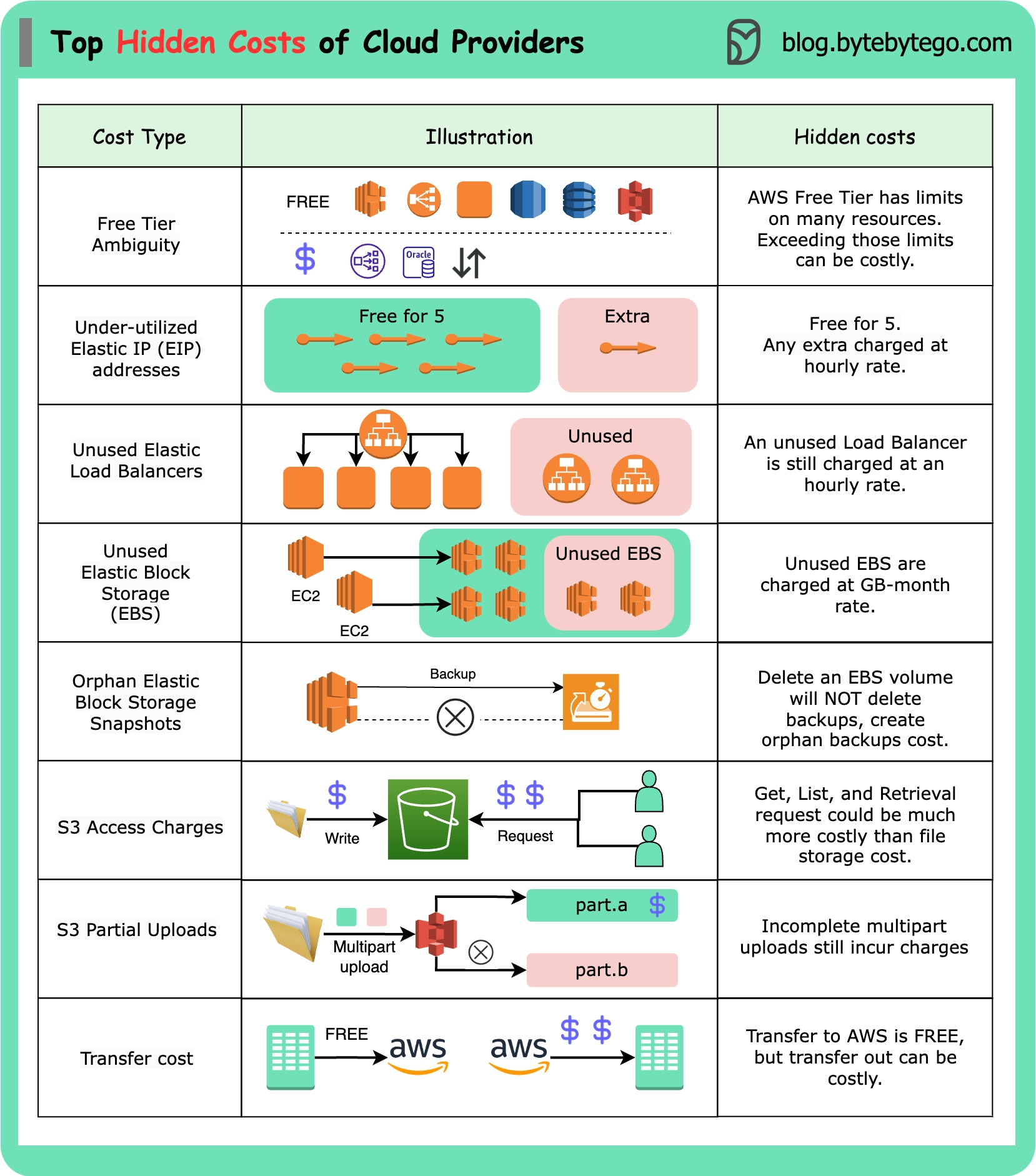
+
+While AWS is used as an example, similar cost structures apply to other cloud providers.
+
+## Hidden Cloud Costs
+
+* **Free Tier Ambiguity:** AWS offers three different types of free offerings for common services. However, services not included in the free tier can charge you. Even for services that do provide free resources, there's often a limit. Exceeding that limit can result in higher costs than anticipated.
+
+* **Elastic IP Addresses:** AWS allows up to five Elastic IP addresses. Exceeding this limit incurs a small hourly rate, which varies depending on the region. This is a recurring charge.
+
+* **Load Balancers:** They are billed hourly, even if not actively used. Furthermore, you'll face additional charges if data is transferred in and out of the load balancer.
+
+* **Elastic Block Storage (EBS) Charges:** EBS is billed on a GB-per-month basis. You will be charged for attached and unattached EBS volumes, even if they're not actively used.
+
+* **EBS Snapshots:** Deleting an EBS volume does not automatically remove the associated snapshots. Orphaned EBS snapshots will still appear on your bill.
+
+* **S3 Access Charges:** While the pricing for S3 storage is generally reasonable, the costs associated with accessing stored objects, such as GET and LIST requests, can sometimes exceed the storage costs.
+
+* **S3 Partial Uploads:** If you have an unsuccessful multipart upload in S3, you will still be billed for the successfully uploaded parts. It's essential to clean these up to avoid unnecessary costs.
+
+* **Data Transfer Costs:** Transferring data to AWS, for instance, from a data center, is free. However, transferring data out of AWS can be significantly more expensive.
diff --git a/data/guides/how-applegoogle-pay-works.md b/data/guides/how-applegoogle-pay-works.md
new file mode 100644
index 0000000..6be0af3
--- /dev/null
+++ b/data/guides/how-applegoogle-pay-works.md
@@ -0,0 +1,42 @@
+---
+title: "How do Apple Pay and Google Pay work?"
+description: "Explore the mechanics of Apple Pay and Google Pay for secure transactions."
+image: "https://assets.bytebytego.com/diagrams/0002-apple-pay.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "Mobile Payments"
+---
+
+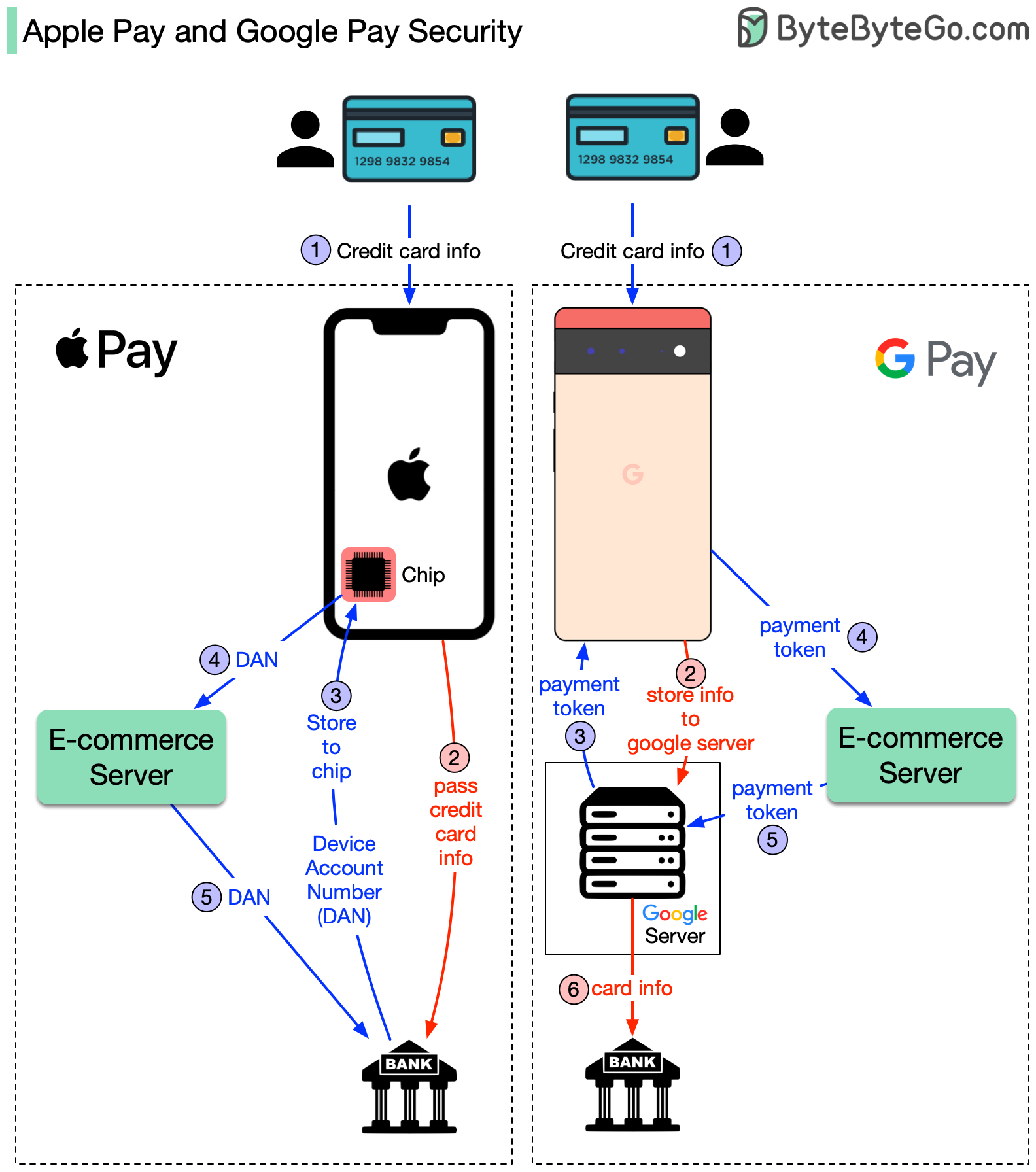
+
+The diagram above shows the differences. Both approaches are very secure, but the implementations are different. To understand the difference, we break down the process into two flows.
+
+## Registering your credit card flow
+
+## Basic payment flow
+
+1. The registration flow is represented by steps 1~3 for both cases. The difference is:
+
+* **Apple Pay:** Apple doesn’t store any card info. It passes the card info to the bank. Bank returns a token called DAN (device account number) to the iPhone. iPhone then stores DAN into a special hardware chip.
+
+* **Google Pay:** When you register the credit card with Google Pay, the card info is stored in the Google server. Google returns a payment token to the phone.
+
+2. When you click the “Pay” button on your phone, the basic payment flow starts. Here are the differences:
+
+* **Apple Pay:** For iPhone, the e-commerce server passes the DAN to the bank.
+
+* **Google Pay:** In the Google Pay case, the e-commerce server passes the payment token to the Google server. Google server looks up the credit card info and passes it to the bank.
+
+In the diagram, the red arrow means the credit card info is available on the public network, although it is encrypted.
+
+References:
+
+[1] [Apple Pay security and privacy overview](https://support.apple.com/en-us/101554)
+
+[2] [Google Pay for Payments](https://developers.google.com/pay/api/android/overview)
+
+[3] [Apple Pay vs. Google Pay: How They Work](https://www.investopedia.com/articles/personal-finance/010215/apple-pay-vs-google-wallet-how-they-work.asp)
diff --git a/data/guides/how-are-notifications-pushed-to-our-phones-or-pcs.md b/data/guides/how-are-notifications-pushed-to-our-phones-or-pcs.md
new file mode 100644
index 0000000..97f4220
--- /dev/null
+++ b/data/guides/how-are-notifications-pushed-to-our-phones-or-pcs.md
@@ -0,0 +1,32 @@
+---
+title: "How are Notifications Pushed to Our Phones or PCs?"
+description: "Learn how push notifications work on phones and PCs using FCM."
+image: "https://assets.bytebytego.com/diagrams/0309-push-notifiction.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "notifications"
+ - "mobile"
+---
+
+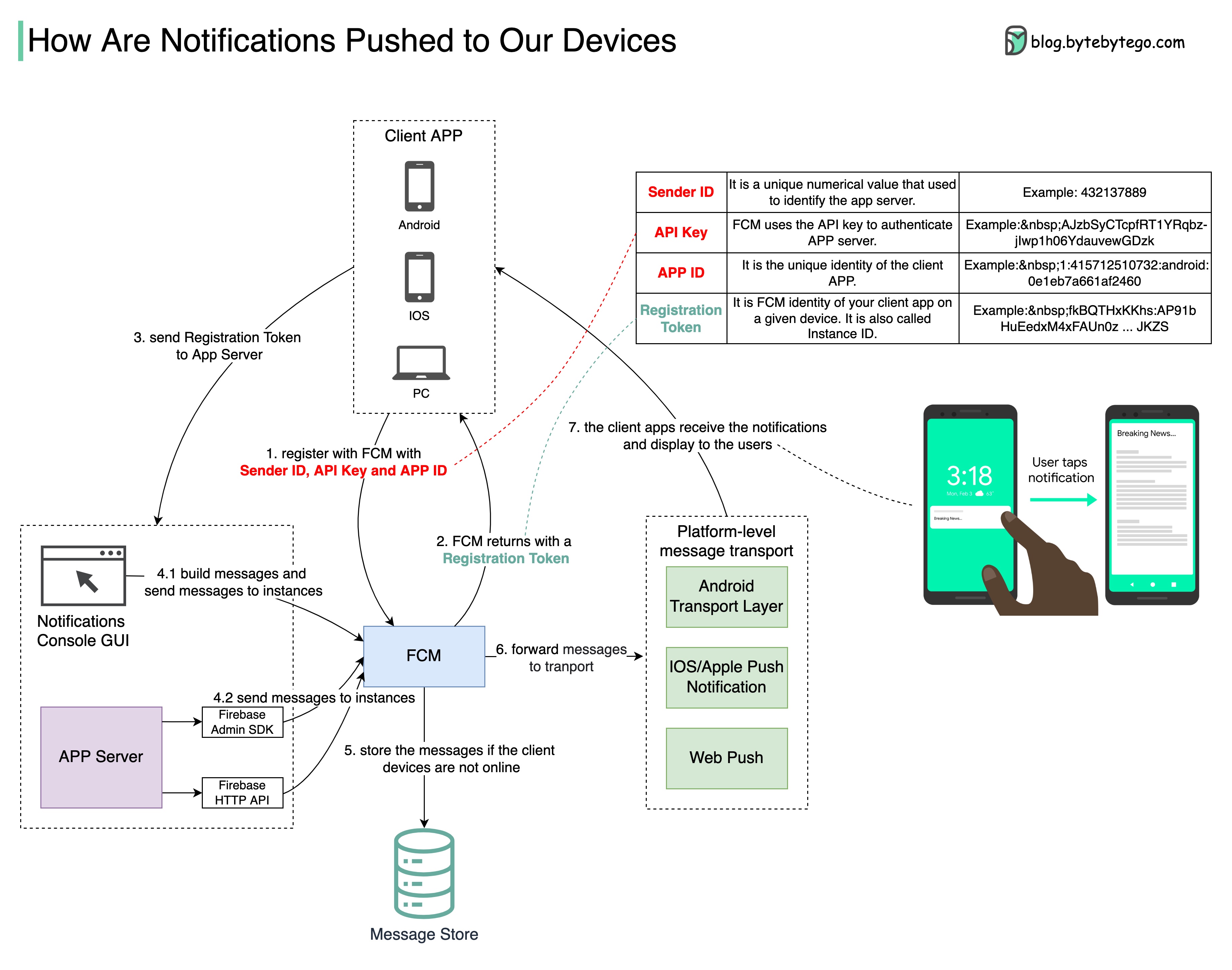
+
+A messaging solution (Firebase) can be used to support the notification push.
+
+The diagram below shows how Firebase Cloud Messaging (FCM) works.
+
+FCM is a cross-platform messaging solution that can compose, send, queue, and route notifications reliably. It provides a unified API between message senders (app servers) and receivers (client apps). The app developer can use this solution to drive user retention.
+
+Steps 1 - 2: When the client app starts for the first time, the client app sends credentials to FCM, including Sender ID, API Key, and App ID. FCM generates Registration Token for the client app instance (so the Registration Token is also called Instance ID). This token must be included in the notifications.
+
+Step 3: The client app sends the Registration Token to the app server. The app server caches the token for subsequent communications. Over time, the app server has too many tokens to maintain, so the recommended practice is to store the token with timestamps and to remove stale tokens from time to time.
+
+Step 4: There are two ways to send messages. One is to compose messages directly in the console GUI (Step 4.1,) and the other is to send the messages from the app server (Step 4.2.) We can use the Firebase Admin SDK or HTTP for the latter.
+
+Step 5: FCM receives the messages, and queues the messages in the storage if the devices are not online.
+
+Step 6: FCM forwards the messages to platform-level transport. This transport layer handles platform-specific configurations.
+
+Step 7: The messages are routed to the targeted devices. The notifications can be displayed according to the configurations sent from the app server.
diff --git a/data/guides/how-can-cache-systems-go-wrong.md b/data/guides/how-can-cache-systems-go-wrong.md
new file mode 100644
index 0000000..1725eda
--- /dev/null
+++ b/data/guides/how-can-cache-systems-go-wrong.md
@@ -0,0 +1,44 @@
+---
+title: "How Can Cache Systems Go Wrong?"
+description: "Explore common cache pitfalls and effective mitigation strategies."
+image: "https://assets.bytebytego.com/diagrams/0038-how-caches-can-go-wrong.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Caching
+ - Performance
+---
+
+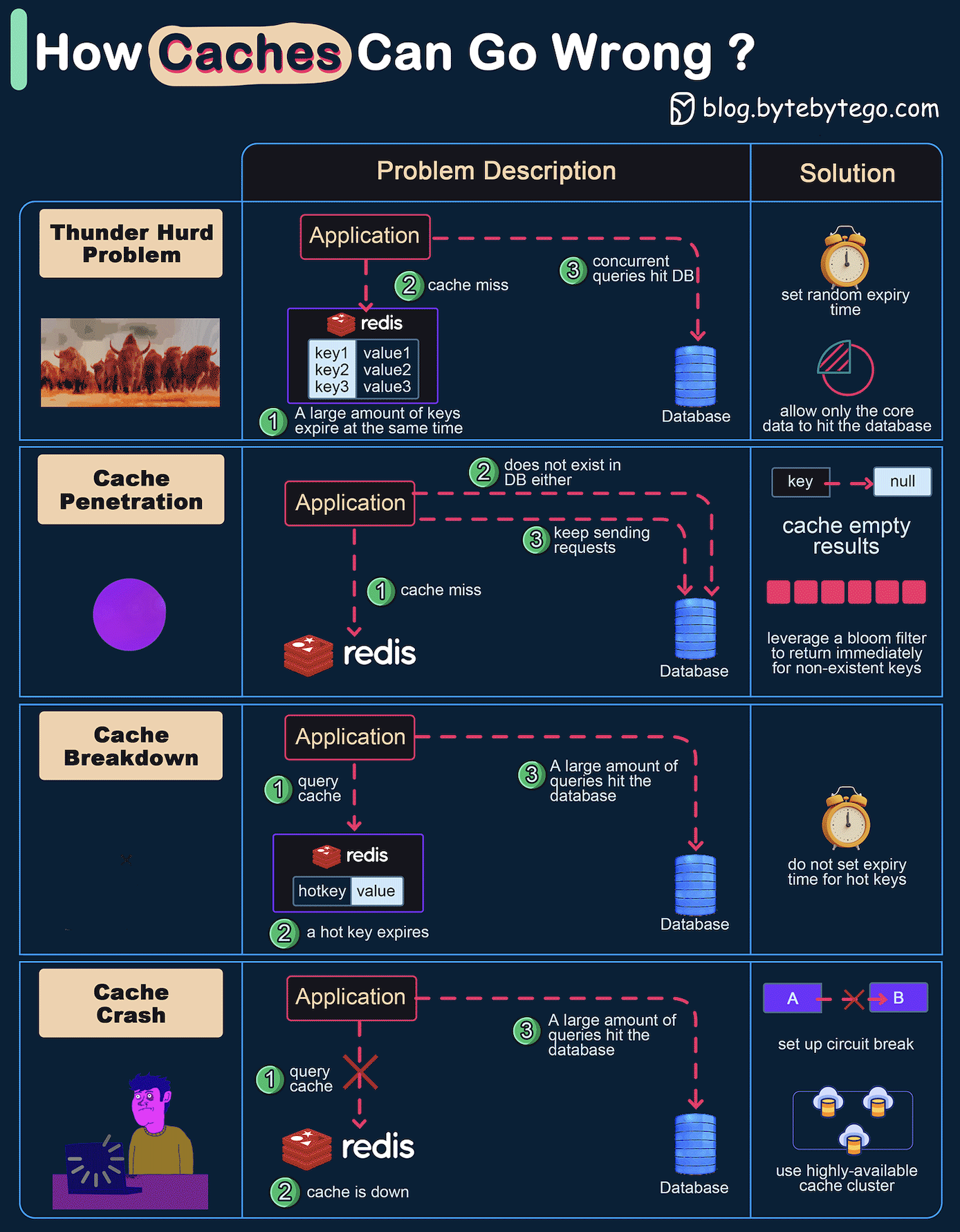
+
+The diagram above shows 4 typical cases where caches can go wrong and their solutions.
+
+## 1. Thunder Herd Problem
+
+This happens when a large number of keys in the cache expire at the same time. Then the query requests directly hit the database, which overloads the database.
+
+There are two ways to mitigate this issue: one is to avoid setting the same expiry time for the keys, adding a random number in the configuration; the other is to allow only the core business data to hit the database and prevent non-core data to access the database until the cache is back up.
+
+## 2. Cache Penetration
+
+This happens when the key doesn’t exist in the cache or the database. The application cannot retrieve relevant data from the database to update the cache. This problem creates a lot of pressure on both the cache and the database.
+
+To solve this, there are two suggestions.
+* Cache a null value for non-existent keys, avoiding hitting the database.
+* Use a bloom filter to check the key existence first, and if the key doesn’t exist, we can avoid hitting the database.
+
+## 3. Cache Breakdown
+
+This is similar to the thunder herd problem. It happens when a hot key expires. A large number of requests hit the database.
+
+Since the hot keys take up 80% of the queries, we do not set an expiration time for them.
+
+## 4. Cache Crash
+
+This happens when the cache is down and all the requests go to the database.
+
+There are two ways to solve this problem.
+* Set up a circuit breaker, and when the cache is down, the application services cannot visit the cache or the database.
+* Set up a cluster for the cache to improve cache availability.
diff --git a/data/guides/how-can-redis-be-used.md b/data/guides/how-can-redis-be-used.md
new file mode 100644
index 0000000..a9b97ce
--- /dev/null
+++ b/data/guides/how-can-redis-be-used.md
@@ -0,0 +1,58 @@
+---
+title: "How can Redis be used?"
+description: "Explore various use cases of Redis beyond caching."
+image: "https://assets.bytebytego.com/diagrams/0388-how-can-redis-be-used.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Redis
+ - Use Cases
+---
+
+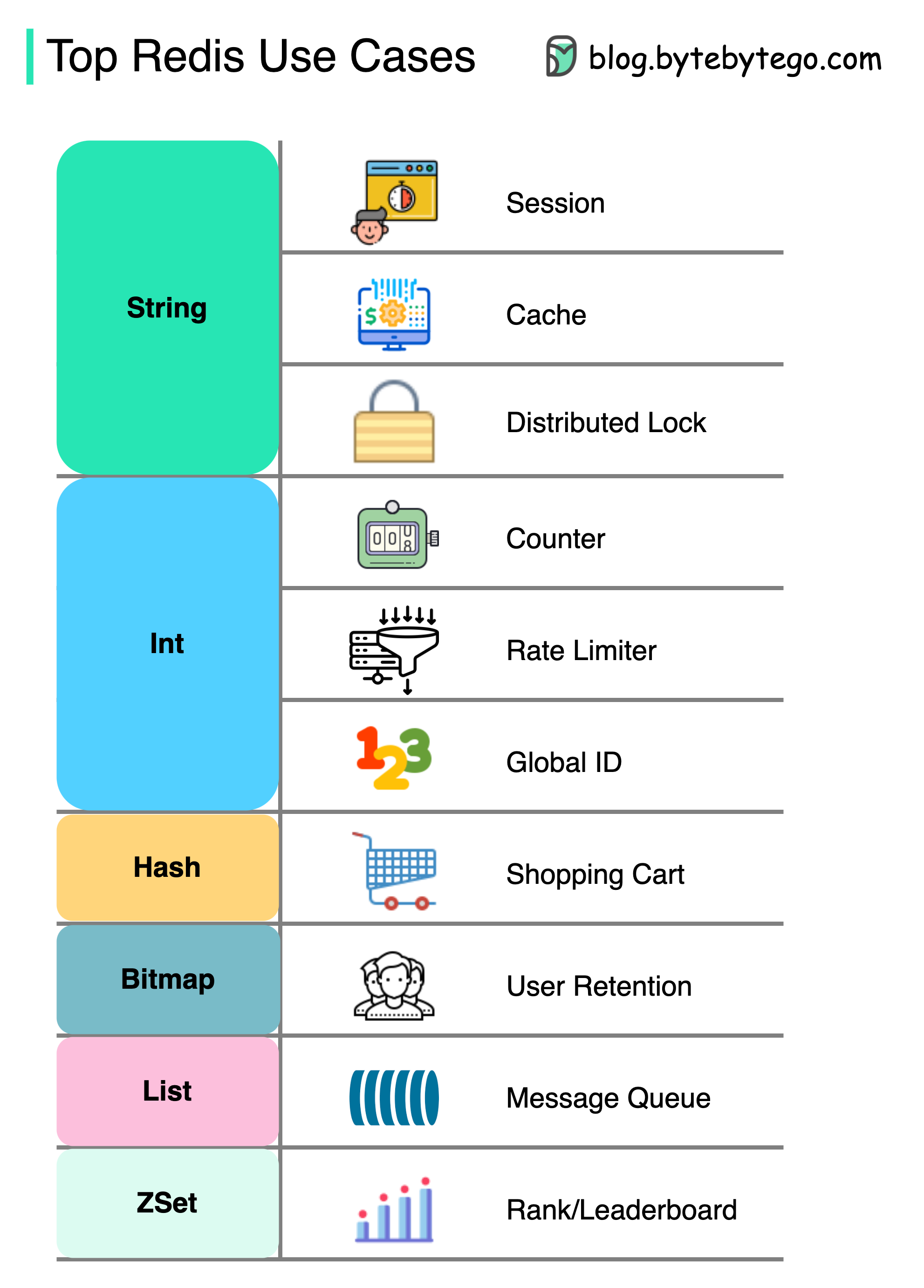
+
+There is more to Redis than just caching.
+
+Redis can be used in a variety of scenarios as shown in the diagram.
+
+* **Session**
+
+ We can use Redis to share user session data among different services.
+
+* **Cache**
+
+ We can use Redis to cache objects or pages, especially for hotspot data.
+
+* **Distributed lock**
+
+ We can use a Redis string to acquire locks among distributed services.
+
+* **Counter**
+
+ We can count how many likes or how many reads for articles.
+
+* **Rate limiter**
+
+ We can apply a rate limiter for certain user IPs.
+
+* **Global ID generator**
+
+ We can use Redis Int for global ID.
+
+* **Shopping cart**
+
+ We can use Redis Hash to represent key-value pairs in a shopping cart.
+
+* **Calculate user retention**
+
+ We can use Bitmap to represent the user login daily and calculate user retention.
+
+* **Message queue**
+
+ We can use List for a message queue.
+
+* **Ranking**
+
+ We can use ZSet to sort the articles.
diff --git a/data/guides/how-digital-signatures-work.md b/data/guides/how-digital-signatures-work.md
new file mode 100644
index 0000000..7d085e3
--- /dev/null
+++ b/data/guides/how-digital-signatures-work.md
@@ -0,0 +1,36 @@
+---
+title: "How Digital Signatures Work"
+description: "Learn how digital signatures work to secure electronic documents."
+image: "https://assets.bytebytego.com/diagrams/0219-how-digital-signatures-work.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - security
+tags:
+ - Cryptography
+ - Security
+---
+
+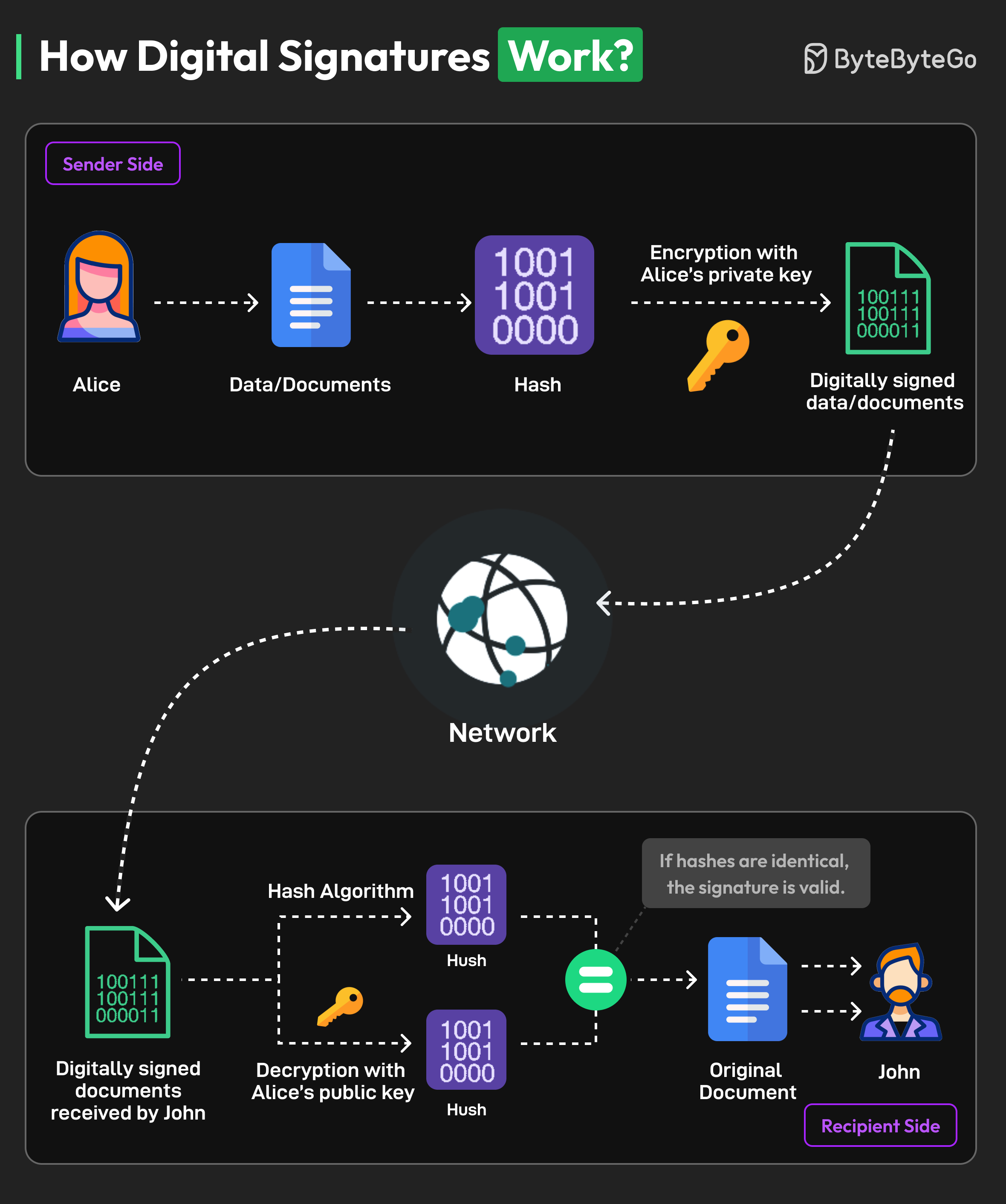
+
+A digital signature is a specific kind of electronic signature to sign and secure electronically transmitted documents.
+
+Digital signatures are similar to physical signatures since they are unique to every person. They identify the identity of the signer.
+
+Here’s an example of the working process of a digital signature with Alice as the sender and John as the recipient:
+
+1. Alice generates a cryptographic key pair consisting of a private key and a corresponding public key. The private key remains confidential and is known only to the signer, while the public key can be shared openly.
+
+2. The signer (Alice) uses a hash function to create a unique fixed-length string of numbers and letters, called a hash, from the document. This hash value represents the contents of the document.
+
+3. Alice uses their private key to encrypt the hash value of the message. This hash value is known as the digital signature.
+
+4. The digital signature is attached to the original document, creating a digitally signed document. It is transmitted over the network to the recipient.
+
+5. The recipient (John) extracts both the digital signature and the original hash value from the document.
+
+6. The recipient uses Alice’s public key to decrypt the digital signature. This produces a hash value that was originally encrypted with the private key.
+
+7. The recipient calculates a new hash value for the received message using the same hashing algorithm as the signer. They then compare this recalculated hash with the decrypted hash value obtained from the digital signature.
+
+8. If the hash values are equal, the digital signature is valid, and it is determined that the document has not been tampered with or altered.
diff --git a/data/guides/how-discord-stores-trillions-of-messages.md b/data/guides/how-discord-stores-trillions-of-messages.md
new file mode 100644
index 0000000..8b02016
--- /dev/null
+++ b/data/guides/how-discord-stores-trillions-of-messages.md
@@ -0,0 +1,34 @@
+---
+title: How Discord Stores Trillions of Messages
+description: Learn how Discord evolved its message storage to handle trillions.
+image: 'https://assets.bytebytego.com/diagrams/0174-discord-store-messages.png'
+createdAt: '2024-03-12'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Databases
+ - Architecture
+---
+
+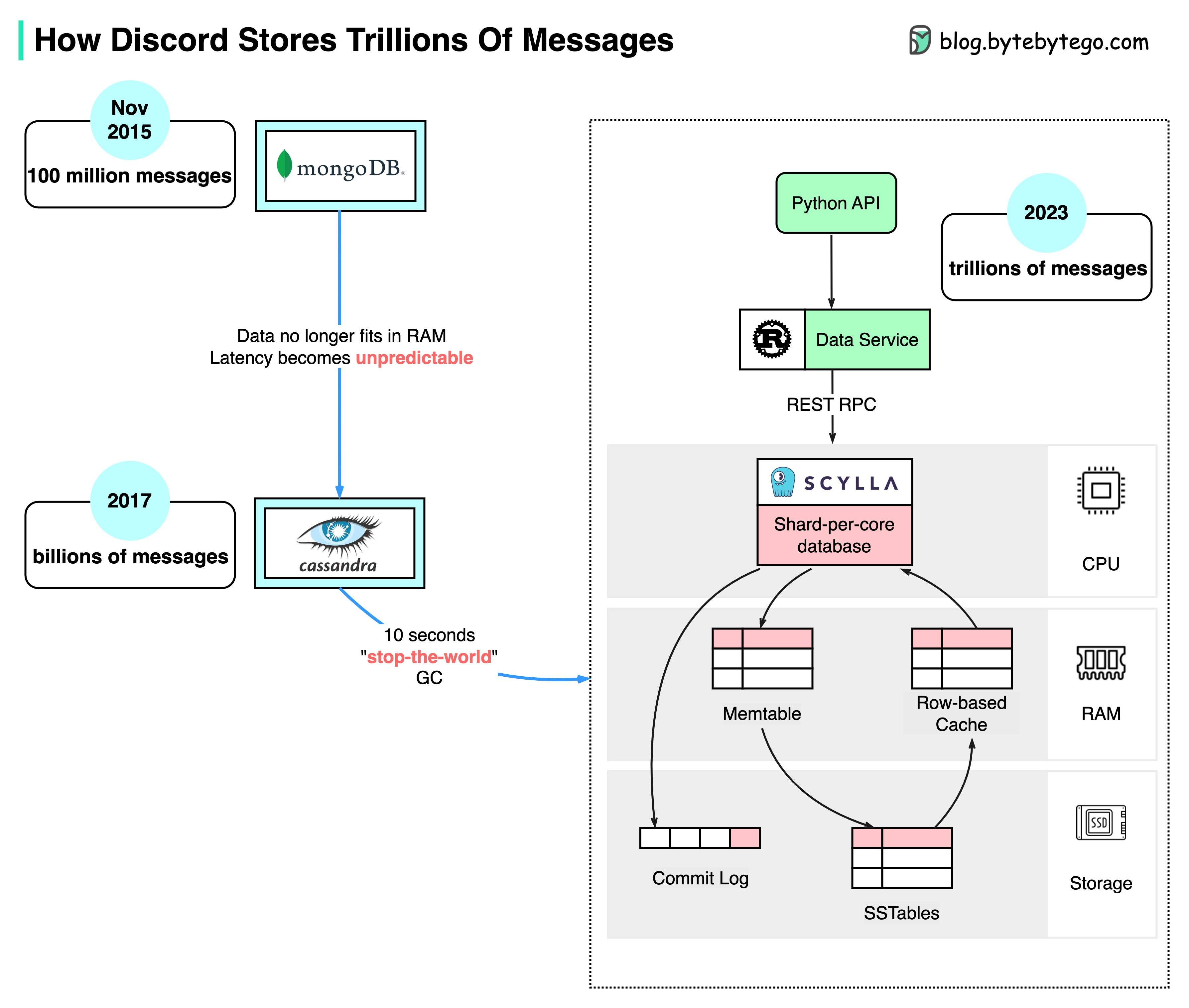
+
+The diagram above shows the evolution of message storage at Discord:
+
+MongoDB ➡️ Cassandra ➡️ ScyllaDB
+
+In 2015, the first version of Discord was built on top of a single MongoDB replica. Around Nov 2015, MongoDB stored 100 million messages and the RAM couldn’t hold the data and index any longer. The latency became unpredictable. Message storage needs to be moved to another database. Cassandra was chosen.
+
+In 2017, Discord had 12 Cassandra nodes and stored billions of messages.
+
+At the beginning of 2022, it had 177 nodes with trillions of messages. At this point, latency was unpredictable, and maintenance operations became too expensive to run.
+
+There are several reasons for the issue:
+
+* Cassandra uses the LSM tree for the internal data structure. The reads are more expensive than the writes. There can be many concurrent reads on a server with hundreds of users, resulting in hotspots.
+* Maintaining clusters, such as compacting SSTables, impacts performance.
+* Garbage collection pauses would cause significant latency spikes
+
+ScyllaDB is Cassandra compatible database written in C++. Discord redesigned its architecture to have a monolithic API, a data service written in Rust, and ScyllaDB-based storage.
+
+The p99 read latency in ScyllaDB is 15ms compared to 40-125ms in Cassandra. The p99 write latency is 5ms compared to 5-70ms in Cassandra.
diff --git a/data/guides/how-do-airtags-work.md b/data/guides/how-do-airtags-work.md
new file mode 100644
index 0000000..ecf50a6
--- /dev/null
+++ b/data/guides/how-do-airtags-work.md
@@ -0,0 +1,28 @@
+---
+title: "How do AirTags work?"
+description: "Learn how AirTags use Bluetooth and Apple's Find My network to locate items."
+image: "https://assets.bytebytego.com/diagrams/0216-how-airtag-works.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - Bluetooth
+ - Tracking
+---
+
+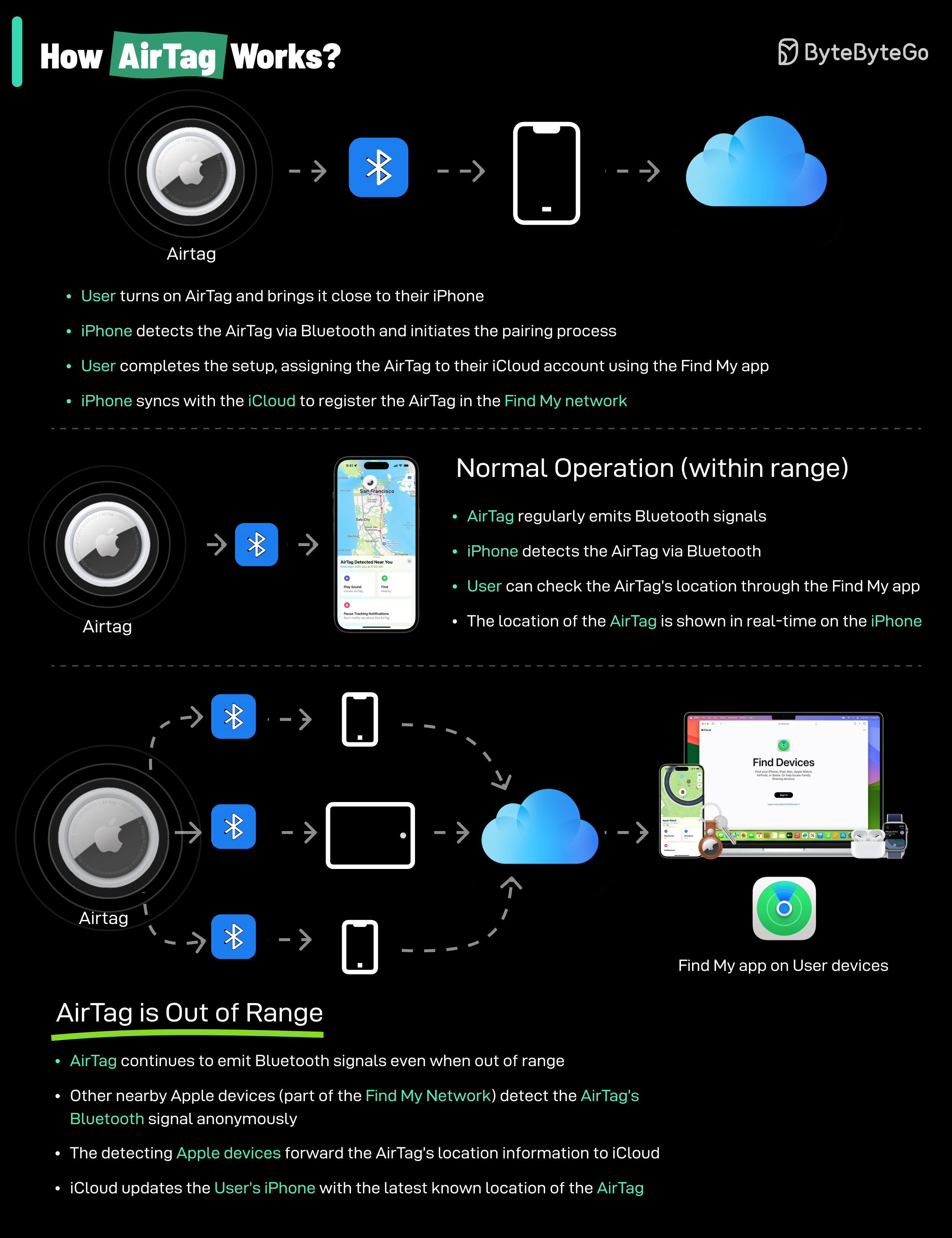
+
+AirTags work by leveraging a combination of Bluetooth technology and the vast network of Apple devices to help you locate your lost items.
+
+Here's a breakdown of how they function:
+
+* Bluetooth Signal: Each AirTag emits a secure Bluetooth signal that can be detected by nearby Apple devices (iPhones, iPads, etc.) within the Find My network.
+
+* Find My Network: When an AirTag comes within range of an Apple device in the Find My network, that device anonymously and securely relays the AirTag's location information to iCloud.
+
+* Location Tracking: You can then use the Find My app on your own Apple device to see the approximate location of your AirTag on a map.
+
+## Limitations
+
+Please note that AirTags rely on Bluetooth technology and the presence of Apple devices within the Find My network. If your AirTag is in an area with few Apple devices, its location may not be updated as frequently or accurately.
diff --git a/data/guides/how-do-big-keys-impact-redis-persistence.md b/data/guides/how-do-big-keys-impact-redis-persistence.md
new file mode 100644
index 0000000..aa36a26
--- /dev/null
+++ b/data/guides/how-do-big-keys-impact-redis-persistence.md
@@ -0,0 +1,36 @@
+---
+title: "How Big Keys Impact Redis Persistence"
+description: "Explore the impact of large keys on Redis AOF persistence modes."
+image: "https://assets.bytebytego.com/diagrams/0085-big-keys.png"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Persistence"
+---
+
+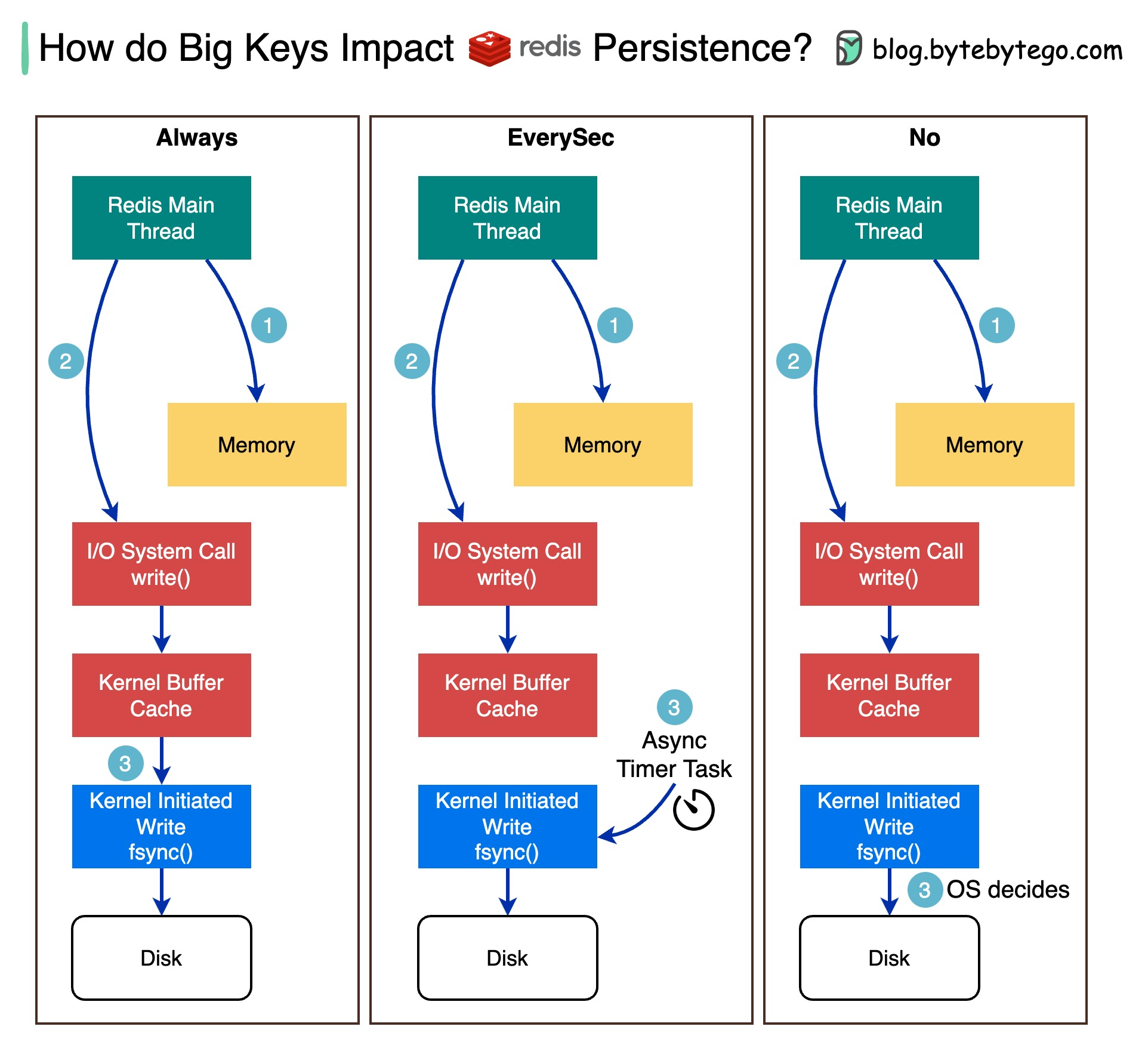
+
+We call a key that contains a large size of data a big key. For example, the size of the key is 5 MB.
+
+The diagram shows how big keys impact Redis AOF (Append-Only-File) persistence.
+
+There are three modes when we turn on AOF persistence:
+
+* Always - synchronously write data to the disk whenever there is a data update in memory.
+
+* EverySec - write to the disk every second.
+
+* No - Redis doesn’t control when the data is written to the disk. Instead, the operating system decides when the data is written to the disk.
+
+## How do we analyze the impact of big keys?
+
+Redis writes keys into memory first, then calls write() to write the data into the kernel buffer cache. Then fsync() flushes all modified in-core data of the file to the disk device. There are 3 modes.
+
+In “Always” mode, it calls fsync() synchronously. If we need to update a big key, the main thread will be blocked because it has to wait for the write to complete.
+
+“EveySec” starts a background timer task to call fsync() every second, so big keys have no impact on the Redis main thread.
+
+“No” mode never calls fsync(). It is up to the operating system. Big keys have no impact on the main thread.
diff --git a/data/guides/how-do-c++-java-python-work.md b/data/guides/how-do-c++-java-python-work.md
new file mode 100644
index 0000000..db8677a
--- /dev/null
+++ b/data/guides/how-do-c++-java-python-work.md
@@ -0,0 +1,24 @@
+---
+title: "How Do C++, Java, Python Work?"
+description: "Understanding the inner workings of C++, Java, and Python."
+image: "https://assets.bytebytego.com/diagrams/0003-how-python-works.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - software-development
+tags:
+ - "programming-languages"
+ - "compilers"
+---
+
+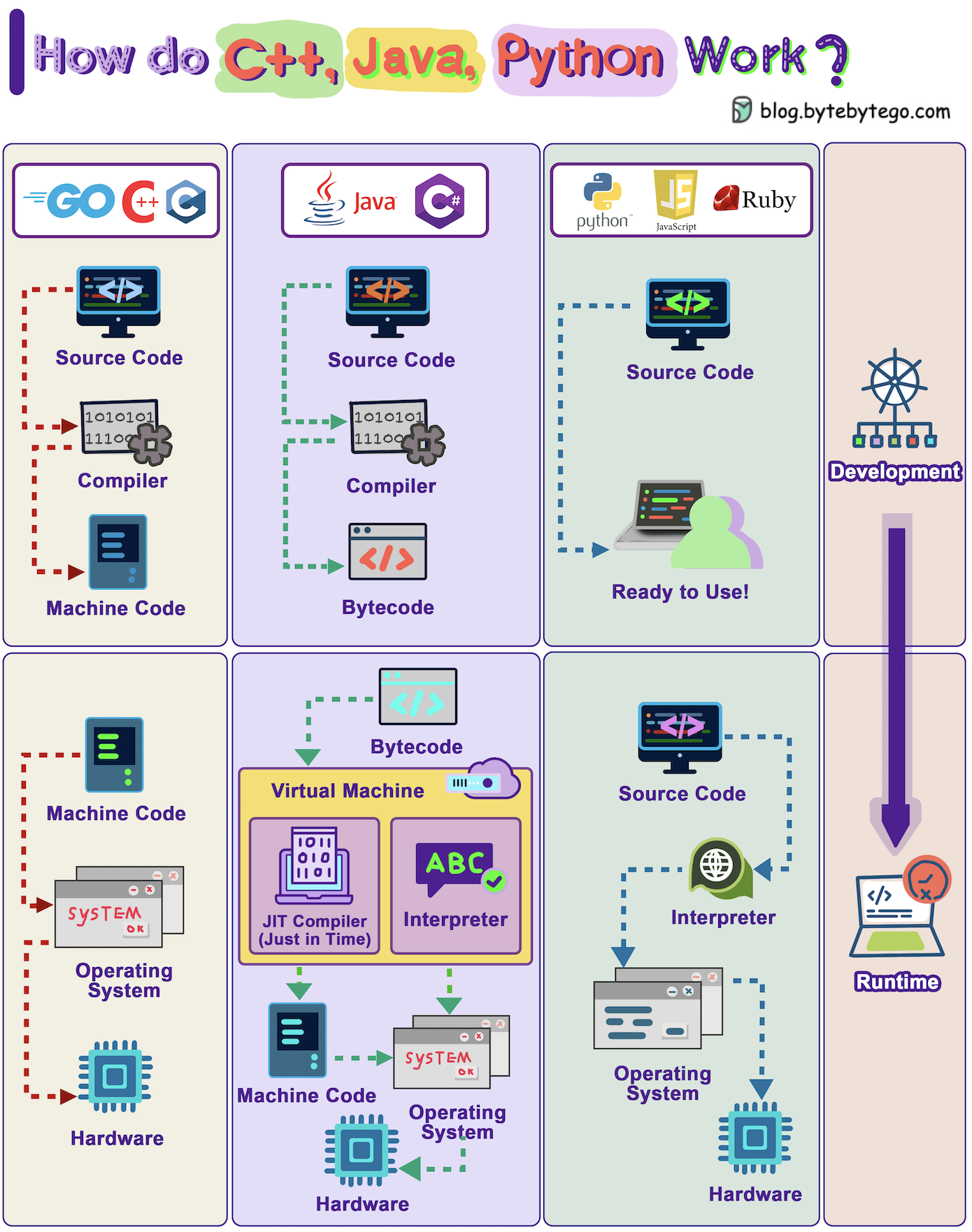
+
+The diagram shows how the compilation and execution work.
+
+Compiled languages are compiled into machine code by the compiler. The machine code can later be executed directly by the CPU. Examples: C, C++, Go.
+
+A bytecode language like Java, compiles the source code into bytecode first, then the JVM executes the program. Sometimes JIT (Just-In-Time) compiler compiles the source code into machine code to speed up the execution. Examples: Java, C#
+
+Interpreted languages are not compiled. They are interpreted by the interpreter during runtime. Examples: Python, Javascript, Ruby
+
+Compiled languages in general run faster than interpreted languages.
diff --git a/data/guides/how-do-companies-ship-code-to-production.md b/data/guides/how-do-companies-ship-code-to-production.md
new file mode 100644
index 0000000..9fa6a1a
--- /dev/null
+++ b/data/guides/how-do-companies-ship-code-to-production.md
@@ -0,0 +1,36 @@
+---
+title: "How do Companies Ship Code to Production?"
+description: "Explore the process companies use to ship code to production efficiently."
+image: "https://assets.bytebytego.com/diagrams/0334-ship-to-prod.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - software-engineering
+ - deployment
+---
+
+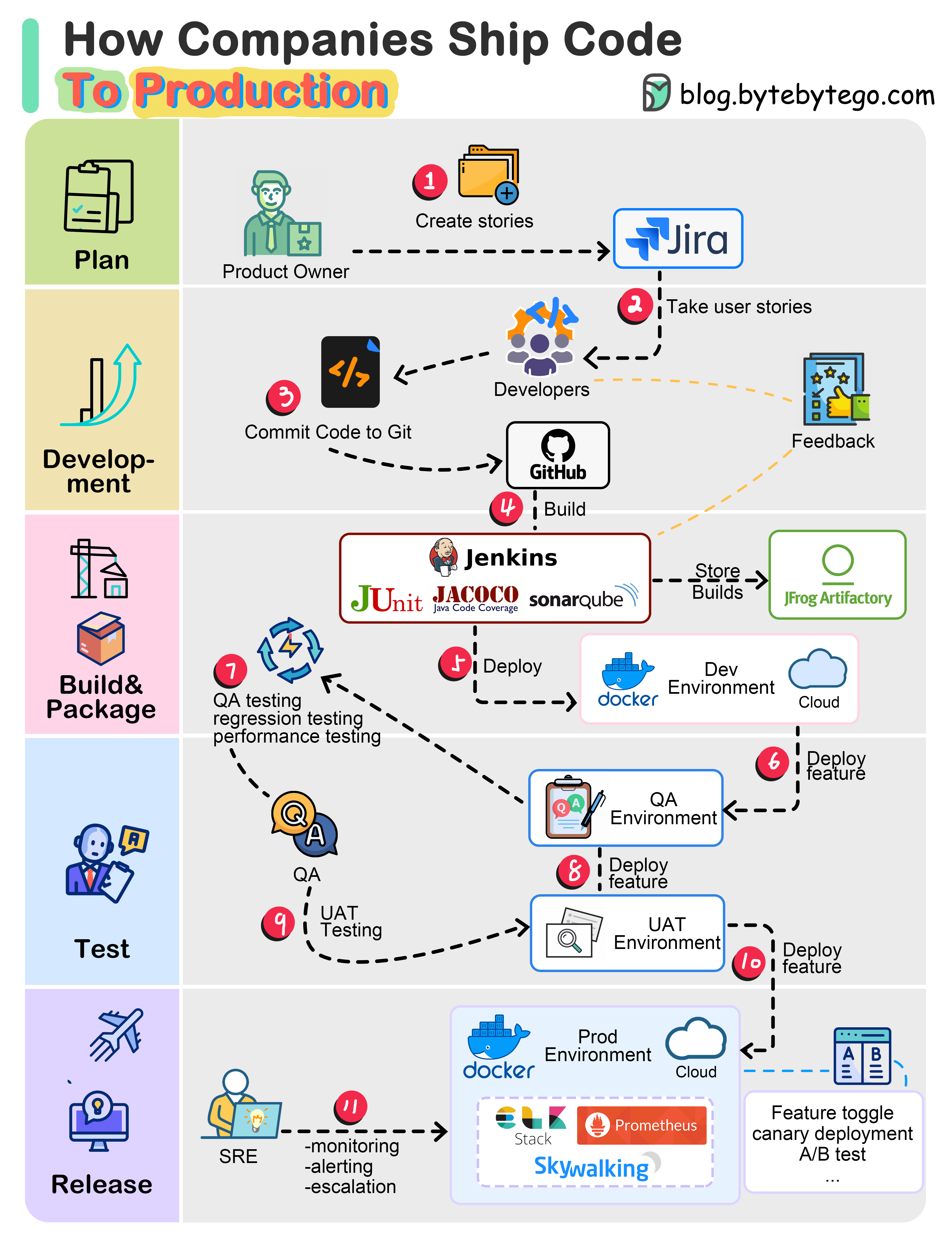
+
+The diagram below illustrates the typical workflow.
+
+Step 1: The process starts with a product owner creating user stories based on requirements.
+
+Step 2: The dev team picks up the user stories from the backlog and puts them into a sprint for a two-week dev cycle.
+
+Step 3: The developers commit source code into the code repository Git.
+
+Step 4: A build is triggered in Jenkins. The source code must pass unit tests, code coverage threshold, and gates in SonarQube.
+
+Step 5: Once the build is successful, the build is stored in artifactory. Then the build is deployed into the dev environment.
+
+Step 6: There might be multiple dev teams working on different features. The features need to be tested independently, so they are deployed to QA1 and QA2.
+
+Step 7: The QA team picks up the new QA environments and performs QA testing, regression testing, and performance testing.
+
+Step 8: Once the QA builds pass the QA team’s verification, they are deployed to the UAT environment.
+
+Step 9: If the UAT testing is successful, the builds become release candidates and will be deployed to the production environment on schedule.
+
+Step 10: SRE (Site Reliability Engineering) team is responsible for prod monitoring.
diff --git a/data/guides/how-do-computer-programs-run.md b/data/guides/how-do-computer-programs-run.md
new file mode 100644
index 0000000..7cb9011
--- /dev/null
+++ b/data/guides/how-do-computer-programs-run.md
@@ -0,0 +1,50 @@
+---
+title: "How Do Computer Programs Run?"
+description: "Explore the execution flow of computer programs from start to finish."
+image: "https://assets.bytebytego.com/diagrams/0218-how-do-computer-programs-run.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - operating-systems
+ - execution
+---
+
+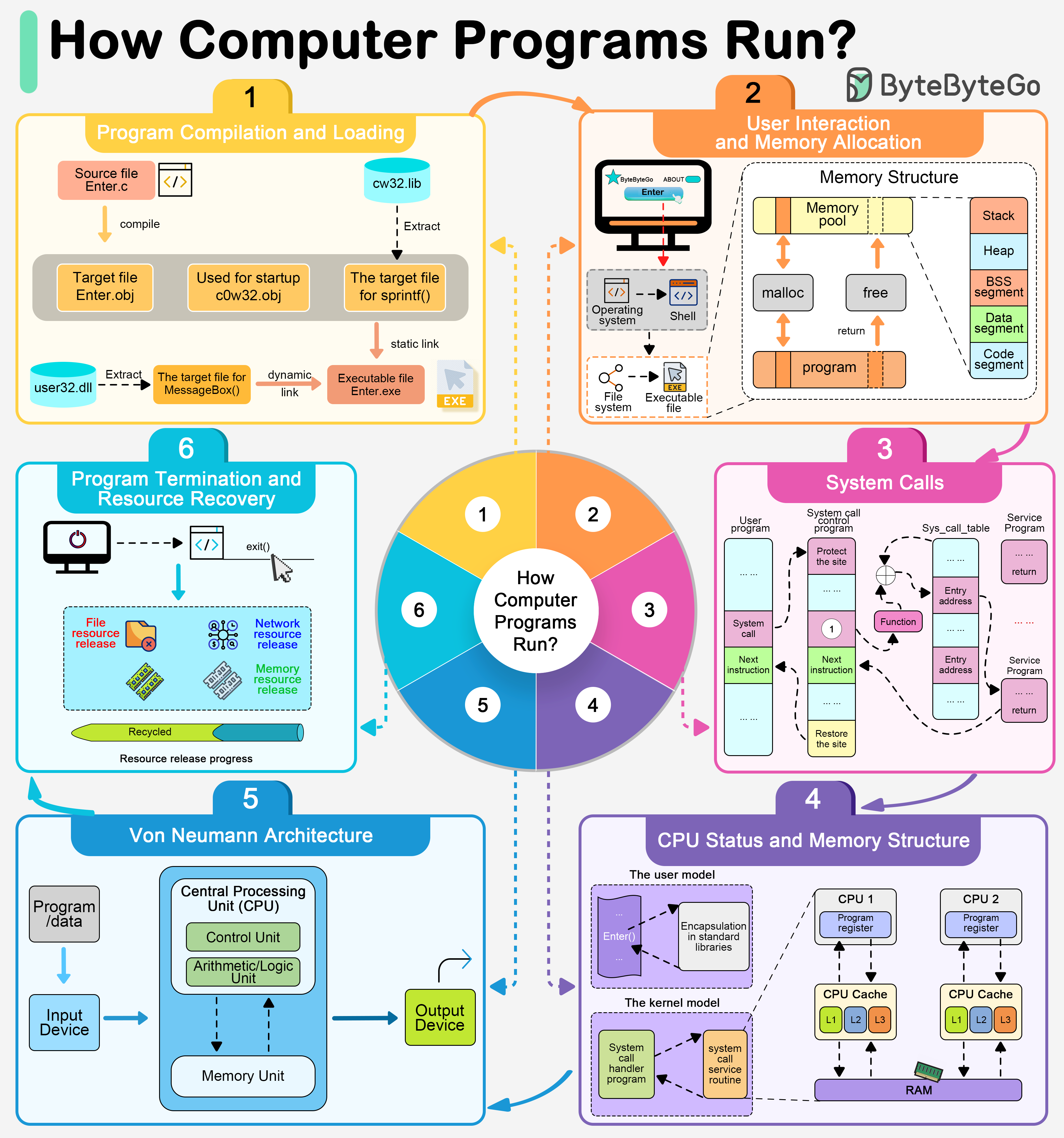
+
+The diagram shows the steps.
+
+## User Interaction and Command Initiation
+
+By double-clicking a program, a user is instructing the operating system to launch an application via the graphical user interface.
+
+## Program Preloading
+
+Once the execution request has been initiated, the operating system first retrieves the program's executable file.
+
+The operating system locates this file through the file system and loads it into memory in preparation for execution.
+
+## Dependency Resolution and Loading
+
+Most modern applications rely on a number of shared libraries, such as dynamic link libraries (DLLs).
+
+## Allocating Memory Space
+
+The operating system is responsible for allocating space in memory.
+
+## Initializing the Runtime Environment
+
+After allocating memory, the operating system and execution environment (e.g., Java's JVM or the .NET Framework) will initialize various resources needed to run the program.
+
+## System Calls and Resource Management
+
+The entry point of a program (usually a function named `main`) is called to begin execution of the code written by the programmer.
+
+## Von Neumann Architecture
+
+In the Von Neumann architecture, the CPU executes instructions stored in memory.
+
+## Program Termination
+
+Eventually, when the program has completed its task, or the user actively terminates the application, the program will begin a cleanup phase. This includes closing open file descriptors, freeing up network resources, and returning memory to the system.
diff --git a/data/guides/how-do-googleapple-maps-blur-license-plates-and-human-faces-on-street-view.md b/data/guides/how-do-googleapple-maps-blur-license-plates-and-human-faces-on-street-view.md
new file mode 100644
index 0000000..c6c687e
--- /dev/null
+++ b/data/guides/how-do-googleapple-maps-blur-license-plates-and-human-faces-on-street-view.md
@@ -0,0 +1,38 @@
+---
+title: "How Google/Apple Maps Blur License Plates and Faces"
+description: "Explore how Google/Apple Maps blur sensitive data on Street View."
+image: "https://assets.bytebytego.com/diagrams/0347-street-view-blurring-system.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Machine Learning"
+ - "Image Processing"
+---
+
+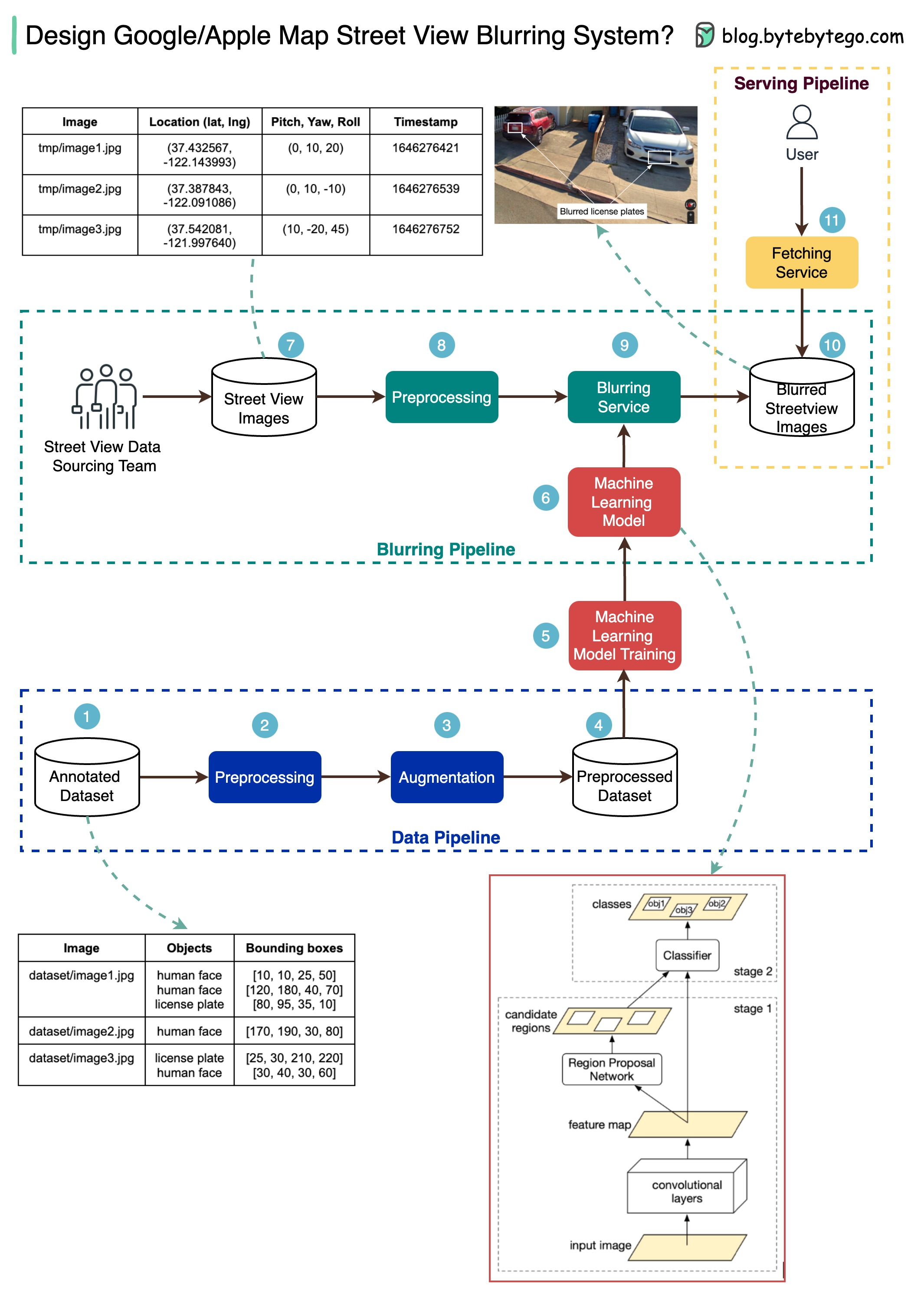
+
+The diagram below presents a possible solution that might work in an interview setting.
+
+The high-level architecture is broken down into three stages:
+
+* Data pipeline - prepare the training data set
+* Blurring pipeline - extract and classify objects and blur relevant objects, for example, license plates and faces.
+* Serving pipeline - serve blurred street view images to users.
+
+## Data Pipeline
+
+Step 1: We get the annotated dataset for training. The objects are marked in bounding boxes.
+
+Steps 2-4: The dataset goes through preprocessing and augmentation to be normalized and scaled.
+
+Steps 5-6: The annotated dataset is then used to train the machine learning model, which is a 2-stage network.
+
+## Blurring Pipeline
+
+Steps 7-10: The street view images go through preprocessing, and object boundaries are detected in the images. Then sensitive objects are blurred, and the images are stored in an object store.
+
+## Serving Pipeline
+
+Step 11: The blurred images can now be retrieved by users.
diff --git a/data/guides/how-do-message-queue-architectures-evolve.md b/data/guides/how-do-message-queue-architectures-evolve.md
new file mode 100644
index 0000000..3f02940
--- /dev/null
+++ b/data/guides/how-do-message-queue-architectures-evolve.md
@@ -0,0 +1,34 @@
+---
+title: "IBM MQ -> RabbitMQ -> Kafka -> Pulsar: Message Queue Evolution"
+description: "Explore the evolution of message queue architectures: IBM MQ to Pulsar."
+image: "https://assets.bytebytego.com/diagrams/0271-message-queue-evolve.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - "database-and-storage"
+tags:
+ - "Message Queues"
+ - "System Design"
+---
+
+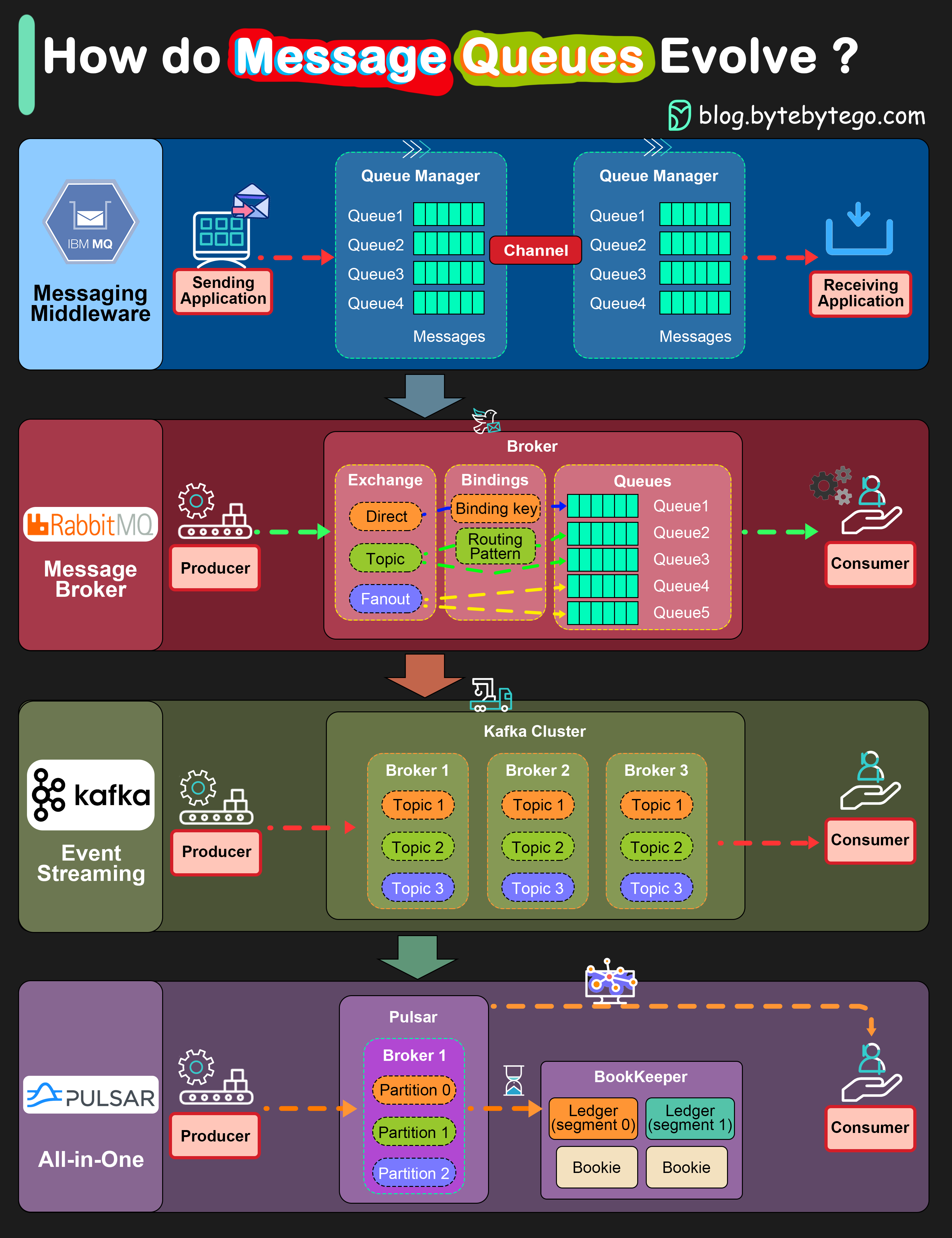
+
+* IBM MQ
+
+IBM MQ was launched in 1993. It was originally called MQSeries and was renamed WebSphere MQ in 2002. It was renamed to IBM MQ in 2014. IBM MQ is a very successful product widely used in the financial sector. Its revenue still reached 1 billion dollars in 2020.
+
+* RabbitMQ
+
+RabbitMQ architecture differs from IBM MQ and is more similar to Kafka concepts. The producer publishes a message to an exchange with a specified exchange type. It can be direct, topic, or fanout. The exchange then routes the message into the queues based on different message attributes and the exchange type. The consumers pick up the message accordingly.
+
+* Kafka
+
+In early 2011, LinkedIn open sourced Kafka, which is a distributed event streaming platform. It was named after Franz Kafka. As the name suggested, Kafka is optimized for writing. It offers a high-throughput, low-latency platform for handling real-time data feeds. It provides a unified event log to enable event streaming and is widely used in internet companies.
+
+Kafka defines producer, broker, topic, partition, and consumer. Its simplicity and fault tolerance allow it to replace previous products like AMQP-based message queues.
+
+* Pulsar
+
+Pulsar, developed originally by Yahoo, is an all-in-one messaging and streaming platform. Compared with Kafka, Pulsar incorporates many useful features from other products and supports a wide range of capabilities. Also, Pulsar architecture is more cloud-native, providing better support for cluster scaling and partition migration, etc.
+
+There are two layers in Pulsar architecture: the serving layer and the persistent layer. Pulsar natively supports tiered storage, where we can leverage cheaper object storage like AWS S3 to persist messages for a longer term.
diff --git a/data/guides/how-do-processes-talk-to-each-other-on-linux.md b/data/guides/how-do-processes-talk-to-each-other-on-linux.md
new file mode 100644
index 0000000..628e5a9
--- /dev/null
+++ b/data/guides/how-do-processes-talk-to-each-other-on-linux.md
@@ -0,0 +1,36 @@
+---
+title: "Inter-Process Communication on Linux"
+description: "Explore how processes communicate with each other in Linux systems."
+image: "https://assets.bytebytego.com/diagrams/0234-inter-process-communication.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Linux"
+ - "IPC"
+---
+
+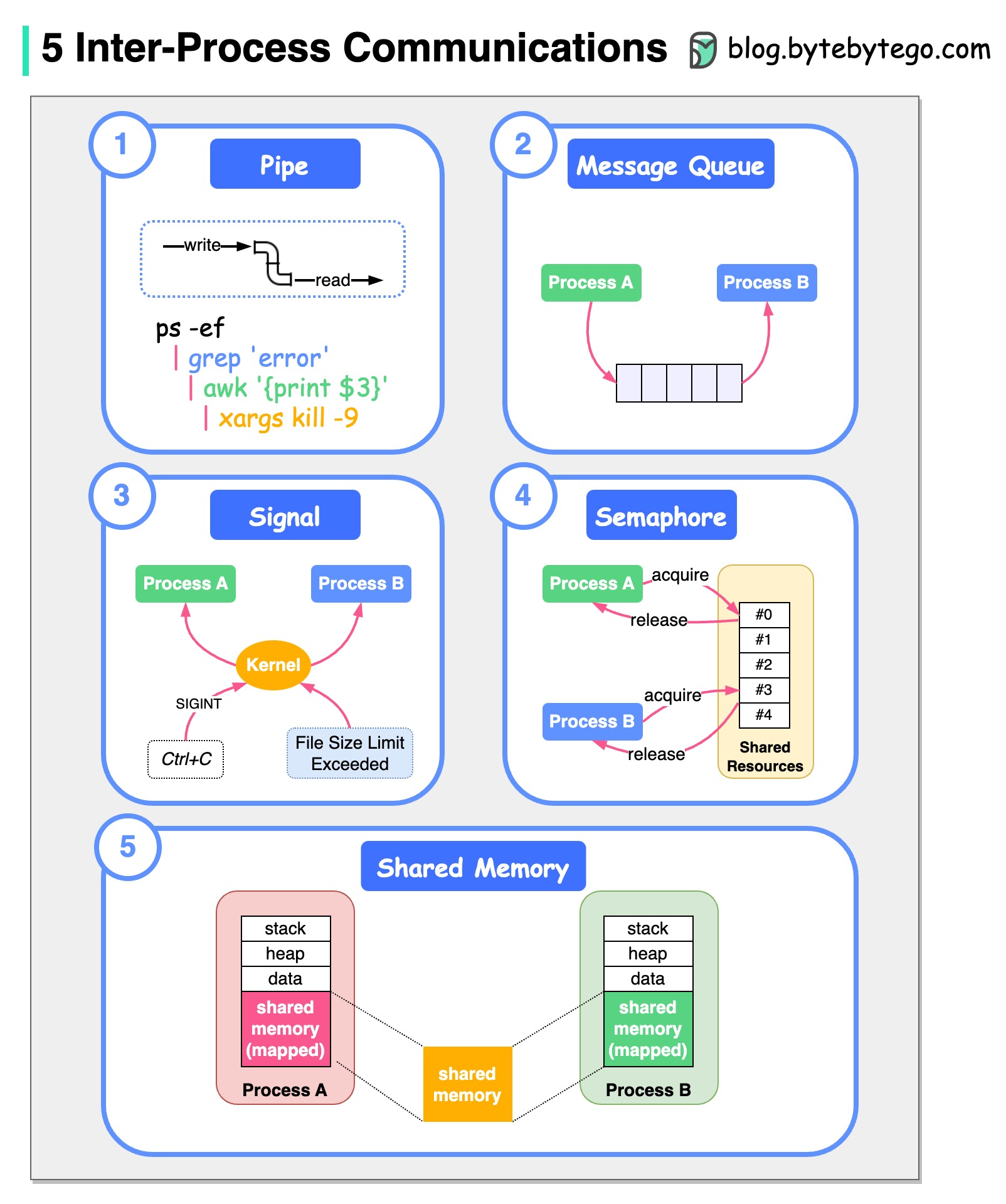
+
+The diagram above shows 5 ways of Inter-Process Communication.
+
+## Pipe
+
+Pipes are unidirectional byte streams that connect the standard output from one process to the standard input of another process.
+
+## Message Queue
+
+Message queues allow one or more processes to write messages, which will be read by one or more reading processes.
+
+## Signal
+
+Signals are one of the oldest inter-process communication methods used by Unix systems. A signal could be generated by a keyboard interrupt or an error condition such as the process attempting to access a non-existent location in its virtual memory. There are a set of defined signals that the kernel can generate or that can be generated by other processes in the system. For example, Ctrl+C sends a SIGINT signal to process A.
+
+## Semaphore
+
+A semaphore is a location in memory whose value can be tested and set by more than one process. Depending on the result of the test and set operation one process may have to sleep until the semaphore's value is changed by another process.
+
+## Shared Memory
+
+Shared memory allows one or more processes to communicate via memory that appears in all of their virtual address spaces. When processes no longer wish to share the virtual memory, they detach from it.
diff --git a/data/guides/how-do-search-engines-work.md b/data/guides/how-do-search-engines-work.md
new file mode 100644
index 0000000..7342179
--- /dev/null
+++ b/data/guides/how-do-search-engines-work.md
@@ -0,0 +1,32 @@
+---
+title: "How Do Search Engines Work?"
+description: "Explore the inner workings of search engines: crawling, indexing, and ranking."
+image: "https://assets.bytebytego.com/diagrams/0103-how-do-search-engines-work.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Search Engines"
+ - "Algorithms"
+---
+
+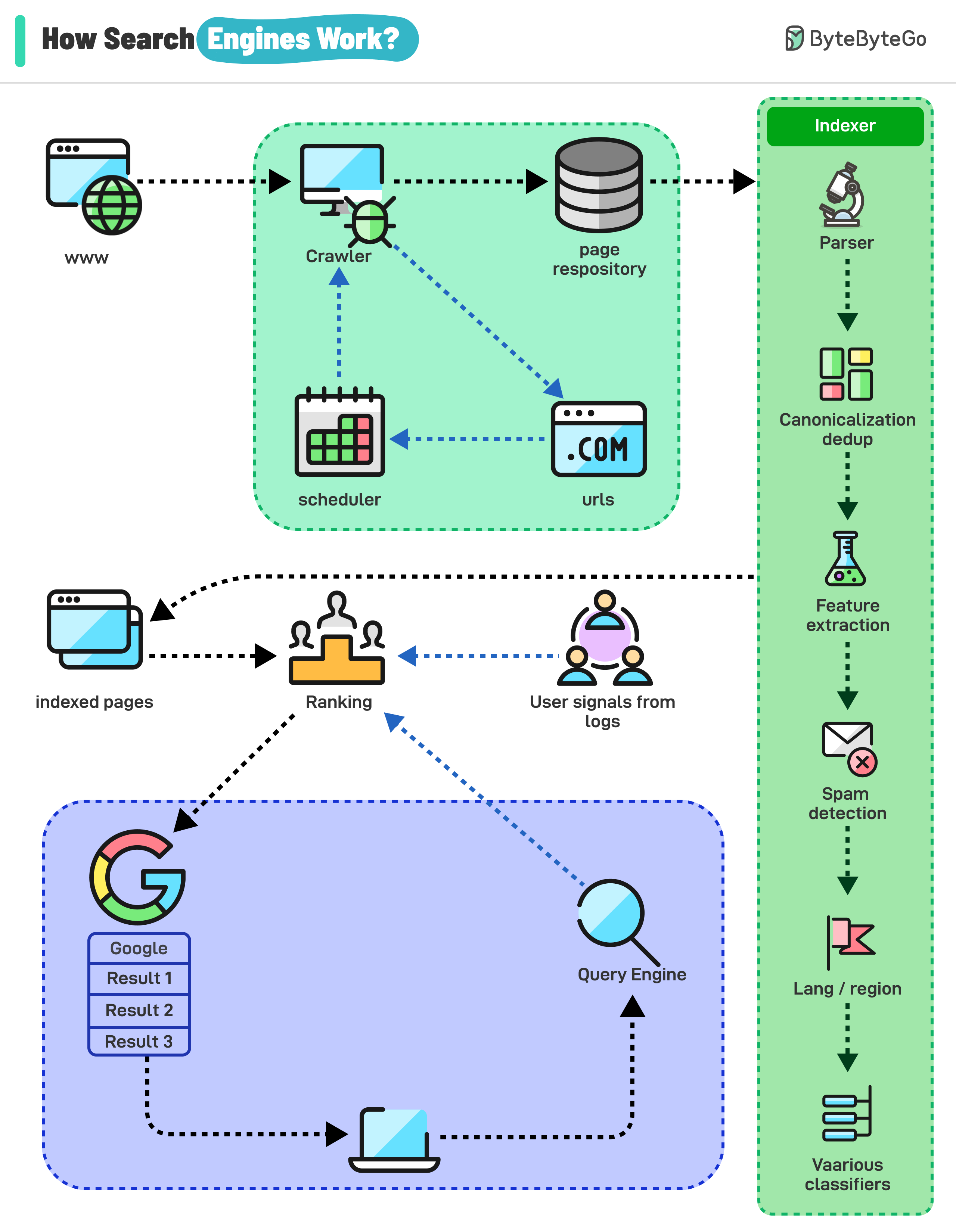
+
+Search engines work through a combination of three core processes:
+
+## Crawling
+
+Search engines use automated programs called "crawlers" to discover and download web pages from the internet. These crawlers start with a list of known web pages (seeds) and follow links on those pages to find new ones, creating a vast network of interconnected content.
+
+## Indexing
+
+The information collected by the crawlers is then analyzed and organized into a massive database called an index. This process involves extracting key elements such as keywords, content type, freshness, language, and other classification signals to understand what each page is about and how relevant it might be to different search queries.
+
+## Serving Search Results
+
+When a user enters a query, the search engine's algorithm sifts through the index to identify the most relevant and helpful pages. Here's a breakdown of how it works:
+
+* **Query Analysis:** The search engine analyzes the user's query to understand its meaning and intent. This includes identifying keywords, recognizing synonyms, and interpreting context.
+* **Retrieval:** The search engine retrieves relevant pages from its vast index based on the query analysis. This involves matching the query's keywords with the indexed content of web pages.
+* **Ranking:** The retrieved pages are then ranked based on their relevance and other factors.
diff --git a/data/guides/how-do-sql-joins-work.md b/data/guides/how-do-sql-joins-work.md
new file mode 100644
index 0000000..fae6a42
--- /dev/null
+++ b/data/guides/how-do-sql-joins-work.md
@@ -0,0 +1,32 @@
+---
+title: "How do SQL Joins Work?"
+description: "Learn how SQL joins work with detailed explanations and examples."
+image: "https://assets.bytebytego.com/diagrams/0367-top-4-types-of-sql-joins.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "SQL"
+ - "Database"
+---
+
+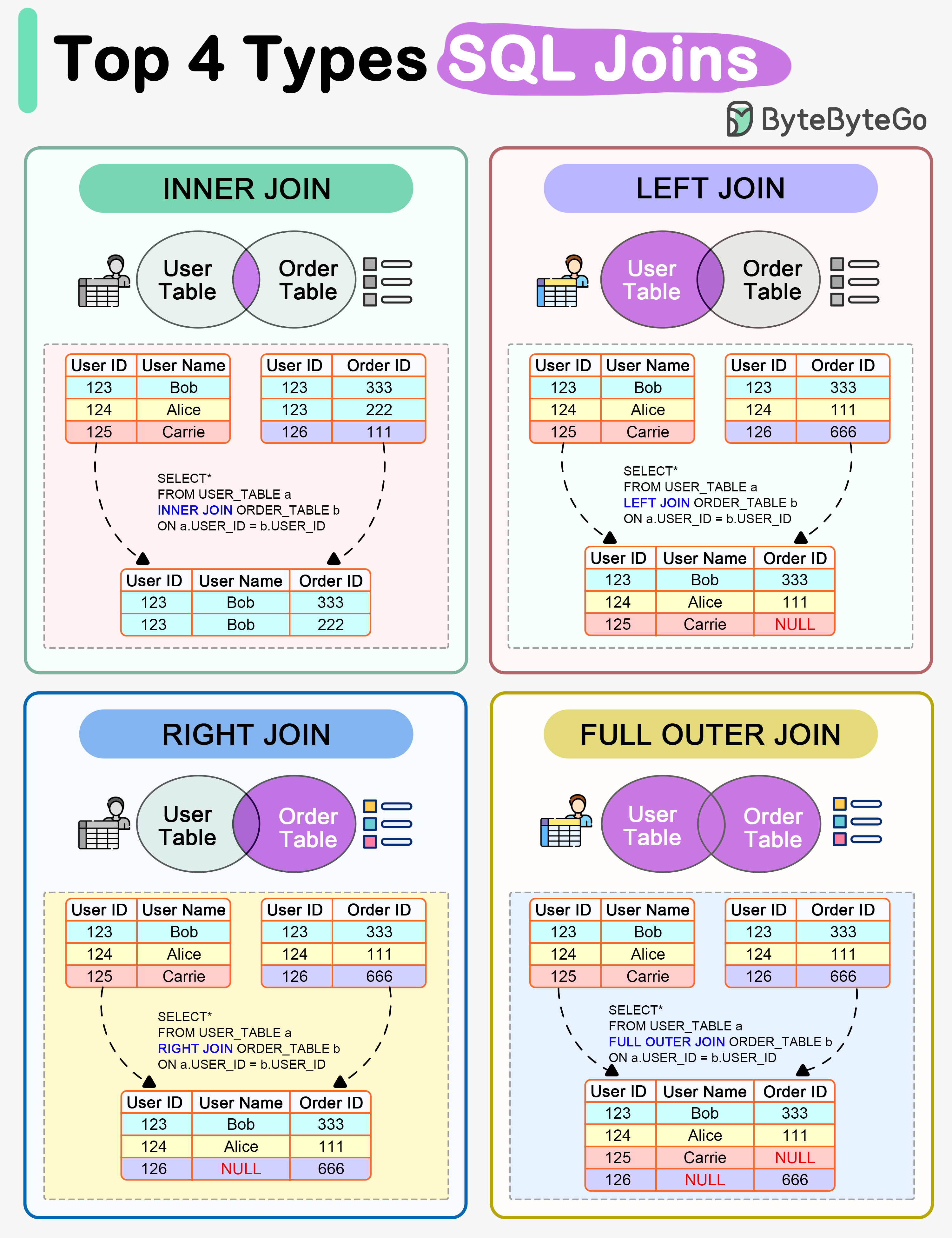
+
+The diagram above shows how 4 types of SQL joins work in detail.
+
+## INNER JOIN
+
+Returns matching rows in both tables.
+
+## LEFT JOIN
+
+Returns all records from the left table, and the matching records from the right table.
+
+## RIGHT JOIN
+
+Returns all records from the right table, and the matching records from the left table.
+
+## FULL OUTER JOIN
+
+Returns all records where there is a match in either left or right table.
diff --git a/data/guides/how-do-we-design-a-chat-application-like-whatsapp-facebook-messenger-or-discord.md b/data/guides/how-do-we-design-a-chat-application-like-whatsapp-facebook-messenger-or-discord.md
new file mode 100644
index 0000000..9456b31
--- /dev/null
+++ b/data/guides/how-do-we-design-a-chat-application-like-whatsapp-facebook-messenger-or-discord.md
@@ -0,0 +1,38 @@
+---
+title: "Designing a Chat Application"
+description: "Explore the architecture of chat apps like WhatsApp and Messenger."
+image: "https://assets.bytebytego.com/diagrams/0134-chat-app.jpeg"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - architecture
+ - messaging
+---
+
+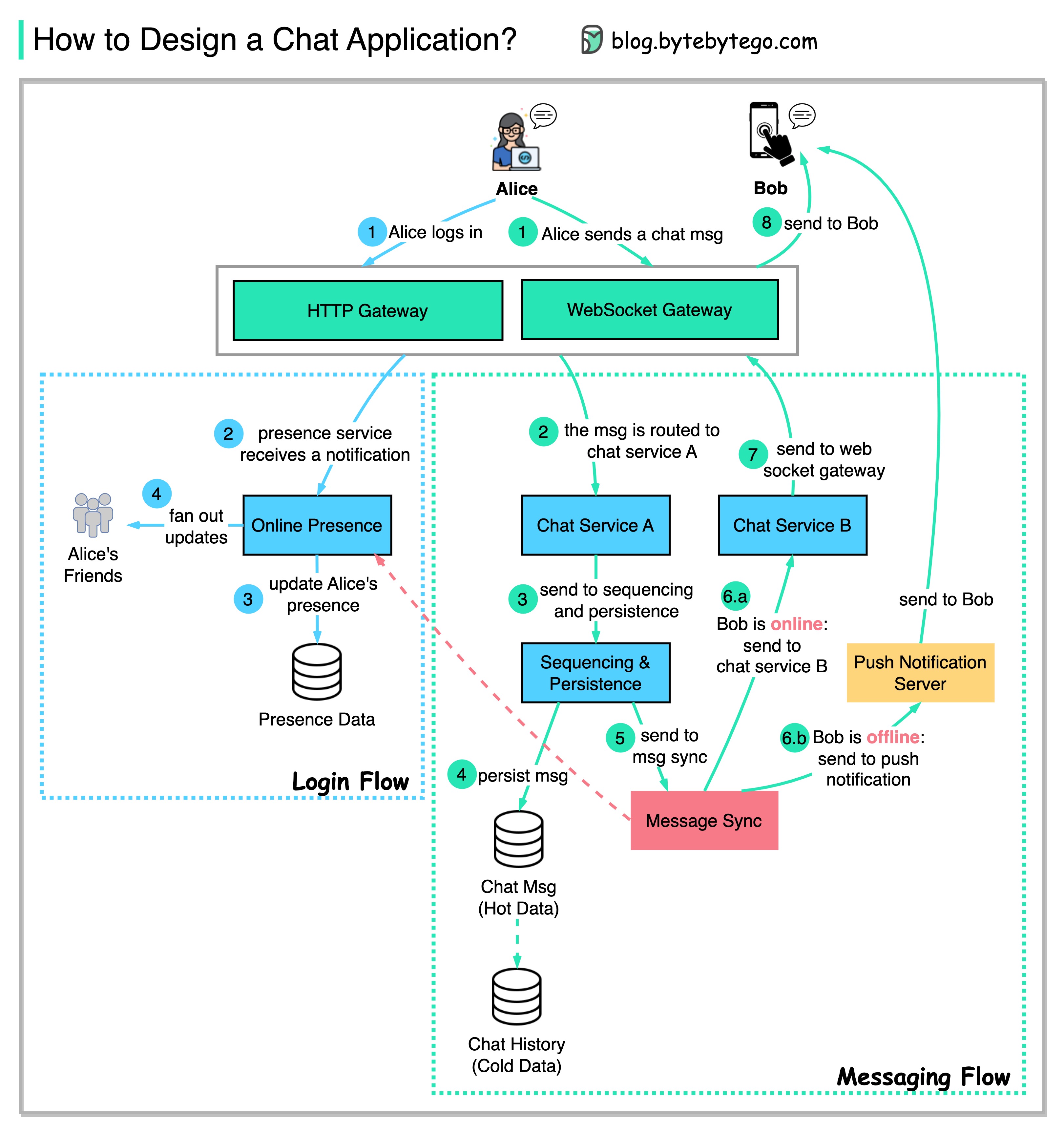
+
+The diagram below shows a design for a simplified 1-to-1 chat application.
+
+## User Login Flow
+
+* Step 1: Alice logs in to the chat application and establishes a web socket connection with the server side.
+
+* Steps 2-4: The presence service receives Alice's notification, updates her presence, and notifies Alice's friends about her presence.
+
+## Messaging Flow
+
+* Steps 1-2: Alice sends a chat message to Bob. The chat message is routed to Chat Service A.
+
+* Steps 3-4: The chat message is sent to the sequencing service, which generates a unique ID, and is persisted in the message store.
+
+* Step 5: The chat message is sent to the message sync queue to sync to Bob’s chat service.
+
+* Step 6: Before forwarding the messaging, the message sync service checks Bob’s presence:
+
+ * If Bob is online, the chat message is sent to chat service B.
+
+ * If Bob is offline, the message is sent to the push server and pushed to Bob’s device.
+
+* Steps 7-8: If Bob is online, the chat message is pushed to Bob via the web socket.
diff --git a/data/guides/how-do-we-design-a-permission-system.md b/data/guides/how-do-we-design-a-permission-system.md
new file mode 100644
index 0000000..8a8501c
--- /dev/null
+++ b/data/guides/how-do-we-design-a-permission-system.md
@@ -0,0 +1,50 @@
+---
+title: "Designing a Permission System"
+description: "Explore common permission system designs: ACL, DAC, MAC, ABAC, and RBAC."
+image: "https://assets.bytebytego.com/diagrams/0300-permission-systems.png"
+createdAt: "2024-02-13"
+draft: false
+categories:
+ - security
+tags:
+ - access control
+ - rbac
+---
+
+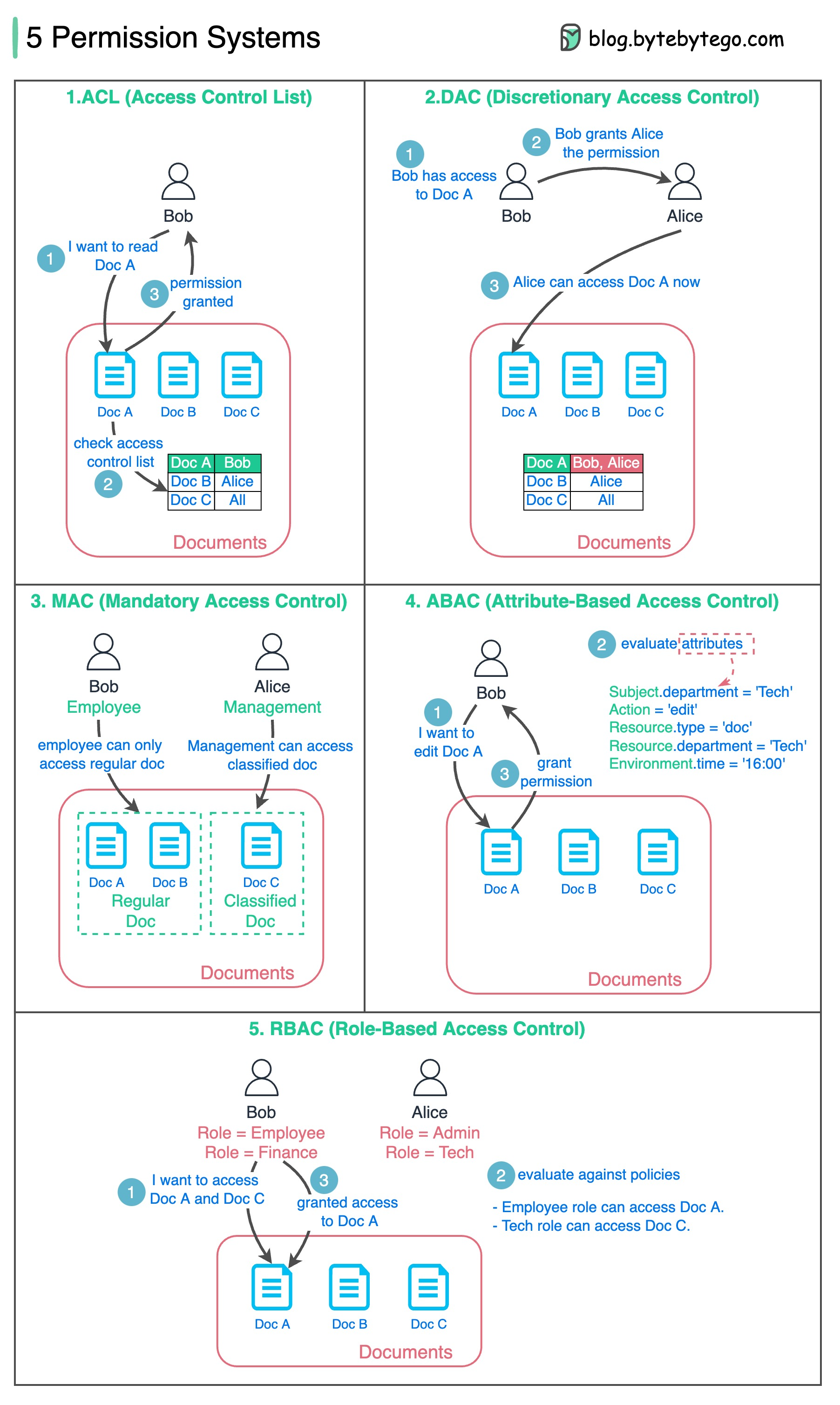
+
+The diagram below lists 5 common ways.
+
+## 1. ACL (Access Control List)
+
+ACL is a list of rules that specifies which users are granted or denied access to a particular resource.
+
+* Pros - Easy to understand.
+* Cons - error-prone, maintenance cost is high
+
+## 2. DAC (Discretionary Access Control)
+
+This is based on ACL. It grants or restricts object access via an access policy determined by an object's owner group.
+
+* Pros - Easy and flexible. Linux file system supports DAC.
+* Cons - Scattered permission control, too much power for the object’s owner group.
+
+## 3. MAC (Mandatory Access Control)
+
+Both resource owners and resources have classification labels. Different labels are granted with different permissions.
+
+* Pros - strict and straightforward.
+* Cons - not flexible.
+
+## 4. ABAC (Attribute-based access control)
+
+Evaluate permissions based on attributes of the Resource owner, Action, Resource, and Environment.
+
+* Pros - flexible
+* Cons - the rules can be complicated, and the implementation is hard. It is not commonly used.
+
+## 5. RBAC (Role-based Access Control)
+
+Evaluate permissions based on roles
+
+* Pros - flexible in assigning roles.
diff --git a/data/guides/how-do-we-design-a-secure-system.md b/data/guides/how-do-we-design-a-secure-system.md
new file mode 100644
index 0000000..203782b
--- /dev/null
+++ b/data/guides/how-do-we-design-a-secure-system.md
@@ -0,0 +1,33 @@
+---
+title: "How to Design a Secure System"
+description: "A cheat sheet for designing secure systems with key design points."
+image: "https://assets.bytebytego.com/diagrams/0138-cheat-sheet-for-designing-secure-systems.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - security
+tags:
+ - "security design"
+ - "system design"
+---
+
+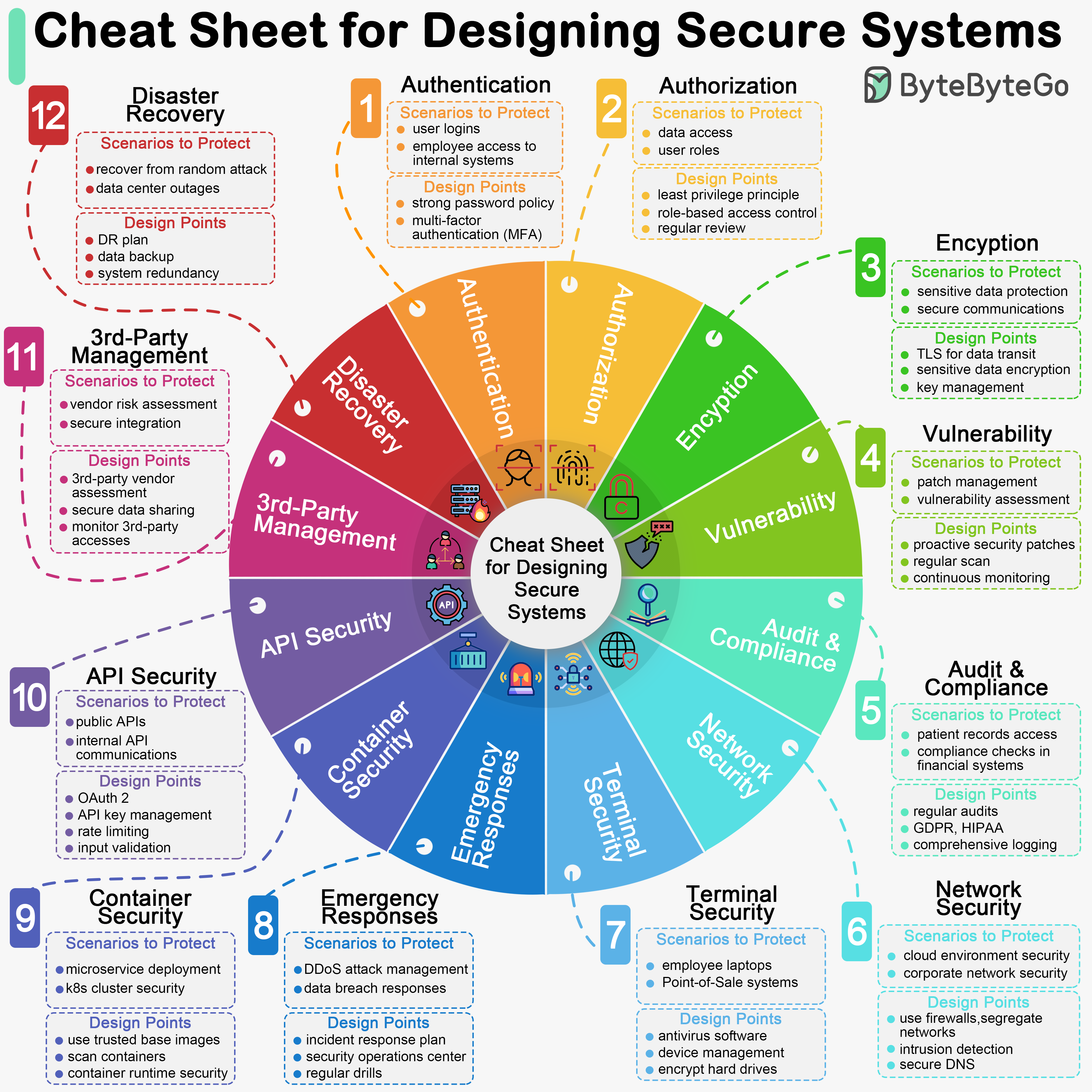
+
+Designing secure systems is important for a multitude of reasons, spanning from protecting sensitive information to ensuring the stability and reliability of the infrastructure. As developers, we should design and implement these security guidelines by default.
+
+The diagram below is a pragmatic cheat sheet with the use cases and key design points.
+
+## Key Design Points
+
+* Authentication
+* Authorization
+* Encryption
+* Vulnerability
+* Audit & Compliance
+* Network Security
+* Terminal Security
+* Emergency Responses
+* Container Security
+* API Security
+* 3rd-Party Vendor Management
+* Disaster Recovery
diff --git a/data/guides/how-do-we-design-a-system-for-internationalization.md b/data/guides/how-do-we-design-a-system-for-internationalization.md
new file mode 100644
index 0000000..043fdc7
--- /dev/null
+++ b/data/guides/how-do-we-design-a-system-for-internationalization.md
@@ -0,0 +1,50 @@
+---
+title: "How to Design a System for Internationalization"
+description: "Learn how to design a system for internationalization effectively."
+image: "https://assets.bytebytego.com/diagrams/0235-internationalization.jpeg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "internationalization"
+ - "system design"
+---
+
+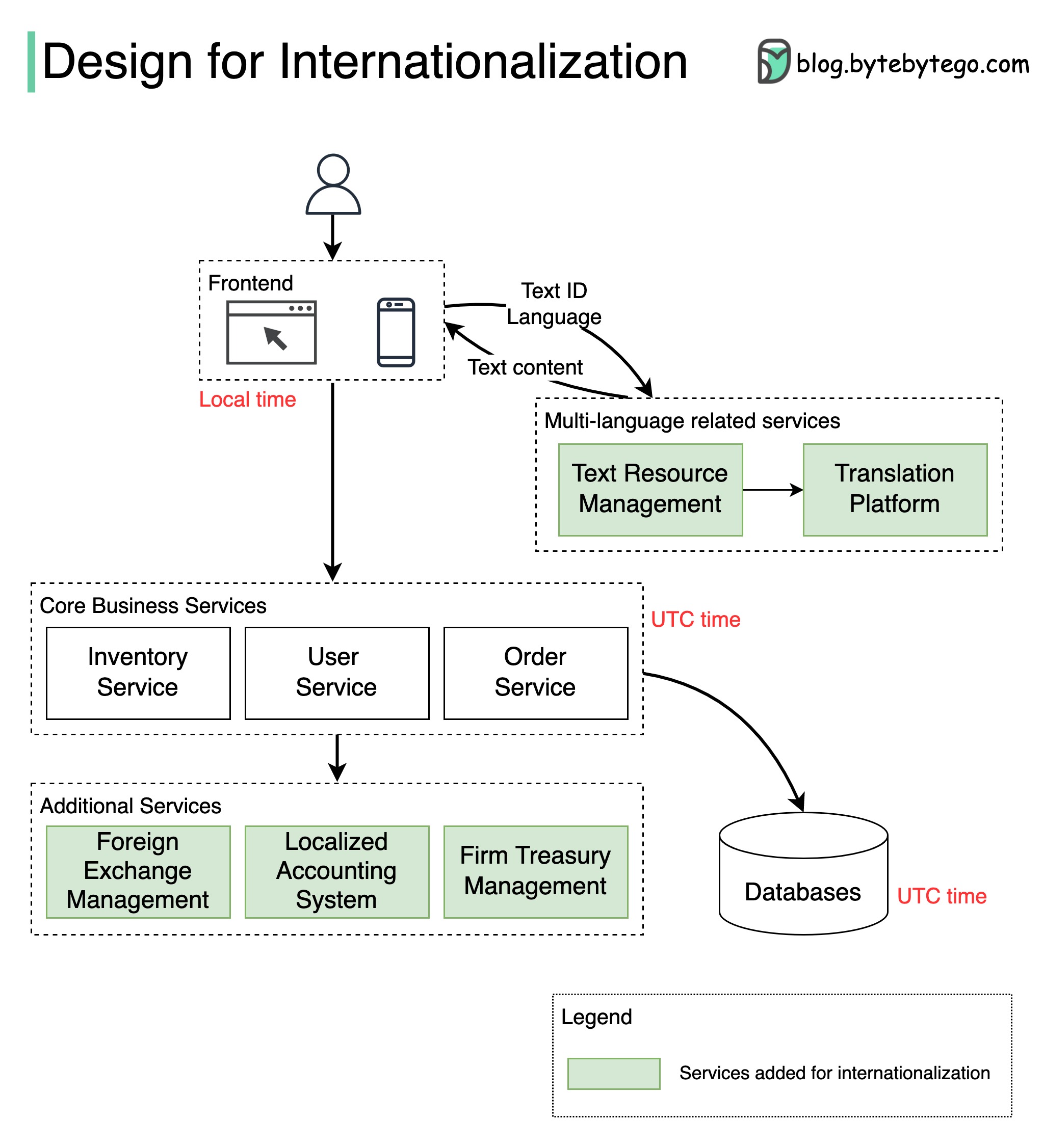
+
+The diagram below shows how we can internationalize a simple e-commerce website.
+
+Different countries have differing cultures, values, and habits. When we design an application for international markets, we need to localize the application in several ways:
+
+## Language
+
+* Extract and maintain all texts in a separate system. For example:
+
+ * We shouldn’t put any prompts in the source code.
+ * We should avoid string concatenation in the code.
+ * We should remove text from graphics.
+
+* Use complete sentences and avoid dynamic text elements.
+* Display business data such as currencies in different languages.
+
+## Layout
+
+* Describe text length and reserve enough space around the text for different languages.
+* Plan for line wrap and truncation.
+* Keep text labels short on buttons.
+* Adjust the display for numerals, dates, timestamps, and addresses.
+
+## Time zone
+
+The time display should be segregated from timestamp storage.
+
+Common practice is to use the UTC (Coordinated Universal Time) timestamp for the database and backend services and to use the local time zone for the frontend display.
+
+## Currency
+
+We need to define the displayed currencies and settlement currency. We also need to design a foreign exchange service for quoting prices.
+
+## Company entity and accounting
+
+Since we need to set up different entities for individual countries, and these entities follow different regulations and accounting standards, the system needs to support multiple bookkeeping methods. Company-level treasury management is often needed. We also need to extract business logic to account for different usage habits in different countries or regions.
diff --git a/data/guides/how-do-we-design-effective-and-safe-apis.md b/data/guides/how-do-we-design-effective-and-safe-apis.md
new file mode 100644
index 0000000..3280da5
--- /dev/null
+++ b/data/guides/how-do-we-design-effective-and-safe-apis.md
@@ -0,0 +1,18 @@
+---
+title: 'How to Design Effective and Safe APIs'
+description: 'Learn how to design effective and safe APIs with best practices.'
+image: 'https://assets.bytebytego.com/diagrams/0180-effective-apis.jpeg'
+createdAt: '2024-03-05'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Design
+ - Software Engineering
+---
+
+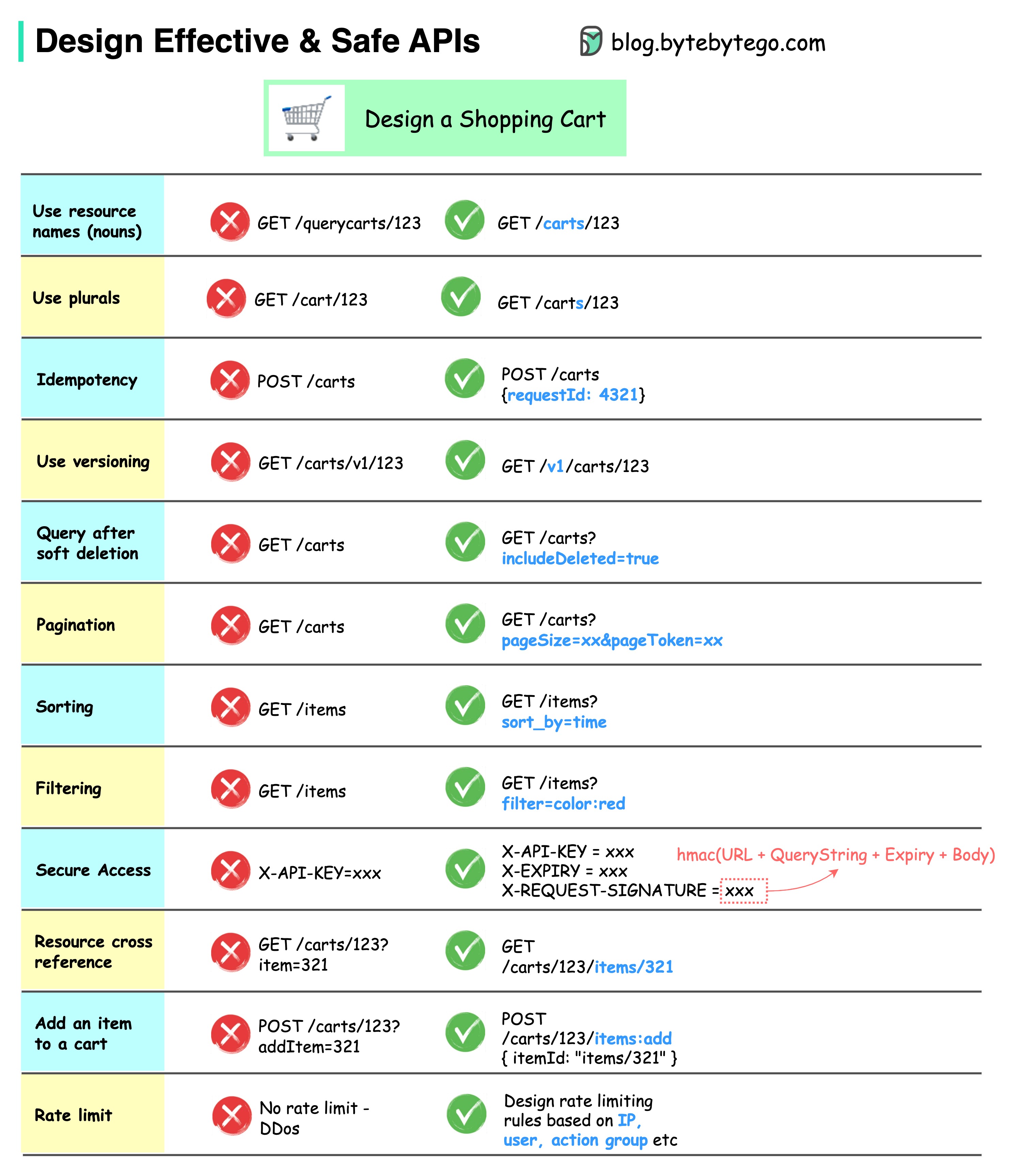
+
+The diagram above shows typical API designs with a shopping cart example.
+
+Note that API design is not just URL path design. Most of the time, we need to choose the proper resource names, identifiers, and path patterns. It is equally important to design proper HTTP header fields or to design effective rate-limiting rules within the API gateway.
diff --git a/data/guides/how-do-we-design-for-high-availability.md b/data/guides/how-do-we-design-for-high-availability.md
new file mode 100644
index 0000000..e5fd7f2
--- /dev/null
+++ b/data/guides/how-do-we-design-for-high-availability.md
@@ -0,0 +1,36 @@
+---
+title: "How to Design for High Availability"
+description: "Explore key strategies for designing systems with high availability."
+image: "https://assets.bytebytego.com/diagrams/0211-high-availability.jpg"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - high-availability
+ - system-design
+---
+
+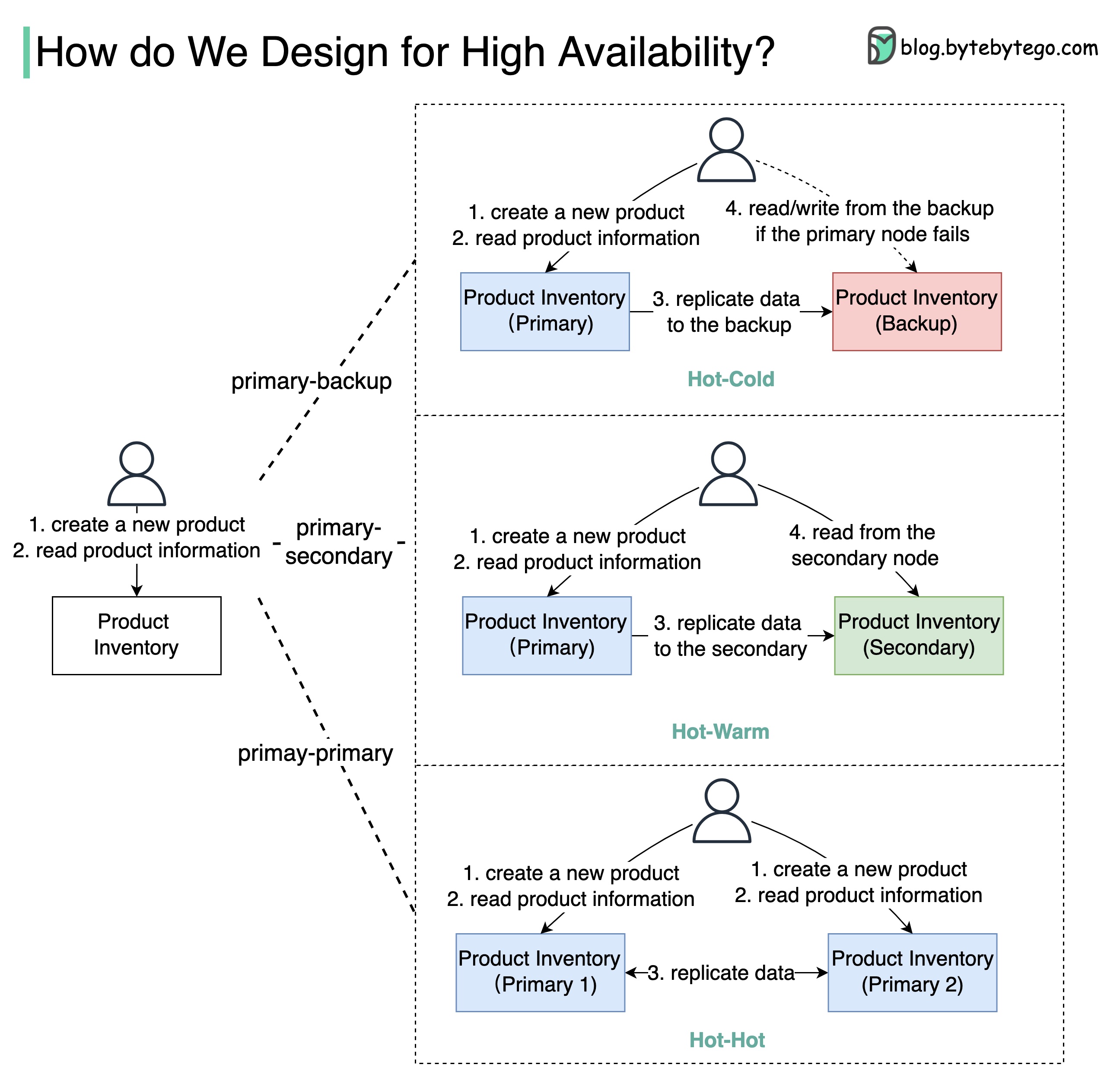
+
+What does Availability mean when you design a system?
+
+In the famous CAP theorem by computer scientist Eric Brewer, Availability means all (non-failing) nodes are available for queries in a distributed system. When you send out requests to the nodes, a non-failing node will return a reasonable response within a reasonable amount of time (with no error or timeout).
+
+Usually, we design a system for high availability. For example, when we say the design target is 4-9’s, it means the services should be up 99.99% of the time. This also means the services can only be down for 52.5 minutes per year.
+
+Note that availability only guarantees that we will receive a response; it doesn’t guarantee the data is the most up-to-date.
+
+The diagram below shows how we can turn a single-node “Product Inventory” into a double-node architecture with high availability.
+
+## High Availability Architectures
+
+* **Primary-Backup:** the backup node is just a stand-by, and the data is replicated from primary to backup. When the primary fails, we need to manually switch to the backup node.
+
+ The backup node might be a waste of hardware resources.
+
+* **Primary-Secondary:** this architecture looks similar to primary-backup architecture, but the secondary node can take read requests to balance the reading load. Due to latency when replicating data from primary to secondary, the data read from the secondary may be inconsistent with the primary.
+
+* **Primary-Primary:** both nodes act as primary nodes, both nodes can handle read/write operations, and the data is replicated between the two nodes. This type of architecture increases the throughput, but it has limited use cases. For example, if both nodes need to update the same product, the final state might be unpredictable. Use this architecture with caution!
+
+ If we deploy the node on Amazon EC2, which has 90% availability, the double-node architecture will increase availability from 90% to 99%.
diff --git a/data/guides/how-do-we-detect-node-failures-in-distributed-systems.md b/data/guides/how-do-we-detect-node-failures-in-distributed-systems.md
new file mode 100644
index 0000000..65c2ee5
--- /dev/null
+++ b/data/guides/how-do-we-detect-node-failures-in-distributed-systems.md
@@ -0,0 +1,40 @@
+---
+title: "How to Detect Node Failures in Distributed Systems"
+description: "Explore heartbeat mechanisms for detecting node failures in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0370-top-6-heartbeat-detection-mechanisms.png"
+createdAt: "2024-02-03"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - distributed systems
+ - failure detection
+---
+
+
+
+Heartbeat mechanisms are crucial in distributed systems for monitoring the health and status of various components. Here are several types of heartbeat detection mechanisms commonly used in distributed systems:
+
+## Push-Based Heartbeat
+
+The most basic form of heartbeat involves a periodic signal sent from one node to another or to a monitoring service. If the heartbeat signals stop arriving within a specified interval, the system assumes that the node has failed. This is simple to implement, but network congestion can lead to false positives.
+
+## Pull-Based Heartbeat
+
+Instead of nodes sending heartbeats actively, a central monitor might periodically "pull" status information from nodes. It reduces network traffic but might increase latency in failure detection.
+
+## Heartbeat with Health Check
+
+This includes diagnostic information about the node's health in the heartbeat signal. This information can include CPU usage, memory usage, or application-specific metrics. It Provides more detailed information about the node, allowing for more nuanced decision-making. However, it increases complexity and potential for larger network overhead.
+
+## Heartbeat with Timestamps
+
+Heartbeats that include timestamps can help the receiving node or service determine not just if a node is alive, but also if there are network delays affecting communication.
+
+## Heartbeat with Acknowledgement
+
+The receiver of the heartbeat message must send back an acknowledgment in this model. This ensures that not only is the sender alive, but the network path between the sender and receiver is also functional.
+
+## Heartbeat with Quorum
+
+In some distributed systems, especially those involving consensus protocols like Paxos or Raft, the concept of a quorum (a majority of nodes) is used. Heartbeats might be used to establish or maintain a quorum, ensuring that a sufficient number of nodes are operational for the system to make decisions. This brings complexity in implementation and managing quorum changes as nodes join or leave the system.
diff --git a/data/guides/how-do-we-incorporate-event-sourcing-into-the-systems.md b/data/guides/how-do-we-incorporate-event-sourcing-into-the-systems.md
new file mode 100644
index 0000000..839bac2
--- /dev/null
+++ b/data/guides/how-do-we-incorporate-event-sourcing-into-the-systems.md
@@ -0,0 +1,28 @@
+---
+title: "How do we incorporate Event Sourcing into systems?"
+description: "Explore incorporating Event Sourcing: from NYT archives to microservices."
+image: "https://assets.bytebytego.com/diagrams/0037-use-cases-for-event-sourcing.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "event sourcing"
+ - "microservices"
+---
+
+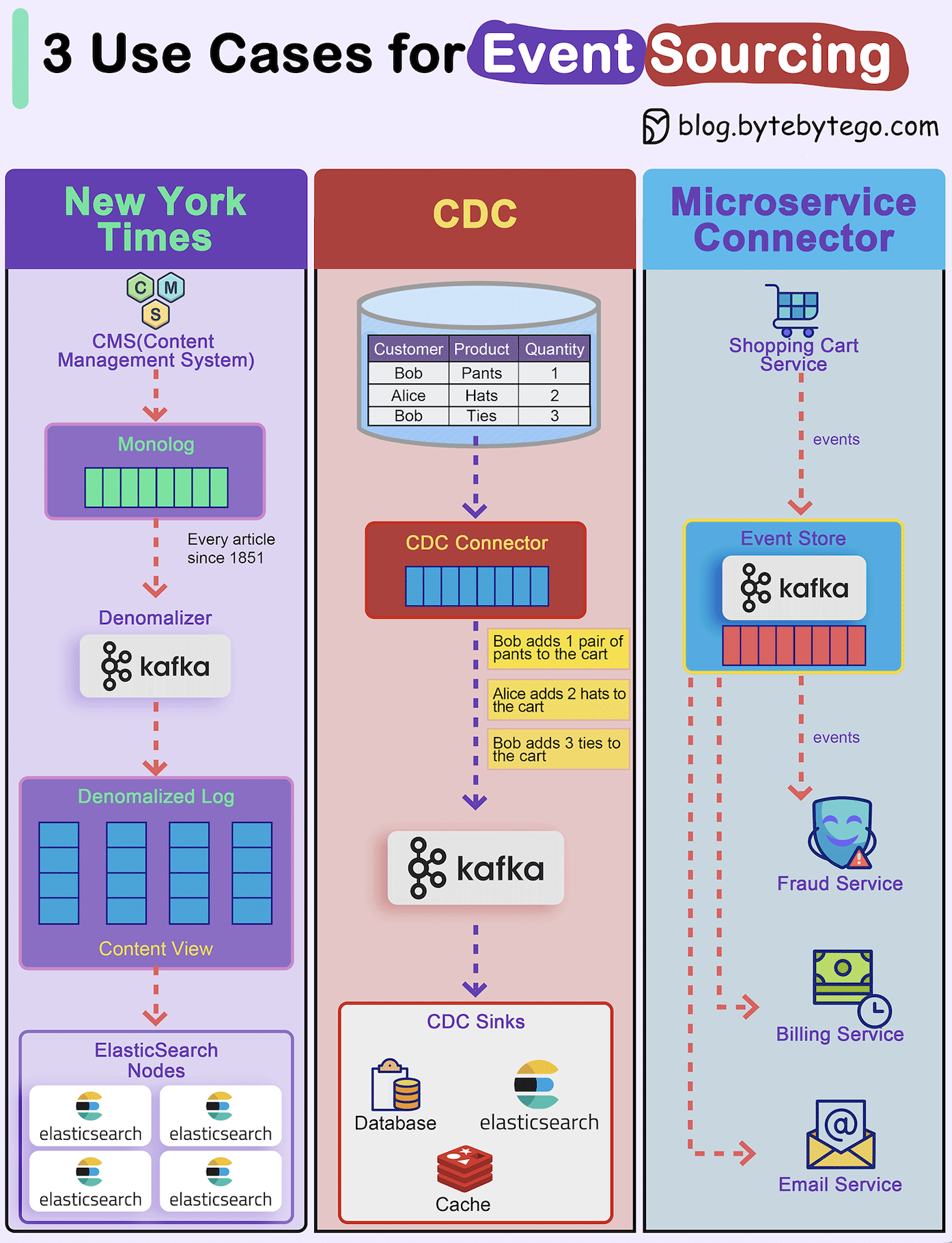
+
+Event sourcing changes the programming paradigm from persisting states to persisting events. The event store is the source of truth. Let's look at three examples.
+
+## New York Times
+
+The newspaper website stores every article, image, and byline since 1851 in an event store. The raw data is then denormalized into different views and fed into different ElasticSearch nodes for website searches.
+
+## CDC (Change Data Capture)
+
+A CDC connector pulls data from the tables and transforms it into events. These events are pushed to Kafka and other sinks consume events from Kafka.
+
+## Microservice Connector
+
+We can also use event event-sourcing paradigm for transmitting events among microservices. For example, the shopping cart service generates various events for adding or removing items from the cart. Kafka broker acts as the event store, and other services including the fraud service, billing service, and email service consume events from the event store. Since events are the source of truth, each service can determine the domain model on its own.
diff --git a/data/guides/how-do-we-learn-elasticsearch.md b/data/guides/how-do-we-learn-elasticsearch.md
new file mode 100644
index 0000000..ca26c8f
--- /dev/null
+++ b/data/guides/how-do-we-learn-elasticsearch.md
@@ -0,0 +1,33 @@
+---
+title: "How to Learn Elasticsearch"
+description: "Learn about Elasticsearch features, use cases, and core data structures."
+image: "https://assets.bytebytego.com/diagrams/0182-elastic-search.jpeg"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Elasticsearch
+ - Search
+---
+
+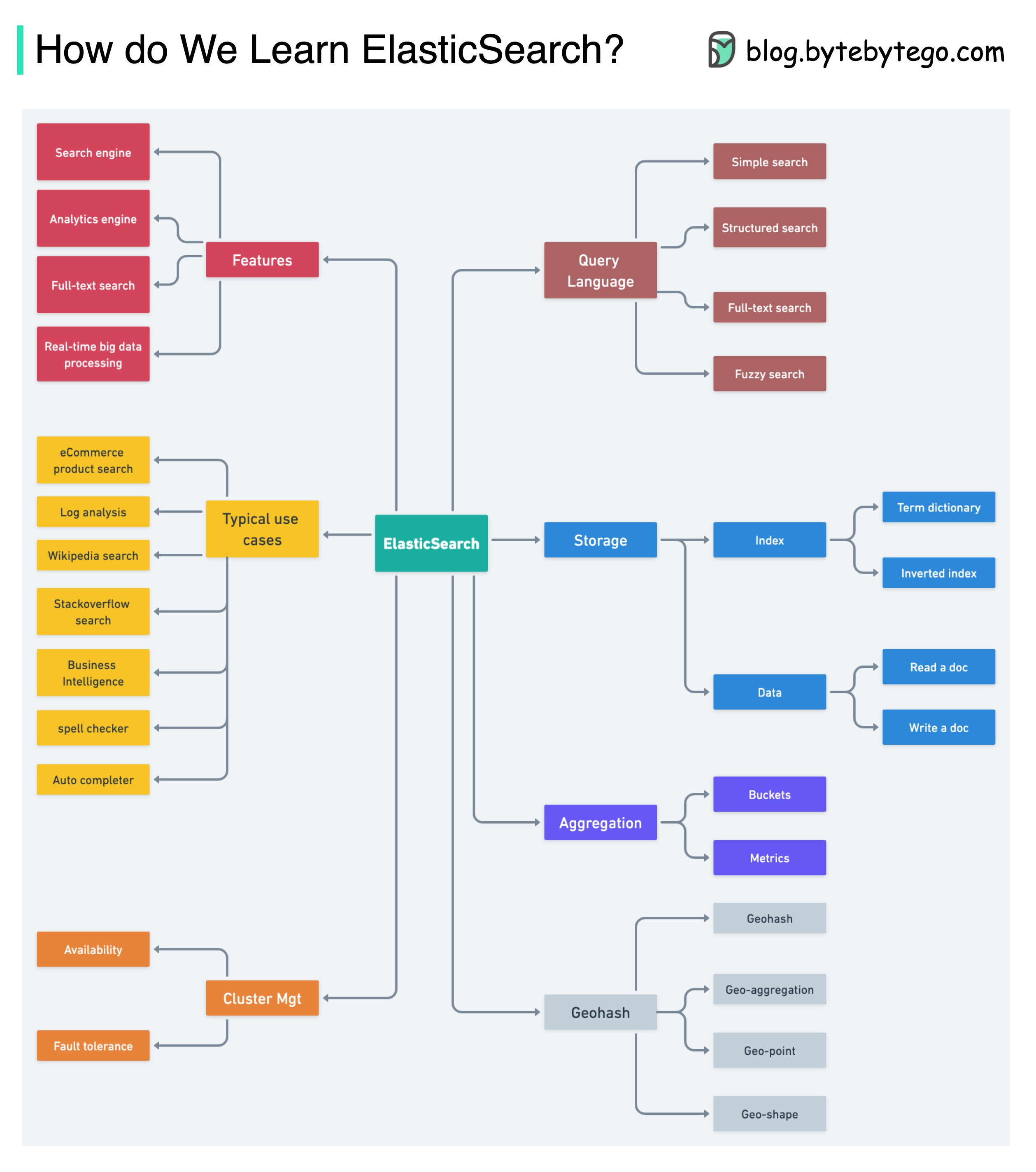
+
+Based on the Lucene library, Elasticsearch provides search capabilities. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. The diagram above shows the outline.
+
+## Features of ElasticSearch:
+
+* Real-time full-text search
+* Analytics engine
+* Distributed Lucene
+
+## ElasticSearch use cases:
+
+* Product search on an eCommerce website
+* Log analysis
+* Auto completer, spell checker
+* Business intelligence analysis
+* Full-text search on Wikipedia
+* Full-text search on StackOverflow
+
+The core of ElasticSearch lies in the data structure and indexing. It is important to understand how ES builds the **term dictionary** using **LSM Tree** (Log-Strucutured Merge Tree).
diff --git a/data/guides/how-do-we-manage-configurations-in-a-system.md b/data/guides/how-do-we-manage-configurations-in-a-system.md
new file mode 100644
index 0000000..7b777ad
--- /dev/null
+++ b/data/guides/how-do-we-manage-configurations-in-a-system.md
@@ -0,0 +1,34 @@
+---
+title: "How do we manage configurations in a system?"
+description: "Comparing traditional configuration management with Infrastructure as Code (IaC)."
+image: "https://assets.bytebytego.com/diagrams/0056-how-we-manage-configuration.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Infrastructure as Code
+ - Configuration Management
+---
+
+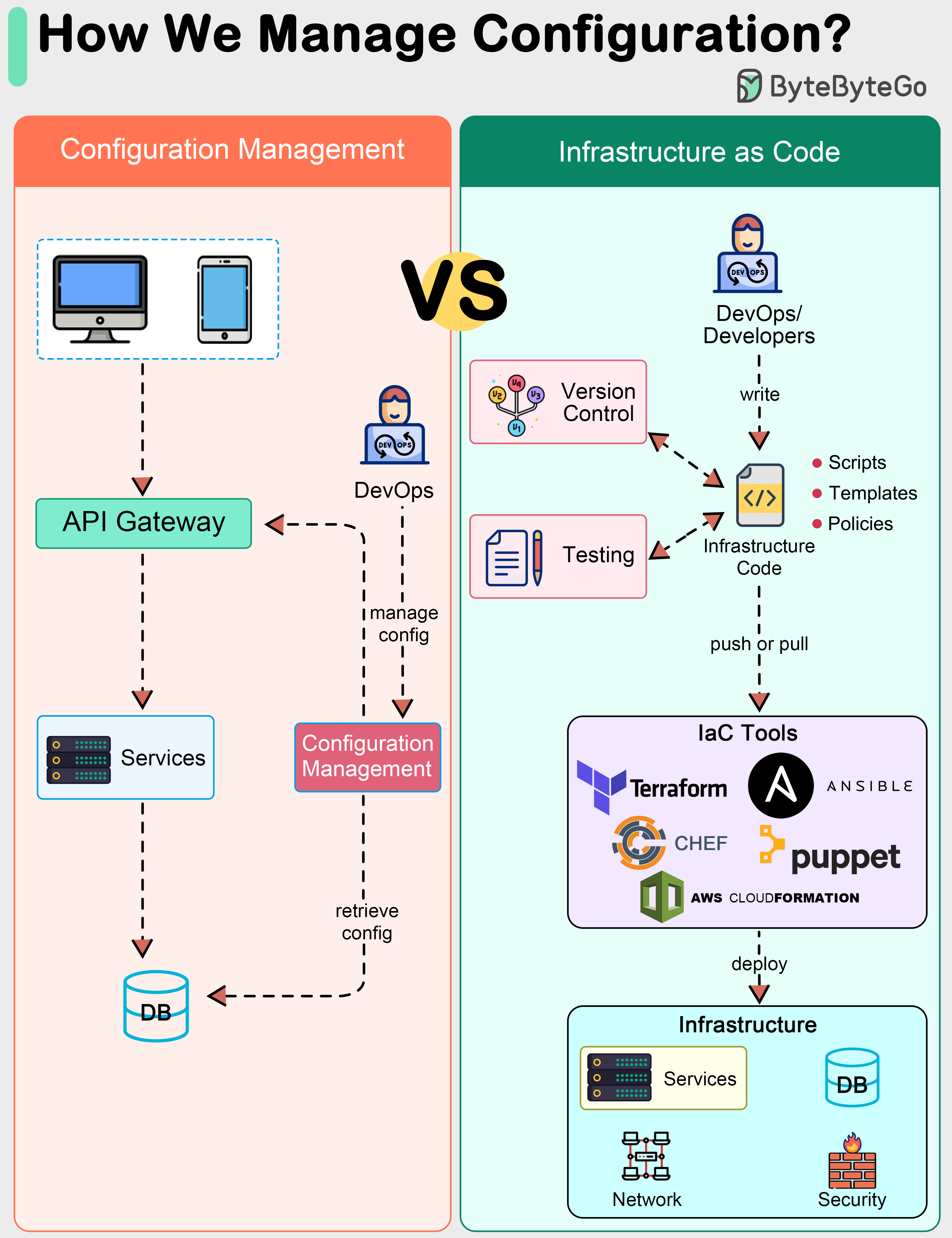
+
+The diagram shows a comparison between traditional configuration management and IaC (Infrastructure as Code).
+
+## Configuration Management
+
+Configuration Management is designed to manage and provision IT infrastructure through systematic and repeatable processes. This is critical for ensuring that the system performs as intended.
+
+Traditional configuration management focuses on maintaining the desired state of the system's configuration items, such as servers, network devices, and applications, after they have been provisioned.
+
+It usually involves initial manual setup by DevOps. Changes are managed by step-by-step commands.
+
+## What is IaC?
+
+IaC, on the other hand, represents a shift in how infrastructure is provisioned and managed, treating infrastructure setup and changes as software development practices.
+
+IaC automates the provisioning of infrastructure, starting and managing the system through code. It often uses a declarative approach, where the desired state of the infrastructure is described.
+
+Tools like Terraform, AWS CloudFormation, Chef, and Puppet are used to define infrastructure in code files that are source controlled.
+
+IaC represents an evolution towards automation, repeatability, and the application of software development practices to infrastructure management.
diff --git a/data/guides/how-do-we-manage-data.md b/data/guides/how-do-we-manage-data.md
new file mode 100644
index 0000000..7044ce4
--- /dev/null
+++ b/data/guides/how-do-we-manage-data.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Data Management Patterns"
+description: "Explore 6 key data management patterns for efficient data handling."
+image: "https://assets.bytebytego.com/diagrams/0379-top-6-data-management-patterns.png"
+createdAt: "2024-02-04"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "data management"
+ - "data patterns"
+---
+
+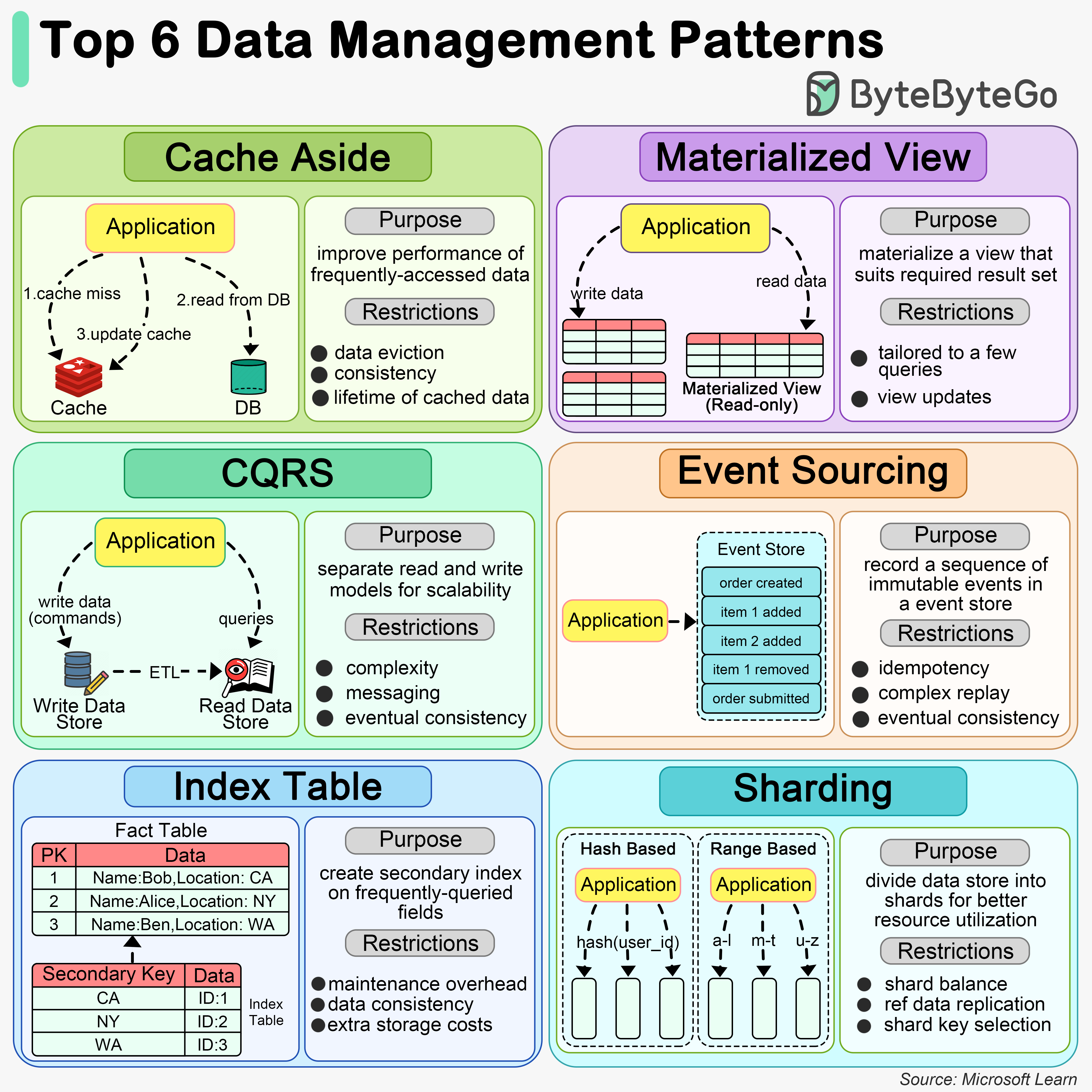
+
+### Here are top 6 data management patterns
+
+## Cache Aside
+
+When an application needs to access data, it first checks the cache. If the data is not present (a cache miss), it fetches the data from the data store, stores it in the cache, and then returns the data to the user. This pattern is particularly useful for scenarios where data is read frequently but updated less often.
+
+## Materialized View
+
+A Materialized View is a database object that contains the results of a query. It is physically stored, meaning the data is actually computed and stored on disk, as opposed to being dynamically generated upon each request. This can significantly speed up query times for complex calculations or aggregations that would otherwise need to be computed on the fly. Materialized views are especially beneficial in data warehousing and business intelligence scenarios where query performance is critical.
+
+## CQRS
+
+CQRS is an architectural pattern that separates the models for reading and writing data. This means that the data structures used for querying data (reads) are separated from the structures used for updating data (writes). This separation allows for optimization of each operation independently, improving performance, scalability, and security. CQRS can be particularly useful in complex systems where the read and write operations have very different requirements.
+
+## Event Sourcing
+
+Event Sourcing is a pattern where changes to the application state are stored as a sequence of events. Instead of storing just the current state of data in a domain, Event Sourcing stores a log of all the changes (events) that have occurred over time. This allows the application to reconstruct past states and provides an audit trail of changes. Event Sourcing is beneficial in scenarios requiring complex business transactions, auditability, and the ability to rollback or replay events.
+
+## Index Table
+
+The Index Table pattern involves creating additional tables in a database that are optimized for specific query operations. These tables act as secondary indexes and are designed to speed up the retrieval of data without requiring a full scan of the primary data store. Index tables are particularly useful in scenarios with large datasets and where certain queries are performed frequently.
+
+## Sharding
+
+Sharding is a data partitioning pattern where data is divided into smaller, more manageable pieces, or "shards", each of which can be stored on different database servers. This pattern is used to distribute the data across multiple machines to improve scalability and performance. Sharding is particularly effective in high-volume applications, as it allows for horizontal scaling, spreading the load across multiple servers to handle more users and transactions.
diff --git a/data/guides/how-do-we-manage-sensitive-data-in-a-system.md b/data/guides/how-do-we-manage-sensitive-data-in-a-system.md
new file mode 100644
index 0000000..6bac697
--- /dev/null
+++ b/data/guides/how-do-we-manage-sensitive-data-in-a-system.md
@@ -0,0 +1,44 @@
+---
+title: "How do we manage sensitive data in a system?"
+description: "A cheat sheet for managing sensitive data in a system."
+image: "https://assets.bytebytego.com/diagrams/0058-cheatsheet-for-managing-sensitive-data.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - security
+tags:
+ - data security
+ - data management
+---
+
+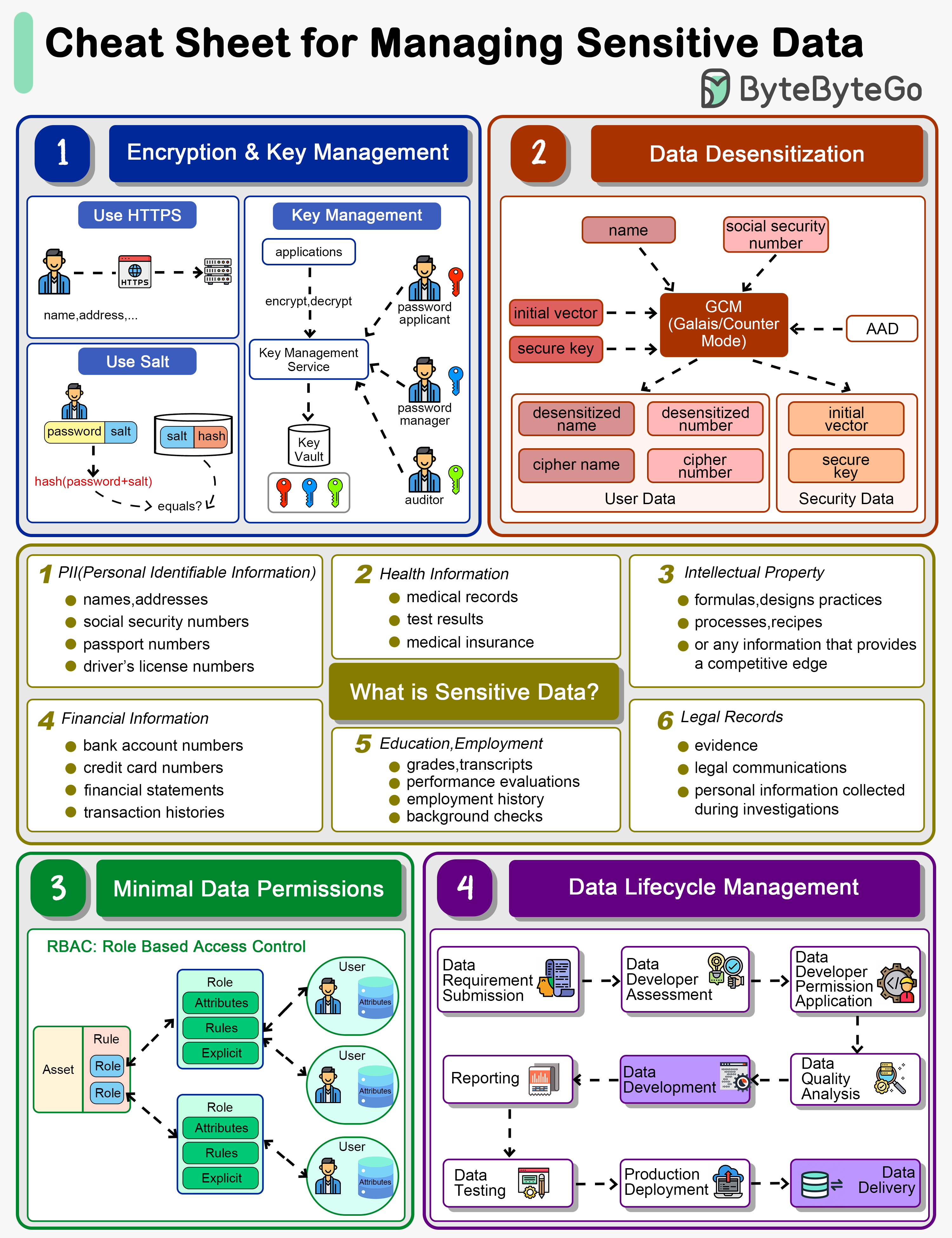
+
+The cheat sheet below shows a list of guidelines.
+
+## What is Sensitive Data?
+
+Personal Identifiable Information (PII), health information, intellectual property, financial information, education and legal records are all sensitive data.
+
+Most countries have laws and regulations that require the protection of sensitive data. For example, the General Data Protection Regulation (GDPR) in the European Union sets stringent rules for data protection and privacy. Non-compliance with such regulations can result in hefty fines, legal actions, and sanctions against the violating entity.
+
+When we design systems, we need to design for data protection.
+
+## Encryption & Key Management
+
+The data transmission needs to be encrypted using SSL. Passwords shouldn’t be stored in plain text.
+
+For key storage, we design different roles including password applicant, password manager and auditor, all holding one piece of the key. We will need all three keys to open a lock.
+
+## Data Desensitization
+
+Data desensitization, also known as data anonymization or data sanitization, refers to the process of removing or modifying personal information from a dataset so that individuals cannot be readily identified. This practice is crucial in protecting individuals' privacy and ensuring compliance with data protection laws and regulations. Data desensitization is often used when sharing data externally, such as for research or statistical analysis, or even internally within an organization, to limit access to sensitive information.
+
+Algorithms like GCM store cipher data and keys separately so that hackers are not able to decipher the user data.
+
+## Minimal Data Permissions
+
+To protect sensitive data, we should grant minimal permissions to the users. Often we design Role-Based Access Control (RBAC) to restrict access to authorized users based on their roles within an organization. It is a widely used access control mechanism that simplifies the management of user permissions, ensuring that users have access to only the information and resources necessary for their roles.
+
+## Data Lifecycle Management
+
+When we develop data products like reports or data feeds, we need to design a process to maintain data quality. Data developers should be granted with necessary permissions during development. After the data is online, they should be revoked from the data access.
diff --git a/data/guides/how-do-we-perform-pagination-in-api-design.md b/data/guides/how-do-we-perform-pagination-in-api-design.md
new file mode 100644
index 0000000..3806b02
--- /dev/null
+++ b/data/guides/how-do-we-perform-pagination-in-api-design.md
@@ -0,0 +1,60 @@
+---
+title: How do we Perform Pagination in API Design?
+description: Learn about API pagination techniques for efficient data retrieval.
+image: 'https://assets.bytebytego.com/diagrams/0076-api-pagination-101.png'
+createdAt: '2024-03-04'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Design
+ - Pagination
+---
+
+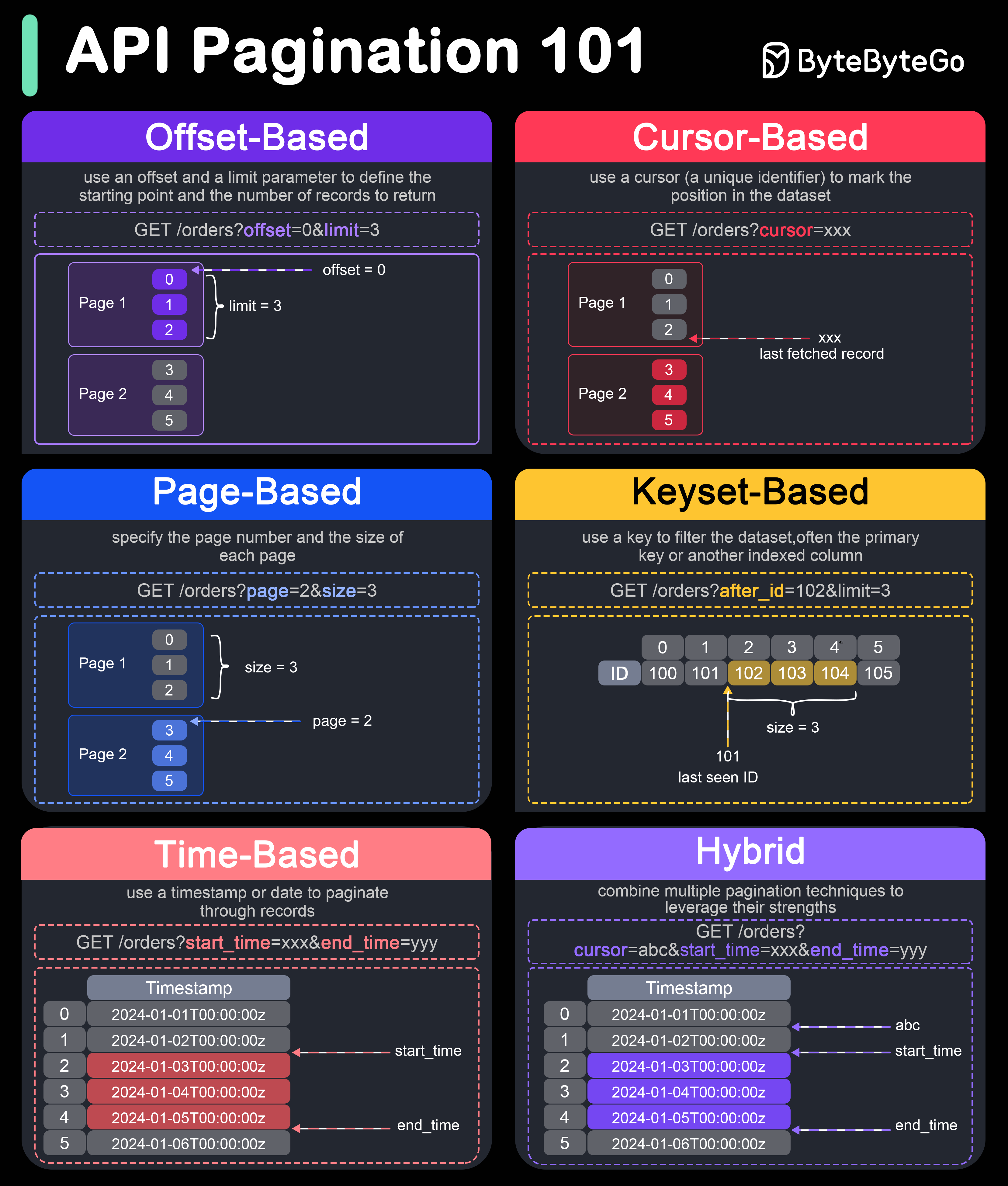
+
+Pagination is crucial in API design to handle large datasets efficiently and improve performance. Here are six popular pagination techniques:
+
+* **Offset-based Pagination:**
+
+ This technique uses an offset and a limit parameter to define the starting point and the number of records to return.
+
+ * Example: GET /orders?offset=0&limit=3
+ * Pros: Simple to implement and understand.
+ * Cons: Can become inefficient for large offsets, as it requires scanning and skipping rows.
+* **Cursor-based Pagination:**
+
+ This technique uses a cursor (a unique identifier) to mark the position in the dataset. Typically, the cursor is an encoded string that points to a specific record.
+
+ * Example: GET /orders?cursor=xxx
+ * Pros: More efficient for large datasets, as it doesn't require scanning skipped records.
+ * Cons: Slightly more complex to implement and understand.
+* **Page-based Pagination:**
+
+ This technique specifies the page number and the size of each page.
+
+ * Example: GET /items?page=2&size=3
+ * Pros: Easy to implement and use.
+ * Cons: Similar performance issues as offset-based pagination for large page numbers.
+* **Keyset-based Pagination:**
+
+ This technique uses a key to filter the dataset, often the primary key or another indexed column.
+
+ * Example: GET /items?after\_id=102&limit=3
+ * Pros: Efficient for large datasets and avoids performance issues with large offsets.
+ * Cons: Requires a unique and indexed key, and can be complex to implement.
+* **Time-based Pagination:**
+
+ This technique uses a timestamp or date to paginate through records.
+
+ * Example: GET /items?start\_time=xxx&end\_time=yyy
+ * Pros: Useful for datasets ordered by time, ensures no records are missed if new ones are added.
+ * Cons: Requires a reliable and consistent timestamp.
+* **Hybrid Pagination:**
+
+ This technique combines multiple pagination techniques to leverage their strengths.
+
+ * Example: Combining cursor and time-based pagination for efficient scrolling through time-ordered records.
+ * Example: GET /items?cursor=abc&start\_time=xxx&end\_time=yyy
+ * Pros: Can offer the best performance and flexibility for complex datasets.
+ * Cons: More complex to implement and requires careful design.
diff --git a/data/guides/how-do-we-retry-on-failures.md b/data/guides/how-do-we-retry-on-failures.md
new file mode 100644
index 0000000..4920d7e
--- /dev/null
+++ b/data/guides/how-do-we-retry-on-failures.md
@@ -0,0 +1,48 @@
+---
+title: "Retry Strategies for System Failures"
+description: "Explore retry strategies for handling transient errors in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0229-how-do-we-retry-on-failures.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "distributed systems"
+ - "retry strategies"
+---
+
+
+
+In distributed systems and networked applications, retry strategies are crucial for handling transient errors and network instability effectively. The diagram shows 4 common retry strategies.
+
+## Linear Backoff
+
+Linear backoff involves waiting for a progressively increasing fixed interval between retry attempts.
+
+* **Advantages**: Simple to implement and understand.
+
+* **Disadvantages**: May not be ideal under high load or in high-concurrency environments as it could lead to resource contention or "retry storms".
+
+## Linear Jitter Backoff
+
+Linear jitter backoff modifies the linear backoff strategy by introducing randomness to the retry intervals. This strategy still increases the delay linearly but adds a random "jitter" to each interval.
+
+* **Advantages**: The randomness helps spread out the retry attempts over time, reducing the chance of synchronized retries across instances.
+
+* **Disadvantages**: Although better than simple linear backoff, this strategy might still lead to potential issues with synchronized retries as the base interval increases only linearly.
+
+## Exponential Backoff
+
+Exponential backoff involves increasing the delay between retries exponentially. The interval might start at 1 second, then increase to 2 seconds, 4 seconds, 8 seconds, and so on, typically up to a maximum delay. This approach is more aggressive in spacing out retries than linear backoff.
+
+* **Advantages**: Significantly reduces the load on the system and the likelihood of collision or overlap in retry attempts, making it suitable for high-load environments.
+
+* **Disadvantages**: In situations where a quick retry might resolve the issue, this approach can unnecessarily delay the resolution.
+
+## Exponential Jitter Backoff
+
+Exponential jitter backoff combines exponential backoff with randomness. After each retry, the backoff interval is exponentially increased, and then a random jitter is applied. The jitter can be either additive (adding a random amount to the exponential delay) or multiplicative (multiplying the exponential delay by a random factor).
+
+* **Advantages**: Offers all the benefits of exponential backoff, with the added advantage of reducing retry collisions even further due to the introduction of jitter.
+
+* **Disadvantages**: The randomness can sometimes result in longer than necessary delays, especially if the jitter is significant.
diff --git a/data/guides/how-do-we-transform-a-system-to-be-cloud-native.md b/data/guides/how-do-we-transform-a-system-to-be-cloud-native.md
new file mode 100644
index 0000000..b911c65
--- /dev/null
+++ b/data/guides/how-do-we-transform-a-system-to-be-cloud-native.md
@@ -0,0 +1,25 @@
+---
+title: "How to Transform a System to be Cloud Native"
+description: "A blueprint for adopting cloud-native architecture in your organization."
+image: "https://assets.bytebytego.com/diagrams/0149-how-doe-we-adopt-cloud-native.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "cloud-native"
+ - "architecture"
+---
+
+The diagram below shows the action spectrum and adoption roadmap. You can use it as a blueprint for adopting cloud-native in your organization.
+
+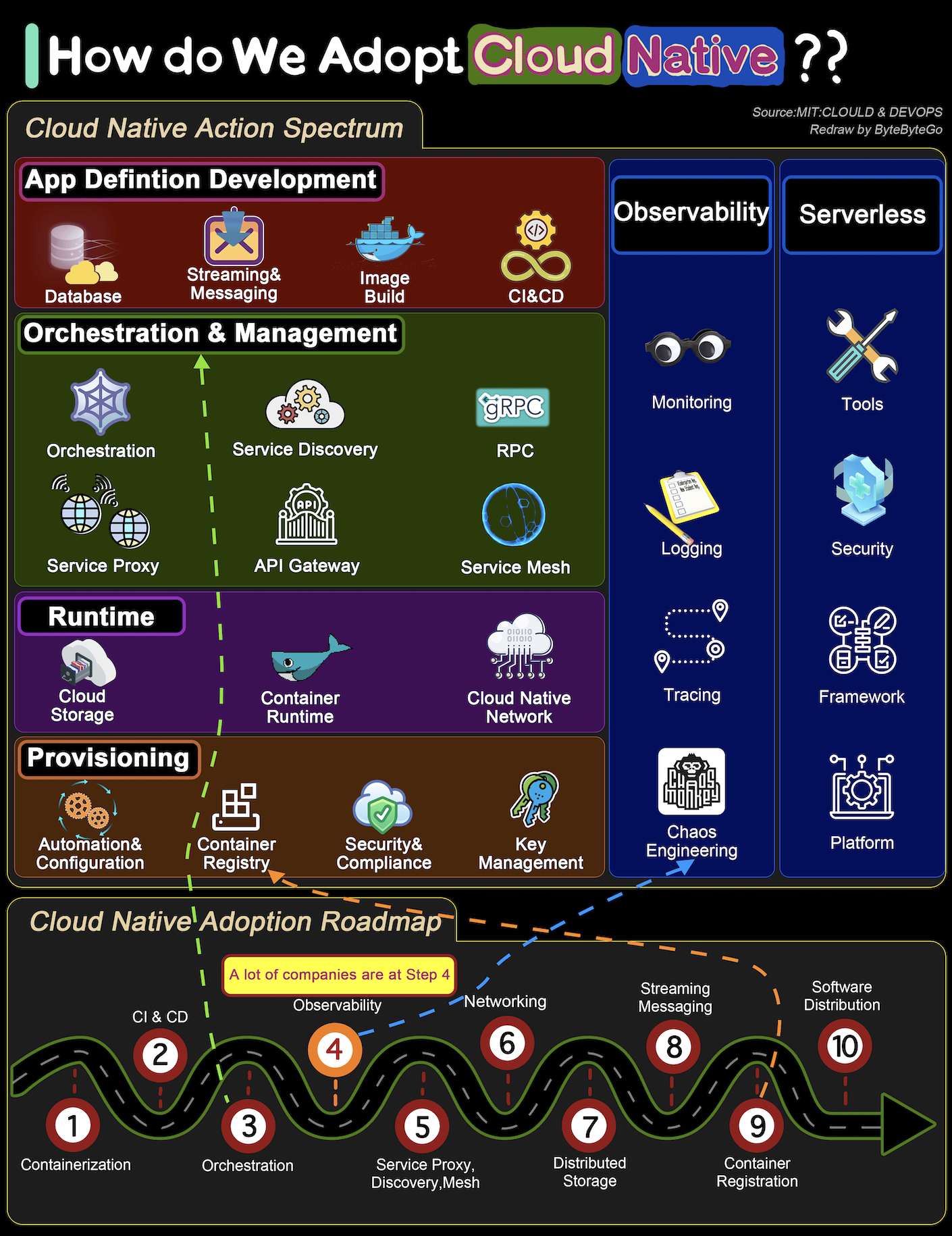
+
+For a company to adopt cloud native architecture, there are 6 aspects in the spectrum:
+
+* Application definition development
+* Orchestration and management
+* Runtime
+* Provisioning
+* Observability
+* Serverless
diff --git a/data/guides/how-do-you-decide-which-type-of-database-to-use.md b/data/guides/how-do-you-decide-which-type-of-database-to-use.md
new file mode 100644
index 0000000..a319073
--- /dev/null
+++ b/data/guides/how-do-you-decide-which-type-of-database-to-use.md
@@ -0,0 +1,30 @@
+---
+title: "How to Decide Which Type of Database to Use"
+description: "A guide to choosing the right database for your specific needs."
+image: "https://assets.bytebytego.com/diagrams/0160-database-types.jpg"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - database selection
+ - database types
+---
+
+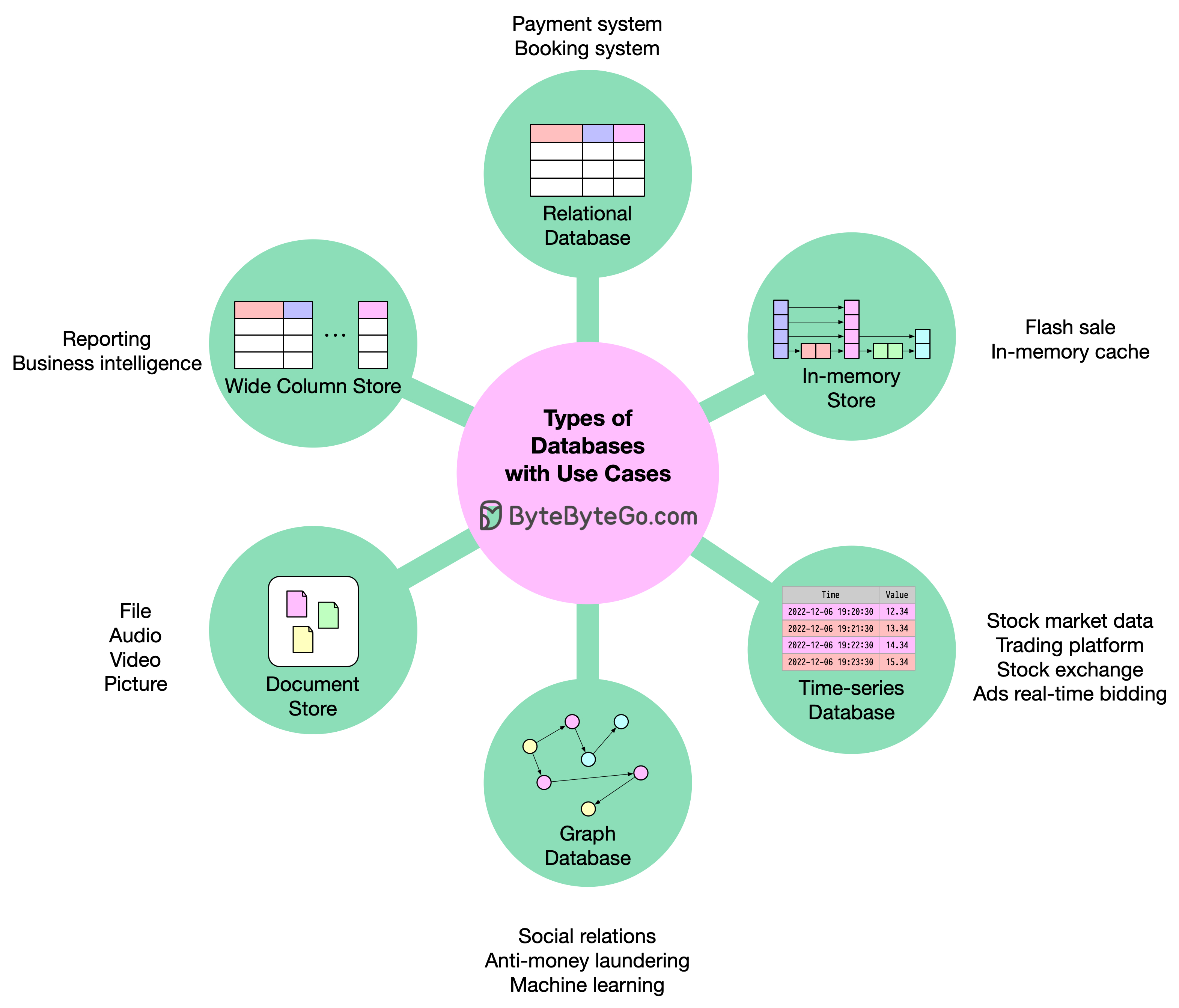
+
+There are hundreds or even thousands of databases available today, such as Oracle, MySQL, MariaDB, SQLite, PostgreSQL, Redis, ClickHouse, MongoDB, S3, Ceph, etc. How do you select the architecture for your system? My short summary is as follows:
+
+## Database Types
+
+* Relational database: Almost anything could be solved by them.
+
+* In-memory store: Their speed and limited data size make them ideal for fast operations.
+
+* Time-series database: Store and manage time-stamped data.
+
+* Graph database: It is suitable for complex relationships between unstructured objects.
+
+* Document store: They are good for large immutable data.
+
+* Wide column store: They are usually used for big data, analytics, reporting, etc., which needs denormalized data.
diff --git a/data/guides/how-does-a-password-manager-such-as-1password-or-lastpass-work.md b/data/guides/how-does-a-password-manager-such-as-1password-or-lastpass-work.md
new file mode 100644
index 0000000..84e87cb
--- /dev/null
+++ b/data/guides/how-does-a-password-manager-such-as-1password-or-lastpass-work.md
@@ -0,0 +1,42 @@
+---
+title: "How Password Managers Work"
+description: "Learn how password managers like 1Password and LastPass keep passwords safe."
+image: "https://assets.bytebytego.com/diagrams/0297-password-manager.png"
+createdAt: "2024-02-14"
+draft: false
+categories:
+ - security
+tags:
+ - "security"
+ - "passwords"
+---
+
+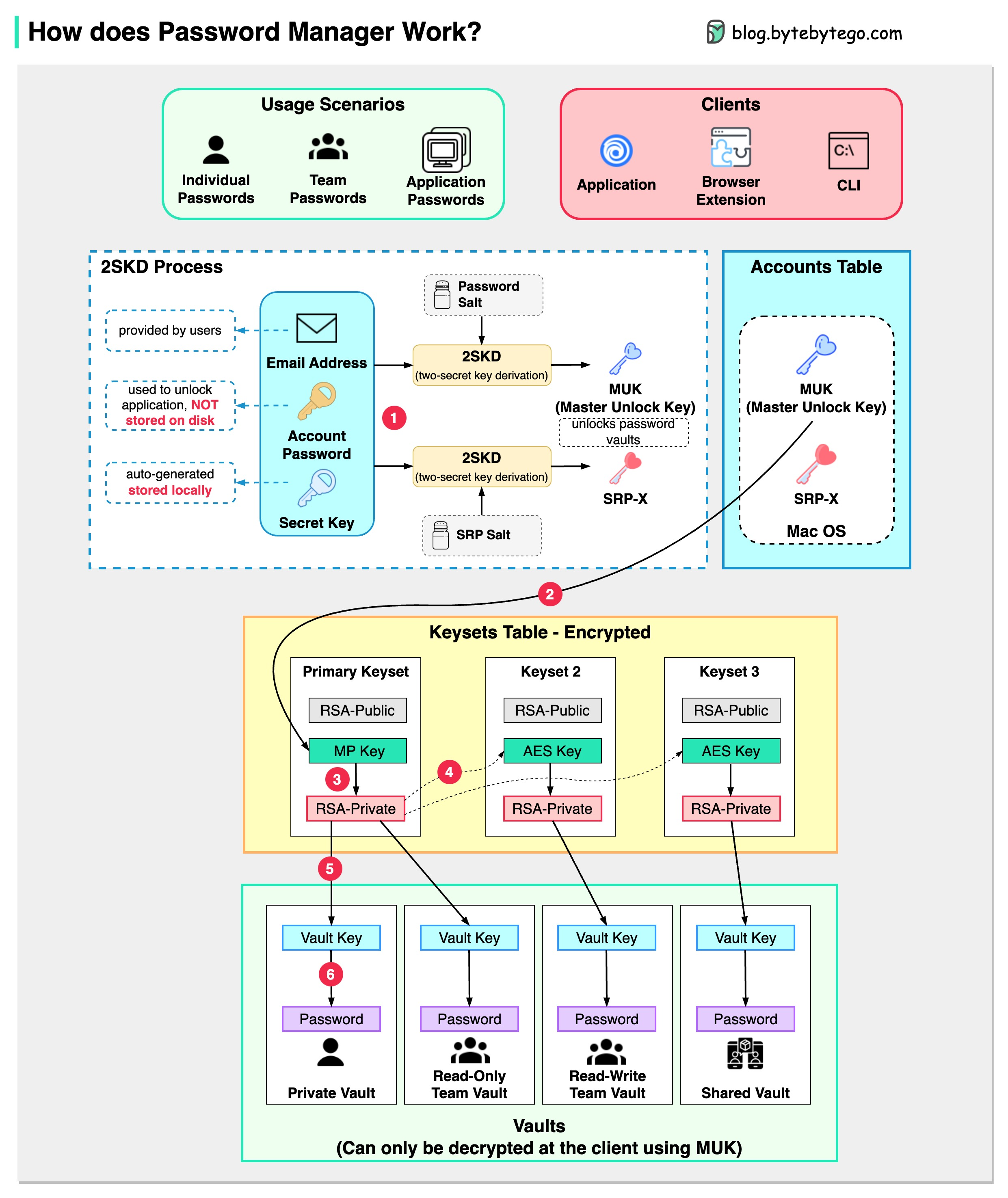
+
+How does it keep our passwords safe?
+
+The diagram below shows how a typical password manager works.
+
+A password manager generates and stores passwords for us. We can use it via application, browser extension, or command line.
+
+Not only does a password manager store passwords for individuals but also it supports password management for teams in small businesses and big enterprises.
+
+Let’s go through the steps.
+
+## Step 1
+
+When we sign up for a password manager, we enter our email address and set up an account password. The password manager generates a secret key for us. The 3 fields are used to generate MUK (Master Unlock Key) and SRP-X using the 2SKD algorithm. MUK is used to decrypt vaults that store our passwords. Note that the secret key is stored locally, and will not be sent to the password manager’s server side.
+
+## Step 2
+
+The MUK generated in Step 1 is used to generate the encrypted MP key of the primary keyset.
+
+## Steps 3-5
+
+The MP key is then used to generate a private key, which can be used to generate AES keys in other keysets. The private key is also used to generate the vault key. Vault stores a collection of items for us on the server side. The items can be passwords notes etc.
+
+## Step 6
+
+The vault key is used to encrypt the items in the vault.
+
+Because of the complex process, the password manager has no way to know the encrypted passwords. We only need to remember one account password, and the password manager will remember the rest.
diff --git a/data/guides/how-does-a-typical-push-notification-system-work.md b/data/guides/how-does-a-typical-push-notification-system-work.md
new file mode 100644
index 0000000..69ece5f
--- /dev/null
+++ b/data/guides/how-does-a-typical-push-notification-system-work.md
@@ -0,0 +1,29 @@
+---
+title: How Does a Typical Push Notification System Work?
+description: Explore the architecture of a typical push notification system.
+image: 'https://assets.bytebytego.com/diagrams/0042-design-a-notification-push-system.png'
+createdAt: '2024-02-24'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Notifications
+---
+
+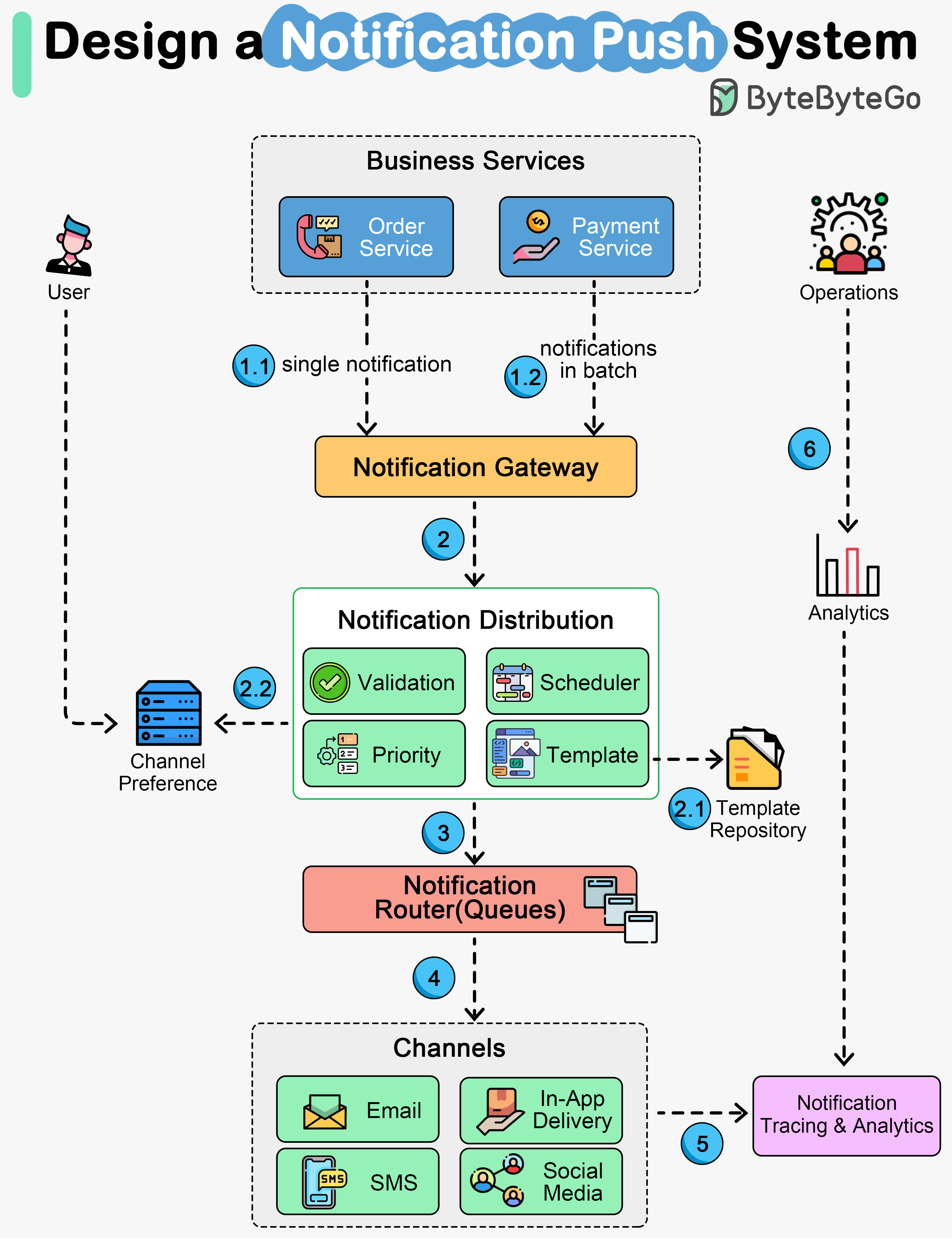
+
+The diagram above shows the architecture of a notification system that covers major notification channels:
+
+* **In-App notifications**
+* **Email notifications**
+* **SMS and OTP notifications**
+* **Social media pushes**
+
+Let’s walk through the steps.
+
+* Steps 1.1 and 1.2 - The business services send notifications to the notification gateway. The gateway can handle two modes: one mode receives one notification each time, and the other receives notifications in batches.
+* Steps 2, 2.1, and 2.2 - The notification gateway forwards the notifications to the distribution service, where the messages are validated, formatted, and scheduled based on settings. The notification template repository allows users to pre-define the message format. The channel preference repository allows users to pre-define the preferred delivery channels.
+* Step 3 - The notifications are then sent to the routers, normally message queues.
+* Step 4 - The channel services communicate with various internal and external delivery channels, including in-app notifications, email delivery, SMS delivery, and social media apps.
+* Steps 5 and 6 - The delivery metrics are captured by the notification tracking and analytics service, where the operations team can view the analytical reports and improve user experiences.
diff --git a/data/guides/how-does-a-vpn-work.md b/data/guides/how-does-a-vpn-work.md
new file mode 100644
index 0000000..d667d97
--- /dev/null
+++ b/data/guides/how-does-a-vpn-work.md
@@ -0,0 +1,44 @@
+---
+title: "How Does a VPN Work?"
+description: "Explore how VPNs create secure connections for online privacy."
+image: "https://assets.bytebytego.com/diagrams/0052-how-a-vpn-works.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - security
+tags:
+ - "VPN"
+ - "Security"
+---
+
+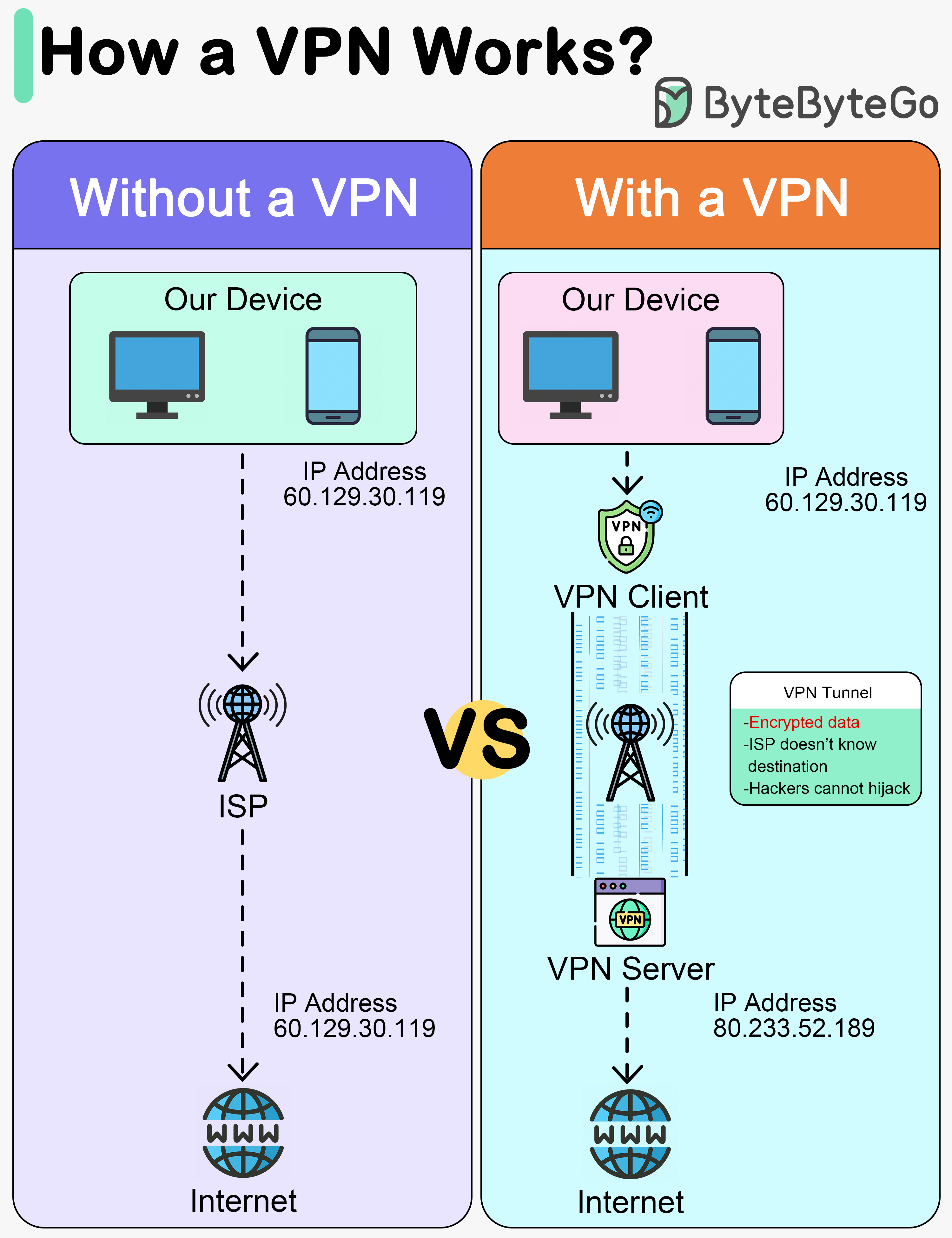
+
+This diagram below shows how we access the internet with and without VPNs.
+
+A VPN, or Virtual Private Network, is a technology that creates a secure, encrypted connection over a less secure network, such as the public internet. The primary purpose of a VPN is to provide privacy and security to data and communications.
+
+A VPN acts as a tunnel through which the encrypted data goes from one location to another. Any external party cannot see the data transferring.
+
+A VPN works in 4 steps:
+
+* Step 1 - Establish a secure tunnel between our device and the VPN server.
+
+* Step 2 - Encrypt the data transmitted.
+
+* Step 3 - Mask our IP address, so it appears as if our internet activity is coming from the VPN server.
+
+* Step 4 - Our internet traffic is routed through the VPN server.
+
+## Advantages of a VPN:
+
+* **Privacy**
+* **Anonymity**
+* **Security**
+* **Encryption**
+* **Masking the original IP address**
+
+## Disadvantages of a VPN:
+
+* **VPN blocking**
+* **Slow down connections**
+* **Trust in VPN provider**
diff --git a/data/guides/how-does-ach-payment-work.md b/data/guides/how-does-ach-payment-work.md
new file mode 100644
index 0000000..1fb5dfe
--- /dev/null
+++ b/data/guides/how-does-ach-payment-work.md
@@ -0,0 +1,36 @@
+---
+title: "How ACH Payment Works"
+description: "Learn how ACH payments work in the US, including direct deposit."
+image: "https://assets.bytebytego.com/diagrams/0067-how-does-ach-payment-work.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - ACH
+ - Payments
+---
+
+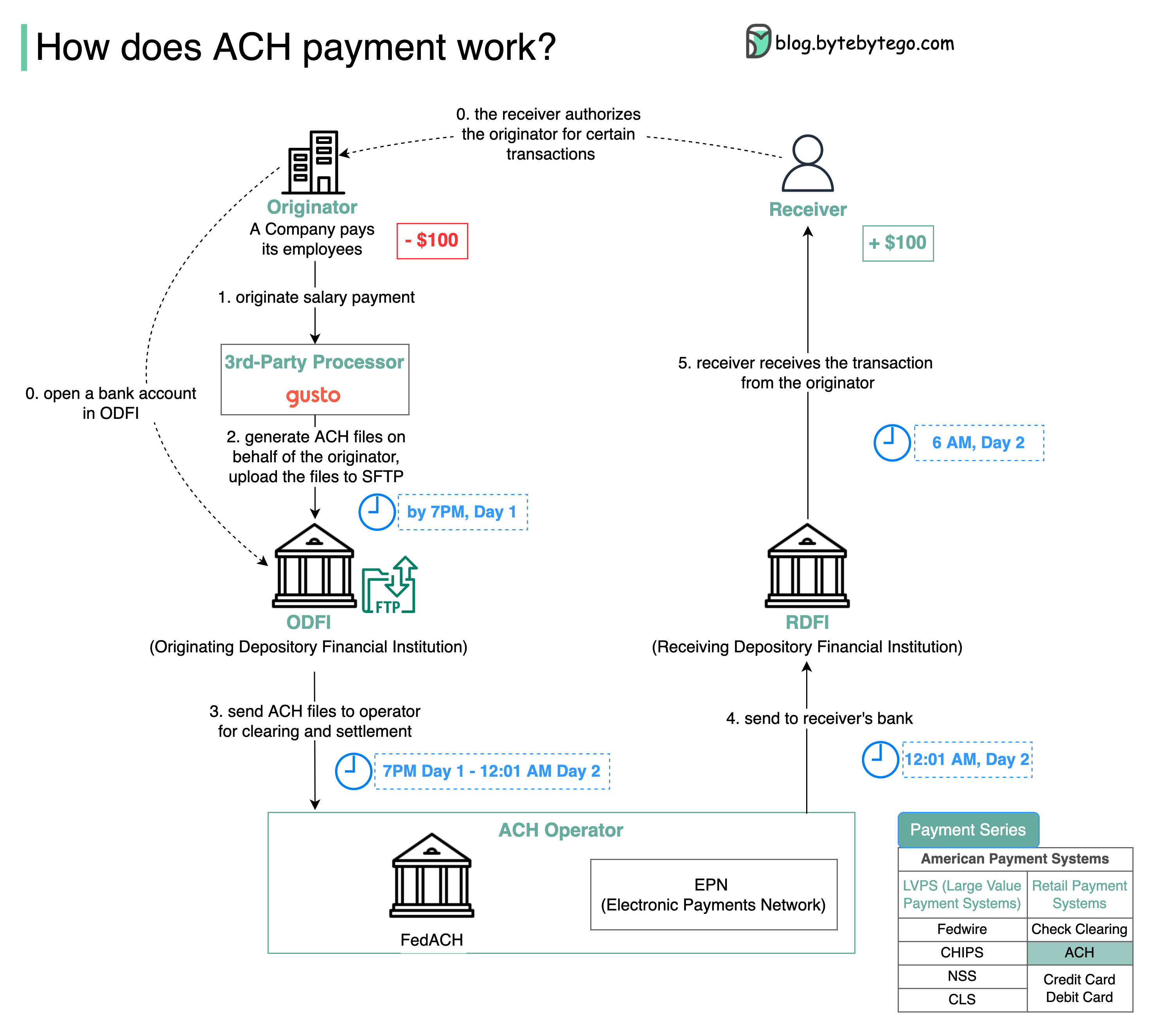
+
+Do you know how you get paid at work? In the US, tech companies usually run payrolls via Automatic Clearing House (**ACH**).
+
+ACH handles retail transactions and is part of American retail payment systems. It processes transactions in **batches**, not in real-time. The diagram above shows how ACH direct deposit works with payrolls.
+
+### How ACH Direct Deposit Works
+
+* Step 0: Before we can use the ACH network, the originator who starts the transactions needs to open an account at a commercial bank because only banks are allowed to initiate ACH transactions directly. The bank is called ODFI (Originating Depository Financial Institution). Then the transaction receiver needs to authorize the originator for certain types of transactions.
+
+* Step 1: The originator company originates salary payment transactions. The transactions are sent to a 3rd-party processor like Gusto. The third-party processor helps with ACH-related services like generating ACH files, etc.
+
+* Step 2: The third-party processor generates ACH files on behalf of the originator. The files are uploaded to an SFTP established by the ODFI. This should be done by the 7 PM cut-off time, as specified by the ODFI bank.
+
+* Step 3: After normal business hours in the evening, the ODFI bank forwards the ACH files to the ACH operator for clearing and settlement. There are two ACH operators, one is the Federal Reserve (FedACH), and the other is EPN (Electronic Payment Network – which is operated by a private company).
+
+* Step 4: The ACH files are processed around midnight and made available to the receiving bank RDFI (Receiving Depository Financial Institution.)
+
+* Step 5: The RDFI operates on the receiver’s bank accounts based on the instructions in the ACH files. In our case, the receiver receives $100 from the originator. This is done when the RDFI opens for business at 6 AM the next day.
+
+ACH is a next-day settlement system. It means transactions sent out by 7 PM on one day will arrive the following morning.
+
+Since 2018, it’s possible to choose Same Day ACH so funds can be transferred on the same business day.
diff --git a/data/guides/how-does-amazon-build-system-work.md b/data/guides/how-does-amazon-build-system-work.md
new file mode 100644
index 0000000..a17f17b
--- /dev/null
+++ b/data/guides/how-does-amazon-build-system-work.md
@@ -0,0 +1,26 @@
+---
+title: "Amazon's Build System: Brazil"
+description: "Explore Amazon's Brazil build system for micro-repo driven collaboration."
+image: "https://assets.bytebytego.com/diagrams/0069-amazon-build-system.jpeg"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Build Systems
+ - Amazon
+---
+
+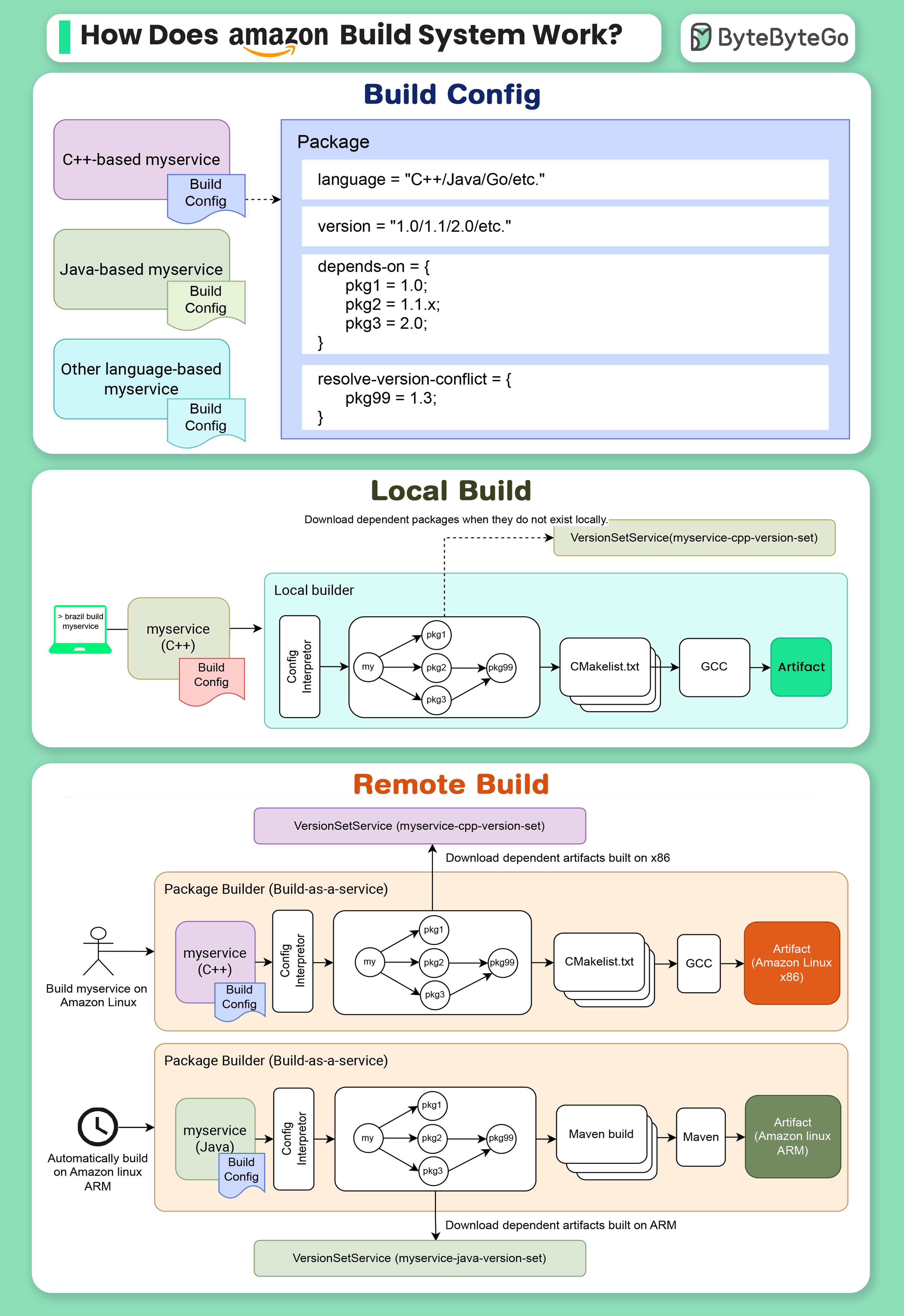
+
+Discover Amazon's innovative build system - Brazil.
+
+Amazon's ownership model requires each team to manage its own repositories, which allows for more rapid innovation. Amazon has created a unique build system, known as Brazil, to enhance productivity and empower Amazon’s micro-repo driven collaboration. This system is certainly worth examining!
+
+With Brazil, developers can focus on developing the code and create a simple-to-understand build configuration file. The build system will then process the output artifact repeatedly and consistently. The build config minimizes the build requirement, including language, versioning, dependencies, major versions, and lastly, how to resolve version conflicts.
+
+For local builds, the Brazil build tool interprets the build configuration as a Directed Acyclic Graph (DAG), retrieves packages from the myservice’s private space (VersionSet) called myservice-cpp-version-set, generates the language-specific build configuration, and employs the specific build tool to produce the output artifact.
+
+A version set is a collection of package versions that offers a private space for the package and its dependencies. When a new package dependency is introduced, it must also be merged into this private space. There is a default version set called "live," which serves as a public space where anyone can publish any version.
+
+Remotely, the package builder service provides an intuitive experience by selecting a version set and building targets. This service supports Amazon Linux on x86, x64, and ARM. Builds can be initiated manually or automatically upon a new commit to the master branch. The package builder guarantees build consistency and reproducibility, with each build process being snapshotted and the output artifact versioned.
diff --git a/data/guides/how-does-aws-lambda-work-behind-the-scenes.md b/data/guides/how-does-aws-lambda-work-behind-the-scenes.md
new file mode 100644
index 0000000..8758bee
--- /dev/null
+++ b/data/guides/how-does-aws-lambda-work-behind-the-scenes.md
@@ -0,0 +1,42 @@
+---
+title: "How AWS Lambda Works Behind the Scenes"
+description: "Explore the inner workings of AWS Lambda and its serverless architecture."
+image: "https://assets.bytebytego.com/diagrams/0249-lambda.jpg"
+createdAt: "2024-01-26"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "AWS Lambda"
+ - "Serverless"
+---
+
+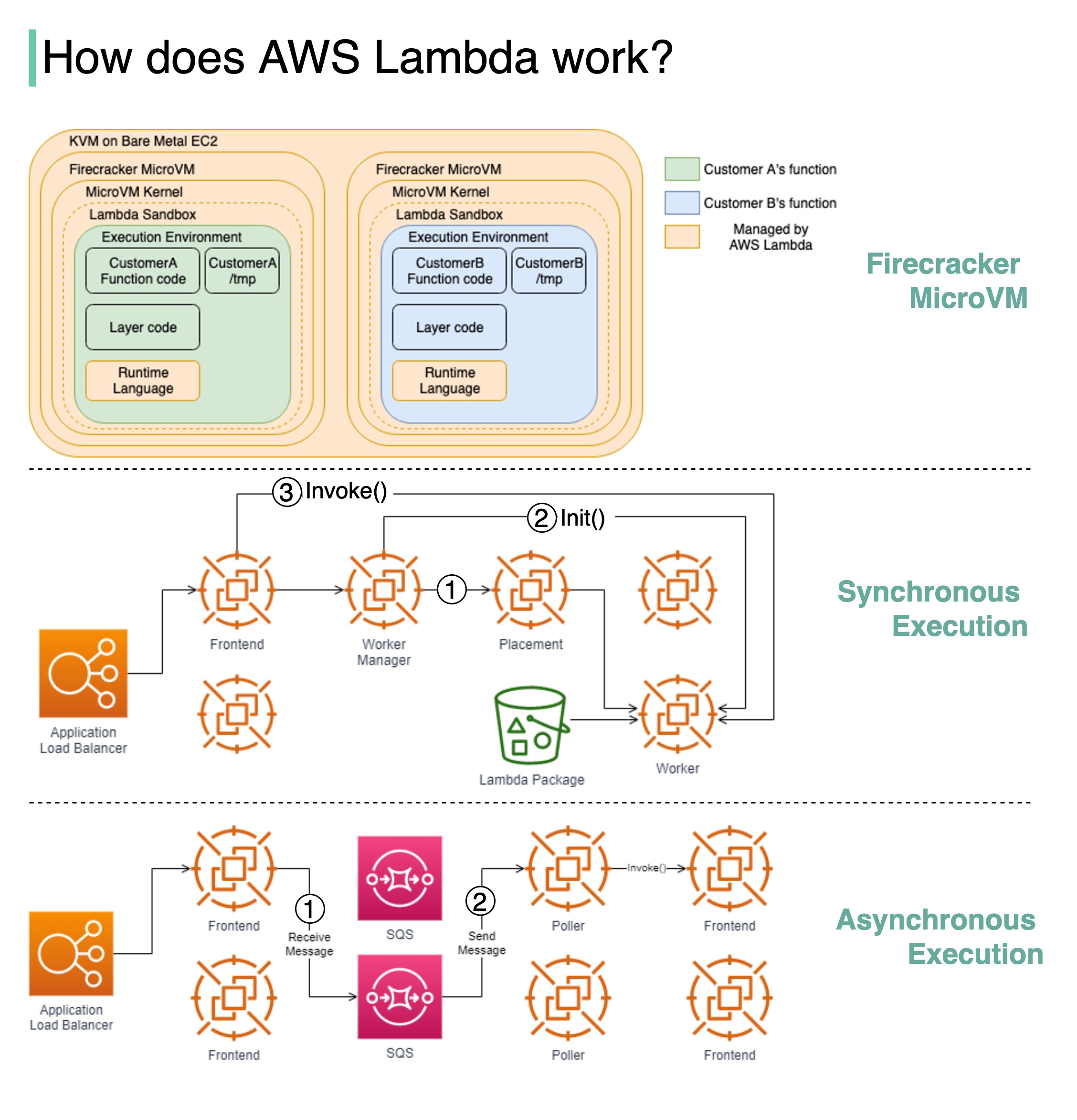
+
+**Serverless** is one of the hottest topics in cloud services. How does AWS **Lambda** work behind the scenes?
+
+Lambda is a **serverless** computing service provided by Amazon Web Services (AWS), which runs functions in response to events.
+
+## Firecracker MicroVM
+
+Firecracker is the engine powering all of the Lambda functions. It is a virtualization technology developed at Amazon and written in Rust.
+
+The diagram below illustrates the isolation model for AWS Lambda Workers.
+
+Lambda functions run within a sandbox, which provides a minimal Linux userland, some common libraries and utilities. It creates the Execution environment (worker) on EC2 instances.
+
+How are lambdas initiated and invoked? There are two ways.
+
+## Synchronous execution
+
+* Step1: "The Worker Manager communicates with a Placement Service which is responsible to place a workload on a location for the given host (it’s provisioning the sandbox) and returns that to the Worker Manager".
+
+* Step 2: "The Worker Manager can then call *Init* to initialize the function for execution by downloading the Lambda package from S3 and setting up the Lambda runtime"
+
+* Step 3: The Frontend Worker is now able to call *Invoke*.
+
+## Asynchronous execution
+
+* Step 1: The Application Load Balancer forwards the invocation to an available Frontend which places the event onto an internal queue(SQS).
+
+* Step 2: There is "a set of pollers assigned to this internal queue which are responsible for polling it and moving the event onto a Frontend synchronously. After it’s been placed onto the Frontend it follows the synchronous invocation call pattern which we covered earlier".
diff --git a/data/guides/how-does-chatgpt-work.md b/data/guides/how-does-chatgpt-work.md
new file mode 100644
index 0000000..05f603b
--- /dev/null
+++ b/data/guides/how-does-chatgpt-work.md
@@ -0,0 +1,36 @@
+---
+title: How does ChatGPT work?
+description: This article explains how ChatGPT works in detail.
+image: 'https://assets.bytebytego.com/diagrams/0135-chat-gpt.jpeg'
+createdAt: '2024-03-15'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - ChatGPT
+ - Machine Learning
+---
+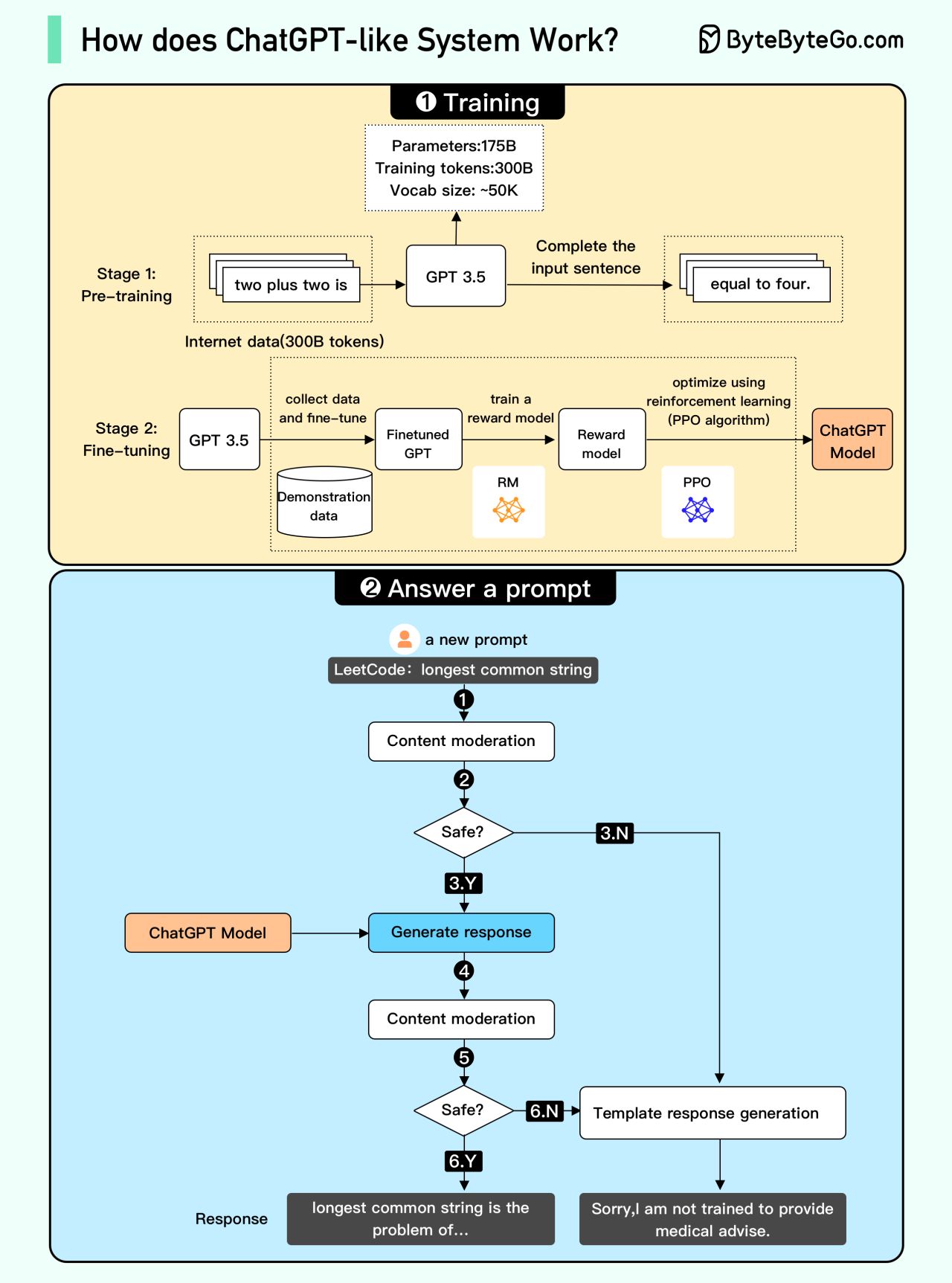
+
+Since OpenAI hasn't provided all the details, some parts of the diagram may be inaccurate.
+
+We attempted to explain how it works in the diagram above. The process can be broken down into two parts.
+
+## Training
+
+To train a ChatGPT model, there are two stages:
+
+- **Pre-training:** In this stage, we train a GPT model (decoder-only transformer) on a large chunk of internet data. The objective is to train a model that can predict future words given a sentence in a way that is grammatically correct and semantically meaningful similar to the internet data. After the pre-training stage, the model can complete given sentences, but it is not capable of responding to questions.
+
+- **Fine-tuning:** This stage is a 3-step process that turns the pre-trained model into a question-answering ChatGPT model:
+ - Collect training data (questions and answers), and fine-tune the pre-trained model on this data. The model takes a question as input and learns to generate an answer similar to the training data.
+ - Collect more data (question, several answers) and train a reward model to rank these answers from most relevant to least relevant.
+ - Use reinforcement learning (PPO optimization) to fine-tune the model so the model's answers are more accurate.
+
+## Answer a prompt
+
+- Step 1: The user enters the full question, “Explain how a classification algorithm works”.
+- Step 2: The question is sent to a content moderation component. This component ensures that the question does not violate safety guidelines and filters inappropriate questions.
+- Steps 3-4: If the input passes content moderation, it is sent to the chatGPT model. If the input doesn’t pass content moderation, it goes straight to template response generation.
+- Step 5-6: Once the model generates the response, it is sent to a content moderation component again. This ensures the generated response is safe, harmless, unbiased, etc.
+- Step 7: If the input passes content moderation, it is shown to the user. If the input doesn’t pass content moderation, it goes to template response generation and shows a template answer to the user.
diff --git a/data/guides/how-does-cnd-work.md b/data/guides/how-does-cnd-work.md
new file mode 100644
index 0000000..525753e
--- /dev/null
+++ b/data/guides/how-does-cnd-work.md
@@ -0,0 +1,44 @@
+---
+title: "How Does CDN Work?"
+description: "Explore how Content Delivery Networks (CDNs) accelerate content delivery."
+image: "https://assets.bytebytego.com/diagrams/0230-how-cdn-works.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "CDN"
+ - "Networking"
+---
+
+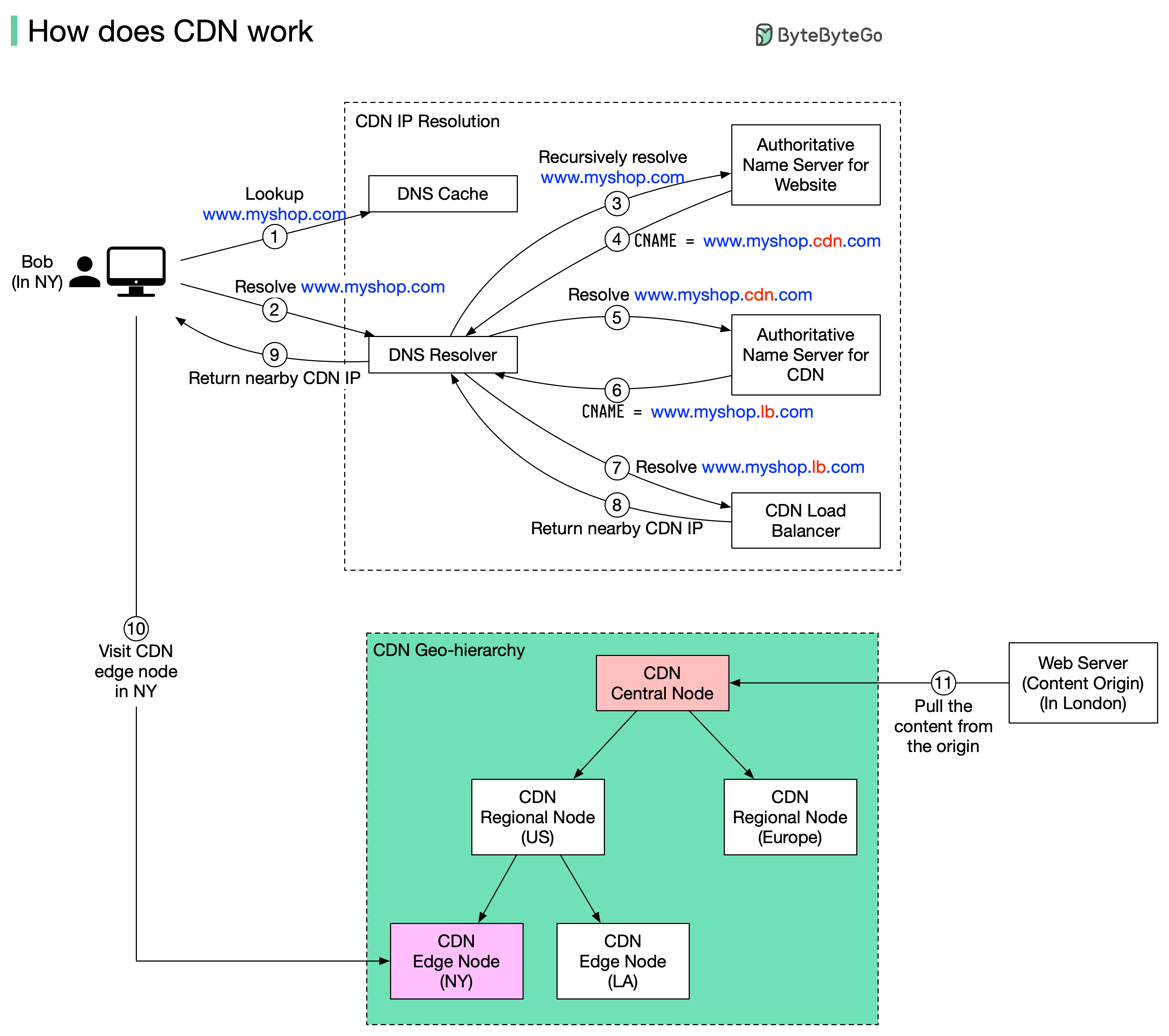
+
+A content delivery network (CDN) refers to geographically distributed servers (also called edge servers) that provide fast delivery of static and dynamic content. Let’s take a look at how it works.
+
+Suppose Bob who lives in New York wants to visit an eCommerce website that is deployed in London. If the request goes to servers located in London, the response will be quite slow. So we deploy CDN servers close to where Bob lives, and the content will be loaded from the nearby CDN server.
+
+The diagram above illustrates the process:
+
+## How CDN Works
+
+* Bob types in [www.myshop.com](http://www.myshop.com/) in the browser. The browser looks up the domain name in the local DNS cache.
+
+* If the domain name does not exist in the local DNS cache, the browser goes to the DNS resolver to resolve the name. The DNS resolver usually sits in the Internet Service Provider (ISP).
+
+* The DNS resolver recursively resolves the domain name (see my previous post for details). Finally, it asks the authoritative name server to resolve the domain name.
+
+* If we don’t use CDN, the authoritative name server returns the IP address for [www.myshop.com](http://www.myshop.com/). But with CDN, the authoritative name server has an alias pointing to [www.myshop.cdn.com](http://www.myshop.cdn.com/) (the domain name of the CDN server).
+
+* The DNS resolver asks the authoritative name server to resolve [www.myshop.cdn.com](http://www.myshop.cdn.com/).
+
+* The authoritative name server returns the domain name for the load balancer of CDN [www.myshop.lb.com](http://www.myshop.lb.com/).
+
+* The DNS resolver asks the CDN load balancer to resolve [www.myshop.lb.com](http://www.myshop.lb.com/). The load balancer chooses an optimal CDN edge server based on the user’s IP address, user’s ISP, the content requested, and the server load.
+
+* The CDN load balancer returns the CDN edge server’s IP address for [www.myshop.lb.com](http://www.myshop.lb.com/).
+
+* Now we finally get the actual IP address to visit. The DNS resolver returns the IP address to the browser.
+
+* The browser visits the CDN edge server to load the content. There are two types of contents cached on the CDN servers: static contents and dynamic contents. The former contains static pages, pictures, videos; the latter one includes results of edge computing.
+
+* If the edge CDN server cache doesn't contain the content, it goes upward to the regional CDN server. If the content is still not found, it will go upward to the central CDN server, or even go to the origin - the London web server. This is called the CDN distribution network, where the servers are deployed geographically.
diff --git a/data/guides/how-does-docker-work.md b/data/guides/how-does-docker-work.md
new file mode 100644
index 0000000..5fe7b26
--- /dev/null
+++ b/data/guides/how-does-docker-work.md
@@ -0,0 +1,38 @@
+---
+title: "How does Docker work?"
+description: "Explore the inner workings of Docker: architecture and key components."
+image: "https://assets.bytebytego.com/diagrams/0414-how-does-docker-work.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Docker"
+ - "Containers"
+---
+
+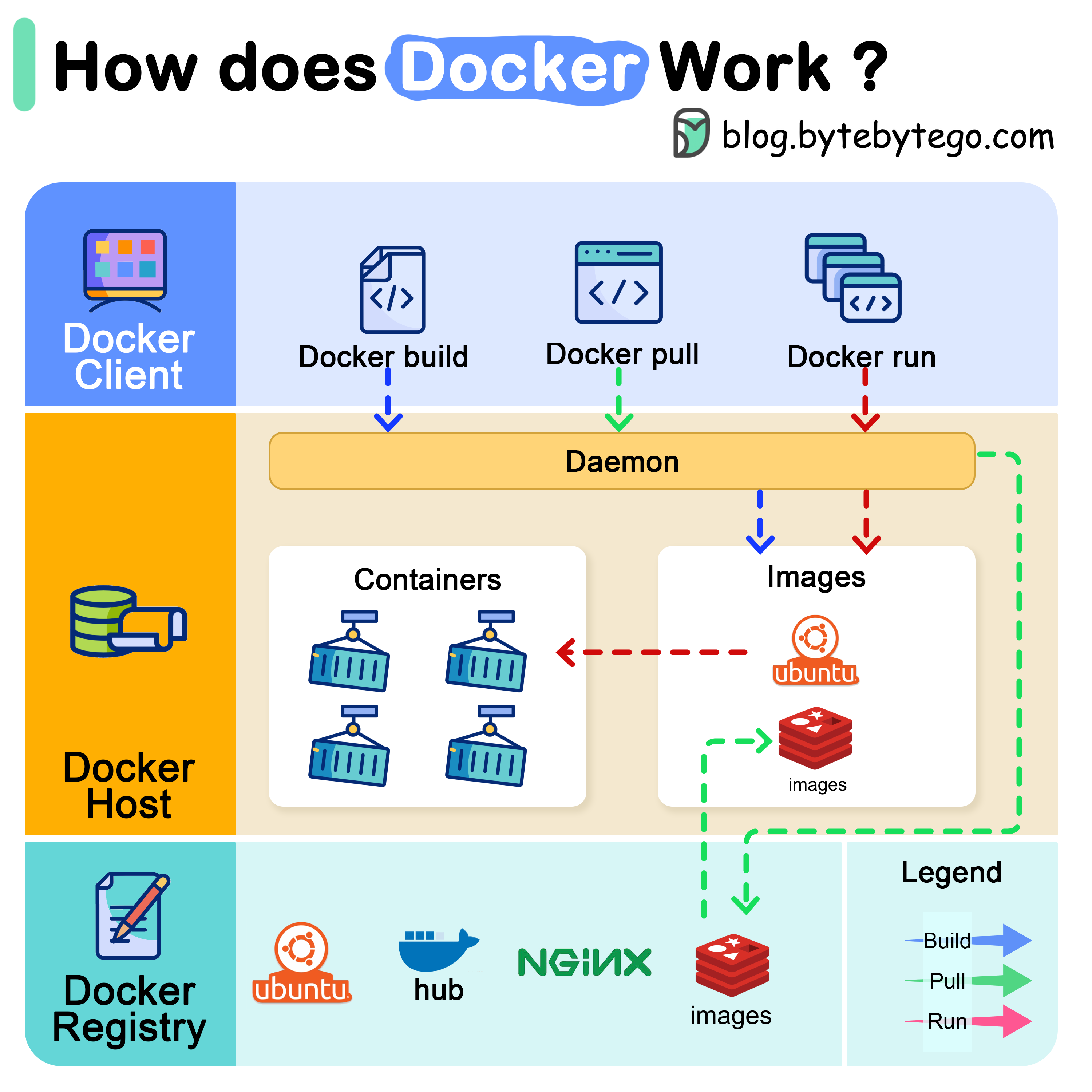
+
+The diagram below shows the architecture of Docker and how it works when we run “docker build”, “docker pull” and “docker run”.
+
+There are 3 components in Docker architecture:
+
+* **Docker client**
+
+ The docker client talks to the Docker daemon.
+
+* **Docker host**
+
+ The Docker daemon listens for Docker API requests and manages Docker objects such as images, containers, networks, and volumes.
+
+* **Docker registry**
+
+ A Docker registry stores Docker images. Docker Hub is a public registry that anyone can use.
+
+Let’s take the “docker run” command as an example.
+
+* Docker pulls the image from the registry.
+* Docker creates a new container.
+* Docker allocates a read-write filesystem to the container.
+* Docker creates a network interface to connect the container to the default network.
+* Docker starts the container.
diff --git a/data/guides/how-does-garbage-collection-work.md b/data/guides/how-does-garbage-collection-work.md
new file mode 100644
index 0000000..ecbd281
--- /dev/null
+++ b/data/guides/how-does-garbage-collection-work.md
@@ -0,0 +1,42 @@
+---
+title: "How does Garbage Collection work?"
+description: "Explore how garbage collection reclaims unused memory automatically."
+image: "https://assets.bytebytego.com/diagrams/0200-garbage-collection-101.png"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - software-development
+tags:
+ - "garbage collection"
+ - "memory management"
+---
+
+Garbage collection is an automatic memory management feature used in programming languages to reclaim memory no longer used by the program.
+
+
+
+## Java
+
+Java provides several garbage collectors, each suited for different use cases:
+
+* Serial Garbage Collector: Best for single-threaded environments or small applications.
+
+* Parallel Garbage Collector: Also known as the "Throughput Collector."
+
+* CMS (Concurrent Mark-Sweep) Garbage Collector: Low-latency collector aiming to minimize pause times.
+
+* G1 (Garbage-First) Garbage Collector: Aims to balance throughput and latency.
+
+* Z Garbage Collector (ZGC): A low-latency garbage collector designed for applications that require large heap sizes and minimal pause times.
+
+## Python
+
+Python's garbage collection is based on reference counting and a cyclic garbage collector:
+
+* Reference Counting: Each object has a reference count; when it reaches zero, the memory is freed.
+
+* Cyclic Garbage Collector: Handles circular references that can't be resolved by reference counting.
+
+## GoLang
+
+Concurrent Mark-and-Sweep Garbage Collector: Go's garbage collector operates concurrently with the application, minimizing stop-the-world pauses.
diff --git a/data/guides/how-does-git-work.md b/data/guides/how-does-git-work.md
new file mode 100644
index 0000000..737f2ed
--- /dev/null
+++ b/data/guides/how-does-git-work.md
@@ -0,0 +1,26 @@
+---
+title: "How Git Works"
+description: "Understanding the inner workings of Git and its storage locations."
+image: "https://assets.bytebytego.com/diagrams/0202-git-commands.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "git"
+ - "version control"
+---
+
+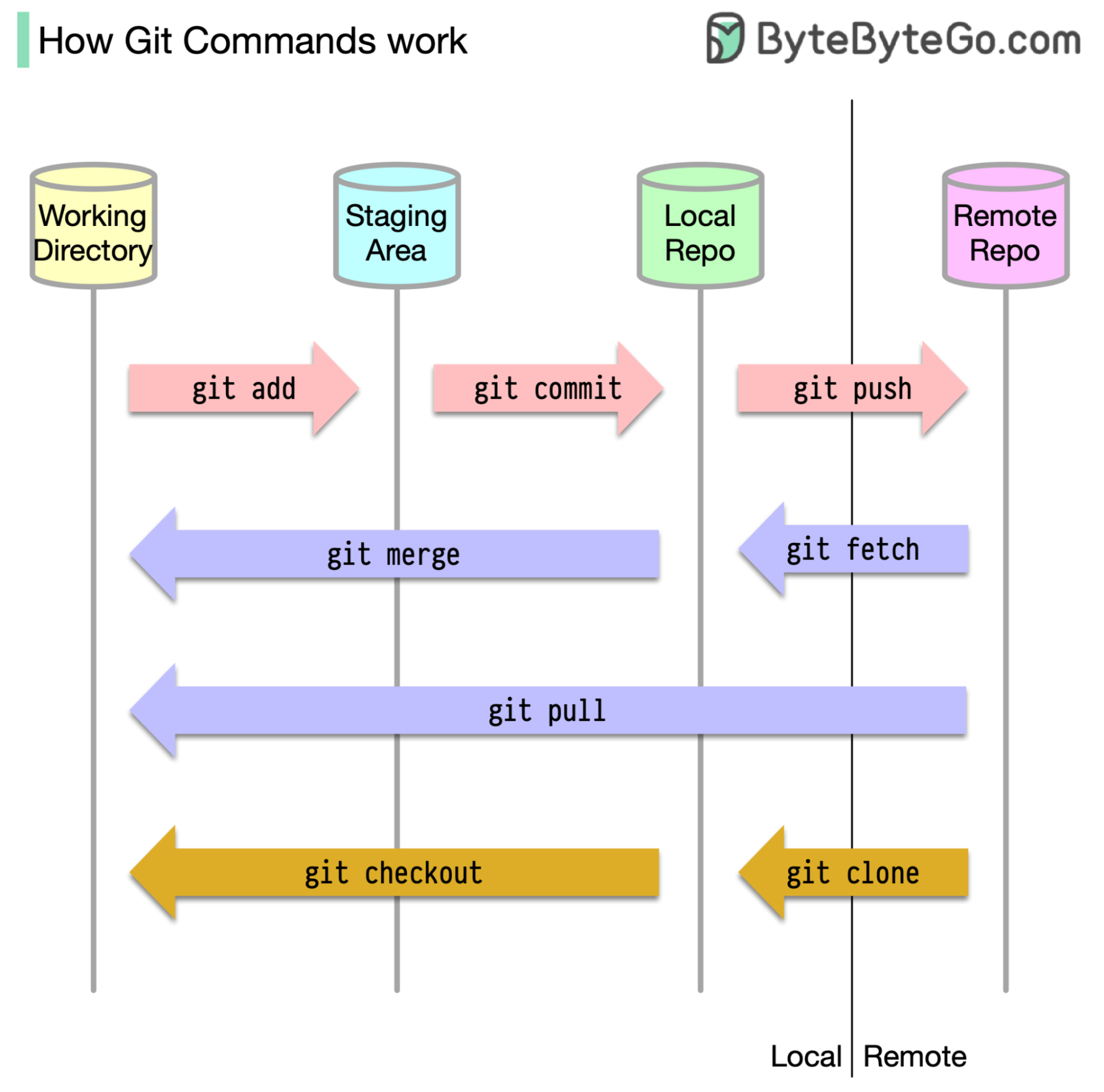
+
+To begin with, it's essential to identify where our code is stored. The common assumption is that there are only two locations - one on a remote server like Github and the other on our local machine. However, this isn't entirely accurate. Git maintains three local storages on our machine, which means that our code can be found in four places:
+
+* Working directory: where we edit files
+
+* Staging area: a temporary location where files are kept for the next commit
+
+* Local repository: contains the code that has been committed
+
+* Remote repository: the remote server that stores the code
+
+Most Git commands primarily move files between these four locations.
diff --git a/data/guides/how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work.md b/data/guides/how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work.md
new file mode 100644
index 0000000..9283f99
--- /dev/null
+++ b/data/guides/how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work.md
@@ -0,0 +1,52 @@
+---
+title: "How Google Authenticator Works"
+description: "Explore the mechanics of Google Authenticator and 2-factor authentication."
+image: "https://assets.bytebytego.com/diagrams/0079-authenticator.jpg"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - security
+tags:
+ - "2FA"
+ - "Authentication"
+---
+
+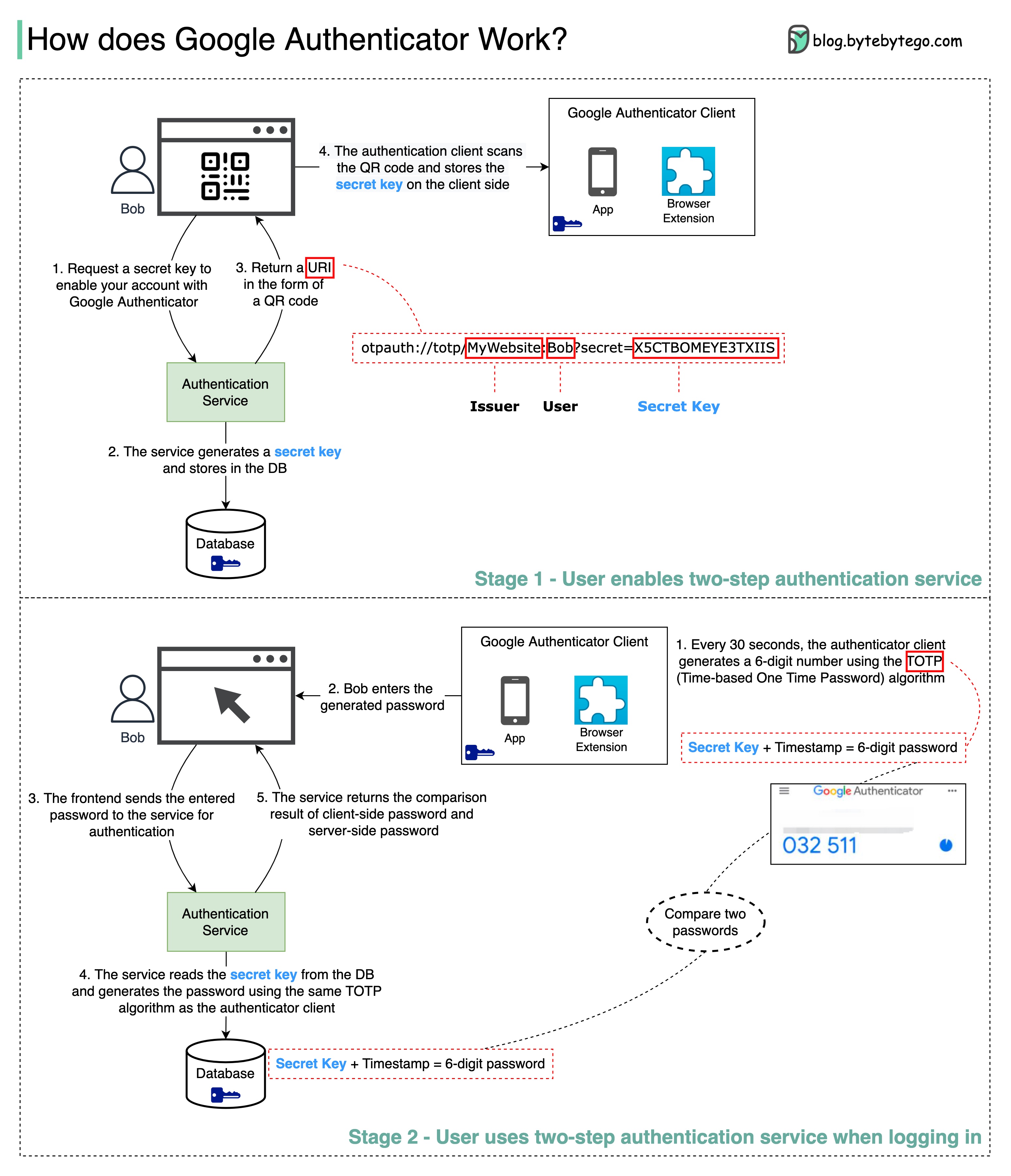
+
+Google Authenticator is commonly used for logging into our accounts when 2-factor authentication is enabled. How does it guarantee security?
+
+Google Authenticator is a software-based authenticator that implements a two-step verification service. The diagram below provides detail.
+
+There are two stages involved:
+
+* Stage 1 - The user enables Google two-step verification
+
+* Stage 2 - The user uses the authenticator for logging in, etc.
+
+Let’s look at these stages.
+
+## Stage 1
+
+Steps 1 and 2: Bob opens the web page to enable two-step verification. The front end requests a secret key. The authentication service generates the secret key for Bob and stores it in the database.
+
+Step 3: The authentication service returns a URI to the frontend. The URI is composed of a key issuer, username, and secret key. The URI is displayed in the form of a QR code on the web page.
+
+Step 4: Bob then uses Google Authenticator to scan the generated QR code. The secret key is stored in the authenticator.
+
+## Stage 2
+
+Steps 1 and 2: Bob wants to log into a website with Google two-step verification. For this, he needs the password. Every 30 seconds, Google Authenticator generates a 6-digit password using the TOTP (Time-based One Time Password) algorithm. Bob uses the password to enter the website.
+
+Steps 3 and 4: The frontend sends the password Bob enters to the backend for authentication. The authentication service reads the secret key from the database and generates a 6-digit password using the same TOTP algorithm as the client.
+
+Step 5: The authentication service compares the two passwords generated by the client and the server, and returns the comparison result to the frontend. Bob can proceed with the login process only if the two passwords match.
+
+### Is this authentication mechanism safe?
+
+Can the secret key be obtained by others?
+
+We need to make sure the secret key is transmitted using HTTPS. The authenticator client and the database store the secret key, and we need to make sure the secret keys are encrypted.
+
+Can the 6-digit password be guessed by hackers?
+
+No. The password has 6 digits, so the generated password has 1 million potential combinations. Plus, the password changes every 30 seconds. If hackers want to guess the password in 30 seconds, they need to enter 30,000 combinations per second.
diff --git a/data/guides/how-does-graphql-work-in-the-real-world.md b/data/guides/how-does-graphql-work-in-the-real-world.md
new file mode 100644
index 0000000..7c79746
--- /dev/null
+++ b/data/guides/how-does-graphql-work-in-the-real-world.md
@@ -0,0 +1,43 @@
+---
+title: How GraphQL Works at LinkedIn
+description: Learn how LinkedIn uses GraphQL to improve its development workflow.
+image: 'https://assets.bytebytego.com/diagrams/0209-graphql-linkedin.jpeg'
+createdAt: '2024-02-12'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - GraphQL
+ - LinkedIn
+---
+
+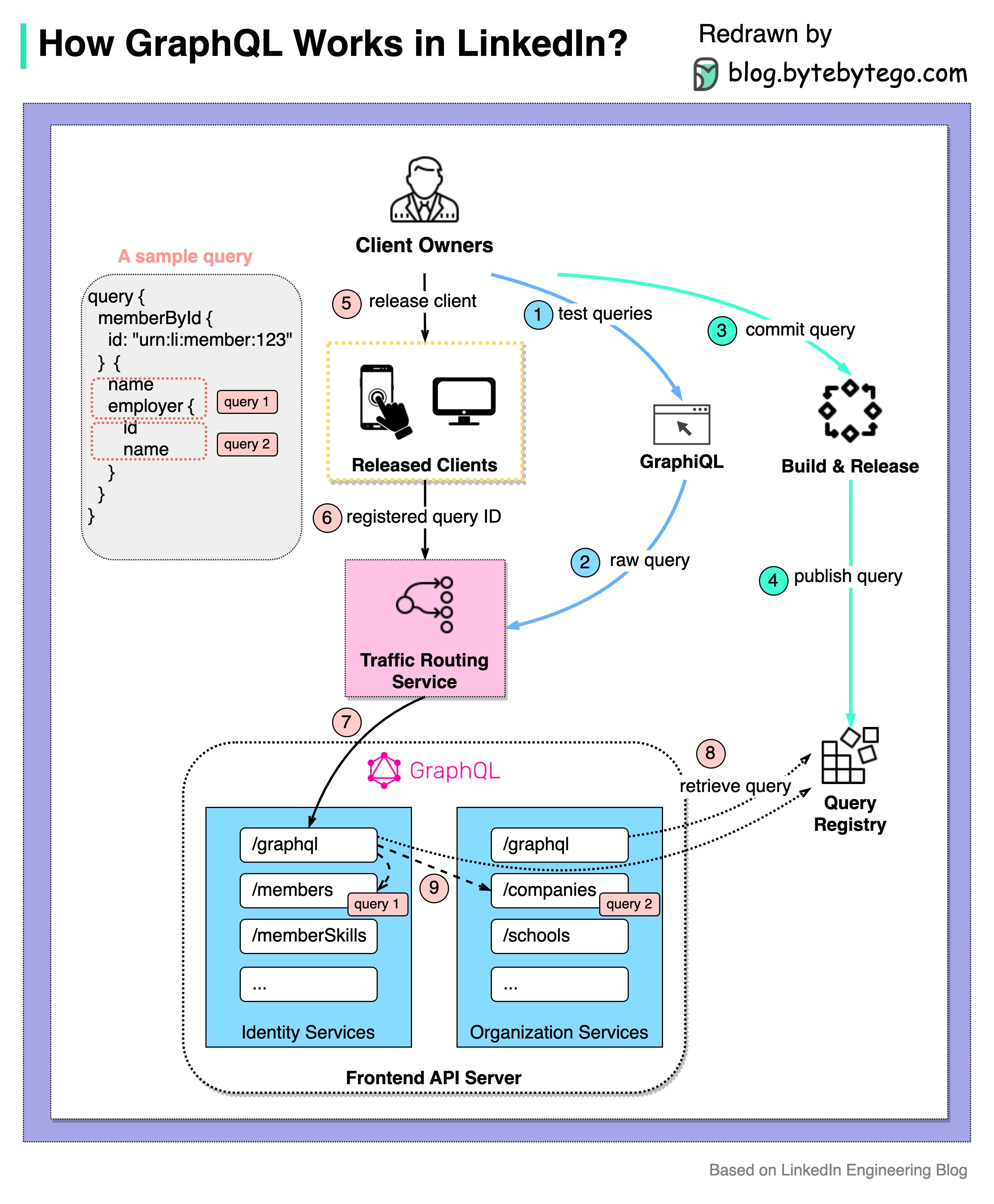
+
+The diagram above shows how LinkedIn adopts GraphQL.
+
+“Moving to GraphQL was a huge initiative that changed the development workflow for thousands of engineers...” \[1\]
+
+The overall workflow after adopting GraphQL has 3 parts:
+
+## Part 1 - Edit and Test a Query
+
+**Steps 1-2:** The client-side developer develops a query and tests with backend services.
+
+## Part 2 - Register a Query
+
+**Steps 3-4:** The client-side developer commits the query and publishes the query to the query registry.
+
+## Part 3 - Use in Production
+
+**Step 5:** The query is released together with the client code.
+
+**Steps 6-7:** The routing metadata is included with each registered query. The metadata is used at the traffic routing tier to route the incoming requests to the correct service cluster.
+
+**Step 8:** The registered queries are cached at service runtime.
+
+**Step 9:** The sample query goes to the identity service first to retrieve members and then goes to the organization service to retrieve company information.
+
+LinkedIn doesn’t deploy a GraphQL gateway for two reasons:
+
+1. Prevent an additional network hop
+2. Avoid single point of failure
diff --git a/data/guides/how-does-grpc-work.md b/data/guides/how-does-grpc-work.md
new file mode 100644
index 0000000..da39fb5
--- /dev/null
+++ b/data/guides/how-does-grpc-work.md
@@ -0,0 +1,30 @@
+---
+title: How does gRPC work?
+description: Learn how gRPC works, its data flow, and performance benefits.
+image: 'https://assets.bytebytego.com/diagrams/0210-grpc.png'
+createdAt: '2024-01-28'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - gRPC
+ - RPC
+---
+
+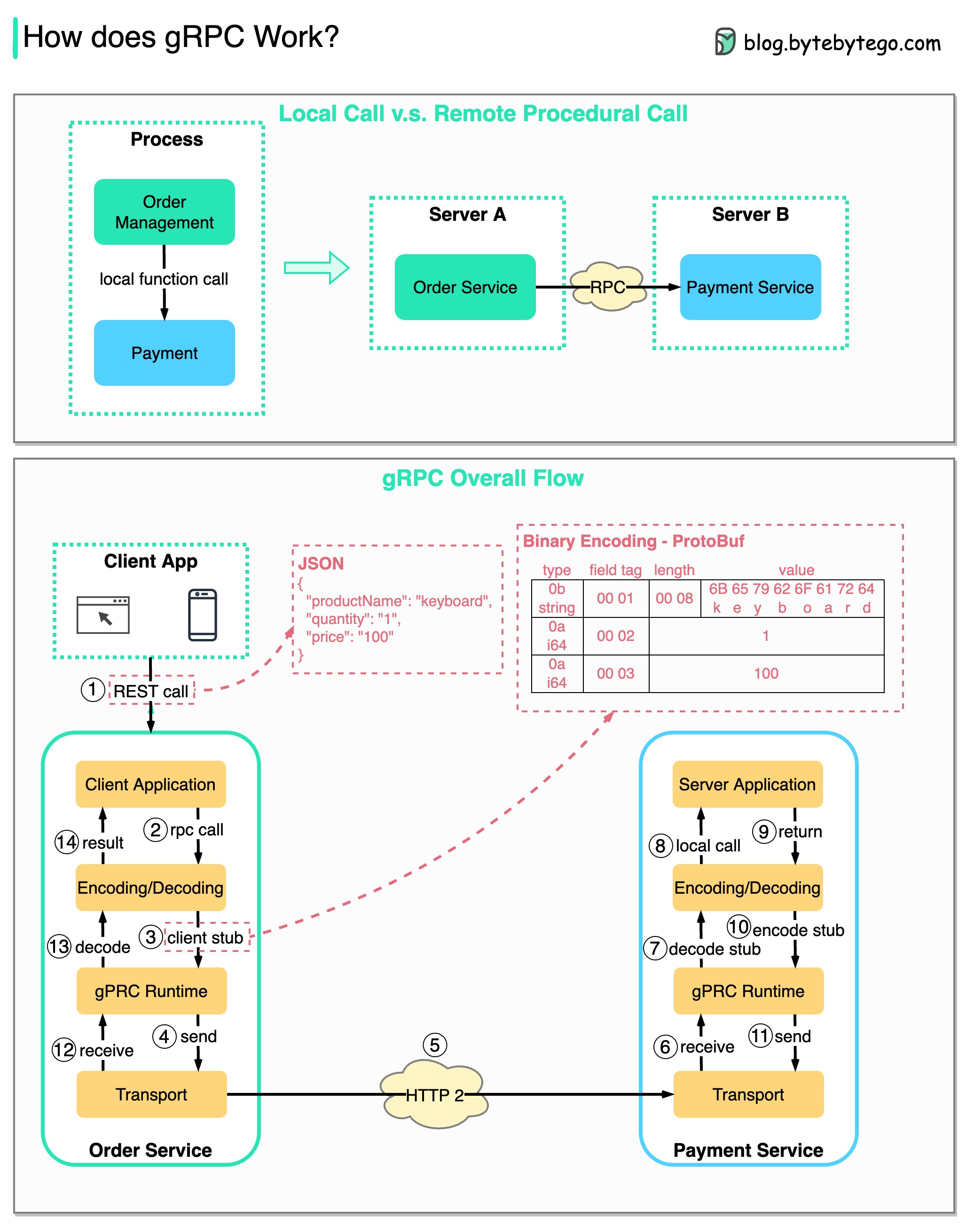
+
+RPC (Remote Procedure Call) is called **“remote”** because it enables communications between remote services when services are deployed to different servers under microservice architecture. From the user’s point of view, it acts like a local function call.
+
+The diagram above illustrates the overall data flow for **gRPC.**
+
+* Step 1: A REST call is made from the client. The request body is usually in JSON format.
+
+* Steps 2 - 4: The order service (gRPC client) receives the REST call, transforms it, and makes an RPC call to the payment service. gPRC encodes the **client stub** into a binary format and sends it to the low-level transport layer.
+
+* Step 5: gRPC sends the packets over the network via HTTP2. Because of binary encoding and network optimizations, gRPC is said to be 5X faster than JSON.
+
+* Steps 6 - 8: The payment service (gRPC server) receives the packets from the network, decodes them, and invokes the server application.
+
+* Steps 9 - 11: The result is returned from the server application, and gets encoded and sent to the transport layer.
+
+* Steps 12 - 14: The order service receives the packets, decodes them, and sends the result to the client application.
diff --git a/data/guides/how-does-https-work.md b/data/guides/how-does-https-work.md
new file mode 100644
index 0000000..cd9cda6
--- /dev/null
+++ b/data/guides/how-does-https-work.md
@@ -0,0 +1,36 @@
+---
+title: "How does HTTPS work?"
+description: "Learn how HTTPS encrypts data for secure communication over the internet."
+image: "https://assets.bytebytego.com/diagrams/0220-how-does-https-work.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - security
+tags:
+ - "HTTPS"
+ - "Encryption"
+---
+
+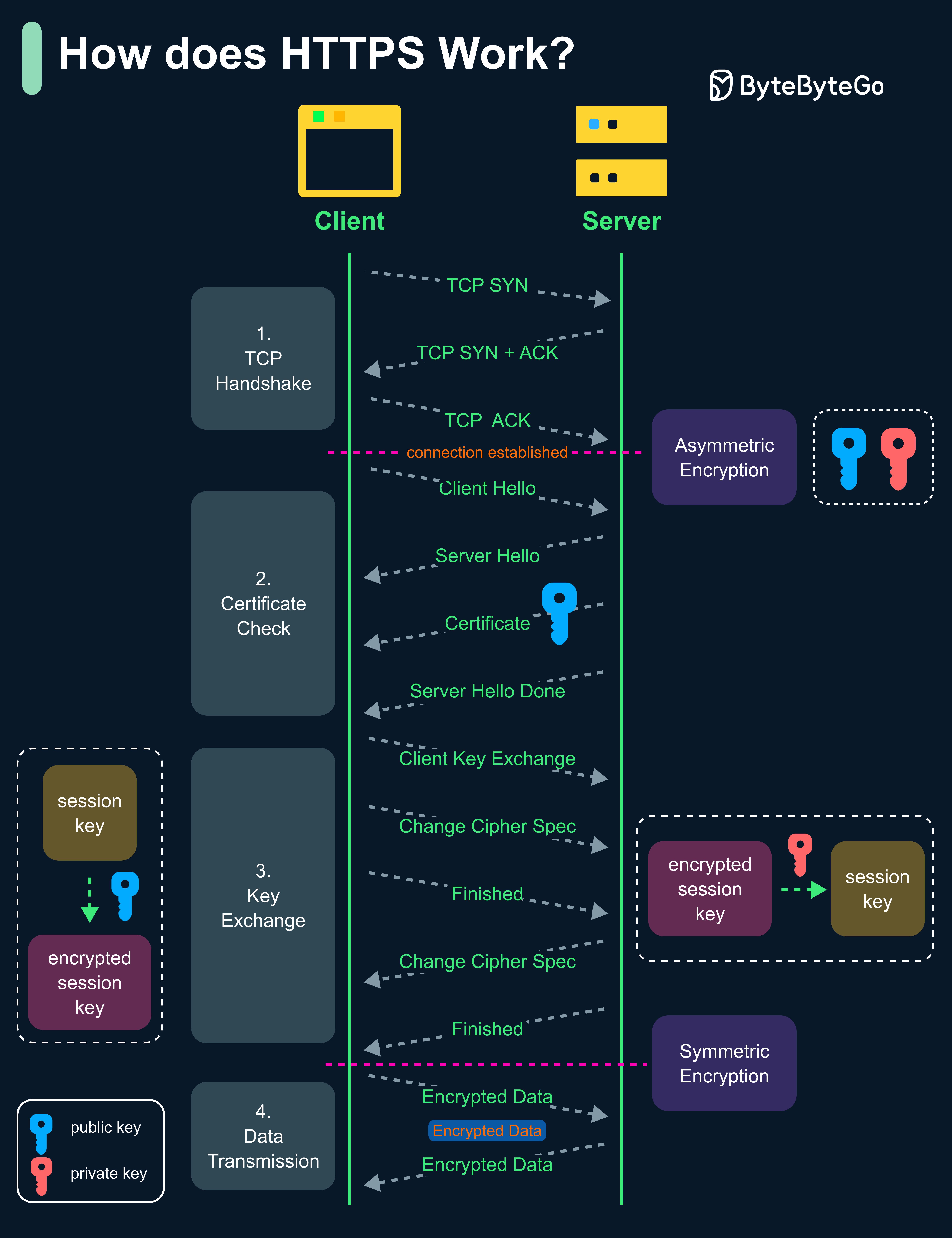
+
+Hypertext Transfer Protocol Secure (HTTPS) is an extension of the Hypertext Transfer Protocol (HTTP.) HTTPS transmits encrypted data using Transport Layer Security (TLS.) If the data is hijacked online, all the hijacker gets is binary code.
+
+## How is the data encrypted and decrypted?
+
+Step 1 - The client (browser) and the server establish a TCP connection.
+
+Step 2 - The client sends a “client hello” to the server. The message contains a set of necessary encryption algorithms (cipher suites) and the latest TLS version it can support. The server responds with a “server hello” so the browser knows whether it can support the algorithms and TLS version.
+
+The server then sends the SSL certificate to the client. The certificate contains the public key, hostname, expiry dates, etc. The client validates the certificate.
+
+Step 3 - After validating the SSL certificate, the client generates a session key and encrypts it using the public key. The server receives the encrypted session key and decrypts it with the private key.
+
+Step 4 - Now that both the client and the server hold the same session key (symmetric encryption), the encrypted data is transmitted in a secure bi-directional channel.
+
+## Why does HTTPS switch to symmetric encryption during data transmission?
+
+There are two main reasons:
+
+* **Security:** The asymmetric encryption goes only one way. This means that if the server tries to send the encrypted data back to the client, anyone can decrypt the data using the public key.
+
+* **Server resources:** The asymmetric encryption adds quite a lot of mathematical overhead. It is not suitable for data transmissions in long sessions.
diff --git a/data/guides/how-does-javascript-work.md b/data/guides/how-does-javascript-work.md
new file mode 100644
index 0000000..f3249fd
--- /dev/null
+++ b/data/guides/how-does-javascript-work.md
@@ -0,0 +1,37 @@
+---
+title: How does Javascript Work?
+description: Learn about Javascript's core features and how it operates.
+image: 'https://assets.bytebytego.com/diagrams/0241-javascript-js-explained.png'
+createdAt: '2024-02-07'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - javascript
+ - programming
+---
+
+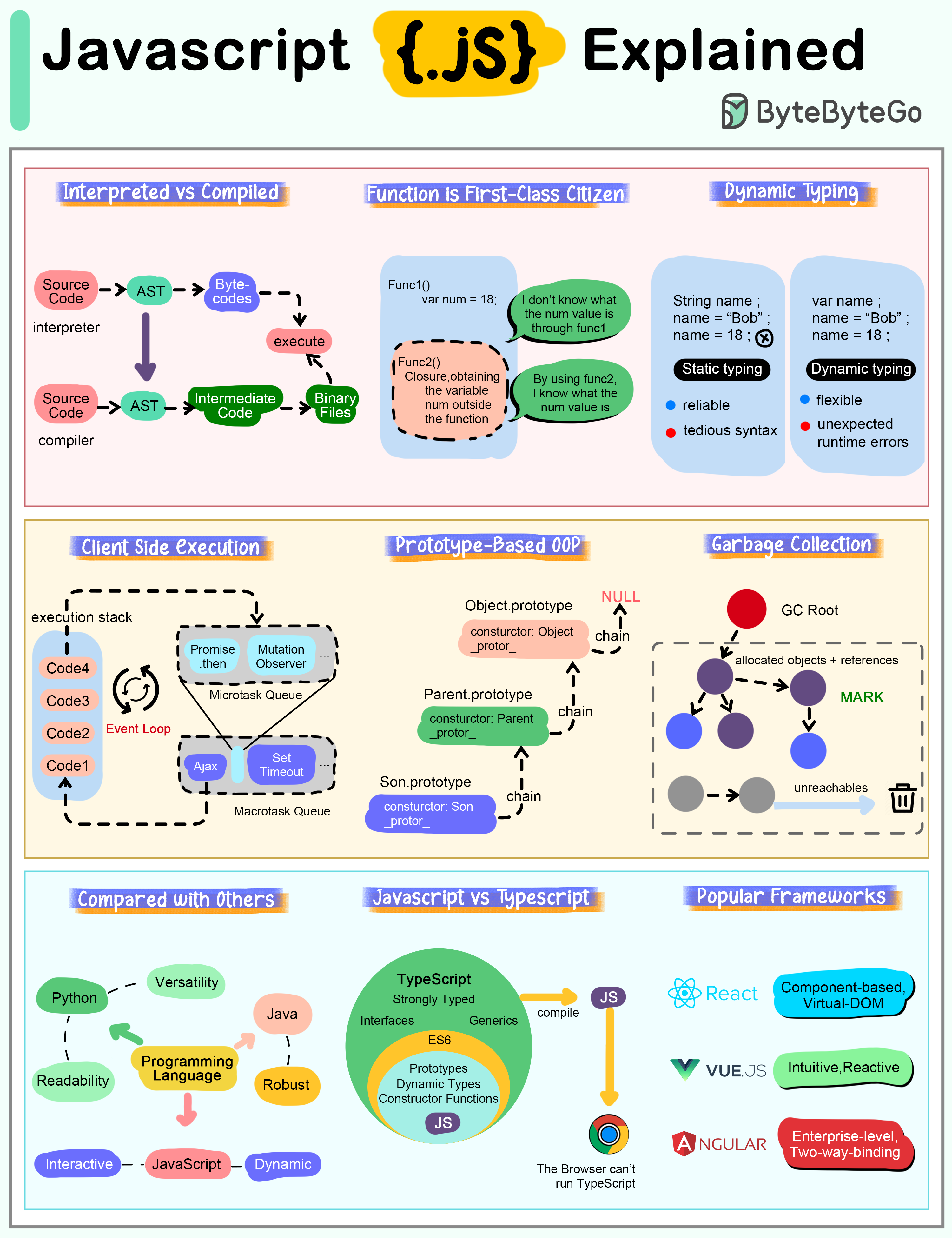
+
+The cheat sheet below shows the most important characteristics of Javascript.
+
+* **Interpreted Language**
+ JavaScript code is executed by the browser or JavaScript engine rather than being compiled into machine language beforehand. This makes it highly portable across different platforms. Modern engines such as V8 utilize Just-In-Time (JIT) technology to compile code into directly executable machine code.
+* **Function is First-Class Citizen**
+ In JavaScript, functions are treated as first-class citizens, meaning they can be stored in variables, passed as arguments to other functions, and returned from functions.
+* **Dynamic Typing**
+ JavaScript is a loosely typed or dynamic language, meaning we don't have to declare a variable's type ahead of time, and the type can change at runtime.
+* **Client-Side Execution**
+ JavaScript supports asynchronous programming, allowing operations like reading files, making HTTP requests, or querying databases to run in the background and trigger callbacks or promises when complete. This is particularly useful in web development for improving performance and user experience.
+* **Prototype-Based OOP**
+ Unlike class-based object-oriented languages, JavaScript uses prototypes for inheritance. This means that objects can inherit properties and methods from other objects.
+* **Automatic Garbage Collection**
+ Garbage collection in JavaScript is a form of automatic memory management. The primary goal of garbage collection is to reclaim memory occupied by objects that are no longer in use by the program, which helps prevent memory leaks and optimizes the performance of the application.
+* **Compared with Other Languages**
+ JavaScript is special compared to programming languages like Python or Java because of its position as a major language for web development.
+
+ While Python is known to provide good code readability and versatility, and Java is known for its structure and robustness, JavaScript is an interpreted language that runs directly on the browser without compilation, emphasizing flexibility and dynamism.
+* **Relationship with Typescript**
+ TypeScript is a superset of JavaScript, which means that it extends JavaScript by adding features to the language, most notably type annotations. This relationship allows any valid JavaScript code to also be considered valid TypeScript code.
+* **Popular Javascript Frameworks**
+ React is known for its flexibility and large number of community-driven plugins, while Vue is clean and intuitive with highly integrated and responsive features. Angular, on the other hand, offers a strict set of development specifications for enterprise-level JS development.
diff --git a/data/guides/how-does-netflix-scale-push-messaging-for-millions-of-devices.md b/data/guides/how-does-netflix-scale-push-messaging-for-millions-of-devices.md
new file mode 100644
index 0000000..171929e
--- /dev/null
+++ b/data/guides/how-does-netflix-scale-push-messaging-for-millions-of-devices.md
@@ -0,0 +1,33 @@
+---
+title: 'How Netflix Scales Push Messaging'
+description: 'Explore how Netflix scales push messaging for millions of devices.'
+image: 'https://assets.bytebytego.com/diagrams/0291-netflix-pn.png'
+createdAt: '2024-02-28'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Push Notifications
+---
+
+This post draws from an article published on Netflix’s engineering blog. Here’s my understanding of how the online streaming giant’s system works.
+
+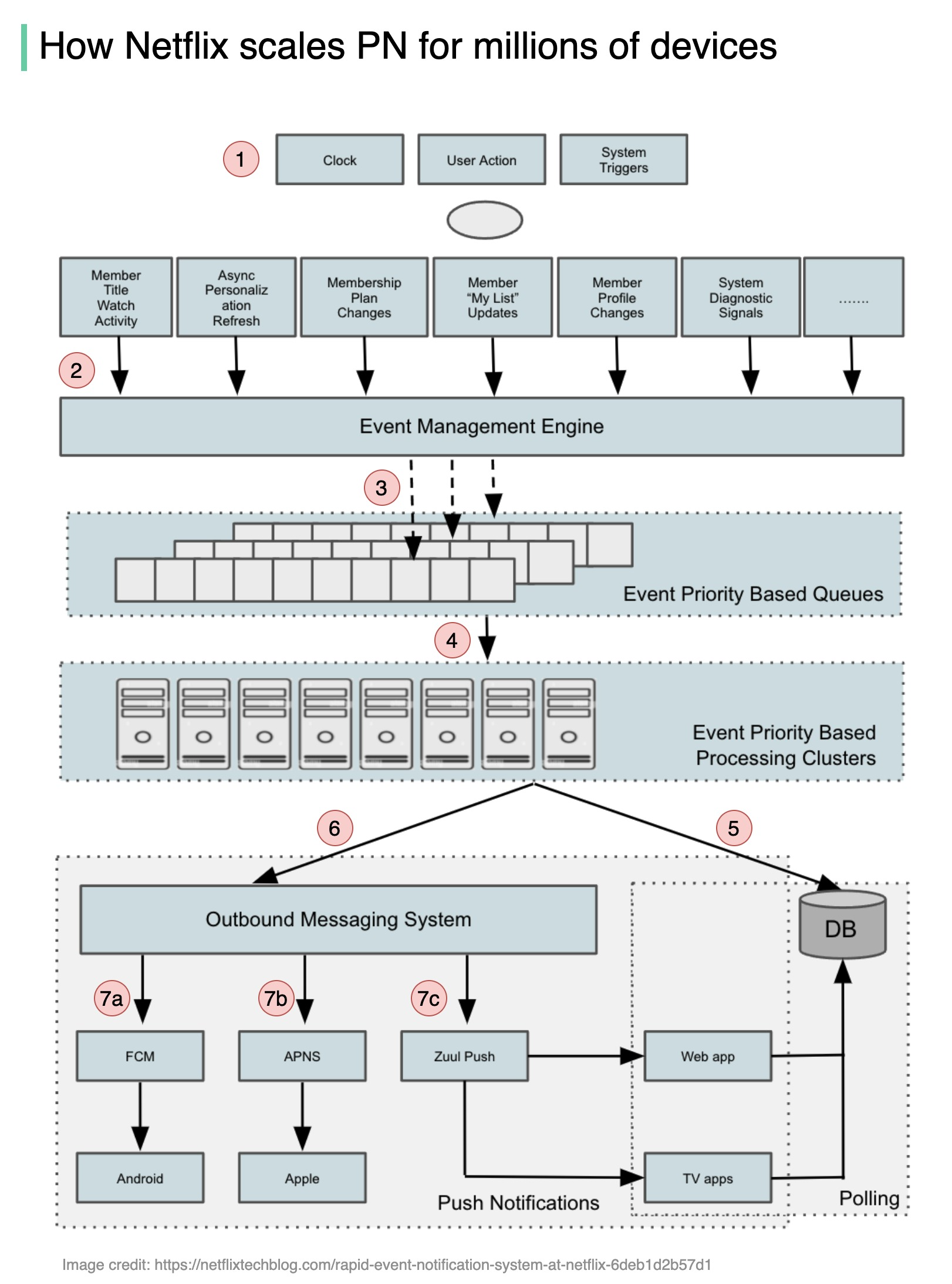
+
+**Requirements & Scale**
+
+* 220 million users
+* Near real-time
+* Backend systems need to send notifications to various clients
+* Supported clients: iOS, Android, smart TVs, Roku, Amazon FireStick, web browser
+
+**The Life of a Push Notification**
+
+1. Push notification events are triggered by the clock, user actions, or by systems.
+2. Events are sent to the event management engine.
+3. The event management engine listens to specific events and forward events to different queues. The queues are populated by priority-based event forwarding rules.
+4. The “event priority-based processing cluster” processes events and generates push notifications data for devices.
+5. A Cassandra database is used to store the notification data.
+6. A push notification is sent to outbound messaging systems.
+7. For Android, FCM is used to send push notifications. For Apple devices, APNs are used. For web, TV, and other streaming devices, Netflix’s homegrown solution called ‘Zuul Push’ is used.
diff --git a/data/guides/how-does-redis-persist-data.md b/data/guides/how-does-redis-persist-data.md
new file mode 100644
index 0000000..a23000a
--- /dev/null
+++ b/data/guides/how-does-redis-persist-data.md
@@ -0,0 +1,43 @@
+---
+title: "How Does Redis Persist Data?"
+description: "Explore Redis data persistence: AOF, RDB, and mixed approaches."
+image: "https://assets.bytebytego.com/diagrams/0214-how-redis-presists-data.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Data Persistence"
+---
+
+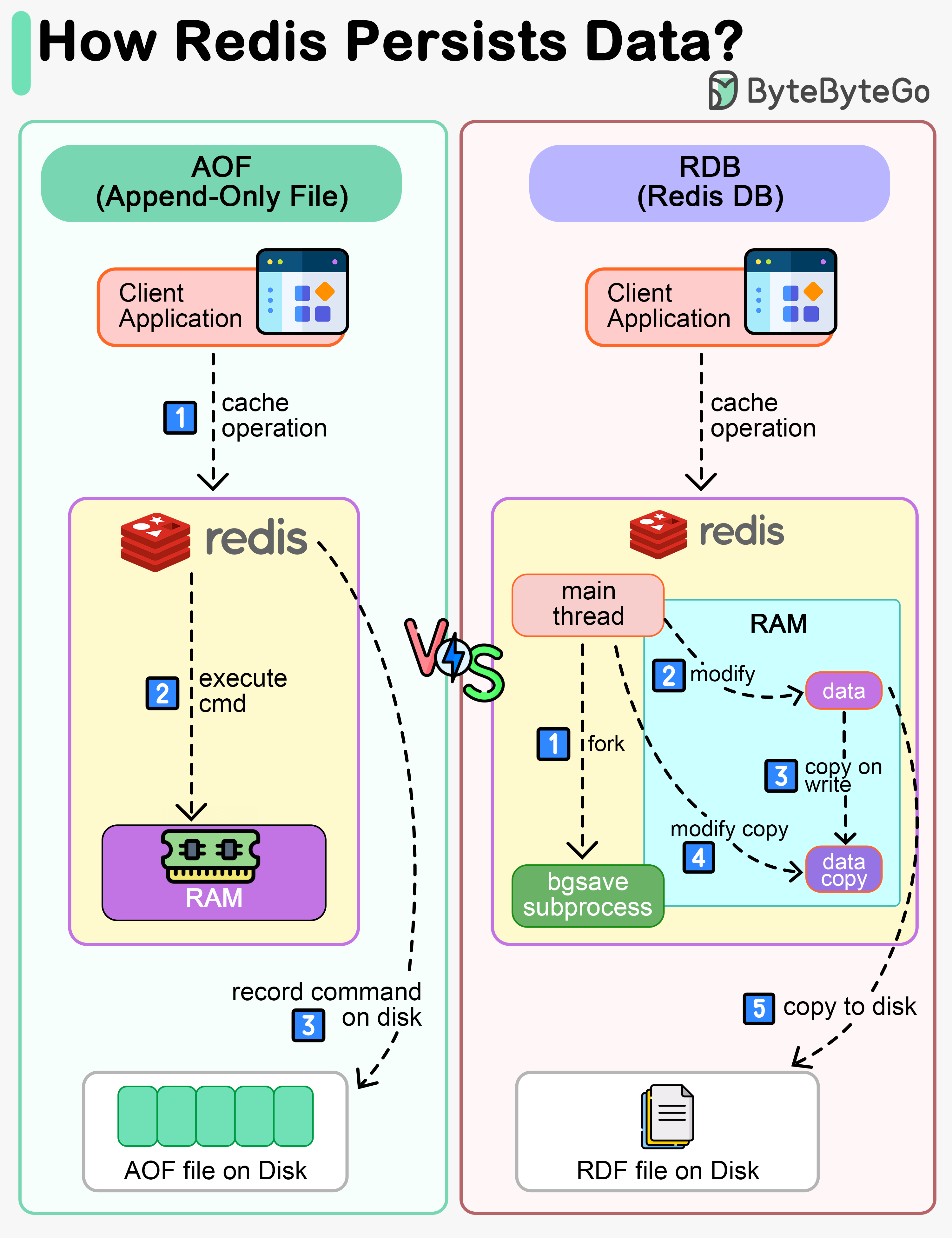
+
+Redis is an in-memory database. If the server goes down, the data will be lost.
+
+The diagram above shows two ways to persist Redis data on disk:
+
+1. AOF (Append-Only File)
+2. RDB (Redis Database)
+
+Note that data persistence is not performed on the critical path and doesn't block the write process in Redis.
+
+## AOF (Append-Only File)
+
+Unlike a write-ahead log, the Redis AOF log is a write-after log. Redis executes commands to modify the data in memory first and then writes it to the log file. AOF log records the commands instead of the data. The event-based design simplifies data recovery. Additionally, AOF records commands after the command has been executed in memory, so it does not block the current write operation.
+
+## RDB (Redis Database)
+
+The restriction of AOF is that it persists commands instead of data. When we use the AOF log for recovery, the whole log must be scanned. When the size of the log is large, Redis takes a long time to recover. So Redis provides another way to persist data - RDB.
+
+RDB records snapshots of data at specific points in time. When the server needs to be recovered, the data snapshot can be directly loaded into memory for fast recovery.
+
+Step 1: The main thread forks the ‘bgsave’ sub-process, which shares all the in-memory data of the main thread. ‘bgsave’ reads the data from the main thread and writes it to the RDB file.
+
+Steps 2 and 3: If the main thread modifies data, a copy of the data is created.
+
+Steps 4 and 5: The main thread then operates on the data copy. Meanwhile ‘bgsave’ sub-process continues to write data to the RDB file.
+
+## Mixed Approach
+
+Usually in production systems, we can choose a mixed approach, where we use RDB to record data snapshots from time to time and use AOF to record the commands since the last snapshot.
diff --git a/data/guides/how-does-rest-api-work.md b/data/guides/how-does-rest-api-work.md
new file mode 100644
index 0000000..fcee2a8
--- /dev/null
+++ b/data/guides/how-does-rest-api-work.md
@@ -0,0 +1,20 @@
+---
+title: 'How does REST API work?'
+description: 'Explore REST API principles, methods, constraints, and best practices.'
+image: 'https://assets.bytebytego.com/diagrams/0317-rest-api-authentication-methods.png'
+createdAt: '2024-02-10'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - rest-api
+ - web-development
+---
+
+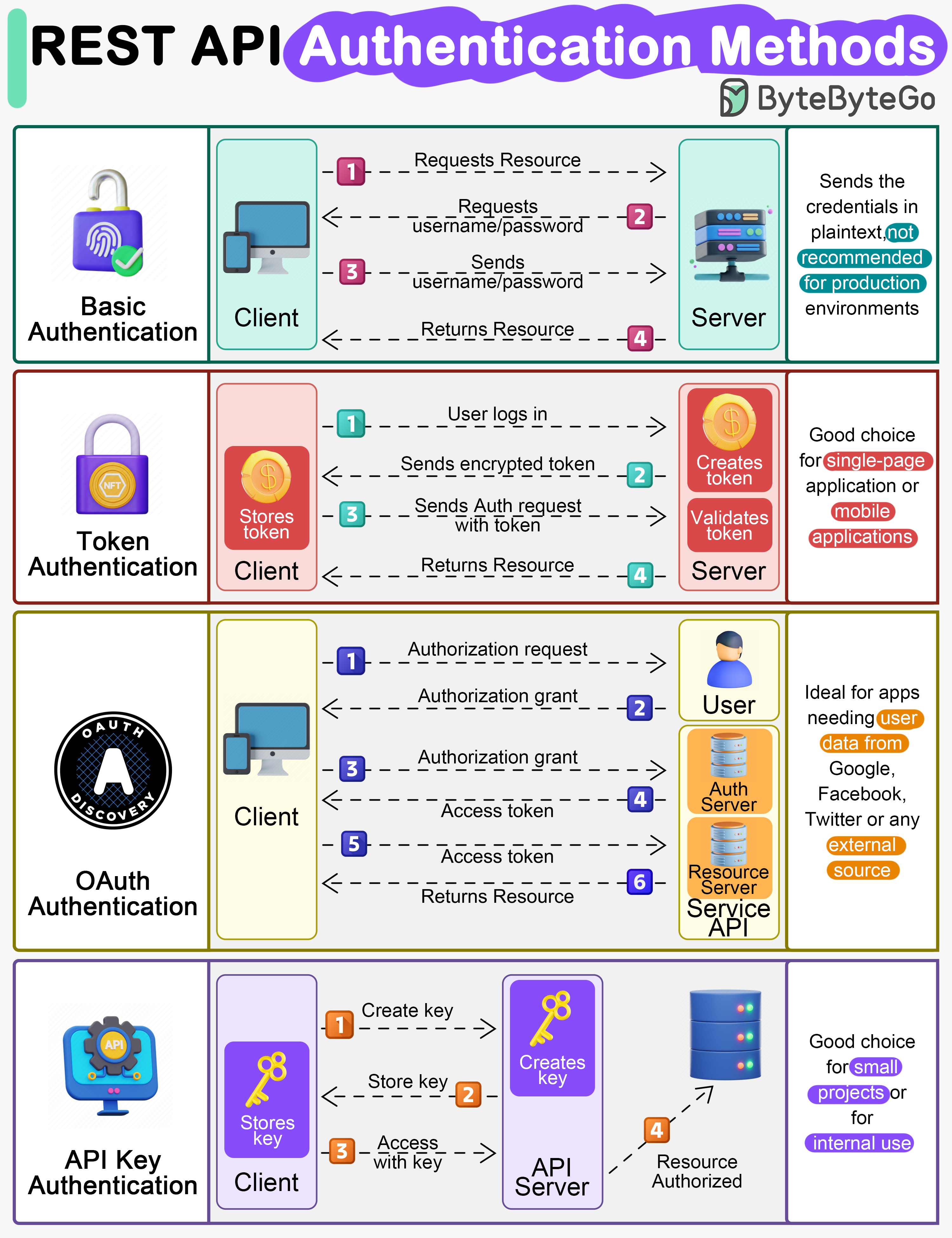
+
+What are its principles, methods, constraints, and best practices?
+
+I hope the diagram above gives you a quick overview.
+
+
diff --git a/data/guides/how-does-scan-to-pay-work.md b/data/guides/how-does-scan-to-pay-work.md
new file mode 100644
index 0000000..c7cf5f8
--- /dev/null
+++ b/data/guides/how-does-scan-to-pay-work.md
@@ -0,0 +1,39 @@
+---
+title: "How Scan to Pay Works"
+description: "Explore the mechanics behind scan-to-pay systems and digital wallets."
+image: "https://assets.bytebytego.com/diagrams/0323-scan-to-pay.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "QR Codes"
+---
+
+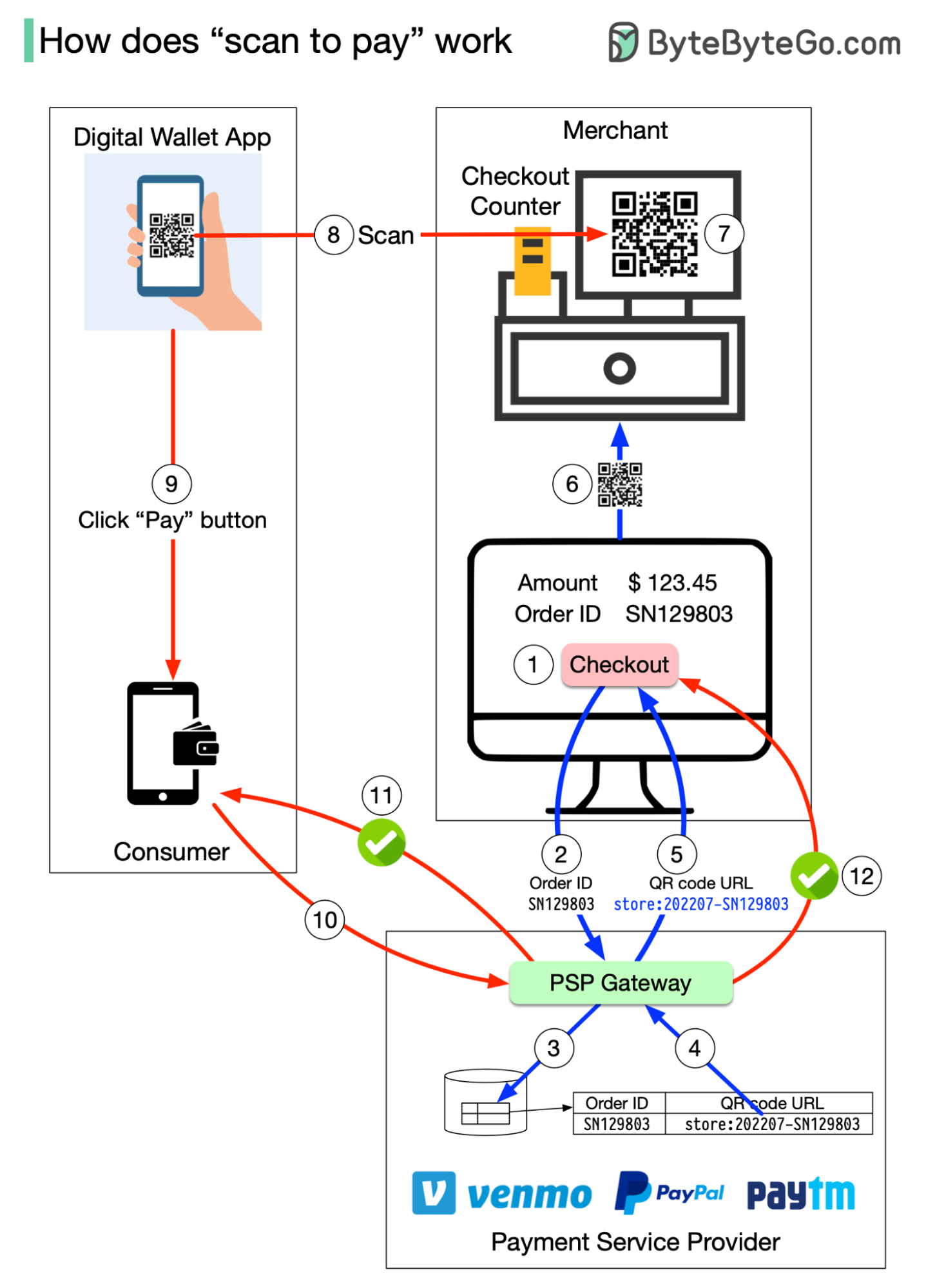
+
+How do you pay from your digital wallet, such as Paypal, Paytm and Venmo, by scanning the QR code?
+
+To understand the process involved, we need to divide the “scan to pay” process into two sub-processes:
+
+1. Merchant generates a QR code and displays it on the screen
+2. Consumer scans the QR code and pays
+
+Here are the steps for generating the QR code:
+
+1. When you want to pay for your shopping, the cashier tallies up all the goods and calculates the total amount due, for example, $123.45. The checkout has an order ID of SN129803. The cashier clicks the “checkout” button.
+2. The cashier’s computer sends the order ID and the amount to PSP.
+3. The PSP saves this information to the database and generates a QR code URL.
+4. PSP’s Payment Gateway service reads the QR code URL.
+5. The payment gateway returns the QR code URL to the merchant’s computer.
+6. The merchant’s computer sends the QR code URL (or image) to the checkout counter.
+7. The checkout counter displays the QR code.
+
+These 7 steps complete in less than a second. Now it’s the consumer’s turn to pay from their digital wallet by scanning the QR code:
+
+1. The consumer opens their digital wallet app to scan the QR code.
+2. After confirming the amount is correct, the client clicks the “pay” button.
+3. The digital wallet App notifies the PSP that the consumer has paid the given QR code.
+4. The PSP payment gateway marks this QR code as paid and returns a success message to the consumer’s digital wallet App.
+5. The PSP payment gateway notifies the merchant that the consumer has paid the given QR code.
diff --git a/data/guides/how-does-ssh-work.md b/data/guides/how-does-ssh-work.md
new file mode 100644
index 0000000..abbeaba
--- /dev/null
+++ b/data/guides/how-does-ssh-work.md
@@ -0,0 +1,32 @@
+---
+title: "How does SSH work?"
+description: "Explore the inner workings of SSH, a secure network protocol."
+image: "https://assets.bytebytego.com/diagrams/0224-how-does-ssh-work.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - security
+tags:
+ - "SSH"
+ - "Security"
+---
+
+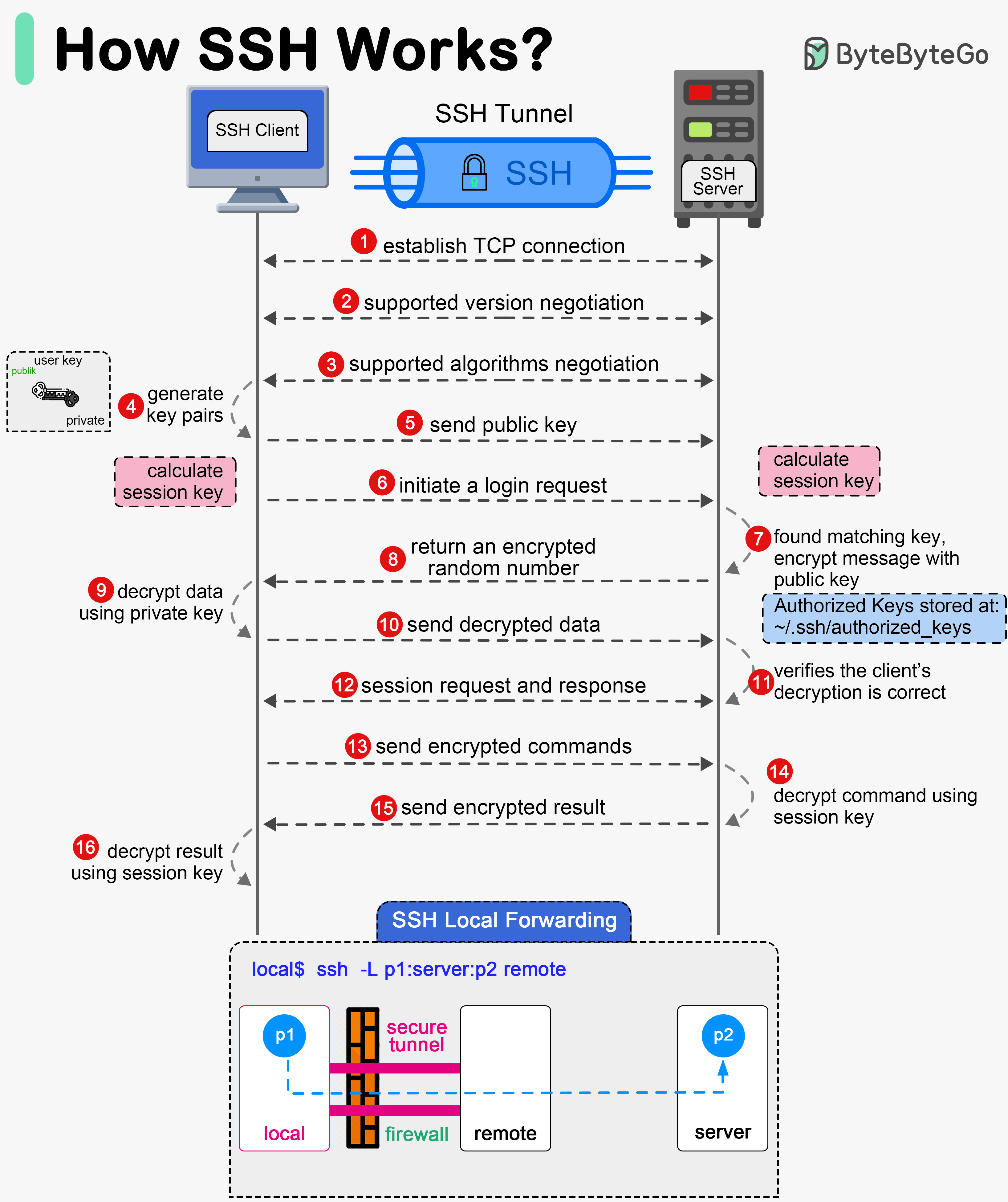
+
+SSH (Secure Shell) is a network protocol used to securely connect to remote machines over an unsecured network. It encrypts the connection and provides various mechanisms for authentication and data transfer.
+
+SSH has two versions: SSH-1 and SSH-2. SSH-2 was standardized by the IETF.
+
+It has three main layers: Transport Layer, Authentication Layer, and Connection Layer.
+
+## Transport Layer
+
+The Transport Layer provides encryption, integrity, and data protection to ensure secure communication between the client and server.
+
+## Authentication Layer
+
+The Authentication Layer verifies the identity of the client to ensure that only authorized users can access the server.
+
+## Connection Layer
+
+The Connection Layer multiplexes the encrypted and authenticated communication into multiple logical channels.
diff --git a/data/guides/how-does-terraform-turn-code-into-cloud.md b/data/guides/how-does-terraform-turn-code-into-cloud.md
new file mode 100644
index 0000000..43a6555
--- /dev/null
+++ b/data/guides/how-does-terraform-turn-code-into-cloud.md
@@ -0,0 +1,44 @@
+---
+title: "How does Terraform turn Code into Cloud?"
+description: "Explore how Terraform transforms code into cloud infrastructure."
+image: "https://assets.bytebytego.com/diagrams/0225-how-terraform-creates-infra-at-scale.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Terraform"
+ - "Infrastructure as Code"
+---
+
+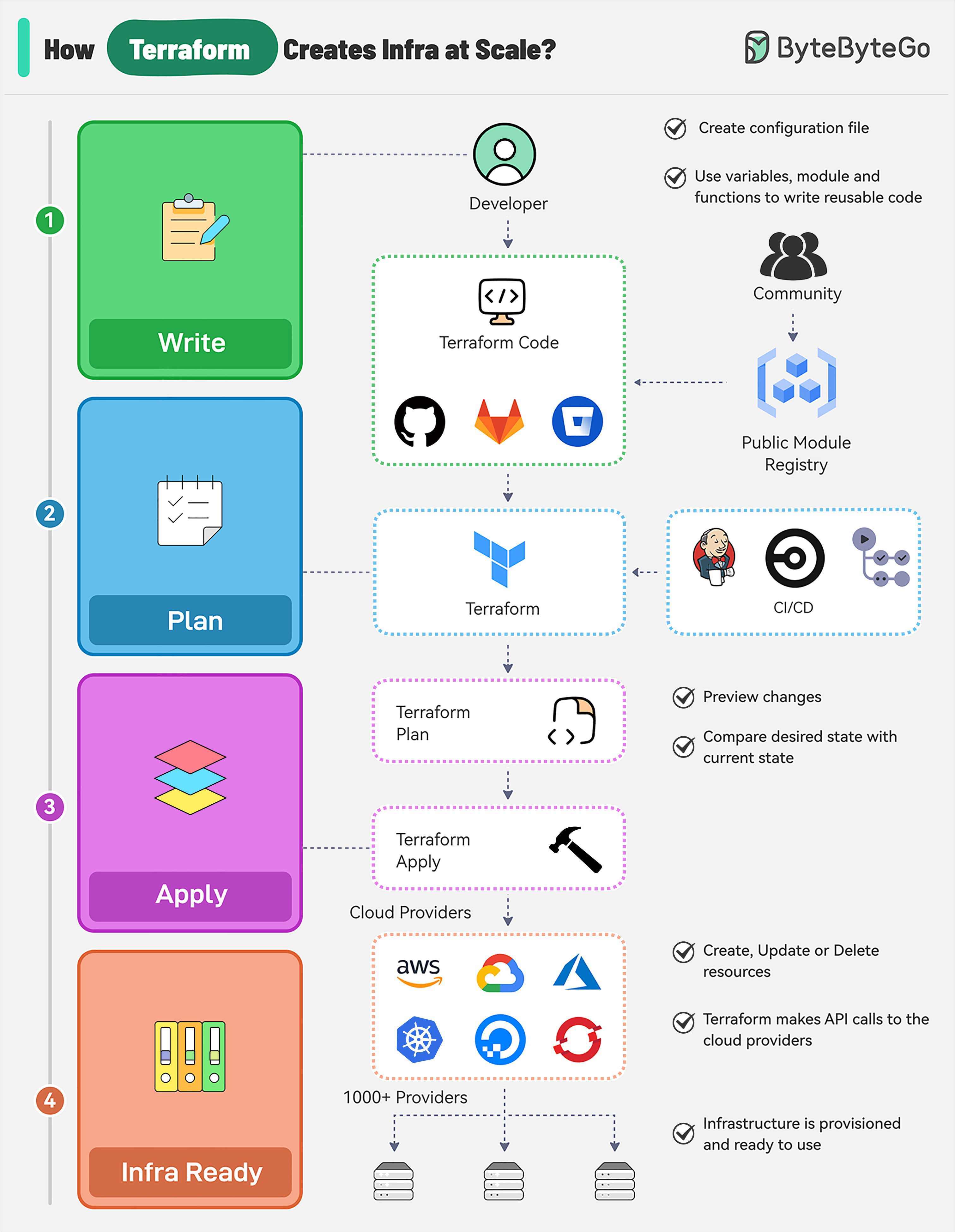
+
+There are multiple stages in a Terraform workflow:
+
+## Write Infrastructure as Code
+
+* Define resources, providers, and configurations in Terraform configuration files.
+
+* Use variables, modules, and functions to make the code reusable and maintainable.
+
+* Integrate with Terraform community registries for ready-to-use modules.
+
+## Terraform Plan
+
+Preview the changes Terraform will make to the infrastructure by running “terraform plan”. It can be triggered as part of a CI/CD pipeline.
+
+Terraform compares the desired state defined in the configuration file with the current state in the state file.
+
+## Terraform Apply
+
+Run “terraform apply” to create, update, or delete resources based on the plan.
+
+Terraform makes API calls to the specified providers (AWS, Azure, GCP, Kubernetes, etc) to provision the resources.
+
+The state file is updated to reflect the new state of the infrastructure.
+
+## Infrastructure Ready
+
+Terraform state file acts as a single source of truth for the current state of the infrastructure.
+
+State file enables version control and collaboration between team members for future changes.
diff --git a/data/guides/how-does-the-browser-render-a-web-page.md b/data/guides/how-does-the-browser-render-a-web-page.md
new file mode 100644
index 0000000..4ff1f63
--- /dev/null
+++ b/data/guides/how-does-the-browser-render-a-web-page.md
@@ -0,0 +1,36 @@
+---
+title: 'How Browsers Render Web Pages'
+description: 'Explore how browsers render web pages: from HTML parsing to display.'
+image: 'https://assets.bytebytego.com/diagrams/0090-browser-render-page.jpg'
+createdAt: '2024-02-01'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - browsers
+ - rendering
+---
+
+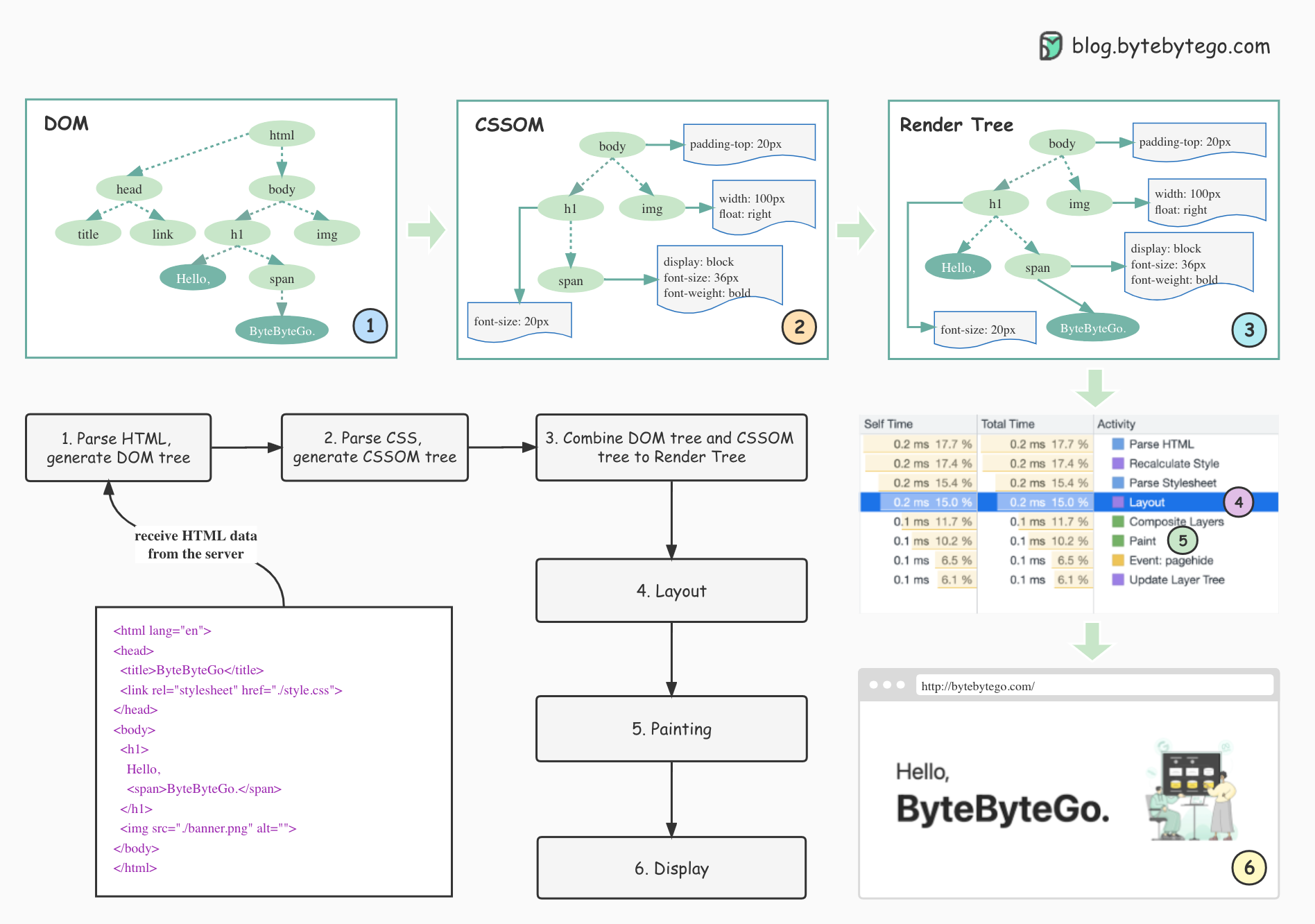
+
+* **Parse HTML and generate a Document Object Model (DOM) tree.**
+
+ When the browser receives the HTML data from the server, it immediately parses it and converts it into a DOM tree.
+
+* **Parse CSS and generate CSSOM tree.**
+
+ The styles (CSS files) are loaded and parsed to the CSSOM (CSS Object Model).
+
+* **Combine DOM tree and CSSOM tree to construct the Render Tree.** The render tree maps all DOM structures except invisible elements (such as `` or tags with `display:none;`). In other words, the render tree is a visual representation of the DOM.
+
+* **Layout**
+
+ The content in each element of the rendering tree will be calculated to get the geometric information (position, size), which is called layout.
+
+* **Painting**
+
+ After the layout is complete, the rendering tree is transformed into the actual content on the screen. This step is called painting. The browser gets the absolute pixels of the content.
+
+* **Display**
+
+ Finally, the browser sends the absolute pixels to the GPU and displays them on the page.
diff --git a/data/guides/how-does-the-domain-name-system-dns-lookup-work.md b/data/guides/how-does-the-domain-name-system-dns-lookup-work.md
new file mode 100644
index 0000000..b59e73f
--- /dev/null
+++ b/data/guides/how-does-the-domain-name-system-dns-lookup-work.md
@@ -0,0 +1,46 @@
+---
+title: "How Does the Domain Name System (DNS) Lookup Work?"
+description: "Learn how DNS translates domain names to IP addresses for web access."
+image: "https://assets.bytebytego.com/diagrams/0176-dns-look-up.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "DNS"
+ - "Networking"
+---
+
+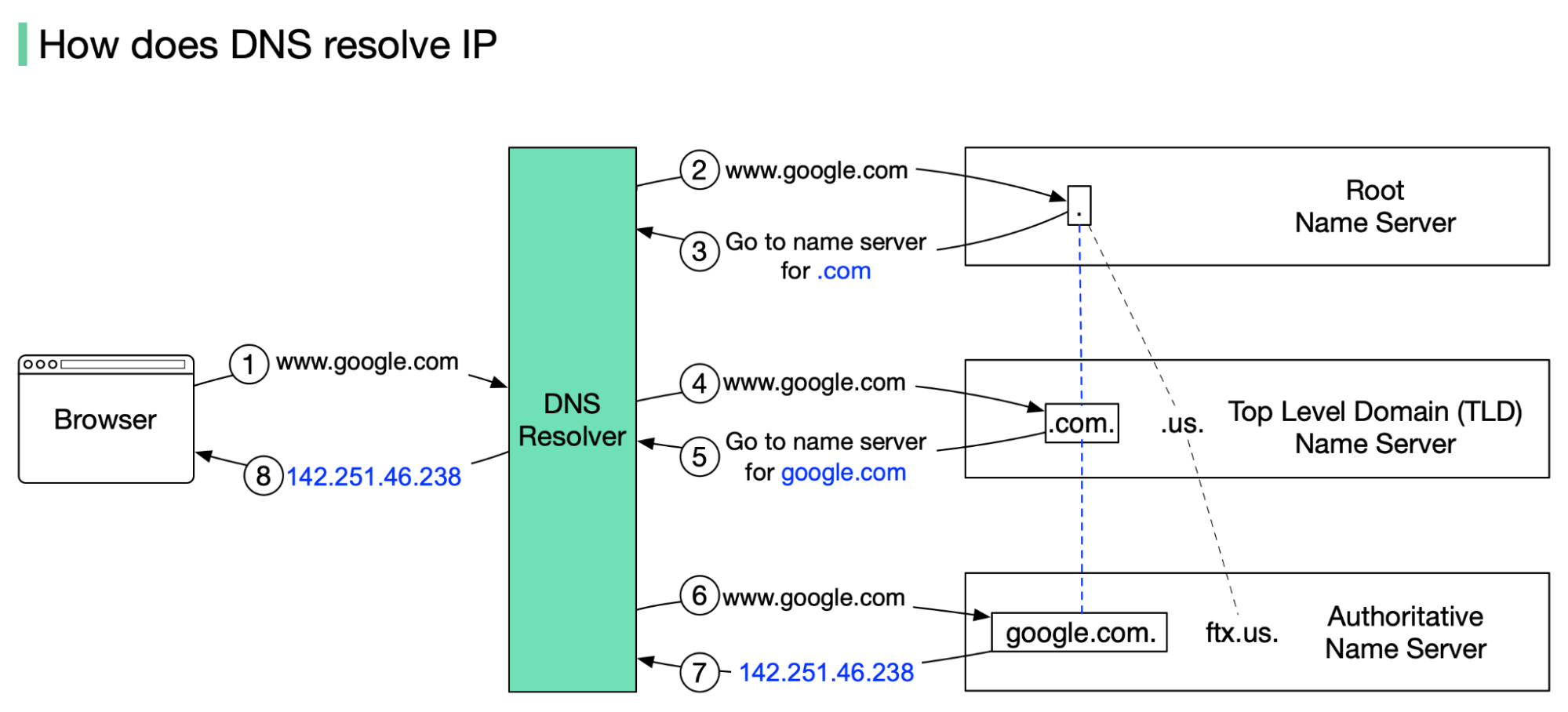
+
+DNS acts as an address book. It translates human-readable domain names ([google.com](http://google.com/)) to machine-readable IP addresses ([142.251.46.238](http://142.251.46.238/)).
+
+To achieve better scalability, the DNS servers are organized in a hierarchical tree structure.
+
+There are 3 basic levels of DNS servers:
+
+* Root name server (.). It stores the IP addresses of Top Level Domain (TLD) name servers. There are 13 logical root name servers globally.
+
+* TLD name server. It stores the IP addresses of authoritative name servers. There are several types of TLD names. For example, generic TLD (.com, .org), country code TLD (.us), test TLD (.test).
+
+* Authoritative name server. It provides actual answers to the DNS query. You can register authoritative name servers with domain name registrar such as GoDaddy, Namecheap, etc.
+
+The diagram below illustrates how DNS lookup works under the hood:
+
+1. [google.com](http://google.com/) is typed into the browser, and the browser sends the domain name to the DNS resolver.
+
+2. The resolver queries a DNS root name server.
+
+3. The root server responds to the resolver with the address of a TLD DNS server. In this case, it is .com.
+
+4. The resolver then makes a request to the .com TLD.
+
+5. The TLD server responds with the IP address of the domain’s name server, [google.com](http://google.com/) (authoritative name server).
+
+6. The DNS resolver sends a query to the domain’s nameserver.
+
+7. The IP address for [google.com](http://google.com/) is then returned to the resolver from the nameserver.
+
+8. The DNS resolver responds to the web browser with the IP address ([142.251.46.238](http://142.251.46.238/)) of the domain requested initially.
+
+DNS lookups on average take between 20-120 milliseconds to complete (according to YSlow).
diff --git a/data/guides/how-does-twitter-recommend-tweets.md b/data/guides/how-does-twitter-recommend-tweets.md
new file mode 100644
index 0000000..b6203b6
--- /dev/null
+++ b/data/guides/how-does-twitter-recommend-tweets.md
@@ -0,0 +1,30 @@
+---
+title: How does Twitter recommend “For You” Timeline in 1.5 seconds?
+description: Twitter's "For You" timeline recommendation system explained.
+image: 'https://assets.bytebytego.com/diagrams/0121-twitter-serving-pipeline.jpeg'
+createdAt: '2024-02-22'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Recommendation Systems
+---
+
+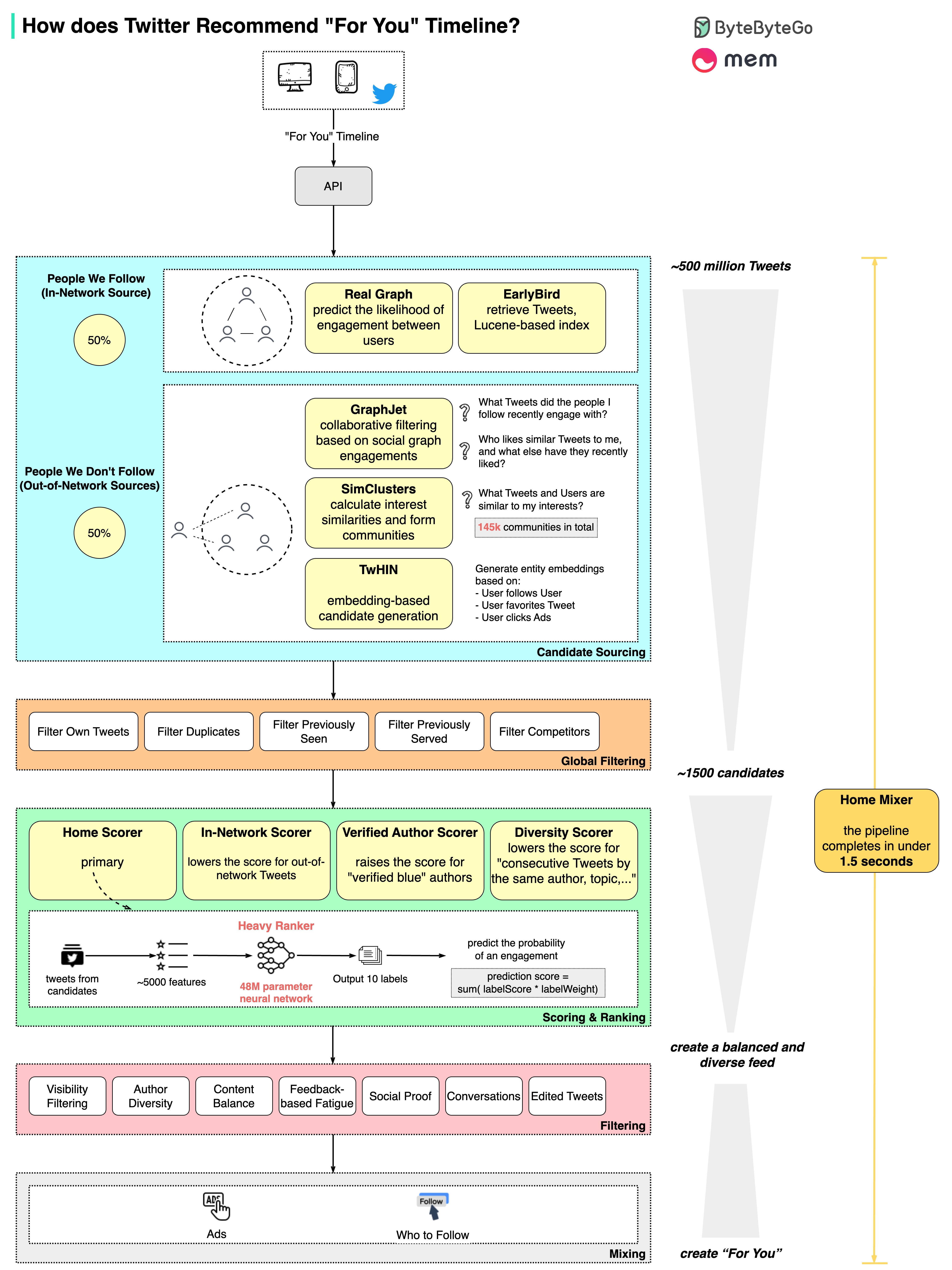
+
+We spent a few days analyzing it.
+
+The diagram above shows the detailed pipeline based on the open-sourced algorithm.
+
+The process involves 5 stages:
+
+* **Candidate Sourcing** ~ start with 500 million Tweets
+* **Global Filtering** ~ down to 1500 candidates
+* **Scoring & Ranking** ~ 48M parameter neural network, Twitter Blue boost
+* **Filtering** ~ to achieve author and content diversity
+* **Mixing** ~ with Ads recommendation and Who to Follow
+
+The post was jointly created by ByteByteGo and [Mem](https://www.linkedin.com/company/memdotai/). Special thanks [Scott Mackie](https://www.linkedin.com/in/ACoAABLDe9kBSK7DsORQHK2G1srZCmM1isaUun8), founding engineer at Mem, for putting this together.
+
+Mem is building the world’s first knowledge assistant. In next week’s ByteByteGo guest newsletter, Mem will be sharing lessons they’ve learned from their extensive work with large language models and building AI-native infrastructure.
diff --git a/data/guides/how-does-visa-make-money.md b/data/guides/how-does-visa-make-money.md
new file mode 100644
index 0000000..32d72b7
--- /dev/null
+++ b/data/guides/how-does-visa-make-money.md
@@ -0,0 +1,38 @@
+---
+title: "How does Visa make money?"
+description: "Explore Visa's revenue streams and credit card payment flow economics."
+image: "https://assets.bytebytego.com/diagrams/0041-how-does-visa-make-money.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Fintech"
+ - "Visa"
+---
+
+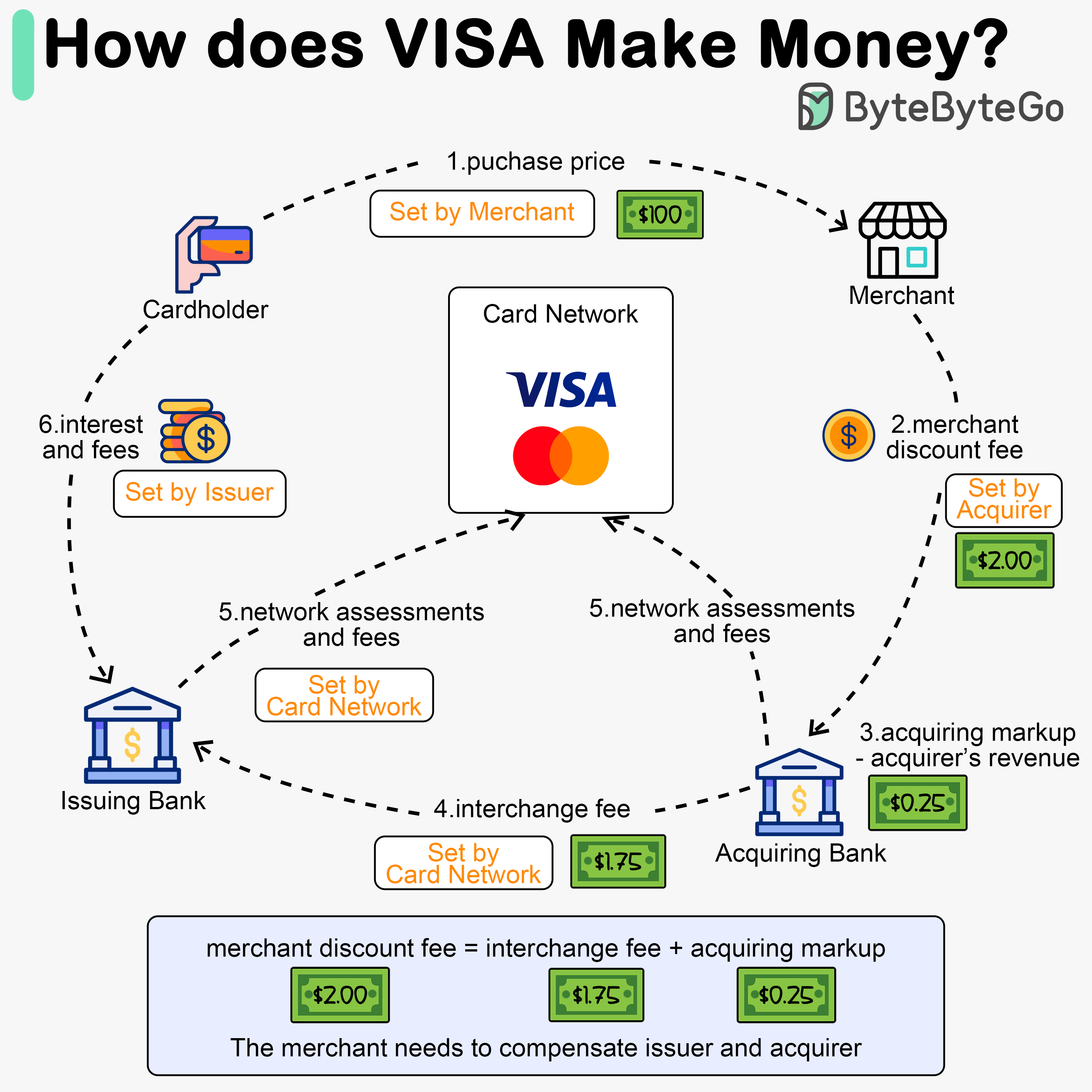
+
+Why is the credit card called “the most profitable product in banks”? How does VISA/Mastercard make money?
+
+The diagram above shows the economics of the credit card payment flow.
+
+- **Step 1.** The cardholder pays a merchant $100 to buy a product.
+
+- **Step 2.** The merchant benefits from the use of the credit card with higher sales volume and needs to compensate the issuer and the card network for providing the payment service. The acquiring bank sets a fee with the merchant, called the "**merchant discount fee**."
+
+- **Step 3 - 4.** The acquiring bank keeps $0.25 as the **acquiring markup**, and $1.75 is paid to the issuing bank as the **interchange fee**. The merchant discount fee should cover the interchange fee. The interchange fee is set by the card network because it is less efficient for each issuing bank to negotiate fees with each merchant.
+
+- **Step 5.** The card network sets up the **network assessments and fees** with each bank, which pays the card network for its services every month. For example, VISA charges a 0.11% assessment, plus a $0.0195 usage fee, for every swipe.
+
+- **Step 6.** The cardholder pays the issuing bank for its services.
+
+## Why should the issuing bank be compensated?
+
+* The issuer pays the merchant even if the cardholder fails to pay the issuer.
+
+* The issuer pays the merchant before the cardholder pays the issuer.
+
+* The issuer has other operating costs, including managing customer accounts, providing statements, fraud detection, risk management, clearing & settlement, etc.
+
+Over to you: Does the card network charge the same interchange fee for big merchants as for small merchants?
diff --git a/data/guides/how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchant's-shop.md b/data/guides/how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchant's-shop.md
new file mode 100644
index 0000000..a225295
--- /dev/null
+++ b/data/guides/how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchant's-shop.md
@@ -0,0 +1,44 @@
+---
+title: "How VISA Works When Swiping a Credit Card"
+description: "Explore the VISA payment process from authorization to settlement."
+image: "https://assets.bytebytego.com/diagrams/0403-visa-payment.jpg"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "VISA"
+ - "Payment Processing"
+---
+
+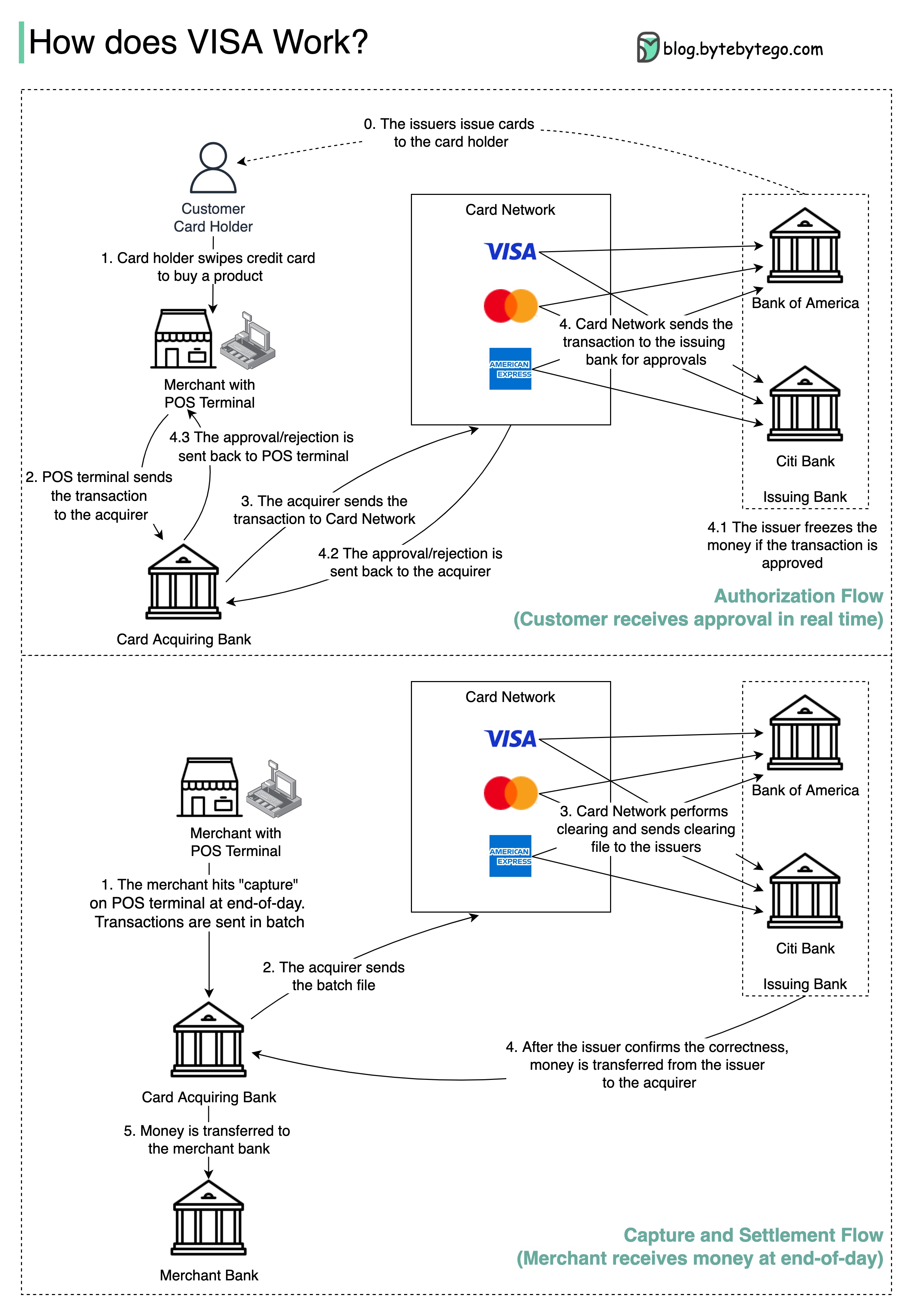
+
+VISA, Mastercard, and American Express act as card networks for clearing and settling funds. The card acquiring bank and the card issuing bank can be – and often are – different. If banks were to settle transactions one by one without an intermediary, each bank would have to settle the transactions with all the other banks. This is quite inefficient.
+
+The diagram shows VISA’s role in the credit card payment process. There are two flows involved. Authorization flow happens when the customer swipes the credit card. Capture and settlement flow occurs when the merchant wants to get the money at the end of the day.
+
+## Authorization Flow
+
+* Step 0: The card issuing bank issues credit cards to its customers.
+
+* Step 1: The cardholder wants to buy a product and swipes the credit card at the Point of Sale (POS) terminal in the merchant’s shop.
+
+* Step 2: The POS terminal sends the transaction to the acquiring bank, which has provided the POS terminal.
+
+* Steps 3 and 4: The acquiring bank sends the transaction to the card network, also called the card scheme. The card network sends the transaction to the issuing bank for approval.
+
+* Steps 4.1, 4.2, and 4.3: The issuing bank freezes the money if the transaction is approved. The approval or rejection is sent back to the acquirer, as well as the POS terminal.
+
+## Capture and Settlement Flow
+
+* Steps 1 and 2: The merchant wants to collect the money at the end of the day, so they hit ”capture” on the POS terminal. The transactions are sent to the acquirer in batches. The acquirer sends the batch file with transactions to the card network.
+
+* Step 3: The card network performs clearing for the transactions collected from different acquirers, and sends the clearing files to different issuing banks.
+
+* Step 4: The issuing banks confirm the correctness of the clearing files, and transfer money to the relevant acquiring banks.
+
+* Step 5: The acquiring bank then transfers money to the merchant’s bank.
+
+* Step 4: The card network clears the transactions from different acquiring banks. Clearing is a process in which mutual offset transactions are netted, so the number of total transactions is reduced.
+
+In the process, the card network takes on the burden of talking to each bank and receives service fees in return.
diff --git a/data/guides/how-does-youtube-handle-massive-video-content-upload.md b/data/guides/how-does-youtube-handle-massive-video-content-upload.md
new file mode 100644
index 0000000..f8a7635
--- /dev/null
+++ b/data/guides/how-does-youtube-handle-massive-video-content-upload.md
@@ -0,0 +1,34 @@
+---
+title: 'How YouTube Handles Massive Video Uploads'
+description: "Explore YouTube's architecture for handling massive video uploads."
+image: 'https://assets.bytebytego.com/diagrams/0425-yt-massive-upload.png'
+createdAt: '2024-02-23'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Scalability
+---
+
+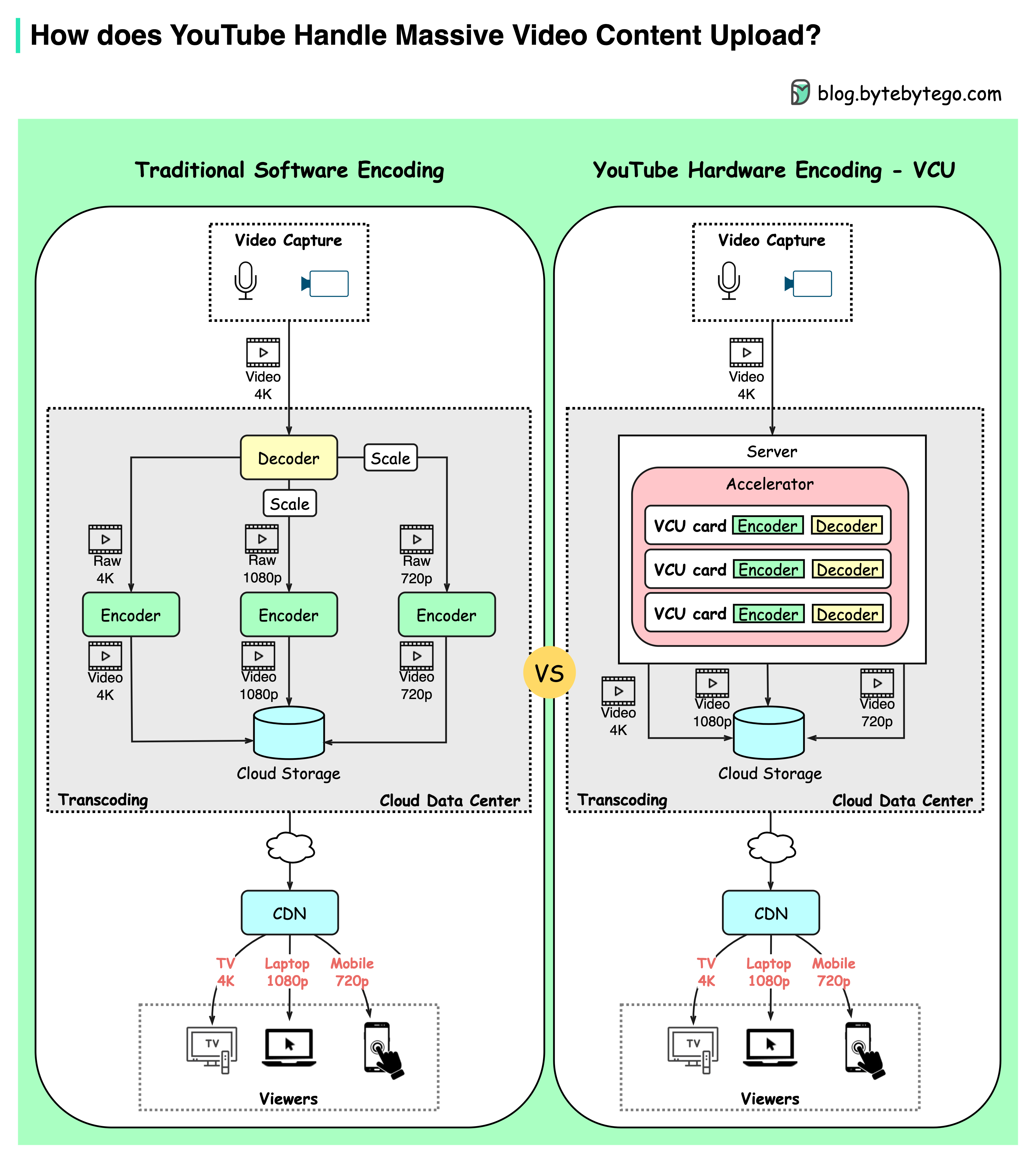
+
+YouTube handles 500+ hours of video content uploads every minute on average. How does it manage this?
+
+The diagram above shows YouTube’s innovative hardware encoding published in 2021.
+
+* **Traditional Software Encoding**
+
+YouTube’s mission is to transcode raw video into different compression rates to adapt to different viewing devices - mobile(720p), laptop(1080p), or high-resolution TV(4k).
+
+Creators upload a massive amount of video content on YouTube every minute. Especially during the COVID-19 pandemic, video consumption is greatly increased as people are sheltered at home. Software-based encoding became slow and costly. This means there was a need for a specialized processing brain tailored made for video encoding/decoding.
+
+* **YouTube’s Transcoding Brain - VCU**
+
+Like GPU or TPU was used for graphics or machine learning calculations, YouTube developed VCU (Video transCoding Unit) for warehouse-scale video processing.
+
+Each cluster has a number of VCU accelerated servers. Each server has multiple accelerator trays, each containing multiple VCU cards. Each card has encoders, decoders, etc.
+
+VCU cluster generates video content with different resolutions and stores it in cloud storage.
+
+This new design brought 20-33x improvements in computing efficiency compared to the previous optimized system.
diff --git a/data/guides/how-is-a-sql-statement-executed-in-the-database.md b/data/guides/how-is-a-sql-statement-executed-in-the-database.md
new file mode 100644
index 0000000..f52d62a
--- /dev/null
+++ b/data/guides/how-is-a-sql-statement-executed-in-the-database.md
@@ -0,0 +1,48 @@
+---
+title: "SQL Statement Execution in Database"
+description: "Explore the steps of SQL statement execution within a database system."
+image: "https://assets.bytebytego.com/diagrams/0340-sql-execution-order-in-db.jpeg"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - SQL
+ - Database Internals
+---
+
+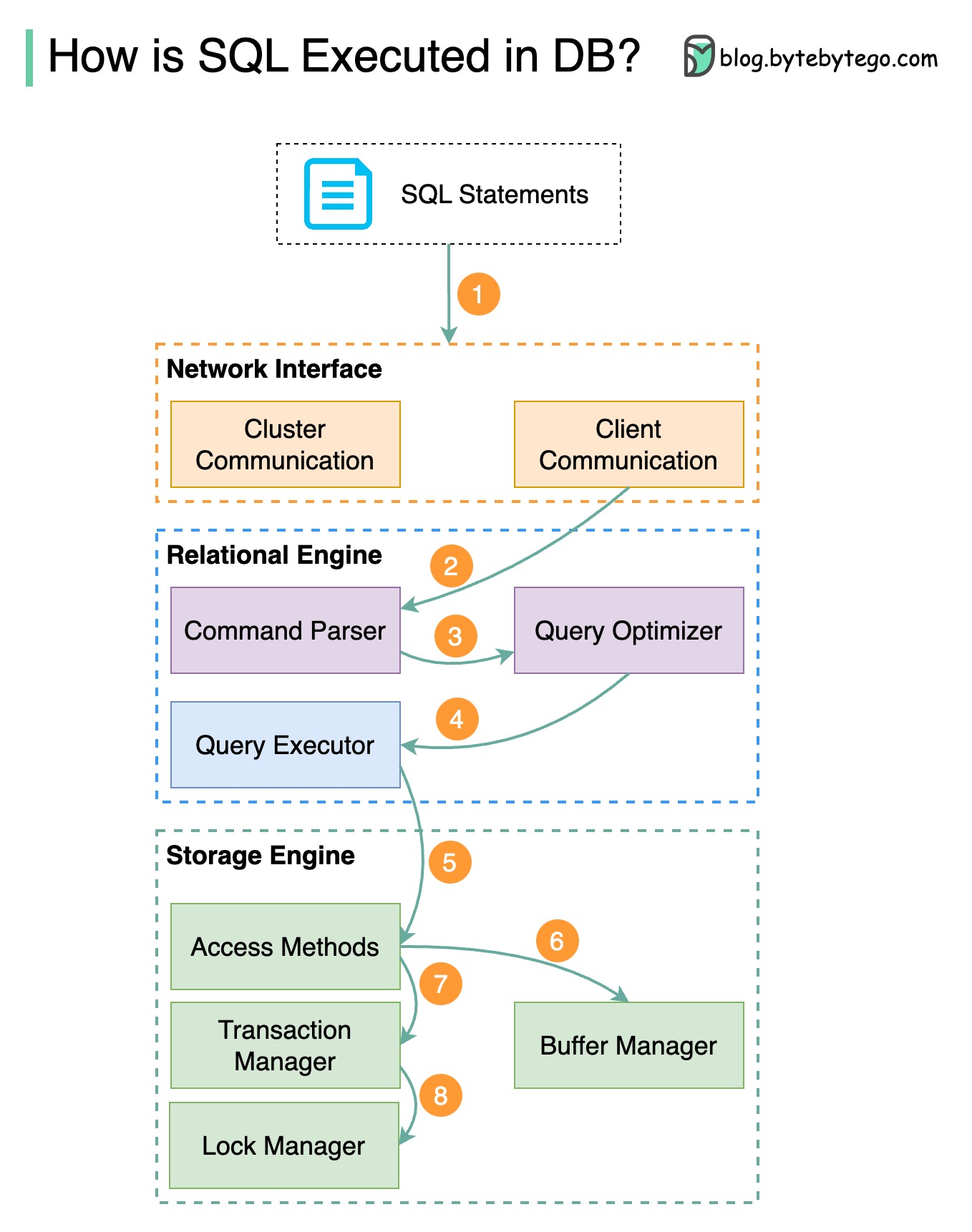
+
+The diagram above shows the process. Note that the architectures for different databases are different, the diagram demonstrates some common designs.
+
+## Step 1 - Transport Layer
+
+A SQL statement is sent to the database via a transport layer protocol (e.g. TCP).
+
+## Step 2 - Command Parser
+
+The SQL statement is sent to the command parser, where it goes through syntactic and semantic analysis, and a query tree is generated afterward.
+
+## Step 3 - Optimizer
+
+The query tree is sent to the optimizer. The optimizer creates an execution plan.
+
+## Step 4 - Executor
+
+The execution plan is sent to the executor. The executor retrieves data from the execution.
+
+## Step 5 - Access Methods
+
+Access methods provide the data fetching logic required for execution, retrieving data from the storage engine.
+
+## Step 6 - Buffer Manager (Read-Only Queries)
+
+Access methods decide whether the SQL statement is read-only. If the query is read-only (SELECT statement), it is passed to the buffer manager for further processing. The buffer manager looks for the data in the cache or data files.
+
+## Step 7 - Transaction Manager (Update/Insert)
+
+If the statement is an UPDATE or INSERT, it is passed to the transaction manager for further processing.
+
+## Step 8 - Lock Manager
+
+During a transaction, the data is in lock mode. This is guaranteed by the lock manager. It also ensures the transaction’s ACID properties.
diff --git a/data/guides/how-is-data-transmitted-between-applications.md b/data/guides/how-is-data-transmitted-between-applications.md
new file mode 100644
index 0000000..6b4b44f
--- /dev/null
+++ b/data/guides/how-is-data-transmitted-between-applications.md
@@ -0,0 +1,22 @@
+---
+title: "Data Transmission Between Applications"
+description: "Explore how data travels between applications in detail."
+image: "https://assets.bytebytego.com/diagrams/0159-data-transfer-between-apps.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - software-development
+tags:
+ - networking
+ - data-transfer
+---
+
+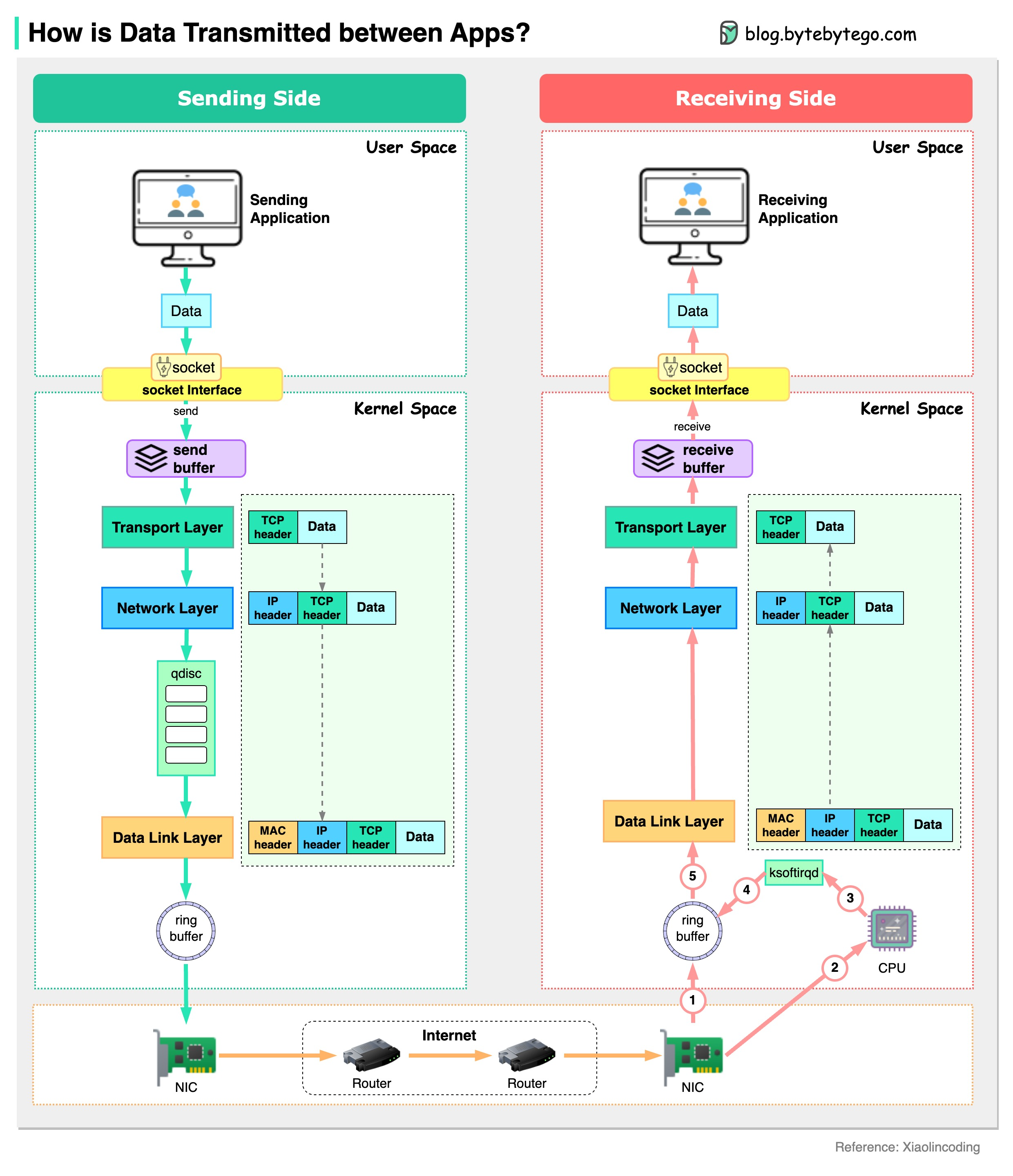
+
+The diagram below shows how a server sends data to another server.
+
+Assume a chat application running in the user space sends out a chat message. The message is sent to the send buffer in the kernel space. The data then goes through the network stack and is wrapped with a TCP header, an IP header, and a MAC header. The data also goes through qdisc (Queueing Disciplines) for flow control. Then the data is sent to the NIC (Network Interface Card) via a ring buffer.
+
+The data is sent to the internet via NIC. After many hops among routers and switches, the data arrives at the NIC of the receiving server.
+
+The NIC of the receiving server puts the data in the ring buffer and sends a hard interrupt to the CPU. The CPU sends a soft interrupt so that ksoftirqd receives data from the ring buffer. Then the data is unwrapped through the data link layer, network layer and transport layer. Eventually, the data (chat message) is copied to the user space and reaches the chat application on the receiving side.
diff --git a/data/guides/how-is-email-delivered.md b/data/guides/how-is-email-delivered.md
new file mode 100644
index 0000000..1a7b300
--- /dev/null
+++ b/data/guides/how-is-email-delivered.md
@@ -0,0 +1,28 @@
+---
+title: "How is Email Delivered?"
+description: "Explore the journey of an email, from sender to receiver, step by step."
+image: "https://assets.bytebytego.com/diagrams/0185-email-deliver.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - EmailProtocols
+ - EmailDelivery
+---
+
+Do you know how an email is delivered?
+
+When I first learned how similar email is to traditional ‘snail’ mail, I was surprised. Maybe you will be, too. Allow me to explain.
+
+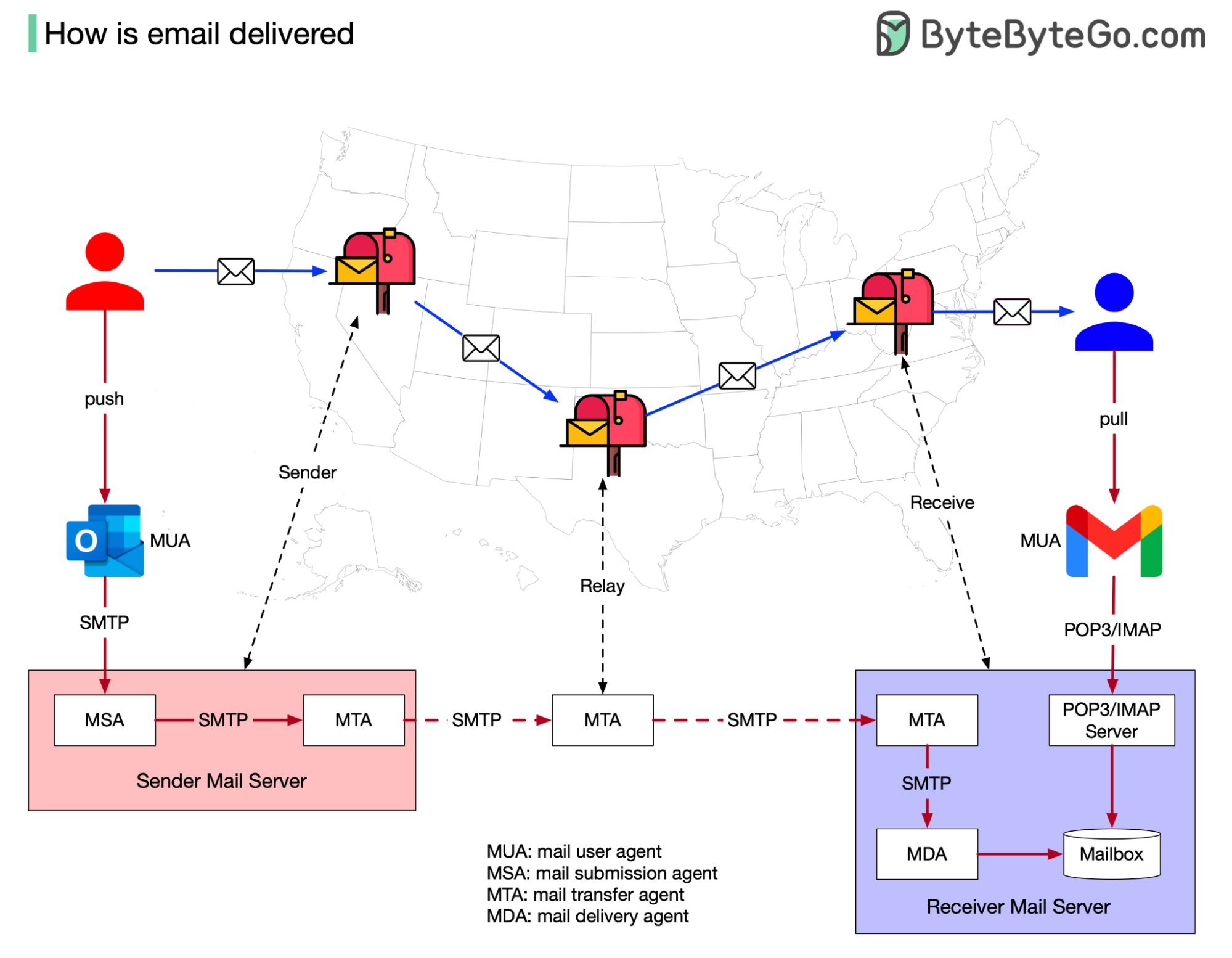
+
+In the physical world, if I want to send a postcard to a friend, I would put it in a nearby mailbox. The postal office collects the mail regularly and relays it to the destination postal office. This postal office then puts the postcard in my friend’s mailbox. This process usually takes a few days and my friend receives my gratitude in paper form.
+
+Email functions in a similar way. The terminology changes because it is an internet-based solution, but the fundamentals are the same:
+
+* Instead of putting mail in a mailbox, the sender pushes an email to the Sender Mail Server using MUA (mail user agent,) such as Outlook or Gmail.
+
+* Instead of using postal offices to relay mail, MTA (mail transmission agent) relays the email. It communicates via the SMTP protocol.
+
+The email is received by the Receiver Mail Server. It stores the email to the Mailbox by using MDA (mail delivery agent.) The receiver uses MUA to retrieve the email using the POP3/IMAP protocol.
diff --git a/data/guides/how-levelsfyi-scaled-to-millions-of-users-with-google-sheets.md b/data/guides/how-levelsfyi-scaled-to-millions-of-users-with-google-sheets.md
new file mode 100644
index 0000000..1c4dde8
--- /dev/null
+++ b/data/guides/how-levelsfyi-scaled-to-millions-of-users-with-google-sheets.md
@@ -0,0 +1,22 @@
+---
+title: 'How Levelsfyi Scaled to Millions of Users with Google Sheets'
+description: 'Learn how Levelsfyi scaled to millions of users using Google Sheets.'
+image: 'https://assets.bytebytego.com/diagrams/0255-levels-fyi.jpg'
+createdAt: '2024-02-17'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Scalability
+ - Google Sheets
+---
+
+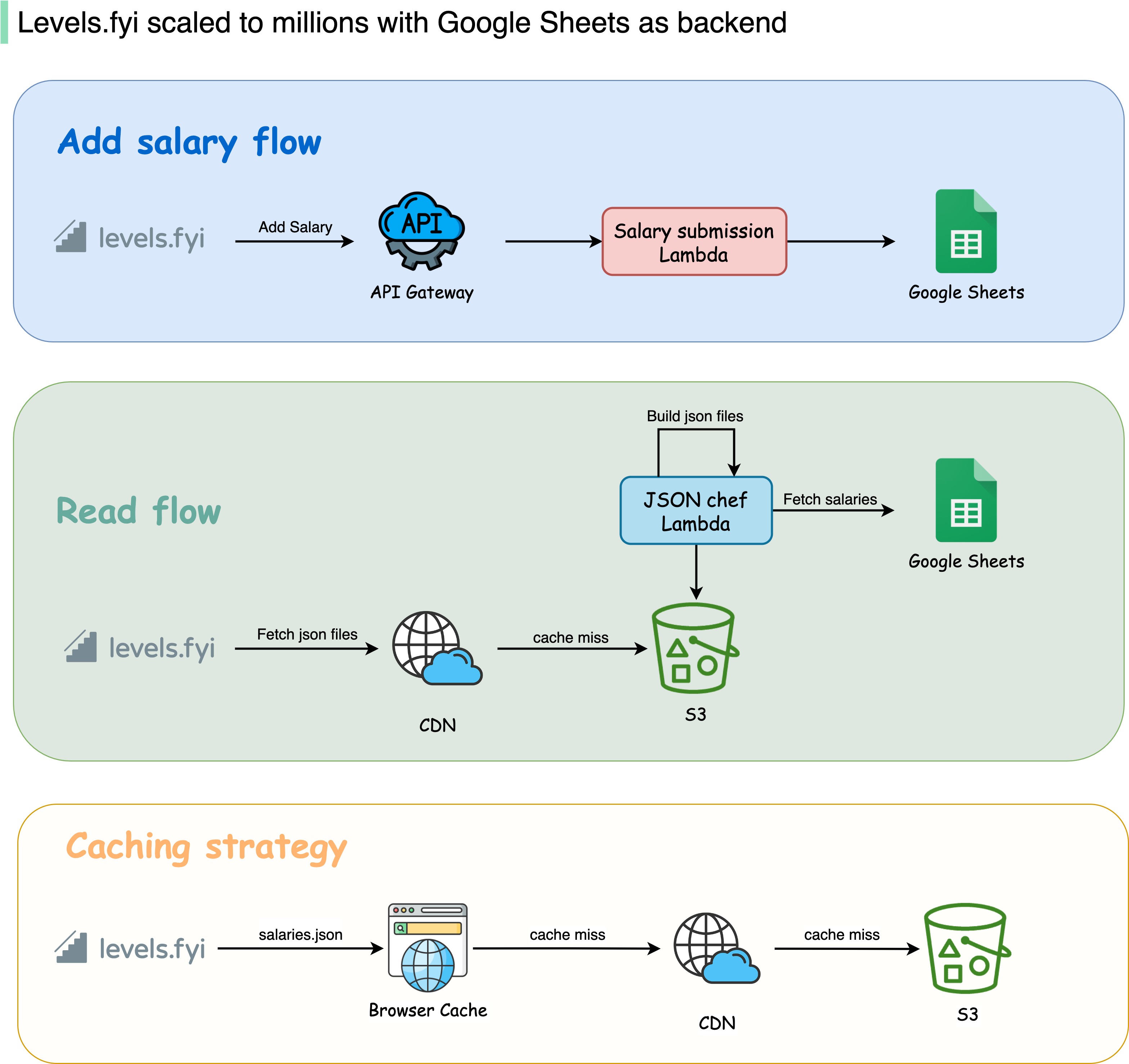
+
+I read something unbelievable today: Levelsfyi scaled to millions of users using Google Sheets as a backend!
+
+They started off on Google Forms and Sheets, which helped them reach millions of monthly active users before switching to a proper backend.
+
+To be fair, they do use serverless computing, but using Google Sheets as the database is an interesting choice.
+
+Why do they use Google Sheets as a backend? Using their own words: "It seems like a pretty counterintuitive idea for a site with our traffic volume to not have a backend or any fancy infrastructure, but our philosophy to building products has always been, start simple and iterate. This allows us to move fast and focus on what’s important".
diff --git a/data/guides/how-nat-made-the-growth-of-the-internet-possible.md b/data/guides/how-nat-made-the-growth-of-the-internet-possible.md
new file mode 100644
index 0000000..ee73767
--- /dev/null
+++ b/data/guides/how-nat-made-the-growth-of-the-internet-possible.md
@@ -0,0 +1,31 @@
+---
+title: 'How NAT Enabled the Internet'
+description: 'Explore how NAT facilitated the expansion of the internet.'
+image: 'https://assets.bytebytego.com/diagrams/0231-http-header.png'
+createdAt: '2024-01-29'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - NAT
+ - Networking
+---
+
+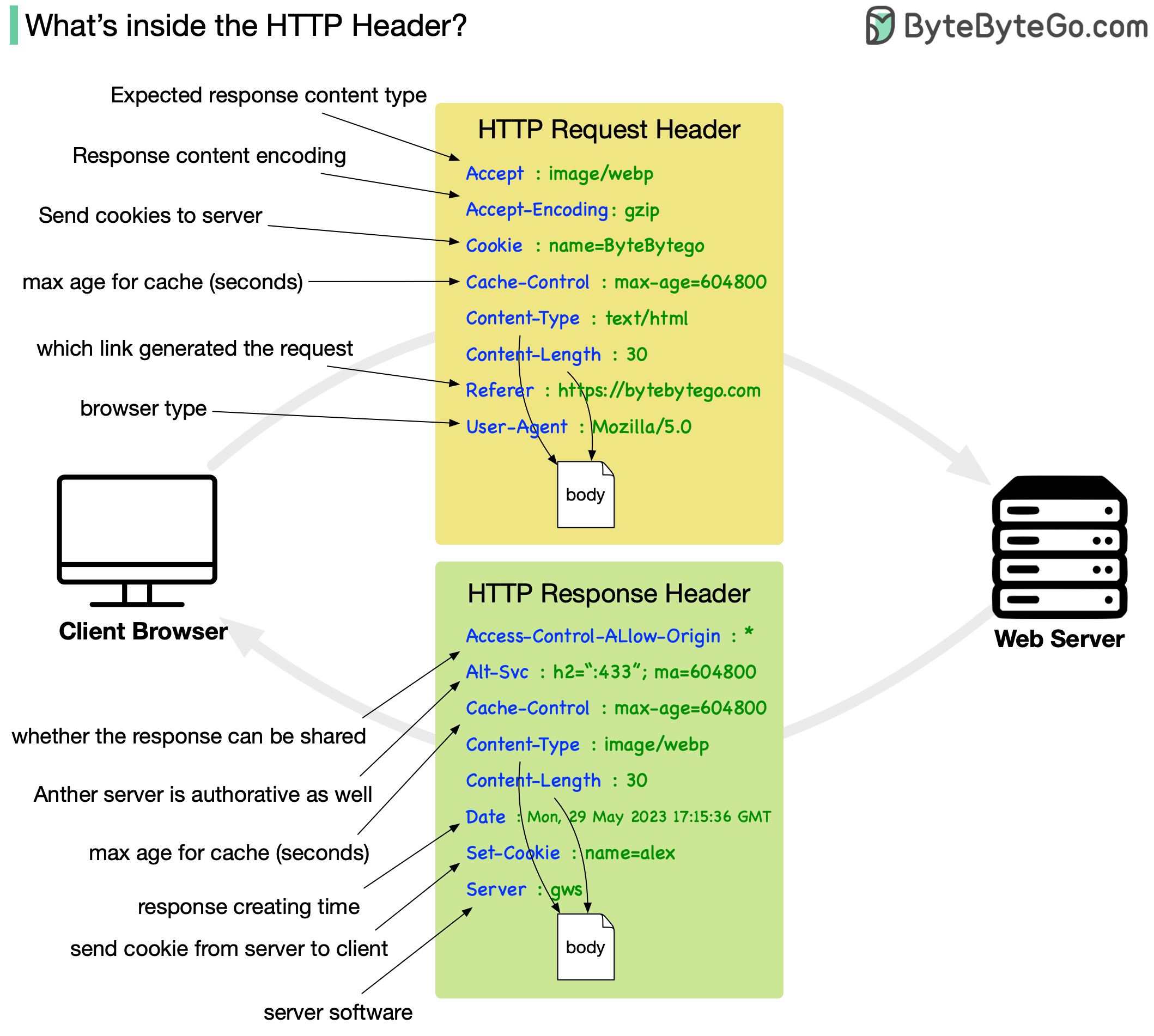
+
+Network Address Translation (NAT) is the process that has made the growth of the Internet possible.
+
+But how does it work?
+
+1. In a corporate or home setting, multiple devices (phones, computers, etc.) share one router with a single public IP address.
+2. When a device wants to access the internet, it sends a request to your router. The request contains the device's private IP address.
+3. The router’s NAT process replaces the private IP with the router’s public IP.
+4. The modified request is sent to the internet.
+5. When the response comes back, NAT checks its record and replaces the public IP with the correct private IP. It sends the response to the right device.
+
+NAT has several important uses:
+
+* **Conserves public IP addresses:** Without NAT, IPv4 addresses would have been depleted much faster, severely limiting the growth of the Internet.
+* **Allows sharing:** It allows sharing a single public IP address across multiple devices.
+* **Acts as a basic firewall:** NAT acts as a basic firewall that hides internal IP addresses.
+* **Eases network management:** NAT also makes it easy to manage large networks.
diff --git a/data/guides/how-netflix-really-uses-java.md b/data/guides/how-netflix-really-uses-java.md
new file mode 100644
index 0000000..e5fbb2d
--- /dev/null
+++ b/data/guides/how-netflix-really-uses-java.md
@@ -0,0 +1,36 @@
+---
+title: How Netflix Really Uses Java
+description: Explore Netflix's extensive use of Java in its microservices architecture.
+image: 'https://assets.bytebytego.com/diagrams/0102-how-netflix-really-uses-java.png'
+createdAt: '2024-03-04'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Java
+ - Microservices
+---
+
+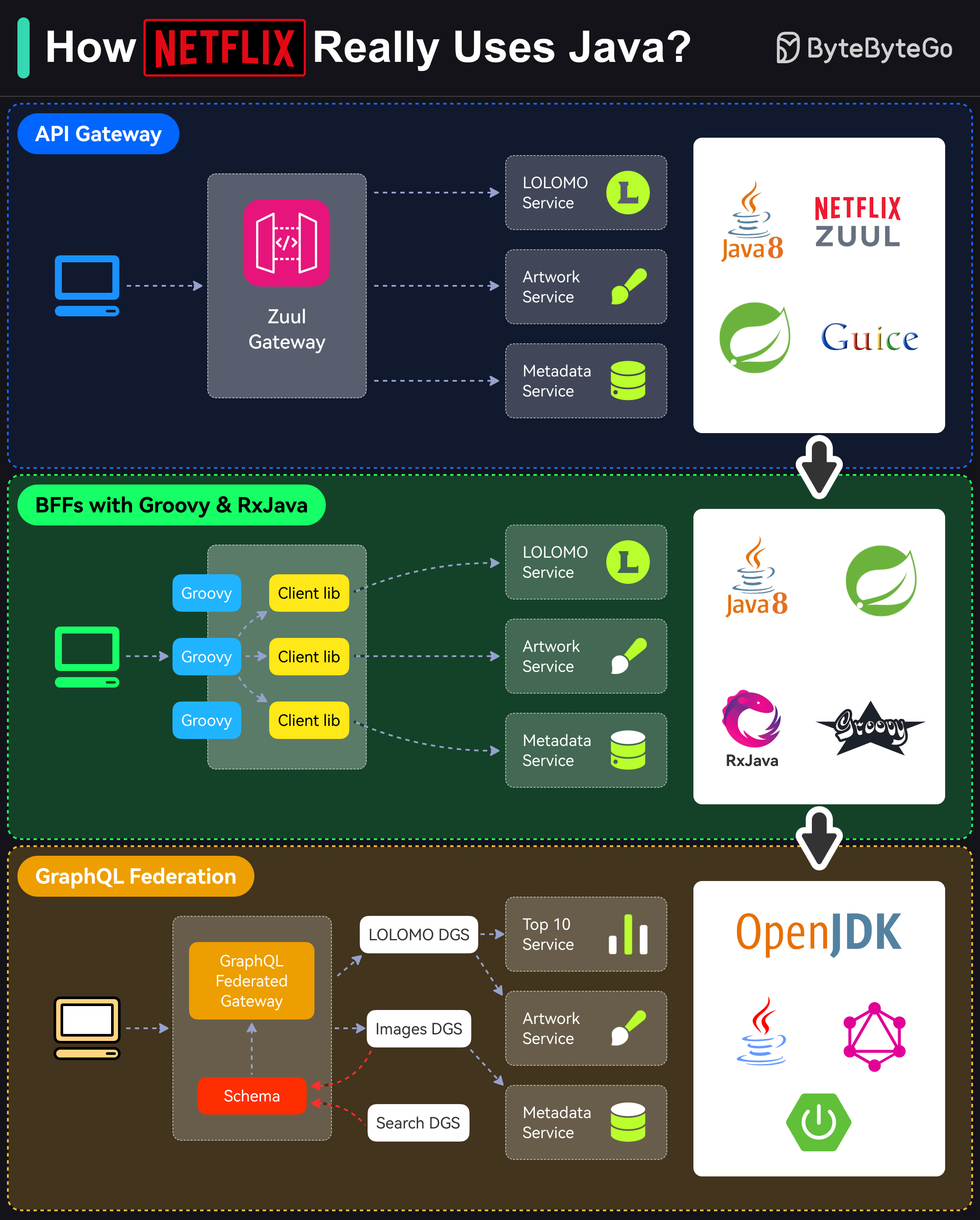
+
+Netflix is predominantly a Java shop.
+
+Every backend application (including internal apps, streaming, and movie production apps) at Netflix is a Java application.
+
+However, the Java stack is not static and has gone through multiple iterations over the years.
+
+Here are the details of those iterations:
+
+* **API Gateway**
+
+ Netflix follows a microservices architecture. Every piece of functionality and data is owned by a microservice built using Java (initially version 8)
+
+* **BFFs with Groovy & RxJava**
+
+ Using a single gateway for multiple clients was a problem for Netflix because each client (such as TV, mobile apps, or web browser) had subtle differences.
+
+ To handle this, Netflix used the Backend-for-Frontend (BFF) pattern. Zuul was moved to the role of a proxy
+
+* **GraphQL Federation**
+
+ The Groovy and RxJava approach required more work from the UI developers in creating the Groovy scripts. Also, reactive programming is generally hard.
diff --git a/data/guides/how-redis-architecture-evolve.md b/data/guides/how-redis-architecture-evolve.md
new file mode 100644
index 0000000..cd08e0f
--- /dev/null
+++ b/data/guides/how-redis-architecture-evolve.md
@@ -0,0 +1,48 @@
+---
+title: "How Redis Architecture Evolved"
+description: "Explore the evolution of Redis architecture, from standalone to cluster."
+image: "https://assets.bytebytego.com/diagrams/0223-how-redis-architecture-evolve.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Redis
+ - Architecture
+---
+
+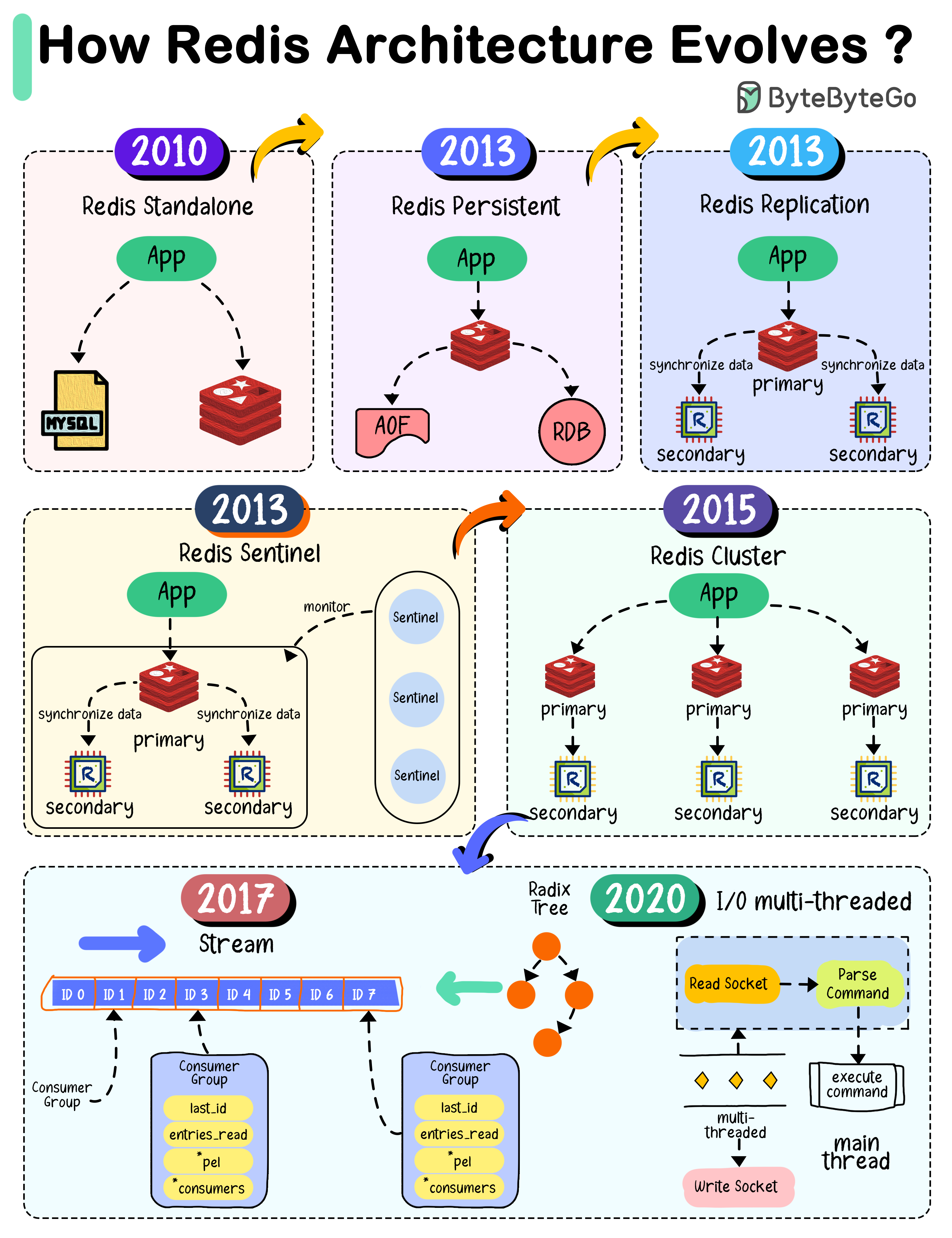
+
+Redis is a popular in-memory cache. How did it evolve to the architecture it is today?
+
+## 2010 - Standalone Redis
+
+When Redis 1.0 was released in 2010, the architecture was quite simple. It is usually used as a cache to the business application.
+
+However, Redis stores data in memory. When we restart Redis, we will lose all the data and the traffic directly hits the database.
+
+## 2013 - Persistence
+
+When Redis 2.8 was released in 2013, it addressed the previous restrictions. Redis introduced RDB in-memory snapshots to persist data. It also supports AOF (Append-Only-File), where each write command is written to an AOF file.
+
+## 2013 - Replication
+
+Redis 2.8 also added replication to increase availability. The primary instance handles real-time read and write requests, while replica synchronizes the primary's data.
+
+## 2013 - Sentinel
+
+Redis 2.8 introduced Sentinel to monitor the Redis instances in real time. is a system designed to help managing Redis instances. It performs the following four tasks: monitoring, notification, automatic failover and configuration provider.
+
+## 2015 - Cluster
+
+In 2015, Redis 3.0 was released. It added Redis clusters.
+
+A Redis cluster is a distributed database solution that manages data through sharding. The data is divided into 16384 slots, and each node is responsible for a portion of the slot.
+
+## Looking Ahead
+
+Redis is popular because of its high performance and rich data structures that dramatically reduce the complexity of developing a business application.
+
+In 2017, Redis 5.0 was released, adding the stream data type.
+
+In 2020, Redis 6.0 was released, introducing the multi-threaded I/O in the network module. Redis model is divided into the network module and the main processing module. The Redis developers the network module tends to become a bottleneck in the system.
diff --git a/data/guides/how-tiktok-manages-a-200k-file-frontend-monorepo.md b/data/guides/how-tiktok-manages-a-200k-file-frontend-monorepo.md
new file mode 100644
index 0000000..2efcd71
--- /dev/null
+++ b/data/guides/how-tiktok-manages-a-200k-file-frontend-monorepo.md
@@ -0,0 +1,35 @@
+---
+title: How TikTok Manages a 200K File Frontend MonoRepo
+description: TikTok's strategy for managing a large frontend MonoRepo with 200K files.
+image: 'https://assets.bytebytego.com/diagrams/0226-how-tiktok-manages-a-200k-file-frontend-monorepo.png'
+createdAt: '2024-03-03'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Monorepo
+ - Performance
+---
+
+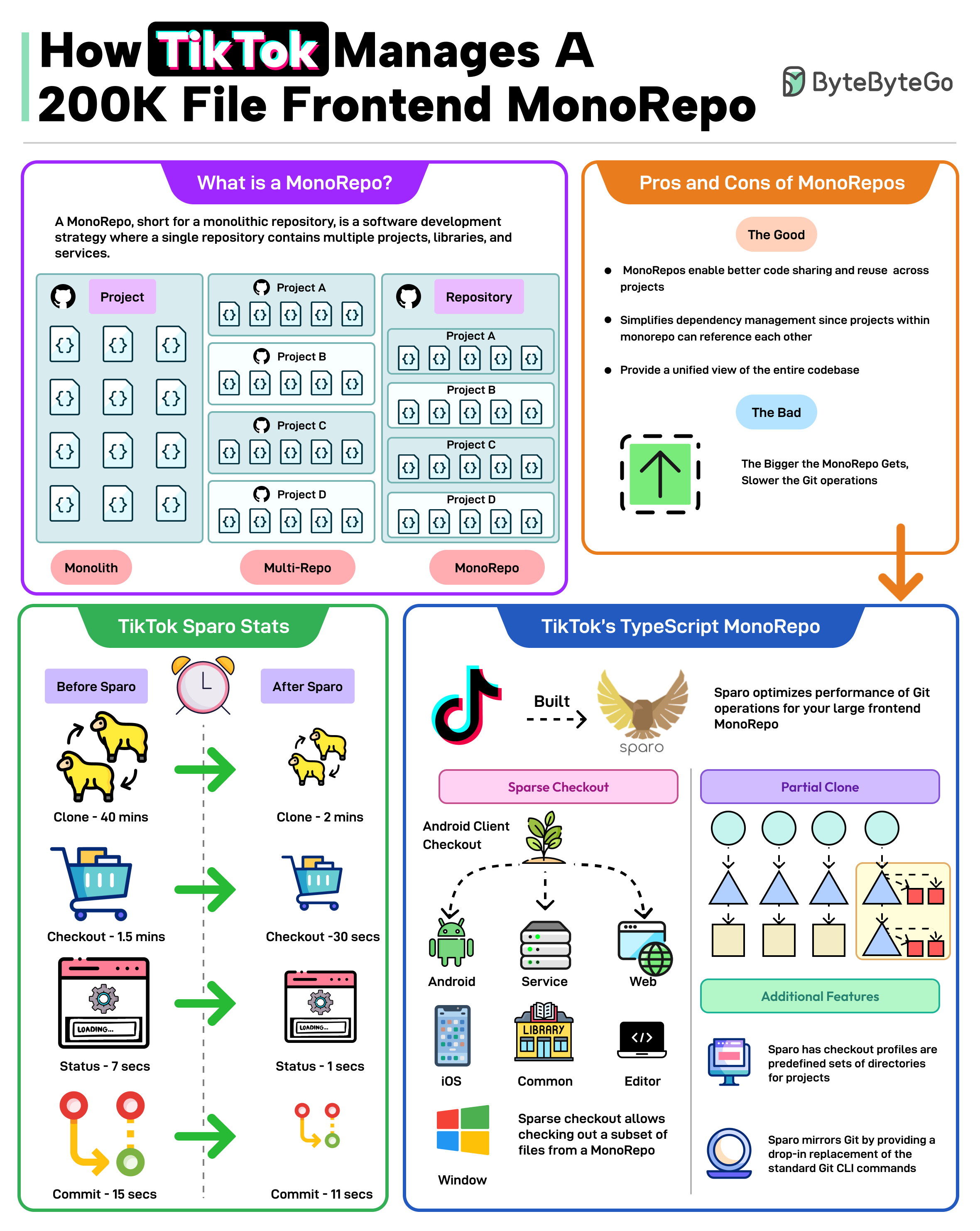
+
+A MonoRepo, short for a monolithic repository, is a software development strategy where a single repository contains multiple projects, libraries, and services.
+
+The good parts of a MonoRepo are:
+
+* **Better code sharing**
+* **Simplified dependency management**
+* **A unified view of the code base**
+
+However, the bigger the MonoRepo gets, the slower the various Git operations.
+
+TikTok faced a similar change with its frontend TypeScript MonoRepo with 200K files.
+
+To deal with this, TikTok built a tool named Sparo that optimizes the performance of Git operations for large frontend MonoRepos.
+
+Sparo dramatically improved the performance of Git operations. Some stats are as follows
+
+* Git clone time went from 40 mins to just 2 mins.
+* Checkout went from 1.5 minutes to 30 seconds.
+* Status went from 7 seconds to 1 second.
+* Git commit time went from 15 seconds to 11 seconds.
diff --git a/data/guides/how-to-ace-system-design-interviews-like-a-boss.md b/data/guides/how-to-ace-system-design-interviews-like-a-boss.md
new file mode 100644
index 0000000..9de9027
--- /dev/null
+++ b/data/guides/how-to-ace-system-design-interviews-like-a-boss.md
@@ -0,0 +1,46 @@
+---
+title: "How to Ace System Design Interviews"
+description: "A 7-step process to excel in system design interviews."
+image: "https://assets.bytebytego.com/diagrams/0104-how-to-ace-system-design-interviews-like-a-boss.png"
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "System Design"
+ - "Interview Preparation"
+---
+
+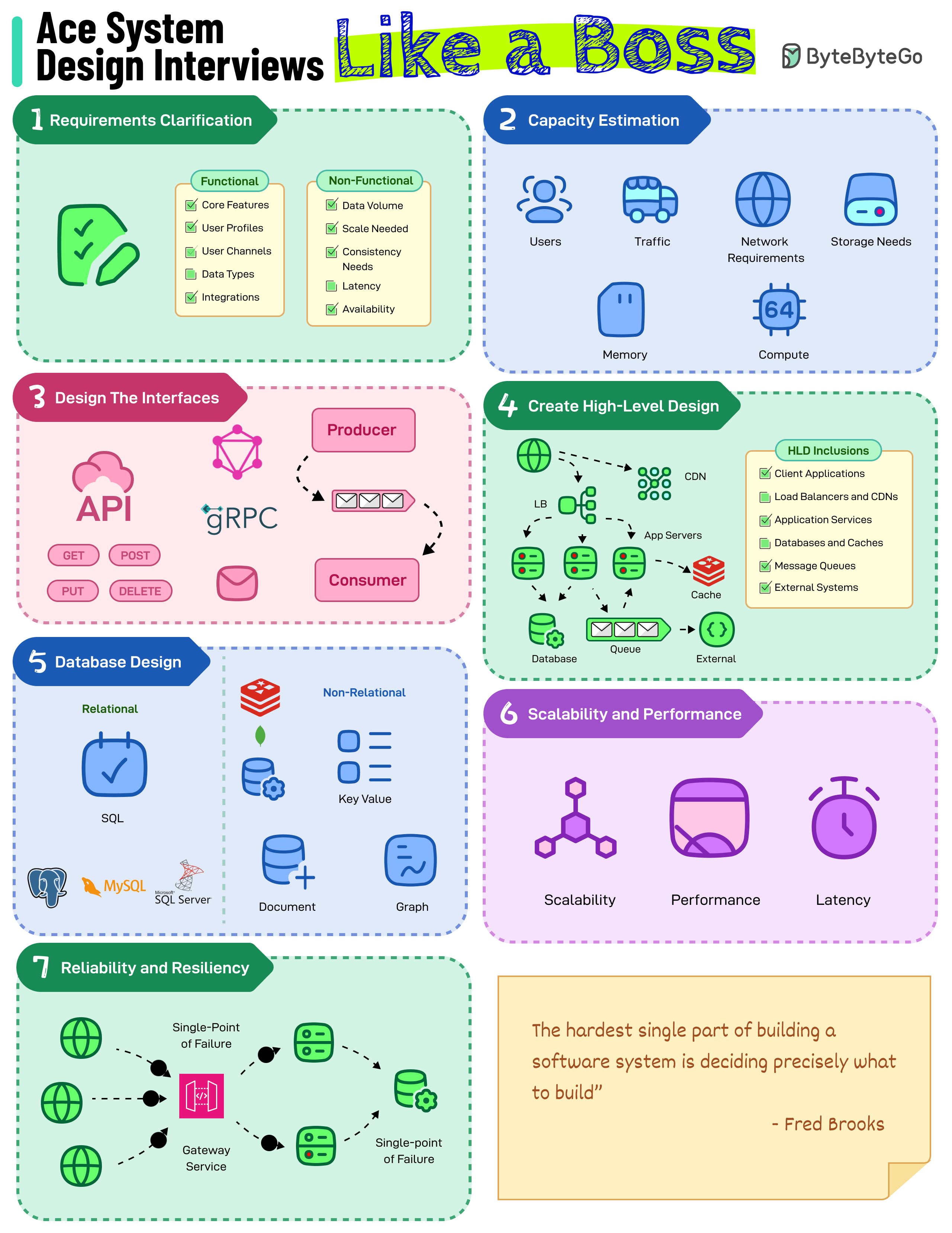
+
+Follow this 7-step process to do well in a System Design Round
+
+## 1. Requirements Clarification
+
+In the first step, clarify functional and non-functional requirements. Ask questions to understand the core features of the system as well as non-functional aspects such as data volume, availability, scale, etc.
+
+## 2. Capacity Estimation
+
+Next, estimate the capacity of the system. Focus on attributes like the number of users, traffic, storage/memory needs, and compute and networking requirements.
+
+## 3. Create High-Level Design
+
+Break down the system into components such as client apps, servers, load balancers, databases, etc.
+
+Start with drawing a simple block diagram that shows these components and their potential interaction with each other. Focus on the data flow.
+
+## 4. Database Design
+
+Model the data and choose the right database type for the system. Once done, focus on the database schema.
+
+## 5. Interface Design
+
+Next, focus on the interfaces to the system. This could be API endpoints or event models exchanged between the various components of the system. Also, choose a communication approach such as REST, GraphQL, gRPC, or an event-driven
+
+## 6. Scalability and Performance
+
+Address the scalability, performance, and latency aspects of the system by suggesting techniques that will be used. For example, vertical and horizontal scaling, caching, indexing, denormalizing, sharding, replication, CDNs, etc.
+
+## 7. Reliability and Resiliency
+
+Lastly, address the reliability and resiliency of the design. Identify single points of failure and mitigate their impact.
diff --git a/data/guides/how-to-avoid-crawling-duplicate-urls-at-google-scale.md b/data/guides/how-to-avoid-crawling-duplicate-urls-at-google-scale.md
new file mode 100644
index 0000000..fea2fb0
--- /dev/null
+++ b/data/guides/how-to-avoid-crawling-duplicate-urls-at-google-scale.md
@@ -0,0 +1,39 @@
+---
+title: "How to Avoid Crawling Duplicate URLs at Google Scale?"
+description: "Learn how to avoid crawling duplicate URLs at Google scale."
+image: "https://assets.bytebytego.com/diagrams/0089-bloomfilter.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Bloom Filter"
+ - "Web Crawling"
+---
+
+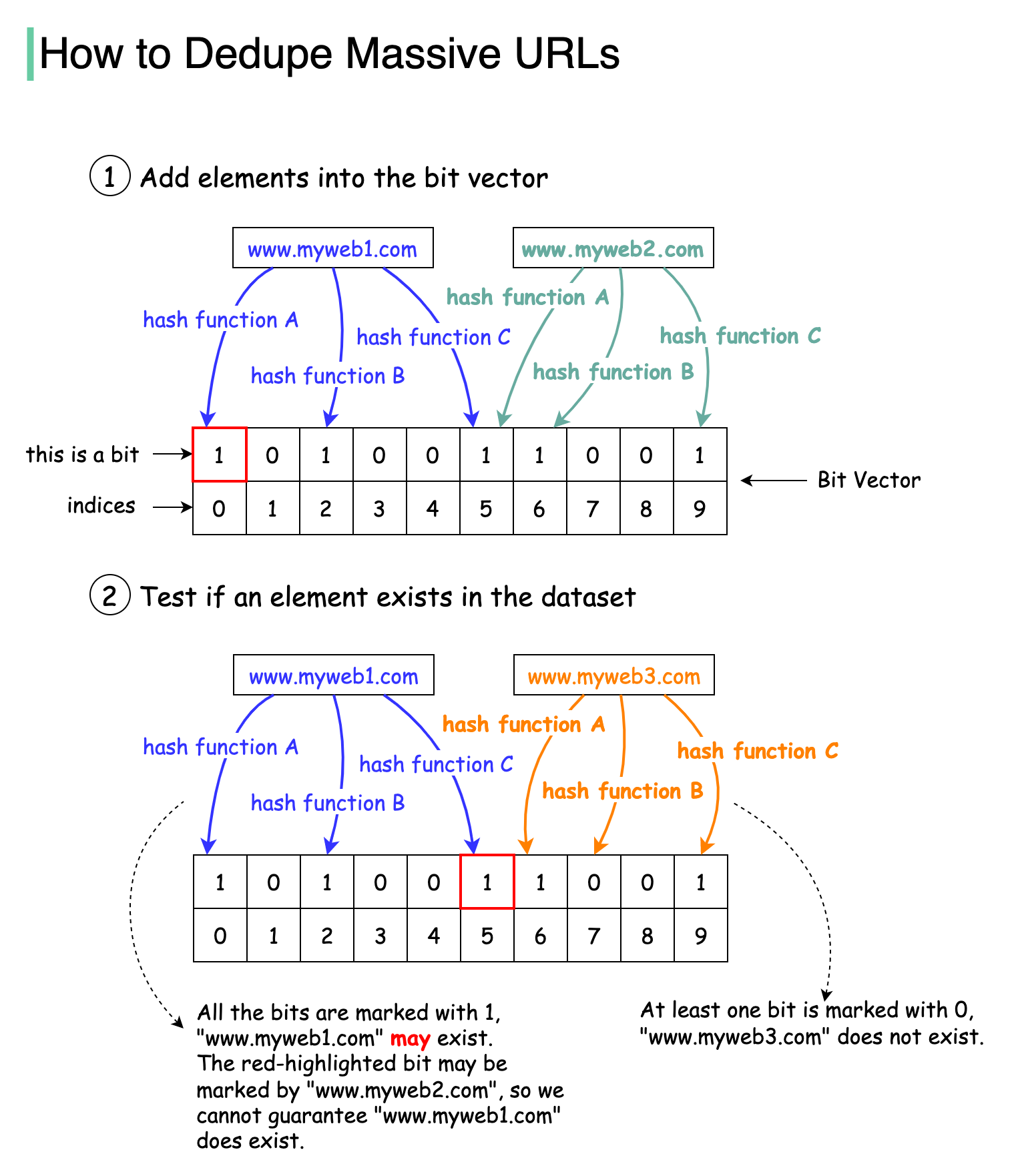
+
+Option 1: Use a Set data structure to check if a URL already exists or not. Set is fast, but it is not space-efficient.
+
+Option 2: Store URLs in a database and check if a new URL is in the database. This can work but the load to the database will be very high.
+
+### Option 3: Bloom Filter
+
+This option is preferred. Bloom filter was proposed by Burton Howard Bloom in 1970. It is a probabilistic data structure that is used to test whether an element is a member of a set.
+
+* false: the element is definitely not in the set.
+* true: the element is probably in the set.
+
+False-positive matches are possible, but false negatives are not.
+
+The diagram below illustrates how the Bloom filter works. The basic data structure for the Bloom filter is Bit Vector. Each bit represents a hashed value.
+
+### Step 1
+
+To add an element to the bloom filter, we feed it to 3 different hash functions (A, B, and C) and set the bits at the resulting positions. Note that both “[www.myweb1.com](http://www.myweb1.com/)” and “[www.myweb2.com](http://www.myweb2.com/)” mark the same bit with 1 at index 5. False positives are possible because a bit might be set by another element.
+
+### Step 2
+
+When testing the existence of a URL string, the same hash functions A, B, and C are applied to the URL string. If all three bits are 1, then the URL may exist in the dataset; if any of the bits is 0, then the URL definitely does not exist in the dataset.
+
+Hash function choices are important. They must be uniformly distributed and fast. For example, RedisBloom and Apache Spark use murmur, and InfluxDB uses xxhash.
diff --git a/data/guides/how-to-avoid-double-payment.md b/data/guides/how-to-avoid-double-payment.md
new file mode 100644
index 0000000..ad01016
--- /dev/null
+++ b/data/guides/how-to-avoid-double-payment.md
@@ -0,0 +1,33 @@
+---
+title: "How to Avoid Double Payment"
+description: "Learn how to prevent double payments in your payment system."
+image: "https://assets.bytebytego.com/diagrams/0178-double-charge.jpg"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - Payment Systems
+ - Idempotency
+---
+
+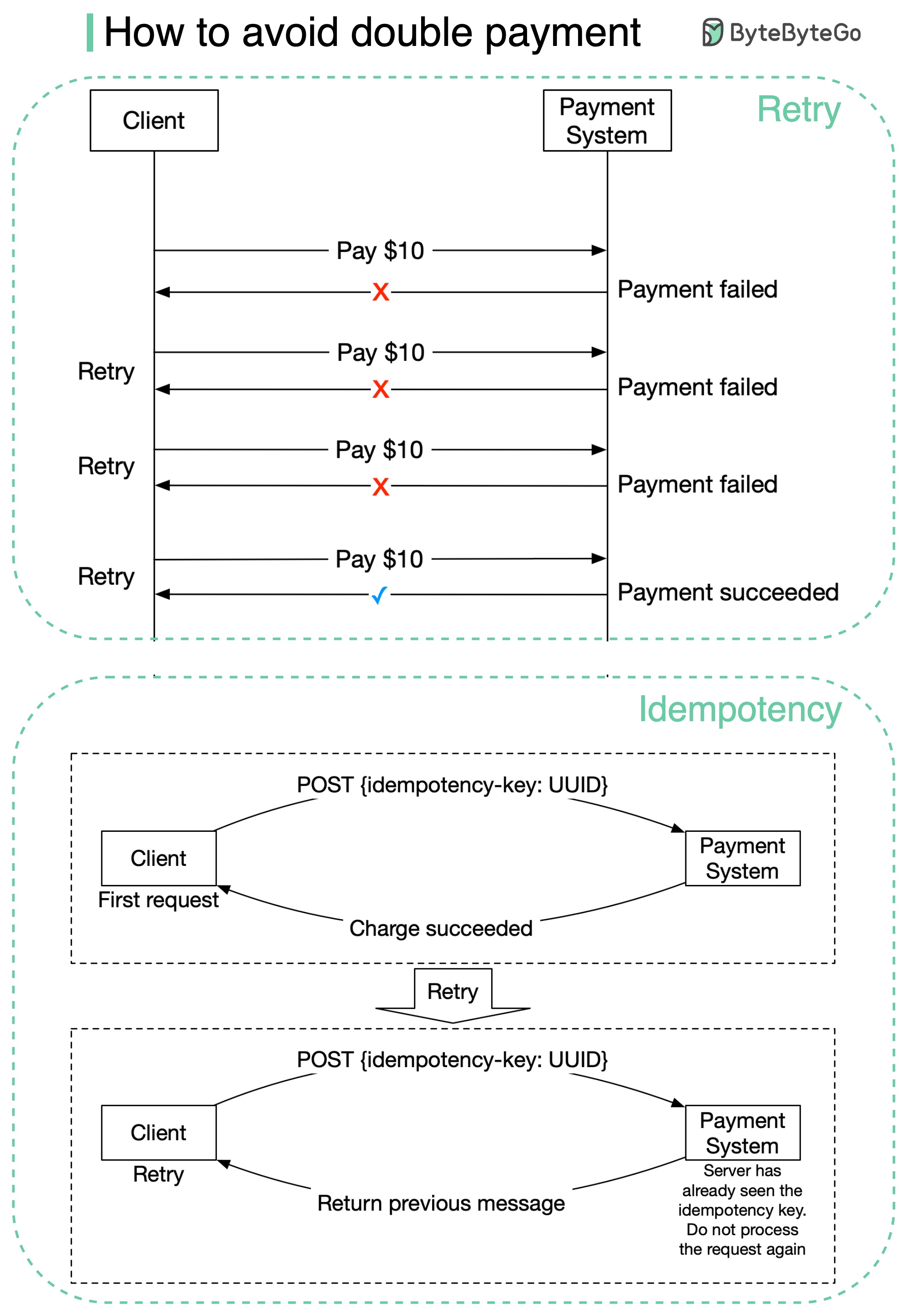
+
+One of the most serious problems a payment system can have is to **double charge** a customer. When we design the payment system, it is important to guarantee that the payment system executes a payment order exactly-once.
+
+At the first glance, exactly-once delivery seems very hard to tackle, but if we divide the problem into two parts, it is much easier to solve. Mathematically, an operation is executed exactly-once if:
+
+* It is executed at least once.
+* At the same time, it is executed at most once.
+
+We now explain how to implement at least once using retry and at most once using idempotency check.
+
+## Retry
+
+Occasionally, we need to retry a payment transaction due to network errors or timeout. Retry provides the at-least-once guarantee. For example, as shown in Figure 10, the client tries to make a $10 payment, but the payment keeps failing due to a poor network connection. Considering the network condition might get better, the client retries the request and this payment finally succeeds at the fourth attempt.
+
+## Idempotency
+
+From an API standpoint, idempotency means clients can make the same call repeatedly and produce the same result.
+
+For communication between clients (web and mobile applications) and servers, an idempotency key is usually a unique value that is generated by clients and expires after a certain period of time. A UUID is commonly used as an idempotency key and it is recommended by many tech companies such as Stripe and PayPal. To perform an idempotent payment request, an idempotency key is added to the HTTP header: .
diff --git a/data/guides/how-to-choose-the-right-database.md b/data/guides/how-to-choose-the-right-database.md
new file mode 100644
index 0000000..1aeb5d5
--- /dev/null
+++ b/data/guides/how-to-choose-the-right-database.md
@@ -0,0 +1,30 @@
+---
+title: "How to Choose the Right Database"
+description: "A guide to selecting the optimal database for your specific needs."
+image: "https://assets.bytebytego.com/diagrams/0227-how-to-choose-the-right-database.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "database selection"
+ - "data storage"
+---
+
+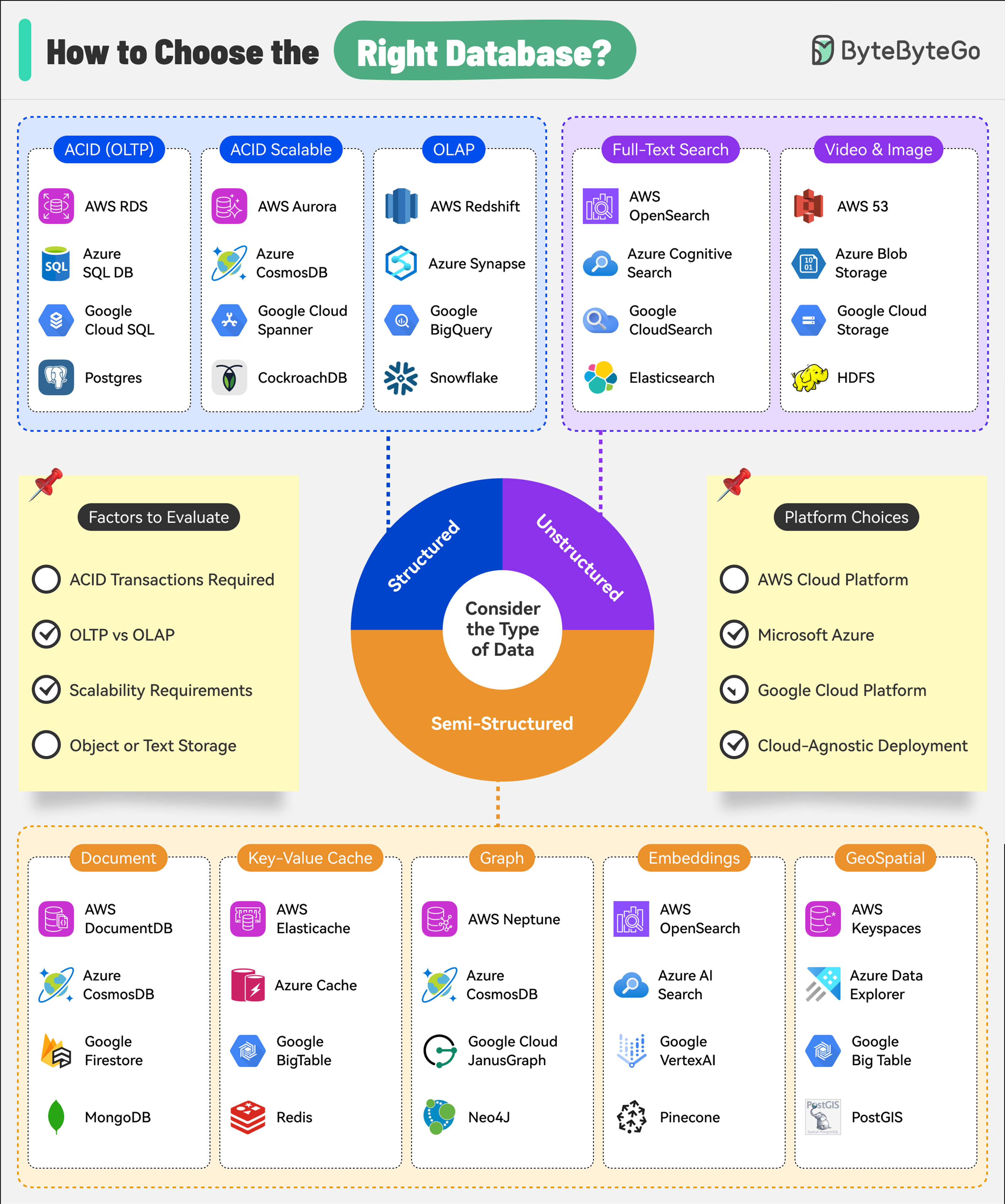
+
+* OLTP: For transactional systems requiring strong consistency
+
+* OLAP: Optimized for complex queries and data analysis
+
+* Full-Text Search: Fast, flexible text search capabilities
+
+* Document Stores: JSON-like document storage and querying
+
+* Key-Value Stores: High-speed, simple data models
+
+* Graph Databases: Managing highly connected data
+
+* Embeddings: Efficient storage and retrieval of vector representations
+
+* Geospatial: Specialized for location-based data and queries
diff --git a/data/guides/how-to-deploy-services.md b/data/guides/how-to-deploy-services.md
new file mode 100644
index 0000000..627eae9
--- /dev/null
+++ b/data/guides/how-to-deploy-services.md
@@ -0,0 +1,32 @@
+---
+title: "Deployment Strategies"
+description: "Explore risk mitigation strategies for deploying and upgrading services."
+image: "https://assets.bytebytego.com/diagrams/0166-deployment-strategies.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Deployment"
+ - "DevOps"
+---
+
+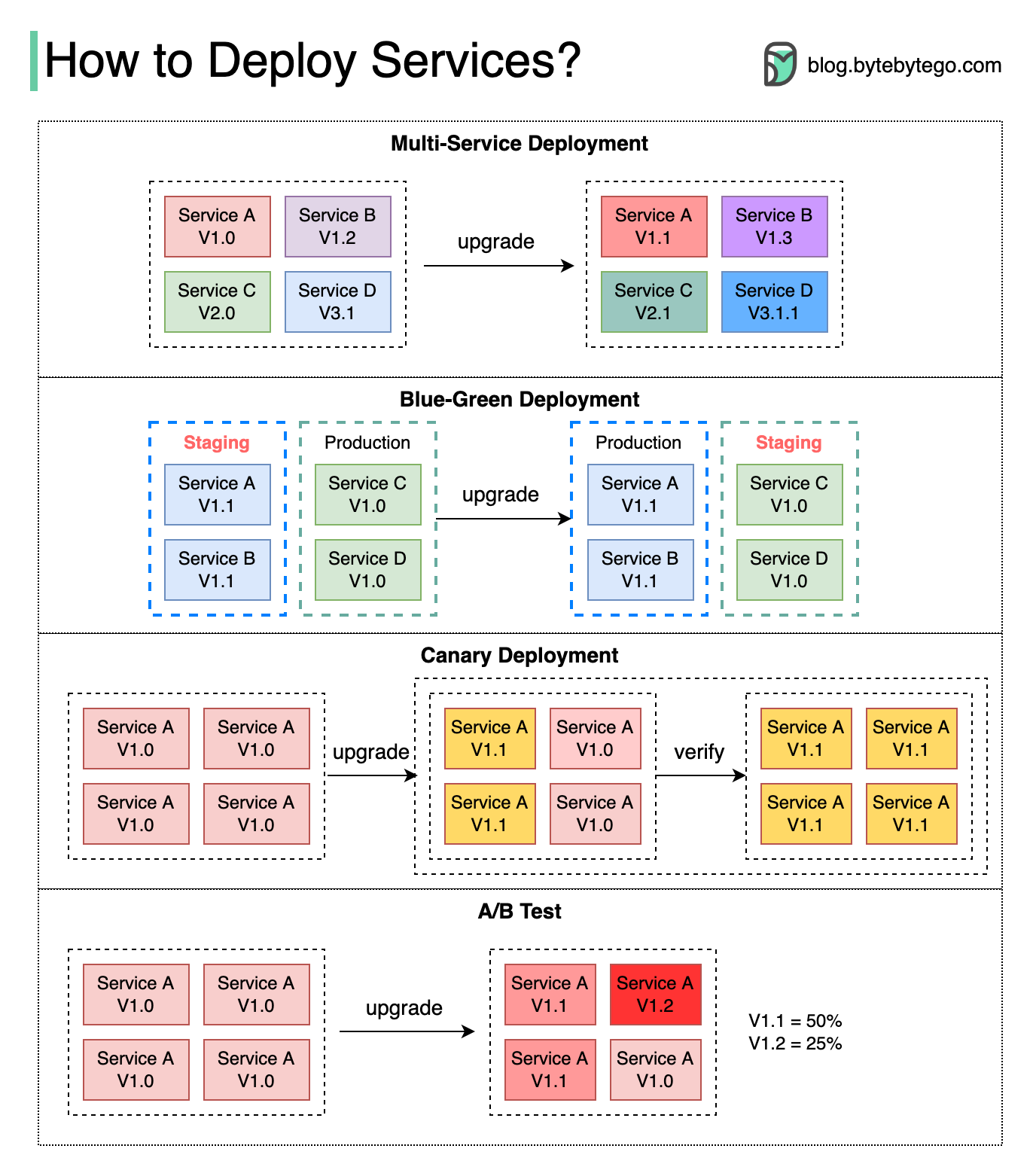
+
+Deploying or upgrading services is risky. In this post, we explore risk mitigation strategies.
+
+## Multi-Service Deployment
+
+In this model, we deploy new changes to multiple services simultaneously. This approach is easy to implement. But since all the services are upgraded at the same time, it is hard to manage and test dependencies. It’s also hard to rollback safely.
+
+## Blue-Green Deployment
+
+With blue-green deployment, we have two identical environments: one is staging (blue) and the other is production (green). The staging environment is one version ahead of production. Once testing is done in the staging environment, user traffic is switched to the staging environment, and the staging becomes the production. This deployment strategy is simple to perform rollback, but having two identical production quality environments could be expensive.
+
+## Canary Deployment
+
+A canary deployment upgrades services gradually, each time to a subset of users. It is cheaper than blue-green deployment and easy to perform rollback. However, since there is no staging environment, we have to test on production. This process is more complicated because we need to monitor the canary while gradually migrating more and more users away from the old version.
+
+## A/B Test
+
+In the A/B test, different versions of services run in production simultaneously. Each version runs an “experiment” for a subset of users. A/B test is a cheap method to test new features in production. We need to control the deployment process in case some features are pushed to users by accident.
diff --git a/data/guides/how-to-design-google-docs.md b/data/guides/how-to-design-google-docs.md
new file mode 100644
index 0000000..2337abf
--- /dev/null
+++ b/data/guides/how-to-design-google-docs.md
@@ -0,0 +1,32 @@
+---
+title: "How to Design Google Docs"
+description: "Learn how to design Google Docs with this detailed guide."
+image: "https://assets.bytebytego.com/diagrams/0206-google-doc.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "System Design"
+ - "Real-time Collaboration"
+---
+
+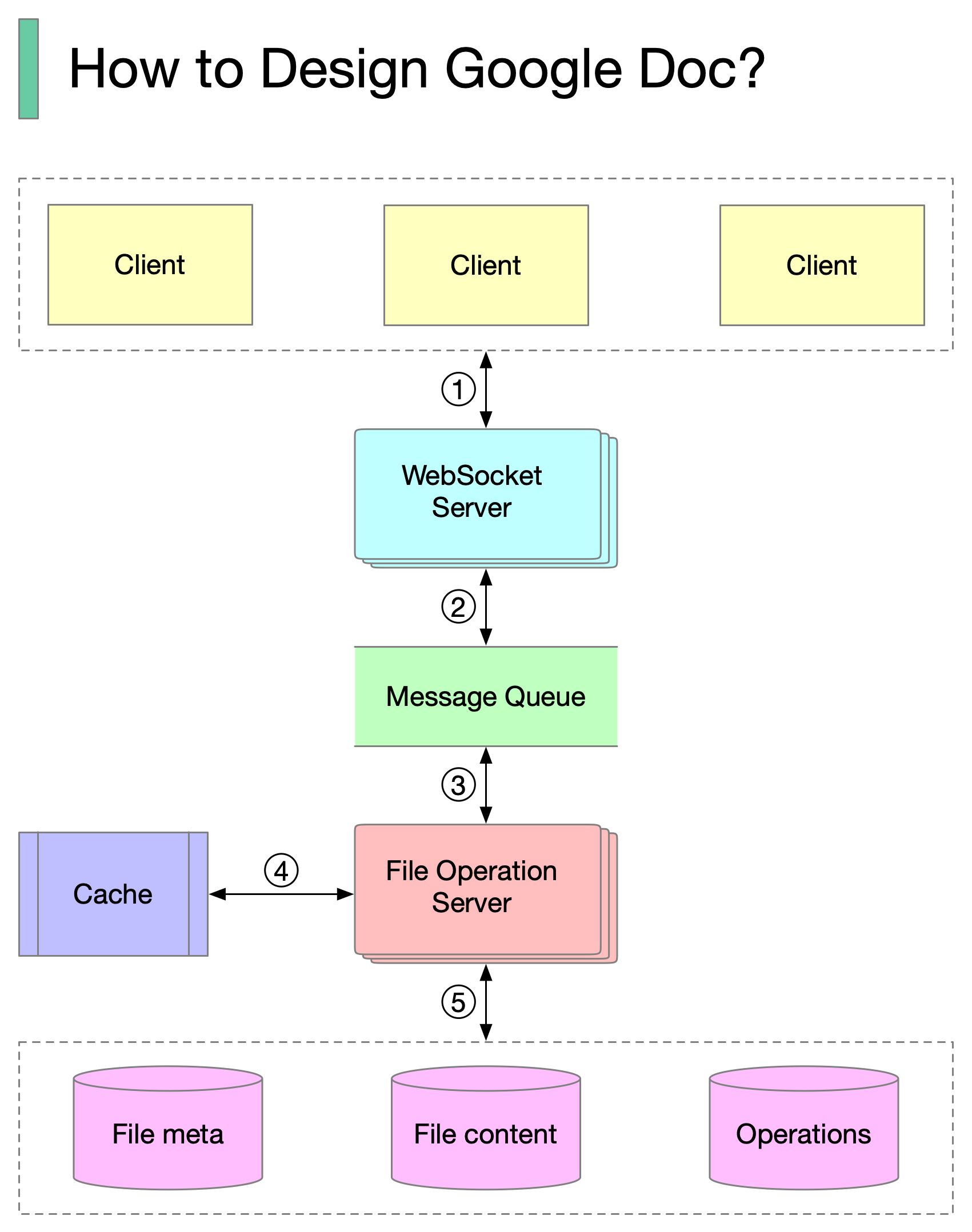
+
+1. Clients send document editing operations to the WebSocket Server.
+
+2. The real-time communication is handled by the WebSocket Server.
+
+3. Documents operations are persisted in the Message Queue.
+
+4. The File Operation Server consumes operations produced by clients and generates transformed operations using collaboration algorithms.
+
+5. Three types of data are stored: file metadata, file content, and operations.
+
+One of the biggest challenges is real-time conflict resolution. Common algorithms include:
+
+* Operational transformation (OT)
+* Differential Synchronization (DS)
+* Conflict-free replicated data type (CRDT)
+
+Google Doc uses OT according to its Wikipedia page and CRDT is an active area of research for real-time concurrent editing.
diff --git a/data/guides/how-to-design-secure-web-api-access-for-your-website.md b/data/guides/how-to-design-secure-web-api-access-for-your-website.md
new file mode 100644
index 0000000..29a98ae
--- /dev/null
+++ b/data/guides/how-to-design-secure-web-api-access-for-your-website.md
@@ -0,0 +1,45 @@
+---
+title: How to Design Secure Web API Access
+description: Learn how to design secure web API access for your website.
+image: 'https://assets.bytebytego.com/diagrams/0325-secure-api.png'
+createdAt: '2024-03-06'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Security
+ - Authentication
+---
+
+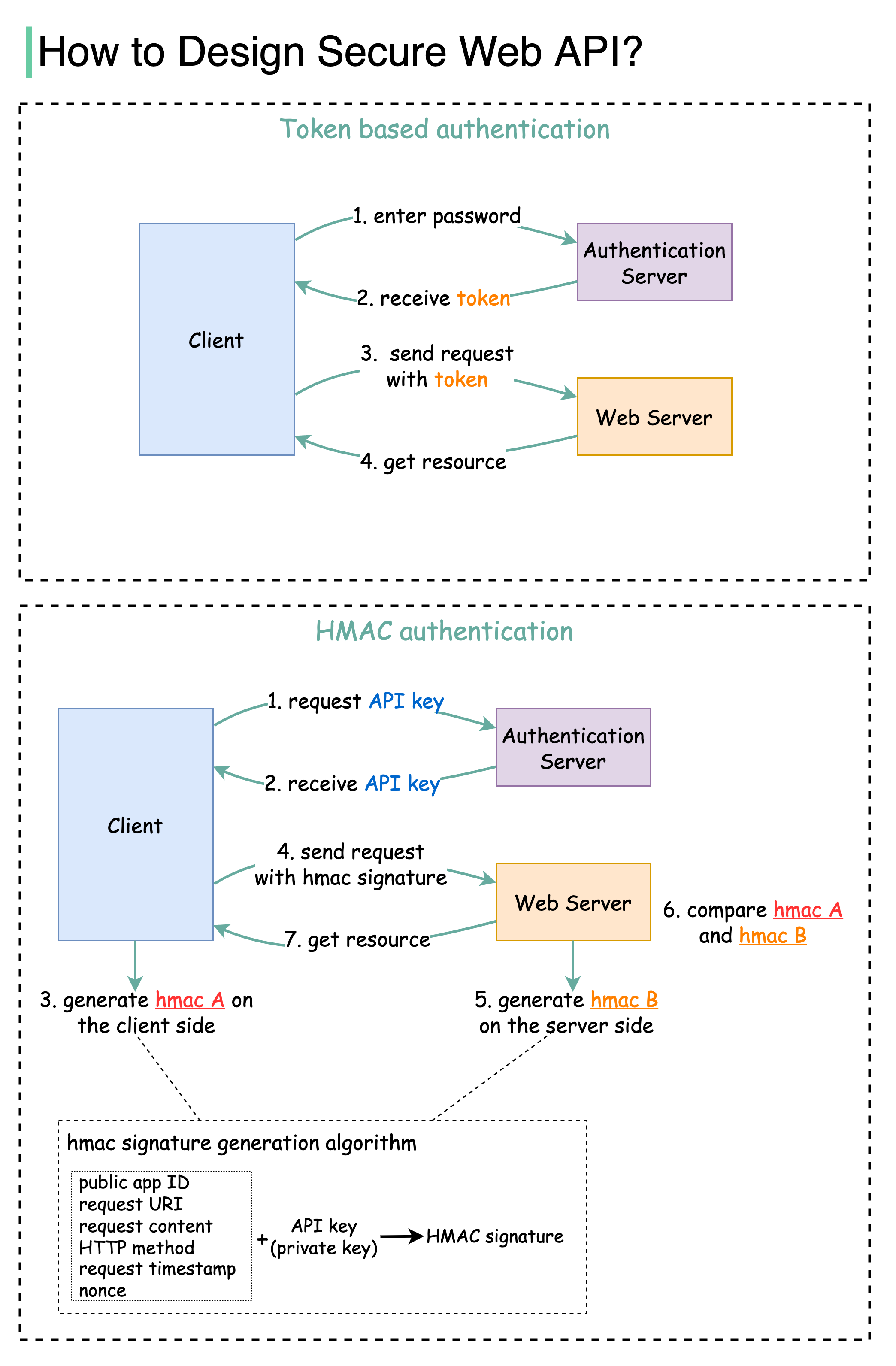
+
+When we open web API access to users, we need to make sure each API call is authenticated. This means the user must be who they claim to be.
+
+In this post, we explore two common ways:
+
+* Token based authentication
+* HMAC (Hash-based Message Authentication Code) authentication
+
+The diagram above illustrates how they work.
+
+**Token based**
+
+Step 1 - the user enters their password into the client, and the client sends the password to the Authentication Server.
+
+Step 2 - the Authentication Server authenticates the credentials and generates a token with an expiry time.
+
+Steps 3 and 4 - now the client can send requests to access server resources with the token in the HTTP header. This access is valid until the token expires.
+
+**HMAC based**
+
+This mechanism generates a Message Authentication Code (signature) by using a hash function (SHA256 or MD5).
+
+Steps 1 and 2 - the server generates two keys, one is Public APP ID (public key) and the other one is API Key (private key).
+
+Step 3 - we now generate a HMAC signature on the client side (hmac A). This signature is generated with a set of attributes listed in the diagram.
+
+Step 4 - the client sends requests to access server resources with hmac A in the HTTP header.
+
+Step 5 - the server receives the request which contains the request data and the authentication header. It extracts the necessary attributes from the request and uses the API key that’s stored on the server side to generate a signature (hmac B.)
+
+Steps 6 and 7 - the server compares hmac A (generated on the client side) and hmac B (generated on the server side). If they are matched, the requested resource will be returned to the client.
diff --git a/data/guides/how-to-handle-web-request-error.md b/data/guides/how-to-handle-web-request-error.md
new file mode 100644
index 0000000..e3c8533
--- /dev/null
+++ b/data/guides/how-to-handle-web-request-error.md
@@ -0,0 +1,36 @@
+---
+title: "How to Handle Web Request Errors"
+description: "Learn how to handle HTTP errors on both the client and server sides."
+image: "https://assets.bytebytego.com/diagrams/0144-client-handle-error.png"
+createdAt: "2024-02-13"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Error Handling"
+ - "Web Requests"
+---
+
+
+
+How do we properly deal with HTTP errors on the browser side? And how do we handle them correctly on the server side when the client side is at fault?
+
+From the browser's point of view, the easiest thing to do is to try again and hope the error just goes away. This is a good idea in a distributed network, but we also have to be very careful not to make things worse. Here’s two general rules:
+
+* For 4XX HTTP error code, do not retry.
+
+* For 5XX HTTP error code, try again carefully.
+
+So which things should we do carefully in the browser? We definitely should not overwhelm the server with retried requests. An algorithm named exponential backoff might be able to help. It controls two things:
+
+* The latency between two retries. The latency will increase exponentially.
+
+* The number of retries is usually capped.
+
+Will all browsers handle their retry logic in a graceful way? Most likely not. So the server has to take care of its own safety. A common way to control the flow of HTTP requests is to set up a flow control gateway in front of the server. This provides two useful tools:
+
+* **Rate limiter:** which limits how often a request can be made. It has two slightly different choices; the token bucket and the leaky bucket.
+
+* **Circuit breaker:** This will stop the HTTP flow immediately when the error threshold is exceeded. After a set amount of time, it will only let a limited amount of HTTP traffic through. If everything works well, it will slowly let all HTTP traffic through.
+
+We should be able to handle intermittent errors effectively with exponential backoff in the browser and with a flow control gateway on the server side. Any remaining issues are real errors that need to be fixed carefully.
diff --git a/data/guides/how-to-implement-read-replica-pattern.md b/data/guides/how-to-implement-read-replica-pattern.md
new file mode 100644
index 0000000..bc9522e
--- /dev/null
+++ b/data/guides/how-to-implement-read-replica-pattern.md
@@ -0,0 +1,43 @@
+---
+title: "How to Implement Read Replica Pattern"
+description: "Learn how to implement the read replica pattern using database middleware."
+image: "https://assets.bytebytego.com/diagrams/0162-database-middleware.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - Database
+ - Read Replicas
+---
+
+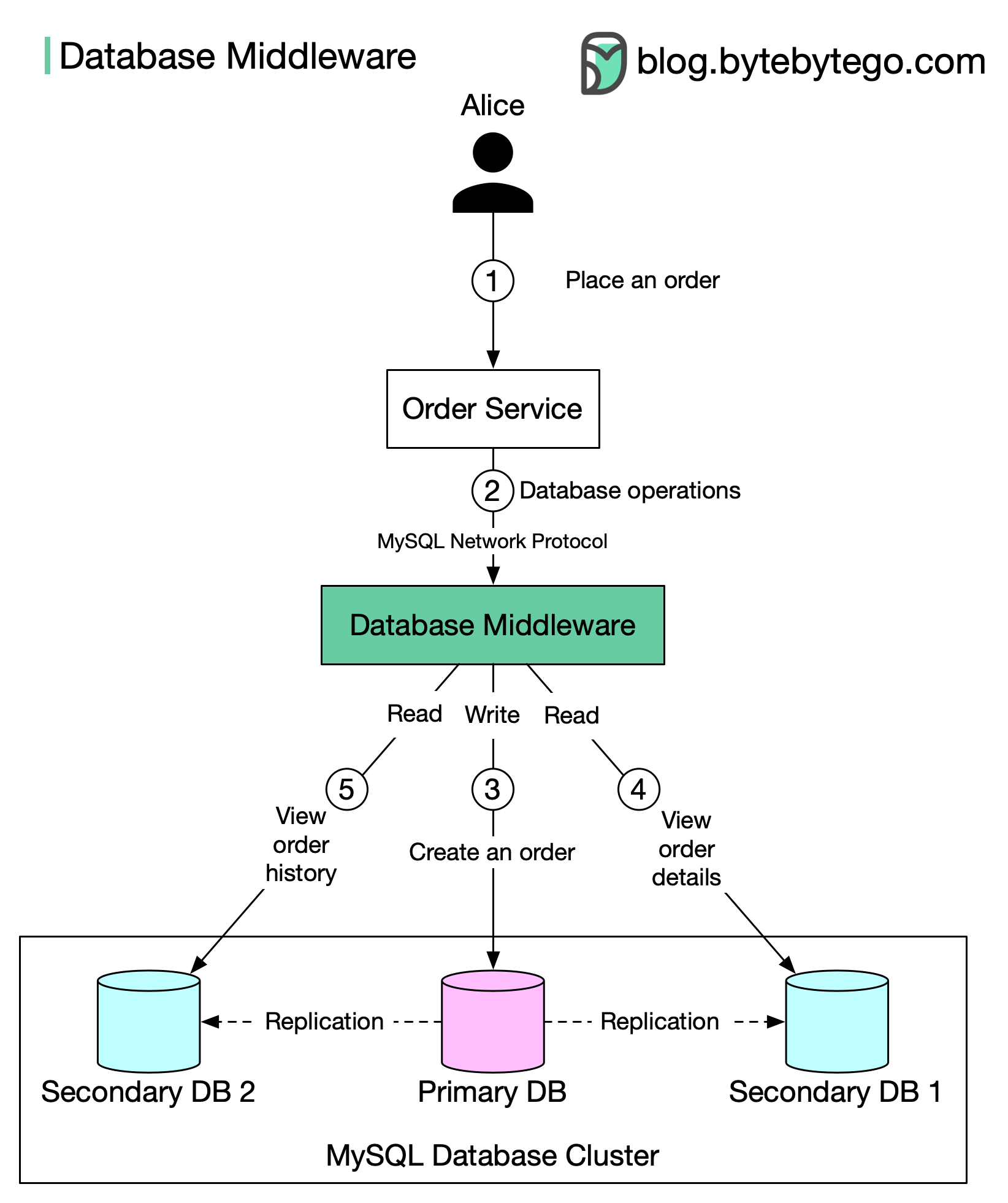
+
+There are two common ways to implement the read replica pattern:
+
+* Embed the routing logic in the application code (explained in the last post).
+* Use database middleware.
+
+We focus on option 2 here. The middleware provides transparent routing between the application and database servers. We can customize the routing logic based on difficult rules such as user, schema, statement, etc.
+
+The diagram above illustrates the setup:
+
+1. When Alice places an order on amazon, the request is sent to Order Service.
+2. Order Service does not directly interact with the database. Instead, it sends database queries to the database middleware.
+3. The database middleware routes writes to the primary database. Data is replicated to two replicas.
+4. Alice views the order details (read). The request is sent through the middleware.
+5. Alice views the recent order history (read). The request is sent through the middleware.
+
+The database middleware acts as a proxy between the application and databases. It uses standard MySQL network protocol for communication.
+
+## Pros
+
+* Simplified application code. The application doesn’t need to be aware of the database topology and manage access to the database directly.
+
+* Better compatibility. The middleware uses the MySQL network protocol. Any MySQL compatible client can connect to the middleware easily. This makes database migration easier.
+
+## Cons
+
+* Increased system complexity. A database middleware is a complex system. Since all database queries go through the middleware, it usually requires a high availability setup to avoid a single point of failure.
+
+* Additional middleware layer means additional network latency. Therefore, this layer requires excellent performance.
diff --git a/data/guides/how-to-learn-payments.md b/data/guides/how-to-learn-payments.md
new file mode 100644
index 0000000..78cfdc2
--- /dev/null
+++ b/data/guides/how-to-learn-payments.md
@@ -0,0 +1,48 @@
+---
+title: "How to Learn Payments"
+description: "A guide to understanding the payment industry and its key components."
+image: "https://assets.bytebytego.com/diagrams/0254-learn-payment.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Fintech"
+---
+
+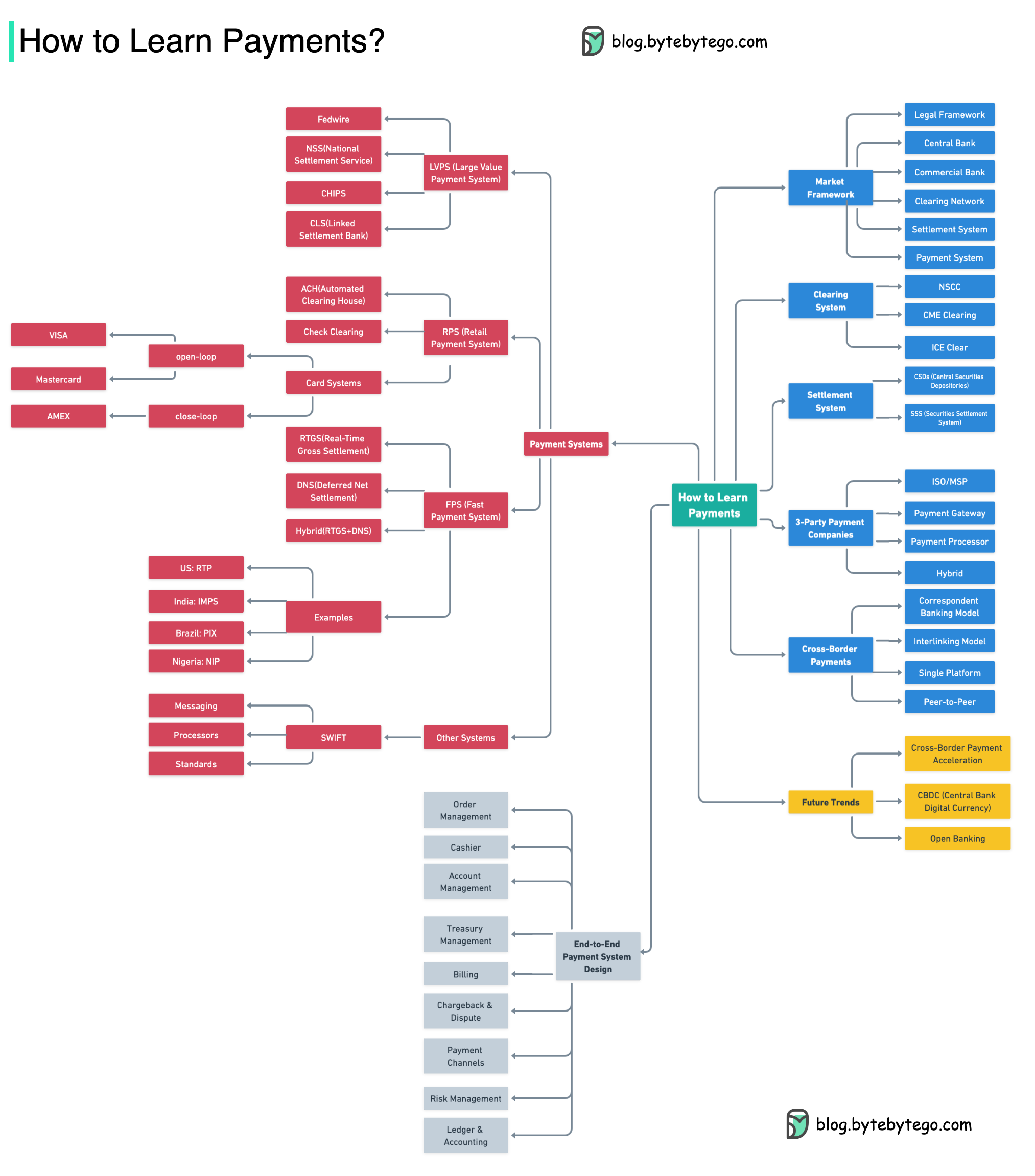
+
+The mind map below shows an extensive outline of payment knowledge.
+
+This gives us 𝐚 𝐭𝐨𝐩-𝐝𝐨𝐰𝐧 𝐯𝐢𝐞𝐰 𝐨𝐟 𝐭𝐡𝐞 𝐢𝐧𝐝𝐮𝐬𝐭𝐫𝐲 and an overview of how the payment systems work.
+
+Notice that different countries have different payment frameworks. But in general, the payment industry is composed of below parts:
+
+* Regulatory Authority
+
+* Central Bank
+
+* Commercial Banks
+
+* Non-Bank Payment Companies
+
+* Payment Systems
+
+* Clearing Networks
+
+* Settlement Systems
+
+## More Useful Materials
+
+Here are some useful materials for your reference:
+
+* Payment Systems in the U.S. by GlenBrook
+
+* BIS (Bank for International Settlements) Website
+
+* PayPal documents
+
+* Stripe documents
+
+* SWIFT documents
diff --git a/data/guides/how-to-load-your-websites-at-lightning-speed.md b/data/guides/how-to-load-your-websites-at-lightning-speed.md
new file mode 100644
index 0000000..df4e378
--- /dev/null
+++ b/data/guides/how-to-load-your-websites-at-lightning-speed.md
@@ -0,0 +1,32 @@
+---
+title: "Frontend Performance Optimization"
+description: "Boost your website's speed with these frontend optimization tips."
+image: "https://assets.bytebytego.com/diagrams/0198-frontend-performance-cheatsheet.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "frontend"
+ - "performance"
+---
+
+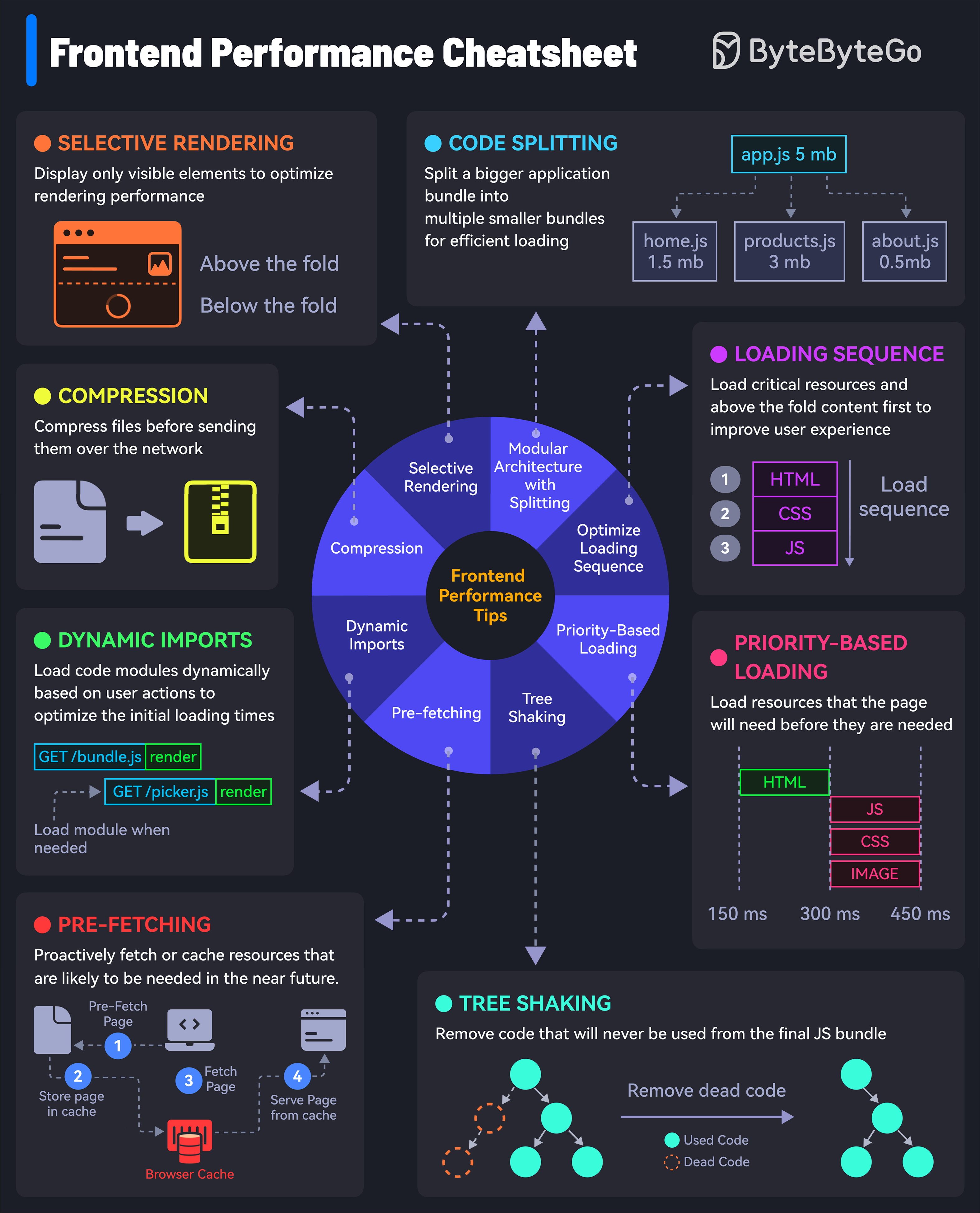
+
+Check out these 8 tips to boost frontend performance:
+
+* **Compression** Compress files and minimize data size before transmission to reduce network load.
+
+* **Selective Rendering/Windowing** Display only visible elements to optimize rendering performance. For example, in a dynamic list, only render visible items.
+
+* **Modular Architecture with Code Splitting** Split a bigger application bundle into multiple smaller bundles for efficient loading.
+
+* **Priority-Based Loading** Prioritize essential resources and visible (or above-the-fold) content for a better user experience.
+
+* **Pre-loading** Fetch resources in advance before they are requested to improve loading speed.
+
+* **Tree Shaking or Dead Code Removal** Optimize the final JS bundle by removing dead code that will never be used.
+
+* **Pre-fetching** Proactively fetch or cache resources that are likely to be needed soon.
+
+* **Dynamic Imports** Load code modules dynamically based on user actions to optimize the initial loading times.
diff --git a/data/guides/how-to-release-a-mobile-app.md b/data/guides/how-to-release-a-mobile-app.md
new file mode 100644
index 0000000..068648e
--- /dev/null
+++ b/data/guides/how-to-release-a-mobile-app.md
@@ -0,0 +1,53 @@
+---
+title: "How To Release A Mobile App"
+description: "A simplified guide to the mobile app release process."
+image: "https://assets.bytebytego.com/diagrams/0228-how-to-release-a-mobile-app.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Mobile Development"
+ - "App Release"
+---
+
+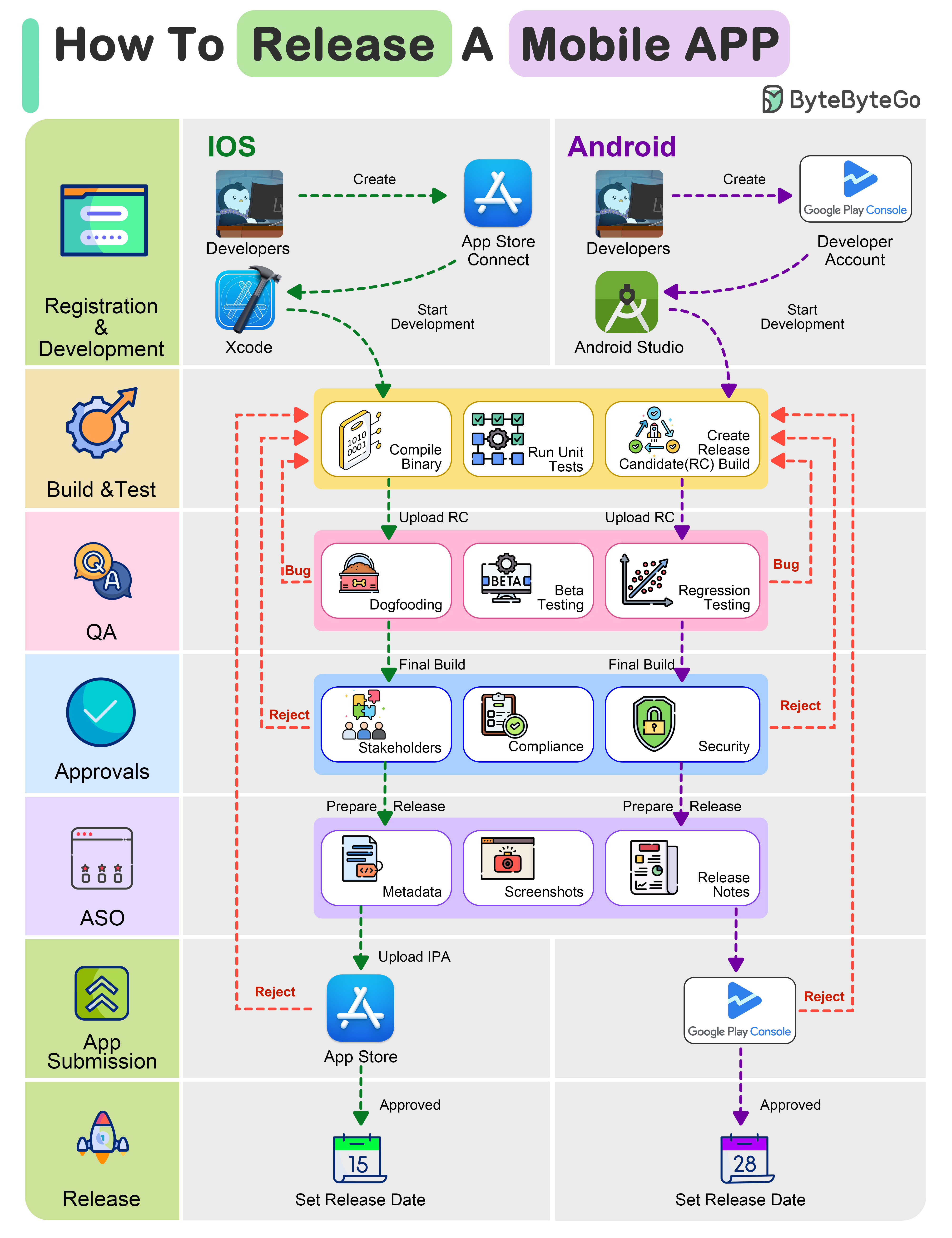
+
+The mobile app release process differs from conventional methods. This illustration simplifies the journey to help you understand.
+
+### 1. Registration & Development (iOS & Android):
+
+- Enroll in Apple's Developer Program and Google Play Console as iOS and Android developer
+- Code using platform-specific tools: Swift/Obj-C for iOS, and Java/Kotlin for Android
+
+### 2. Build & Test (iOS & Android):
+
+Compile the app's binary, run extensive tests on both platforms to ensure functionality and performance. Create a release candidate build.
+
+### 3. QA:
+
+- Internally test the app for issue identification (dogfooding)
+- Beta test with external users to collect feedback
+- Conduct regression testing to maintain feature stability
+
+### 4. Internal Approvals:
+
+- Obtain approval from stakeholders and key team members.
+- Comply with app store guidelines and industry regulations
+- Obtain security approvals to safeguard user data and privacy
+
+### 5. App Store Optimization (ASO):
+
+- Optimize metadata, including titles, descriptions, and keywords, for better search visibility
+- Design captivating screenshots and icons to entice users
+- Prepare engaging release notes to inform users about new features and updates
+
+### 6. App Submission To Store:
+
+- Submit the iOS app via App Store Connect following Apple's guidelines
+- Submit the Android app via Google Play Console, adhering to Google's policies
+- Both platforms may request issues resolution for approval
+
+### 7. Release:
+
+- Upon approval, set a release date to coordinate the launch on both iOS and Android platforms
diff --git a/data/guides/how-to-scale-a-website-to-support-millions-of-users.md b/data/guides/how-to-scale-a-website-to-support-millions-of-users.md
new file mode 100644
index 0000000..9f00569
--- /dev/null
+++ b/data/guides/how-to-scale-a-website-to-support-millions-of-users.md
@@ -0,0 +1,46 @@
+---
+title: "Scaling Websites for Millions of Users"
+description: "Learn how to scale your website architecture to support millions of users."
+image: "https://assets.bytebytego.com/diagrams/0322-scale-to-million.jpg"
+createdAt: "2024-02-07"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - scalability
+ - architecture
+---
+
+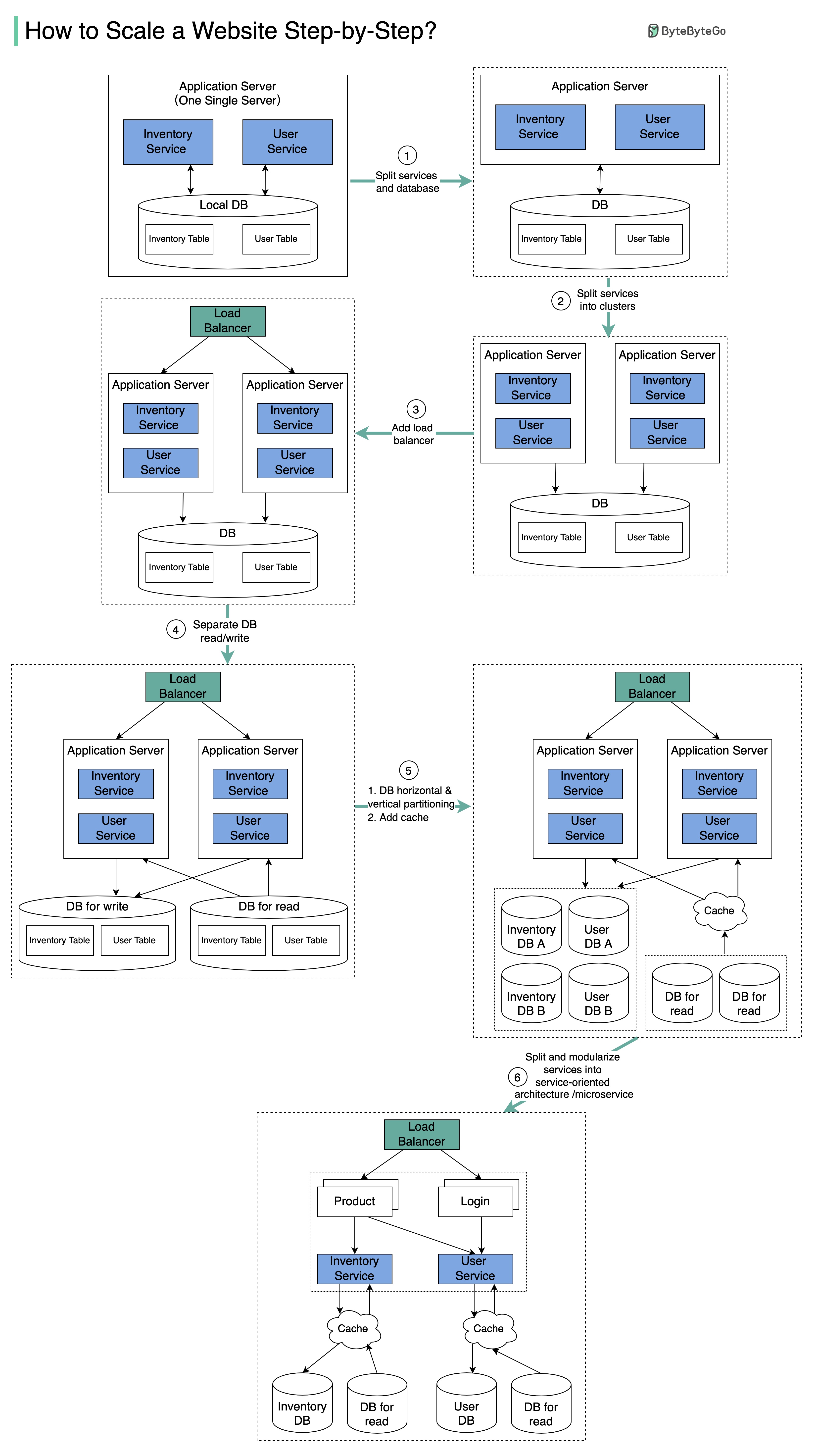
+
+The diagram below illustrates the evolution of a simplified eCommerce website. It goes from a monolithic design on one single server, to a service-oriented/microservice architecture.
+
+Suppose we have two services: inventory service (handles product descriptions and inventory management) and user service (handles user information, registration, login, etc.).
+
+## Step 1
+
+With the growth of the user base, one single application server cannot handle the traffic anymore. We put the application server and the database server into two separate servers.
+
+## Step 2
+
+The business continues to grow, and a single application server is no longer enough. So we deploy a cluster of application servers.
+
+## Step 3
+
+Now the incoming requests have to be routed to multiple application servers, how can we ensure each application server gets an even load? The load balancer handles this nicely.
+
+## Step 4
+
+With the business continuing to grow, the database might become the bottleneck. To mitigate this, we separate reads and writes in a way that frequent read queries go to read replicas. With this setup, the throughput for the database writes can be greatly increased.
+
+## Step 5
+
+Suppose the business continues to grow. One single database cannot handle the load on both the inventory table and user table. We have a few options:
+
+* **Vertical partition.** Adding more power (CPU, RAM, etc.) to the database server. It has a hard limit.
+* **Horizontal partition** by adding more database servers.
+* Adding a caching layer to offload read requests.
+
+## Step 6
+
+Now we can modularize the functions into different services. The architecture becomes service-oriented / microservice.
diff --git a/data/guides/how-to-store-passwords-in-the-database.md b/data/guides/how-to-store-passwords-in-the-database.md
new file mode 100644
index 0000000..c1afc3b
--- /dev/null
+++ b/data/guides/how-to-store-passwords-in-the-database.md
@@ -0,0 +1,44 @@
+---
+title: "Storing Passwords Safely: A Comprehensive Guide"
+description: "Learn how to securely store and validate passwords in your database."
+image: "https://assets.bytebytego.com/diagrams/0321-salt.png"
+createdAt: "2024-02-12"
+draft: false
+categories:
+ - security
+tags:
+ - "password security"
+ - "data protection"
+---
+
+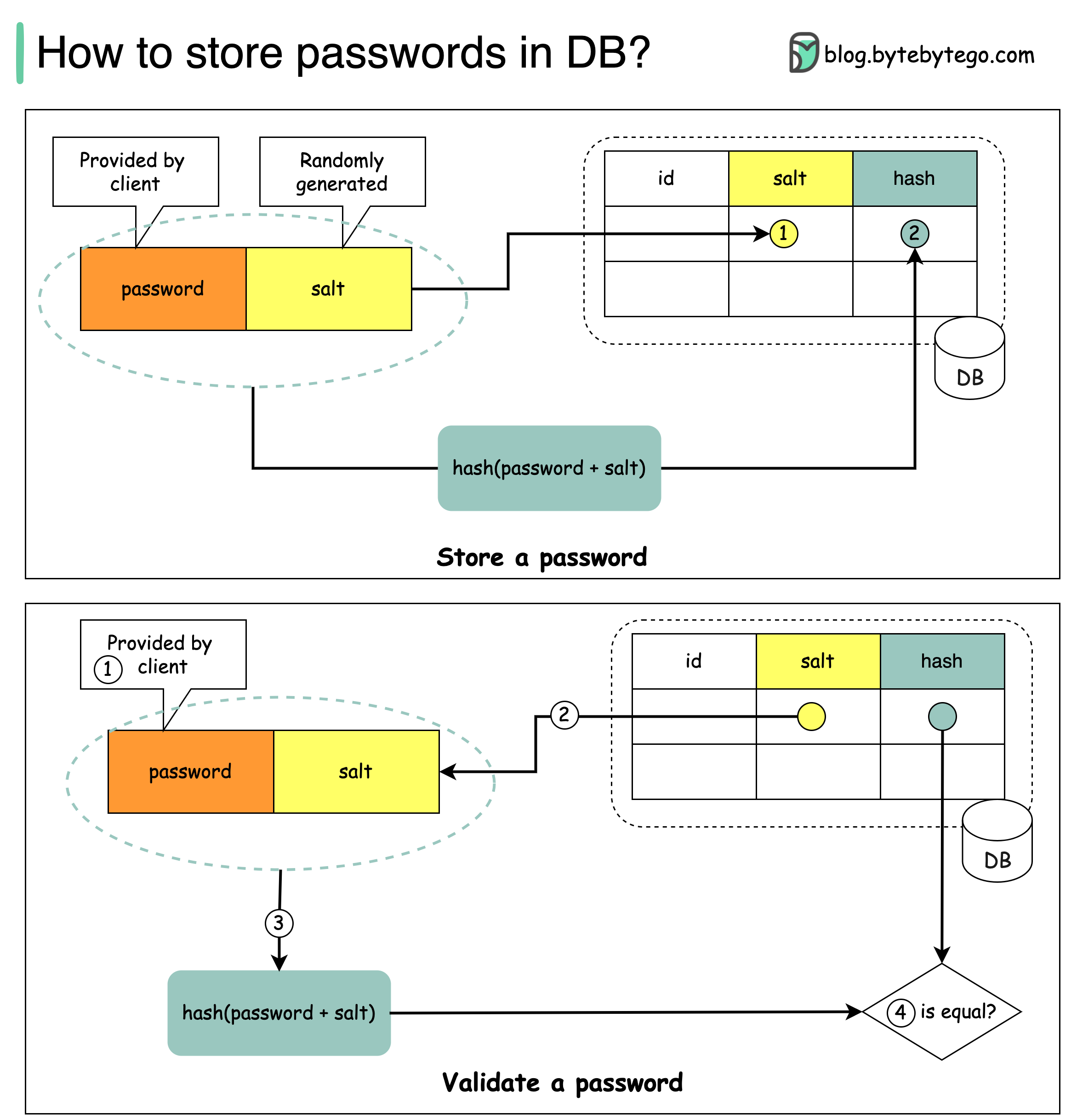
+
+## Things NOT to do
+
+* Storing passwords in plain text is not a good idea because anyone with internal access can see them.
+
+* Storing password hashes directly is not sufficient because it is prone to precomputation attacks, such as rainbow tables.
+
+* To mitigate precomputation attacks, we salt the passwords.
+
+## What is salt?
+
+According to OWASP guidelines, “a salt is a unique, randomly generated string that is added to each password as part of the hashing process”.
+
+## How to store a password and salt?
+
+1. A salt is not meant to be secret and it can be stored in plain text in the database. It is used to ensure the hash result is unique to each password.
+
+2. The password can be stored in the database using the following format: 𝘩𝘢𝘴𝘩( 𝘱𝘢𝘴𝘴𝘸𝘰𝘳𝘥 + 𝘴𝘢𝘭𝘵).
+
+## How to validate a password?
+
+To validate a password, it can go through the following process:
+
+1. A client enters the password.
+
+2. The system fetches the corresponding salt from the database.
+
+3. The system appends the salt to the password and hashes it. Let’s call the hashed value H1.
+
+4. The system compares H1 and H2, where H2 is the hash stored in the database. If they are the same, the password is valid.
diff --git a/data/guides/how-to-upload-a-large-file-to-s3.md b/data/guides/how-to-upload-a-large-file-to-s3.md
new file mode 100644
index 0000000..08ea66e
--- /dev/null
+++ b/data/guides/how-to-upload-a-large-file-to-s3.md
@@ -0,0 +1,32 @@
+---
+title: "How to Upload a Large File to S3"
+description: "Optimize performance when uploading large files to object storage like S3."
+image: "https://assets.bytebytego.com/diagrams/0284-multipart-upload.png"
+createdAt: "2024-01-30"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "S3"
+ - "Object Storage"
+---
+
+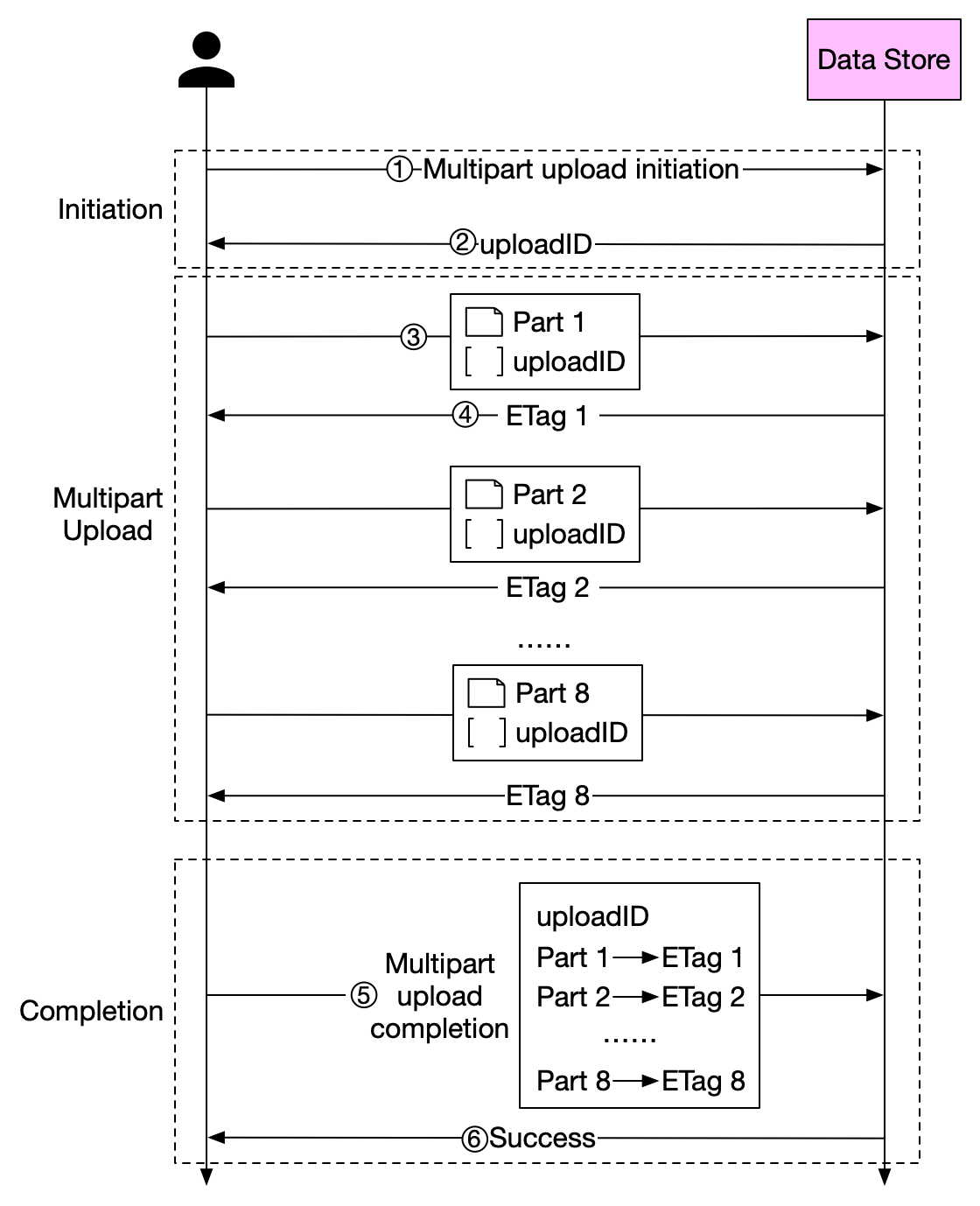
+
+How can we optimize performance when we **upload large files** to object storage service such as S3?
+
+Before we answer this question, let's take a look at why we need to optimize this process. Some files might be larger than a few GBs. It is possible to upload such a large object file directly, but it could take a long time. If the network connection fails in the middle of the upload, we have to start over. A better solution is to slice a large object into smaller parts and upload them independently. After all the parts are uploaded, the object store re-assembles the object from the parts. This process is called **multipart upload**.
+
+The diagram above illustrates how multipart upload works:
+
+1. The client calls the object storage to initiate a multipart upload.
+
+2. The data store returns an uploadID, which uniquely identifies the upload.
+
+3. The client splits the large file into small objects and starts uploading. Let’s assume the size of the file is 1.6GB and the client splits it into 8 parts, so each part is 200 MB in size. The client uploads the first part to the data store together with the uploadID it received in step 2.
+
+4. When a part is uploaded, the data store returns an ETag, which is essentially the md5 checksum of that part. It is used to verify multipart uploads.
+
+5. After all parts are uploaded, the client sends a complete multipart upload request, which includes the uploadID, part numbers, and ETags.
+
+6. The data store reassembles the object from its parts based on the part number. Since the object is really large, this process may take a few minutes. After reassembly is complete, it returns a success message to the client.
diff --git a/data/guides/how-will-you-design-the-stack-overflow-website.md b/data/guides/how-will-you-design-the-stack-overflow-website.md
new file mode 100644
index 0000000..cfce3f8
--- /dev/null
+++ b/data/guides/how-will-you-design-the-stack-overflow-website.md
@@ -0,0 +1,31 @@
+---
+title: 'How to Design Stack Overflow'
+description: 'Explore the architecture of Stack Overflow and its design considerations.'
+image: 'https://assets.bytebytego.com/diagrams/0343-stack-overflow-architecture.png'
+createdAt: '2024-02-20'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Architecture
+---
+
+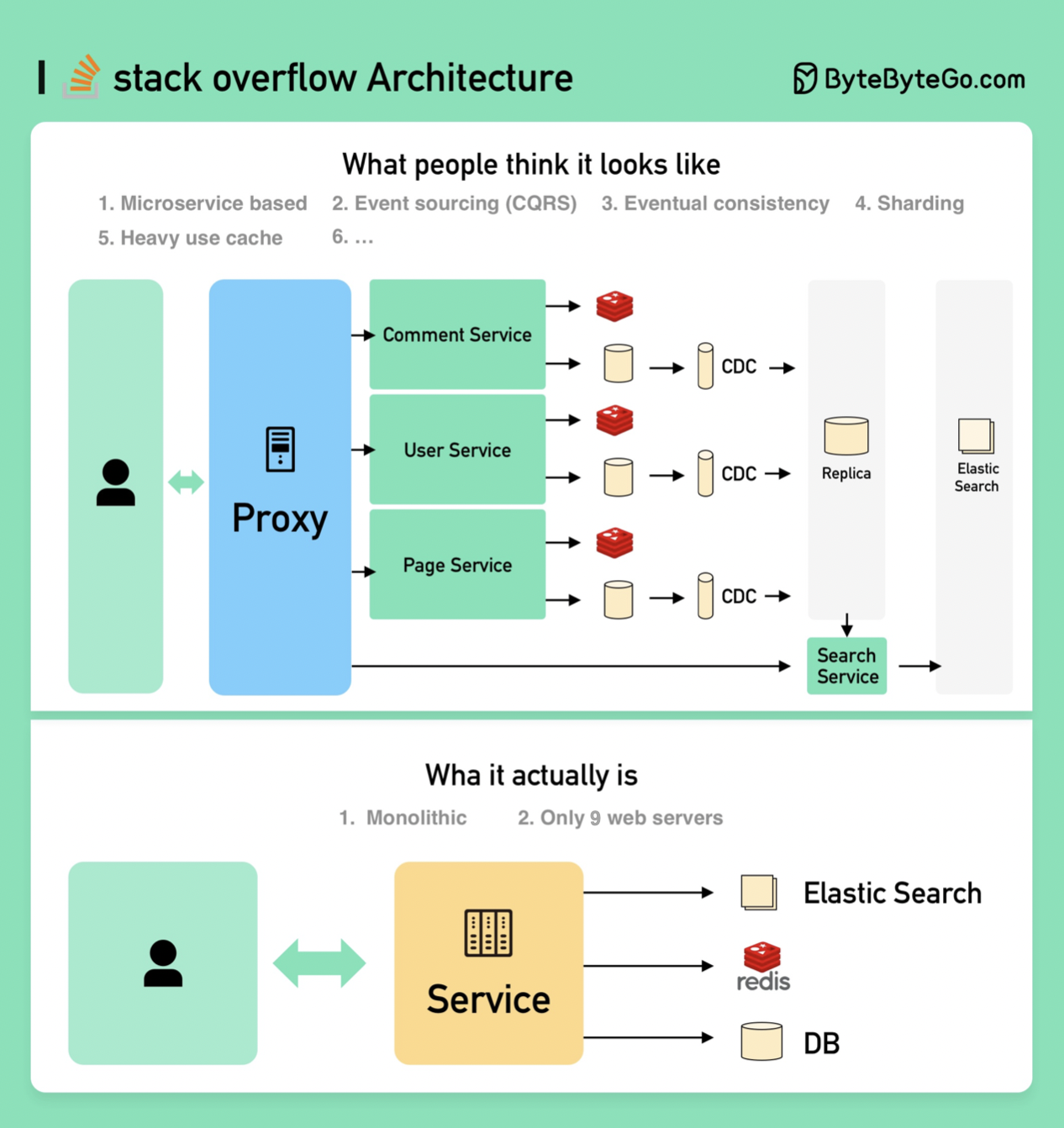
+
+If your answer is on-premise servers and monolith, you would likely fail the interview, but that's how it is built in reality!
+
+**What people think it should look like**
+The interviewer is probably expecting something on the left side.
+
+* Microservice is used to decompose the system into small components.
+* Each service has its own database. Use cache heavily.
+* The service is sharded.
+* The services talk to each other asynchronously through message queues.
+* The service is implemented using Event Sourcing with CQRS.
+* Showing off knowledge in distributed systems such as eventual consistency, CAP theorem, etc.
+
+**What it actually is**
+Stack Overflow serves all the traffic with only 9 on-premise web servers, and it’s on monolith! It has its own servers and does not run on the cloud.
+
+This is contrary to all our popular beliefs these days.
diff --git a/data/guides/http-cookies-explained-with-a-simple-diagram.md b/data/guides/http-cookies-explained-with-a-simple-diagram.md
new file mode 100644
index 0000000..87b4fac
--- /dev/null
+++ b/data/guides/http-cookies-explained-with-a-simple-diagram.md
@@ -0,0 +1,26 @@
+---
+title: "HTTP Cookies Explained With a Simple Diagram"
+description: "Understand HTTP cookies with a simple diagram and clear explanations."
+image: "https://assets.bytebytego.com/diagrams/0153-cookies.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - security
+tags:
+ - HTTP
+ - Web Development
+---
+
+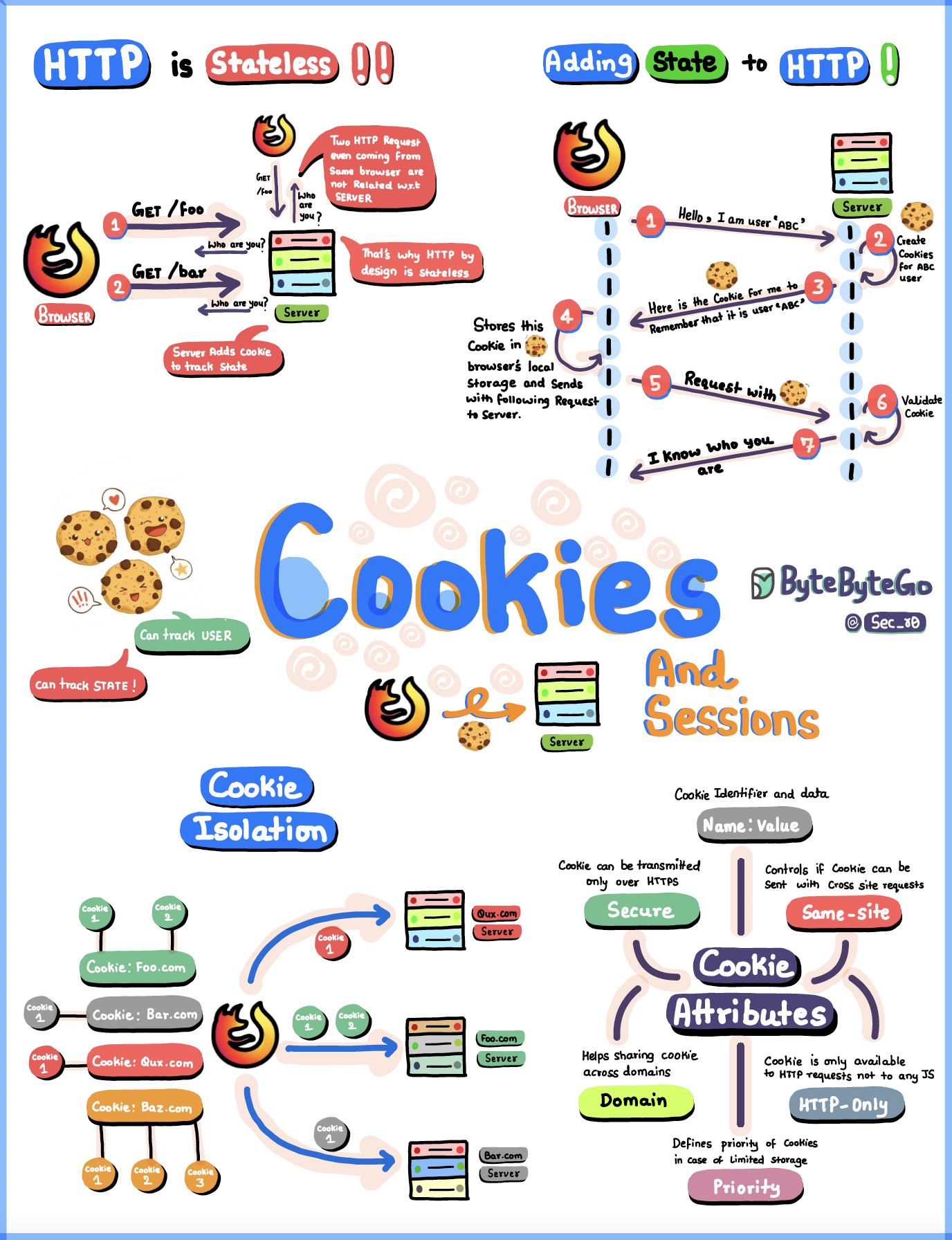
+
+HTTP, the language of the web, is naturally "stateless." But hey, we all want that seamless, continuous browsing experience, right? Enter the unsung heroes - Cookies!
+
+So, here's the scoop in this cookie flyer:
+
+* HTTP is like a goldfish with no memory - it forgets you instantly! But cookies swoop in to the rescue, adding that "session secret sauce" to your web interactions.
+
+* Cookies? Think of them as little notes you pass to the web server, saying, "Remember me, please!" And yes, they're stored there, like cherished mementos.
+
+* Browsers are like cookie bouncers, making sure your cookies don't party crash at the wrong website.
+
+* Finally, meet the cookie celebrities - SameSite, Name, Value, Secure, Domain, and HttpOnly. They're the cool kids setting the rules in the cookie jar!
diff --git a/data/guides/http-status-code-you-should-know.md b/data/guides/http-status-code-you-should-know.md
new file mode 100644
index 0000000..965b216
--- /dev/null
+++ b/data/guides/http-status-code-you-should-know.md
@@ -0,0 +1,22 @@
+---
+title: 'HTTP Status Codes You Should Know'
+description: 'Understand HTTP status codes: categories and common examples.'
+image: 'https://assets.bytebytego.com/diagrams/0233-http-status-code.png'
+createdAt: '2024-02-24'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - API
+---
+
+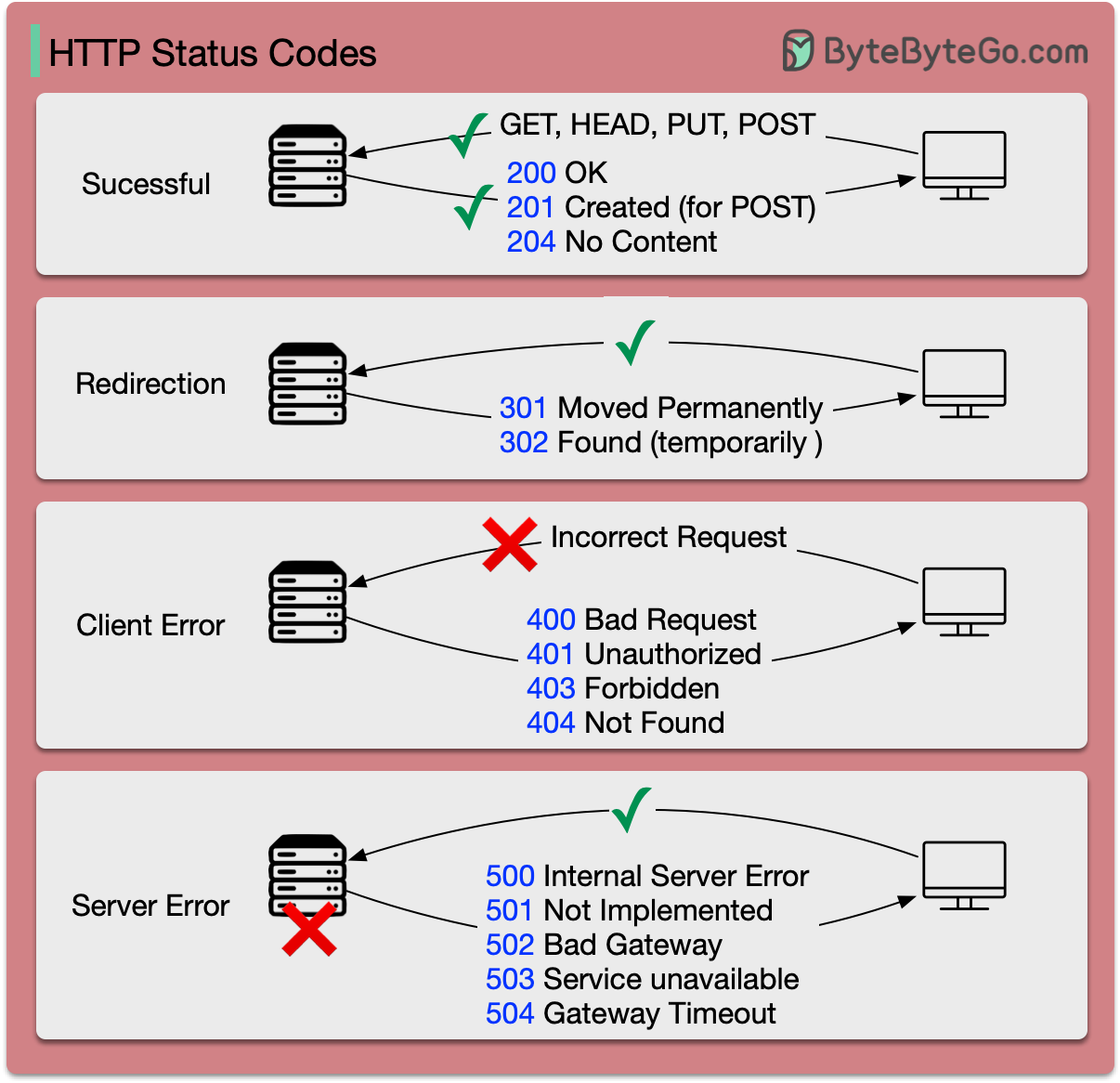
+
+The response codes for HTTP are divided into five categories:
+
+* **Informational (100-199)**
+* **Success (200-299)**
+* **Redirection (300-399)**
+* **Client Error (400-499)**
+* **Server Error (500-599)**
diff --git a/data/guides/http1-http2-http3.md b/data/guides/http1-http2-http3.md
new file mode 100644
index 0000000..ffa9adc
--- /dev/null
+++ b/data/guides/http1-http2-http3.md
@@ -0,0 +1,22 @@
+---
+title: 'HTTP/1 -> HTTP/2 -> HTTP/3'
+description: 'Explore the evolution of HTTP: from HTTP/1 to the latest HTTP/3.'
+image: 'https://assets.bytebytego.com/diagrams/0101-http-1-http-2-http-3.png'
+createdAt: '2024-03-02'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - Protocols
+---
+
+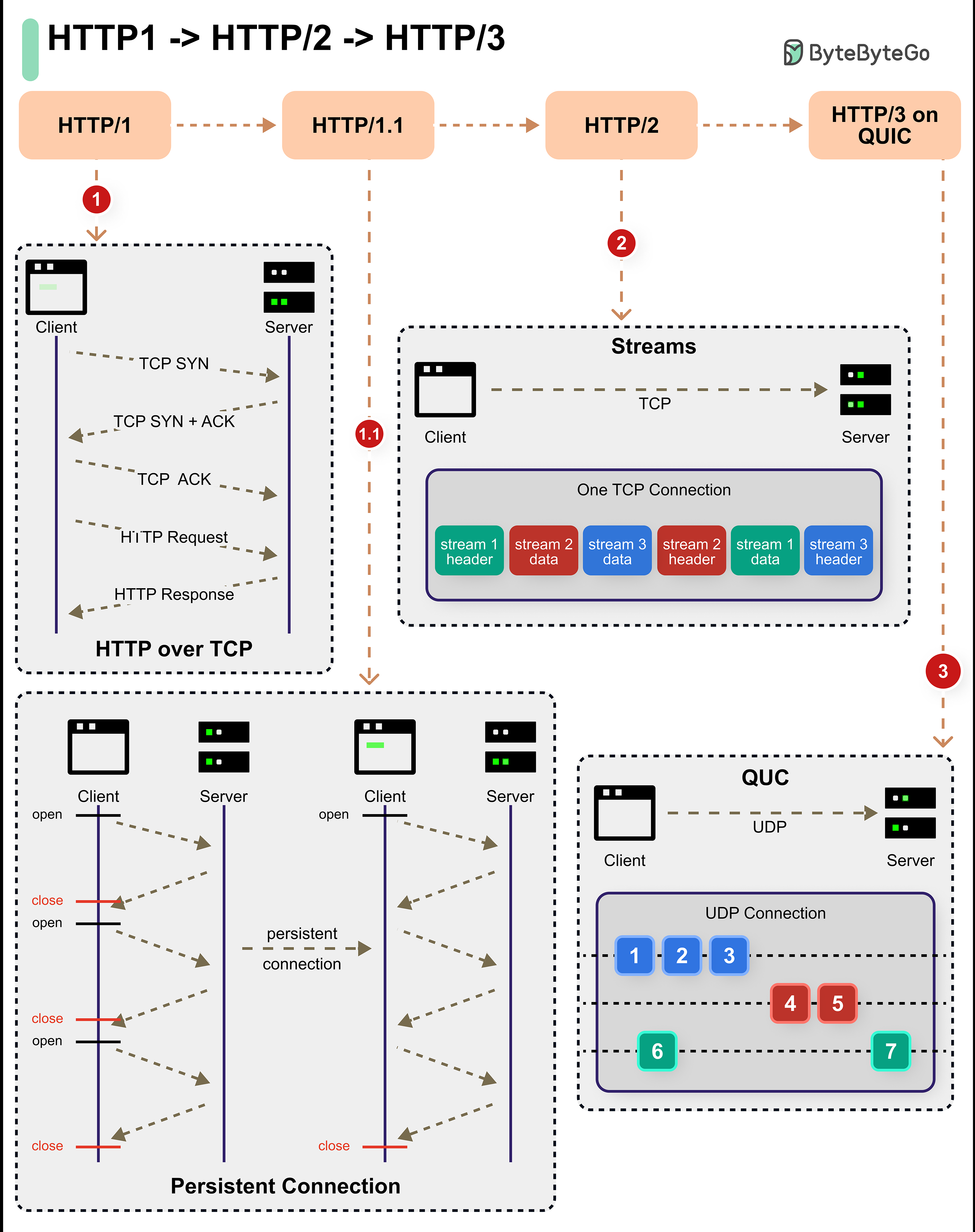
+
+HTTP 1 started in 1996 followed by HTTP 1.1 the very next year. In 2015, HTTP 2 came about and in 2019 we got HTTP 3.
+
+With each iteration, the protocol has evolved in new and interesting ways.
+
+* **HTTP 1** (and its sub-versions) introduced features like persistent connections, pipelining, and the concept of headers. The protocol was built on top of TCP and provided a reliable way of communication over the World Wide Web. It is still used despite being over 25 years old.
+* **HTTP 2** brought new features such as multiplexing, stream prioritization, server push, and HPACK compression. However, it still used TCP as the underlying protocol.
+* **HTTP 3** uses Google’s QUIC, which is built on top of UDP. In other words, HTTP 3 has moved away from TCP.
diff --git a/data/guides/https-ssl-handshake-and-data-encryption-explained-to-kids.md b/data/guides/https-ssl-handshake-and-data-encryption-explained-to-kids.md
new file mode 100644
index 0000000..e1ec9ad
--- /dev/null
+++ b/data/guides/https-ssl-handshake-and-data-encryption-explained-to-kids.md
@@ -0,0 +1,22 @@
+---
+title: "HTTPS, SSL Handshake, and Data Encryption Explained"
+description: "Learn about HTTPS, SSL handshake, and data encryption in simple terms."
+image: "https://assets.bytebytego.com/diagrams/0409-https-ssl-handshake-and-data-encryption-explained-to-kids.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - security
+tags:
+ - "HTTPS"
+ - "Encryption"
+---
+
+
+
+HTTPS: Safeguards your data from eavesdroppers and breaches. Understand how encryption and digital certificates create an impregnable shield.
+
+SSL Handshake: Behind the Scenes — Witness the cryptographic protocols that establish a secure connection. Experience the intricate exchange of keys and negotiation.
+
+Secure Data Transmission: Navigating the Tunnel — Journey through the encrypted tunnel forged by HTTPS. Learn how your information travels while shielded from cyber threats.
+
+HTML's Role: Peek into HTML's role in structuring the web. Uncover how hyperlinks and content come together seamlessly. And why is it called HYPER TEXT.
diff --git a/data/guides/imperative-vs-functional-vs-object-oriented-programming.md b/data/guides/imperative-vs-functional-vs-object-oriented-programming.md
new file mode 100644
index 0000000..1e8e2fd
--- /dev/null
+++ b/data/guides/imperative-vs-functional-vs-object-oriented-programming.md
@@ -0,0 +1,46 @@
+---
+title: "Imperative vs Functional vs Object-oriented Programming"
+description: "Explore imperative, functional, and object-oriented programming paradigms."
+image: "https://assets.bytebytego.com/diagrams/0035-imperative-vs-functional-vs-oop.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - software-development
+tags:
+ - Programming Paradigms
+ - Software Design
+---
+
+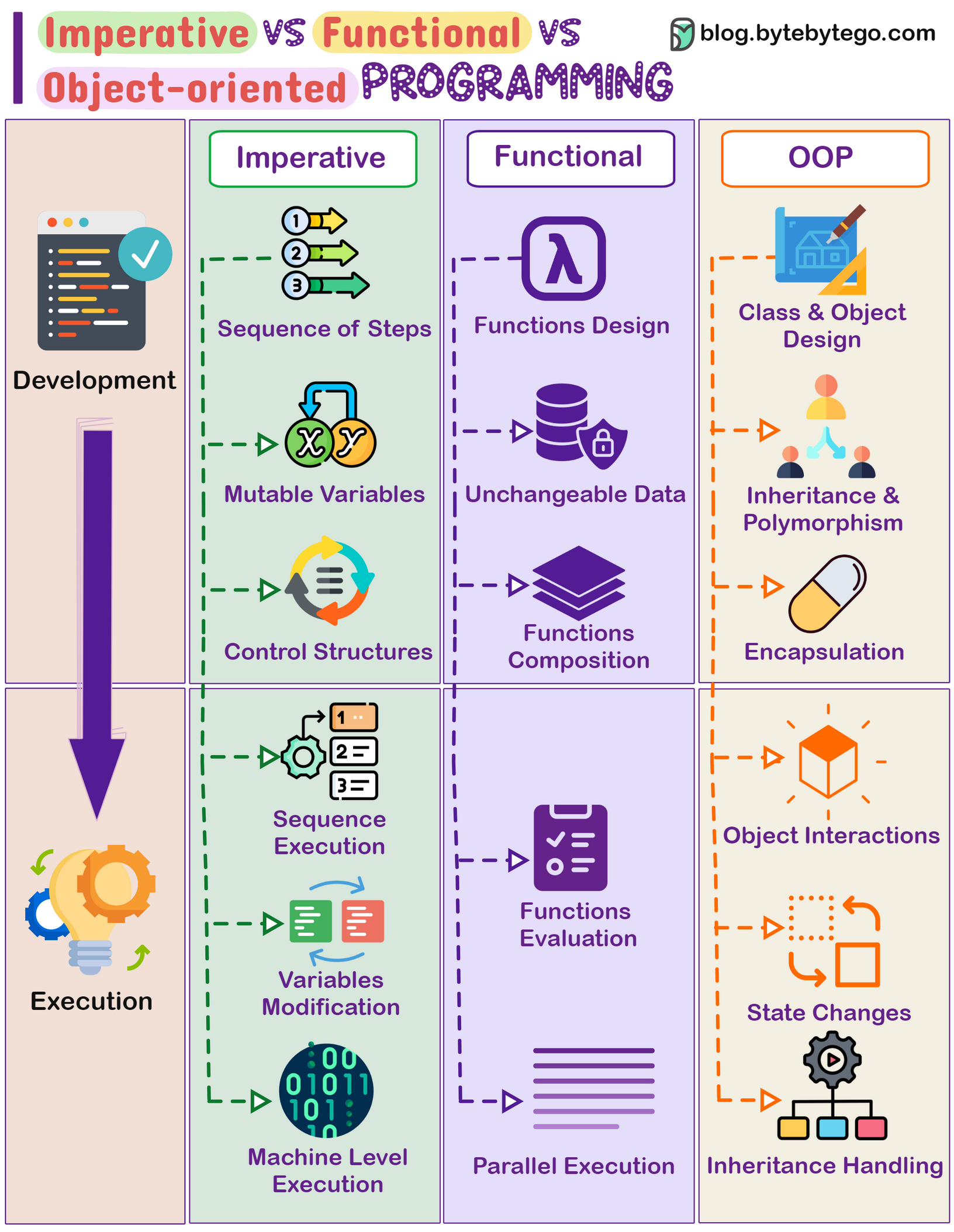
+
+In software development, different programming paradigms offer unique ways to structure code. Three main paradigms are Imperative, Functional, and Object-oriented programming, each with distinct approaches to problem-solving.
+
+## Imperative Programming
+
+* Works by changing program state through a sequence of commands.
+
+* Uses control structures like loops and conditional statements for execution flow.
+
+* Emphasizes mutable data and explicit steps for task completion.
+
+* Examples: C, Python, and most procedural languages.
+
+## Functional Programming
+
+* Relies on pure functions, emphasizing computation without side effects.
+
+* Promotes immutability and the avoidance of mutable state.
+
+* Supports higher-order functions, recursion, and declarative programming.
+
+* Examples: Haskell, Lisp, Scala, and functional features in languages like JavaScript.
+
+## Object-oriented Programming
+
+* Focuses on modeling real-world entities as objects, containing data and methods.
+
+* Encourages concepts such as inheritance, encapsulation, and polymorphism.
+
+* Utilizes classes, objects, and interfaces to structure code.
+
+* Examples: Java, C++, Python, and Ruby.
diff --git a/data/guides/important-things-about-http-headers-you-may-not-know.md b/data/guides/important-things-about-http-headers-you-may-not-know.md
new file mode 100644
index 0000000..9000212
--- /dev/null
+++ b/data/guides/important-things-about-http-headers-you-may-not-know.md
@@ -0,0 +1,20 @@
+---
+title: 'Important Things About HTTP Headers'
+description: 'Learn about essential HTTP headers for client-server communication.'
+image: 'https://assets.bytebytego.com/diagrams/0231-http-header.png'
+createdAt: '2024-01-30'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - Headers
+---
+
+
+
+HTTP requests are like asking for something from a server, and HTTP responses are the server's replies. It's like sending a message and receiving a reply.
+
+An HTTP request header is an extra piece of information you include when making a request, such as what kind of data you are sending or who you are. In response headers, the server provides information about the response it is sending you, such as what type of data you're receiving or if you have special instructions.
+
+A header serves a vital role in enabling client-server communication when building RESTful applications. In order to send the right information with their requests and interpret the server's responses correctly, you need to understand these headers.
diff --git a/data/guides/internet-traffic-routing-policies.md b/data/guides/internet-traffic-routing-policies.md
new file mode 100644
index 0000000..ad8b1c2
--- /dev/null
+++ b/data/guides/internet-traffic-routing-policies.md
@@ -0,0 +1,23 @@
+---
+title: 'Internet Traffic Routing Policies'
+description: 'Explore internet traffic routing policies for efficient network management.'
+image: 'https://assets.bytebytego.com/diagrams/0106-internet-traffic-routing-policies.png'
+createdAt: '2024-01-31'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Networking
+ - Routing
+---
+
+
+
+Internet traffic routing policies (DNS policies) play a crucial role in efficiently managing and directing network traffic. Let's discuss the different types of policies.
+
+* **Simple:** Directs all traffic to a single endpoint based on a standard DNS query without any special conditions or requirements.
+* **Failover:** Routes traffic to a primary endpoint but automatically switches to a secondary endpoint if the primary is unavailable.
+* **Geolocation:** Distributes traffic based on the geographic location of the requester, aiming to provide localized content or services.
+* **Latency:** Directs traffic to the endpoint that provides the lowest latency for the requester, enhancing user experience with faster response times.
+* **Multivalue Answer:** Responds to DNS queries with multiple IP addresses, allowing the client to select an endpoint. However, it should not be considered a replacement for a load balancer.
+* **Weighted Routing Policy:** Distributes traffic across multiple endpoints with assigned weights, allowing for proportional traffic distribution based on these weights.
diff --git a/data/guides/ipv4-vs-ipv6.md b/data/guides/ipv4-vs-ipv6.md
new file mode 100644
index 0000000..ec5164b
--- /dev/null
+++ b/data/guides/ipv4-vs-ipv6.md
@@ -0,0 +1,34 @@
+---
+title: "IPv4 vs. IPv6: Differences"
+description: "Explore the key differences between IPv4 and IPv6 protocols."
+image: "https://assets.bytebytego.com/diagrams/0236-ipv4-vs-ipv6.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Networking"
+ - "Protocols"
+---
+
+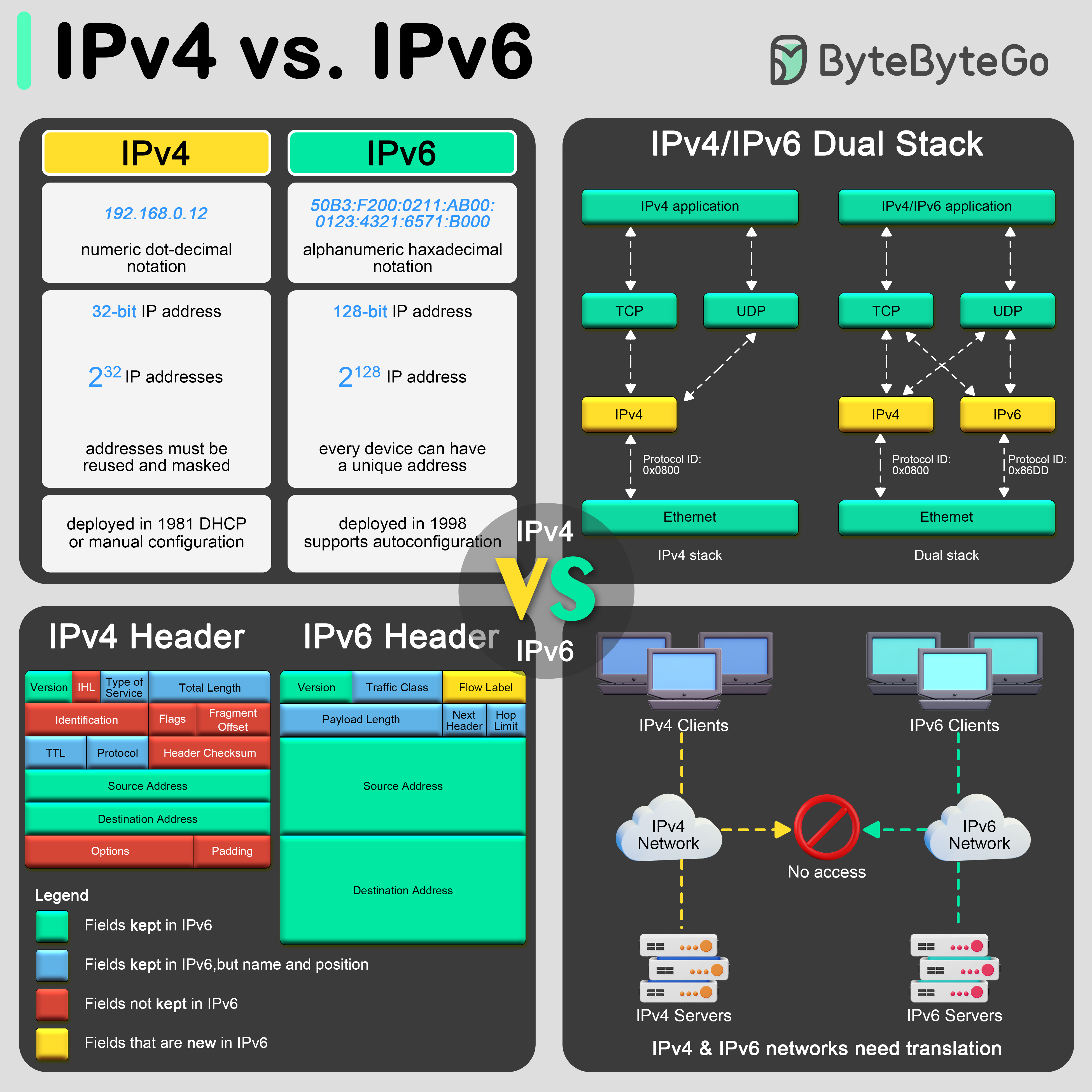
+
+The transition from Internet Protocol version 4 (IPv4) to Internet Protocol version 6 (IPv6) is primarily driven by the need for more internet addresses, alongside the desire to streamline certain aspects of network management.
+
+## Format and Length
+
+IPv4 uses a 32-bit address format, which is typically displayed as four decimal numbers separated by dots (e.g., 192.168.0.12). The 32-bit format allows for approximately 4.3 billion unique addresses, a number that is rapidly proving insufficient due to the explosion of internet-connected devices.
+
+In contrast, IPv6 utilizes a 128-bit address format, represented by eight groups of four hexadecimal digits separated by colons (e.g., 50B3:F200:0211:AB00:0123:4321:6571:B000). This expansion allows for approximately much more addresses, ensuring the internet's growth can continue unabated.
+
+## Header
+
+The IPv4 header is more complex and includes fields such as the header length, service type, total length, identification, flags, fragment offset, time to live (TTL), protocol, header checksum, source and destination IP addresses, and options.
+
+IPv6 headers are designed to be simpler and more efficient. The fixed header size is 40 bytes and includes less frequently used fields in optional extension headers. The main fields include version, traffic class, flow label, payload length, next header, hop limit, and source and destination addresses. This simplification helps improve packet processing speeds.
+
+## Translation between IPv4 and IPv6
+
+As the internet transitions from IPv4 to IPv6, mechanisms to allow these protocols to coexist have become essential:
+
+* **Dual Stack:** This technique involves running IPv4 and IPv6 simultaneously on the same network devices. It allows seamless communication in both protocols, depending on the destination address availability and compatibility. The dual stack is considered one of the best approaches for the smooth transition from IPv4 to IPv6.
diff --git a/data/guides/iqiyi-database-selection-trees.md b/data/guides/iqiyi-database-selection-trees.md
new file mode 100644
index 0000000..62fbb9b
--- /dev/null
+++ b/data/guides/iqiyi-database-selection-trees.md
@@ -0,0 +1,30 @@
+---
+title: "iQIYI Database Selection Trees"
+description: "Explore iQIYI's database selection process for relational and NoSQL."
+image: "https://assets.bytebytego.com/diagrams/0215-how-to-choose-db.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - database selection
+ - iQIYI
+---
+
+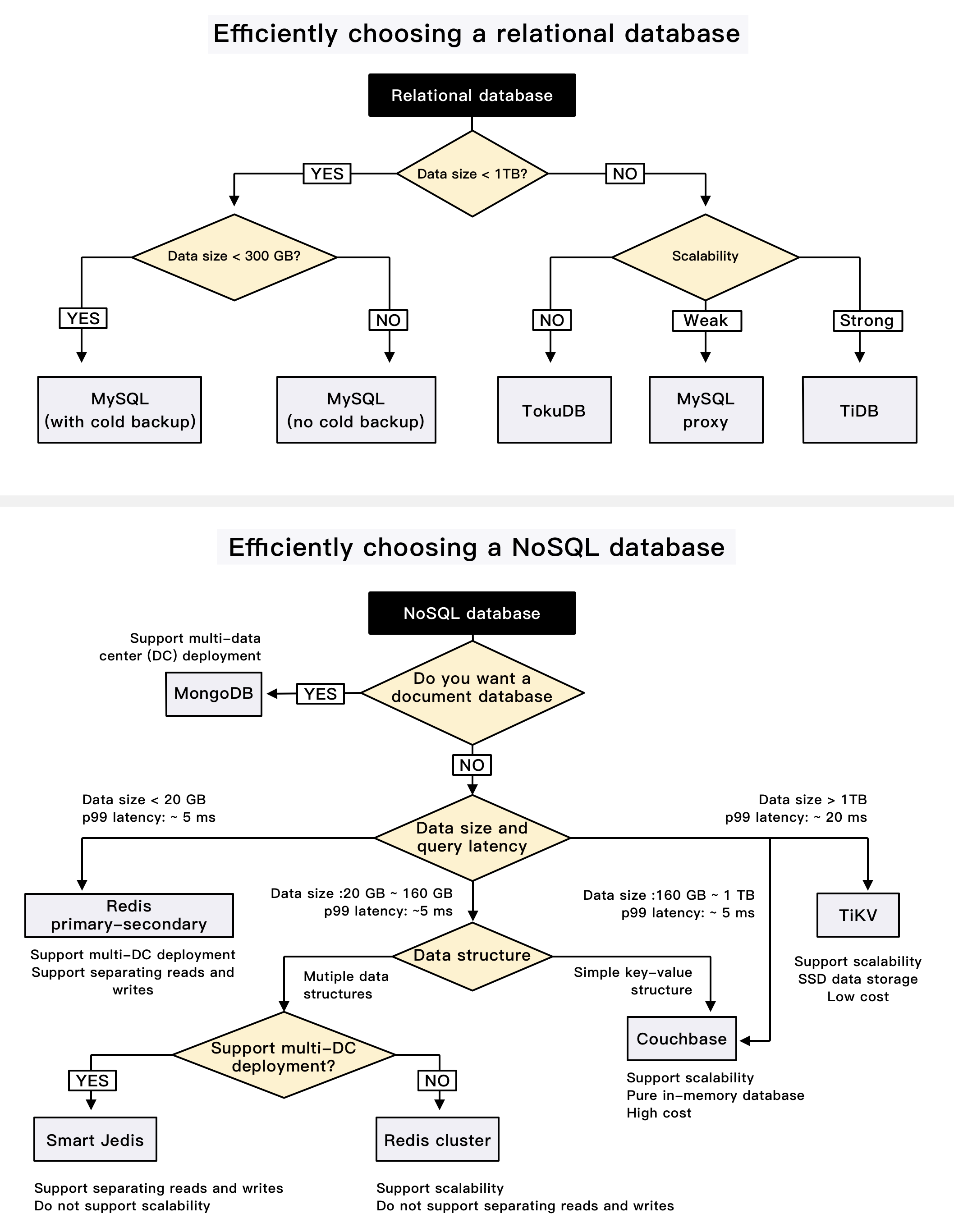
+
+One picture is worth a thousand words.
+
+iQIYI is one of the largest online video sites in the world, with over 500 million monthly active users. Let's look at how they choose relational and NoSQL databases.
+
+The following databases are used at iQIYI:
+
+* MySQL
+* Redis
+* TiDB: a hybrid transactional/analytical processing (HTAP) distributed database
+* Couchbase: distributed multi-model NoSQL document-oriented database
+* TokuDB: open-source storage engine for MySQL and MariaDB.
+* Big data analytical systems, like Hive and Impala
+* Other databases, like MongoDB, HiGraph, and TiKV
+
+The database selection trees below explain how they choose a database.
diff --git a/data/guides/is-https-safe.md b/data/guides/is-https-safe.md
new file mode 100644
index 0000000..19a954b
--- /dev/null
+++ b/data/guides/is-https-safe.md
@@ -0,0 +1,36 @@
+---
+title: "Is HTTPS Safe?"
+description: "Explore HTTPS security, vulnerabilities, and how tools capture packets."
+image: "https://assets.bytebytego.com/diagrams/0238-is-https-reliable.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - security
+tags:
+ - "HTTPS"
+ - "Security"
+---
+
+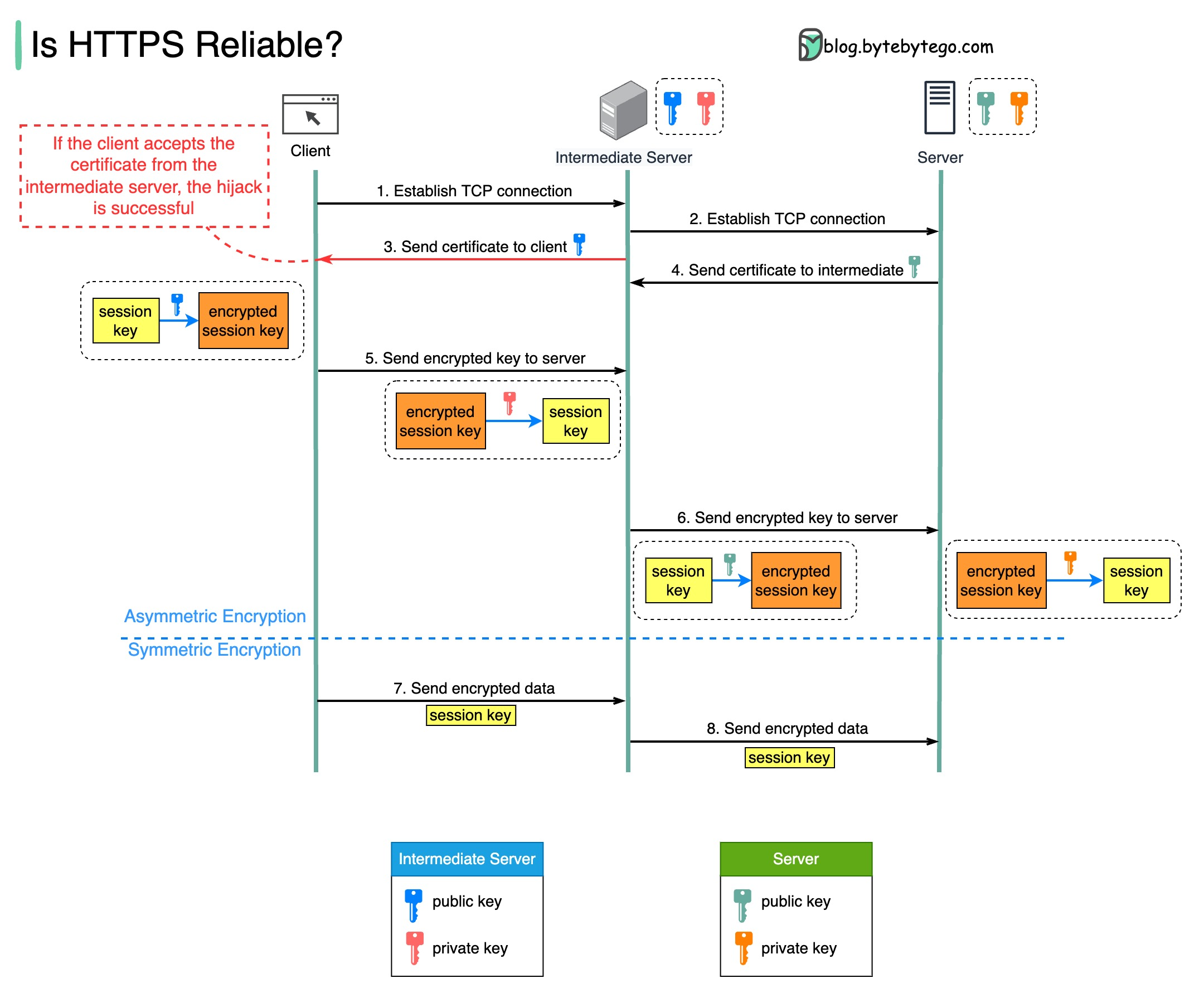
+
+If HTTPS is safe, how can tools like Fiddler capture network packets sent via HTTPS?
+
+The diagram below shows a scenario where a malicious intermediate hijacks the packets.
+
+Prerequisite: root certificate of the intermediate server is present in the trust-store.
+
+## How Packets are Hijacked
+
+**Step 1** - The client requests to establish a TCP connection with the server. The request is maliciously routed to an intermediate server, instead of the real backend server. Then, a TCP connection is established between the client and the intermediate server.
+
+**Step 2** - The intermediate server establishes a TCP connection with the actual server.
+
+**Step 3** - The intermediate server sends the SSL certificate to the client. The certificate contains the public key, hostname, expiry dates, etc. The client validates the certificate.
+
+**Step 4** - The legitimate server sends its certificate to the intermediate server. The intermediate server validates the certificate.
+
+**Step 5** - The client generates a session key and encrypts it using the public key from the intermediate server. The intermediate server receives the encrypted session key and decrypts it with the private key.
+
+**Step 6** - The intermediate server encrypts the session key using the public key from the actual server and then sends it there. The legitimate server decrypts the session key with the private key.
+
+**Steps 7 and 8** - Now, the client and the server can communicate using the session key (symmetric encryption.) The encrypted data is transmitted in a secure bi-directional channel. The intermediate server can always decrypt the data.
diff --git a/data/guides/is-it-possible-to-run-c-c++-or-rust-on-a-web-browser.md b/data/guides/is-it-possible-to-run-c-c++-or-rust-on-a-web-browser.md
new file mode 100644
index 0000000..eb2cb25
--- /dev/null
+++ b/data/guides/is-it-possible-to-run-c-c++-or-rust-on-a-web-browser.md
@@ -0,0 +1,26 @@
+---
+title: "Running C, C++, or Rust in a Web Browser"
+description: "Explore running C, C++, and Rust code in web browsers using WASM."
+image: "https://assets.bytebytego.com/diagrams/0406-how-wasm-work.jpeg"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - software-development
+tags:
+ - "WebAssembly"
+ - "Performance"
+---
+
+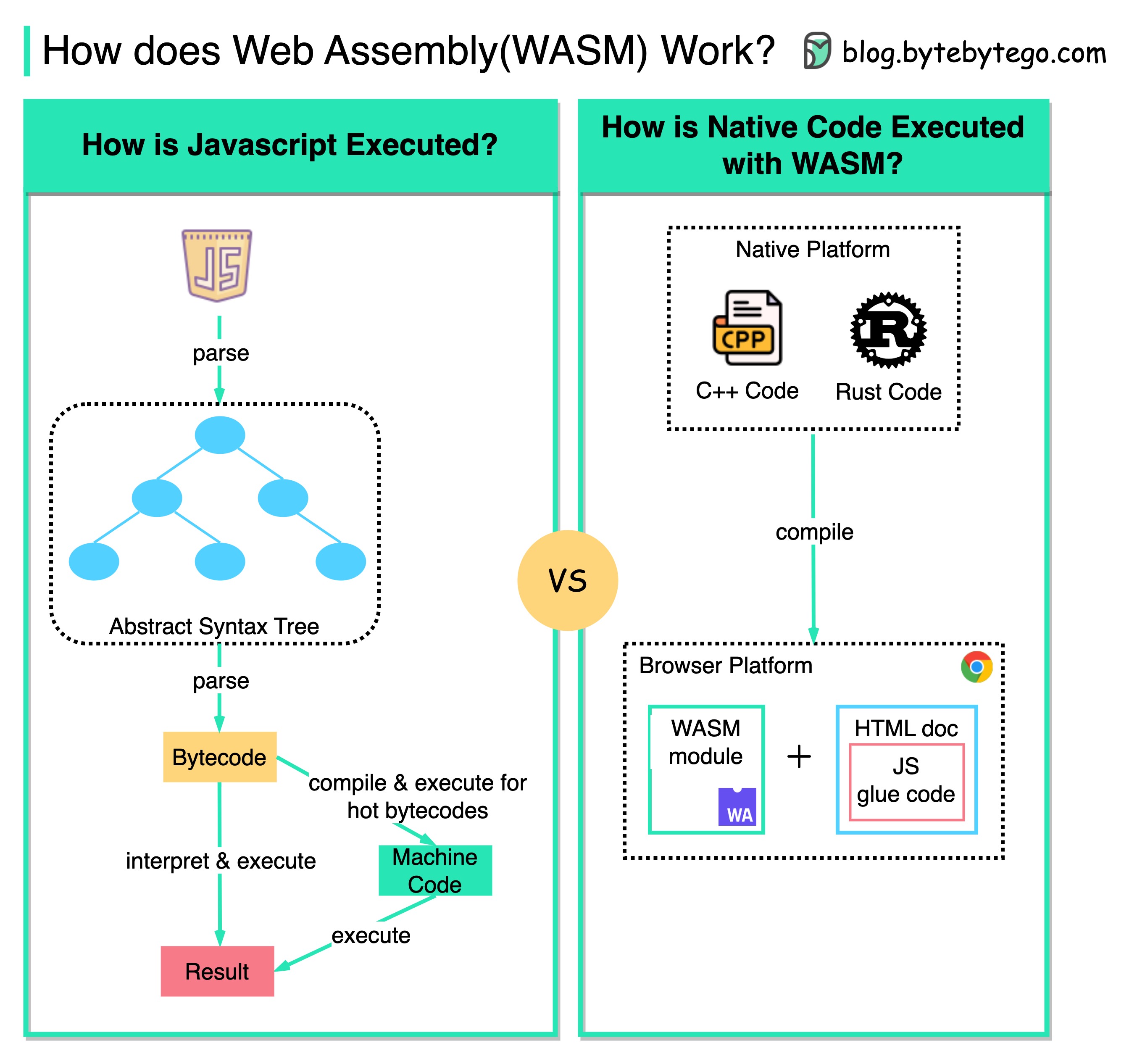
+
+What is **web assembly** (WASM)? Why does it attract so much attention?
+
+The diagram shows how we can run native C/C++/Rust code inside a web browser with WASM.
+
+Traditionally, we can only work with Javascript in the web browser, and the performance cannot compare with native code like C/C++ because it is interpreted.
+
+However, with WASM, we can **reuse** existing native code libraries developed in C/C++/Rust, etc to run in the web browser. These web applications have near-native performance.
+
+For example, we can run the **video encoding/decoding** library (written in C++) in the web browser.
+
+This opens a lot of possibilities for cloud computing and **edge computing**. We can run serverless applications with fewer resources and instant startup time.
diff --git a/data/guides/is-microservice-architecture-the-silver-bullet.md b/data/guides/is-microservice-architecture-the-silver-bullet.md
new file mode 100644
index 0000000..2ba5d2a
--- /dev/null
+++ b/data/guides/is-microservice-architecture-the-silver-bullet.md
@@ -0,0 +1,26 @@
+---
+title: "Is Microservice Architecture the Silver Bullet?"
+description: "Explore when microservices aren't the best choice for your architecture."
+image: "https://assets.bytebytego.com/diagrams/0278-monolithic-arch-use-cases.jpg"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "microservices"
+ - "architecture patterns"
+---
+
+The diagram above shows why **real-time gaming** and **low-latency trading** applications should not use microservice architecture.
+
+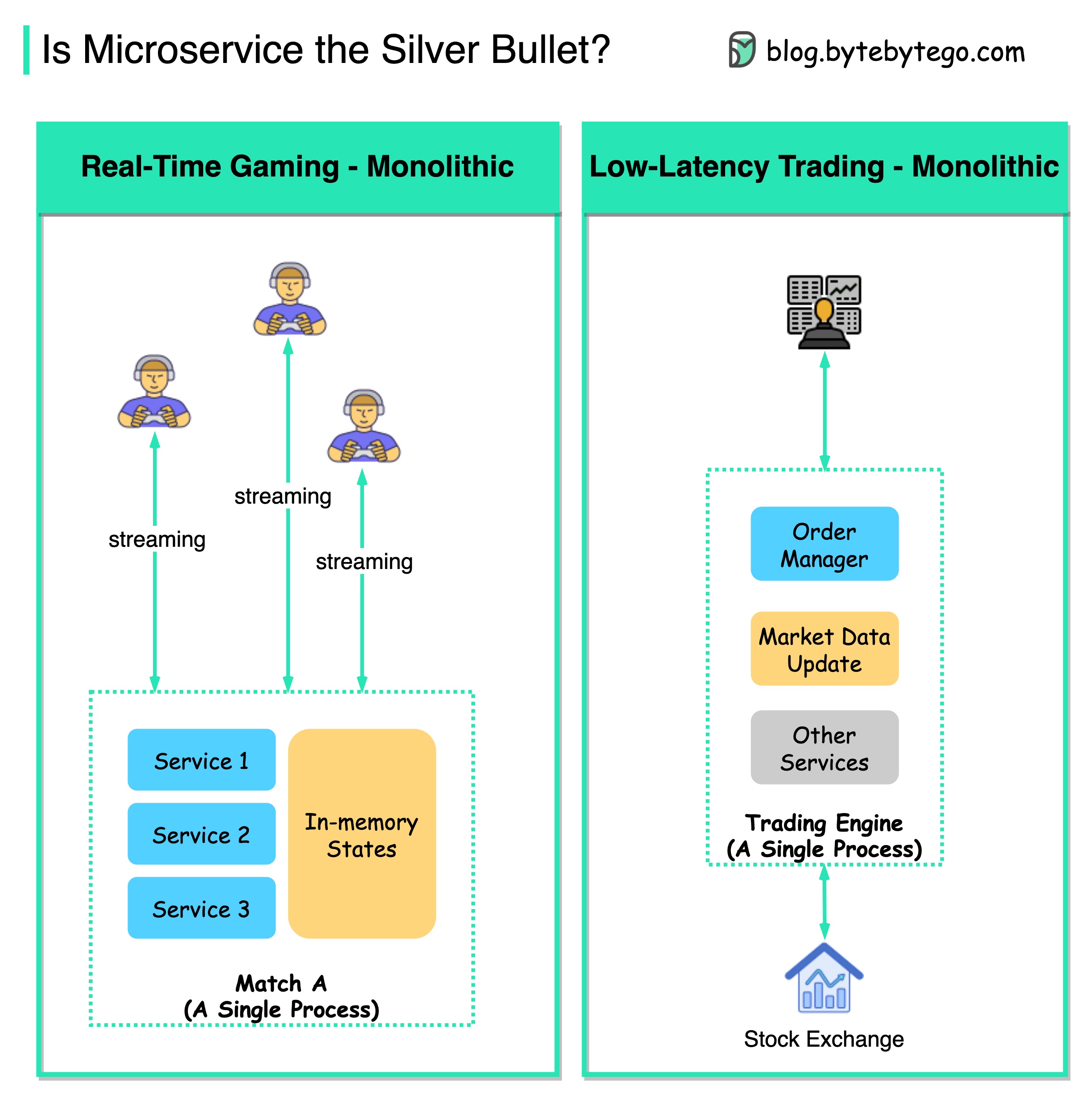
+
+There are some common features of these applications, which make them choose monolithic architecture:
+
+* These applications are very **latency-sensitive**. For real-time gaming, the latency should be at the milli-second level; for low-latency trading, the latency should be at the micro-second level. We cannot separate the services into different processes because the network latency is unbearable.
+
+* Microservice architecture is usually **stateless**, and the states are persisted in the database. Real-time gaming and low-latency trading need to **store the states in memory** for quick updates. For example, when a character is injured in a game, we don’t want to see the update 3 seconds later. This kind of user experience can kill a game.
+
+* Real-time gaming and low-latency trading need to talk to the server in high frequency, and the requests need to go to the same running instance. So **web socket** connections and **sticky routing** are needed.
+
+So microservice architecture is designed to solve problems for certain domains. We need to think about “why” when designing applications.
diff --git a/data/guides/is-passkey-shaping-a-passwordless-future.md b/data/guides/is-passkey-shaping-a-passwordless-future.md
new file mode 100644
index 0000000..f3071e9
--- /dev/null
+++ b/data/guides/is-passkey-shaping-a-passwordless-future.md
@@ -0,0 +1,34 @@
+---
+title: "Is PassKey Shaping a Passwordless Future?"
+description: "Exploring PassKey's potential to revolutionize online security."
+image: "https://assets.bytebytego.com/diagrams/0296-is-passkey-shaping-a-passwordless-future.png"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Passkeys"
+---
+
+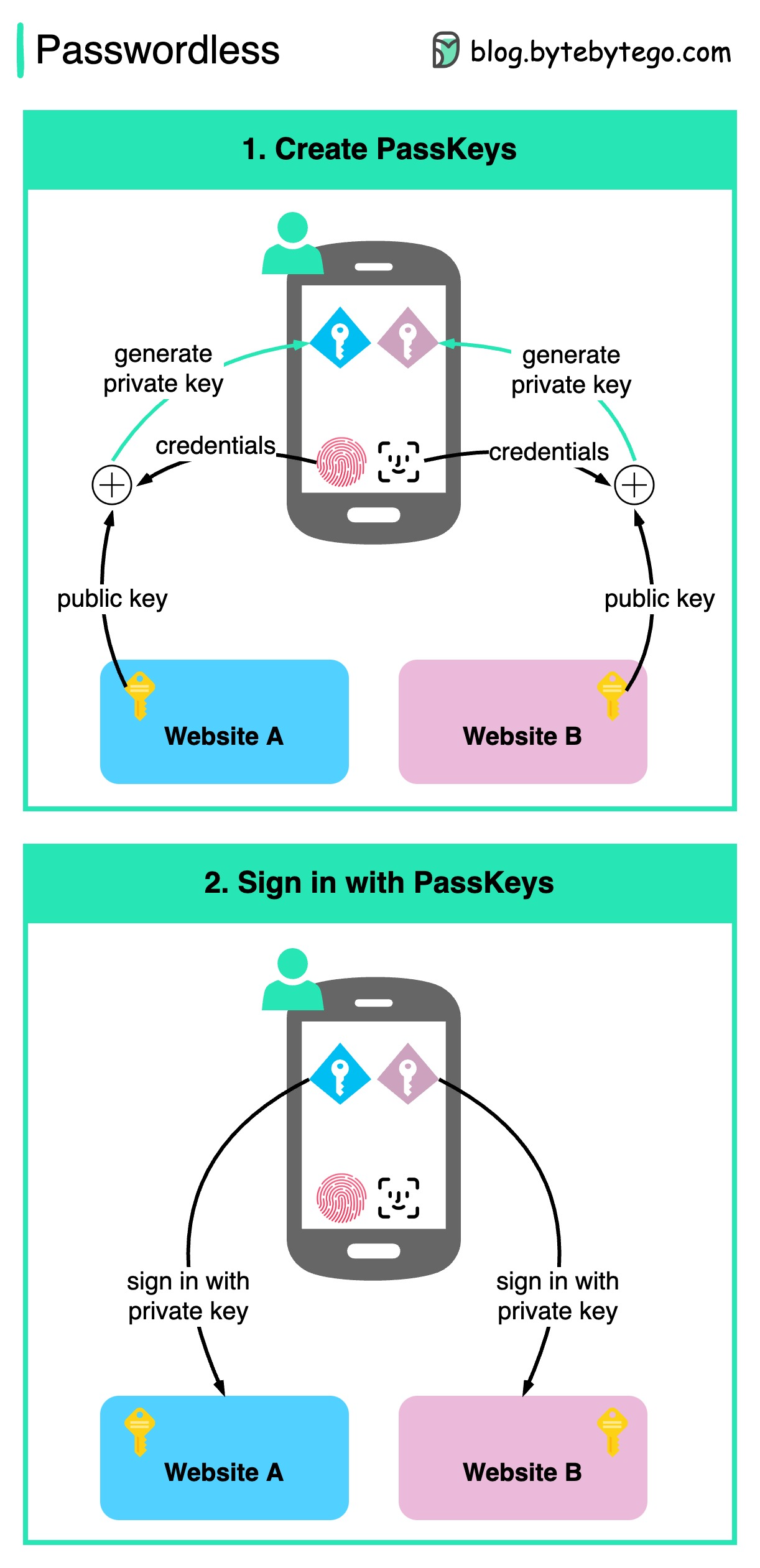
+
+Google recently announced PassKey support for both Android and Chrome.
+
+Passkey, also backed by Apple and Microsoft, is claimed to be a significantly **safer replacement** for passwords.
+
+## How PassKeys Work
+
+* **Step 1 - Create PassKeys**
+
+ The end-user needs to confirm the account information and present their credentials (face ID, touch ID, etc.).
+
+ A private key is generated based on the public key provided by the website. The private key is stored on the device.
+
+* **Step 2 - Sign in with PassKeys on devices**
+
+ When the user tries to sign in to a website, they use the generated private key. Just select the account information and present the credentials to unlock the private key.
+
+Consequently, there is no risk of password leakage since no passwords are stored in the websites' databases.
+
+Passkeys are built on **industry standards**, and it works across different platforms and browsers - including Windows, macOS and iOS, and ChromeOS, with a **uniform user experience**.
diff --git a/data/guides/is-postgresql-eating-the-database-world.md b/data/guides/is-postgresql-eating-the-database-world.md
new file mode 100644
index 0000000..4c19df7
--- /dev/null
+++ b/data/guides/is-postgresql-eating-the-database-world.md
@@ -0,0 +1,50 @@
+---
+title: "Is PostgreSQL Eating the Database World?"
+description: "Explore PostgreSQL's versatility and its impact on the database landscape."
+image: "https://assets.bytebytego.com/diagrams/0237-is-postgresql-eating-the-database-world.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "PostgreSQL"
+ - "Databases"
+---
+
+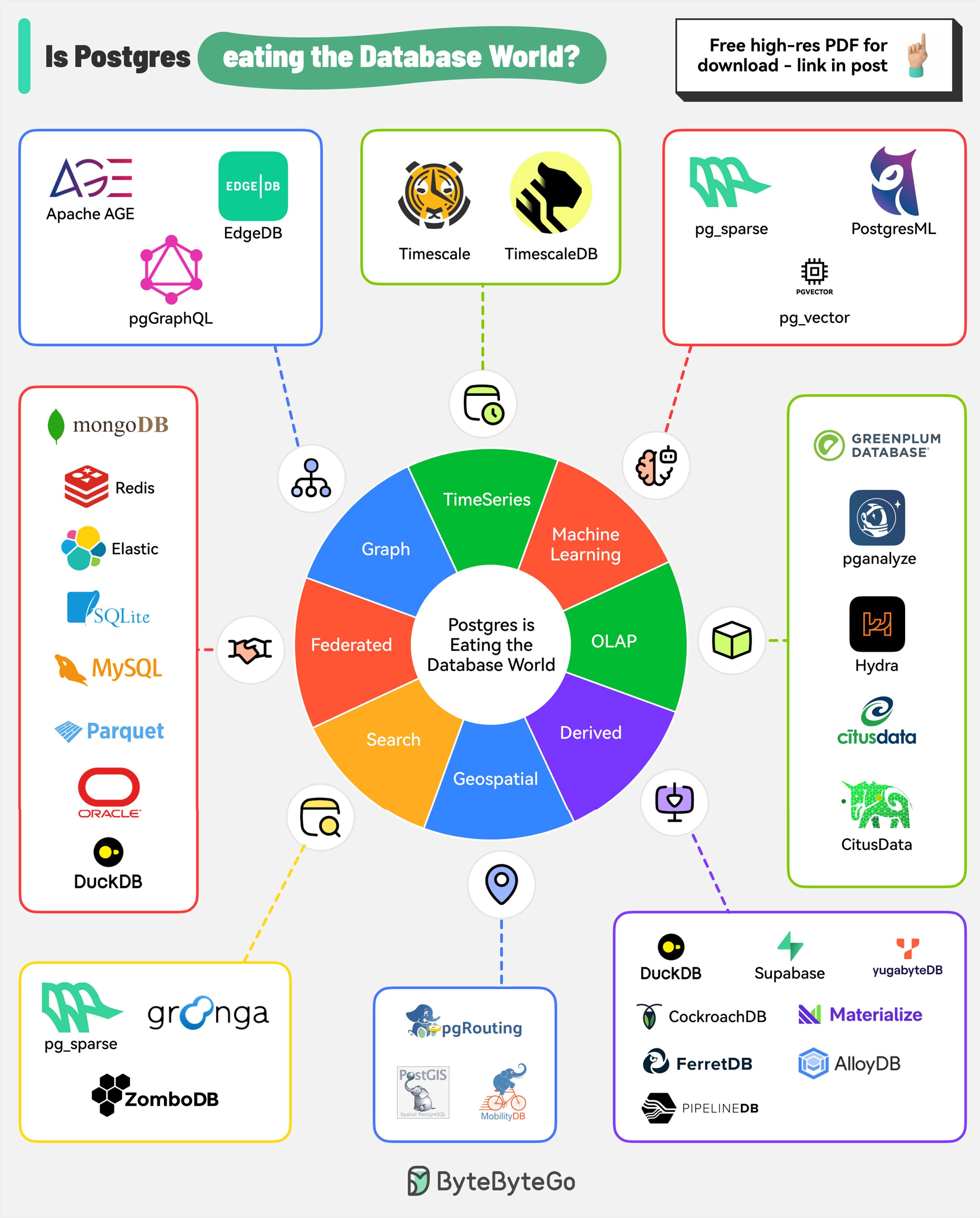
+
+It seems that no matter what the use case, PostgreSQL supports it. When in doubt, you can simply use PostgreSQL.
+
+## PostgreSQL Capabilities
+
+* **TimeSeries**
+
+ PostgreSQL embraces Timescale, a powerful time-series database extension for efficient handling of time-stamped data.
+
+* **Machine Learning**
+
+ With pgVector and PostgresML, Postgres can support machine learning capabilities and vector similarity searches.
+
+* **OLAP**
+
+ Postgres can support OLAP with tools such as Hydra, Citus, and pg\_analytics.
+
+* **Derived**
+
+ Even derived databases such as DuckDB, FerretDB, CockroachDB, AlloyDB, YugaByte DB, Supabase, etc provide PostgreSQL.
+
+* **GeoSpatial**
+
+ PostGIS extends PostgreSQL with geospatial capabilities, enabling you to easily store, query, and analyze geographic data.
+
+* **Search**
+
+ Postgres extensions like pgroonga, ParadeDB, and ZomboDB provide full-text search, text indexing, and data parsing capabilities.
+
+* **Federated**
+
+ Postgres seamlessly integrates with various data sources such as MongoDB, MySQL, Redis, Oracle, ParquetDB, SQLite, etc, enabling federated querying and data access.
+
+* **Graph**
+
+ Apache AGE and EdgeDB are graph databases built on top of PostgreSQL. Also, pg\_graphql is an extension that provides GraphQL support for Postgres.
diff --git a/data/guides/is-telegram-secure.md b/data/guides/is-telegram-secure.md
new file mode 100644
index 0000000..6599b75
--- /dev/null
+++ b/data/guides/is-telegram-secure.md
@@ -0,0 +1,32 @@
+---
+title: Is Telegram Secure?
+description: Exploring Telegram's security features and encryption methods.
+image: 'https://assets.bytebytego.com/diagrams/0354-is-telegram-secure.jpg'
+createdAt: '2024-02-15'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Security
+ - Encryption
+---
+
+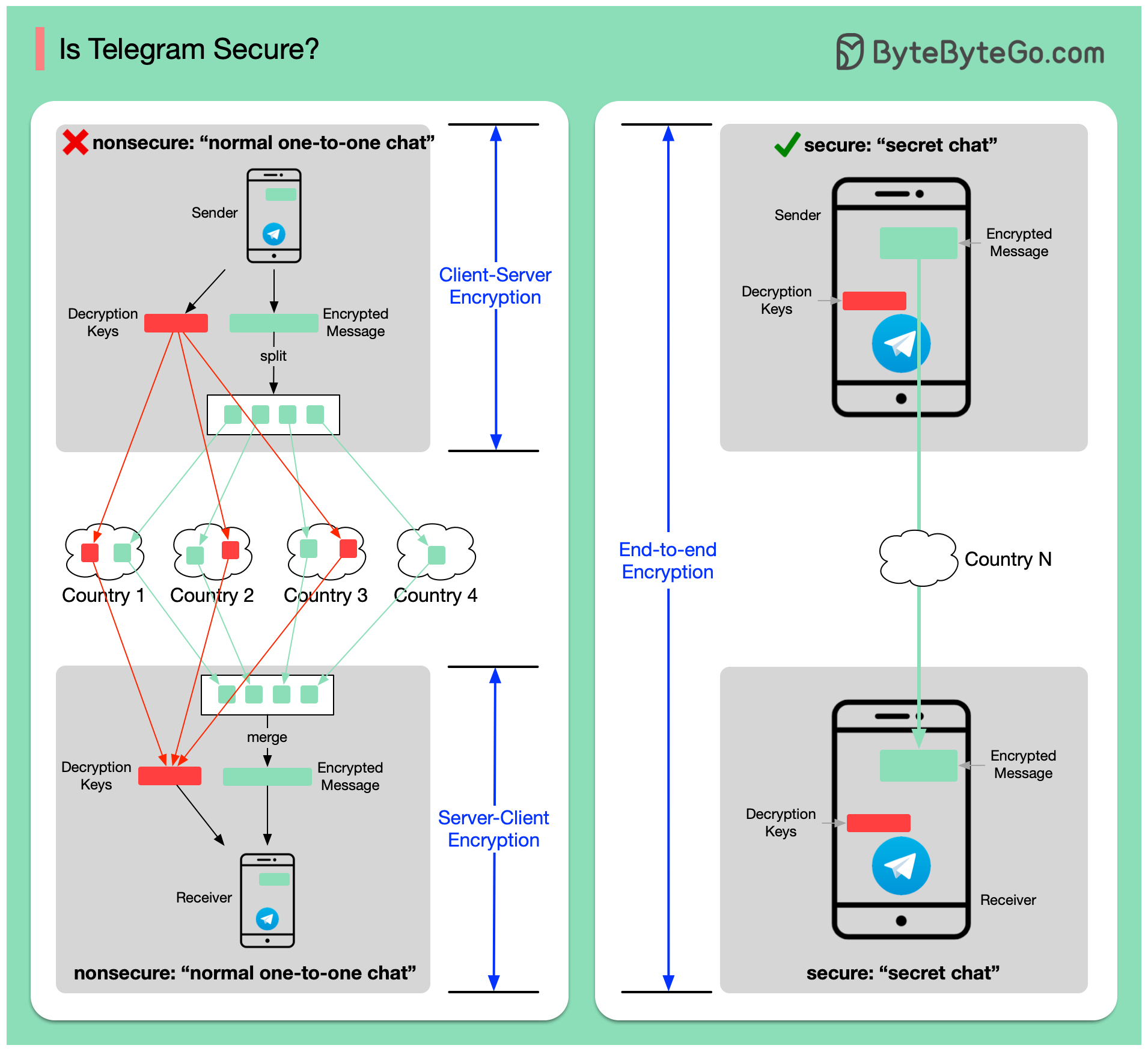
+
+Let’s first define what “secure” means. A “secure” chat in a messaging App generally means the message is encrypted at the sender side and is only decryptable at the receiver side. It is also called “E2EE” (end-to-end encryption).
+
+𝐓𝐞𝐥𝐞𝐠𝐫𝐚𝐦'𝐬 𝐮𝐬𝐮𝐚𝐥 𝐩𝐫𝐢𝐯𝐚𝐭𝐞 𝐚𝐧𝐝 𝐠𝐫𝐨𝐮𝐩 𝐜𝐡𝐚𝐭𝐬 𝐚𝐫𝐞𝐧'𝐭 𝐞𝐧𝐝-𝐭𝐨-𝐞𝐧𝐝 𝐞𝐧𝐜𝐫𝐲𝐩𝐭𝐞𝐝
+
+It generally means third parties can intercept and read your messages. Telegram uses the following approach for security:
+
+* The encrypted message is stored in Telegram servers, but split into several pieces and stored in different countries.
+* The decryption keys are also split and saved in different countries.
+
+This means the hacker needs to get message chunks and keys from all places. It is possible but extremely difficult.
+
+𝐒𝐞𝐜𝐫𝐞𝐭 𝐜𝐡𝐚𝐭𝐬 𝐚𝐫𝐞 𝐞𝐧𝐝-𝐭𝐨-𝐞𝐧𝐝 𝐞𝐧𝐜𝐫𝐲𝐩𝐭𝐞𝐝
+
+If you choose the “secret chat” option, it is end-to-end encrypted. It has several limitations:
+
+* It doesn’t support group chat or normal one-to-one chat.
+* It is only enabled for mobile devices.
diff --git a/data/guides/java-collection-hierarchy.md b/data/guides/java-collection-hierarchy.md
new file mode 100644
index 0000000..fff5806
--- /dev/null
+++ b/data/guides/java-collection-hierarchy.md
@@ -0,0 +1,30 @@
+---
+title: "Java Collection Hierarchy"
+description: "Explore the Java Collection Framework: interfaces, classes, and usage."
+image: "https://assets.bytebytego.com/diagrams/0240-java-collection.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Java"
+ - "Data Structures"
+---
+
+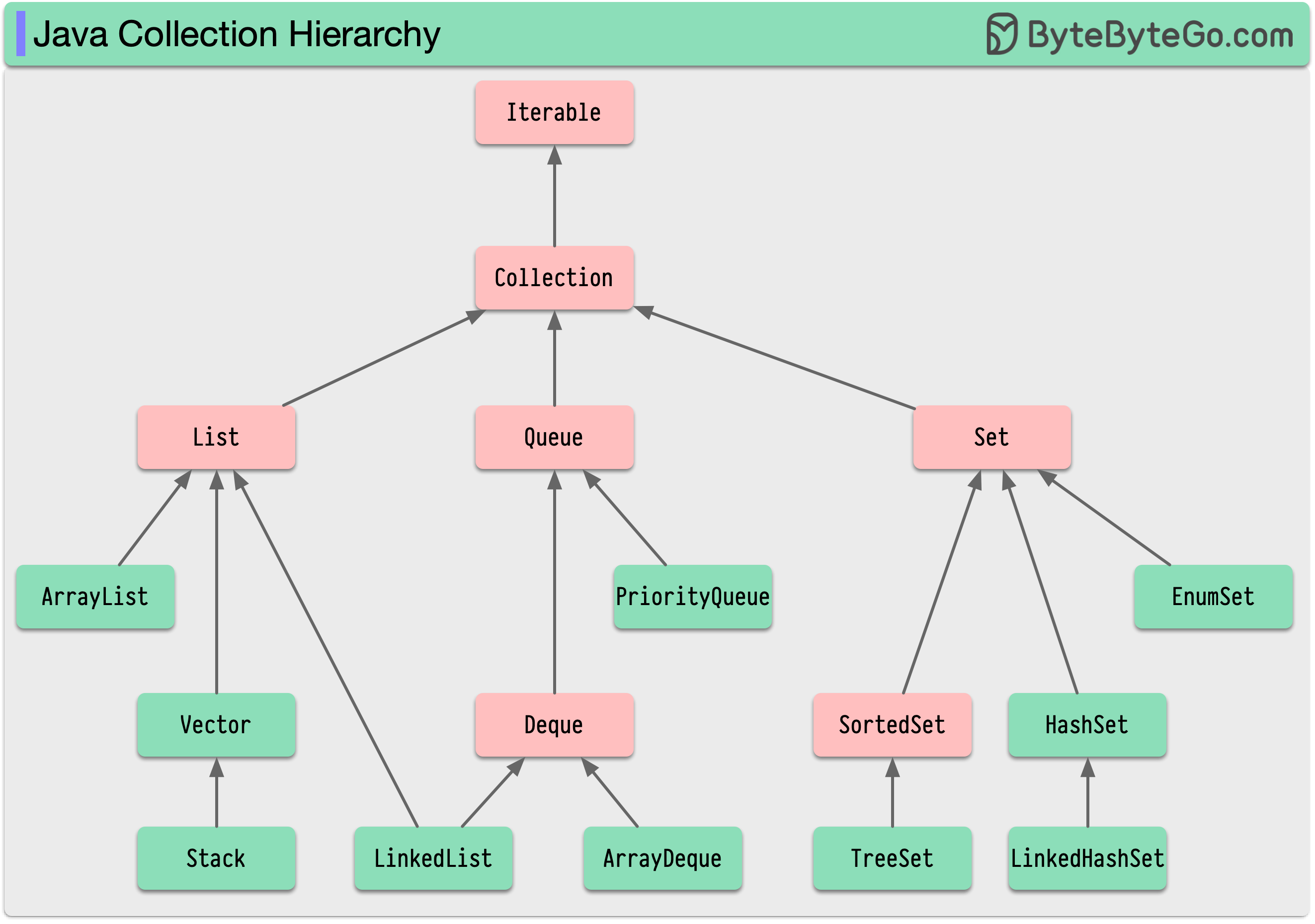
+
+Are you familiar with the Java Collection Framework?
+
+Every Java engineer has encountered the Java Collections Framework (JCF) at some point in their career. It has enabled us to solve complex problems in an efficient and standardized manner.
+
+JCF is built upon a set of interfaces that define the basic operations for common data structures such as lists, sets, and maps. Each data structure is implemented by several concrete classes, which provide specific functionality.
+
+Java Collections are based on the Collection interface. A collection class should support basic operations such as adding, removing, and querying elements.
+
+Through the enhanced for-loop or iterators, the Collection interface extends the Iterable interface, making it convenient to iterate over the elements.
+
+The Collection interface has three main subinterfaces: List, Set, and Queue. Each of these interfaces has its unique characteristics and use cases.
+
+Java engineers need to be familiar with the Java Collection hierarchy to make informed decisions when choosing the right data structure for a particular problem.
+
+We can write more efficient and maintainable code by familiarizing ourselves with the key interfaces and their implementations. We will undoubtedly benefit from mastering the JCF as it is a versatile and powerful tool in our Java arsenal.
diff --git a/data/guides/json-files.md b/data/guides/json-files.md
new file mode 100644
index 0000000..e2e53ec
--- /dev/null
+++ b/data/guides/json-files.md
@@ -0,0 +1,20 @@
+---
+title: "JSON Crack: Visualize JSON Files"
+description: "Visualize and understand complex JSON data with JSON Crack."
+image: "https://assets.bytebytego.com/diagrams/0242-json-crack.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "JSON"
+ - "Visualization"
+---
+
+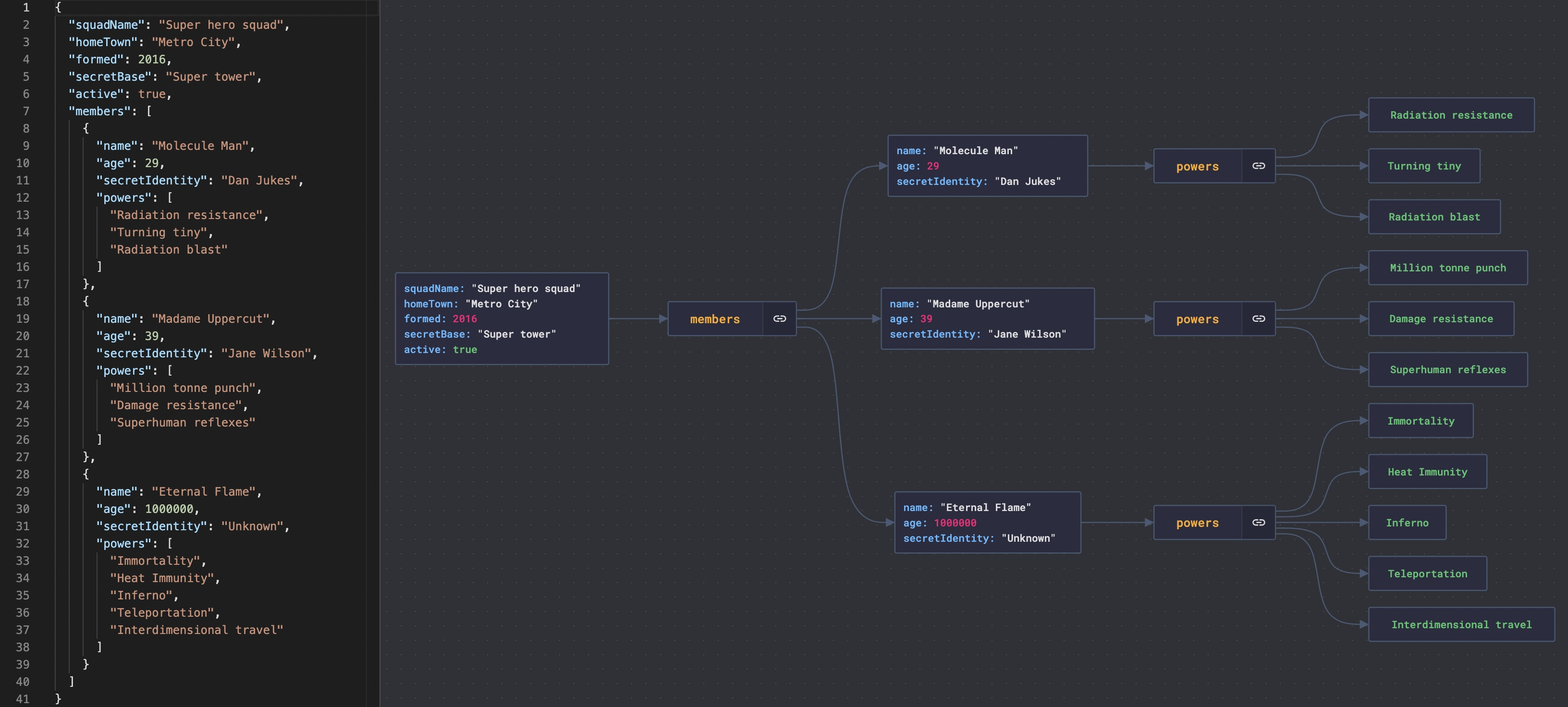
+
+If you use JSON files, you'll probably like this tool 👇
+
+Nested JSON files are hard to read.
+
+JsonCrack generates graph diagrams from JSON files and makes them easy to read.
diff --git a/data/guides/jwt-101-key-to-stateless-authentication.md b/data/guides/jwt-101-key-to-stateless-authentication.md
new file mode 100644
index 0000000..1d17742
--- /dev/null
+++ b/data/guides/jwt-101-key-to-stateless-authentication.md
@@ -0,0 +1,40 @@
+---
+title: "JWT 101: Key to Stateless Authentication"
+description: "Learn about JSON Web Tokens (JWT) for secure, stateless authentication."
+image: "https://assets.bytebytego.com/diagrams/0244-jwt-101-key-to-stateless-authentication.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - security
+tags:
+ - "authentication"
+ - "jwt"
+---
+
+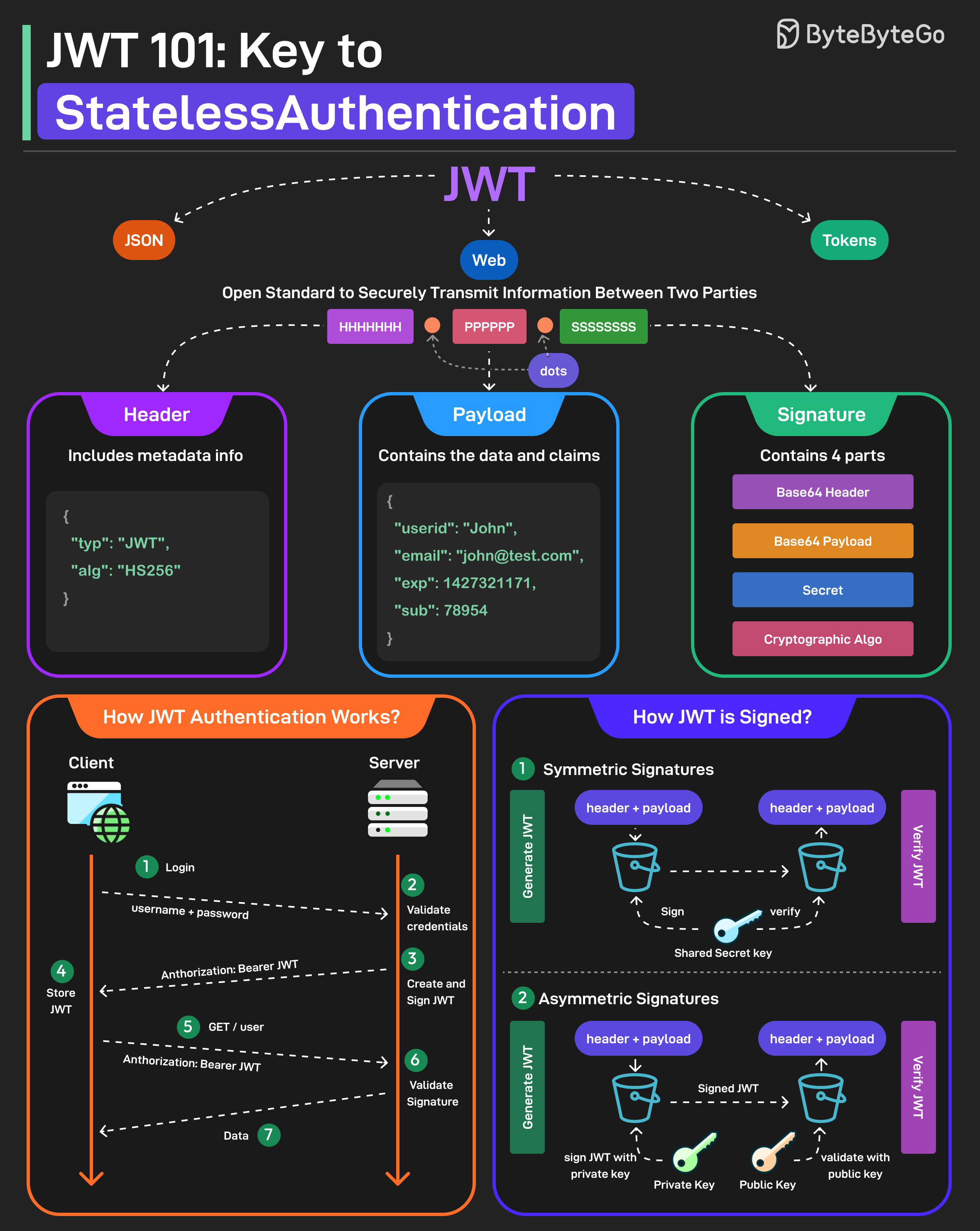
+
+JWT or JSON Web Tokens is an open standard for securely transmitting information between two parties. They are widely used for authentication and authorization.
+
+A JWT consists of three main components:
+
+1. Header
+
+Every JWT carries a header specifying the algorithms for signing the JWT. It’s written in JSON format.
+
+2. Payload
+
+The payload consists of the claims and the user data. There are different types of claims such as registered, public, and private claims.
+
+3. Signature
+
+The signature is what makes the JWT secure. It is created by taking the encoded header, encoded payload, secret key, and the algorithm and signing it.
+
+JWTs can be signed in two different ways:
+
+* **Symmetric Signatures**
+
+ It uses a single secret key for both signing the token and verifying it. The same key must be shared between the server that signs the JWT and the system that verifies it.
+
+* **Asymmetric Signatures**
+
+ In this case, a private key is used to sign the token, and a public key to verify it. The private key is kept secure on the server, while the public key can be distributed to anyone who needs to verify the token.
diff --git a/data/guides/key-concepts-to-understand-database-sharding.md b/data/guides/key-concepts-to-understand-database-sharding.md
new file mode 100644
index 0000000..15a9c87
--- /dev/null
+++ b/data/guides/key-concepts-to-understand-database-sharding.md
@@ -0,0 +1,28 @@
+---
+title: "Key Concepts to Understand Database Sharding"
+description: "Explore key concepts of database sharding with vertical/horizontal strategies."
+image: "https://assets.bytebytego.com/diagrams/0096-dbshards.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Sharding"
+ - "Database Design"
+---
+
+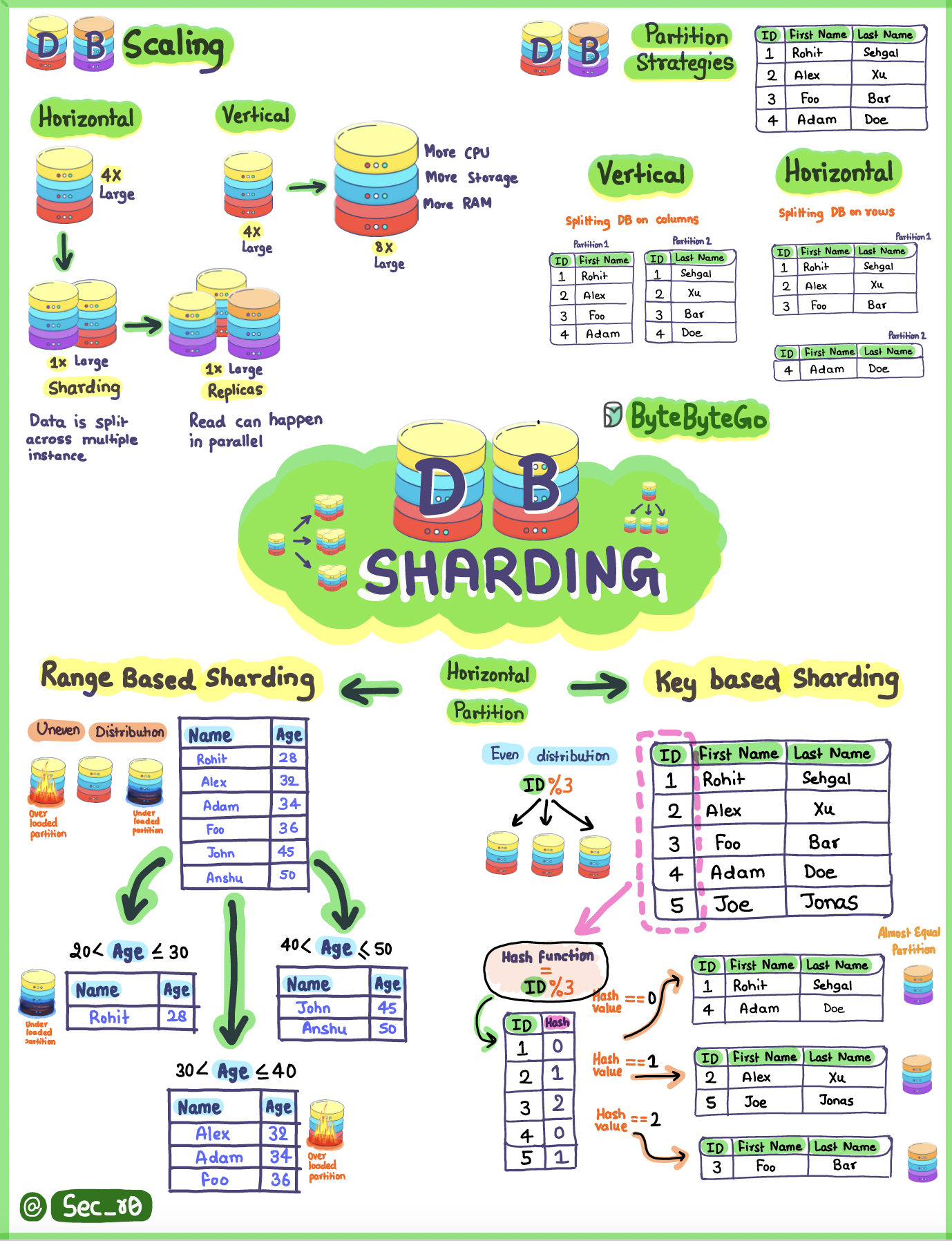
+
+In this concise and visually engaging resource, we break down the key concepts of database partitioning, explaining both vertical and horizontal strategies.
+
+## Range-Based Sharding
+
+Splitting your data into distinct ranges. Think of it as organizing your books by genre on separate shelves.
+
+## Key-Based Sharding (with a dash of %3 hash)
+
+Imagine each piece of data having a unique key, and we distribute them based on a specific rule. It's like sorting your playing cards by suit and number.
+
+## Directory-Based Sharding
+
+A directory, like a phone book, helps you quickly find the information you need. Similarly, this technique uses a directory to route data efficiently.
diff --git a/data/guides/key-data-terms.md b/data/guides/key-data-terms.md
new file mode 100644
index 0000000..5ddcfd6
--- /dev/null
+++ b/data/guides/key-data-terms.md
@@ -0,0 +1,23 @@
+---
+title: 'Key Data Terms'
+description: 'Understand essential data terminology for effective data management.'
+image: 'https://assets.bytebytego.com/diagrams/0158-data-terms.png'
+createdAt: '2024-03-09'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - Data Warehousing
+ - Data Lakes
+---
+
+Data is used everywhere, but do you know all the commonly used data terms?
+
+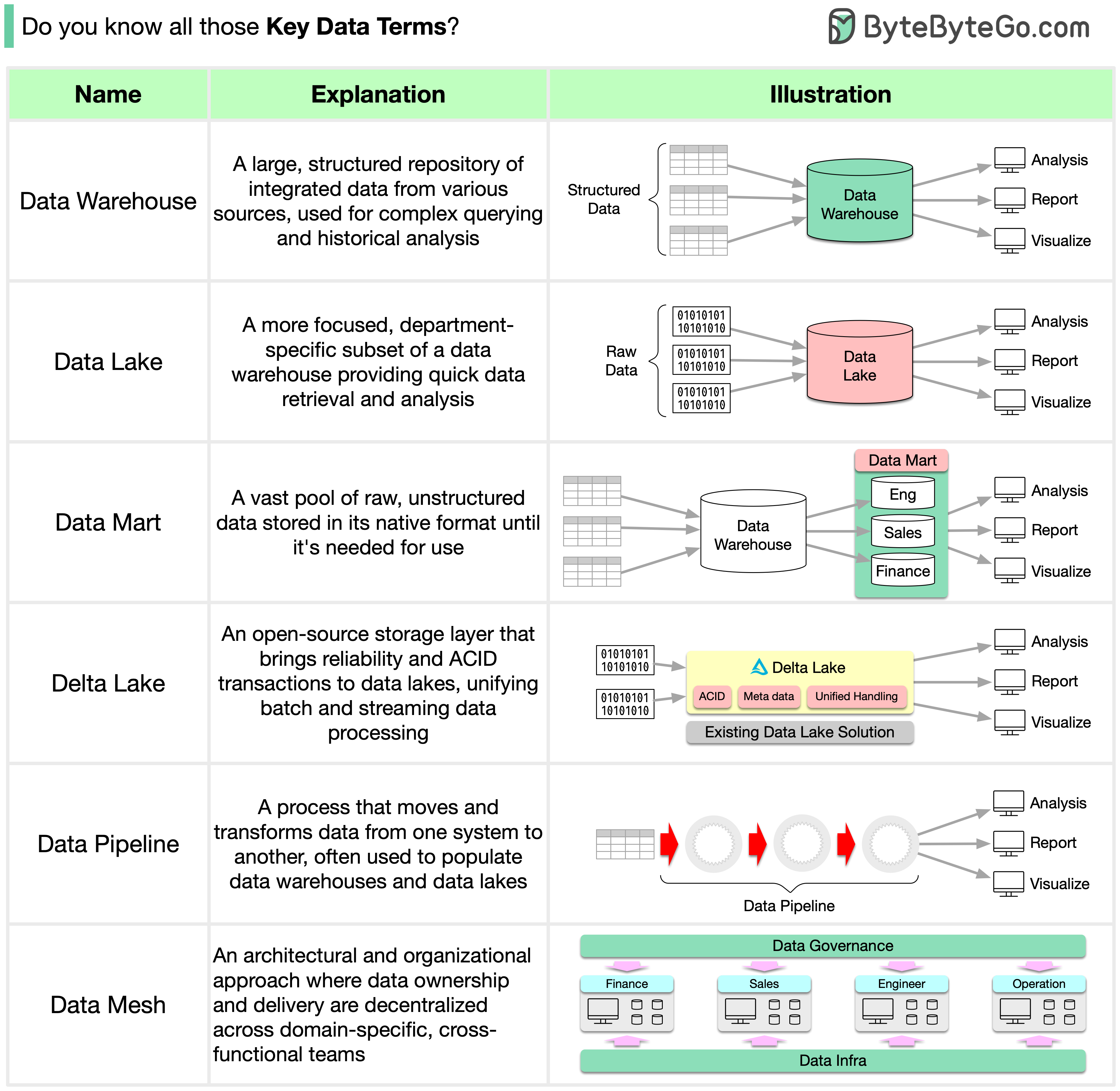
+
+- **Data Warehouse:** A large, structured repository of integrated data from various sources, used for complex querying and historical analysis.
+- **Data Mart:** A more focused, department-specific subset of a data warehouse providing quick data retrieval and analysis.
+- **Data Lake:** A vast pool of raw, unstructured data stored in its native format until it's needed for use.
+- **Delta Lake:** An open-source storage layer that brings reliability and ACID transactions to data lakes, unifying batch, and streaming data processing.
+- **Data Pipeline:** A process that moves and transforms data from one system to another, often used to populate data warehouses and data lakes.
+- **Data Mesh:** An architectural and organizational approach where data ownership and delivery are decentralized across domain-specific, cross-functional teams.
diff --git a/data/guides/key-terms-in-domain-driven-design.md b/data/guides/key-terms-in-domain-driven-design.md
new file mode 100644
index 0000000..8829af5
--- /dev/null
+++ b/data/guides/key-terms-in-domain-driven-design.md
@@ -0,0 +1,38 @@
+---
+title: "Key Terms in Domain-Driven Design"
+description: "Understand key concepts in Domain-Driven Design for better software."
+image: "https://assets.bytebytego.com/diagrams/0163-ddd.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Domain-Driven Design"
+ - "Software Design"
+---
+
+Have you heard of Domain-Driven Design (DDD), a major software design approach?
+
+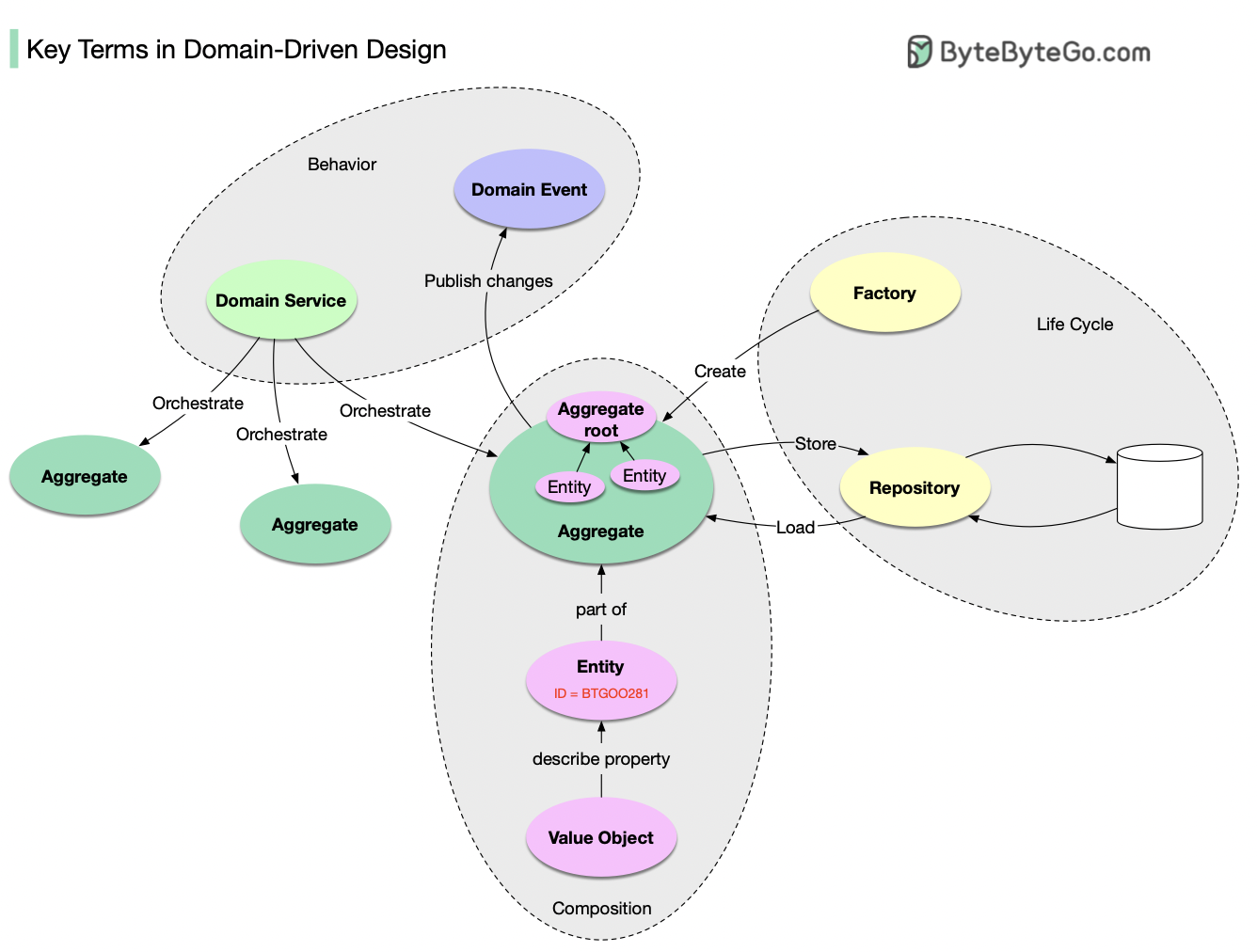
+
+DDD was introduced in Eric Evans’ classic book “Domain-Driven Design: Tackling Complexity in the Heart of Software”. It explained a methodology to model a complex business. In this book, there is a lot of content, so I'll summarize the basics.
+
+## The composition of domain objects:
+
+* **Entity:** a domain object that has ID and life cycle.
+
+* **Value Object:** a domain object without ID. It is used to describe the property of Entity.
+
+* **Aggregate:** a collection of Entities that are bounded together by Aggregate Root (which is also an entity). It is the unit of storage.
+
+## The life cycle of domain objects:
+
+* **Repository:** storing and loading the Aggregate.
+
+* **Factory:** handling the creation of the Aggregate.
+
+## Behavior of domain objects:
+
+* **Domain Service:** orchestrate multiple Aggregate.
+
+* **Domain Event:** a description of what has happened to the Aggregate. The publication is made public so others can consume and reconstruct it.
diff --git a/data/guides/key-use-cases-for-load-balancers.md b/data/guides/key-use-cases-for-load-balancers.md
new file mode 100644
index 0000000..5610ac7
--- /dev/null
+++ b/data/guides/key-use-cases-for-load-balancers.md
@@ -0,0 +1,34 @@
+---
+title: 'Key Use Cases for Load Balancers'
+description: 'Explore key use cases for load balancers in modern architectures.'
+image: 'https://assets.bytebytego.com/diagrams/0046-top-6-load-balancer-use-cases.png'
+createdAt: '2024-02-04'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Load Balancing
+ - Scalability
+---
+
+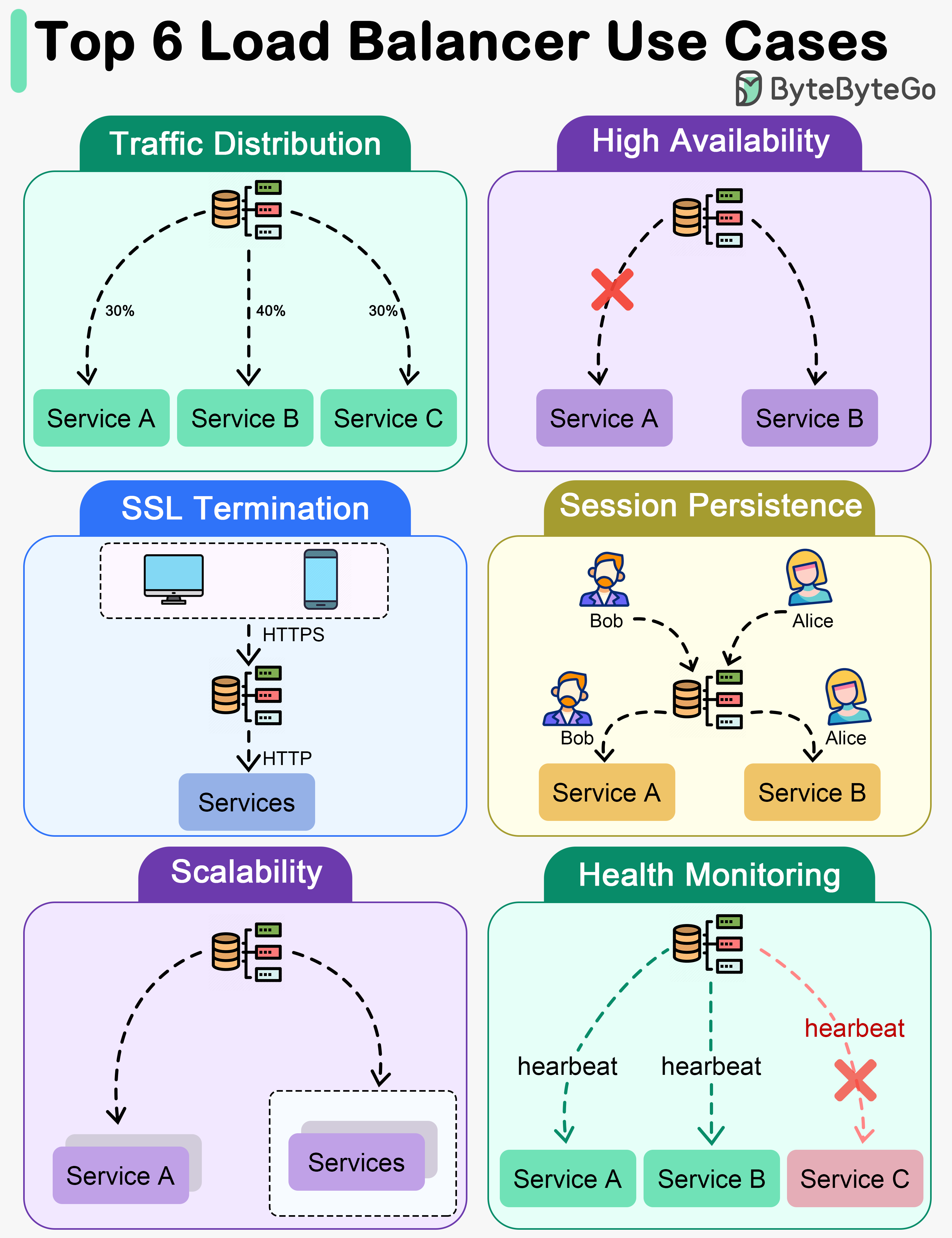
+
+The diagram above shows the top 6 use cases where we use a load balancer.
+
+* **Traffic Distribution**
+ Load balancers evenly distribute incoming traffic among multiple servers, preventing any single server from becoming overwhelmed. This helps maintain optimal performance, scalability, and reliability of applications or websites.
+
+* **High Availability**
+ Load balancers enhance system availability by rerouting traffic away from failed or unhealthy servers to healthy ones. This ensures uninterrupted service even if certain servers experience issues.
+
+* **SSL Termination**
+ Load balancers can offload SSL/TLS encryption and decryption tasks from backend servers, reducing their workload and improving overall performance.
+
+* **Session Persistence**
+ For applications that require maintaining a user's session on a specific server, load balancers can ensure that subsequent requests from a user are sent to the same server.
+
+* **Scalability**
+ Load balancers facilitate horizontal scaling by effectively managing increased traffic. Additional servers can be easily added to the pool, and the load balancer will distribute traffic across all servers.
+
+* **Health Monitoring**
+ Load balancers continuously monitor the health and performance of servers, removing failed or unhealthy servers from the pool to maintain optimal performance.
diff --git a/data/guides/kubernetes-deployment-strategies.md b/data/guides/kubernetes-deployment-strategies.md
new file mode 100644
index 0000000..1b5457d
--- /dev/null
+++ b/data/guides/kubernetes-deployment-strategies.md
@@ -0,0 +1,61 @@
+---
+title: "Kubernetes Deployment Strategies"
+description: "Explore Kubernetes deployment strategies for seamless application updates."
+image: "https://assets.bytebytego.com/diagrams/0247-kubernates-deployment-strategy.jpeg"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Kubernetes"
+ - "Deployment"
+---
+
+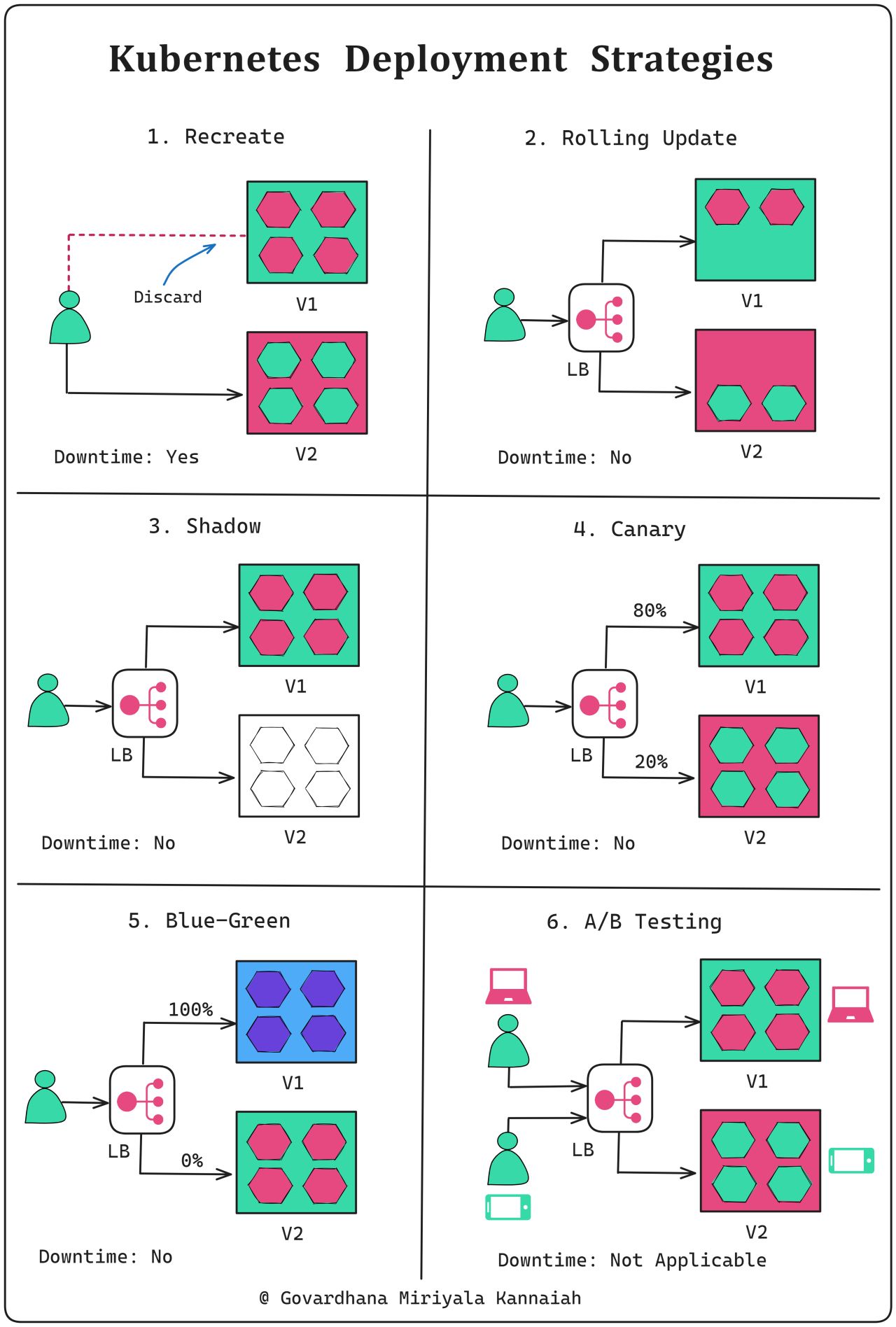
+
+Each strategy offers a unique approach to manage updates.
+
+## Recreate
+
+All existing instances are terminated at once, and new instances with the updated version are created.
+
+* Downtime: Yes
+* Use case: Non-critical applications or during initial development stages
+
+## Rolling Update
+
+Application instances are updated one by one, ensuring high availability during the process.
+
+* Downtime: No
+* Use case: Periodic releases
+
+## Shadow
+
+A copy of the live traffic is redirected to the new version for testing without affecting production users.
+
+This is the most complex deployment strategy and involves establishing mock services to interact with the new version of the deployment.
+
+* Downtime: No
+* Use case: Validating new version performance and behavior in a real environment
+
+## Canary
+
+The new version is released to a subset of users or servers for testing before broader deployment.
+
+* Downtime: No
+* Use case: Impact validation on a subset of users
+
+## Blue-Green
+
+* Two identical environments are maintained: one with the current version (blue) and the other with the updated version (green).
+* Traffic starts with blue, then switches to the prepared green environment for the updated version.
+
+* Downtime: No
+* Use case: High-stake updates
+
+## A/B Testing
+
+Multiple versions are concurrently tested on different users to compare performance or user experience.
+
+* Downtime: Not directly applicable
+* Use case: Optimizing user experience
diff --git a/data/guides/kubernetes-periodic-table.md b/data/guides/kubernetes-periodic-table.md
new file mode 100644
index 0000000..062c4df
--- /dev/null
+++ b/data/guides/kubernetes-periodic-table.md
@@ -0,0 +1,20 @@
+---
+title: "Kubernetes Periodic Table"
+description: "A visual guide to Kubernetes key components and their relationships."
+image: "https://assets.bytebytego.com/diagrams/0108-kubernetes-periodic-table.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - Orchestration
+---
+
+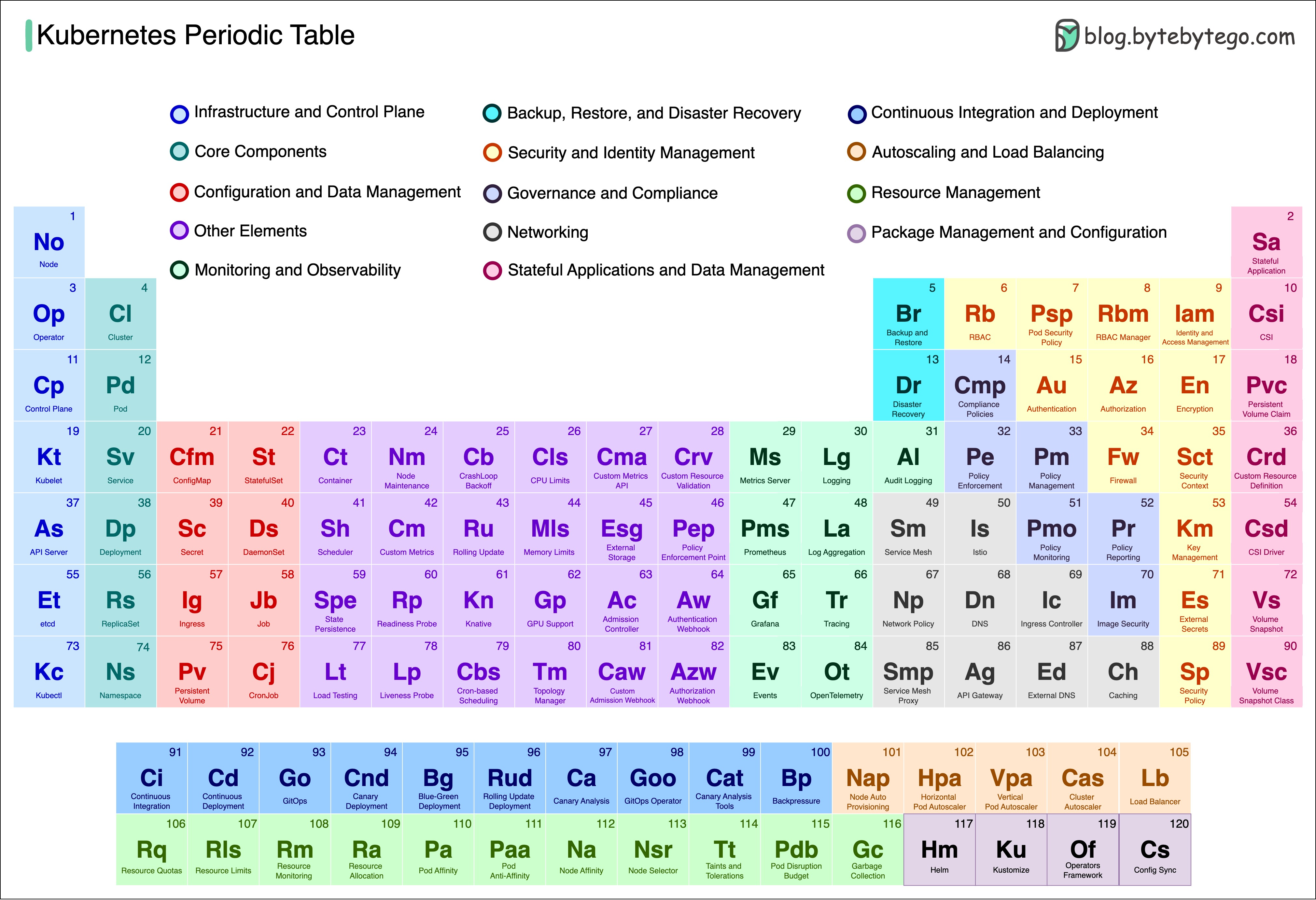
+
+A comprehensive visual guide that demystifies the key building blocks of this powerful container orchestration platform.
+
+This Kubernetes Periodic Table sheds light on the 120 crucial components that make up the Kubernetes ecosystem.
+
+Whether you're a developer, system administrator, or cloud enthusiast, this handy resource will help you navigate the complex Kubernetes landscape.
diff --git a/data/guides/kubernetes-tools-ecosystem.md b/data/guides/kubernetes-tools-ecosystem.md
new file mode 100644
index 0000000..f71207e
--- /dev/null
+++ b/data/guides/kubernetes-tools-ecosystem.md
@@ -0,0 +1,27 @@
+---
+title: "Kubernetes Tools Ecosystem"
+description: "Explore the Kubernetes tools ecosystem for efficient container management."
+image: "https://assets.bytebytego.com/diagrams/0109-kubernetes-tools-ecosystem.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - DevOps
+---
+
+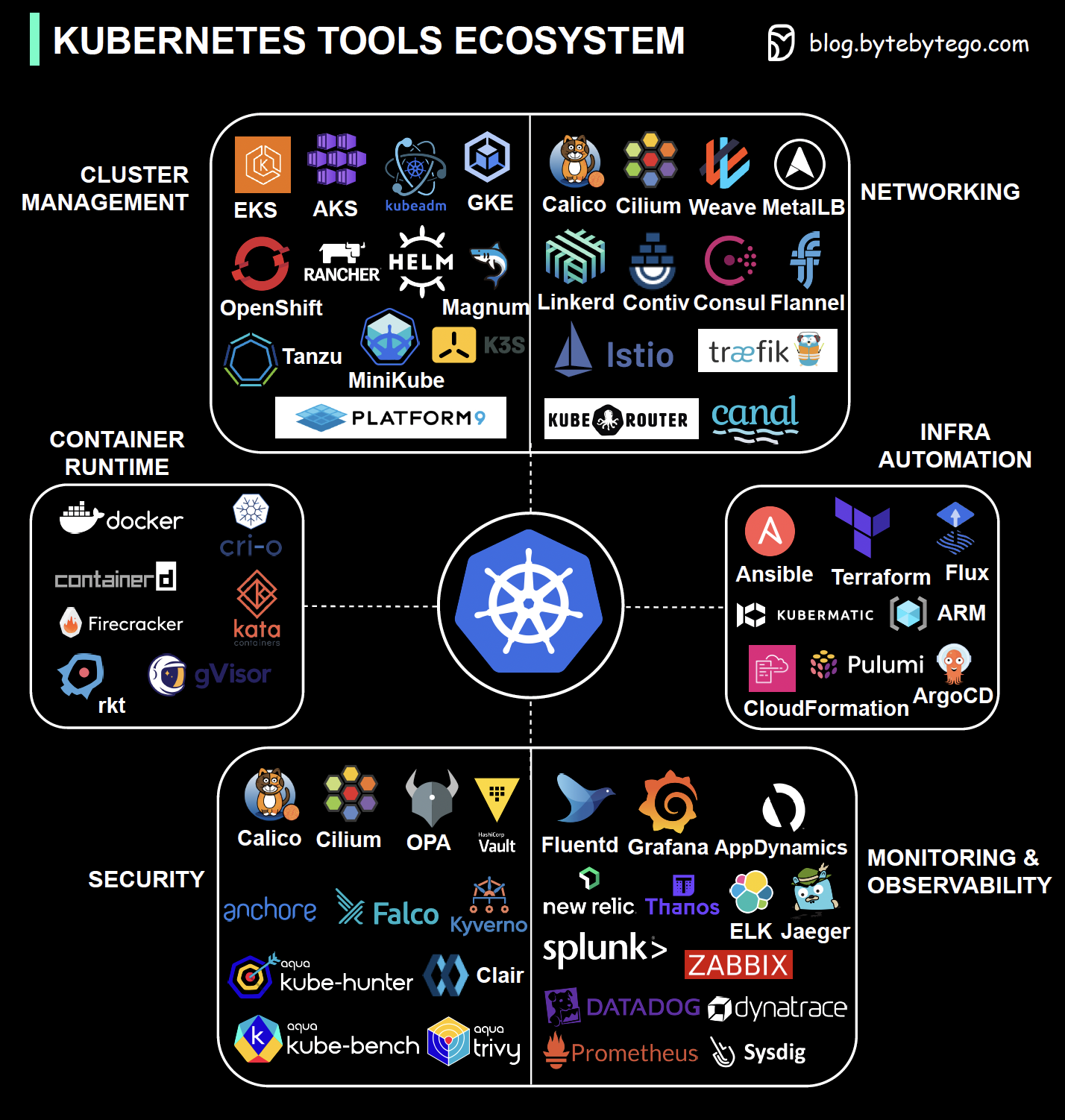
+
+Kubernetes, the leading container orchestration platform, boasts a vast ecosystem of tools and components that collectively empower organizations to efficiently deploy, manage, and scale containerized applications.
+
+Kubernetes practitioners need to be well-versed in these tools to ensure the reliability, security, and performance of containerized applications within Kubernetes clusters.
+
+To introduce a holistic view of the Kubernetes ecosystem, we've created an illustration covering the aspects of:
+
+* Security
+* Networking
+* Container Runtime
+* Cluster Management
+* Monitoring and Observability
+* Infrastructure Orchestration
diff --git a/data/guides/kubernetes-tools-stack-wheel.md b/data/guides/kubernetes-tools-stack-wheel.md
new file mode 100644
index 0000000..e99f954
--- /dev/null
+++ b/data/guides/kubernetes-tools-stack-wheel.md
@@ -0,0 +1,20 @@
+---
+title: "Kubernetes Tools Stack Wheel"
+description: "Explore the Kubernetes tools stack wheel for efficient container orchestration."
+image: "https://assets.bytebytego.com/diagrams/0110-kubernetes-tools-stack-wheel.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - DevOps
+---
+
+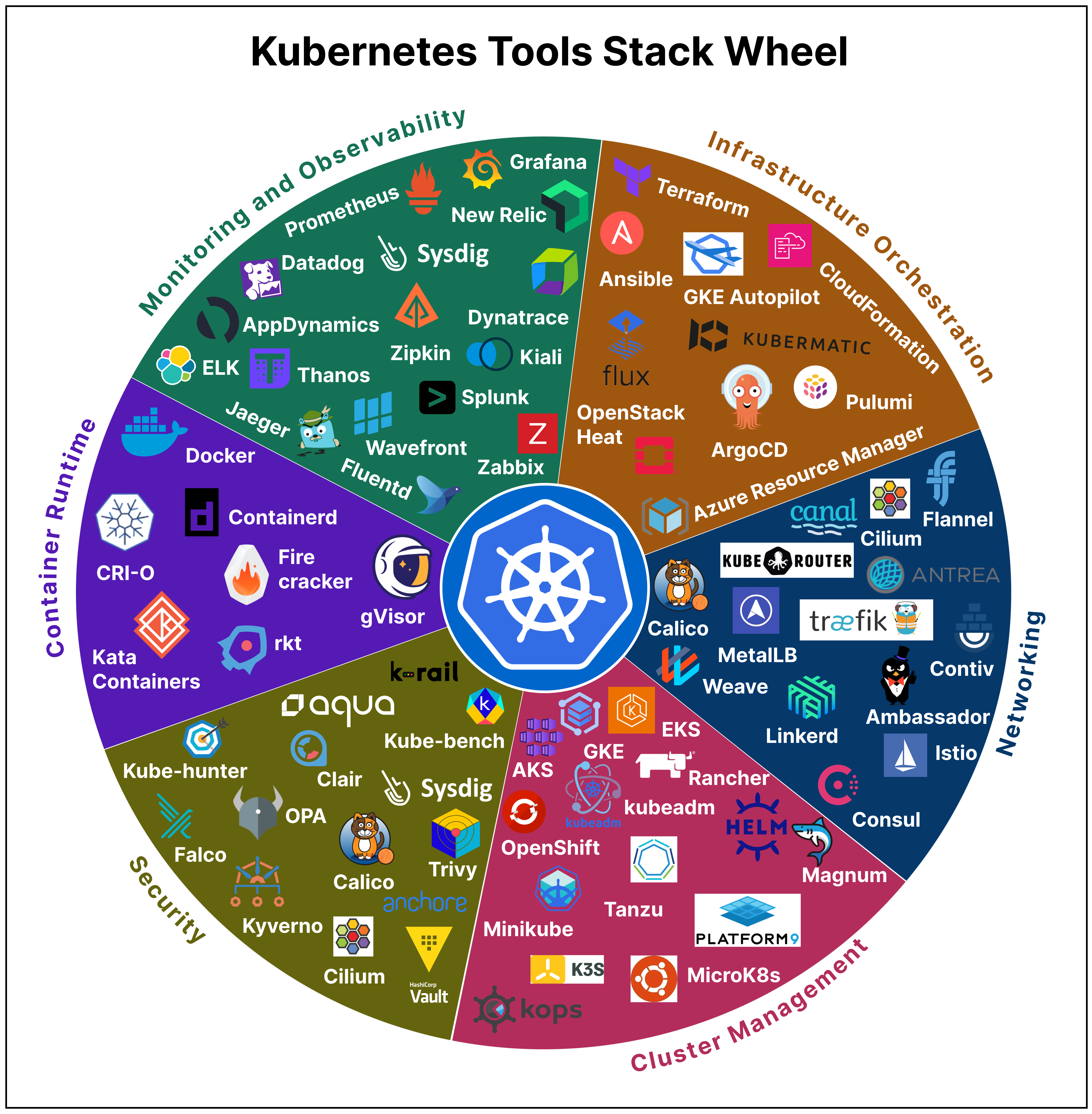
+
+Kubernetes tools continually evolve, offering enhanced capabilities and simplifying container orchestration. The innumerable choice of tools speaks about the vastness and the scope of this dynamic ecosystem, catering to diverse needs in the world of containerization.
+
+In fact, getting to know about the existing tools themselves can be a significant endeavor. With new tools and updates being introduced regularly, staying informed about their features, compatibility, and best practices becomes essential for Kubernetes practitioners, ensuring they can make informed decisions and adapt to the ever-changing landscape effectively.
+
+This tool stack streamlines the decision-making process and keeps up with that evolution, ultimately helping you to choose the right combination of tools for your use cases.
diff --git a/data/guides/learn-cache.md b/data/guides/learn-cache.md
new file mode 100644
index 0000000..ddcaef7
--- /dev/null
+++ b/data/guides/learn-cache.md
@@ -0,0 +1,26 @@
+---
+title: "Learn Cache"
+description: "A visual guide to understanding caching systems and their key considerations."
+image: "https://assets.bytebytego.com/diagrams/0004-learn-cache.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "System Design"
+---
+
+Made a simple visual guide to help everyone understand the key considerations when designing or using caching systems.
+
+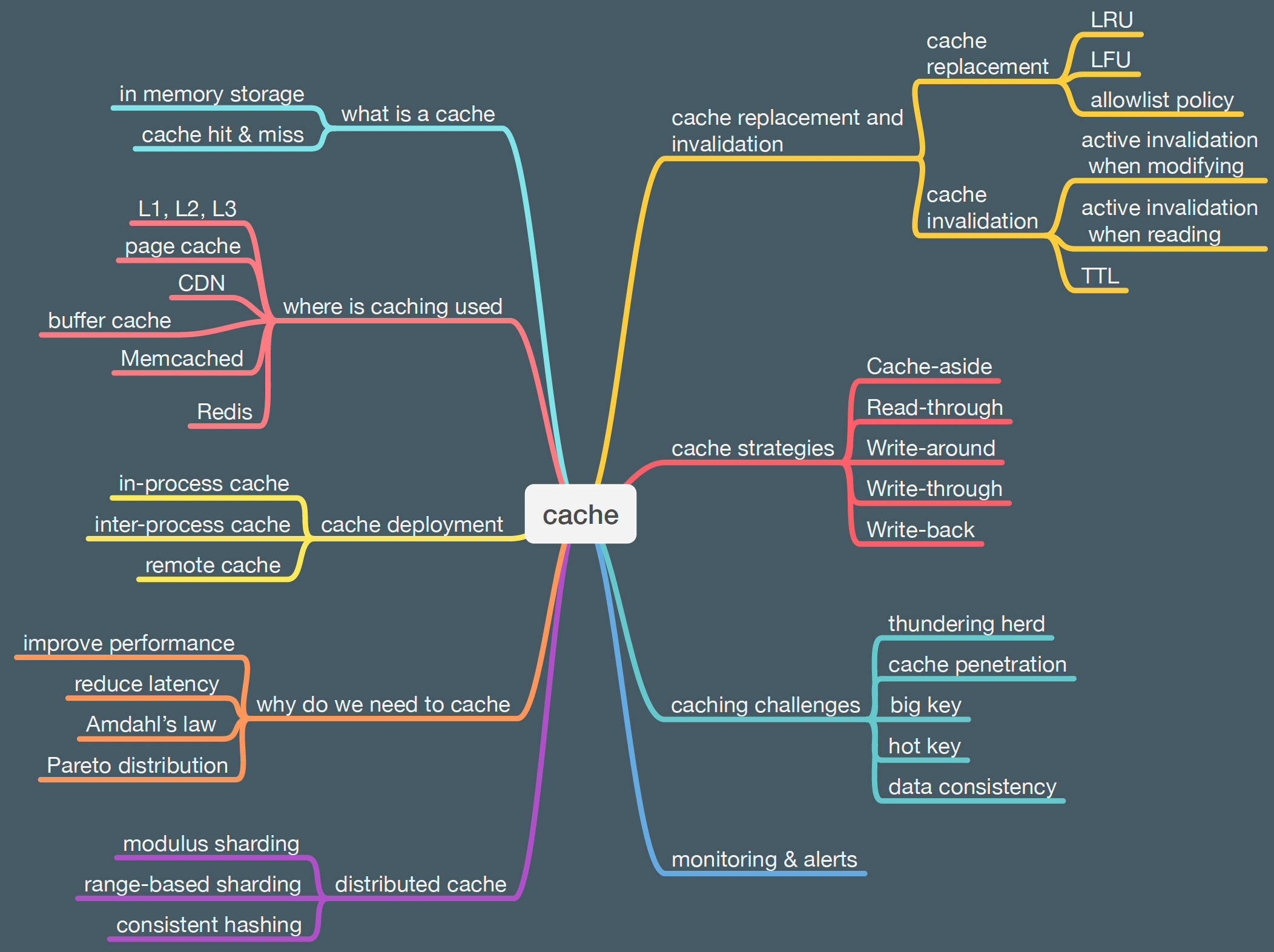
+
+* What is a cache
+* Why do we need cache
+* Where is cache used
+* Cache deployment
+* Distributed cache
+* Cache replacement and invalidation
+* Cache strategies
+* Caching challenges
+* And more.
diff --git a/data/guides/life-is-short-use-dev-tools.md b/data/guides/life-is-short-use-dev-tools.md
new file mode 100644
index 0000000..63f31a0
--- /dev/null
+++ b/data/guides/life-is-short-use-dev-tools.md
@@ -0,0 +1,50 @@
+---
+title: "Life is Short, Use Dev Tools"
+description: "Discover essential dev tools to save time and boost productivity."
+image: "https://assets.bytebytego.com/diagrams/0256-life-is-short-use-dev-tools.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Productivity"
+ - "Dev Tools"
+---
+
+
+
+The right dev tool can save you precious time, energy, and perhaps the weekend as well.
+
+Here are our favorite dev tools:
+
+* **Development Environment**
+
+ A good local dev environment is a force multiplier. Powerful IDEs like VSCode, IntelliJ IDEA, Notepad++, Vim, PyCharm & Jupyter Notebook can make your life easy.
+
+* **Diagramming**
+
+ Showcase your ideas visually with diagramming tools like DrawIO, Excalidraw, mindmap, Mermaid, PlantUML, Microsoft Visio, and Miro.
+
+* **AI Tools**
+
+ AI can boost your productivity. Don’t ignore tools like ChatGPT, GitHub Copilot, Tabnine, Claude, Ollama, Midjourney, and Stable Diffusion.
+
+* **Hosting and Deployment**
+
+ For hosting your applications, explore solutions like AWS, Cloudflare, GitHub, Fly, Heroku, and Digital Ocean.
+
+* **Code Quality**
+
+ Quality code is a great differentiator. Leverage tools like Jest, ESLint, Selenium, SonarQube, FindBugs, and Checkstyle to ensure top-notch quality.
+
+* **Security**
+
+ Don’t ignore the security aspects and use solutions like 1Password, LastPass, OWASP, Snyk, and Nmap.
+
+* **Note-taking**
+
+ Your notes are a reflection of your knowledge. Streamline your note-taking with Notion, Markdown, Obsidian, Roam, Logseq, and Tiddly Wiki.
+
+* **Design**
+
+ Elevate your visual game with design tools like Figma, Sketch, Adobe Illustrator, Canva, and Adobe Photoshop.
diff --git a/data/guides/linux-boot-process-explained.md b/data/guides/linux-boot-process-explained.md
new file mode 100644
index 0000000..afd3a88
--- /dev/null
+++ b/data/guides/linux-boot-process-explained.md
@@ -0,0 +1,49 @@
+---
+title: "Linux Boot Process Explained"
+description: "Explore the Linux boot process, from BIOS/UEFI to user login."
+image: "https://assets.bytebytego.com/diagrams/0213-linux-boot-process-explained.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - software-architecture
+ - software-development
+tags:
+ - "Linux"
+ - "Operating Systems"
+---
+
+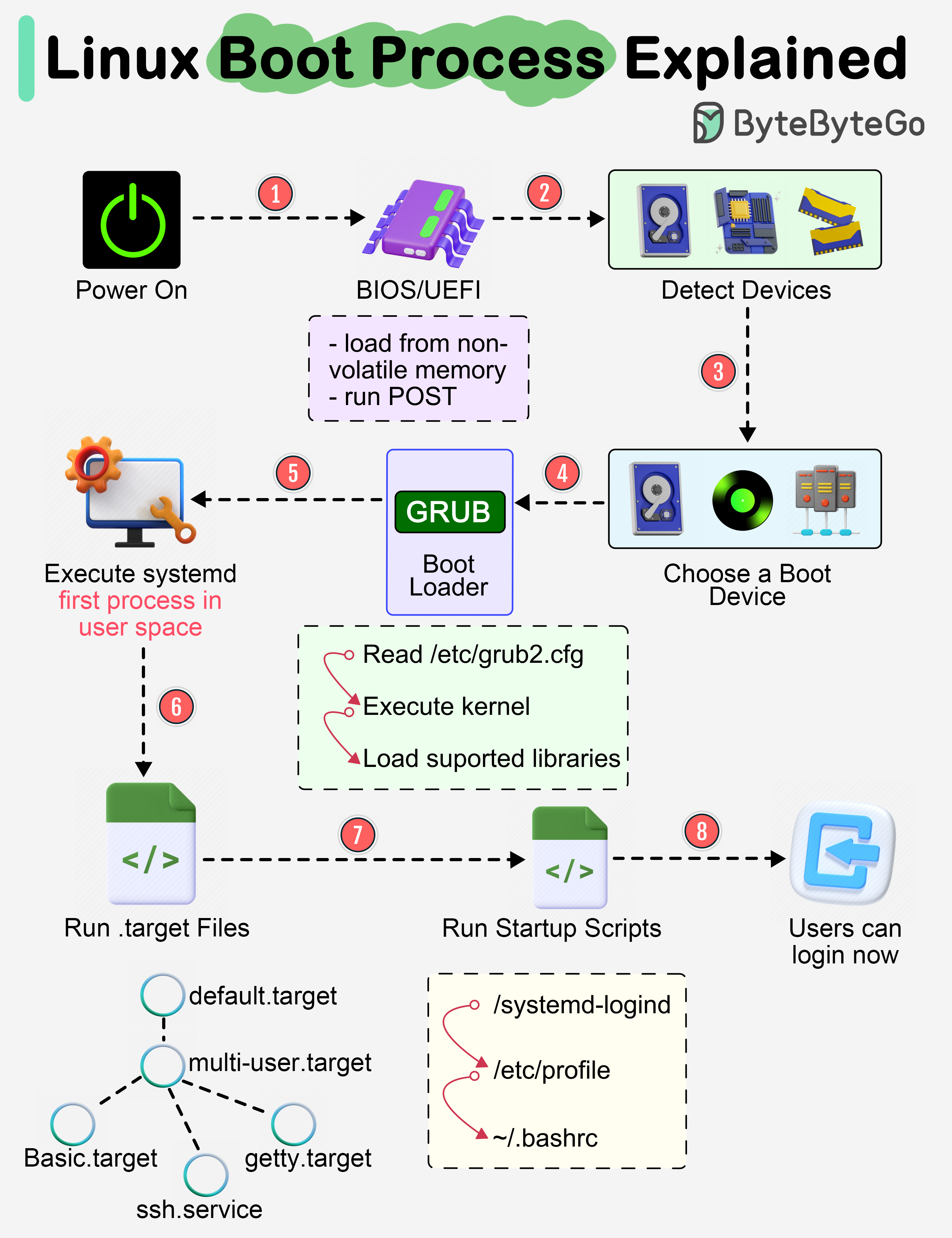
+
+Almost every software engineer has used Linux before, but only a handful know how its Boot Process works. Let's dive in.
+
+## Step 1
+
+When we turn on the power, BIOS (Basic Input/Output System) or UEFI (Unified Extensible Firmware Interface) firmware is loaded from non-volatile memory and executes POST (Power On Self Test).
+
+## Step 2
+
+BIOS/UEFI detects the devices connected to the system, including CPU, RAM, and storage.
+
+## Step 3
+
+Choose a booting device to boot the OS from. This can be the hard drive, the network server, or CD ROM.
+
+## Step 4
+
+BIOS/UEFI runs the boot loader (GRUB), which provides a menu to choose the OS or the kernel functions.
+
+## Step 5
+
+After the kernel is ready, we now switch to the user space. The kernel starts up systemd as the first user-space process, which manages the processes and services, probes all remaining hardware, mounts filesystems, and runs a desktop environment.
+
+## Step 6
+
+systemd activates the default. target unit by default when the system boots. Other analysis units are executed as well.
+
+## Step 7
+
+The system runs a set of startup scripts and configure the environment.
+
+## Step 8
+
+The users are presented with a login window. The system is now ready.
diff --git a/data/guides/linux-file-permission-illustrated.md b/data/guides/linux-file-permission-illustrated.md
new file mode 100644
index 0000000..85bd847
--- /dev/null
+++ b/data/guides/linux-file-permission-illustrated.md
@@ -0,0 +1,34 @@
+---
+title: "Linux File Permissions Illustrated"
+description: "Understand Linux file permissions: owner, group, and others."
+image: "https://assets.bytebytego.com/diagrams/0259-linux-permissions-copy.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Linux"
+ - "File Management"
+---
+
+
+
+## Ownership
+
+Every file or directory is assigned 3 types of owner:
+
+* **Owner**: the owner is the user who created the file or directory.
+
+* **Group**: a group can have multiple users. All users in the group have the same permissions to access the file or directory.
+
+* **Other**: other means those users who are not owners or members of the group.
+
+## Permission
+
+There are only three types of permissions for a file or directory.
+
+* **Read (r)**: the read permission allows the user to read a file.
+
+* **Write (w)**: the write permission allows the user to change the content of the file.
+
+* **Execute (x)**: the execute permission allows a file to be executed.
diff --git a/data/guides/linux-file-system-explained.md b/data/guides/linux-file-system-explained.md
new file mode 100644
index 0000000..37a0e75
--- /dev/null
+++ b/data/guides/linux-file-system-explained.md
@@ -0,0 +1,20 @@
+---
+title: "Linux File System Explained"
+description: "Understanding the Linux file system hierarchy and its importance."
+image: "https://assets.bytebytego.com/diagrams/0258-linux-file-system-explained.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Linux"
+ - "Filesystem"
+---
+
+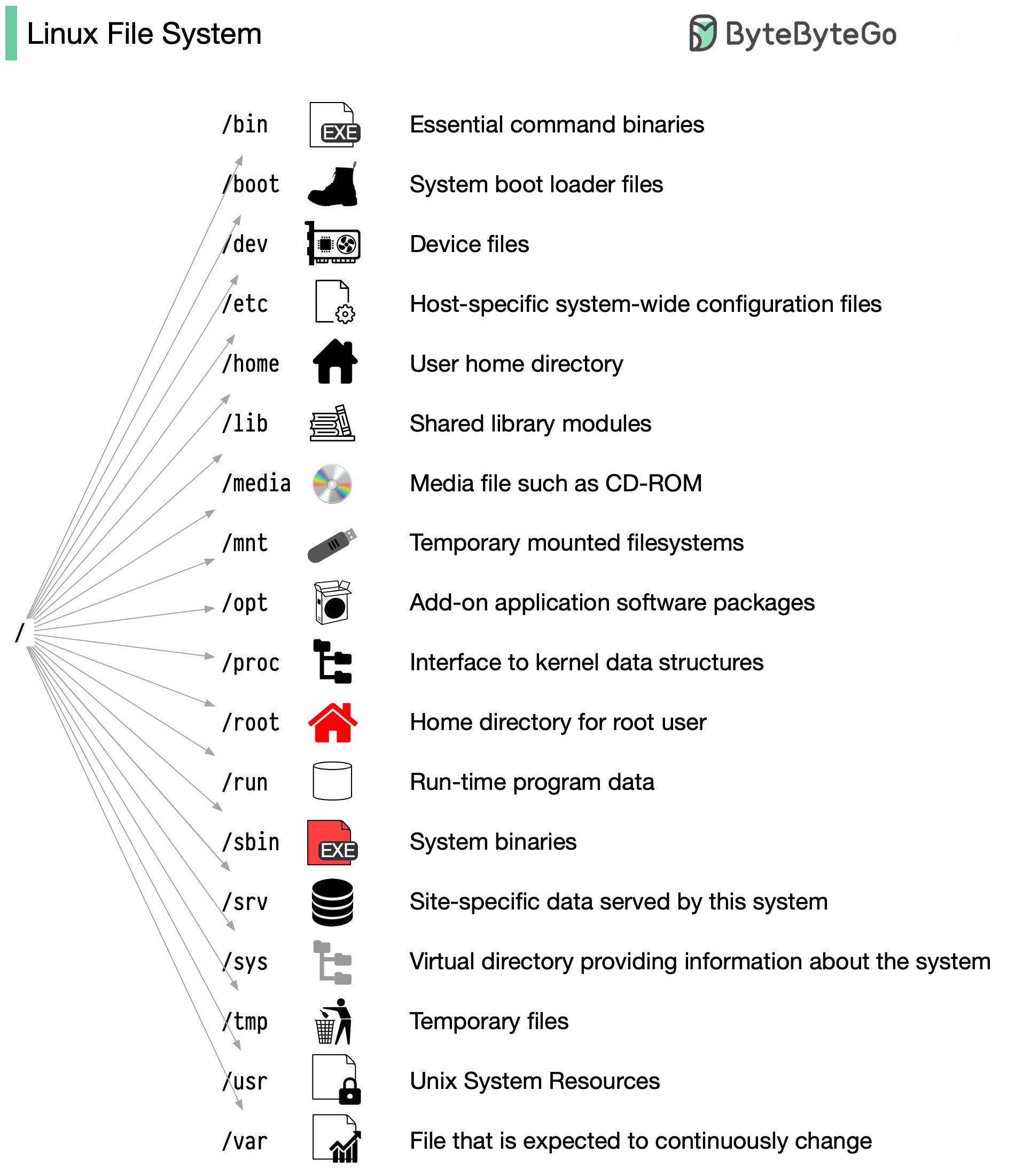
+
+The Linux file system used to resemble an unorganized town where individuals constructed their houses wherever they pleased. However, in 1994, the Filesystem Hierarchy Standard (FHS) was introduced to bring order to the Linux file system.
+
+By implementing a standard like the FHS, software can ensure a consistent layout across various Linux distributions. Nonetheless, not all Linux distributions strictly adhere to this standard. They often incorporate their own unique elements or cater to specific requirements.
+
+To become proficient in this standard, you can begin by exploring. Utilize commands such as "cd" for navigation and "ls" for listing directory contents. Imagine the file system as a tree, starting from the root (/). With time, it will become second nature to you, transforming you into a skilled Linux administrator.
diff --git a/data/guides/live-streaming-explained.md b/data/guides/live-streaming-explained.md
new file mode 100644
index 0000000..711925f
--- /dev/null
+++ b/data/guides/live-streaming-explained.md
@@ -0,0 +1,46 @@
+---
+title: "Live Streaming Explained"
+description: "Learn how live streaming works on platforms like YouTube and Twitch."
+image: "https://assets.bytebytego.com/diagrams/0260-live-streaming-updated.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Live Streaming"
+ - "Video Streaming"
+---
+
+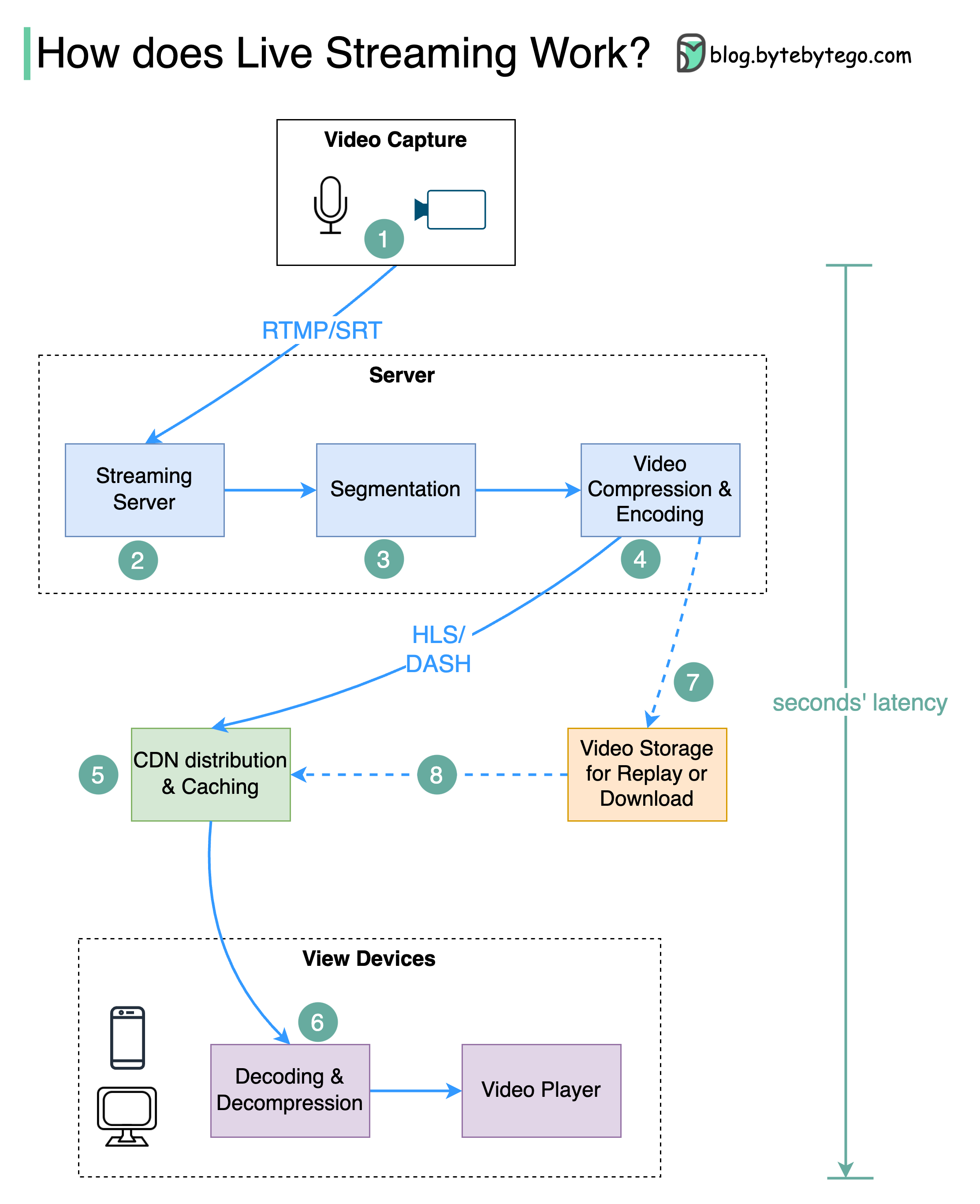
+
+How do video live streamings work on YouTube, TikTok live, or Twitch? The technique is called live streaming.
+
+Livestreaming differs from regular streaming because the video content is sent via the internet in real-time, usually with a latency of just a few seconds.
+
+The diagram below explains what happens behind the scenes to make this possible.
+
+## Live Streaming Steps
+
+**Step 1**: The raw video data is captured by a microphone and camera. The data is sent to the server side.
+
+**Step 2**: The video data is compressed and encoded. For example, the compressing algorithm separates the background and other video elements. After compression, the video is encoded to standards such as H.264. The size of the video data is much smaller after this step.
+
+**Step 3**: The encoded data is divided into smaller segments, usually seconds in length, so it takes much less time to download or stream.
+
+**Step 4**: The segmented data is sent to the streaming server. The streaming server needs to support different devices and network conditions. This is called ‘Adaptive Bitrate Streaming.’ This means we need to produce multiple files at different bitrates in steps 2 and 3.
+
+**Step 5**: The live streaming data is pushed to edge servers supported by CDN (Content Delivery Network.) Millions of viewers can watch the video from an edge server nearby. CDN significantly lowers data transmission latency.
+
+**Step 6**: The viewers’ devices decode and decompress the video data and play the video in a video player.
+
+**Steps 7 and 8**: If the video needs to be stored for replay, the encoded data is sent to a storage server, and viewers can request a replay from it later.
+
+## Standard Protocols for Live Streaming
+
+Standard protocols for live streaming include:
+
+* **RTMP (Real-Time Messaging Protocol)**: This was originally developed by Macromedia to transmit data between a Flash player and a server. Now it is used for streaming video data over the internet. Note that video conferencing applications like Skype use RTC (Real-Time Communication) protocol for lower latency.
+* **HLS (HTTP Live Streaming)**: It requires the H.264 or H.265 encoding. Apple devices accept only HLS format.
+* **DASH (Dynamic Adaptive Streaming over HTTP)**: DASH does not support Apple devices.
+
+Both HLS and DASH support adaptive bitrate streaming.
diff --git a/data/guides/load-balancer-realistic-use-cases-you-may-not-know.md b/data/guides/load-balancer-realistic-use-cases-you-may-not-know.md
new file mode 100644
index 0000000..7c1a3c6
--- /dev/null
+++ b/data/guides/load-balancer-realistic-use-cases-you-may-not-know.md
@@ -0,0 +1,25 @@
+---
+title: 'Load Balancer Realistic Use Cases'
+description: 'Explore load balancer use cases for efficient network traffic management.'
+image: 'https://assets.bytebytego.com/diagrams/0232-http-status-code-shouldnt-exist.png'
+createdAt: '2024-01-26'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Load Balancing
+ - Scalability
+---
+
+Load balancers are inherently dynamic and adaptable, designed to efficiently address multiple purposes and use cases in network traffic and server workload management.
+
+
+
+Let's explore some of the use cases:
+
+* **Failure Handling:** Automatically redirects traffic away from malfunctioning elements to maintain continuous service and reduce service interruptions.
+* **Instance Health Checks:** Continuously evaluates the functionality of instances, directing incoming requests exclusively to those that are fully operational and efficient.
+* **Platform Specific Routing:** Routes requests from different device types (like mobiles, desktops) to specialized backend systems, providing customized responses based on platform.
+* **SSL Termination:** Handles the encryption and decryption of SSL traffic, reducing the processing burden on backend infrastructure.
+* **Cross Zone Load Balancing:** Distributes incoming traffic across various geographic or network zones, increasing the system's resilience and capacity for handling large volumes of requests.
+* **User Stickiness:** Maintains user session integrity and tailored user interactions by consistently directing requests from specific users to designated backend servers.
diff --git a/data/guides/log-parsing-cheat-sheet.md b/data/guides/log-parsing-cheat-sheet.md
new file mode 100644
index 0000000..1822c28
--- /dev/null
+++ b/data/guides/log-parsing-cheat-sheet.md
@@ -0,0 +1,48 @@
+---
+title: "Log Parsing Cheat Sheet"
+description: "A handy guide to log parsing commands for efficient log analysis."
+image: "https://assets.bytebytego.com/diagrams/0263-log-parsing.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Log Analysis"
+ - "Command Line"
+---
+
+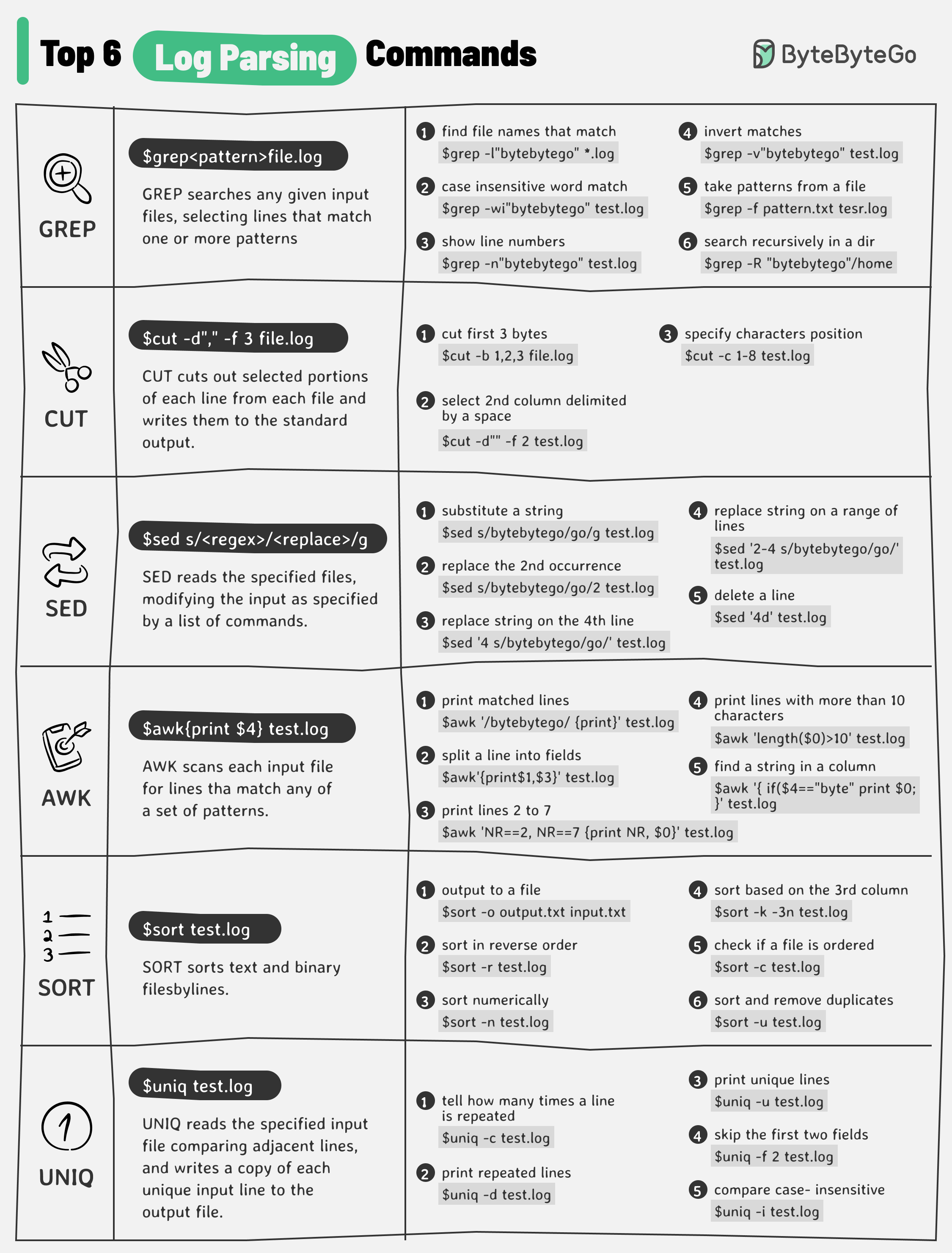
+
+The diagram below lists the top 6 log parsing commands.
+
+## Log Parsing Commands
+
+* **GREP**
+
+ GREP searches any given input files, selecting lines that match one or more patterns.
+
+* **CUT**
+
+ CUT cuts out selected portions of each line from each file and writes them to the standard output.
+
+* **SED**
+
+ SED reads the specified files, modifying the input as specified by a list of commands.
+
+* **AWK**
+
+ AWK scans each input file for lines that match any of a set of patterns.
+
+* **SORT**
+
+ SORT sorts text and binary files by lines.
+
+* **UNIQ**
+
+ UNIQ reads the specified input file comparing adjacent lines and writes a copy of each unique input line to the output file.
+
+These commands are often used in combination to quickly find useful information from the log files. For example, the below commands list the timestamps (column 2) when there is an exception happening for xxService.
+
+```bash
+grep “xxService” service.log | grep “Exception” | cut -d” “ -f 2
+```
diff --git a/data/guides/logging-tracing-metrics.md b/data/guides/logging-tracing-metrics.md
new file mode 100644
index 0000000..acb7749
--- /dev/null
+++ b/data/guides/logging-tracing-metrics.md
@@ -0,0 +1,28 @@
+---
+title: "Logging, Tracing, and Metrics"
+description: "Understand logging, tracing, and metrics for system observability."
+image: "https://assets.bytebytego.com/diagrams/0264-logging-tracing-metrics.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "observability"
+ - "monitoring"
+---
+
+Logging, tracing, and metrics are 3 pillars of system observability. The diagram below shows their definitions and typical architectures.
+
+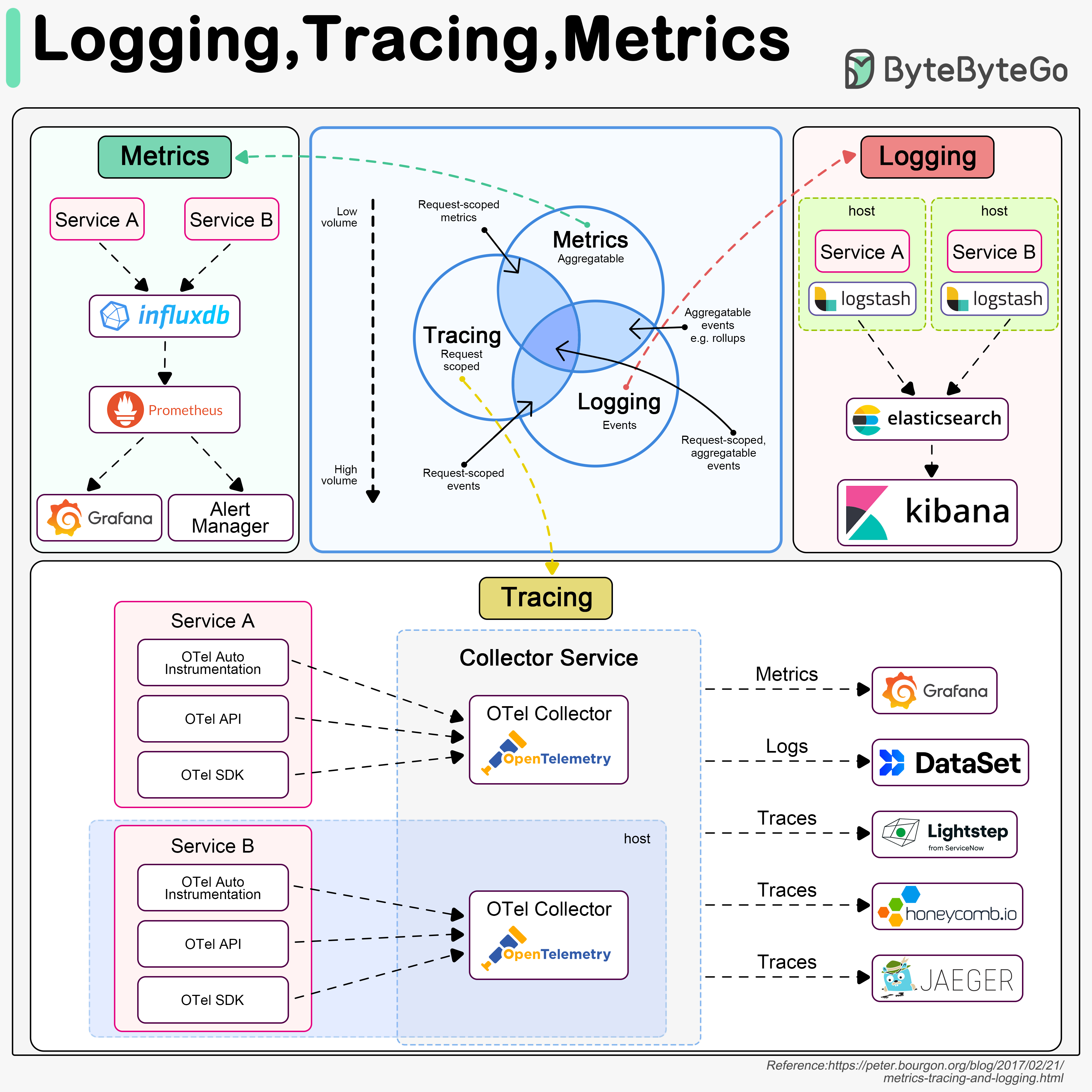
+
+## Logging
+
+Logging records discrete events in the system. For example, we can record an incoming request or a visit to databases as events. It has the highest volume. ELK (Elastic-Logstash-Kibana) stack is often used to build a log analysis platform. We often define a standardized logging format for different teams to implement, so that we can leverage keywords when searching among massive amounts of logs.
+
+## Tracing
+
+Tracing is usually request-scoped. For example, a user request goes through the API gateway, load balancer, service A, service B, and database, which can be visualized in the tracing systems. This is useful when we are trying to identify the bottlenecks in the system. We use OpenTelemetry to showcase the typical architecture, which unifies the 3 pillars in a single framework.
+
+## Metrics
+
+Metrics are usually aggregatable information from the system. For example, service QPS, API responsiveness, service latency, etc. The raw data is recorded in time-series databases like InfluxDB. Prometheus pulls the data and transforms the data based on pre-defined alerting rules. Then the data is sent to Grafana for display or to the alert manager which then sends out email, SMS, or Slack notifications or alerts.
diff --git a/data/guides/low-latency-stock-exchange.md b/data/guides/low-latency-stock-exchange.md
new file mode 100644
index 0000000..ed3d229
--- /dev/null
+++ b/data/guides/low-latency-stock-exchange.md
@@ -0,0 +1,50 @@
+---
+title: "Low Latency Stock Exchange"
+description: "Explore the architecture of a low-latency stock exchange system."
+image: "https://assets.bytebytego.com/diagrams/0265-low-latency-stock-exchange.jpg"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Low Latency"
+ - "Stock Exchange"
+---
+
+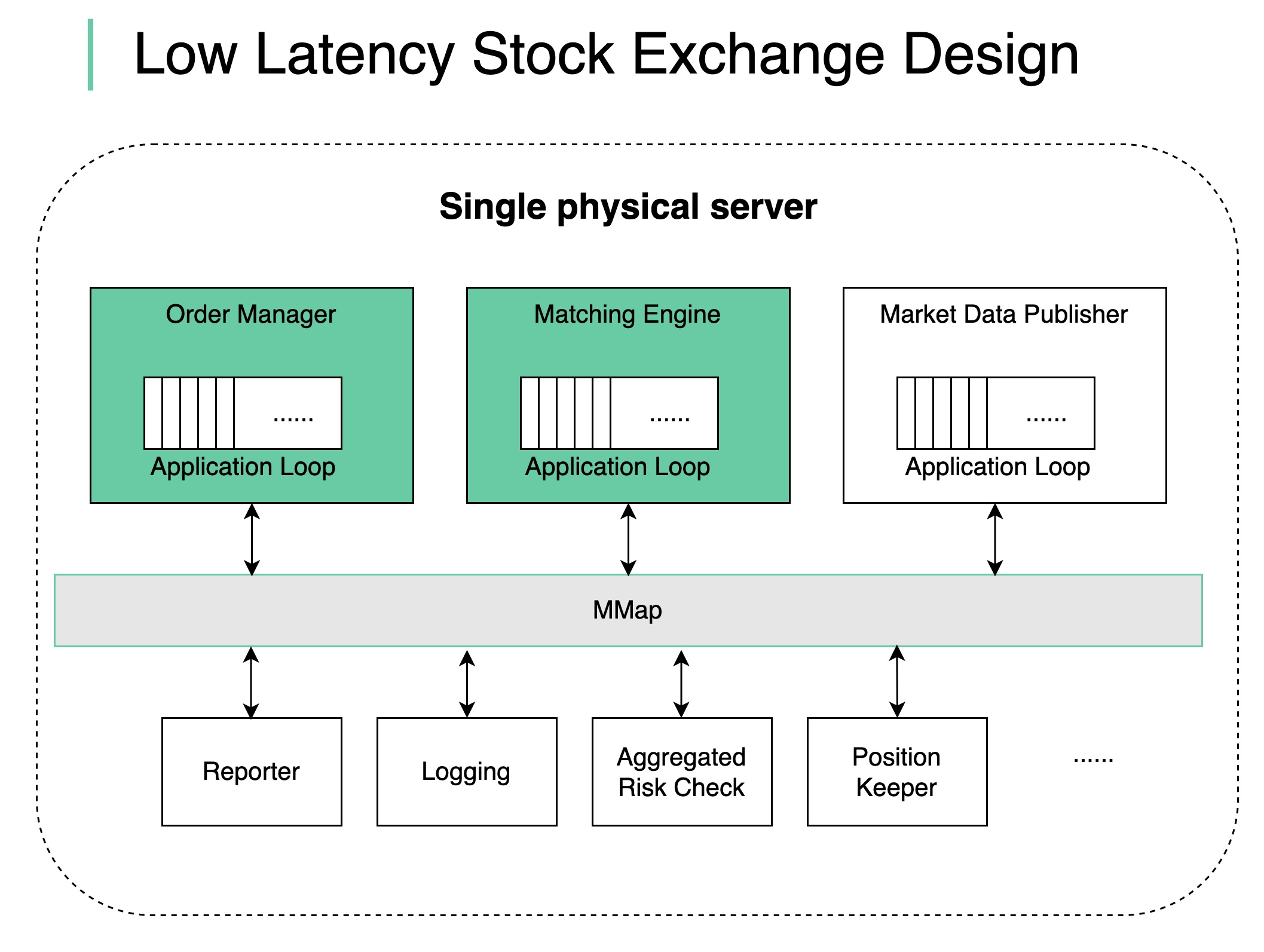
+
+How does a modern stock exchange achieve **microsecond latency**? The principal is:
+
+**Do less on the critical path**
+
+* Fewer tasks on the critical path
+
+* Less time on each task
+
+* Fewer network hops
+
+* Less disk usage
+
+For the stock exchange, the critical path is:
+
+* **start**: an order comes into the order manager
+
+* mandatory risk checks
+
+* the order gets matched and the execution is sent back
+
+* **end**: the execution comes out of the order manager
+
+Other non-critical tasks should be removed from the critical path.
+
+We put together a design as shown in the diagram:
+
+* deploy all the components in a single giant server (no containers)
+
+* use shared memory as an event bus to communicate among the components, no hard disk
+
+* key components like Order Manager and Matching Engine are single-threaded on the critical path, and each pinned to a CPU so that there is **no context switch** and **no locks**
+
+* the single-threaded application loop executes tasks one by one in sequence
+
+* other components listen on the event bus and react accordingly
diff --git a/data/guides/making-sense-of-search-engine-optimization.md b/data/guides/making-sense-of-search-engine-optimization.md
new file mode 100644
index 0000000..5b5dfba
--- /dev/null
+++ b/data/guides/making-sense-of-search-engine-optimization.md
@@ -0,0 +1,54 @@
+---
+title: "Making Sense of Search Engine Optimization"
+description: "Understand how search engines rank websites and optimize your website."
+image: "https://assets.bytebytego.com/diagrams/0326-seo.jpg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "SEO"
+ - "Web Development"
+---
+
+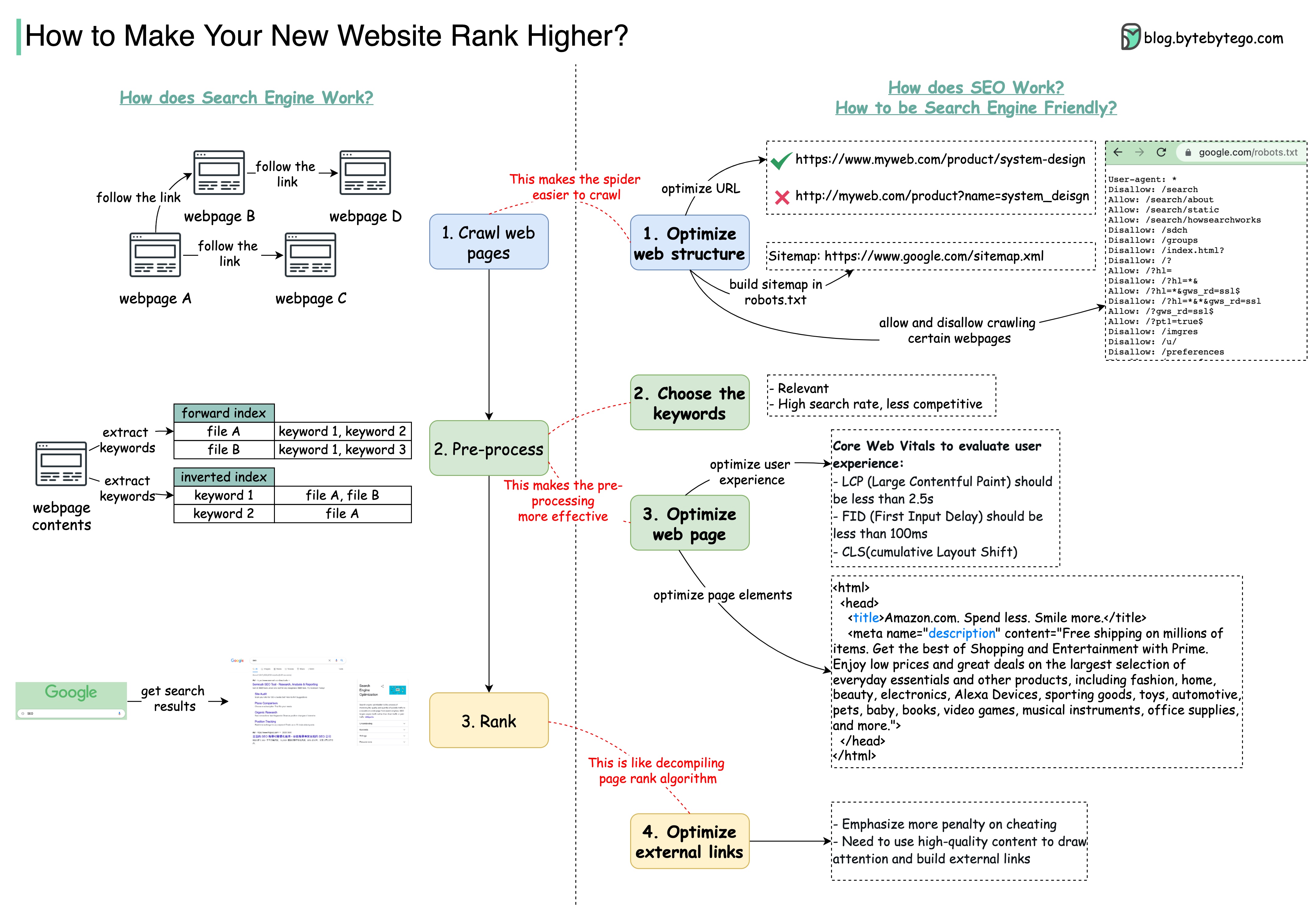
+
+You have just developed a new website. What does it take to be ranked at the top?
+
+We need to understand how search engines rank websites and optimize our website to be search engine-friendly. This is called SEO (Search Engine Optimization).
+
+A search engine works in 3 stages:
+
+* The crawler reads the page content (HTML code) and follows the hyperlink to read more web pages.
+
+* The preprocessor also works in 3 steps:
+
+ * It removes HTML tags and ‘Stop’ words, which are words like ‘a’ or ‘an’ or ‘the.’ It also removes other noise that is not relevant to the web page's content, for example, the disclaimer.
+
+ * Then the keywords form structured indices, called forward indices and inverted indices.
+
+ * The preprocessor calculates the hyperlink relationships, for example, how many hyperlinks are on the web page and how many hyperlinks point to it.
+
+* When a user types in a search term, the search engine uses the indices and ranking algorithms to rank the web pages and presents the search results to the user.
+
+How do we make our website rank higher in search results? The diagram below shows some ways to do this.
+
+## Optimize website structure:
+
+We need to make it easier for the crawler to crawl our website. Remove anything the crawler cannot read, including flash, frames, and dynamic URLs. Make the website hierarchy less deep, so the web pages are less distant from the main home page.
+
+The URLs must be short and descriptive. Try to include keywords in the URLs, as well. It will also help to use HTTPS. But don’t use underscore in the URL because that will screw up the tokenization.
+
+## Choose the keywords to optimize for:
+
+Keywords must be relevant to what the website is selling, and they must have business values. For example, a keyword is considered valuable if it’s a popular search, but has fewer search results.
+
+## Optimize the web page
+
+The crawler crawls the HTML contents. Therefore the title and description should be optimized to include keywords and be concise. The body of the web page should include relevant keywords.
+
+Another aspect is the user experience. In May 2020, Google published Core Web Vitals, officially listing user experience as an important factor of page ranking algorithms.
+
+## External link
+
+If our website is referenced by a highly-ranked website, it will increase our website’s ranking. So carefully building external links is important. Publishing high-quality content on your website which is useful to other users, is a good way to attract external links.
diff --git a/data/guides/mcdonald's-event-driven-architecture.md b/data/guides/mcdonald's-event-driven-architecture.md
new file mode 100644
index 0000000..01c92e9
--- /dev/null
+++ b/data/guides/mcdonald's-event-driven-architecture.md
@@ -0,0 +1,27 @@
+---
+title: 'McDonald’s Event-Driven Architecture'
+description: 'Explore McDonald’s event-driven architecture for scalability and efficiency.'
+image: 'https://assets.bytebytego.com/diagrams/0266-mcdonald-s-event-driven-architecture.png'
+createdAt: '2024-02-18'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Event-Driven Architecture
+ - Case Study
+---
+
+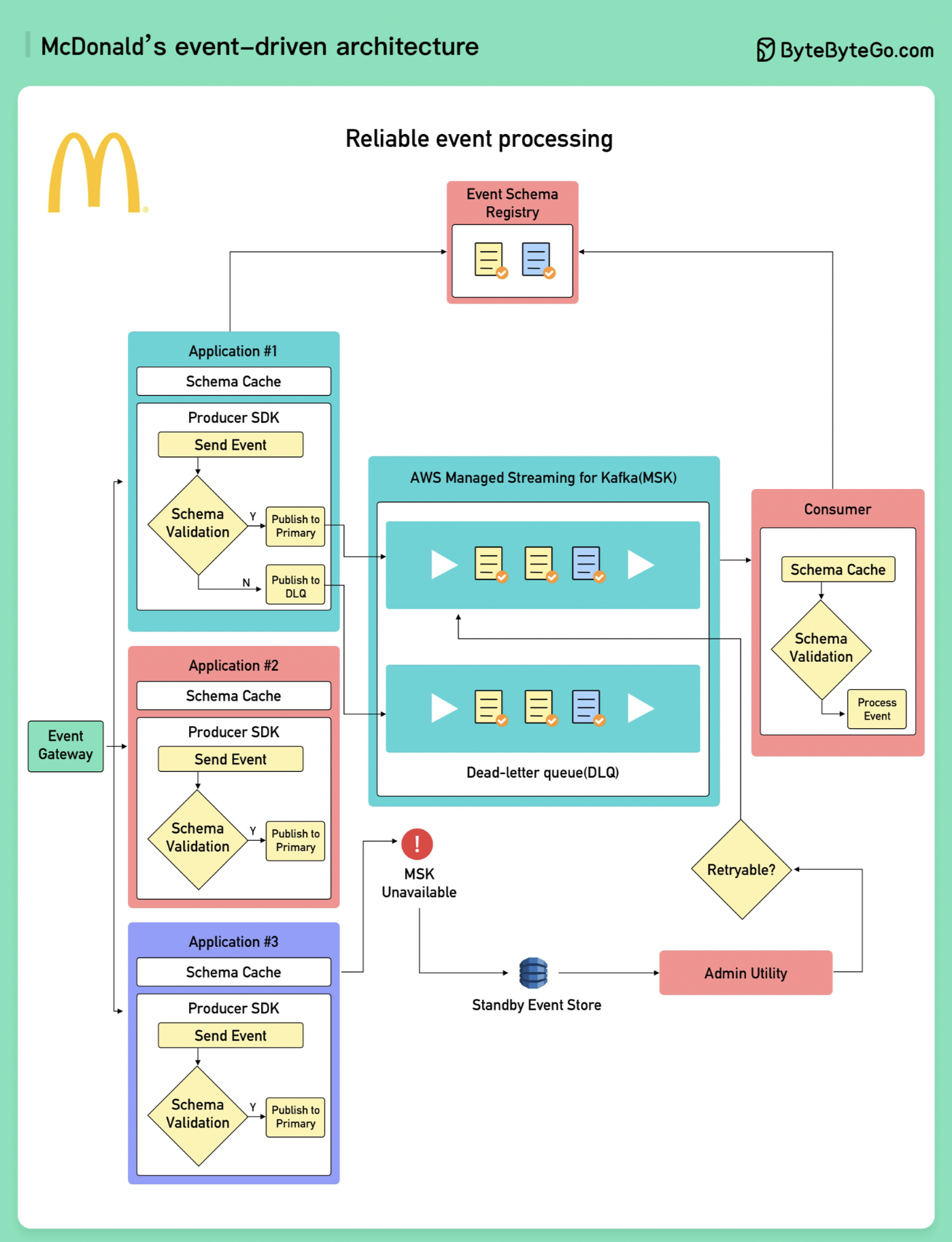
+
+Think you know everything about McDonald's? What about its event-driven architecture?
+
+McDonald's standardizes events using the following components:
+
+* **Event Registry:** An event registry to define a standardized schema.
+* **Custom SDKs:** Custom software development kits (SDKs) to process events and handle errors.
+* **Event Gateway:** An event gateway that performs identity authentication and authorization.
+* **Utilities and Tools:** Utilities and tools to fix events, keep the cluster healthy, and perform administrative tasks.
+
+To scale event processing, McDonald uses a regional architecture that provides global availability based on AWS. Within a region, producers shard events by domains, and each domain is processed by an MSK cluster. The cluster auto-scales based on MSK metrics (e.g., CPU usage), and the auto-scale workflow is based on step-functions and re-assignment tasks.
+
+Reference: Behind the scenes: [McDonald’s event-driven architecture](https://medium.com/mcdonalds-technical-blog/behind-the-scenes-mcdonalds-event-driven-architecture-51a6542c0d86)
diff --git a/data/guides/memcached-vs-redis.md b/data/guides/memcached-vs-redis.md
new file mode 100644
index 0000000..cedcae4
--- /dev/null
+++ b/data/guides/memcached-vs-redis.md
@@ -0,0 +1,26 @@
+---
+title: "Memcached vs Redis"
+description: "Explore the key differences between Memcached and Redis for caching."
+image: "https://assets.bytebytego.com/diagrams/0267-memcached-redis.jpg"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "memcached"
+ - "redis"
+---
+
+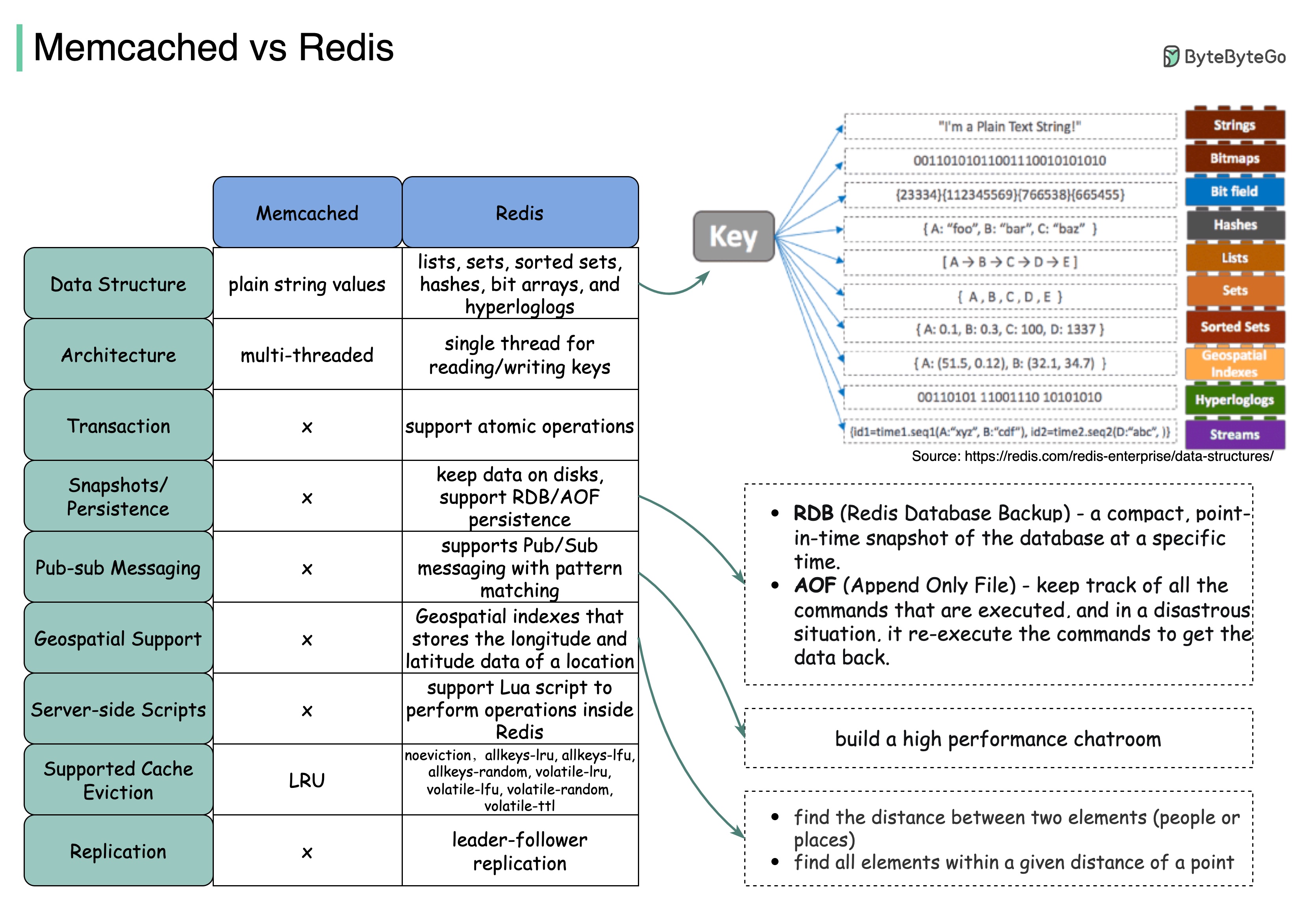
+
+Popular interview question - what are the differences between Redis and Memcached?
+
+The diagram above illustrates the key differences. The advantages of data structures make Redis a good choice for:
+
+* Recording the number of clicks and comments for each post (hash)
+
+* Sorting the commented user list and deduping the users (zset)
+
+* Caching user behavior history and filtering malicious behaviors (zset, hash)
+
+* Storing boolean information of extremely large data into small space. For example, login status, membership status. (bitmap)
diff --git a/data/guides/money-movement.md b/data/guides/money-movement.md
new file mode 100644
index 0000000..32dd5b5
--- /dev/null
+++ b/data/guides/money-movement.md
@@ -0,0 +1,58 @@
+---
+title: "Money Movement"
+description: "Understanding the flow of money during online transactions."
+image: "https://assets.bytebytego.com/diagrams/0127-buy-something-money-movement.jpg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Fintech"
+---
+
+One picture is worth more than a thousand words. This is what happens when you buy a product using Paypal/bank card under the hood.
+
+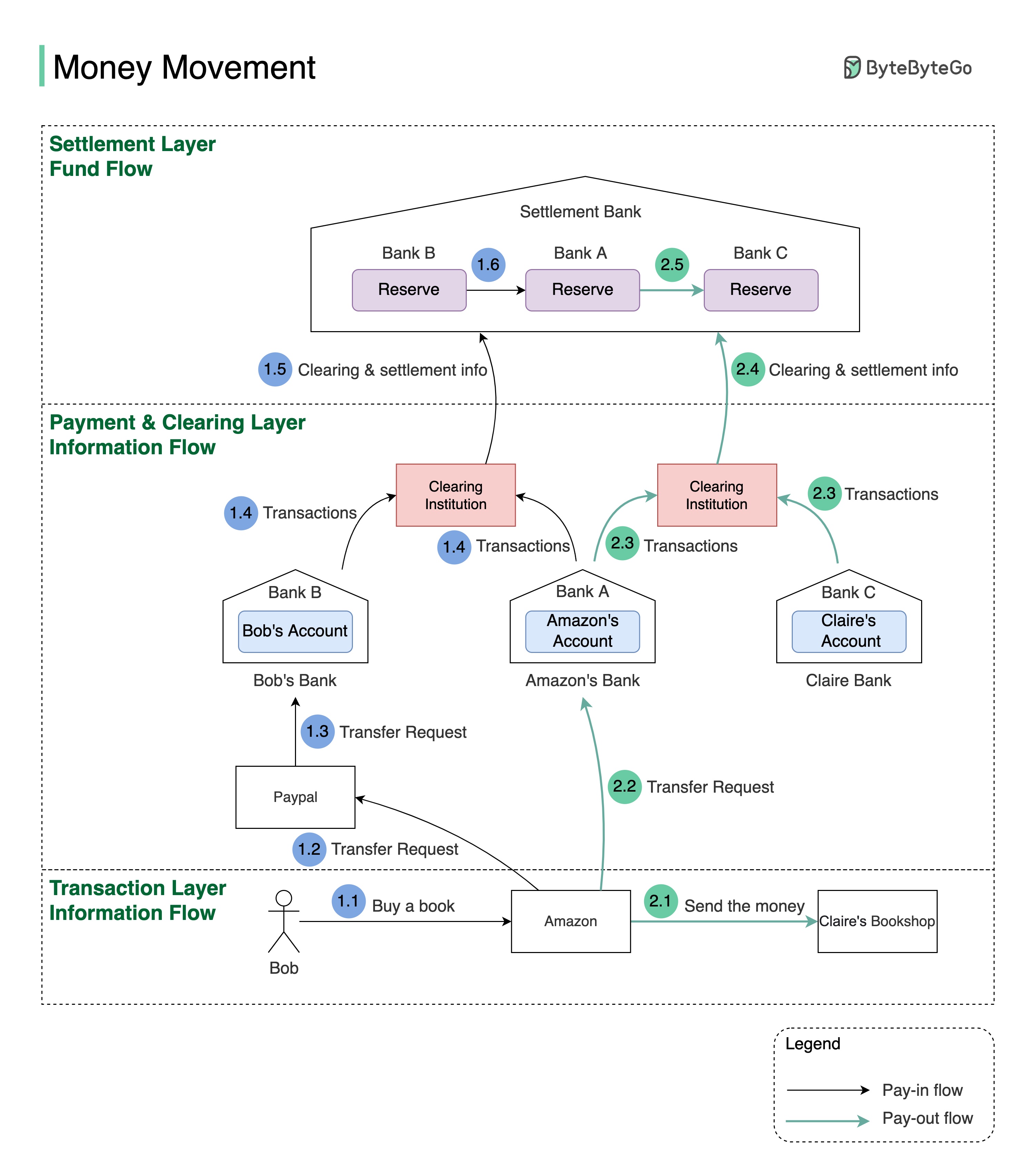
+
+To understand this, we need to digest two concepts: **clearing & settlement**. Clearing is a process that calculates who should pay whom with how much money; while settlement is a process where real money moves between reserves in the settlement bank.
+
+Let’s say Bob wants to buy an SDI book from Claire’s shop on Amazon.
+
+### Pay-in flow (Bob pays Amazon money):
+
+* Bob buys a book on Amazon using Paypal.
+
+* Amazon issues a money transfer request to Paypal.
+
+* Since the payment token of Bob’s debit card is stored in Paypal, Paypal can transfer money, on Bob’s behalf, to Amazon’s bank account in Bank A.
+
+* Both Bank A and Bank B send transaction statements to the clearing institution. It reduces the transactions that need to be settled. Let’s assume Bank A owes Bank B $100 and Bank B owes bank A $500 at the end of the day. When they settle, the net position is that Bank B pays Bank A $400.
+
+* 1. 5 & 1.6 The clearing institution sends clearing and settlement information to the settlement bank. Both Bank A and Bank B have pre-deposited funds in the settlement bank as money reserves, so actual money movement happens between two reserve accounts in the settlement bank.
+
+### Pay-out flow (Amazon pays the money to the seller: Claire):
+
+* Amazon informs the seller (Claire) that she will get paid soon.
+
+* Amazon issues a money transfer request from its owe bank (Bank A) to the seller bank (bank C). Here both banks record the transactions, but no real money is moved.
+
+* Both Bank A and Bank C send transaction statements to the clearing institution.
+
+* 2. 4 & 2.5 The clearing institution sends clearing and settlement information to the settlement bank. Money is transferred from Bank A’s reserve to Bank C’s reserve.
+
+Notice that we have three layers:
+
+* Transaction layer: where the online purchases happen
+
+* Payment and clearing layer: where the payment instructions and transaction netting happen
+
+* Settlement layer: where the actual money movement happen
+
+The first two layers are called information flow, and the settlement layer is called fund flow.
+
+You can see the **information flow and fund flow are separated**. In the info flow, the money seems to be deducted from one bank account and added to another bank account, but the actual money movement happens in the settlement bank at the end of the day.
+
+Because of the asynchronous nature of the info flow and the fund flow, reconciliation is very important for data consistency in the systems along with the flow.
+
+It makes things even more interesting when Bob wants to buy a book in the Indian market, where Bob pays USD but the seller can only receive INR.
diff --git a/data/guides/monorepo-vs.md b/data/guides/monorepo-vs.md
new file mode 100644
index 0000000..1d52b68
--- /dev/null
+++ b/data/guides/monorepo-vs.md
@@ -0,0 +1,40 @@
+---
+title: "Monorepo vs. Microrepo: Which is Best?"
+description: "Explore the monorepo vs. microrepo approach to code management."
+image: "https://assets.bytebytego.com/diagrams/0279-monorepo-microrepo.png"
+createdAt: "2024-02-12"
+draft: false
+categories:
+ - "cloud-distributed-systems"
+tags:
+ - "Monorepo"
+ - "Microservices"
+---
+
+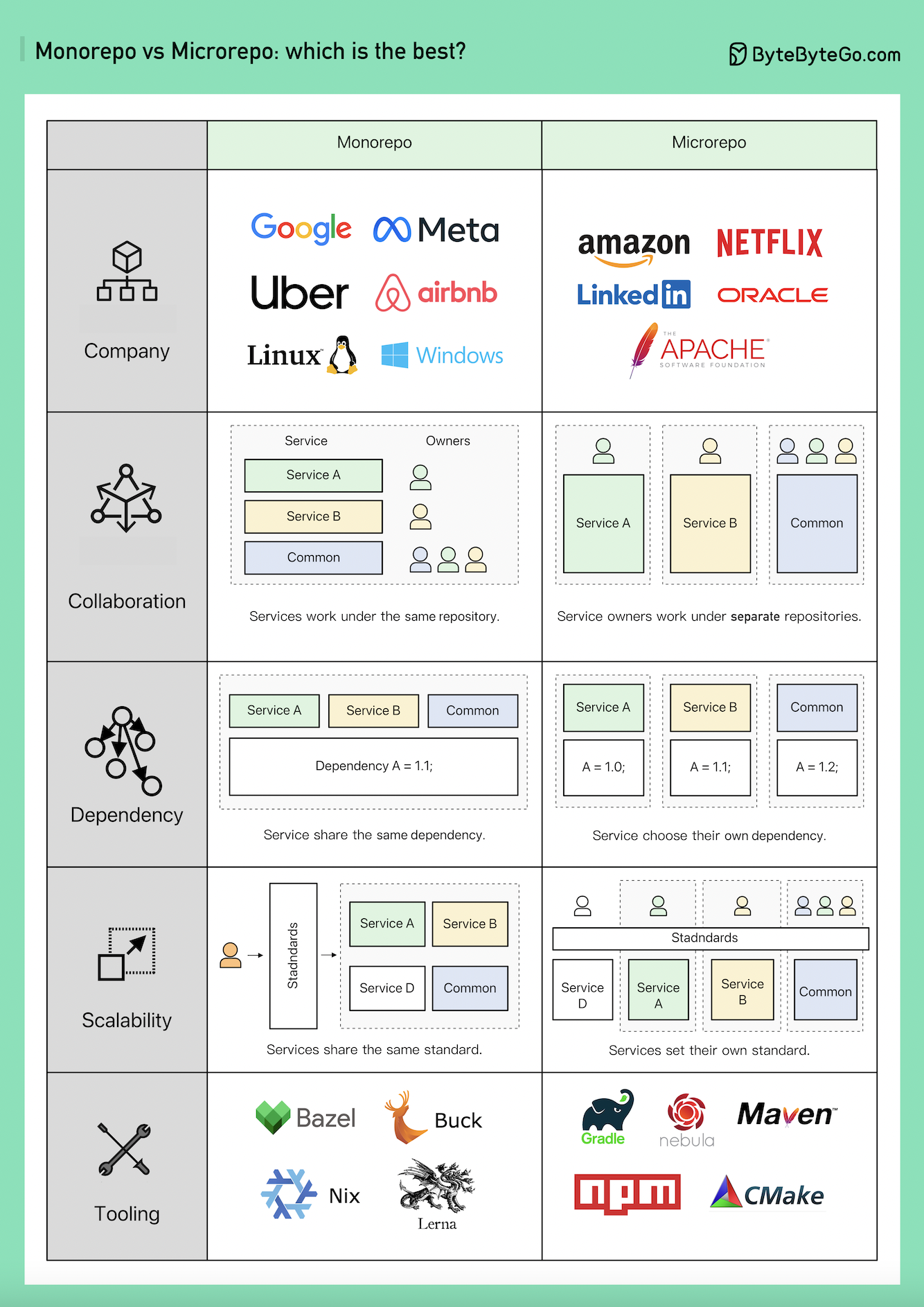
+
+Why do different companies choose different options?
+
+## Do you believe that Google, Meta, Uber, and Airbnb put almost all of their code in one repository?
+
+This practice is called a monorepo. Guest post by [Xiong Wang](https://www.linkedin.com/in/wangxiong/).
+
+Monorepo isn't new; Linux and Windows were both created using Monorepo. To improve scalability and build speed, Google developed its internal dedicated toolchain to scale it faster and strict coding quality standards to keep it consistent.
+
+Amazon and Netflix are major ambassadors of the Microservice philosophy. This approach naturally separates the service code into separate repositories. It scales faster but can lead to governance pain points later on.
+
+Within Monorepo, each service is a folder, and every folder has a BUILD config and OWNERS permission control. Every service member is responsible for their own folder.
+
+On the other hand, in Microrepo, each service is responsible for its repository, with the build config and permissions typically set for the entire repository.
+
+In Monorepo, dependencies are shared across the entire codebase regardless of your business, so when there's a version upgrade, every codebase upgrades their version.
+
+In Microrepo, dependencies are controlled within each repository. Businesses choose when to upgrade their versions based on their own schedules.
+
+Monorepo has a standard for check-ins. Google's code review process is famously known for setting a high bar, ensuring a coherent quality standard for Monorepo, regardless of the business.
+
+Microrepo can either set their own standard or adopt a shared standard by incorporating best practices. It can scale faster for business, but the code quality might be a bit different.
+
+Google engineers built Bazel, and Meta built Buck. There are other open-source tools available, including Nix, Lerna, and others.
+
+Over the years, Microrepo has had more supported tools, including Maven and Gradle for Java, NPM for NodeJS, and CMake for C/C++, among others.
diff --git a/data/guides/most-popular-cache-eviction.md b/data/guides/most-popular-cache-eviction.md
new file mode 100644
index 0000000..4340ed1
--- /dev/null
+++ b/data/guides/most-popular-cache-eviction.md
@@ -0,0 +1,48 @@
+---
+title: "Cache Eviction Policies"
+description: "Explore popular cache eviction strategies and their impact on performance."
+image: "https://assets.bytebytego.com/diagrams/0281-most-popular-cache-eviction.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Algorithms"
+---
+
+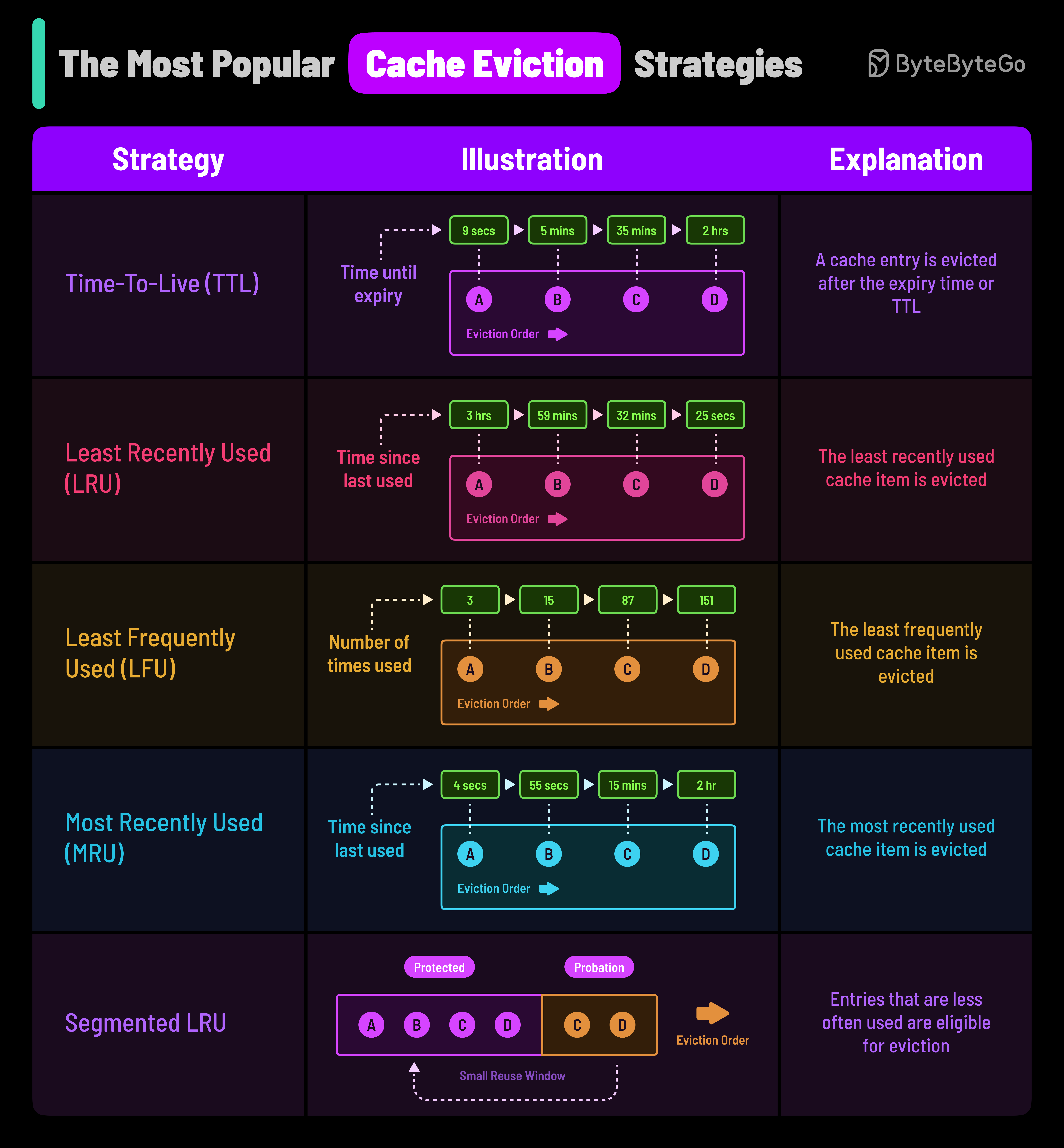
+
+What are the most popular Cache Eviction strategies? And how do they work?
+
+Caching can provide a boost to your application’s performance by storing data in memory for faster access.
+
+But when the cache gets full, you need to evict some data to make room for new stuff.
+
+This is where cache eviction strategies come into play.
+
+The strategy you choose can have a significant impact on your system's performance, memory usage, and hit rates. Here are five popular strategies to consider:
+
+## Time-to-Live (TTL)
+
+Items are evicted after a predetermined time period, regardless of access patterns. It’s simple to implement but can lead to premature eviction of frequently used data. TTL is suitable for data that is only valid for a certain period of time such as session information. It is also used as a default fallback strategy.
+
+## Least-Recently Used (LRU)
+
+Evicts the least recently accessed items first. This strategy works well when access patterns exhibit temporal locality, i.e., recently accessed items are likely to be accessed again soon.
+
+## Least Frequently Used (LFU)
+
+Evicts the least frequently accessed items first. Suitable when some items are accessed more often than others, and you want to keep only the most popular items in the cache. However, you also need a mechanism to maintain a count of the number of times an item is accessed.
+
+## Most Recently Used (MRU)
+
+Evicts the most recently accessed items first. Counterintuitive but useful in specific scenarios like operating system buffer caches, where recently evicted items are unlikely to be needed again soon. Also useful in streaming or batch-processing requirements.
+
+## Segmented LRU (SLRU)
+
+Divides the cache into probationary and protected segments, applying LRU separately to each. Newly added items go into the probationary segment, and frequently accessed items are promoted to the protected segment, shielding them from being evicted too soon.
+
+The best caching strategy depends on the context of your system requirements and constraints. But having a broad understanding of them can help make the right choice.
+
+Over to you: have you used any other cache eviction strategy?
diff --git a/data/guides/most-used-linux-commands-map.md b/data/guides/most-used-linux-commands-map.md
new file mode 100644
index 0000000..1245916
--- /dev/null
+++ b/data/guides/most-used-linux-commands-map.md
@@ -0,0 +1,30 @@
+---
+title: "Most Used Linux Commands Map"
+description: "A concise guide to the most used Linux commands."
+image: "https://assets.bytebytego.com/diagrams/0283-most-used-linux.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "linux"
+ - "commands"
+---
+
+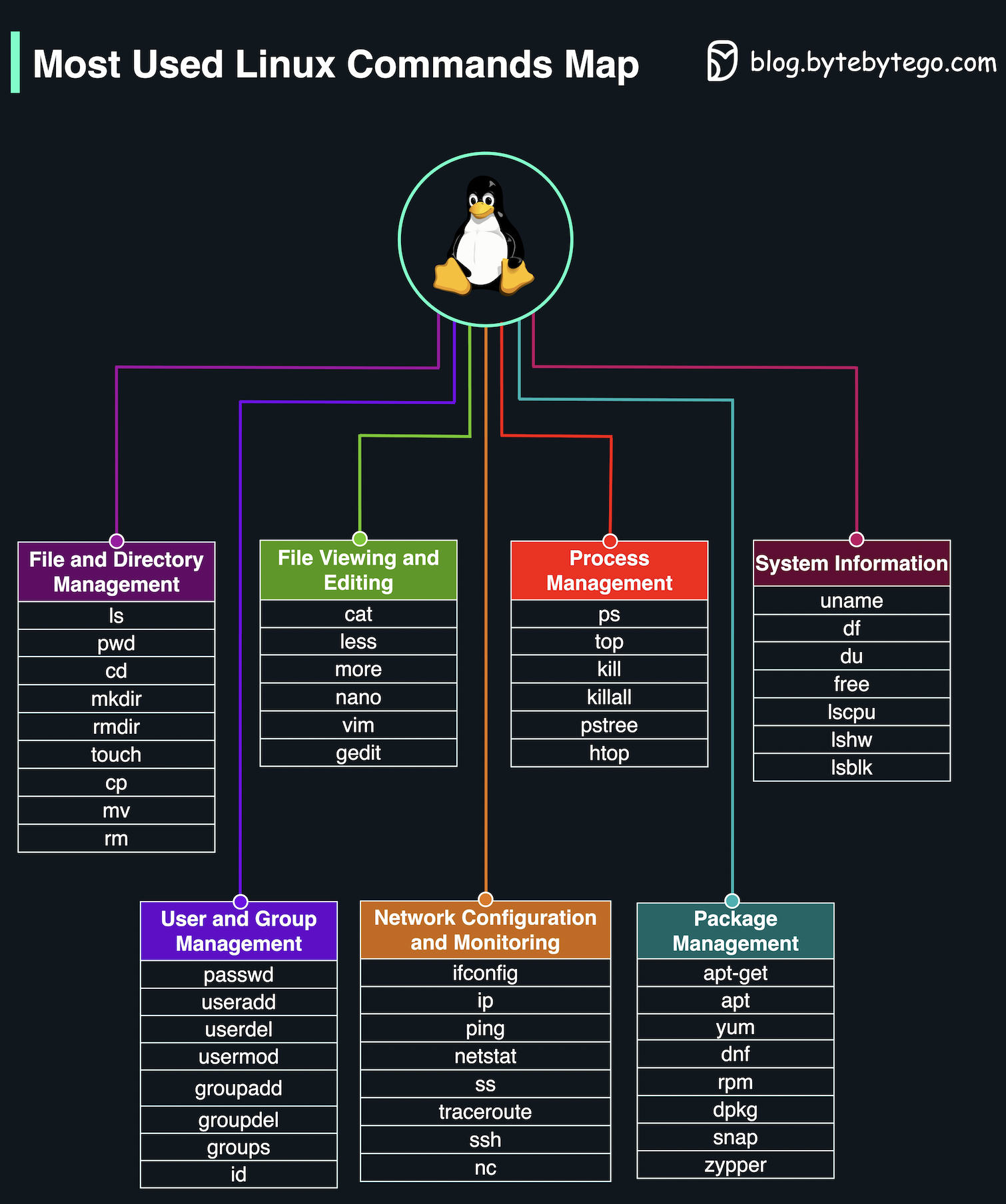
+
+This map provides a concise overview of the most commonly used Linux commands, categorized by their primary function.
+
+## File and Directory Management
+
+## File Viewing and Editing
+
+## Process Management
+
+## System Information
+
+## User and Group Management
+
+## Network Configuration and Monitoring
+
+## Package Management
diff --git a/data/guides/must-know-system-design-building-blocks.md b/data/guides/must-know-system-design-building-blocks.md
new file mode 100644
index 0000000..9983706
--- /dev/null
+++ b/data/guides/must-know-system-design-building-blocks.md
@@ -0,0 +1,58 @@
+---
+title: "Must Know System Design Building Blocks"
+description: "Essential system design components for building scalable applications."
+image: "https://assets.bytebytego.com/diagrams/0285-must-know-system-design-building-blocks.png"
+createdAt: "2024-02-11"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "scalability"
+---
+
+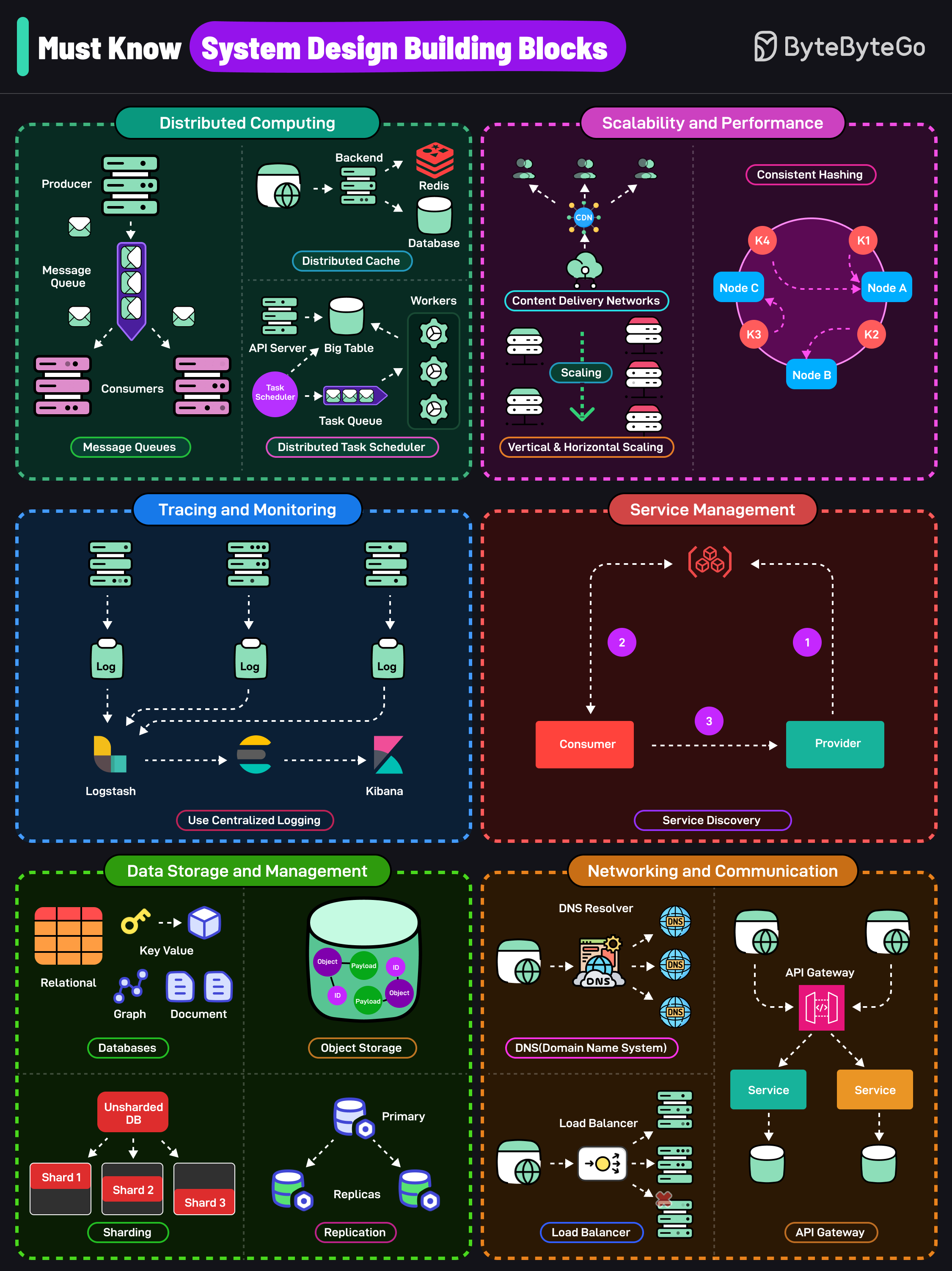
+
+These are divided into 6 broad categories
+
+## Distributed Computing
+
+* Distributed message queues facilitate async communication and decouple services
+
+* Distributed caching improves performance by storing frequently accessed data in memory
+
+* A Distributed task scheduler manages and coordinates the execution of tasks
+
+## Scalability and Performance
+
+* Scaling services help adjust the capacity of services to handle changes in demand
+
+* CDNs serve content from geographically closer locations to improve performance and reduce latency.
+
+* Consistent hashing minimizes the remapping of keys when nodes are added or removed
+
+## Service Management
+
+* Service discovery enables services to find and communicate with each other without hard-coding network locations
+
+## Networking and Communication
+
+* DNS translates human-readable domain names into IP addresses
+
+* Load Balancer distributes incoming network traffic across multiple servers
+
+* API Gateway acts as a single entry point for a group of microservices
+
+## Data Storage and Management
+
+* Databases store and manage structured data
+
+* Object storage helps store complex objects like images, videos, and documents
+
+* Sharding helps horizontally partition data across multiple nodes
+
+* Replication helps horizontally scale the database by copying data to multiple nodes
+
+## Observability and Resiliency
+
+Gain insights into the system's internal state through metrics, logging, and tracing.
diff --git a/data/guides/mvc-mvp-mvvm-viper-patterns.md b/data/guides/mvc-mvp-mvvm-viper-patterns.md
new file mode 100644
index 0000000..634f337
--- /dev/null
+++ b/data/guides/mvc-mvp-mvvm-viper-patterns.md
@@ -0,0 +1,28 @@
+---
+title: "MVC, MVP, MVVM, VIPER Patterns"
+description: "Comparing MVC, MVP, MVVM, and VIPER architectural patterns."
+image: "https://assets.bytebytego.com/diagrams/0143-client-arch-patterns.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "architectural patterns"
+ - "software design"
+---
+
+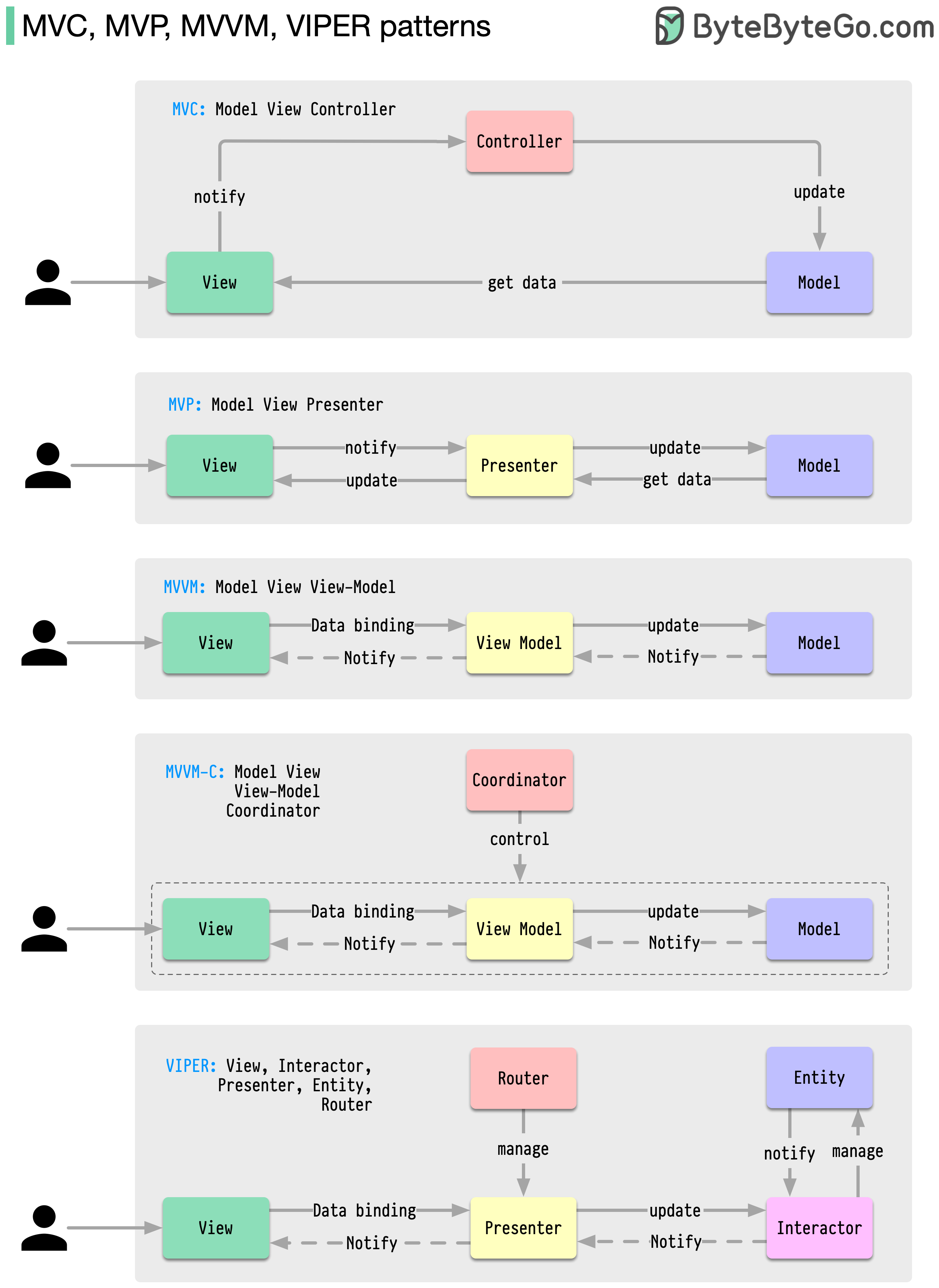
+
+What distinguishes MVC, MVP, MVVM, MVVM-C, and VIPER architecture patterns from each other?
+
+These architecture patterns are among the most commonly used in app development, whether on iOS or Android platforms. Developers have introduced them to overcome the limitations of earlier patterns. So, how do they differ?
+
+* MVC, the oldest pattern, dates back almost 50 years
+
+* Every pattern has a "view" (V) responsible for displaying content and receiving user input
+
+* Most patterns include a "model" (M) to manage business data
+
+* "Controller," "presenter," and "view-model" are translators that mediate between the view and the model ("entity" in the VIPER pattern)
+
+* These translators can be quite complex to write, so various patterns have been proposed to make them more maintainable
diff --git a/data/guides/my-recommended-materials-for-cracking-your-next-technical-interview.md b/data/guides/my-recommended-materials-for-cracking-your-next-technical-interview.md
new file mode 100644
index 0000000..7066b04
--- /dev/null
+++ b/data/guides/my-recommended-materials-for-cracking-your-next-technical-interview.md
@@ -0,0 +1,50 @@
+---
+title: "Recommended Materials for Technical Interviews"
+description: "Ace your technical interviews with these recommended resources."
+image: "https://assets.bytebytego.com/diagrams/0353-my-recommended-materials-for-cracking-your-next-technical-interview.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "interview preparation"
+ - "system design"
+---
+
+
+
+## Coding
+
+* Leetcode
+* Cracking the coding interview book
+* Neetcode
+
+## System Design Interview
+
+* System Design Interview Book 1, 2 by Alex Xu, Sahn Lam
+* Grokking the system design by Design Guru
+* Design Data-intensive Application book
+
+## Behavioral interview
+
+* Tech Interview Handbook (Github repo)
+* A Life Engineered (YT)
+* STAR method (general method)
+
+## OOD Interview
+
+* Interviewready
+* OOD by educative
+* Head First Design Patterns Book
+
+## Mock interviews
+
+* Interviewingio
+* Pramp
+* Meetapro
+
+## Apply for Jobs
+
+* Linkedin
+* Monster
+* Indeed
diff --git a/data/guides/netflix-tech-stack-cicd-pipeline.md b/data/guides/netflix-tech-stack-cicd-pipeline.md
new file mode 100644
index 0000000..e6c6e99
--- /dev/null
+++ b/data/guides/netflix-tech-stack-cicd-pipeline.md
@@ -0,0 +1,31 @@
+---
+title: 'Netflix Tech Stack - CI/CD Pipeline'
+description: "Netflix's CI/CD pipeline: from planning to incident reporting."
+image: 'https://assets.bytebytego.com/diagrams/0287-netflix-ci-cd.png'
+createdAt: '2024-03-02'
+draft: false
+categories:
+ - real-world-case-studies
+ - devops-cicd
+tags:
+ - CI/CD
+ - Streaming
+---
+
+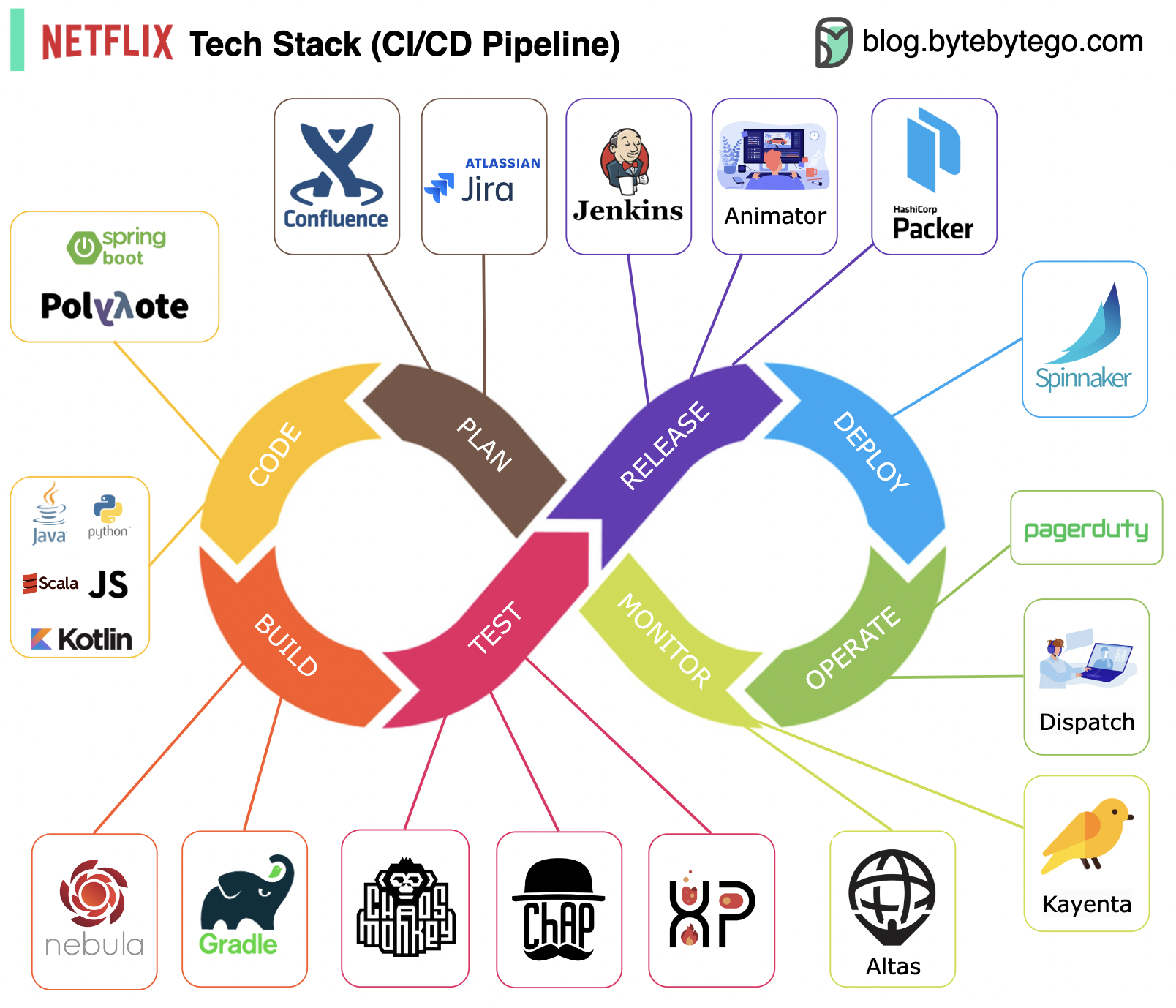
+
+* **Planning:** Netflix Engineering uses JIRA for planning and Confluence for documentation.
+
+* **Coding:** Java is the primary programming language for the backend service, while other languages are used for different use cases.
+
+* **Build:** Gradle is mainly used for building, and Gradle plugins are built to support various use cases.
+
+* **Packaging:** Package and dependencies are packed into an Amazon Machine Image (AMI) for release.
+
+* **Testing:** Testing emphasizes the production culture's focus on building chaos tools.
+
+* **Deployment:** Netflix uses its self-built Spinnaker for canary rollout deployment.
+
+* **Monitoring:** The monitoring metrics are centralized in Atlas, and Kayenta is used to detect anomalies.
+
+* **Incident report:** Incidents are dispatched according to priority, and PagerDuty is used for incident handling.
diff --git a/data/guides/netflix-tech-stack-databases.md b/data/guides/netflix-tech-stack-databases.md
new file mode 100644
index 0000000..e985f83
--- /dev/null
+++ b/data/guides/netflix-tech-stack-databases.md
@@ -0,0 +1,30 @@
+---
+title: Netflix Tech Stack - Databases
+description: Netflix uses a variety of databases to power streaming at scale.
+image: 'https://assets.bytebytego.com/diagrams/0098-databases-used-in-netflix.jpg'
+createdAt: '2024-02-26'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Databases
+ - Tech Stack
+---
+
+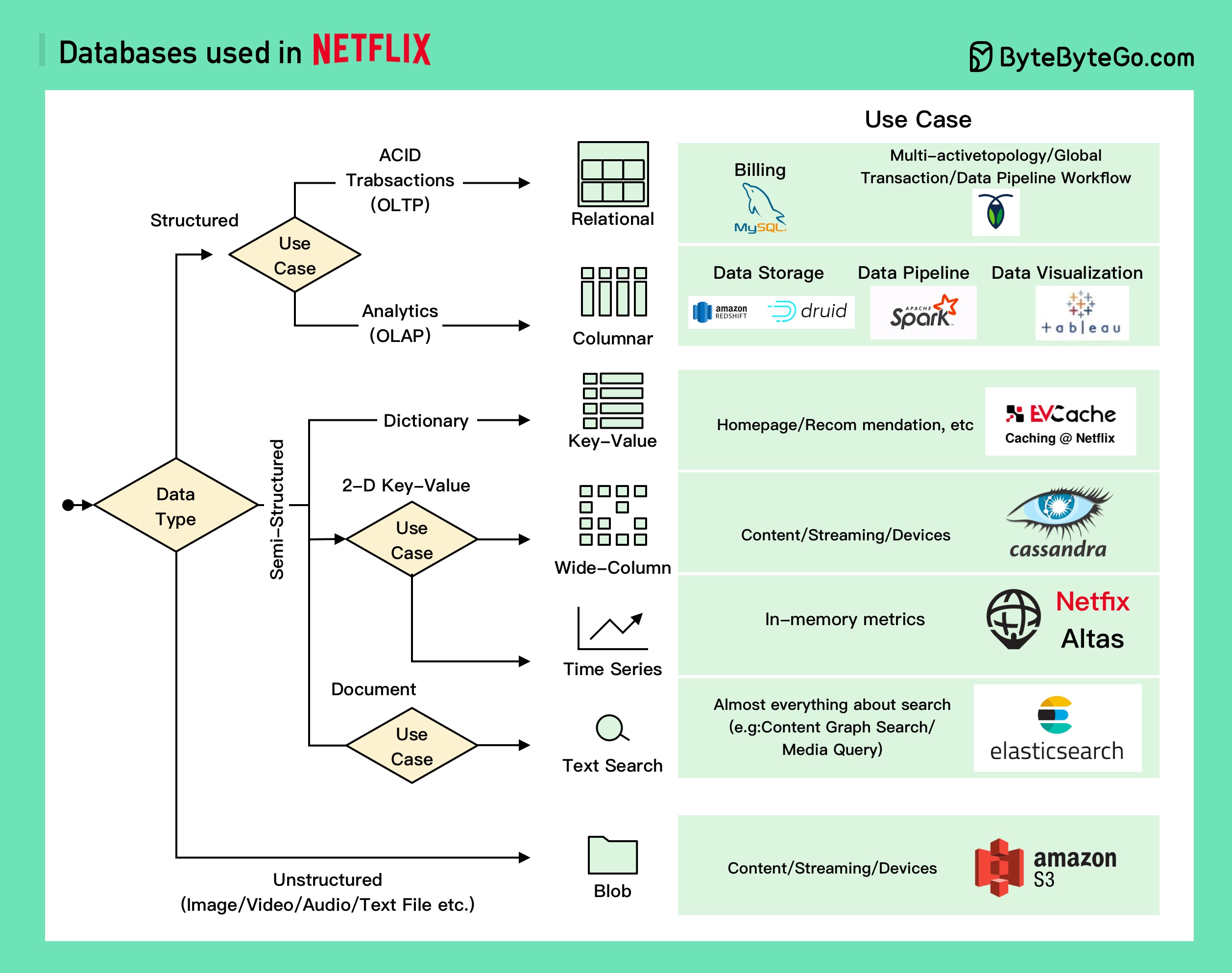
+
+The Netflix Engineering team selects a variety of databases to empower streaming at scale.
+
+* **Relational databases:** Netflix chooses MySql for billing transactions, subscriptions, taxes, and revenue. They also use CockroachDB to support a multi-region active-active architecture, global transactions, and data pipeline workflows.
+
+* **Columnar databases:** Netflix primarily uses them for analytics purposes. They utilize Redshift and Druid for structured data storage, Spark and data pipeline processing, and Tableau for data visualization.
+
+* **Key-value databases:** Netflix mainly uses EVCache built on top of Memcached. EVCache has been with Netflix for over 10 years and is used for most services, caching various data such as the Netflix Homepage and Personal Recommendations.
+
+* **Wide-column databases:** Cassandra is usually the default choice at Netflix. They use it for almost everything, including Video/Actor information, User Data, Device information, and Viewing History.
+
+* **Time-series databases:** Netflix built an open-source in-memory database called Atlas for metrics storage and aggregation.
+
+* **Unstructured data:** S3 is the default choice and stores almost everything related to Image/Video/Metrics/Log files. Apache Iceberg is also used with S3 for big data storage.
+
+If you work for a large company and wish to discuss your company's technology stack, feel free to get in touch with me. By default, all communications will be treated as anonymous.
diff --git a/data/guides/netflixs-overall-architecture.md b/data/guides/netflixs-overall-architecture.md
new file mode 100644
index 0000000..ad57206
--- /dev/null
+++ b/data/guides/netflixs-overall-architecture.md
@@ -0,0 +1,32 @@
+---
+title: "Netflix's Overall Architecture"
+description: "Explore Netflix's architecture: from frontend to backend services."
+image: 'https://assets.bytebytego.com/diagrams/0288-netflix-overal-arch.png'
+createdAt: '2024-03-01'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Streaming
+---
+
+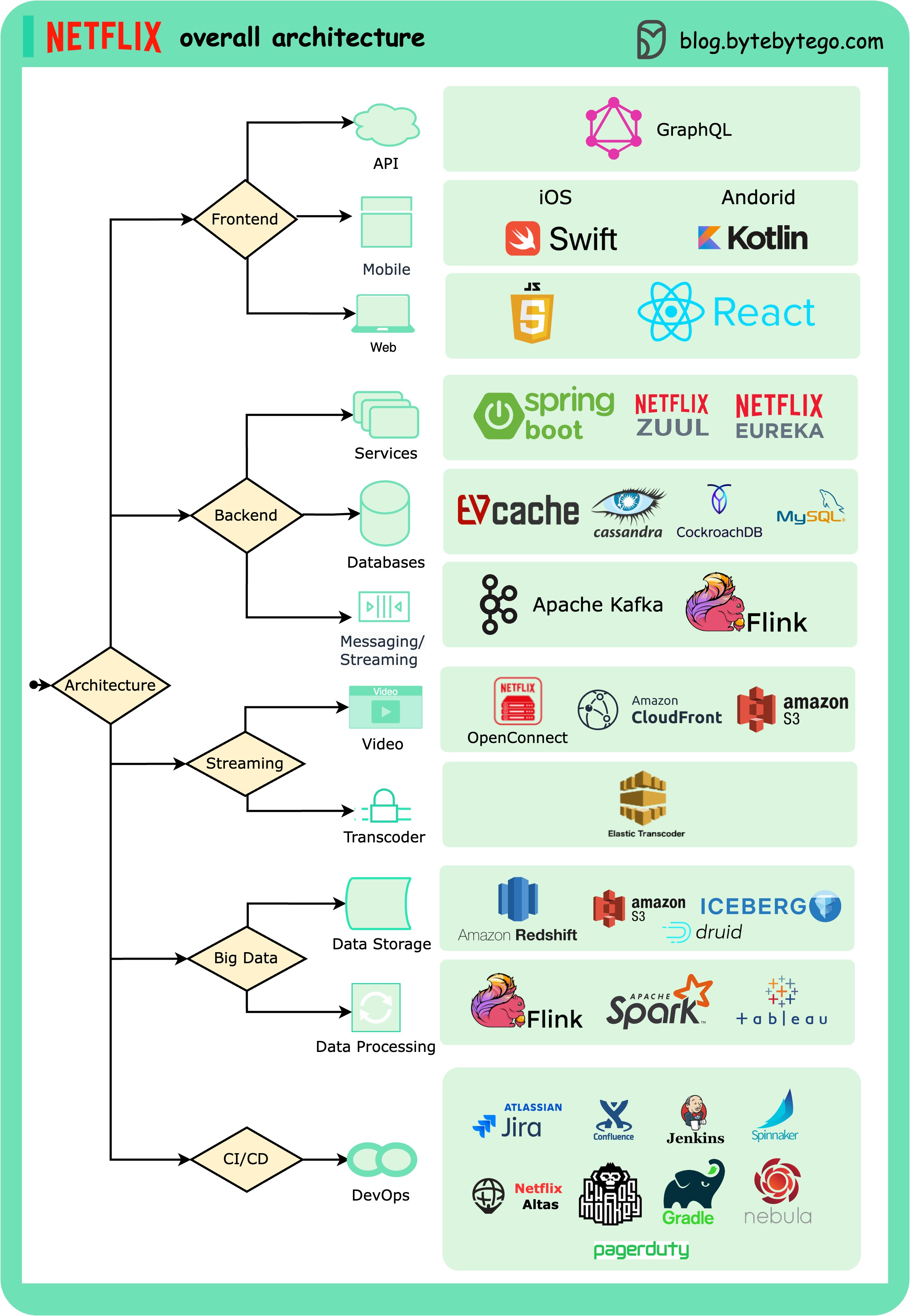
+
+This post is based on research from many Netflix engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us.
+
+Mobile and web: Netflix has adopted Swift and Kotlin to build native mobile apps. For its web application, it uses React.
+
+Frontend/server communication: Netflix uses GraphQL.
+
+Backend services: Netflix relies on ZUUL, Eureka, the Spring Boot framework, and other technologies.
+
+Databases: Netflix utilizes EV cache, Cassandra, CockroachDB, and other databases.
+
+Messaging/streaming: Netflix employs Apache Kafka and Fink for messaging and streaming purposes.
+
+Video storage: Netflix uses S3 and Open Connect for video storage.
+
+Data processing: Netflix utilizes Flink and Spark for data processing, which is then visualized using Tableau. Redshift is used for processing structured data warehouse information.
+
+CI/CD: Netflix employs various tools such as JIRA, Confluence, PagerDuty, Jenkins, Gradle, Chaos Monkey, Spinnaker, Altas, and more for CI/CD processes.
diff --git a/data/guides/netflixs-tech-stack.md b/data/guides/netflixs-tech-stack.md
new file mode 100644
index 0000000..bcb14a6
--- /dev/null
+++ b/data/guides/netflixs-tech-stack.md
@@ -0,0 +1,32 @@
+---
+title: Netflix's Tech Stack
+description: Explore the technologies behind Netflix's streaming infrastructure.
+image: 'https://assets.bytebytego.com/diagrams/0286-netflix-tech-stack.png'
+createdAt: '2024-03-15'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Streaming
+---
+
+This post is based on research from many Netflix engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us.
+
+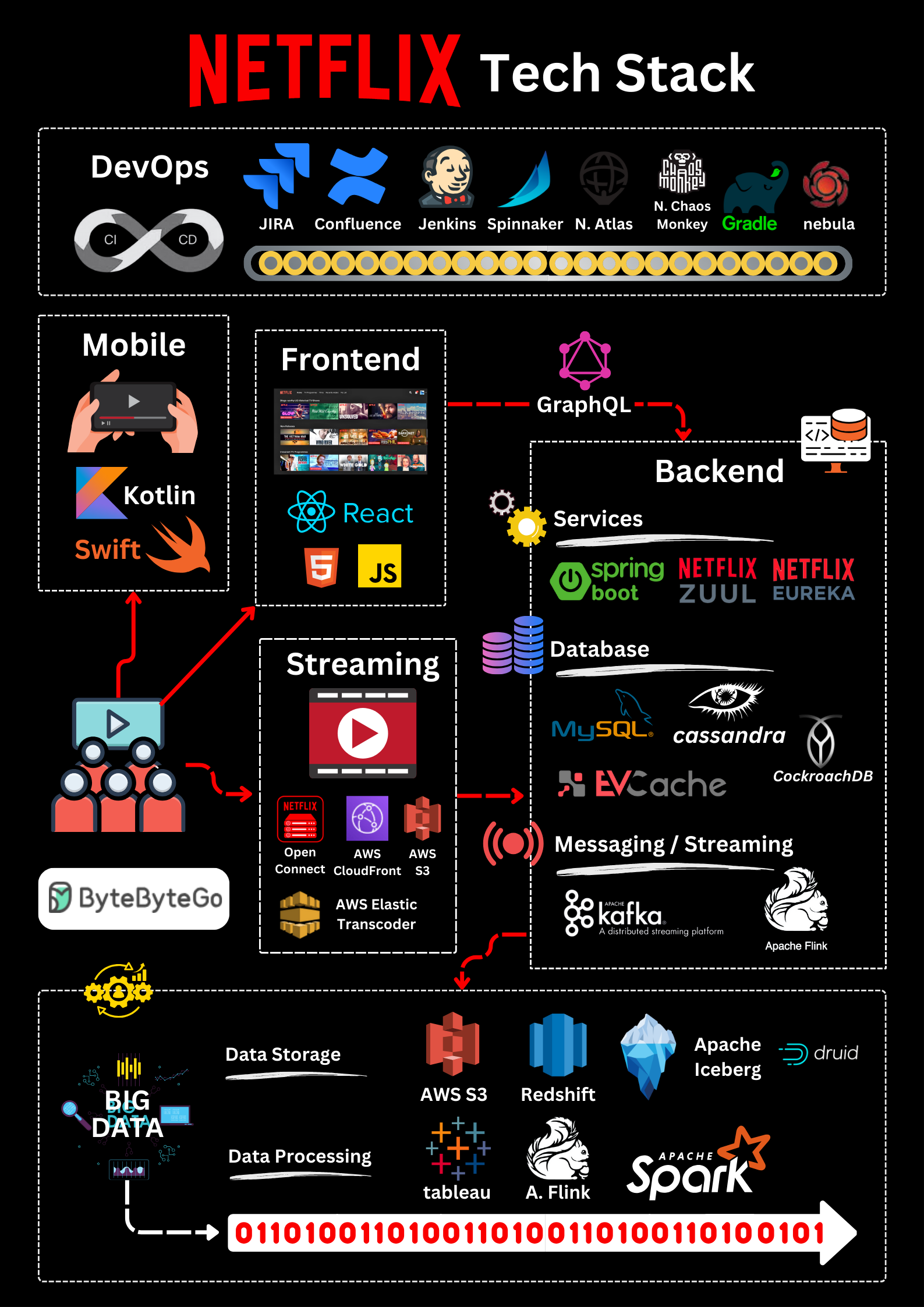
+
+* Mobile and web: Netflix has adopted Swift and Kotlin to build native mobile apps. For its web application, it uses React.
+
+* Frontend/server communication: GraphQL.
+
+* Backend services: Netflix relies on ZUUL, Eureka, the Spring Boot framework, and other technologies.
+
+* Databases: Netflix utilizes EV cache, Cassandra, CockroachDB, and other databases.
+
+* Messaging/streaming: Netflix employs Apache Kafka and Fink for messaging and streaming purposes.
+
+* Video storage: Netflix uses S3 and Open Connect for video storage.
+
+* Data processing: Netflix utilizes Flink and Spark for data processing, which is then visualized using Tableau. Redshift is used for processing structured data warehouse information.
+
+* CI/CD: Netflix employs various tools such as JIRA, Confluence, PagerDuty, Jenkins, Gradle, Chaos Monkey, Spinnaker, Altas, and more for CI/CD processes.
diff --git a/data/guides/oauth-2-explained-with-siple-terms.md b/data/guides/oauth-2-explained-with-siple-terms.md
new file mode 100644
index 0000000..6596c86
--- /dev/null
+++ b/data/guides/oauth-2-explained-with-siple-terms.md
@@ -0,0 +1,30 @@
+---
+title: "OAuth 2.0 Explained With Simple Terms"
+description: "Learn about OAuth 2.0, a secure framework for app interactions."
+image: "https://assets.bytebytego.com/diagrams/0111-what-is-oauth.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - security
+tags:
+ - "OAuth 2.0"
+ - "Authentication"
+---
+
+
+
+OAuth 2.0 is a powerful and secure framework that allows different applications to securely interact with each other on behalf of users without sharing sensitive credentials.
+
+The entities involved in OAuth are the User, the Server, and the Identity Provider (IDP).
+
+## What Can an OAuth Token Do?
+
+When you use OAuth, you get an OAuth token that represents your identity and permissions. This token can do a few important things:
+
+* Single Sign-On (SSO): With an OAuth token, you can log into multiple services or apps using just one login, making life easier and safer.
+
+* Authorization Across Systems: The OAuth token allows you to share your authorization or access rights across various systems, so you don't have to log in separately everywhere.
+
+* Accessing User Profile: Apps with an OAuth token can access certain parts of your user profile that you allow, but they won't see everything.
+
+Remember, OAuth 2.0 is all about keeping you and your data safe while making your online experiences seamless and hassle-free across different applications and services.
diff --git a/data/guides/oauth-20-flows.md b/data/guides/oauth-20-flows.md
new file mode 100644
index 0000000..932df53
--- /dev/null
+++ b/data/guides/oauth-20-flows.md
@@ -0,0 +1,30 @@
+---
+title: "OAuth 2.0 Flows"
+description: "Explore OAuth 2.0 flows: Authorization Code, Client Credentials, and more."
+image: "https://assets.bytebytego.com/diagrams/0112-oauth-flows.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - security
+tags:
+ - "OAuth 2.0"
+ - "Authorization"
+---
+
+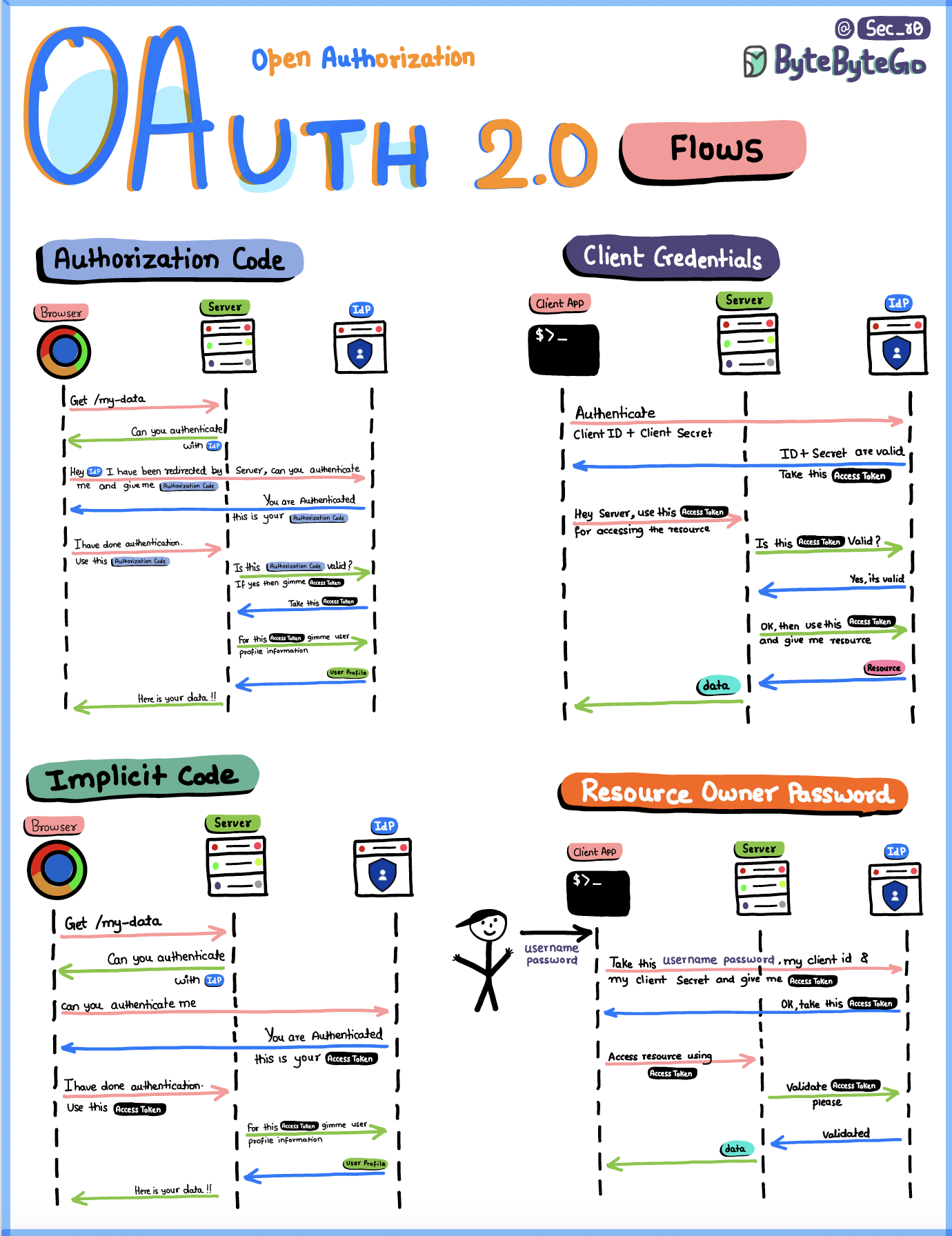
+
+## Authorization Code Flow
+
+The most common OAuth flow. After user authentication, the client receives an authorization code and exchanges it for an access token and refresh token.
+
+## Client Credentials Flow
+
+Designed for single-page applications. The access token is returned directly to the client without an intermediate authorization code.
+
+## Implicit Code Flow
+
+Designed for single-page applications. The access token is returned directly to the client without an intermediate authorization code.
+
+## Resource Owner Password Grant Flow
+
+Allows users to provide their username and password directly to the client, which then exchanges them for an access token.
diff --git a/data/guides/orchestration-vs-choreography-microservices.md b/data/guides/orchestration-vs-choreography-microservices.md
new file mode 100644
index 0000000..7d7306e
--- /dev/null
+++ b/data/guides/orchestration-vs-choreography-microservices.md
@@ -0,0 +1,36 @@
+---
+title: "Orchestration vs. Choreography in Microservices"
+description: "Explore orchestration vs. choreography for microservice collaboration."
+image: "https://assets.bytebytego.com/diagrams/0113-orchestration-vs-choreography-microservices.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Microservices
+ - Architecture
+---
+
+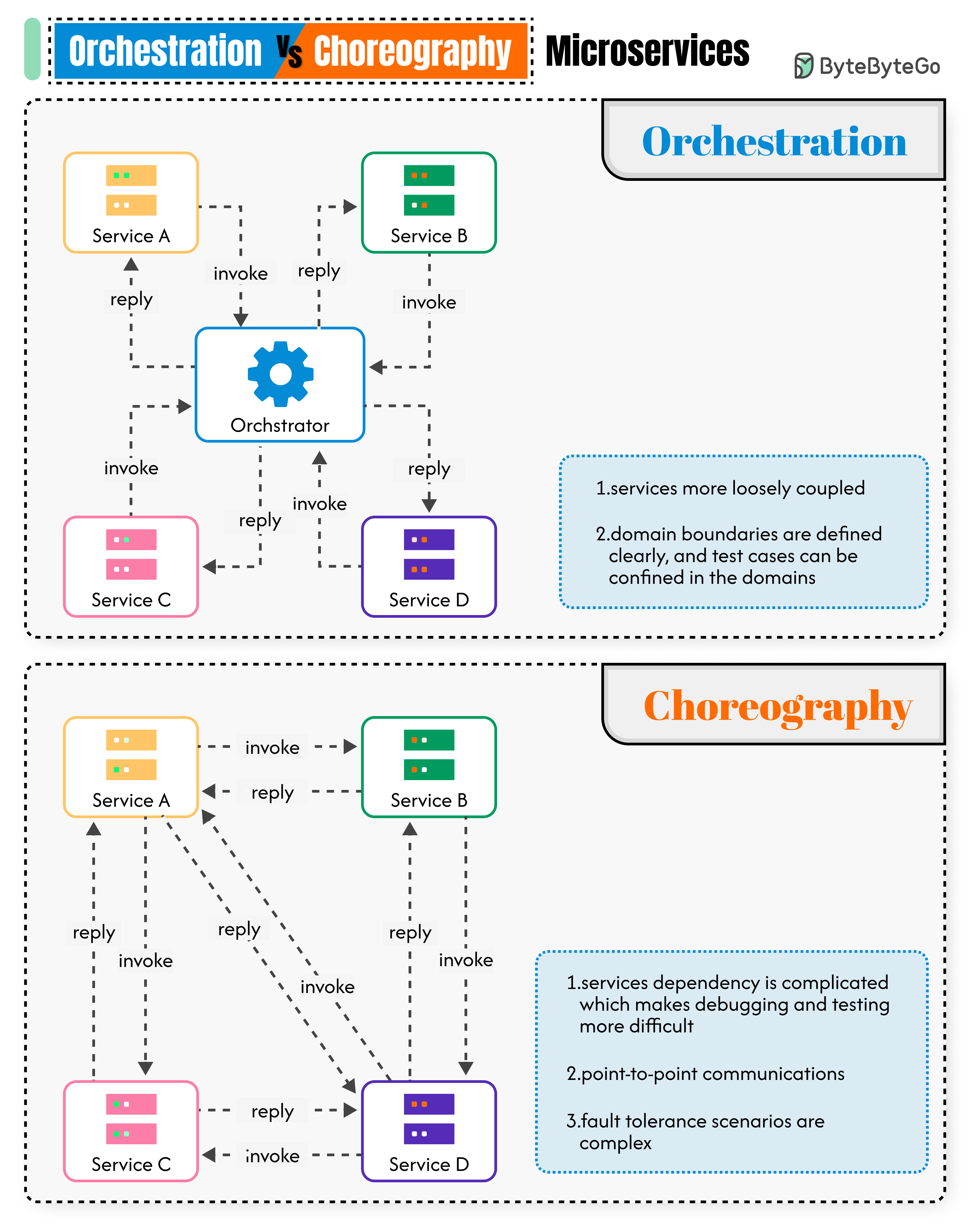
+
+How do microservices collaborate and interact with each other?
+
+There are two ways: 𝐨𝐫𝐜𝐡𝐞𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧 and 𝐜𝐡𝐨𝐫𝐞𝐨𝐠𝐫𝐚𝐩𝐡𝐲.
+
+Choreography is like having a choreographer set all the rules. Then the dancers on stage (the microservices) interact according to them. Service choreography describes this exchange of messages and the rules by which the microservices interact.
+
+Orchestration is different. The orchestrator acts as a center of authority. It is responsible for invoking and combining the services. It describes the interactions between all the participating services. It is just like a conductor leading the musicians in a musical symphony. The orchestration pattern also includes the transaction management among different services.
+
+## The benefits of orchestration:
+
+* **Reliability** - orchestration has built-in transaction management and error handling, while choreography is point-to-point communications and the fault tolerance scenarios are much more complicated.
+
+* **Scalability** - when adding a new service into orchestration, only the orchestrator needs to modify the interaction rules, while in choreography all the interacting services need to be modified.
+
+## Some limitations of orchestration:
+
+* **Performance** - all the services talk via a centralized orchestrator, so latency is higher than it is with choreography. Also, the throughput is bound to the capacity of the orchestrator.
+
+* **Single point of failure** - if the orchestrator goes down, no services can talk to each other. To mitigate this, the orchestrator must be highly available.
+
+Real-world use case: Netflix Conductor is a microservice orchestrator and you can read more details on the orchestrator design.
diff --git a/data/guides/paradigm-shift-how-developer-to-tester-ratio-changed-from-11-to-1001.md b/data/guides/paradigm-shift-how-developer-to-tester-ratio-changed-from-11-to-1001.md
new file mode 100644
index 0000000..0f55a65
--- /dev/null
+++ b/data/guides/paradigm-shift-how-developer-to-tester-ratio-changed-from-11-to-1001.md
@@ -0,0 +1,40 @@
+---
+title: "Paradigm Shift: Developer to Tester Ratio"
+description: "Explore the paradigm shift in developer to tester ratios over the years."
+image: "https://assets.bytebytego.com/diagrams/0170-dev-tester-ratio.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Software Testing"
+ - "DevOps"
+---
+
+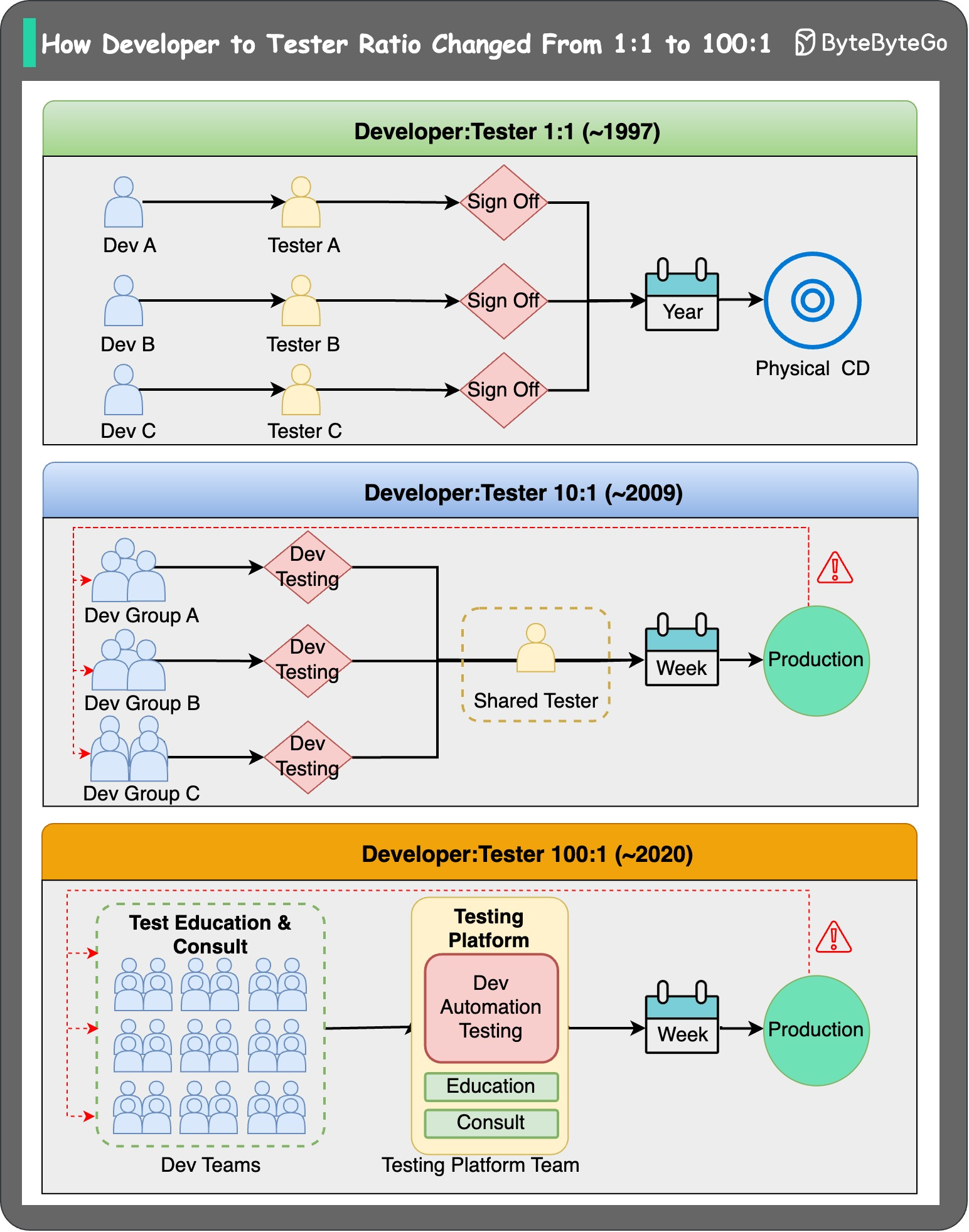
+
+This post is inspired by the article "The Paradigm Shifts with Different Dev:Test Ratios" by [Carlos Arguelles](https://www.linkedin.com/in/ACoAAABj60kByWwNDRyWLdeCCmaKZYUHd4LynqQ). I highly recommend that you read the original article [here](https://lnkd.in/ehbZzZck).
+
+## 1:1 ratio (~1997)
+
+Software used to be burned onto physical CDs and delivered to customers. The development process was waterfall-style, builds were certified, and versions were released roughly every three years.
+
+If you had a bug, that bug would live forever. It wasn’t until years later that companies added the ability for software to ping the internet for updates and automatically install them.
+
+## 10:1 ratio (~2009)
+
+Around 2009, the release-to-production speed increased significantly. Patches could be installed within weeks, and the agile movement, along with iteration-driven development, changed the development process.
+
+For example, at Amazon, the web services are mainly developed and tested by the developers. They are also responsible for dealing with production issues, and testing resources are stretched thin (10:1 ratio).
+
+## 100:1 ratio (~2020)
+
+Around 2015, big tech companies like Google and Microsoft removed SDET or SETI titles, and Amazon slowed down the hiring of SDETs.
+
+But how is this going to work for big tech in terms of testing?
+
+Firstly, the testing aspect of the software has shifted towards highly scalable, standardized testing tools. These tools have been widely adopted by developers for building their own automated tests.
+
+Secondly, testing knowledge is disseminated through education and consulting.
+
+Together, these factors have facilitated a smooth transition to the 100:1 testing ratio we see today.
diff --git a/data/guides/payment-system.md b/data/guides/payment-system.md
new file mode 100644
index 0000000..d6c825d
--- /dev/null
+++ b/data/guides/payment-system.md
@@ -0,0 +1,39 @@
+---
+title: "Payment System"
+description: "Explore the architecture and flow of a typical payment system."
+image: "https://assets.bytebytego.com/diagrams/0299-payment-system.jpeg"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - payment-and-fintech
+ - how-it-works
+tags:
+ - "Payment Processing"
+ - "System Design"
+---
+
+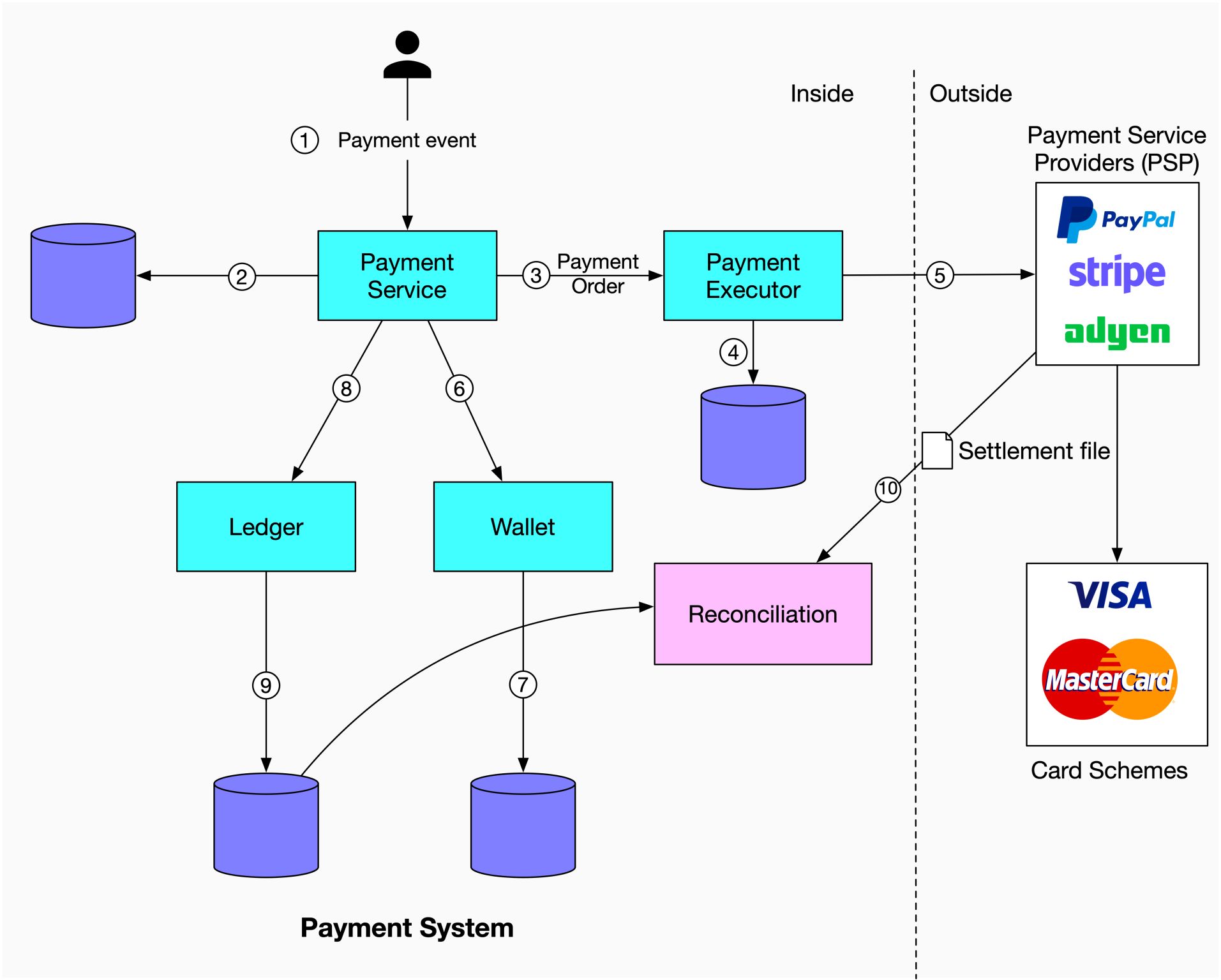
+
+Here is how money moves when you click the Buy button on Amazon or any of your favorite shopping websites.
+
+## Payment Flow
+
+* When a user clicks the “Buy” button, a payment event is generated and sent to the payment service.
+
+* The payment service stores the payment event in the database.
+
+* Sometimes a single payment event may contain several payment orders. For example, you may select products from multiple sellers in a single checkout process. The payment service will call the payment executor for each payment order.
+
+* The payment executor stores the payment order in the database.
+
+* The payment executor calls an external PSP to finish the credit card payment.
+
+* After the payment executor has successfully executed the payment, the payment service will update the wallet to record how much money a given seller has.
+
+* The wallet server stores the updated balance information in the database.
+
+* After the wallet service has successfully updated the seller’s balance information, the payment service will call the ledger to update it.
+
+* The ledger service appends the new ledger information to the database.
+
+* Every night the PSP or banks send settlement files to their clients. The settlement file contains the balance of the bank account, together with all the transactions that took place on this bank account during the day.
diff --git a/data/guides/pessimistic-vs-optimistic-locking.md b/data/guides/pessimistic-vs-optimistic-locking.md
new file mode 100644
index 0000000..7a5c4a5
--- /dev/null
+++ b/data/guides/pessimistic-vs-optimistic-locking.md
@@ -0,0 +1,30 @@
+---
+title: "Pessimistic vs Optimistic Locking"
+description: "Explore pessimistic and optimistic locking strategies for data consistency."
+image: "https://assets.bytebytego.com/diagrams/0301-pessimistic-vs-optimistic-locking.png"
+createdAt: "2024-01-29"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Concurrency Control"
+ - "Database Transactions"
+---
+
+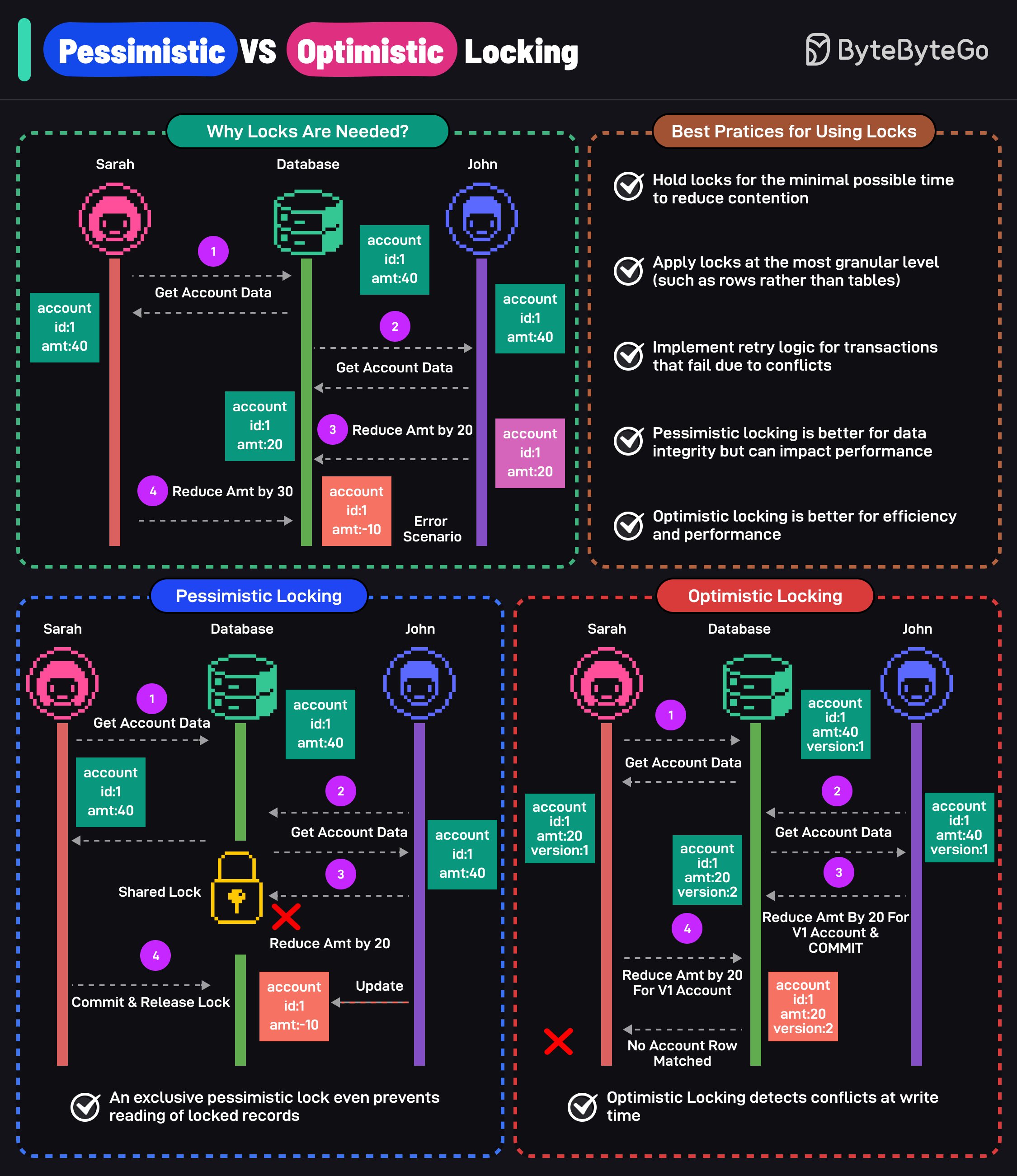
+
+Locks are essential to maintain data consistency and integrity in multi-user environments. They prevent simultaneous modifications that can lead to data inconsistencies.
+
+Pessimistic locking assumes conflicts will occur and locks the data before any changes are made. It prevents other users from accessing and updating the data until the lock is released.
+
+Optimistic locking assumes conflicts are rare. It allows multiple users to access data simultaneously and checks for conflicts when changes are committed. If a conflict is detected, the operation is rolled back.
+
+## Best Practices
+
+Here are some best practices to consider:
+
+* Hold locks for the minimum possible time to reduce contention.
+* Apply locks at the most granular level such as rows rather than tables.
+* Implement retry logic for transactions that fail due to conflicts.
+* Pessimistic locking is better for data integrity but can impact performance.
+* Optimistic locking is better for efficiency and performance.
diff --git a/data/guides/polling-vs-webhooks.md b/data/guides/polling-vs-webhooks.md
new file mode 100644
index 0000000..7074f33
--- /dev/null
+++ b/data/guides/polling-vs-webhooks.md
@@ -0,0 +1,44 @@
+---
+title: "Polling vs Webhooks"
+description: "Polling vs webhooks: a detailed comparison of two data retrieval methods."
+image: 'https://assets.bytebytego.com/diagrams/0057-pooling-vs-webhook.png'
+createdAt: '2024-03-03'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - APIs
+ - Webhooks
+---
+
+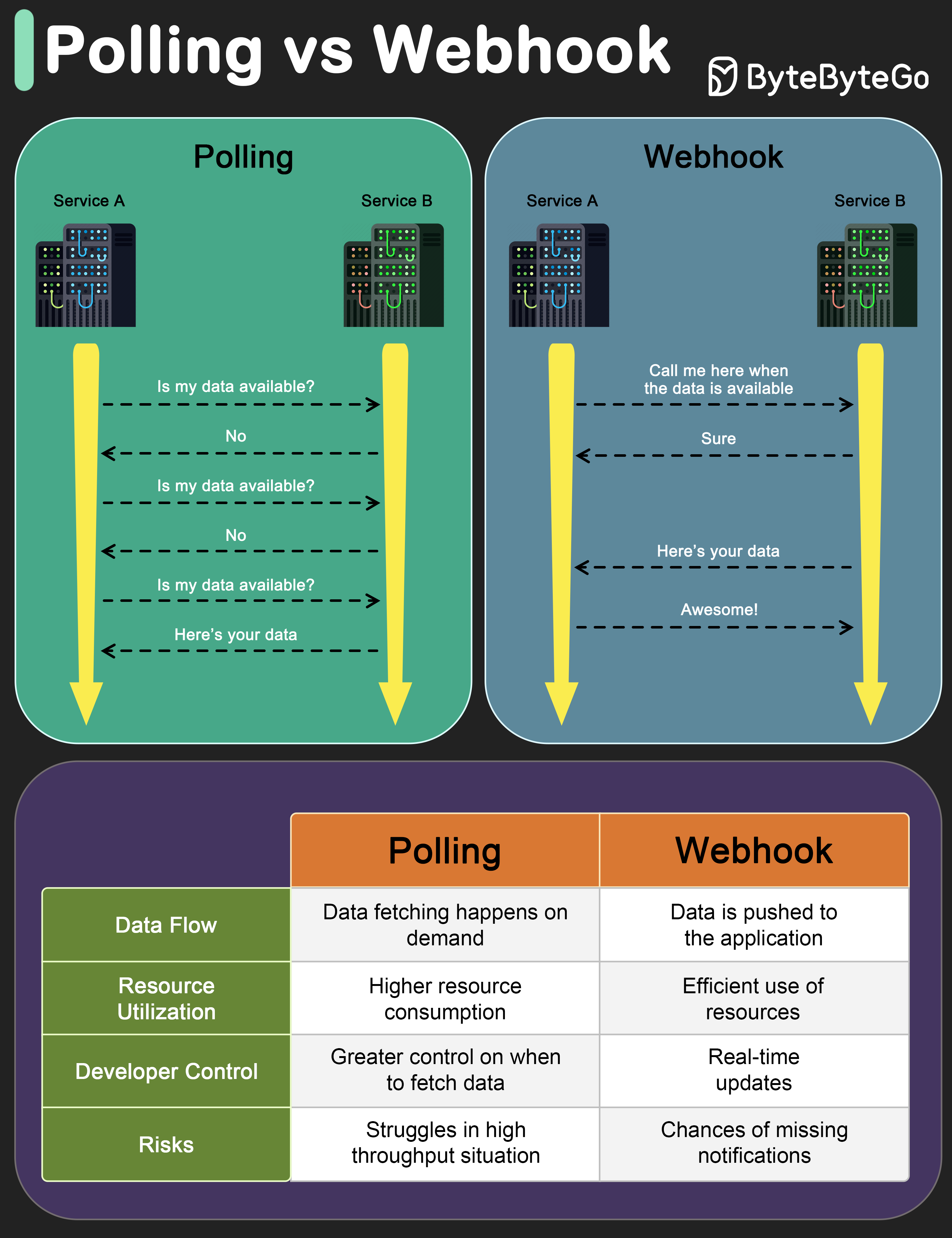
+
+## Polling
+
+Polling involves repeatedly checking the external service or endpoint at fixed intervals to retrieve updated information.
+
+It’s like constantly asking, “Do you have something new for me?” even where there might not be any update.
+
+This approach is resource-intensive and inefficient.
+
+Also, you get updates only when you ask for it, thereby missing any real-time information.
+
+However, developers have more control over when and how the data is fetched.
+
+## Webhooks
+
+Webhooks are like having a built-in notification system.
+
+You don’t continuously ask for information.
+
+Instead you create an endpoint in your application server and provide it as a callback to the external service (such as a payment processor or a shipping vendor)
+
+Every time something interesting happens, the external service calls the endpoint and provides the information.
+
+This makes webhooks ideal for dealing with real-time updates because data is pushed to your application as soon as it’s available.
+
+So, when to use Polling or Webhook?
+
+Polling is a solid option when there is some infrastructural limitation that prevents the use of webhooks. Also, with webhooks there is a risk of missed notifications due to network issues, hence proper retry mechanisms are needed.
+
+Webhooks are recommended for applications that need instant data delivery. Also, webhooks are efficient in terms of resource utilization especially in high throughput environments.
diff --git a/data/guides/possible-experiment-platform-architecture.md b/data/guides/possible-experiment-platform-architecture.md
new file mode 100644
index 0000000..6f316a8
--- /dev/null
+++ b/data/guides/possible-experiment-platform-architecture.md
@@ -0,0 +1,26 @@
+---
+title: "Experiment Platform Architecture"
+description: "Explore the architecture of an experiment platform with key components."
+image: "https://assets.bytebytego.com/diagrams/0189-experiment-framework.jpg"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "A/B Testing"
+ - "Experimentation"
+---
+
+[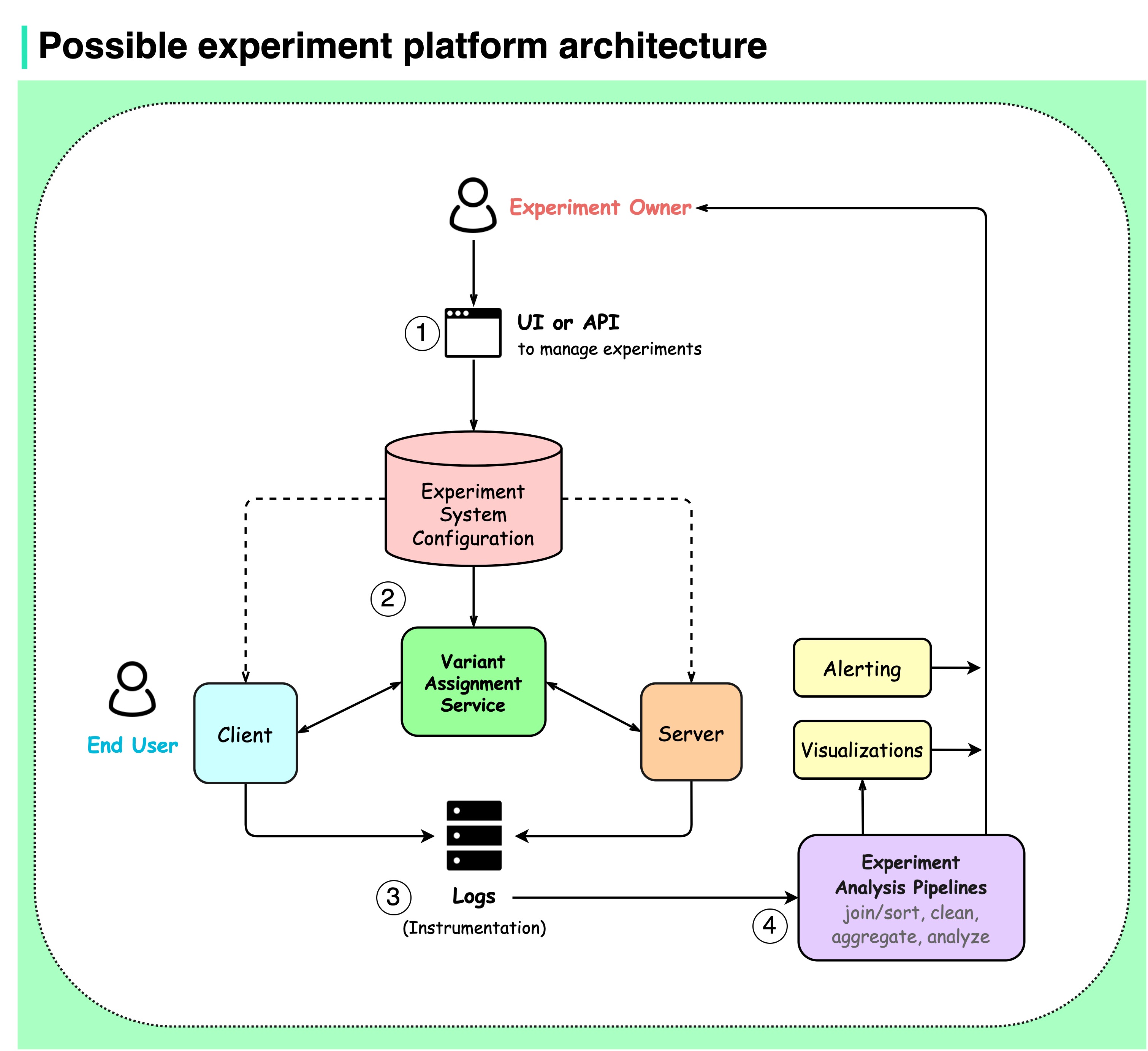](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd79ea50e-e386-41c9-9f66-e28006ed1115_1677x1536.jpeg)
+
+The architecture of a potential experiment platform is depicted in the diagram below. This content of the visual is from the book: "Trustworthy Online Controlled Experiments" (redrawn by me). The platform contains 4 high-level components.
+
+## Key Components
+
+* **Experiment definition, setup, and management via a UI.** They are stored in the experiment system configuration.
+
+* **Experiment deployment** to both the server and client-side (covers variant assignment and parameterization as well).
+
+* **Experiment instrumentation.**
+
+* **Experiment analysis.**
diff --git a/data/guides/proximity-service.md b/data/guides/proximity-service.md
new file mode 100644
index 0000000..aae7ae3
--- /dev/null
+++ b/data/guides/proximity-service.md
@@ -0,0 +1,48 @@
+---
+title: "Proximity Service"
+description: "Explore the design of proximity services for finding nearby locations."
+image: "https://assets.bytebytego.com/diagrams/0306-proximity-service-design.jpg"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Location Services"
+ - "Geospatial Data"
+---
+
+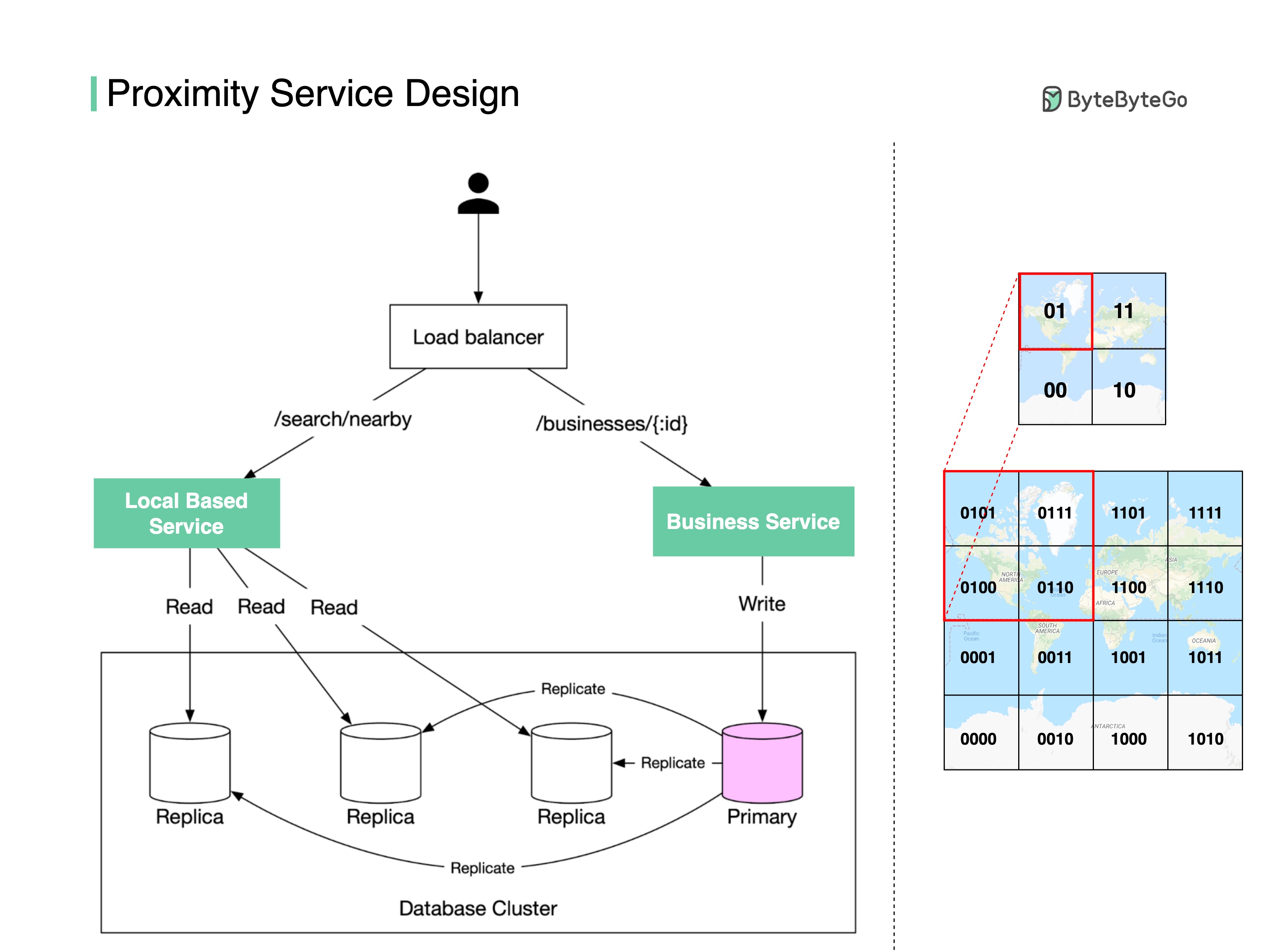
+
+How do we find nearby restaurants on Yelp or Google Maps? Here are some design details behind the scenes.
+
+There are two key services (see the diagram below):
+
+## Business Service
+
+* Add/delete/update restaurant information
+* Customers view restaurant details
+
+## Location-based Service
+
+* Given a radius and location, return a list of nearby restaurants
+
+How are the restaurant locations stored in the database so that LBS can return nearby restaurants efficiently?
+
+Store the latitude and longitude of restaurants in the database? The query will be very inefficient when you need to calculate the distance between you and every restaurant.
+
+One way to speed up the search is using the geohash algorithm.
+
+First, divide the planet into four quadrants along with the prime meridian and equator:
+
+* Latitude range \[-90, 0] is represented by 0
+* Latitude range \[0, 90] is represented by 1
+* Longitude range \[-180, 0] is represented by 0
+* Longitude range \[0, 180] is represented by 1
+
+Second, divide each grid into four smaller grids. Each grid can be represented by alternating between longitude bit and latitude bit.
+
+So when you want to search for the nearby restaurants in the red-highlighted grid, you can write SQL like:
+
+SELECT \* FROM geohash\_index WHERE geohash LIKE \`01%\`
+
+Geohash has some limitations. There can be a lot of restaurants in one grid (downtown New York), but none in another grid (ocean). So there are other more complicated algorithms to optimize the process. Let me know if you are interested in the details.
diff --git a/data/guides/proxy-vs-reverse-proxy.md b/data/guides/proxy-vs-reverse-proxy.md
new file mode 100644
index 0000000..f25a285
--- /dev/null
+++ b/data/guides/proxy-vs-reverse-proxy.md
@@ -0,0 +1,27 @@
+---
+title: 'Proxy vs Reverse Proxy'
+description: 'Understanding the differences between forward and reverse proxies.'
+image: 'https://assets.bytebytego.com/diagrams/0196-forward-proxy-vs-reverse-proxy.png'
+createdAt: '2024-03-01'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Networking
+ - Security
+---
+
+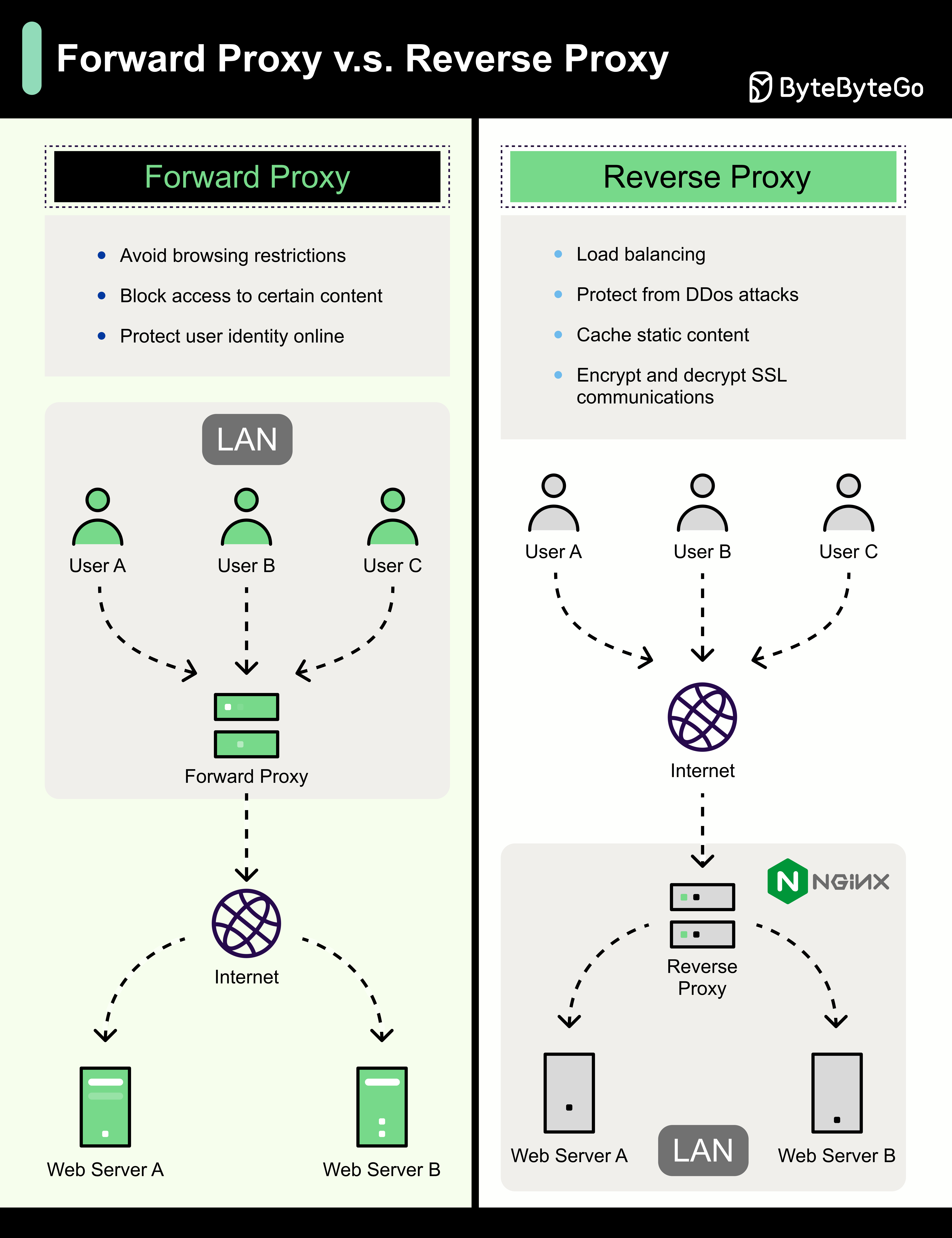
+
+A forward proxy is a server that sits between user devices and the internet. A forward proxy is commonly used for:
+
+* **Protect clients**
+* **Avoid browsing restrictions**
+* **Block access to certain content**
+
+A reverse proxy is a server that accepts a request from the client, forwards the request to web servers, and returns the results to the client as if the proxy server had processed the request. A reverse proxy is good for:
+
+* **Protect servers**
+* **Load balancing**
+* **Cache static contents**
+* **Encrypt and decrypt SSL communications**
diff --git a/data/guides/push-vs-pull-in-metrics-collecting-systems.md b/data/guides/push-vs-pull-in-metrics-collecting-systems.md
new file mode 100644
index 0000000..41cf2e1
--- /dev/null
+++ b/data/guides/push-vs-pull-in-metrics-collecting-systems.md
@@ -0,0 +1,32 @@
+---
+title: "Push vs Pull in Metrics Collection Systems"
+description: "Explore push vs pull models in metrics collection systems."
+image: "https://assets.bytebytego.com/diagrams/0274-metrics-push-pull.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "metrics"
+ - "monitoring"
+---
+
+[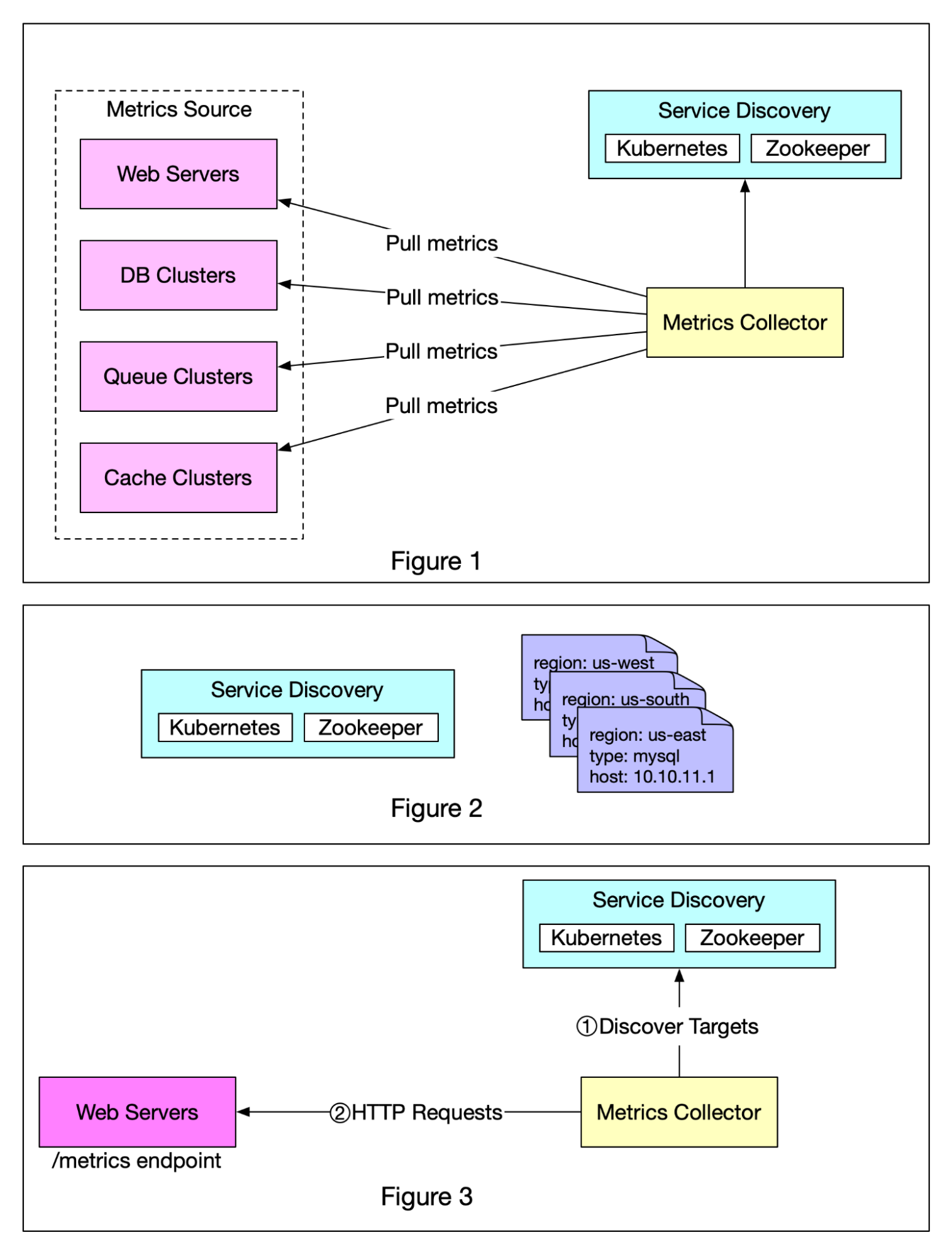](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F197e300b-7e29-40b4-ac0e-8e9280133bf0_1514x1999.png)
+
+There are two ways metrics data can be collected, pull or push. It is a routine debate as to which one is better and there is no clear answer. In this post, we will take a look at the pull model.
+
+Figure 1 shows data collection with a pull model over HTTP. We have dedicated metric collectors which pull metrics values from the running applications periodically.
+
+In this approach, the metrics collector needs to know the complete list of service endpoints to pull data from. One naive approach is to use a file to hold DNS/IP information for every service endpoint on the “metric collector” servers. While the idea is simple, this approach is hard to maintain in a large-scale environment where servers are added or removed frequently, and we want to ensure that metric collectors don’t miss out on collecting metrics from any new servers.
+
+The good news is that we have a reliable, scalable, and maintainable solution available through Service Discovery, provided by Kubernetes, Zookeeper, etc., wherein services register their availability and the metrics collector can be notified by the Service Discovery component whenever the list of service endpoints changes. Service discovery contains configuration rules about when and where to collect metrics as shown in Figure 2.
+
+Figure 3 explains the pull model in detail.
+
+### Pull Model Details
+
+* The metrics collector fetches configuration metadata of service endpoints from Service Discovery. Metadata include pulling interval, IP addresses, timeout and retries parameters, etc.
+
+* The metrics collector pulls metrics data via a pre-defined HTTP endpoint (for example, /metrics). To expose the endpoint, a client library usually needs to be added to the service. In Figure 3, the service is Web Servers.
+
+* Optionally, the metrics collector registers a change event notification with Service Discovery to receive an update whenever the service endpoints change. Alternatively, the metrics collector can poll for endpoint changes periodically.
diff --git a/data/guides/quadtree.md b/data/guides/quadtree.md
new file mode 100644
index 0000000..765b5d5
--- /dev/null
+++ b/data/guides/quadtree.md
@@ -0,0 +1,38 @@
+---
+title: "Quadtree"
+description: "Explore the quadtree data structure for spatial data partitioning."
+image: "https://assets.bytebytego.com/diagrams/0311-quadtree.jpg"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Data Structures"
+ - "Algorithms"
+---
+
+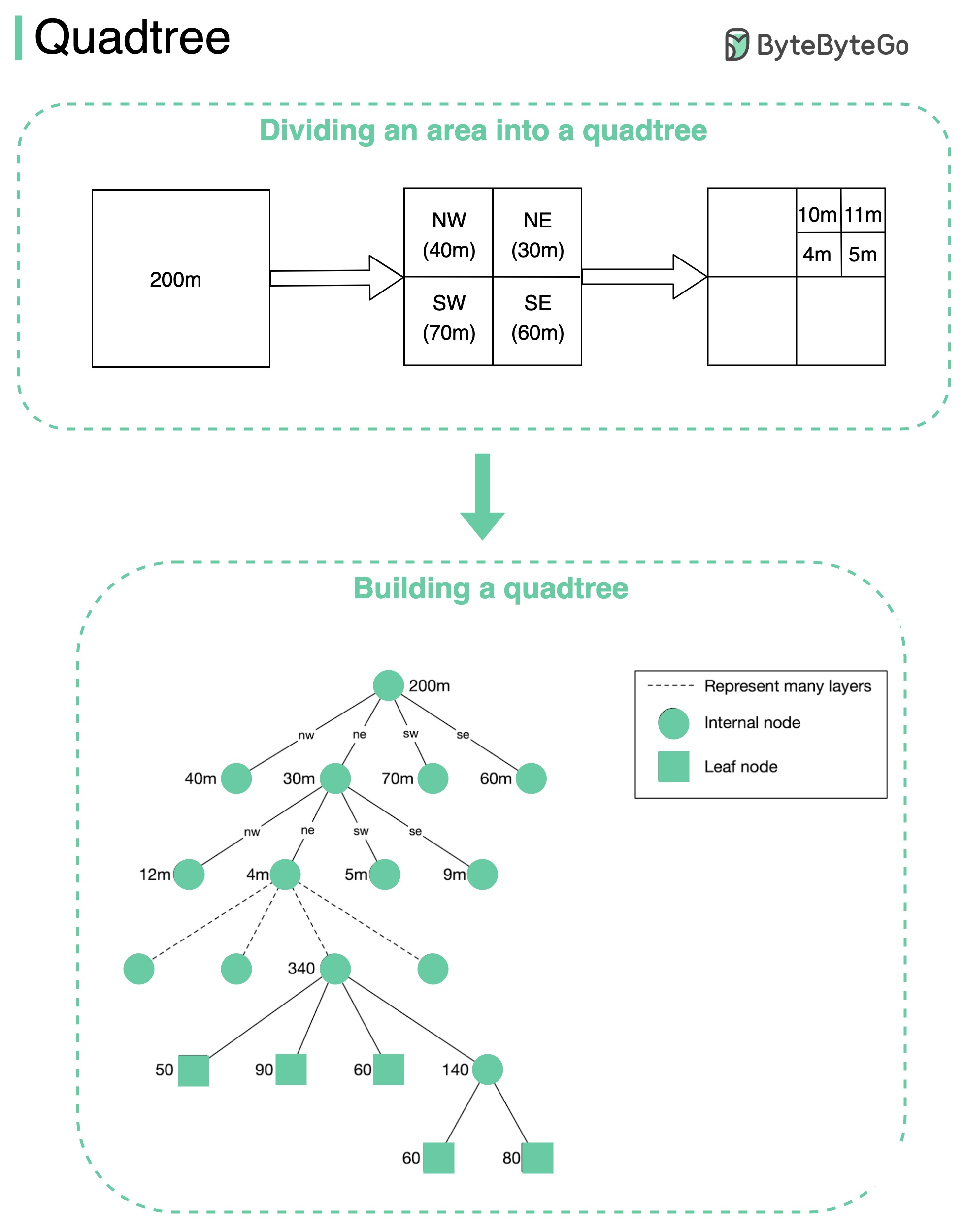
+
+Let's explore another data structure to find nearby restaurants on Yelp or Google Maps.
+
+A quadtree is a data structure that is commonly used to partition a two-dimensional space by recursively subdividing it into four quadrants (grids) until the contents of the grids meet certain criteria.
+
+A quadtree is an **in-memory data structure** and it is not a database solution. It runs on each LBS (Location-Based Service, see last week’s post) server, and the data structure is built at server start-up time.
+
+The second diagram explains the quadtree building process in more detail. The root node represents the whole world map. The root node is recursively broken down into 4 quadrants until no nodes are left with more than 100 businesses.
+
+## How to get nearby businesses with quadtree?
+
+* Build the quadtree in memory.
+
+* After the quadtree is built, start searching from the root and traverse the tree, until we find the leaf node where the search origin is.
+
+* If that leaf node has 100 businesses, return the node. Otherwise, add businesses from its neighbors until enough businesses are returned.
+
+## Update LBS server and rebuild quadtree
+
+* It may take a few minutes to build a quadtree in memory with 200 million businesses at the server start-up time.
+
+* While the quadtree is being built, the server cannot serve traffic.
+
+* Therefore, we should roll out a new release of the server incrementally to a small subset of servers at a time. This avoids taking a large swathe of the server cluster offline and causes service brownout.
diff --git a/data/guides/read-replica-pattern.md b/data/guides/read-replica-pattern.md
new file mode 100644
index 0000000..246b80b
--- /dev/null
+++ b/data/guides/read-replica-pattern.md
@@ -0,0 +1,37 @@
+---
+title: "Read Replica Pattern"
+description: "Explore the read replica pattern for database design and optimization."
+image: "https://assets.bytebytego.com/diagrams/0312-read-replica-pattern.png"
+createdAt: "2024-01-28"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Replication"
+ - "Read Scalability"
+---
+
+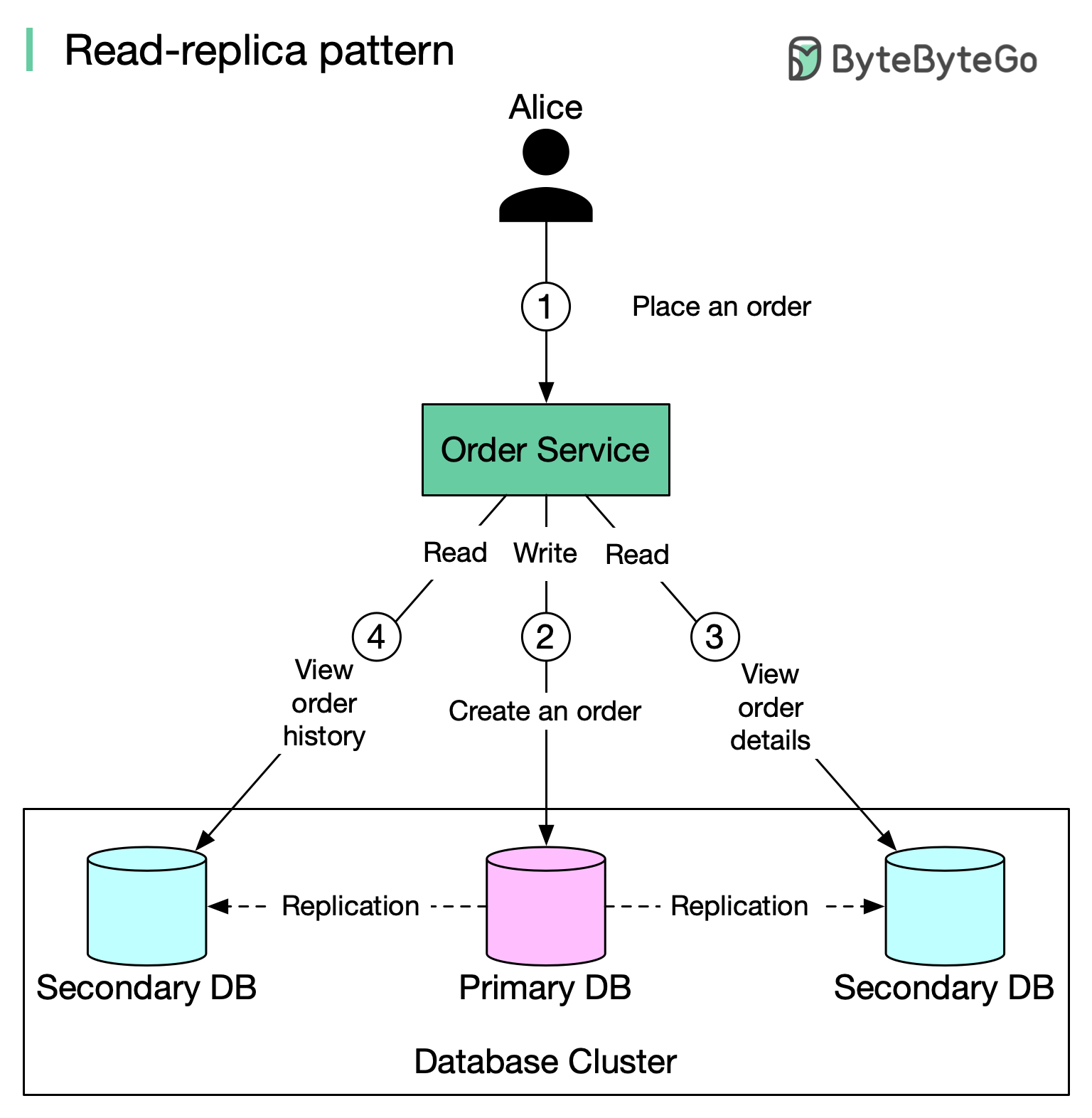
+
+In this post, we talk about a simple yet commonly used database design pattern (setup): **Read replica pattern**.
+
+In this setup, all data-modifying commands like insert, delete, or update are sent to the primary DB and reads are sent to read replicas.
+
+The diagram above illustrates the setup:
+
+1. When Alice places an order on amazon.com, the request is sent to Order Service.
+2. Order Service creates a record about the order in the primary DB (write). Data is replicated to two replicas.
+3. Alice views the order details. Data is served from a replica (read).
+4. Alice views the recent order history. Data is served from a replica (read).
+
+There is one major problem in this setup: **replication lag**.
+
+Under certain circumstances (network delay, server overload, etc.), data in replicas might be seconds or even minutes behind. In this case, if Alice immediately checks the order status (query is served by the replica) after the order is placed, she might not see the order at all. This leaves Alice confused. In this case, we need “read-after-write” consistency.
+
+## Possible solutions to mitigate this problem:
+
+* Latency sensitive reads are sent to the primary database.
+
+* Reads that immediately follow writes are routed to the primary database.
+
+* A relational DB generally provides a way to check if a replica is caught up with the primary. If data is up to date, query the replica. Otherwise fail the read request or read from the primary.
diff --git a/data/guides/reconciliation-in-payment.md b/data/guides/reconciliation-in-payment.md
new file mode 100644
index 0000000..e3c217f
--- /dev/null
+++ b/data/guides/reconciliation-in-payment.md
@@ -0,0 +1,50 @@
+---
+title: "Reconciliation in Payment"
+description: "Explore payment reconciliation: challenges, solutions, and its importance."
+image: "https://assets.bytebytego.com/diagrams/0298-payment-reconciliation.jpg"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "Data Reconciliation"
+---
+
+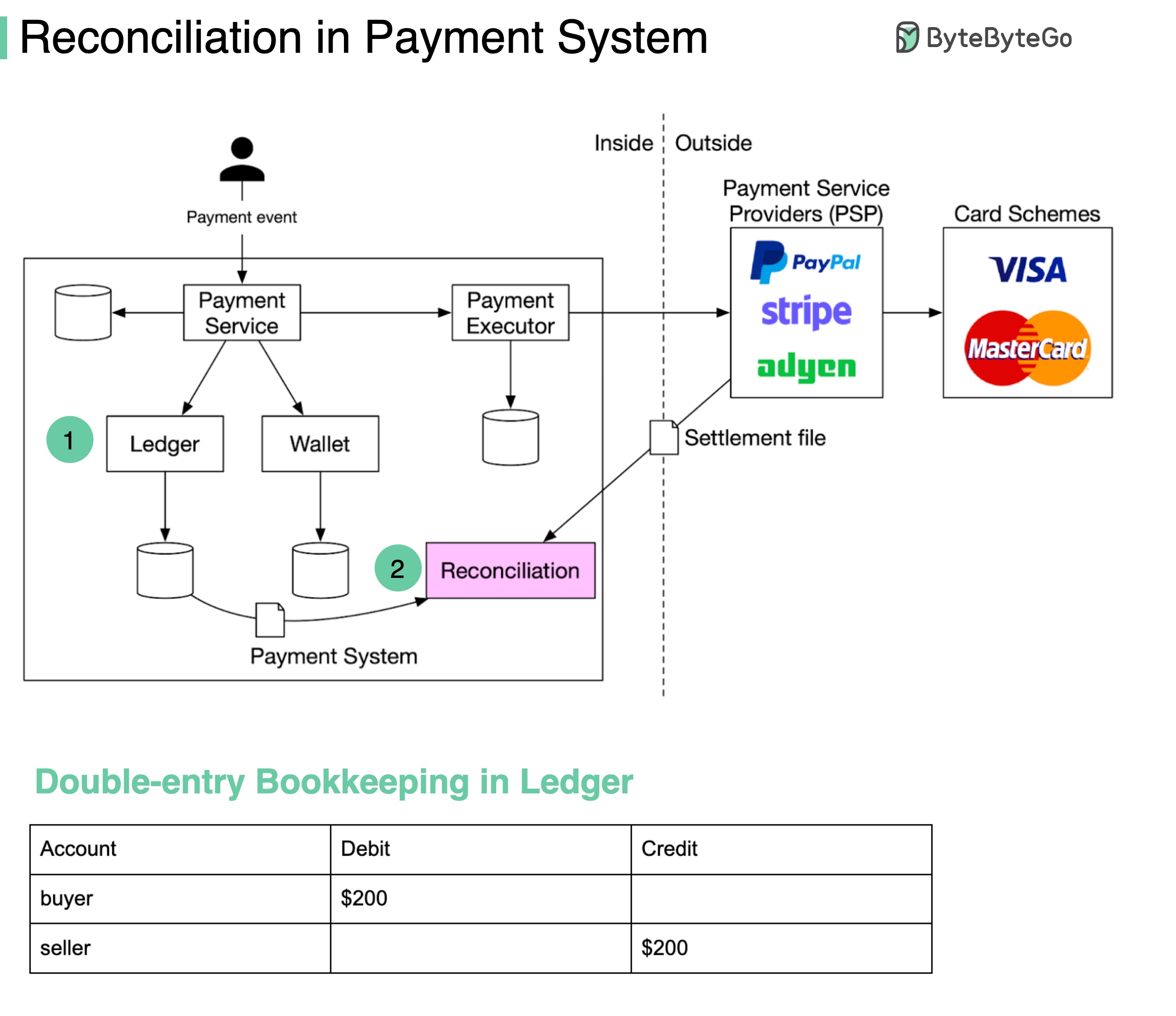
+
+Reconciliation might be the most painful process in a payment system. It is the process of comparing records in different systems to make sure the amounts match each other.
+
+For example, if you pay $200 to buy a watch with Paypal:
+
+* The eCommerce website should have a record of the $200 purchase order.
+
+* There should be a transaction record of $200 in Paypal (marked with 2 in the diagram).
+
+* The Ledger should record a debit of $200 dollars for the buyer, and a credit of $200 for the seller. This is called double-entry bookkeeping (see the table below).
+
+Let’s take a look at some pain points and how we can address them:
+
+## Problem 1: Data normalization
+
+When comparing records in different systems, they come in different formats. For example, the timestamp can be “2022/01/01” in one system and “Jan 1, 2022” in another.
+
+### Possible solution
+
+We can add a layer to transform different formats into the same format.
+
+## Problem 2: Massive data volume
+
+### Possible solution
+
+We can use big data processing techniques to speed up data comparisons. If we need near real-time reconciliation, a streaming platform such as Flink is used; otherwise, end-of-day batch processing such as Hadoop is enough.
+
+## Problem 3: Cut-off time issue
+
+For example, if we choose 00:00:00 as the daily cut-off time, one record is stamped with 23:59:55 in the internal system, but might be stamped 00:00:30 in the external system (Paypal), which is the next day. In this case, we couldn’t find this record in today’s Paypal records. It causes a discrepancy.
+
+### Possible solution
+
+We need to categorize this break as a “temporary break” and run it later against the next day’s Paypal records. If we find a match in the next day’s Paypal records, the break is cleared, and no more action is needed.
+
+You may argue that if we have exactly-once semantics in the system, there shouldn’t be any discrepancies. But the truth is, there are so many places that can go wrong. Having a reconciliation system is always necessary. It is like having a safety net to keep you sleeping well at night.
diff --git a/data/guides/reddit's-core-architecture.md b/data/guides/reddit's-core-architecture.md
new file mode 100644
index 0000000..68fd96c
--- /dev/null
+++ b/data/guides/reddit's-core-architecture.md
@@ -0,0 +1,30 @@
+---
+title: Reddit's Core Architecture
+description: Overview of Reddit's architecture for serving millions of users.
+image: 'https://assets.bytebytego.com/diagrams/0356-the-core-reddit-architecture.png'
+createdAt: '2024-03-06'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Social Media
+---
+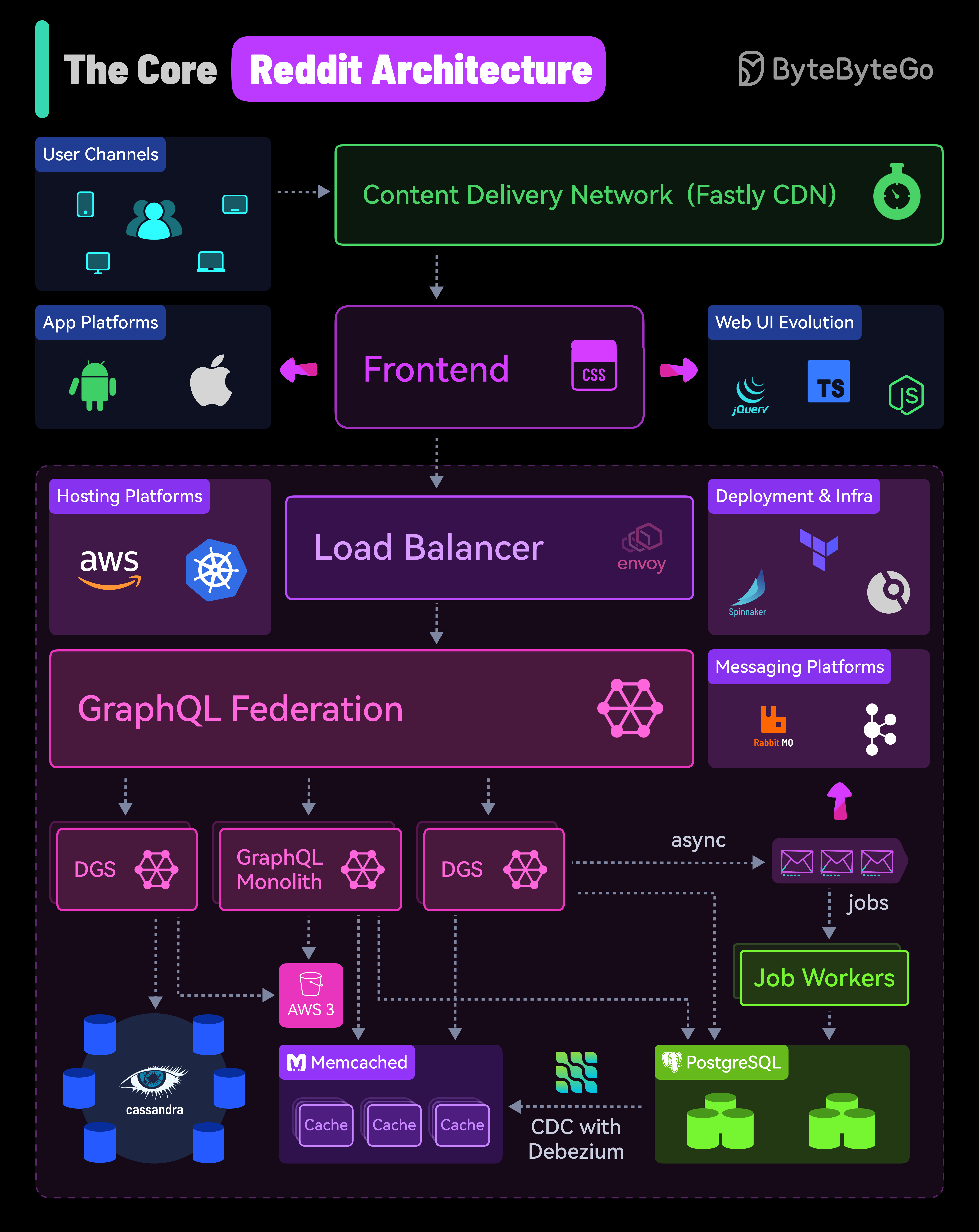
+
+A quick look at Reddit’s Core Architecture that helps it serve over 1 billion users every month.
+
+This information is based on research from many Reddit engineering blogs. But since architecture is ever-evolving, things might have changed in some aspects.
+
+The main points of Reddit’s architecture are as follows:
+
+* Reddit uses a Content Delivery Network (CDN) from Fastly as a front for the application.
+* Reddit started using jQuery in early 2009. Later on, they started using Typescript and have now moved to modern Node.js frameworks. Over the years, Reddit has also built mobile apps for Android and iOS.
+* Within the application stack, the load balancer sits in front and routes incoming requests to the appropriate services.
+* Reddit started as a Python-based monolithic application but has since started moving to microservices built using Go.
+* Reddit heavily uses GraphQL for its API layer. In early 2021, they started moving to GraphQL Federation, which is a way to combine multiple smaller GraphQL APIs known as Domain Graph Services (DGS). In 2022, the GraphQL team at Reddit added several new Go subgraphs for core Reddit entities thereby splitting the GraphQL monolith.
+* From a data storage point of view, Reddit relies on Postgres for its core data model. To reduce the load on the database, they use memcached in front of Postgres. Also, they use Cassandra quite heavily for new features mainly because of its resiliency and availability properties.
+* To support data replication and maintain cache consistency, Reddit uses Debezium to run a Change Data Capture process.
+* Expensive operations such as a user voting or submitting a link are deferred to an async job queue via RabbitMQ and processed by job workers. For content safety checks and moderation, they use Kafka to transfer data in real-time to run rules over them.
+* Reddit uses AWS and Kubernetes as the hosting platform for its various apps and internal services.
+* For deployment and infrastructure, they use Spinnaker, Drone CI, and Terraform.
diff --git a/data/guides/resiliency-patterns.md b/data/guides/resiliency-patterns.md
new file mode 100644
index 0000000..df61c78
--- /dev/null
+++ b/data/guides/resiliency-patterns.md
@@ -0,0 +1,31 @@
+---
+title: "Resiliency Patterns"
+description: "Explore cloud design patterns for building resilient systems."
+image: "https://assets.bytebytego.com/diagrams/0316-reliciency-patterns.jpg"
+createdAt: "2024-02-08"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Resilience"
+ - "Design Patterns"
+---
+
+Have you noticed that the largest incidents are usually caused by something very small?
+
+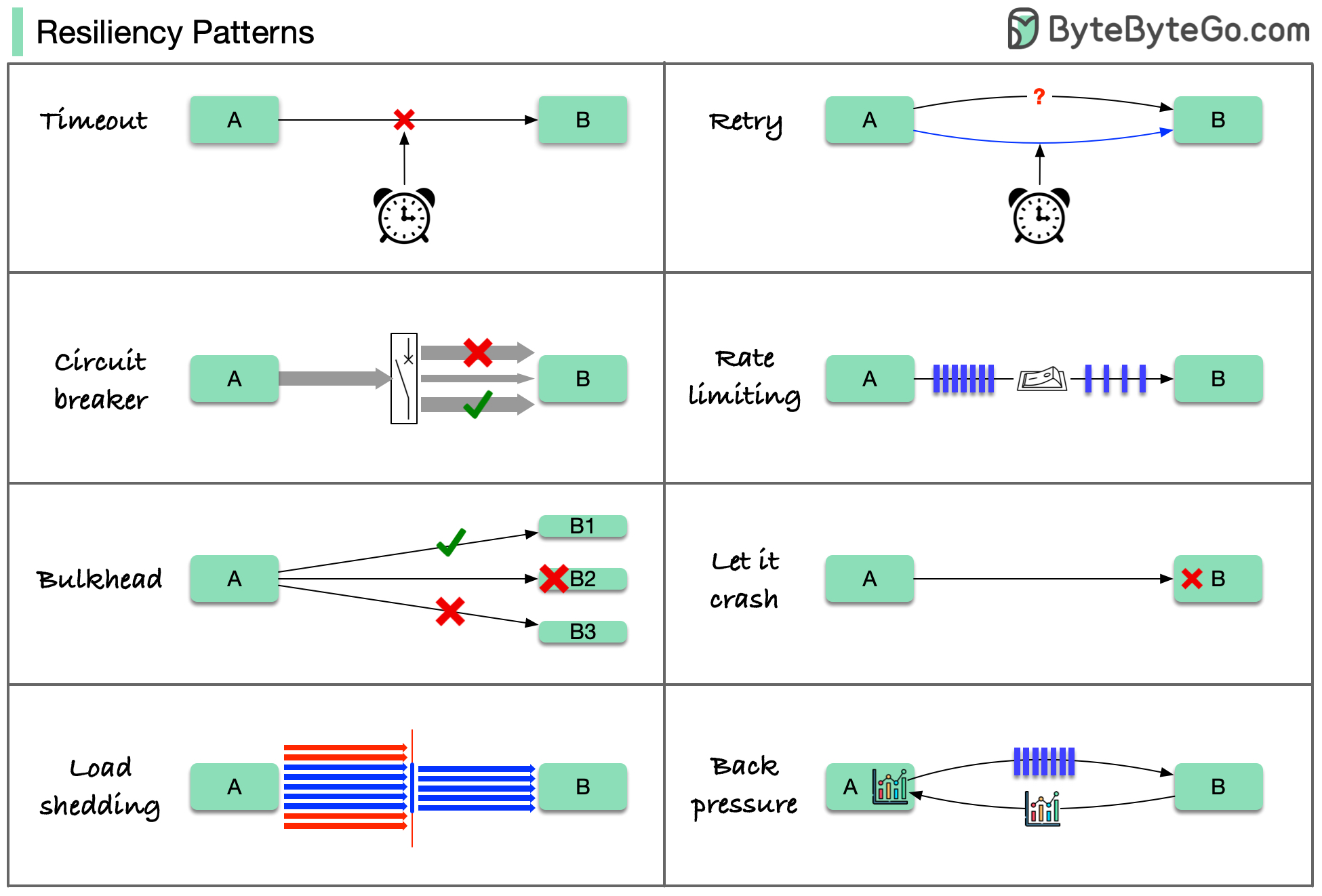
+
+A minor error starts the snowball effect that keeps building up. Suddenly, everything is down.
+
+Here are 8 cloud design patterns to reduce the damage done by failures.
+
+* Timeout
+* Retry
+* Circuit breaker
+* Rate limiting
+* Load shedding
+* Bulkhead
+* Back pressure
+* Let it crash
+
+These patterns are usually not used alone. To apply them effectively, we need to understand why we need them, how they work, and their limitations.
diff --git a/data/guides/rest-api-cheatsheet.md b/data/guides/rest-api-cheatsheet.md
new file mode 100644
index 0000000..0a19ca2
--- /dev/null
+++ b/data/guides/rest-api-cheatsheet.md
@@ -0,0 +1,24 @@
+---
+title: 'REST API Cheatsheet'
+description: 'A concise guide to REST API principles, components, and best practices.'
+image: 'https://assets.bytebytego.com/diagrams/0040-rest-api-cheatsheet.png'
+createdAt: '2024-03-13'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - REST
+---
+
+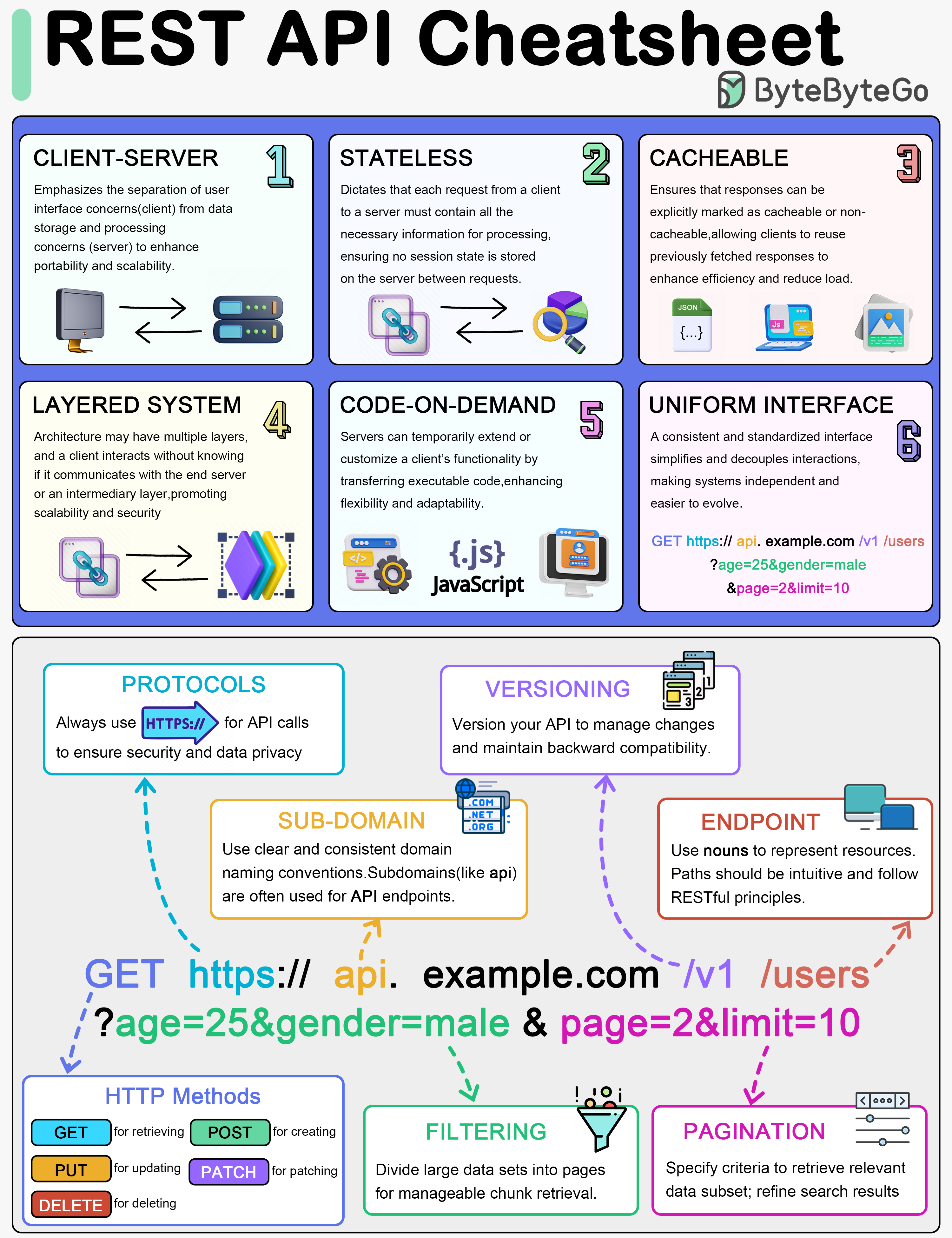
+
+This guide is designed to help you understand the world of RESTful APIs in a clear and engaging way.
+
+What's inside:
+
+* An exploration of the six fundamental principles of REST API design.
+* Insights into key components such as HTTP methods, protocols, versioning, and more.
+* A special focus on practical aspects like pagination, filtering, and endpoint design.
+
+Whether you're beginning your API journey or looking to refresh your knowledge, this blog and cheat sheet combo is the perfect toolkit for success.
diff --git a/data/guides/rest-api-vs-graphql.md b/data/guides/rest-api-vs-graphql.md
new file mode 100644
index 0000000..bd207f1
--- /dev/null
+++ b/data/guides/rest-api-vs-graphql.md
@@ -0,0 +1,34 @@
+---
+title: 'REST API vs. GraphQL'
+description: 'Explore the differences between REST API and GraphQL for API design.'
+image: 'https://assets.bytebytego.com/diagrams/0036-rest-vs-graphql.png'
+createdAt: '2024-03-11'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - GraphQL
+---
+
+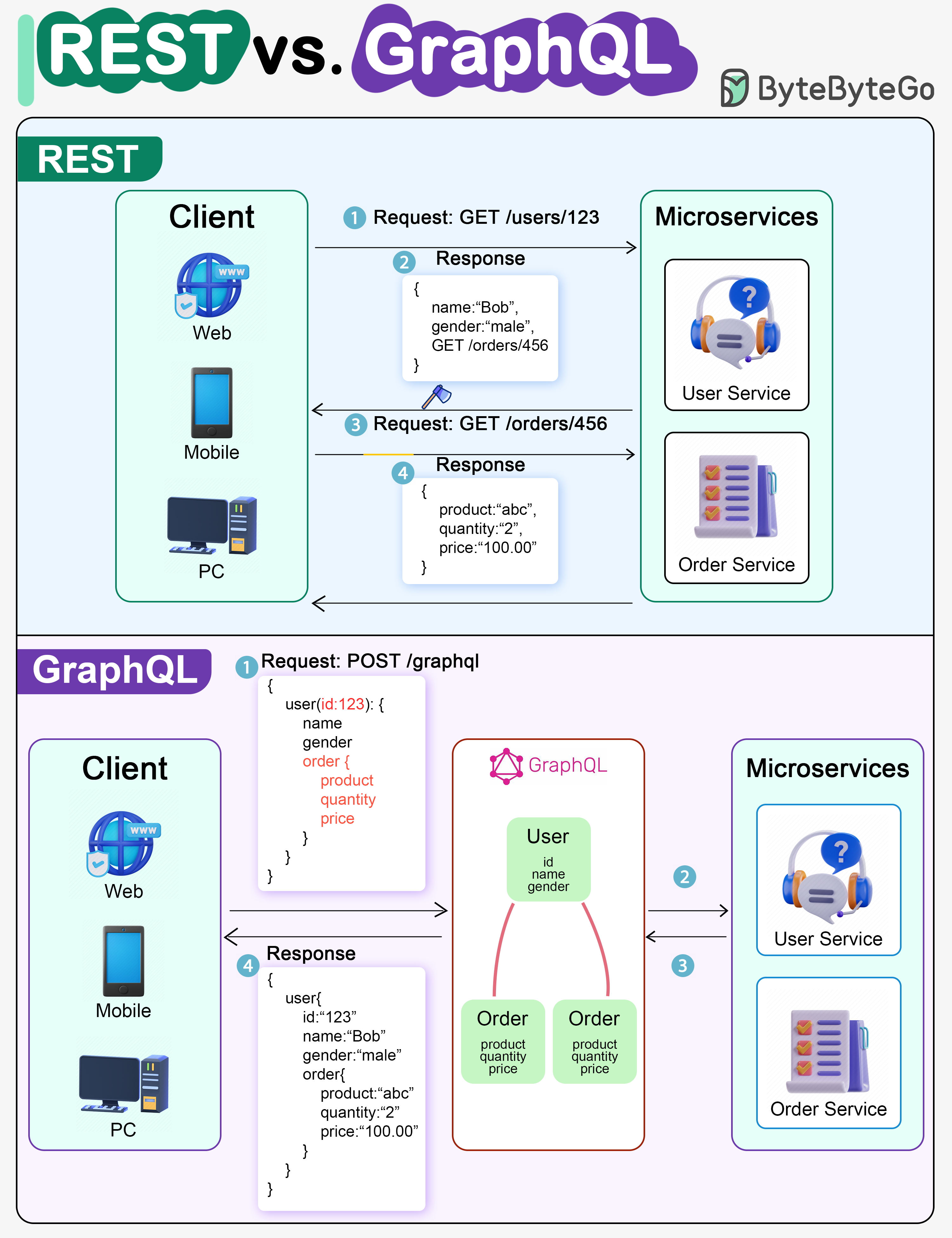
+
+When it comes to API design, REST and GraphQL each have their own strengths and weaknesses.
+
+**REST**
+
+* Uses standard HTTP methods like GET, POST, PUT, DELETE for CRUD operations.
+* Works well when you need simple, uniform interfaces between separate services/applications.
+* Caching strategies are straightforward to implement.
+* The downside is it may require multiple roundtrips to assemble related data from separate endpoints.
+
+**GraphQL**
+
+* Provides a single endpoint for clients to query for precisely the data they need.
+* Clients specify the exact fields required in nested queries, and the server returns optimized payloads containing just those fields.
+* Supports Mutations for modifying data and Subscriptions for real-time notifications.
+* Great for aggregating data from multiple sources and works well with rapidly evolving frontend requirements.
+* However, it shifts complexity to the client side and can allow abusive queries if not properly safeguarded.
+* Caching strategies can be more complicated than REST.
+
+The best choice between REST and GraphQL depends on the specific requirements of the application and development team. GraphQL is a good fit for complex or frequently changing frontend needs, while REST suits applications where simple and consistent contracts are preferred.
diff --git a/data/guides/reverse-proxy-vs-api-gateway-vs-load-balancer.md b/data/guides/reverse-proxy-vs-api-gateway-vs-load-balancer.md
new file mode 100644
index 0000000..be4677b
--- /dev/null
+++ b/data/guides/reverse-proxy-vs-api-gateway-vs-load-balancer.md
@@ -0,0 +1,28 @@
+---
+title: 'Reverse Proxy vs. API Gateway vs. Load Balancer'
+description: 'Understand the differences between reverse proxy, API gateway, and load balancer.'
+image: 'https://assets.bytebytego.com/diagrams/0320-reverse-gateway-lb.png'
+createdAt: '2024-02-09'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Load Balancing
+---
+
+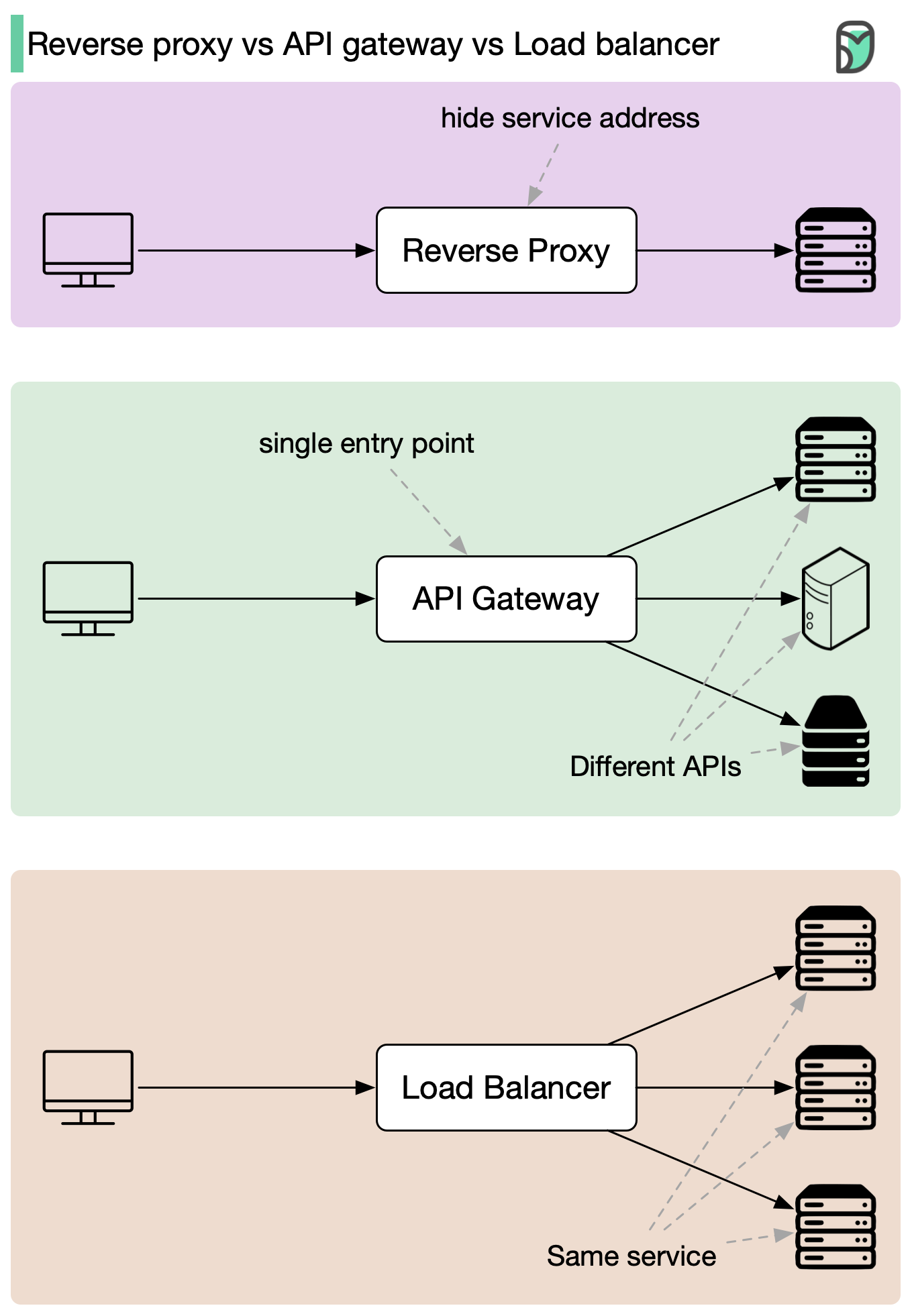
+
+As modern websites and applications are like busy beehives, we use a variety of tools to manage the buzz. Here we'll explore three superheroes: Reverse Proxy, API Gateway, and Load Balancer.
+
+* **Reverse Proxy:** change identity
+ * Fetching data secretly, keeping servers hidden.
+ * Perfect for shielding sensitive websites from cyber-attacks and prying eyes.
+* **API Gateway:** postman
+ * Delivers requests to the right services.
+ * Ideal for bustling applications with numerous intercommunicating services.
+* **Load Balancer:** traffic cop
+ * Directs traffic evenly across servers, preventing bottlenecks
+ * Essential for popular websites with heavy traffic and high demand.
+
+In a nutshell, choose a Reverse Proxy for stealth, an API Gateway for organized communications, and a Load Balancer for traffic control. Sometimes, it's wise to have all three - they make a super team that keeps your digital kingdom safe and efficient.
diff --git a/data/guides/session-cookie-jwt-token-sso-and-oauth-2.md b/data/guides/session-cookie-jwt-token-sso-and-oauth-2.md
new file mode 100644
index 0000000..097058c
--- /dev/null
+++ b/data/guides/session-cookie-jwt-token-sso-and-oauth-2.md
@@ -0,0 +1,28 @@
+---
+title: "Session, Cookie, JWT, Token, SSO, and OAuth 2.0 Explained"
+description: "Understanding sessions, cookies, JWT, SSO, and OAuth 2.0 in one diagram."
+image: "https://assets.bytebytego.com/diagrams/0152-cookies-session-jwt.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Authorization"
+---
+
+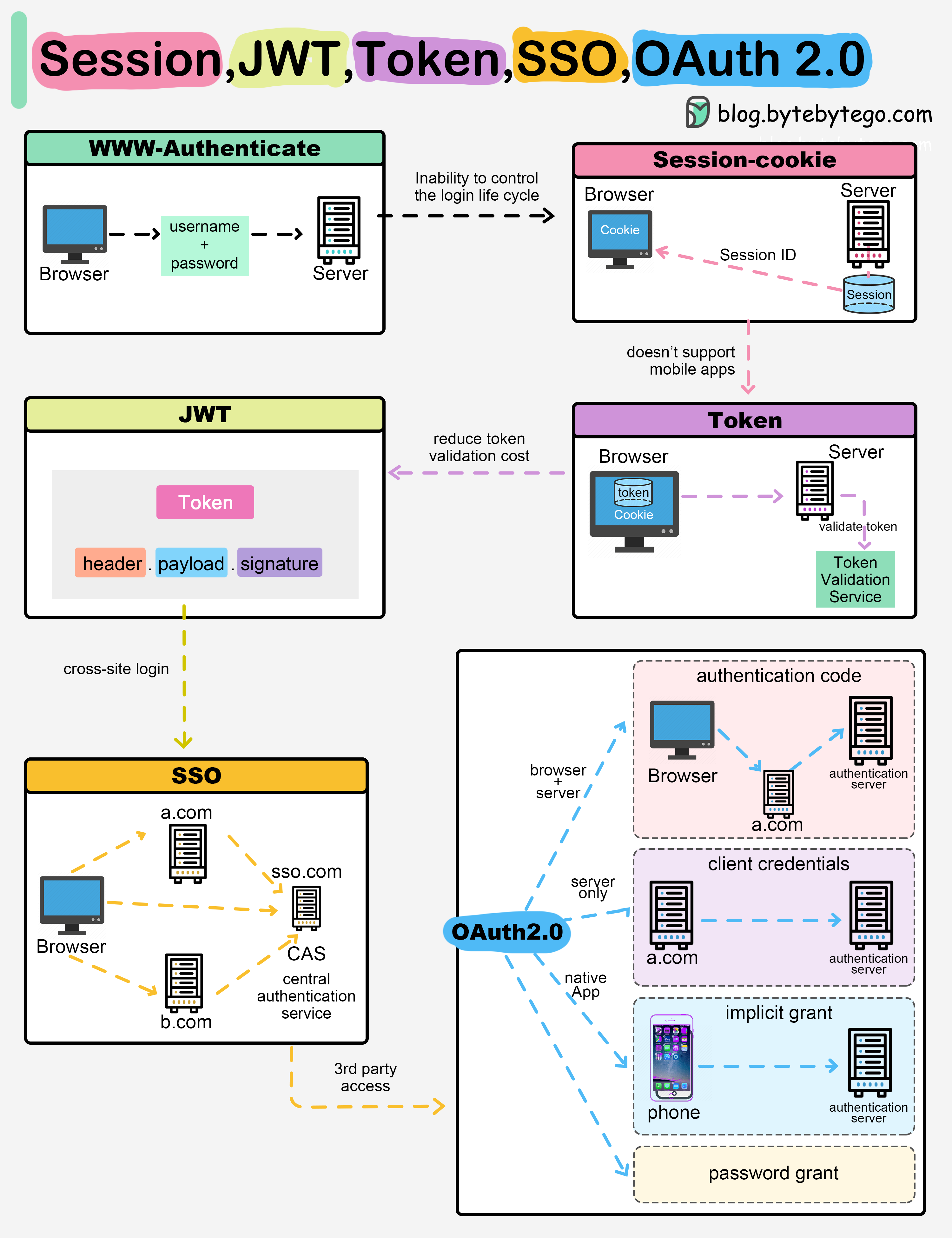
+
+When you login to a website, your identity needs to be managed. Here is how different solutions work:
+
+* **Session** - The server stores your identity and gives the browser a session ID cookie. This allows the server to track login state. But cookies don't work well across devices.
+
+* **Token** - Your identity is encoded into a token sent to the browser. The browser sends this token on future requests for authentication. No server session storage is required. But tokens need encryption/decryption.
+
+* **JWT** - JSON Web Tokens standardize identity tokens using digital signatures for trust. The signature is contained in the token so no server session is needed.
+
+* **SSO** - Single Sign On uses a central authentication service. This allows a single login to work across multiple sites.
+
+* **OAuth2** - Allows limited access to your data on one site by another site, without giving away passwords.
+
+* **QR Code** - Encodes a random token into a QR code for mobile login. Scanning the code logs you in without typing a password.
diff --git a/data/guides/shortlong-polling-sse-websocket.md b/data/guides/shortlong-polling-sse-websocket.md
new file mode 100644
index 0000000..a0aaac9
--- /dev/null
+++ b/data/guides/shortlong-polling-sse-websocket.md
@@ -0,0 +1,21 @@
+---
+title: 'Short/long polling, SSE, WebSocket'
+description: 'Explore real-time web updates: polling, SSE, and WebSockets.'
+image: 'https://assets.bytebytego.com/diagrams/0337-short-long-polling-sse-websocket.jpeg'
+createdAt: '2024-01-25'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - WebSockets
+ - SSE
+---
+
+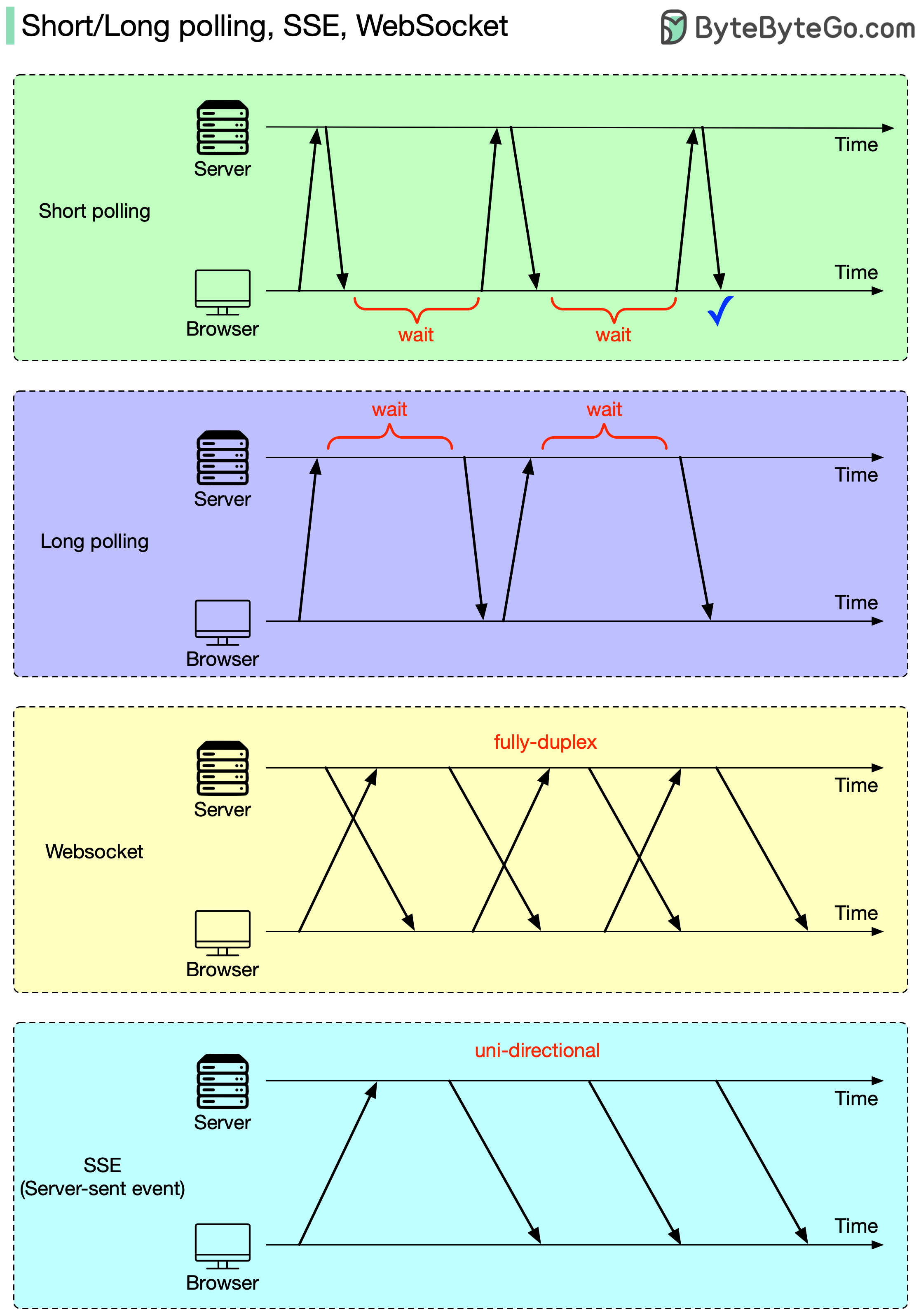
+
+An HTTP server cannot automatically initiate a connection to a browser. As a result, the web browser is the initiator. What should we do next to get real-time updates from the HTTP server?
+
+Both the web browser and the HTTP server could be responsible for this task.
+
+* **Web browsers do the heavy lifting**: short polling or long polling. With short polling, the browser will retry until it gets the latest data. With long polling, the HTTP server doesn’t return results until new data has arrived.
+* **HTTP server and web browser cooperate**: WebSocket or SSE (server-sent event). In both cases, the HTTP server could directly send the latest data to the browser after the connection is established. The difference is that SSE is uni-directional, so the browser cannot send a new request to the server, while WebSocket is fully-duplex, so the browser can keep sending new requests.
diff --git a/data/guides/smooth-data-migration-with-avro.md b/data/guides/smooth-data-migration-with-avro.md
new file mode 100644
index 0000000..6c3a746
--- /dev/null
+++ b/data/guides/smooth-data-migration-with-avro.md
@@ -0,0 +1,25 @@
+---
+title: "Smooth Data Migration with Avro"
+description: "Learn how Apache Avro facilitates smooth data migration with schema evolution."
+image: "https://assets.bytebytego.com/diagrams/0080-avro.png"
+createdAt: "2024-02-01"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Migration"
+ - "Apache Avro"
+---
+
+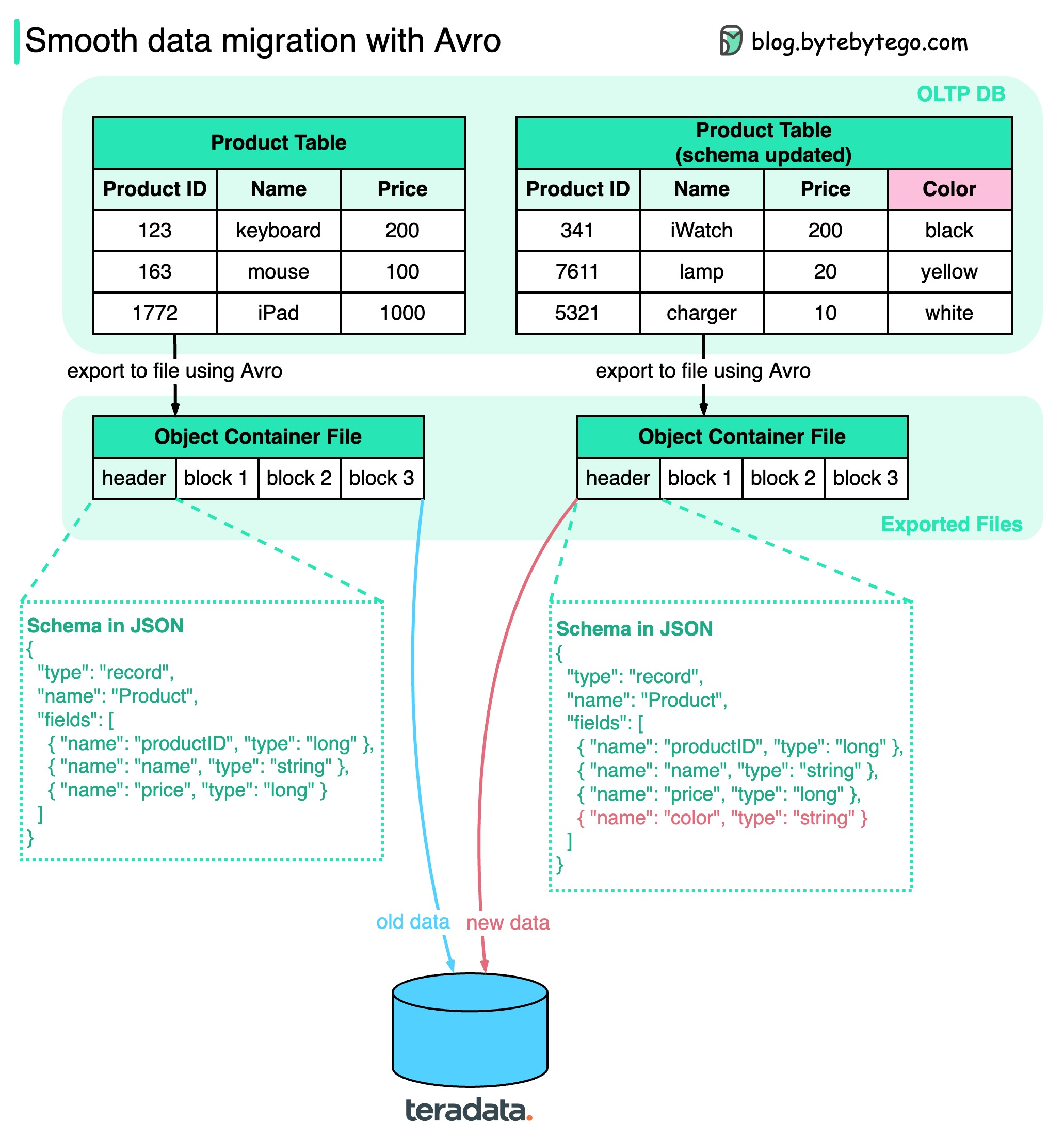
+
+How do we ensure when performing data migration? The diagram above shows how Apache Avro manages the schema evolution during data migration.
+
+Avro was started in 2009, initially as a subproject of Apache Hadoop to address Thrift’s limitation in Hadoop use cases. Avro is mainly used for two things: Data serialization and RPC.
+
+Key points in the diagram:
+
+* We can export the data to **object container files**, where schema sits together with the data blocks. Avro **dynamically** generates the schemas based on the columns, so if the schema is changed, a new schema is generated and stored with new data.
+
+* When the exported files are loaded into another data storage (for example, teradata), anyone can read the schema and know how to read the data. The old data and new data can be successfully migrated to the new database.
+ Unlike gRPC or Thrift, which statically generate schemas, Avro makes the data migration process easier.
diff --git a/data/guides/soap-vs-rest-vs-graphql-vs-rpc.md b/data/guides/soap-vs-rest-vs-graphql-vs-rpc.md
new file mode 100644
index 0000000..b9cdeaf
--- /dev/null
+++ b/data/guides/soap-vs-rest-vs-graphql-vs-rpc.md
@@ -0,0 +1,20 @@
+---
+title: 'SOAP vs REST vs GraphQL vs RPC'
+description: 'A comparison of API styles: SOAP, REST, GraphQL, and RPC.'
+image: 'https://assets.bytebytego.com/diagrams/0126-api-style-compare.jpg'
+createdAt: '2024-02-25'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Architecture
+---
+
+The diagram above illustrates the API timeline and API styles comparison.
+
+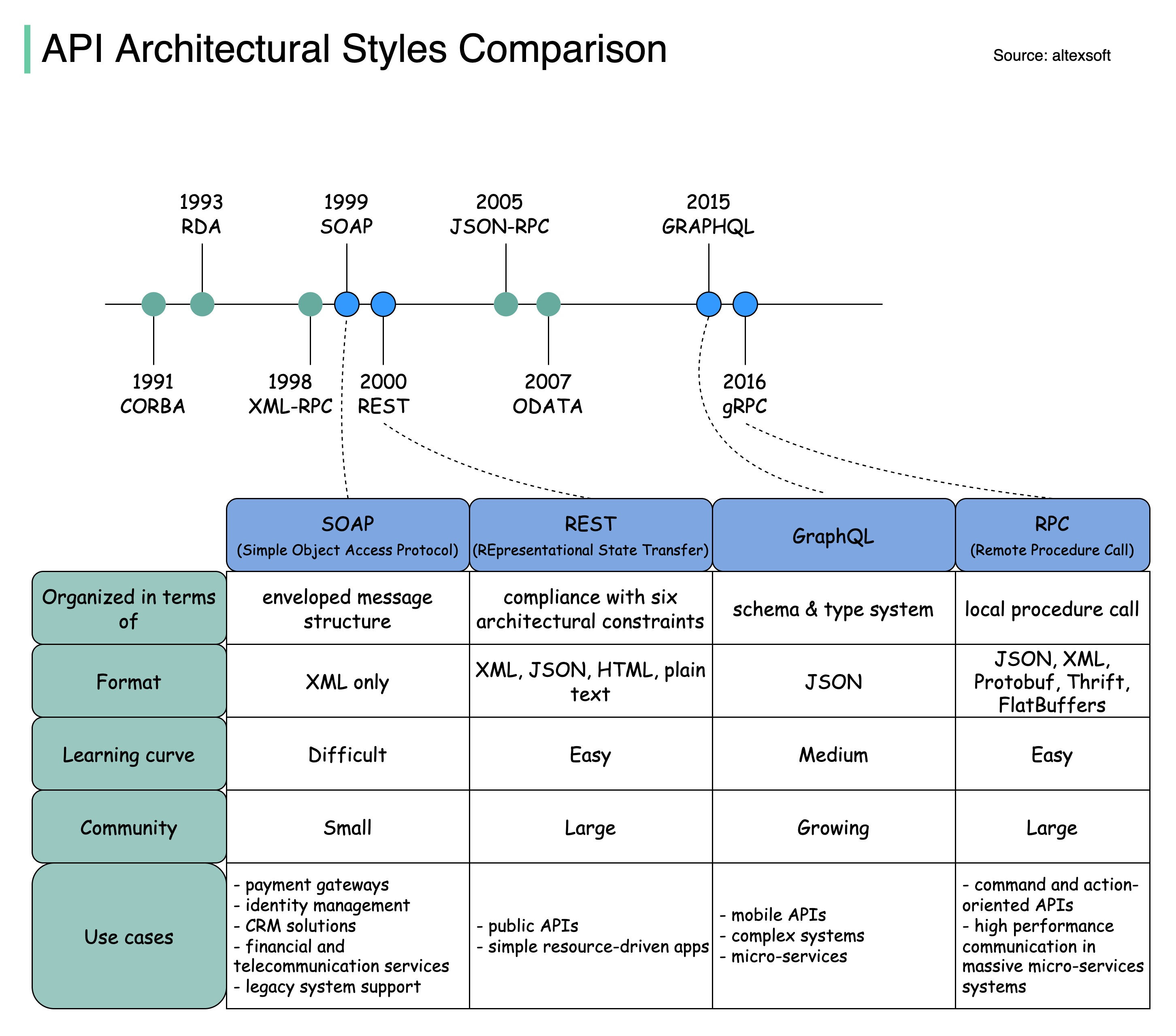
+
+Over time, different API architectural styles are released. Each of them has its own patterns of standardizing data exchange.
+
+You can check out the use cases of each style in the diagram.
diff --git a/data/guides/some-devops-books-i-find-enlightening.md b/data/guides/some-devops-books-i-find-enlightening.md
new file mode 100644
index 0000000..90e7712
--- /dev/null
+++ b/data/guides/some-devops-books-i-find-enlightening.md
@@ -0,0 +1,28 @@
+---
+title: "Some DevOps Books I Find Enlightening"
+description: "A list of enlightening DevOps books covering SRE, delivery, and more."
+image: "https://assets.bytebytego.com/diagrams/0171-dev-ops-books.jpg"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - DevOps
+ - SRE
+---
+
+
+
+## DevOps Books
+
+* **Accelerate** - presents both the findings and the science behind measuring software delivery performance.
+
+* **Continuous Delivery** - introduces automated architecture management and data migration. It also pointed out key problems and optimal solutions in each area.
+
+* **Site Reliability Engineering** - famous Google SRE book. It explains the whole life cycle of Google’s development, deployment, and monitoring, and how to manage the world’s biggest software systems.
+
+* **Effective DevOps** - provides effective ways to improve team coordination.
+
+* **The Phoenix Project** - a classic novel about effectiveness and communications. IT work is like manufacturing plant work, and a system must be established to streamline the workflow. Very interesting read!
+
+* **The DevOps Handbook** - introduces product development, quality assurance, IT operations, and information security.
diff --git a/data/guides/storage-systems-overview.md b/data/guides/storage-systems-overview.md
new file mode 100644
index 0000000..66755c8
--- /dev/null
+++ b/data/guides/storage-systems-overview.md
@@ -0,0 +1,42 @@
+---
+title: "Storage Systems Overview"
+description: "A detailed overview of block, file, and object storage systems."
+image: "https://assets.bytebytego.com/diagrams/0346-storage-system.png"
+createdAt: "2024-02-13"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Storage Systems"
+ - "Data Storage"
+---
+
+
+
+# **Storage systems overview**
+
+Let's review the storage systems in general.
+
+Storage systems fall into three broad categories:
+
+* Block storage
+* File storage
+* Object storage
+
+The diagram above illustrates the comparison of different storage systems.
+
+## Block Storage
+
+Block storage came first, in the 1960s. Common storage devices like hard disk drives (HDD) and solid-state drives (SSD) that are physically attached to servers are all considered as block storage.
+
+Block storage presents the raw blocks to the server as a volume. This is the most flexible and versatile form of storage. The server can format the raw blocks and use them as a file system, or it can hand control of those blocks to an application. Some applications like a database or a virtual machine engine manage these blocks directly in order to squeeze every drop of performance out of them.
+
+Block storage is not limited to physically attached storage. Block storage could be connected to a server over a high-speed network or over industry-standard connectivity protocols like Fibre Channel (FC) and iSCSI. Conceptually, the network-attached block storage still presents raw blocks. To the servers, it works the same as physically attached block storage. Whether to a network or physically attached, block storage is fully owned by a single server. It is not a shared resource.
+
+## File storage
+
+File storage is built on top of block storage. It provides a higher-level abstraction to make it easier to handle files and directories. Data is stored as files under a hierarchical directory structure. File storage is the most common general-purpose storage solution. File storage could be made accessible by a large number of servers using common file-level network protocols like SMB/CIFS and NFS. The servers accessing file storage do not need to deal with the complexity of managing the blocks, formatting volume, etc. The simplicity of file storage makes it a great solution for sharing a large number of files and folders within an organization.
+
+## Object storage
+
+Object storage is new. It makes a very deliberate tradeoff to sacrifice performance for high durability, vast scale, and low cost. It targets relatively “cold” data and is mainly used for archival and backup. Object storage stores all data as objects in a flat structure. There is no hierarchical directory structure. Data access is normally provided via a RESTful API. It is relatively slow compared to other storage types. Most public cloud service providers have an object storage offering, such as AWS S3, Google block storage, and Azure blob storage.
diff --git a/data/guides/swift-payment-messaging-system.md b/data/guides/swift-payment-messaging-system.md
new file mode 100644
index 0000000..22cd975
--- /dev/null
+++ b/data/guides/swift-payment-messaging-system.md
@@ -0,0 +1,54 @@
+---
+title: "SWIFT Payment Messaging System"
+description: "Explore the SWIFT system, its role in secure, cross-border payments."
+image: "https://assets.bytebytego.com/diagrams/0348-swift-payment-messaging-system.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Finance"
+---
+
+
+
+You probably heard about SWIFT. What is SWIFT? What role does it play in cross-border payments? You can find answers to those questions in this post.
+
+The Society for Worldwide Interbank Financial Telecommunication (SWIFT) is the main secure **messaging system** that links the world’s banks.
+
+The Belgium-based system is run by its member banks and handles millions of payment messages per day. The diagram above illustrates how payment messages are transmitted from Bank A (in New York) to Bank B (in London).
+
+## SWIFT Message Flow
+
+Step 1: Bank A sends a message with transfer details to Regional Processor A in New York. The destination is Bank B.
+
+Step 2: Regional processor validates the format and sends it to Slice Processor A. The Regional Processor is responsible for input message validation and output message queuing. The Slice Processor is responsible for storing and routing messages safely.
+
+Step 3: Slice Processor A stores the message.
+
+Step 4: Slice Processor A informs Regional Processor A the message is stored.
+
+Step 5: Regional Processor A sends ACK/NAK to Bank A. ACK means a message will be sent to Bank B. NAK means the message will NOT be sent to Bank B.
+
+Step 6: Slice Processor A sends the message to Regional Processor B in London.
+
+Step 7: Regional Processor B stores the message temporarily.
+
+Step 8: Regional Processor B assigns a unique ID MON (Message Output Number) to the message and sends it to Slice Processor B
+
+Step 9: Slice Processor B validates MON.
+
+Step 10: Slice Processor B authorizes Regional Processor B to send the message to Bank B.
+
+Step 11: Regional Processor B sends the message to Bank B.
+
+Step 12: Bank B receives the message and stores it.
+
+Step 13: Bank B sends UAK/UNK to Regional Processor B. UAK (user positive acknowledgment) means Bank B received the message without error; UNK (user negative acknowledgment) means Bank B received checksum failure.
+
+Step 14: Regional Processor B creates a report based on Bank B’s response, and sends it to Slice Processor B.
+
+Step 15: Slice Processor B stores the report.
+
+Step 16 - 17: Slice Processor B sends a copy of the report to Slice Processor A. Slice Processor A stores the report.
diff --git a/data/guides/symmetric-encryption-vs-asymmetric-encryption.md b/data/guides/symmetric-encryption-vs-asymmetric-encryption.md
new file mode 100644
index 0000000..4d37e83
--- /dev/null
+++ b/data/guides/symmetric-encryption-vs-asymmetric-encryption.md
@@ -0,0 +1,20 @@
+---
+title: "Symmetric vs Asymmetric Encryption"
+description: "Explore symmetric vs asymmetric encryption: methods, security, and use cases."
+image: "https://assets.bytebytego.com/diagrams/0349-symmetric-encryption-vs-asymmetric-encryption.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - security
+tags:
+ - "Encryption"
+ - "Cryptography"
+---
+
+
+
+Symmetric encryption and asymmetric encryption are two types of cryptographic techniques used to secure data and communications, but they differ in their methods of encryption and decryption.
+
+* In symmetric encryption, a single key is used for both encryption and decryption of data. It is faster and can be applied to bulk data encryption/decryption. For example, we can use it to encrypt massive amounts of PII (Personally Identifiable Information) data. It poses challenges in key management because the sender and receiver share the same key.
+
+* Asymmetric encryption uses a pair of keys: a public key and a private key. The public key is freely distributed and used to encrypt data, while the private key is kept secret and used to decrypt the data. It is more secure than symmetric encryption because the private key is never shared. However, asymmetric encryption is slower because of the complexity of key generation and maths computations. For example, HTTPS uses asymmetric encryption to exchange session keys during TLS handshake, and after that, HTTPS uses symmetric encryption for subsequent communications.
diff --git a/data/guides/system-design-blueprint-the-ultimate-guide.md b/data/guides/system-design-blueprint-the-ultimate-guide.md
new file mode 100644
index 0000000..fa2bf18
--- /dev/null
+++ b/data/guides/system-design-blueprint-the-ultimate-guide.md
@@ -0,0 +1,35 @@
+---
+title: "System Design Blueprint: The Ultimate Guide"
+description: "A system design blueprint to tackle various system design problems."
+image: "https://assets.bytebytego.com/diagrams/0324-system-design-blueprint.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system-design"
+ - "interview-preparation"
+---
+
+We've created a template to tackle various system design problems in interviews.
+
+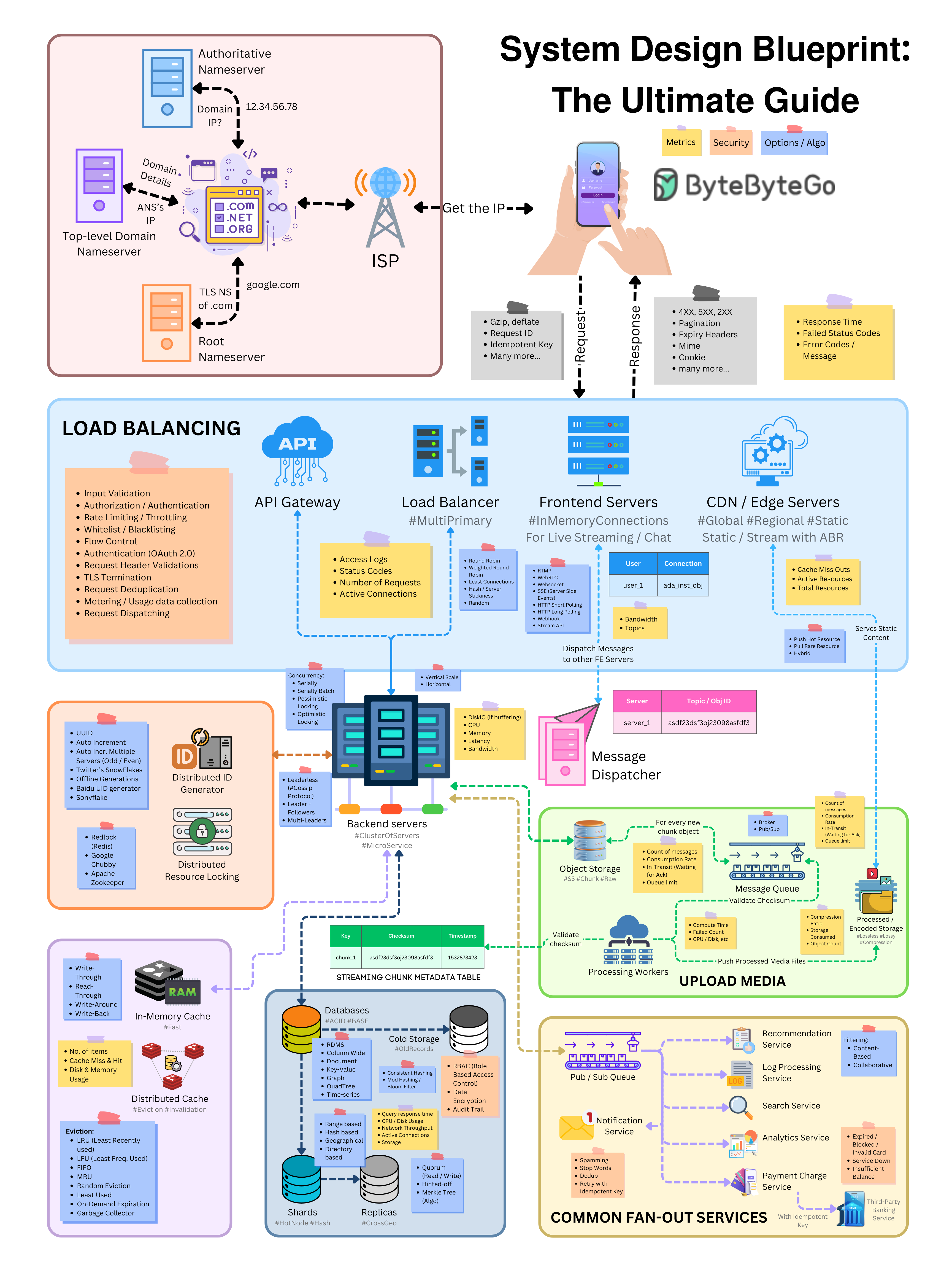
+
+Hope this checklist is useful to guide your discussions during the interview process.
+
+This briefly touches on the following discussion points:
+
+* Load Balancing
+* API Gateway
+* Communication Protocols
+* Content Delivery Network (CDN)
+* Database
+* Cache
+* Message Queue
+* Unique ID Generation
+* Scalability
+* Availability
+* Performance
+* Security
+* Fault Tolerance and Resilience
+* And more
diff --git a/data/guides/system-design-cheat-sheet.md b/data/guides/system-design-cheat-sheet.md
new file mode 100644
index 0000000..675f5ea
--- /dev/null
+++ b/data/guides/system-design-cheat-sheet.md
@@ -0,0 +1,39 @@
+---
+title: "System Design Cheat Sheet"
+description: "A system design cheat sheet with common solutions for system architects."
+image: "https://assets.bytebytego.com/diagrams/0351-system-design-cheat-sheet.png"
+createdAt: "2024-01-28"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "System Design"
+ - "Scalability"
+---
+
+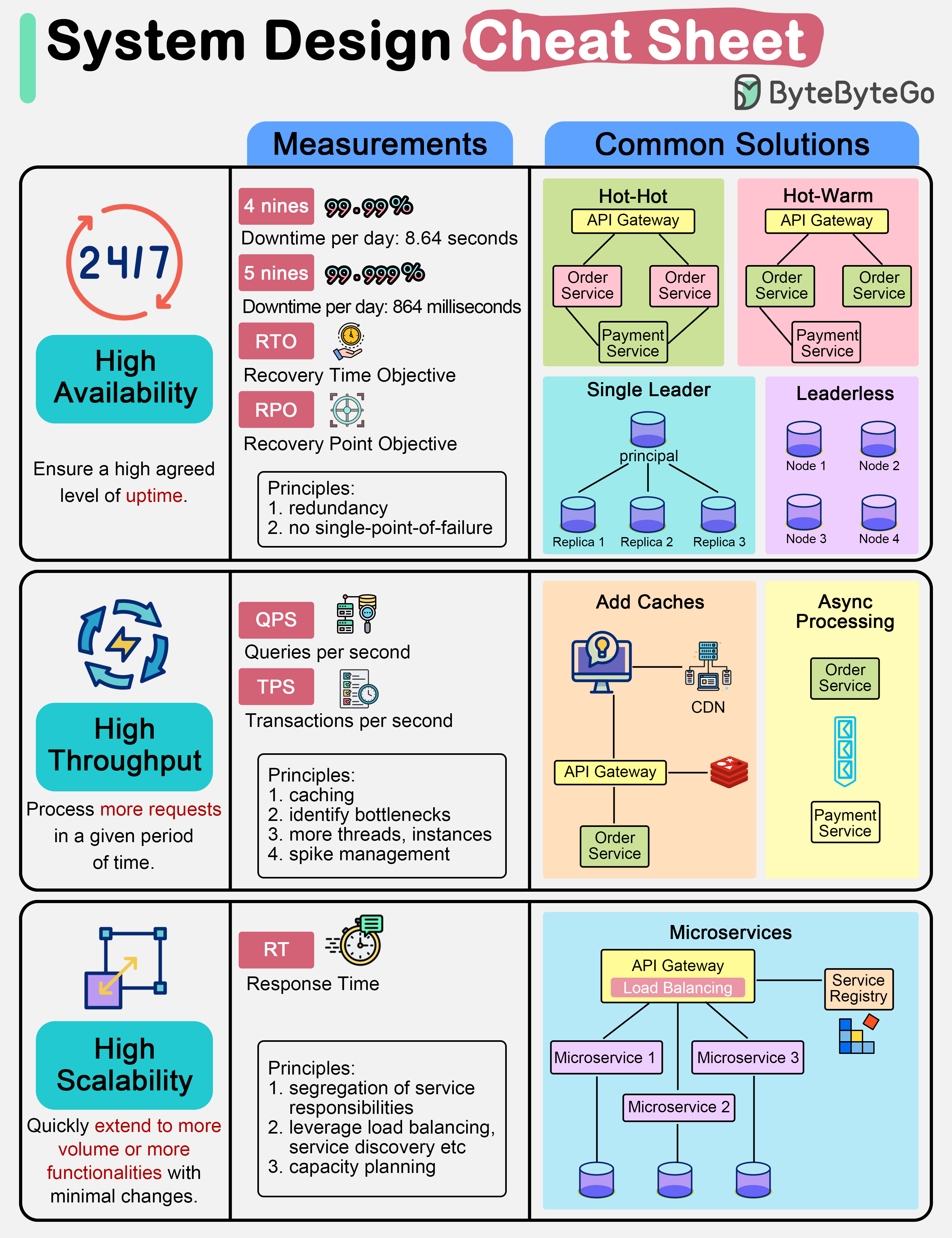
+
+We are often asked to design for high availability, high scalability, and high throughput. What do they mean exactly?
+
+The diagram below is a system design cheat sheet with common solutions.
+
+## High Availability
+
+This means we need to ensure a high agreed level of uptime. We often describe the design target as “3 nines” or “4 nines”. “4 nines”, 99.99% uptime, means the service can only be down 8.64 seconds per day.
+
+To achieve high availability, we need to design redundancy in the system. There are several ways to do this:
+
+* Hot-hot: two instances receive the same input and send the output to the downstream service. In case one side is down, the other side can immediately take over. Since both sides send output to the downstream, the downstream system needs to dedupe.
+* Hot-warm: two instances receive the same input and only the hot side sends the output to the downstream service. In case the hot side is down, the warm side takes over and starts to send output to the downstream service.
+* Single-leader cluster: one leader instance receives data from the upstream system and replicates to other replicas.
+* Leaderless cluster: there is no leader in this type of cluster. Any write will get replicated to other instances. As long as the number of write instances plus the number of read instances are larger than the total number of instances, we should get valid data.
+
+## High Throughput
+
+This means the service needs to handle a high number of requests given a period of time. Commonly used metrics are QPS (query per second) or TPS (transaction per second).
+
+To achieve high throughput, we often add caches to the architecture so that the request can return without hitting slower I/O devices like databases or disks. We can also increase the number of threads for computation-intensive tasks. However, adding too many threads can deteriorate the performance. We then need to identify the bottlenecks in the system and increase its throughput. Using asynchronous processing can often effectively isolate heavy-lifting components.
+
+## High Scalability
+
+This means a system can quickly and easily extend to accommodate more volume (horizontal scalability) or more functionalities (vertical scalability). Normally we watch the response time to decide if we need to scale the system.
diff --git a/data/guides/the-12-factor-app.md b/data/guides/the-12-factor-app.md
new file mode 100644
index 0000000..d63d29f
--- /dev/null
+++ b/data/guides/the-12-factor-app.md
@@ -0,0 +1,66 @@
+---
+title: "The 12-Factor App"
+description: "Best practices for building modern, scalable, and reliable applications."
+image: "https://assets.bytebytego.com/diagrams/0028-12-factor-app.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Application Architecture"
+ - "Best Practices"
+---
+
+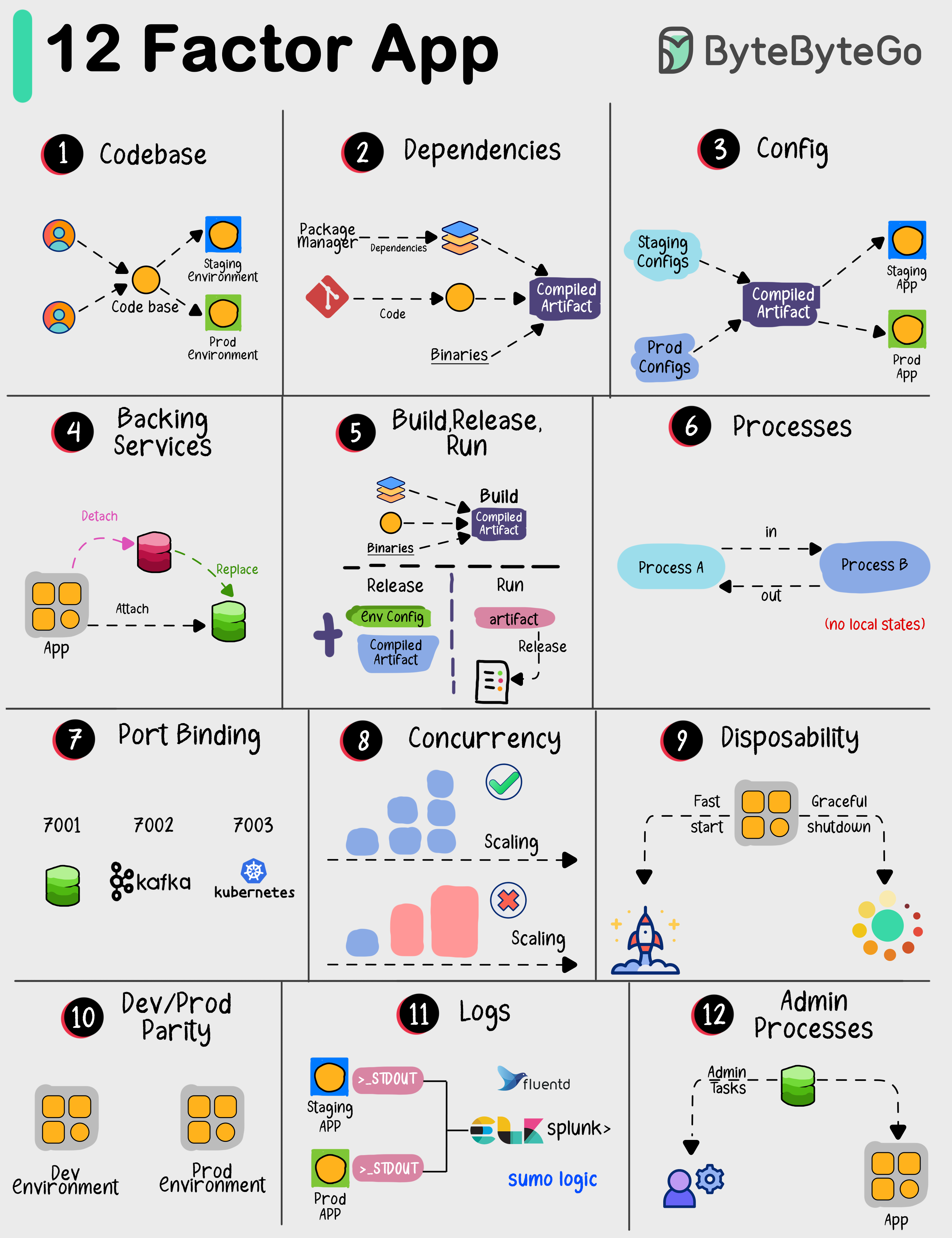
+
+The "12 Factor App" offers a set of best practices for building modern software applications. Following these 12 principles can help developers and teams in building reliable, scalable, and manageable applications.
+
+Here's a brief overview of each principle:
+
+## I. Codebase
+
+Have one place to keep all your code, and manage it using version control like Git.
+
+## II. Dependencies
+
+List all the things your app needs to work properly, and make sure they're easy to install.
+
+## III. Config
+
+Keep important settings like database credentials separate from your code, so you can change them without rewriting code.
+
+## IV. Backing Services
+
+Use other services (like databases or payment processors) as separate components that your app connects to.
+
+## V. Build, Release, Run
+
+Make a clear distinction between preparing your app, releasing it, and running it in production.
+
+## VI. Processes
+
+Design your app so that each part doesn't rely on a specific computer or memory. It's like making LEGO blocks that fit together.
+
+## VII. Port Binding
+
+Let your app be accessible through a network port, and make sure it doesn't store critical information on a single computer.
+
+## VIII. Concurrency
+
+Make your app able to handle more work by adding more copies of the same thing, like hiring more workers for a busy restaurant.
+
+## IX. Disposability
+
+Your app should start quickly and shut down gracefully, like turning off a light switch instead of yanking out the power cord.
+
+## X. Dev/Prod Parity
+
+Ensure that what you use for developing your app is very similar to what you use in production, to avoid surprises.
+
+## XI. Logs
+
+Keep a record of what happens in your app so you can understand and fix issues, like a diary for your software.
+
+## XII. Admin Processes
+
+Run special tasks separately from your app, like doing maintenance work in a workshop instead of on the factory floor.
diff --git a/data/guides/the-9-algorithms-that-dominate-our-world.md b/data/guides/the-9-algorithms-that-dominate-our-world.md
new file mode 100644
index 0000000..40e6385
--- /dev/null
+++ b/data/guides/the-9-algorithms-that-dominate-our-world.md
@@ -0,0 +1,34 @@
+---
+title: "The 9 Algorithms That Dominate Our World"
+description: "Explore the 9 algorithms that power our daily digital experiences."
+image: "https://assets.bytebytego.com/diagrams/0018-9-algorithms-that-dominate-our-world.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Algorithms"
+ - "Data Science"
+---
+
+
+
+The diagram below shows the most commonly used algorithms in our daily lives. They are used in internet search engines, social networks, WiFi, cell phones, and even satellites.
+
+## 1. Sorting
+
+## 2. Dijkstra’s Algorithm
+
+## 3. Transformers
+
+## 4. Link Analysis
+
+## 5. RSA Algorithm
+
+## 6. Integer Factorization
+
+## 7. Convolutional Neural Networks
+
+## 8. Huffman Coding
+
+## 9. Secure Hash Algorithm
diff --git a/data/guides/the-evolving-landscape-of-api-protocols-in-2023.md b/data/guides/the-evolving-landscape-of-api-protocols-in-2023.md
new file mode 100644
index 0000000..12f5a34
--- /dev/null
+++ b/data/guides/the-evolving-landscape-of-api-protocols-in-2023.md
@@ -0,0 +1,20 @@
+---
+title: 'The Evolving Landscape of API Protocols in 2023'
+description: 'Explore the evolving landscape of API protocols in 2023.'
+image: 'https://assets.bytebytego.com/diagrams/0077-api-protocols.png'
+createdAt: '2024-03-15'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Protocols
+---
+
+This is a brief summary of the blog post I wrote for Postman.
+
+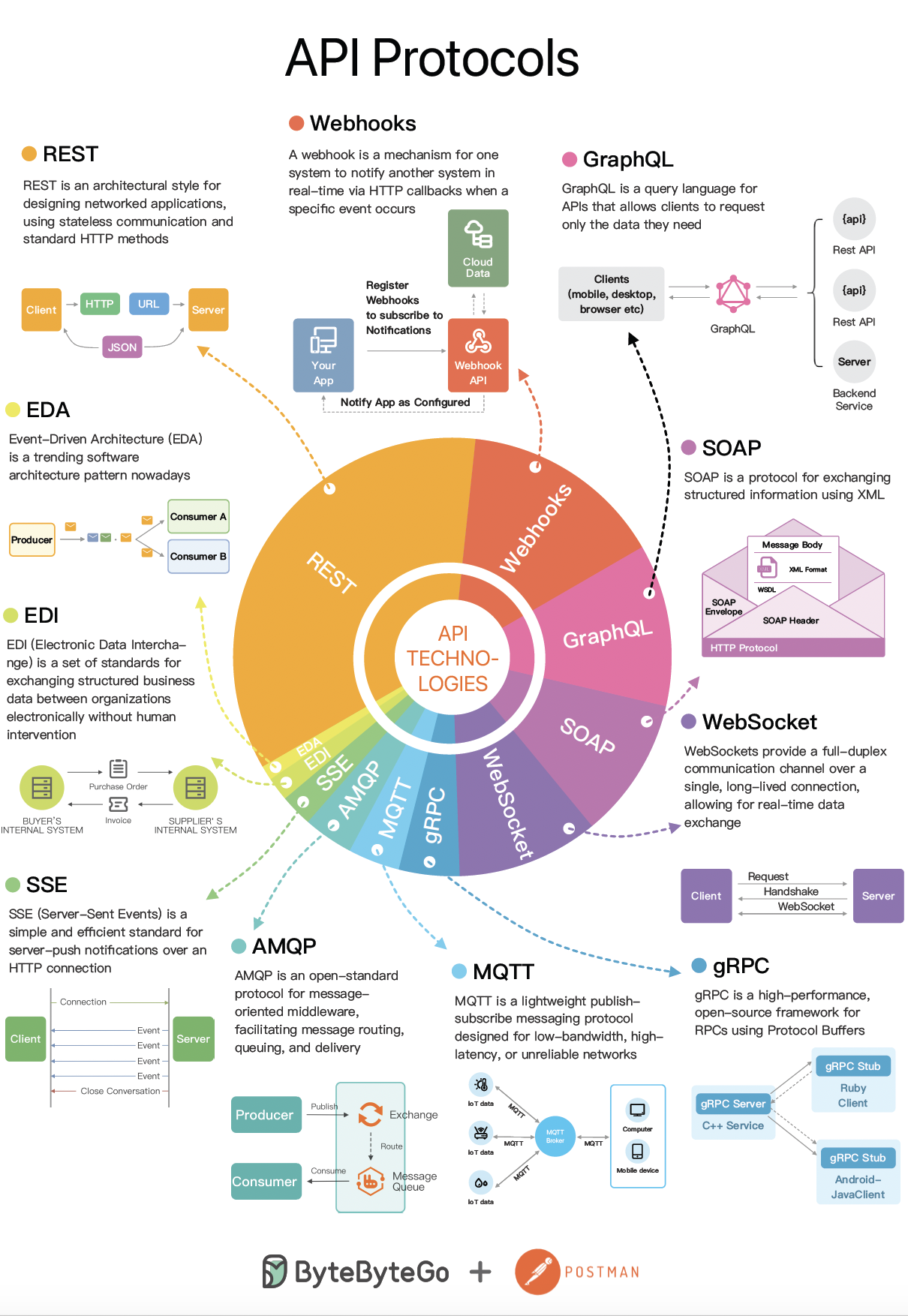
+
+In this blog post, I cover the six most popular API protocols: REST, Webhooks, GraphQL, SOAP, WebSocket, and gRPC. The discussion includes the benefits and challenges associated with each protocol.
+
+You can read the [full blog post here](https://blog.postman.com/api-protocols-in-2023/).
diff --git a/data/guides/the-fundamental-pillars-of-object-oriented-programming.md b/data/guides/the-fundamental-pillars-of-object-oriented-programming.md
new file mode 100644
index 0000000..5afa6ba
--- /dev/null
+++ b/data/guides/the-fundamental-pillars-of-object-oriented-programming.md
@@ -0,0 +1,32 @@
+---
+title: "The Fundamental Pillars of Object-Oriented Programming"
+description: "Explore the core principles of object-oriented programming (OOP)."
+image: "https://assets.bytebytego.com/diagrams/0197-4-fundamental-pillars-of-object-oriented-programming.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - software-development
+tags:
+ - OOP
+ - Principles
+---
+
+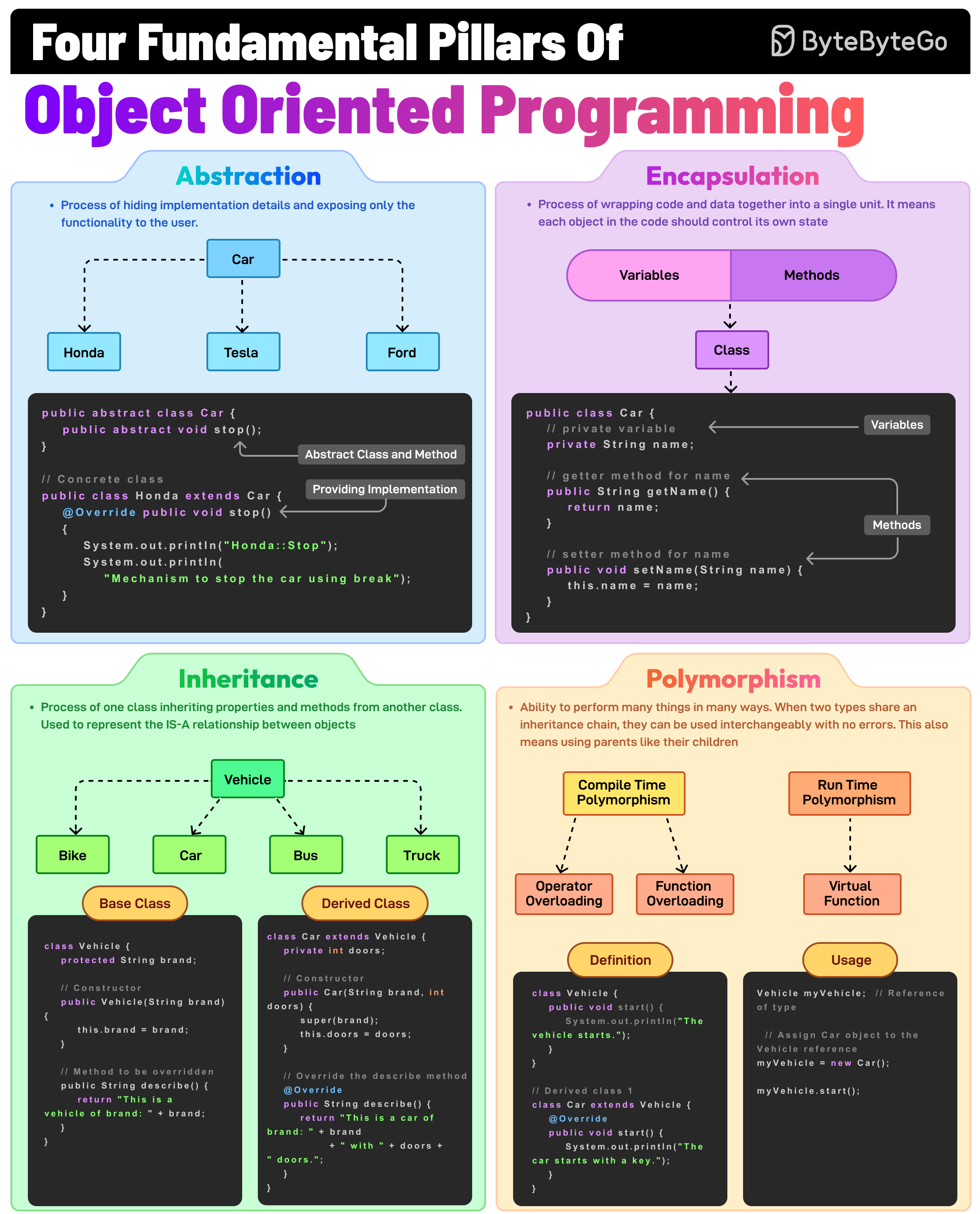
+
+Abstraction, Encapsulation, Inheritance, and Polymorphism are the four pillars of object-oriented programming. What do they mean?
+
+## Abstraction
+
+This is the process of hiding implementation details and showing only the essential features of an object. For example, a Vehicle class with an abstract stop method.
+
+## Encapsulation
+
+It involves wrapping data (fields) and methods in a single unit (class) and restricting direct access using access modifiers. For example, private fields with public getters and setters.
+
+## Inheritance
+
+The process of creating a new class (child) that inherits attributes and methods from an existing class (parent), thereby promoting code reuse. For example, a Car class inherits from a Vehicle class.
+
+## Polymorphism
+
+It allows methods to perform differently based on the object they are invoked on. When two types share an inheritance chain, they can be used interchangeably with no errors.
diff --git a/data/guides/the-one-line-change-that-reduced-clone-times-by-a-whopping-99-says-pinterest.md b/data/guides/the-one-line-change-that-reduced-clone-times-by-a-whopping-99-says-pinterest.md
new file mode 100644
index 0000000..309564b
--- /dev/null
+++ b/data/guides/the-one-line-change-that-reduced-clone-times-by-a-whopping-99-says-pinterest.md
@@ -0,0 +1,46 @@
+---
+title: 'The one-line change that reduced clone times by 99% at Pinterest'
+description: 'A one-line change reduced clone times by 99% at Pinterest.'
+image: 'https://assets.bytebytego.com/diagrams/0302-pinterest-one-line-change.png'
+createdAt: '2024-02-14'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - DevOps
+ - Git
+---
+
+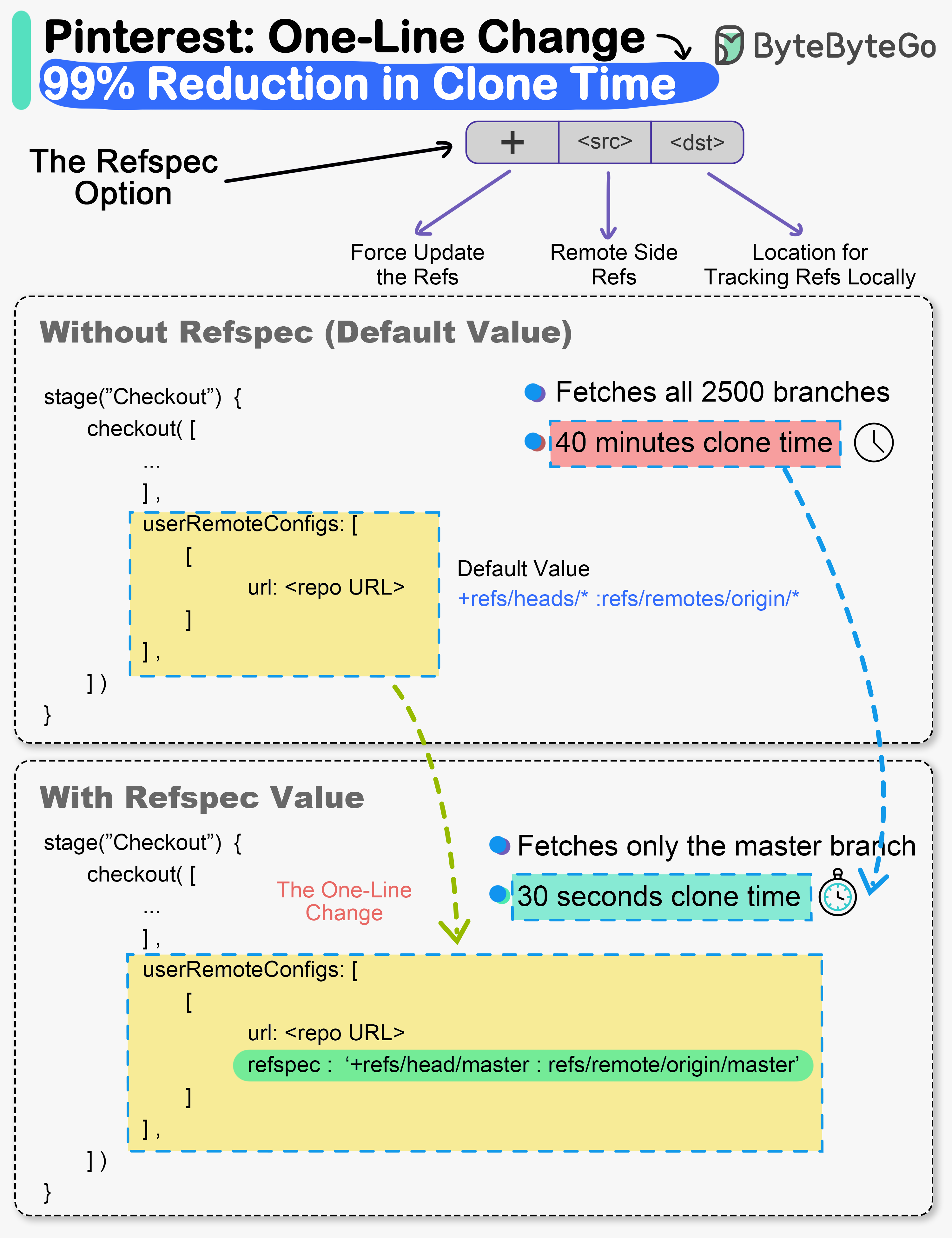
+
+While it may sound cliché, small changes can definitely create a big impact.
+
+The Engineering Productivity team at Pinterest witnessed this first-hand.
+
+They made a small change in the Jenkins build pipeline of their monorepo codebase called Pinboard.
+
+And it brought down clone times from 40 minutes to a staggering 30 seconds.
+
+For reference, Pinboard is the oldest and largest monorepo at Pinterest. Some facts about it:
+
+* **350K commits**
+* **20 GB in size when cloned fully**
+* **60K git pulls on every business day**
+
+Cloning monorepos having a lot of code and history is time consuming. This was exactly what was happening with Pinboard.
+
+The build pipeline (written in Groovy) started with a “Checkout” stage where the repository was cloned for the build and test steps.
+
+The clone options were set to shallow clone, no fetching of tags and only fetching the last 50 commits.
+
+But it missed a vital piece of optimization.
+
+The Checkout step didn’t use the Git refspec option.
+
+This meant that Git was effectively fetching all refspecs for every build. For the Pinboard monorepo, it meant fetching more than 2500 branches.
+
+𝐒𝐨 - 𝐰𝐡𝐚𝐭 𝐰𝐚𝐬 𝐭𝐡𝐞 𝐟𝐢𝐱?
+
+The team simply added the refspec option and specified which ref they cared about. It was the “master” branch in this case.
+
+This single change allowed Git clone to deal with only one branch and significantly reduced the overall build time of the monorepo.
diff --git a/data/guides/the-open-source-ai-stack.md b/data/guides/the-open-source-ai-stack.md
new file mode 100644
index 0000000..d8727c0
--- /dev/null
+++ b/data/guides/the-open-source-ai-stack.md
@@ -0,0 +1,39 @@
+---
+title: 'The Open Source AI Stack'
+description: 'Explore the open-source AI stack: tools and frameworks for AI development.'
+image: 'https://assets.bytebytego.com/diagrams/0359-the-open-source-ai-stack.png'
+createdAt: '2024-03-12'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI
+ - Open Source
+---
+
+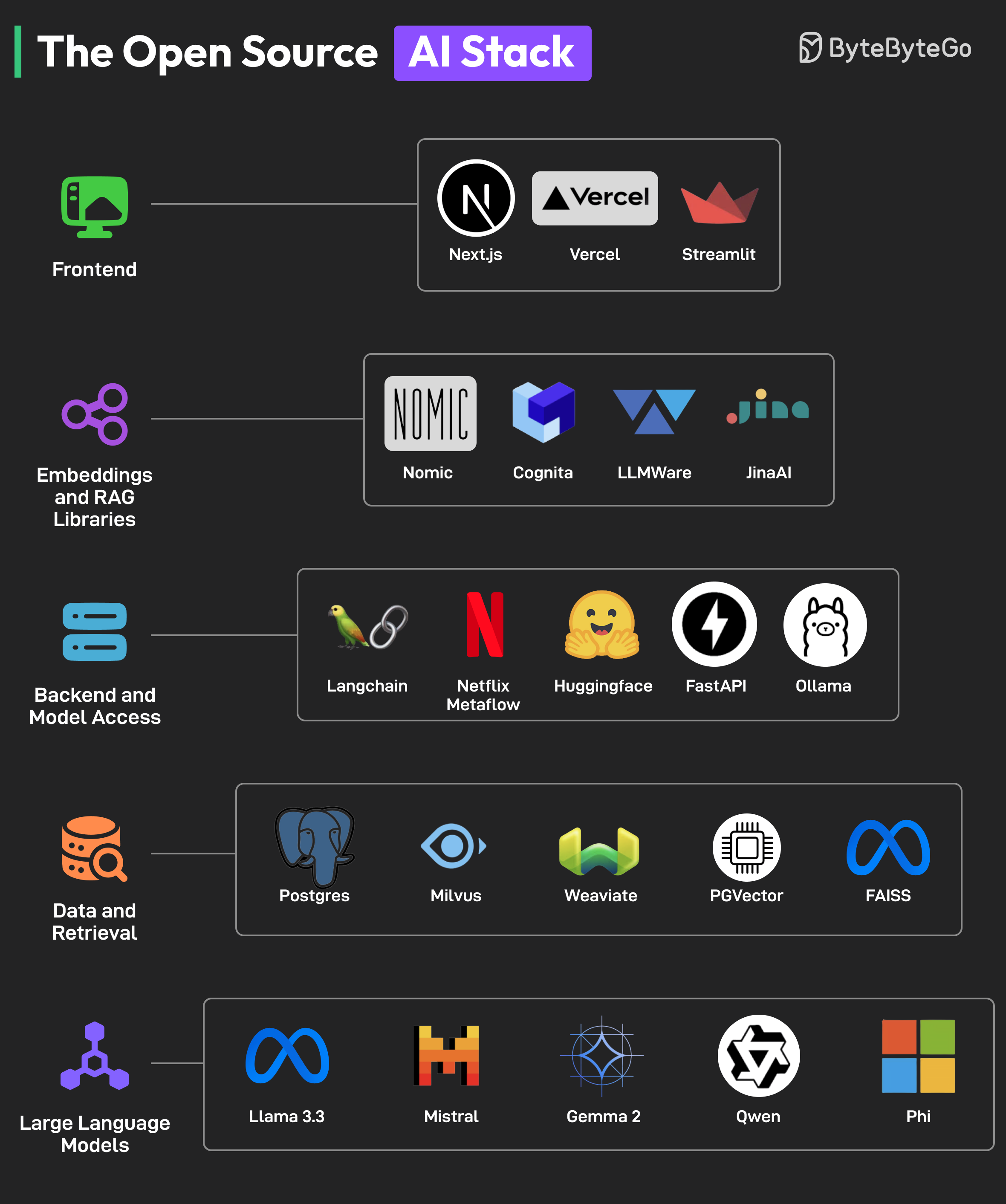
+
+You don’t need to spend a fortune to build an AI application. The best AI developer tools are open-source, and an excellent ecosystem is evolving that can make AI accessible to everyone.
+
+The key components of this open-source AI stack are as follows:
+
+## Frontend
+
+To build beautiful AI UIs, frameworks like NextJS and Streamlit are extremely useful. Also, Vercel can help with deployment.
+
+## Embeddings and RAG libraries
+
+Embedding models and RAG libraries like Nomic, JinaAI, Cognito, and LLMAware help developers build accurate search and RAG features.
+
+## Backend and Model Access
+
+For backend development, developers can rely on frameworks like FastAPI, Langchain, and Netflix Metaflow. Options like Ollama and Huggingface are available
+for model access.
+## Data and Retrieval
+
+For data storage and retrieval, several options like Postgres, Milvus, Weaviate, PGVector, and FAISS are available.
+
+## Large-Language Models
+
+Based on performance benchmarks, open-source models like Llama, Mistral, Qwen, Phi, and Gemma are great alternatives to proprietary LLMs like GPT and Claude.
+
diff --git a/data/guides/the-payments-ecosystem.md b/data/guides/the-payments-ecosystem.md
new file mode 100644
index 0000000..f8488a7
--- /dev/null
+++ b/data/guides/the-payments-ecosystem.md
@@ -0,0 +1,34 @@
+---
+title: "The Payments Ecosystem"
+description: "Explore the key players and processes in the payments ecosystem."
+image: "https://assets.bytebytego.com/diagrams/0360-the-payments-ecosystem.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - Fintech
+ - Payments
+---
+
+How do fintech startups find new opportunities among so many payment companies? What do PayPal, Stripe, and Square do exactly?!
+
+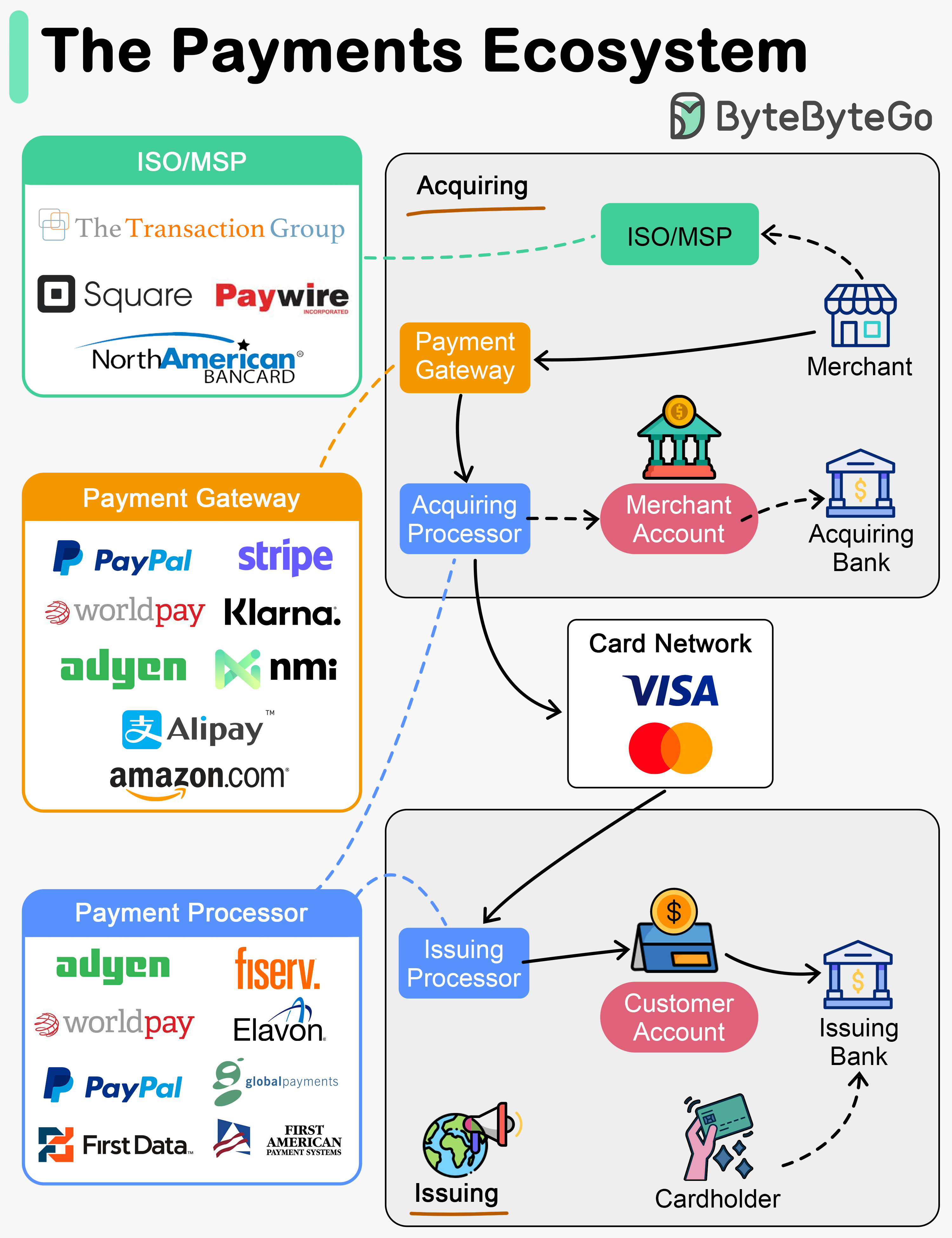
+
+## Steps 0-1
+
+The cardholder opens an account in the issuing bank and gets the debit/credit card. The merchant registers with ISO (Independent Sales Organization) or MSP (Member Service Provider) for in-store sales. ISO/MSP partners with payment processors to open merchant accounts.
+
+## Steps 2-5
+
+The acquiring process.
+
+The payment gateway accepts the purchase transaction and collects payment information. It is then sent to a payment processor, which uses customer information to collect payments. The acquiring processor sends the transaction to the card network. It also owns and operates the merchant’s account during settlement, which doesn’t happen in real-time.
+
+## Steps 6-8
+
+The issuing process.
+
+The issuing processor talks to the card network on the issuing bank’s behalf. It validates and operates the customer’s account.
+
+I’ve listed some companies in different verticals in the diagram. Notice payment companies usually start from one vertical, but later expand to multiple verticals.
diff --git a/data/guides/the-ultimate-api-learning-roadmap.md b/data/guides/the-ultimate-api-learning-roadmap.md
new file mode 100644
index 0000000..578d2f7
--- /dev/null
+++ b/data/guides/the-ultimate-api-learning-roadmap.md
@@ -0,0 +1,37 @@
+---
+title: The Ultimate API Learning Roadmap
+description: "Your guide to mastering APIs: from basics to advanced techniques."
+image: 'https://assets.bytebytego.com/diagrams/0361-the-ultimate-api-learning-roadmap.png'
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Roadmap
+---
+
+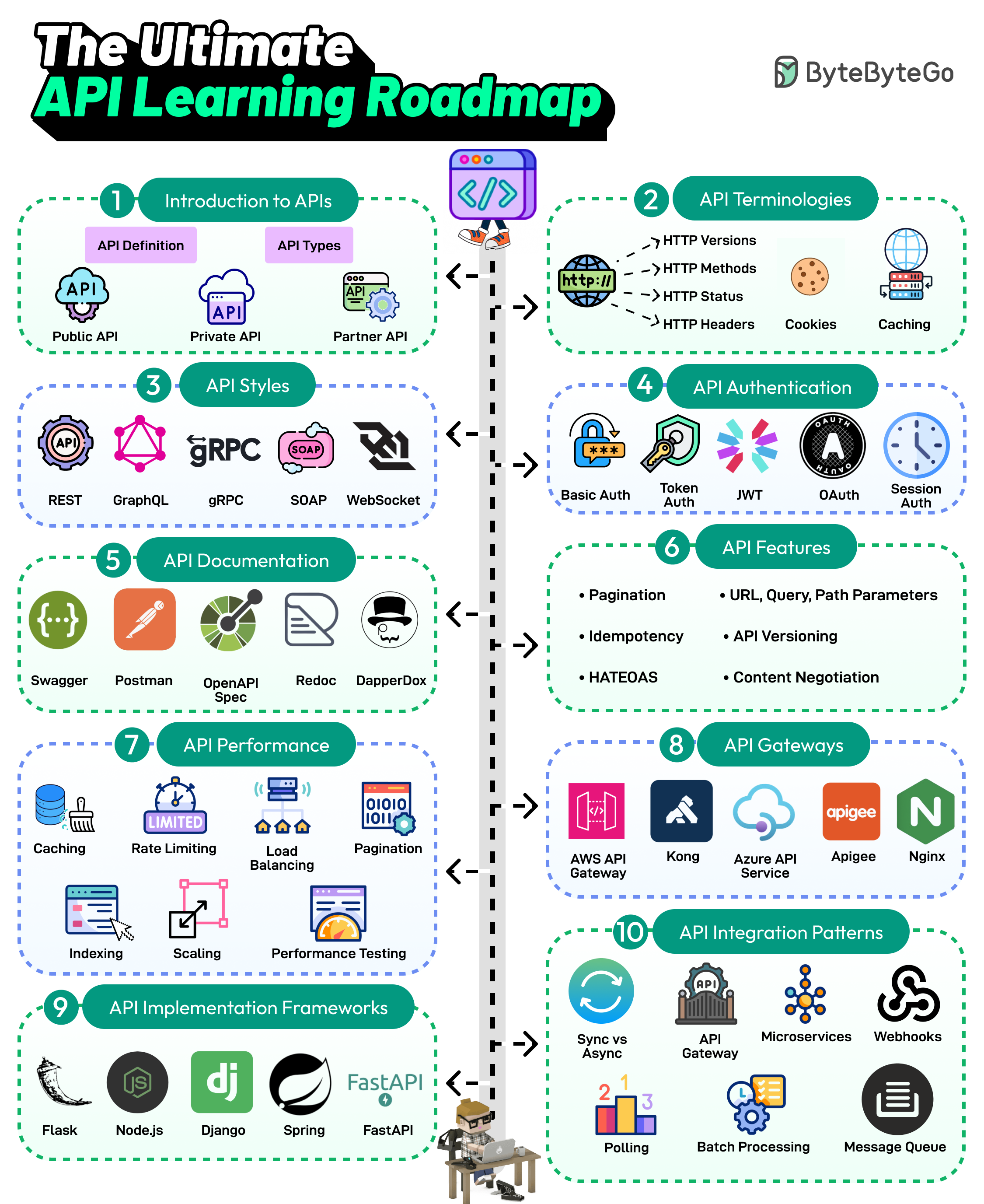
+
+APIs are the backbone of communication over the Internet. Every developer needs to learn about APIs. Here’s a roadmap that covers the most important topics:
+
+* **Introduction to APIs**
+ * API is a set of protocols and tools for building applications. Different types of APIs exist, such as public, private, and partner.
+* **API Terminologies**
+ * Various API terminologies, such as HTTP versions, cookies, and caching, need to be understood.
+* **API Styles**
+ * The most common API styles are REST, SOAP, GraphQL, gRPC, and WebSockets
+* **API Authentication**
+ * API Authentication techniques like Basic Auth, Token, JWTs, OAuth, and Session Auth
+* **API Documentation**
+ * A good API is understandable. API Documentation tools like Swagger, Postman, Redoc, and DapperDox make it possible.
+* **API Features**
+ * Key API features include pagination, parameters, idempotency, API versioning, HATEOAS, and content negotiation
+* **API Performance Techniques**
+ * Common API performance techniques are caching, rate limiting, load balancing, pagination, DB indexing, scaling, and performance testing.
+* **API Gateways**
+ * Learn about API Gateways such as Amazon API Gateway, Azure API Services, Kong, Nginx, etc.
+* **API Implementation Frameworks**
+ * The most popular API development frameworks are Node.js, Spring, Flask, Django, and FastAPI
+* **API Integration Patterns**
+ * Learn about various API integration patterns such as gateways, event-driven, webhook, polling, and batch processing.
diff --git a/data/guides/the-ultimate-kafka-101-you-cannot-miss.md b/data/guides/the-ultimate-kafka-101-you-cannot-miss.md
new file mode 100644
index 0000000..28c76b2
--- /dev/null
+++ b/data/guides/the-ultimate-kafka-101-you-cannot-miss.md
@@ -0,0 +1,50 @@
+---
+title: "The Ultimate Kafka 101 You Cannot Miss"
+description: "Learn the fundamentals of Kafka in 8 simple steps."
+image: "https://assets.bytebytego.com/diagrams/0246-kafka-101-8-steps-to-learn-the-fundamentals-of-kafka.png"
+createdAt: "2024-02-02"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Kafka"
+ - "Distributed Systems"
+---
+
+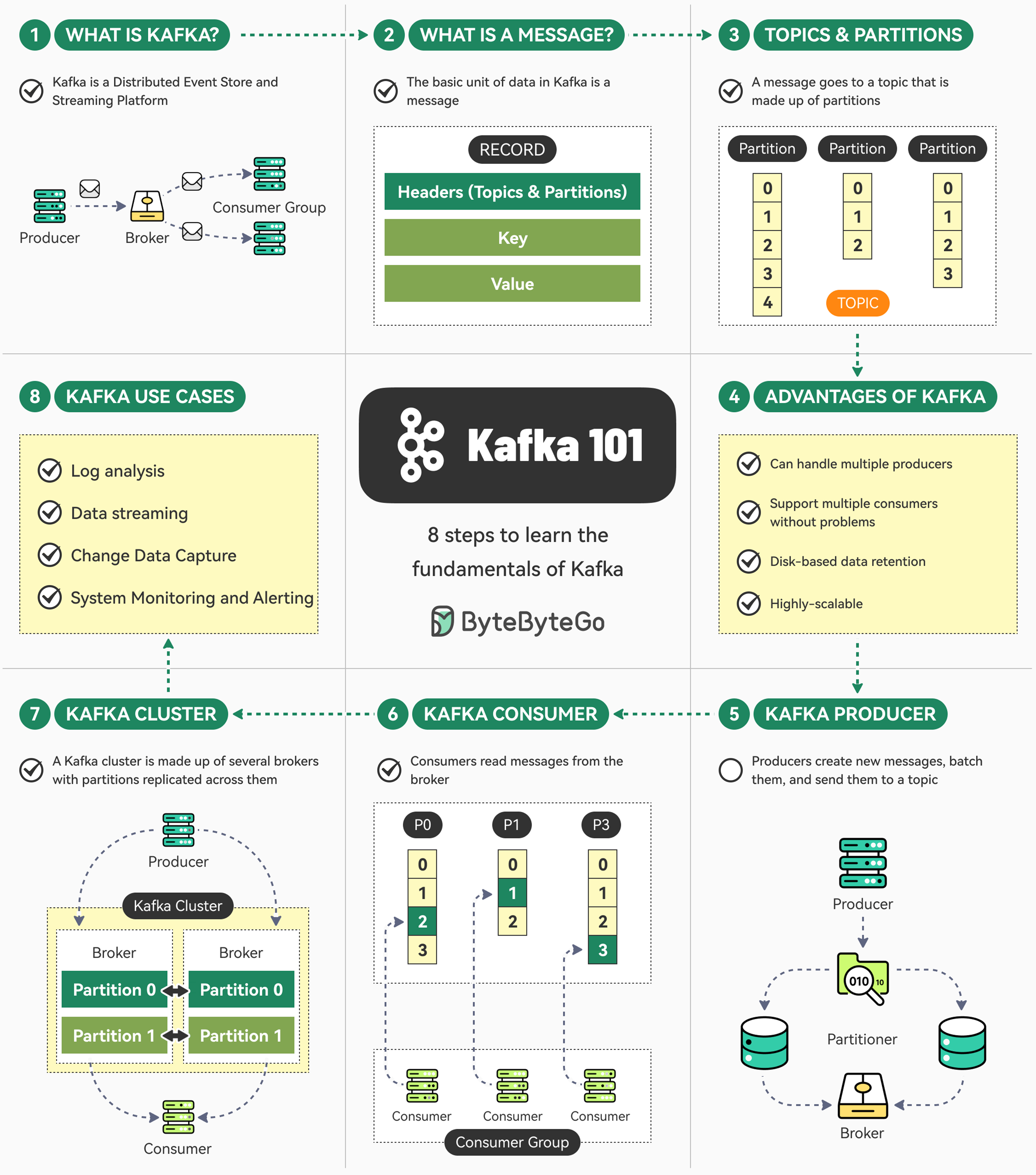
+
+Kafka is super-popular but can be overwhelming in the beginning.
+
+Here are 8 simple steps that can help you understand the fundamentals of Kafka.
+
+## What is Kafka?
+
+Kafka is a distributed event store and a streaming platform. It began as an internal project at LinkedIn and now powers some of the largest data pipelines in the world in orgs like Netflix, Uber, etc.
+
+## Kafka Messages
+
+Message is the basic unit of data in Kafka. It’s like a record in a table consisting of headers, key, and value.
+
+## Kafka Topics and Partitions
+
+Every message goes to a particular Topic. Think of the topic as a folder on your computer. Topics also have multiple partitions.
+
+## Advantages of Kafka
+
+Kafka can handle multiple producers and consumers, while providing disk-based data retention and high scalability.
+
+## Kafka Producer
+
+Producers in Kafka create new messages, batch them, and send them to a Kafka topic. They also take care of balancing messages across different partitions.
+
+## Kafka Consumer
+
+Kafka consumers work together as a consumer group to read messages from the broker.
+
+## Kafka Cluster
+
+A Kafka cluster consists of several brokers where each partition is replicated across multiple brokers to ensure high availability and redundancy.
+
+## Use Cases of Kafka
+
+Kafka can be used for log analysis, data streaming, change data capture, and system monitoring.
diff --git a/data/guides/the-ultimate-kubernetes-command-cheatsheet.md b/data/guides/the-ultimate-kubernetes-command-cheatsheet.md
new file mode 100644
index 0000000..b7bb19e
--- /dev/null
+++ b/data/guides/the-ultimate-kubernetes-command-cheatsheet.md
@@ -0,0 +1,32 @@
+---
+title: "Kubernetes Command Cheatsheet"
+description: "Your go-to guide for essential Kubernetes commands."
+image: "https://assets.bytebytego.com/diagrams/0248-kubernetes-command-cheatsheet.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - DevOps
+---
+
+
+
+Kubernetes is an open-source container orchestration platform. It automates the deployment, scaling, and management of containerized applications.
+
+Initially developed by Google, Kubernetes is now maintained by CNCF (Cloud Native Computing Foundation).
+
+This cheat sheet contains the most important Kubernetes commands for different purposes:
+
+* Kubernetes Setup
+
+* General Cluster Management
+
+* Kubernetes Deployments
+
+* Kubernetes Pod Inspection
+
+* Troubleshooting and Configuration
+
+* Miscellaneous commands related to services, config maps, and managing ingresses.
diff --git a/data/guides/the-ultimate-redis-101.md b/data/guides/the-ultimate-redis-101.md
new file mode 100644
index 0000000..e870a29
--- /dev/null
+++ b/data/guides/the-ultimate-redis-101.md
@@ -0,0 +1,50 @@
+---
+title: "The Ultimate Redis 101"
+description: "Learn the fundamentals of Redis with these simple steps."
+image: "https://assets.bytebytego.com/diagrams/0009-steps-to-learn-the-fundamentals-of-redis-101.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Database"
+---
+
+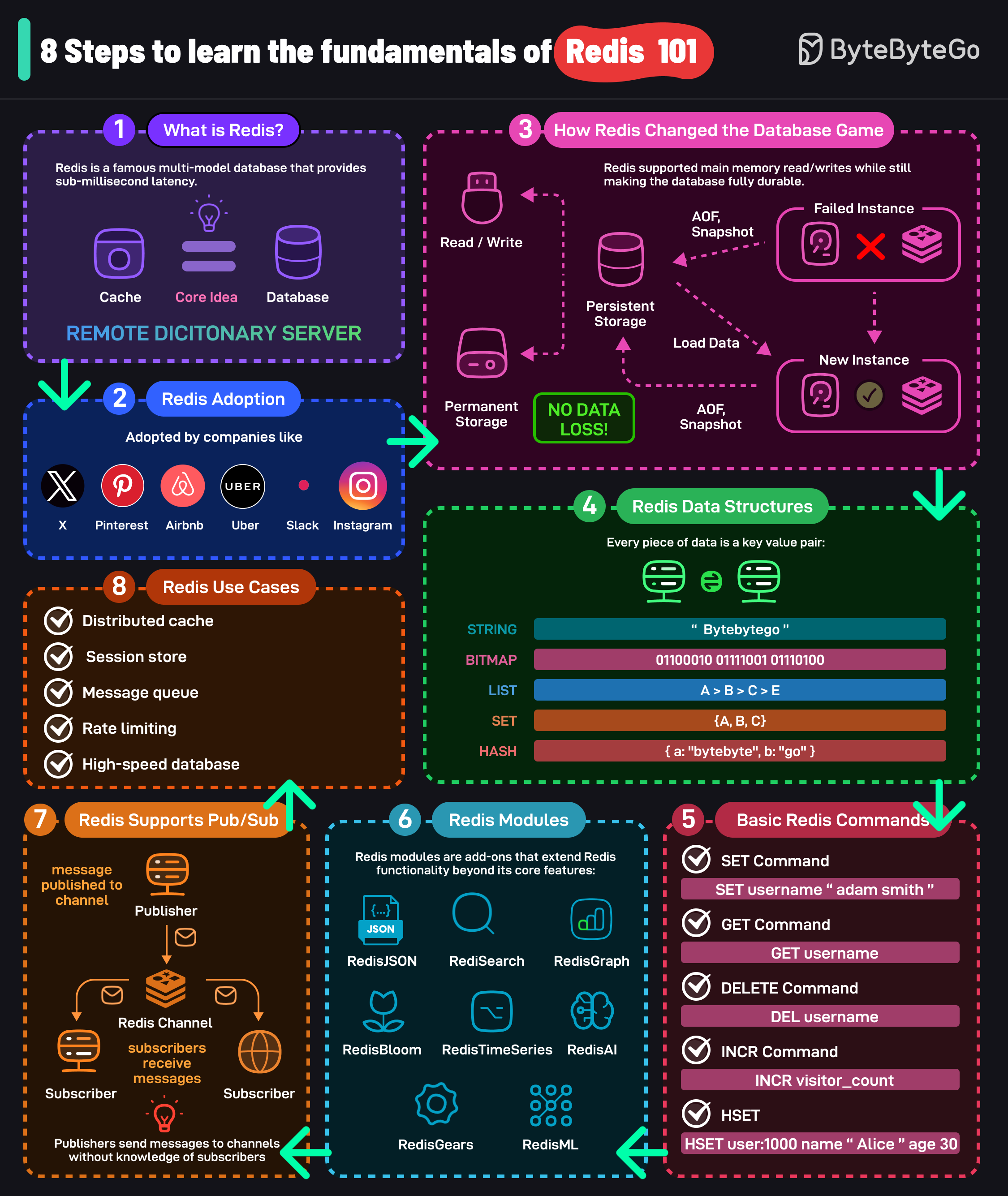
+
+Redis is one of the most popular data stores in the world and is packed with features.
+
+Here are 8 simple steps that can help you understand the fundamentals of Redis.
+
+## What is Redis?
+
+Redis (Remote Dictionary Server) is a multi-modal database that provides sub-millisecond latency. The core idea behind Redis is that a cache can also act as a full-fledged database.
+
+## Redis Adoption
+
+High-traffic internet websites like Airbnb, Uber, Slack, and many others have adopted Redis in their technology stack.
+
+## How Redis Changed the Database Game?
+
+Redis supports main memory read/writes while still supporting fully durable storage. Read and writes are served from the main memory but the data is also persisted to the disk. This is done using snapshots (RDB) and AOF.
+
+## Redis Data Structures
+
+Redis stores data in key-value format. It supports various data structures such as strings, bitmaps, lists, sets, sorted sets, hash, JSON, etc.
+
+## Basic Redis Commands
+
+Some of the most used Redis commands are SET, GET, DELETE, INCR, HSET, etc. There are many more commands available.
+
+## Redis Modules
+
+Redis modules are add-ons that extend Redis functionality beyond its core features. Some prominent modules are RediSearch, RedisJSON, RedisGraph, RedisBloom, RedisAI, RedisTimeSeries, RedisGears, RedisML, and so on.
+
+## Redis Pub/Sub
+
+Redis also supports even-driven architecture using a publish-subscribe communication model.
+
+## Redis Use Cases
+
+Top Redis use cases are Distributed Caching, Session Storage, Message Queue, Rate Limiting, High-Speed Database, etc.
diff --git a/data/guides/the-ultimate-software-architect-knowledge-map.md b/data/guides/the-ultimate-software-architect-knowledge-map.md
new file mode 100644
index 0000000..5764460
--- /dev/null
+++ b/data/guides/the-ultimate-software-architect-knowledge-map.md
@@ -0,0 +1,52 @@
+---
+title: "The Ultimate Software Architect Knowledge Map"
+description: "A guide to the essential knowledge for software architects."
+image: "https://assets.bytebytego.com/diagrams/0118-the-ultimate-software-architect-knowledge-map.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Software Architecture
+ - Career Development
+---
+
+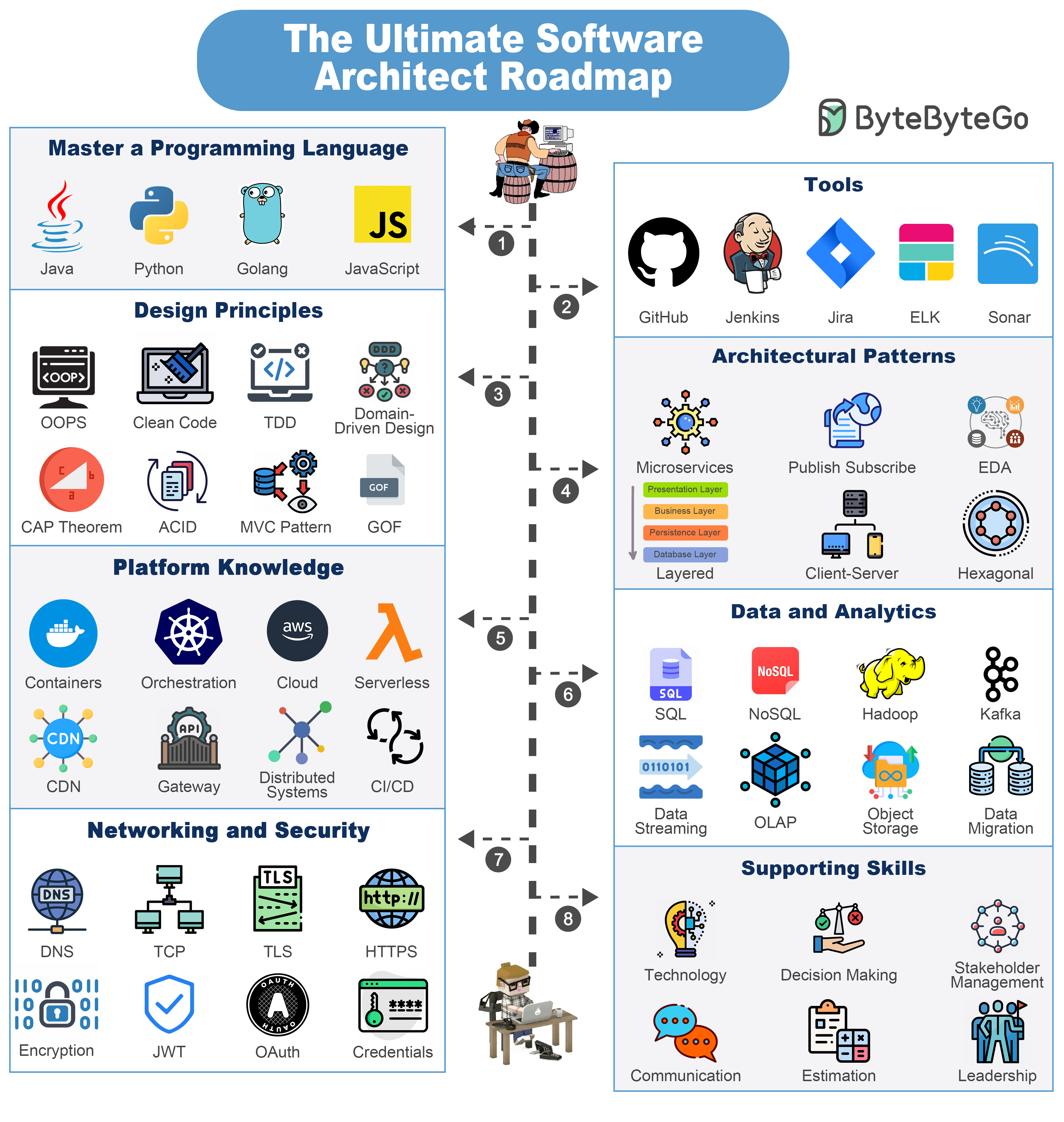
+
+Becoming a Software Architect is a journey where you are always learning. But there are some things you must definitely strive to know.
+
+## Essential Skills for Software Architects
+
+* **Master a Programming Language**
+
+ Look to master 1-2 programming languages such as Java, Python, Golang, JavaScript, etc.
+
+* **Tools**
+
+ Build proficiency with key tools such as GitHub, Jenkins, Jira, ELK, Sonar, etc.
+
+* **Design Principles**
+
+ Learn about important design principles such as OOPS, Clean Code, TDD, DDD, CAP Theorem, MVC Pattern, ACID, and GOF.
+
+* **Architectural Principles**
+
+ Become proficient in multiple architectural patterns such as Microservices, Publish-Subscribe, Layered, Event-Driven, Client-Server, Hexagonal, etc.
+
+* **Platform Knowledge**
+
+ Get to know about several platforms such as containers, orchestration, cloud, serverless, CDN, API Gateways, Distributed Systems, and CI/CD
+
+* **Data Analytics**
+
+ Build a solid knowledge of data and analytics components like SQL and NoSQL databases, data streaming solutions with Kafka, object storage, data migration, OLAP, and so on.
+
+* **Networking and Security**
+
+ Learn about networking and security concepts such as DNS, TCP, TLS, HTTPS, Encryption, JWT, OAuth, and Credential Management.
+
+* **Supporting Skills**
+
+ Apart from technical, software architects also need several supporting skills such as decision-making, technology knowledge, stakeholder management, communication, estimation, leadership, etc.
+
+Over to you - What else would you add to the roadmap?
diff --git a/data/guides/things-to-consider-when-using-cache.md b/data/guides/things-to-consider-when-using-cache.md
new file mode 100644
index 0000000..2a84c38
--- /dev/null
+++ b/data/guides/things-to-consider-when-using-cache.md
@@ -0,0 +1,70 @@
+---
+title: "Things to Consider When Using Cache"
+description: "Top 5 things to consider when using cache to build fast online systems."
+image: "https://assets.bytebytego.com/diagrams/0362-things-to-consider-when-using-cache.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Performance"
+---
+
+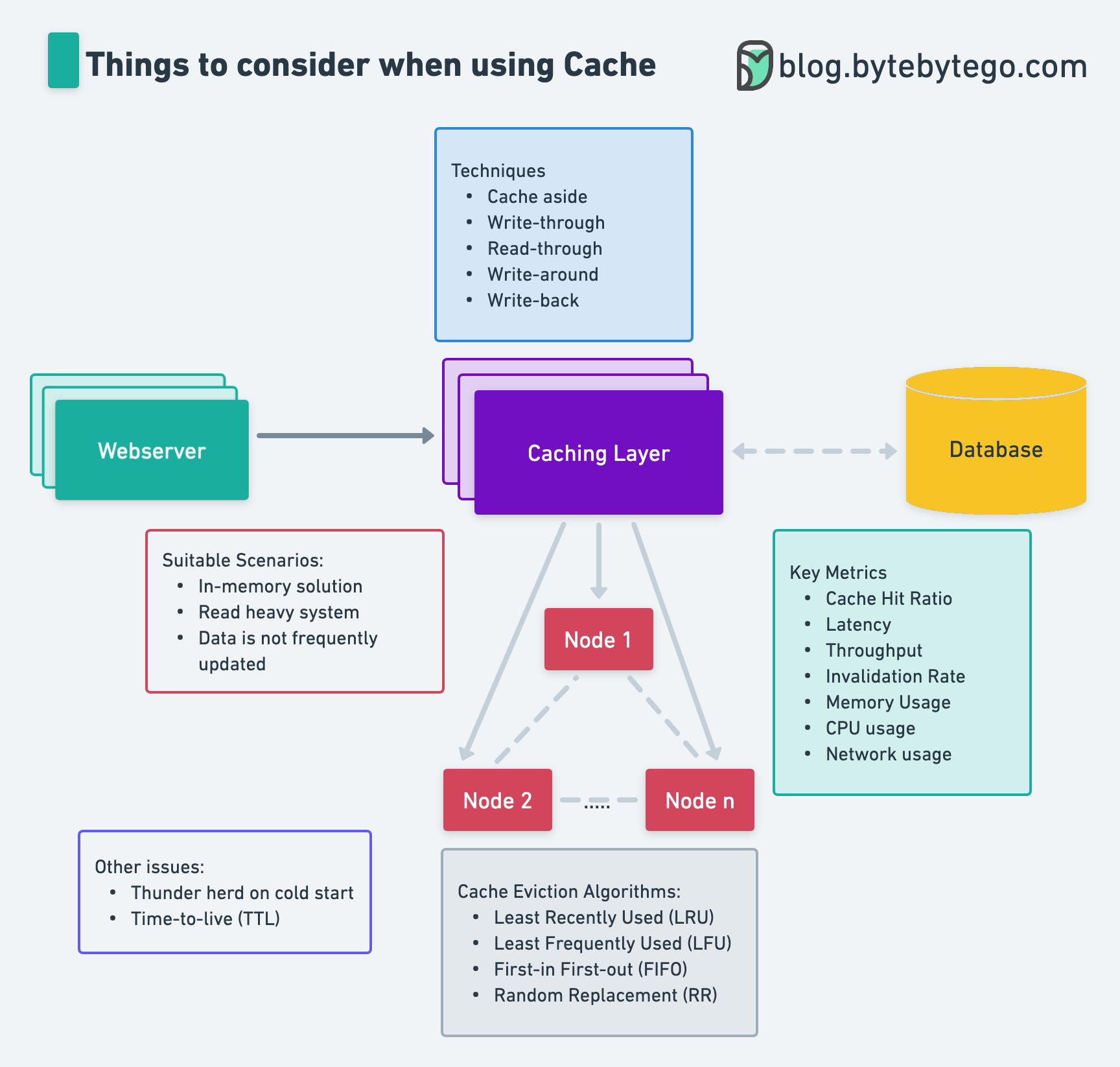
+
+Caching is one of the 𝐦𝐨𝐬𝐭 𝐜𝐨𝐦𝐦𝐨𝐧𝐥𝐲 used techniques when building fast online systems. When using a cache, here are the top 5 things to consider:
+
+The first version of the cheatsheet was written by guest author [Love Sharma](https://twitter.com/Zonito87).
+
+## Suitable Scenarios
+
+* In-memory solution
+
+* Read heavy system
+
+* Data is not frequently updated
+
+## Caching Techniques
+
+* Cache aside
+
+* Write-through
+
+* Read-through
+
+* Write-around
+
+* Write-back
+
+## Cache Eviction Algorithms
+
+* Least Recently Used (LRU)
+
+* Least Frequently Used (LFU)
+
+* First-in First-out (FIFO)
+
+* Random Replacement (RR)
+
+## Key Metrics
+
+* Cache Hit Ratio
+
+* Latency
+
+* Throughput
+
+* Invalidation Rate
+
+* Memory Usage
+
+* CPU usage
+
+* Network usage
+
+## Other Issues
+
+* Thunder herd on cold start
+
+* Time-to-live (TTL)
diff --git a/data/guides/time-series-db-tsdb-in-20-lines.md b/data/guides/time-series-db-tsdb-in-20-lines.md
new file mode 100644
index 0000000..6454a3f
--- /dev/null
+++ b/data/guides/time-series-db-tsdb-in-20-lines.md
@@ -0,0 +1,34 @@
+---
+title: "Time Series DB (TSDB) in 20 Lines"
+description: "Learn about Time Series Databases (TSDB) and their applications."
+image: "https://assets.bytebytego.com/diagrams/0364-time-series-db-tsdb-in-20-lines.jpeg"
+createdAt: "2024-02-07"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database"
+ - "TimeSeries"
+---
+
+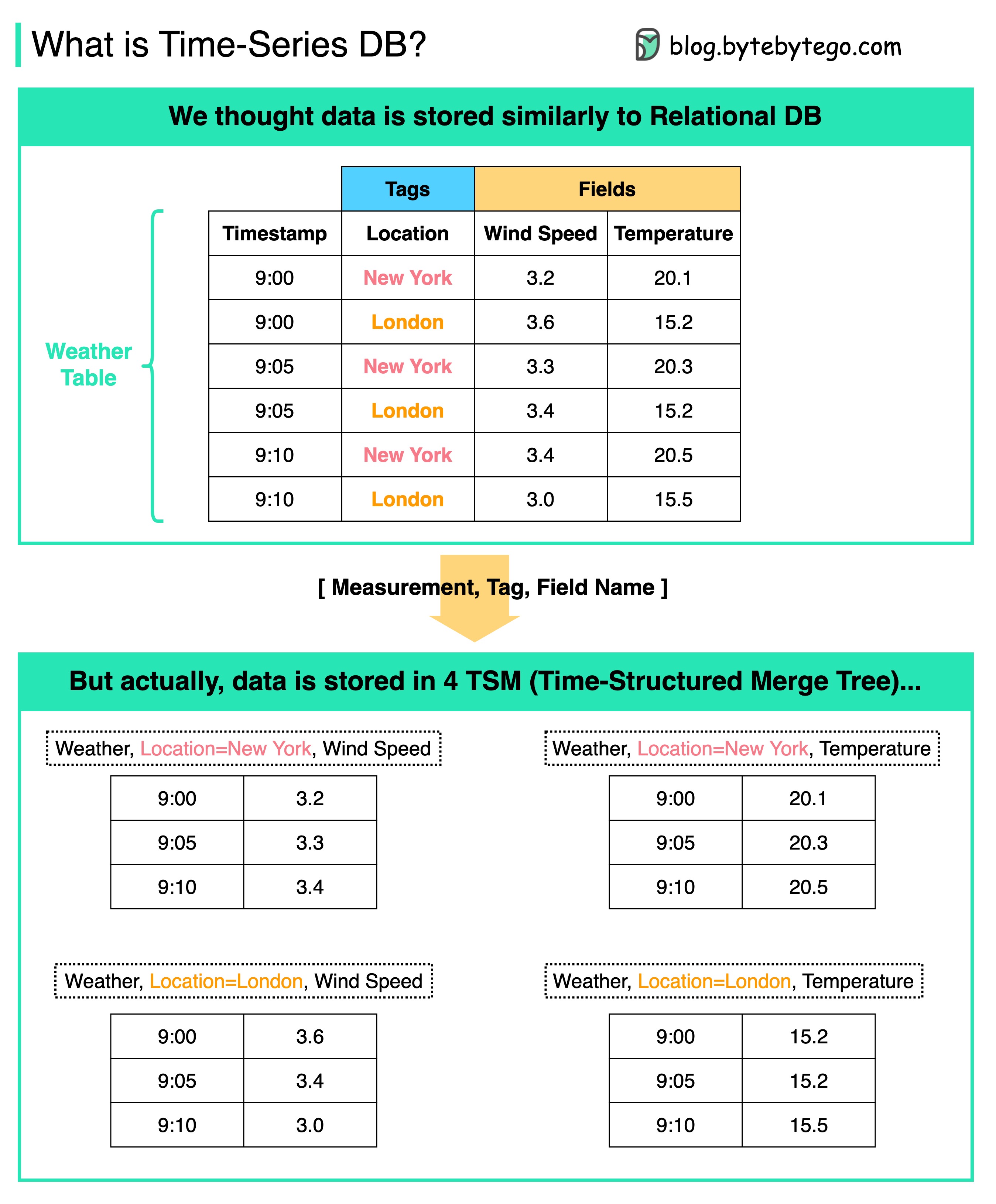
+
+What is **Time-Series DB** (TSDB)? How is it different from Relational DB?
+
+The diagram above shows the **internal data model** of a typical Time-Series DB.
+
+A TSDB is a database optimized for time series data.
+
+* From the users’ perspective, the data looks similar to the relational DB table. But behind the scenes, the weather table is stored in 4 TSMs (Time-Structured Merge Trees) in the format of \[Measurement, Tag, Field Name].
+
+* In this way, we can quickly aggregate and analyze data based on time and tags.
+
+* Typical usage:
+
+ * Trades and market data updates in a market
+ * Server metrics
+ * Application performance monitoring
+ * Network data
+ * Sensor data
+ * Events
+ * Clicks streams
diff --git a/data/guides/token-cookie-session.md b/data/guides/token-cookie-session.md
new file mode 100644
index 0000000..7f97f0c
--- /dev/null
+++ b/data/guides/token-cookie-session.md
@@ -0,0 +1,44 @@
+---
+title: "Token, Cookie, Session"
+description: "Understanding tokens, cookies, and sessions for user identity management."
+image: "https://assets.bytebytego.com/diagrams/0331-session-cookie-jwt.jpg"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Authorization"
+---
+
+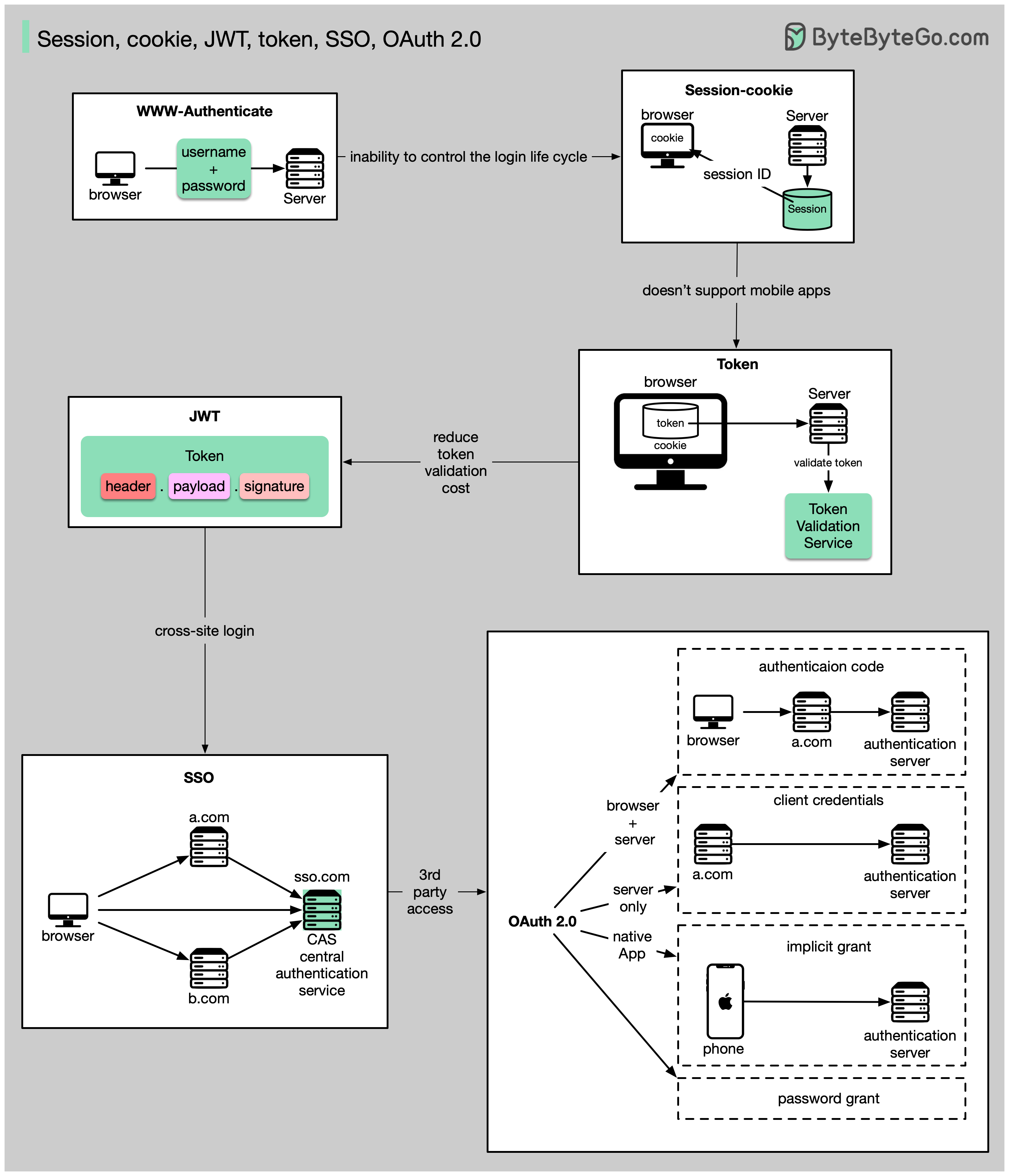
+
+Session, cookie, JWT, token, SSO, and OAuth 2.0 - what are they?!
+
+These terms are all related to user identity management. When you log into a website, you declare who you are (identification). Your identity is verified (authentication), and you are granted the necessary permissions (authorization). Many solutions have been proposed in the past, and the list keeps growing.
+
+From simple to complex, here is my understanding of user identity management:
+
+## WWW-Authenticate
+
+WWW-Authenticate is the most basic method. You are asked for the username and password by the browser. As a result of the inability to control the login life cycle, it is seldom used today.
+
+## Session-Cookie
+
+A finer control over the login life cycle is session-cookie. The server maintains session storage, and the browser keeps the ID of the session. A cookie usually only works with browsers and is not mobile app friendly.
+
+## Token
+
+To address the compatibility issue, the token can be used. The client sends the token to the server, and the server validates the token. The downside is that the token needs to be encrypted and decrypted, which may be time-consuming.
+
+## JWT
+
+JWT is a standard way of representing tokens. This information can be verified and trusted because it is digitally signed. Since JWT contains the signature, there is no need to save session information on the server side.
+
+## SSO (Single Sign-On)
+
+By using SSO (single sign-on), you can sign on only once and log in to multiple websites. It uses CAS (central authentication service) to maintain cross-site information
+
+## OAuth 2.0
+
+By using OAuth 2.0, you can authorize one website to access your information on another website
diff --git a/data/guides/top-10-k8s-design-patterns.md b/data/guides/top-10-k8s-design-patterns.md
new file mode 100644
index 0000000..208f7be
--- /dev/null
+++ b/data/guides/top-10-k8s-design-patterns.md
@@ -0,0 +1,70 @@
+---
+title: "Top 10 Kubernetes Design Patterns"
+description: "Explore the top 10 Kubernetes design patterns with detailed explanations."
+image: "https://assets.bytebytego.com/diagrams/0372-top-10-k8s-design-patterns.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Kubernetes"
+ - "Design Patterns"
+---
+
+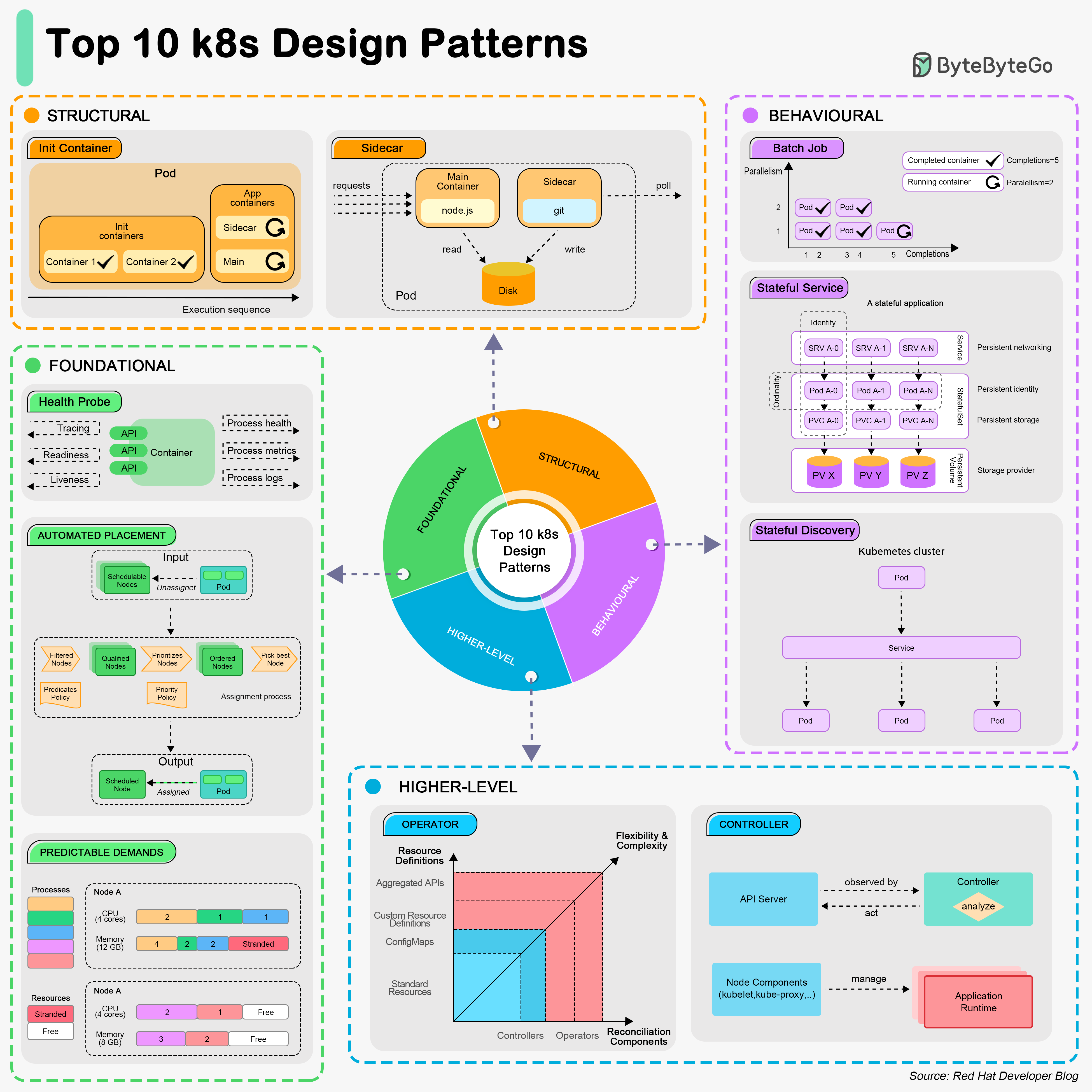
+
+## Foundational Patterns
+
+These patterns are the fundamental principles for applications to be automated on k8s, regardless of the application's nature.
+
+* **Health Probe Pattern**
+
+ This pattern requires that every container must implement observable APIs for the platform to manage the application.
+
+* **Predictable Demands Pattern**
+
+ This pattern requires that we should declare application requirements and runtime dependencies. Every container should declare its resource profile.
+
+* **Automated Placement Pattern**
+
+ This pattern describes the principles of Kubernetes’ scheduling algorithm.
+
+## Structural Patterns
+
+These patterns focus on structuring and organizing containers in a Pod.
+
+* **Init Container Pattern**
+
+ This pattern has a separate life cycle for initialization-releated tasks.
+
+* **Sidecar Pattern**
+
+ This pattern extends a container’s functionalities without changing it.
+
+## Behavioral Patterns
+
+These patterns describe the life cycle management of a Pod. Depending on the type of the workload, it can run as a service or a batch job.
+
+* **Batch Job Pattern**
+
+ This pattern is used to manage isolated atomic units of work.
+
+* **Stateful Service Pattern**
+
+ This pattern creates distributed stateful applications.
+
+* **Service Discovery Pattern**
+
+ This pattern describes how clients discover the services.
+
+## Higher-Level Patterns
+
+These patterns focus on higher-level application management.
+
+* **Controller Pattern**
+
+ This pattern monitors the current state and reconciles with the declared target state.
+
+* **Operator Pattern**
+
+ This pattern defines operational knowledge in an algorithmic and automated form.
diff --git a/data/guides/top-10-most-popular-open-source-databases.md b/data/guides/top-10-most-popular-open-source-databases.md
new file mode 100644
index 0000000..05bf9f8
--- /dev/null
+++ b/data/guides/top-10-most-popular-open-source-databases.md
@@ -0,0 +1,29 @@
+---
+title: "Top 10 Most Popular Open-Source Databases"
+description: "Explore the top 10 open-source databases and their impact."
+image: "https://assets.bytebytego.com/diagrams/0282-top-10-most-popular-open-source-databases.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Databases"
+ - "Open Source"
+---
+
+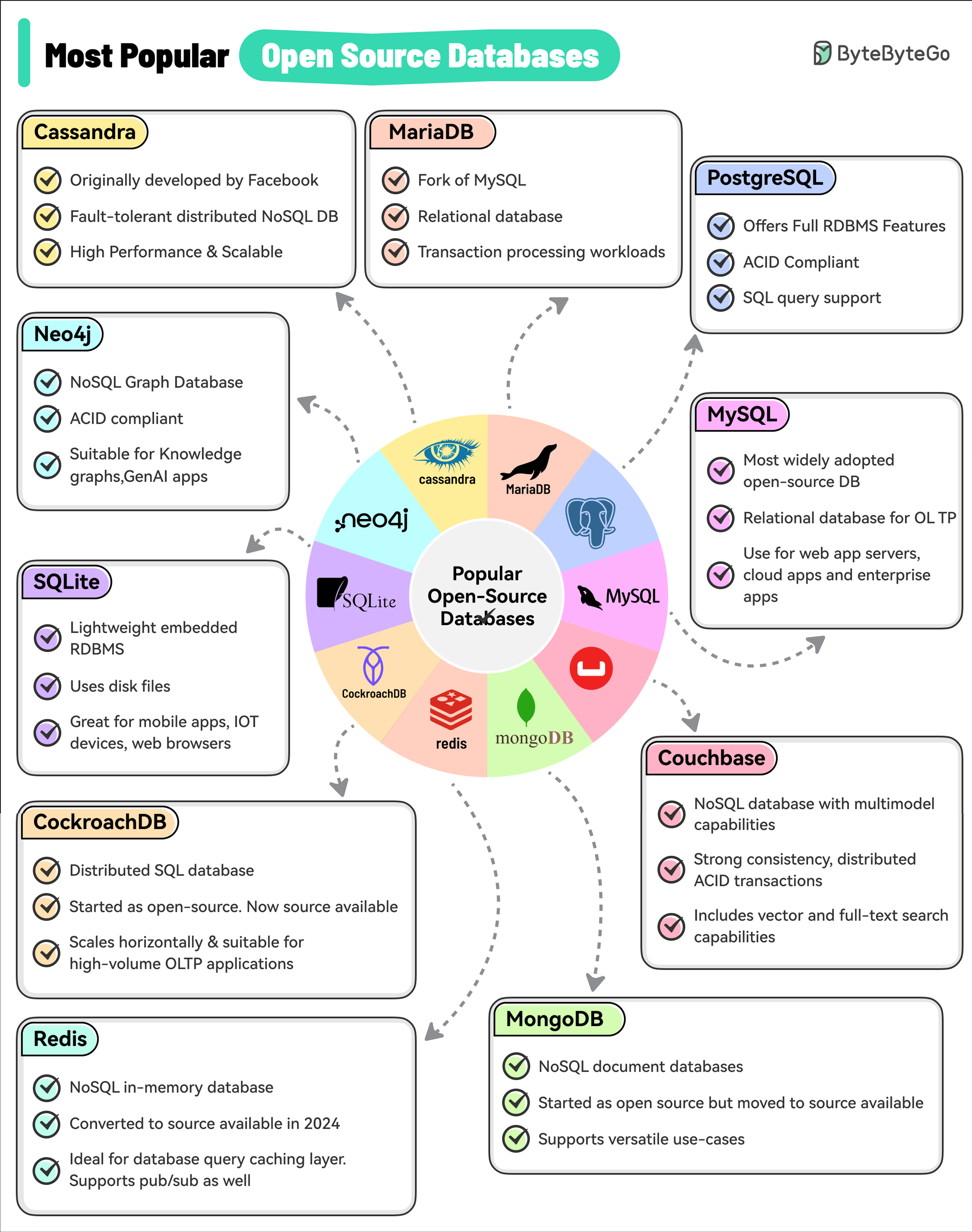
+
+This list is based on factors like adoption, industry impact, and the general awareness of the database among the developer community.
+
+## Top 10 Most Popular Open-Source Databases
+
+* MySQL
+* PostgreSQL
+* MariaDB
+* Apache Cassandra
+* Neo4j
+* SQLite
+* CockroachDB
+* Redis
+* MongoDB
+* Couchbase
diff --git a/data/guides/top-12-tips-for-api-security.md b/data/guides/top-12-tips-for-api-security.md
new file mode 100644
index 0000000..307dda0
--- /dev/null
+++ b/data/guides/top-12-tips-for-api-security.md
@@ -0,0 +1,27 @@
+---
+title: 'Top 12 Tips for API Security'
+description: 'Enhance API security with these top 12 essential tips.'
+image: 'https://assets.bytebytego.com/diagrams/0027-12-tips-for-api-security.png'
+createdAt: '2024-03-09'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Security
+ - Web Security
+---
+
+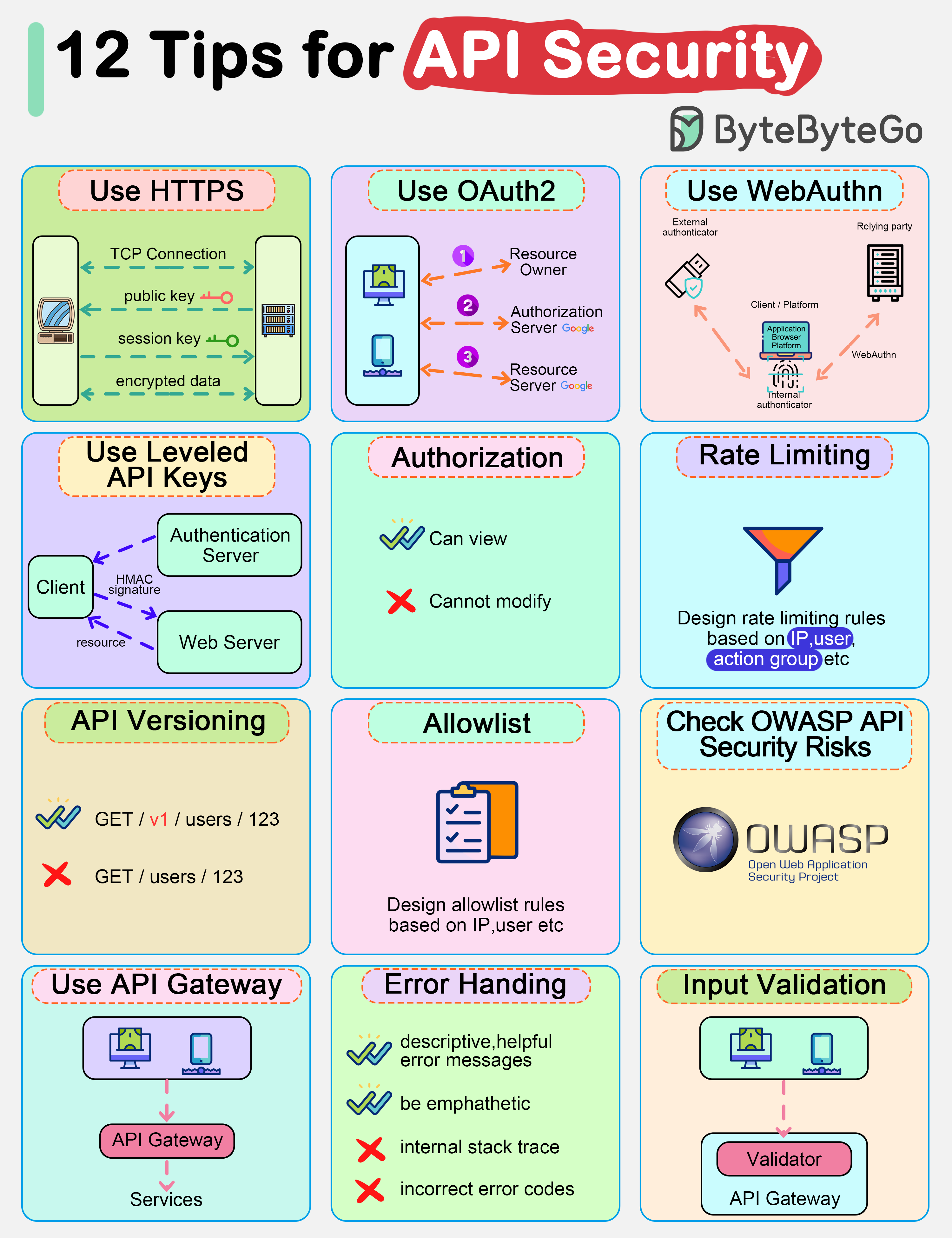
+
+* Use HTTPS
+* Use OAuth2
+* Use WebAuthn
+* Use Leveled API Keys
+* Authorization
+* Rate Limiting
+* API Versioning
+* Whitelisting
+* Check OWASP API Security Risks
+* Use API Gateway
+* Error Handling
+* Input Validation
diff --git a/data/guides/top-3-api-gateway-use-cases.md b/data/guides/top-3-api-gateway-use-cases.md
new file mode 100644
index 0000000..3bcbf0e
--- /dev/null
+++ b/data/guides/top-3-api-gateway-use-cases.md
@@ -0,0 +1,23 @@
+---
+title: 'Top 3 API Gateway Use Cases'
+description: 'Explore the top 3 use cases for API gateways in modern architectures.'
+image: 'https://assets.bytebytego.com/diagrams/0073-top-3-api-gateway-use-cases.png'
+createdAt: '2024-02-16'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Microservices
+---
+
+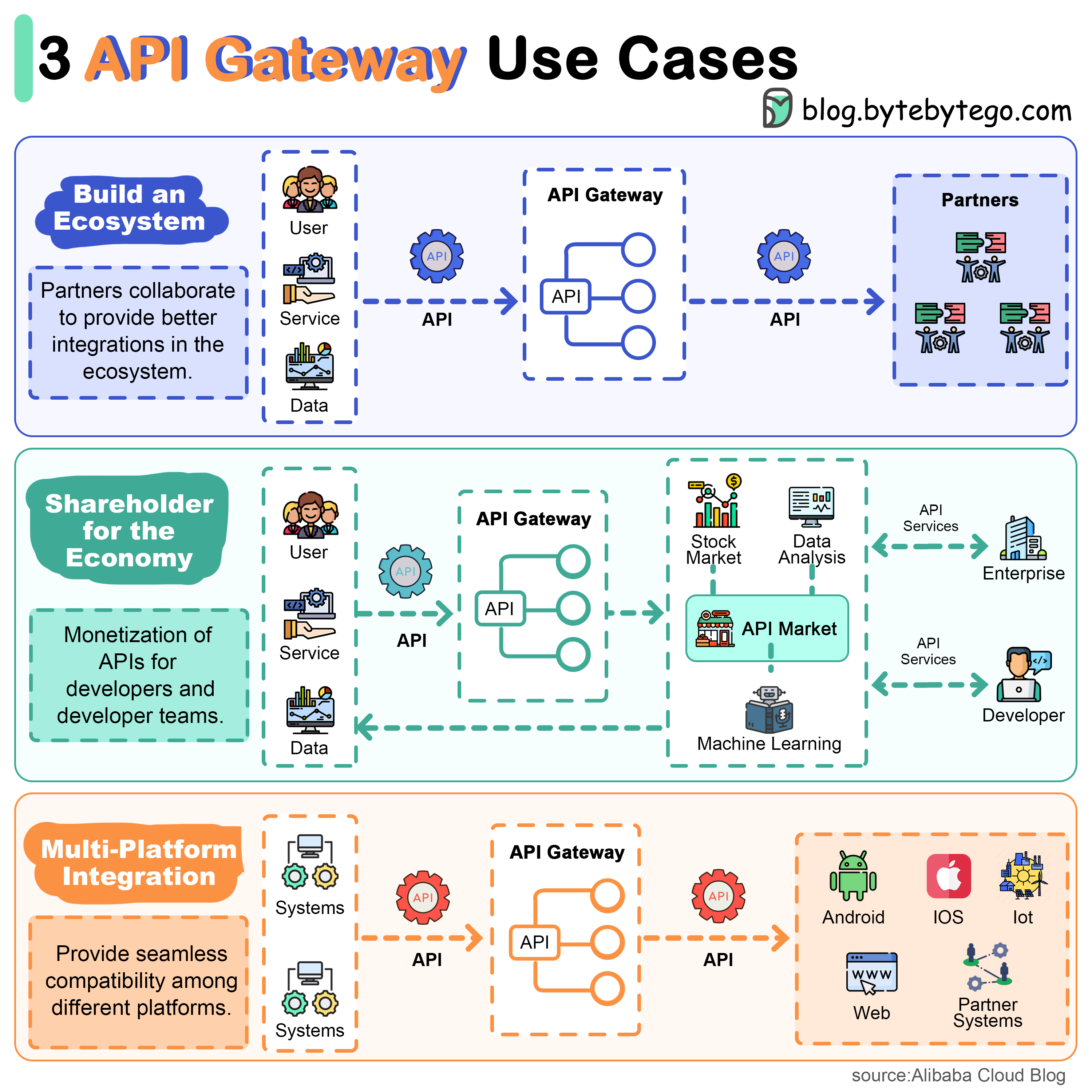
+
+API gateway sits between the clients and services, providing API communications between them.
+
+* **API gateway helps build an ecosystem.**
+ The users can leverage an API gateway to access a wider set of tools. The partners in the ecosystem collaborate with each other to provide better integrations for the users.
+* **API gateway builds API marketplace**
+ The API marketplace hosts fundamental functionalities for everyone. The developers and businesses can easily develop or innovate in this ecosystem and sell APIs on the marketplace.
+* **API gateway provides compatibility with multiple platforms**
+ When dealing with multiple platforms, an API gateway can help work across multiple complex architectures.
diff --git a/data/guides/top-4-data-sharding-algorithms-explained.md b/data/guides/top-4-data-sharding-algorithms-explained.md
new file mode 100644
index 0000000..d91b057
--- /dev/null
+++ b/data/guides/top-4-data-sharding-algorithms-explained.md
@@ -0,0 +1,34 @@
+---
+title: "Top 4 Data Sharding Algorithms Explained"
+description: "Explore the top data sharding algorithms for efficient data management."
+image: "https://assets.bytebytego.com/diagrams/0373-top-4-data-sharding-algorithms-explained.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Sharding"
+ - "Algorithms"
+---
+
+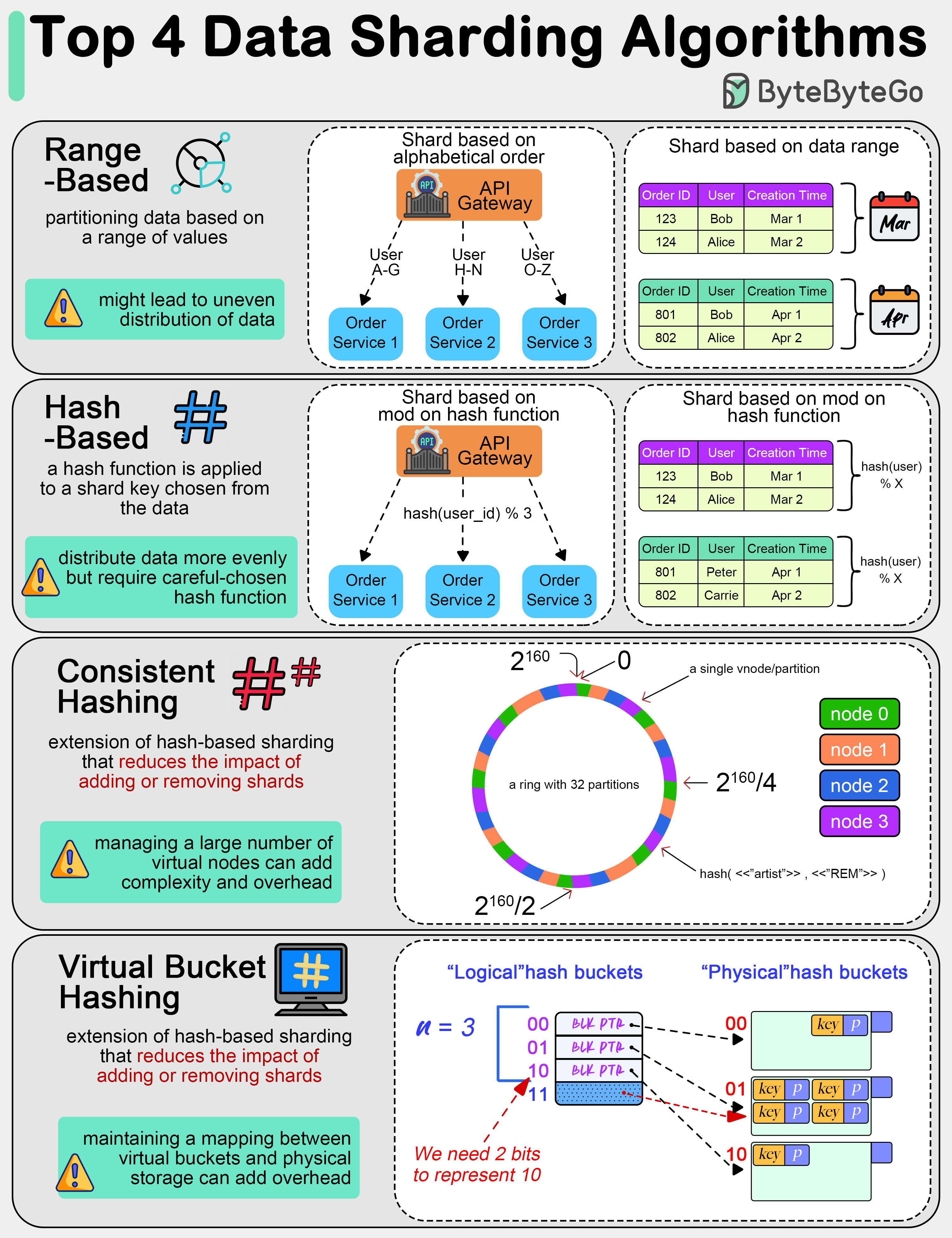
+
+We are dealing with massive amounts of data. Often we need to split data into smaller, more manageable pieces, or “shards”. Here are some of the top data sharding algorithms commonly used:
+
+## Range-Based Sharding
+
+This involves partitioning data based on a range of values. For example, customer data can be sharded based on alphabetical order of last names, or transaction data can be sharded based on date ranges.
+
+## Hash-Based Sharding
+
+In this method, a hash function is applied to a shard key chosen from the data (like a customer ID or transaction ID).
+
+This tends to distribute data more evenly across shards compared to range-based sharding. However, we need to choose a proper hash function to avoid hash collisions.
+
+## Consistent Hashing
+
+This is an extension of hash-based sharding that reduces the impact of adding or removing shards. It distributes data more evenly and minimizes the amount of data that needs to be relocated when shards are added or removed.
+
+## Virtual Bucket Sharding
+
+Data is mapped into virtual buckets, and these buckets are then mapped to physical shards. This two-level mapping allows for more flexible shard management and rebalancing without significant data movement.
diff --git a/data/guides/top-4-forms-of-authentication-mechanisms.md b/data/guides/top-4-forms-of-authentication-mechanisms.md
new file mode 100644
index 0000000..3ef146e
--- /dev/null
+++ b/data/guides/top-4-forms-of-authentication-mechanisms.md
@@ -0,0 +1,34 @@
+---
+title: "Top 4 Authentication Mechanisms"
+description: "Explore the top 4 authentication mechanisms for secure access."
+image: "https://assets.bytebytego.com/diagrams/0078-authentication-mechanisms.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Security"
+---
+
+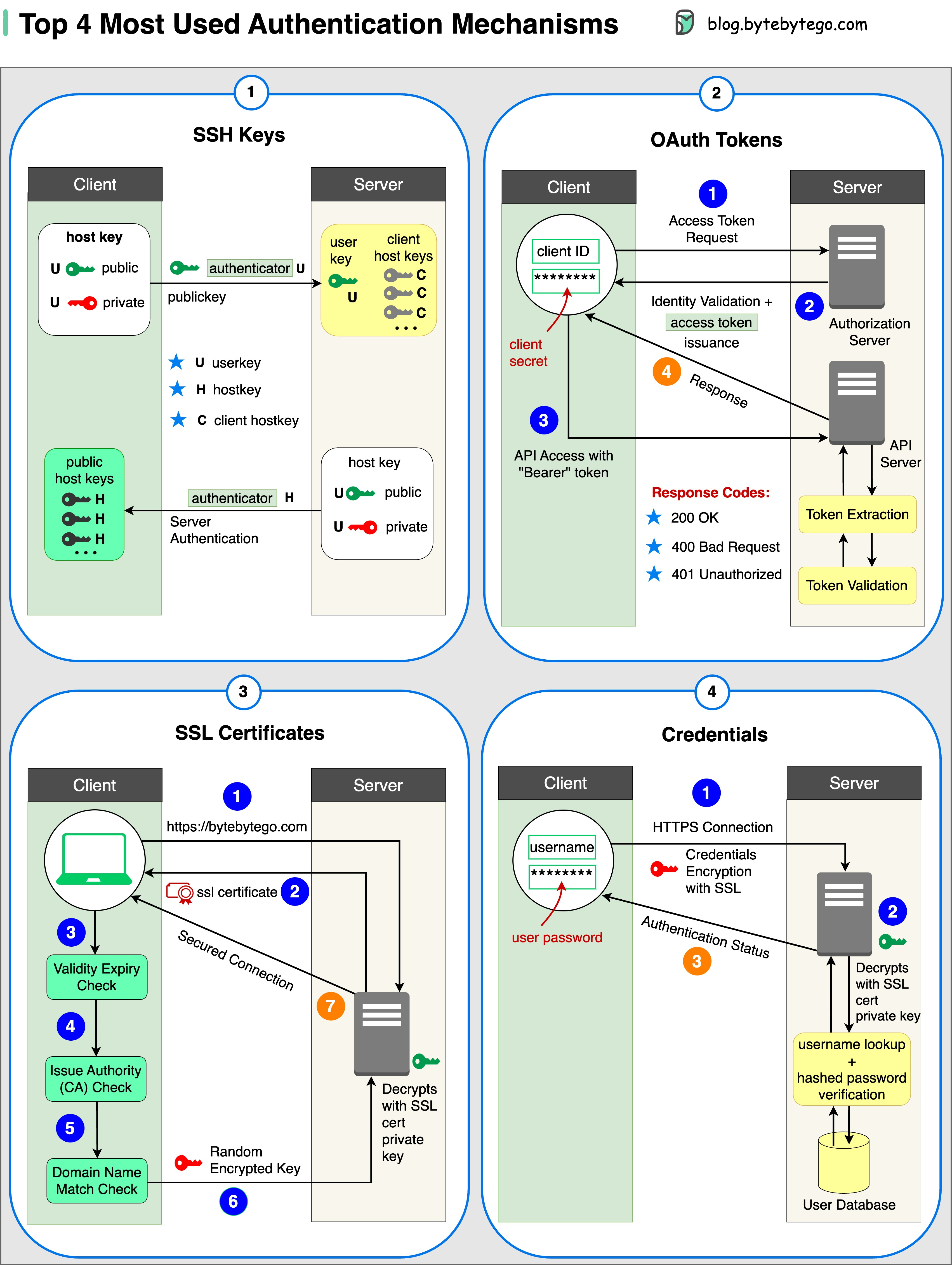
+
+## 1. SSH Keys
+
+Cryptographic keys are used to access remote systems and servers securely.
+
+## 2. OAuth Tokens
+
+Tokens that provide limited access to user data on third-party applications.
+
+## 3. SSL Certificates
+
+Digital certificates ensure secure and encrypted communication between servers and clients.
+
+## 4. Credentials
+
+User authentication information is used to verify and grant access to various systems and services.
+
+Over to you: How do you manage those security keys? Is it a good idea to put them in a GitHub repository?
+
+Guest post by [Govardhana Miriyala Kannaiah](https://www.linkedin.com/in/govardhana-miriyala-kannaiah/?lipi=urn%3Ali%3Apage%3Ad_flagship3_profile_view_base_recent_activity_content_view%3B453ttTK1RbaZ6dUsydRz9Q%3D%3D).
diff --git a/data/guides/top-4-kubernetes-service-types-in-one-diagram.md b/data/guides/top-4-kubernetes-service-types-in-one-diagram.md
new file mode 100644
index 0000000..9a5bac4
--- /dev/null
+++ b/data/guides/top-4-kubernetes-service-types-in-one-diagram.md
@@ -0,0 +1,38 @@
+---
+title: "Top 4 Kubernetes Service Types"
+description: "Explore the top 4 Kubernetes service types with a helpful diagram."
+image: "https://assets.bytebytego.com/diagrams/0005-4-k8s-service-types.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - Networking
+---
+
+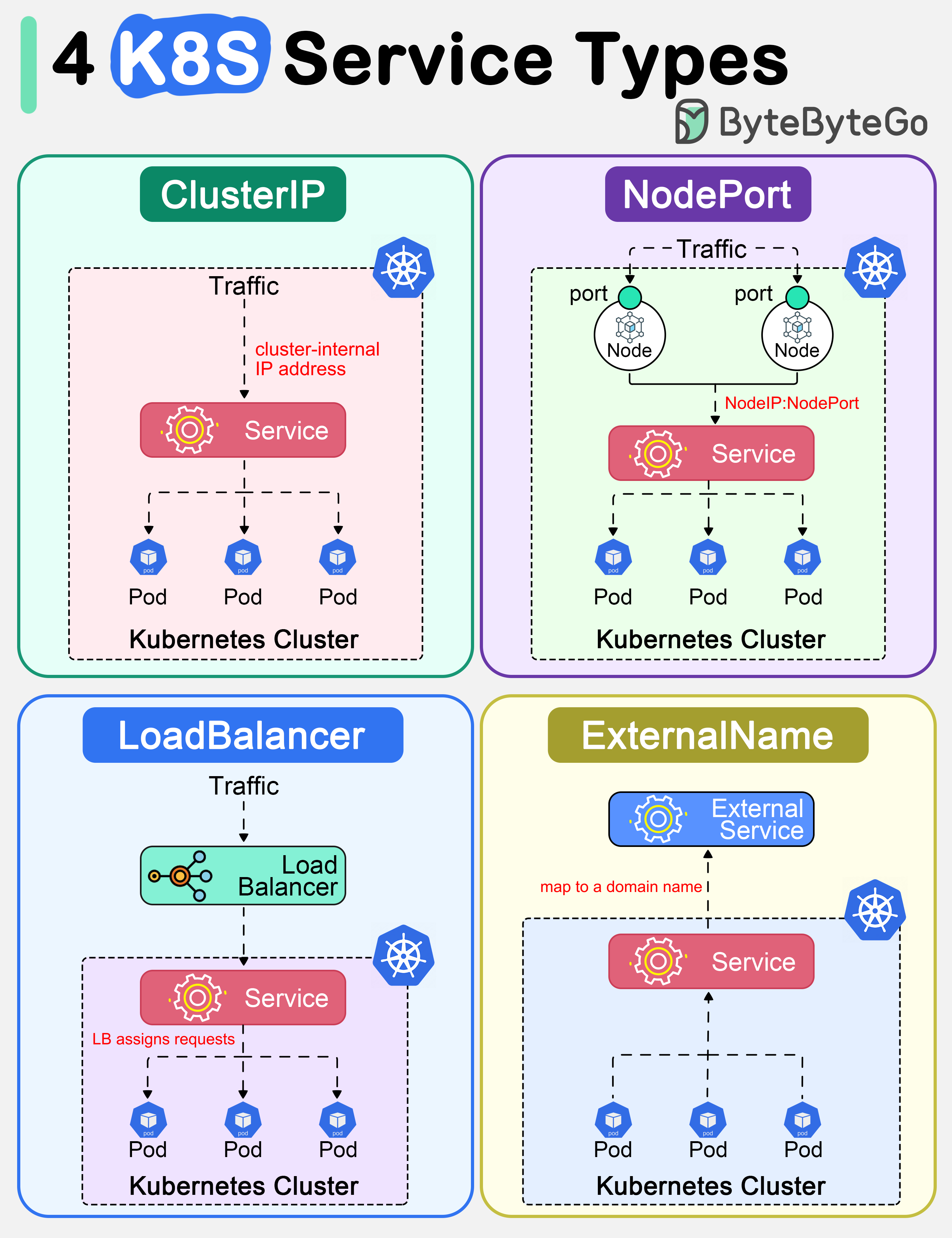
+
+The diagram below shows 4 ways to expose a Service.
+
+In Kubernetes, a Service is a method for exposing a network application in the cluster. We use a Service to make that set of Pods available on the network so that users can interact with it.
+
+There are 4 types of Kubernetes services: ClusterIP, NodePort, LoadBalancer and ExternalName. The “type” property in the Service's specification determines how the service is exposed to the network.
+
+## Kubernetes Service Types
+
+* **ClusterIP**
+
+ ClusterIP is the default and most common service type. Kubernetes will assign a cluster-internal IP address to ClusterIP service. This makes the service only reachable within the cluster.
+
+* **NodePort**
+
+ This exposes the service outside of the cluster by adding a cluster-wide port on top of ClusterIP. We can request the service by NodeIP:NodePort.
+
+* **LoadBalancer**
+
+ This exposes the Service externally using a cloud provider’s load balancer.
+
+* **ExternalName**
+
+ This maps a Service to a domain name. This is commonly used to create a service within Kubernetes to represent an external database.
diff --git a/data/guides/top-4-most-popular-use-cases-for-udp.md b/data/guides/top-4-most-popular-use-cases-for-udp.md
new file mode 100644
index 0000000..7aecbf6
--- /dev/null
+++ b/data/guides/top-4-most-popular-use-cases-for-udp.md
@@ -0,0 +1,32 @@
+---
+title: "Top 4 Most Popular Use Cases for UDP"
+description: "Explore the top 4 use cases for UDP: streaming, DNS, multicast, and IoT."
+image: "https://assets.bytebytego.com/diagrams/0044-top-4-udp-use-cases.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "UDP"
+ - "Networking"
+---
+
+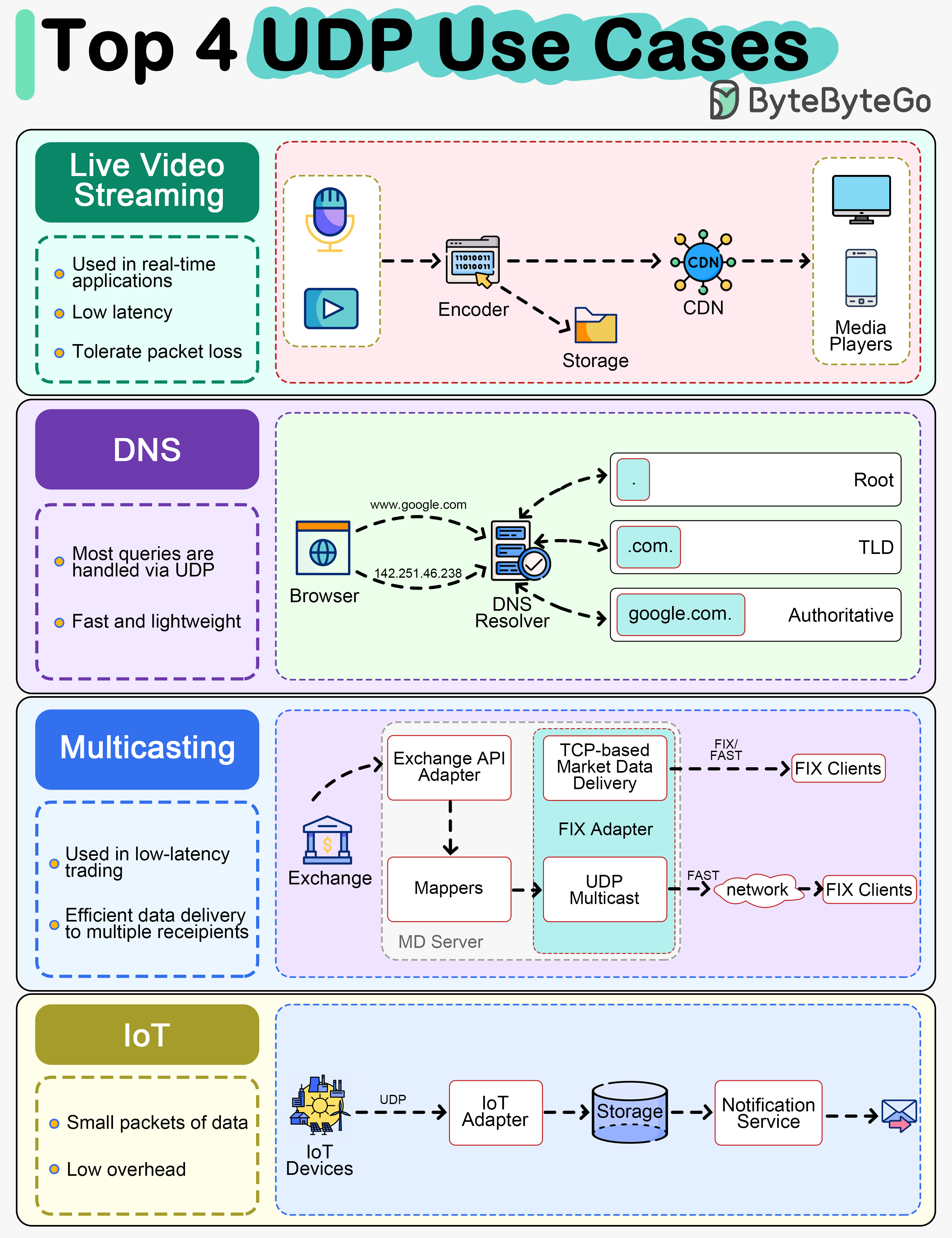
+
+### UDP (User Datagram Protocol) is used in various software architectures for its simplicity, speed, and low overhead compared to other protocols like TCP.
+
+## Live Video Streaming
+
+Many VoIP and video conferencing applications leverage UDP due to its lower overhead and ability to tolerate packet loss. Real-time communication benefits from UDP's reduced latency compared to TCP.
+
+## DNS
+
+DNS (Domain Name Service) queries typically use UDP for their fast and lightweight nature. Although DNS can also use TCP for large responses or zone transfers, most queries are handled via UDP.
+
+## Market Data Multicast
+
+In low-latency trading, UDP is utilized for efficient market data delivery to multiple recipients simultaneously.
+
+## IoT
+
+UDP is often used in IoT devices for communications, sending small packets of data between devices.
diff --git a/data/guides/top-5-caching-strategies.md b/data/guides/top-5-caching-strategies.md
new file mode 100644
index 0000000..180d44a
--- /dev/null
+++ b/data/guides/top-5-caching-strategies.md
@@ -0,0 +1,31 @@
+---
+title: "Top 5 Caching Strategies"
+description: "Explore the top 5 caching strategies to optimize data synchronization."
+image: "https://assets.bytebytego.com/diagrams/0374-top-5-caching-strategies.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Data Synchronization"
+---
+
+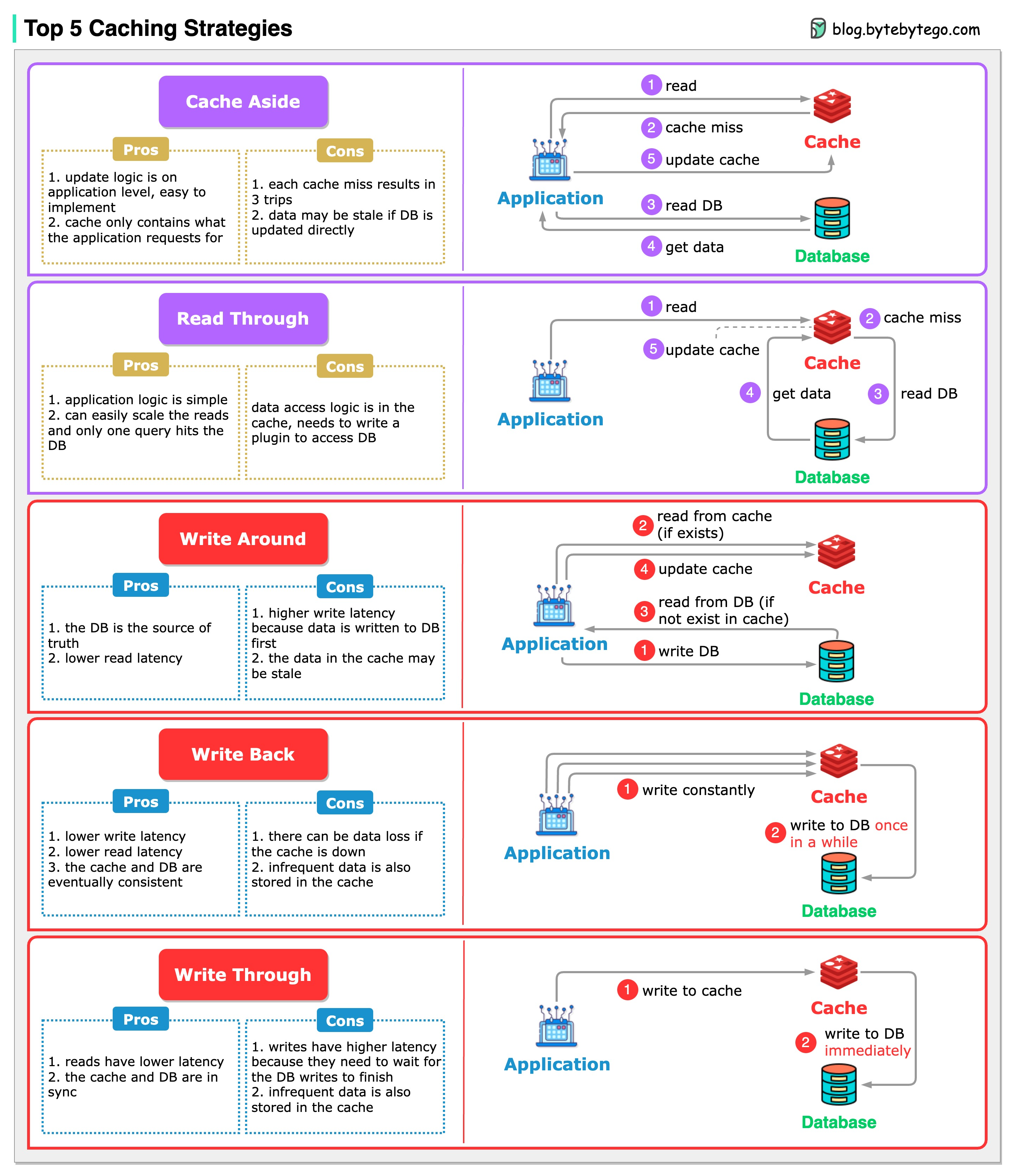
+
+When we introduce a cache into the architecture, synchronization between the cache and the database becomes inevitable.
+
+Let’s look at 5 common strategies for how we keep the data in sync.
+
+## Read Strategies
+
+* Cache aside
+* Read through
+
+## Write Strategies
+
+* Write around
+* Write back
+* Write through
+
+The caching strategies are often used in combination. For example, write-around is often used together with cache-aside to make sure the cache is up-to-date.
diff --git a/data/guides/top-5-common-ways-to-improve-api-performance.md b/data/guides/top-5-common-ways-to-improve-api-performance.md
new file mode 100644
index 0000000..d593ecc
--- /dev/null
+++ b/data/guides/top-5-common-ways-to-improve-api-performance.md
@@ -0,0 +1,34 @@
+---
+title: "Top 5 Common Ways to Improve API Performance"
+description: "Explore 5 common ways to boost your API's performance effectively."
+image: "https://assets.bytebytego.com/diagrams/0001-how-to-improve-api-performance.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - api performance
+ - optimization
+---
+
+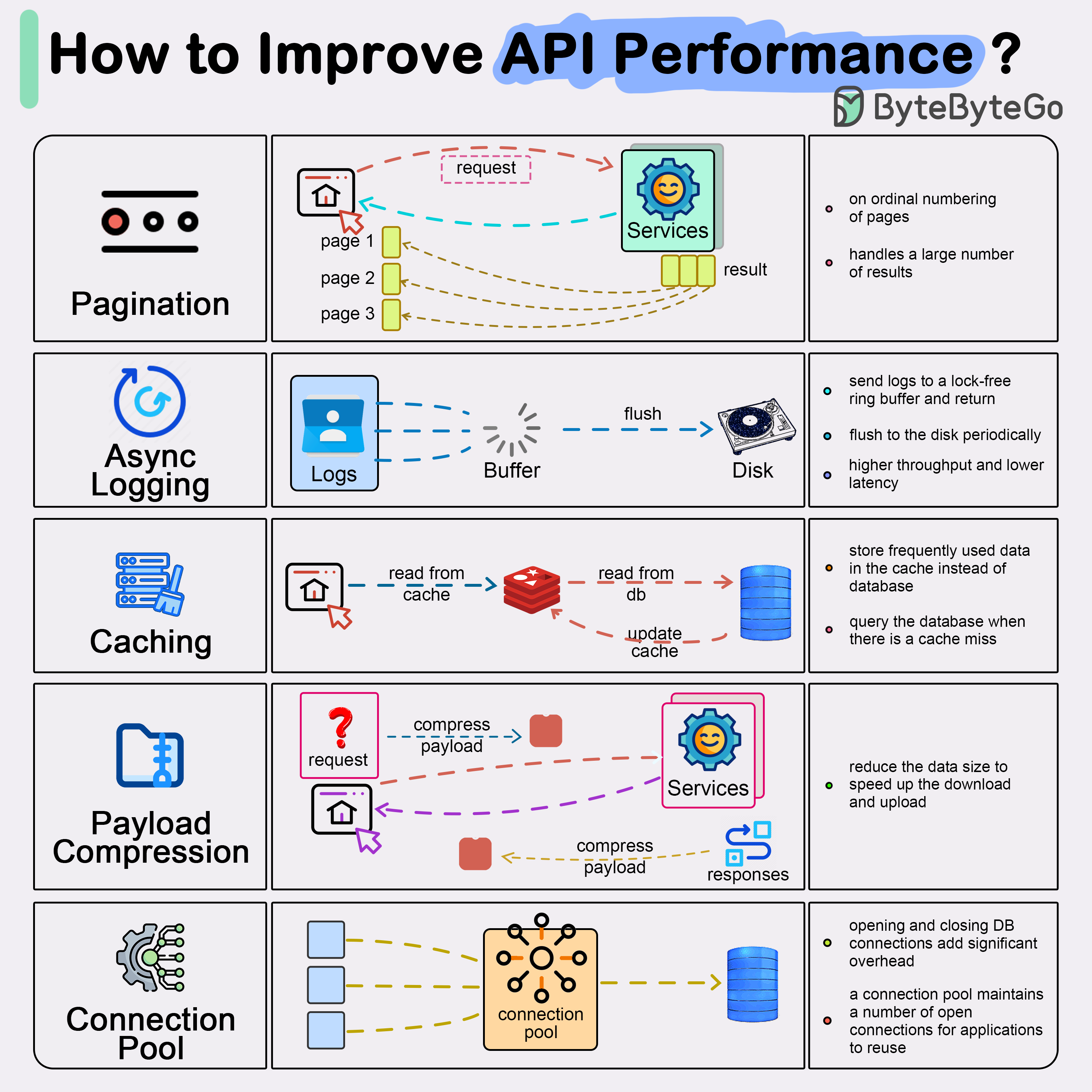
+
+## 1. Result Pagination:
+
+This method is used to optimize large result sets by streaming them back to the client, enhancing service responsiveness and user experience.
+
+## 2. Asynchronous Logging:
+
+This approach involves sending logs to a lock-free buffer and returning immediately, rather than dealing with the disk on every call. Logs are periodically flushed to the disk, significantly reducing I/O overhead.
+
+## 3. Data Caching:
+
+Frequently accessed data can be stored in a cache to speed up retrieval. Clients check the cache before querying the database, with data storage solutions like Redis offering faster access due to in-memory storage.
+
+## 4. Payload Compression:
+
+To reduce data transmission time, requests and responses can be compressed (e.g., using gzip), making the upload and download processes quicker.
+
+## 5. Connection Pooling:
+
+This technique involves using a pool of open connections to manage database interaction, which reduces the overhead associated with opening and closing connections each time data needs to be loaded. The pool manages the lifecycle of connections for efficient resource use.
diff --git a/data/guides/top-5-kafka-use-cases.md b/data/guides/top-5-kafka-use-cases.md
new file mode 100644
index 0000000..7575ba2
--- /dev/null
+++ b/data/guides/top-5-kafka-use-cases.md
@@ -0,0 +1,28 @@
+---
+title: "Top 5 Kafka Use Cases"
+description: "Explore the top 5 Kafka use cases for data streaming and processing."
+image: "https://assets.bytebytego.com/diagrams/0368-top-5-kafka-use-cases.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Kafka"
+ - "Data Streaming"
+---
+
+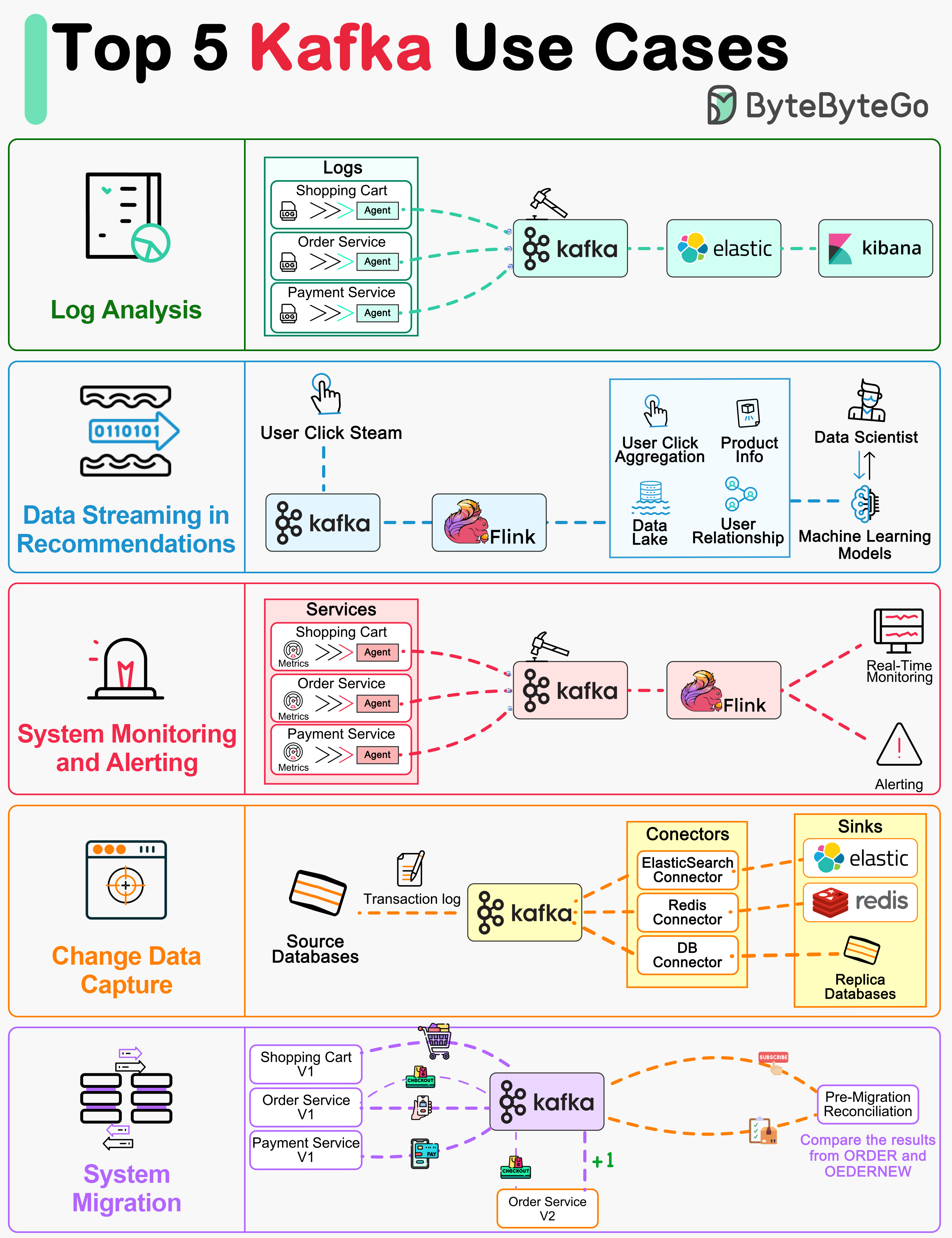
+
+Kafka was originally built for massive log processing. It retains messages until expiration and lets consumers pull messages at their own pace.
+
+Let’s review the popular Kafka use cases.
+
+* Log processing and analysis
+
+* Data streaming in recommendations
+
+* System monitoring and alerting
+
+* CDC (Change data capture)
+
+* System migration
diff --git a/data/guides/top-5-most-used-deployment-strategies.md b/data/guides/top-5-most-used-deployment-strategies.md
new file mode 100644
index 0000000..6231515
--- /dev/null
+++ b/data/guides/top-5-most-used-deployment-strategies.md
@@ -0,0 +1,26 @@
+---
+title: "Top 5 Most-Used Deployment Strategies"
+description: "Explore the top 5 deployment strategies for efficient software releases."
+image: "https://assets.bytebytego.com/diagrams/0358-the-most-popular-deployment-strategies.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "deployment strategies"
+ - "software deployment"
+---
+
+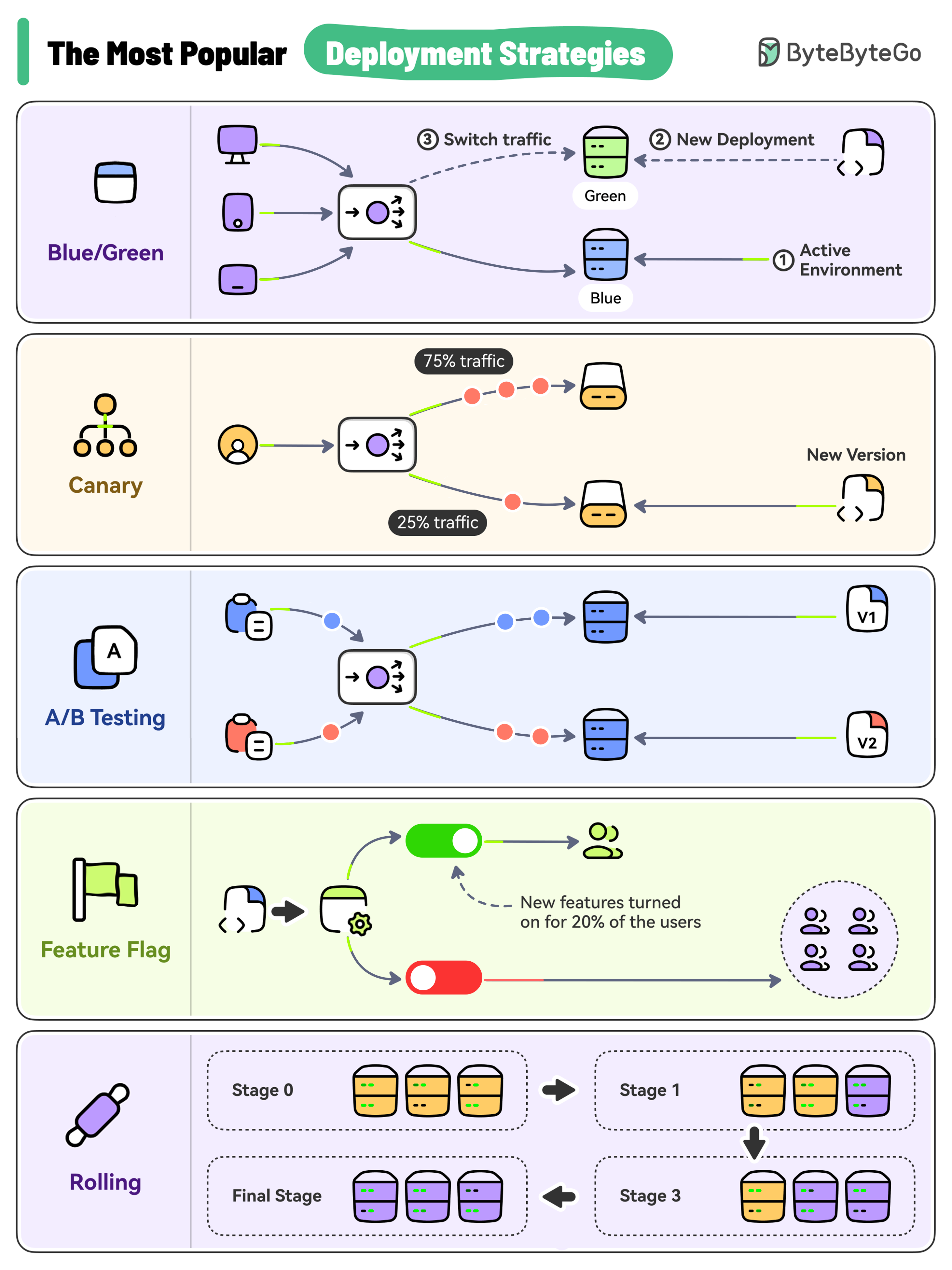
+
+Here are the top 5 most-used deployment strategies:
+
+* **Big Bang Deployment**
+
+* **Rolling Deployment**
+
+* **Blue-Green Deployment**
+
+* **Canary Deployment**
+
+* **Feature Toggle**
diff --git a/data/guides/top-5-software-architectural-patterns.md b/data/guides/top-5-software-architectural-patterns.md
new file mode 100644
index 0000000..c82dfc4
--- /dev/null
+++ b/data/guides/top-5-software-architectural-patterns.md
@@ -0,0 +1,20 @@
+---
+title: "Top 5 Software Architectural Patterns"
+description: "Explore the top 5 software architectural patterns for system design."
+image: "https://assets.bytebytego.com/diagrams/0339-software-architecture-styles.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Software Architecture"
+ - "Design Patterns"
+---
+
+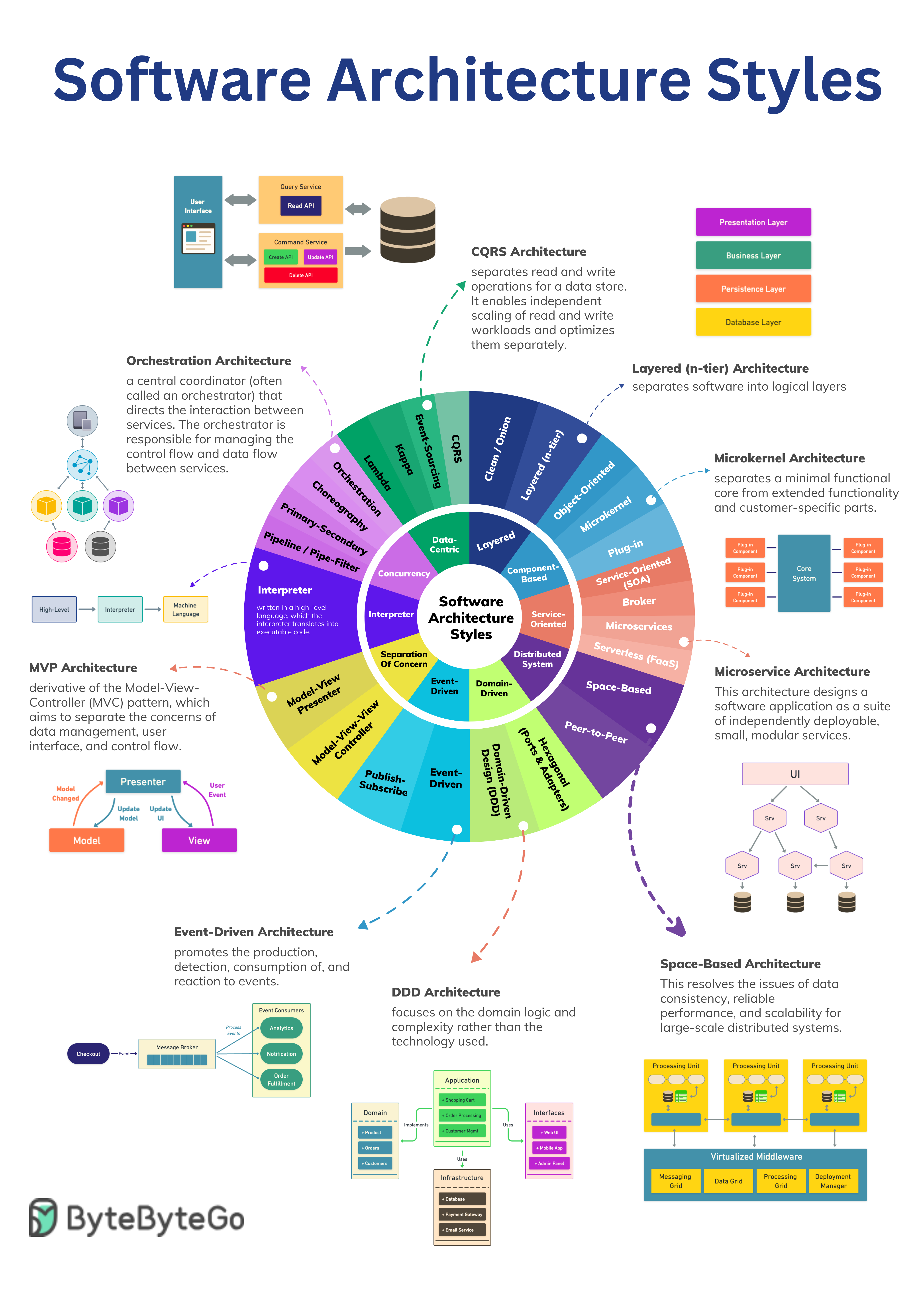
+
+In software development, architecture plays a crucial role in shaping the structure and behavior of software systems. It provides a blueprint for system design, detailing how components interact with each other to deliver specific functionality. They also offer solutions to common problems, saving time and effort and leading to more robust and maintainable systems.
+
+However, with the vast array of architectural styles and patterns available, it can take time to discern which approach best suits a particular project or system. Aims to shed light on these concepts, helping you make informed decisions in your architectural endeavors.
+
+To help you navigate the vast landscape of architectural styles and patterns, there is a cheat sheet that encapsulates all. This cheat sheet is a handy reference guide that you can use to quickly recall the main characteristics of each architectural style and pattern.
diff --git a/data/guides/top-5-strategies-to-reduce-latency.md b/data/guides/top-5-strategies-to-reduce-latency.md
new file mode 100644
index 0000000..f71fabe
--- /dev/null
+++ b/data/guides/top-5-strategies-to-reduce-latency.md
@@ -0,0 +1,27 @@
+---
+title: "Top 5 Strategies to Reduce Latency"
+description: "Explore top strategies to minimize latency in high-scale systems."
+image: "https://assets.bytebytego.com/diagrams/0375-top-5-strategies-to-reduce-latency.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Latency"
+ - "Optimization"
+---
+
+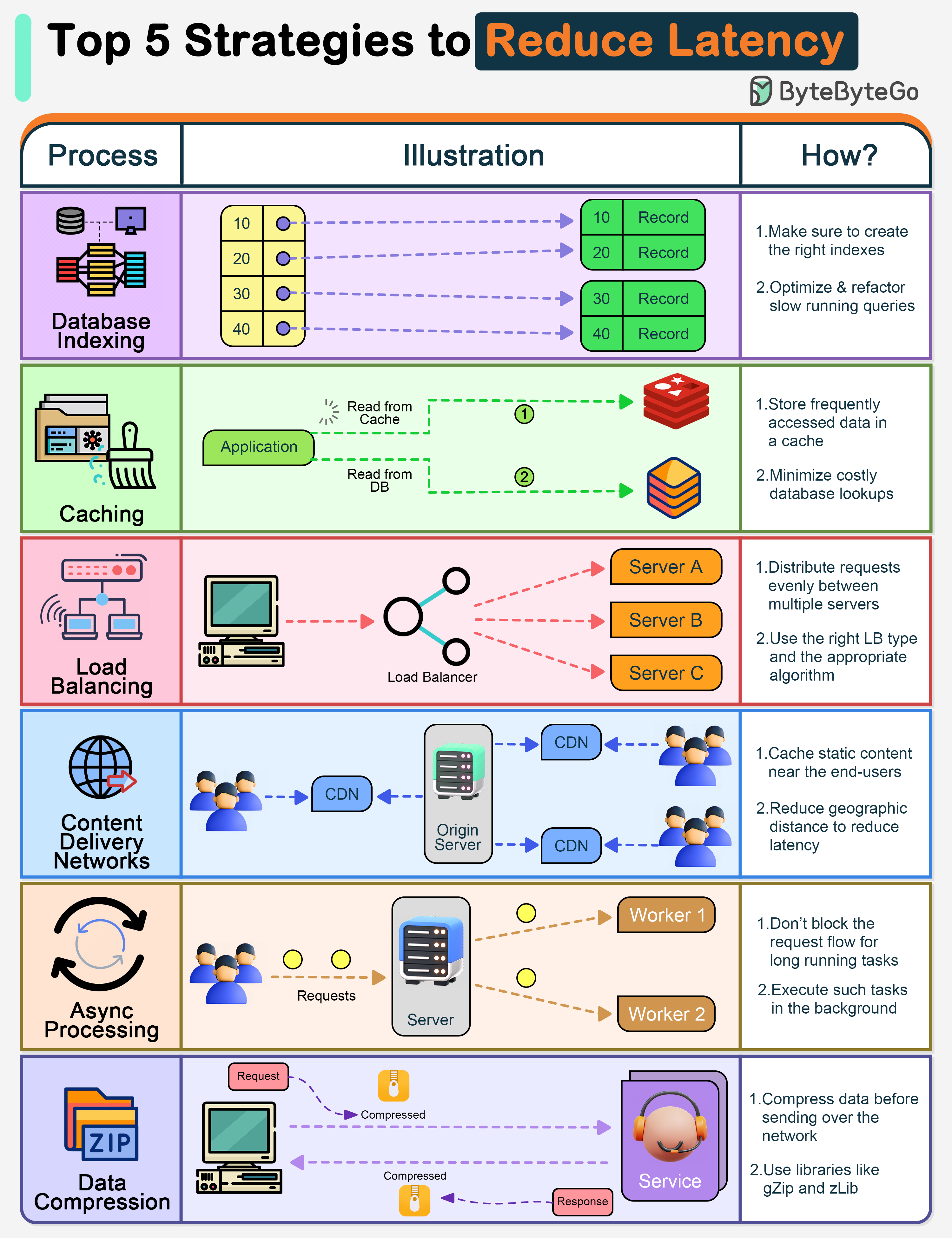
+
+10 years ago, Amazon found that every 100ms of latency cost them 1% in sales. That’s a staggering $5.7 billion in today’s terms.
+
+For high-scale user-facing systems, high latency is a big loss of revenue.
+
+Here are the top strategies to reduce latency:
+
+* **Database Indexing**
+* **Caching**
+* **Load Balancing**
+* **Content Delivery Network**
+* **Async Processing**
+* **Data Compression**
diff --git a/data/guides/top-5-trade-offs-in-system-designs.md b/data/guides/top-5-trade-offs-in-system-designs.md
new file mode 100644
index 0000000..a36d319
--- /dev/null
+++ b/data/guides/top-5-trade-offs-in-system-designs.md
@@ -0,0 +1,24 @@
+---
+title: "Top 5 Trade-offs in System Designs"
+description: "Explore the top 5 trade-offs in system design for optimal solutions."
+image: "https://assets.bytebytego.com/diagrams/0376-top-5-trade-offs-in-system-designs.png"
+createdAt: "2024-02-02"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "trade-offs"
+---
+
+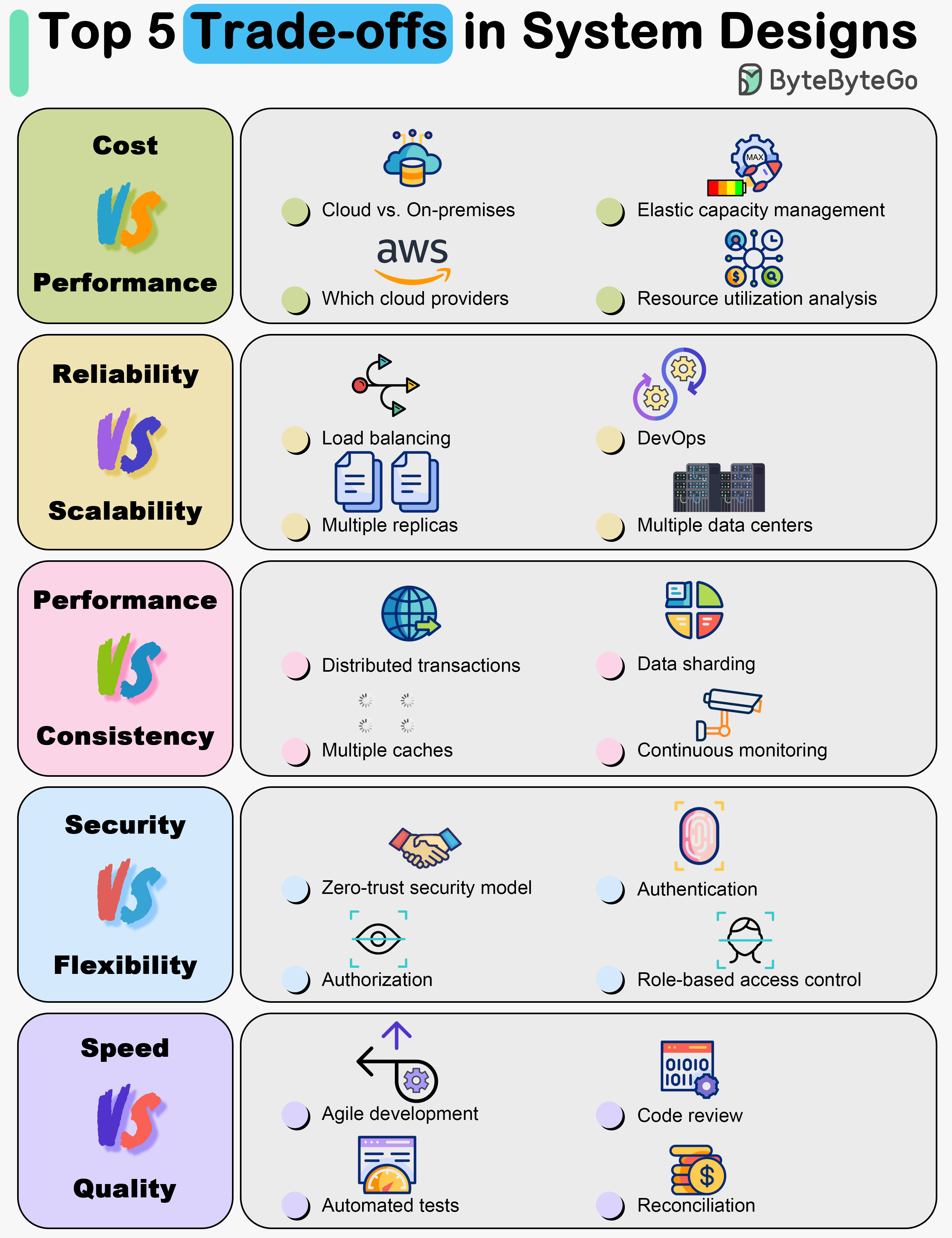
+
+Everything is a trade-off. Everything is a compromise. There is no right or wrong design.
+
+The diagram below shows some of the most important trade-offs.
+
+* **Cost vs. Performance**
+* **Reliability vs. Scalability**
+* **Performance vs. Consistency**
+* **Security vs. Flexibility**
+* **Development Speed vs. Quality**
diff --git a/data/guides/top-6-cases-to-apply-idempotency.md b/data/guides/top-6-cases-to-apply-idempotency.md
new file mode 100644
index 0000000..4d15ce4
--- /dev/null
+++ b/data/guides/top-6-cases-to-apply-idempotency.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Cases to Apply Idempotency"
+description: "Explore 6 key use cases where idempotency is crucial for reliable systems."
+image: "https://assets.bytebytego.com/diagrams/0377-top-6-cases-of-leveraging-idempotency.png"
+createdAt: "2024-02-01"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Idempotency"
+ - "Distributed Systems"
+---
+
+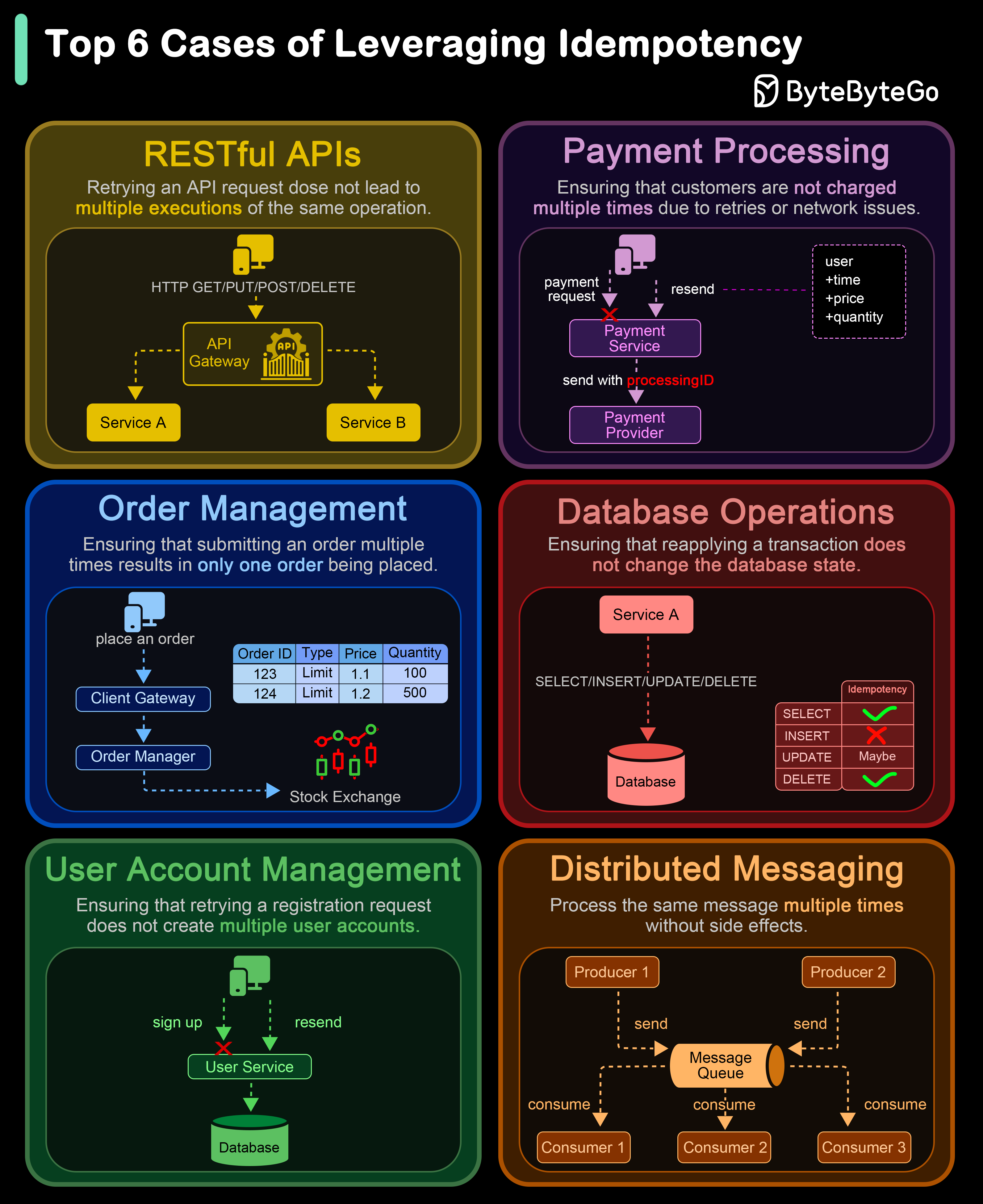
+
+Idempotency is essential in various scenarios, particularly where operations might be retried or executed multiple times. Here are the top 6 use cases where idempotency is crucial:
+
+## 1. RESTful API Requests
+
+We need to ensure that retrying an API request does not lead to multiple executions of the same operation. Implement idempotent methods (like PUT and DELETE) to maintain consistent resource states.
+
+## 2. Payment Processing
+
+We need to ensure that customers are not charged multiple times due to retries or network issues. Payment gateways often need to retry transactions; idempotency ensures only one charge is made.
+
+## 3. Order Management Systems
+
+We need to ensure that submitting an order multiple times results in only one order being placed. We design a safe mechanism to prevent duplicate inventory deductions or updates.
+
+## 4. Database Operations
+
+We need to ensure that reapplying a transaction does not change the database state beyond the initial application.
+
+## 5. User Account Management
+
+We need to ensure that retrying a registration request does not create multiple user accounts. Also, we need to ensure that multiple password reset requests result in a single reset action.
+
+## 6. Distributed Systems and Messaging
+
+We need to ensure that reprocessing messages from a queue does not result in duplicate processing. We Implement handlers that can process the same message multiple times without side effects.
diff --git a/data/guides/top-6-cloud-messaging-patterns.md b/data/guides/top-6-cloud-messaging-patterns.md
new file mode 100644
index 0000000..0974125
--- /dev/null
+++ b/data/guides/top-6-cloud-messaging-patterns.md
@@ -0,0 +1,44 @@
+---
+title: "Top 6 Cloud Messaging Patterns"
+description: "Explore 6 key cloud messaging patterns for distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0378-top-6-cloud-messaging-patterns.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Messaging"
+ - "Design Patterns"
+---
+
+How do services communicate with each other? The diagram below shows 6 cloud messaging patterns.
+
+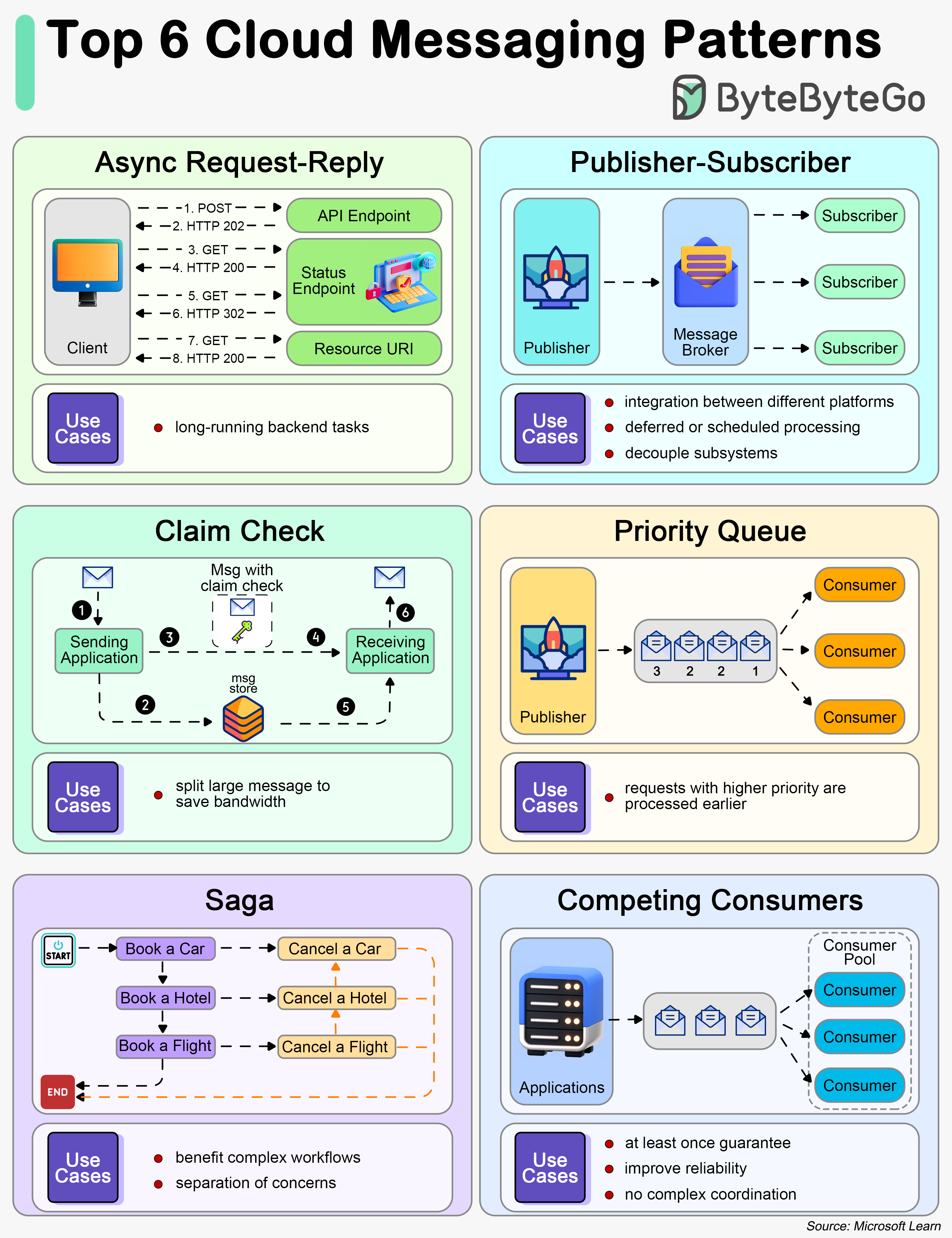
+
+## Asynchronous Request-Reply
+
+This pattern aims at providing determinism for long-running backend tasks. It decouples backend processing from frontend clients.
+
+In the diagram below, the client makes a synchronous call to the API, triggering a long-running operation on the backend. The API returns an HTTP 202 (Accepted) status code, acknowledging that the request has been received for processing.
+
+## Publisher-Subscriber
+
+This pattern targets decoupling senders from consumers, and avoiding blocking the sender to wait for a response.
+
+## Claim Check
+
+This pattern solves the transmision of large messages. It stores the whole message payload into a database and transmits only the reference to the message, which will be used later to retrieve the payload from the database.
+
+## Priority Queue
+
+This pattern prioritizes requests sent to services so that requests with a higher priority are received and processed more quickly than those with a lower priority.
+
+## Saga
+
+Saga is used to manage data consistency across multiple services in distributed systems, especially in microservices architectures where each service manages its own database.
+
+The saga pattern addresses the challenge of maintaining data consistency without relying on distributed transactions, which are difficult to scale and can negatively impact system performance.
+
+## Competing Consumers
+
+This pattern enables multiple concurrent consumers to process messages received on the same messaging channel. There is no need to configure complex coordination between the consumers. However, this pattern cannot guarantee message ordering.
diff --git a/data/guides/top-6-database-models.md b/data/guides/top-6-database-models.md
new file mode 100644
index 0000000..8e652e2
--- /dev/null
+++ b/data/guides/top-6-database-models.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Database Models"
+description: "Explore the top 6 database models and their unique characteristics."
+image: "https://assets.bytebytego.com/diagrams/0369-top-6-database-models.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Models"
+ - "Data Structures"
+---
+
+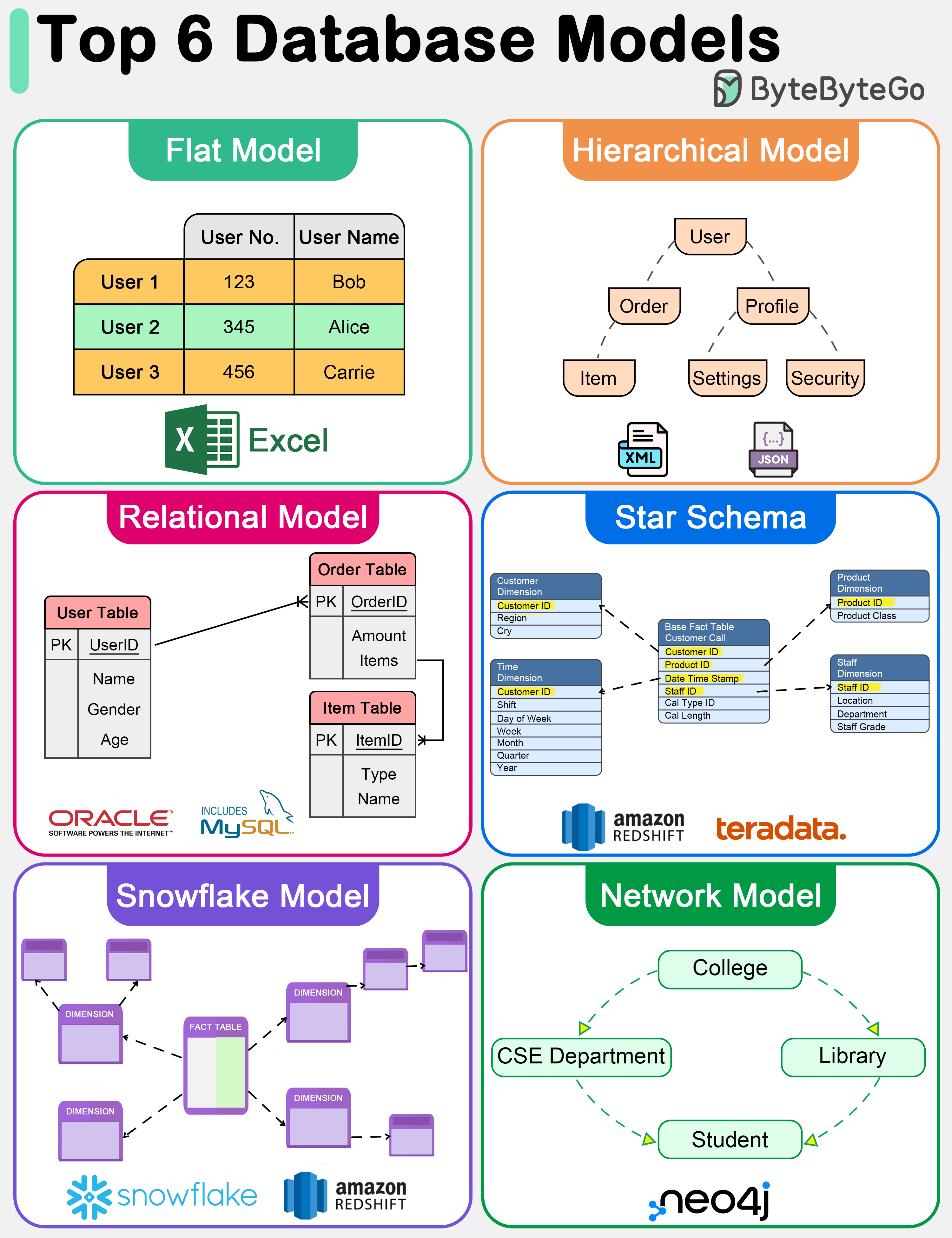
+
+The diagram above shows top 6 data models.
+
+* **Flat Model**
+
+ The flat data model is one of the simplest forms of database models. It organizes data into a single table where each row represents a record and each column represents an attribute. This model is similar to a spreadsheet and is straightforward to understand and implement. However, it lacks the ability to efficiently handle complex relationships between data entities.
+
+* **Hierarchical Model**
+
+ The hierarchical data model organizes data into a tree-like structure, where each record has a single parent but can have multiple children. This model is efficient for scenarios with a clear "parent-child" relationship among data entities. However, it struggles with many-to-many relationships and can become complex and rigid.
+
+* **Relational Model**
+
+ Introduced by E.F. Codd in 1970, the relational model represents data in tables (relations), consisting of rows (tuples) and columns (attributes). It supports data integrity and avoids redundancy through the use of keys and normalization. The relational model's strength lies in its flexibility and the simplicity of its query language, SQL (Structured Query Language), making it the most widely used data model for traditional database systems. It efficiently handles many-to-many relationships and supports complex queries and transactions.
+
+* **Star Schema**
+
+ The star schema is a specialized data model used in data warehousing for OLAP (Online Analytical Processing) applications. It features a central fact table that contains measurable, quantitative data, surrounded by dimension tables that contain descriptive attributes related to the fact data. This model is optimized for query performance in analytical applications, offering simplicity and fast data retrieval by minimizing the number of joins needed for queries.
+
+* **Snowflake Model**
+
+ The snowflake model is a variation of the star schema where the dimension tables are normalized into multiple related tables, reducing redundancy and improving data integrity. This results in a structure that resembles a snowflake. While the snowflake model can lead to more complex queries due to the increased number of joins, it offers benefits in terms of storage efficiency and can be advantageous in scenarios where dimension tables are large or frequently updated.
+
+* **Network Model**
+
+ The network data model allows each record to have multiple parents and children, forming a graph structure that can represent complex relationships between data entities. This model overcomes some of the hierarchical model's limitations by efficiently handling many-to-many relationships.
diff --git a/data/guides/top-6-elasticsearch-use-cases.md b/data/guides/top-6-elasticsearch-use-cases.md
new file mode 100644
index 0000000..76a7c1d
--- /dev/null
+++ b/data/guides/top-6-elasticsearch-use-cases.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Elasticsearch Use Cases"
+description: "Explore the top 6 use cases of Elasticsearch in various applications."
+image: "https://assets.bytebytego.com/diagrams/0380-top-6-elasticsearch-use-cases.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Search
+ - Analytics
+---
+
+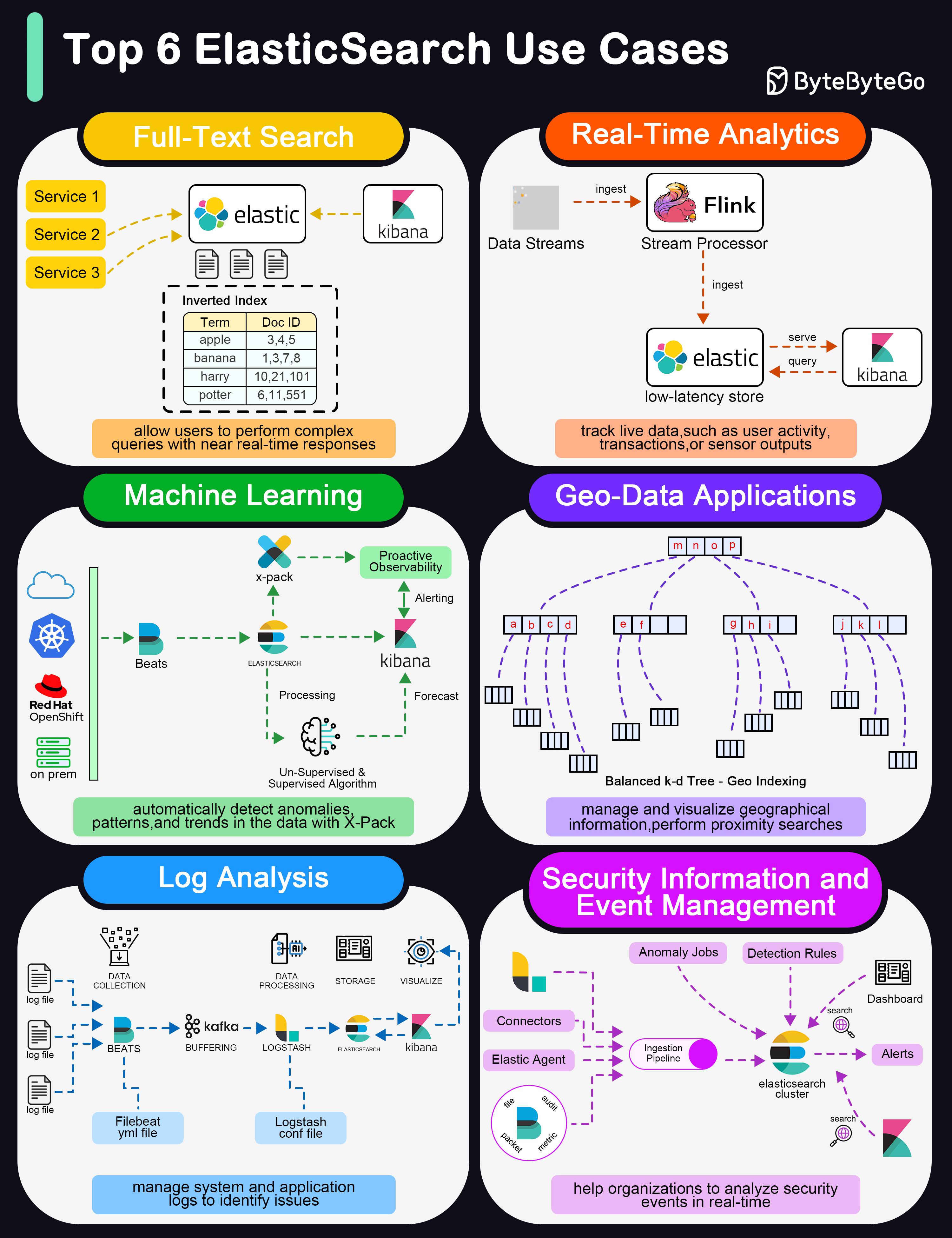
+
+Elasticsearch is widely used for its powerful and versatile search capabilities. The diagram above shows the top 6 use cases:
+
+## Full-Text Search
+
+Elasticsearch excels in full-text search scenarios due to its robust, scalable, and fast search capabilities. It allows users to perform complex queries with near real-time responses.
+
+## Real-Time Analytics
+
+Elasticsearch's ability to perform analytics in real-time makes it suitable for dashboards that track live data, such as user activity, transactions, or sensor outputs.
+
+## Machine Learning
+
+With the addition of the machine learning feature in X-Pack, Elasticsearch can automatically detect anomalies, patterns, and trends in the data.
+
+## Geo-Data Applications
+
+Elasticsearch supports geo-data through geospatial indexing and searching capabilities. This is useful for applications that need to manage and visualize geographical information, such as mapping and location-based services.
+
+## Log and Event Data Analysis
+
+Organizations use Elasticsearch to aggregate, monitor, and analyze logs and event data from various sources. It's a key component of the ELK stack (Elasticsearch, Logstash, Kibana), which is popular for managing system and application logs to identify issues and monitor system health.
+
+## Security Information and Event Management (SIEM)
+
+Elasticsearch can be used as a tool for SIEM, helping organizations to analyze security events in real time.
diff --git a/data/guides/top-6-firewall-use-cases.md b/data/guides/top-6-firewall-use-cases.md
new file mode 100644
index 0000000..cea917e
--- /dev/null
+++ b/data/guides/top-6-firewall-use-cases.md
@@ -0,0 +1,38 @@
+---
+title: "Top 6 Firewall Use Cases"
+description: "Explore the top 6 firewall use cases for enhanced network security."
+image: "https://assets.bytebytego.com/diagrams/0047-top-6-firewall-use-cases.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - security
+tags:
+ - "Network Security"
+ - "Firewall"
+---
+
+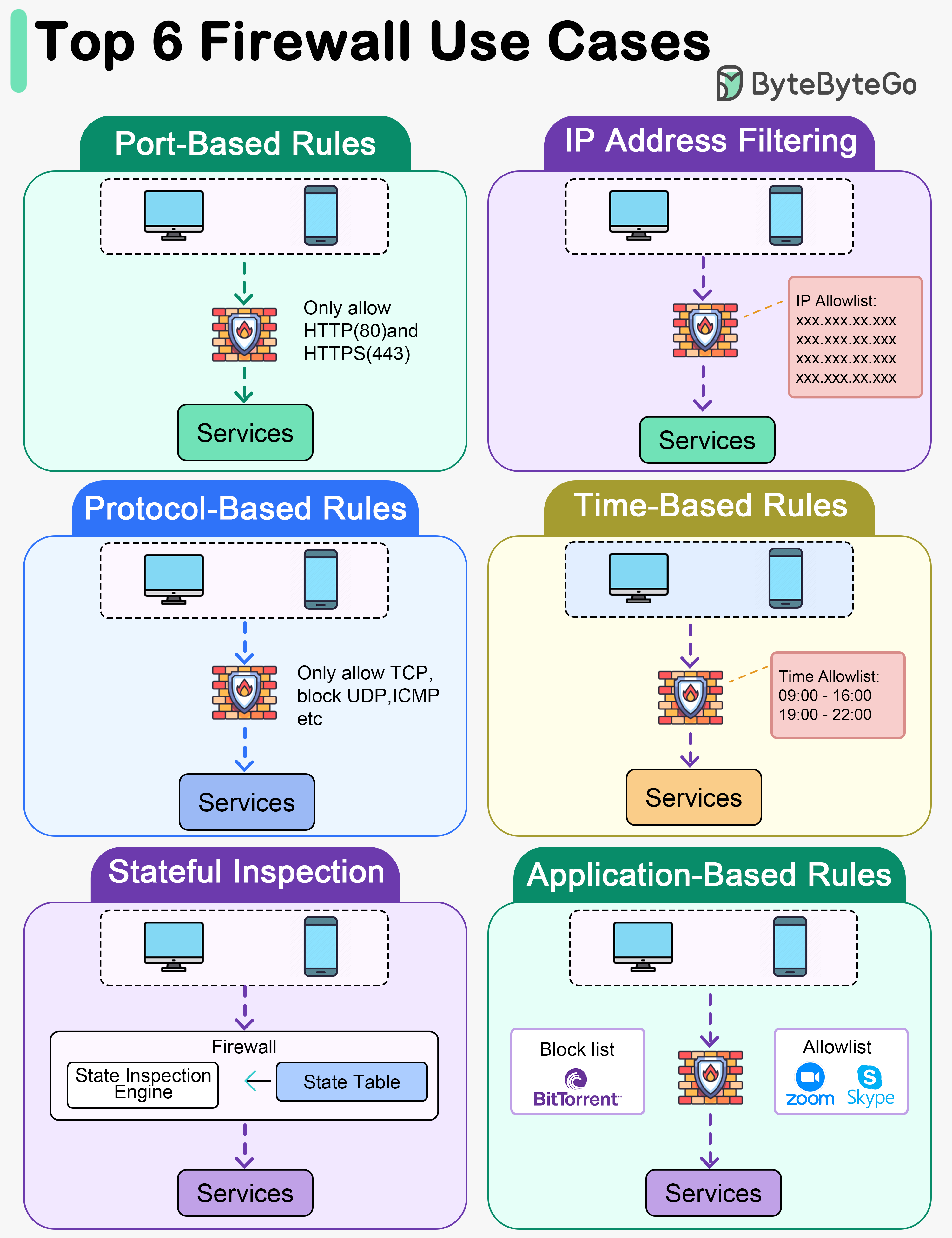
+
+## Port-Based Rules
+
+Firewall rules can be set to allow or block traffic based on specific ports. For example, allowing only traffic on ports 80 (HTTP) and 443 (HTTPS) for web browsing.
+
+## IP Address Filtering
+
+Rules can be configured to allow or deny traffic based on source or destination IP addresses. This can include whitelisting trusted IP addresses or blacklisting known malicious ones.
+
+## Protocol-Based Rules
+
+Firewalls can be configured to allow or block traffic based on specific network protocols such as TCP, UDP, ICMP, etc. For instance, allowing only TCP traffic on port 22 (SSH).
+
+## Time-Based Rules
+
+Firewalls can be configured to enforce rules based on specific times or schedules. This can be useful for setting different access rules during business hours versus after-hours.
+
+## Stateful Inspection
+
+**Stateful Inspection:** Stateful firewalls monitor the state of active connections and allow traffic only if it matches an established connection, preventing unauthorized access from the outside.
+
+## Application-Based Rules
+
+Some firewalls offer application-level control by allowing or blocking traffic based on specific applications or services. For instance, allowing or restricting access to certain applications like Skype, BitTorrent, etc.
diff --git a/data/guides/top-6-load-balancing-algorithms.md b/data/guides/top-6-load-balancing-algorithms.md
new file mode 100644
index 0000000..2c5e463
--- /dev/null
+++ b/data/guides/top-6-load-balancing-algorithms.md
@@ -0,0 +1,44 @@
+---
+title: "Top 6 Load Balancing Algorithms"
+description: "Explore the top 6 load balancing algorithms in detail."
+image: "https://assets.bytebytego.com/diagrams/0251-lb-algorithms.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Load Balancing"
+ - "Algorithms"
+---
+
+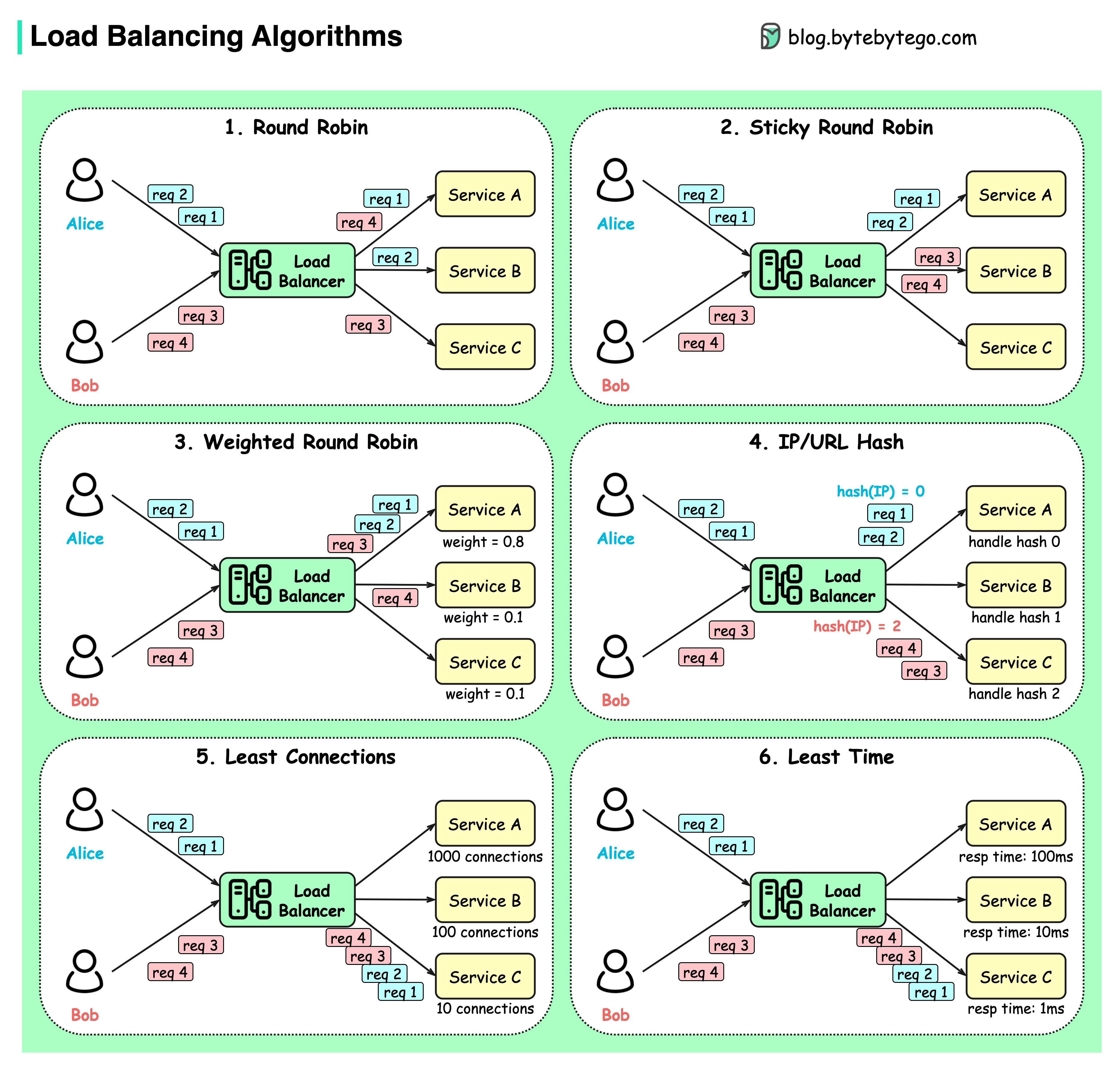
+
+## Top 6 Load Balancing Algorithms
+
+* **Static Algorithms**
+
+ * Round robin
+
+ The client requests are sent to different service instances in sequential order. The services are usually required to be stateless.
+
+ * Sticky round-robin
+
+ This is an improvement of the round-robin algorithm. If Alice’s first request goes to service A, the following requests go to service A as well.
+
+ * Weighted round-robin
+
+ The admin can specify the weight for each service. The ones with a higher weight handle more requests than others.
+
+ * Hash
+
+ This algorithm applies a hash function on the incoming requests’ IP or URL. The requests are routed to relevant instances based on the hash function result.
+
+* **Dynamic Algorithms**
+
+ * Least connections
+
+ A new request is sent to the service instance with the least concurrent connections.
+
+ * Least response time
+
+ A new request is sent to the service instance with the fastest response time.
diff --git a/data/guides/top-6-most-commonly-used-server-types.md b/data/guides/top-6-most-commonly-used-server-types.md
new file mode 100644
index 0000000..7829d42
--- /dev/null
+++ b/data/guides/top-6-most-commonly-used-server-types.md
@@ -0,0 +1,38 @@
+---
+title: "Top 6 Most Commonly Used Server Types"
+description: "Explore the top 6 most commonly used server types in modern infrastructure."
+image: "https://assets.bytebytego.com/diagrams/0327-server-types.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - software-development
+tags:
+ - "servers"
+ - "networking"
+---
+
+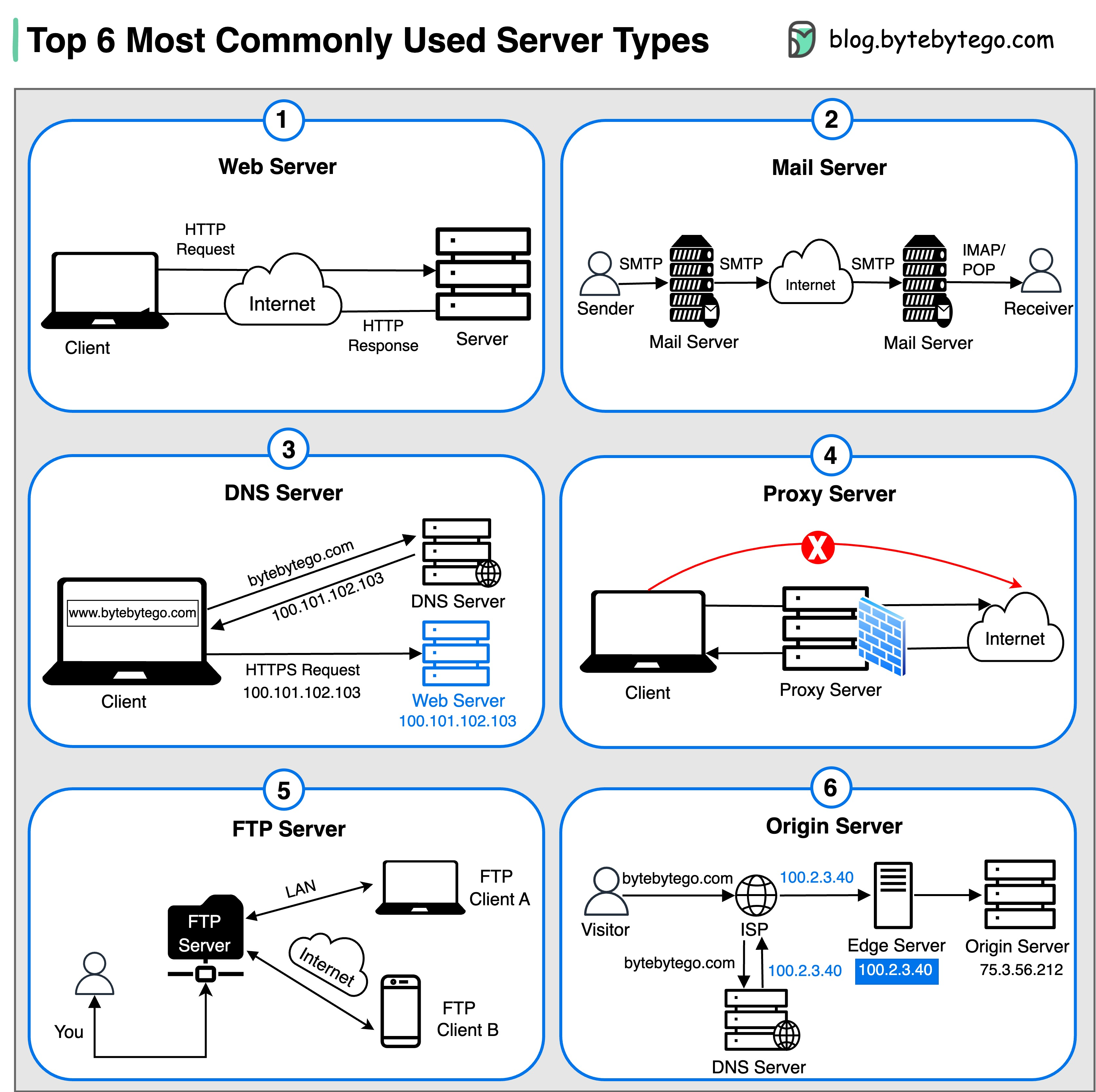
+
+## 1. Web Server
+
+Hosts websites and delivers web content to clients over the internet.
+
+## 2. Mail Server
+
+Handles the sending, receiving, and routing of emails across networks.
+
+## 3. DNS Server
+
+Translates domain names (like bytebytego.com) into IP addresses, enabling users to access websites by their human-readable names.
+
+## 4. Proxy Server
+
+An intermediary server that acts as a gateway between clients and other servers, providing additional security, performance optimization, and anonymity.
+
+## 5. FTP Server
+
+Facilitates the transfer of files between clients and servers over a network.
+
+## 6. Origin Server
+
+Hosts central source of content that is cached and distributed to edge servers for faster delivery to end users.
diff --git a/data/guides/top-6-multithreading-design-patterns-you-must-know.md b/data/guides/top-6-multithreading-design-patterns-you-must-know.md
new file mode 100644
index 0000000..b5e3121
--- /dev/null
+++ b/data/guides/top-6-multithreading-design-patterns-you-must-know.md
@@ -0,0 +1,42 @@
+---
+title: "Top 6 Multithreading Design Patterns You Must Know"
+description: "Explore essential multithreading design patterns for concurrent programming."
+image: "https://assets.bytebytego.com/diagrams/0381-top-6-multithreading-design-patterns-you-must-know.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - software-development
+tags:
+ - Concurrency
+ - Design Patterns
+---
+
+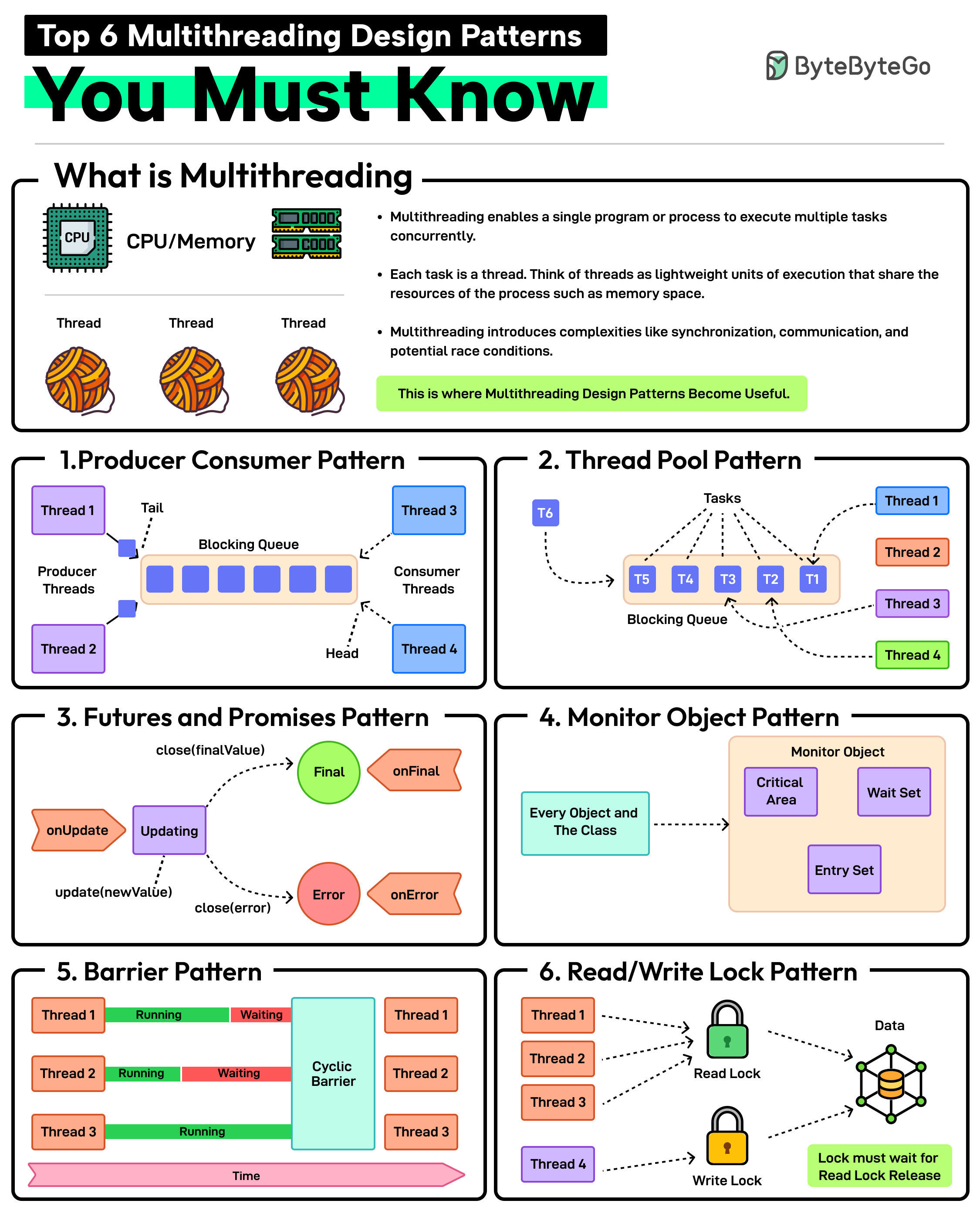
+
+Multithreading enables a single program or process to execute multiple tasks concurrently. Each task is a thread. Think of threads as lightweight units of execution that share the resources of the process such as memory space.
+
+However, multithreading also introduces complexities like synchronization, communication, and potential race conditions. This is where patterns help.
+
+## Producer-Consumer Pattern
+
+This pattern involves two types of threads: producers generating data and consumers processing that data. A blocking queue acts as a buffer between the two.
+
+## Thread Pool Pattern
+
+In this pattern, there is a pool of worker threads that can be reused for executing tasks. Using a pool removes the overhead of creating and destroying threads. Great for executing a large number of short-lived tasks.
+
+## Futures and Promises Pattern
+
+In this pattern, the promise is an object that holds the eventual results and the future provides a way to access the result. This is great for executing long-running operations concurrently without blocking the main thread.
+
+## Monitor Object Pattern
+
+Ensures that only one thread can access or modify a shared resource within an object at a time. This helps prevent race conditions. The pattern is required when you need to protect shared data or resources from concurrent access.
+
+## Barrier Pattern
+
+Synchronizes a group of threads. Each thread executes until it reaches a barrier point in the code and blocks until all threads have reached the same barrier. Ideal for parallel tasks that need to reach a specific stage before starting the next stage.
+
+## Read-Write Lock Pattern
+
+It allows multiple threads to read from a shared resource but only allows one thread to write to it at a time. Ideal for managing shared resources where reads are more frequent than writes.
diff --git a/data/guides/top-6-tools-to-turn-code-into-beautiful-diagrams.md b/data/guides/top-6-tools-to-turn-code-into-beautiful-diagrams.md
new file mode 100644
index 0000000..bf138f3
--- /dev/null
+++ b/data/guides/top-6-tools-to-turn-code-into-beautiful-diagrams.md
@@ -0,0 +1,23 @@
+---
+title: "Top 6 Tools to Turn Code into Beautiful Diagrams"
+description: "Explore the best tools for transforming code into stunning diagrams."
+image: "https://assets.bytebytego.com/diagrams/0382-top-6-tools-to-turn-code-into-beautiful-diagrams.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Diagramming"
+ - "Code Visualization"
+---
+
+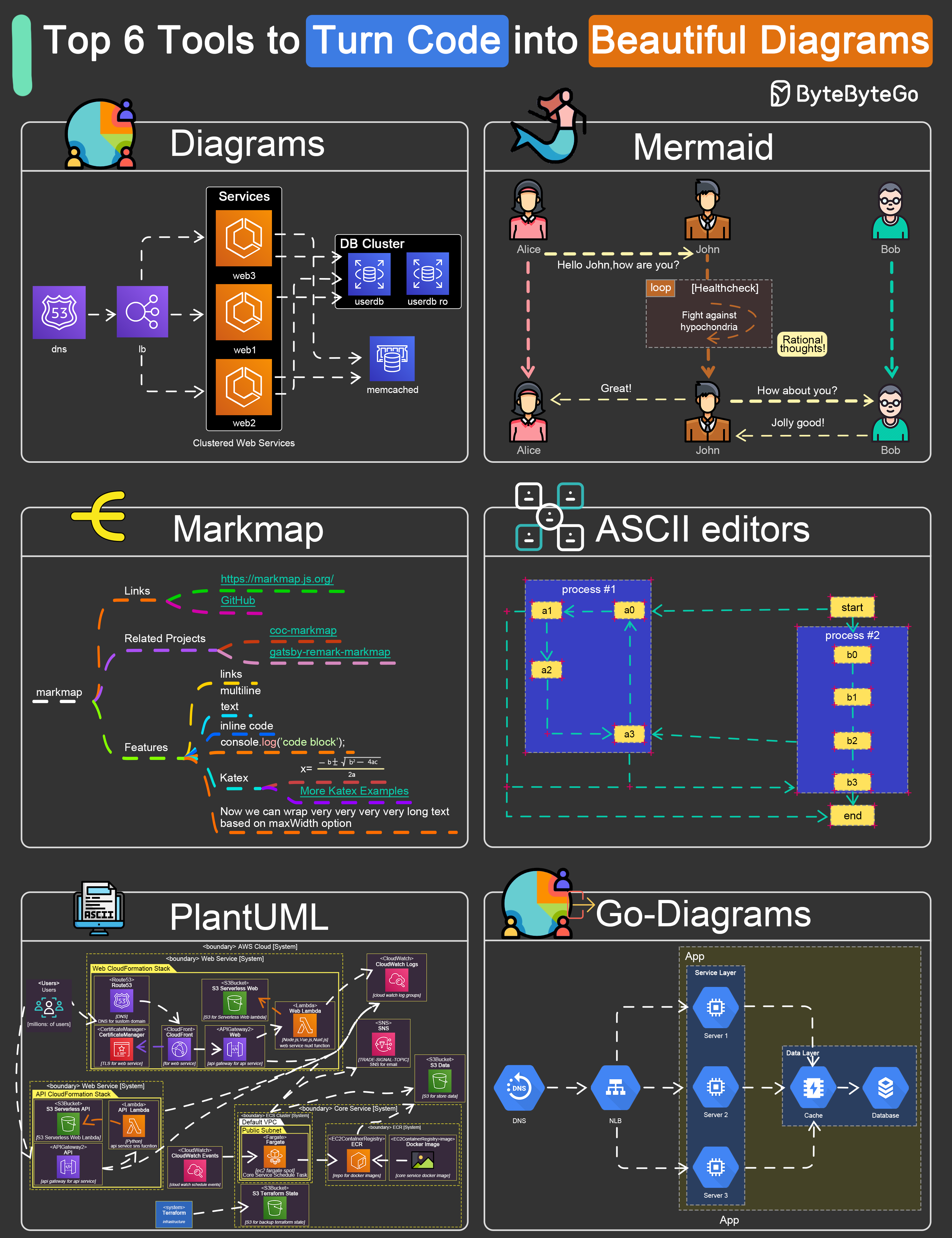
+
+Here are the top tools to turn code into diagrams:
+
+* Diagrams
+* Go Diagrams
+* Mermaid
+* PlantUML
+* ASCII diagrams
+* Markmap
diff --git a/data/guides/top-7-most-used-distributed-system-patterns.md b/data/guides/top-7-most-used-distributed-system-patterns.md
new file mode 100644
index 0000000..576252e
--- /dev/null
+++ b/data/guides/top-7-most-used-distributed-system-patterns.md
@@ -0,0 +1,22 @@
+---
+title: "Top 7 Most-Used Distributed System Patterns"
+description: "Explore the top 7 most-used patterns in distributed system design."
+image: "https://assets.bytebytego.com/diagrams/0119-top-7-most-used-distributed-system-patterns.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "distributed systems"
+ - "system design"
+---
+
+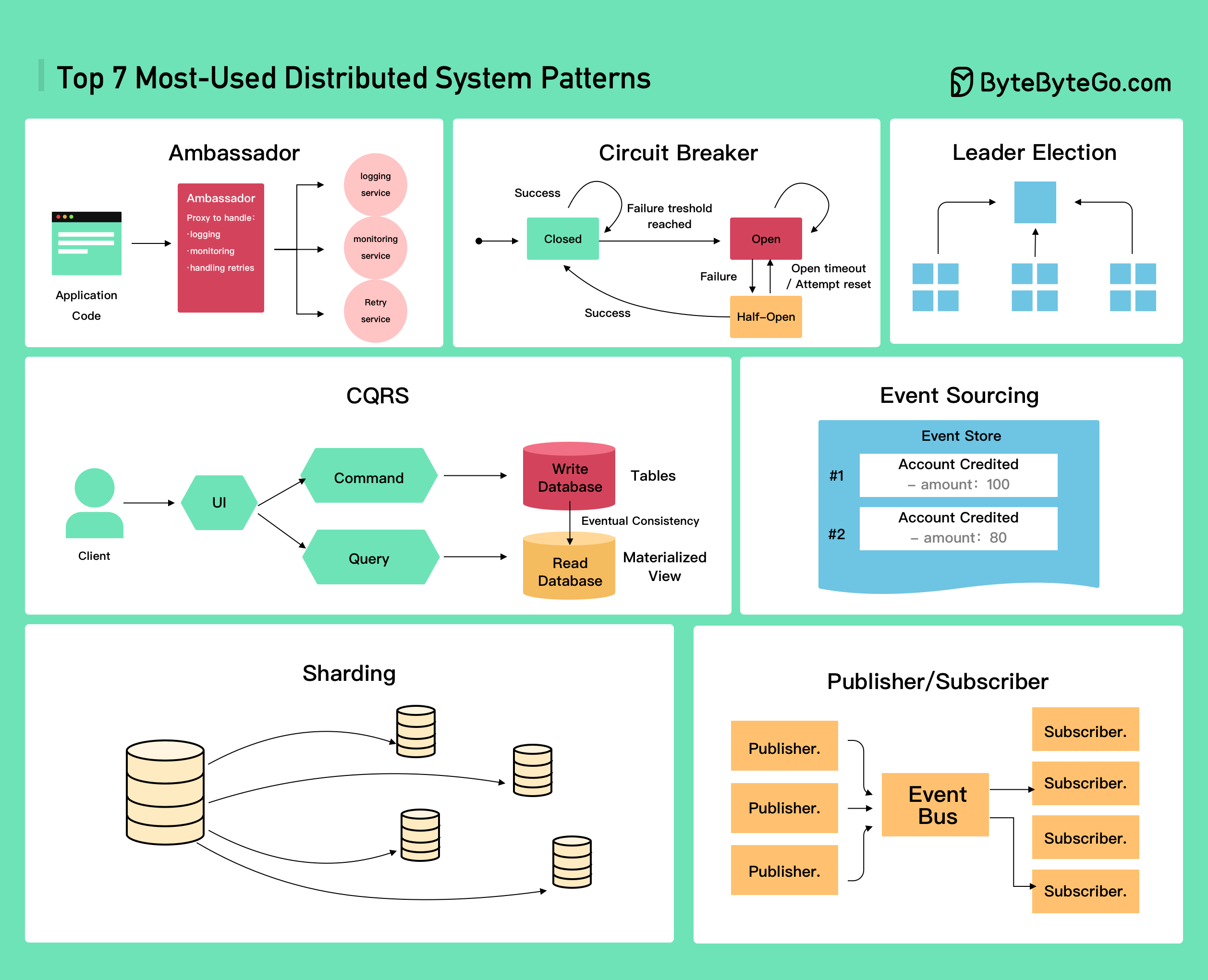
+
+* Ambassador
+* Circuit Breaker
+* CQRS
+* Event Sourcing
+* Leader Election
+* Publisher/Subscriber
+* Sharding
diff --git a/data/guides/top-8-c++-use-cases.md b/data/guides/top-8-c++-use-cases.md
new file mode 100644
index 0000000..0a4c317
--- /dev/null
+++ b/data/guides/top-8-c++-use-cases.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 C++ Use Cases"
+description: "Explore the top use cases for C++ in various industries."
+image: "https://assets.bytebytego.com/diagrams/0384-top-8-c-use-cases.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - software-development
+tags:
+ - "C++"
+ - "Use Cases"
+---
+
+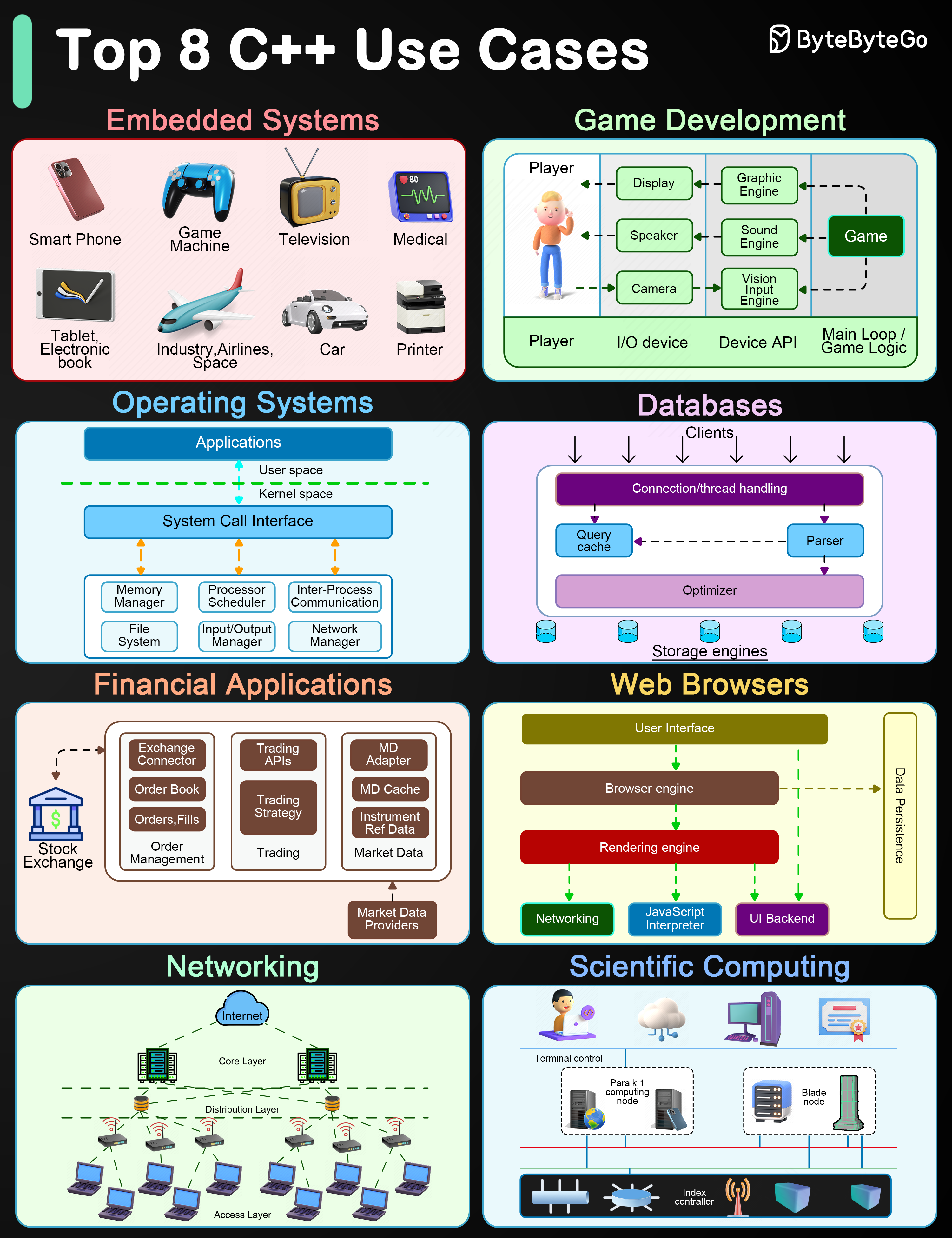
+
+C++ is a highly versatile programming language that is suitable for a wide range of applications.
+
+## Embedded Systems
+
+* The language's efficiency and fine control over hardware resources make it excellent for embedded systems development.
+
+## Game Development
+
+* C++ is a staple in the game development industry due to its performance and efficiency.
+
+## Operating Systems
+
+* C++ provides extensive control over system resources and memory, making it ideal for developing operating systems and low-level system utilities.
+
+## Databases
+
+* Many high-performance database systems are implemented in C++ to manage memory efficiently and ensure fast execution of queries.
+
+## Financial Applications
+
+## Web Browsers
+
+* C++ is used in the development of web browsers and their components, such as rendering engines.
+
+## Networking
+
+* C++ is often used for developing network devices and simulation tools.
+
+## Scientific Computing
+
+* C++ finds extensive use in scientific computing and engineering applications that require high performance and precise control over computational resources.
diff --git a/data/guides/top-8-cache-eviction-strategies.md b/data/guides/top-8-cache-eviction-strategies.md
new file mode 100644
index 0000000..ea95ea9
--- /dev/null
+++ b/data/guides/top-8-cache-eviction-strategies.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 Cache Eviction Strategies"
+description: "Explore 8 key cache eviction strategies to optimize performance."
+image: "https://assets.bytebytego.com/diagrams/0059-top-8-cache-eviction-strategies.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Algorithms"
+---
+
+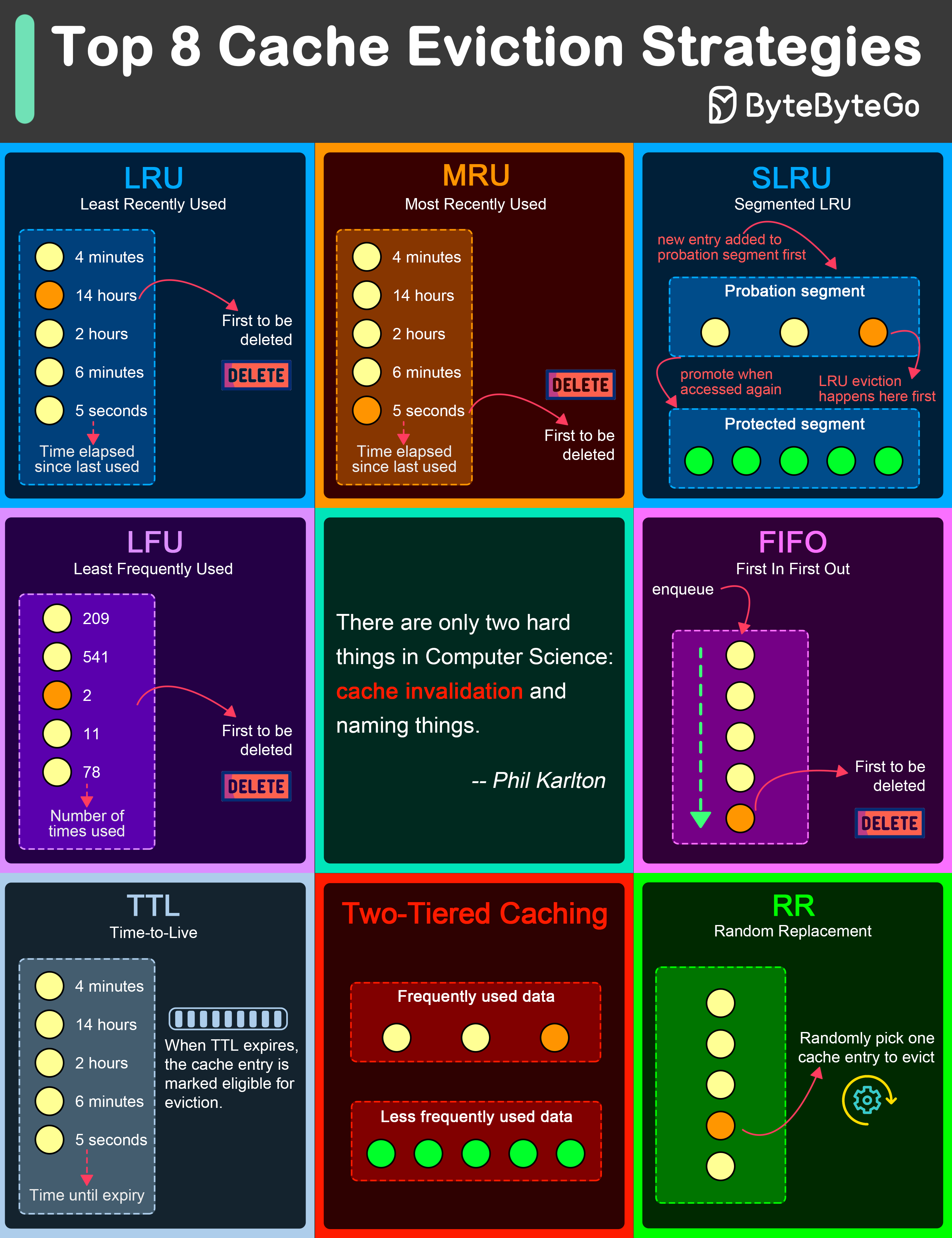
+
+## LRU (Least Recently Used)
+
+LRU eviction strategy removes the least recently accessed items first. This approach is based on the principle that items accessed recently are more likely to be accessed again in the near future.
+
+## MRU (Most Recently Used)
+
+Contrary to LRU, the MRU algorithm removes the most recently used items first. This strategy can be useful in scenarios where the most recently accessed items are less likely to be accessed again soon.
+
+## SLRU (Segmented LRU)
+
+SLRU divides the cache into two segments: a probationary segment and a protected segment. New items are initially placed into the probationary segment. If an item in the probationary segment is accessed again, it is promoted to the protected segment.
+
+## LFU (Least Frequently Used)
+
+LFU algorithm evicts the items with the lowest access frequency.
+
+## FIFO (First In First Out)
+
+FIFO is one of the simplest caching strategies, where the cache behaves in a queue-like manner, evicting the oldest items first, regardless of their access patterns or frequency.
+
+## TTL (Time-to-Live)
+
+While not strictly an eviction algorithm, TTL is a strategy where each cache item is given a specific lifespan.
+
+## Two-Tiered Caching
+
+In Two-Tiered Caching strategy, we use an in-memory cache for the first layer and a distributed cache for the second layer.
+
+## RR (Random Replacement)
+
+Random Replacement algorithm randomly selects a cache item and evicts it to make space for new items. This method is also simple to implement and does not require tracking access patterns or frequencies.
diff --git a/data/guides/top-8-must-know-docker-concepts.md b/data/guides/top-8-must-know-docker-concepts.md
new file mode 100644
index 0000000..edb8adc
--- /dev/null
+++ b/data/guides/top-8-must-know-docker-concepts.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 Must-Know Docker Concepts"
+description: "Learn the essential Docker concepts for efficient application deployment."
+image: "https://assets.bytebytego.com/diagrams/0012-8-must-know-docker-concepts.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Docker"
+ - "Containers"
+---
+
+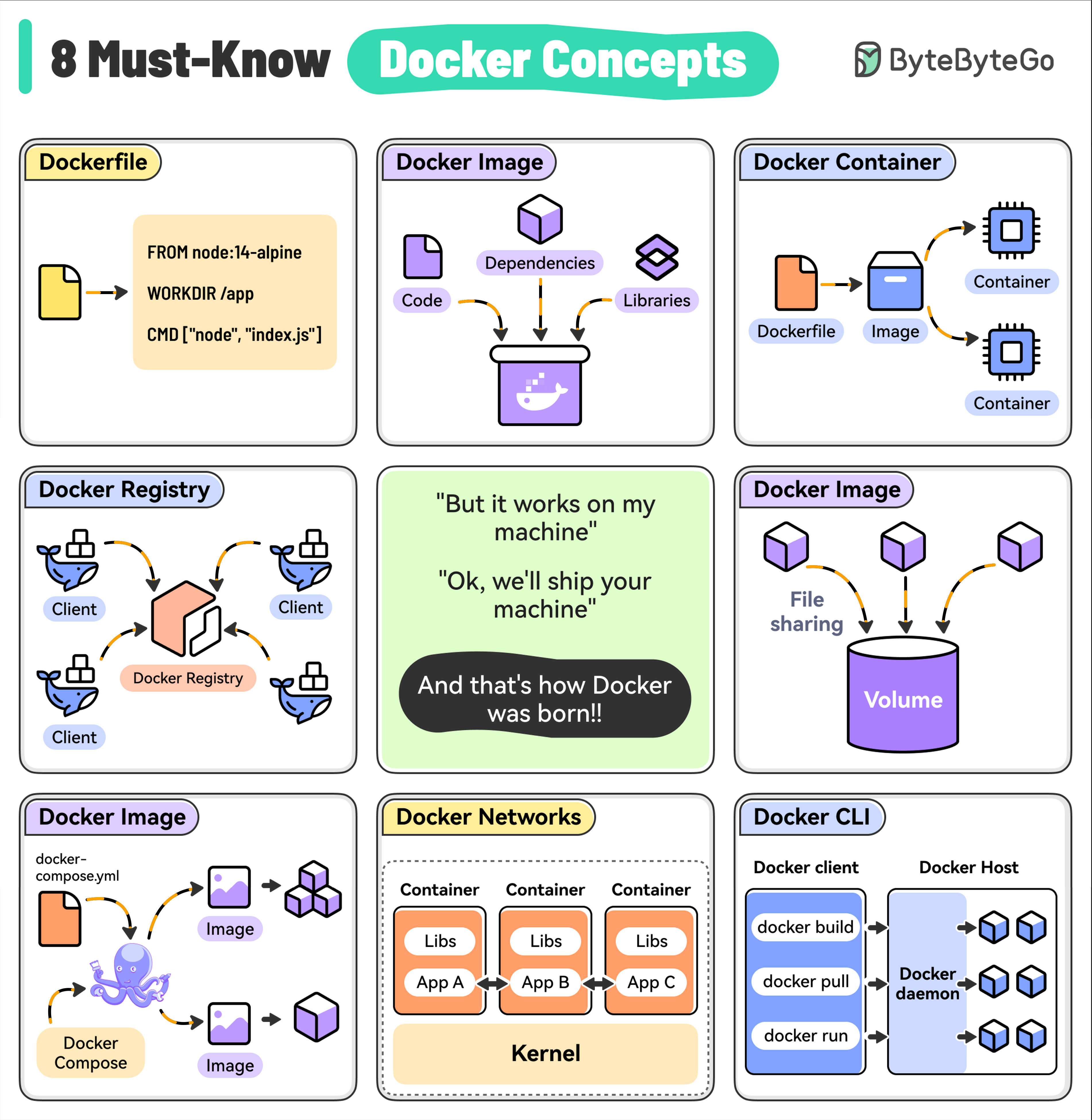
+
+## Dockerfile
+
+It contains the instructions to build a Docker image by specifying the base image, dependencies, and run command.
+
+## Docker Image
+
+A lightweight, standalone package that includes everything (code, libraries, and dependencies) needed to run your application. Images are built from a Dockerfile and can be versioned.
+
+## Docker Container
+
+A running instance of a Docker image. Containers are isolated from each other and the host system, providing a secure and reproducible environment for running your apps.
+
+## Docker Registry
+
+A centralized repository for storing and distributing Docker images. For example, Docker Hub is the default public registry but you can also set up private registries.
+
+## Docker Volumes
+
+A way to persist data generated by containers. Volumes are outside the container’s file system and can be shared between multiple containers.
+
+## Docker Compose
+
+A tool for defining and running multi-container Docker applications, making it easy to manage the entire stack.
+
+## Docker Networks
+
+Used to enable communication between containers and the host system. Custom networks can isolate containers or enable selective communication.
+
+## Docker CLI
+
+The primary way to interact with Docker, providing commands for building images, running containers, managing volumes, and performing other operations.
diff --git a/data/guides/top-8-programming-paradigms.md b/data/guides/top-8-programming-paradigms.md
new file mode 100644
index 0000000..85421a2
--- /dev/null
+++ b/data/guides/top-8-programming-paradigms.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 Programming Paradigms"
+description: "Explore the top 8 programming paradigms shaping modern software development."
+image: "https://assets.bytebytego.com/diagrams/0120-top-8-programming-paradigms-2.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Programming Paradigms"
+ - "Software Development"
+---
+
+
+
+## Imperative Programming
+
+Imperative programming describes a sequence of steps that change the program’s state. Languages like C, C++, Java, Python (to an extent), and many others support imperative programming styles.
+
+## Declarative Programming
+
+Declarative programming emphasizes expressing logic and functionalities without describing the control flow explicitly. Functional programming is a popular form of declarative programming.
+
+## Object-Oriented Programming (OOP)
+
+Object-oriented programming (OOP) revolves around the concept of objects, which encapsulate data (attributes) and behavior (methods or functions). Common object-oriented programming languages include Java, C++, Python, Ruby, and C#.
+
+## Aspect-Oriented Programming (AOP)
+
+Aspect-oriented programming (AOP) aims to modularize concerns that cut across multiple parts of a software system. AspectJ is one of the most well-known AOP frameworks that extends Java with AOP capabilities.
+
+## Functional Programming
+
+Functional Programming (FP) treats computation as the evaluation of mathematical functions and emphasizes the use of immutable data and declarative expressions. Languages like Haskell, Lisp, Erlang, and some features in languages like JavaScript, Python, and Scala support functional programming paradigms.
+
+## Reactive Programming
+
+Reactive Programming deals with asynchronous data streams and the propagation of changes. Event-driven applications, and streaming data processing applications benefit from reactive programming.
+
+## Generic Programming
+
+Generic Programming aims at creating reusable, flexible, and type-independent code by allowing algorithms and data structures to be written without specifying the types they will operate on. Generic programming is extensively used in libraries and frameworks to create data structures like lists, stacks, queues, and algorithms like sorting, searching.
+
+## Concurrent Programming
+
+Concurrent Programming deals with the execution of multiple tasks or processes simultaneously, improving performance and resource utilization. Concurrent programming is utilized in various applications, including multi-threaded servers, parallel processing, concurrent web servers, and high-performance computing.
diff --git a/data/guides/top-8-standards-every-developer-should-know.md b/data/guides/top-8-standards-every-developer-should-know.md
new file mode 100644
index 0000000..be97438
--- /dev/null
+++ b/data/guides/top-8-standards-every-developer-should-know.md
@@ -0,0 +1,48 @@
+---
+title: "Top 8 Standards Every Developer Should Know"
+description: "Explore the top 8 essential standards every developer should know."
+image: "https://assets.bytebytego.com/diagrams/0015-8-standards-developers-should-know.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Software Standards"
+ - "Web Development"
+---
+
+
+
+## TCP/IP
+
+Developed by the IETF organization, the TCP/IP protocol is the foundation of the Internet and one of the best-known networking standards.
+
+## HTTP
+
+The IETF has also developed the HTTP protocol, which is essential for all web developers.
+
+## SQL
+
+Structured Query Language (SQL) is a domain-specific language used to manage data.
+
+## OAuth
+
+OAuth (Open Authorization) is an open standard for access delegation commonly used to grant websites or applications limited access to user information without exposing their passwords.
+
+## HTML/CSS
+
+With HTML, web pages are rendered uniformly across browsers, which reduces development effort spent on compatibility issues.HTML tags.
+
+CSS standards are often used in conjunction with HTML.
+
+## ECMAScript
+
+ECMAScript is a standardized scripting language specification that serves as the foundation for several programming languages, the most well-known being JavaScript.
+
+## ISO Date
+
+It is common for developers to have problems with inconsistent time formats on a daily basis. ISO 8601 is a date and time format standard developed by the ISO (International Organization for Standardization) to provide a common format for exchanging date and time data across borders, cultures, and industries.
+
+## OpenAPI
+
+OpenAPI, also known as the OpenAPI Specification (OAS), is a standardized format for describing and documenting RESTful APIs.
diff --git a/data/guides/top-9-architectural-patterns-for-data-and-communication-flow.md b/data/guides/top-9-architectural-patterns-for-data-and-communication-flow.md
new file mode 100644
index 0000000..9f70931
--- /dev/null
+++ b/data/guides/top-9-architectural-patterns-for-data-and-communication-flow.md
@@ -0,0 +1,50 @@
+---
+title: "Top 9 Architectural Patterns for Data and Communication Flow"
+description: "Explore 9 key architectural patterns for efficient data and communication."
+image: "https://assets.bytebytego.com/diagrams/0387-top-9-system-integrations.png"
+createdAt: "2024-01-31"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Architecture"
+ - "Data Flow"
+---
+
+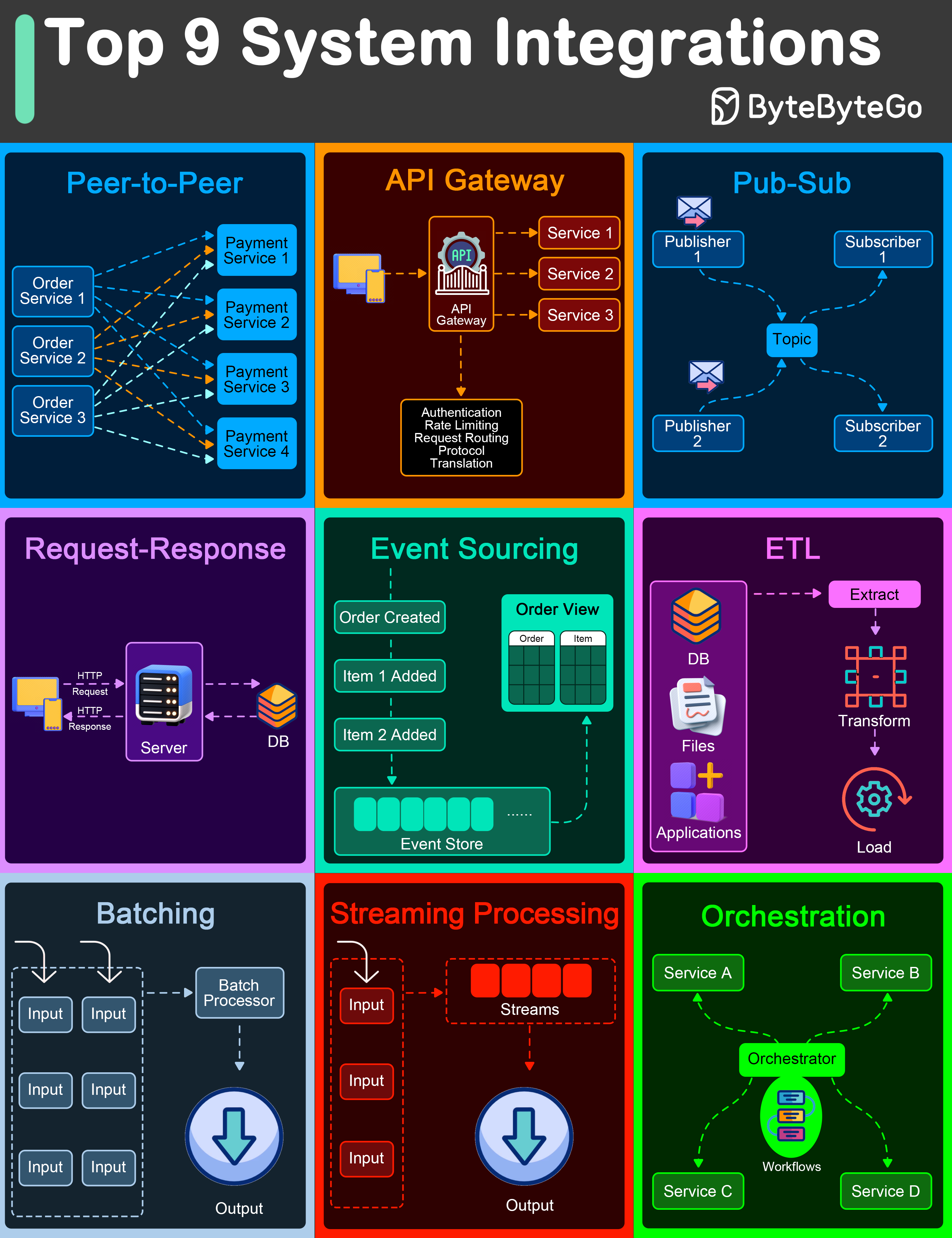
+
+* **Peer-to-Peer**
+
+ The Peer-to-Peer pattern involves direct communication between two components without the need for a central coordinator.
+
+* **API Gateway**
+
+ An API Gateway acts as a single entry point for all client requests to the backend services of an application.
+
+* **Pub-Sub**
+
+ The Pub-Sub pattern decouples the producers of messages (publishers) from the consumers of messages (subscribers) through a message broker.
+
+* **Request-Response**
+
+ This is one of the most fundamental integration patterns, where a client sends a request to a server and waits for a response.
+
+* **Event Sourcing**
+
+ Event Sourcing involves storing the state changes of an application as a sequence of events.
+
+* **ETL**
+
+ ETL is a data integration pattern used to gather data from multiple sources, transform it into a structured format, and load it into a destination database.
+
+* **Batching**
+
+ Batching involves accumulating data over a period or until a certain threshold is met before processing it as a single group.
+
+* **Streaming Processing**
+
+ Streaming Processing allows for the continuous ingestion, processing, and analysis of data streams in real-time.
+
+* **Orchestration**
+
+ Orchestration involves a central coordinator (an orchestrator) managing the interactions between distributed components or services to achieve a workflow or business process.
diff --git a/data/guides/top-9-cases-behind-100-cpu-usage.md b/data/guides/top-9-cases-behind-100-cpu-usage.md
new file mode 100644
index 0000000..772cd78
--- /dev/null
+++ b/data/guides/top-9-cases-behind-100-cpu-usage.md
@@ -0,0 +1,28 @@
+---
+title: "Top 9 Causes of 100% CPU Usage"
+description: "Explore the top causes behind 100% CPU usage and how to resolve them."
+image: "https://assets.bytebytego.com/diagrams/0386-top-9-cases-behind-100-cpu-usage.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "CPU Usage"
+ - "Troubleshooting"
+---
+
+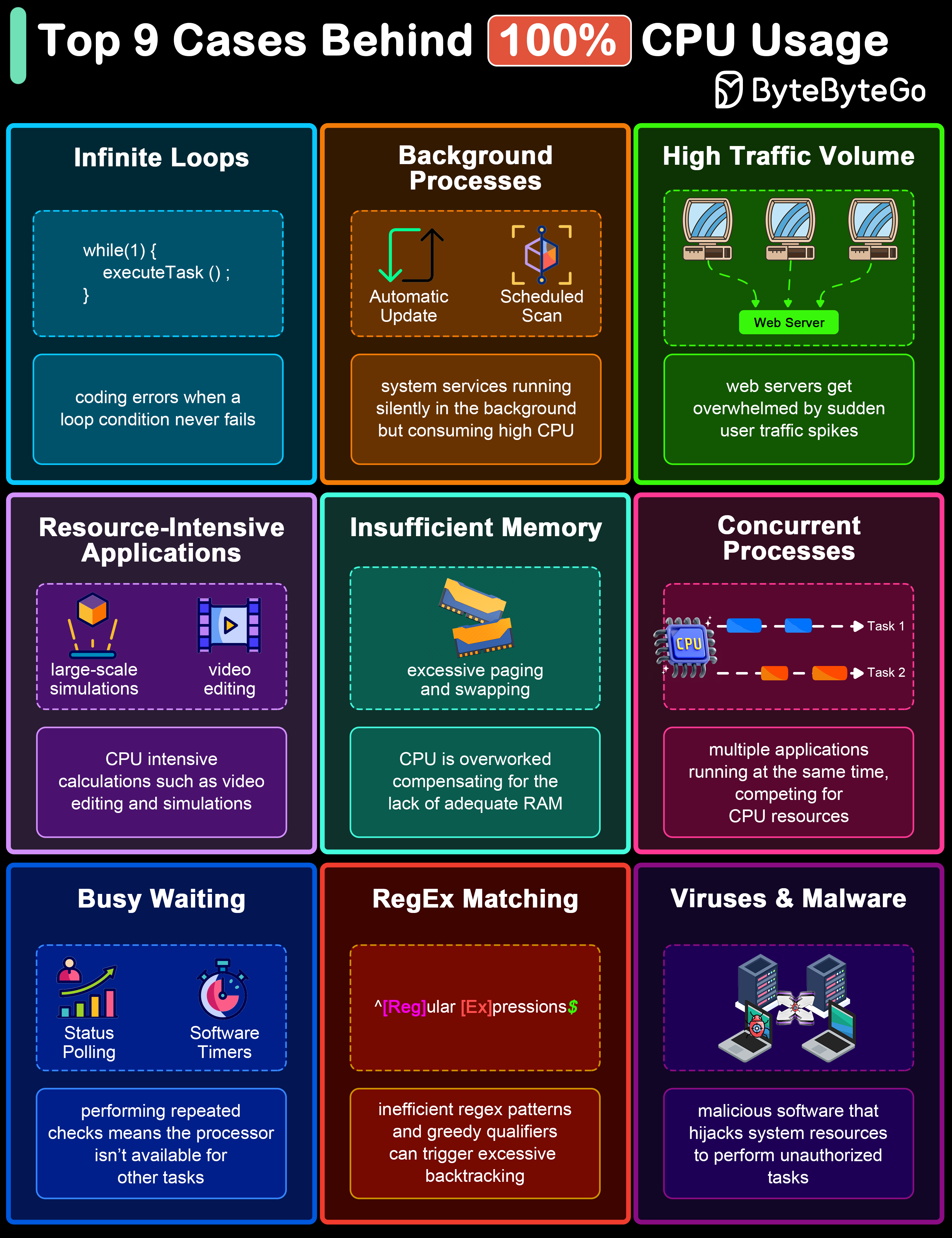
+
+The diagram below shows common culprits that can lead to 100% CPU usage. Understanding these can help in diagnosing problems and improving system efficiency.
+
+## Top 9 Causes of 100% CPU Usage
+
+* Infinite Loops
+* Background Processes
+* High Traffic Volume
+* Resource-Intensive Applications
+* Insufficient Memory
+* Concurrent Processes
+* Busy Waiting
+* Regular Expression Matching
+* Malware and Viruses
diff --git a/data/guides/top-9-engineering-blog-favorites.md b/data/guides/top-9-engineering-blog-favorites.md
new file mode 100644
index 0000000..f527d3f
--- /dev/null
+++ b/data/guides/top-9-engineering-blog-favorites.md
@@ -0,0 +1,26 @@
+---
+title: 'Top 9 Engineering Blogs'
+description: 'My favorite engineering blogs to stay up-to-date with the industry.'
+image: 'https://assets.bytebytego.com/diagrams/0190-9-of-my-favorite-engg-blogs.png'
+createdAt: '2024-03-09'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Engineering Blogs
+ - Software Development
+---
+
+
+
+There are over 1,000 engineering blogs. Here are my top 9 favorites:
+
+* Netflix TechBlog
+* Uber Blog
+* Cloudflare Blog
+* Engineering at Meta
+* LinkedIn Engineering
+* Discord Blog
+* AWS Architecture
+* Slack Engineering
+* Stripe Blog
diff --git a/data/guides/top-9-http-request-methods.md b/data/guides/top-9-http-request-methods.md
new file mode 100644
index 0000000..9b70e9f
--- /dev/null
+++ b/data/guides/top-9-http-request-methods.md
@@ -0,0 +1,44 @@
+---
+title: 'Top 9 HTTP Request Methods'
+description: 'Explore the top 9 HTTP request methods with clear explanations.'
+image: 'https://assets.bytebytego.com/diagrams/0371-top-9-http-request-methods.png'
+createdAt: '2024-02-27'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - API
+---
+
+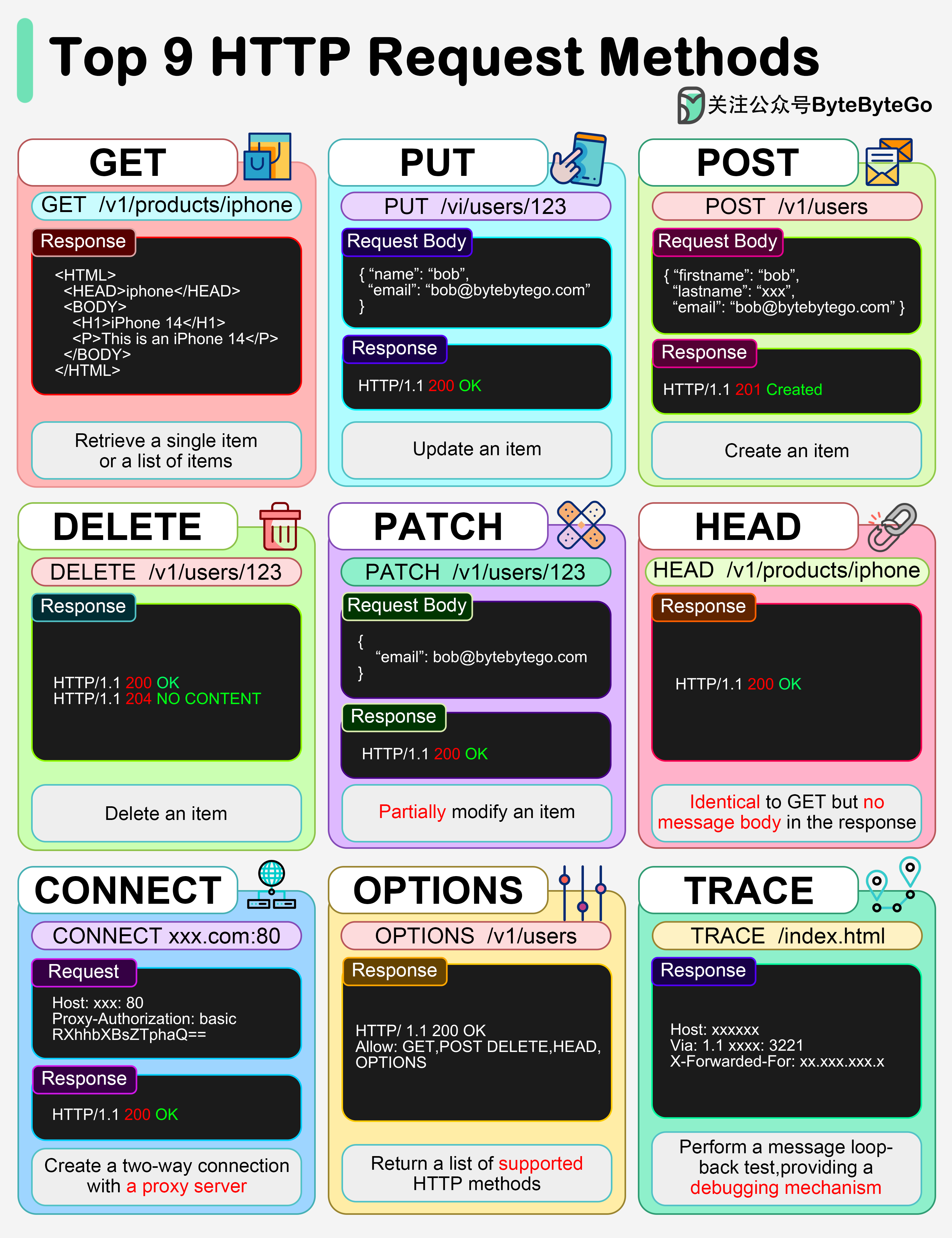
+
+GET, POST, PUT... Common HTTP “verbs” in one figure.
+
+* **HTTP GET**
+
+ This retrieves a resource from the server. It is idempotent. Multiple identical requests return the same result.
+* **HTTP PUT**
+
+ This updates or Creates a resource. It is idempotent. Multiple identical requests will update the same resource.
+* **HTTP POST**
+
+ This is used to create new resources. It is not idempotent, making two identical POST will duplicate the resource creation.
+* **HTTP DELETE**
+
+ This is used to delete a resource. It is idempotent. Multiple identical requests will delete the same resource.
+* **HTTP PATCH**
+
+ The PATCH method applies partial modifications to a resource.
+* **HTTP HEAD**
+
+ The HEAD method asks for a response identical to a GET request but without the response body.
+* **HTTP CONNECT**
+
+ The CONNECT method establishes a tunnel to the server identified by the target resource.
+* **HTTP OPTIONS**
+
+ This describes the communication options for the target resource.
+* **HTTP TRACE**
+
+ This performs a message loop-back test along the path to the target resource.
diff --git a/data/guides/top-9-website-performance-metrics-you-cannot-ignore.md b/data/guides/top-9-website-performance-metrics-you-cannot-ignore.md
new file mode 100644
index 0000000..5e683db
--- /dev/null
+++ b/data/guides/top-9-website-performance-metrics-you-cannot-ignore.md
@@ -0,0 +1,50 @@
+---
+title: "Top 9 Website Performance Metrics You Cannot Ignore"
+description: "Explore the top website performance metrics for optimal user experience."
+image: "https://assets.bytebytego.com/diagrams/0021-must-know-website-performance-metrics.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - web-performance
+ - metrics
+---
+
+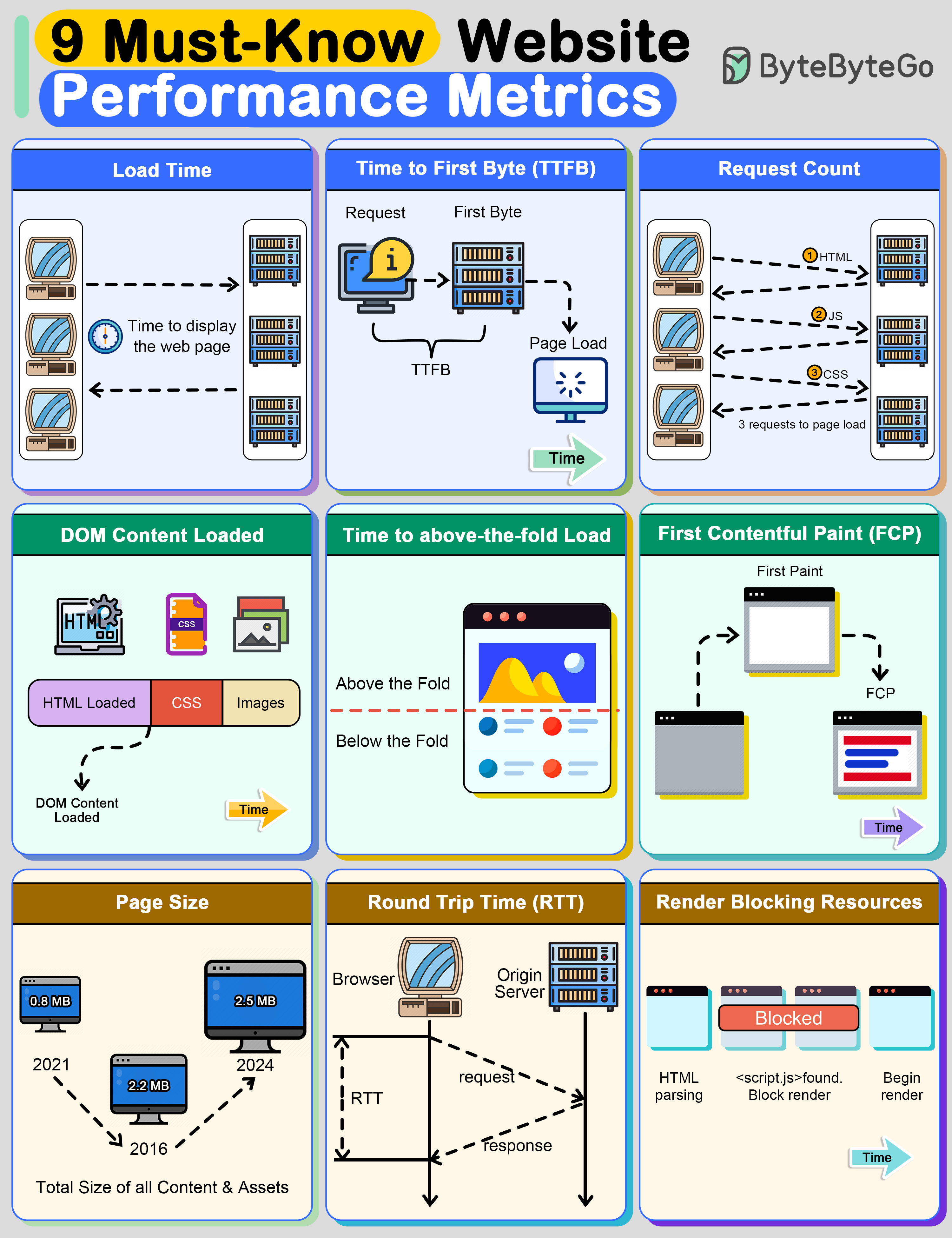
+
+## Load Time
+
+This is the time taken by the web browser to download and display the webpage. It’s measured in milliseconds.
+
+## Time to First Byte (TTFB)
+
+It’s the time taken by the browser to receive the first byte of data from the web server. TTFB is crucial because it indicates the general ability of the server to handle traffic.
+
+## Request Count
+
+The number of HTTP requests a browser has to make to fully load the page. The lower this count, the faster a website will feel to the user.
+
+## DOMContentLoaded (DCL)
+
+This is the time it takes for the full HTML code of a webpage to be loaded. The faster this happens, the faster users can see useful functionality. This time doesn’t include loading CSS and other assets
+
+## Time to Above-the-Fold Load
+
+“Above the fold” is the area of a webpage that fits in a browser window without a user having to scroll down. This is the content that is first seen by the user and often dictates whether they’ll continue reading the webpage.
+
+## First Contentful Paint (FCP)
+
+This is the time at which content first begins to be “painted” by the browser. It can be a text, image, or even background color.
+
+## Page Size
+
+This is the total file size of all content and assets that appear on the page. Over the last several years, the page size of websites has been growing constantly. The bigger the size of a webpage, the longer it will take to load
+
+## Round Trip Time (RTT)
+
+This is the amount of time a round trip takes. A round trip constitutes a request traveling from the browser to the origin server and the response from the server going to the browser. Reducing RTT is one of the key approaches to improving a website’s performance.
+
+## Render Blocking Resources
+
+Some resources block other parts of the page from being loaded. It’s important to track the number of such resources. The more render-blocking resources a webpage has, the greater the delay for the browser to load the page.
diff --git a/data/guides/top-eventual-consistency-patterns-you-must-know.md b/data/guides/top-eventual-consistency-patterns-you-must-know.md
new file mode 100644
index 0000000..8057512
--- /dev/null
+++ b/data/guides/top-eventual-consistency-patterns-you-must-know.md
@@ -0,0 +1,34 @@
+---
+title: "Top Eventual Consistency Patterns You Must Know"
+description: "Explore eventual consistency patterns for distributed database design."
+image: "https://assets.bytebytego.com/diagrams/0100-eventual-consistency-patterns-you-must-know.png"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Consistency"
+ - "Databases"
+---
+
+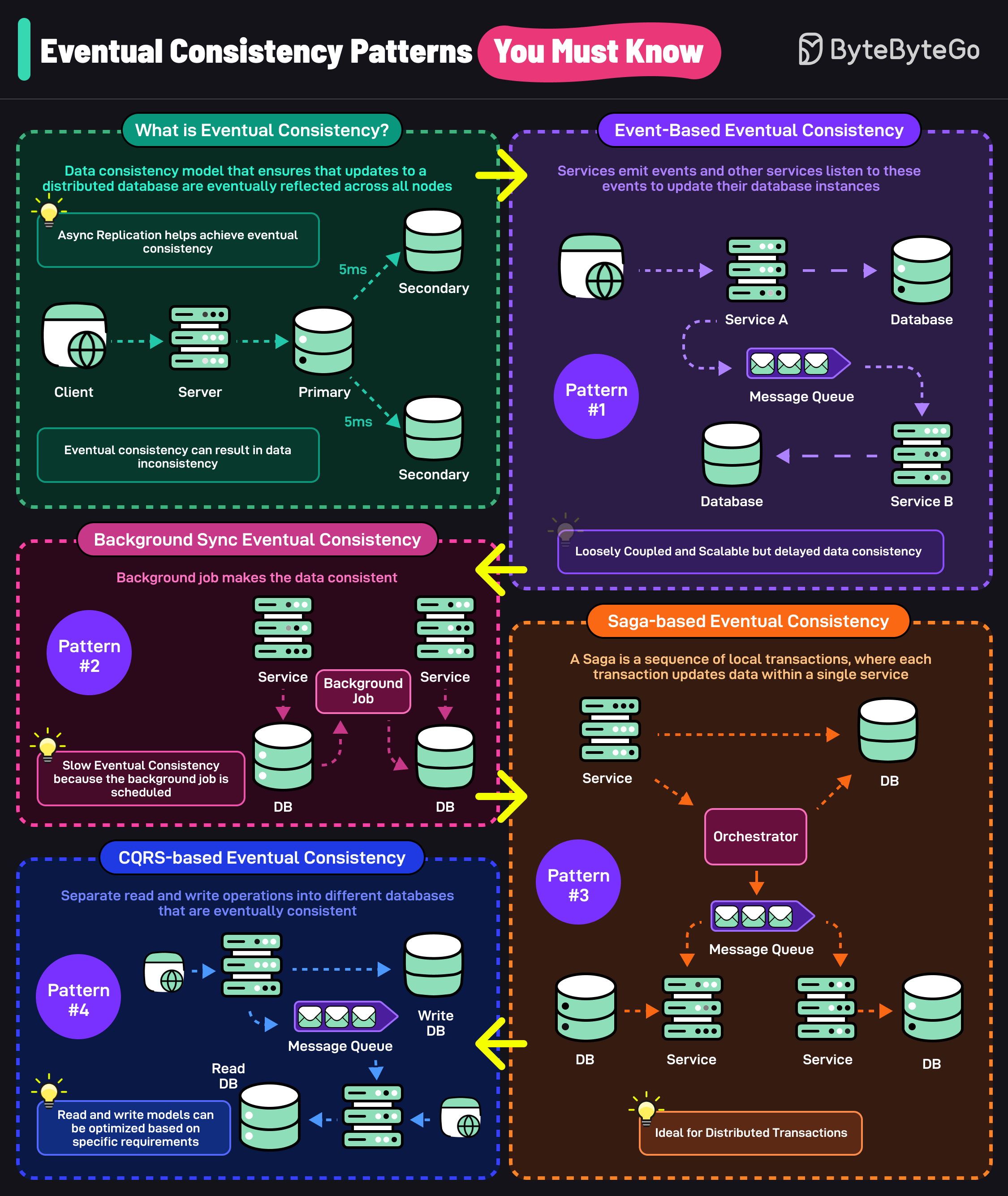
+
+Eventual consistency is a data consistency model that ensures that updates to a distributed database are eventually reflected across all nodes. Techniques like async replication help achieve eventual consistency.
+
+However, eventual consistency can also result in data inconsistency. Here are 4 patterns that can help you design applications.
+
+## Event-based Eventual Consistency
+
+Services emit events and other services listen to these events to update their database instances. This makes services loosely coupled but delays data consistency.
+
+## Background Sync Eventual Consistency
+
+In this pattern, a background job makes the data across databases consistent. It results in slower eventual consistency since the background job runs on a specific schedule.
+
+## Saga-based Eventual Consistency
+
+Saga is a sequence of local transactions where each transaction updates data with a single service. It is used to manage long-lived transactions that are eventually consistent.
+
+## CQRS-based Eventual Consistency
+
+Separate read and write operations into different databases that are eventually consistent. Read and write models can be optimized for specific requirements.
diff --git a/data/guides/top-network-security-cheatsheet.md b/data/guides/top-network-security-cheatsheet.md
new file mode 100644
index 0000000..a492bc0
--- /dev/null
+++ b/data/guides/top-network-security-cheatsheet.md
@@ -0,0 +1,57 @@
+---
+title: "Top Network Security Cheatsheet"
+description: "A concise guide to network security threats across OSI layers."
+image: "https://assets.bytebytego.com/diagrams/0049-top-network-security-cheatsheet.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - security
+tags:
+ - "Network Security"
+ - "Cybersecurity"
+---
+
+The diagram below shows some possible network attacks in 7 OSI model layers.
+
+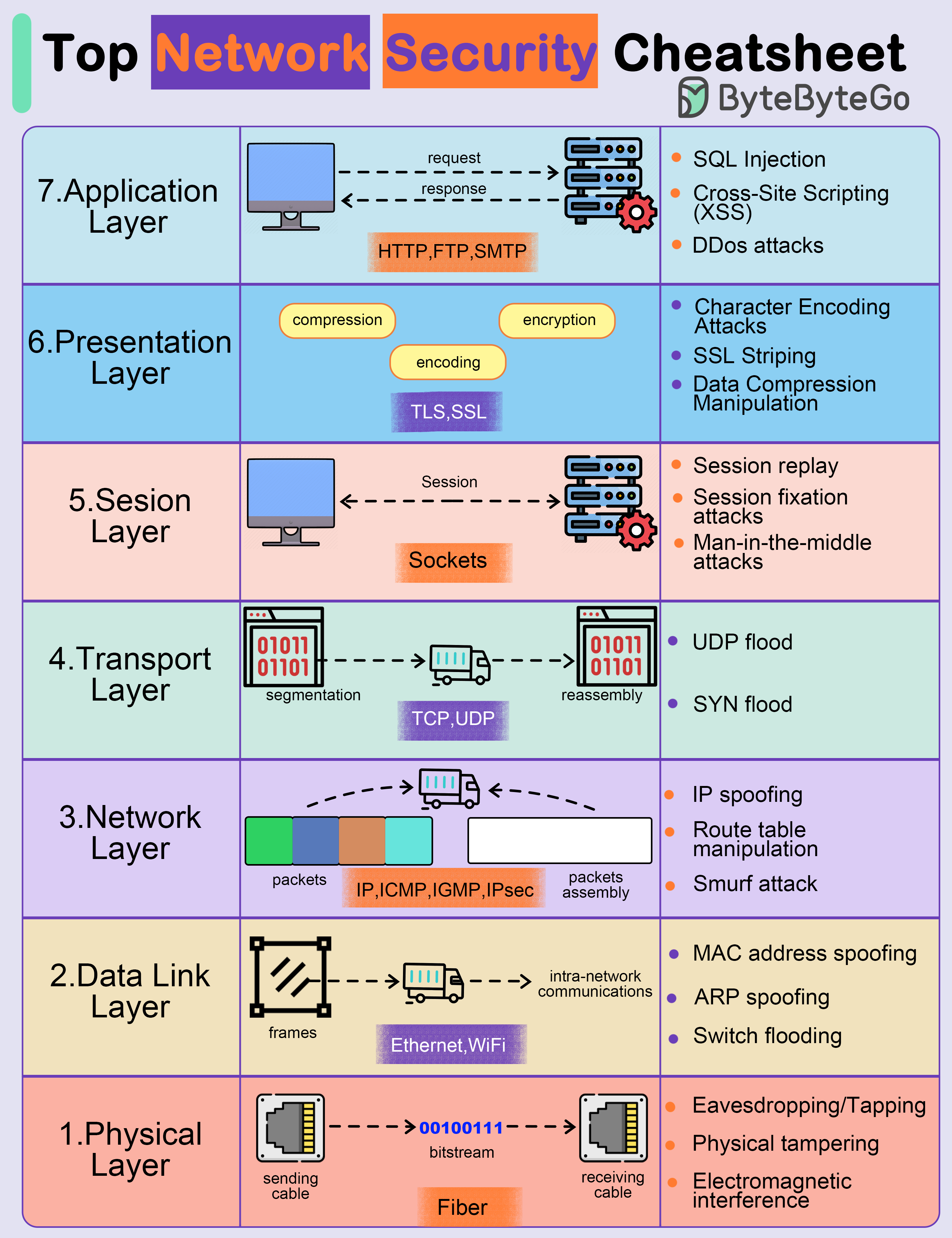
+
+## Application Layer
+
+* Pushing
+* Malware injection
+* DDoS attacks
+
+## Presentation Layer
+
+* Encoding/decoding vulnerabilities
+* Format string attacks
+* Malicious code injection
+
+## Session Layer
+
+* Session hijacking
+* Session fixation attacks
+* Brute force attacks
+
+## Transport Layer
+
+* Man-in-the-middle attacks
+* SYN/ACK flood
+
+## Network Layer
+
+* IP spoofing
+* Route table manipulation
+* DDoS attacks
+
+## Data Link Layer
+
+* MAC address spoofing
+* ARP spoofing
+* VLAN hopping
+
+## Physical Layer
+
+* Wiretapping
+* Physical tampering
+* Electromagnetic interference
diff --git a/data/guides/twitter-10-tech-stack.md b/data/guides/twitter-10-tech-stack.md
new file mode 100644
index 0000000..f9aa2a7
--- /dev/null
+++ b/data/guides/twitter-10-tech-stack.md
@@ -0,0 +1,20 @@
+---
+title: 'Twitter 1.0 Tech Stack'
+description: 'Explore the tech stack behind Twitter 1.0: a deep dive into its architecture.'
+image: 'https://assets.bytebytego.com/diagrams/0122-twitter1-0-tech-stack.jpg'
+createdAt: '2024-02-21'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Social Media
+---
+
+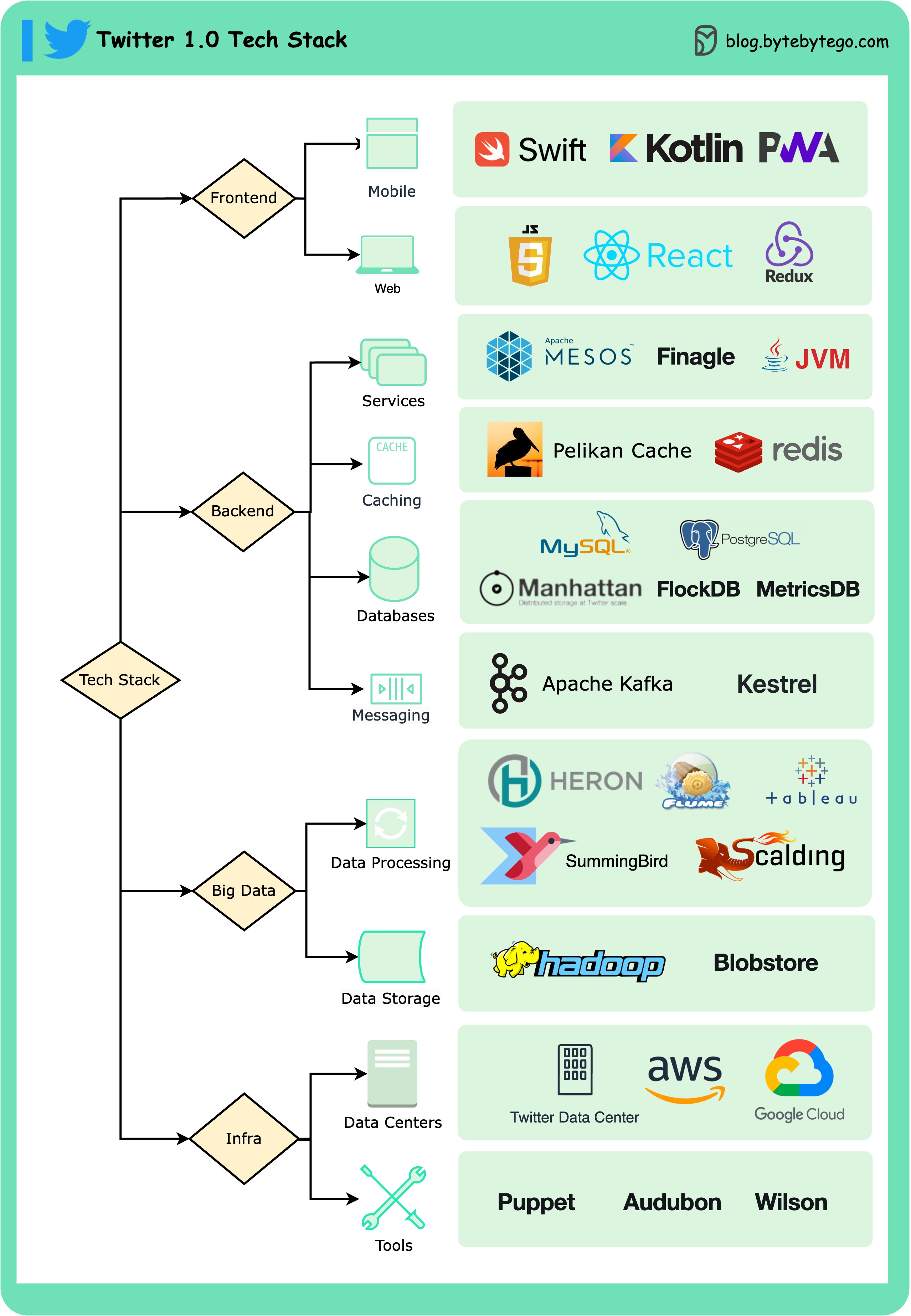
+
+* **Mobile:** Swift, Kotlin, PWA
+* **Web:** JS, React, Redux
+* **Services:** Mesos, Finagle
+* **Caching:** Pelikan Cache, Redis
+* **Databases:** Manhattan, MySQL, PostgreSQL
diff --git a/data/guides/twitter-architecture-2022-vs-2012.md b/data/guides/twitter-architecture-2022-vs-2012.md
new file mode 100644
index 0000000..73730ab
--- /dev/null
+++ b/data/guides/twitter-architecture-2022-vs-2012.md
@@ -0,0 +1,16 @@
+---
+title: 'Twitter Architecture 2022 vs. 2012'
+description: "A look at how Twitter's architecture evolved over the past decade."
+image: 'https://assets.bytebytego.com/diagrams/0392-twitter-architecture-2022-vs-2012.jpeg'
+createdAt: '2024-03-13'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Scalability
+---
+
+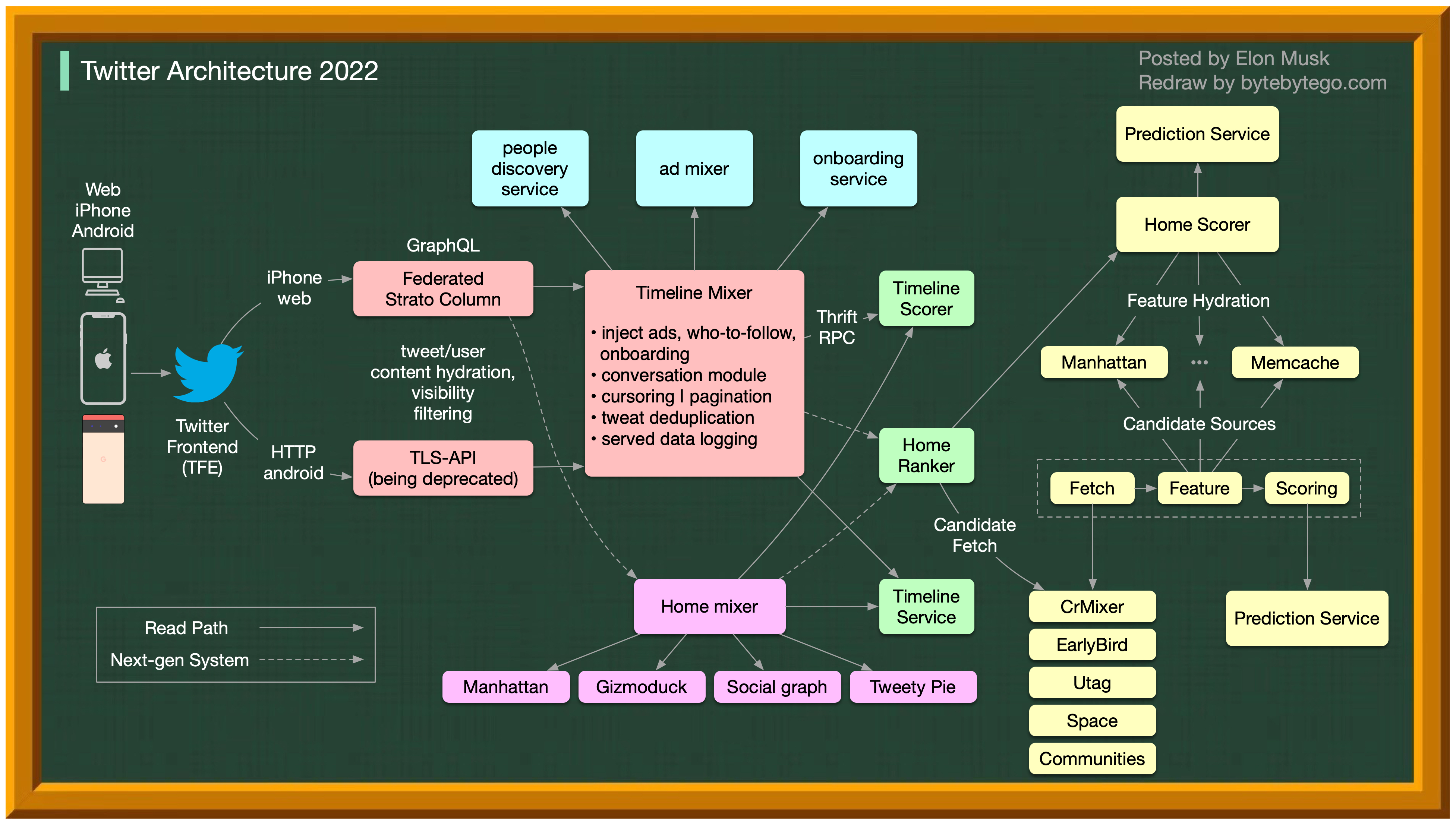
+
+What’s changed over the past 10 years?!
diff --git a/data/guides/types-of-databases.md b/data/guides/types-of-databases.md
new file mode 100644
index 0000000..69860e7
--- /dev/null
+++ b/data/guides/types-of-databases.md
@@ -0,0 +1,38 @@
+---
+title: "Types of Databases"
+description: "Explore common database types: relational, OLAP, NoSQL, and more."
+image: "https://assets.bytebytego.com/diagrams/0097-dbtypes.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - Database
+ - NoSQL
+---
+
+What is a database? What are some common types of databases?
+
+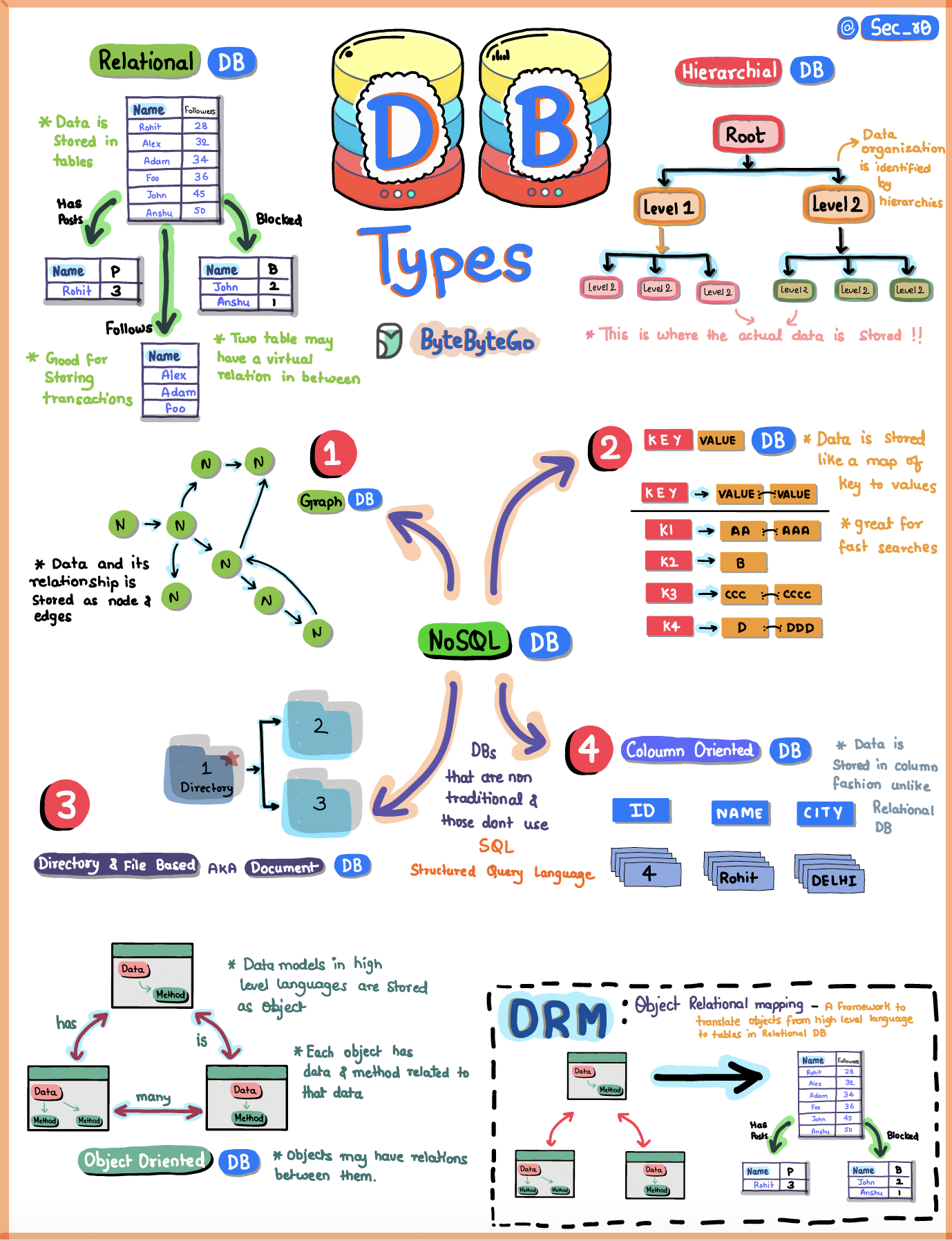
+
+First off, what's a database? Think of it as a digital playground where we organize and store loads of information in a structured manner. Now, let's shake things up and look at the main types of databases.
+
+## Relational DB
+
+Imagine it's like organizing data in neat tables. Think of it as the well-behaved sibling, keeping everything in order.
+
+## OLAP DB
+
+Online Analytical Processing (OLAP) is a technology optimized for reporting and analysis purposes.
+
+## NoSQL DBs
+
+These rebels have their own cool club, saying "No" to traditional SQL ways. NoSQL databases come in four exciting flavors:
+
+* **Graph DB:** Think of social networks, where relationships between people matter most. It's like mapping who's friends with whom.
+
+* **Key-value Store DB:** It's like a treasure chest, with each item having its unique key. Finding what you need is a piece of cake.
+
+* **Document DB:** A document database is a kind of database that stores information in a format similar to JSON. It's different from traditional databases and is made for working with documents instead of tables.
+
+* **Column DB:** Imagine slicing and dicing your data like a chef prepping ingredients. It's efficient and speedy.
diff --git a/data/guides/types-of-memory-and-storage.md b/data/guides/types-of-memory-and-storage.md
new file mode 100644
index 0000000..021127e
--- /dev/null
+++ b/data/guides/types-of-memory-and-storage.md
@@ -0,0 +1,23 @@
+---
+title: "Types of Memory and Storage"
+description: "Explore computer memory and storage: RAM, ROM, HDD, SSD, and more."
+image: "https://assets.bytebytego.com/diagrams/0268-memory-storage.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "memory"
+ - "storage"
+---
+
+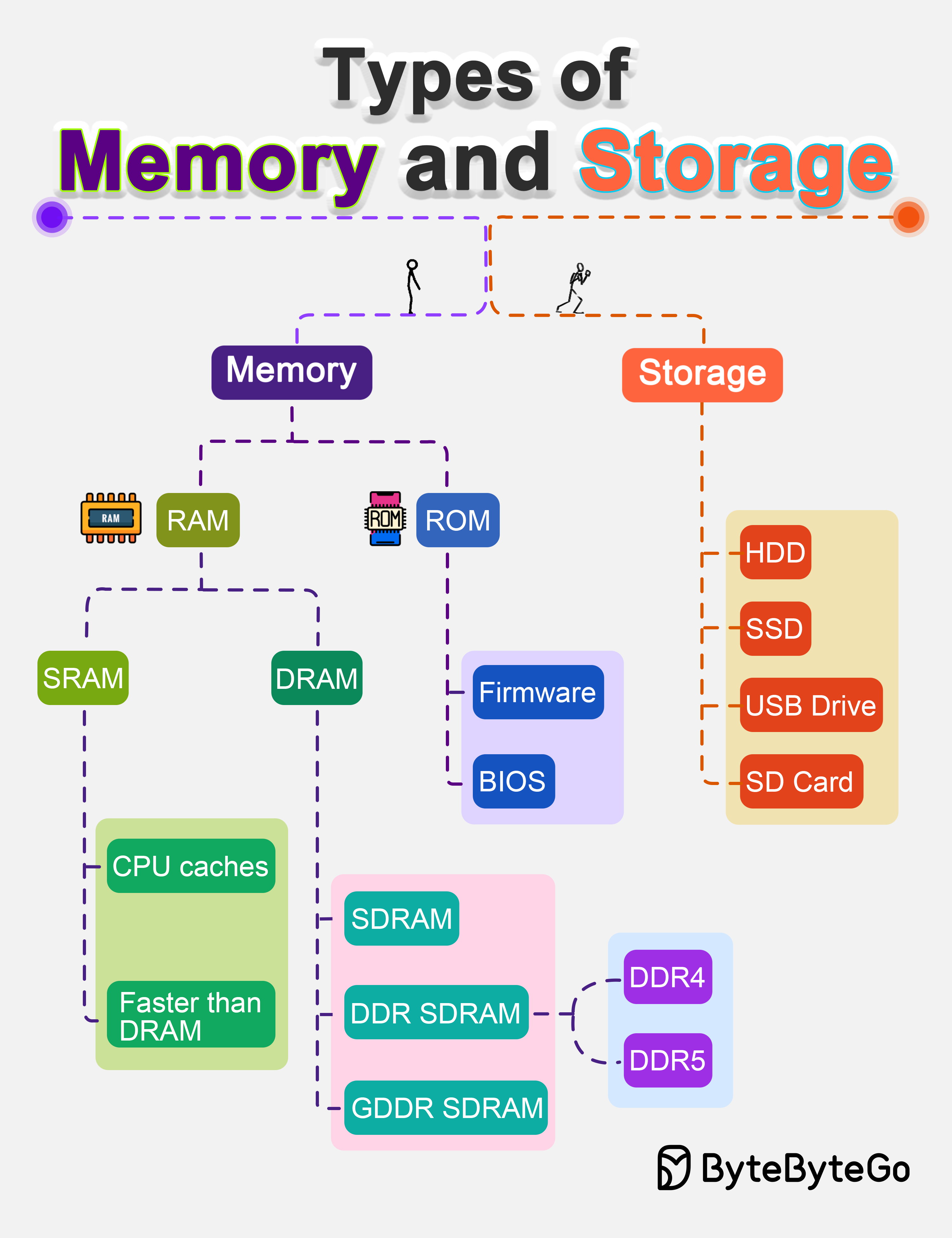
+
+Diving into the world of computer memory and storage.
+
+* The fundamental duo: RAM and ROM
+* DDR4 and DDR5
+* Firmware and BIOS
+* SRAM and DRAM
+* HDD, SSD, USB Drive, SD Card
+* and more
diff --git a/data/guides/types-of-memory.md b/data/guides/types-of-memory.md
new file mode 100644
index 0000000..e34db46
--- /dev/null
+++ b/data/guides/types-of-memory.md
@@ -0,0 +1,32 @@
+---
+title: "Types of Memory"
+description: "Explore the hierarchy of memory types, from registers to remote storage."
+image: "https://assets.bytebytego.com/diagrams/0045-memory-types.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Memory Management"
+ - "System Architecture"
+---
+
+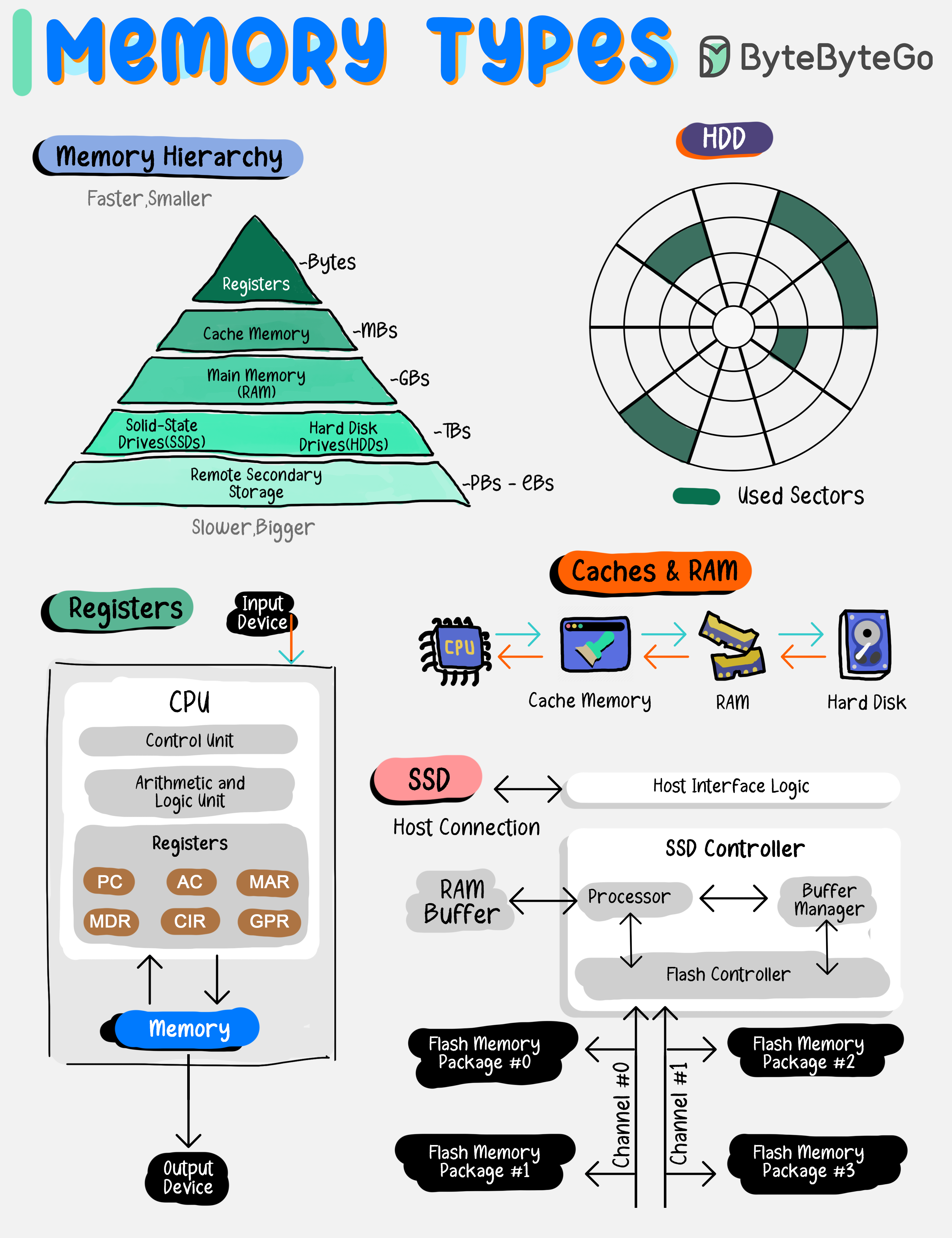
+
+Memory types vary by speed, size, and function, creating a multi-layered architecture that balances cost with the need for rapid data access.
+
+By grasping the roles and capabilities of each memory type, developers and system architects can design systems that effectively leverage the strengths of each storage layer, leading to improved overall system performance and user experience.
+
+Some of the common Memory types are:
+
+* **Registers:** Tiny, ultra-fast storage within the CPU for immediate data access.
+
+* **Caches:** Small, quick memory located close to the CPU to speed up data retrieval.
+
+* **Main Memory (RAM):** Larger, primary storage for currently executing programs and data.
+
+* **Solid-State Drives (SSDs):** Fast, reliable storage with no moving parts, used for persistent data.
+
+* **Hard Disk Drives (HDDs):** Mechanical drives with large capacities for long-term storage.
+
+* **Remote Secondary Storage:** Offsite storage for data backup and archiving, accessible over a network.
diff --git a/data/guides/types-of-message-queue.md b/data/guides/types-of-message-queue.md
new file mode 100644
index 0000000..2e3e91f
--- /dev/null
+++ b/data/guides/types-of-message-queue.md
@@ -0,0 +1,36 @@
+---
+title: "Types of Message Queues"
+description: "Explore different types of message queues and their key features."
+image: "https://assets.bytebytego.com/diagrams/0272-message-queues.png"
+createdAt: "2024-01-31"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Message Queue"
+ - "Messaging Systems"
+---
+
+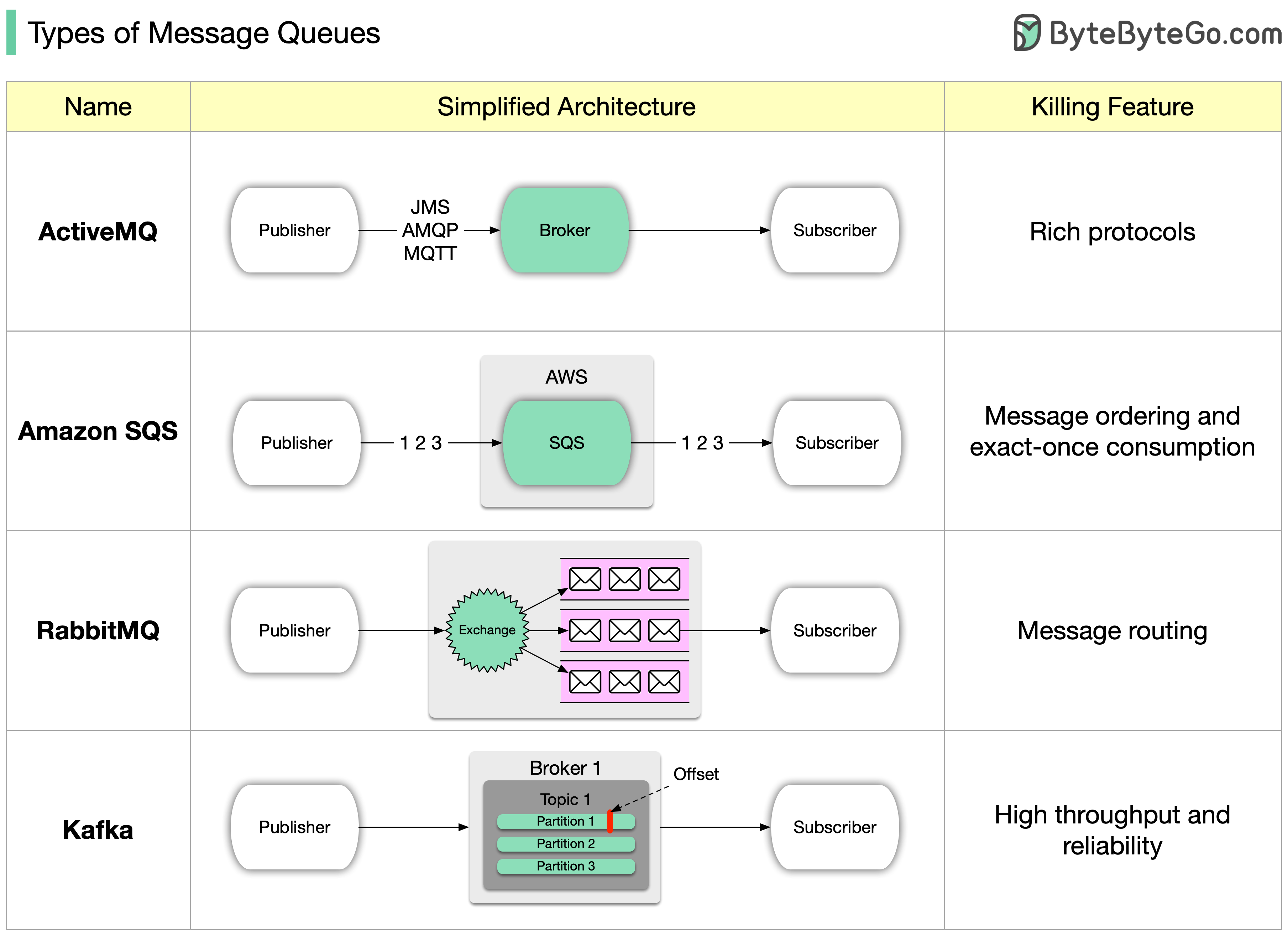
+
+### How many message queues do you know?
+
+Like a post office, a message queue helps computer programs communicate in an organized manner. Imagine little digital envelopes being passed around to keep everything on track. There are a few key features to consider when selecting message queues:
+
+* Speed: How fast messages are sent and received
+
+* Scalability: Can it grow with more messages
+
+* Reliability: Will it make sure messages don’t get lost
+
+* Durability: Can it keep messages safe over time
+
+* Ease of Use: Is it simple to set up and manage
+
+* Ecosystem: Are there helpful tools available
+
+* Integration: Can it play nice with other software
+
+* Protocol Support: What languages can it speak
+
+Try out a message queue and practice sending and receiving messages until you're comfortable. Choose an easy one like Kafka and experiment with sending and receiving messages. Read books or take online courses as you get more comfortable. Build little projects and learn from those who have already been there. Soon, you'll know everything about message queues.
diff --git a/data/guides/types-of-vpns.md b/data/guides/types-of-vpns.md
new file mode 100644
index 0000000..efba417
--- /dev/null
+++ b/data/guides/types-of-vpns.md
@@ -0,0 +1,16 @@
+---
+title: "Types of VPNs"
+description: "Explore different VPN types and their use cases for secure connections."
+image: "https://assets.bytebytego.com/diagrams/0404-vpns.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - security
+tags:
+ - VPN
+ - Security
+---
+
+
+
+Think you know how VPNs work? Think again! 😳 It's so complex.
diff --git a/data/guides/typical-aws-network-architecture-in-one-diagram.md b/data/guides/typical-aws-network-architecture-in-one-diagram.md
new file mode 100644
index 0000000..4778730
--- /dev/null
+++ b/data/guides/typical-aws-network-architecture-in-one-diagram.md
@@ -0,0 +1,62 @@
+---
+title: "Typical AWS Network Architecture"
+description: "Explore a typical AWS network architecture with key components."
+image: "https://assets.bytebytego.com/diagrams/0123-typical-aws-network-architecture.png"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - AWS Networking
+ - Cloud Architecture
+---
+
+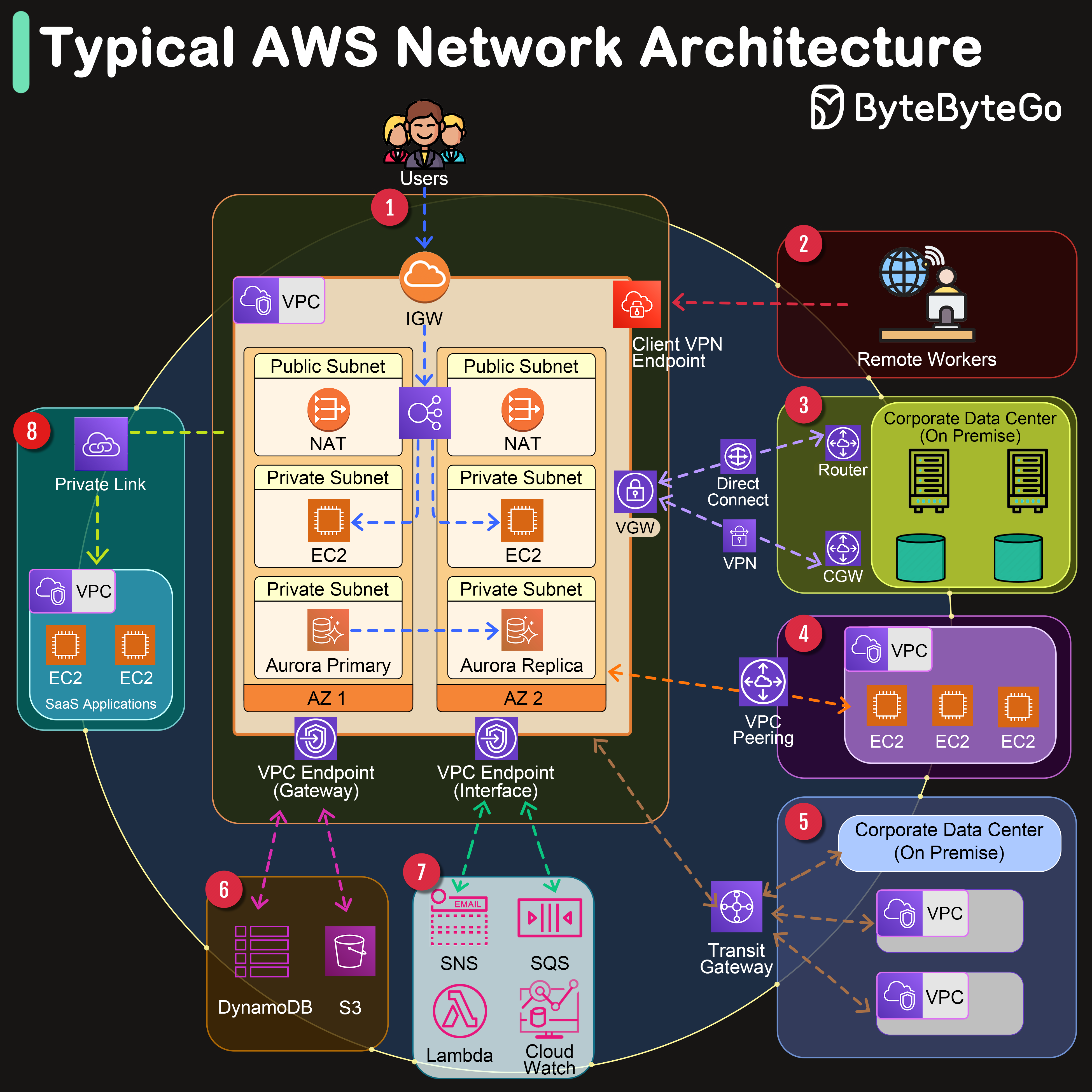
+
+Amazon Web Services (AWS) offers a comprehensive suite of networking services designed to provide businesses with secure, scalable, and highly available network infrastructure. AWS's network architecture components enable seamless connectivity between the internet, remote workers, corporate data centers, and within the AWS ecosystem itself.
+
+## Key Components
+
+* **VPC (Virtual Private Cloud)**
+
+ At the heart of AWS's networking services is the Amazon VPC, which allows users to provision a logically isolated section of the AWS Cloud. Within this isolated environment, users can launch AWS resources in a virtual network that they define.
+
+* **AZ (Availability Zone)**
+
+ An AZ in AWS refers to one or more discrete data centers with redundant power, networking, and connectivity in an AWS Region.
+
+Now let’s go through the network connectivity one by one:
+
+## Network Connectivity
+
+### 1. Connect to the Internet - Internet Gateway (IGW)
+
+An IGW serves as the doorway between your AWS VPC and the internet, facilitating bidirectional communication.
+
+### 2. Remote Workers - Client VPN Endpoint
+
+AWS offers a Client VPN service that enables remote workers to access AWS resources or an on-premises network securely over the internet. It provides a secure and easy-to-manage VPN solution.
+
+### 3. Corporate Data Center Connection - Virtual Gateway (VGW)
+
+A VGW is the VPN concentrator on the Amazon side of the Site-to-Site VPN connection between your network and your VPC.
+
+### 4. VPC Peering
+
+VPC Peering allows you to connect two VPCs, enabling you to route traffic between them using private IPv4 or IPv6 addresses.
+
+### 5. Transit Gateway
+
+AWS Transit Gateway acts as a network transit hub, enabling you to connect multiple VPCs, VPNs, and AWS accounts together.
+
+### 6. VPC Endpoint (Gateway)
+
+A VPC Endpoint (Gateway type) allows you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, VPN.
+
+### 7. VPC Endpoint (Interface)
+
+An Interface VPC Endpoint (powered by AWS PrivateLink) enables private connections between your VPC and supported AWS services, other VPCs, or AWS Marketplace services, without requiring an IGW, VGW, or NAT device.
+
+### 8. SaaS Private Link Connection
+
+AWS PrivateLink provides private connectivity between VPCs and services hosted on AWS or on-premises, ideal for accessing SaaS applications securely.
diff --git a/data/guides/uber-tech-stack-cicd.md b/data/guides/uber-tech-stack-cicd.md
new file mode 100644
index 0000000..e86f04e
--- /dev/null
+++ b/data/guides/uber-tech-stack-cicd.md
@@ -0,0 +1,38 @@
+---
+title: Uber Tech Stack - CI/CD
+description: "Uber's CI/CD tech stack: Tools and platforms for efficient delivery."
+image: 'https://assets.bytebytego.com/diagrams/0398-uber-tech-stack-ci-cd.png'
+createdAt: '2024-02-19'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - CI/CD
+ - Uber
+---
+
+Uber is one of the most innovative companies in the engineering field. Let’s take a look at their CI/CD tech stacks.
+
+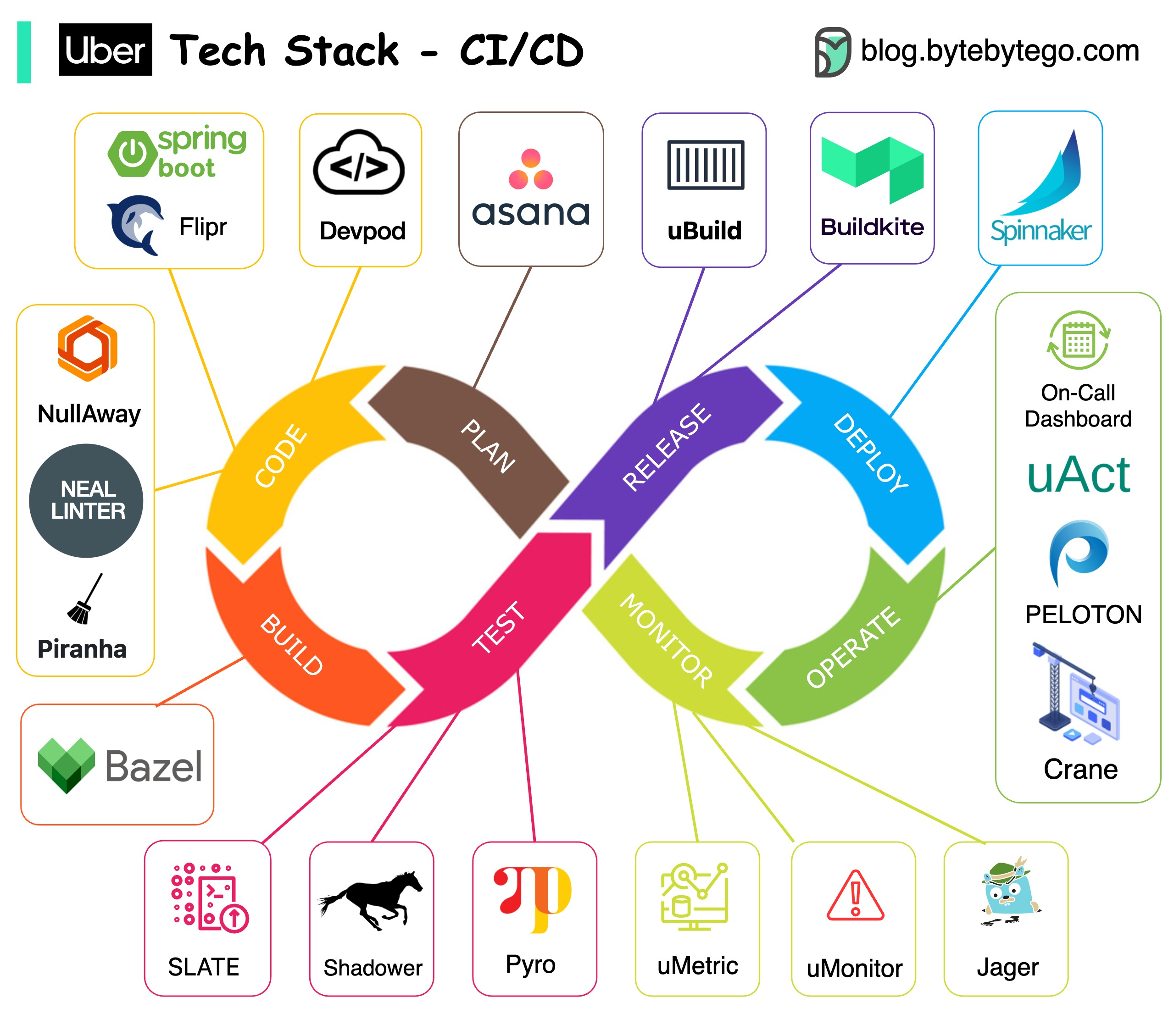
+
+Note: This post is based on research on Uber engineering blogs. If you spot any inaccuracies, please let us know.
+
+* **Project planning:** JIRA
+
+* **Backend services:** Spring Boot to develop their backend services. And to make things even faster, they've created a nifty configuration system called Flipr that allows for speedy configuration releases.
+
+* **Code issues:** They developed NullAway to tackle NullPointer problems and NEAL to lint the code. Plus, they built Piranha to clean out-dated feature flags.
+
+* **Repository:** They believe in Monorepo. It uses Bazel on a large scale.
+
+* **Testing:** They use SLATE to manage short-lived testing environments and rely on Shadower for load testing by replaying production traffic. They even developed Ballast to ensure a smooth user experience.
+
+* **Experiment platform:** it is based on deep learning and they've generously open-sourced parts of it, like Pyro.
+
+* **Build:** Uber packages their services into containers using uBuild. It's their go-to tool, powered by Buildkite, for all the packaging tasks.
+
+* **Deploying applications:** Netflix Spinnaker. It's their trusted tool for getting things into production smoothly and efficiently.
+
+* **Monitoring:** Uber built their own monitoring systems. They use the uMetric platform, built on Cassandra, to keep things consistent.
+
+* **Special tooling:** Uber relies on Peloton for capacity planning, scheduling, and operations. Crane builds a multi-cloud infrastructure to optimize costs. And with uAct and the OnCall dashboard, they've got event tracing and on-call duty management covered.
diff --git a/data/guides/uber-tech-stack.md b/data/guides/uber-tech-stack.md
new file mode 100644
index 0000000..f911324
--- /dev/null
+++ b/data/guides/uber-tech-stack.md
@@ -0,0 +1,32 @@
+---
+title: Uber Tech Stack
+description: Explore the tech stack that powers Uber's real-time transportation network.
+image: 'https://assets.bytebytego.com/diagrams/0124-uber-tech-stack-overall.png'
+createdAt: '2024-03-10'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Scalability
+---
+
+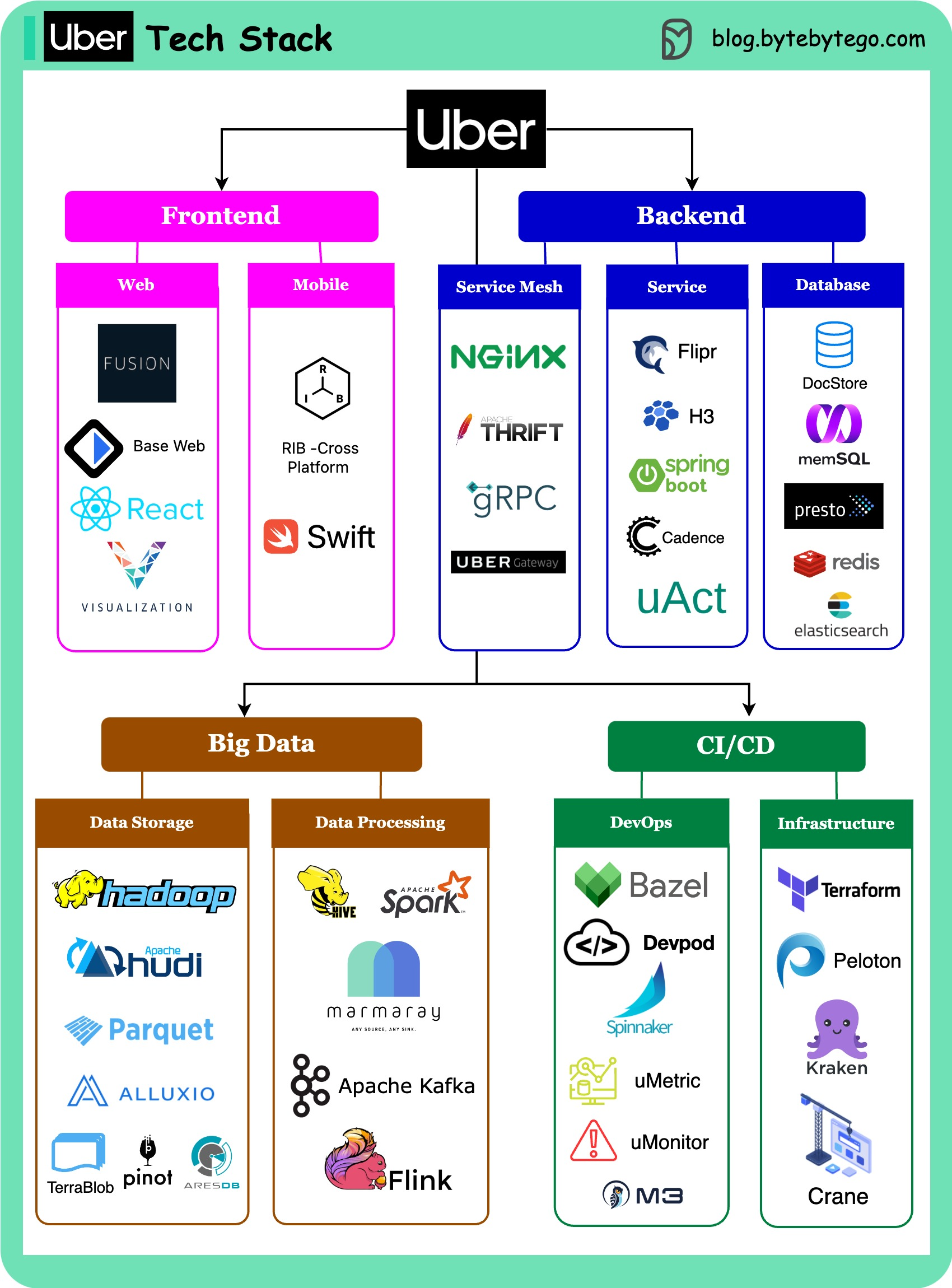
+
+This post is based on research from many Uber engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us. The corresponding links are added in the comment section.
+
+**Web frontend:** Uber builds Fusion.js as a modern React framework to create robust web applications. They also develop visualization.js for geospatial visualization scenarios.
+
+**Mobile side:** Uber builds the RIB cross-platform with the VIPER architecture instead of MVC. This architecture can work with different languages: Swift for iOS, and Java for Android.
+
+**Service mesh:** Uber built Uber Gateway as a dynamic configuration on top of NGINX. The service uses gRPC and QUIC for client-server communication, and Apache Thrift for API definition.
+
+**Service side:** Uber built a unified configuration store named Flipr (later changed to UCDP), H3 as a location-index store library. They use Spring Boot for Java-based services, uAct for event-driven architecture, and Cadence for async workflow orchestration.
+
+**Database end:** the OLTP mainly uses the strongly-consistent DocStore, which employs MySQL and PostgreSQL, along with the RocksDB database engine.
+
+**Big data:** managed through the Hadoop family. Hudi and Parquet are used as file formats, and Alluxio serves as cache. Time-series data is stored in Pinot and AresDB.
+
+**Data processing:** Hive, Spark, and the open-source data ingestion framework Marmaray. Messaging and streaming middleware include Apache Kafka and Apache Flink.
+
+**DevOps side:** Uber utilizes a Monorepo, with a simplified development environment called devpod. Continuous delivery is managed through Netflix Spinnaker, metrics are emitted to uMetric, alarms on uMonitor, and a consistent observability database M3.
diff --git a/data/guides/understanding-database-types.md b/data/guides/understanding-database-types.md
new file mode 100644
index 0000000..cc9fe36
--- /dev/null
+++ b/data/guides/understanding-database-types.md
@@ -0,0 +1,16 @@
+---
+title: "Understanding Database Types"
+description: "Explore different database types and their use cases."
+image: "https://assets.bytebytego.com/diagrams/0394-understanding-database-types.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "databases"
+ - "data management"
+---
+
+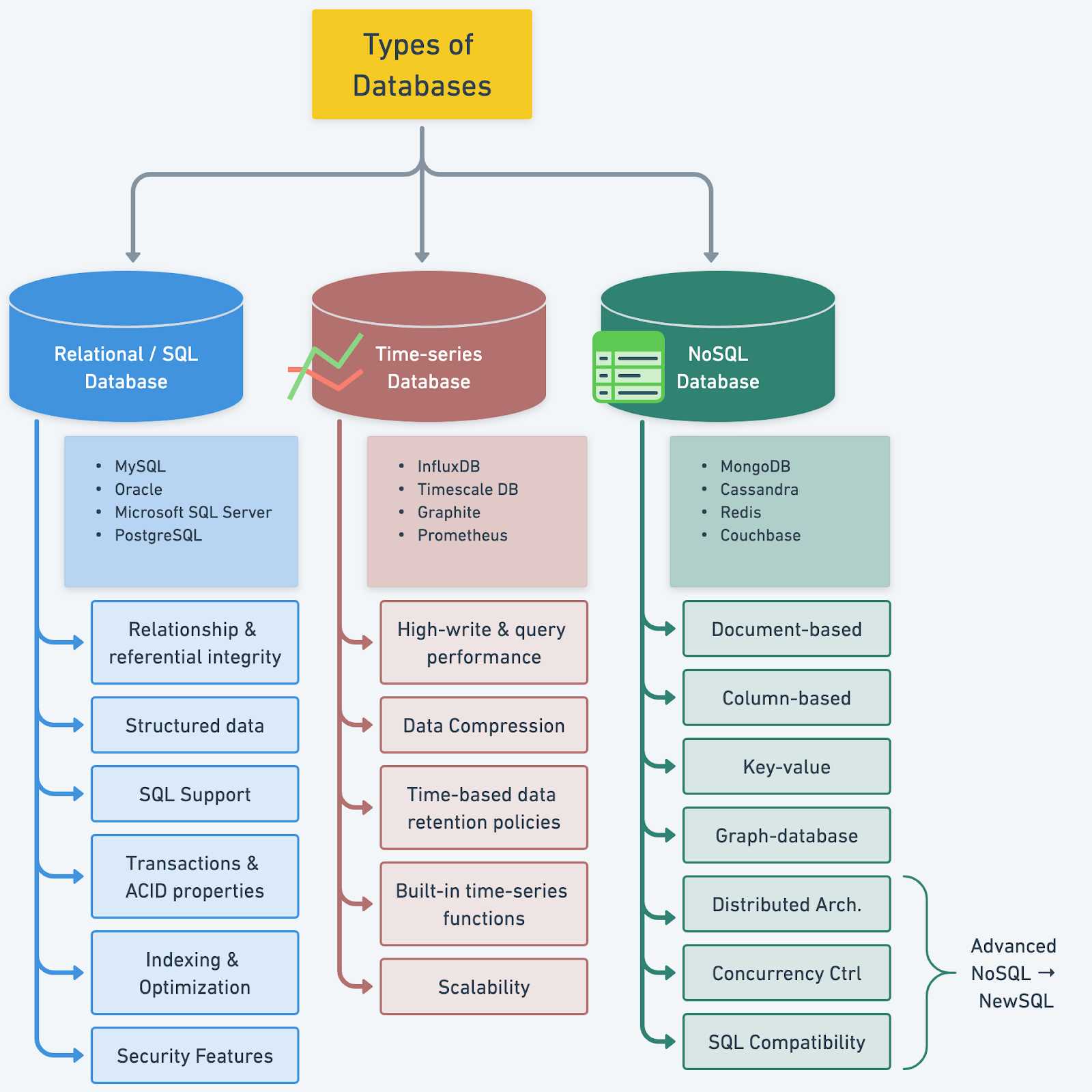
+
+To make the best decision for our projects, it is essential to understand the various types of databases available in the market. We need to consider key characteristics of different database types, including popular options for each, and compare their use cases.
diff --git a/data/guides/unicast-vs-broadcast-vs-multicast-vs-anycast.md b/data/guides/unicast-vs-broadcast-vs-multicast-vs-anycast.md
new file mode 100644
index 0000000..7b1649e
--- /dev/null
+++ b/data/guides/unicast-vs-broadcast-vs-multicast-vs-anycast.md
@@ -0,0 +1,48 @@
+---
+title: 'Unicast vs Broadcast vs Multicast vs Anycast'
+description: 'Understand the differences between unicast, broadcast, multicast, and anycast.'
+image: 'https://assets.bytebytego.com/diagrams/0125-unicast-vs-broadcast-vs-multicast-vs-anycast.png'
+createdAt: '2024-02-19'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Network Communication
+ - Protocols
+---
+
+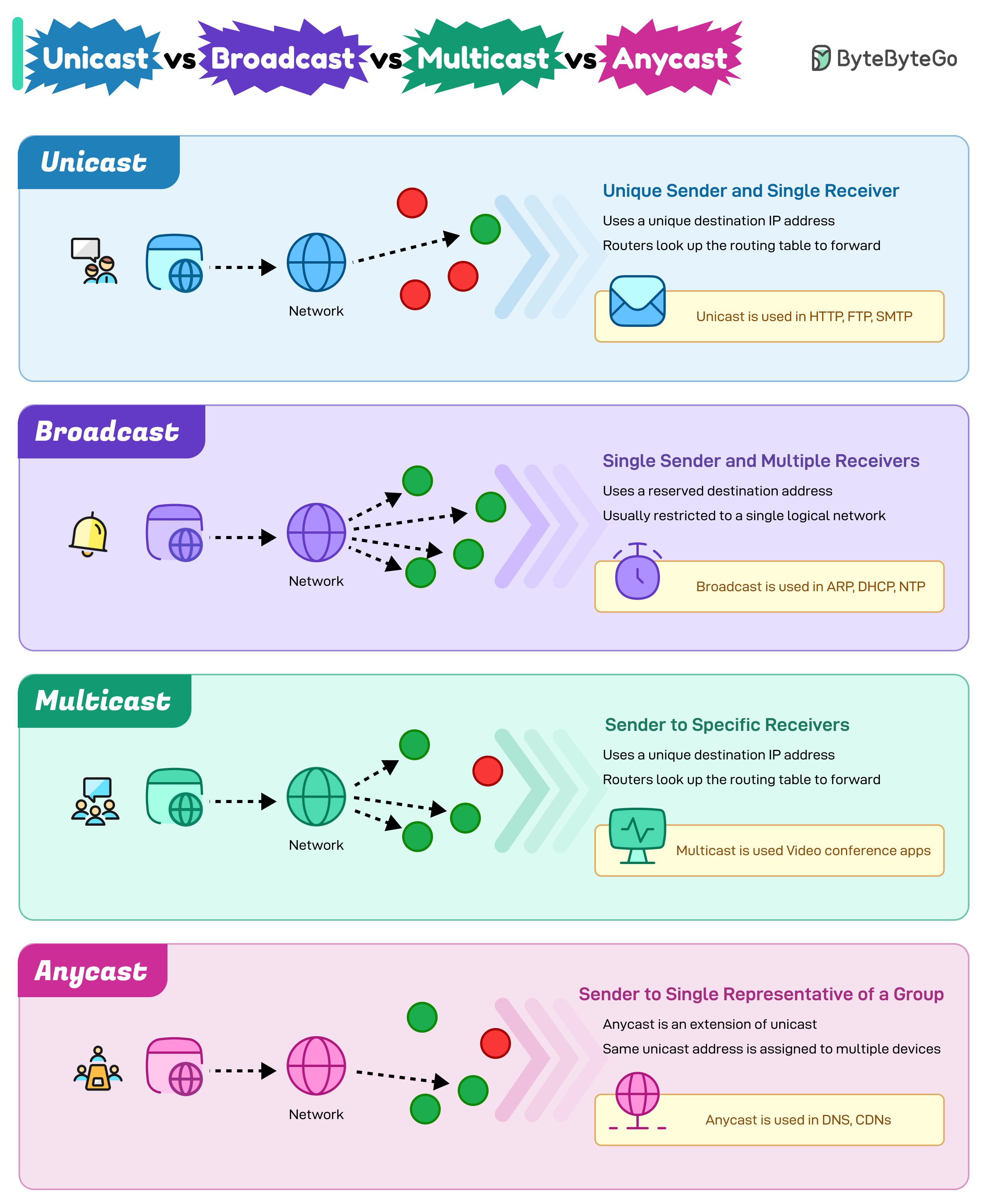
+
+These are 4 network communication methods you must know.
+
+* **Unicast**
+
+ Unique sender and a single receiver.
+
+ For example, communication between two people in a party.
+
+ Used in protocols such as HTTP, FTP, and SMTP.
+
+* **Broadcast**
+
+ Single sender and multiple receivers.
+
+ For example, a person at a party stands up on a podium and shouts a message to everyone. However, it doesn’t mean that every receiver gets the message.
+
+ Used in Address Resolution Protocol, DHCP, and NTP
+
+* **Multicast**
+
+ Sender to a specific group of devices in a network. This is a specialized case of broadcast routing.
+
+ For example, a member of the group talks and listens to other members of the group within a party.
+
+ Used in IPTV and video conference applications.
+
+* **Anycast**
+
+ Sender to a single device or a specific group of devices.
+
+ For example, saying thank you to one host out of a group of hosts organizing a party. All other hosts also expected to receive the thank you note.
+
+ Used in DNS querying and CDNs.
diff --git a/data/guides/unified-payments-interface-upi-in-india.md b/data/guides/unified-payments-interface-upi-in-india.md
new file mode 100644
index 0000000..7780b10
--- /dev/null
+++ b/data/guides/unified-payments-interface-upi-in-india.md
@@ -0,0 +1,62 @@
+---
+title: "Unified Payments Interface (UPI)"
+description: "Explore the architecture and workings of India's UPI payment system."
+image: "https://assets.bytebytego.com/diagrams/0400-upi-2.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Fintech"
+ - "UPI"
+---
+
+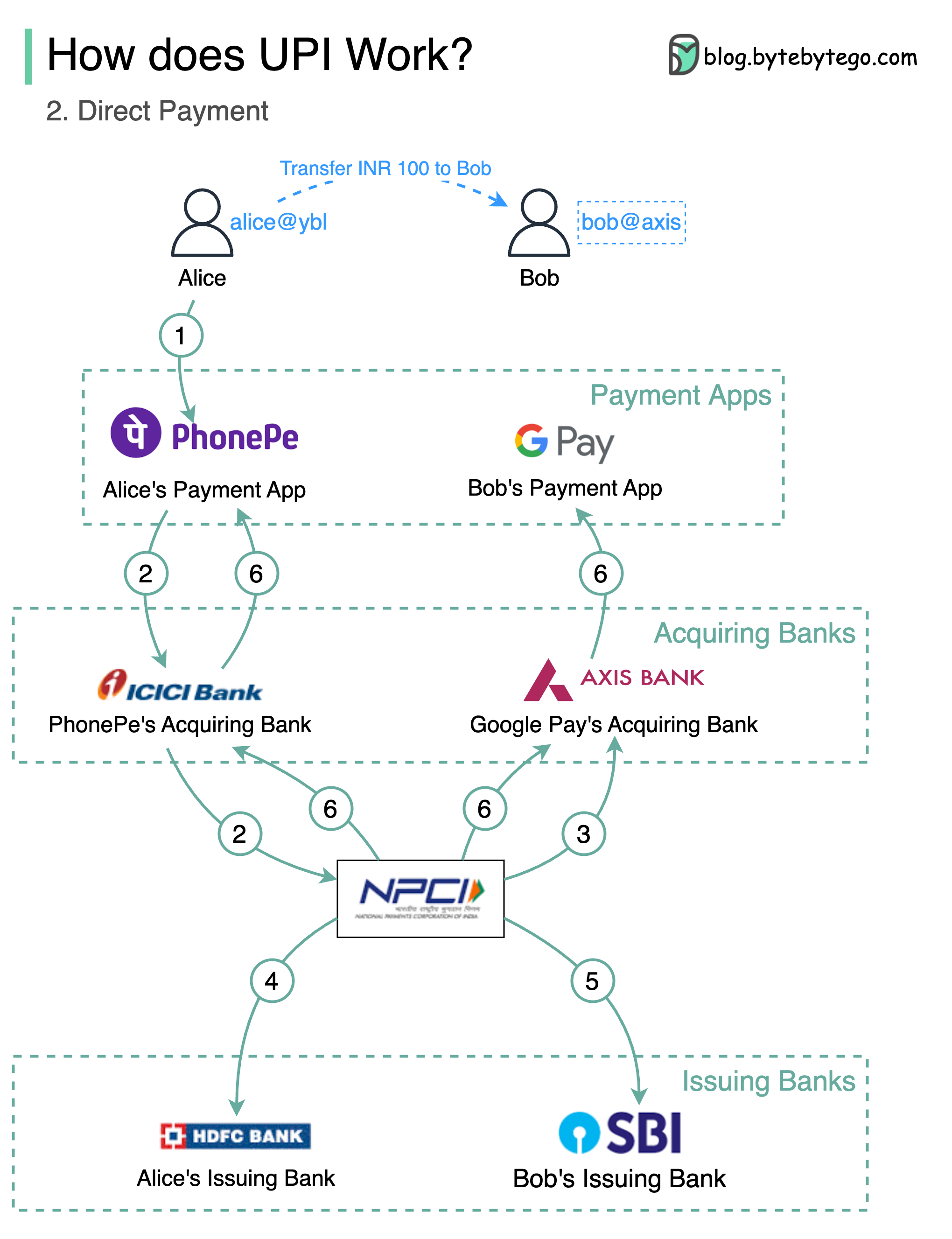
+
+The Unified Payments Interface (UPI) for real-time transactions in India is a good case study for other nations in the payment space.
+
+## What’s UPI?
+
+UPI is an instant real-time payment system developed by the National Payments Corporation of India.
+
+It accounts for 60% of digital retail transactions in India today and is still growing.
+
+UPI = payment markup language + standard for interoperable payments
+
+Let's take a look at how it works.
+
+## Registration
+
+* Bob wants to open an account and provides his phone number +91 12345678
+
+* Bob performs OTP (One-Time Password) phone verification
+
+* Bob sets up VPA (Virtual Payment Address) bobaxis
+
+* Bob’s payment app creates VPA with the acquiring bank
+
+* The acquiring bank returns with VPA
+
+* The payment app returns VPA to Bob
+
+## Link to Bank Account
+
+* Bob wants to link his SBI bank account with VPA bob at the axis. The request is forwarded to NPCI (National Payments Corporation of India).
+
+* NPCI acts as a switch between acquiring banks and issuing banks. It resolves the account detail from VPA with different issuing banks.
+
+* Bob authenticates with account details and sets the PIN, which is used for 2FA. This goes all the way to the issuing bank.
+
+## Direct payment
+
+1. Alice enters Bob’s UPI ID bob and the amount INR 100
+
+2. PhonePe verifies and forwards the request to NPCI via ICICI bank
+
+3. NPCI requests Axis Bank to resolve detail for bob at axis
+
+4. NPCI deducts Alice’s HDFC bank account by INR 100
+
+5. NPCI sends an instruction to SBI bank and add INR 100 to Bob’s account in SBI bank.
+
+6. Upon success, NPCI notifies the payment apps via acquiring banks.
diff --git a/data/guides/unique-id-generator.md b/data/guides/unique-id-generator.md
new file mode 100644
index 0000000..692c334
--- /dev/null
+++ b/data/guides/unique-id-generator.md
@@ -0,0 +1,32 @@
+---
+title: "Unique ID Generator"
+description: "Explore unique ID generation for scalable backend systems."
+image: "https://assets.bytebytego.com/diagrams/0105-id-generator.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "ID Generation"
+ - "System Design"
+---
+
+
+
+IDs are very important for the backend. Do you know how to generate globally unique IDs?
+
+In this post, we explore common requirements for IDs that are used in social media such as Facebook, Twitter, and LinkedIn.
+
+## Requirements:
+
+* Globally unique
+
+* Roughly sorted by time
+
+* Numerical values only
+
+* 64 bits
+
+* Highly scalable, low latency
+
+The implementation details of the algorithms can be found online so we will not go into detail here.
diff --git a/data/guides/url-uri-urn-do-you-know-the-differences.md b/data/guides/url-uri-urn-do-you-know-the-differences.md
new file mode 100644
index 0000000..ecb8513
--- /dev/null
+++ b/data/guides/url-uri-urn-do-you-know-the-differences.md
@@ -0,0 +1,33 @@
+---
+title: 'URL, URI, URN - Differences Explained'
+description: 'Understand the differences between URL, URI, and URN with clear examples.'
+image: 'https://assets.bytebytego.com/diagrams/0401-url-uri-urn.png'
+createdAt: '2024-02-21'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Networking
+ - Web
+---
+
+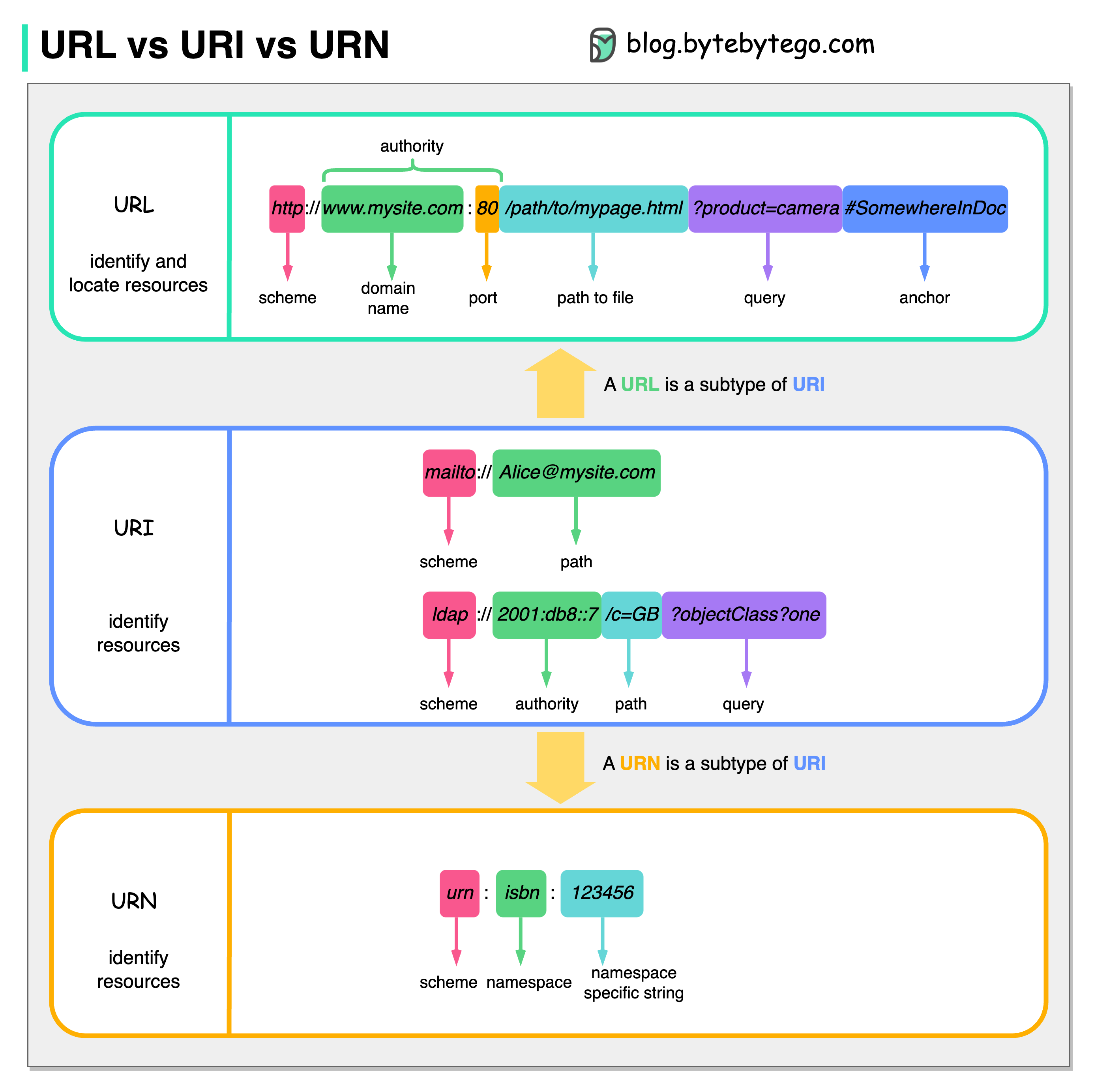
+
+The diagram above shows a comparison of URL, URI, and URN.
+
+* **URI**
+
+ URI stands for Uniform Resource Identifier. It identifies a logical or physical resource on the web. URL and URN are subtypes of URI. URL locates a resource, while URN names a resource.
+
+A URI is composed of the following parts:
+
+```
+scheme:[//authority]path[?query][#fragment]
+```
+
+* **URL**
+
+ URL stands for Uniform Resource Locator, the key concept of HTTP. It is the address of a unique resource on the web. It can be used with other protocols like FTP and JDBC.
+* **URN**
+
+ URN stands for Uniform Resource Name. It uses the urn scheme. URNs cannot be used to locate a resource. A simple example given in the diagram is composed of a namespace and a namespace-specific string.
diff --git a/data/guides/v1what-is-sso-single-sign-on.md b/data/guides/v1what-is-sso-single-sign-on.md
new file mode 100644
index 0000000..f2f4841
--- /dev/null
+++ b/data/guides/v1what-is-sso-single-sign-on.md
@@ -0,0 +1,36 @@
+---
+title: "What is SSO (Single Sign-On)?"
+description: "Learn about Single Sign-On (SSO) and how it simplifies user authentication."
+image: "https://assets.bytebytego.com/diagrams/0342-how-does-sso-work.jpeg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - security
+tags:
+ - "authentication"
+ - "SSO"
+---
+
+
+
+A friend recently went through the irksome experience of being signed out from a number of websites they use daily. This event will be familiar to millions of web users, and it is a tedious process to fix. It can involve trying to remember multiple long-forgotten passwords, or typing in the names of pets from childhood to answer security questions. SSO removes this inconvenience and makes life online better. But how does it work?
+
+Basically, Single Sign-On (SSO) is an authentication scheme. It allows a user to log in to different systems using a single ID.
+
+The diagram below illustrates how SSO works.
+
+## How SSO Works
+
+Step 1: A user visits Gmail, or any email service. Gmail finds the user is not logged in and so redirects them to the SSO authentication server, which also finds the user is not logged in. As a result, the user is redirected to the SSO login page, where they enter their login credentials.
+
+Steps 2-3: The SSO authentication server validates the credentials, creates the global session for the user, and creates a token.
+
+Steps 4-7: Gmail validates the token in the SSO authentication server. The authentication server registers the Gmail system, and returns “valid.” Gmail returns the protected resource to the user.
+
+Step 8: From Gmail, the user navigates to another Google-owned website, for example, YouTube.
+
+Steps 9-10: YouTube finds the user is not logged in, and then requests authentication. The SSO authentication server finds the user is already logged in and returns the token.
+
+Steps 11-14: YouTube validates the token in the SSO authentication server. The authentication server registers the YouTube system, and returns “valid.” YouTube returns the protected resource to the user.
+
+The process is complete and the user gets back access to their account.
diff --git a/data/guides/vertical-partitioning-vs-horizontal-partitioning.md b/data/guides/vertical-partitioning-vs-horizontal-partitioning.md
new file mode 100644
index 0000000..f5ac2b6
--- /dev/null
+++ b/data/guides/vertical-partitioning-vs-horizontal-partitioning.md
@@ -0,0 +1,42 @@
+---
+title: "Vertical vs Horizontal Partitioning"
+description: "Explore vertical vs horizontal partitioning strategies in databases."
+image: "https://assets.bytebytego.com/diagrams/0402-vertical-partitioning-vs-horizontal-partitioning.png"
+createdAt: "2024-01-30"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Database Partitioning"
+ - "Sharding"
+---
+
+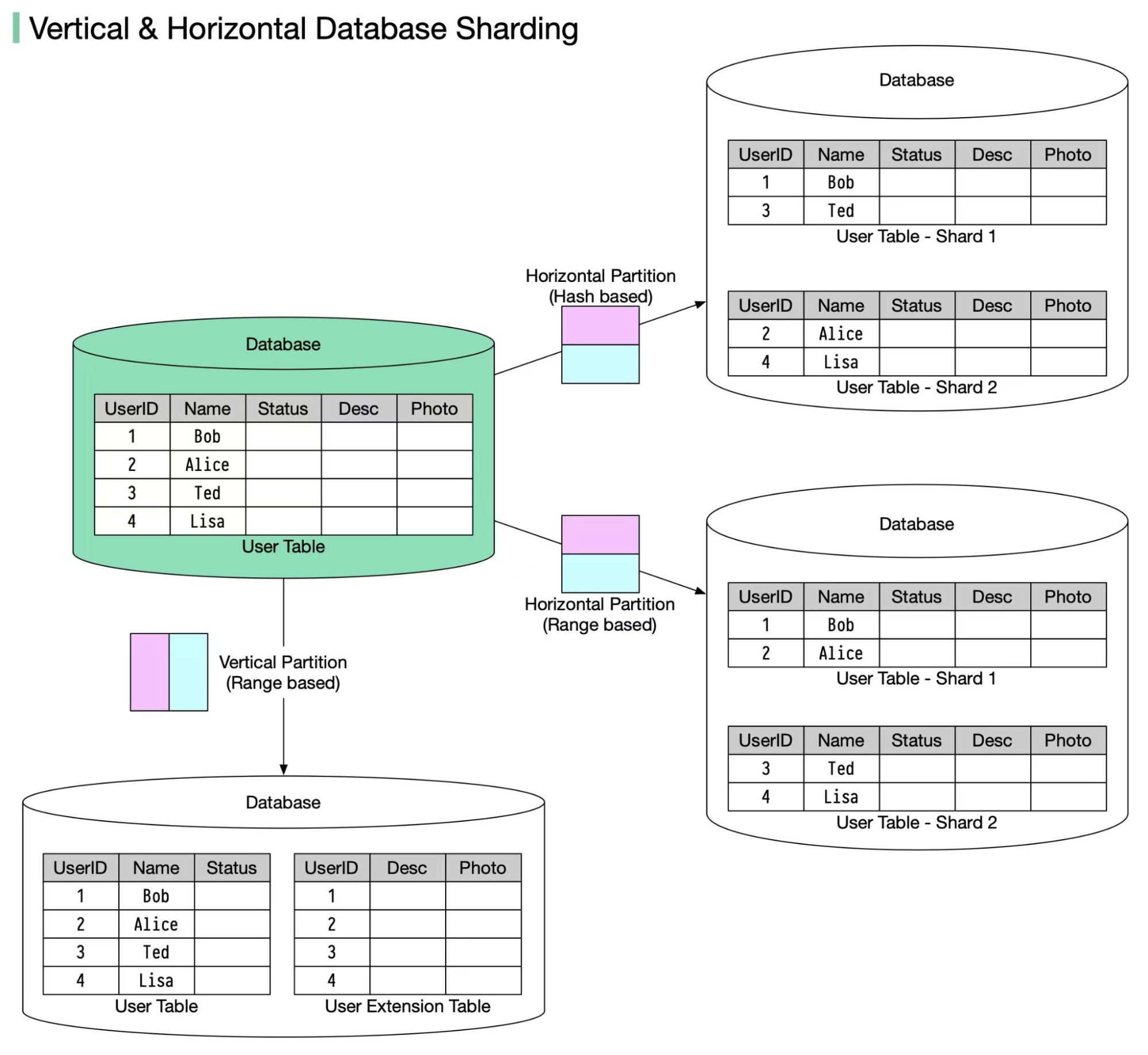
+
+In many large-scale applications, data is divided into partitions that can be accessed separately. There are two typical strategies for partitioning data.
+
+* Vertical partitioning: it means some columns are moved to new tables. Each table contains the same number of rows but fewer columns (see diagram below).
+
+* Horizontal partitioning (often called sharding): it divides a table into multiple smaller tables. Each table is a separate data store, and it contains the same number of columns, but fewer rows (see diagram below).
+
+Horizontal partitioning is widely used so let’s take a closer look.
+
+## Routing algorithm
+
+The routing algorithm decides which partition (shard) stores the data.
+
+* Range-based sharding. This algorithm uses ordered columns, such as integers, longs, timestamps, to separate the rows. For example, the diagram below uses the User ID column for range partition: User IDs 1 and 2 are in shard 1, User IDs 3 and 4 are in shard 2.
+
+* Hash-based sharding. This algorithm applies a hash function to one column or several columns to decide which row goes to which table. For example, the diagram below uses **User ID mod 2** as a hash function. User IDs 1 and 3 are in shard 1, User IDs 2 and 4 are in shard 2.
+
+## Benefits
+
+* Facilitate horizontal scaling. Sharding facilitates the possibility of adding more machines to spread out the load.
+
+* Shorten response time. By sharding one table into multiple tables, queries go over fewer rows, and results are returned much more quickly.
+
+## Drawbacks
+
+* The order by operation is more complicated. Usually, we need to fetch data from different shards and sort the data in the application's code.
+
+* Uneven distribution. Some shards may contain more data than others (this is also called the hotspot).
diff --git a/data/guides/visualizing-a-sql-query.md b/data/guides/visualizing-a-sql-query.md
new file mode 100644
index 0000000..7f8c105
--- /dev/null
+++ b/data/guides/visualizing-a-sql-query.md
@@ -0,0 +1,24 @@
+---
+title: "Visualizing a SQL Query"
+description: "Understand the logical order of operations in a SQL query."
+image: "https://assets.bytebytego.com/diagrams/0114-sql-query-logical-order.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "SQL"
+ - "Databases"
+---
+
+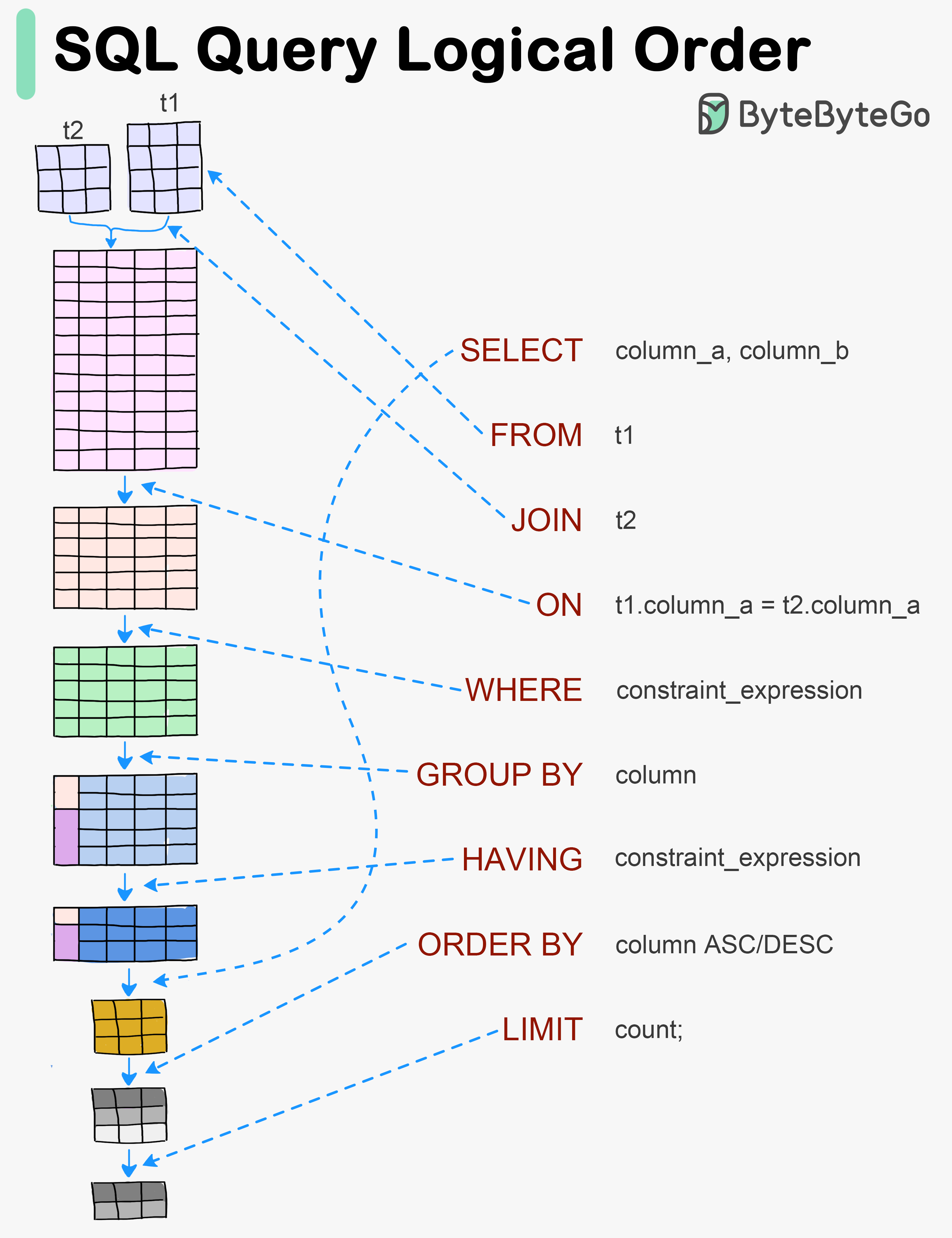
+
+SQL statements are executed by the database system in several steps, including:
+
+* Parsing the SQL statement and checking its validity
+
+* Transforming the SQL into an internal representation, such as relational algebra
+
+* Optimizing the internal representation and creating an execution plan that utilizes index information
+
+* Executing the plan and returning the results
diff --git a/data/guides/what's-the-difference-between-session-based-authentication-and-jwts.md b/data/guides/what's-the-difference-between-session-based-authentication-and-jwts.md
new file mode 100644
index 0000000..8341bab
--- /dev/null
+++ b/data/guides/what's-the-difference-between-session-based-authentication-and-jwts.md
@@ -0,0 +1,46 @@
+---
+title: "Session-based Authentication vs. JWT"
+description: "Understand the key differences between session and JWT authentication."
+image: "https://assets.bytebytego.com/diagrams/0333-what-s-the-difference-between-session-based-authentication-and-jwts.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "JWT"
+---
+
+
+
+Here’s a simple breakdown for both approaches:
+
+## Session-Based Authentication
+
+In this approach, you store the session information in a database or session store and hand over a session ID to the user.
+
+Think of it like a passenger getting just the Ticket ID of their flight while all other details are stored in the airline’s database.
+
+Here’s how it works:
+
+* The user makes a login request and the frontend app sends the request to the backend server.
+* The backend creates a session using a secret key and stores the data in session storage.
+* The server sends a cookie back to the client with the unique session ID.
+* The user makes a new request and the browser sends the session ID along with the request.
+* The server authenticates the user using the session ID.
+
+## JWT-Based Authentication
+
+In the JWT-based approach, you don’t store the session information in the session store.
+
+The entire information is available within the token.
+
+Think of it like getting the flight ticket along with all the details available on the ticket but encoded.
+
+Here’s how it works:
+
+* The user makes a login request and it goes to the backend server.
+* The server verifies the credentials and issues a JWT. The JWT is signed using a private key and no session storage is involved.
+* The JWT is passed to the client, either as a cookie or in the response body. Both approaches have their pros and cons but we’ve gone with the cookie approach.
+* For every subsequent request, the browser sends the cookie with the JWT.
+* The server verifies the JWT using the secret private key and extracts the user info.
diff --git a/data/guides/what-are-database-isolation-levels.md b/data/guides/what-are-database-isolation-levels.md
new file mode 100644
index 0000000..ad1867b
--- /dev/null
+++ b/data/guides/what-are-database-isolation-levels.md
@@ -0,0 +1,42 @@
+---
+title: "Database Isolation Levels"
+description: "Explore database isolation levels and their impact on transaction concurrency."
+image: "https://assets.bytebytego.com/diagrams/0239-isolation-level.png"
+createdAt: "2024-02-03"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Databases"
+ - "Transactions"
+---
+
+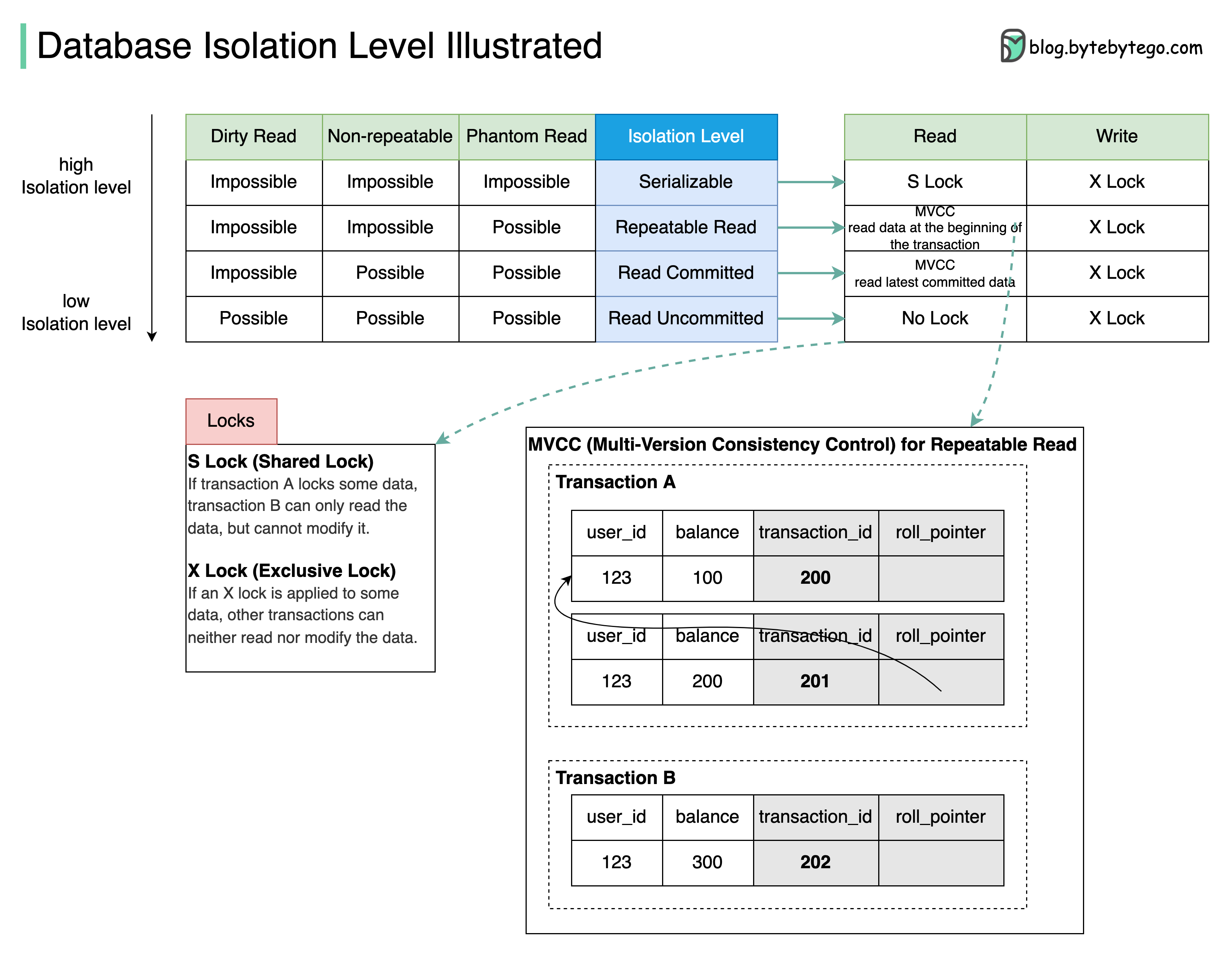
+
+## What are they used for?
+
+Database isolation allows a transaction to execute as if there are no other concurrently running transactions.
+
+The diagram above illustrates four isolation levels.
+
+## Isolation Levels
+
+* **Serializable:** This is the highest isolation level. Concurrent transactions are guaranteed to be executed in sequence.
+
+* **Repeatable Read:** Data read during the transaction stays the same as the transaction starts.
+
+* **Read Committed:** Data modification can only be read after the transaction is committed.
+
+* **Read Uncommitted:** The data modification can be read by other transactions before a transaction is committed.
+
+The isolation is guaranteed by MVCC (Multi-Version Consistency Control) and locks.
+
+## MVCC Example
+
+The diagram takes Repeatable Read as an example to demonstrate how MVCC works:
+
+There are two hidden columns for each row: transaction\_id and roll\_pointer. When transaction A starts, a new Read View with transaction\_id=201 is created. Shortly afterward, transaction B starts, and a new Read View with transaction\_id=202 is created.
+
+Now transaction A modifies the balance to 200, a new row of the log is created, and the roll\_pointer points to the old row. Before transaction A commits, transaction B reads the balance data. Transaction B finds that transaction\_id 201 is not committed, it reads the next committed record(transaction\_id=200).
+
+Even when transaction A commits, transaction B still reads data based on the Read View created when transaction B starts. So transaction B always reads the data with balance=100.
diff --git a/data/guides/what-are-the-differences-among-database-locks.md b/data/guides/what-are-the-differences-among-database-locks.md
new file mode 100644
index 0000000..7760057
--- /dev/null
+++ b/data/guides/what-are-the-differences-among-database-locks.md
@@ -0,0 +1,56 @@
+---
+title: "Database Locks Explained"
+description: "Explore the different types of database locks and their functionalities."
+image: "https://assets.bytebytego.com/diagrams/0022-9-types-of-database-locks.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Locking"
+ - "Concurrency Control"
+---
+
+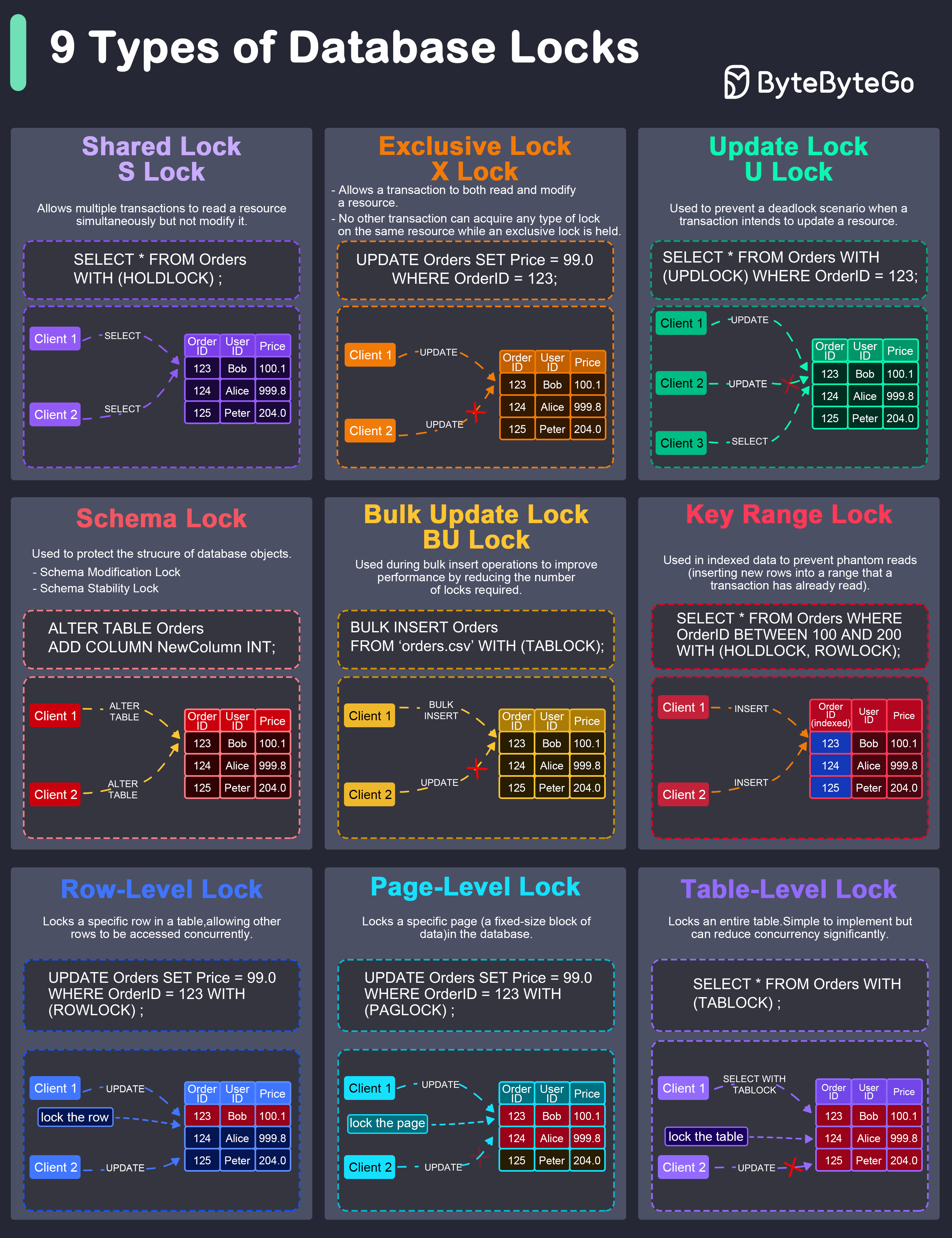
+
+In database management, locks are mechanisms that prevent concurrent access to data to ensure data integrity and consistency.
+
+## Common Types of Locks
+
+Here are the common types of locks used in databases:
+
+* **Shared Lock (S Lock)**
+
+ It allows multiple transactions to read a resource simultaneously but not modify it. Other transactions can also acquire a shared lock on the same resource.
+
+* **Exclusive Lock (X Lock)**
+
+ It allows a transaction to both read and modify a resource. No other transaction can acquire any type of lock on the same resource while an exclusive lock is held.
+
+* **Update Lock (U Lock)**
+
+ It is used to prevent a deadlock scenario when a transaction intends to update a resource.
+
+* **Schema Lock**
+
+ It is used to protect the structure of database objects.
+
+* **Bulk Update Lock (BU Lock)**
+
+ It is used during bulk insert operations to improve performance by reducing the number of locks required.
+
+* **Key-Range Lock**
+
+ It is used in indexed data to prevent phantom reads (inserting new rows into a range that a transaction has already read).
+
+* **Row-Level Lock**
+
+ It locks a specific row in a table, allowing other rows to be accessed concurrently.
+
+* **Page-Level Lock**
+
+ It locks a specific page (a fixed-size block of data) in the database.
+
+* **Table-Level Lock**
+
+ It locks an entire table. This is simple to implement but can reduce concurrency significantly.
diff --git a/data/guides/what-are-the-differences-between-a-load-balancer-and-an-api-gateway.md b/data/guides/what-are-the-differences-between-a-load-balancer-and-an-api-gateway.md
new file mode 100644
index 0000000..755a17e
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-a-load-balancer-and-an-api-gateway.md
@@ -0,0 +1,26 @@
+---
+title: 'Load Balancer vs. API Gateway'
+description: 'Explore the key differences between load balancers and API gateways.'
+image: 'https://assets.bytebytego.com/diagrams/0252-lb-api-gateway.png'
+createdAt: '2024-02-11'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Load Balancer
+---
+
+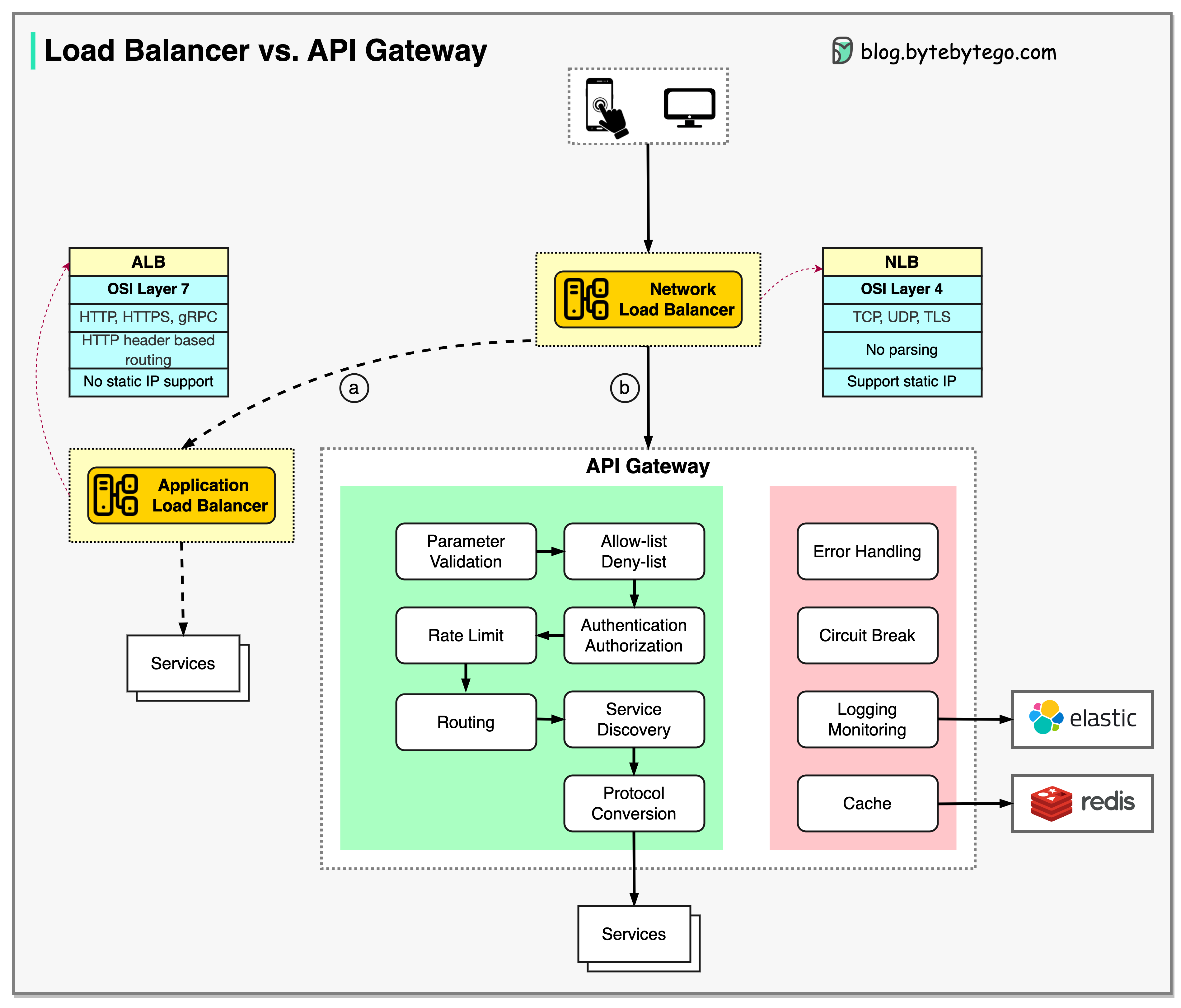
+
+First, let's clarify some concepts before discussing the differences.
+
+* NLB (Network Load Balancer) is usually deployed before the API gateway, handling traffic routing based on IP. It does not parse the HTTP requests.
+* ALB (Application Load Balancer) routes requests based on HTTP header or URL and thus can provide richer routing rules. We can choose the load balancer based on routing requirements. For simple services with a smaller scale, one load balancer is enough.
+* The API gateway performs tasks more on the application level. So it has different responsibilities from the load balancer.
+
+The diagram above shows the detail. Often, they are used in combination to provide a scalable and secure architecture for modern web apps.
+
+Option a: ALB is used to distribute requests among different services. Due to the fact that the services implement their own rating limitation, authentication, etc., this approach is more flexible but requires more work at the service level.
+
+Option b: An API gateway takes care of authentication, rate limiting, caching, etc., so there is less work at the service level. However, this option is less flexible compared with the ALB approach.
diff --git a/data/guides/what-are-the-differences-between-cookies-and-sessions.md b/data/guides/what-are-the-differences-between-cookies-and-sessions.md
new file mode 100644
index 0000000..178de35
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-cookies-and-sessions.md
@@ -0,0 +1,24 @@
+---
+title: "Cookies vs Sessions"
+description: "Explore the key differences between cookies and sessions in web development."
+image: "https://assets.bytebytego.com/diagrams/0154-cookies-vs-session.png"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - security
+tags:
+ - "cookies"
+ - "sessions"
+---
+
+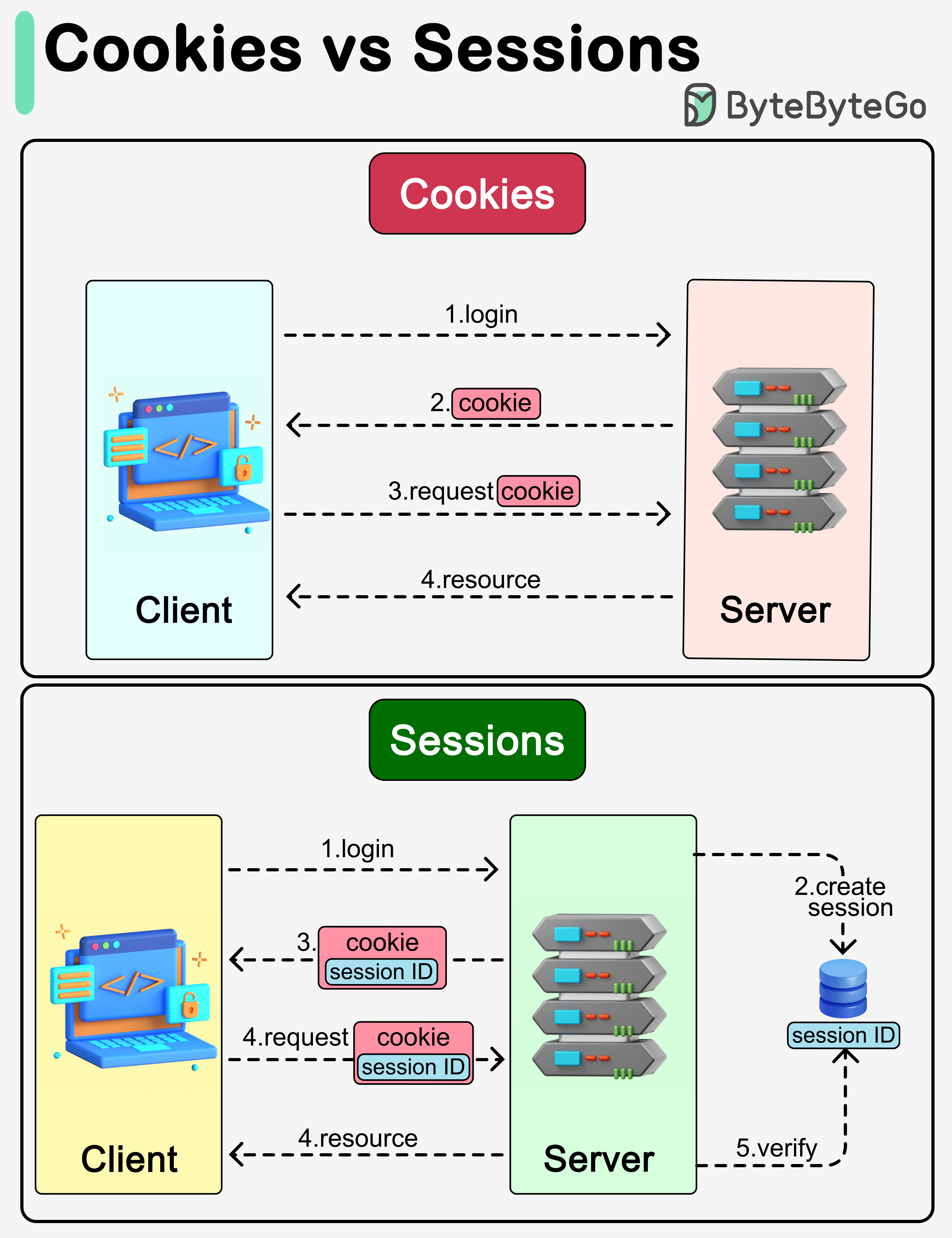
+
+Cookies and sessions are both used to carry user information over HTTP requests, including user login status, user permissions, etc.
+
+## Cookies
+
+Cookies typically have size limits (4KB). They carry small pieces of information and are stored on the users’ devices. Cookies are sent with each subsequent user request. Users can choose to ban cookies in their browsers.
+
+## Sessions
+
+Unlike cookies, sessions are created and stored on the server side. There is usually a unique session ID generated on the server, which is attached to a specific user session. This session ID is returned to the client side in a cookie. Sessions can hold larger amounts of data. Since the session data is not directly accessed by the client, the session offers more security.
diff --git a/data/guides/what-are-the-differences-between-paging-and-segmentation.md b/data/guides/what-are-the-differences-between-paging-and-segmentation.md
new file mode 100644
index 0000000..65f5fff
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-paging-and-segmentation.md
@@ -0,0 +1,46 @@
+---
+title: "Paging vs Segmentation"
+description: "Explore paging vs segmentation: memory management techniques."
+image: "https://assets.bytebytego.com/diagrams/0269-memory-allocation-paging-vs-segmentation.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Memory Management"
+ - "Operating Systems"
+---
+
+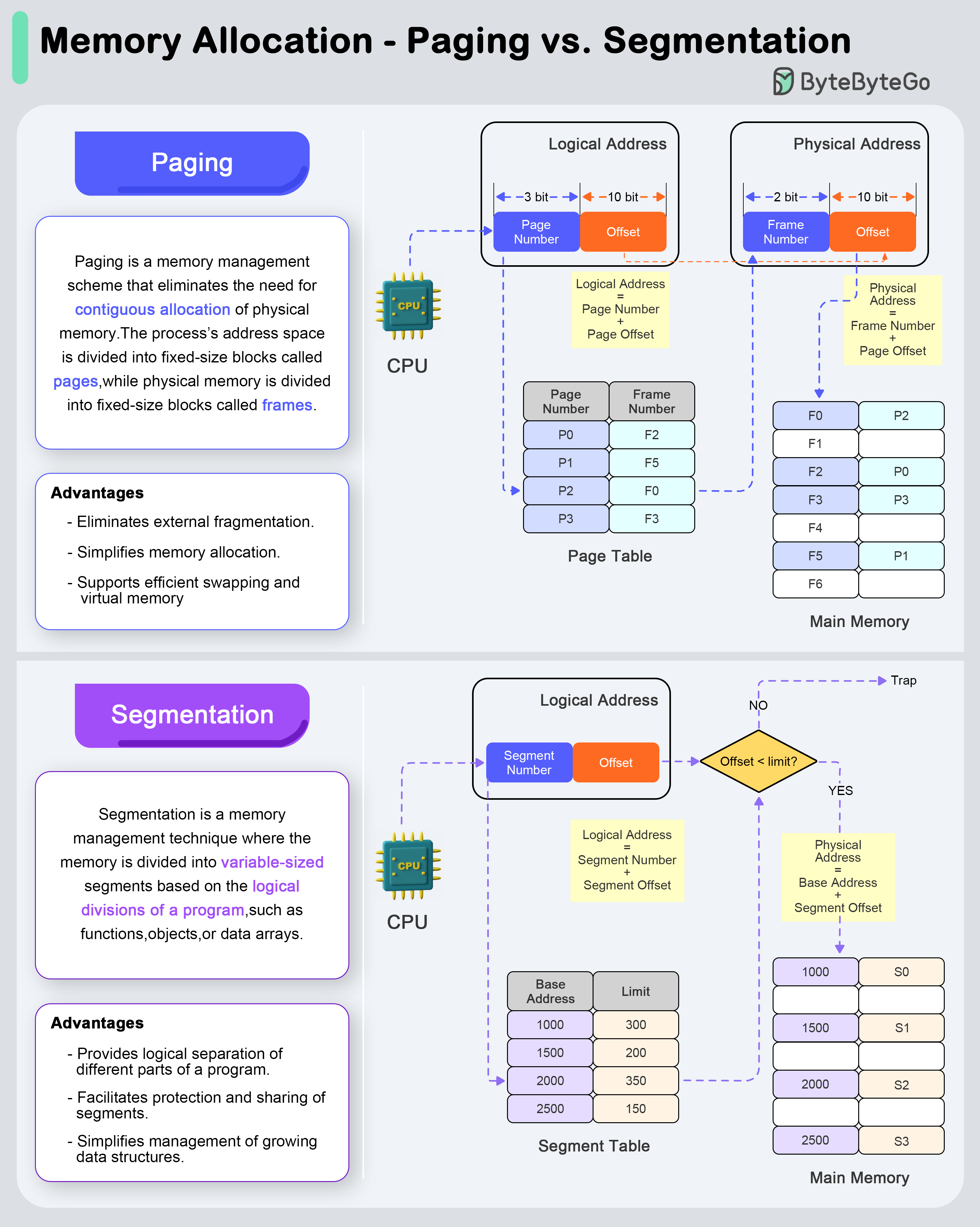
+
+## Paging
+
+Paging is a memory management scheme that eliminates the need for contiguous allocation of physical memory. The process's address space is divided into fixed-size blocks called pages, while physical memory is divided into fixed-size blocks called frames.
+
+The address translation process works in 3 steps:
+
+* Logical Address Space: The logical address (generated by the CPU) is divided into a page number and a page offset.
+* Page Table Lookup: The page number is used as an index into the page table to find the corresponding frame number.
+* Physical Address Formation: The frame number is combined with the page offset to form the physical address in memory.
+
+### Advantages:
+
+* Eliminates external fragmentation.
+* Simplifies memory allocation.
+* Supports efficient swapping and virtual memory.
+
+## Segmentation
+
+Segmentation is a memory management technique where the memory is divided into variable-sized segments based on the logical divisions of a program, such as functions, objects, or data arrays.
+
+The address tranlation process works in 3 steps:
+
+* Logical Address Space: The logical address consists of a segment number and an offset within that segment.
+* Segment Table Lookup: The segment number is used as an index into the segment table to find the base address of the segment.
+* Physical Address Formation: The base address is added to the offset to form the physical address in memory.
+
+### Advantages:
+
+* Provides logical separation of different parts of a program.
+* Facilitates protection and sharing of segments.
+* Simplifies management of growing data structures.
diff --git a/data/guides/what-are-the-differences-between-wan-lan-pan-and-man.md b/data/guides/what-are-the-differences-between-wan-lan-pan-and-man.md
new file mode 100644
index 0000000..f2c0bc5
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-wan-lan-pan-and-man.md
@@ -0,0 +1,56 @@
+---
+title: 'What are the differences between WAN, LAN, PAN and MAN?'
+description: 'Explore the key differences between WAN, LAN, PAN, and MAN networks.'
+image: 'https://assets.bytebytego.com/diagrams/0405-wan-lan-pan-man-explained.png'
+createdAt: '2024-02-06'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - network types
+ - network architecture
+---
+
+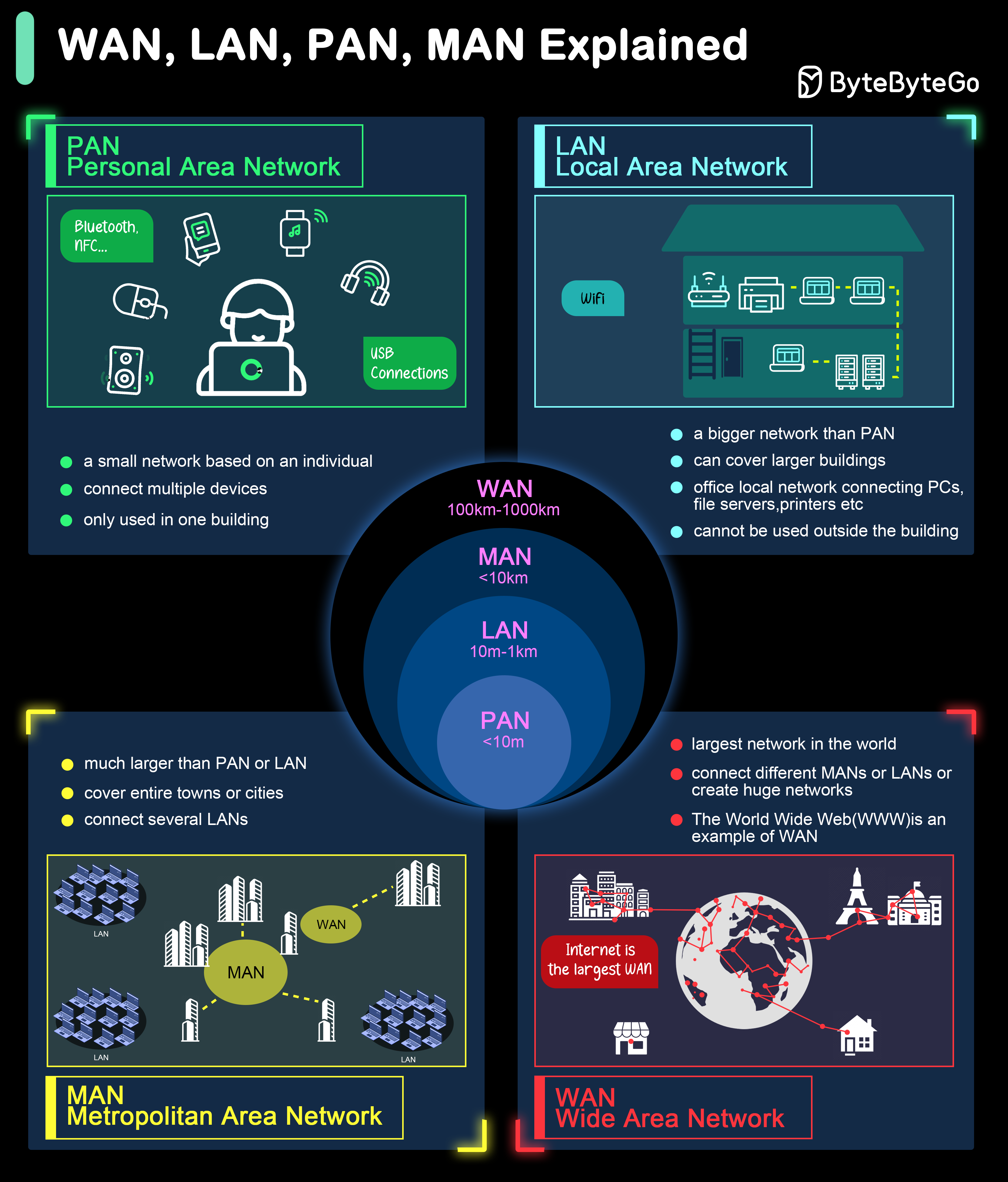
+
+In the world of networking, different types of networks are defined based on their size, range, and purpose. The most common types of networks are WAN (Wide Area Network), MAN (Metropolitan Area Network), LAN (Local Area Network), and PAN (Personal Area Network).
+
+* **Personal Area Network (PAN)**
+
+ A PAN is a network used for communication among devices close to one person, typically within a range of a few meters.
+
+ Use Cases:
+
+ * Connecting personal devices like smartphones, tablets, and wearables.
+ * Enabling hands-free communication through Bluetooth headsets.
+ * Synchronizing data between a computer and a smartphone.
+
+* **Local Area Network (LAN)**
+
+ A LAN is a network that connects computers and devices within a limited area such as a home, office, or building.
+
+ Use Cases:
+
+ * Sharing resources like printers and file servers within an office.
+ * Facilitating communication and collaboration among employees.
+ * Providing internet access within a home or small business.
+
+* **Metropolitan Area Network (MAN)**
+
+ A MAN covers a larger geographic area than a LAN but smaller than a WAN, typically spanning a city or a large campus.
+
+ Use Cases:
+
+ * Connecting multiple campuses of a university.
+ * Providing high-speed internet access across a city.
+ * Linking local government offices within a metropolitan area.
+
+* **Wide Area Network (WAN)**
+
+ A WAN spans a large geographic area, often a country or continent. The most prominent example of a WAN is the Internet.
+
+ Use Cases:
+
+ * Connecting branch offices of multinational companies.
+ * Facilitating global communication and data exchange.
+ * Enabling remote access to central resources.
diff --git a/data/guides/what-are-the-greenest-programming-languages.md b/data/guides/what-are-the-greenest-programming-languages.md
new file mode 100644
index 0000000..6b4a765
--- /dev/null
+++ b/data/guides/what-are-the-greenest-programming-languages.md
@@ -0,0 +1,18 @@
+---
+title: "What Are the Greenest Programming Languages?"
+description: "Explore energy efficiency in programming languages and their impact."
+image: "https://assets.bytebytego.com/diagrams/0186-energy-efficient-language.jpg"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Programming Languages"
+ - "Energy Efficiency"
+---
+
+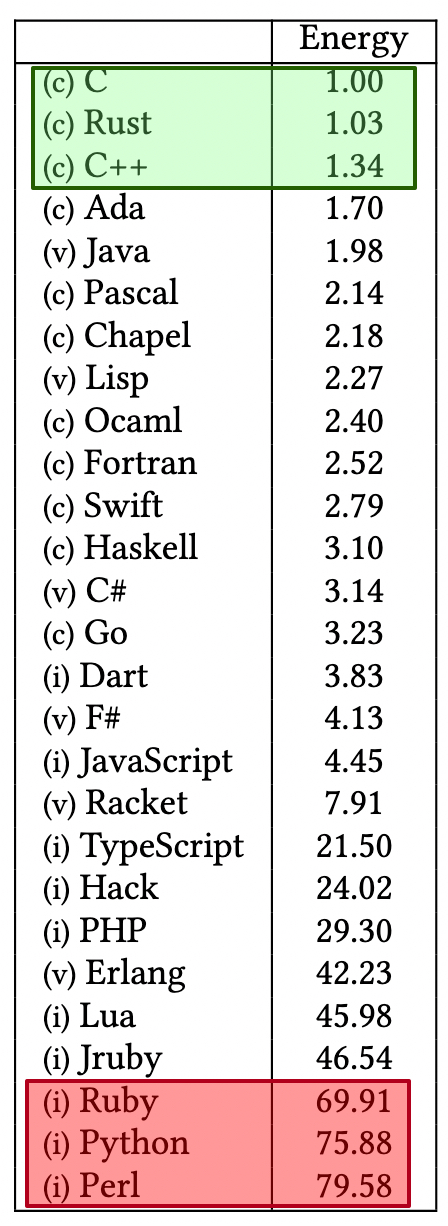
+
+The study below runs 10 benchmark problems in 28 languages. It measures the runtime, memory usage, and energy consumption of each language. This take might be controversial.
+
+“This paper presents a study of the runtime, memory usage, and energy consumption of twenty-seven well-known software languages. We monitor the performance of such languages using ten different programming problems, expressed in each of the languages. Our results show interesting findings, such as slower/faster languages consuming less/more energy, and how memory usage influences energy consumption. We show how to use our results to provide software engineers support to decide which language to use when energy efficiency is a concern”.
diff --git a/data/guides/what-are-the-most-important-aws-services-to-learn.md b/data/guides/what-are-the-most-important-aws-services-to-learn.md
new file mode 100644
index 0000000..07b837b
--- /dev/null
+++ b/data/guides/what-are-the-most-important-aws-services-to-learn.md
@@ -0,0 +1,28 @@
+---
+title: "Most Important AWS Services to Learn"
+description: "Explore essential AWS services for cloud computing and architecture."
+image: "https://assets.bytebytego.com/diagrams/0280-most-important-aws-services.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - AWS
+ - Cloud Computing
+---
+
+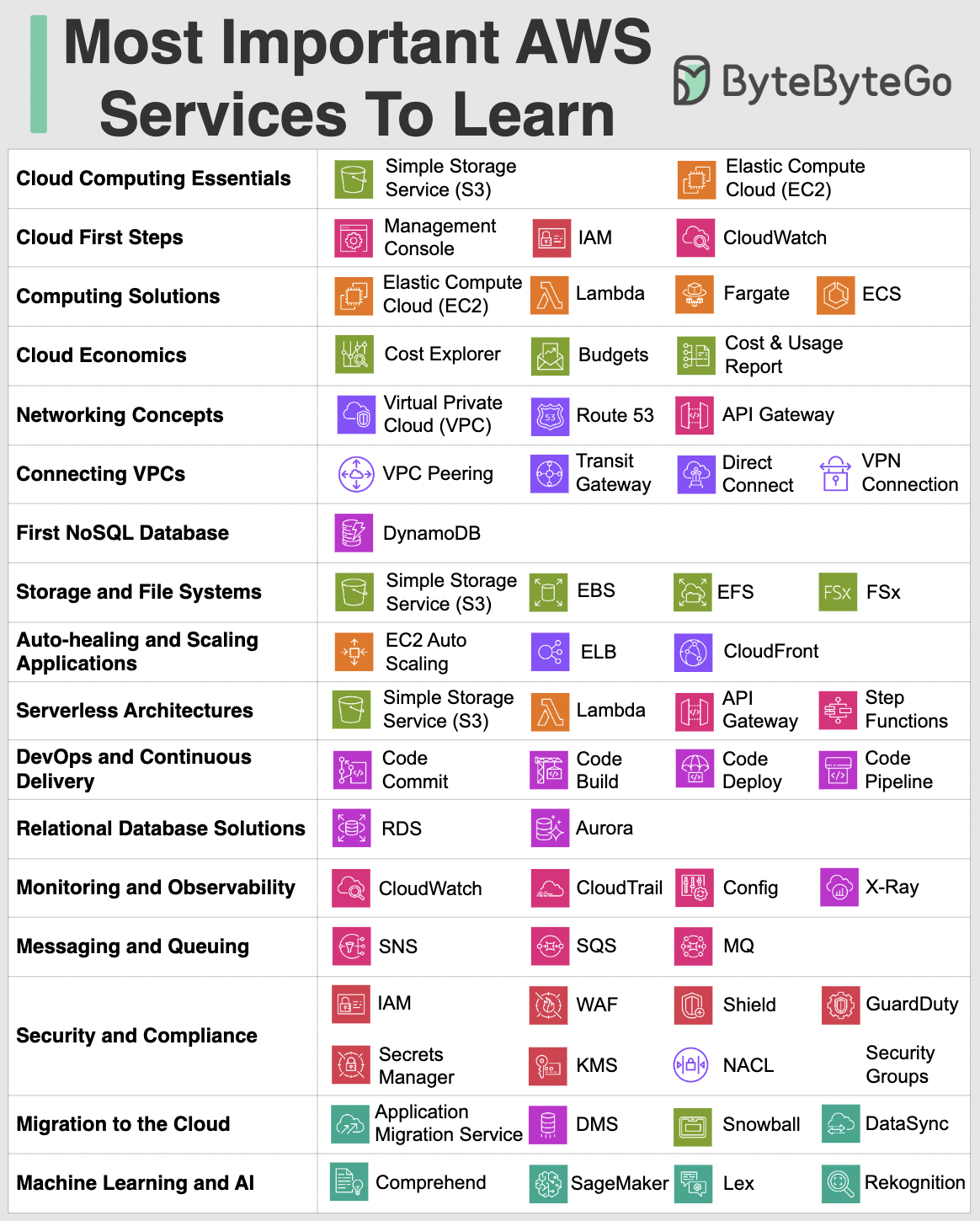
+
+Since its inception in 2006, AWS has rapidly evolved from simple offerings like S3 and EC2 to an expansive, versatile cloud ecosystem.
+
+Today, AWS provides a highly reliable, scalable infrastructure platform with over 200 services in the cloud, powering hundreds of thousands of businesses in 190 countries around the world.
+
+For both newcomers and seasoned professionals, navigating the broad set of AWS services is no small feat.
+
+From computing power, storage options, and networking capabilities to database management, analytics, and machine learning, AWS provides a wide array of tools that can be daunting to understand and master.
+
+Each service is tailored to specific needs and use cases, requiring a deep understanding of not just the services themselves, but also how they interact and integrate within an IT ecosystem.
+
+This attached illustration can serve as both a starting point and a quick reference for anyone looking to demystify AWS and focus their efforts on the services that matter most.
+
+It provides a visual roadmap, outlining the foundational services that underpin cloud computing essentials, as well as advanced services catering to specific needs like serverless architectures, DevOps, and machine learning.
diff --git a/data/guides/what-are-the-top-caching-strategies.md b/data/guides/what-are-the-top-caching-strategies.md
new file mode 100644
index 0000000..1f4f546
--- /dev/null
+++ b/data/guides/what-are-the-top-caching-strategies.md
@@ -0,0 +1,31 @@
+---
+title: "Top Caching Strategies"
+description: "Explore the top caching strategies to optimize system performance."
+image: "https://assets.bytebytego.com/diagrams/0129-caching-strategy.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "caching"
+ - "performance"
+---
+
+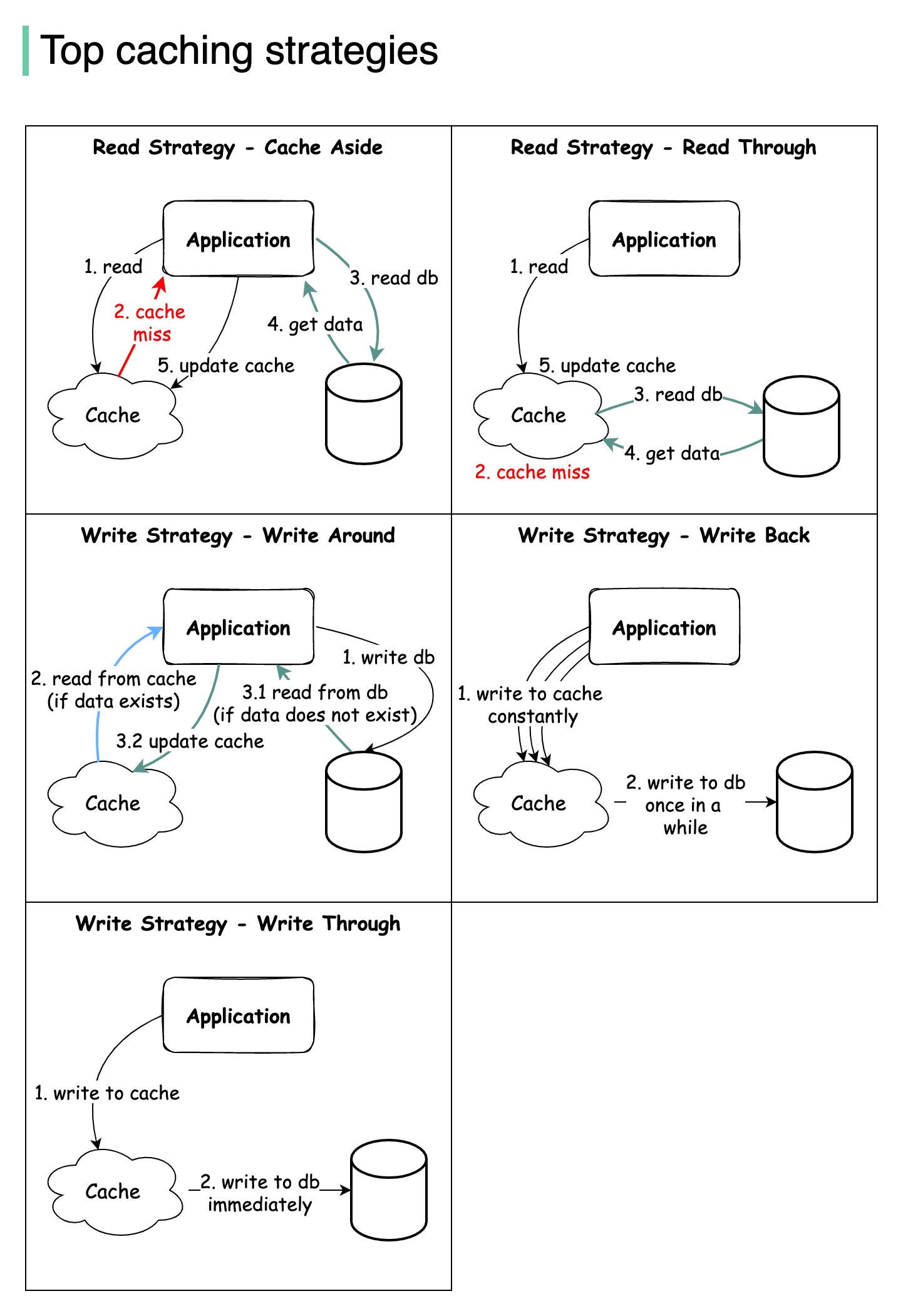
+
+Read data from the system:
+
+* **Cache aside**
+* **Read through**
+
+Write data to the system:
+
+* **Write around**
+* **Write back**
+* **Write through**
+
+The diagram above illustrates how those 5 strategies work. Some of the caching strategies can be used together.
+
+I left out a lot of details as that will make the post very long.
+
+Feel free to leave a comment so we can learn from each other.
diff --git a/data/guides/what-do-version-numbers-mean.md b/data/guides/what-do-version-numbers-mean.md
new file mode 100644
index 0000000..0a59847
--- /dev/null
+++ b/data/guides/what-do-version-numbers-mean.md
@@ -0,0 +1,33 @@
+---
+title: What do version numbers mean?
+description: "Understand version numbers: MAJOR, MINOR, PATCH and Semantic Versioning."
+image: 'https://assets.bytebytego.com/diagrams/0415-what-do-version-numbers-mean.png'
+createdAt: '2024-02-17'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Versioning
+ - SemVer
+---
+
+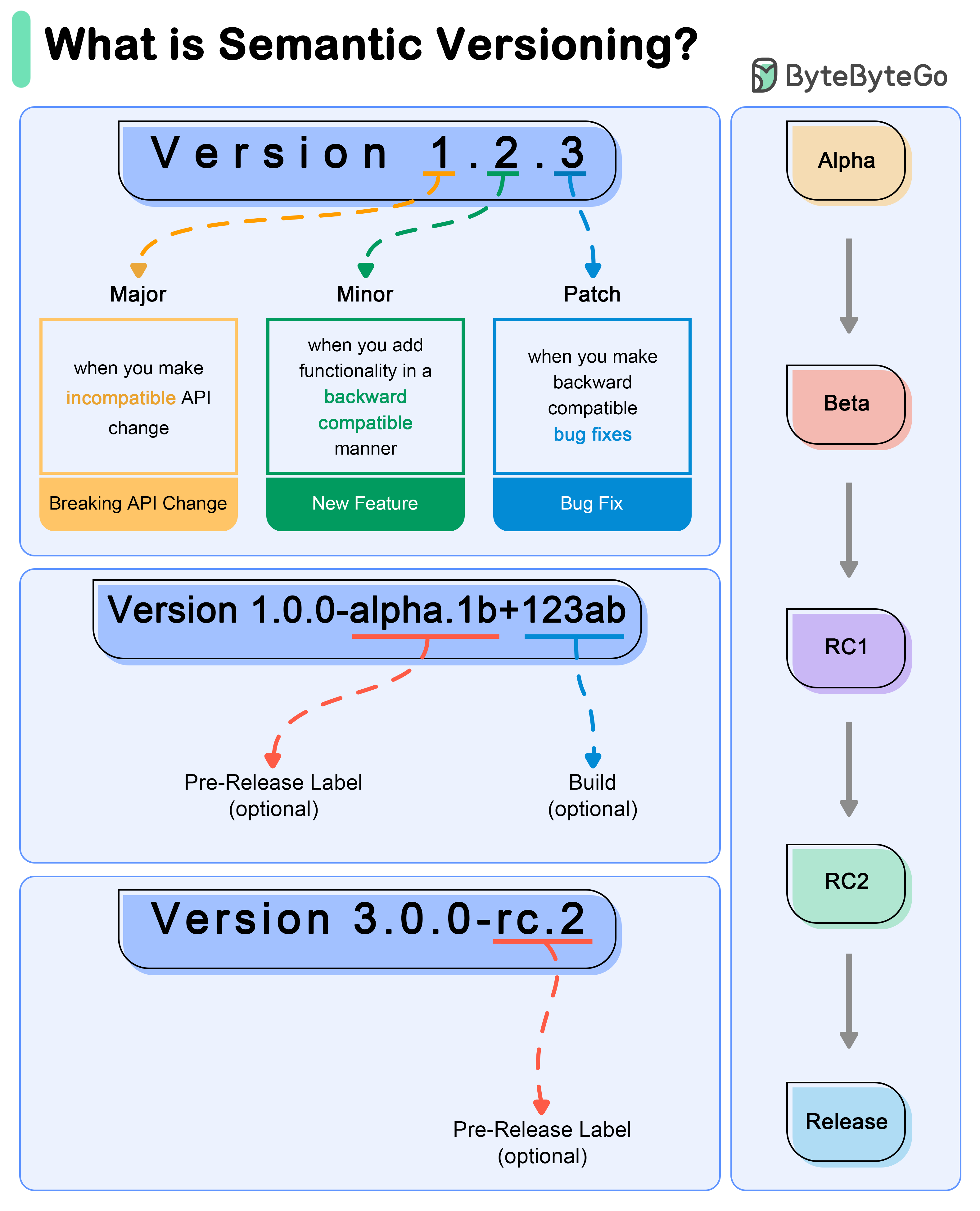
+
+Semantic Versioning (SemVer) is a versioning scheme for software that aims to convey meaning about the underlying changes in a release.
+
+* SemVer uses a three-part version number: MAJOR.MINOR.PATCH.
+ * **MAJOR version**: Incremented when there are incompatible API changes.
+ * **MINOR version**: Incremented when functionality is added in a backward-compatible manner.
+ * **PATCH version**: Incremented when backward-compatible bug fixes are made.
+* **Example Workflow**
+ * **Initial Development Phase**
+ * Start with version 0.1.0.
+ * **First Stable Release**
+ * Reach a stable release: 1.0.0.
+ * **Subsequent Changes**
+ * **Patch Release**: A bug fix is needed for 1.0.0. Update to 1.0.1.
+ * **Minor Release**: A new, backward-compatible feature is added to 1.0.3. Update to 1.1.0.
+ * **Major Release**: A significant change that is not backward-compatible is introduced in 1.2.2. Update to 2.0.0.
+ * **Special Versions and Pre-releases**
+ * **Pre-release Versions**: 1.0.0-alpha, 1.0.0-beta, 1.0.0-rc.1.
+ * **Build Metadata**: 1.0.0+20130313144700.
diff --git a/data/guides/what-does-a-typical-microservice-architecture-look-like.md b/data/guides/what-does-a-typical-microservice-architecture-look-like.md
new file mode 100644
index 0000000..a84ae6f
--- /dev/null
+++ b/data/guides/what-does-a-typical-microservice-architecture-look-like.md
@@ -0,0 +1,32 @@
+---
+title: "Typical Microservice Architecture"
+description: "Explore a typical microservice architecture with key components."
+image: "https://assets.bytebytego.com/diagrams/0396-typical-microservice-architecture.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Microservices
+ - Architecture
+---
+
+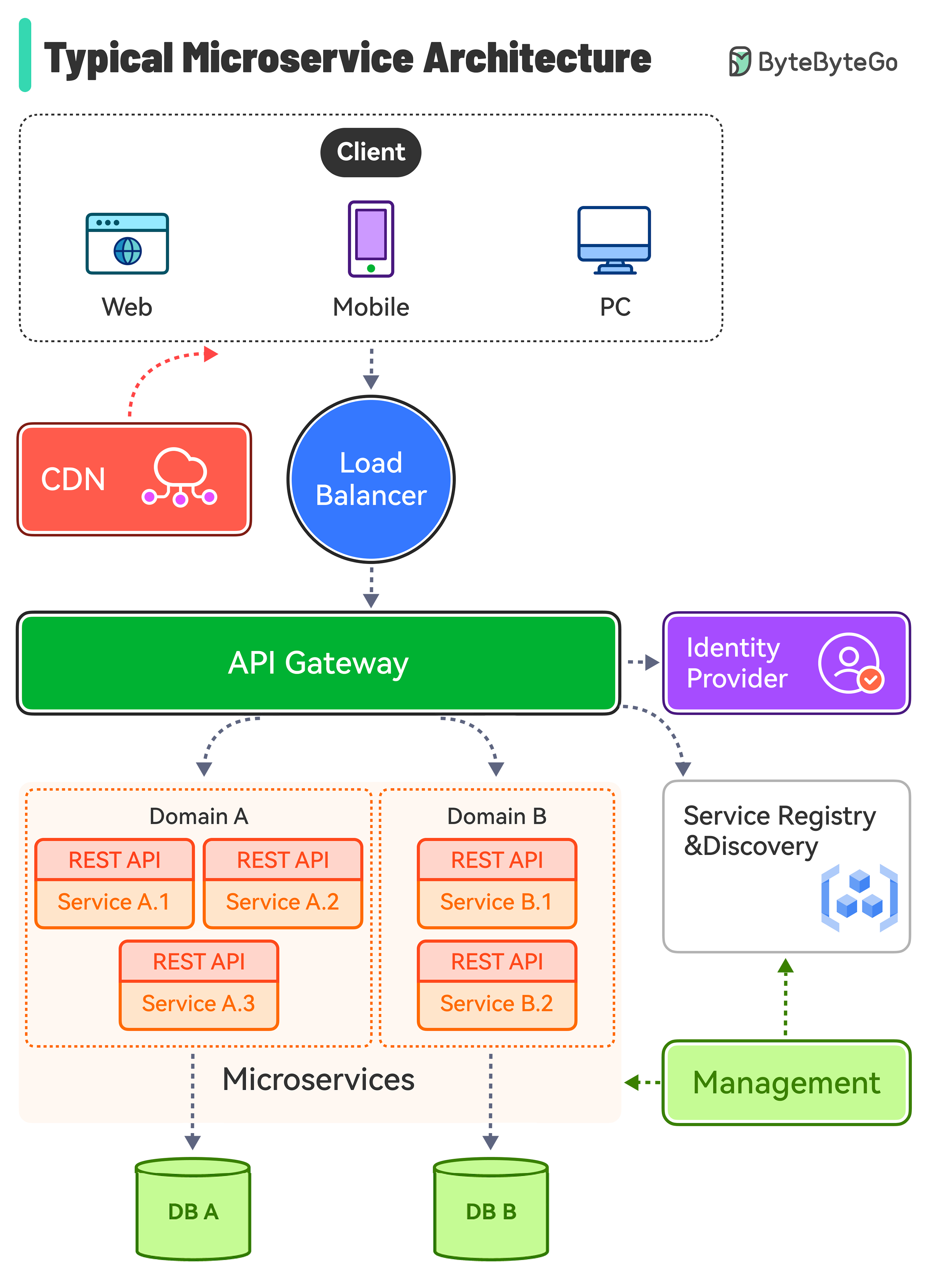
+
+The diagram above shows a typical microservice architecture.
+
+## Key Components
+
+* **Load Balancer:** This distributes incoming traffic across multiple backend services.
+
+* **CDN (Content Delivery Network):** CDN is a group of geographically distributed servers that hold static content for faster delivery. The clients look for content in CDN first, then progress to backend services.
+
+* **API Gateway:** This handles incoming requests and routes them to the relevant services. It talks to the identity provider and service discovery.
+
+* **Identity Provider:** This handles authentication and authorization for users.
+
+* **Service Registry & Discovery:** Microservice registration and discovery happen in this component, and the API gateway looks for relevant services in this component to talk to.
+
+* **Management:** This component is responsible for monitoring the services.
+
+* **Microservices:** Microservices are designed and deployed in different domains. Each domain has its database.
diff --git a/data/guides/what-does-acid-mean.md b/data/guides/what-does-acid-mean.md
new file mode 100644
index 0000000..c3250b4
--- /dev/null
+++ b/data/guides/what-does-acid-mean.md
@@ -0,0 +1,34 @@
+---
+title: "What does ACID mean?"
+description: "Understand the ACID properties of database transactions."
+image: "https://assets.bytebytego.com/diagrams/0407-what-does-acid-mean.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Databases"
+ - "ACID"
+---
+
+The diagram above explains what ACID means in the context of a database transaction.
+
+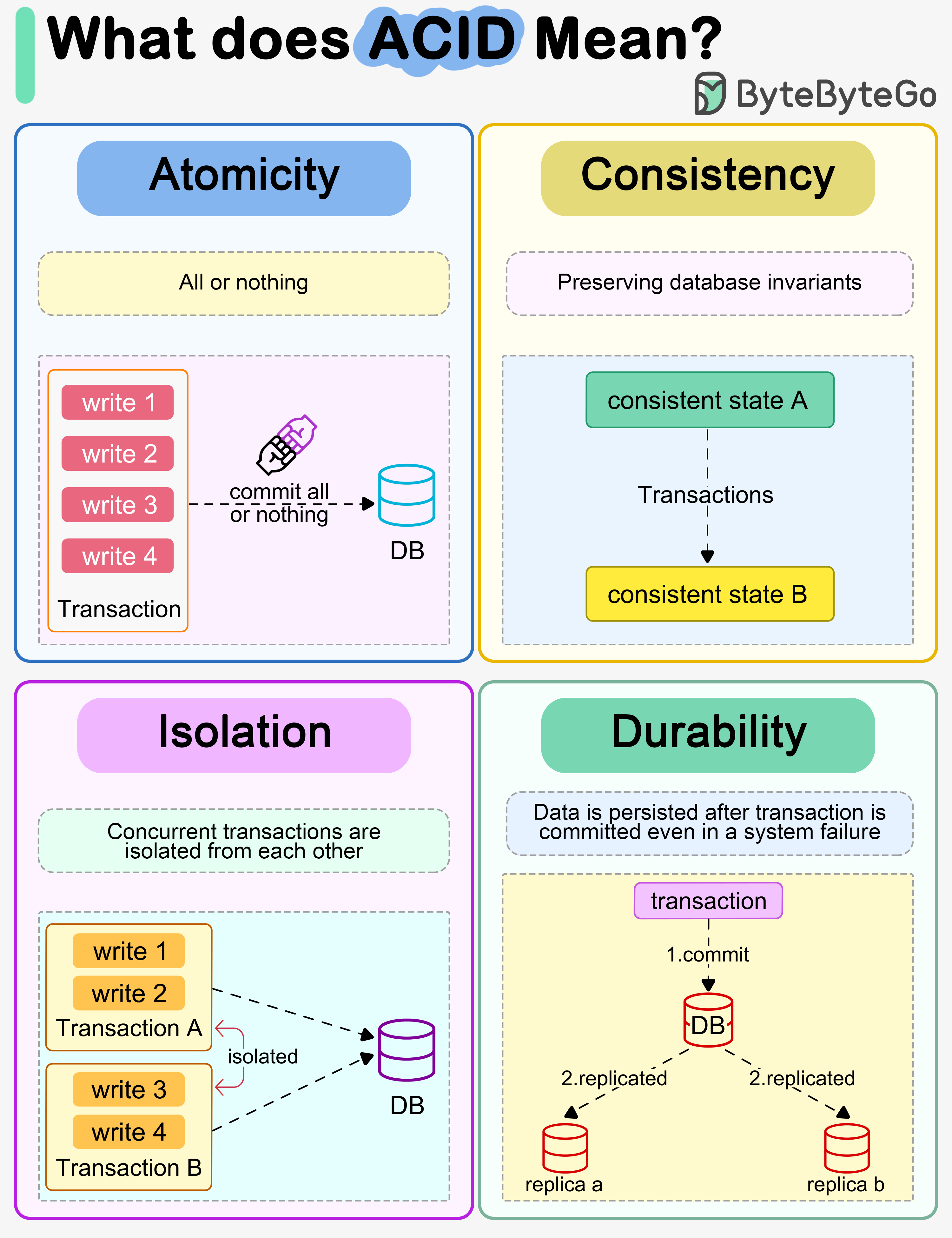
+
+## Atomicity
+
+The writes in a transaction are executed all at once and cannot be broken into smaller parts. If there are faults when executing the transaction, the writes in the transaction are rolled back.
+
+So atomicity means “all or nothing”.
+
+## Consistency
+
+Unlike “consistency” in CAP theorem, which means every read receives the most recent write or an error, here consistency means preserving database invariants. Any data written by a transaction must be valid according to all defined rules and maintain the database in a good state.
+
+## Isolation
+
+When there are concurrent writes from two different transactions, the two transactions are isolated from each other. The most strict isolation is “serializability”, where each transaction acts like it is the only transaction running in the database. However, this is hard to implement in reality, so we often adopt loser isolation level.
+
+## Durability
+
+Data is persisted after a transaction is committed even in a system failure. In a distributed system, this means the data is replicated to some other nodes.
diff --git a/data/guides/what-does-api-gateway-do.md b/data/guides/what-does-api-gateway-do.md
new file mode 100644
index 0000000..e96f8da
--- /dev/null
+++ b/data/guides/what-does-api-gateway-do.md
@@ -0,0 +1,32 @@
+---
+title: 'What Does an API Gateway Do?'
+description: 'Explore the functions and benefits of using an API gateway in microservices.'
+image: 'https://assets.bytebytego.com/diagrams/0072-what-does-api-gateway-do.png'
+createdAt: '2024-03-07'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Microservices
+---
+
+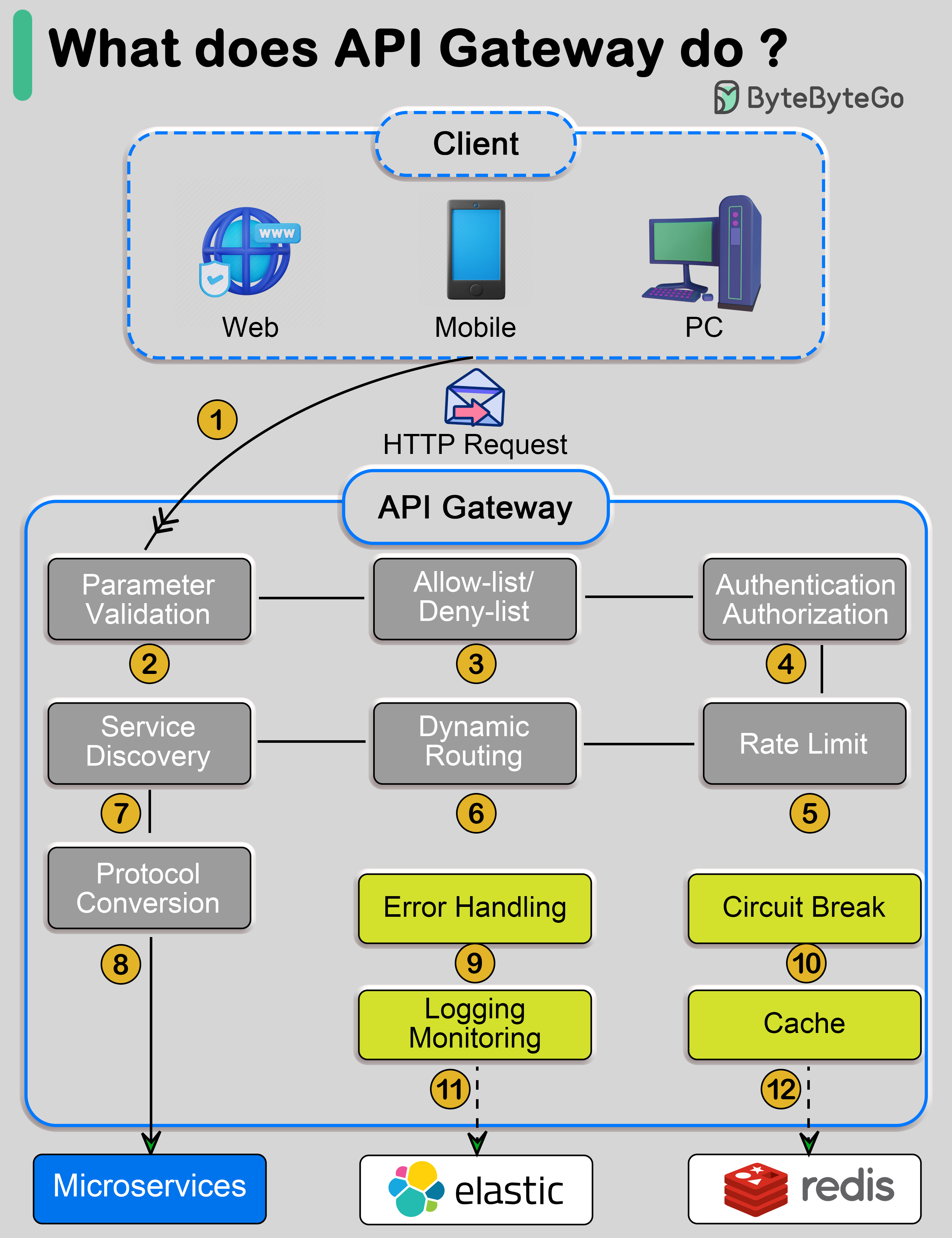
+
+The diagram above shows the details.
+
+**Step 1** - The client sends an HTTP request to the API gateway.
+
+**Step 2** - The API gateway parses and validates the attributes in the HTTP request.
+
+**Step 3** - The API gateway performs allow-list/deny-list checks.
+
+**Step 4** - The API gateway talks to an identity provider for authentication and authorization.
+
+**Step 5** - The rate limiting rules are applied to the request. If it is over the limit, the request is rejected.
+
+**Steps 6 and 7** - Now that the request has passed basic checks, the API gateway finds the relevant service to route to by path matching.
+
+**Step 8** - The API gateway transforms the request into the appropriate protocol and sends it to backend microservices.
+
+**Steps 9-12** - The API gateway can handle errors properly and deals with faults if the error takes a longer time to recover (circuit break). It can also leverage ELK (Elastic-Logstash-Kibana) stack for logging and monitoring. We sometimes cache data in the API gateway.
diff --git a/data/guides/what-happens-when-you-type-a-url-into-your-browser.md b/data/guides/what-happens-when-you-type-a-url-into-your-browser.md
new file mode 100644
index 0000000..f365d41
--- /dev/null
+++ b/data/guides/what-happens-when-you-type-a-url-into-your-browser.md
@@ -0,0 +1,50 @@
+---
+title: "What Happens When You Type a URL Into Your Browser?"
+description: "Explore the journey of a URL from browser input to webpage display."
+image: "https://assets.bytebytego.com/diagrams/0393-type-a-url-into-your-browser.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "Networking"
+ - "Browsers"
+---
+
+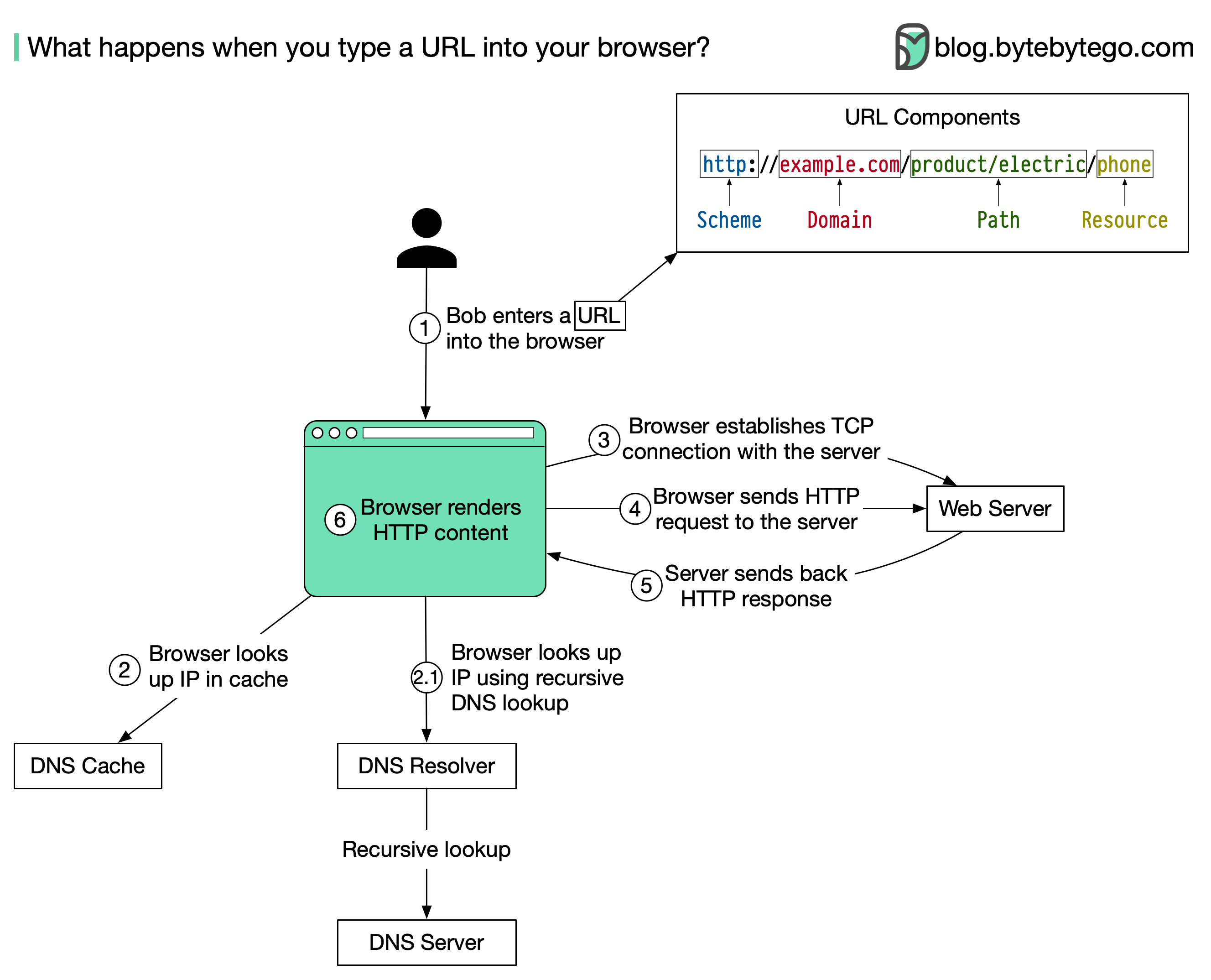
+
+The diagram above illustrates the steps.
+
+- Bob enters a URL into the browser and hits Enter. In this example, the URL is composed of 4 parts:
+ - **scheme** - *http://*. This tells the browser to send a connection to the server using HTTP.
+ - **domain** - *example.com*. This is the domain name of the site.
+ - **path** - *product/electric*. It is the path on the server to the requested resource: phone.
+ - **resource** - *phone*. It is the name of the resource Bob wants to visit.
+
+- The browser looks up the IP address for the domain with a domain name system (DNS) lookup. To make the lookup process fast, data is cached at different layers: browser cache, OS cache, local network cache, and ISP cache.
+ - If the IP address cannot be found at any of the caches, the browser goes to DNS servers to do a recursive DNS lookup until the IP address is found (this will be covered in another post).
+
+- Now that we have the IP address of the server, the browser establishes a TCP connection with the server.
+
+- The browser sends an HTTP request to the server. The request looks like this:
+
+ ```
+ 𝘎𝘌𝘛 /𝘱𝘩𝘰𝘯𝘦 𝘏𝘛𝘛𝘗/1.1
+ 𝘏𝘰𝘴𝘵: 𝘦𝘹𝘢𝘮𝘱𝘭𝘦.𝘤𝘰𝘮
+ ```
+
+- The server processes the request and sends back the response. For a successful response (the status code is 200). The HTML response might look like this:
+
+ ```
+ 𝘏𝘛𝘛𝘗/1.1 200 𝘖𝘒
+ 𝘋𝘢𝘵𝘦: 𝘚𝘶𝘯, 30 𝘑𝘢𝘯 2022 00:01:01 𝘎𝘔𝘛
+ 𝘚𝘦𝘳𝘷𝘦𝘳: 𝘈𝘱𝘢𝘤𝘩𝘦
+ 𝘊𝘰𝘯𝘵𝘦𝘯𝘵-𝘛𝘺𝘱𝘦: 𝘵𝘦𝘹𝘵/𝘩𝘵𝘮𝘭; 𝘤𝘩𝘢𝘳𝘴𝘦𝘵=𝘶𝘵𝘧-8
+
+ <**!𝘋𝘖𝘊𝘛𝘠𝘗𝘌** 𝘩𝘵𝘮𝘭>
+ <**𝘩𝘵𝘮𝘭** 𝘭𝘢𝘯𝘨="𝘦𝘯">
+ 𝘏𝘦𝘭𝘭𝘰 𝘸𝘰𝘳𝘭𝘥
+
+ ```
+
+- The browser renders the HTML content.
diff --git a/data/guides/what-happens-when-you-type-google.md b/data/guides/what-happens-when-you-type-google.md
new file mode 100644
index 0000000..9f60699
--- /dev/null
+++ b/data/guides/what-happens-when-you-type-google.md
@@ -0,0 +1,30 @@
+---
+title: "What Happens When You Type google.com Into a Browser?"
+description: "Explore the journey of typing google.com into a browser."
+image: "https://assets.bytebytego.com/diagrams/0410-what-happens-when-you-type-google-in-your-browser.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "Networking"
+ - "Web Browsers"
+---
+
+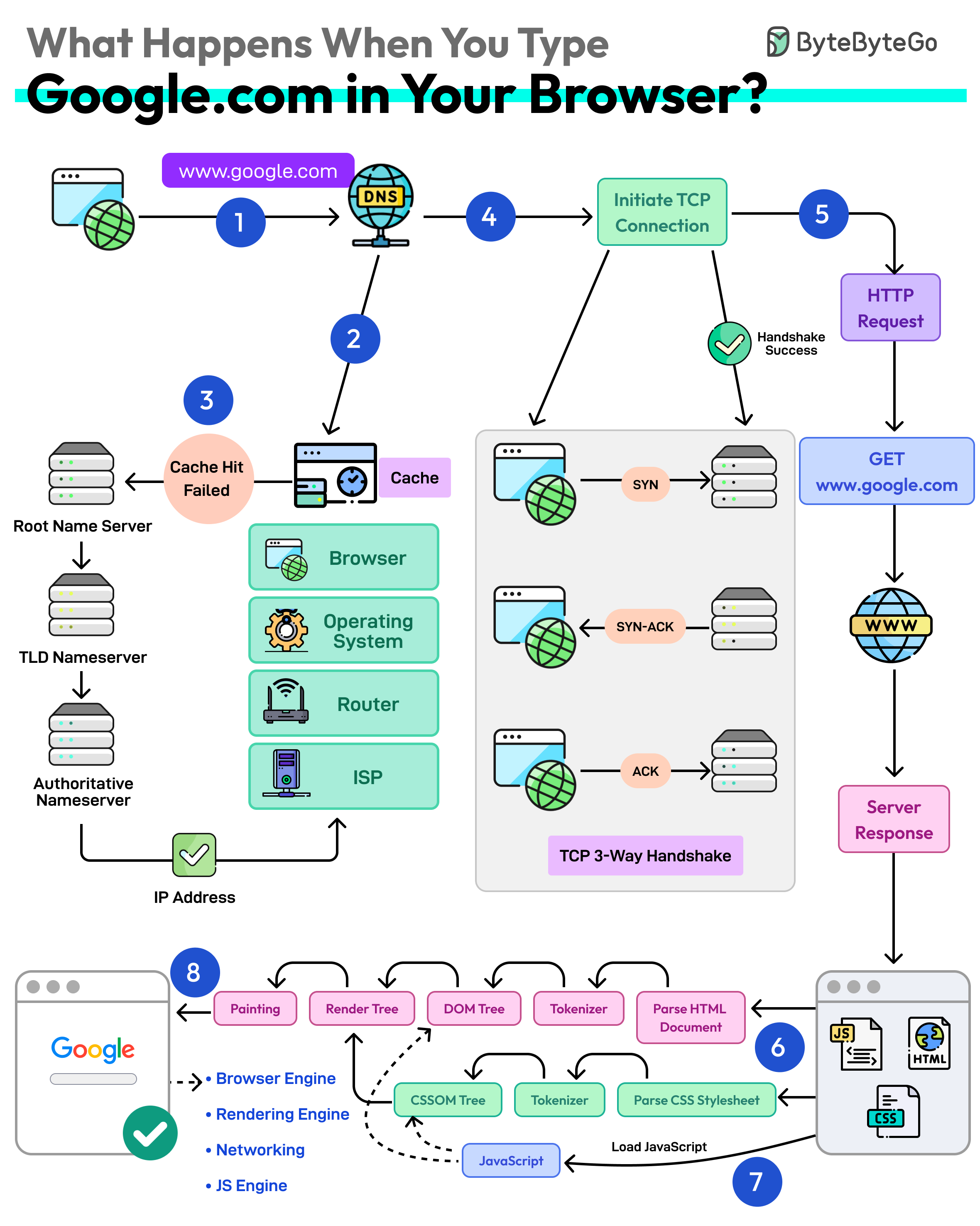
+
+1. First up, you type the website address in the browser’s address bar.
+
+2. The browser checks its cache first. If there’s a cache miss, it must find the IP address.
+
+3. DNS lookup begins (think of it as looking up a phone number). The request goes through different DNS servers (root, TLD, and authoritative). Finally, the IP address is retrieved.
+
+4. Next, your browser initiates a TCP connection like a handshake. For example, in the case of HTTP 1.1, the client and server perform a TCP three-way handshake with SYN, SYN-ACK, and ACK messages.
+
+5. Once the handshake is successful, the browser makes an HTTP request to the server and the server responds with HTML, CSS, and JS files.
+
+6. Finally, the browser processes everything. It parses the HTML document and creates DOM and CSSOM trees.
+
+7. The browser executes the JavaScript and renders the page through various steps (tokenizer, parser, render tree, layout, and painting).
+
+8. Finally, the webpage appears on your screen.
diff --git a/data/guides/what-happens-when-you-upload-a-file-to-amazon-s3.md b/data/guides/what-happens-when-you-upload-a-file-to-amazon-s3.md
new file mode 100644
index 0000000..5fabaa3
--- /dev/null
+++ b/data/guides/what-happens-when-you-upload-a-file-to-amazon-s3.md
@@ -0,0 +1,43 @@
+---
+title: "What Happens When You Upload a File to Amazon S3?"
+description: "Explore the process of uploading a file to Amazon S3 in detail."
+image: "https://assets.bytebytego.com/diagrams/0169-design-s3.jpg"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Amazon S3"
+ - "Cloud Storage"
+---
+
+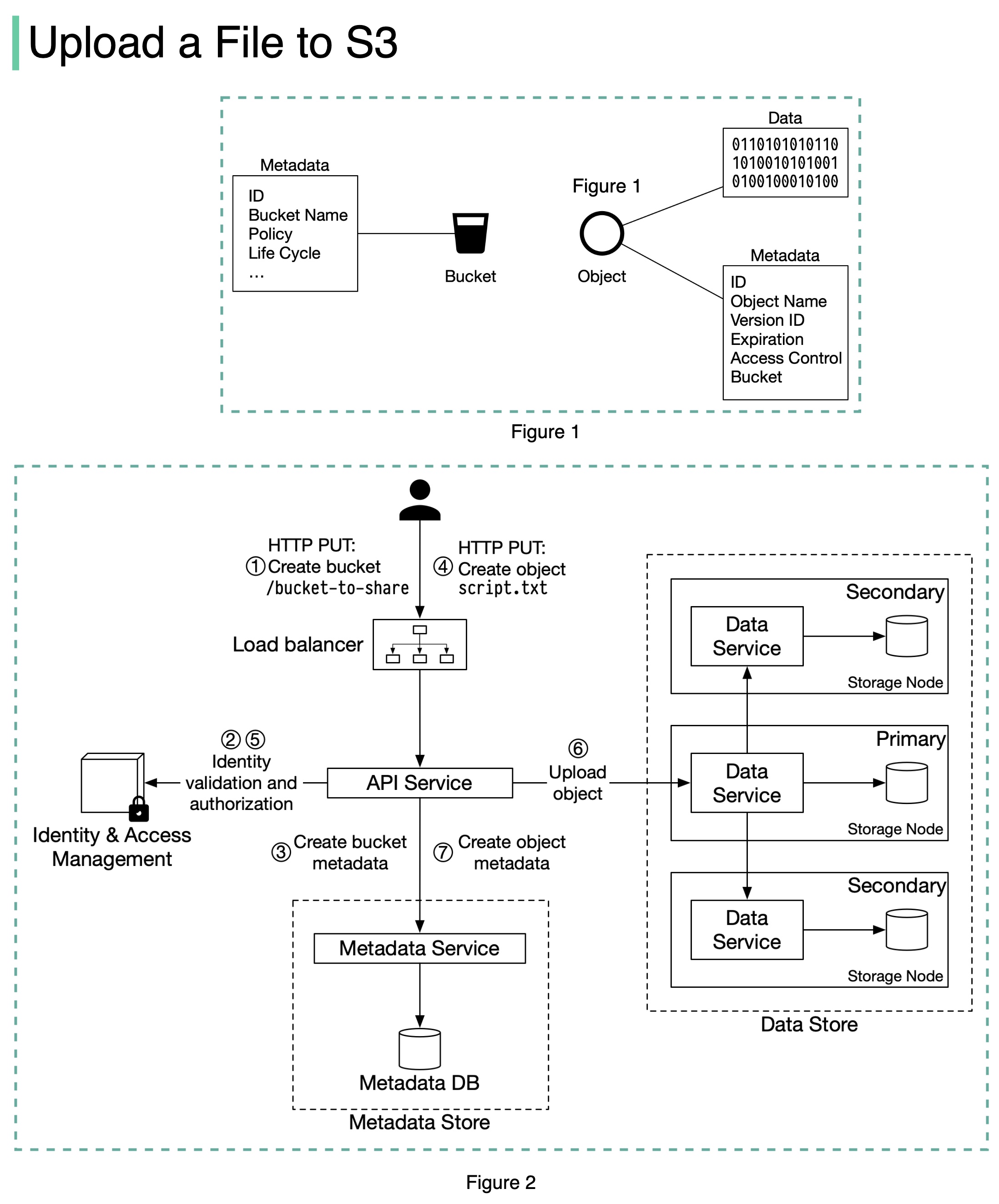
+
+Before we dive into the design, let’s define some terms.
+
+**Bucket**. A logical container for objects. The bucket name is globally unique. To upload data to S3, we must first create a bucket.
+
+**Object**. An object is an individual piece of data we store in a bucket. It contains object data (also called payload) and metadata. Object data can be any sequence of bytes we want to store. The metadata is a set of name-value pairs that describe the object.
+
+An S3 object consists of (Figure 1):
+
+* Metadata. It is mutable and contains attributes such as ID, bucket name, object name, etc.
+* Object data. It is immutable and contains the actual data.
+
+In S3, an object resides in a bucket. The path looks like this: /bucket-to-share/script.txt. The bucket only has metadata. The object has metadata and the actual data.
+
+The diagram below (Figure 2) illustrates how file uploading works. In this example, we first create a bucket named “bucket-to-share” and then upload a file named “script.txt” to the bucket.
+
+1. The client sends an HTTP PUT request to create a bucket named “bucket-to-share.” The request is forwarded to the API service.
+
+2. The API service calls Identity and Access Management (IAM) to ensure the user is authorized and has WRITE permission.
+
+3. The API service calls the metadata store to create an entry with the bucket info in the metadata database. Once the entry is created, a success message is returned to the client.
+
+4. After the bucket is created, the client sends an HTTP PUT request to create an object named “script.txt”.
+
+5. The API service verifies the user’s identity and ensures the user has WRITE permission on the bucket.
+
+6. Once validation succeeds, the API service sends the object data in the HTTP PUT payload to the data store. The data store persists the payload as an object and returns the UUID of the object.
+
+7. The API service calls the metadata store to create a new entry in the metadata database. It contains important metadata such as the object\_id (UUID), bucket\_id (which bucket the object belongs to), object\_name, etc.
diff --git a/data/guides/what-is-a-cookie.md b/data/guides/what-is-a-cookie.md
new file mode 100644
index 0000000..23d04eb
--- /dev/null
+++ b/data/guides/what-is-a-cookie.md
@@ -0,0 +1,20 @@
+---
+title: "What is a Cookie?"
+description: "Learn about cookies, how they work, and their role in web browsing."
+image: "https://assets.bytebytego.com/diagrams/0043-what-is-a-cookie.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - security
+tags:
+ - "Web Security"
+ - "Cookies"
+---
+
+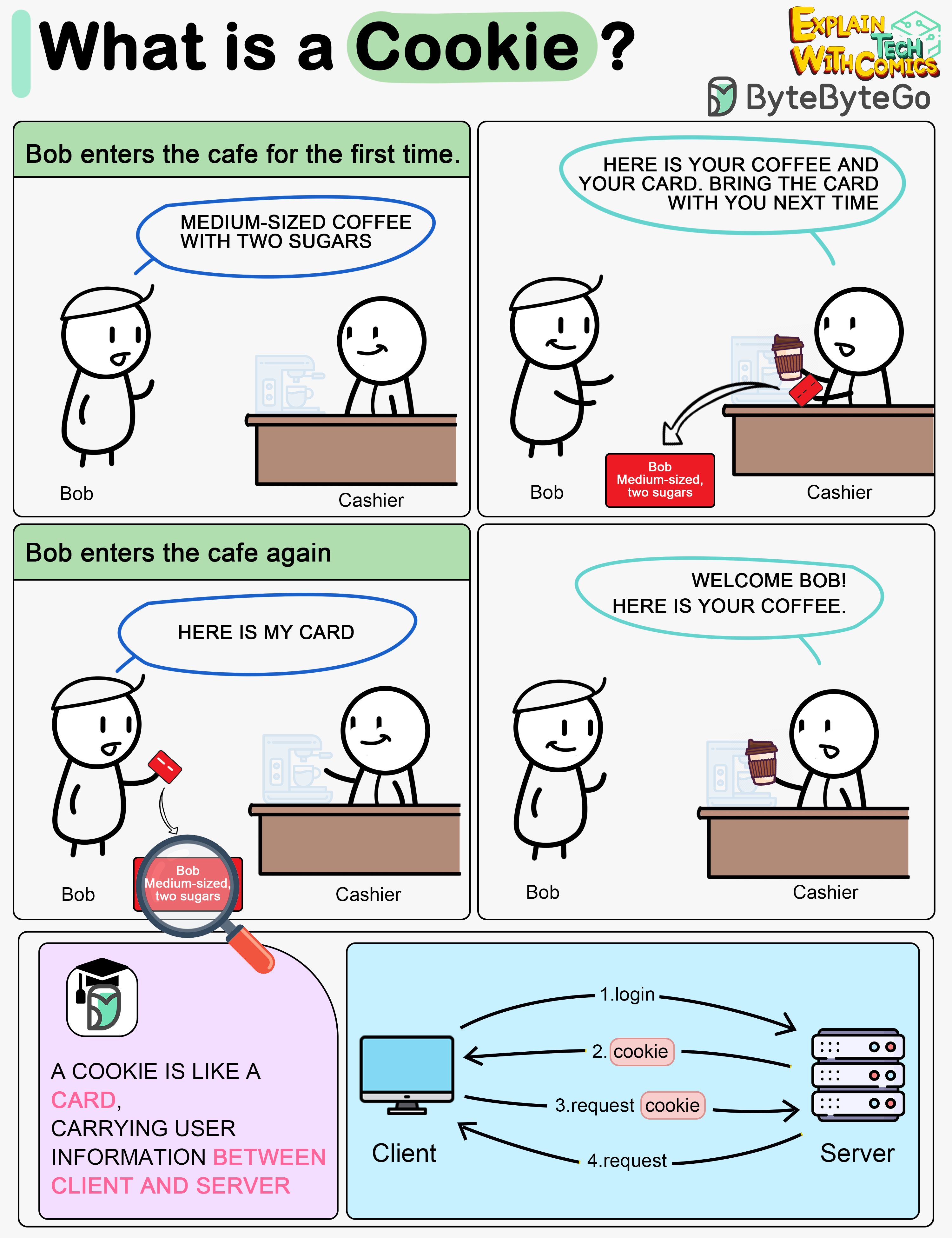
+
+Imagine Bob goes to a coffee shop for the first time, orders a medium-sized espresso with two sugars. The cashier records Bob’s identity and preferences on a card and hands it over to Bob with a cup of coffee.
+
+The next time Bob goes to the cafe, he shows the cashier the preference card. The cashier immediately knows who the customer is and what kind of coffee he likes.
+
+A cookie acts as the preference card. When we log in to a website, the server issues a cookie to us with a small amount of data. The cookie is stored on the client side, so the next time we send a request to the server with the cookie, the server knows our identity and preferences immediately without looking into the database.
diff --git a/data/guides/what-is-a-deadlock.md b/data/guides/what-is-a-deadlock.md
new file mode 100644
index 0000000..97baedf
--- /dev/null
+++ b/data/guides/what-is-a-deadlock.md
@@ -0,0 +1,39 @@
+---
+title: "What is a Deadlock?"
+description: "Explore deadlocks: conditions, prevention, and recovery strategies."
+image: "https://assets.bytebytego.com/diagrams/0411-what-is-a-deadlock.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Concurrency"
+ - "Databases"
+---
+
+A deadlock occurs when two or more transactions are waiting for each other to release locks on resources they need to continue processing. This results in a situation where neither transaction can proceed, and they end up waiting indefinitely.
+
+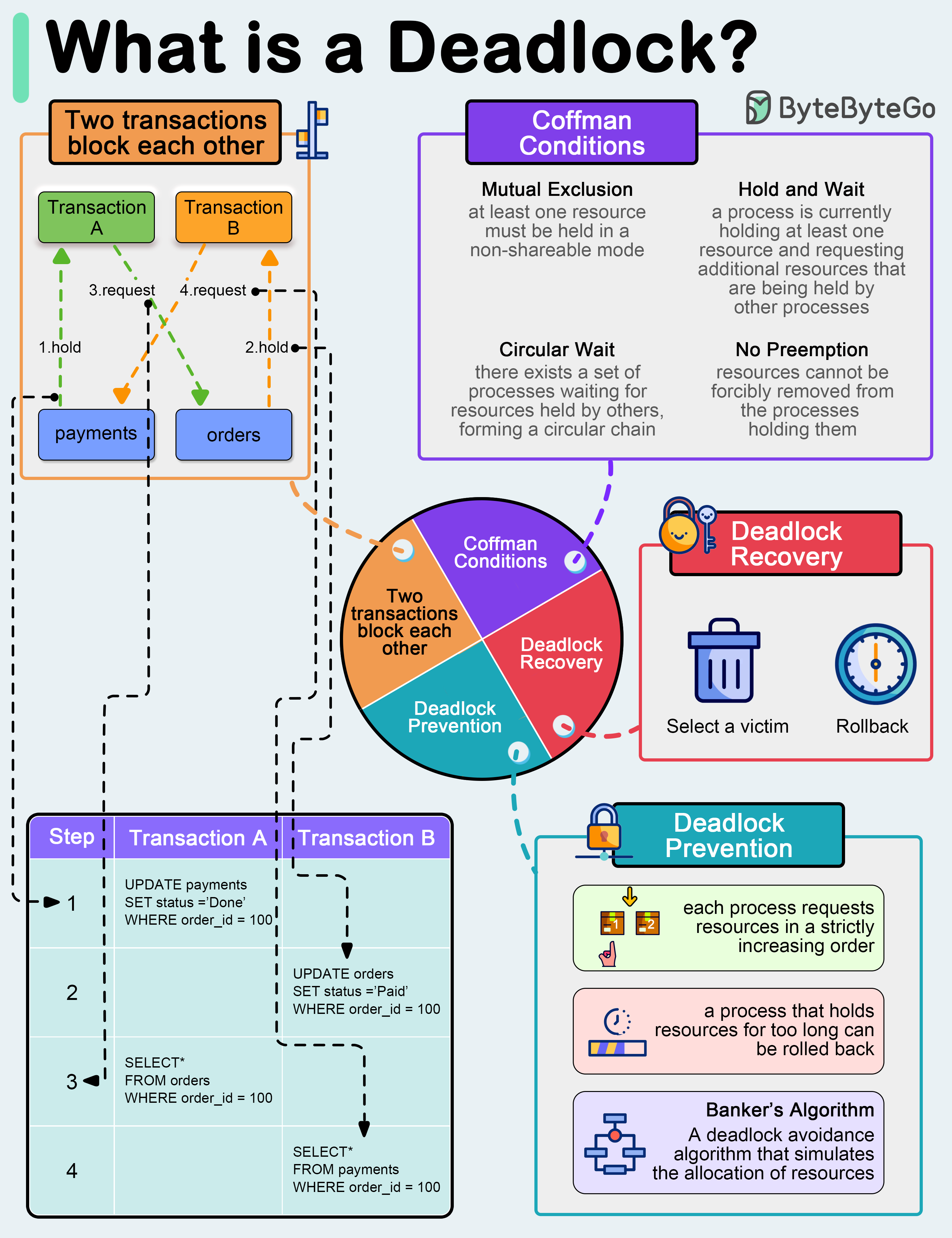
+
+## Coffman Conditions
+
+The Coffman conditions, named after Edward G. Coffman, Jr., who first outlined them in 1971, describe four necessary conditions that must be present simultaneously for a deadlock to occur:
+
+* Mutual Exclusion
+* Hold and Wait
+* No Preemption
+* Circular Wait
+
+## Deadlock Prevention
+
+* Resource ordering: impose a total ordering of all resource types, and require that each process requests resources in a strictly increasing order.
+
+* Timeouts: A process that holds resources for too long can be rolled back.
+
+* Banker’s Algorithm: A deadlock avoidance algorithm that simulates the allocation of resources to processes and helps in deciding whether it is safe to grant a resource request based on the future availability of resources, thus avoiding unsafe states.
+
+## Deadlock Recovery
+
+* Selecting a victim: Most modern Database Management Systems (DBMS) and Operating Systems implement sophisticated algorithms for detecting deadlocks and selecting victims, often allowing customization of the victim selection criteria via configuration settings. The selection can be based on resource utilization, transaction priority, cost of rollback etc.
+
+* Rollback: The database may roll back the entire transaction or just enough of it to break the deadlock. Rolled-back transactions can be restarted automatically by the database management system.
diff --git a/data/guides/what-is-a-load-balancer.md b/data/guides/what-is-a-load-balancer.md
new file mode 100644
index 0000000..98268f5
--- /dev/null
+++ b/data/guides/what-is-a-load-balancer.md
@@ -0,0 +1,32 @@
+---
+title: What is a Load Balancer?
+description: Distributes network traffic across multiple servers to optimize resources.
+image: 'https://assets.bytebytego.com/diagrams/0261-what-is-a-load-balancer.png'
+createdAt: '2024-02-28'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Load Balancing
+ - Networking
+---
+
+
+
+A load balancer is a device or software application that distributes network or application traffic across multiple servers.
+
+* **What Does a Load Balancer Do?**
+
+ * Distributes Traffic
+ * Ensures Availability and Reliability
+ * Improves Performance
+ * Scales Applications
+
+* **Types of Load Balancers**
+
+ * Hardware Load Balancers: These are physical devices designed to distribute traffic across servers.
+ * Software Load Balancers: These are applications that can be installed on standard hardware or virtual machines.
+ * Cloud-based Load Balancers: Provided by cloud service providers, these load balancers are integrated into the cloud infrastructure. Examples include AWS Elastic Load Balancer, Google Cloud Load Balancing, and Azure Load Balancer.
+ * Layer 4 Load Balancers (Transport Layer): Operate at the transport layer (OSI Layer 4) and make forwarding decisions based on IP address and TCP/UDP ports.
+ * Layer 7 Load Balancers (Application Layer): Operate at the application layer (OSI Layer 7).
+ * Global Server Load Balancing (GSLB): Distributes traffic across multiple geographical locations to improve redundancy and performance on a global scale.
diff --git a/data/guides/what-is-a-stop-loss-order-and-how-does-it-work.md b/data/guides/what-is-a-stop-loss-order-and-how-does-it-work.md
new file mode 100644
index 0000000..9dbb435
--- /dev/null
+++ b/data/guides/what-is-a-stop-loss-order-and-how-does-it-work.md
@@ -0,0 +1,36 @@
+---
+title: "What is a Stop-Loss Order and How Does it Work?"
+description: "Learn about stop-loss orders and how they help minimize investment losses."
+image: "https://assets.bytebytego.com/diagrams/0345-stop-loss.jpg"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Trading"
+ - "Risk Management"
+---
+
+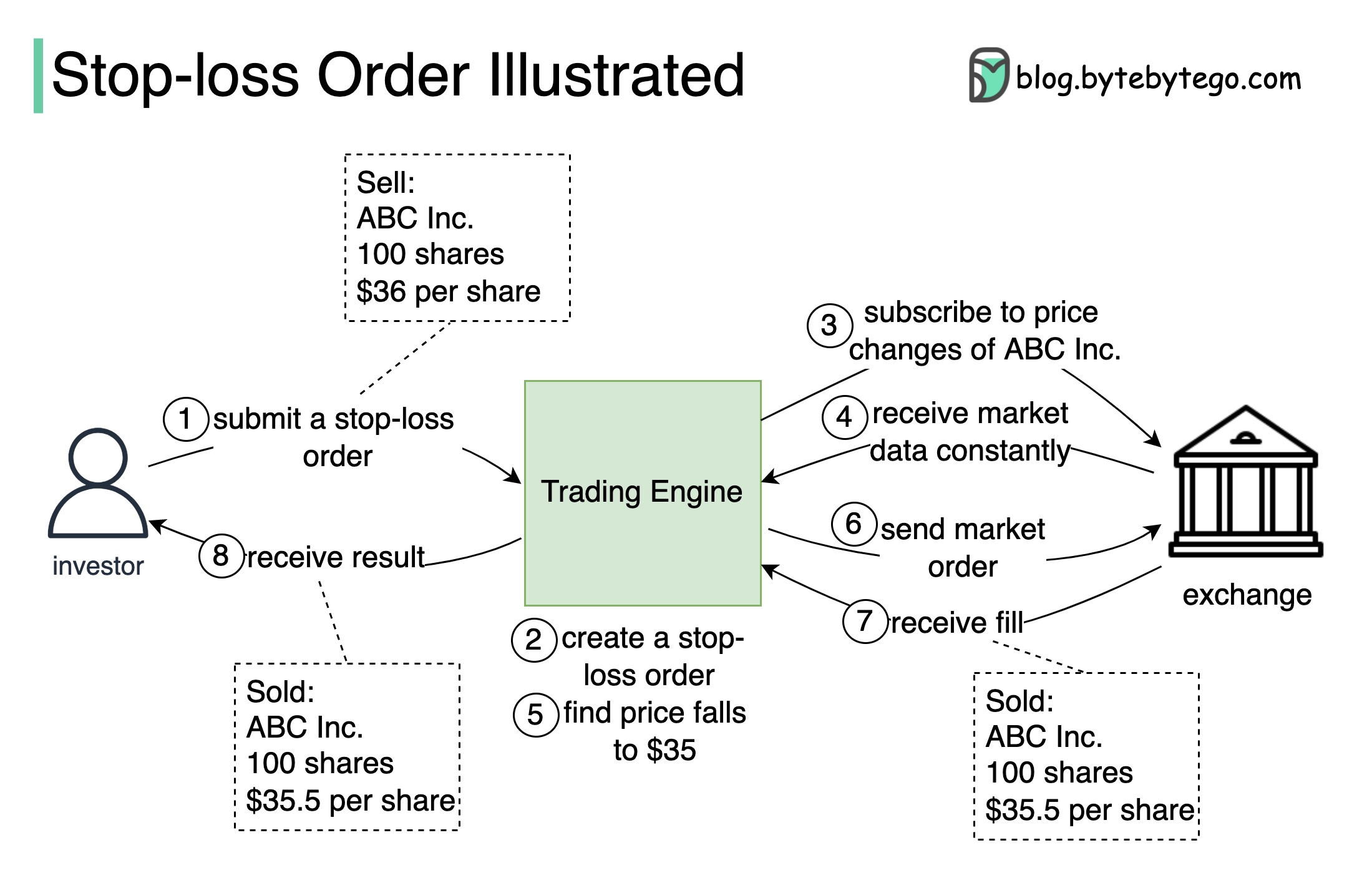
+
+A stop-loss order allows us to set a price called the ‘stop-loss price’ of a stock or a share. This is a value the investor chooses, at which they will sell it to minimize their loss on the investment.
+
+When the price of the stock hits the stop-loss point, the stop-loss order is triggered and it turns into a market order to sell at the current market price.
+
+For example, let's say an investor has 100 shares in ABC Inc., and the current price is $40 per share. The investor wants to sell the stock if the market price falls to or below $36, in order to limit their loss.
+
+The diagram above illustrates how a stop-loss order is executed by a trading system.
+
+## Stop-Loss Order Execution
+
+* The investor submits a stop-loss order to the trading system with 100 shares, to sell for $36.
+
+* Upon receiving the order request, the trading engine creates the stop-loss order.
+
+* The trading engine subscribes to the market data of ABC Inc. from the exchange and monitors its real-time market price.
+
+* If the trading engine detects that the market price of ABC Inc. falls to, say, $35, it immediately creates a market order and then submits it to the exchange to sell the 100 shares for the current best market price.
+
+* The order is filled (i.e. matched to the best buy orders in the market,) usually instantaneously. Then the trading engine receives from the exchange a ‘fill report’ stating the shares have been sold for, say, $35.5 per share.
+
+* The trading system notifies the investor that the 100 shares have been sold for $35.5 per share.
diff --git a/data/guides/what-is-an-ai-agent.md b/data/guides/what-is-an-ai-agent.md
new file mode 100644
index 0000000..2523a05
--- /dev/null
+++ b/data/guides/what-is-an-ai-agent.md
@@ -0,0 +1,32 @@
+---
+title: 'What is an AI Agent?'
+description: 'Explore the concept of AI agents, their characteristics, and applications.'
+image: 'https://assets.bytebytego.com/diagrams/0412-what-is-an-ai-agent.png'
+createdAt: '2024-03-13'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI Agents
+ - Machine Learning
+---
+
+[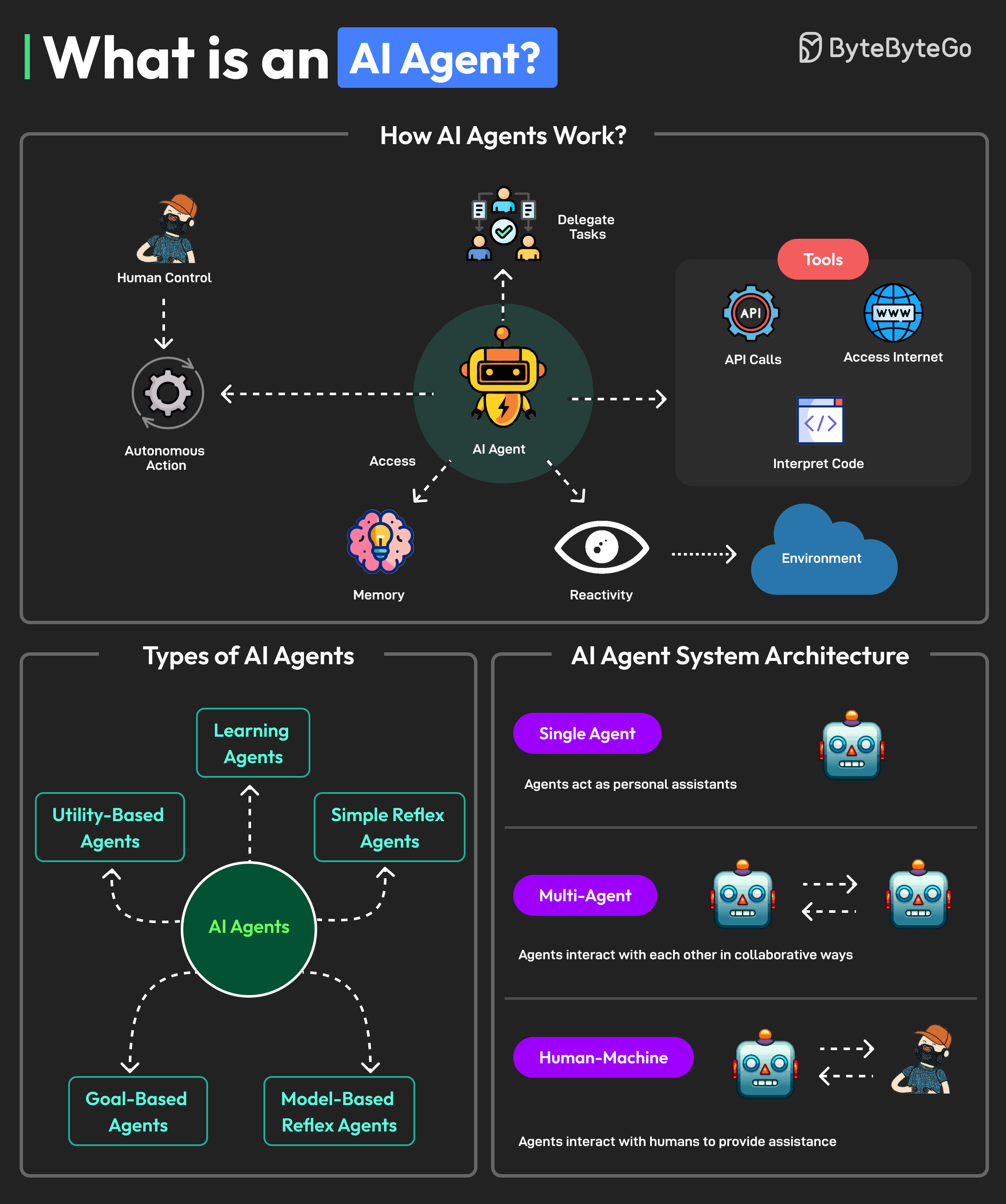]()
+
+An AI agent is a software program that can interact with its environment, gather data, and use that data to achieve predetermined goals. AI agents can choose the best actions to perform to meet those goals.
+
+Key characteristics of AI agents are as follows:
+
+* An agent can perform autonomous actions without constant human intervention. Also, they can have a human in the loop to maintain control.
+* Agents have a memory to store individual preferences and allow for personalization. It can also store knowledge. An LLM can undertake information processing and decision-making functions.
+* Agents must be able to perceive and process the information available from their environment.
+* Agents can also use tools such as accessing the internet, using code interpreters and making API calls.
+* Agents can also collaborate with other agents or humans.
+
+Multiple types of AI agents are available such as learning agents, simple reflex agents, model-based reflex agents, goal-based agents, and utility-based agents.
+
+A system with AI agents can be built with different architectural approaches.
+
+1. **Single Agent**: Agents can serve as personal assistants.
+2. **Multi-Agent**: Agents can interact with each other in collaborative or competitive ways.
+3. **Human Machine**: Agents can interact with humans to execute tasks more efficiently.
diff --git a/data/guides/what-is-cdn-content-delivery-network.md b/data/guides/what-is-cdn-content-delivery-network.md
new file mode 100644
index 0000000..c9d68b4
--- /dev/null
+++ b/data/guides/what-is-cdn-content-delivery-network.md
@@ -0,0 +1,30 @@
+---
+title: "What is CDN (Content Delivery Network)?"
+description: "Learn how CDNs accelerate content delivery and improve website security."
+image: "https://assets.bytebytego.com/diagrams/0132-cdn.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "CDN"
+ - "Content Delivery"
+---
+
+How does CDN make content delivery faster? The diagram above shows why.
+
+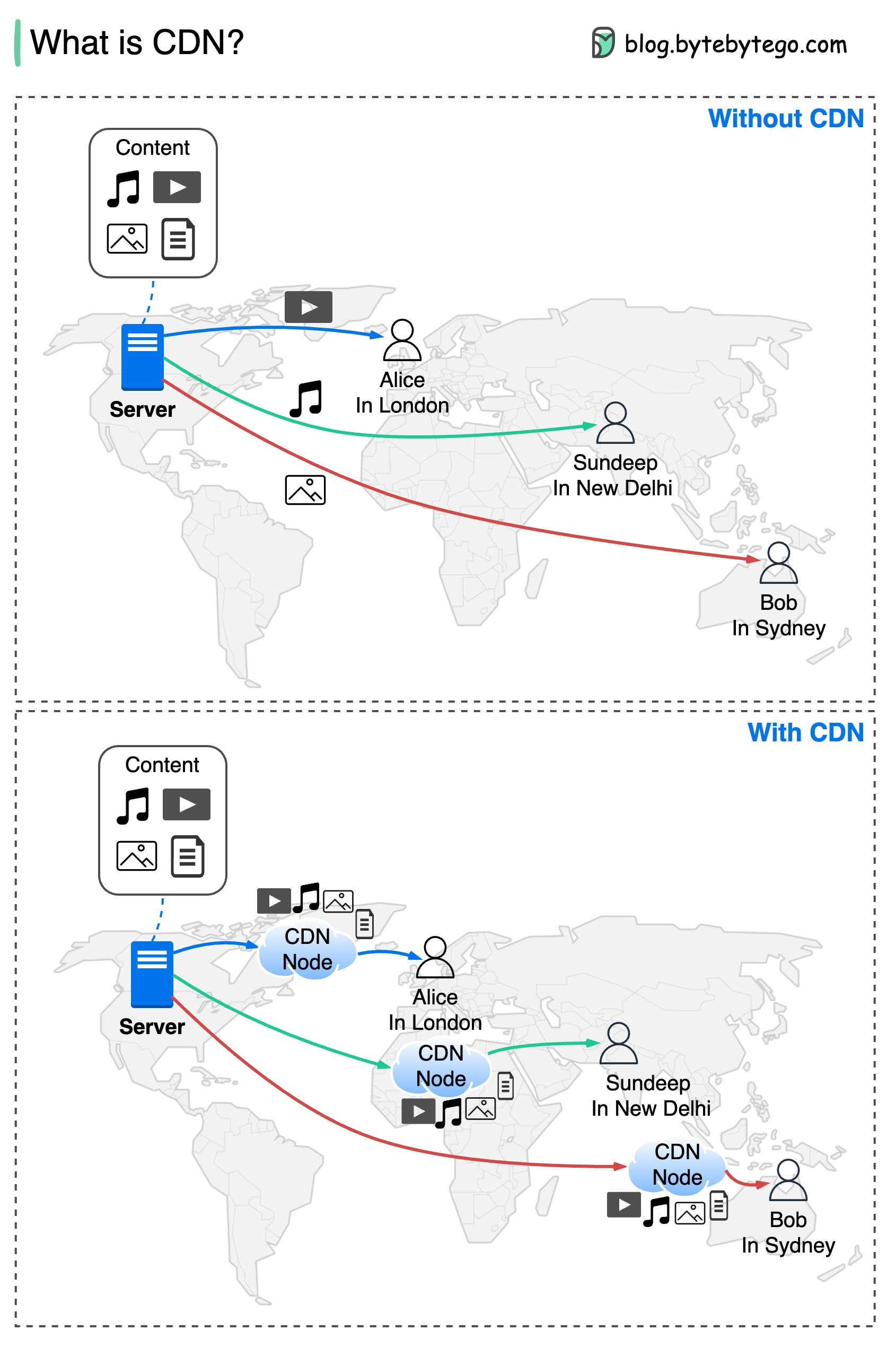
+
+A CDN refers to geographically distributed servers (also called edge servers) that provide fast delivery of **static and dynamic content**.
+
+With CDN, users don’t need to retrieve content (music, video, files, pictures, etc.) from the origin server. Instead, the content is cached at CDN nodes around the globe, and users can retrieve the content from nearby CDN nodes.
+
+## The benefits of CDN are:
+
+* Reducing latency
+
+* Reducing bandwidth
+
+* Improving website security, especially protecting against DDoS (Distributed Denial-of-Service) attack
+
+* Increasing content availability
diff --git a/data/guides/what-is-cloud-native.md b/data/guides/what-is-cloud-native.md
new file mode 100644
index 0000000..36abd8f
--- /dev/null
+++ b/data/guides/what-is-cloud-native.md
@@ -0,0 +1,38 @@
+---
+title: "What is Cloud Native?"
+description: "Explore cloud native technologies and their impact on application architecture."
+image: "https://assets.bytebytego.com/diagrams/0413-what-is-cloud-native.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Computing
+ - Microservices
+---
+
+Below is a diagram showing the evolution of architecture and processes since the 1980s.
+
+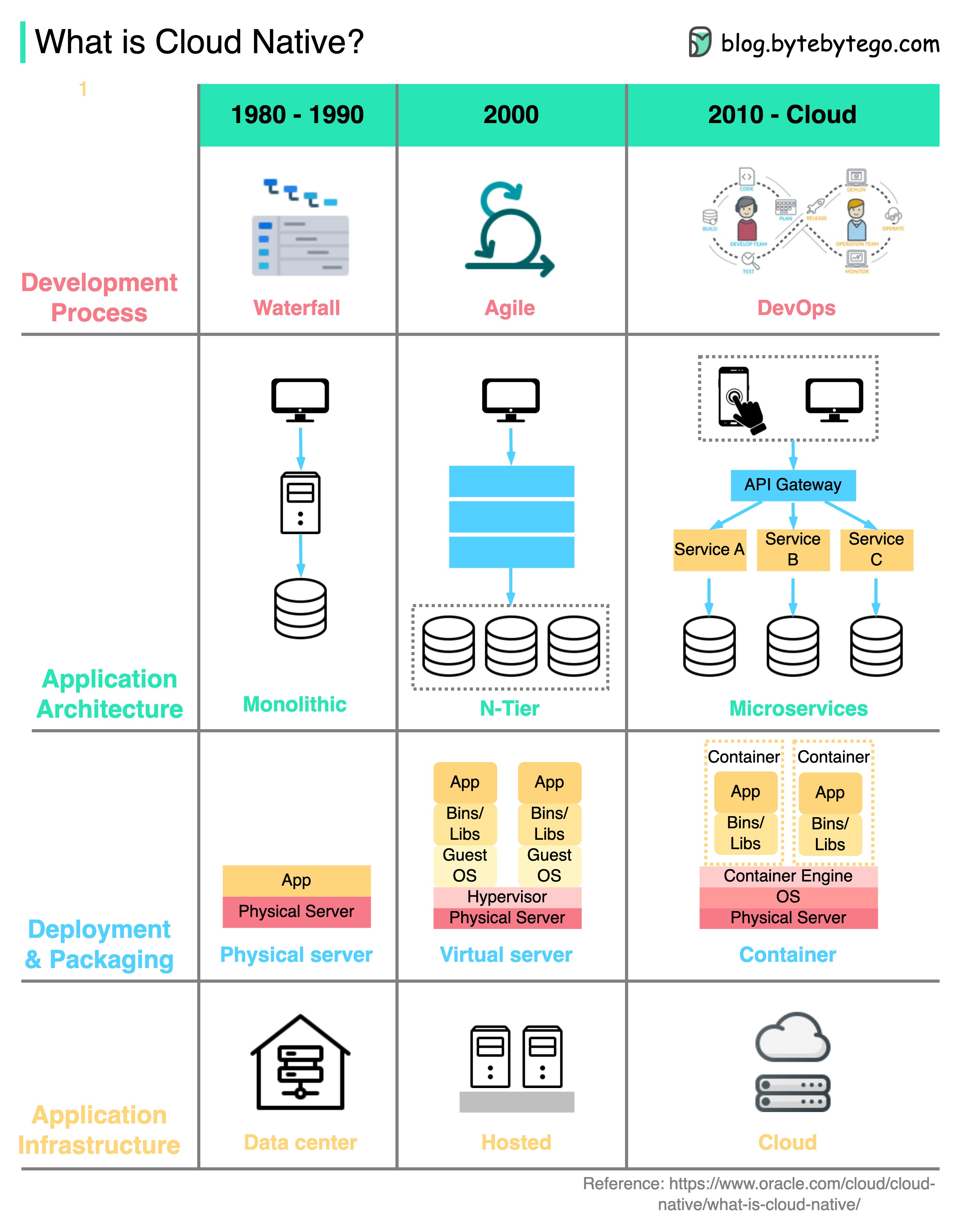
+
+Organizations can build and run scalable applications on public, private, and hybrid clouds using cloud native technologies.
+
+This means the applications are designed to leverage cloud features, so they are resilient to load and easy to scale.
+
+Cloud native includes 4 aspects:
+
+* **Development process**
+
+ This has progressed from waterfall to agile to DevOps.
+
+* **Application Architecture**
+
+ The architecture has gone from monolithic to microservices. Each service is designed to be small, and adaptive to the limited resources in cloud containers.
+
+* **Deployment & packaging**
+
+ The applications used to be deployed on physical servers. Then around 2000, the applications that were not sensitive to latency were usually deployed on virtual servers. With cloud native applications, they are packaged into docker images and deployed in containers.
+
+* **Application infrastructure**
+
+ The applications are massively deployed on cloud infrastructure instead of self-hosted servers.
diff --git a/data/guides/what-is-css-cascading-style-sheets.md b/data/guides/what-is-css-cascading-style-sheets.md
new file mode 100644
index 0000000..b9d6e76
--- /dev/null
+++ b/data/guides/what-is-css-cascading-style-sheets.md
@@ -0,0 +1,41 @@
+---
+title: What is CSS (Cascading Style Sheets)?
+description: CSS is a markup language for describing the presentation of web pages.
+image: 'https://assets.bytebytego.com/diagrams/0408-what-is-css-cascading-style-sheets.png'
+createdAt: '2024-02-03'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - CSS
+ - Web Development
+---
+
+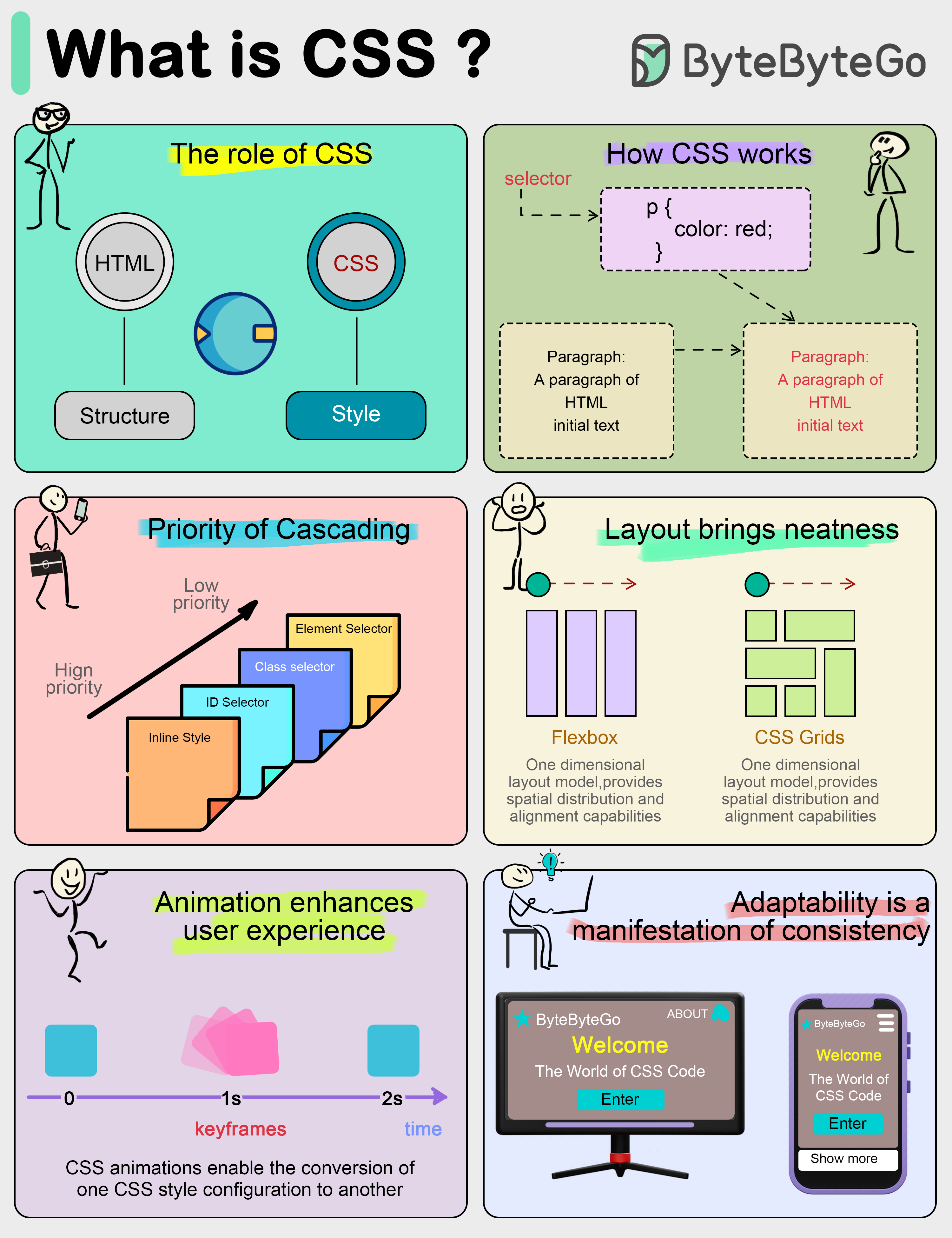
+
+Front-end development requires not only content presentation, but also good-looking. CSS is a markup language used to describe how elements on a web page should be rendered.
+
+* **What CSS does**
+ CSS separates the content and presentation of a document. In the early days of web development, HTML acted as both content and style.
+
+ CSS divides structure (HTML) and style (CSS). This has many benefits, for example, when we change the color scheme of a web page, all we need to do is to tweak the CSS file.
+* **How CSS works**
+ CSS consists of a selector and a set of properties, which can be thought of as individual rules. Selectors are used to locate HTML elements that we want to change the style of, and properties are the specific style descriptions for those elements, such as color, size, position, etc.
+
+ For example, if we want to make all the text in a paragraph blue, we write CSS code like this:
+ p { color: blue; }
+ Here “p” is the selector and “color: blue” is the attribute that declares the color of the paragraph text to be blue.
+* **Cascading in CSS**
+ The concept of cascading is crucial to understanding CSS.
+
+ When multiple style rules conflict, the browser needs to decide which rule to use based on a specific prioritization rule. The one with the highest weight wins. The weight can be determined by a variety of factors, including selector type and the order of the source.
+* **Powerful Layout Capabilities of CSS**
+ In the past, CSS was only used for simple visual effects such as text colors, font styles, or backgrounds. Today, CSS has evolved into a powerful layout tool capable of handling complex design layouts.
+
+ The “Flexbox” and “Grid” layout modules are two popular CSS layout modules that make it easy to create responsive designs and precise placement of web elements, so web developers no longer have to rely on complex tables or floating layouts.
+* **CSS Animation**
+ Animation and interactive elements can greatly enhance the user experience.
+
+ CSS3 introduces animation features that allow us to transform and animate elements without using JavaScript. For example, “@keyframes” rule defines animation sequences, and the `transition` property can be used to set animated transitions from one state to another.
+* **Responsive Design**
+ CSS allows the layout and style of a website to be adapted to different screen sizes and resolutions, so that we can provide an optimized browsing experience for different devices such as cell phones, tablets and computers.
diff --git a/data/guides/what-is-devsecops.md b/data/guides/what-is-devsecops.md
new file mode 100644
index 0000000..562f213
--- /dev/null
+++ b/data/guides/what-is-devsecops.md
@@ -0,0 +1,40 @@
+---
+title: "What is DevSecOps?"
+description: "Explore DevSecOps: integrating security into the DevOps lifecycle."
+image: "https://assets.bytebytego.com/diagrams/0060-what-is-devsecops.png"
+createdAt: "2024-02-10"
+draft: false
+categories:
+ - security
+tags:
+ - "DevOps"
+ - "Security"
+---
+
+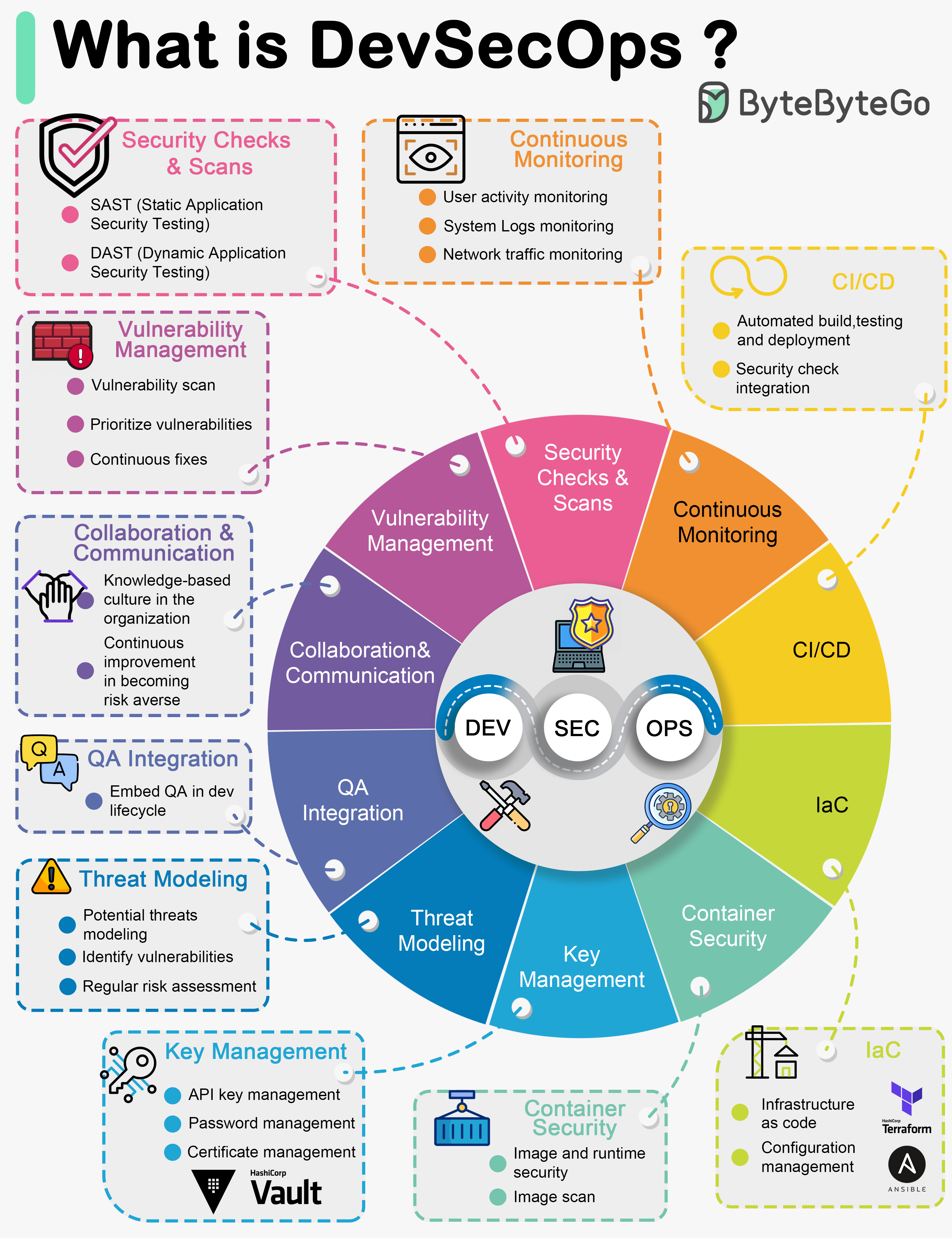
+
+DevSecOps emerged as a natural evolution of DevOps practices with a focus on integrating security into the software development and deployment process. The term "DevSecOps" represents the convergence of Development (Dev), Security (Sec), and Operations (Ops) practices, emphasizing the importance of security throughout the software development lifecycle.
+
+The diagram below shows the important concepts in DevSecOps.
+
+## Key Concepts in DevSecOps
+
+* Automated Security Checks
+
+* Continuous Monitoring
+
+* CI/CD Automation
+
+* Infrastructure as Code (IaC)
+
+* Container Security
+
+* Secret Management
+
+* Threat Modeling
+
+* Quality Assurance (QA) Integration
+
+* Collaboration and Communication
+
+* Vulnerability Management
diff --git a/data/guides/what-is-elk-stack-and-why-is-it-so-popular-for-log-management.md b/data/guides/what-is-elk-stack-and-why-is-it-so-popular-for-log-management.md
new file mode 100644
index 0000000..b434f0b
--- /dev/null
+++ b/data/guides/what-is-elk-stack-and-why-is-it-so-popular-for-log-management.md
@@ -0,0 +1,38 @@
+---
+title: "What is ELK Stack and Why is it Popular?"
+description: "Learn about the ELK Stack: Elasticsearch, Logstash, and Kibana."
+image: "https://assets.bytebytego.com/diagrams/0183-elk.jpg"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "ELK Stack"
+ - "Log Management"
+---
+
+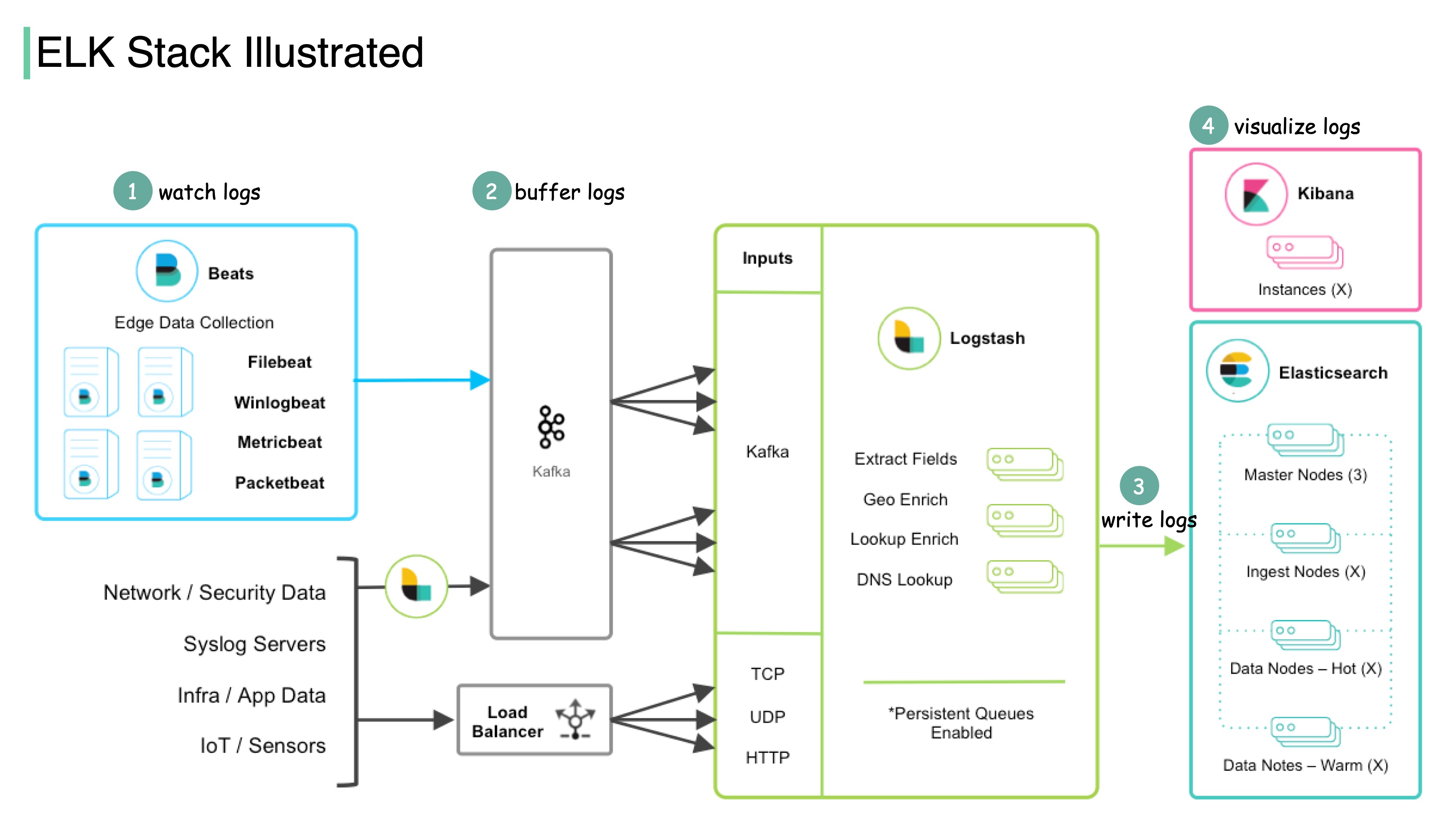
+
+The ELK Stack is composed of three open-source products. ELK stands for Elasticsearch, Logstash, and Kibana.
+
+* Elasticsearch is a full-text search and analysis engine, leveraging Apache Lucene search engine as its core component.
+
+* Logstash collects data from all kinds of edge collectors, then transforms that data and sends it to various destinations for further processing or visualization.
+
+In order to scale the edge data ingestion, a new product Beats is later developed as lightweight agents installed on edge hosts to collect and ship logs to Logstash.
+
+* Kibana is a visualization layer with which users analyze and visualize the data.
+
+The diagram above shows how ELK Stack works:
+
+## ELK Stack Workflow
+
+Step 1 - Beats collects data from various data sources. For example, Filebeat and Winlogbeat work with logs, and Packetbeat works with network traffic.
+
+Step 2 - Beats sends data to Logstash for aggregation and transformation. If we work with massive data, we can add a message queue (Kafka) to decouple the data producers and consumers.
+
+Step 3 - Logstash writes data into Elasticsearch for data indexing and storage.
+
+Step 4 - Kibana builds on top of Elasticsearch and provides users with various search tools and dashboards with which to visualize the data.
+
+ELK Stack is pretty convenient for troubleshooting and monitoring. It became popular by providing a simple and robust suite in the log analytics space, for a reasonable price.
diff --git a/data/guides/what-is-graphql.md b/data/guides/what-is-graphql.md
new file mode 100644
index 0000000..14c0962
--- /dev/null
+++ b/data/guides/what-is-graphql.md
@@ -0,0 +1,37 @@
+---
+title: What is GraphQL?
+description: "GraphQL explained: a query language for APIs."
+image: 'https://assets.bytebytego.com/diagrams/0055-what-is-graphql.png'
+createdAt: '2024-03-12'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - GraphQL
+ - API
+---
+
+
+
+### Is it a replacement for the REST API?
+
+GraphQL is a query language for APIs and a runtime for executing those queries by using a type system you define for your data. It was developed internally by Meta in 2012 before being publicly released in 2015.
+
+Unlike the more traditional REST API, GraphQL allows clients to request exactly the data they need, making it possible to fetch data from multiple sources with a single query. This efficiency in data retrieval can lead to improved performance for web and mobile applications.
+
+GraphQL servers sit in between the client and the backend services. It can aggregate multiple REST requests into one query. GraphQL server organizes the resources in a graph.
+
+GraphQL supports queries, mutations (applying data modifications to resources), and subscriptions (receiving notifications on schema modifications).
+
+**Benefits of GraphQL:**
+
+* GraphQL is more efficient in data fetching.
+* GraphQL returns more accurate results.
+* GraphQL has a strong type system to manage the structure of entities, reducing errors.
+* GraphQL is suitable for managing complex microservices.
+
+**Disadvantages of GraphQL**
+
+* Increased complexity.
+* Over fetching by design
+* Caching complexity
diff --git a/data/guides/what-is-grpc.md b/data/guides/what-is-grpc.md
new file mode 100644
index 0000000..5cf07b5
--- /dev/null
+++ b/data/guides/what-is-grpc.md
@@ -0,0 +1,25 @@
+---
+title: What is gRPC?
+description: Learn about gRPC, a high-performance RPC framework by Google.
+image: 'https://assets.bytebytego.com/diagrams/0054-what-is-grpc.png'
+createdAt: '2024-03-08'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - gRPC
+ - Microservices
+---
+
+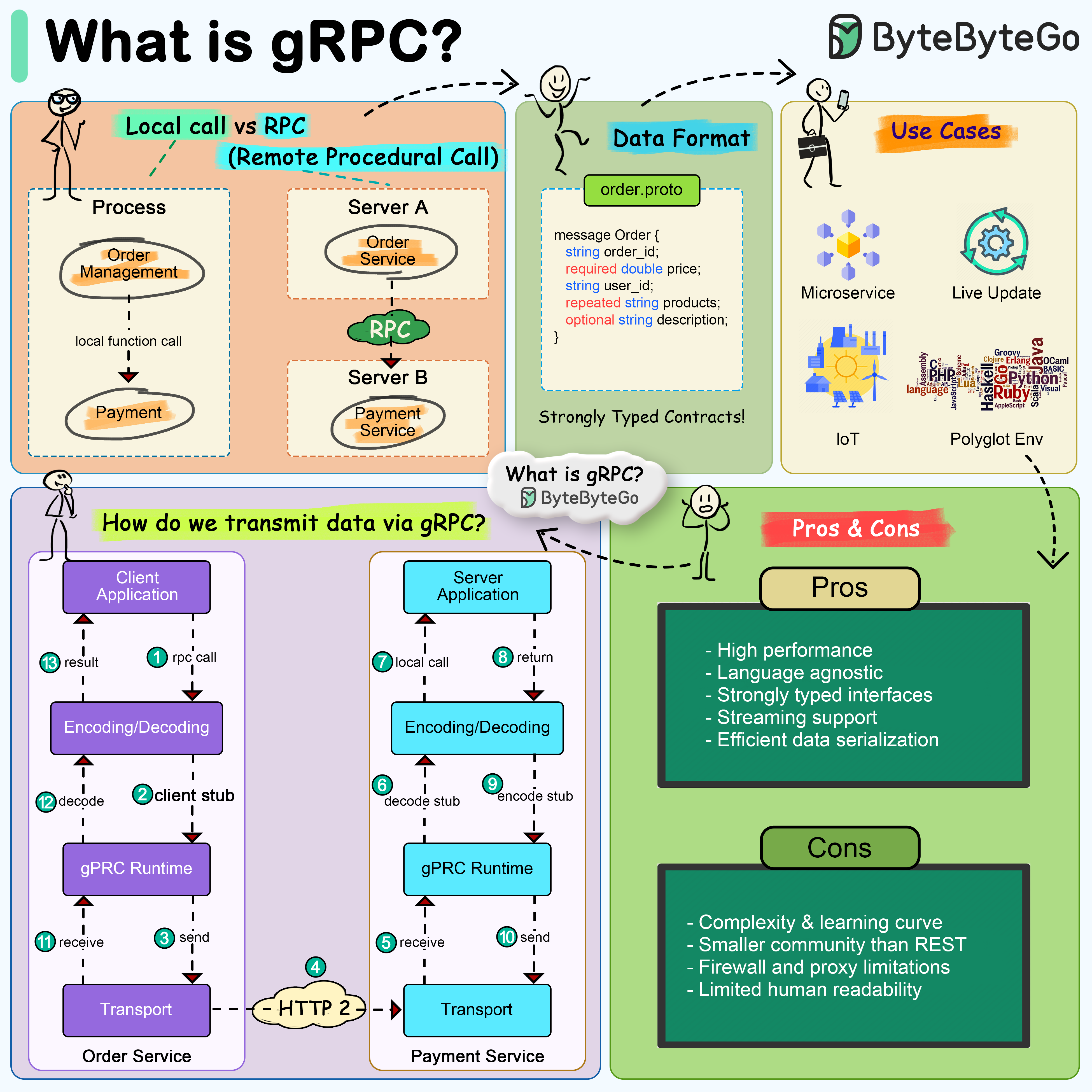
+
+gRPC is a high-performance, open-source universal RPC (Remote Procedure Call) framework initially developed by Google. It leverages HTTP/2 for transport, Protocol Buffers as the interface description language, and provides features such as authentication, load balancing, and more.
+
+gRPC is designed to enable efficient and robust communication between services in a microservices architecture, making it a popular choice for building distributed systems and APIs.
+
+**Key Features of gRPC:**
+
+* **Protocol Buffers:** By default, gRPC uses Protocol Buffers (proto files) as its interface definition language (IDL). This makes gRPC messages smaller and faster compared to JSON or XML.
+* **HTTP/2 Based Transport:** gRPC uses HTTP/2 for transport, which allows for many improvements over HTTP/1.x.
+* **Multiple Language Support:** gRPC supports a wide range of programming languages.
+* **Bi-Directional Streaming:** gRPC supports streaming requests and responses, allowing for the development of sophisticated real-time applications with bidirectional communication like chat services.
diff --git a/data/guides/what-is-k8s-kubernetes.md b/data/guides/what-is-k8s-kubernetes.md
new file mode 100644
index 0000000..59e6c6a
--- /dev/null
+++ b/data/guides/what-is-k8s-kubernetes.md
@@ -0,0 +1,52 @@
+---
+title: "What is Kubernetes (k8s)?"
+description: "Learn about Kubernetes, a container orchestration system for deployment."
+image: "https://assets.bytebytego.com/diagrams/0245-k8s.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Kubernetes"
+ - "Containers"
+---
+
+[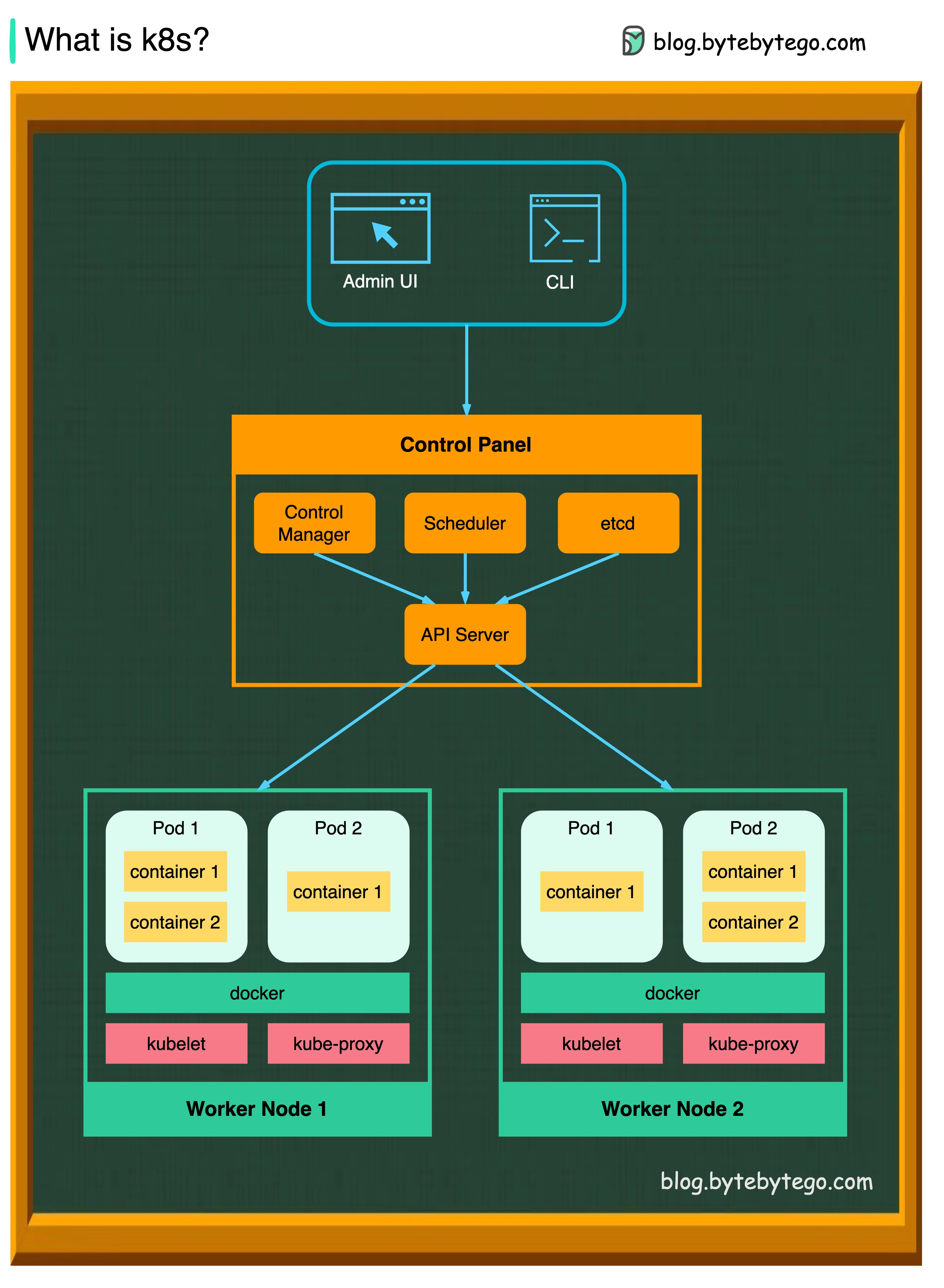](https://assets.bytebytego.com/diagrams/0245-k8s.png)
+
+k8s is a container orchestration system. It is used for container deployment and management. Its design is greatly impacted by Google’s internal system Borg.
+
+A k8s cluster consists of a set of worker machines, called nodes, that run containerized applications. Every cluster has at least one worker node. \[1]
+
+The worker node(s) host the Pods that are the components of the application workload. The control plane manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers and a cluster usually runs multiple nodes, providing fault tolerance and high availability. \[1]
+
+## Control Plane Components
+
+* **API Server**
+
+ The API server talks to all the components in the k8s cluster. All the operations on pods are executed by talking to the API server.
+
+* **Scheduler**
+
+ The scheduler watches the workloads on pods and assigns loads on newly created pods.
+
+* **Controller Manager**
+
+ The controller manager runs the controllers, including Node Controller, Job Controller, EndpointSlice Controller, and ServiceAccount Controller.
+
+* **etcd**
+
+ etcd is a key-value store used as Kubernetes' backing store for all cluster data.
+
+## Nodes
+
+* **Pods**
+
+ A pod is a group of containers and is the smallest unit that k8s administers. Pods have a single IP address applied to every container within the pod.
+
+* **Kubelet**
+
+ An agent that runs on each node in the cluster. It ensures containers are running in a Pod. \[1]
+
+* **Kube Proxy**
+
+ kube-proxy is a network proxy that runs on each node in your cluster. It routes traffic coming into a node from the service. It forwards requests for work to the correct containers.
diff --git a/data/guides/what-is-osi-model.md b/data/guides/what-is-osi-model.md
new file mode 100644
index 0000000..a136eb8
--- /dev/null
+++ b/data/guides/what-is-osi-model.md
@@ -0,0 +1,32 @@
+---
+title: "OSI Model Explained"
+description: "Learn about the OSI model and how data is transmitted over a network."
+image: "https://assets.bytebytego.com/diagrams/0295-osi-model.jpeg"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Networking"
+ - "OSI Model"
+---
+
+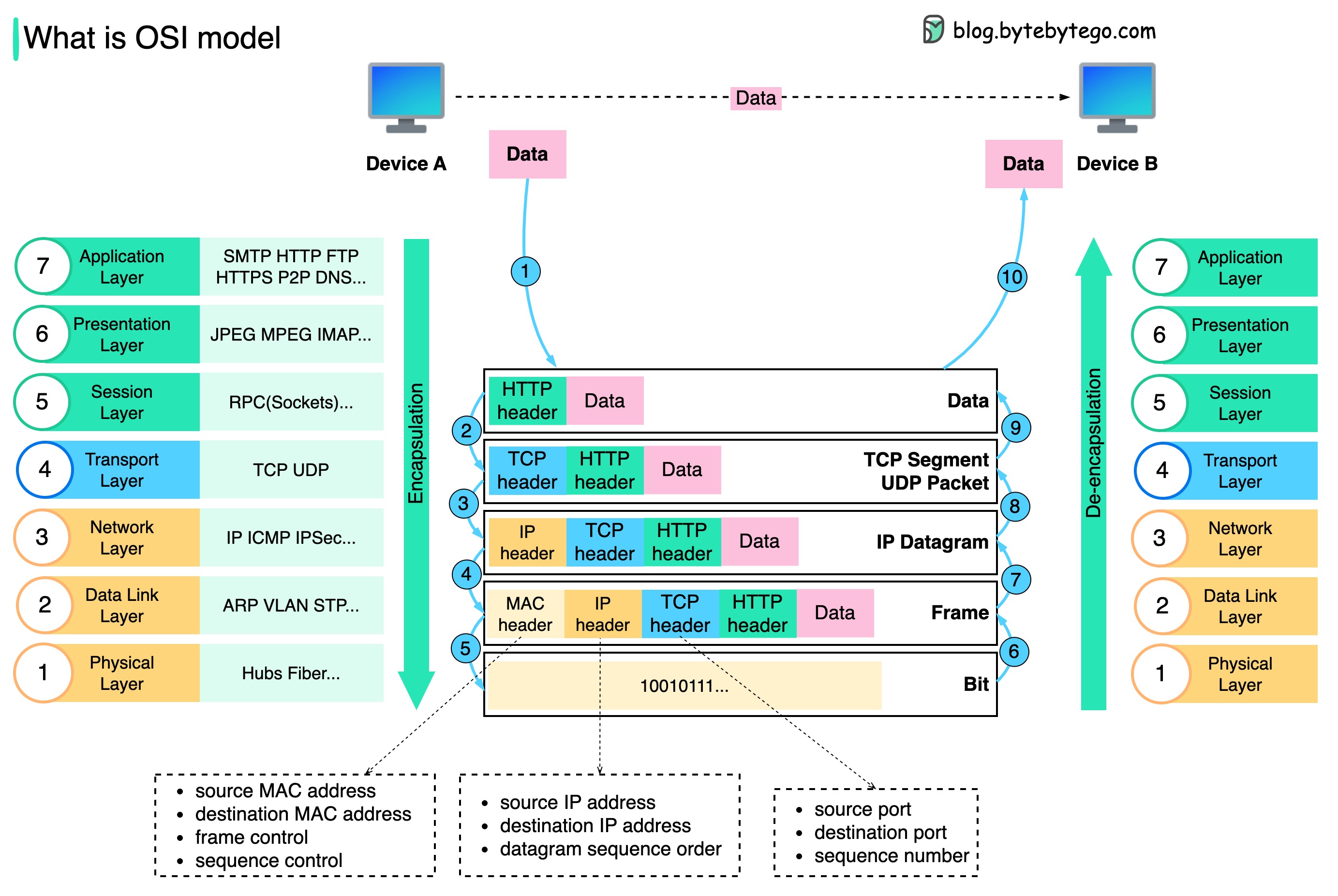
+
+How is data sent over the network? Why do we need so many layers in the OSI model?
+
+The diagram below shows how data is encapsulated and de-encapsulated when transmitting over the network.
+
+* Step 1: When Device A sends data to Device B over the network via the HTTP protocol, it is first added an HTTP header at the application layer.
+
+* Step 2: Then a TCP or a UDP header is added to the data. It is encapsulated into TCP segments at the transport layer. The header contains the source port, destination port, and sequence number.
+
+* Step 3: The segments are then encapsulated with an IP header at the network layer. The IP header contains the source/destination IP addresses.
+
+* Step 4: The IP datagram is added a MAC header at the data link layer, with source/destination MAC addresses.
+
+* Step 5: The encapsulated frames are sent to the physical layer and sent over the network in binary bits.
+
+* Steps 6-10: When Device B receives the bits from the network, it performs the de-encapsulation process, which is a reverse processing of the encapsulation process. The headers are removed layer by layer, and eventually, Device B can read the data.
+
+We need layers in the network model because each layer focuses on its own responsibilities. Each layer can rely on the headers for processing instructions and does not need to know the meaning of the data from the last layer.
diff --git a/data/guides/what-is-serverless-db.md b/data/guides/what-is-serverless-db.md
new file mode 100644
index 0000000..8f39dc7
--- /dev/null
+++ b/data/guides/what-is-serverless-db.md
@@ -0,0 +1,24 @@
+---
+title: "What is Serverless DB?"
+description: "Explore serverless databases, their benefits, and how they differ."
+image: "https://assets.bytebytego.com/diagrams/0329-serverlessdb.jpeg"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Serverless"
+ - "Database"
+---
+
+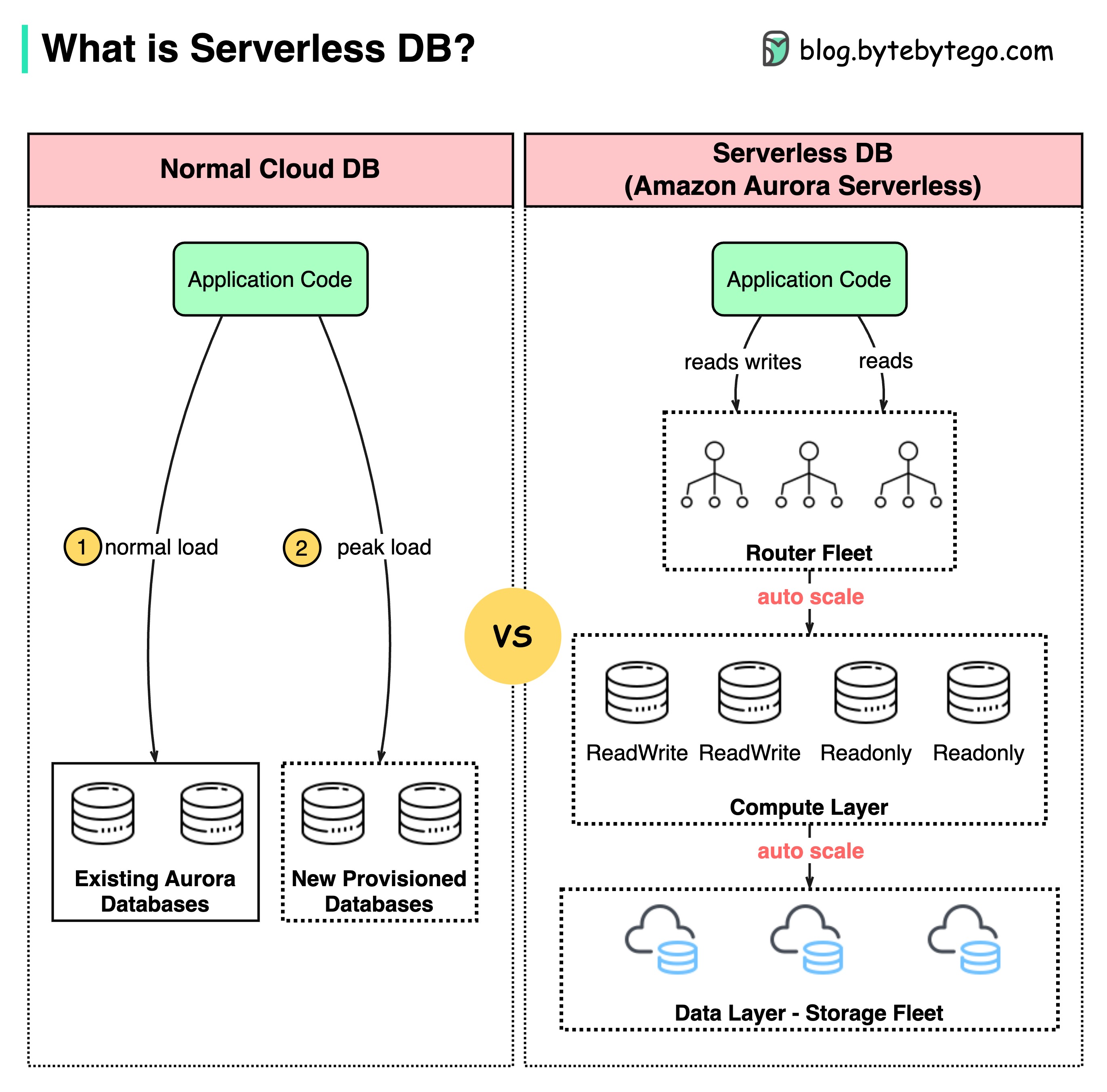
+
+Are serverless databases the future? How do serverless databases differ from traditional cloud databases?
+
+Amazon Aurora Serverless, depicted in the diagram above, is a configuration that is auto-scaling and available on-demand for Amazon Aurora.
+
+## Key Features of Aurora Serverless
+
+* Aurora Serverless has the ability to scale capacity automatically up or down as per business requirements. For example, an eCommerce website preparing for a major promotion can scale the load to multiple databases within a few milliseconds. In comparison to regular cloud databases, which necessitate the provision and administration of database instances, Aurora Serverless can automatically start up and shut down.
+
+* By decoupling the compute layer from the data storage layer, Aurora Serverless is able to charge fees in a more precise manner. Additionally, Aurora Serverless can be a combination of provisioned and serverless instances, enabling existing provisioned databases to become a part of the serverless pool.
diff --git a/data/guides/what-is-the-best-way-to-learn-sql.md b/data/guides/what-is-the-best-way-to-learn-sql.md
new file mode 100644
index 0000000..79a576c
--- /dev/null
+++ b/data/guides/what-is-the-best-way-to-learn-sql.md
@@ -0,0 +1,32 @@
+---
+title: "What is the Best Way to Learn SQL?"
+description: "A guide to efficiently learn SQL and its components for different roles."
+image: "https://assets.bytebytego.com/diagrams/0031-how-to-learn-sql.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "SQL"
+ - "Databases"
+---
+
+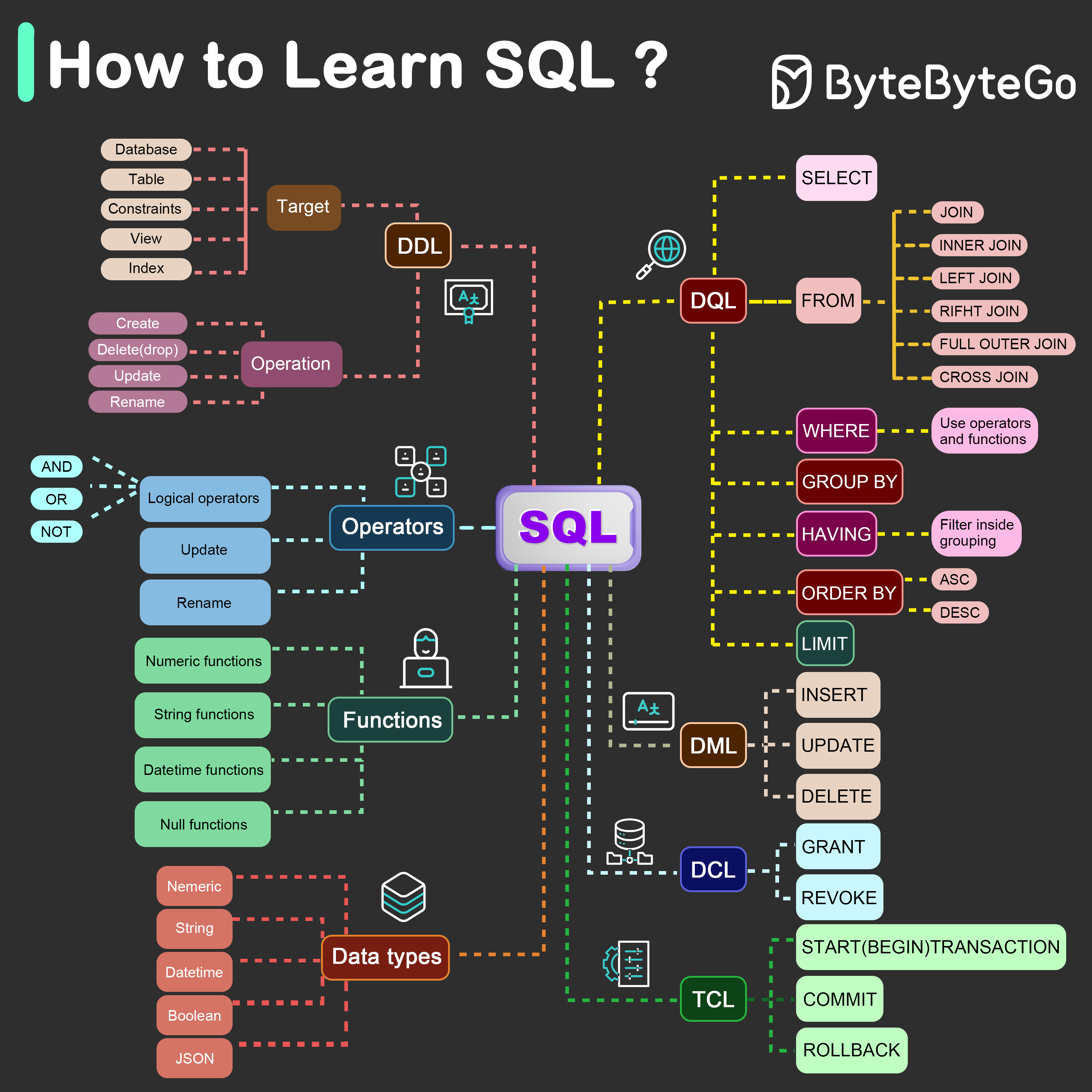
+
+In 1986, SQL (Structured Query Language) became a standard. Over the next 40 years, it became the dominant language for relational database management systems. Reading the latest standard (ANSI SQL 2016) can be time-consuming. How can I learn it?
+
+## SQL Components
+
+There are 5 components of the SQL language:
+
+* **DDL**: data definition language, such as CREATE, ALTER, DROP
+
+* **DQL**: data query language, such as SELECT
+
+* **DML**: data manipulation language, such as INSERT, UPDATE, DELETE
+
+* **DCL**: data control language, such as GRANT, REVOKE
+
+* **TCL**: transaction control language, such as COMMIT, ROLLBACK
+
+For a backend engineer, you may need to know most of it. As a data analyst, you may need to have a good understanding of DQL. Select the topics that are most relevant to you.
diff --git a/data/guides/what-is-the-difference-between-process-and-thread.md b/data/guides/what-is-the-difference-between-process-and-thread.md
new file mode 100644
index 0000000..99619e0
--- /dev/null
+++ b/data/guides/what-is-the-difference-between-process-and-thread.md
@@ -0,0 +1,40 @@
+---
+title: "Process vs Thread: Key Differences"
+description: "Understand the core differences between processes and threads."
+image: "https://assets.bytebytego.com/diagrams/0304-program-process-thread.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Operating Systems"
+ - "Concurrency"
+---
+
+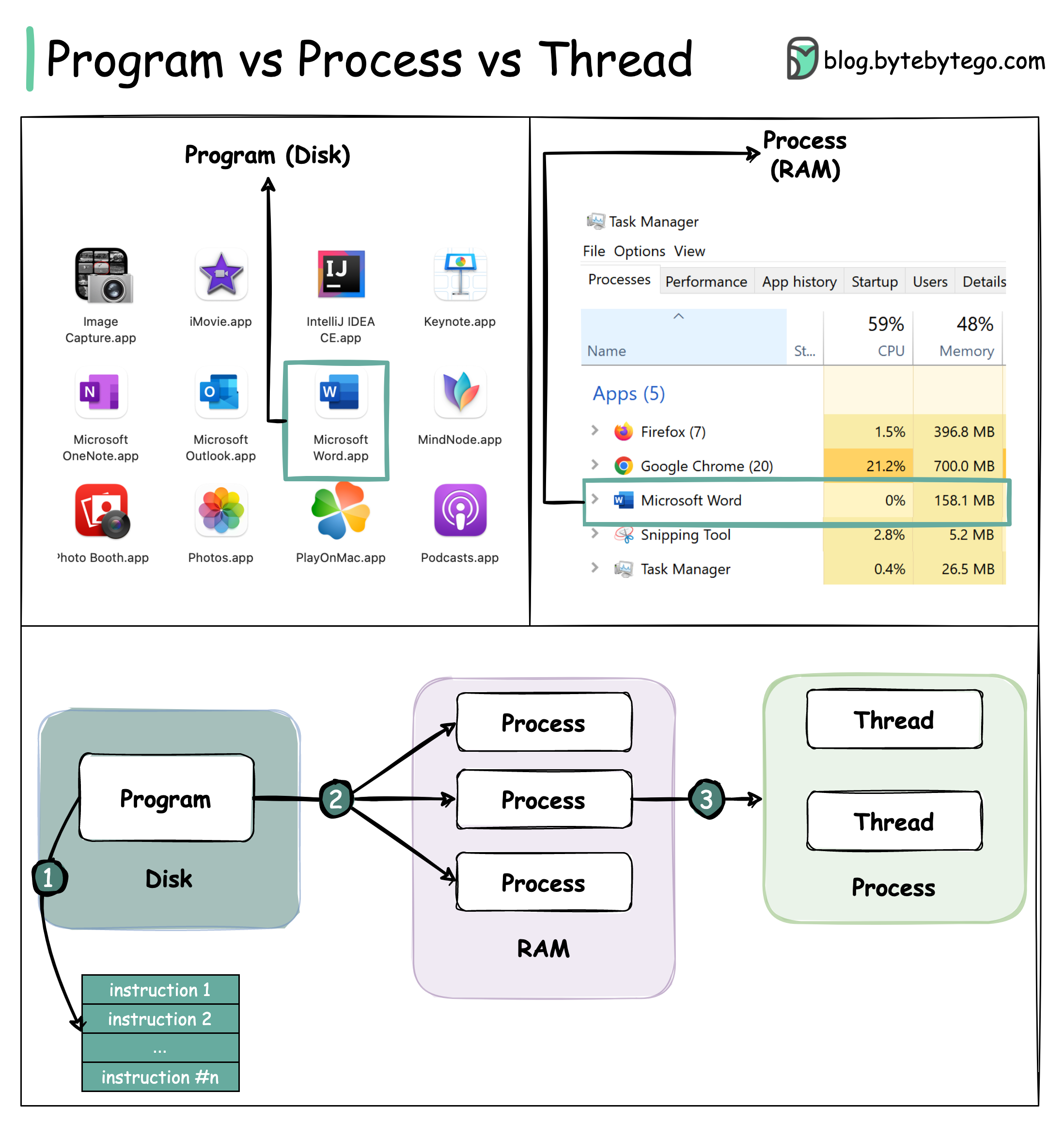
+
+To better understand this question, let’s first take a look at what a Program is. A Program is an executable file containing a set of instructions and passively stored on disk. One program can have multiple processes. For example, the Chrome browser creates a different process for every single tab.
+
+A Process means a program is in execution. When a program is loaded into the memory and becomes active, the program becomes a process. The process requires some essential resources such as registers, program counter, and stack.
+
+A Thread is the smallest unit of execution within a process.
+
+The following process explains the relationship between program, process, and thread.
+
+1. The program contains a set of instructions.
+
+2. The program is loaded into memory. It becomes one or more running processes.
+
+3. When a process starts, it is assigned memory and resources. A process can have one or more threads. For example, in the Microsoft Word app, a thread might be responsible for spelling checking and the other thread for inserting text into the doc.
+
+## Main differences between process and thread:
+
+* Processes are usually independent, while threads exist as subsets of a process.
+
+* Each process has its own memory space. Threads that belong to the same process share the same memory.
+
+* A process is a heavyweight operation. It takes more time to create and terminate.
+
+* Context switching is more expensive between processes.
+
+* Inter-thread communication is faster for threads.
diff --git a/data/guides/what-is-the-journey-of-a-slack-message.md b/data/guides/what-is-the-journey-of-a-slack-message.md
new file mode 100644
index 0000000..2f7b6eb
--- /dev/null
+++ b/data/guides/what-is-the-journey-of-a-slack-message.md
@@ -0,0 +1,29 @@
+---
+title: 'What is the Journey of a Slack Message?'
+description: 'Explore the journey of a Slack message from sender to receiver.'
+image: 'https://assets.bytebytego.com/diagrams/0338-slack-message-journey.jpg'
+createdAt: '2024-03-08'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Messaging
+---
+
+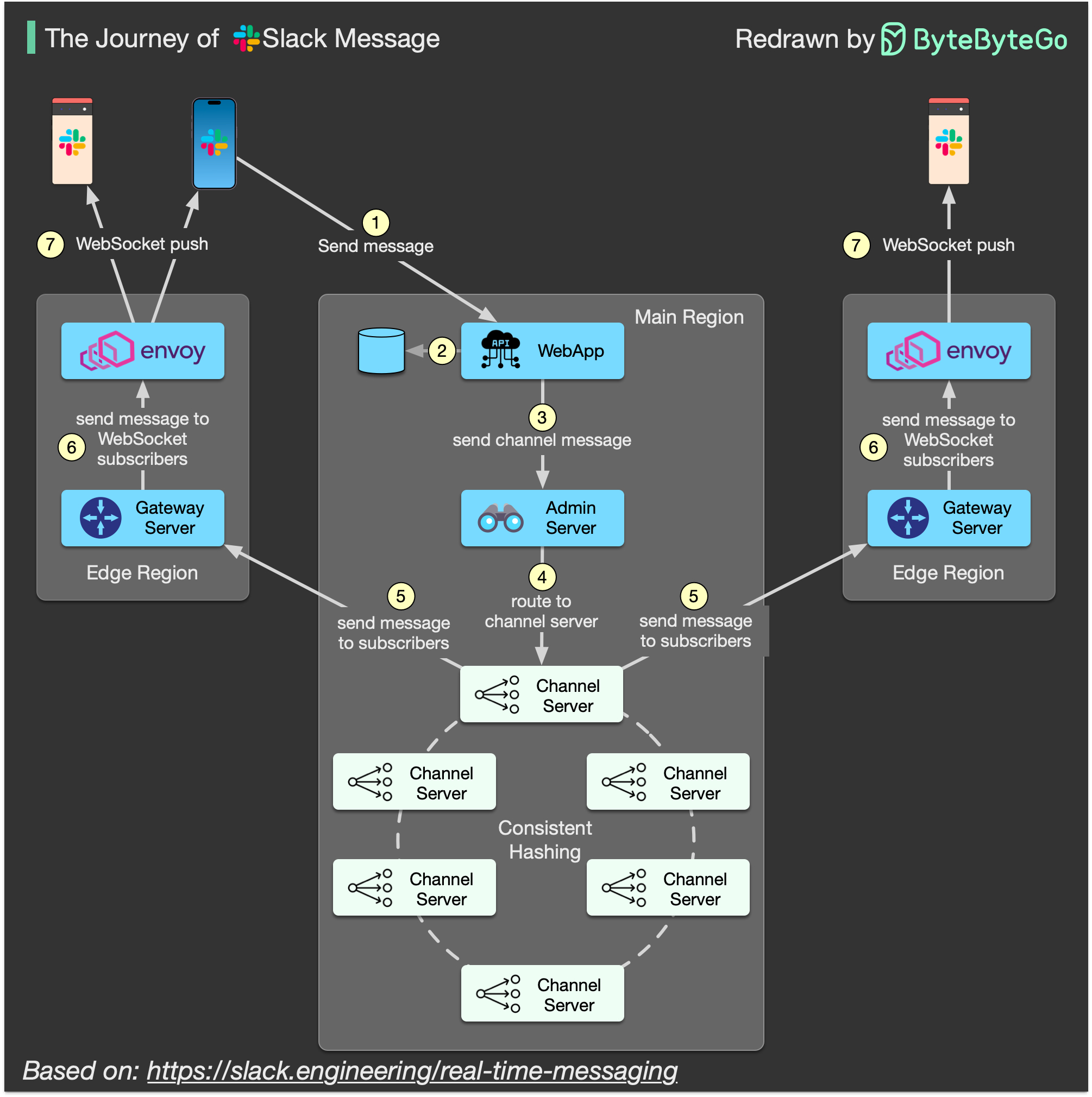
+
+In a recent technical article, Slack explains how its real-time messaging framework works. Here is my short summary:
+
+A Slack message travels through five important servers:
+
+* **WebApp:** defines the API that a Slack client could use
+* **Admin Server (AS):** finds the correct Channel Server using channel ID
+* **Channel Server (CS):** maintains the history of message channel
+* **Gateway Server (GS):** deployed in each geographic region. Maintain WebSocket channel subscription
+* **Envoy:** service proxy for cloud-native applications
+
+* Because there are too many channels, the Channel Server (CS) uses consistent hashing to allocate millions of channels to many channel servers.
+* Slack messages are delivered through WebApp and Admin Server to the correct Channel Server.
+* Through Gate Server and Envoy (a proxy), the Channel Server will push messages to message receivers.
+* Message receivers use WebSocket, which is a bi-directional messaging mechanism, so they are able to receive updates in real-time.
diff --git a/data/guides/what-is-web-3.md b/data/guides/what-is-web-3.md
new file mode 100644
index 0000000..94100bf
--- /dev/null
+++ b/data/guides/what-is-web-3.md
@@ -0,0 +1,36 @@
+---
+title: "What is Web 3.0? Why doesn't it have ads?"
+description: "Explore Web 3.0: ownership, decentralization, and ad-free potential."
+image: "https://assets.bytebytego.com/diagrams/0416-what-is-web-3.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Web3"
+ - "Decentralization"
+---
+
+The diagram above shows Web 1.0/Web 2.0/Web 3.0 from a bird's-eye view.
+
+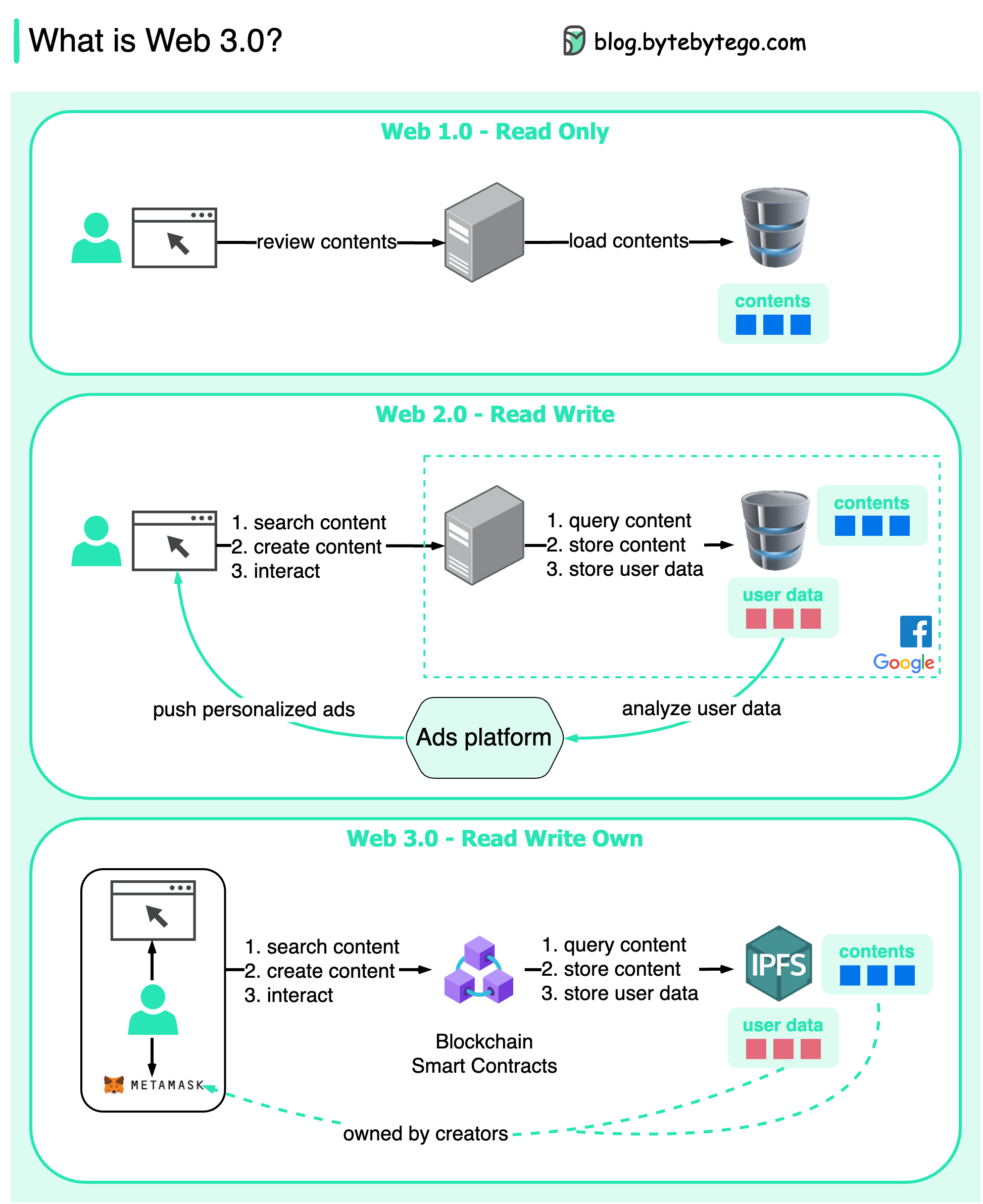
+
+* Web 1.0 - Read Only
+
+Between 1991 and 2004, the internet was like a **catalog of static pages**. We can browse the content by jumping from one hyperlink to another. It doesn’t provide any interactions with the content.
+
+* Web 2.0 - Read Write
+
+From 2004 to now, the internet has evolved to have search engines, social media apps, and recommendation algorithms backed apps.
+
+Because the apps digitalize human behaviors and persist user data when users interact with these apps, big companies leverage user data for advertisements, which becomes **one of the main business models** in Web 2.0.
+
+That’s why people say the apps know you better than your friends, family, or even yourself.
+
+* Web 3.0 - Read Write Own
+
+The idea has been discussed a lot recently due to the development of blockchain and decentralized apps. The creators’ content is stored on IPFS (InterPlanetary File System) and **owned by the users**.
+
+If apps want to access the data, they need to get **authorization** from the users and **pay** for it.
+
+In Web 3.0, the ownership change may lead to some major innovations.
diff --git a/data/guides/what-makes-aws-lambda-so-fast.md b/data/guides/what-makes-aws-lambda-so-fast.md
new file mode 100644
index 0000000..1817f48
--- /dev/null
+++ b/data/guides/what-makes-aws-lambda-so-fast.md
@@ -0,0 +1,48 @@
+---
+title: "What makes AWS Lambda so fast?"
+description: "Explore the key factors behind AWS Lambda's impressive speed."
+image: "https://assets.bytebytego.com/diagrams/0417-what-makes-aws-lambda-so-fast.png"
+createdAt: "2024-02-06"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "AWS Lambda"
+ - "Serverless"
+---
+
+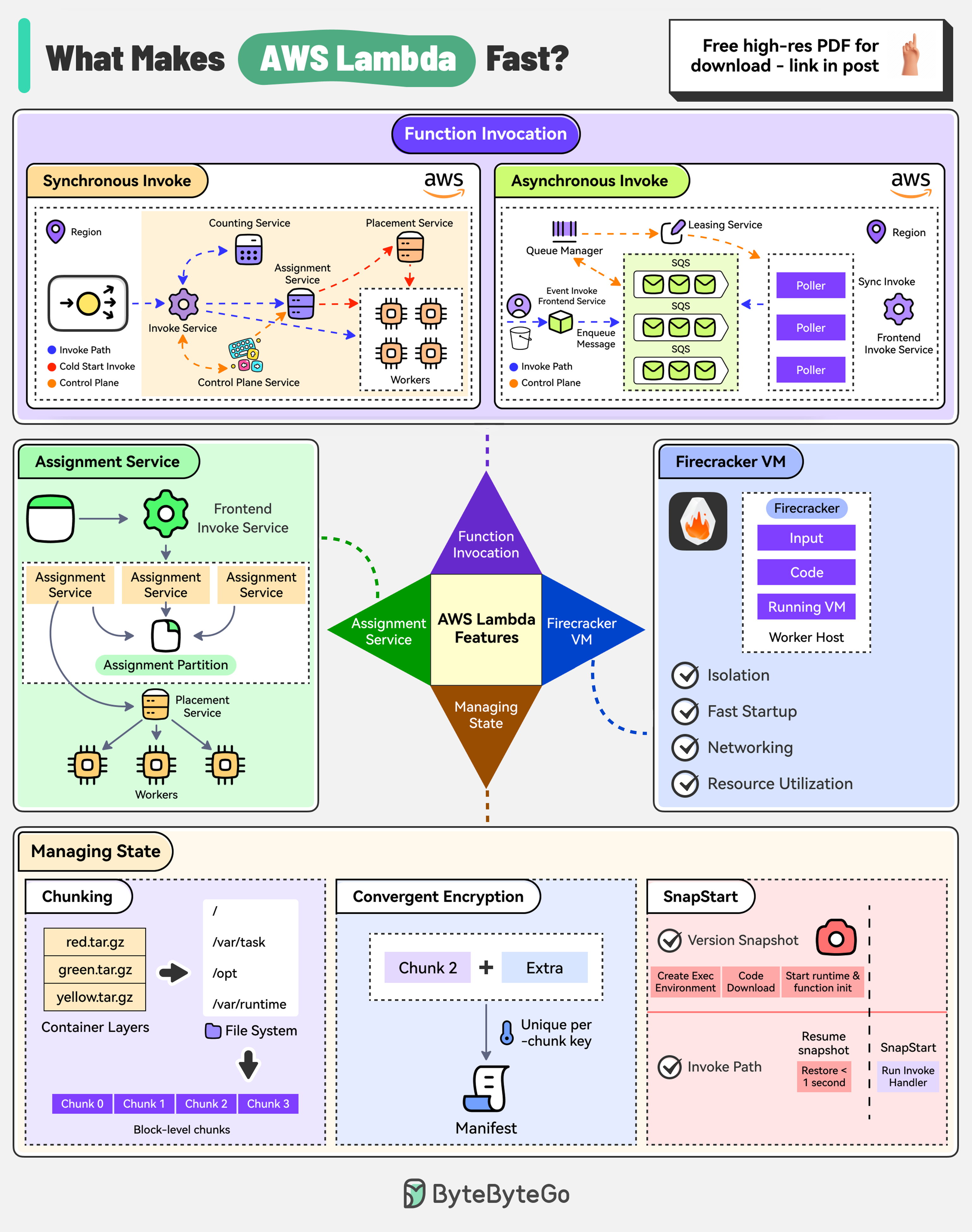
+
+There are 4 main pillars:
+
+## Function Invocation
+
+AWS Lambda supports synchronous and asynchronous invocation.
+
+In synchronous invocation, the caller directly calls the Lambda function using AWS CLI, SDK, or other services.
+
+In asynchronous invocation, the caller doesn’t wait for the function’s response. The request is authorized and an event is placed in an internal SQS queue. Pollers read messages from the queue and send them for processing.
+
+## Assignment Service
+
+The Assignment Service manages the execution environments.
+
+The service is written in Rust for high performance and is divided into multiple partitions with a leader-follower approach for high availability.
+
+The state of execution environments is written to an external journal log.
+
+## Firecracker MicroVM
+
+Firecracker is a lightweight virtual machine manager designed for running serverless workloads such as AWS Lambda and AWS Fargate.
+
+It uses Linux’s Kernel-based virtual machine to create and manage secure, fast-booting microVMs.
+
+## Component Storage
+
+AWS Lambda also has to manage the state consisting of input data and function code.
+
+To make it efficient, it uses multiple techniques:
+
+* Chunking to store the container images more efficiently.
+* Using convergent encryption to secure the shared data. This involves appending additional data to the chunk to compute a more robust hash.
+* SnapStart feature to reduce cold start latency by pre-initializing the execution environment
diff --git a/data/guides/what-makes-http2-faster-than-http1.md b/data/guides/what-makes-http2-faster-than-http1.md
new file mode 100644
index 0000000..2271f5a
--- /dev/null
+++ b/data/guides/what-makes-http2-faster-than-http1.md
@@ -0,0 +1,31 @@
+---
+title: What makes HTTP2 faster than HTTP1?
+description: Discover the key features that make HTTP2 faster than HTTP1.
+image: 'https://assets.bytebytego.com/diagrams/0421-why-http2-is-faster-than-http1.png'
+createdAt: '2024-02-02'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP2
+ - Performance
+---
+
+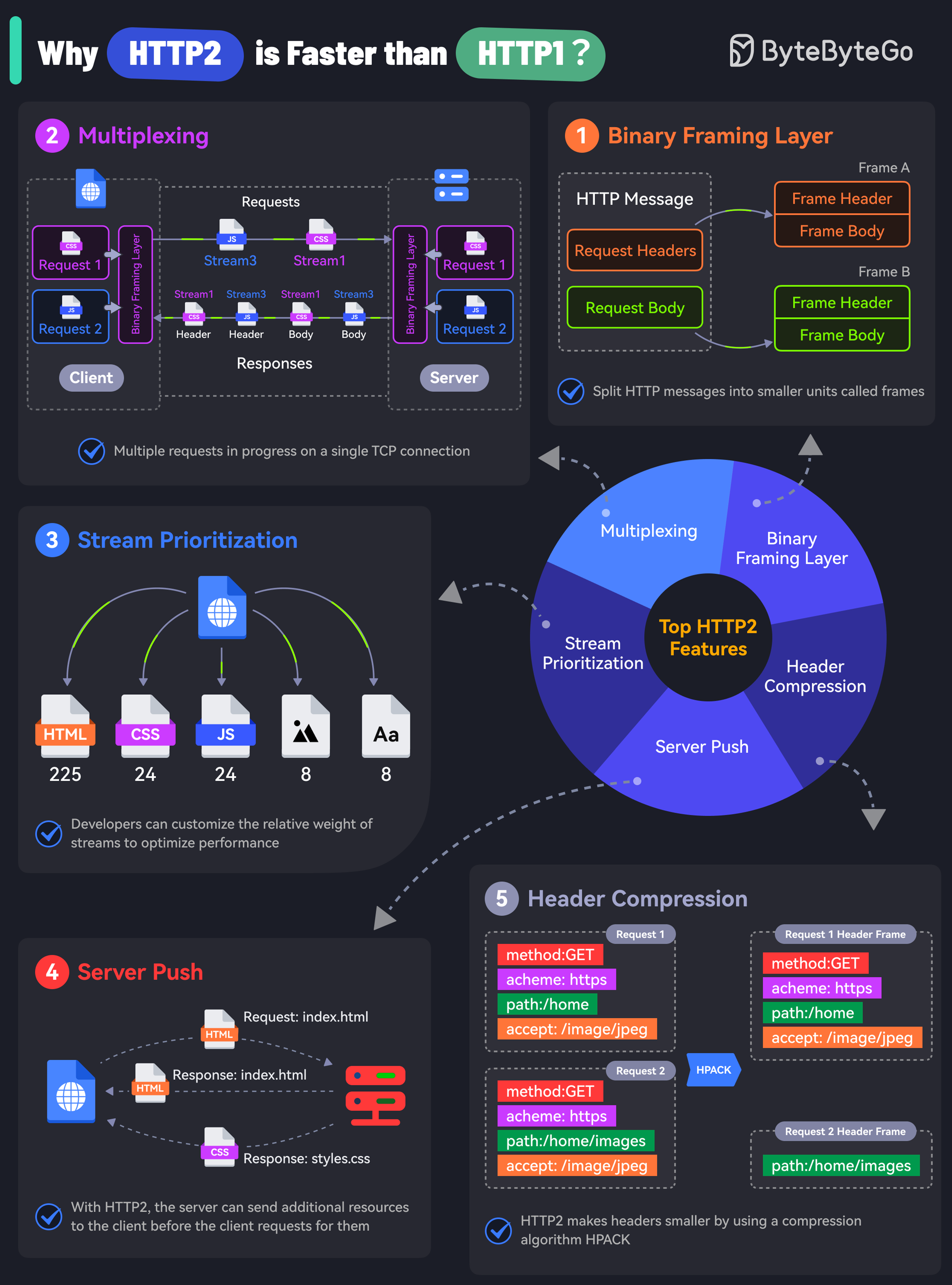
+
+The key features of HTTP2 play a big role in this. Let’s look at them:
+
+* **Binary Framing Layer**
+ HTTP2 encodes the messages into binary format.
+ This allows the messages into smaller units called frames, which are then sent over the TCP connection, resulting in more efficient processing.
+* **Multiplexing**
+ The Binary Framing allows full request and response multiplexing.
+ Clients and servers can interleave frames during transmissions and reassemble them on the other side.
+* **Stream Prioritization**
+ With stream prioritization, developers can customize the relative weight of requests or streams to make the server send more frames for higher-priority requests.
+* **Server Push**
+ Since HTTP2 allows multiple concurrent responses to a client’s request, a server can send additional resources along with the requested page to the client.
+* **HPACK Header Compression**
+ HTTP2 uses a special compression algorithm called HPACK to make the headers smaller for multiple requests, thereby saving bandwidth.
+
+Of course, despite these features, HTTP2 can also be slow depending on the exact technical scenario. Therefore, developers need to test and optimize things to maximize the benefits of HTTP2.
diff --git a/data/guides/what-protocol-does-online-gaming-use-to-transmit-data.md b/data/guides/what-protocol-does-online-gaming-use-to-transmit-data.md
new file mode 100644
index 0000000..0fa77db
--- /dev/null
+++ b/data/guides/what-protocol-does-online-gaming-use-to-transmit-data.md
@@ -0,0 +1,28 @@
+---
+title: "TCP vs UDP for Online Gaming"
+description: "Explore TCP and UDP protocols in online gaming for data transmission."
+image: "https://assets.bytebytego.com/diagrams/0315-reliable-udp.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - Networking
+ - Protocols
+---
+
+
+
+A common practice is to use RUDP (Reliable UDP). It adds a **reliable** mechanism on top of UDP to provide **much lower latency** than TCP and guarantee accuracy.
+
+The diagram below shows how reliable data delivery is implemented in online gaming to get eventually-synchronized states.
+
+Suppose there is a big fight in a simulation shooter game. Characters A, B, and C open fires in sequence. How does the game server transmit the states from the game server to the game client?
+
+* **Steps 1 and 2** - Character A opens fires. The packet (packet 0) is sent to the client. The client acknowledges the server.
+
+* **Step 3** - Character B opens fire. The packet is lost during transmission.
+
+* **Steps 4 and 5** - Character C opens fire. The packet (packet 2) is sent to the client. Since the last successfully delivered packet is packet 0, the client knows that packet 1 is lost, so packet 2 is **buffered** on the client side. The client acknowledges the server for the reception of packet 2.
+
+* **Steps 6 and 7** - The server doesn’t receive the ack for packet 1 for a while, so it resends packet 1. When the client receives packet 1, all the subsequent packets become effective, so packets 1 and 2 become “**delivered**”. The client then acknowledges the server for the reception of packet 1. No packets are buffered at this point.
diff --git a/data/guides/what-tools-does-your-team-use-to-ship-code-to-production-and-ensure-code-quality.md b/data/guides/what-tools-does-your-team-use-to-ship-code-to-production-and-ensure-code-quality.md
new file mode 100644
index 0000000..1509390
--- /dev/null
+++ b/data/guides/what-tools-does-your-team-use-to-ship-code-to-production-and-ensure-code-quality.md
@@ -0,0 +1,32 @@
+---
+title: "Tools for Shipping Code to Production"
+description: "Explore tools for shipping code to production and ensuring code quality."
+image: "https://assets.bytebytego.com/diagrams/0335-ship-to-prod-tools.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - DevOps
+ - Software Delivery
+---
+
+
+
+The approach generally depends on the size of the company. There is no one-size-fits-all solution, but we try to provide a general overview.
+
+## 1-10 employees
+
+In the early stages of a company, the focus is on finding a product-market fit. The emphasis is primarily on delivery and experimentation. Utilizing existing free or low-cost tools, developers handle testing and deployment. They also pay close attention to customer feedback and reports.
+
+## 10-100 employees
+
+Once the product-market fit is found, companies strive to scale. They are able to invest more in quality for critical functionalities and can create rapid evolution processes, such as scheduled deployments and testing procedures. Companies also proactively establish customer support processes to handle customer issues and provide proactive alerts.
+
+## 100-1,000 employees
+
+When a company's go-to-market strategy proves successful, and the product scales and grows rapidly, it starts to optimize its engineering efficiency. More commercial tools can be purchased, such as Atlassian products. A certain level of standardization across tools is introduced, and automation comes into play.
+
+## 1,000-10,000+ employees
+
+Large tech companies build experimental tooling and automation to ensure quality and gather customer feedback at scale. Netflix, for example, is well known for its "Test in Production" strategy, which conducts everything through experiments.
diff --git a/data/guides/which-latency-numbers-should-you-know.md b/data/guides/which-latency-numbers-should-you-know.md
new file mode 100644
index 0000000..4efa155
--- /dev/null
+++ b/data/guides/which-latency-numbers-should-you-know.md
@@ -0,0 +1,50 @@
+---
+title: "Which Latency Numbers Should You Know?"
+description: "Essential latency benchmarks for developers and system designers."
+image: "https://assets.bytebytego.com/diagrams/0250-latency-numbers.jpg"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "latency"
+ - "performance"
+---
+
+Please note those are not accurate numbers. They are based on some online benchmarks (Jeff Dean’s latency numbers + some other sources).
+
+
+
+* **L1 and L2 caches: 1 ns, 10 ns**
+
+ E.g.: They are usually built onto the microprocessor chip. Unless you work with hardware directly, you probably don’t need to worry about them.
+
+* **RAM access: 100 ns**
+
+ E.g.: It takes around 100 ns to read data from memory. Redis is an in-memory data store, so it takes about 100 ns to read data from Redis.
+
+* **Send 1K bytes over 1 Gbps network: 10 us**
+
+ E.g.: It takes around 10 us to send 1KB of data from Memcached through the network.
+
+* **Read from SSD: 100 us**
+
+ E.g.: RocksDB is a disk-based K/V store, so the read latency is around 100 us on SSD.
+
+* **Database insert operation: 1 ms**
+
+ E.g.: Postgresql commit might take 1ms. The database needs to store the data, create the index, and flush logs. All these actions take time.
+
+* **Send packet CA->Netherlands->CA: 100 ms**
+
+ E.g.: If we have a long-distance Zoom call, the latency might be around 100 ms.
+
+* **Retry/refresh internal: 1-10s**
+
+ E.g: In a monitoring system, the refresh interval is usually set to 5~10 seconds (default value on Grafana).
+
+## Notes
+
+1 ns = 10^-9 seconds
+1 us = 10^-6 seconds = 1,000 ns
+1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
diff --git a/data/guides/who-are-the-fantastic-four-of-system-design.md b/data/guides/who-are-the-fantastic-four-of-system-design.md
new file mode 100644
index 0000000..cc8ff44
--- /dev/null
+++ b/data/guides/who-are-the-fantastic-four-of-system-design.md
@@ -0,0 +1,34 @@
+---
+title: "The Fantastic Four of System Design"
+description: "Explore the core principles of system design: scalability, availability..."
+image: 'https://assets.bytebytego.com/diagrams/0357-who-are-the-fantastic-four-of-system-design.png'
+createdAt: '2024-02-05'
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "scalability"
+---
+
+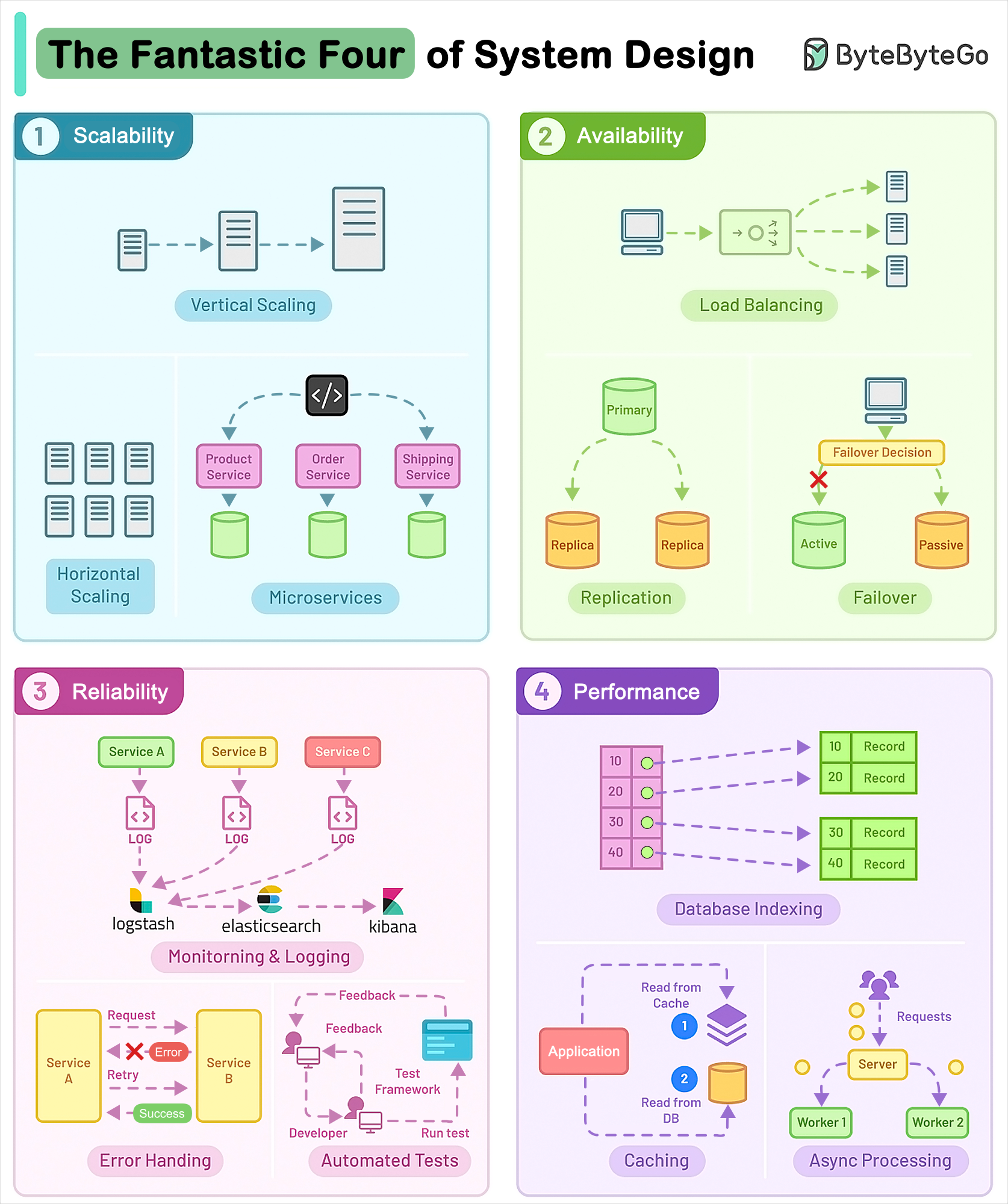
+
+Scalability, Availability, Reliability, and Performance. They are the most critical components to crafting successful software systems.
+
+Let’s look at each of them with implementation techniques:
+
+* **Scalability**
+
+ Scalability ensures that your application can handle more load without compromising performance.
+
+* **Availability**
+
+ Availability makes sure that your application is always ready to serve the users and downtime is minimal.
+
+* **Reliability**
+
+ Reliability is about building software that consistently delivers correct results.
+
+* **Performance**
+
+ Performance is the ability of a system to carry out its tasks at an expected rate under peak load using available resources.
diff --git a/data/guides/why-are-content-delivery-networks-cdn-so-popular.md b/data/guides/why-are-content-delivery-networks-cdn-so-popular.md
new file mode 100644
index 0000000..cd9f39f
--- /dev/null
+++ b/data/guides/why-are-content-delivery-networks-cdn-so-popular.md
@@ -0,0 +1,54 @@
+---
+title: "Why are Content Delivery Networks (CDN) so Popular?"
+description: "Explore the popularity of CDNs and their impact on performance."
+image: "https://assets.bytebytego.com/diagrams/0420-why-cdns-are-so-popular.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - CDN
+ - Performance
+---
+
+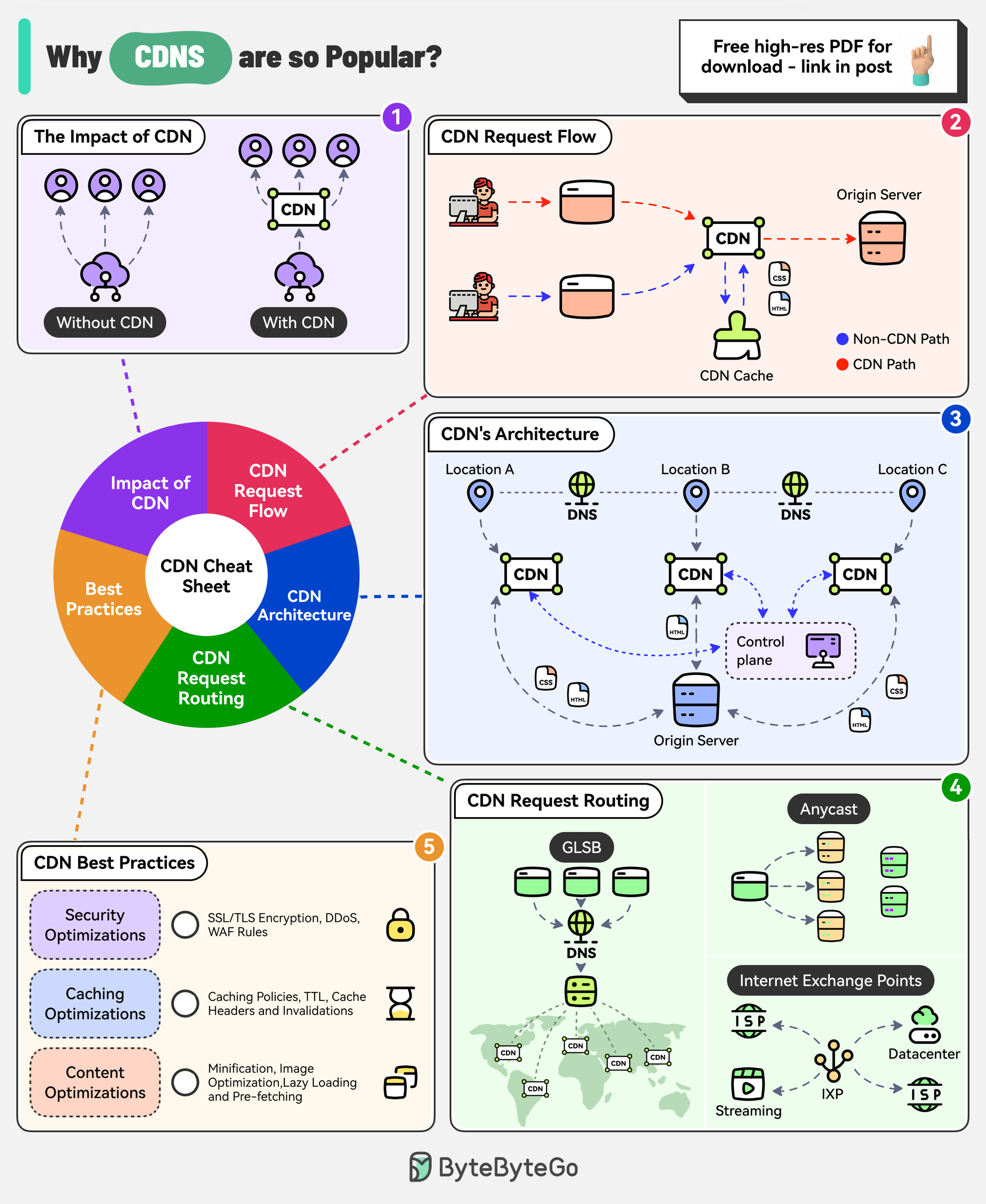
+
+The CDN market is expected to reach nearly $38 billion by 2028. Companies like Akamai, Cloudflare, and Amazon CloudFront are investing heavily in this area.
+
+## The Impact of CDN
+
+CDNs improve performance, increase availability, and enhance bandwidth costs. With the use of CDN, there is a significant reduction in latency.
+
+## CDN Request Flow
+
+After DNS resolution, the user’s device sends the content request to the CDN edge server.
+
+* The edge server checks its local cache for the content. If found, the edge server serves the content to the user.
+
+* If not found, the edge server forwards the request to the origin server.
+
+* After receiving the content from the origin server, the edge server stores a copy in its cache and delivers it to the user.
+
+## The Architecture of CDN
+
+There are multiple components in a CDN’s architecture:
+
+* **Origin Server:** This is the primary source of content.
+
+* **Edge Servers:** They cache and server content to the users and are distributed across the world.
+
+* **DNS:** The DNS resolves the domain name to the IP address of the nearest edge server
+
+* **Control Plane:** Responsible for configuring and managing the edge servers.
+
+## CDN Request Routing
+
+* **GSLB:** Routes user requests to the server based on factors like geographic proximity, server load, network conditions
+
+* **Anycast DNS:** Allows multiple servers to share the same IP address. It helps route incoming traffic to the nearest data center.
+
+* **Internet Exchange Points:** CDN providers establish a presence at major IXPs, allowing them to exchange traffic directly with ISPs and other networks.
+
+## Best Practices
+
+Some key best practices to optimize CDN performance are related to security aspects, caching optimizations, and content optimizations.
diff --git a/data/guides/why-do-we-need-to-use-a-distributed-lock.md b/data/guides/why-do-we-need-to-use-a-distributed-lock.md
new file mode 100644
index 0000000..2c857ad
--- /dev/null
+++ b/data/guides/why-do-we-need-to-use-a-distributed-lock.md
@@ -0,0 +1,42 @@
+---
+title: "Why Use a Distributed Lock?"
+description: "Explore the top use cases for distributed locks in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0383-top-6-use-cases-of-distributed-lock.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "distributed systems"
+ - "concurrency"
+---
+
+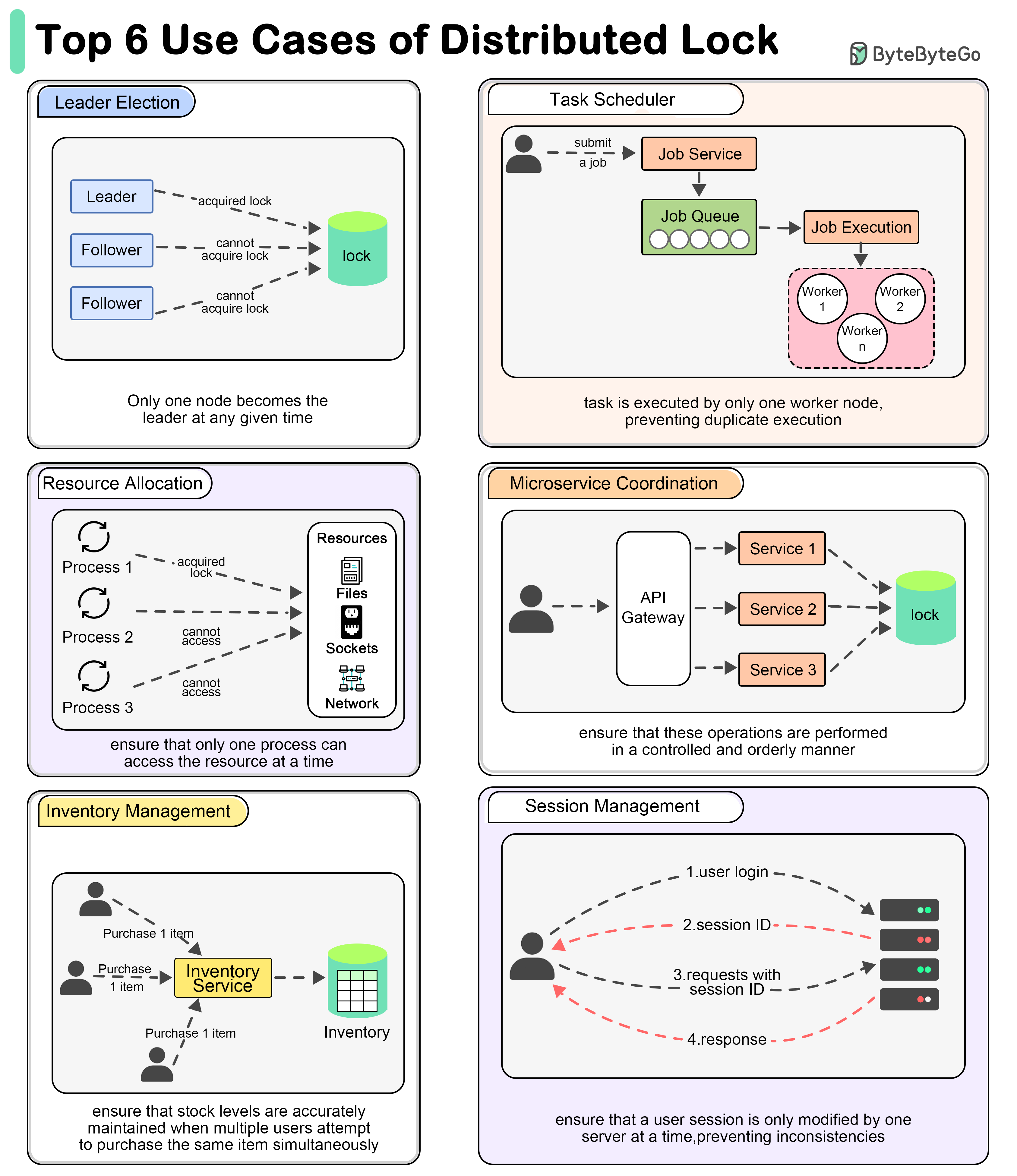
+
+A distributed lock is a mechanism that ensures mutual exclusion across a distributed system.
+
+## Top 6 Use Cases for Distributed Locks
+
+* **Leader Election**
+
+ Distributed locks can be used to ensure that only one node becomes the leader at any given time.
+
+* **Task Scheduling**
+
+ In a distributed task scheduler, distributed locks ensure that a scheduled task is executed by only one worker node, preventing duplicate execution.
+
+* **Resource Allocation**
+
+ When managing shared resources like file systems, network sockets, or hardware devices, distributed locks ensure that only one process can access the resource at a time.
+
+* **Microservices Coordination**
+
+ When multiple microservices need to perform coordinated operations, such as updating related data in different databases, distributed locks ensure that these operations are performed in a controlled and orderly manner.
+
+* **Inventory Management**
+
+ In e-commerce platforms, distributed locks can manage inventory updates to ensure that stock levels are accurately maintained when multiple users attempt to purchase the same item simultaneously.
+
+* **Session Management**
+
+ When handling user sessions in a distributed environment, distributed locks can ensure that a user session is only modified by one server at a time, preventing inconsistencies.
diff --git a/data/guides/why-is-kafka-fast.md b/data/guides/why-is-kafka-fast.md
new file mode 100644
index 0000000..a0f105a
--- /dev/null
+++ b/data/guides/why-is-kafka-fast.md
@@ -0,0 +1,40 @@
+---
+title: "Why is Kafka Fast?"
+description: "Explore the key design choices behind Kafka's high performance."
+image: "https://assets.bytebytego.com/diagrams/0424-why-is-kafka-fast.jpg"
+createdAt: "2024-02-05"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Kafka"
+ - "Performance"
+---
+
+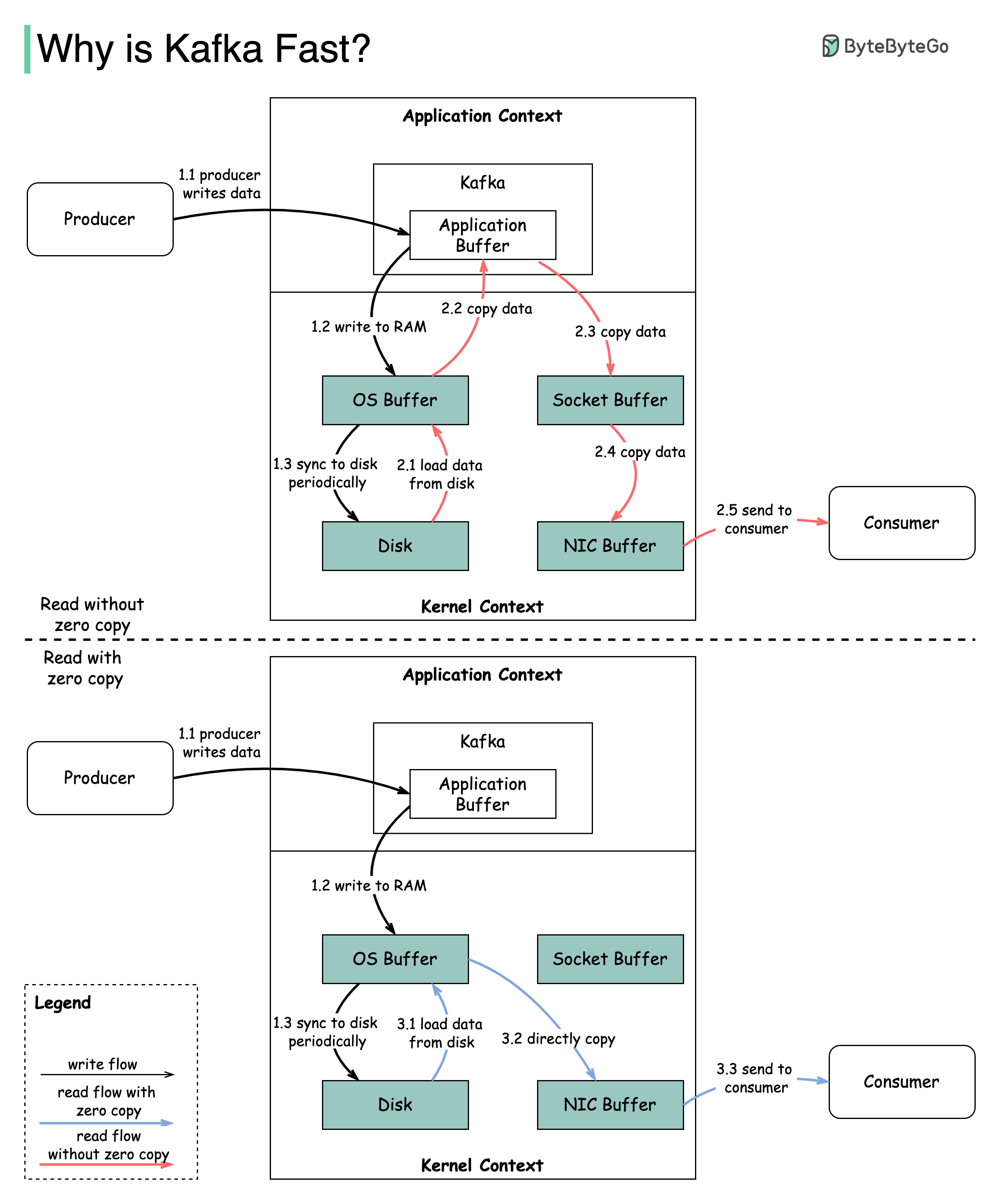
+
+There are many design decisions that contributed to Kafka’s performance. In this post, we’ll focus on two. We think these two carried the most weight.
+
+## Sequential I/O
+
+The first one is Kafka’s reliance on Sequential I/O.
+
+## Zero Copy
+
+The second design choice that gives Kafka its performance advantage is its focus on efficiency: zero copy principle.
+
+The diagram above illustrates how the data is transmitted between producer and consumer, and what zero-copy means.
+
+* Step 1.1 - 1.3: Producer writes data to the disk
+* Step 2: Consumer reads data without zero-copy
+ * 2.1: The data is loaded from disk to OS cache
+ * 2.2 The data is copied from OS cache to Kafka application
+ * 2.3 Kafka application copies the data into the socket buffer
+ * 2.4 The data is copied from socket buffer to network card
+ * 2.5 The network card sends data out to the consumer
+* Step 3: Consumer reads data with zero-copy
+ * 3.1: The data is loaded from disk to OS cache
+ * 3.2 OS cache directly copies the data to the network card via sendfile() command
+ * 3.3 The network card sends data out to the consumer
+
+Zero copy is a shortcut to save multiple data copies between the application context and kernel context.
diff --git a/data/guides/why-is-nginx-so-popular.md b/data/guides/why-is-nginx-so-popular.md
new file mode 100644
index 0000000..2b73cf0
--- /dev/null
+++ b/data/guides/why-is-nginx-so-popular.md
@@ -0,0 +1,27 @@
+---
+title: "Why is Nginx so Popular?"
+description: "Explore the reasons behind Nginx's widespread popularity and usage."
+image: "https://assets.bytebytego.com/diagrams/0423-why-is-nginx-so-popular.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Nginx"
+ - "Web Servers"
+---
+
+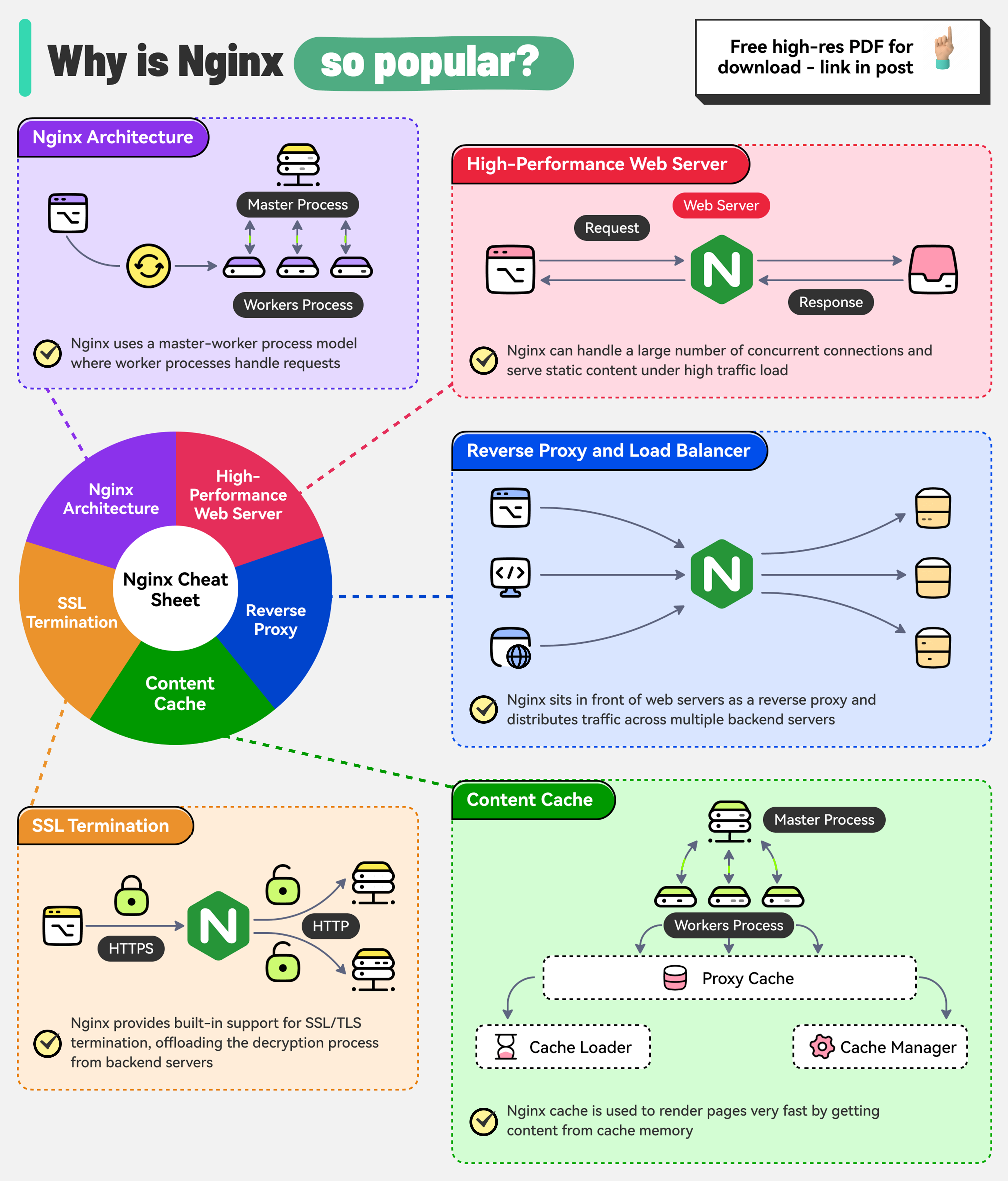
+
+Nginx is a high-performance web server and reverse proxy.
+
+It follows a master-worker process model that contributes to its stability, scalability, and efficient resource utilization.
+
+The master process is responsible for reading the configuration and managing worker processes. Worker processes handle incoming connections using an event-driven non-blocking I/O model.
+
+Due to its architecture, Nginx excels in supporting multiple features such as:
+
+* **High-Performance Web Server**
+* **Reverse Proxy and Load Balancing**
+* **Content Cache**
+* **SSL Termination**
diff --git a/data/guides/why-is-postgresql-voted-as-the-most-loved-database-by-stackoverflow-2022-developer-survey.md b/data/guides/why-is-postgresql-voted-as-the-most-loved-database-by-stackoverflow-2022-developer-survey.md
new file mode 100644
index 0000000..2357038
--- /dev/null
+++ b/data/guides/why-is-postgresql-voted-as-the-most-loved-database-by-stackoverflow-2022-developer-survey.md
@@ -0,0 +1,46 @@
+---
+title: "Why PostgreSQL is the Most Loved Database"
+description: "Explore why PostgreSQL was voted the most loved database in the 2022 survey."
+image: "https://assets.bytebytego.com/diagrams/0303-postgres.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "PostgreSQL"
+ - "Database"
+---
+
+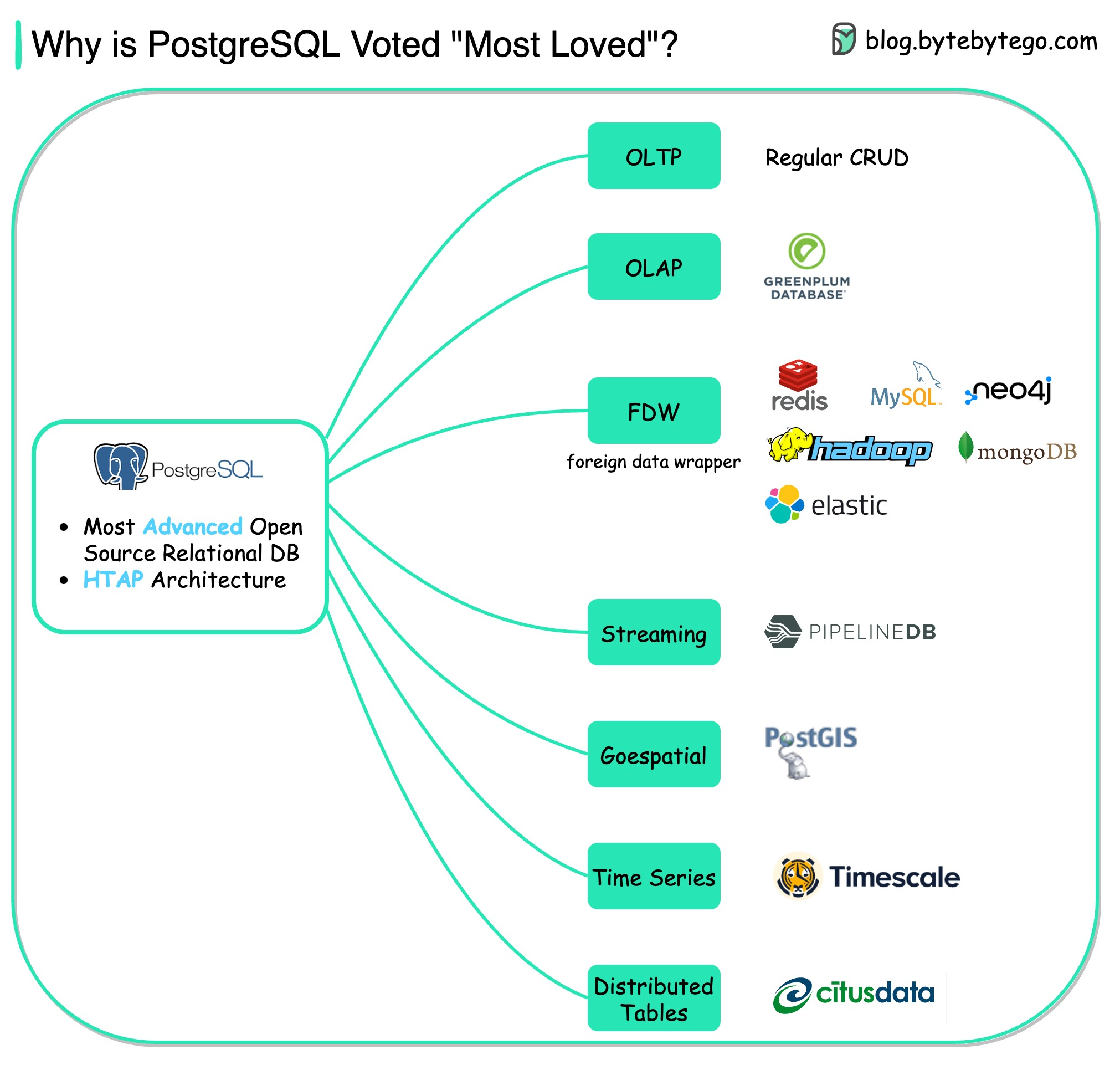
+
+The diagram shows the many use cases of PostgreSQL - one database that includes almost **all the use cases** developers need.
+
+## Use Cases of PostgreSQL
+
+* **OLTP (Online Transaction Processing)**
+
+ We can use PostgreSQL for CRUD (Create-Read-Update-Delete) operations.
+
+* **OLAP (Online Analytical Processing)**
+
+ We can use PostgreSQL for analytical processing. PostgreSQL is based on **HTAP**(Hybrid transactional/analytical processing) architecture, so it can handle both OLTP and OLAP well.
+
+* **FDW (Foreign Data Wrapper)**
+
+ A FDW is an extension available in PostgreSQL that allows us to access a table or schema in one database from another.
+
+* **Streaming**
+
+ PipelineDB is a PostgreSQL extension for high-performance time-series aggregation, designed to power real-time reporting and analytics applications.
+
+* **Geospatial**
+
+ PostGIS is a spatial database extender for PostgreSQL object-relational database. It adds support for geographic objects, allowing location queries to be run in SQL.
+
+* **Time Series**
+
+ Timescale extends PostgreSQL for time series and analytics. For example, developers can combine relentless streams of financial and tick data with other business data to build new apps and uncover unique insights.
+
+* **Distributed Tables**
+
+ CitusData scales Postgres by distributing data & queries.
diff --git a/data/guides/why-is-redis-so-fast.md b/data/guides/why-is-redis-so-fast.md
new file mode 100644
index 0000000..a4ce7f9
--- /dev/null
+++ b/data/guides/why-is-redis-so-fast.md
@@ -0,0 +1,22 @@
+---
+title: "Why is Redis so Fast?"
+description: "Explore the key factors behind Redis's exceptional speed."
+image: "https://assets.bytebytego.com/diagrams/0422-why-is-redis-so-fast.png"
+createdAt: '2024-03-07'
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Performance"
+---
+
+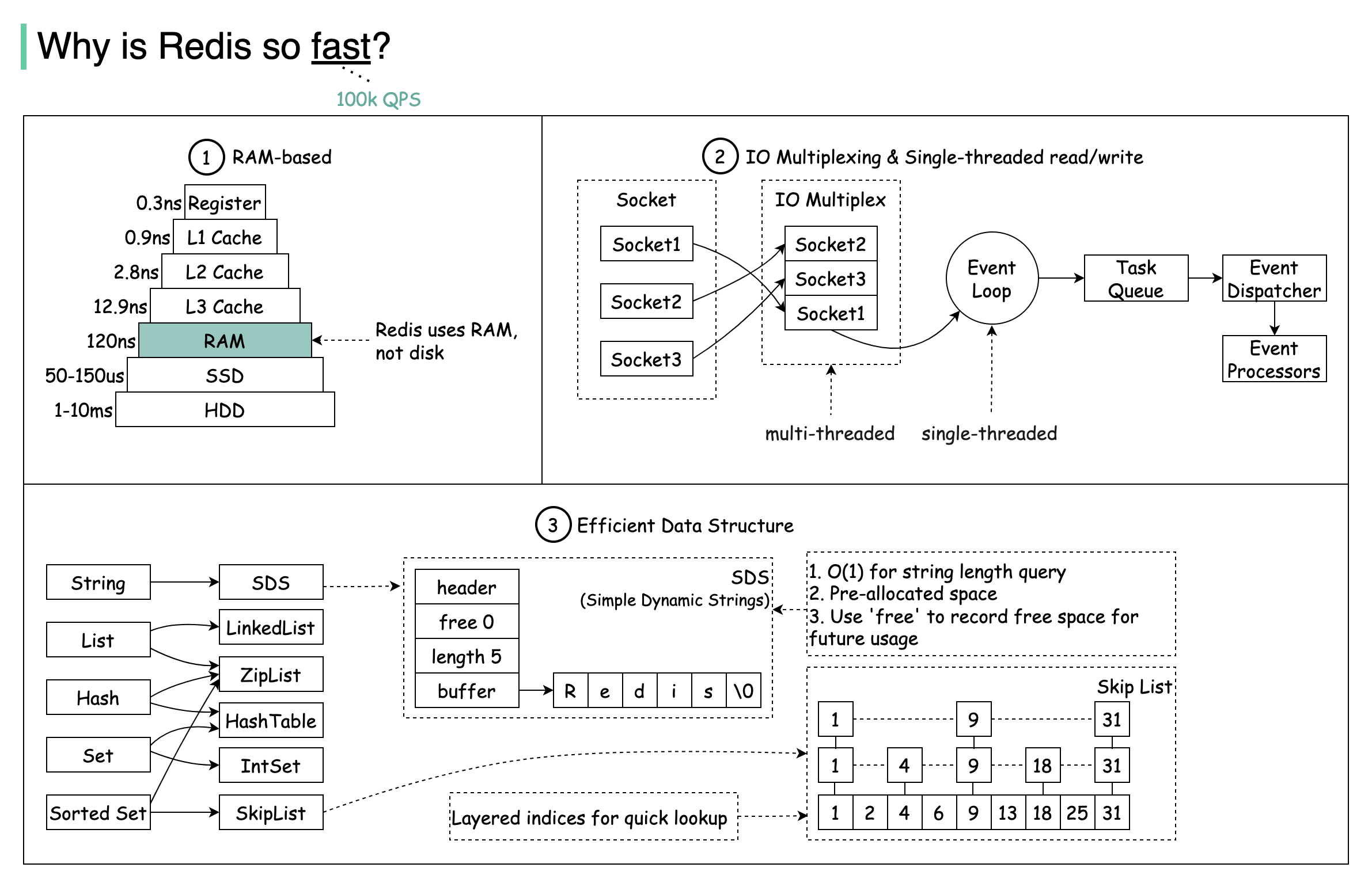
+
+There are 3 main reasons as shown in the diagram above.
+
+* Redis is a RAM-based database. RAM access is at least 1000 times faster than random disk access.
+
+* Redis leverages IO multiplexing and single-threaded execution loop for execution efficiency.
+
+* Redis leverages several efficient lower-level data structures.
diff --git a/images/18 Most-Used Linux Commands You Should Know-01.jpeg b/images/18 Most-Used Linux Commands You Should Know-01.jpeg
deleted file mode 100644
index cb3f15a..0000000
Binary files a/images/18 Most-Used Linux Commands You Should Know-01.jpeg and /dev/null differ
diff --git a/images/18-oo-patterns.png b/images/18-oo-patterns.png
deleted file mode 100644
index f257d6f..0000000
Binary files a/images/18-oo-patterns.png and /dev/null differ
diff --git a/images/8-ds-db.jpg b/images/8-ds-db.jpg
deleted file mode 100644
index 6a5ff99..0000000
Binary files a/images/8-ds-db.jpg and /dev/null differ
diff --git a/images/Forward Proxy v.s. Reverse Proxy2x.jpg b/images/Forward Proxy v.s. Reverse Proxy2x.jpg
deleted file mode 100644
index 89f6eda..0000000
Binary files a/images/Forward Proxy v.s. Reverse Proxy2x.jpg and /dev/null differ
diff --git a/images/SOAP vs REST vs GraphQL vs RPC.jpeg b/images/SOAP vs REST vs GraphQL vs RPC.jpeg
deleted file mode 100644
index 9bd3e04..0000000
Binary files a/images/SOAP vs REST vs GraphQL vs RPC.jpeg and /dev/null differ
diff --git a/images/Types_of_Memory_and_Storage.jpeg b/images/Types_of_Memory_and_Storage.jpeg
deleted file mode 100644
index f0182e0..0000000
Binary files a/images/Types_of_Memory_and_Storage.jpeg and /dev/null differ
diff --git a/images/airbnb_arch.jpeg b/images/airbnb_arch.jpeg
deleted file mode 100644
index 3b49450..0000000
Binary files a/images/airbnb_arch.jpeg and /dev/null differ
diff --git a/images/api-architecture-styles.png b/images/api-architecture-styles.png
deleted file mode 100644
index 0878f9d..0000000
Binary files a/images/api-architecture-styles.png and /dev/null differ
diff --git a/images/api-performance.jpg b/images/api-performance.jpg
deleted file mode 100644
index f2be80d..0000000
Binary files a/images/api-performance.jpg and /dev/null differ
diff --git a/images/api_first.jpg b/images/api_first.jpg
deleted file mode 100644
index 479efdf..0000000
Binary files a/images/api_first.jpg and /dev/null differ
diff --git a/images/api_gateway.jpg b/images/api_gateway.jpg
deleted file mode 100644
index 97eec07..0000000
Binary files a/images/api_gateway.jpg and /dev/null differ
diff --git a/images/bytebytego.png b/images/bytebytego.png
deleted file mode 100644
index 0117392..0000000
Binary files a/images/bytebytego.png and /dev/null differ
diff --git a/images/cap theorem.jpeg b/images/cap theorem.jpeg
deleted file mode 100644
index d87a977..0000000
Binary files a/images/cap theorem.jpeg and /dev/null differ
diff --git a/images/ci-cd-pipeline.jpg b/images/ci-cd-pipeline.jpg
deleted file mode 100644
index ce97c26..0000000
Binary files a/images/ci-cd-pipeline.jpg and /dev/null differ
diff --git a/images/client arch patterns.png b/images/client arch patterns.png
deleted file mode 100644
index faa9973..0000000
Binary files a/images/client arch patterns.png and /dev/null differ
diff --git a/images/cloud-compare.jpg b/images/cloud-compare.jpg
deleted file mode 100644
index 87f5879..0000000
Binary files a/images/cloud-compare.jpg and /dev/null differ
diff --git a/images/cloud-dbs2.png b/images/cloud-dbs2.png
deleted file mode 100644
index c15b8a7..0000000
Binary files a/images/cloud-dbs2.png and /dev/null differ
diff --git a/images/cloud-native.jpeg b/images/cloud-native.jpeg
deleted file mode 100644
index bac9239..0000000
Binary files a/images/cloud-native.jpeg and /dev/null differ
diff --git a/images/devops-sre-platform.jpg b/images/devops-sre-platform.jpg
deleted file mode 100644
index e01a1f9..0000000
Binary files a/images/devops-sre-platform.jpg and /dev/null differ
diff --git a/images/diagrams_as_code.jpeg b/images/diagrams_as_code.jpeg
deleted file mode 100644
index 4c2190d..0000000
Binary files a/images/diagrams_as_code.jpeg and /dev/null differ
diff --git a/images/discord-store-messages.jpg b/images/discord-store-messages.jpg
deleted file mode 100644
index c826add..0000000
Binary files a/images/discord-store-messages.jpg and /dev/null differ
diff --git a/images/docker-vs-k8s.jpg b/images/docker-vs-k8s.jpg
deleted file mode 100644
index 5f12a51..0000000
Binary files a/images/docker-vs-k8s.jpg and /dev/null differ
diff --git a/images/docker.jpg b/images/docker.jpg
deleted file mode 100644
index e299ad7..0000000
Binary files a/images/docker.jpg and /dev/null differ
diff --git a/images/git-commands.png b/images/git-commands.png
deleted file mode 100644
index a19032f..0000000
Binary files a/images/git-commands.png and /dev/null differ
diff --git a/images/git-merge-git-rebase.jpeg b/images/git-merge-git-rebase.jpeg
deleted file mode 100644
index 35521bb..0000000
Binary files a/images/git-merge-git-rebase.jpeg and /dev/null differ
diff --git a/images/git-workflow.jpeg b/images/git-workflow.jpeg
deleted file mode 100644
index 82f6034..0000000
Binary files a/images/git-workflow.jpeg and /dev/null differ
diff --git a/images/google_authenticate.jpeg b/images/google_authenticate.jpeg
deleted file mode 100644
index 0650686..0000000
Binary files a/images/google_authenticate.jpeg and /dev/null differ
diff --git a/images/graphQL.jpg b/images/graphQL.jpg
deleted file mode 100644
index de9d183..0000000
Binary files a/images/graphQL.jpg and /dev/null differ
diff --git a/images/grpc.jpg b/images/grpc.jpg
deleted file mode 100644
index e7b9ac9..0000000
Binary files a/images/grpc.jpg and /dev/null differ
diff --git a/images/hotstar_emojis.jpeg b/images/hotstar_emojis.jpeg
deleted file mode 100644
index 5025172..0000000
Binary files a/images/hotstar_emojis.jpeg and /dev/null differ
diff --git a/images/how does visa makes money.jpg b/images/how does visa makes money.jpg
deleted file mode 100644
index 4bac278..0000000
Binary files a/images/how does visa makes money.jpg and /dev/null differ
diff --git a/images/how-does-upi-work.png b/images/how-does-upi-work.png
deleted file mode 100644
index 5e2b8cb..0000000
Binary files a/images/how-does-upi-work.png and /dev/null differ
diff --git a/images/how-to-learn-sql.jpg b/images/how-to-learn-sql.jpg
deleted file mode 100644
index 33cb28f..0000000
Binary files a/images/how-to-learn-sql.jpg and /dev/null differ
diff --git a/images/http-status-code.jpg b/images/http-status-code.jpg
deleted file mode 100644
index f856f75..0000000
Binary files a/images/http-status-code.jpg and /dev/null differ
diff --git a/images/http3.jpg b/images/http3.jpg
deleted file mode 100644
index e761ab7..0000000
Binary files a/images/http3.jpg and /dev/null differ
diff --git a/images/https.jpg b/images/https.jpg
deleted file mode 100644
index 62100e8..0000000
Binary files a/images/https.jpg and /dev/null differ
diff --git a/images/json-cracker.jpeg b/images/json-cracker.jpeg
deleted file mode 100644
index 4933924..0000000
Binary files a/images/json-cracker.jpeg and /dev/null differ
diff --git a/images/jwt.jpg b/images/jwt.jpg
deleted file mode 100644
index 05f4f5f..0000000
Binary files a/images/jwt.jpg and /dev/null differ
diff --git a/images/k8s.jpeg b/images/k8s.jpeg
deleted file mode 100644
index 568dc71..0000000
Binary files a/images/k8s.jpeg and /dev/null differ
diff --git a/images/lb-algorithms.jpg b/images/lb-algorithms.jpg
deleted file mode 100644
index 0463e49..0000000
Binary files a/images/lb-algorithms.jpg and /dev/null differ
diff --git a/images/learn-payments.jpg b/images/learn-payments.jpg
deleted file mode 100644
index 4abdee5..0000000
Binary files a/images/learn-payments.jpg and /dev/null differ
diff --git a/images/linux-file-systems.jpg b/images/linux-file-systems.jpg
deleted file mode 100644
index c247db9..0000000
Binary files a/images/linux-file-systems.jpg and /dev/null differ
diff --git a/images/live_streaming_updated.jpg b/images/live_streaming_updated.jpg
deleted file mode 100644
index 99a90cf..0000000
Binary files a/images/live_streaming_updated.jpg and /dev/null differ
diff --git a/images/microservice-best-practices.jpeg b/images/microservice-best-practices.jpeg
deleted file mode 100644
index a08b89c..0000000
Binary files a/images/microservice-best-practices.jpeg and /dev/null differ
diff --git a/images/microservice-tech.jpeg b/images/microservice-tech.jpeg
deleted file mode 100644
index 653be78..0000000
Binary files a/images/microservice-tech.jpeg and /dev/null differ
diff --git a/images/monorepo-microrepo.jpg b/images/monorepo-microrepo.jpg
deleted file mode 100644
index 4692f79..0000000
Binary files a/images/monorepo-microrepo.jpg and /dev/null differ
diff --git a/images/netflix tech stack.png b/images/netflix tech stack.png
deleted file mode 100644
index a7d7e81..0000000
Binary files a/images/netflix tech stack.png and /dev/null differ
diff --git a/images/netflix-ci-cd.jpg b/images/netflix-ci-cd.jpg
deleted file mode 100644
index e023d29..0000000
Binary files a/images/netflix-ci-cd.jpg and /dev/null differ
diff --git a/images/network-protocols.gif b/images/network-protocols.gif
deleted file mode 100644
index 22bf691..0000000
Binary files a/images/network-protocols.gif and /dev/null differ
diff --git a/images/oAuth2.jpg b/images/oAuth2.jpg
deleted file mode 100644
index 0f6c37d..0000000
Binary files a/images/oAuth2.jpg and /dev/null differ
diff --git a/images/osi model.jpeg b/images/osi model.jpeg
deleted file mode 100644
index d2946fb..0000000
Binary files a/images/osi model.jpeg and /dev/null differ
diff --git a/images/safe-apis.jpg b/images/safe-apis.jpg
deleted file mode 100644
index b6d8bc2..0000000
Binary files a/images/safe-apis.jpg and /dev/null differ
diff --git a/images/salt.jpg b/images/salt.jpg
deleted file mode 100644
index ff3cd10..0000000
Binary files a/images/salt.jpg and /dev/null differ
diff --git a/images/serverless-to-monolithic.jpeg b/images/serverless-to-monolithic.jpeg
deleted file mode 100644
index 6b49615..0000000
Binary files a/images/serverless-to-monolithic.jpeg and /dev/null differ
diff --git a/images/session.jpeg b/images/session.jpeg
deleted file mode 100644
index f217471..0000000
Binary files a/images/session.jpeg and /dev/null differ
diff --git a/images/sql execution order in db.jpeg b/images/sql execution order in db.jpeg
deleted file mode 100644
index a41c99b..0000000
Binary files a/images/sql execution order in db.jpeg and /dev/null differ
diff --git a/images/sql-execution-order.jpg b/images/sql-execution-order.jpg
deleted file mode 100644
index 1e768ef..0000000
Binary files a/images/sql-execution-order.jpg and /dev/null differ
diff --git a/images/stackoverflow.jpg b/images/stackoverflow.jpg
deleted file mode 100644
index 2ccdd0c..0000000
Binary files a/images/stackoverflow.jpg and /dev/null differ
diff --git a/images/top-redis-use-cases.jpg b/images/top-redis-use-cases.jpg
deleted file mode 100644
index 77db6dd..0000000
Binary files a/images/top-redis-use-cases.jpg and /dev/null differ
diff --git a/images/top4-most-used-auth.jpg b/images/top4-most-used-auth.jpg
deleted file mode 100644
index b5c7dd1..0000000
Binary files a/images/top4-most-used-auth.jpg and /dev/null differ
diff --git a/images/top_caching_strategy.jpeg b/images/top_caching_strategy.jpeg
deleted file mode 100644
index a63a429..0000000
Binary files a/images/top_caching_strategy.jpeg and /dev/null differ
diff --git a/images/twitter-arch.jpeg b/images/twitter-arch.jpeg
deleted file mode 100644
index 7c31bb5..0000000
Binary files a/images/twitter-arch.jpeg and /dev/null differ
diff --git a/images/typical-microservice-arch.jpg b/images/typical-microservice-arch.jpg
deleted file mode 100644
index 4b98e9f..0000000
Binary files a/images/typical-microservice-arch.jpg and /dev/null differ
diff --git a/images/url-uri-urn.jpg b/images/url-uri-urn.jpg
deleted file mode 100644
index a78183f..0000000
Binary files a/images/url-uri-urn.jpg and /dev/null differ
diff --git a/images/visa_payment.jpeg b/images/visa_payment.jpeg
deleted file mode 100644
index b879f64..0000000
Binary files a/images/visa_payment.jpeg and /dev/null differ
diff --git a/images/webhook.jpeg b/images/webhook.jpeg
deleted file mode 100644
index 79279cb..0000000
Binary files a/images/webhook.jpeg and /dev/null differ
diff --git a/images/where do we cache data.jpeg b/images/where do we cache data.jpeg
deleted file mode 100644
index 9ad7e34..0000000
Binary files a/images/where do we cache data.jpeg and /dev/null differ
diff --git a/images/why_is_kafka_fast.jpeg b/images/why_is_kafka_fast.jpeg
deleted file mode 100644
index 6c40f7a..0000000
Binary files a/images/why_is_kafka_fast.jpeg and /dev/null differ
diff --git a/images/why_redis_fast.jpeg b/images/why_redis_fast.jpeg
deleted file mode 100644
index 0b4b882..0000000
Binary files a/images/why_redis_fast.jpeg and /dev/null differ
diff --git a/images/youtube.png b/images/youtube.png
deleted file mode 100644
index 48e3ca4..0000000
Binary files a/images/youtube.png and /dev/null differ
diff --git a/package.json b/package.json
new file mode 100644
index 0000000..2b8d9ec
--- /dev/null
+++ b/package.json
@@ -0,0 +1,15 @@
+{
+ "name": "system-design-101",
+ "version": "1.0.0",
+ "description": "Explain complex systems using visuals and simple terms.",
+ "scripts": {
+ "update-readme": "tsx scripts/readme.ts"
+ },
+ "author": "",
+ "license": "cc-by-nc-sd-4.0",
+ "devDependencies": {
+ "@types/node": "^22.13.14",
+ "gray-matter": "^4.0.3",
+ "tsx": "^4.19.3"
+ }
+}
diff --git a/pnpm-lock.yaml b/pnpm-lock.yaml
new file mode 100644
index 0000000..025effe
--- /dev/null
+++ b/pnpm-lock.yaml
@@ -0,0 +1,399 @@
+lockfileVersion: '9.0'
+
+settings:
+ autoInstallPeers: true
+ excludeLinksFromLockfile: false
+
+importers:
+
+ .:
+ devDependencies:
+ '@types/node':
+ specifier: ^22.13.14
+ version: 22.13.14
+ gray-matter:
+ specifier: ^4.0.3
+ version: 4.0.3
+ tsx:
+ specifier: ^4.19.3
+ version: 4.19.3
+
+packages:
+
+ '@esbuild/aix-ppc64@0.25.2':
+ resolution: {integrity: sha512-wCIboOL2yXZym2cgm6mlA742s9QeJ8DjGVaL39dLN4rRwrOgOyYSnOaFPhKZGLb2ngj4EyfAFjsNJwPXZvseag==}
+ engines: {node: '>=18'}
+ cpu: [ppc64]
+ os: [aix]
+
+ '@esbuild/android-arm64@0.25.2':
+ resolution: {integrity: sha512-5ZAX5xOmTligeBaeNEPnPaeEuah53Id2tX4c2CVP3JaROTH+j4fnfHCkr1PjXMd78hMst+TlkfKcW/DlTq0i4w==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [android]
+
+ '@esbuild/android-arm@0.25.2':
+ resolution: {integrity: sha512-NQhH7jFstVY5x8CKbcfa166GoV0EFkaPkCKBQkdPJFvo5u+nGXLEH/ooniLb3QI8Fk58YAx7nsPLozUWfCBOJA==}
+ engines: {node: '>=18'}
+ cpu: [arm]
+ os: [android]
+
+ '@esbuild/android-x64@0.25.2':
+ resolution: {integrity: sha512-Ffcx+nnma8Sge4jzddPHCZVRvIfQ0kMsUsCMcJRHkGJ1cDmhe4SsrYIjLUKn1xpHZybmOqCWwB0zQvsjdEHtkg==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [android]
+
+ '@esbuild/darwin-arm64@0.25.2':
+ resolution: {integrity: sha512-MpM6LUVTXAzOvN4KbjzU/q5smzryuoNjlriAIx+06RpecwCkL9JpenNzpKd2YMzLJFOdPqBpuub6eVRP5IgiSA==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [darwin]
+
+ '@esbuild/darwin-x64@0.25.2':
+ resolution: {integrity: sha512-5eRPrTX7wFyuWe8FqEFPG2cU0+butQQVNcT4sVipqjLYQjjh8a8+vUTfgBKM88ObB85ahsnTwF7PSIt6PG+QkA==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [darwin]
+
+ '@esbuild/freebsd-arm64@0.25.2':
+ resolution: {integrity: sha512-mLwm4vXKiQ2UTSX4+ImyiPdiHjiZhIaE9QvC7sw0tZ6HoNMjYAqQpGyui5VRIi5sGd+uWq940gdCbY3VLvsO1w==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [freebsd]
+
+ '@esbuild/freebsd-x64@0.25.2':
+ resolution: {integrity: sha512-6qyyn6TjayJSwGpm8J9QYYGQcRgc90nmfdUb0O7pp1s4lTY+9D0H9O02v5JqGApUyiHOtkz6+1hZNvNtEhbwRQ==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [freebsd]
+
+ '@esbuild/linux-arm64@0.25.2':
+ resolution: {integrity: sha512-gq/sjLsOyMT19I8obBISvhoYiZIAaGF8JpeXu1u8yPv8BE5HlWYobmlsfijFIZ9hIVGYkbdFhEqC0NvM4kNO0g==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [linux]
+
+ '@esbuild/linux-arm@0.25.2':
+ resolution: {integrity: sha512-UHBRgJcmjJv5oeQF8EpTRZs/1knq6loLxTsjc3nxO9eXAPDLcWW55flrMVc97qFPbmZP31ta1AZVUKQzKTzb0g==}
+ engines: {node: '>=18'}
+ cpu: [arm]
+ os: [linux]
+
+ '@esbuild/linux-ia32@0.25.2':
+ resolution: {integrity: sha512-bBYCv9obgW2cBP+2ZWfjYTU+f5cxRoGGQ5SeDbYdFCAZpYWrfjjfYwvUpP8MlKbP0nwZ5gyOU/0aUzZ5HWPuvQ==}
+ engines: {node: '>=18'}
+ cpu: [ia32]
+ os: [linux]
+
+ '@esbuild/linux-loong64@0.25.2':
+ resolution: {integrity: sha512-SHNGiKtvnU2dBlM5D8CXRFdd+6etgZ9dXfaPCeJtz+37PIUlixvlIhI23L5khKXs3DIzAn9V8v+qb1TRKrgT5w==}
+ engines: {node: '>=18'}
+ cpu: [loong64]
+ os: [linux]
+
+ '@esbuild/linux-mips64el@0.25.2':
+ resolution: {integrity: sha512-hDDRlzE6rPeoj+5fsADqdUZl1OzqDYow4TB4Y/3PlKBD0ph1e6uPHzIQcv2Z65u2K0kpeByIyAjCmjn1hJgG0Q==}
+ engines: {node: '>=18'}
+ cpu: [mips64el]
+ os: [linux]
+
+ '@esbuild/linux-ppc64@0.25.2':
+ resolution: {integrity: sha512-tsHu2RRSWzipmUi9UBDEzc0nLc4HtpZEI5Ba+Omms5456x5WaNuiG3u7xh5AO6sipnJ9r4cRWQB2tUjPyIkc6g==}
+ engines: {node: '>=18'}
+ cpu: [ppc64]
+ os: [linux]
+
+ '@esbuild/linux-riscv64@0.25.2':
+ resolution: {integrity: sha512-k4LtpgV7NJQOml/10uPU0s4SAXGnowi5qBSjaLWMojNCUICNu7TshqHLAEbkBdAszL5TabfvQ48kK84hyFzjnw==}
+ engines: {node: '>=18'}
+ cpu: [riscv64]
+ os: [linux]
+
+ '@esbuild/linux-s390x@0.25.2':
+ resolution: {integrity: sha512-GRa4IshOdvKY7M/rDpRR3gkiTNp34M0eLTaC1a08gNrh4u488aPhuZOCpkF6+2wl3zAN7L7XIpOFBhnaE3/Q8Q==}
+ engines: {node: '>=18'}
+ cpu: [s390x]
+ os: [linux]
+
+ '@esbuild/linux-x64@0.25.2':
+ resolution: {integrity: sha512-QInHERlqpTTZ4FRB0fROQWXcYRD64lAoiegezDunLpalZMjcUcld3YzZmVJ2H/Cp0wJRZ8Xtjtj0cEHhYc/uUg==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [linux]
+
+ '@esbuild/netbsd-arm64@0.25.2':
+ resolution: {integrity: sha512-talAIBoY5M8vHc6EeI2WW9d/CkiO9MQJ0IOWX8hrLhxGbro/vBXJvaQXefW2cP0z0nQVTdQ/eNyGFV1GSKrxfw==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [netbsd]
+
+ '@esbuild/netbsd-x64@0.25.2':
+ resolution: {integrity: sha512-voZT9Z+tpOxrvfKFyfDYPc4DO4rk06qamv1a/fkuzHpiVBMOhpjK+vBmWM8J1eiB3OLSMFYNaOaBNLXGChf5tg==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [netbsd]
+
+ '@esbuild/openbsd-arm64@0.25.2':
+ resolution: {integrity: sha512-dcXYOC6NXOqcykeDlwId9kB6OkPUxOEqU+rkrYVqJbK2hagWOMrsTGsMr8+rW02M+d5Op5NNlgMmjzecaRf7Tg==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [openbsd]
+
+ '@esbuild/openbsd-x64@0.25.2':
+ resolution: {integrity: sha512-t/TkWwahkH0Tsgoq1Ju7QfgGhArkGLkF1uYz8nQS/PPFlXbP5YgRpqQR3ARRiC2iXoLTWFxc6DJMSK10dVXluw==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [openbsd]
+
+ '@esbuild/sunos-x64@0.25.2':
+ resolution: {integrity: sha512-cfZH1co2+imVdWCjd+D1gf9NjkchVhhdpgb1q5y6Hcv9TP6Zi9ZG/beI3ig8TvwT9lH9dlxLq5MQBBgwuj4xvA==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [sunos]
+
+ '@esbuild/win32-arm64@0.25.2':
+ resolution: {integrity: sha512-7Loyjh+D/Nx/sOTzV8vfbB3GJuHdOQyrOryFdZvPHLf42Tk9ivBU5Aedi7iyX+x6rbn2Mh68T4qq1SDqJBQO5Q==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [win32]
+
+ '@esbuild/win32-ia32@0.25.2':
+ resolution: {integrity: sha512-WRJgsz9un0nqZJ4MfhabxaD9Ft8KioqU3JMinOTvobbX6MOSUigSBlogP8QB3uxpJDsFS6yN+3FDBdqE5lg9kg==}
+ engines: {node: '>=18'}
+ cpu: [ia32]
+ os: [win32]
+
+ '@esbuild/win32-x64@0.25.2':
+ resolution: {integrity: sha512-kM3HKb16VIXZyIeVrM1ygYmZBKybX8N4p754bw390wGO3Tf2j4L2/WYL+4suWujpgf6GBYs3jv7TyUivdd05JA==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [win32]
+
+ '@types/node@22.13.14':
+ resolution: {integrity: sha512-Zs/Ollc1SJ8nKUAgc7ivOEdIBM8JAKgrqqUYi2J997JuKO7/tpQC+WCetQ1sypiKCQWHdvdg9wBNpUPEWZae7w==}
+
+ argparse@1.0.10:
+ resolution: {integrity: sha512-o5Roy6tNG4SL/FOkCAN6RzjiakZS25RLYFrcMttJqbdd8BWrnA+fGz57iN5Pb06pvBGvl5gQ0B48dJlslXvoTg==}
+
+ esbuild@0.25.2:
+ resolution: {integrity: sha512-16854zccKPnC+toMywC+uKNeYSv+/eXkevRAfwRD/G9Cleq66m8XFIrigkbvauLLlCfDL45Q2cWegSg53gGBnQ==}
+ engines: {node: '>=18'}
+ hasBin: true
+
+ esprima@4.0.1:
+ resolution: {integrity: sha512-eGuFFw7Upda+g4p+QHvnW0RyTX/SVeJBDM/gCtMARO0cLuT2HcEKnTPvhjV6aGeqrCB/sbNop0Kszm0jsaWU4A==}
+ engines: {node: '>=4'}
+ hasBin: true
+
+ extend-shallow@2.0.1:
+ resolution: {integrity: sha512-zCnTtlxNoAiDc3gqY2aYAWFx7XWWiasuF2K8Me5WbN8otHKTUKBwjPtNpRs/rbUZm7KxWAaNj7P1a/p52GbVug==}
+ engines: {node: '>=0.10.0'}
+
+ fsevents@2.3.3:
+ resolution: {integrity: sha512-5xoDfX+fL7faATnagmWPpbFtwh/R77WmMMqqHGS65C3vvB0YHrgF+B1YmZ3441tMj5n63k0212XNoJwzlhffQw==}
+ engines: {node: ^8.16.0 || ^10.6.0 || >=11.0.0}
+ os: [darwin]
+
+ get-tsconfig@4.10.0:
+ resolution: {integrity: sha512-kGzZ3LWWQcGIAmg6iWvXn0ei6WDtV26wzHRMwDSzmAbcXrTEXxHy6IehI6/4eT6VRKyMP1eF1VqwrVUmE/LR7A==}
+
+ gray-matter@4.0.3:
+ resolution: {integrity: sha512-5v6yZd4JK3eMI3FqqCouswVqwugaA9r4dNZB1wwcmrD02QkV5H0y7XBQW8QwQqEaZY1pM9aqORSORhJRdNK44Q==}
+ engines: {node: '>=6.0'}
+
+ is-extendable@0.1.1:
+ resolution: {integrity: sha512-5BMULNob1vgFX6EjQw5izWDxrecWK9AM72rugNr0TFldMOi0fj6Jk+zeKIt0xGj4cEfQIJth4w3OKWOJ4f+AFw==}
+ engines: {node: '>=0.10.0'}
+
+ js-yaml@3.14.1:
+ resolution: {integrity: sha512-okMH7OXXJ7YrN9Ok3/SXrnu4iX9yOk+25nqX4imS2npuvTYDmo/QEZoqwZkYaIDk3jVvBOTOIEgEhaLOynBS9g==}
+ hasBin: true
+
+ kind-of@6.0.3:
+ resolution: {integrity: sha512-dcS1ul+9tmeD95T+x28/ehLgd9mENa3LsvDTtzm3vyBEO7RPptvAD+t44WVXaUjTBRcrpFeFlC8WCruUR456hw==}
+ engines: {node: '>=0.10.0'}
+
+ resolve-pkg-maps@1.0.0:
+ resolution: {integrity: sha512-seS2Tj26TBVOC2NIc2rOe2y2ZO7efxITtLZcGSOnHHNOQ7CkiUBfw0Iw2ck6xkIhPwLhKNLS8BO+hEpngQlqzw==}
+
+ section-matter@1.0.0:
+ resolution: {integrity: sha512-vfD3pmTzGpufjScBh50YHKzEu2lxBWhVEHsNGoEXmCmn2hKGfeNLYMzCJpe8cD7gqX7TJluOVpBkAequ6dgMmA==}
+ engines: {node: '>=4'}
+
+ sprintf-js@1.0.3:
+ resolution: {integrity: sha512-D9cPgkvLlV3t3IzL0D0YLvGA9Ahk4PcvVwUbN0dSGr1aP0Nrt4AEnTUbuGvquEC0mA64Gqt1fzirlRs5ibXx8g==}
+
+ strip-bom-string@1.0.0:
+ resolution: {integrity: sha512-uCC2VHvQRYu+lMh4My/sFNmF2klFymLX1wHJeXnbEJERpV/ZsVuonzerjfrGpIGF7LBVa1O7i9kjiWvJiFck8g==}
+ engines: {node: '>=0.10.0'}
+
+ tsx@4.19.3:
+ resolution: {integrity: sha512-4H8vUNGNjQ4V2EOoGw005+c+dGuPSnhpPBPHBtsZdGZBk/iJb4kguGlPWaZTZ3q5nMtFOEsY0nRDlh9PJyd6SQ==}
+ engines: {node: '>=18.0.0'}
+ hasBin: true
+
+ undici-types@6.20.0:
+ resolution: {integrity: sha512-Ny6QZ2Nju20vw1SRHe3d9jVu6gJ+4e3+MMpqu7pqE5HT6WsTSlce++GQmK5UXS8mzV8DSYHrQH+Xrf2jVcuKNg==}
+
+snapshots:
+
+ '@esbuild/aix-ppc64@0.25.2':
+ optional: true
+
+ '@esbuild/android-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/android-arm@0.25.2':
+ optional: true
+
+ '@esbuild/android-x64@0.25.2':
+ optional: true
+
+ '@esbuild/darwin-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/darwin-x64@0.25.2':
+ optional: true
+
+ '@esbuild/freebsd-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/freebsd-x64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-arm@0.25.2':
+ optional: true
+
+ '@esbuild/linux-ia32@0.25.2':
+ optional: true
+
+ '@esbuild/linux-loong64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-mips64el@0.25.2':
+ optional: true
+
+ '@esbuild/linux-ppc64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-riscv64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-s390x@0.25.2':
+ optional: true
+
+ '@esbuild/linux-x64@0.25.2':
+ optional: true
+
+ '@esbuild/netbsd-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/netbsd-x64@0.25.2':
+ optional: true
+
+ '@esbuild/openbsd-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/openbsd-x64@0.25.2':
+ optional: true
+
+ '@esbuild/sunos-x64@0.25.2':
+ optional: true
+
+ '@esbuild/win32-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/win32-ia32@0.25.2':
+ optional: true
+
+ '@esbuild/win32-x64@0.25.2':
+ optional: true
+
+ '@types/node@22.13.14':
+ dependencies:
+ undici-types: 6.20.0
+
+ argparse@1.0.10:
+ dependencies:
+ sprintf-js: 1.0.3
+
+ esbuild@0.25.2:
+ optionalDependencies:
+ '@esbuild/aix-ppc64': 0.25.2
+ '@esbuild/android-arm': 0.25.2
+ '@esbuild/android-arm64': 0.25.2
+ '@esbuild/android-x64': 0.25.2
+ '@esbuild/darwin-arm64': 0.25.2
+ '@esbuild/darwin-x64': 0.25.2
+ '@esbuild/freebsd-arm64': 0.25.2
+ '@esbuild/freebsd-x64': 0.25.2
+ '@esbuild/linux-arm': 0.25.2
+ '@esbuild/linux-arm64': 0.25.2
+ '@esbuild/linux-ia32': 0.25.2
+ '@esbuild/linux-loong64': 0.25.2
+ '@esbuild/linux-mips64el': 0.25.2
+ '@esbuild/linux-ppc64': 0.25.2
+ '@esbuild/linux-riscv64': 0.25.2
+ '@esbuild/linux-s390x': 0.25.2
+ '@esbuild/linux-x64': 0.25.2
+ '@esbuild/netbsd-arm64': 0.25.2
+ '@esbuild/netbsd-x64': 0.25.2
+ '@esbuild/openbsd-arm64': 0.25.2
+ '@esbuild/openbsd-x64': 0.25.2
+ '@esbuild/sunos-x64': 0.25.2
+ '@esbuild/win32-arm64': 0.25.2
+ '@esbuild/win32-ia32': 0.25.2
+ '@esbuild/win32-x64': 0.25.2
+
+ esprima@4.0.1: {}
+
+ extend-shallow@2.0.1:
+ dependencies:
+ is-extendable: 0.1.1
+
+ fsevents@2.3.3:
+ optional: true
+
+ get-tsconfig@4.10.0:
+ dependencies:
+ resolve-pkg-maps: 1.0.0
+
+ gray-matter@4.0.3:
+ dependencies:
+ js-yaml: 3.14.1
+ kind-of: 6.0.3
+ section-matter: 1.0.0
+ strip-bom-string: 1.0.0
+
+ is-extendable@0.1.1: {}
+
+ js-yaml@3.14.1:
+ dependencies:
+ argparse: 1.0.10
+ esprima: 4.0.1
+
+ kind-of@6.0.3: {}
+
+ resolve-pkg-maps@1.0.0: {}
+
+ section-matter@1.0.0:
+ dependencies:
+ extend-shallow: 2.0.1
+ kind-of: 6.0.3
+
+ sprintf-js@1.0.3: {}
+
+ strip-bom-string@1.0.0: {}
+
+ tsx@4.19.3:
+ dependencies:
+ esbuild: 0.25.2
+ get-tsconfig: 4.10.0
+ optionalDependencies:
+ fsevents: 2.3.3
+
+ undici-types@6.20.0: {}
diff --git a/scripts/readme.ts b/scripts/readme.ts
new file mode 100644
index 0000000..0b8bfe9
--- /dev/null
+++ b/scripts/readme.ts
@@ -0,0 +1,82 @@
+import fs from 'fs'
+import path from 'path'
+import matter from 'gray-matter'
+
+interface Category {
+ id: string
+ title: string
+ sort: number
+}
+
+interface Guide {
+ id: string
+ title: string
+ createdAt: string
+ categories: string[]
+}
+
+const CATEGORIES_DIR = path.join(process.cwd(), 'data/categories')
+const GUIDES_DIR = path.join(process.cwd(), 'data/guides')
+const README_PATH = path.join(process.cwd(), 'README.md')
+
+function getCategories(): Category[] {
+ const files = fs.readdirSync(CATEGORIES_DIR)
+ return files
+ .map(file => {
+ const content = fs.readFileSync(path.join(CATEGORIES_DIR, file), 'utf8')
+ const { data } = matter(content)
+ return {
+ id: file.replace('.md', ''),
+ title: data.title,
+ sort: data.sort
+ }
+ })
+ .sort((a, b) => a.sort - b.sort)
+}
+
+function getGuides(): Guide[] {
+ const files = fs.readdirSync(GUIDES_DIR)
+ return files
+ .map(file => {
+ const content = fs.readFileSync(path.join(GUIDES_DIR, file), 'utf8')
+ const { data } = matter(content)
+ return {
+ id: file.replace('.md', ''),
+ title: data.title,
+ createdAt: data.createdAt,
+ categories: data.categories || []
+ }
+ })
+ .sort((a, b) => new Date(a.createdAt).getTime() - new Date(b.createdAt).getTime())
+}
+
+function generateMarkdownList() {
+ const categories = getCategories()
+ const guides = getGuides()
+
+ let markdown = ''
+
+ categories.forEach(category => {
+ markdown += `* [${category.title}](https://bytebytego.com/guides/${category.id})\n`
+
+ const categoryGuides = guides.filter(guide => guide.categories.includes(category.id))
+ if (categoryGuides.length > 0) {
+ categoryGuides.forEach(guide => {
+ markdown += ` * [${guide.title}](https://bytebytego.com/guides/${guide.id})\n`
+ })
+ }
+ })
+
+ return markdown
+}
+
+function updateReadmeToc() {
+ const readmeContent = fs.readFileSync(README_PATH, 'utf8')
+ const tocRegex = /\n([\s\S]*?)\n/
+ const newToc = `\n\n${generateMarkdownList()}\n\n`
+ const updatedContent = readmeContent.replace(tocRegex, newToc)
+ fs.writeFileSync(README_PATH, updatedContent)
+ console.log('TOC updated successfully!')
+}
+
+updateReadmeToc()
diff --git a/translations/TRANSLATIONS.md b/translations/TRANSLATIONS.md
deleted file mode 100644
index d3a3f0a..0000000
--- a/translations/TRANSLATIONS.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# Translations
-
-We'd like for the repo to be available in many languages. Here is the process for maintaining translations:
-
-* Please put new translation README files here.
-* We'll migrate the existing translations when they are ready.
-* All diagrams are maintained in English and will not be translated.
-* To start a new translation, please:
- 1. Make an issue (for collaboration with other translators)
- 2. Make a pull request to collaborate and commit to.
- 3. Let us know when it's ready to merge.
-
-### Translation template credits
-
-Thanks to [coding-interview-university](https://github.com/jwasham/coding-interview-university/blob/main/translations/how-to.md) for the translation template.
+
+* Perforated cards were the first generation of programming languages. Assembly languages, which are machine-oriented, are the second generation of programming language. Third-generation languages, which are human-oriented, have been around since 1957.
+
+* Early languages like Fortran and LISP proposed garbage collection, recursion, exceptions. These features still exist in modern programming languages.
+
+* In 1972, two influential languages were born: Smalltalk and C. Smalltalk greatly influenced scripting languages and client-side languages. C language was developed for unix programming.
+
+* In the 1980s, object-oriented languages became popular because of its advantage in graphic user interfaces. Object-C and C++ are two famous ones.
+
+* In the 1990s, the PCs became cheaper. The programming languages at this stage emphasized on security and simplicity. Python was born in this decade. It was easy to learn and extend and it quickly gained popularity. In 1995, Java, Javascript, PHP and Ruby were born.
+
+* In 2000, C# was released by Microsoft. Although it was bundled with .NET framework, this language carried a lot of advanced features.
+
+* A number of languages were developed in the 2010s to improve C++ or Java. In the C++ family, we have D, Rust, Zig and most recently Carbon. In the Java family, we have Golang and Kotlin. The use of Flutter made Dart popular, and Typescript was developed to be fully compatible with Javascript. Also, Apple finally released Swift to replace Object-C.
diff --git a/data/guides/a-cheat-sheet-for-api-designs.md b/data/guides/a-cheat-sheet-for-api-designs.md
new file mode 100644
index 0000000..1e51e00
--- /dev/null
+++ b/data/guides/a-cheat-sheet-for-api-designs.md
@@ -0,0 +1,40 @@
+---
+title: 'A cheat sheet for API designs'
+description: 'A handy cheat sheet for designing secure and efficient APIs.'
+image: 'https://assets.bytebytego.com/diagrams/0137-cheat-sheet-for-api-design.png'
+createdAt: '2024-02-14'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Design
+ - Security
+---
+
+
+
+APIs expose business logic and data to external systems, so designing them securely and efficiently is important.
+
+## API key generation
+
+We normally generate one unique app ID for each client and generate different pairs of public key (access key) and private key (secret key) to cater to different authorizations. For example, we can generate one pair of keys for read-only access and another pair for read-write access.
+
+## Signature generation
+
+Signatures are used to verify the authenticity and integrity of API requests. They are generated using the secret key and typically involve the following steps:
+
+* Collect parameters
+* Create a string to sign
+* Hash the string: Use a cryptographic hash function, like HMAC (Hash-based Message Authentication Code) in combination with SHA-256, to hash the string using the secret key.
+* Send the requests
+
+When designing an API, deciding what should be included in HTTP request parameters is crucial. Include the following in the request parameters:
+
+* Authentication Credentials
+* Timestamp: To prevent replay attacks.
+* Request-specific Data: Necessary to process the request, such as user IDs, transaction details, or search queries.
+* Nonces: Randomly generated strings included in each request to ensure that each request is unique and to prevent replay attacks.
+
+## Security guidelines
+
+To safeguard APIs against common vulnerabilities and threats, adhere to these security guidelines.
diff --git a/data/guides/a-cheat-sheet-for-designing-fault-tolerant-systems.md b/data/guides/a-cheat-sheet-for-designing-fault-tolerant-systems.md
new file mode 100644
index 0000000..d19fb06
--- /dev/null
+++ b/data/guides/a-cheat-sheet-for-designing-fault-tolerant-systems.md
@@ -0,0 +1,40 @@
+---
+title: "A Cheat Sheet for Designing Fault-Tolerant Systems"
+description: "Top principles for designing robust, fault-tolerant systems."
+image: "https://assets.bytebytego.com/diagrams/0139-cheat-sheet-for-fault-tolerant-systems.png"
+createdAt: "2024-02-14"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Fault Tolerance"
+ - "System Design"
+---
+
+
+
+Designing fault-tolerant systems is crucial for ensuring high availability and reliability in various applications. Here are six top principles of designing fault-tolerant systems:
+
+## Replication
+
+Replication involves creating multiple copies of data or services across different nodes or locations.
+
+## Redundancy
+
+Redundancy refers to having additional components or systems that can take over in case of a failure.
+
+## Load Balancing
+
+Load balancing distributes incoming network traffic across multiple servers to ensure no single server becomes a point of failure.
+
+## Failover Mechanisms
+
+Failover mechanisms automatically switch to a standby system or component when the primary one fails.
+
+## Graceful Degradation
+
+Graceful degradation ensures that a system continues to operate at reduced functionality rather than completely failing when some components fail.
+
+## Monitoring and Alerting
+
+Continuously monitor the system's health and performance, and set up alerts for any anomalies or failures.
diff --git a/data/guides/a-cheat-sheet-for-system-designs.md b/data/guides/a-cheat-sheet-for-system-designs.md
new file mode 100644
index 0000000..c2744c1
--- /dev/null
+++ b/data/guides/a-cheat-sheet-for-system-designs.md
@@ -0,0 +1,32 @@
+---
+title: "A cheat sheet for system designs"
+description: "15 core concepts for system design in a handy cheat sheet."
+image: "https://assets.bytebytego.com/diagrams/0352-a-cheat-sheet-for-system-designs.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "architecture"
+---
+
+
+
+The diagram below lists 15 core concepts when we design systems. The cheat sheet is straightforward to go through one by one. Save it for future reference!
+
+* Requirement gathering
+* System architecture
+* Data design
+* Domain design
+* Scalability
+* Reliability
+* Availability
+* Performance
+* Security
+* Maintainability
+* Testing
+* User experience design
+* Cost estimation
+* Documentation
+* Migration plan
diff --git a/data/guides/a-cheatsheet-for-uml-class-diagrams.md b/data/guides/a-cheatsheet-for-uml-class-diagrams.md
new file mode 100644
index 0000000..f7f3920
--- /dev/null
+++ b/data/guides/a-cheatsheet-for-uml-class-diagrams.md
@@ -0,0 +1,48 @@
+---
+title: "UML Class Diagrams Cheatsheet"
+description: "A quick reference guide to UML class diagrams and their components."
+image: "https://assets.bytebytego.com/diagrams/0399-a-cheatsheet-for-uml-class-diagrams.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - UML
+ - Design Patterns
+---
+
+
+
+UML is a standard way to visualize the design of your system and class diagrams are used across the industry.
+
+They consist of:
+
+* **Class**
+
+ Acts as the blueprint that defines the properties and behavior of an object.
+
+* **Attributes**
+
+ Attributes in a UML class diagram represent the data fields of the class.
+
+* **Methods**
+
+ Methods in a UML class diagram represent the behavior that a class can perform.
+
+* **Interfaces**
+
+ Defines a contract for classes that implement it. Includes a set of methods that the implementing classes must provide.
+
+* **Enumeration**
+
+ A special data type that defines a set of named values such as product category or months in a year.
+
+* **Relationships**
+
+ Determines how one class is related to another. Some common relationships are as follows:
+
+ * Association
+ * Aggregation
+ * Composition
+ * Inheritance
+ * Implementation
diff --git a/data/guides/a-cheatsheet-on-comparing-api-architectural-styles.md b/data/guides/a-cheatsheet-on-comparing-api-architectural-styles.md
new file mode 100644
index 0000000..0877a94
--- /dev/null
+++ b/data/guides/a-cheatsheet-on-comparing-api-architectural-styles.md
@@ -0,0 +1,23 @@
+---
+title: 'A Cheatsheet on Comparing API Architectural Styles'
+description: 'A quick reference guide comparing popular API architectural styles.'
+image: 'https://assets.bytebytego.com/diagrams/0092-cheatsheet-on-comparing-api-architectural-styles.png'
+createdAt: '2024-02-26'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Architecture
+---
+
+
+
+It covers the 6 most popular API architectural styles:
+
+* SOAP
+* REST
+* GraphQL
+* gRPC
+* WebSocket
+* Webhook
diff --git a/data/guides/a-cheatsheet-on-database-performance.md b/data/guides/a-cheatsheet-on-database-performance.md
new file mode 100644
index 0000000..f9ce7e3
--- /dev/null
+++ b/data/guides/a-cheatsheet-on-database-performance.md
@@ -0,0 +1,88 @@
+---
+title: "A Cheatsheet on Database Performance"
+description: "Concise guide to optimize database performance with key strategies."
+image: "https://assets.bytebytego.com/diagrams/0062-a-cheatsheet-on-database-performance.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "database"
+ - "performance"
+---
+
+
+
+## Database Performance Cheatsheet
+
+Here's a cheatsheet on database performance:
+
+### **1. Indexing**
+
+* **Purpose**: Speed up data retrieval.
+* **Considerations**:
+ * Over-indexing can slow down writes.
+ * Regularly review and optimize indexes.
+
+### **2. Query Optimization**
+
+* **Techniques**:
+ * Use `EXPLAIN` to analyze query plans.
+ * Avoid `SELECT *`.
+ * Write efficient `WHERE` clauses.
+
+### **3. Connection Pooling**
+
+* **Benefits**:
+ * Reduces overhead of establishing new connections.
+ * Improves response times.
+
+### **4. Caching**
+
+* **Levels**:
+ * Application-level (e.g., Memcached, Redis).
+ * Database-level (query cache).
+
+### **5. Sharding**
+
+* **Definition**: Distribute data across multiple databases.
+* **Use Cases**:
+ * Handling large datasets.
+ * Improving write performance.
+
+### **6. Replication**
+
+* **Types**:
+ * Master-slave.
+ * Master-master.
+* **Purpose**:
+ * Read scaling.
+ * High availability.
+
+### **7. Hardware**
+
+* **Considerations**:
+ * Sufficient RAM.
+ * Fast storage (SSD).
+ * Adequate CPU.
+
+### **8. Monitoring**
+
+* **Metrics**:
+ * Query response times.
+ * CPU usage.
+ * Disk I/O.
+
+### **9. Normalization/Denormalization**
+
+* **Normalization**: Reduces redundancy.
+* **Denormalization**: Improves read performance (trade-off with redundancy).
+
+### **10. Partitioning**
+
+* **Types**:
+ * Horizontal.
+ * Vertical.
+* **Purpose**:
+ * Improve query performance.
+ * Easier data management.
diff --git a/data/guides/a-cheatsheet-on-infrastructure-as-code-landscape.md b/data/guides/a-cheatsheet-on-infrastructure-as-code-landscape.md
new file mode 100644
index 0000000..e1c68c0
--- /dev/null
+++ b/data/guides/a-cheatsheet-on-infrastructure-as-code-landscape.md
@@ -0,0 +1,30 @@
+---
+title: "Infrastructure as Code Landscape Cheatsheet"
+description: "A quick reference guide to the Infrastructure as Code landscape."
+image: "https://assets.bytebytego.com/diagrams/0063-a-cheatsheet-on-infrastructure-as-code-landscape.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Infrastructure as Code"
+ - "DevOps"
+---
+
+
+
+Scalable infrastructure provisioning provides several benefits related to availability, scalability, repeatability, and cost-effectiveness.
+
+But how do you achieve this?
+
+Provisioning infrastructure using code is the key to scalable infra management.
+
+There are multiple strategies that can help:
+
+* Containerization is one of the first strategies to make application deployments based on code. Docker is one of the most popular ways to containerize the application.
+
+* Next, container orchestration becomes a necessity when dealing with multiple containers in an application. This is where container orchestration tools like Kubernetes become important.
+
+* IaC treats infrastructure provisioning and configuration as code, allowing developers to define the application infrastructure in files that can be versioned, tested, and reused. Popular tools such as Terraform, AWS CloudFormation, and Ansible can be used. Ansible is more of a configuration tool.
+
+* GitOps leverages a Git workflow combined with CI/CD to automate infrastructure and configuration updates.
diff --git a/data/guides/a-cheatsheet-to-build-secure-apis.md b/data/guides/a-cheatsheet-to-build-secure-apis.md
new file mode 100644
index 0000000..456be8c
--- /dev/null
+++ b/data/guides/a-cheatsheet-to-build-secure-apis.md
@@ -0,0 +1,45 @@
+---
+title: A Cheatsheet to Build Secure APIs
+description: Concise strategies for building secure APIs to protect your application.
+image: https://assets.bytebytego.com/diagrams/0064-a-cheatsheet-to-build-secure-apis.png
+createdAt: '2024-02-23'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Security
+ - Security
+---
+
+
+
+An insecure API can compromise your entire application. Follow these strategies to mitigate the risk:
+
+## Using HTTPS
+
+- Encrypts data in transit and protects against man-in-the-middle attacks.
+- This ensures that data hasn’t been tampered with during transmission.
+
+## Rate Limiting and Throttling
+- Rate limiting prevents DoS attacks by limiting requests from a single IP or user.
+- The goal is to ensure fairness and prevent abuse.
+
+## Validation of Inputs
+- Defends against injection attacks and unexpected data format.
+- Validate headers, inputs, and payload.
+
+## Authentication and Authorization
+- Don’t use basic auth for authentication.
+- Instead, use a standard authentication approach like JWTs
+ * Use a random key that is hard to guess as the JWT secret
+ * Make token expiration short
+-For authorization, use OAuth
+
+## Using Role-based Access Control
+- RBAC simplifies access management for APIs and reduces the risk of unauthorized actions.
+- Granular control over user permission based on roles.
+
+## Monitoring
+- Monitoring the APIs is the key to detecting issues and threats early.
+ - Use tools like Kibana, Cloudwatch, Datadog, and Slack for monitoring
+ - Don’t log sensitive data like credit card info, passwords, credentials, etc.
diff --git a/data/guides/a-crash-course-in-database-sharding.md b/data/guides/a-crash-course-in-database-sharding.md
new file mode 100644
index 0000000..a2efa98
--- /dev/null
+++ b/data/guides/a-crash-course-in-database-sharding.md
@@ -0,0 +1,68 @@
+---
+title: "A Crash Course on Database Sharding"
+description: "Learn database sharding: concepts, techniques, and implementation."
+image: "https://assets.bytebytego.com/diagrams/0065-a-crash-course-on-database-sharding.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "database"
+ - "sharding"
+---
+
+
+
+## What is Database Sharding?
+
+Database sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards. The word shard means a small piece of something bigger.
+
+Sharding is also known as horizontal partitioning. Each shard contains a portion of the data, and all shards together contain all of the data.
+
+## Why Sharding?
+
+Sharding is implemented to solve these problems:
+
+* **Too much data on one machine**: A single database server can only handle so much data.
+
+* **Too many requests on one machine**: A single database server can only handle so many requests.
+
+* **High Latency**: As data grows, query latency increases.
+
+## How Sharding Works
+
+Sharding involves splitting a database into multiple, independent parts (shards) and distributing them across different servers or machines. Each shard contains a subset of the data, and all shards collectively hold the entire dataset.
+
+### Sharding Key
+
+A sharding key is a column in the database table that determines how the data is distributed across the shards. The sharding key is used by the sharding algorithm to determine which shard a particular row of data should be stored in.
+
+### Sharding Algorithm
+
+The sharding algorithm is the logic that determines which shard a particular row of data should be stored in. The sharding algorithm uses the sharding key to make this determination.
+
+Here are some common sharding algorithms:
+
+* **Range-based sharding**: Data is divided into ranges based on the sharding key. For example, users with IDs from 1 to 1000 might be stored in shard 1, users with IDs from 1001 to 2000 in shard 2, and so on.
+
+* **Hash-based sharding**: A hash function is applied to the sharding key to determine the shard. For example, `shard_id = hash(user_id) % num_shards`.
+
+* **Directory-based sharding**: A lookup table (or directory) is used to map sharding keys to shard locations.
+
+## Sharding Approaches
+
+* **Application-level sharding**: The application is responsible for determining which shard to use for each query.
+
+* **Middleware sharding**: A middleware layer sits between the application and the database and handles the sharding logic.
+
+* **Database-native sharding**: The database system itself provides sharding capabilities.
+
+## Sharding Challenges
+
+* **Increased Complexity**: Sharding adds complexity to the database infrastructure and application code.
+
+* **Data Distribution**: Choosing the right sharding key and algorithm is crucial for even data distribution and performance.
+
+* **Joins and Transactions**: Performing joins and transactions across shards can be challenging and may require distributed transaction management.
+
+* **Resharding**: Changing the sharding scheme after the database has been sharded can be a complex and time-consuming process.
diff --git a/data/guides/a-crash-course-on-architectural-scalability.md b/data/guides/a-crash-course-on-architectural-scalability.md
new file mode 100644
index 0000000..5f21792
--- /dev/null
+++ b/data/guides/a-crash-course-on-architectural-scalability.md
@@ -0,0 +1,35 @@
+---
+title: "A Crash Course on Architectural Scalability"
+description: "Learn about architectural scalability, bottlenecks, and key techniques."
+image: "https://assets.bytebytego.com/diagrams/0293-a-crash-course-on-architectural-scalability.png"
+createdAt: "2024-02-10"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Scalability"
+ - "Architecture"
+---
+
+
+
+Scalability is the ability of a system to handle an increased workload without losing performance.
+
+However, we can also look at scalability in terms of the scaling strategy.
+
+Scalability is the system’s ability to handle an increased workload by repeatedly applying a cost-effective strategy. This means it can be difficult to scale a system beyond a certain point if the scaling strategy is not financially viable.
+
+Three main bottlenecks to scalability are:
+
+1. Centralized components: This can become a single point of failure
+2. High Latency Components: These are components that perform time-consuming operations.
+3. Tight Coupling: Makes the components difficult to scale
+
+Therefore, to build a scalable system, we should follow the principles of statelessness, loose coupling, and asynchronous processing.
+
+Some common techniques for improving scalability are as follows:
+
+* Load Balancing: Spread requests across multiple servers to prevent a single server from becoming a bottleneck.
+* Caching: Store the most commonly request information in memory.
+* Event-Driven Processing: Use an async processing approach to process long-running tasks.
+* Sharding: Split a large dataset into smaller subsets called shards for horizontal scalability.
diff --git a/data/guides/a-roadmap-for-full-stack-development.md b/data/guides/a-roadmap-for-full-stack-development.md
new file mode 100644
index 0000000..03ee45d
--- /dev/null
+++ b/data/guides/a-roadmap-for-full-stack-development.md
@@ -0,0 +1,46 @@
+---
+title: "A Roadmap for Full-Stack Development"
+description: "A guide to the technologies and skills needed for full-stack development."
+image: "https://assets.bytebytego.com/diagrams/0199-full-stack-developer-roadmap.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Full-Stack Development"
+ - "Software Development"
+---
+
+
+
+A full-stack developer needs to be proficient in a wide range of technologies and tools across different areas of software development. Here’s a comprehensive look at the technical stacks required for a full-stack developer.
+
+## Technical Stacks for Full-Stack Development
+
+* **Frontend Development**
+
+ Frontend development involves creating the user interface and user experience of a web application.
+
+* **Backend Development**
+
+ Backend development involves managing the server-side logic, databases, and integration of various services.
+
+* **Database Development**
+
+ Database development involves managing data storage, retrieval, and manipulation.
+
+* **Mobile Development**
+
+ Mobile development involves creating applications for mobile devices.
+
+* **Cloud Computing**
+
+ Cloud computing involves deploying and managing applications on cloud platforms.
+
+* **UI/UX Design**
+
+ UI/UX design involves designing the user interface and experience of applications.
+
+* **Infrastructure and DevOps**
+
+ Infrastructure and DevOps involve managing the infrastructure, deployment, and continuous integration/continuous delivery (CI/CD) of applications.
diff --git a/data/guides/airbnb-artchitectural-evolution.md b/data/guides/airbnb-artchitectural-evolution.md
new file mode 100644
index 0000000..e462ec0
--- /dev/null
+++ b/data/guides/airbnb-artchitectural-evolution.md
@@ -0,0 +1,35 @@
+---
+title: "0 to 1.5 Billion Guests: Airbnb's Architectural Evolution"
+description: "Explore Airbnb's architectural evolution to support 1.5 billion guests."
+image: 'https://assets.bytebytego.com/diagrams/0427-zero-to-1-5-billion-guests-airbnb-s-architectural-evolution.png'
+createdAt: '2024-02-27'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Microservices
+---
+
+
+
+Airbnb operates in 200+ countries and has helped 4 million hosts welcome over 1.5 billion guests across the world.
+
+What powers Airbnb technically?
+
+Airbnb started as a monolithic application. It was built using Ruby-on-Rails and was internally known as the Monorail.
+
+The monolith was a single-tier unit responsible for both client and server-side functionality.
+
+However, as Airbnb went into hypergrowth, the Monorail started facing issues. This is when they began a migration journey to move from monolithic to Service-Oriented Architecture.
+
+For Airbnb, SOA is a network of loosely coupled services where clients make their requests to a gateway and the gateway routes these requests to multiple services and databases.
+
+Various types of services were built such as:
+
+* **Data Service:** This is the bottom layer and acts as the entry point for all read and write operations on the data entities.
+* **Derived Data Service:** These services read from data services and apply basic business logic.
+* **Middle Tier Service:** They manage important business logic that doesn’t fit at the data service level or derived data service level.
+* **Presentation Service:** They aggregate data from all other services and also apply some frontend-specific business logic.
+
+After the migration, the Monorail was eliminated and all reads/writes were migrated to the new services.
diff --git a/data/guides/algorithms-you-should-know-before-taking-system-design-interviews.md b/data/guides/algorithms-you-should-know-before-taking-system-design-interviews.md
new file mode 100644
index 0000000..0ad544a
--- /dev/null
+++ b/data/guides/algorithms-you-should-know-before-taking-system-design-interviews.md
@@ -0,0 +1,30 @@
+---
+title: "Algorithms for System Design Interviews"
+description: "Essential algorithms for system design interviews and software engineers."
+image: "https://assets.bytebytego.com/diagrams/0068-algorithms-geo-hash-linkedin.jpg"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - software-development
+tags:
+ - System Design
+ - Algorithms
+---
+
+
+
+What are some of the algorithms you should know before taking system design interviews?
+
+I put together a list and explained why they are important. Those algorithms are not only useful for interviews but good to understand for any software engineer.
+
+One thing to keep in mind is that understanding “how those algorithms are used in real-world systems” is generally more important than the implementation details in a system design interview.
+
+What do the stars mean in the diagram?
+
+It’s very difficult to rank algorithms by importance objectively. I’m open to suggestions and making adjustments.
+
+Five-star: Very important. Try to understand how it works and why.
+
+Three-star: Important to some extent. You may not need to know the implementation details.
+
+One-star: Advanced. Good to know for senior candidates.
diff --git a/data/guides/amazon-prime-video-monitoring-service.md b/data/guides/amazon-prime-video-monitoring-service.md
new file mode 100644
index 0000000..05ea194
--- /dev/null
+++ b/data/guides/amazon-prime-video-monitoring-service.md
@@ -0,0 +1,44 @@
+---
+title: "Amazon Prime Video Monitoring Service"
+description: "Learn how Amazon Prime Video monitoring saved 90% cost by moving to monolith."
+image: "https://assets.bytebytego.com/diagrams/0328-serverless-to-monolithic.jpeg"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Microservices"
+ - "System Design"
+---
+
+
+
+Why did Amazon Prime Video monitoring move **from serverless to monolithic**? How can it save 90% cost?
+
+The diagram above shows the architecture comparison before and after the migration.
+
+## What is Amazon Prime Video Monitoring Service?
+
+Prime Video service needs to monitor the quality of thousands of live streams. The monitoring tool automatically analyzes the streams in real time and identifies quality issues like block corruption, video freeze, and sync problems. This is an important process for customer satisfaction.
+
+There are 3 steps: media converter, defect detector, and real-time notification.
+
+* What is the problem with the old architecture?
+
+ The old architecture was based on Amazon Lambda, which was good for building services quickly. However, it was not cost-effective when running the architecture at a high scale. The two most expensive operations are:
+
+ 1. The orchestration workflow - AWS step functions charge users by state transitions and the orchestration performs multiple state transitions every second.
+
+ 2. Data passing between distributed components - the intermediate data is stored in Amazon S3 so that the next stage can download. The download can be costly when the volume is high.
+
+* Monolithic architecture saves 90% cost
+
+ A monolithic architecture is designed to address the cost issues. There are still 3 components, but the media converter and defect detector are deployed in the same process, saving the cost of passing data over the network. Surprisingly, this approach to deployment architecture change led to 90% cost savings!
+
+ This is an interesting and unique case study because microservices have become a go-to and fashionable choice in the tech industry. It's good to see that we are having more discussions about evolving the architecture and having more honest discussions about its pros and cons. Decomposing components into distributed microservices comes with a cost.
+
+* What did Amazon leaders say about this?
+
+ Amazon CTO Werner Vogels: “Building **evolvable software systems** is a strategy, not a religion. And revisiting your architectures with an open mind is a must.”
+
+ Ex Amazon VP Sustainability Adrian Cockcroft: “The Prime Video team had followed a path I call **Serverless First**…I don’t advocate **Serverless Only**”.
diff --git a/data/guides/api-gateway-101.md b/data/guides/api-gateway-101.md
new file mode 100644
index 0000000..2eb6b08
--- /dev/null
+++ b/data/guides/api-gateway-101.md
@@ -0,0 +1,27 @@
+---
+title: 'API Gateway 101'
+description: 'Learn the fundamentals of API Gateways: functions, benefits, and more.'
+image: 'https://assets.bytebytego.com/diagrams/0074-api-gateway-101.png'
+createdAt: '2024-02-15'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Microservices
+---
+
+
+
+An API gateway is a server that acts as an API front-end, receiving API requests, enforcing throttling and security policies, passing requests to the back-end service, and then returning the appropriate result to the client.
+
+It is essentially a middleman between the client and the server, managing and optimizing API traffic.
+
+**Key Functions of an API Gateway**
+
+* **Request Routing:** Directs incoming API requests to the appropriate backend service.
+* **Load Balancing:** Distributes requests across multiple servers to ensure no single server is overwhelmed.
+* **Security:** Implements security measures like authentication, authorization, and data encryption.
+* **Rate Limiting and Throttling:** Controls the number of requests a client can make within a certain period.
+* **API Composition:** Combines multiple backend API requests into a single frontend request to optimize performance.
+* **Caching:** Stores responses temporarily to reduce the need for repeated processing.
diff --git a/data/guides/api-of-apis-app-integrations.md b/data/guides/api-of-apis-app-integrations.md
new file mode 100644
index 0000000..38bf57d
--- /dev/null
+++ b/data/guides/api-of-apis-app-integrations.md
@@ -0,0 +1,20 @@
+---
+title: 'API of APIs - App Integrations'
+description: 'Explore API of APIs and app integrations in this detailed guide.'
+image: 'https://assets.bytebytego.com/diagrams/0426-api-of-apis-app-integrations.png'
+createdAt: '2024-02-13'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - API Integration
+ - No-Code
+---
+
+
+
+No-code tools such as Zapier, IFTTT, etc., allow anyone to build apps and automate workflows using a visual interface.
+
+The flowchart below shows how it works.
+
+Image source: Paper: IFTTT vs. Zapier: A Comparative Study of Trigger-Action Programming Frameworks
diff --git a/data/guides/api-vs-sdk.md b/data/guides/api-vs-sdk.md
new file mode 100644
index 0000000..8189347
--- /dev/null
+++ b/data/guides/api-vs-sdk.md
@@ -0,0 +1,34 @@
+---
+title: 'API vs SDK'
+description: 'Understand the key differences between APIs and SDKs in software development.'
+image: 'https://assets.bytebytego.com/diagrams/0071-api-vs-sdk.png'
+createdAt: '2024-02-22'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - SDK
+---
+
+
+
+API (Application Programming Interface) and SDK (Software Development Kit) are essential tools in the software development world, but they serve distinct purposes:
+
+**API:**
+
+An API is a set of rules and protocols that allows different software applications and services to communicate with each other.
+
+* It defines how software components should interact.
+* Facilitates data exchange and functionality access between software components.
+* Typically consists of endpoints, requests, and responses.
+
+**SDK:**
+
+An SDK is a comprehensive package of tools, libraries, sample code, and documentation that assists developers in building applications for a particular platform, framework, or hardware.
+
+* Offers higher-level abstractions, simplifying development for a specific platform.
+* Tailored to specific platforms or frameworks, ensuring compatibility and optimal performance on that platform.
+* Offer access to advanced features and capabilities specific to the platform, which might be otherwise challenging to implement from scratch.
+
+The choice between APIs and SDKs depends on the development goals and requirements of the project.
diff --git a/data/guides/aws-services-cheat-sheet.md b/data/guides/aws-services-cheat-sheet.md
new file mode 100644
index 0000000..8237559
--- /dev/null
+++ b/data/guides/aws-services-cheat-sheet.md
@@ -0,0 +1,22 @@
+---
+title: "AWS Services Cheat Sheet"
+description: "A visual guide to navigate AWS expansive landscape of cloud services."
+image: "https://assets.bytebytego.com/diagrams/0082-aws-cloud-services-cheat-sheet.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "AWS"
+ - "Cloud Computing"
+---
+
+
+
+AWS grew from an in-house project to the market leader in cloud services, offering so many different services that even experts can find it a lot to take in.
+
+The platform not only caters to foundational cloud needs but also stays at the forefront of emerging technologies such as machine learning and IoT, establishing itself as a bedrock for cutting-edge innovation. AWS continuously refines its array of services, ensuring advanced capabilities for security, scalability, and operational efficiency are available.
+
+For those navigating the complex array of options, this AWS Services Guide is a helpful visual aid.
+
+It simplifies the exploration of AWS's expansive landscape, making it accessible for users to identify and leverage the right tools for their cloud-based endeavors.
diff --git a/data/guides/aws-services-evolution.md b/data/guides/aws-services-evolution.md
new file mode 100644
index 0000000..5c25a47
--- /dev/null
+++ b/data/guides/aws-services-evolution.md
@@ -0,0 +1,30 @@
+---
+title: "AWS Services Evolution"
+description: "Explore the evolution of AWS from its early days to a comprehensive cloud platform."
+image: "https://assets.bytebytego.com/diagrams/0081-aws-services-evolution.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "AWS"
+---
+
+[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fbb384f75-2fbb-4c5b-9d5e-b97557d02f33_1572x1894.png)
+
+How did AWS grow from just a few services in 2006 to over 200 fully-featured services? Let's take a look.
+
+Since 2006, it has become a cloud computing leader, offering foundational infrastructure, platforms, and advanced capabilities like serverless computing and AI.
+
+This expansion empowered innovation, allowing complex applications without extensive hardware management. AWS also explored edge and quantum computing, staying at tech's forefront.
+
+This evolution mirrors cloud computing's shift from niche to essential, benefiting global businesses with efficiency and scalability.
+
+Happy to present the curated list of AWS services introduced over the years below.
+
+Note:
+
+* The announcement or preview year differs from the public release year for certain services. In these cases, we've noted the service under the release year
+
+* Unreleased services noted in announcement years
diff --git a/data/guides/azure-services-cheat-sheet.md b/data/guides/azure-services-cheat-sheet.md
new file mode 100644
index 0000000..1fd3d93
--- /dev/null
+++ b/data/guides/azure-services-cheat-sheet.md
@@ -0,0 +1,22 @@
+---
+title: "Azure Services Cheat Sheet"
+description: "A concise guide to Microsoft Azure services and their applications."
+image: "https://assets.bytebytego.com/diagrams/0083-azure-cloud-services-cheat-sheet.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Azure"
+ - "Cloud Computing"
+---
+
+
+
+Launched in 2010, Microsoft Azure has quickly grown to hold the No. 2 position in market share by evolving from basic offerings to a comprehensive, flexible cloud ecosystem.
+
+Today, Azure not only supports traditional cloud applications but also caters to emerging technologies such as AI, IoT, and blockchain, making it a crucial platform for innovation and development.
+
+As it evolves, Azure continues to enhance its capabilities to provide advanced solutions for security, scalability, and efficiency, meeting the demands of modern enterprises and startups alike. This expansion allows organizations to adapt and thrive in a rapidly changing digital landscape.
+
+The attached illustration can serve as both an introduction and a quick reference for anyone aiming to understand Azure.
diff --git a/data/guides/b-tree-vs.md b/data/guides/b-tree-vs.md
new file mode 100644
index 0000000..4798125
--- /dev/null
+++ b/data/guides/b-tree-vs.md
@@ -0,0 +1,34 @@
+---
+title: "B-Tree vs. LSM-Tree"
+description: "Explore the differences between B-Tree and LSM-Tree data structures."
+image: "https://assets.bytebytego.com/diagrams/0091-btree-lsm.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Structures"
+ - "Databases"
+---
+
+
+
+## B-Tree
+
+B-Tree is the most widely used indexing data structure in almost all relational databases.
+
+The basic unit of information storage in B-Tree is usually called a “page”. Looking up a key traces down the range of keys until the actual value is found.
+
+## LSM-Tree
+
+LSM-Tree (Log-Structured Merge Tree) is widely used by many NoSQL databases, such as Cassandra, LevelDB, and RocksDB.
+
+LSM-trees maintain key-value pairs and are persisted to disk using a Sorted Strings Table (SSTable), in which the keys are sorted.
+
+Level 0 segments are periodically merged into Level 1 segments. This process is called **compaction.**
+
+The biggest difference is probably this:
+
+* B-Tree enables faster reads
+
+* LSM-Tree enables fast writes
diff --git a/data/guides/big-data-pipeline-cheatsheet-for-aws-azure-and-google-cloud.md b/data/guides/big-data-pipeline-cheatsheet-for-aws-azure-and-google-cloud.md
new file mode 100644
index 0000000..42de0cc
--- /dev/null
+++ b/data/guides/big-data-pipeline-cheatsheet-for-aws-azure-and-google-cloud.md
@@ -0,0 +1,32 @@
+---
+title: "Big Data Pipeline Cheatsheet for AWS, Azure, and Google Cloud"
+description: "Big data pipeline cheatsheet for AWS, Azure, and Google Cloud."
+image: "https://assets.bytebytego.com/diagrams/0086-big-data-pipeline-cheatsheet-for-aws-azure-and-gcp.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Big Data"
+ - "Cloud Computing"
+---
+
+
+
+Each platform offers a comprehensive suite of services that cover the entire lifecycle:
+
+* Ingestion: Collecting data from various sources
+
+* Data Lake: Storing raw data
+
+* Computation: Processing and analyzing data
+
+* Data Warehouse: Storing structured data
+
+* Presentation: Visualizing and reporting insights
+
+AWS uses services like Kinesis for data streaming, S3 for storage, EMR for processing, RedShift for warehousing, and QuickSight for visualization.
+
+Azure’s pipeline includes Event Hubs for ingestion, Data Lake Store for storage, Databricks for processing, Cosmos DB for warehousing, and Power BI for presentation.
+
+GCP offers PubSub for data streaming, Cloud Storage for data lakes, DataProc and DataFlow for processing, BigQuery for warehousing, and Data Studio for visualization.
diff --git a/data/guides/big-endian-vs-little-endian.md b/data/guides/big-endian-vs-little-endian.md
new file mode 100644
index 0000000..8347df4
--- /dev/null
+++ b/data/guides/big-endian-vs-little-endian.md
@@ -0,0 +1,26 @@
+---
+title: "Big Endian vs Little Endian"
+description: "Explore big endian vs little endian byte ordering in computer architecture."
+image: "https://assets.bytebytego.com/diagrams/0084-big-endian-vs-little-endian.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Computer Architecture"
+ - "Data Representation"
+---
+
+
+
+Microprocessor architectures commonly use two different methods to store the individual bytes in memory. This difference is referred to as “byte ordering” or “endian nature”.
+
+## Little Endian
+
+Intel x86 processors store a two-byte integer with the least significant byte first, followed by the most significant byte. This is called little-endian byte ordering.
+
+## Big Endian
+
+In big endian byte order, the most significant byte is stored at the lowest memory address, and the least significant byte is stored at the highest memory address. Older PowerPC and Motorola 68k architectures often use big endian. In network communications and file storage, we also use big endian.
+
+The byte ordering becomes significant when data is transferred between systems or processed by systems with different endianness. It's important to handle byte order correctly to interpret data consistently across diverse systems.
diff --git a/data/guides/blocking-vs-non-blocking-queue.md b/data/guides/blocking-vs-non-blocking-queue.md
new file mode 100644
index 0000000..32d7c32
--- /dev/null
+++ b/data/guides/blocking-vs-non-blocking-queue.md
@@ -0,0 +1,50 @@
+---
+title: "Blocking vs Non-Blocking Queue"
+description: "Explore blocking vs non-blocking queues, differences, and implementation."
+image: "https://assets.bytebytego.com/diagrams/0088-blocking-noblocking-queue.jpeg"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - software-development
+tags:
+ - Concurrency
+ - Data Structures
+---
+
+
+
+How do we implement a **non-blocking** queue? What are the differences between blocking and non-blocking algorithms?
+
+The terms we use when discussing blocking and non-blocking algorithms can be confusing, so let’s start by reviewing the terminology in the concurrency area with a diagram.
+
+## Blocking vs Non-Blocking Algorithms
+
+* **Blocking**
+
+ The blocking algorithm uses locks. Thread A acquires the lock first, and Thread B might wait for arbitrary lengthy periods if Thread A gets suspended while holding the lock. This algorithm may cause Thread B to starve.
+
+* **Non-blocking**
+
+ The non-blocking algorithm allows Thread A to access the queue, but Thread A must complete a task in a certain number of steps. Other threads like Thread B may still starve due to the rejections.
+
+This is the main **difference** between blocking and non-blocking algorithms: The blocking algorithm blocks Thread B until the lock is released. A non-blocking algorithm notifies Thread B that access is rejected.
+
+* **Starvation-free**
+
+ Thread Starvation means a thread cannot acquire access to certain shared resources and cannot proceed. Starvation-free means this situation does not occur.
+
+* **Wait-free**
+
+ All threads can complete the tasks within a finite number of steps.
+
+𝘞𝘢𝘪𝘵-𝘧𝘳𝘦𝘦 = 𝘕𝘰𝘯-𝘉𝘭𝘰𝘤𝘬𝘪𝘯𝘨 + 𝘚𝘵𝘢𝘳𝘷𝘢𝘵𝘪𝘰𝘯-𝘧𝘳𝘦𝘦
+
+## Non-Blocking Queue Implementation
+
+We can use Compare and Swap (CAS) to implement a non-blocking queue. The diagram below illustrates the algorithm.
+
+## Benefits
+
+1. No thread suspension. Thread B can get a response immediately and then decide what to do next. In this way, the thread latency is greatly reduced.
+
+2. No deadlocks. Threads A and B do not wait for the lock to release, meaning that there is no possibility of a deadlock occurring.
diff --git a/data/guides/build-a-simple-chat-application.md b/data/guides/build-a-simple-chat-application.md
new file mode 100644
index 0000000..f459ac5
--- /dev/null
+++ b/data/guides/build-a-simple-chat-application.md
@@ -0,0 +1,36 @@
+---
+title: "Build a Simple Chat Application with Redis"
+description: "Learn to build a simple chat application using Redis pub/sub."
+image: "https://assets.bytebytego.com/diagrams/0314-redis-chat.jpg"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - Redis
+ - Chat Application
+---
+
+
+
+How do we build a simple chat application using Redis?
+
+The diagram below shows how we can leverage the pub-sub functionality of Redis to develop a chat application.
+
+## Stage 1: Connection Initialization
+
+* Steps 1 and 2: Bob opens the chat application. A web socket is established between the client and the server.
+
+* Steps 3 and 4: The pub-sub server establishes several connections to Redis. One connection is used to update the Redis data models and publish messages to a topic. Other connections are used to subscribe and listen to updates for topics.
+
+* Steps 5 and 6: Bob’s client application requires the chat member list and the historical message list. The information is retrieved from Redis and sent to the client application.
+
+* Steps 7 and 8: Since Bob is a new member joining the chat application, a message is published to the “member\_add” topic, and as a result, other participants of the chat application can see Bob.
+
+## Stage 2: Message Handling
+
+* Step 1: Bob sends a message to Alice in the chat application.
+
+* Step 2: The new chat message is added to Redis SortedSet by calling ‘zadd.’ The chat messages are sorted based on arrival time. The pub-sub server then publishes the chat message to the “messages” topic so subscribers can pick it up.
+
+* Step 3: Alice’s client application receives the chat message from Bob.
diff --git a/data/guides/cache-miss-attack.md b/data/guides/cache-miss-attack.md
new file mode 100644
index 0000000..a884089
--- /dev/null
+++ b/data/guides/cache-miss-attack.md
@@ -0,0 +1,28 @@
+---
+title: "Cache Miss Attack"
+description: "Explore cache miss attacks, their impact, and mitigation strategies."
+image: "https://assets.bytebytego.com/diagrams/0128-cache-miss-attack.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Security"
+---
+
+
+
+Caching is awesome but it doesn’t come without a cost, just like many things in life.
+
+One of the issues is 𝐂𝐚𝐜𝐡𝐞 𝐌𝐢𝐬𝐬 𝐀𝐭𝐭𝐚𝐜𝐤. Please correct me if this is not the right term. It refers to the scenario where data to fetch doesn't exist in the database and the data isn’t cached either. So every request hits the database eventually, defeating the purpose of using a cache. If a malicious user initiates lots of queries with such keys, the database can easily be overloaded.
+
+The diagram above illustrates the process.
+
+## Solutions
+
+Two approaches are commonly used to solve this problem:
+
+* **Cache keys with null value.** Set a short TTL (Time to Live) for keys with null value.
+
+* **Using Bloom filter.** A Bloom filter is a data structure that can rapidly tell us whether an element is present in a set or not. If the key exists, the request first goes to the cache and then queries the database if needed. If the key doesn't exist in the data set, it means the key doesn’t exist in the cache/database. In this case, the query will not hit the cache or database layer.
diff --git a/data/guides/cache-systems-every-developer-should-know.md b/data/guides/cache-systems-every-developer-should-know.md
new file mode 100644
index 0000000..872c078
--- /dev/null
+++ b/data/guides/cache-systems-every-developer-should-know.md
@@ -0,0 +1,40 @@
+---
+title: "Cache Systems Every Developer Should Know"
+description: "Explore essential caching layers for developers to optimize performance."
+image: "https://assets.bytebytego.com/diagrams/0418-cache-systems-every-developer-should-know.jpeg"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Caching
+ - Performance
+---
+
+
+
+Data is cached everywhere, from the client-facing side to backend systems. Let's look at the many caching layers:
+
+## Caching Layers
+
+1. Client Apps: Browsers cache HTTP responses. Server responses include caching directives in headers. Upon subsequent requests, browsers may serve cached data if still fresh.
+
+2. Content Delivery Networks: CDNs cache static content like images, stylesheets, and JavaScript files. They serve cached content from locations closer to users, reducing latency and load times.
+
+3. Load Balancers: Some load balancers cache frequently requested data. This allows serving responses without engaging backend servers, reducing load and response times.
+
+4. Message Brokers: Systems like Kafka can cache messages on disk per a retention policy. Consumers then pull messages according to their own schedule.
+
+5. Services: Individual services often employ caching to improve data retrieval speeds, first checking in-memory caches before querying databases. Services may also utilize disk caching for larger datasets.
+
+6. Distributed Caches: Systems like Redis cache key-value pairs across services, providing faster read/write capabilities compared to traditional databases.
+
+7. Full-text Search Engines: Platforms like Elasticsearch index data for efficient text search. This index is effectively a form of cache, optimized for quick text search retrieval.
+
+8. Databases: There are specialized mechanisms to enhance performance, some of which include caching concepts:
+
+### Database Caching Mechanisms
+
+* **Bufferpool:** This is a cache within the database that holds copies of data pages. It allows for quick reads and writes to temporary storage in memory, reducing the need to access data from disk.
+
+* **Materialized Views:** They are similar to caches in that they store the results of computationally expensive queries. The database can return these precomputed results quickly, rather than recalculating them.
diff --git a/data/guides/can-kafka-lose-messages.md b/data/guides/can-kafka-lose-messages.md
new file mode 100644
index 0000000..ecd210e
--- /dev/null
+++ b/data/guides/can-kafka-lose-messages.md
@@ -0,0 +1,46 @@
+---
+title: "Can Kafka Lose Messages?"
+description: "Explore Kafka's message loss scenarios and prevention strategies."
+image: "https://assets.bytebytego.com/diagrams/0130-can-kafka-lose-messages.png"
+createdAt: "2024-02-12"
+draft: false
+categories:
+ - "database-and-storage"
+tags:
+ - "Kafka"
+ - "Message Loss"
+---
+
+Error handling is one of the most important aspects of building reliable systems.
+
+Today, we will discuss an important topic: Can Kafka lose messages?
+
+
+
+A common belief among many developers is that Kafka, by its very design, guarantees no message loss. However, understanding the nuances of Kafka's architecture and configuration is essential to truly grasp how and when it might lose messages, and more importantly, how to prevent such scenarios.
+
+The diagram above shows how a message can be lost during its lifecycle in Kafka.
+
+## Producer
+
+When we call producer.send() to send a message, it doesn't get sent to the broker directly. There are two threads and a queue involved in the message-sending process:
+
+* Application thread
+* Record accumulator
+* Sender thread (I/O thread)
+
+We need to configure proper ‘acks’ and ‘retries’ for the producer to make sure messages are sent to the broker.
+
+## Broker
+
+A broker cluster should not lose messages when it is functioning normally. However, we need to understand which extreme situations might lead to message loss:
+
+* The messages are usually flushed to the disk asynchronously for higher I/O throughput, so if the instance is down before the flush happens, the messages are lost.
+
+* The replicas in the Kafka cluster need to be properly configured to hold a valid copy of the data. The determinism in data synchronization is important.
+
+## Consumer
+
+Kafka offers different ways to commit messages. Auto-committing might acknowledge the processing of records before they are actually processed. When the consumer is down in the middle of processing, some records may never be processed.
+
+A good practice is to combine both synchronous and asynchronous commits, where we use asynchronous commits in the processing loop for higher throughput and synchronous commits in exception handling to make sure the last offset is always committed.
diff --git a/data/guides/cap-base-solid-kiss-what-do-these-acronyms-mean.md b/data/guides/cap-base-solid-kiss-what-do-these-acronyms-mean.md
new file mode 100644
index 0000000..e31f002
--- /dev/null
+++ b/data/guides/cap-base-solid-kiss-what-do-these-acronyms-mean.md
@@ -0,0 +1,55 @@
+---
+title: "CAP, BASE, SOLID, KISS, What do these acronyms mean?"
+description: "Understanding common acronyms in system design: CAP, BASE, SOLID, and KISS."
+image: "https://assets.bytebytego.com/diagrams/0350-cap-base-solid-kiss.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "System Design"
+ - "Software Engineering"
+---
+
+The diagram below explains the common acronyms in system designs.
+
+
+
+* **CAP**
+
+ CAP theorem states that any distributed data store can only provide two of the following three guarantees:
+
+ 1. Consistency - Every read receives the most recent write or an error.
+ 2. Availability - Every request receives a response.
+ 3. Partition tolerance - The system continues to operate in network faults.
+
+ However, this theorem was criticized for being too narrow for distributed systems, and we shouldn’t use it to categorize the databases. Network faults are guaranteed to happen in distributed systems, and we must deal with this in any distributed systems.
+
+ You can read more on this in “Please stop calling databases CP or AP” by Martin Kleppmann.
+
+* **BASE**
+
+ The ACID (Atomicity-Consistency-Isolation-Durability) model used in relational databases is too strict for NoSQL databases. The BASE principle offers more flexibility, choosing availability over consistency. It states that the states will eventually be consistent.
+
+* **SOLID**
+
+ SOLID principle is quite famous in OOP. There are 5 components to it.
+
+ 1. SRP (Single Responsibility Principle)
+ Each unit of code should have one responsibility.
+
+ 2. OCP (Open Close Principle)
+ Units of code should be open for extension but closed for modification.
+
+ 3. LSP (Liskov Substitution Principle)
+ A subclass should be able to be substituted by its base class.
+
+ 4. ISP (Interface Segregation Principle)
+ Expose multiple interfaces with specific responsibilities.
+
+ 5. DIP (Dependency Inversion Principle)
+ Use abstractions to decouple dependencies in the system.
+
+* **KISS**
+
+ "Keep it simple, stupid!" is a design principle first noted by the U.S. Navy in 1960. It states that most systems work best if they are kept simple.
diff --git a/data/guides/cap-theorem-one-of-the-most-misunderstood-terms.md b/data/guides/cap-theorem-one-of-the-most-misunderstood-terms.md
new file mode 100644
index 0000000..5a101f9
--- /dev/null
+++ b/data/guides/cap-theorem-one-of-the-most-misunderstood-terms.md
@@ -0,0 +1,42 @@
+---
+title: "CAP Theorem: One of the Most Misunderstood Terms"
+description: "Explore the CAP theorem, its implications, and common misunderstandings."
+image: "https://assets.bytebytego.com/diagrams/0131-cap-theorem.jpeg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "distributed systems"
+ - "cap theorem"
+---
+
+
+
+The CAP theorem is one of the most famous terms in computer science, but I bet different developers have different understandings. Let’s examine what it is and why it can be confusing.
+
+CAP theorem states that a distributed system can't provide more than two of these three guarantees simultaneously.
+
+## Consistency
+
+Consistency means all clients see the same data at the same time no matter which node they connect to.
+
+## Availability
+
+Availability means any client which requests data gets a response even if some of the nodes are down.
+
+## Partition Tolerance
+
+Partition tolerance means the system continues to operate despite network partitions.
+
+The “2 of 3” formulation can be useful, but this simplification could be misleading.
+
+* Picking a database is not easy. Justifying our choice purely based on the CAP theorem is not enough. For example, companies don't choose Cassandra for chat applications simply because it is an AP system. There is a list of good characteristics that make Cassandra a desirable option for storing chat messages. We need to dig deeper.
+
+* “CAP prohibits only a tiny part of the design space: perfect availability and consistency in the presence of partitions, which are rare”. Quoted from the paper: CAP Twelve Years Later: How the “Rules” Have Changed.
+
+* The theorem is about 100% availability and consistency. A more realistic discussion would be the trade-offs between latency and consistency when there is no network partition. See PACELC theorem for more details.
+
+## Is the CAP theorem really useful?
+
+I think it is still useful as it opens our minds to a set of tradeoff discussions, but it is only part of the story. We need to dig deeper when picking the right database.
diff --git a/data/guides/change-data-capture-key-to-leverage-real-time-data.md b/data/guides/change-data-capture-key-to-leverage-real-time-data.md
new file mode 100644
index 0000000..9eaec49
--- /dev/null
+++ b/data/guides/change-data-capture-key-to-leverage-real-time-data.md
@@ -0,0 +1,40 @@
+---
+title: "Change Data Capture: Key to Leverage Real-time Data"
+description: "Learn how Change Data Capture (CDC) helps leverage real-time data."
+image: "https://assets.bytebytego.com/diagrams/0133-change-data-capture-key-to-leverage-real-time-data.png"
+createdAt: "2024-02-11"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Streaming"
+ - "Data Synchronization"
+---
+
+
+
+90% of the world’s data was created in the last two years and this growth will only get faster.
+
+However, the biggest challenge is to leverage this data in real-time. Constant data changes make databases, data lakes, and data warehouses out of sync.
+
+CDC or Change Data Capture can help you overcome this challenge.
+
+CDC identifies and captures changes made to the data in a database, allowing you to replicate and sync data across multiple systems.
+
+## How Change Data Capture Works
+
+So, how does Change Data Capture work? Here's a step-by-step breakdown:
+
+1. Data Modification: A change is made to the data in the source database. It could be an insert, update, or delete operation on a table.
+
+2. Change Capture: A CDC tool monitors the database transaction logs to capture the modifications. It uses the source connector to connect to the database and read the logs.
+
+3. Change Processing: The captured changes are processed and transformed into a format suitable for the downstream systems.
+
+4. Change Propagation: The processed changes are published to a message queue and propagated to the target systems, such as data warehouses, analytics platforms, distributed caches like Redis, and so on.
+
+5. Real-Time Integration: The CDC tool uses its sink connector to consume the log and update the target systems. The changes are received in real time, allowing for conflict-free data analysis and decision-making.
+
+Users only need to take care of step 1 while all other steps are transparent.
+
+A popular CDC solution uses Debezium with Kafka Connect to stream data changes from the source to target systems using Kafka as the broker. Debezium has connectors for most databases such as MySQL, PostgreSQL, Oracle, etc.
diff --git a/data/guides/chatgpt-timeline.md b/data/guides/chatgpt-timeline.md
new file mode 100644
index 0000000..5306126
--- /dev/null
+++ b/data/guides/chatgpt-timeline.md
@@ -0,0 +1,42 @@
+---
+title: ChatGPT Timeline
+description: A visual guide to the evolution of ChatGPT and its underlying tech.
+image: 'https://assets.bytebytego.com/diagrams/0136-chatgpt-how-we-get-here.png'
+createdAt: '2024-03-10'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI History
+ - NLP
+---
+
+A picture is worth a thousand words. ChatGPT seems to come out of nowhere. Little did we know that it was built on top of decades of research.
+
+
+
+The diagram above shows how we get here.
+
+## 1950s
+
+In this stage, people still used primitive models that are based on rules.
+
+## 1980s
+
+Since the 1980s, machine learning started to pick up and was used for classification. The training was conducted on a small range of data.
+
+## 1990s - 2000s
+
+Since the 1990s, neural networks started to imitate human brains for labeling and training. There are generally 3 types:
+
+- CNN (Convolutional Neural Network): often used in visual-related tasks.
+- RNN (Recurrent Neural Network): useful in natural language tasks
+- GAN (Generative Adversarial Network): comprised of two networks(Generative and Discriminative). This is a generative model that can generate novel images that look alike.
+
+## 2017
+
+“Attention is all you need” represents the foundation of generative AI. The transformer model greatly shortens the training time by parallelism.
+
+## 2018 - Now
+
+In this stage, due to the major progress of the transformer model, we see various models train on a massive amount of data. Human demonstration becomes the learning content of the model. We’ve seen many AI writers that can write articles, news, technical docs, and even code. This has great commercial value as well and sets off a global whirlwind.
diff --git a/data/guides/choose-the-right-database-for-metric-collecting-system.md b/data/guides/choose-the-right-database-for-metric-collecting-system.md
new file mode 100644
index 0000000..d80be54
--- /dev/null
+++ b/data/guides/choose-the-right-database-for-metric-collecting-system.md
@@ -0,0 +1,32 @@
+---
+title: "Choose the Right Database for Metric Collection"
+description: "A guide to choosing the right database for a metric collecting system."
+image: "https://assets.bytebytego.com/diagrams/0273-metrics-access-pattern.jpg"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "databases"
+ - "metrics"
+---
+
+
+
+Which database shall I use for the **metric collecting system**? This is one of the most important questions we need to address in a system design interview.
+
+## Data access pattern
+
+As shown in the diagram, each label on the y-axis represents a time series (uniquely identified by the names and labels) while the x-axis represents time.
+
+The write load is heavy. As you can see, there can be many time-series data points written at any moment. There are millions of operational metrics written per day, and many metrics are collected at high frequency, so the traffic is undoubtedly write-heavy.
+
+At the same time, the read load is spiky. Both visualization and alert services send queries to the database and depending on the access patterns of the graphs and alerts, the read volume could be bursty.
+
+## Choose the right database
+
+The data storage system is the heart of the design. It’s not recommended to build your own storage system or use a general-purpose storage system (MySQL) for this job.
+
+A general-purpose database, in theory, could support time-series data, but it would require expert-level tuning to make it work at our scale. Specifically, a relational database is not optimized for operations you would commonly perform against time-series data. For example, computing the moving average in a rolling time window requires complicated SQL that is difficult to read (there is an example of this in the deep dive section). Besides, to support tagging/labeling data, we need to add an index for each tag. Moreover, a general-purpose relational database does not perform well under constant heavy write load. At our scale, we would need to expend significant effort in tuning the database, and even then, it might not perform well.
+
+How about NoSQL? In theory, a few NoSQL databases on the market could handle time-series data effectively. For example, Cassandra and Bigtable can both be used for time series data. However, this would require deep knowledge of the internal workings of each NoSQL to devise a scalable schema for effectively storing and querying time-series data. With industrial-scale time-series databases readily available, using a general-purpose NoSQL database is not appealing.
diff --git a/data/guides/cicd-pipeline-explained-in-simple-terms.md b/data/guides/cicd-pipeline-explained-in-simple-terms.md
new file mode 100644
index 0000000..eb6936d
--- /dev/null
+++ b/data/guides/cicd-pipeline-explained-in-simple-terms.md
@@ -0,0 +1,44 @@
+---
+title: "CI/CD Pipeline Explained in Simple Terms"
+description: "Learn about CI/CD pipelines, their stages, and benefits in software delivery."
+image: "https://assets.bytebytego.com/diagrams/0140-ci-cd-pipeline.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "CI/CD"
+ - "DevOps"
+---
+
+
+
+## SDLC with CI/CD
+
+The software development life cycle (SDLC) consists of several key stages: development, testing, deployment, and maintenance. CI/CD automates and integrates these stages to enable faster, more reliable releases.
+
+When code is pushed to a git repository, it triggers an automated build and test process. End-to-end (e2e) test cases are run to validate the code. If tests pass, the code can be automatically deployed to staging/production. If issues are found, the code is sent back to development for bug fixing. This automation provides fast feedback to developers and reduces risk of bugs in production.
+
+## Difference between CI and CD
+
+Continuous Integration (CI) automates the build, test, and merge process. It runs tests whenever code is committed to detect integration issues early. This encourages frequent code commits and rapid feedback.
+
+Continuous Delivery (CD) automates release processes like infrastructure changes and deployment. It ensures software can be released reliably at any time through automated workflows. CD may also automate the manual testing and approval steps required before production deployment.
+
+## CI/CD Pipeline
+
+A typical CI/CD pipeline has several connected stages:
+
+* Developer commits code changes to source control
+
+* CI server detects changes and triggers build
+
+* Code is compiled, tested (unit, integration tests)
+
+* Test results reported to developer
+
+* On success, artifacts are deployed to staging environments
+
+* Further testing may be done on staging before release
+
+* CD system deploys approved changes to production
diff --git a/data/guides/cicd-simplified-visual-guide.md b/data/guides/cicd-simplified-visual-guide.md
new file mode 100644
index 0000000..9725717
--- /dev/null
+++ b/data/guides/cicd-simplified-visual-guide.md
@@ -0,0 +1,26 @@
+---
+title: "CI/CD Simplified Visual Guide"
+description: "A visual guide to understanding and improving CI/CD pipelines."
+image: "https://assets.bytebytego.com/diagrams/0141-ci-cd-workflow.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "CI/CD"
+ - "DevOps"
+---
+
+
+
+Whether you're a developer, a DevOps specialist, a tester, or involved in any modern IT role, CI/CD pipelines have become an integral part of the software development process.
+
+## Continuous Integration (CI)
+
+Continuous Integration (CI) is a practice where code changes are frequently combined into a shared repository. This process includes automatic checks to ensure the new code works well with the existing code.
+
+## Continuous Deployment (CD)
+
+Continuous Deployment (CD) takes care of automatically putting these code changes into real-world use. It makes sure that the process of moving new code to production is smooth and reliable.
+
+This visual guide is designed to help you grasp and enhance your methods for creating and delivering software more effectively.
diff --git a/data/guides/cloud-comparison-cheat-sheet.md b/data/guides/cloud-comparison-cheat-sheet.md
new file mode 100644
index 0000000..54d5f44
--- /dev/null
+++ b/data/guides/cloud-comparison-cheat-sheet.md
@@ -0,0 +1,20 @@
+---
+title: "Cloud Comparison Cheat Sheet"
+description: "A handy cheat sheet comparing different cloud services."
+image: "https://assets.bytebytego.com/diagrams/0093-cloud-comparison-cheat-sheet.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Computing
+ - Comparison
+---
+
+
+
+## Cloud comparison Cheat Sheet
+
+A nice cheat sheet of different cloud services (2023 edition)!
+
+Guest post by [Govardhana Miriyala Kannaiah](https://www.linkedin.com/in/govardhana-miriyala-kannaiah/).
diff --git a/data/guides/cloud-cost-reduction-techniques.md b/data/guides/cloud-cost-reduction-techniques.md
new file mode 100644
index 0000000..3849349
--- /dev/null
+++ b/data/guides/cloud-cost-reduction-techniques.md
@@ -0,0 +1,33 @@
+---
+title: "Cloud Cost Reduction Techniques"
+description: "Learn effective strategies to minimize cloud spending and optimize resources."
+image: "https://assets.bytebytego.com/diagrams/0145-cloud-cost-reduction-techniques.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Cost Optimization
+ - Resource Management
+---
+
+
+
+Irrational Cloud Cost is the biggest challenge many organizations are battling as they navigate the complexities of cloud computing.
+Efficiently managing these costs is crucial for optimizing cloud usage and maintaining financial health.
+
+The following techniques can help businesses effectively control and minimize their cloud expenses.
+
+* **Reduce Usage:** Fine-tune the volume and scale of resources to ensure efficiency without compromising on the performance of applications (e.g., downsizing instances, minimizing storage space, consolidating services).
+
+* **Terminate Idle Resources:** Locate and eliminate resources that are not in active use, such as dormant instances, databases, or storage units.
+
+* **Right Sizing:** Adjust instance sizes to adequately meet the demands of your applications, ensuring neither underuse nor overuse.
+
+* **Shutdown Resources During Off-Peak Times:** Set up automatic mechanisms or schedules for turning off non-essential resources when they are not in use, especially during low-activity periods.
+
+* **Reserve to Reduce Rate:** Adopt cost-effective pricing models like Reserved Instances or Savings Plans that align with your specific workload needs.
+
+ Bonus Tip: Consider using Spot Instances and lower-tier storage options for additional cost savings.
+
+* **Optimize Data Transfers:** Utilize methods such as data compression and Content Delivery Networks (CDNs) to cut down on bandwidth expenses, and strategically position resources to reduce data transfer costs, focusing on intra-region transfers.
diff --git a/data/guides/cloud-database-cheat-sheet.md b/data/guides/cloud-database-cheat-sheet.md
new file mode 100644
index 0000000..9e7160c
--- /dev/null
+++ b/data/guides/cloud-database-cheat-sheet.md
@@ -0,0 +1,22 @@
+---
+title: "Cloud Database Cheat Sheet"
+description: "A handy guide to cloud databases and their open-source alternatives."
+image: "https://assets.bytebytego.com/diagrams/0146-cloud-dbs2.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Cloud Computing"
+ - "Databases"
+---
+
+
+
+A cheat sheet of various databases in cloud services, along with their corresponding open-source/3rd-party options.
+
+Choosing the right database for your project is a complex task. The multitude of database options, each suited to distinct use cases, can quickly lead to decision fatigue.
+
+We hope this cheat sheet provides the high level direction to pinpoint the right service that aligns with your project's needs and avoid potential pitfalls.
+
+Note: Google has limited documentation for their database use cases. Even though we did our best to look at what was available and arrived at the best option, some of the entries may be not accurate.
diff --git a/data/guides/cloud-disaster-recovery-strategies.md b/data/guides/cloud-disaster-recovery-strategies.md
new file mode 100644
index 0000000..69be567
--- /dev/null
+++ b/data/guides/cloud-disaster-recovery-strategies.md
@@ -0,0 +1,52 @@
+---
+title: "Cloud Disaster Recovery Strategies"
+description: "Explore cloud disaster recovery strategies: RTO, RPO, and key approaches."
+image: "https://assets.bytebytego.com/diagrams/0050-cloud-disaster-recovery-strategies.png"
+createdAt: "2024-01-29"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "Disaster Recovery"
+---
+
+
+
+An effective Disaster Recovery (DR) plan is not just a precaution; it's a necessity.
+
+The key to any robust DR strategy lies in understanding and setting two pivotal benchmarks: Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
+
+* **Recovery Time Objective (RTO)** refers to the maximum acceptable length of time that your application or network can be offline after a disaster.
+
+* **Recovery Point Objective (RPO)**, on the other hand, indicates the maximum acceptable amount of data loss measured in time.
+
+Let's explore four widely adopted DR strategies:
+
+## Backup and Restore Strategy:
+
+This method involves regular backups of data and systems to facilitate post-disaster recovery.
+
+* **Typical RTO:** From several hours to a few days.
+* **Typical RPO:** From a few hours up to the time of the last successful backup.
+
+## Pilot Light Approach:
+
+Maintains crucial components in a ready-to-activate mode, enabling rapid scaling in response to a disaster.
+
+* **Typical RTO:** From a few minutes to several hours.
+* **Typical RPO:** Depends on how often data is synchronized.
+
+## Warm Standby Solution:
+
+Establishes a semi-active environment with current data to reduce recovery time.
+
+* **Typical RTO:** Generally within a few minutes to hours.
+* **Typical RPO:** Up to the last few minutes or hours.
+
+## Hot Site / Multi-Site Configuration:
+
+Ensures a fully operational, duplicate environment that runs parallel to the primary system.
+
+* **Typical RTO:** Almost immediate, often just a few minutes.
+* **Typical RPO:** Extremely minimal, usually only a few seconds old.
diff --git a/data/guides/cloud-load-balancer-cheat-sheet.md b/data/guides/cloud-load-balancer-cheat-sheet.md
new file mode 100644
index 0000000..1009e11
--- /dev/null
+++ b/data/guides/cloud-load-balancer-cheat-sheet.md
@@ -0,0 +1,20 @@
+---
+title: "Cloud Load Balancer Cheat Sheet"
+description: "A concise guide to cloud load balancers and their optimal use cases."
+image: "https://assets.bytebytego.com/diagrams/0094-cloud-load-balancer-cheatsheet.gif"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "Load Balancing"
+---
+
+
+
+In today's multi-cloud landscape, mastering load balancing is essential to ensure seamless user experiences and maximize resource utilization, especially when orchestrating applications across multiple cloud providers. Having the right knowledge is key to overcoming these challenges and achieving consistent, reliable application delivery.
+
+In selecting the appropriate load balancer type, it's essential to consider factors such as application traffic patterns, scalability requirements, and security considerations. By carefully evaluating your specific use case, you can make informed decisions that enhance your cloud infrastructure's efficiency and reliability.
+
+This Cloud Load Balancer cheat sheet would help you in simplifying the decision-making process and helping you implement the most effective load balancing strategy for your cloud-based applications.
diff --git a/data/guides/cloud-monitoring-cheat-sheet.md b/data/guides/cloud-monitoring-cheat-sheet.md
new file mode 100644
index 0000000..e3ba70b
--- /dev/null
+++ b/data/guides/cloud-monitoring-cheat-sheet.md
@@ -0,0 +1,38 @@
+---
+title: "Cloud Monitoring Cheat Sheet"
+description: "A handy guide to cloud monitoring across major providers and tools."
+image: "https://assets.bytebytego.com/diagrams/0095-cloud-monitoring-cheat-sheet.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Computing"
+ - "Monitoring"
+---
+
+
+
+A nice cheat sheet of different monitoring infrastructure in cloud services.
+
+This cheat sheet offers a concise yet comprehensive comparison of key monitoring elements across the three major cloud providers and open-source / 3rd party tools.
+
+Let's delve into the essential monitoring aspects covered:
+
+* **Data Collection:** Gather information from diverse sources to enhance decision-making.
+
+* **Data Storage:** Safely store and manage data for future analysis and reference.
+
+* **Data Analysis:** Extract valuable insights from data to drive informed actions.
+
+* **Alerting:** Receive real-time notifications about critical events or anomalies.
+
+* **Visualization:** Present data in a visually comprehensible format for better understanding.
+
+* **Reporting and Compliance:** Generate reports and ensure adherence to regulatory standards.
+
+* **Automation:** Streamline processes and tasks through automated workflows.
+
+* **Integration:** Seamlessly connect and exchange data between different systems or tools.
+
+* **Feedback Loops:** Continuously refine strategies based on feedback and performance analysis.
diff --git a/data/guides/cloud-native-anti-patterns.md b/data/guides/cloud-native-anti-patterns.md
new file mode 100644
index 0000000..0089c01
--- /dev/null
+++ b/data/guides/cloud-native-anti-patterns.md
@@ -0,0 +1,54 @@
+---
+title: "Cloud Native Anti-Patterns"
+description: "Avoid common pitfalls in cloud-native development for robust applications."
+image: "https://assets.bytebytego.com/diagrams/0070-cloud-native-anti-patterns.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Cloud Native"
+ - "Anti-Patterns"
+---
+
+By being aware of these anti-patterns and following cloud-native best practices, you can design, build, and operate more robust, scalable, and cost-efficient cloud-native applications.
+
+
+
+## Monolithic Architecture
+
+One large, tightly coupled application running on the cloud, hindering scalability and agility.
+
+## Ignoring Cost Optimization
+
+Cloud services can be expensive, and not optimizing costs can result in budget overruns.
+
+## Mutable Infrastructure
+
+* Infrastructure components are to be treated as disposable and are never modified in place.
+
+* Failing to embrace this approach can lead to configuration drift, increased maintenance, and decreased reliability.
+
+## Inefficient DB Access Patterns
+
+Use of overly complex queries or lacking database indexing, can lead to performance degradation and database bottlenecks.
+
+## Large Containers or Bloated Images
+
+Creating large containers or using bloated images can increase deployment times, consume more resources, and slow down application scaling.
+
+## Ignoring CI/CD Pipelines
+
+Deployments become manual and error-prone, impeding the speed and frequency of software releases.
+
+## Shared Resources Dependency
+
+Applications relying on shared resources like databases can create contention and bottlenecks, affecting overall performance.
+
+## Using Too Many Cloud Services Without a Strategy
+
+While cloud providers offer a vast array of services, using too many of them without a clear strategy can create complexity and make it harder to manage the application.
+
+## Stateful Components
+
+Relying on persistent state in applications can introduce complexity, hinder scalability, and limit fault tolerance.
diff --git a/data/guides/concurrency-is-not-parallelism.md b/data/guides/concurrency-is-not-parallelism.md
new file mode 100644
index 0000000..cb12aaa
--- /dev/null
+++ b/data/guides/concurrency-is-not-parallelism.md
@@ -0,0 +1,28 @@
+---
+title: "Concurrency vs Parallelism"
+description: "Understand the difference between concurrency and parallelism in system design."
+image: "https://assets.bytebytego.com/diagrams/0150-concurrency-is-not-parallelism.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Concurrency"
+ - "Parallelism"
+---
+
+
+
+In system design, it is important to understand the difference between concurrency and parallelism.
+
+As Rob Pyke(one of the creators of GoLang) stated:“ Concurrency is about **dealing with** lots of things at once. Parallelism is about **doing** lots of things at once." This distinction emphasizes that concurrency is more about the **design** of a program, while parallelism is about the **execution**.
+
+Concurrency is about dealing with multiple things at once. It involves structuring a program to handle multiple tasks simultaneously, where the tasks can start, run, and complete in overlapping time periods, but not necessarily at the same instant.
+
+Concurrency is about the composition of independently executing processes and describes a program's ability to manage multiple tasks by making progress on them without necessarily completing one before it starts another.
+
+Parallelism, on the other hand, refers to the simultaneous execution of multiple computations. It is the technique of running two or more tasks or computations at the same time, utilizing multiple processors or cores within a computer to perform several operations concurrently. Parallelism requires hardware with multiple processing units, and its primary goal is to increase the throughput and computational speed of a system.
+
+In practical terms, concurrency enables a program to remain responsive to input, perform background tasks, and handle multiple operations in a seemingly simultaneous manner, even on a single-core processor. It's particularly useful in I/O-bound and high-latency operations where programs need to wait for external events, such as file, network, or user interactions.
+
+Parallelism, with its ability to perform multiple operations at the same time, is crucial in CPU-bound tasks where computational speed and throughput are the bottlenecks. Applications that require heavy mathematical computations, data analysis, image processing, and real-time processing can significantly benefit from parallel execution.
diff --git a/data/guides/consistent-hashing.md b/data/guides/consistent-hashing.md
new file mode 100644
index 0000000..4e00758
--- /dev/null
+++ b/data/guides/consistent-hashing.md
@@ -0,0 +1,52 @@
+---
+title: "Consistent Hashing Explained"
+description: "Explore consistent hashing: its benefits, and real-world applications."
+image: "https://assets.bytebytego.com/diagrams/0151-consistent-hashing.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Consistent Hashing"
+ - "Distributed Systems"
+---
+
+
+
+## Algorithm 1: Consistent Hashing
+
+What do Amazon DynamoDB, Apache Cassandra, Discord, and Akamai CDN have in common?
+
+They all use consistent hashing. Let’s dive right in.
+
+## What’s the issue with simple hashing?
+
+In a large-scale distributed system, data does not fit on a single server. They are “distributed” across many machines. This is called horizontal scaling.
+
+To build such a system with predictable performance, it is important to distribute the data evenly across those servers.
+
+Simple hashing: serverIndex = hash(key) % N, where N is the size of the server pool
+
+This approach works well when the size of the cluster is fixed, and the data distribution is even. But when new servers get added to meet new demand, or when existing servers get removed, it triggers a storm of misses and a lot of objects to be moved.
+
+## Consistent hashing
+
+Consistent hashing is an effective technique to mitigate this issue.
+
+The goal of consistent hashing is simple. We want almost all objects to stay assigned to the same server even as the number of servers changes.
+
+As shown in the diagram, using a hash function, we hash each server by its name or IP address, and place the server onto the ring. Next, we hash each object by its key with the same hashing function.
+
+To locate the server for a particular object, we go clockwise from the location of the object key on the ring until a server is found. Continue with our example, key 0 is on server 0, key 1 is on server 1.
+
+Now let’s take a look at what happens when we add a server.
+
+Here we insert a new server s4 to the left of s0 on the ring. Note that only k0 needs to be moved from s0 to s4. This is because s4 is the first server k0 encounters by going clockwise from k0’s position on the ring. Keys k1, k2, and k3 are not affected.
+
+## How consistent hashing is used in the real world
+
+* **Amazon DynamoDB and Apache Cassandra:** minimize data movement during rebalancing
+
+* **Content delivery networks like Akamai:** distribute web contents evenly among the edge servers
+
+* **Load balancers like Google Network Load Balancer:** distribute persistent connections evenly across backend servers
diff --git a/data/guides/cookies-vs-sessions-vs-jwt-vs-paseto.md b/data/guides/cookies-vs-sessions-vs-jwt-vs-paseto.md
new file mode 100644
index 0000000..ba8d970
--- /dev/null
+++ b/data/guides/cookies-vs-sessions-vs-jwt-vs-paseto.md
@@ -0,0 +1,36 @@
+---
+title: "Cookies vs Sessions vs JWT vs PASETO"
+description: "Explore cookies, sessions, JWT, and PASETO for modern authentication."
+image: "https://assets.bytebytego.com/diagrams/0155-cookies-vs-sessions-vs-jwt-vs-paseto.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Security"
+---
+
+
+
+Authentication ensures that only authorized users gain access to an application’s resources. It answers the question of the user’s identity i.e. “Who are you?”
+
+The modern authentication landscape has multiple approaches: Cookies, Sessions, JWTs, and PASETO. Here’s what they mean:
+
+## Cookies and Sessions
+
+Cookies and sessions are authentication mechanisms where session data is stored on the server and referenced via a client-side cookie.
+
+Sessions are ideal for applications requiring strict server-side control over user data. On the downside, sessions may face scalability challenges in distributed systems.
+
+## JWT
+
+JSON Web Token (JWT) is a stateless, self-contained authentication method that stores all user data within the token.
+
+JWTs are highly scalable but require careful handling to mitigate the chances of token theft and manage token expiration.
+
+## PASETO
+
+Platform-Agnostic Security Tokens or PASETO improve upon JWT by enforcing stronger cryptographic defaults and eliminating algorithmic vulnerabilities.
+
+PASETO simplifies token implementation by avoiding the risks associated with misconfiguration.
diff --git a/data/guides/cybersecurity-101-in-one-picture.md b/data/guides/cybersecurity-101-in-one-picture.md
new file mode 100644
index 0000000..a58691d
--- /dev/null
+++ b/data/guides/cybersecurity-101-in-one-picture.md
@@ -0,0 +1,32 @@
+---
+title: "Cybersecurity 101"
+description: "A concise overview of cybersecurity fundamentals and key concepts."
+image: "https://assets.bytebytego.com/diagrams/0156-cybersecurity-101-in-one-picture.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - security
+tags:
+ - "Cybersecurity"
+ - "Fundamentals"
+---
+
+
+
+## Introduction to Cybersecurity
+
+## The CIA Triad
+
+## Common Cybersecurity Threats
+
+## Basic Defense Mechanisms
+
+To combat these threats, several basic defense mechanisms are employed:
+
+* **Firewalls:** Network security devices that monitor and control incoming and outgoing network traffic.
+
+* **Antivirus Software:** Programs designed to detect and remove malware.
+
+* **Encryption:** The process of converting information into a code to prevent unauthorized access.
+
+## Cybersecurity Frameworks
diff --git a/data/guides/data-pipelines-overview.md b/data/guides/data-pipelines-overview.md
new file mode 100644
index 0000000..d110acb
--- /dev/null
+++ b/data/guides/data-pipelines-overview.md
@@ -0,0 +1,38 @@
+---
+title: Data Pipelines Overview
+description: Learn about the essential phases of data pipelines.
+image: 'https://assets.bytebytego.com/diagrams/0157-data-pipeline-overview.png'
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - data-pipelines
+ - data-processing
+---
+
+
+
+Data pipelines are a fundamental component of managing and processing data efficiently within modern systems. These pipelines typically encompass 5 predominant phases: Collect, Ingest, Store, Compute, and Consume.
+
+## Collect:
+
+Data is acquired from data stores, data streams, and applications, sourced remotely from devices, applications, or business systems.
+
+## Ingest:
+
+During the ingestion process, data is loaded into systems and organized within event queues.
+
+## Store:
+
+Post ingestion, organized data is stored in data warehouses, data lakes, and data lakehouses, along with various systems like databases, ensuring post-ingestion storage.
+
+## Compute:
+
+Data undergoes aggregation, cleansing, and manipulation to conform to company standards, including tasks such as format conversion, data compression, and partitioning. This phase employs both batch and stream processing techniques.
+
+## Consume:
+
+Processed data is made available for consumption through analytics and visualization tools, operational data stores, decision engines, user-facing applications, dashboards, data science, machine learning services, business intelligence, and self-service analytics.
+
+The efficiency and effectiveness of each phase contribute to the overall success of data-driven operations within an organization.
diff --git a/data/guides/database-middleware.md b/data/guides/database-middleware.md
new file mode 100644
index 0000000..47a2ed0
--- /dev/null
+++ b/data/guides/database-middleware.md
@@ -0,0 +1,41 @@
+---
+title: "Database Middleware"
+description: "Explore database middleware for transparent routing and simplified code."
+image: "https://assets.bytebytego.com/diagrams/0276-middleware-png.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Database Routing
+ - Proxy
+---
+
+
+
+There are two common ways to implement the read replica pattern:
+
+1. Embed the routing logic in the application code (explained in the last post).
+2. Use database middleware.
+
+We focus on option 2 here. The middleware provides transparent routing between the application and database servers. We can customize the routing logic based on difficult rules such as user, schema, statement, etc.
+
+The diagram above illustrates the setup:
+
+1. When Alice places an order on amazon, the request is sent to Order Service.
+2. Order Service does not directly interact with the database. Instead, it sends database queries to the database middleware.
+3. The database middleware routes writes to the primary database. Data is replicated to two replicas.
+4. Alice views the order details (read). The request is sent through the middleware.
+5. Alice views the recent order history (read). The request is sent through the middleware.
+
+The database middleware acts as a proxy between the application and databases. It uses standard MySQL network protocol for communication.
+
+## Pros
+
+* Simplified application code. The application doesn’t need to be aware of the database topology and manage access to the database directly.
+* Better compatibility. The middleware uses the MySQL network protocol. Any MySQL compatible client can connect to the middleware easily. This makes database migration easier.
+
+## Cons
+
+* Increased system complexity. A database middleware is a complex system. Since all database queries go through the middleware, it usually requires a high availability setup to avoid a single point of failure.
+* Additional middleware layer means additional network latency. Therefore, this layer requires excellent performance.
diff --git a/data/guides/deepseek-1-pager.md b/data/guides/deepseek-1-pager.md
new file mode 100644
index 0000000..45d4a5f
--- /dev/null
+++ b/data/guides/deepseek-1-pager.md
@@ -0,0 +1,32 @@
+---
+title: 'DeepSeek 1-Pager'
+description: "Explore DeepSeek's cost-effective AI model and its innovative R1 release."
+image: 'https://assets.bytebytego.com/diagrams/0164-deepseek.png'
+createdAt: '2024-03-11'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI Models
+ - DeepSeek
+---
+
+
+
+It is said to have developed a powerful AI model at a remarkably low cost, approximately $6 million for the final training run. In January 2025, it is said to have released its latest reasoning-focused model known as DeepSeek R1.
+
+The release made it the No. 1 downloaded free app on the Apple Play Store.
+
+Most AI models are trained using supervised fine-tuning, meaning they learn by mimicking large datasets of human-annotated examples. This method has limitations.
+
+DeepSeek R1 overcomes these limitations by using Group Relative Policy Optimization (GRPO), a reinforcement learning technique that improves reasoning efficiency by comparing multiple possible answers within the same context.
+
+Some facts about DeepSeek’s R1 model are as follows:
+
+- DeepSeek-R1 uses a Mixture-of-Experts (MoE) architecture with 671 billion total parameters, activating only 37 billion parameters per task.
+- It employs selective parameter activation through MoE for resource optimization.
+- The model is pre-trained on 14.8 trillion tokens across 52 languages.
+- DeepSeek-R1 was trained using just 2000 Nvidia GPUs. By comparison, ChatGPT-4 needed approximately 25K Nvidia GPUs over 90-100 days.
+- The model is 85-90% more cost-effective than competitors.
+- It excels in mathematics, coding, and reasoning tasks.
+- Also, the model has been released as open-source under the MIT license.
diff --git a/data/guides/delivery-semantics.md b/data/guides/delivery-semantics.md
new file mode 100644
index 0000000..daef139
--- /dev/null
+++ b/data/guides/delivery-semantics.md
@@ -0,0 +1,41 @@
+---
+title: "Delivery Semantics"
+description: "Understand at-most once, at-least once, and exactly once delivery semantics."
+image: "https://assets.bytebytego.com/diagrams/0165-delivery-semantics.png"
+createdAt: "2024-02-10"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Message Queues"
+ - "Delivery Semantics"
+---
+
+
+
+In modern architecture, systems are broken up into small and independent building blocks with well-defined interfaces between them. Message queues provide communication and coordination for those building blocks. Today, let’s discuss different delivery semantics: at-most once, at-least once, and exactly once.
+
+## At-most once
+
+As the name suggests, at-most once means a message will be delivered not more than once. Messages may be lost but are not redelivered. This is how at-most once delivery works at the high level.
+
+### Use cases:
+
+* It is suitable for use cases like monitoring metrics, where a small amount of data loss is acceptable.
+
+## At-least once
+
+With this data delivery semantic, it’s acceptable to deliver a message more than once, but no message should be lost.
+
+### Use cases:
+
+* With at-least once, messages won’t be lost but the same message might be delivered multiple times. While not ideal from a user perspective, at-least once delivery semantics are usually good enough for use cases where data duplication is not a big issue or deduplication is possible on the consumer side.
+* For example, with a unique key in each message, a message can be rejected when writing duplicate data to the database.
+
+## Exactly once
+
+Exactly once is the most difficult delivery semantic to implement. It is friendly to users, but it has a high cost for the system’s performance and complexity.
+
+### Use cases:
+
+* Financial-related use cases (payment, trading, accounting, etc.). Exactly once is especially important when duplication is not acceptable and the downstream service or third party doesn’t support idempotency.
diff --git a/data/guides/design-gmail.md b/data/guides/design-gmail.md
new file mode 100644
index 0000000..13f66d9
--- /dev/null
+++ b/data/guides/design-gmail.md
@@ -0,0 +1,26 @@
+---
+title: "Design Gmail"
+description: "Explore the design of Gmail: from sending to receiving emails."
+image: "https://assets.bytebytego.com/diagrams/0184-email.jpg"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Email"
+ - "System Design"
+---
+
+
+
+One picture is worth more than a thousand words. In this post, we will take a look at what happens when Alice sends an email to Bob.
+
+## Sending an Email: A Step-by-Step Guide
+
+1. Alice logs in to her Outlook client, composes an email, and presses “send”. The email is sent to the Outlook mail server. The communication protocol between the Outlook client and mail server is SMTP.
+
+2. Outlook mail server queries the DNS (not shown in the diagram) to find the address of the recipient’s SMTP server. In this case, it is Gmail’s SMTP server. Next, it transfers the email to the Gmail mail server. The communication protocol between the mail servers is SMTP.
+
+3. The Gmail server stores the email and makes it available to Bob, the recipient.
+
+4. Gmail client fetches new emails through the IMAP/POP server when Bob logs in to Gmail.
diff --git a/data/guides/design-google-maps.md b/data/guides/design-google-maps.md
new file mode 100644
index 0000000..945282d
--- /dev/null
+++ b/data/guides/design-google-maps.md
@@ -0,0 +1,45 @@
+---
+title: "Design Google Maps"
+description: "Learn how to design a simplified version of Google Maps."
+image: "https://assets.bytebytego.com/diagrams/0207-google-maps.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "System Design"
+ - "Maps"
+---
+
+
+
+Google started project **Google Maps** in 2005. As of March 2021, Google Maps had one billion daily active users, 99% coverage of the world.
+
+Although Google Maps is a very complex system, we can break it down into 3 high-level components. In this post, let’s take a look at how to design a simplified Google Maps.
+
+## Location Service
+
+The location service is responsible for recording a user’s location update. The Google Map clients send location updates every few seconds. The user location data is used in many cases:
+
+* detect new and recently closed roads.
+* improve the accuracy of the map over time.
+* used as an input for live traffic data.
+
+## Map Rendering
+
+The world’s map is projected into a huge 2D map image. It is broken down into small image blocks called “tiles” (see below). The tiles are static. They don’t change very often. An efficient way to serve static tile files is with a CDN backed by cloud storage like S3. The users can load the necessary tiles to compose a map from nearby CDN.
+
+What if a user is zooming and panning the map viewpoint on the client to explore their surroundings?
+
+An efficient way is to pre-calculate the map blocks with different zoom levels and load the images when needed.
+
+## Navigation Service
+
+This component is responsible for finding a reasonably fast route from point A to point B. It calls two services to help with the path calculation:
+
+1. Geocoding Service: resolve the given address to a latitude/longitude pair.
+2. Route Planner Service: this service does three things in sequence:
+
+ * Calculate top-K shortest paths between A and B
+ * Calculate the estimation of time for each path based on current traffic and historical data
+ * Rank the paths by time predictions and user filtering. For example, the user doesn’t want to avoid tolls.
diff --git a/data/guides/design-patterns-cheat-sheet-part-1-and-part-2.md b/data/guides/design-patterns-cheat-sheet-part-1-and-part-2.md
new file mode 100644
index 0000000..4c78a4f
--- /dev/null
+++ b/data/guides/design-patterns-cheat-sheet-part-1-and-part-2.md
@@ -0,0 +1,25 @@
+---
+title: "Design Patterns Cheat Sheet"
+description: "Concise guide to design patterns with examples and use cases."
+image: "https://assets.bytebytego.com/diagrams/0167-design-patterns-cheat-sheet-part-2.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "design patterns"
+ - "software design"
+---
+
+
+
+The cheat sheet briefly explains each pattern and how to use it.
+
+What's included?
+
+* Factory
+* Builder
+* Prototype
+* Singleton
+* Chain of Responsibility
+* And many more!
diff --git a/data/guides/design-stock-exchange.md b/data/guides/design-stock-exchange.md
new file mode 100644
index 0000000..bf983f9
--- /dev/null
+++ b/data/guides/design-stock-exchange.md
@@ -0,0 +1,34 @@
+---
+title: "Design Stock Exchange"
+description: "Explore the design of a stock exchange and its key components."
+image: "https://assets.bytebytego.com/diagrams/0344-stock-exchange.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "System Design"
+ - "Trading Systems"
+---
+
+
+
+Let’s trace the life of an order through various components in the diagram to see how the pieces fit together.
+
+First, we follow the order through the trading flow. This is the critical path with strict latency requirements. Everything has to happen fast in the flow:
+
+### Step 1: A client places an order via the broker’s web or mobile app.
+
+### Step 2: The broker sends the order to the exchange.
+
+### Step 3: The order enters the exchange through the client gateway. The client gateway performs basic gatekeeping functions such as input validation, rate limiting, authentication, normalization, etc. The client gateway then forwards the order to the order manager.
+
+### Step 4 - 5: The order manager performs risk checks based on rules set by the risk manager.
+
+### Step 6: After passing risk checks, the order manager verifies there are sufficient funds in the wallet for the order.
+
+### Step 7 - 9: The order is sent to the matching engine. When a match is found, the matching engine emits two executions, with one each for the buy and sell sides. To guarantee that matching results are deterministic when replayed, both orders and executions are sequenced.
+
+### Step 10 - 14: The executions are returned to the client.
+
+Note that the trading flow (steps 1 to 14) is on the critical path, while the market data flow and reporting flow are not. They have different latency requirements.
diff --git a/data/guides/devops-vs-noops.md b/data/guides/devops-vs-noops.md
new file mode 100644
index 0000000..9e856ee
--- /dev/null
+++ b/data/guides/devops-vs-noops.md
@@ -0,0 +1,24 @@
+---
+title: "DevOps vs NoOps: What's the Difference?"
+description: "How do DevOps, NoOps change the software development lifecycle (SDLC)?"
+image: "https://assets.bytebytego.com/diagrams/0099-devops-vs-noops.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Nginx"
+ - "Web Servers"
+---
+
+The diagram below compares traditional SDLC, DevOps and NoOps.
+
+
+
+In a traditional software development, code, build, test, release and monitoring are siloed functions. Each stage works independently and hands over to the next stage.
+
+DevOps, on the other hand, encourages continuous development and collaboration between developers and operations. This shortens the overall life cycle and provides continuous software delivery.
+
+NoOps is a newer concept with the development of serverless computing. Since we can architect the system using FaaS (Function-as-a-Service) and BaaS (Backend-as-a-Service), the cloud service providers can take care of most operations tasks. The developers can focus on feature development and automate operations tasks.
+
+NoOps is a pragmatic and effective methodology for startups or smaller-scale applications, which moves shortens the SDLC even more than DevOps.
diff --git a/data/guides/devops-vs-sre-vs-paltform-engg.md b/data/guides/devops-vs-sre-vs-paltform-engg.md
new file mode 100644
index 0000000..29f0169
--- /dev/null
+++ b/data/guides/devops-vs-sre-vs-paltform-engg.md
@@ -0,0 +1,28 @@
+---
+title: "DevOps vs. SRE vs. Platform Engineering"
+description: "Explore the differences between DevOps, SRE, and Platform Engineering."
+image: "https://assets.bytebytego.com/diagrams/0172-devops-sre-platform.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - DevOps
+ - SRE
+---
+
+
+
+The concepts of DevOps, SRE, and Platform Engineering have emerged at different times and have been developed by various individuals and organizations.
+
+By guest author [Xiong Wang](https://www.linkedin.com/in/wangxiong/)
+
+## Introduction
+
+DevOps as a concept was introduced in 2009 by Patrick Debois and Andrew Shafer at the Agile conference. They sought to bridge the gap between software development and operations by promoting a collaborative culture and shared responsibility for the entire software development lifecycle.
+
+SRE, or Site Reliability Engineering, was pioneered by Google in the early 2000s to address operational challenges in managing large-scale, complex systems. Google developed SRE practices and tools, such as the Borg cluster management system and the Monarch monitoring system, to improve the reliability and efficiency of their services.
+
+Platform Engineering is a more recent concept, building on the foundation of SRE engineering. The precise origins of Platform Engineering are less clear, but it is generally understood to be an extension of the DevOps and SRE practices, with a focus on delivering a comprehensive platform for product development that supports the entire business perspective.
+
+It's worth noting that while these concepts emerged at different times. They are all related to the broader trend of improving collaboration, automation, and efficiency in software development and operations.
diff --git a/data/guides/diagram-as-code.md b/data/guides/diagram-as-code.md
new file mode 100644
index 0000000..cedee97
--- /dev/null
+++ b/data/guides/diagram-as-code.md
@@ -0,0 +1,28 @@
+---
+title: "Diagram as Code"
+description: "Explore Diagram as Code for cloud system architecture prototyping."
+image: "https://assets.bytebytego.com/diagrams/0173-diagrams-as-code-twitter.jpeg"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "diagrams"
+ - "architecture"
+---
+
+
+
+Would it be nice if the code we wrote automatically turned into architecture diagrams?
+
+I recently discovered a Github repo that does exactly this: Diagram as Code for prototyping cloud system architectures.
+
+## What does it do?
+
+* Draw the cloud system architecture in Python code.
+
+* Diagrams can also be rendered directly inside the Jupyter Notebooks.
+
+* No design tools are needed.
+
+* Supports the following providers: AWS, Azure, GCP, Kubernetes, Alibaba Cloud, Oracle Cloud, etc.
diff --git a/data/guides/differences-in-event-sourcing-system-design.md b/data/guides/differences-in-event-sourcing-system-design.md
new file mode 100644
index 0000000..5855e41
--- /dev/null
+++ b/data/guides/differences-in-event-sourcing-system-design.md
@@ -0,0 +1,20 @@
+---
+title: "Differences in Event Sourcing System Design"
+description: "Explore the nuances of event sourcing system design and its benefits."
+image: "https://assets.bytebytego.com/diagrams/0188-event-sourcing.jpeg"
+createdAt: "2024-02-08"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "event sourcing"
+ - "system design"
+---
+
+
+
+How do we design a system using the event sourcing paradigm? How is it different from normal system design? What are the benefits? We will talk about it in this post.
+
+The diagram above shows the comparison of a normal CRUD system design with an event sourcing system design. We use an e-commerce system that can place orders and pay for the orders to demonstrate how event sourcing works.
+
+The event sourcing paradigm is used to design a system with determinism. This changes the philosophy of normal system designs.
diff --git a/data/guides/digital-wallet-in-traditional-banks-vs-wallet-in-blockchain.md b/data/guides/digital-wallet-in-traditional-banks-vs-wallet-in-blockchain.md
new file mode 100644
index 0000000..c985a08
--- /dev/null
+++ b/data/guides/digital-wallet-in-traditional-banks-vs-wallet-in-blockchain.md
@@ -0,0 +1,38 @@
+---
+title: "Digital Wallets: Banks vs. Blockchain"
+description: "Explore the differences between digital wallets in banks and blockchain."
+image: "https://assets.bytebytego.com/diagrams/0087-blockchains.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Blockchain"
+ - "Digital Wallets"
+---
+
+How does blockchain change the design of digital wallets? Why do VISA and PayPal invest in blockchains?
+
+
+
+## In banking systems
+
+* Deposit process: Bob goes to Bank of America (BoA) to open an account and deposit $100. A new account B1234 is created in the wallet system for Bob. The cash goes to the bank’s vault and Bob’s wallet now has $100. If Bob wants to use the banking services of Citibank (Citi,) he needs to go through the same process all over again.
+
+* Transfer process: Bob opens BoA’s App and transfers $50 to Alice’s account at Citi. The amount is deducted from Bob’s account B1234 and credited to Alice’s account C512. The actual movement of cash doesn’t happen instantly. It happens after BoA and Citi settle all transactions at end-of-day.
+
+* Withdrawal process: Bob withdraws his remaining $50 from account B1234. The amount is deducted from B1234, and Bob gets the cash.
+
+## With Blockchains
+
+* Deposit & Withdraw: Blockchains support cryptocurrencies, with no cash involved. Bob needs to generate an address as the transfer recipient and store the private key in a crypto wallet like Metamask. Then Bob can receive cryptocurrencies.
+
+* Transfer: Bob opens Metamask and enters Alice’s address, and sends it 2 ETHs. Then Bob signs the transaction to authorize the transfer with the private key. When this transaction is confirmed on blockchains, Bob’s address has 8 ETHs and Alice’s address has 101 ETHs.
+
+👉 Can you spot the differences?
+
+Blockchain is distributed ledger. It provides a unified interface to handle the common operations we perform on wallets. Instead of opening multiple accounts with different banks, we just need to open a single account on blockchains, which is the address.
+
+All transfers are confirmed on blockchains in pseudo real-time, saving us from waiting until end-of-day reconciliations.
+
+With blockchains, we can merge wallet services from different banks into one global service.
diff --git a/data/guides/dns-record-types-you-should-know.md b/data/guides/dns-record-types-you-should-know.md
new file mode 100644
index 0000000..5ace65b
--- /dev/null
+++ b/data/guides/dns-record-types-you-should-know.md
@@ -0,0 +1,48 @@
+---
+title: "DNS Record Types You Should Know"
+description: "Learn about the most common and important DNS record types."
+image: "https://assets.bytebytego.com/diagrams/0175-dns-record-types-you-should-know.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "DNS"
+ - "Networking"
+---
+
+
+
+Here are the 8 most commonly used DNS Record Types.
+
+## A (Address) Record
+
+Maps a domain name to an IPv4 address. It is one of the most essential records for translating human-readable domain names into IP addresses.
+
+## CNAME (Canonical Name) Record
+
+Used to alias one domain name to another. Often used for subdomains, pointing them to the main domain while keeping the actual domain name hidden.
+
+## AAAA Record
+
+Similar to an A record but maps a domain name to an IPv6 address. They are used for websites and services that support the IPv6 protocol.
+
+## PTR Record
+
+Provides reverse DNS lookup, mapping an IP address back to a domain name. It is commonly used in verifying the authenticity of a server.
+
+## MX Record
+
+Directs email traffic to the correct mail server.
+
+## NS (Name Server) Record
+
+Specifies the authoritative DNS servers for the domain. These records help direct queries to the correct DNS servers for further lookups.
+
+## SRV (Service) Record
+
+SRV record specifies a host and port for specific services such as VoIP. They are used in conjunction with A records.
+
+## TXT (Text) Record
+
+Allows the administrator to add human-readable text to the DNS records. It is used to include verification records, like SPF, for email security.
diff --git a/data/guides/do-you-know-all-the-components-of-a-url.md b/data/guides/do-you-know-all-the-components-of-a-url.md
new file mode 100644
index 0000000..ef790d9
--- /dev/null
+++ b/data/guides/do-you-know-all-the-components-of-a-url.md
@@ -0,0 +1,24 @@
+---
+title: 'Do you know all the components of a URL?'
+description: 'Learn about the different components that make up a URL.'
+image: 'https://assets.bytebytego.com/diagrams/0116-structure-of-url.png'
+createdAt: '2024-02-18'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - networking
+ - web-development
+---
+
+
+
+Uniform Resource Locator (URL) is a term familiar to most people, as it is used to locate resources on the internet. When you type a URL into a web browser's address bar, you are accessing a "resource", not just a webpage.
+
+URLs comprise several components:
+
+* **The protocol or scheme**, such as http, https, and ftp.
+* **The domain name and port**, separated by a period (.)
+* **The path to the resource**, separated by a slash (/)
+* **The parameters**, which start with a question mark (?) and consist of key-value pairs, such as a=b&c=d.
+* **The fragment or anchor**, indicated by a pound sign (#), which is used to bookmark a specific section of the resource.
diff --git a/data/guides/do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.md b/data/guides/do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.md
new file mode 100644
index 0000000..1aca593
--- /dev/null
+++ b/data/guides/do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.md
@@ -0,0 +1,18 @@
+---
+title: "Why Meta, Google, and Amazon Stop Using Leap Seconds"
+description: "Explore why tech giants are moving away from leap seconds."
+image: "https://assets.bytebytego.com/diagrams/0363-do-you-know-why-meta-google-and-amazon-all-stop-using-leap-seconds.jpeg"
+createdAt: "2024-02-04"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Time Synchronization"
+ - "Leap Seconds"
+---
+
+
+
+Every few years, there is a special phenomenon that the second after “23:59:59” is not “00:00:00” but “23:59:60”. It is called leap second, which could easily cause time-processing bugs if not handled carefully.
+
+Do we always need to handle leap seconds? It depends on which time representation is used. Commonly used time representations include UTC, GMT, TAI, Unix Timestamp, Epoc time, TrueTime, and GPS time.
diff --git a/data/guides/e-commerce-workflow.md b/data/guides/e-commerce-workflow.md
new file mode 100644
index 0000000..bb5f798
--- /dev/null
+++ b/data/guides/e-commerce-workflow.md
@@ -0,0 +1,46 @@
+---
+title: "E-commerce Workflow"
+description: "Explore the behind-the-scenes of e-commerce: procurement to delivery."
+image: "https://assets.bytebytego.com/diagrams/0179-e-commerce-works.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - "payment-and-fintech"
+tags:
+ - "E-commerce"
+ - "Supply Chain"
+---
+
+What happens behind the scenes when we shop online?
+
+Disclaimer: I have limited knowledge of the eCommerce system. The diagram above is based on my research. Please suggest better names for the components or let me know if you spot an error.
+
+
+
+The diagram above shows the 4 key business areas in a typical e-commerce company: procurement, inventory, eComm platform, and transportation.
+
+## Procurement
+
+* Step 1 - The procurement department selects suppliers and manages contracts with them.
+
+* Step 2 - The procurement department places orders with suppliers, manages the return of goods, and settles invoices with suppliers.
+
+## Inventory
+
+* Step 3 - The products or goods from suppliers are delivered to a storage facility. All products/goods are managed by inventory management systems.
+
+## EComm platform
+
+* Steps 4-7 - The “eComm platform - Product Management” system creates the product info managed by the product system. The pricing system prices the products. Then the products are ready to be listed for sale. The promotion system defines big sale activities, coupons, etc.
+
+* Step 8-11 - Consumers can now purchase products on the e-commerce APP. First, users register or log in to the APP. Next, users browse the product list and details, adding products to the shopping cart. They then place purchasing orders.
+
+* Steps 12,13 - The order management system reserves stock in the inventory management system. Then the users pay for the product.
+
+## Transportation
+
+* Steps 14,15 - The inventory system sends the outbound order to the transportation system, which manages the physical delivery of the goods.
+
+* Step 16 - Sign for item delivery (optional)
+
+Quick question: If a user buys many products, their big order might be divided into several small orders based on warehouse locations, product types, etc. Where would you place the “order splitting” system in the process outlined below?
diff --git a/data/guides/encoding-vs-encryption-vs-tokenization.md b/data/guides/encoding-vs-encryption-vs-tokenization.md
new file mode 100644
index 0000000..6e3b957
--- /dev/null
+++ b/data/guides/encoding-vs-encryption-vs-tokenization.md
@@ -0,0 +1,36 @@
+---
+title: "Encoding vs Encryption vs Tokenization"
+description: "Understand encoding, encryption, and tokenization for data handling."
+image: "https://assets.bytebytego.com/diagrams/0033-encoding-vs-encryption-vs-tokenization.png"
+createdAt: "2024-02-11"
+draft: false
+categories:
+ - security
+tags:
+ - "Data Security"
+ - "Data Handling"
+---
+
+
+
+Encoding, encryption, and tokenization are three distinct processes that handle data in different ways for various purposes, including data transmission, security, and compliance.
+
+In system designs, we need to select the right approach for handling sensitive information.
+
+## Encoding
+
+Encoding converts data into a different format using a scheme that can be easily reversed. Examples include Base64 encoding, which encodes binary data into ASCII characters, making it easier to transmit data over media that are designed to deal with textual data.
+
+Encoding is not meant for securing data. The encoded data can be easily decoded using the same scheme without the need for a key.
+
+## Encryption
+
+Encryption involves complex algorithms that use keys for transforming data. Encryption can be symmetric (using the same key for encryption and decryption) or asymmetric (using a public key for encryption and a private key for decryption).
+
+Encryption is designed to protect data confidentiality by transforming readable data (plaintext) into an unreadable format (ciphertext) using an algorithm and a secret key. Only those with the correct key can decrypt and access the original data.
+
+## Tokenization
+
+Tokenization is the process of substituting sensitive data with non-sensitive placeholders called tokens. The mapping between the original data and the token is stored securely in a token vault. These tokens can be used in various systems and processes without exposing the original data, reducing the risk of data breaches.
+
+Tokenization is often used for protecting credit card information, personal identification numbers, and other sensitive data. Tokenization is highly secure, as the tokens do not contain any part of the original data and thus cannot be reverse-engineered to reveal the original data. It is particularly useful for compliance with regulations like PCI DSS.
diff --git a/data/guides/erasure-coding.md b/data/guides/erasure-coding.md
new file mode 100644
index 0000000..ecb49c4
--- /dev/null
+++ b/data/guides/erasure-coding.md
@@ -0,0 +1,30 @@
+---
+title: "Erasure Coding"
+description: "Explore erasure coding: enhancing data durability in object storage."
+image: "https://assets.bytebytego.com/diagrams/0187-erasure-coding.png"
+createdAt: "2024-02-09"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Storage"
+ - "Data Redundancy"
+---
+
+
+
+A really cool technique that’s commonly used in object storage such as S3 to improve durability is called **Erasure Coding**. Let’s take a look at how it works.
+
+Erasure coding deals with data durability differently from replication. It chunks data into smaller pieces (placed on different servers) and creates parities for redundancy. In the event of failures, we can use chunk data and parities to reconstruct the data. Let’s take a look at a concrete example (4 + 2 erasure coding) as shown in Figure 1.
+
+* Data is broken up into four even-sized data chunks d1, d2, d3, and d4.
+
+* The mathematical formula is used to calculate the parities p1 and p2. To give a much simplified example, p1 = d1 + 2\*d2 - d3 + 4\*d4 and p2 = -d1 + 5\*d2 + d3 - 3\*d4.
+
+* Data d3 and d4 are lost due to node crashes.
+
+* The mathematical formula is used to reconstruct lost data d3 and d4, using the known values of d1, d2, p1, and p2.
+
+How much extra space does erasure coding need? For every two chunks of data, we need one parity block, so the storage overhead is 50% (Figure 2). While in 3-copy replication, the storage overhead is 200% (Figure 2).
+
+Does erasure coding increase data durability? Let’s assume a node has a 0.81% annual failure rate. According to the calculation done by Backblaze, erasure coding can achieve 11 nines durability vs 3-copy replication can achieve 6 nines durability.
diff --git a/data/guides/evolution-of-airbnb's-microservice.md b/data/guides/evolution-of-airbnb's-microservice.md
new file mode 100644
index 0000000..ad8af0a
--- /dev/null
+++ b/data/guides/evolution-of-airbnb's-microservice.md
@@ -0,0 +1,45 @@
+---
+title: 'Evolution of Airbnb’s Microservice Architecture'
+description: 'Explore the evolution of Airbnb’s microservice architecture in detail.'
+image: 'https://assets.bytebytego.com/diagrams/0014-airbnb-arch.jpg'
+createdAt: '2024-03-05'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Microservices
+ - Architecture
+---
+
+[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F7c90c105-a6bf-46f4-b896-73390fcfe60b_3396x1839.jpeg)
+
+Airbnb’s microservice architecture went through 3 main stages. This post is based on the tech talk by Jessica Tai.
+
+**Monolith** (2008 - 2017)
+
+Airbnb began as a simple marketplace for hosts and guests. This is built in a Ruby on Rails application - the monolith.
+
+**What’s the challenge?**
+
+* Confusing team ownership + unowned code
+* Slow deployment
+
+**Microservices** (2017 - 2020)
+
+Microservice aims to solve those challenges. In the microservice architecture, key services include:
+
+* Data fetching service
+* Business logic data service
+* Write workflow service
+* UI aggregation service
+* Each service had one owning team
+
+**What’s the challenge?**
+
+Hundreds of services and dependencies were difficult for humans to manage.
+
+**Micro + macroservices** (2020 - present)
+
+This is what Airbnb is working on now. The micro and macroservice hybrid model focuses on the unification of APIs.
+
+Reference: [The Human Side of Airbnb’s Microservice Architecture](https://www.infoq.com/presentations/airbnb-culture-soa/)
diff --git a/data/guides/evolution-of-the-netflix-api-architecture.md b/data/guides/evolution-of-the-netflix-api-architecture.md
new file mode 100644
index 0000000..5e25858
--- /dev/null
+++ b/data/guides/evolution-of-the-netflix-api-architecture.md
@@ -0,0 +1,24 @@
+---
+title: 'Evolution of the Netflix API Architecture'
+description: 'Explore the evolution of Netflix API architecture through four stages.'
+image: 'https://assets.bytebytego.com/diagrams/0290-netflix-api.png'
+createdAt: '2024-03-11'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - API Architecture
+ - Netflix
+---
+
+
+
+The Netflix API architecture went through 4 main stages.
+
+**Monolith**. The application is packaged and deployed as a monolith, such as a single Java WAR file, Rails app, etc. Most startups begin with a monolith architecture.
+
+**Direct access**. In this architecture, a client app can make requests directly to the microservices. With hundreds or even thousands of microservices, exposing all of them to clients is not ideal.
+
+**Gateway aggregation layer**. Some use cases may span multiple services, we need a gateway aggregation layer. Imagine the Netflix app needs 3 APIs (movie, production, talent) to render the frontend. The gateway aggregation layer makes it possible.
+
+**Federated gateway**. As the number of developers grew and domain complexity increased, developing the API aggregation layer became increasingly harder. GraphQL federation allows Netflix to set up a single GraphQL gateway that fetches data from all the other APIs.
diff --git a/data/guides/evolution-of-uber's-api-layer.md b/data/guides/evolution-of-uber's-api-layer.md
new file mode 100644
index 0000000..08f8f46
--- /dev/null
+++ b/data/guides/evolution-of-uber's-api-layer.md
@@ -0,0 +1,22 @@
+---
+title: Evolution of Uber's API Layer
+description: Learn about the evolution of Uber's API layer.
+image: 'https://assets.bytebytego.com/diagrams/0397-uber-api-layer.png'
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - API Gateway
+ - Microservices
+---
+
+
+
+Uber’s API gateway went through 3 main stages.
+
+First gen: the organic evolution. Uber's architecture in 2014 would have two key services: dispatch and API. A dispatch service connects a rider with a driver, while an API service stores the long-term data of users and trips.
+
+Second gen: the all-encompassing gateway. Uber adopted a microservice architecture very early on. By 2019, Uber's products were powered by 2,200+ microservices as a result of this architectural decision.
+
+Third gen: self-service, decentralized, and layered. As of early 2018, Uber had completely new business lines and numerous new applications. Freight, ATG, Elevate, groceries, and more are among the growing business lines. With a new set of goals comes the third generation.
diff --git a/data/guides/explain-the-top-6-use-cases-of-object-stores.md b/data/guides/explain-the-top-6-use-cases-of-object-stores.md
new file mode 100644
index 0000000..c9bf577
--- /dev/null
+++ b/data/guides/explain-the-top-6-use-cases-of-object-stores.md
@@ -0,0 +1,44 @@
+---
+title: "Explain the Top 6 Use Cases of Object Stores"
+description: "Explore the top 6 use cases of object stores in modern data management."
+image: "https://assets.bytebytego.com/diagrams/0117-explain-the-top-6-use-cases-of-object-stores.png"
+createdAt: "2024-02-14"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Object Storage"
+ - "Data Management"
+---
+
+
+
+What is an object store?
+
+Object store uses objects to store data. Compared with file storage which uses a hierarchical structure to store files, or block storage which divides files into equal block sizes, object storage stores metadata together with the objects. Typical products include AWS S3, Google Cloud Storage, and Azure Blob Storage.
+
+An object store provides flexibility in formats and scales easily.
+
+## Case 1: Data Archiving
+
+With the ever-growing amounts of business data, we cannot store all the data in core storage systems. We need to have layers of storage plan. An object store can be used to archive old data that exists for auditing or client statements. This is a cost-effective approach.
+
+## Case 2: Unstructured Data Storage
+
+We often need to deal with unstructured data or semi-structured data. In the past, they were usually stored as blobs in the relational database, which was quite inefficient. An object store is a good match for music, video files, and text documents. Companies like Spotify or Netflix uses object store to persist their media files.
+
+## Case 3: Cloud Native Storage
+
+For cloud-native applications, we need the data storage system to be flexible and scalable. Major public cloud providers have easy API access to their object store products and can be used for economical storage choices.
+
+## Case 4: Data Lake
+
+There are many types of data in a distributed system. An object store-backed data lake provides a good place for different business lines to dump their data for later analytics or machine learning. The efficient reads and writes of the object store facilitate more steps down the data processing pipeline, including ETL(Extract-Transform-Load) or constructing a data warehouse.
+
+## Case 5: Internet of Things (IoT)
+
+IoT sensors produce all kinds of data. An object store can store this type of time series and later run analytics or AI algorithms on them. Major public cloud providers provide pipelines to ingest raw IoT data into the object store.
+
+## Case 6: Backup and Recovery
+
+An object store can be used to store database or file system backups. Later, the backups can be loaded for fast recovery. This improves the system’s availability.
diff --git a/data/guides/explaining-5-unique-id-generators-in-distributed-systems.md b/data/guides/explaining-5-unique-id-generators-in-distributed-systems.md
new file mode 100644
index 0000000..70ff459
--- /dev/null
+++ b/data/guides/explaining-5-unique-id-generators-in-distributed-systems.md
@@ -0,0 +1,38 @@
+---
+title: "Explaining 5 Unique ID Generators"
+description: "Explore 5 unique ID generators and their pros and cons in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0006-explaining-5-unique-id-generators-in-distributed-systems.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Distributed Systems
+ - Unique IDs
+---
+
+
+
+The diagram below shows how they work. Each generator has its pros and cons.
+
+## UUID
+
+A UUID has 128 bits. It is simple to generate and no need to call another service. However, it is not sequential and inefficient for database indexing. Additionally, UUID doesn’t guarantee global uniqueness. We need to be careful with ID conflicts (although the chances are slim.)
+
+## Snowflake
+
+Snowflake’s ID generation process has multiple components: timestamp, machine ID, and serial number. The first bit is unused to ensure positive IDs. This generator doesn’t need to talk to an ID generator via the network, so is fast and scalable.
+
+Snowflake implementations vary. For example, data center ID can be added to the “MachineID” component to guarantee global uniqueness.
+
+## DB auto-increment
+
+Most database products offer auto-increment identity columns. Since this is supported in the database, we can leverage its transaction management to handle concurrent visits to the ID generator. This guarantees uniqueness in one table. However, this involves network communications and may expose sensitive business data to the outside. For example, if we use this as a user ID, our business competitors will have a rough idea of the total number of users registered on our website.
+
+## DB segment
+
+An alternative approach is to retrieve IDs from the database in batches and cache them in the ID servers, each ID server handling a segment of IDs. This greatly saves the I/O pressure on the database.
+
+## Redis
+
+We can also use Redis key-value pair to generate unique IDs. Redis stores data in memory, so this approach offers better performance than the database.
diff --git a/data/guides/explaining-8-popular-network-protocols-in-1-diagram.md b/data/guides/explaining-8-popular-network-protocols-in-1-diagram.md
new file mode 100644
index 0000000..079a6eb
--- /dev/null
+++ b/data/guides/explaining-8-popular-network-protocols-in-1-diagram.md
@@ -0,0 +1,48 @@
+---
+title: "Explaining 8 Popular Network Protocols in 1 Diagram"
+description: "A visual guide to understanding 8 common network protocols."
+image: "https://assets.bytebytego.com/diagrams/0292-explaining-8-popular-network-protocols-in-1-diagram.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Networking"
+ - "Protocols"
+---
+
+Network protocols are standard methods of transferring data between two computers in a network.
+
+
+
+## 1. HTTP (HyperText Transfer Protocol)
+
+HTTP is a protocol for fetching resources such as HTML documents. It is the foundation of any data exchange on the Web and it is a client-server protocol.
+
+## 2. HTTP/3
+
+HTTP/3 is the next major revision of the HTTP. It runs on QUIC, a new transport protocol designed for mobile-heavy internet usage. It relies on UDP instead of TCP, which enables faster web page responsiveness. VR applications demand more bandwidth to render intricate details of a virtual scene and will likely benefit from migrating to HTTP/3 powered by QUIC.
+
+## 3. HTTPS (HyperText Transfer Protocol Secure)
+
+HTTPS extends HTTP and uses encryption for secure communications.
+
+## 4. WebSocket
+
+WebSocket is a protocol that provides full-duplex communications over TCP. Clients establish WebSockets to receive real-time updates from the back-end services. Unlike REST, which always “pulls” data, WebSocket enables data to be “pushed”. Applications, like online gaming, stock trading, and messaging apps leverage WebSocket for real-time communication.
+
+## 5. TCP (Transmission Control Protocol)
+
+TCP is designed to send packets across the internet and ensure the successful delivery of data and messages over networks. Many application-layer protocols build on top of TCP.
+
+## 6. UDP (User Datagram Protocol)
+
+UDP sends packets directly to a target computer, without establishing a connection first. UDP is commonly used in time-sensitive communications where occasionally dropping packets is better than waiting. Voice and video traffic are often sent using this protocol.
+
+## 7. SMTP (Simple Mail Transfer Protocol)
+
+SMTP is a standard protocol to transfer electronic mail from one user to another.
+
+## 8. FTP (File Transfer Protocol)
+
+FTP is used to transfer computer files between client and server. It has separate connections for the control channel and data channel.
diff --git a/data/guides/explaining-9-types-of-api-testing.md b/data/guides/explaining-9-types-of-api-testing.md
new file mode 100644
index 0000000..dfb7630
--- /dev/null
+++ b/data/guides/explaining-9-types-of-api-testing.md
@@ -0,0 +1,34 @@
+---
+title: 'Explaining 9 Types of API Testing'
+description: 'Learn about 9 different types of API testing with detailed explanations.'
+image: 'https://assets.bytebytego.com/diagrams/0017-9-types-of-api-testing.png'
+createdAt: '2024-03-10'
+draft: false
+categories:
+ - api-web-development
+ - software-development
+tags:
+ - API Testing
+ - Software Testing
+---
+
+
+
+* **Smoke Testing**
+ This is done after API development is complete. Simply validate if the APIs are working and nothing breaks.
+* **Functional Testing**
+ This creates a test plan based on the functional requirements and compares the results with the expected results.
+* **Integration Testing**
+ This test combines several API calls to perform end-to-end tests. The intra-service communications and data transmissions are tested.
+* **Regression Testing**
+ This test ensures that bug fixes or new features shouldn’t break the existing behaviors of APIs.
+* **Load Testing**
+ This tests applications’ performance by simulating different loads. Then we can calculate the capacity of the application.
+* **Stress Testing**
+ We deliberately create high loads to the APIs and test if the APIs are able to function normally.
+* **Security Testing**
+ This tests the APIs against all possible external threats.
+* **UI Testing**
+ This tests the UI interactions with the APIs to make sure the data can be displayed properly.
+* **Fuzz Testing**
+ This injects invalid or unexpected input data into the API and tries to crash the API. In this way, it identifies the API vulnerabilities.
diff --git a/data/guides/explaining-json-web-token-jwt-to-a-10-year-old-kid.md b/data/guides/explaining-json-web-token-jwt-to-a-10-year-old-kid.md
new file mode 100644
index 0000000..2e9fa9a
--- /dev/null
+++ b/data/guides/explaining-json-web-token-jwt-to-a-10-year-old-kid.md
@@ -0,0 +1,24 @@
+---
+title: "Explaining JSON Web Token (JWT) to a 10 Year Old Kid"
+description: "Explaining JSON Web Token (JWT) in simple terms for kids."
+image: "https://assets.bytebytego.com/diagrams/0107-explaining-json-web-token-jwt-to-a-10-year-old-kid.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - security
+tags:
+ - "JWT"
+ - "Security"
+---
+
+
+
+Imagine you have a special box called a JWT. Inside this box, there are three parts: a header, a payload, and a signature.
+
+The header is like the label on the outside of the box. It tells us what type of box it is and how it's secured. It's usually written in a format called JSON, which is just a way to organize information using curly braces { } and colons :
+
+The payload is like the actual message or information you want to send. It could be your name, age, or any other data you want to share. It's also written in JSON format, so it's easy to understand and work with.
+
+Now, the signature is what makes the JWT secure. It's like a special seal that only the sender knows how to create. The signature is created using a secret code, kind of like a password. This signature ensures that nobody can tamper with the contents of the JWT without the sender knowing about it.
+
+When you want to send the JWT to a server, you put the header, payload, and signature inside the box. Then you send it over to the server. The server can easily read the header and payload to understand who you are and what you want to do.
diff --git a/data/guides/explaining-sessions-tokens-jwt-sso-and-oauth-in-one-diagram.md b/data/guides/explaining-sessions-tokens-jwt-sso-and-oauth-in-one-diagram.md
new file mode 100644
index 0000000..4f23b46
--- /dev/null
+++ b/data/guides/explaining-sessions-tokens-jwt-sso-and-oauth-in-one-diagram.md
@@ -0,0 +1,18 @@
+---
+title: "Sessions, Tokens, JWT, SSO, and OAuth Explained"
+description: "Understanding sessions, tokens, JWT, SSO, and OAuth concepts."
+image: "https://assets.bytebytego.com/diagrams/0330-session-square.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - security
+tags:
+ - Authentication
+ - Authorization
+---
+
+
+
+Understanding these backstage maneuvers helps us build secure, seamless experiences.
+
+How do you see the evolution of web session management impacting the future of web applications and user experiences?
diff --git a/data/guides/explaining-the-4-most-commonly-used-types-of-queues-in-a-single-diagram.md b/data/guides/explaining-the-4-most-commonly-used-types-of-queues-in-a-single-diagram.md
new file mode 100644
index 0000000..9f5fab2
--- /dev/null
+++ b/data/guides/explaining-the-4-most-commonly-used-types-of-queues-in-a-single-diagram.md
@@ -0,0 +1,38 @@
+---
+title: "Explaining the 4 Most Commonly Used Types of Queues"
+description: "Learn about the 4 most commonly used types of queues in a single diagram"
+image: "https://assets.bytebytego.com/diagrams/0366-types-of-queues.png"
+createdAt: "2024-02-06"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Structures"
+ - "Queues"
+---
+
+
+
+Queues are popular data structures used widely in the system. The diagram above shows 4 different types of queues we often use.
+
+## Simple FIFO Queue
+
+A simple queue follows FIFO (First In First Out). A new element is inserted at the tail of the queue, and an element is removed from the head of the queue.
+
+If we would like to send out email notifications to the users whenever we receive a payment response, we can use a FIFO queue. The emails will be sent out in the same order as the payment responses.
+
+## Circular Queue
+
+A circular queue is also called a circular buffer or a ring buffer. Its last element is linked to the first element. Insertion takes place at the front of the queue and deletion at the end of the queue.
+
+A famous implementation is LMAX’s low-latency ring buffer. Trading components talk to each other via a ring buffer. This is implemented in memory and super fast.
+
+## Priority Queue
+
+The elements in a priority queue have predefined priorities. We take the element with the highest (or lowest) priority from the queue. Under the hood, it is implemented using a max heap or a min heap where the element with the largest or lowest priority is at the root of the heap.
+
+A typical use case is assigning patients with the highest severity to the emergency room while others to the regular rooms.
+
+## Deque
+
+Deque is also called double-ended queue. The insertion and deletion can happen at both the head and the tail. Deque supports both FIFO and LIFO (Last In First Out), so we can use it to implement a stack data structure.
diff --git a/data/guides/firewall-explained-to-kids-and-adults.md b/data/guides/firewall-explained-to-kids-and-adults.md
new file mode 100644
index 0000000..55c8d51
--- /dev/null
+++ b/data/guides/firewall-explained-to-kids-and-adults.md
@@ -0,0 +1,44 @@
+---
+title: "Firewall Explained to Kids and Adults"
+description: "Learn about firewalls: network security, types, and how they protect us."
+image: "https://assets.bytebytego.com/diagrams/0191-firewall.jpeg"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - security
+tags:
+ - "Network Security"
+ - "Firewall"
+---
+
+
+
+A firewall is a network security system that controls and filters network traffic, acting as a watchman between a private network and the public Internet.
+
+They come in two broad categories:
+
+* Software-based: installed on individual devices for protection
+
+* Hardware-based: stand-alone devices that safeguard an entire network.
+
+Firewalls have several types, each designed for specific security needs:
+
+### Packet Filtering Firewalls
+
+Examines packets of data, accepting or rejecting based on source, destination, or protocols.
+
+### Circuit-level Gateways
+
+Monitors TCP handshake between packets to determine session legitimacy.
+
+### Application-level Gateways (Proxy Firewalls)
+
+Filters incoming traffic between your network and traffic source, offering a protective shield against untrusted networks.
+
+### Stateful Inspection Firewalls
+
+Tracks active connections to determine which packets to allow, analyzing in the context of their place in a data stream.
+
+### Next-Generation Firewalls (NGFWs)
+
+Advanced firewalls that integrate traditional methods with functionalities like intrusion prevention systems, deep packet analysis, and application awareness.
diff --git a/data/guides/fixing-bugs-automatically-at-meta-scale.md b/data/guides/fixing-bugs-automatically-at-meta-scale.md
new file mode 100644
index 0000000..1c93c47
--- /dev/null
+++ b/data/guides/fixing-bugs-automatically-at-meta-scale.md
@@ -0,0 +1,39 @@
+---
+title: Fixing Bugs Automatically at Meta Scale
+description: Meta's approach to automated bug fixing at scale using SapFix.
+image: 'https://assets.bytebytego.com/diagrams/0193-fixing-bugs-automatically-at-meta-scale.png'
+createdAt: '2024-02-16'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Automation
+ - Debugging
+---
+
+
+Wouldn't it be nice if a system could automatically detect and fix bugs for us?
+
+Meta released a paper about how they automated end-to-end repair at the Facebook scale. Let's take a closer look.
+
+The goal of a tool called SapFix is to simplify debugging by automatically generating fixes for specific issues.
+
+How successful has SapFix been?
+
+Here are some details that have been made available:
+
+* Used on six key apps in the Facebook app family (Facebook, Messenger, Instagram, FBLite, Workplace and Workchat). Each app consists of tens of millions of lines of code
+
+* It generated 165 patches for 57 crashes in a 90-day pilot phase
+
+* The median time from fault detection to fix sent for human approval was 69 minutes.
+
+Here’s how SapFix actually works:
+
+1. Developers submit changes for review using Phabricator (Facebook’s CI system)
+2. SapFix selects appropriate test cases from Sapienz (Facebook’s automated test case design system) and executes them on the Diff submitted for review
+3. When SapFix detects a crash due to the Diff, it tries to generate potential fixes. There are 4 types of fixes - template, mutation, full revert and partial revert.
+4. For generating a fix, SapFix runs tests on the patched builds and checks what works. Think of it like solving a puzzle by trying out different pieces.
+5. Once the patches are tested, SapFix selects a candidate patch and sends it to a human reviewer for review through Phabricator.
+6. The primary reviewer is the developer who raised the change that caused the crash. This developer often has the best technical context. Other engineers are also subscribed to the proposed Diff.
+7. The developer can accept the patch proposed by SapFix. However, the developer can also reject the fix and discard it.
diff --git a/data/guides/foreign-exchange-payments.md b/data/guides/foreign-exchange-payments.md
new file mode 100644
index 0000000..6aac661
--- /dev/null
+++ b/data/guides/foreign-exchange-payments.md
@@ -0,0 +1,35 @@
+---
+title: "Foreign Exchange Payments"
+description: "Learn how foreign exchange payments work when buying/selling internationally."
+image: "https://assets.bytebytego.com/diagrams/0194-foreign-exchange.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Foreign Exchange"
+---
+
+
+
+The buyer pays in USD, and the European seller receives euros. How does this work?
+
+This process is called foreign exchange.
+
+Suppose Bob (the buyer) needs to pay 100 USD to Alice (the seller), and Alice can only receive EUR. The diagram above illustrates the process.
+
+1. Bob sends 100 USD via a third-party payment provider. In our example, it is Paypal. The money is transferred from Bob’s bank account (Bank B) to Paypal’s account in Bank P1.
+2. Paypal needs to convert USD to EUR. It leverages the foreign exchange provider (Bank E). Paypal sends 100 USD to its USD account in Bank E.
+3. 100 USD is sold to Bank E’s funding pool.
+4. Bank E’s funding pool provides 88 EUR in exchange for 100 USD. The money is put into Paypal’s EUR account in Bank E.
+5. Paypal’s EUR account in Bank P2 receives 88 EUR.
+6. 88 EUR is paid to Alice’s EUR account in Bank A.
+
+Now let’s take a close look at the foreign exchange (forex) market. It has 3 layers:
+
+* Retail market. Funding pools are parts of the retail market. To improve efficiency, Paypal usually buys a certain amount of foreign currencies in advance.
+* Wholesale market. The wholesale business is composed of investment banks, commercial banks, and foreign exchange providers. It usually handles accumulated orders from the retail market.
+* Top-level participants. They are multinational commercial banks that hold lots of money from different countries.
+
+When Bank E’s funding pool needs more EUR, it goes upward to the wholesale market to sell USD and buy EUR. When the wholesale market accumulates enough orders, it goes upward to top-level participants. Steps 3.1-3.3 and 4.1-4.3 explain how it works.
diff --git a/data/guides/git-commands-cheat-sheet.md b/data/guides/git-commands-cheat-sheet.md
new file mode 100644
index 0000000..73b46ff
--- /dev/null
+++ b/data/guides/git-commands-cheat-sheet.md
@@ -0,0 +1,60 @@
+---
+title: "Git Commands Cheat Sheet"
+description: "A handy guide to essential Git commands for developers."
+image: "https://assets.bytebytego.com/diagrams/0201-git-commands-cheat-sheet.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Git
+ - Version Control
+---
+
+
+
+## Getting Started
+
+* **git init**: Initializes a new Git repository.
+
+* **git clone [url]**: Clones a repository from a remote URL.
+
+## Making Changes
+
+* **git add [file]**: Adds a file to the staging area.
+
+* **git commit -m "[message]"**: Commits changes with a descriptive message.
+
+* **git status**: Shows the status of the working directory.
+
+* **git diff**: Shows the differences between the working directory and the staging area.
+
+## Branching and Merging
+
+* **git branch**: Lists all local branches.
+
+* **git branch [branch-name]**: Creates a new branch.
+
+* **git checkout [branch-name]**: Switches to the specified branch.
+
+* **git merge [branch-name]**: Merges the specified branch into the current branch.
+
+* **git branch -d [branch-name]**: Deletes the specified branch.
+
+## Remote Repositories
+
+* **git remote add origin [url]**: Adds a remote repository.
+
+* **git push origin [branch-name]**: Pushes changes to the remote repository.
+
+* **git pull origin [branch-name]**: Pulls changes from the remote repository.
+
+* **git fetch**: Fetches changes from the remote repository without merging.
+
+## Undoing Changes
+
+* **git reset [file]**: Unstages a file.
+
+* **git checkout -- [file]**: Discards changes to a file.
+
+* **git revert [commit]**: Creates a new commit that undoes the changes from the specified commit.
diff --git a/data/guides/git-merge-vs-git-rebate.md b/data/guides/git-merge-vs-git-rebate.md
new file mode 100644
index 0000000..ae20ed3
--- /dev/null
+++ b/data/guides/git-merge-vs-git-rebate.md
@@ -0,0 +1,36 @@
+---
+title: "Git Merge vs. Git Rebase"
+description: "Understand the difference between Git merge and Git rebase commands."
+image: "https://assets.bytebytego.com/diagrams/0203-git-merge-git-rebase.jpg"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Git
+ - Version Control
+---
+
+
+
+What are the differences?
+
+When we 𝐦𝐞𝐫𝐠𝐞 𝐜𝐡𝐚𝐧𝐠𝐞𝐬 from one Git branch to another, we can use ‘git merge’ or ‘git rebase’. The diagram below shows how the two commands work.
+
+## Git Merge
+
+This creates a new commit G’ in the main branch. G’ ties the histories of both main and feature branches.
+
+Git merge is 𝐧𝐨𝐧-𝐝𝐞𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐯𝐞. Neither the main nor the feature branch is changed.
+
+## Git Rebase
+
+Git rebase moves the feature branch histories to the head of the main branch. It creates new commits E’, F’, and G’ for each commit in the feature branch.
+
+The benefit of rebase is that it has 𝐥𝐢𝐧𝐞𝐚𝐫 𝐜𝐨𝐦𝐦𝐢𝐭 𝐡𝐢𝐬𝐭𝐨𝐫𝐲.
+
+Rebase can be dangerous if “the golden rule of git rebase” is not followed.
+
+## The Golden Rule of Git Rebase
+
+Never use it on public branches!
diff --git a/data/guides/git-vs-github.md b/data/guides/git-vs-github.md
new file mode 100644
index 0000000..00c4028
--- /dev/null
+++ b/data/guides/git-vs-github.md
@@ -0,0 +1,36 @@
+---
+title: "Git vs GitHub"
+description: "Explore the differences between Git and GitHub for version control."
+image: "https://assets.bytebytego.com/diagrams/0204-git-vs-github.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Version Control
+ - Git
+---
+
+
+
+Git and GitHub are popular tools for version control. They work together and complement each other to provide effective source control management.
+
+On a high level, Git is focused on version control and code sharing, whereas GitHub is focused on centralized source code hosting for sharing with other developers.
+
+However, they have some key differences
+
+## Key Differences
+
+* Git is a free, open-source version control tool. GitHub is a cloud-based, pay-for-use service that runs Git in the cloud.
+
+* Git is installed locally on a developer’s machine. GitHub is hosted in the cloud.
+
+* The Linux Foundation maintains Git. Microsoft owns GitHub.
+
+* Git can manage different versions of edits, made to files in a git repository. GitHub is a space to upload a copy of the Git repository.
+
+* Git supports version control and source code management. GitHub can be used for hosting code, collaboration, and project management.
+
+* Git has minimal external tool configuration. GitHub provides an active marketplace for tool integration.
+
+Lastly, you can use Git without GitHub but you cannot use GitHub without Git.
diff --git a/data/guides/git-workflow.md b/data/guides/git-workflow.md
new file mode 100644
index 0000000..e22db1c
--- /dev/null
+++ b/data/guides/git-workflow.md
@@ -0,0 +1,18 @@
+---
+title: "How does Git Work?"
+description: "A handy guide to learning how does Git work."
+image: "https://assets.bytebytego.com/diagrams/0205-git-workflow.jpg"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - Git
+ - Version Control
+---
+
+
+
+Git is a distributed version control system that allows multiple developers to work on the same project simultaneously. It is widely used in software development to manage source code history.
+
+The diagram above shows the Git workflow with common commands.
\ No newline at end of file
diff --git a/data/guides/graphql-adoption-patterns.md b/data/guides/graphql-adoption-patterns.md
new file mode 100644
index 0000000..c6f5bf3
--- /dev/null
+++ b/data/guides/graphql-adoption-patterns.md
@@ -0,0 +1,39 @@
+---
+title: 'GraphQL Adoption Patterns'
+description: 'Explore 4 popular GraphQL adoption patterns for your team.'
+image: 'https://assets.bytebytego.com/diagrams/0208-graphql-adoption-patterns.png'
+createdAt: '2024-02-13'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - GraphQL
+ - API
+---
+
+
+Typically, teams begin their GraphQL journey with a basic architecture where a client application queries a single GraphQL server.
+
+However, multiple patterns are available:
+
+* **Client-based GraphQL**
+
+ The client wraps existing APIs behind a single GraphQL endpoint. This approach improves the developer experience but the client still bears the performance costs of aggregating data.
+
+* **GraphQL with BFFs**
+
+ BFF or Backend-for-Frontends adds a new layer where each client has a dedicated BFF service. GraphQL is a natural fit to build a client-focused intermediary layer.
+
+ Performance and developer experience for the clients is improved but there’s a tradeoff in building and maintaining BFFs.
+
+* **The Monolithic GraphQL**
+
+ Multiple teams share one codebase for a GraphQL server used by several clients. Also, a single team owns a GraphQL API that is accessed by multiple client teams.
+
+* **GraphQL Federation**
+
+ This involves consolidating multiple graphs into a supergraph.
+
+ GraphQL Federated Gateway takes care of routing the requests to the downstream subgraph services that take care of a specific part of the GraphQL schema. This approach maintains ownership of data with the domain team while avoiding duplication of effort.
+
+Over to you: Which GraphQL adoption approach have you seen or used?
diff --git a/data/guides/handling-hotspot-accounts.md b/data/guides/handling-hotspot-accounts.md
new file mode 100644
index 0000000..55794a6
--- /dev/null
+++ b/data/guides/handling-hotspot-accounts.md
@@ -0,0 +1,38 @@
+---
+title: "Handling Hotspot Accounts"
+description: "Learn how to handle hotspot accounts in payment systems effectively."
+image: "https://assets.bytebytego.com/diagrams/0212-hotspot-accounts.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "Scalability"
+---
+
+
+
+Big accounts, such as Nike, Procter & Gamble & Nintendo, often cause hotspot issues for the payment system.
+
+A hotspot payment account is an account that has a large number of concurrent operations on it.
+
+For example, when merchant A starts a promotion on Amazon Prime day, it receives many concurrent purchasing orders. In this case, the merchant’s account in the database becomes a hotspot account due to frequent updates.
+
+In normal operations, we put a row lock on the merchant’s balance when it gets updated. However, this locking mechanism leads to low throughput and becomes a system bottleneck.
+
+The diagram above shows several optimizations.
+
+## Optimizations
+
+* **Rate limit**
+
+ We can limit the number of requests within a certain period. The remaining requests will be rejected or retried at a later time. It is a simple way to increase the system’s responsiveness for some users, but this can lead to a bad user experience.
+
+* **Split the balance account into sub-accounts**
+
+ We can set up sub-accounts for the merchant’s account. In this way, one update request only locks one sub-account, and the rest sub-accounts are still available.
+
+* **Use cache to update balance first**
+
+ We can set up a caching layer to update the merchant’s balance. The detailed statements and balances are updated in the database later asynchronously. The in-memory cache can deal with a much higher throughput than the database.
diff --git a/data/guides/hidden-costs-of-the-cloud.md b/data/guides/hidden-costs-of-the-cloud.md
new file mode 100644
index 0000000..58d8b04
--- /dev/null
+++ b/data/guides/hidden-costs-of-the-cloud.md
@@ -0,0 +1,38 @@
+---
+title: "Hidden Costs of the Cloud"
+description: "Uncover hidden cloud costs and learn how to avoid unexpected expenses."
+image: "https://assets.bytebytego.com/diagrams/0148-cloud-hidden-costs.png"
+createdAt: '2024-03-01'
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Cost
+ - Cost Optimization
+---
+
+While it may be inexpensive or even free to get started, the complexity often leads to hidden costs, resulting in large cloud bills.
+
+The purpose of this post is not to discourage using the cloud. I’m a big fan of the cloud. I simply want to raise awareness about this issue, as it's one of the critical topics that isn't often discussed.
+
+
+
+While AWS is used as an example, similar cost structures apply to other cloud providers.
+
+## Hidden Cloud Costs
+
+* **Free Tier Ambiguity:** AWS offers three different types of free offerings for common services. However, services not included in the free tier can charge you. Even for services that do provide free resources, there's often a limit. Exceeding that limit can result in higher costs than anticipated.
+
+* **Elastic IP Addresses:** AWS allows up to five Elastic IP addresses. Exceeding this limit incurs a small hourly rate, which varies depending on the region. This is a recurring charge.
+
+* **Load Balancers:** They are billed hourly, even if not actively used. Furthermore, you'll face additional charges if data is transferred in and out of the load balancer.
+
+* **Elastic Block Storage (EBS) Charges:** EBS is billed on a GB-per-month basis. You will be charged for attached and unattached EBS volumes, even if they're not actively used.
+
+* **EBS Snapshots:** Deleting an EBS volume does not automatically remove the associated snapshots. Orphaned EBS snapshots will still appear on your bill.
+
+* **S3 Access Charges:** While the pricing for S3 storage is generally reasonable, the costs associated with accessing stored objects, such as GET and LIST requests, can sometimes exceed the storage costs.
+
+* **S3 Partial Uploads:** If you have an unsuccessful multipart upload in S3, you will still be billed for the successfully uploaded parts. It's essential to clean these up to avoid unnecessary costs.
+
+* **Data Transfer Costs:** Transferring data to AWS, for instance, from a data center, is free. However, transferring data out of AWS can be significantly more expensive.
diff --git a/data/guides/how-applegoogle-pay-works.md b/data/guides/how-applegoogle-pay-works.md
new file mode 100644
index 0000000..6be0af3
--- /dev/null
+++ b/data/guides/how-applegoogle-pay-works.md
@@ -0,0 +1,42 @@
+---
+title: "How do Apple Pay and Google Pay work?"
+description: "Explore the mechanics of Apple Pay and Google Pay for secure transactions."
+image: "https://assets.bytebytego.com/diagrams/0002-apple-pay.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "Mobile Payments"
+---
+
+
+
+The diagram above shows the differences. Both approaches are very secure, but the implementations are different. To understand the difference, we break down the process into two flows.
+
+## Registering your credit card flow
+
+## Basic payment flow
+
+1. The registration flow is represented by steps 1~3 for both cases. The difference is:
+
+* **Apple Pay:** Apple doesn’t store any card info. It passes the card info to the bank. Bank returns a token called DAN (device account number) to the iPhone. iPhone then stores DAN into a special hardware chip.
+
+* **Google Pay:** When you register the credit card with Google Pay, the card info is stored in the Google server. Google returns a payment token to the phone.
+
+2. When you click the “Pay” button on your phone, the basic payment flow starts. Here are the differences:
+
+* **Apple Pay:** For iPhone, the e-commerce server passes the DAN to the bank.
+
+* **Google Pay:** In the Google Pay case, the e-commerce server passes the payment token to the Google server. Google server looks up the credit card info and passes it to the bank.
+
+In the diagram, the red arrow means the credit card info is available on the public network, although it is encrypted.
+
+References:
+
+[1] [Apple Pay security and privacy overview](https://support.apple.com/en-us/101554)
+
+[2] [Google Pay for Payments](https://developers.google.com/pay/api/android/overview)
+
+[3] [Apple Pay vs. Google Pay: How They Work](https://www.investopedia.com/articles/personal-finance/010215/apple-pay-vs-google-wallet-how-they-work.asp)
diff --git a/data/guides/how-are-notifications-pushed-to-our-phones-or-pcs.md b/data/guides/how-are-notifications-pushed-to-our-phones-or-pcs.md
new file mode 100644
index 0000000..97f4220
--- /dev/null
+++ b/data/guides/how-are-notifications-pushed-to-our-phones-or-pcs.md
@@ -0,0 +1,32 @@
+---
+title: "How are Notifications Pushed to Our Phones or PCs?"
+description: "Learn how push notifications work on phones and PCs using FCM."
+image: "https://assets.bytebytego.com/diagrams/0309-push-notifiction.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "notifications"
+ - "mobile"
+---
+
+
+
+A messaging solution (Firebase) can be used to support the notification push.
+
+The diagram below shows how Firebase Cloud Messaging (FCM) works.
+
+FCM is a cross-platform messaging solution that can compose, send, queue, and route notifications reliably. It provides a unified API between message senders (app servers) and receivers (client apps). The app developer can use this solution to drive user retention.
+
+Steps 1 - 2: When the client app starts for the first time, the client app sends credentials to FCM, including Sender ID, API Key, and App ID. FCM generates Registration Token for the client app instance (so the Registration Token is also called Instance ID). This token must be included in the notifications.
+
+Step 3: The client app sends the Registration Token to the app server. The app server caches the token for subsequent communications. Over time, the app server has too many tokens to maintain, so the recommended practice is to store the token with timestamps and to remove stale tokens from time to time.
+
+Step 4: There are two ways to send messages. One is to compose messages directly in the console GUI (Step 4.1,) and the other is to send the messages from the app server (Step 4.2.) We can use the Firebase Admin SDK or HTTP for the latter.
+
+Step 5: FCM receives the messages, and queues the messages in the storage if the devices are not online.
+
+Step 6: FCM forwards the messages to platform-level transport. This transport layer handles platform-specific configurations.
+
+Step 7: The messages are routed to the targeted devices. The notifications can be displayed according to the configurations sent from the app server.
diff --git a/data/guides/how-can-cache-systems-go-wrong.md b/data/guides/how-can-cache-systems-go-wrong.md
new file mode 100644
index 0000000..1725eda
--- /dev/null
+++ b/data/guides/how-can-cache-systems-go-wrong.md
@@ -0,0 +1,44 @@
+---
+title: "How Can Cache Systems Go Wrong?"
+description: "Explore common cache pitfalls and effective mitigation strategies."
+image: "https://assets.bytebytego.com/diagrams/0038-how-caches-can-go-wrong.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Caching
+ - Performance
+---
+
+
+
+The diagram above shows 4 typical cases where caches can go wrong and their solutions.
+
+## 1. Thunder Herd Problem
+
+This happens when a large number of keys in the cache expire at the same time. Then the query requests directly hit the database, which overloads the database.
+
+There are two ways to mitigate this issue: one is to avoid setting the same expiry time for the keys, adding a random number in the configuration; the other is to allow only the core business data to hit the database and prevent non-core data to access the database until the cache is back up.
+
+## 2. Cache Penetration
+
+This happens when the key doesn’t exist in the cache or the database. The application cannot retrieve relevant data from the database to update the cache. This problem creates a lot of pressure on both the cache and the database.
+
+To solve this, there are two suggestions.
+* Cache a null value for non-existent keys, avoiding hitting the database.
+* Use a bloom filter to check the key existence first, and if the key doesn’t exist, we can avoid hitting the database.
+
+## 3. Cache Breakdown
+
+This is similar to the thunder herd problem. It happens when a hot key expires. A large number of requests hit the database.
+
+Since the hot keys take up 80% of the queries, we do not set an expiration time for them.
+
+## 4. Cache Crash
+
+This happens when the cache is down and all the requests go to the database.
+
+There are two ways to solve this problem.
+* Set up a circuit breaker, and when the cache is down, the application services cannot visit the cache or the database.
+* Set up a cluster for the cache to improve cache availability.
diff --git a/data/guides/how-can-redis-be-used.md b/data/guides/how-can-redis-be-used.md
new file mode 100644
index 0000000..a9b97ce
--- /dev/null
+++ b/data/guides/how-can-redis-be-used.md
@@ -0,0 +1,58 @@
+---
+title: "How can Redis be used?"
+description: "Explore various use cases of Redis beyond caching."
+image: "https://assets.bytebytego.com/diagrams/0388-how-can-redis-be-used.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Redis
+ - Use Cases
+---
+
+
+
+There is more to Redis than just caching.
+
+Redis can be used in a variety of scenarios as shown in the diagram.
+
+* **Session**
+
+ We can use Redis to share user session data among different services.
+
+* **Cache**
+
+ We can use Redis to cache objects or pages, especially for hotspot data.
+
+* **Distributed lock**
+
+ We can use a Redis string to acquire locks among distributed services.
+
+* **Counter**
+
+ We can count how many likes or how many reads for articles.
+
+* **Rate limiter**
+
+ We can apply a rate limiter for certain user IPs.
+
+* **Global ID generator**
+
+ We can use Redis Int for global ID.
+
+* **Shopping cart**
+
+ We can use Redis Hash to represent key-value pairs in a shopping cart.
+
+* **Calculate user retention**
+
+ We can use Bitmap to represent the user login daily and calculate user retention.
+
+* **Message queue**
+
+ We can use List for a message queue.
+
+* **Ranking**
+
+ We can use ZSet to sort the articles.
diff --git a/data/guides/how-digital-signatures-work.md b/data/guides/how-digital-signatures-work.md
new file mode 100644
index 0000000..7d085e3
--- /dev/null
+++ b/data/guides/how-digital-signatures-work.md
@@ -0,0 +1,36 @@
+---
+title: "How Digital Signatures Work"
+description: "Learn how digital signatures work to secure electronic documents."
+image: "https://assets.bytebytego.com/diagrams/0219-how-digital-signatures-work.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - security
+tags:
+ - Cryptography
+ - Security
+---
+
+
+
+A digital signature is a specific kind of electronic signature to sign and secure electronically transmitted documents.
+
+Digital signatures are similar to physical signatures since they are unique to every person. They identify the identity of the signer.
+
+Here’s an example of the working process of a digital signature with Alice as the sender and John as the recipient:
+
+1. Alice generates a cryptographic key pair consisting of a private key and a corresponding public key. The private key remains confidential and is known only to the signer, while the public key can be shared openly.
+
+2. The signer (Alice) uses a hash function to create a unique fixed-length string of numbers and letters, called a hash, from the document. This hash value represents the contents of the document.
+
+3. Alice uses their private key to encrypt the hash value of the message. This hash value is known as the digital signature.
+
+4. The digital signature is attached to the original document, creating a digitally signed document. It is transmitted over the network to the recipient.
+
+5. The recipient (John) extracts both the digital signature and the original hash value from the document.
+
+6. The recipient uses Alice’s public key to decrypt the digital signature. This produces a hash value that was originally encrypted with the private key.
+
+7. The recipient calculates a new hash value for the received message using the same hashing algorithm as the signer. They then compare this recalculated hash with the decrypted hash value obtained from the digital signature.
+
+8. If the hash values are equal, the digital signature is valid, and it is determined that the document has not been tampered with or altered.
diff --git a/data/guides/how-discord-stores-trillions-of-messages.md b/data/guides/how-discord-stores-trillions-of-messages.md
new file mode 100644
index 0000000..8b02016
--- /dev/null
+++ b/data/guides/how-discord-stores-trillions-of-messages.md
@@ -0,0 +1,34 @@
+---
+title: How Discord Stores Trillions of Messages
+description: Learn how Discord evolved its message storage to handle trillions.
+image: 'https://assets.bytebytego.com/diagrams/0174-discord-store-messages.png'
+createdAt: '2024-03-12'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Databases
+ - Architecture
+---
+
+
+
+The diagram above shows the evolution of message storage at Discord:
+
+MongoDB ➡️ Cassandra ➡️ ScyllaDB
+
+In 2015, the first version of Discord was built on top of a single MongoDB replica. Around Nov 2015, MongoDB stored 100 million messages and the RAM couldn’t hold the data and index any longer. The latency became unpredictable. Message storage needs to be moved to another database. Cassandra was chosen.
+
+In 2017, Discord had 12 Cassandra nodes and stored billions of messages.
+
+At the beginning of 2022, it had 177 nodes with trillions of messages. At this point, latency was unpredictable, and maintenance operations became too expensive to run.
+
+There are several reasons for the issue:
+
+* Cassandra uses the LSM tree for the internal data structure. The reads are more expensive than the writes. There can be many concurrent reads on a server with hundreds of users, resulting in hotspots.
+* Maintaining clusters, such as compacting SSTables, impacts performance.
+* Garbage collection pauses would cause significant latency spikes
+
+ScyllaDB is Cassandra compatible database written in C++. Discord redesigned its architecture to have a monolithic API, a data service written in Rust, and ScyllaDB-based storage.
+
+The p99 read latency in ScyllaDB is 15ms compared to 40-125ms in Cassandra. The p99 write latency is 5ms compared to 5-70ms in Cassandra.
diff --git a/data/guides/how-do-airtags-work.md b/data/guides/how-do-airtags-work.md
new file mode 100644
index 0000000..ecf50a6
--- /dev/null
+++ b/data/guides/how-do-airtags-work.md
@@ -0,0 +1,28 @@
+---
+title: "How do AirTags work?"
+description: "Learn how AirTags use Bluetooth and Apple's Find My network to locate items."
+image: "https://assets.bytebytego.com/diagrams/0216-how-airtag-works.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - Bluetooth
+ - Tracking
+---
+
+
+
+AirTags work by leveraging a combination of Bluetooth technology and the vast network of Apple devices to help you locate your lost items.
+
+Here's a breakdown of how they function:
+
+* Bluetooth Signal: Each AirTag emits a secure Bluetooth signal that can be detected by nearby Apple devices (iPhones, iPads, etc.) within the Find My network.
+
+* Find My Network: When an AirTag comes within range of an Apple device in the Find My network, that device anonymously and securely relays the AirTag's location information to iCloud.
+
+* Location Tracking: You can then use the Find My app on your own Apple device to see the approximate location of your AirTag on a map.
+
+## Limitations
+
+Please note that AirTags rely on Bluetooth technology and the presence of Apple devices within the Find My network. If your AirTag is in an area with few Apple devices, its location may not be updated as frequently or accurately.
diff --git a/data/guides/how-do-big-keys-impact-redis-persistence.md b/data/guides/how-do-big-keys-impact-redis-persistence.md
new file mode 100644
index 0000000..aa36a26
--- /dev/null
+++ b/data/guides/how-do-big-keys-impact-redis-persistence.md
@@ -0,0 +1,36 @@
+---
+title: "How Big Keys Impact Redis Persistence"
+description: "Explore the impact of large keys on Redis AOF persistence modes."
+image: "https://assets.bytebytego.com/diagrams/0085-big-keys.png"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Persistence"
+---
+
+
+
+We call a key that contains a large size of data a big key. For example, the size of the key is 5 MB.
+
+The diagram shows how big keys impact Redis AOF (Append-Only-File) persistence.
+
+There are three modes when we turn on AOF persistence:
+
+* Always - synchronously write data to the disk whenever there is a data update in memory.
+
+* EverySec - write to the disk every second.
+
+* No - Redis doesn’t control when the data is written to the disk. Instead, the operating system decides when the data is written to the disk.
+
+## How do we analyze the impact of big keys?
+
+Redis writes keys into memory first, then calls write() to write the data into the kernel buffer cache. Then fsync() flushes all modified in-core data of the file to the disk device. There are 3 modes.
+
+In “Always” mode, it calls fsync() synchronously. If we need to update a big key, the main thread will be blocked because it has to wait for the write to complete.
+
+“EveySec” starts a background timer task to call fsync() every second, so big keys have no impact on the Redis main thread.
+
+“No” mode never calls fsync(). It is up to the operating system. Big keys have no impact on the main thread.
diff --git a/data/guides/how-do-c++-java-python-work.md b/data/guides/how-do-c++-java-python-work.md
new file mode 100644
index 0000000..db8677a
--- /dev/null
+++ b/data/guides/how-do-c++-java-python-work.md
@@ -0,0 +1,24 @@
+---
+title: "How Do C++, Java, Python Work?"
+description: "Understanding the inner workings of C++, Java, and Python."
+image: "https://assets.bytebytego.com/diagrams/0003-how-python-works.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - software-development
+tags:
+ - "programming-languages"
+ - "compilers"
+---
+
+
+
+The diagram shows how the compilation and execution work.
+
+Compiled languages are compiled into machine code by the compiler. The machine code can later be executed directly by the CPU. Examples: C, C++, Go.
+
+A bytecode language like Java, compiles the source code into bytecode first, then the JVM executes the program. Sometimes JIT (Just-In-Time) compiler compiles the source code into machine code to speed up the execution. Examples: Java, C#
+
+Interpreted languages are not compiled. They are interpreted by the interpreter during runtime. Examples: Python, Javascript, Ruby
+
+Compiled languages in general run faster than interpreted languages.
diff --git a/data/guides/how-do-companies-ship-code-to-production.md b/data/guides/how-do-companies-ship-code-to-production.md
new file mode 100644
index 0000000..9fa6a1a
--- /dev/null
+++ b/data/guides/how-do-companies-ship-code-to-production.md
@@ -0,0 +1,36 @@
+---
+title: "How do Companies Ship Code to Production?"
+description: "Explore the process companies use to ship code to production efficiently."
+image: "https://assets.bytebytego.com/diagrams/0334-ship-to-prod.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - software-engineering
+ - deployment
+---
+
+
+
+The diagram below illustrates the typical workflow.
+
+Step 1: The process starts with a product owner creating user stories based on requirements.
+
+Step 2: The dev team picks up the user stories from the backlog and puts them into a sprint for a two-week dev cycle.
+
+Step 3: The developers commit source code into the code repository Git.
+
+Step 4: A build is triggered in Jenkins. The source code must pass unit tests, code coverage threshold, and gates in SonarQube.
+
+Step 5: Once the build is successful, the build is stored in artifactory. Then the build is deployed into the dev environment.
+
+Step 6: There might be multiple dev teams working on different features. The features need to be tested independently, so they are deployed to QA1 and QA2.
+
+Step 7: The QA team picks up the new QA environments and performs QA testing, regression testing, and performance testing.
+
+Step 8: Once the QA builds pass the QA team’s verification, they are deployed to the UAT environment.
+
+Step 9: If the UAT testing is successful, the builds become release candidates and will be deployed to the production environment on schedule.
+
+Step 10: SRE (Site Reliability Engineering) team is responsible for prod monitoring.
diff --git a/data/guides/how-do-computer-programs-run.md b/data/guides/how-do-computer-programs-run.md
new file mode 100644
index 0000000..7cb9011
--- /dev/null
+++ b/data/guides/how-do-computer-programs-run.md
@@ -0,0 +1,50 @@
+---
+title: "How Do Computer Programs Run?"
+description: "Explore the execution flow of computer programs from start to finish."
+image: "https://assets.bytebytego.com/diagrams/0218-how-do-computer-programs-run.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - operating-systems
+ - execution
+---
+
+
+
+The diagram shows the steps.
+
+## User Interaction and Command Initiation
+
+By double-clicking a program, a user is instructing the operating system to launch an application via the graphical user interface.
+
+## Program Preloading
+
+Once the execution request has been initiated, the operating system first retrieves the program's executable file.
+
+The operating system locates this file through the file system and loads it into memory in preparation for execution.
+
+## Dependency Resolution and Loading
+
+Most modern applications rely on a number of shared libraries, such as dynamic link libraries (DLLs).
+
+## Allocating Memory Space
+
+The operating system is responsible for allocating space in memory.
+
+## Initializing the Runtime Environment
+
+After allocating memory, the operating system and execution environment (e.g., Java's JVM or the .NET Framework) will initialize various resources needed to run the program.
+
+## System Calls and Resource Management
+
+The entry point of a program (usually a function named `main`) is called to begin execution of the code written by the programmer.
+
+## Von Neumann Architecture
+
+In the Von Neumann architecture, the CPU executes instructions stored in memory.
+
+## Program Termination
+
+Eventually, when the program has completed its task, or the user actively terminates the application, the program will begin a cleanup phase. This includes closing open file descriptors, freeing up network resources, and returning memory to the system.
diff --git a/data/guides/how-do-googleapple-maps-blur-license-plates-and-human-faces-on-street-view.md b/data/guides/how-do-googleapple-maps-blur-license-plates-and-human-faces-on-street-view.md
new file mode 100644
index 0000000..c6c687e
--- /dev/null
+++ b/data/guides/how-do-googleapple-maps-blur-license-plates-and-human-faces-on-street-view.md
@@ -0,0 +1,38 @@
+---
+title: "How Google/Apple Maps Blur License Plates and Faces"
+description: "Explore how Google/Apple Maps blur sensitive data on Street View."
+image: "https://assets.bytebytego.com/diagrams/0347-street-view-blurring-system.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Machine Learning"
+ - "Image Processing"
+---
+
+
+
+The diagram below presents a possible solution that might work in an interview setting.
+
+The high-level architecture is broken down into three stages:
+
+* Data pipeline - prepare the training data set
+* Blurring pipeline - extract and classify objects and blur relevant objects, for example, license plates and faces.
+* Serving pipeline - serve blurred street view images to users.
+
+## Data Pipeline
+
+Step 1: We get the annotated dataset for training. The objects are marked in bounding boxes.
+
+Steps 2-4: The dataset goes through preprocessing and augmentation to be normalized and scaled.
+
+Steps 5-6: The annotated dataset is then used to train the machine learning model, which is a 2-stage network.
+
+## Blurring Pipeline
+
+Steps 7-10: The street view images go through preprocessing, and object boundaries are detected in the images. Then sensitive objects are blurred, and the images are stored in an object store.
+
+## Serving Pipeline
+
+Step 11: The blurred images can now be retrieved by users.
diff --git a/data/guides/how-do-message-queue-architectures-evolve.md b/data/guides/how-do-message-queue-architectures-evolve.md
new file mode 100644
index 0000000..3f02940
--- /dev/null
+++ b/data/guides/how-do-message-queue-architectures-evolve.md
@@ -0,0 +1,34 @@
+---
+title: "IBM MQ -> RabbitMQ -> Kafka -> Pulsar: Message Queue Evolution"
+description: "Explore the evolution of message queue architectures: IBM MQ to Pulsar."
+image: "https://assets.bytebytego.com/diagrams/0271-message-queue-evolve.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - "database-and-storage"
+tags:
+ - "Message Queues"
+ - "System Design"
+---
+
+
+
+* IBM MQ
+
+IBM MQ was launched in 1993. It was originally called MQSeries and was renamed WebSphere MQ in 2002. It was renamed to IBM MQ in 2014. IBM MQ is a very successful product widely used in the financial sector. Its revenue still reached 1 billion dollars in 2020.
+
+* RabbitMQ
+
+RabbitMQ architecture differs from IBM MQ and is more similar to Kafka concepts. The producer publishes a message to an exchange with a specified exchange type. It can be direct, topic, or fanout. The exchange then routes the message into the queues based on different message attributes and the exchange type. The consumers pick up the message accordingly.
+
+* Kafka
+
+In early 2011, LinkedIn open sourced Kafka, which is a distributed event streaming platform. It was named after Franz Kafka. As the name suggested, Kafka is optimized for writing. It offers a high-throughput, low-latency platform for handling real-time data feeds. It provides a unified event log to enable event streaming and is widely used in internet companies.
+
+Kafka defines producer, broker, topic, partition, and consumer. Its simplicity and fault tolerance allow it to replace previous products like AMQP-based message queues.
+
+* Pulsar
+
+Pulsar, developed originally by Yahoo, is an all-in-one messaging and streaming platform. Compared with Kafka, Pulsar incorporates many useful features from other products and supports a wide range of capabilities. Also, Pulsar architecture is more cloud-native, providing better support for cluster scaling and partition migration, etc.
+
+There are two layers in Pulsar architecture: the serving layer and the persistent layer. Pulsar natively supports tiered storage, where we can leverage cheaper object storage like AWS S3 to persist messages for a longer term.
diff --git a/data/guides/how-do-processes-talk-to-each-other-on-linux.md b/data/guides/how-do-processes-talk-to-each-other-on-linux.md
new file mode 100644
index 0000000..628e5a9
--- /dev/null
+++ b/data/guides/how-do-processes-talk-to-each-other-on-linux.md
@@ -0,0 +1,36 @@
+---
+title: "Inter-Process Communication on Linux"
+description: "Explore how processes communicate with each other in Linux systems."
+image: "https://assets.bytebytego.com/diagrams/0234-inter-process-communication.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Linux"
+ - "IPC"
+---
+
+
+
+The diagram above shows 5 ways of Inter-Process Communication.
+
+## Pipe
+
+Pipes are unidirectional byte streams that connect the standard output from one process to the standard input of another process.
+
+## Message Queue
+
+Message queues allow one or more processes to write messages, which will be read by one or more reading processes.
+
+## Signal
+
+Signals are one of the oldest inter-process communication methods used by Unix systems. A signal could be generated by a keyboard interrupt or an error condition such as the process attempting to access a non-existent location in its virtual memory. There are a set of defined signals that the kernel can generate or that can be generated by other processes in the system. For example, Ctrl+C sends a SIGINT signal to process A.
+
+## Semaphore
+
+A semaphore is a location in memory whose value can be tested and set by more than one process. Depending on the result of the test and set operation one process may have to sleep until the semaphore's value is changed by another process.
+
+## Shared Memory
+
+Shared memory allows one or more processes to communicate via memory that appears in all of their virtual address spaces. When processes no longer wish to share the virtual memory, they detach from it.
diff --git a/data/guides/how-do-search-engines-work.md b/data/guides/how-do-search-engines-work.md
new file mode 100644
index 0000000..7342179
--- /dev/null
+++ b/data/guides/how-do-search-engines-work.md
@@ -0,0 +1,32 @@
+---
+title: "How Do Search Engines Work?"
+description: "Explore the inner workings of search engines: crawling, indexing, and ranking."
+image: "https://assets.bytebytego.com/diagrams/0103-how-do-search-engines-work.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Search Engines"
+ - "Algorithms"
+---
+
+
+
+Search engines work through a combination of three core processes:
+
+## Crawling
+
+Search engines use automated programs called "crawlers" to discover and download web pages from the internet. These crawlers start with a list of known web pages (seeds) and follow links on those pages to find new ones, creating a vast network of interconnected content.
+
+## Indexing
+
+The information collected by the crawlers is then analyzed and organized into a massive database called an index. This process involves extracting key elements such as keywords, content type, freshness, language, and other classification signals to understand what each page is about and how relevant it might be to different search queries.
+
+## Serving Search Results
+
+When a user enters a query, the search engine's algorithm sifts through the index to identify the most relevant and helpful pages. Here's a breakdown of how it works:
+
+* **Query Analysis:** The search engine analyzes the user's query to understand its meaning and intent. This includes identifying keywords, recognizing synonyms, and interpreting context.
+* **Retrieval:** The search engine retrieves relevant pages from its vast index based on the query analysis. This involves matching the query's keywords with the indexed content of web pages.
+* **Ranking:** The retrieved pages are then ranked based on their relevance and other factors.
diff --git a/data/guides/how-do-sql-joins-work.md b/data/guides/how-do-sql-joins-work.md
new file mode 100644
index 0000000..fae6a42
--- /dev/null
+++ b/data/guides/how-do-sql-joins-work.md
@@ -0,0 +1,32 @@
+---
+title: "How do SQL Joins Work?"
+description: "Learn how SQL joins work with detailed explanations and examples."
+image: "https://assets.bytebytego.com/diagrams/0367-top-4-types-of-sql-joins.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "SQL"
+ - "Database"
+---
+
+
+
+The diagram above shows how 4 types of SQL joins work in detail.
+
+## INNER JOIN
+
+Returns matching rows in both tables.
+
+## LEFT JOIN
+
+Returns all records from the left table, and the matching records from the right table.
+
+## RIGHT JOIN
+
+Returns all records from the right table, and the matching records from the left table.
+
+## FULL OUTER JOIN
+
+Returns all records where there is a match in either left or right table.
diff --git a/data/guides/how-do-we-design-a-chat-application-like-whatsapp-facebook-messenger-or-discord.md b/data/guides/how-do-we-design-a-chat-application-like-whatsapp-facebook-messenger-or-discord.md
new file mode 100644
index 0000000..9456b31
--- /dev/null
+++ b/data/guides/how-do-we-design-a-chat-application-like-whatsapp-facebook-messenger-or-discord.md
@@ -0,0 +1,38 @@
+---
+title: "Designing a Chat Application"
+description: "Explore the architecture of chat apps like WhatsApp and Messenger."
+image: "https://assets.bytebytego.com/diagrams/0134-chat-app.jpeg"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - architecture
+ - messaging
+---
+
+
+
+The diagram below shows a design for a simplified 1-to-1 chat application.
+
+## User Login Flow
+
+* Step 1: Alice logs in to the chat application and establishes a web socket connection with the server side.
+
+* Steps 2-4: The presence service receives Alice's notification, updates her presence, and notifies Alice's friends about her presence.
+
+## Messaging Flow
+
+* Steps 1-2: Alice sends a chat message to Bob. The chat message is routed to Chat Service A.
+
+* Steps 3-4: The chat message is sent to the sequencing service, which generates a unique ID, and is persisted in the message store.
+
+* Step 5: The chat message is sent to the message sync queue to sync to Bob’s chat service.
+
+* Step 6: Before forwarding the messaging, the message sync service checks Bob’s presence:
+
+ * If Bob is online, the chat message is sent to chat service B.
+
+ * If Bob is offline, the message is sent to the push server and pushed to Bob’s device.
+
+* Steps 7-8: If Bob is online, the chat message is pushed to Bob via the web socket.
diff --git a/data/guides/how-do-we-design-a-permission-system.md b/data/guides/how-do-we-design-a-permission-system.md
new file mode 100644
index 0000000..8a8501c
--- /dev/null
+++ b/data/guides/how-do-we-design-a-permission-system.md
@@ -0,0 +1,50 @@
+---
+title: "Designing a Permission System"
+description: "Explore common permission system designs: ACL, DAC, MAC, ABAC, and RBAC."
+image: "https://assets.bytebytego.com/diagrams/0300-permission-systems.png"
+createdAt: "2024-02-13"
+draft: false
+categories:
+ - security
+tags:
+ - access control
+ - rbac
+---
+
+
+
+The diagram below lists 5 common ways.
+
+## 1. ACL (Access Control List)
+
+ACL is a list of rules that specifies which users are granted or denied access to a particular resource.
+
+* Pros - Easy to understand.
+* Cons - error-prone, maintenance cost is high
+
+## 2. DAC (Discretionary Access Control)
+
+This is based on ACL. It grants or restricts object access via an access policy determined by an object's owner group.
+
+* Pros - Easy and flexible. Linux file system supports DAC.
+* Cons - Scattered permission control, too much power for the object’s owner group.
+
+## 3. MAC (Mandatory Access Control)
+
+Both resource owners and resources have classification labels. Different labels are granted with different permissions.
+
+* Pros - strict and straightforward.
+* Cons - not flexible.
+
+## 4. ABAC (Attribute-based access control)
+
+Evaluate permissions based on attributes of the Resource owner, Action, Resource, and Environment.
+
+* Pros - flexible
+* Cons - the rules can be complicated, and the implementation is hard. It is not commonly used.
+
+## 5. RBAC (Role-based Access Control)
+
+Evaluate permissions based on roles
+
+* Pros - flexible in assigning roles.
diff --git a/data/guides/how-do-we-design-a-secure-system.md b/data/guides/how-do-we-design-a-secure-system.md
new file mode 100644
index 0000000..203782b
--- /dev/null
+++ b/data/guides/how-do-we-design-a-secure-system.md
@@ -0,0 +1,33 @@
+---
+title: "How to Design a Secure System"
+description: "A cheat sheet for designing secure systems with key design points."
+image: "https://assets.bytebytego.com/diagrams/0138-cheat-sheet-for-designing-secure-systems.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - security
+tags:
+ - "security design"
+ - "system design"
+---
+
+
+
+Designing secure systems is important for a multitude of reasons, spanning from protecting sensitive information to ensuring the stability and reliability of the infrastructure. As developers, we should design and implement these security guidelines by default.
+
+The diagram below is a pragmatic cheat sheet with the use cases and key design points.
+
+## Key Design Points
+
+* Authentication
+* Authorization
+* Encryption
+* Vulnerability
+* Audit & Compliance
+* Network Security
+* Terminal Security
+* Emergency Responses
+* Container Security
+* API Security
+* 3rd-Party Vendor Management
+* Disaster Recovery
diff --git a/data/guides/how-do-we-design-a-system-for-internationalization.md b/data/guides/how-do-we-design-a-system-for-internationalization.md
new file mode 100644
index 0000000..043fdc7
--- /dev/null
+++ b/data/guides/how-do-we-design-a-system-for-internationalization.md
@@ -0,0 +1,50 @@
+---
+title: "How to Design a System for Internationalization"
+description: "Learn how to design a system for internationalization effectively."
+image: "https://assets.bytebytego.com/diagrams/0235-internationalization.jpeg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "internationalization"
+ - "system design"
+---
+
+
+
+The diagram below shows how we can internationalize a simple e-commerce website.
+
+Different countries have differing cultures, values, and habits. When we design an application for international markets, we need to localize the application in several ways:
+
+## Language
+
+* Extract and maintain all texts in a separate system. For example:
+
+ * We shouldn’t put any prompts in the source code.
+ * We should avoid string concatenation in the code.
+ * We should remove text from graphics.
+
+* Use complete sentences and avoid dynamic text elements.
+* Display business data such as currencies in different languages.
+
+## Layout
+
+* Describe text length and reserve enough space around the text for different languages.
+* Plan for line wrap and truncation.
+* Keep text labels short on buttons.
+* Adjust the display for numerals, dates, timestamps, and addresses.
+
+## Time zone
+
+The time display should be segregated from timestamp storage.
+
+Common practice is to use the UTC (Coordinated Universal Time) timestamp for the database and backend services and to use the local time zone for the frontend display.
+
+## Currency
+
+We need to define the displayed currencies and settlement currency. We also need to design a foreign exchange service for quoting prices.
+
+## Company entity and accounting
+
+Since we need to set up different entities for individual countries, and these entities follow different regulations and accounting standards, the system needs to support multiple bookkeeping methods. Company-level treasury management is often needed. We also need to extract business logic to account for different usage habits in different countries or regions.
diff --git a/data/guides/how-do-we-design-effective-and-safe-apis.md b/data/guides/how-do-we-design-effective-and-safe-apis.md
new file mode 100644
index 0000000..3280da5
--- /dev/null
+++ b/data/guides/how-do-we-design-effective-and-safe-apis.md
@@ -0,0 +1,18 @@
+---
+title: 'How to Design Effective and Safe APIs'
+description: 'Learn how to design effective and safe APIs with best practices.'
+image: 'https://assets.bytebytego.com/diagrams/0180-effective-apis.jpeg'
+createdAt: '2024-03-05'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Design
+ - Software Engineering
+---
+
+
+
+The diagram above shows typical API designs with a shopping cart example.
+
+Note that API design is not just URL path design. Most of the time, we need to choose the proper resource names, identifiers, and path patterns. It is equally important to design proper HTTP header fields or to design effective rate-limiting rules within the API gateway.
diff --git a/data/guides/how-do-we-design-for-high-availability.md b/data/guides/how-do-we-design-for-high-availability.md
new file mode 100644
index 0000000..e5fd7f2
--- /dev/null
+++ b/data/guides/how-do-we-design-for-high-availability.md
@@ -0,0 +1,36 @@
+---
+title: "How to Design for High Availability"
+description: "Explore key strategies for designing systems with high availability."
+image: "https://assets.bytebytego.com/diagrams/0211-high-availability.jpg"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - high-availability
+ - system-design
+---
+
+
+
+What does Availability mean when you design a system?
+
+In the famous CAP theorem by computer scientist Eric Brewer, Availability means all (non-failing) nodes are available for queries in a distributed system. When you send out requests to the nodes, a non-failing node will return a reasonable response within a reasonable amount of time (with no error or timeout).
+
+Usually, we design a system for high availability. For example, when we say the design target is 4-9’s, it means the services should be up 99.99% of the time. This also means the services can only be down for 52.5 minutes per year.
+
+Note that availability only guarantees that we will receive a response; it doesn’t guarantee the data is the most up-to-date.
+
+The diagram below shows how we can turn a single-node “Product Inventory” into a double-node architecture with high availability.
+
+## High Availability Architectures
+
+* **Primary-Backup:** the backup node is just a stand-by, and the data is replicated from primary to backup. When the primary fails, we need to manually switch to the backup node.
+
+ The backup node might be a waste of hardware resources.
+
+* **Primary-Secondary:** this architecture looks similar to primary-backup architecture, but the secondary node can take read requests to balance the reading load. Due to latency when replicating data from primary to secondary, the data read from the secondary may be inconsistent with the primary.
+
+* **Primary-Primary:** both nodes act as primary nodes, both nodes can handle read/write operations, and the data is replicated between the two nodes. This type of architecture increases the throughput, but it has limited use cases. For example, if both nodes need to update the same product, the final state might be unpredictable. Use this architecture with caution!
+
+ If we deploy the node on Amazon EC2, which has 90% availability, the double-node architecture will increase availability from 90% to 99%.
diff --git a/data/guides/how-do-we-detect-node-failures-in-distributed-systems.md b/data/guides/how-do-we-detect-node-failures-in-distributed-systems.md
new file mode 100644
index 0000000..65c2ee5
--- /dev/null
+++ b/data/guides/how-do-we-detect-node-failures-in-distributed-systems.md
@@ -0,0 +1,40 @@
+---
+title: "How to Detect Node Failures in Distributed Systems"
+description: "Explore heartbeat mechanisms for detecting node failures in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0370-top-6-heartbeat-detection-mechanisms.png"
+createdAt: "2024-02-03"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - distributed systems
+ - failure detection
+---
+
+
+
+Heartbeat mechanisms are crucial in distributed systems for monitoring the health and status of various components. Here are several types of heartbeat detection mechanisms commonly used in distributed systems:
+
+## Push-Based Heartbeat
+
+The most basic form of heartbeat involves a periodic signal sent from one node to another or to a monitoring service. If the heartbeat signals stop arriving within a specified interval, the system assumes that the node has failed. This is simple to implement, but network congestion can lead to false positives.
+
+## Pull-Based Heartbeat
+
+Instead of nodes sending heartbeats actively, a central monitor might periodically "pull" status information from nodes. It reduces network traffic but might increase latency in failure detection.
+
+## Heartbeat with Health Check
+
+This includes diagnostic information about the node's health in the heartbeat signal. This information can include CPU usage, memory usage, or application-specific metrics. It Provides more detailed information about the node, allowing for more nuanced decision-making. However, it increases complexity and potential for larger network overhead.
+
+## Heartbeat with Timestamps
+
+Heartbeats that include timestamps can help the receiving node or service determine not just if a node is alive, but also if there are network delays affecting communication.
+
+## Heartbeat with Acknowledgement
+
+The receiver of the heartbeat message must send back an acknowledgment in this model. This ensures that not only is the sender alive, but the network path between the sender and receiver is also functional.
+
+## Heartbeat with Quorum
+
+In some distributed systems, especially those involving consensus protocols like Paxos or Raft, the concept of a quorum (a majority of nodes) is used. Heartbeats might be used to establish or maintain a quorum, ensuring that a sufficient number of nodes are operational for the system to make decisions. This brings complexity in implementation and managing quorum changes as nodes join or leave the system.
diff --git a/data/guides/how-do-we-incorporate-event-sourcing-into-the-systems.md b/data/guides/how-do-we-incorporate-event-sourcing-into-the-systems.md
new file mode 100644
index 0000000..839bac2
--- /dev/null
+++ b/data/guides/how-do-we-incorporate-event-sourcing-into-the-systems.md
@@ -0,0 +1,28 @@
+---
+title: "How do we incorporate Event Sourcing into systems?"
+description: "Explore incorporating Event Sourcing: from NYT archives to microservices."
+image: "https://assets.bytebytego.com/diagrams/0037-use-cases-for-event-sourcing.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "event sourcing"
+ - "microservices"
+---
+
+
+
+Event sourcing changes the programming paradigm from persisting states to persisting events. The event store is the source of truth. Let's look at three examples.
+
+## New York Times
+
+The newspaper website stores every article, image, and byline since 1851 in an event store. The raw data is then denormalized into different views and fed into different ElasticSearch nodes for website searches.
+
+## CDC (Change Data Capture)
+
+A CDC connector pulls data from the tables and transforms it into events. These events are pushed to Kafka and other sinks consume events from Kafka.
+
+## Microservice Connector
+
+We can also use event event-sourcing paradigm for transmitting events among microservices. For example, the shopping cart service generates various events for adding or removing items from the cart. Kafka broker acts as the event store, and other services including the fraud service, billing service, and email service consume events from the event store. Since events are the source of truth, each service can determine the domain model on its own.
diff --git a/data/guides/how-do-we-learn-elasticsearch.md b/data/guides/how-do-we-learn-elasticsearch.md
new file mode 100644
index 0000000..ca26c8f
--- /dev/null
+++ b/data/guides/how-do-we-learn-elasticsearch.md
@@ -0,0 +1,33 @@
+---
+title: "How to Learn Elasticsearch"
+description: "Learn about Elasticsearch features, use cases, and core data structures."
+image: "https://assets.bytebytego.com/diagrams/0182-elastic-search.jpeg"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Elasticsearch
+ - Search
+---
+
+
+
+Based on the Lucene library, Elasticsearch provides search capabilities. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. The diagram above shows the outline.
+
+## Features of ElasticSearch:
+
+* Real-time full-text search
+* Analytics engine
+* Distributed Lucene
+
+## ElasticSearch use cases:
+
+* Product search on an eCommerce website
+* Log analysis
+* Auto completer, spell checker
+* Business intelligence analysis
+* Full-text search on Wikipedia
+* Full-text search on StackOverflow
+
+The core of ElasticSearch lies in the data structure and indexing. It is important to understand how ES builds the **term dictionary** using **LSM Tree** (Log-Strucutured Merge Tree).
diff --git a/data/guides/how-do-we-manage-configurations-in-a-system.md b/data/guides/how-do-we-manage-configurations-in-a-system.md
new file mode 100644
index 0000000..7b777ad
--- /dev/null
+++ b/data/guides/how-do-we-manage-configurations-in-a-system.md
@@ -0,0 +1,34 @@
+---
+title: "How do we manage configurations in a system?"
+description: "Comparing traditional configuration management with Infrastructure as Code (IaC)."
+image: "https://assets.bytebytego.com/diagrams/0056-how-we-manage-configuration.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Infrastructure as Code
+ - Configuration Management
+---
+
+
+
+The diagram shows a comparison between traditional configuration management and IaC (Infrastructure as Code).
+
+## Configuration Management
+
+Configuration Management is designed to manage and provision IT infrastructure through systematic and repeatable processes. This is critical for ensuring that the system performs as intended.
+
+Traditional configuration management focuses on maintaining the desired state of the system's configuration items, such as servers, network devices, and applications, after they have been provisioned.
+
+It usually involves initial manual setup by DevOps. Changes are managed by step-by-step commands.
+
+## What is IaC?
+
+IaC, on the other hand, represents a shift in how infrastructure is provisioned and managed, treating infrastructure setup and changes as software development practices.
+
+IaC automates the provisioning of infrastructure, starting and managing the system through code. It often uses a declarative approach, where the desired state of the infrastructure is described.
+
+Tools like Terraform, AWS CloudFormation, Chef, and Puppet are used to define infrastructure in code files that are source controlled.
+
+IaC represents an evolution towards automation, repeatability, and the application of software development practices to infrastructure management.
diff --git a/data/guides/how-do-we-manage-data.md b/data/guides/how-do-we-manage-data.md
new file mode 100644
index 0000000..7044ce4
--- /dev/null
+++ b/data/guides/how-do-we-manage-data.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Data Management Patterns"
+description: "Explore 6 key data management patterns for efficient data handling."
+image: "https://assets.bytebytego.com/diagrams/0379-top-6-data-management-patterns.png"
+createdAt: "2024-02-04"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "data management"
+ - "data patterns"
+---
+
+
+
+### Here are top 6 data management patterns
+
+## Cache Aside
+
+When an application needs to access data, it first checks the cache. If the data is not present (a cache miss), it fetches the data from the data store, stores it in the cache, and then returns the data to the user. This pattern is particularly useful for scenarios where data is read frequently but updated less often.
+
+## Materialized View
+
+A Materialized View is a database object that contains the results of a query. It is physically stored, meaning the data is actually computed and stored on disk, as opposed to being dynamically generated upon each request. This can significantly speed up query times for complex calculations or aggregations that would otherwise need to be computed on the fly. Materialized views are especially beneficial in data warehousing and business intelligence scenarios where query performance is critical.
+
+## CQRS
+
+CQRS is an architectural pattern that separates the models for reading and writing data. This means that the data structures used for querying data (reads) are separated from the structures used for updating data (writes). This separation allows for optimization of each operation independently, improving performance, scalability, and security. CQRS can be particularly useful in complex systems where the read and write operations have very different requirements.
+
+## Event Sourcing
+
+Event Sourcing is a pattern where changes to the application state are stored as a sequence of events. Instead of storing just the current state of data in a domain, Event Sourcing stores a log of all the changes (events) that have occurred over time. This allows the application to reconstruct past states and provides an audit trail of changes. Event Sourcing is beneficial in scenarios requiring complex business transactions, auditability, and the ability to rollback or replay events.
+
+## Index Table
+
+The Index Table pattern involves creating additional tables in a database that are optimized for specific query operations. These tables act as secondary indexes and are designed to speed up the retrieval of data without requiring a full scan of the primary data store. Index tables are particularly useful in scenarios with large datasets and where certain queries are performed frequently.
+
+## Sharding
+
+Sharding is a data partitioning pattern where data is divided into smaller, more manageable pieces, or "shards", each of which can be stored on different database servers. This pattern is used to distribute the data across multiple machines to improve scalability and performance. Sharding is particularly effective in high-volume applications, as it allows for horizontal scaling, spreading the load across multiple servers to handle more users and transactions.
diff --git a/data/guides/how-do-we-manage-sensitive-data-in-a-system.md b/data/guides/how-do-we-manage-sensitive-data-in-a-system.md
new file mode 100644
index 0000000..6bac697
--- /dev/null
+++ b/data/guides/how-do-we-manage-sensitive-data-in-a-system.md
@@ -0,0 +1,44 @@
+---
+title: "How do we manage sensitive data in a system?"
+description: "A cheat sheet for managing sensitive data in a system."
+image: "https://assets.bytebytego.com/diagrams/0058-cheatsheet-for-managing-sensitive-data.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - security
+tags:
+ - data security
+ - data management
+---
+
+
+
+The cheat sheet below shows a list of guidelines.
+
+## What is Sensitive Data?
+
+Personal Identifiable Information (PII), health information, intellectual property, financial information, education and legal records are all sensitive data.
+
+Most countries have laws and regulations that require the protection of sensitive data. For example, the General Data Protection Regulation (GDPR) in the European Union sets stringent rules for data protection and privacy. Non-compliance with such regulations can result in hefty fines, legal actions, and sanctions against the violating entity.
+
+When we design systems, we need to design for data protection.
+
+## Encryption & Key Management
+
+The data transmission needs to be encrypted using SSL. Passwords shouldn’t be stored in plain text.
+
+For key storage, we design different roles including password applicant, password manager and auditor, all holding one piece of the key. We will need all three keys to open a lock.
+
+## Data Desensitization
+
+Data desensitization, also known as data anonymization or data sanitization, refers to the process of removing or modifying personal information from a dataset so that individuals cannot be readily identified. This practice is crucial in protecting individuals' privacy and ensuring compliance with data protection laws and regulations. Data desensitization is often used when sharing data externally, such as for research or statistical analysis, or even internally within an organization, to limit access to sensitive information.
+
+Algorithms like GCM store cipher data and keys separately so that hackers are not able to decipher the user data.
+
+## Minimal Data Permissions
+
+To protect sensitive data, we should grant minimal permissions to the users. Often we design Role-Based Access Control (RBAC) to restrict access to authorized users based on their roles within an organization. It is a widely used access control mechanism that simplifies the management of user permissions, ensuring that users have access to only the information and resources necessary for their roles.
+
+## Data Lifecycle Management
+
+When we develop data products like reports or data feeds, we need to design a process to maintain data quality. Data developers should be granted with necessary permissions during development. After the data is online, they should be revoked from the data access.
diff --git a/data/guides/how-do-we-perform-pagination-in-api-design.md b/data/guides/how-do-we-perform-pagination-in-api-design.md
new file mode 100644
index 0000000..3806b02
--- /dev/null
+++ b/data/guides/how-do-we-perform-pagination-in-api-design.md
@@ -0,0 +1,60 @@
+---
+title: How do we Perform Pagination in API Design?
+description: Learn about API pagination techniques for efficient data retrieval.
+image: 'https://assets.bytebytego.com/diagrams/0076-api-pagination-101.png'
+createdAt: '2024-03-04'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Design
+ - Pagination
+---
+
+
+
+Pagination is crucial in API design to handle large datasets efficiently and improve performance. Here are six popular pagination techniques:
+
+* **Offset-based Pagination:**
+
+ This technique uses an offset and a limit parameter to define the starting point and the number of records to return.
+
+ * Example: GET /orders?offset=0&limit=3
+ * Pros: Simple to implement and understand.
+ * Cons: Can become inefficient for large offsets, as it requires scanning and skipping rows.
+* **Cursor-based Pagination:**
+
+ This technique uses a cursor (a unique identifier) to mark the position in the dataset. Typically, the cursor is an encoded string that points to a specific record.
+
+ * Example: GET /orders?cursor=xxx
+ * Pros: More efficient for large datasets, as it doesn't require scanning skipped records.
+ * Cons: Slightly more complex to implement and understand.
+* **Page-based Pagination:**
+
+ This technique specifies the page number and the size of each page.
+
+ * Example: GET /items?page=2&size=3
+ * Pros: Easy to implement and use.
+ * Cons: Similar performance issues as offset-based pagination for large page numbers.
+* **Keyset-based Pagination:**
+
+ This technique uses a key to filter the dataset, often the primary key or another indexed column.
+
+ * Example: GET /items?after\_id=102&limit=3
+ * Pros: Efficient for large datasets and avoids performance issues with large offsets.
+ * Cons: Requires a unique and indexed key, and can be complex to implement.
+* **Time-based Pagination:**
+
+ This technique uses a timestamp or date to paginate through records.
+
+ * Example: GET /items?start\_time=xxx&end\_time=yyy
+ * Pros: Useful for datasets ordered by time, ensures no records are missed if new ones are added.
+ * Cons: Requires a reliable and consistent timestamp.
+* **Hybrid Pagination:**
+
+ This technique combines multiple pagination techniques to leverage their strengths.
+
+ * Example: Combining cursor and time-based pagination for efficient scrolling through time-ordered records.
+ * Example: GET /items?cursor=abc&start\_time=xxx&end\_time=yyy
+ * Pros: Can offer the best performance and flexibility for complex datasets.
+ * Cons: More complex to implement and requires careful design.
diff --git a/data/guides/how-do-we-retry-on-failures.md b/data/guides/how-do-we-retry-on-failures.md
new file mode 100644
index 0000000..4920d7e
--- /dev/null
+++ b/data/guides/how-do-we-retry-on-failures.md
@@ -0,0 +1,48 @@
+---
+title: "Retry Strategies for System Failures"
+description: "Explore retry strategies for handling transient errors in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0229-how-do-we-retry-on-failures.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "distributed systems"
+ - "retry strategies"
+---
+
+
+
+In distributed systems and networked applications, retry strategies are crucial for handling transient errors and network instability effectively. The diagram shows 4 common retry strategies.
+
+## Linear Backoff
+
+Linear backoff involves waiting for a progressively increasing fixed interval between retry attempts.
+
+* **Advantages**: Simple to implement and understand.
+
+* **Disadvantages**: May not be ideal under high load or in high-concurrency environments as it could lead to resource contention or "retry storms".
+
+## Linear Jitter Backoff
+
+Linear jitter backoff modifies the linear backoff strategy by introducing randomness to the retry intervals. This strategy still increases the delay linearly but adds a random "jitter" to each interval.
+
+* **Advantages**: The randomness helps spread out the retry attempts over time, reducing the chance of synchronized retries across instances.
+
+* **Disadvantages**: Although better than simple linear backoff, this strategy might still lead to potential issues with synchronized retries as the base interval increases only linearly.
+
+## Exponential Backoff
+
+Exponential backoff involves increasing the delay between retries exponentially. The interval might start at 1 second, then increase to 2 seconds, 4 seconds, 8 seconds, and so on, typically up to a maximum delay. This approach is more aggressive in spacing out retries than linear backoff.
+
+* **Advantages**: Significantly reduces the load on the system and the likelihood of collision or overlap in retry attempts, making it suitable for high-load environments.
+
+* **Disadvantages**: In situations where a quick retry might resolve the issue, this approach can unnecessarily delay the resolution.
+
+## Exponential Jitter Backoff
+
+Exponential jitter backoff combines exponential backoff with randomness. After each retry, the backoff interval is exponentially increased, and then a random jitter is applied. The jitter can be either additive (adding a random amount to the exponential delay) or multiplicative (multiplying the exponential delay by a random factor).
+
+* **Advantages**: Offers all the benefits of exponential backoff, with the added advantage of reducing retry collisions even further due to the introduction of jitter.
+
+* **Disadvantages**: The randomness can sometimes result in longer than necessary delays, especially if the jitter is significant.
diff --git a/data/guides/how-do-we-transform-a-system-to-be-cloud-native.md b/data/guides/how-do-we-transform-a-system-to-be-cloud-native.md
new file mode 100644
index 0000000..b911c65
--- /dev/null
+++ b/data/guides/how-do-we-transform-a-system-to-be-cloud-native.md
@@ -0,0 +1,25 @@
+---
+title: "How to Transform a System to be Cloud Native"
+description: "A blueprint for adopting cloud-native architecture in your organization."
+image: "https://assets.bytebytego.com/diagrams/0149-how-doe-we-adopt-cloud-native.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "cloud-native"
+ - "architecture"
+---
+
+The diagram below shows the action spectrum and adoption roadmap. You can use it as a blueprint for adopting cloud-native in your organization.
+
+
+
+For a company to adopt cloud native architecture, there are 6 aspects in the spectrum:
+
+* Application definition development
+* Orchestration and management
+* Runtime
+* Provisioning
+* Observability
+* Serverless
diff --git a/data/guides/how-do-you-decide-which-type-of-database-to-use.md b/data/guides/how-do-you-decide-which-type-of-database-to-use.md
new file mode 100644
index 0000000..a319073
--- /dev/null
+++ b/data/guides/how-do-you-decide-which-type-of-database-to-use.md
@@ -0,0 +1,30 @@
+---
+title: "How to Decide Which Type of Database to Use"
+description: "A guide to choosing the right database for your specific needs."
+image: "https://assets.bytebytego.com/diagrams/0160-database-types.jpg"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - database selection
+ - database types
+---
+
+
+
+There are hundreds or even thousands of databases available today, such as Oracle, MySQL, MariaDB, SQLite, PostgreSQL, Redis, ClickHouse, MongoDB, S3, Ceph, etc. How do you select the architecture for your system? My short summary is as follows:
+
+## Database Types
+
+* Relational database: Almost anything could be solved by them.
+
+* In-memory store: Their speed and limited data size make them ideal for fast operations.
+
+* Time-series database: Store and manage time-stamped data.
+
+* Graph database: It is suitable for complex relationships between unstructured objects.
+
+* Document store: They are good for large immutable data.
+
+* Wide column store: They are usually used for big data, analytics, reporting, etc., which needs denormalized data.
diff --git a/data/guides/how-does-a-password-manager-such-as-1password-or-lastpass-work.md b/data/guides/how-does-a-password-manager-such-as-1password-or-lastpass-work.md
new file mode 100644
index 0000000..84e87cb
--- /dev/null
+++ b/data/guides/how-does-a-password-manager-such-as-1password-or-lastpass-work.md
@@ -0,0 +1,42 @@
+---
+title: "How Password Managers Work"
+description: "Learn how password managers like 1Password and LastPass keep passwords safe."
+image: "https://assets.bytebytego.com/diagrams/0297-password-manager.png"
+createdAt: "2024-02-14"
+draft: false
+categories:
+ - security
+tags:
+ - "security"
+ - "passwords"
+---
+
+
+
+How does it keep our passwords safe?
+
+The diagram below shows how a typical password manager works.
+
+A password manager generates and stores passwords for us. We can use it via application, browser extension, or command line.
+
+Not only does a password manager store passwords for individuals but also it supports password management for teams in small businesses and big enterprises.
+
+Let’s go through the steps.
+
+## Step 1
+
+When we sign up for a password manager, we enter our email address and set up an account password. The password manager generates a secret key for us. The 3 fields are used to generate MUK (Master Unlock Key) and SRP-X using the 2SKD algorithm. MUK is used to decrypt vaults that store our passwords. Note that the secret key is stored locally, and will not be sent to the password manager’s server side.
+
+## Step 2
+
+The MUK generated in Step 1 is used to generate the encrypted MP key of the primary keyset.
+
+## Steps 3-5
+
+The MP key is then used to generate a private key, which can be used to generate AES keys in other keysets. The private key is also used to generate the vault key. Vault stores a collection of items for us on the server side. The items can be passwords notes etc.
+
+## Step 6
+
+The vault key is used to encrypt the items in the vault.
+
+Because of the complex process, the password manager has no way to know the encrypted passwords. We only need to remember one account password, and the password manager will remember the rest.
diff --git a/data/guides/how-does-a-typical-push-notification-system-work.md b/data/guides/how-does-a-typical-push-notification-system-work.md
new file mode 100644
index 0000000..69ece5f
--- /dev/null
+++ b/data/guides/how-does-a-typical-push-notification-system-work.md
@@ -0,0 +1,29 @@
+---
+title: How Does a Typical Push Notification System Work?
+description: Explore the architecture of a typical push notification system.
+image: 'https://assets.bytebytego.com/diagrams/0042-design-a-notification-push-system.png'
+createdAt: '2024-02-24'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Notifications
+---
+
+
+
+The diagram above shows the architecture of a notification system that covers major notification channels:
+
+* **In-App notifications**
+* **Email notifications**
+* **SMS and OTP notifications**
+* **Social media pushes**
+
+Let’s walk through the steps.
+
+* Steps 1.1 and 1.2 - The business services send notifications to the notification gateway. The gateway can handle two modes: one mode receives one notification each time, and the other receives notifications in batches.
+* Steps 2, 2.1, and 2.2 - The notification gateway forwards the notifications to the distribution service, where the messages are validated, formatted, and scheduled based on settings. The notification template repository allows users to pre-define the message format. The channel preference repository allows users to pre-define the preferred delivery channels.
+* Step 3 - The notifications are then sent to the routers, normally message queues.
+* Step 4 - The channel services communicate with various internal and external delivery channels, including in-app notifications, email delivery, SMS delivery, and social media apps.
+* Steps 5 and 6 - The delivery metrics are captured by the notification tracking and analytics service, where the operations team can view the analytical reports and improve user experiences.
diff --git a/data/guides/how-does-a-vpn-work.md b/data/guides/how-does-a-vpn-work.md
new file mode 100644
index 0000000..d667d97
--- /dev/null
+++ b/data/guides/how-does-a-vpn-work.md
@@ -0,0 +1,44 @@
+---
+title: "How Does a VPN Work?"
+description: "Explore how VPNs create secure connections for online privacy."
+image: "https://assets.bytebytego.com/diagrams/0052-how-a-vpn-works.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - security
+tags:
+ - "VPN"
+ - "Security"
+---
+
+
+
+This diagram below shows how we access the internet with and without VPNs.
+
+A VPN, or Virtual Private Network, is a technology that creates a secure, encrypted connection over a less secure network, such as the public internet. The primary purpose of a VPN is to provide privacy and security to data and communications.
+
+A VPN acts as a tunnel through which the encrypted data goes from one location to another. Any external party cannot see the data transferring.
+
+A VPN works in 4 steps:
+
+* Step 1 - Establish a secure tunnel between our device and the VPN server.
+
+* Step 2 - Encrypt the data transmitted.
+
+* Step 3 - Mask our IP address, so it appears as if our internet activity is coming from the VPN server.
+
+* Step 4 - Our internet traffic is routed through the VPN server.
+
+## Advantages of a VPN:
+
+* **Privacy**
+* **Anonymity**
+* **Security**
+* **Encryption**
+* **Masking the original IP address**
+
+## Disadvantages of a VPN:
+
+* **VPN blocking**
+* **Slow down connections**
+* **Trust in VPN provider**
diff --git a/data/guides/how-does-ach-payment-work.md b/data/guides/how-does-ach-payment-work.md
new file mode 100644
index 0000000..1fb5dfe
--- /dev/null
+++ b/data/guides/how-does-ach-payment-work.md
@@ -0,0 +1,36 @@
+---
+title: "How ACH Payment Works"
+description: "Learn how ACH payments work in the US, including direct deposit."
+image: "https://assets.bytebytego.com/diagrams/0067-how-does-ach-payment-work.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - ACH
+ - Payments
+---
+
+
+
+Do you know how you get paid at work? In the US, tech companies usually run payrolls via Automatic Clearing House (**ACH**).
+
+ACH handles retail transactions and is part of American retail payment systems. It processes transactions in **batches**, not in real-time. The diagram above shows how ACH direct deposit works with payrolls.
+
+### How ACH Direct Deposit Works
+
+* Step 0: Before we can use the ACH network, the originator who starts the transactions needs to open an account at a commercial bank because only banks are allowed to initiate ACH transactions directly. The bank is called ODFI (Originating Depository Financial Institution). Then the transaction receiver needs to authorize the originator for certain types of transactions.
+
+* Step 1: The originator company originates salary payment transactions. The transactions are sent to a 3rd-party processor like Gusto. The third-party processor helps with ACH-related services like generating ACH files, etc.
+
+* Step 2: The third-party processor generates ACH files on behalf of the originator. The files are uploaded to an SFTP established by the ODFI. This should be done by the 7 PM cut-off time, as specified by the ODFI bank.
+
+* Step 3: After normal business hours in the evening, the ODFI bank forwards the ACH files to the ACH operator for clearing and settlement. There are two ACH operators, one is the Federal Reserve (FedACH), and the other is EPN (Electronic Payment Network – which is operated by a private company).
+
+* Step 4: The ACH files are processed around midnight and made available to the receiving bank RDFI (Receiving Depository Financial Institution.)
+
+* Step 5: The RDFI operates on the receiver’s bank accounts based on the instructions in the ACH files. In our case, the receiver receives $100 from the originator. This is done when the RDFI opens for business at 6 AM the next day.
+
+ACH is a next-day settlement system. It means transactions sent out by 7 PM on one day will arrive the following morning.
+
+Since 2018, it’s possible to choose Same Day ACH so funds can be transferred on the same business day.
diff --git a/data/guides/how-does-amazon-build-system-work.md b/data/guides/how-does-amazon-build-system-work.md
new file mode 100644
index 0000000..a17f17b
--- /dev/null
+++ b/data/guides/how-does-amazon-build-system-work.md
@@ -0,0 +1,26 @@
+---
+title: "Amazon's Build System: Brazil"
+description: "Explore Amazon's Brazil build system for micro-repo driven collaboration."
+image: "https://assets.bytebytego.com/diagrams/0069-amazon-build-system.jpeg"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Build Systems
+ - Amazon
+---
+
+
+
+Discover Amazon's innovative build system - Brazil.
+
+Amazon's ownership model requires each team to manage its own repositories, which allows for more rapid innovation. Amazon has created a unique build system, known as Brazil, to enhance productivity and empower Amazon’s micro-repo driven collaboration. This system is certainly worth examining!
+
+With Brazil, developers can focus on developing the code and create a simple-to-understand build configuration file. The build system will then process the output artifact repeatedly and consistently. The build config minimizes the build requirement, including language, versioning, dependencies, major versions, and lastly, how to resolve version conflicts.
+
+For local builds, the Brazil build tool interprets the build configuration as a Directed Acyclic Graph (DAG), retrieves packages from the myservice’s private space (VersionSet) called myservice-cpp-version-set, generates the language-specific build configuration, and employs the specific build tool to produce the output artifact.
+
+A version set is a collection of package versions that offers a private space for the package and its dependencies. When a new package dependency is introduced, it must also be merged into this private space. There is a default version set called "live," which serves as a public space where anyone can publish any version.
+
+Remotely, the package builder service provides an intuitive experience by selecting a version set and building targets. This service supports Amazon Linux on x86, x64, and ARM. Builds can be initiated manually or automatically upon a new commit to the master branch. The package builder guarantees build consistency and reproducibility, with each build process being snapshotted and the output artifact versioned.
diff --git a/data/guides/how-does-aws-lambda-work-behind-the-scenes.md b/data/guides/how-does-aws-lambda-work-behind-the-scenes.md
new file mode 100644
index 0000000..8758bee
--- /dev/null
+++ b/data/guides/how-does-aws-lambda-work-behind-the-scenes.md
@@ -0,0 +1,42 @@
+---
+title: "How AWS Lambda Works Behind the Scenes"
+description: "Explore the inner workings of AWS Lambda and its serverless architecture."
+image: "https://assets.bytebytego.com/diagrams/0249-lambda.jpg"
+createdAt: "2024-01-26"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "AWS Lambda"
+ - "Serverless"
+---
+
+
+
+**Serverless** is one of the hottest topics in cloud services. How does AWS **Lambda** work behind the scenes?
+
+Lambda is a **serverless** computing service provided by Amazon Web Services (AWS), which runs functions in response to events.
+
+## Firecracker MicroVM
+
+Firecracker is the engine powering all of the Lambda functions. It is a virtualization technology developed at Amazon and written in Rust.
+
+The diagram below illustrates the isolation model for AWS Lambda Workers.
+
+Lambda functions run within a sandbox, which provides a minimal Linux userland, some common libraries and utilities. It creates the Execution environment (worker) on EC2 instances.
+
+How are lambdas initiated and invoked? There are two ways.
+
+## Synchronous execution
+
+* Step1: "The Worker Manager communicates with a Placement Service which is responsible to place a workload on a location for the given host (it’s provisioning the sandbox) and returns that to the Worker Manager".
+
+* Step 2: "The Worker Manager can then call *Init* to initialize the function for execution by downloading the Lambda package from S3 and setting up the Lambda runtime"
+
+* Step 3: The Frontend Worker is now able to call *Invoke*.
+
+## Asynchronous execution
+
+* Step 1: The Application Load Balancer forwards the invocation to an available Frontend which places the event onto an internal queue(SQS).
+
+* Step 2: There is "a set of pollers assigned to this internal queue which are responsible for polling it and moving the event onto a Frontend synchronously. After it’s been placed onto the Frontend it follows the synchronous invocation call pattern which we covered earlier".
diff --git a/data/guides/how-does-chatgpt-work.md b/data/guides/how-does-chatgpt-work.md
new file mode 100644
index 0000000..05f603b
--- /dev/null
+++ b/data/guides/how-does-chatgpt-work.md
@@ -0,0 +1,36 @@
+---
+title: How does ChatGPT work?
+description: This article explains how ChatGPT works in detail.
+image: 'https://assets.bytebytego.com/diagrams/0135-chat-gpt.jpeg'
+createdAt: '2024-03-15'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - ChatGPT
+ - Machine Learning
+---
+
+
+Since OpenAI hasn't provided all the details, some parts of the diagram may be inaccurate.
+
+We attempted to explain how it works in the diagram above. The process can be broken down into two parts.
+
+## Training
+
+To train a ChatGPT model, there are two stages:
+
+- **Pre-training:** In this stage, we train a GPT model (decoder-only transformer) on a large chunk of internet data. The objective is to train a model that can predict future words given a sentence in a way that is grammatically correct and semantically meaningful similar to the internet data. After the pre-training stage, the model can complete given sentences, but it is not capable of responding to questions.
+
+- **Fine-tuning:** This stage is a 3-step process that turns the pre-trained model into a question-answering ChatGPT model:
+ - Collect training data (questions and answers), and fine-tune the pre-trained model on this data. The model takes a question as input and learns to generate an answer similar to the training data.
+ - Collect more data (question, several answers) and train a reward model to rank these answers from most relevant to least relevant.
+ - Use reinforcement learning (PPO optimization) to fine-tune the model so the model's answers are more accurate.
+
+## Answer a prompt
+
+- Step 1: The user enters the full question, “Explain how a classification algorithm works”.
+- Step 2: The question is sent to a content moderation component. This component ensures that the question does not violate safety guidelines and filters inappropriate questions.
+- Steps 3-4: If the input passes content moderation, it is sent to the chatGPT model. If the input doesn’t pass content moderation, it goes straight to template response generation.
+- Step 5-6: Once the model generates the response, it is sent to a content moderation component again. This ensures the generated response is safe, harmless, unbiased, etc.
+- Step 7: If the input passes content moderation, it is shown to the user. If the input doesn’t pass content moderation, it goes to template response generation and shows a template answer to the user.
diff --git a/data/guides/how-does-cnd-work.md b/data/guides/how-does-cnd-work.md
new file mode 100644
index 0000000..525753e
--- /dev/null
+++ b/data/guides/how-does-cnd-work.md
@@ -0,0 +1,44 @@
+---
+title: "How Does CDN Work?"
+description: "Explore how Content Delivery Networks (CDNs) accelerate content delivery."
+image: "https://assets.bytebytego.com/diagrams/0230-how-cdn-works.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "CDN"
+ - "Networking"
+---
+
+
+
+A content delivery network (CDN) refers to geographically distributed servers (also called edge servers) that provide fast delivery of static and dynamic content. Let’s take a look at how it works.
+
+Suppose Bob who lives in New York wants to visit an eCommerce website that is deployed in London. If the request goes to servers located in London, the response will be quite slow. So we deploy CDN servers close to where Bob lives, and the content will be loaded from the nearby CDN server.
+
+The diagram above illustrates the process:
+
+## How CDN Works
+
+* Bob types in [www.myshop.com](http://www.myshop.com/) in the browser. The browser looks up the domain name in the local DNS cache.
+
+* If the domain name does not exist in the local DNS cache, the browser goes to the DNS resolver to resolve the name. The DNS resolver usually sits in the Internet Service Provider (ISP).
+
+* The DNS resolver recursively resolves the domain name (see my previous post for details). Finally, it asks the authoritative name server to resolve the domain name.
+
+* If we don’t use CDN, the authoritative name server returns the IP address for [www.myshop.com](http://www.myshop.com/). But with CDN, the authoritative name server has an alias pointing to [www.myshop.cdn.com](http://www.myshop.cdn.com/) (the domain name of the CDN server).
+
+* The DNS resolver asks the authoritative name server to resolve [www.myshop.cdn.com](http://www.myshop.cdn.com/).
+
+* The authoritative name server returns the domain name for the load balancer of CDN [www.myshop.lb.com](http://www.myshop.lb.com/).
+
+* The DNS resolver asks the CDN load balancer to resolve [www.myshop.lb.com](http://www.myshop.lb.com/). The load balancer chooses an optimal CDN edge server based on the user’s IP address, user’s ISP, the content requested, and the server load.
+
+* The CDN load balancer returns the CDN edge server’s IP address for [www.myshop.lb.com](http://www.myshop.lb.com/).
+
+* Now we finally get the actual IP address to visit. The DNS resolver returns the IP address to the browser.
+
+* The browser visits the CDN edge server to load the content. There are two types of contents cached on the CDN servers: static contents and dynamic contents. The former contains static pages, pictures, videos; the latter one includes results of edge computing.
+
+* If the edge CDN server cache doesn't contain the content, it goes upward to the regional CDN server. If the content is still not found, it will go upward to the central CDN server, or even go to the origin - the London web server. This is called the CDN distribution network, where the servers are deployed geographically.
diff --git a/data/guides/how-does-docker-work.md b/data/guides/how-does-docker-work.md
new file mode 100644
index 0000000..5fe7b26
--- /dev/null
+++ b/data/guides/how-does-docker-work.md
@@ -0,0 +1,38 @@
+---
+title: "How does Docker work?"
+description: "Explore the inner workings of Docker: architecture and key components."
+image: "https://assets.bytebytego.com/diagrams/0414-how-does-docker-work.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Docker"
+ - "Containers"
+---
+
+
+
+The diagram below shows the architecture of Docker and how it works when we run “docker build”, “docker pull” and “docker run”.
+
+There are 3 components in Docker architecture:
+
+* **Docker client**
+
+ The docker client talks to the Docker daemon.
+
+* **Docker host**
+
+ The Docker daemon listens for Docker API requests and manages Docker objects such as images, containers, networks, and volumes.
+
+* **Docker registry**
+
+ A Docker registry stores Docker images. Docker Hub is a public registry that anyone can use.
+
+Let’s take the “docker run” command as an example.
+
+* Docker pulls the image from the registry.
+* Docker creates a new container.
+* Docker allocates a read-write filesystem to the container.
+* Docker creates a network interface to connect the container to the default network.
+* Docker starts the container.
diff --git a/data/guides/how-does-garbage-collection-work.md b/data/guides/how-does-garbage-collection-work.md
new file mode 100644
index 0000000..ecbd281
--- /dev/null
+++ b/data/guides/how-does-garbage-collection-work.md
@@ -0,0 +1,42 @@
+---
+title: "How does Garbage Collection work?"
+description: "Explore how garbage collection reclaims unused memory automatically."
+image: "https://assets.bytebytego.com/diagrams/0200-garbage-collection-101.png"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - software-development
+tags:
+ - "garbage collection"
+ - "memory management"
+---
+
+Garbage collection is an automatic memory management feature used in programming languages to reclaim memory no longer used by the program.
+
+
+
+## Java
+
+Java provides several garbage collectors, each suited for different use cases:
+
+* Serial Garbage Collector: Best for single-threaded environments or small applications.
+
+* Parallel Garbage Collector: Also known as the "Throughput Collector."
+
+* CMS (Concurrent Mark-Sweep) Garbage Collector: Low-latency collector aiming to minimize pause times.
+
+* G1 (Garbage-First) Garbage Collector: Aims to balance throughput and latency.
+
+* Z Garbage Collector (ZGC): A low-latency garbage collector designed for applications that require large heap sizes and minimal pause times.
+
+## Python
+
+Python's garbage collection is based on reference counting and a cyclic garbage collector:
+
+* Reference Counting: Each object has a reference count; when it reaches zero, the memory is freed.
+
+* Cyclic Garbage Collector: Handles circular references that can't be resolved by reference counting.
+
+## GoLang
+
+Concurrent Mark-and-Sweep Garbage Collector: Go's garbage collector operates concurrently with the application, minimizing stop-the-world pauses.
diff --git a/data/guides/how-does-git-work.md b/data/guides/how-does-git-work.md
new file mode 100644
index 0000000..737f2ed
--- /dev/null
+++ b/data/guides/how-does-git-work.md
@@ -0,0 +1,26 @@
+---
+title: "How Git Works"
+description: "Understanding the inner workings of Git and its storage locations."
+image: "https://assets.bytebytego.com/diagrams/0202-git-commands.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "git"
+ - "version control"
+---
+
+
+
+To begin with, it's essential to identify where our code is stored. The common assumption is that there are only two locations - one on a remote server like Github and the other on our local machine. However, this isn't entirely accurate. Git maintains three local storages on our machine, which means that our code can be found in four places:
+
+* Working directory: where we edit files
+
+* Staging area: a temporary location where files are kept for the next commit
+
+* Local repository: contains the code that has been committed
+
+* Remote repository: the remote server that stores the code
+
+Most Git commands primarily move files between these four locations.
diff --git a/data/guides/how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work.md b/data/guides/how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work.md
new file mode 100644
index 0000000..9283f99
--- /dev/null
+++ b/data/guides/how-does-google-authenticator-or-other-types-of-2-factor-authenticators-work.md
@@ -0,0 +1,52 @@
+---
+title: "How Google Authenticator Works"
+description: "Explore the mechanics of Google Authenticator and 2-factor authentication."
+image: "https://assets.bytebytego.com/diagrams/0079-authenticator.jpg"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - security
+tags:
+ - "2FA"
+ - "Authentication"
+---
+
+
+
+Google Authenticator is commonly used for logging into our accounts when 2-factor authentication is enabled. How does it guarantee security?
+
+Google Authenticator is a software-based authenticator that implements a two-step verification service. The diagram below provides detail.
+
+There are two stages involved:
+
+* Stage 1 - The user enables Google two-step verification
+
+* Stage 2 - The user uses the authenticator for logging in, etc.
+
+Let’s look at these stages.
+
+## Stage 1
+
+Steps 1 and 2: Bob opens the web page to enable two-step verification. The front end requests a secret key. The authentication service generates the secret key for Bob and stores it in the database.
+
+Step 3: The authentication service returns a URI to the frontend. The URI is composed of a key issuer, username, and secret key. The URI is displayed in the form of a QR code on the web page.
+
+Step 4: Bob then uses Google Authenticator to scan the generated QR code. The secret key is stored in the authenticator.
+
+## Stage 2
+
+Steps 1 and 2: Bob wants to log into a website with Google two-step verification. For this, he needs the password. Every 30 seconds, Google Authenticator generates a 6-digit password using the TOTP (Time-based One Time Password) algorithm. Bob uses the password to enter the website.
+
+Steps 3 and 4: The frontend sends the password Bob enters to the backend for authentication. The authentication service reads the secret key from the database and generates a 6-digit password using the same TOTP algorithm as the client.
+
+Step 5: The authentication service compares the two passwords generated by the client and the server, and returns the comparison result to the frontend. Bob can proceed with the login process only if the two passwords match.
+
+### Is this authentication mechanism safe?
+
+Can the secret key be obtained by others?
+
+We need to make sure the secret key is transmitted using HTTPS. The authenticator client and the database store the secret key, and we need to make sure the secret keys are encrypted.
+
+Can the 6-digit password be guessed by hackers?
+
+No. The password has 6 digits, so the generated password has 1 million potential combinations. Plus, the password changes every 30 seconds. If hackers want to guess the password in 30 seconds, they need to enter 30,000 combinations per second.
diff --git a/data/guides/how-does-graphql-work-in-the-real-world.md b/data/guides/how-does-graphql-work-in-the-real-world.md
new file mode 100644
index 0000000..7c79746
--- /dev/null
+++ b/data/guides/how-does-graphql-work-in-the-real-world.md
@@ -0,0 +1,43 @@
+---
+title: How GraphQL Works at LinkedIn
+description: Learn how LinkedIn uses GraphQL to improve its development workflow.
+image: 'https://assets.bytebytego.com/diagrams/0209-graphql-linkedin.jpeg'
+createdAt: '2024-02-12'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - GraphQL
+ - LinkedIn
+---
+
+
+
+The diagram above shows how LinkedIn adopts GraphQL.
+
+“Moving to GraphQL was a huge initiative that changed the development workflow for thousands of engineers...” \[1\]
+
+The overall workflow after adopting GraphQL has 3 parts:
+
+## Part 1 - Edit and Test a Query
+
+**Steps 1-2:** The client-side developer develops a query and tests with backend services.
+
+## Part 2 - Register a Query
+
+**Steps 3-4:** The client-side developer commits the query and publishes the query to the query registry.
+
+## Part 3 - Use in Production
+
+**Step 5:** The query is released together with the client code.
+
+**Steps 6-7:** The routing metadata is included with each registered query. The metadata is used at the traffic routing tier to route the incoming requests to the correct service cluster.
+
+**Step 8:** The registered queries are cached at service runtime.
+
+**Step 9:** The sample query goes to the identity service first to retrieve members and then goes to the organization service to retrieve company information.
+
+LinkedIn doesn’t deploy a GraphQL gateway for two reasons:
+
+1. Prevent an additional network hop
+2. Avoid single point of failure
diff --git a/data/guides/how-does-grpc-work.md b/data/guides/how-does-grpc-work.md
new file mode 100644
index 0000000..da39fb5
--- /dev/null
+++ b/data/guides/how-does-grpc-work.md
@@ -0,0 +1,30 @@
+---
+title: How does gRPC work?
+description: Learn how gRPC works, its data flow, and performance benefits.
+image: 'https://assets.bytebytego.com/diagrams/0210-grpc.png'
+createdAt: '2024-01-28'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - gRPC
+ - RPC
+---
+
+
+
+RPC (Remote Procedure Call) is called **“remote”** because it enables communications between remote services when services are deployed to different servers under microservice architecture. From the user’s point of view, it acts like a local function call.
+
+The diagram above illustrates the overall data flow for **gRPC.**
+
+* Step 1: A REST call is made from the client. The request body is usually in JSON format.
+
+* Steps 2 - 4: The order service (gRPC client) receives the REST call, transforms it, and makes an RPC call to the payment service. gPRC encodes the **client stub** into a binary format and sends it to the low-level transport layer.
+
+* Step 5: gRPC sends the packets over the network via HTTP2. Because of binary encoding and network optimizations, gRPC is said to be 5X faster than JSON.
+
+* Steps 6 - 8: The payment service (gRPC server) receives the packets from the network, decodes them, and invokes the server application.
+
+* Steps 9 - 11: The result is returned from the server application, and gets encoded and sent to the transport layer.
+
+* Steps 12 - 14: The order service receives the packets, decodes them, and sends the result to the client application.
diff --git a/data/guides/how-does-https-work.md b/data/guides/how-does-https-work.md
new file mode 100644
index 0000000..cd9cda6
--- /dev/null
+++ b/data/guides/how-does-https-work.md
@@ -0,0 +1,36 @@
+---
+title: "How does HTTPS work?"
+description: "Learn how HTTPS encrypts data for secure communication over the internet."
+image: "https://assets.bytebytego.com/diagrams/0220-how-does-https-work.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - security
+tags:
+ - "HTTPS"
+ - "Encryption"
+---
+
+
+
+Hypertext Transfer Protocol Secure (HTTPS) is an extension of the Hypertext Transfer Protocol (HTTP.) HTTPS transmits encrypted data using Transport Layer Security (TLS.) If the data is hijacked online, all the hijacker gets is binary code.
+
+## How is the data encrypted and decrypted?
+
+Step 1 - The client (browser) and the server establish a TCP connection.
+
+Step 2 - The client sends a “client hello” to the server. The message contains a set of necessary encryption algorithms (cipher suites) and the latest TLS version it can support. The server responds with a “server hello” so the browser knows whether it can support the algorithms and TLS version.
+
+The server then sends the SSL certificate to the client. The certificate contains the public key, hostname, expiry dates, etc. The client validates the certificate.
+
+Step 3 - After validating the SSL certificate, the client generates a session key and encrypts it using the public key. The server receives the encrypted session key and decrypts it with the private key.
+
+Step 4 - Now that both the client and the server hold the same session key (symmetric encryption), the encrypted data is transmitted in a secure bi-directional channel.
+
+## Why does HTTPS switch to symmetric encryption during data transmission?
+
+There are two main reasons:
+
+* **Security:** The asymmetric encryption goes only one way. This means that if the server tries to send the encrypted data back to the client, anyone can decrypt the data using the public key.
+
+* **Server resources:** The asymmetric encryption adds quite a lot of mathematical overhead. It is not suitable for data transmissions in long sessions.
diff --git a/data/guides/how-does-javascript-work.md b/data/guides/how-does-javascript-work.md
new file mode 100644
index 0000000..f3249fd
--- /dev/null
+++ b/data/guides/how-does-javascript-work.md
@@ -0,0 +1,37 @@
+---
+title: How does Javascript Work?
+description: Learn about Javascript's core features and how it operates.
+image: 'https://assets.bytebytego.com/diagrams/0241-javascript-js-explained.png'
+createdAt: '2024-02-07'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - javascript
+ - programming
+---
+
+
+
+The cheat sheet below shows the most important characteristics of Javascript.
+
+* **Interpreted Language**
+ JavaScript code is executed by the browser or JavaScript engine rather than being compiled into machine language beforehand. This makes it highly portable across different platforms. Modern engines such as V8 utilize Just-In-Time (JIT) technology to compile code into directly executable machine code.
+* **Function is First-Class Citizen**
+ In JavaScript, functions are treated as first-class citizens, meaning they can be stored in variables, passed as arguments to other functions, and returned from functions.
+* **Dynamic Typing**
+ JavaScript is a loosely typed or dynamic language, meaning we don't have to declare a variable's type ahead of time, and the type can change at runtime.
+* **Client-Side Execution**
+ JavaScript supports asynchronous programming, allowing operations like reading files, making HTTP requests, or querying databases to run in the background and trigger callbacks or promises when complete. This is particularly useful in web development for improving performance and user experience.
+* **Prototype-Based OOP**
+ Unlike class-based object-oriented languages, JavaScript uses prototypes for inheritance. This means that objects can inherit properties and methods from other objects.
+* **Automatic Garbage Collection**
+ Garbage collection in JavaScript is a form of automatic memory management. The primary goal of garbage collection is to reclaim memory occupied by objects that are no longer in use by the program, which helps prevent memory leaks and optimizes the performance of the application.
+* **Compared with Other Languages**
+ JavaScript is special compared to programming languages like Python or Java because of its position as a major language for web development.
+
+ While Python is known to provide good code readability and versatility, and Java is known for its structure and robustness, JavaScript is an interpreted language that runs directly on the browser without compilation, emphasizing flexibility and dynamism.
+* **Relationship with Typescript**
+ TypeScript is a superset of JavaScript, which means that it extends JavaScript by adding features to the language, most notably type annotations. This relationship allows any valid JavaScript code to also be considered valid TypeScript code.
+* **Popular Javascript Frameworks**
+ React is known for its flexibility and large number of community-driven plugins, while Vue is clean and intuitive with highly integrated and responsive features. Angular, on the other hand, offers a strict set of development specifications for enterprise-level JS development.
diff --git a/data/guides/how-does-netflix-scale-push-messaging-for-millions-of-devices.md b/data/guides/how-does-netflix-scale-push-messaging-for-millions-of-devices.md
new file mode 100644
index 0000000..171929e
--- /dev/null
+++ b/data/guides/how-does-netflix-scale-push-messaging-for-millions-of-devices.md
@@ -0,0 +1,33 @@
+---
+title: 'How Netflix Scales Push Messaging'
+description: 'Explore how Netflix scales push messaging for millions of devices.'
+image: 'https://assets.bytebytego.com/diagrams/0291-netflix-pn.png'
+createdAt: '2024-02-28'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Push Notifications
+---
+
+This post draws from an article published on Netflix’s engineering blog. Here’s my understanding of how the online streaming giant’s system works.
+
+
+
+**Requirements & Scale**
+
+* 220 million users
+* Near real-time
+* Backend systems need to send notifications to various clients
+* Supported clients: iOS, Android, smart TVs, Roku, Amazon FireStick, web browser
+
+**The Life of a Push Notification**
+
+1. Push notification events are triggered by the clock, user actions, or by systems.
+2. Events are sent to the event management engine.
+3. The event management engine listens to specific events and forward events to different queues. The queues are populated by priority-based event forwarding rules.
+4. The “event priority-based processing cluster” processes events and generates push notifications data for devices.
+5. A Cassandra database is used to store the notification data.
+6. A push notification is sent to outbound messaging systems.
+7. For Android, FCM is used to send push notifications. For Apple devices, APNs are used. For web, TV, and other streaming devices, Netflix’s homegrown solution called ‘Zuul Push’ is used.
diff --git a/data/guides/how-does-redis-persist-data.md b/data/guides/how-does-redis-persist-data.md
new file mode 100644
index 0000000..a23000a
--- /dev/null
+++ b/data/guides/how-does-redis-persist-data.md
@@ -0,0 +1,43 @@
+---
+title: "How Does Redis Persist Data?"
+description: "Explore Redis data persistence: AOF, RDB, and mixed approaches."
+image: "https://assets.bytebytego.com/diagrams/0214-how-redis-presists-data.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Data Persistence"
+---
+
+
+
+Redis is an in-memory database. If the server goes down, the data will be lost.
+
+The diagram above shows two ways to persist Redis data on disk:
+
+1. AOF (Append-Only File)
+2. RDB (Redis Database)
+
+Note that data persistence is not performed on the critical path and doesn't block the write process in Redis.
+
+## AOF (Append-Only File)
+
+Unlike a write-ahead log, the Redis AOF log is a write-after log. Redis executes commands to modify the data in memory first and then writes it to the log file. AOF log records the commands instead of the data. The event-based design simplifies data recovery. Additionally, AOF records commands after the command has been executed in memory, so it does not block the current write operation.
+
+## RDB (Redis Database)
+
+The restriction of AOF is that it persists commands instead of data. When we use the AOF log for recovery, the whole log must be scanned. When the size of the log is large, Redis takes a long time to recover. So Redis provides another way to persist data - RDB.
+
+RDB records snapshots of data at specific points in time. When the server needs to be recovered, the data snapshot can be directly loaded into memory for fast recovery.
+
+Step 1: The main thread forks the ‘bgsave’ sub-process, which shares all the in-memory data of the main thread. ‘bgsave’ reads the data from the main thread and writes it to the RDB file.
+
+Steps 2 and 3: If the main thread modifies data, a copy of the data is created.
+
+Steps 4 and 5: The main thread then operates on the data copy. Meanwhile ‘bgsave’ sub-process continues to write data to the RDB file.
+
+## Mixed Approach
+
+Usually in production systems, we can choose a mixed approach, where we use RDB to record data snapshots from time to time and use AOF to record the commands since the last snapshot.
diff --git a/data/guides/how-does-rest-api-work.md b/data/guides/how-does-rest-api-work.md
new file mode 100644
index 0000000..fcee2a8
--- /dev/null
+++ b/data/guides/how-does-rest-api-work.md
@@ -0,0 +1,20 @@
+---
+title: 'How does REST API work?'
+description: 'Explore REST API principles, methods, constraints, and best practices.'
+image: 'https://assets.bytebytego.com/diagrams/0317-rest-api-authentication-methods.png'
+createdAt: '2024-02-10'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - rest-api
+ - web-development
+---
+
+
+
+What are its principles, methods, constraints, and best practices?
+
+I hope the diagram above gives you a quick overview.
+
+
diff --git a/data/guides/how-does-scan-to-pay-work.md b/data/guides/how-does-scan-to-pay-work.md
new file mode 100644
index 0000000..c7cf5f8
--- /dev/null
+++ b/data/guides/how-does-scan-to-pay-work.md
@@ -0,0 +1,39 @@
+---
+title: "How Scan to Pay Works"
+description: "Explore the mechanics behind scan-to-pay systems and digital wallets."
+image: "https://assets.bytebytego.com/diagrams/0323-scan-to-pay.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "QR Codes"
+---
+
+
+
+How do you pay from your digital wallet, such as Paypal, Paytm and Venmo, by scanning the QR code?
+
+To understand the process involved, we need to divide the “scan to pay” process into two sub-processes:
+
+1. Merchant generates a QR code and displays it on the screen
+2. Consumer scans the QR code and pays
+
+Here are the steps for generating the QR code:
+
+1. When you want to pay for your shopping, the cashier tallies up all the goods and calculates the total amount due, for example, $123.45. The checkout has an order ID of SN129803. The cashier clicks the “checkout” button.
+2. The cashier’s computer sends the order ID and the amount to PSP.
+3. The PSP saves this information to the database and generates a QR code URL.
+4. PSP’s Payment Gateway service reads the QR code URL.
+5. The payment gateway returns the QR code URL to the merchant’s computer.
+6. The merchant’s computer sends the QR code URL (or image) to the checkout counter.
+7. The checkout counter displays the QR code.
+
+These 7 steps complete in less than a second. Now it’s the consumer’s turn to pay from their digital wallet by scanning the QR code:
+
+1. The consumer opens their digital wallet app to scan the QR code.
+2. After confirming the amount is correct, the client clicks the “pay” button.
+3. The digital wallet App notifies the PSP that the consumer has paid the given QR code.
+4. The PSP payment gateway marks this QR code as paid and returns a success message to the consumer’s digital wallet App.
+5. The PSP payment gateway notifies the merchant that the consumer has paid the given QR code.
diff --git a/data/guides/how-does-ssh-work.md b/data/guides/how-does-ssh-work.md
new file mode 100644
index 0000000..abbeaba
--- /dev/null
+++ b/data/guides/how-does-ssh-work.md
@@ -0,0 +1,32 @@
+---
+title: "How does SSH work?"
+description: "Explore the inner workings of SSH, a secure network protocol."
+image: "https://assets.bytebytego.com/diagrams/0224-how-does-ssh-work.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - security
+tags:
+ - "SSH"
+ - "Security"
+---
+
+
+
+SSH (Secure Shell) is a network protocol used to securely connect to remote machines over an unsecured network. It encrypts the connection and provides various mechanisms for authentication and data transfer.
+
+SSH has two versions: SSH-1 and SSH-2. SSH-2 was standardized by the IETF.
+
+It has three main layers: Transport Layer, Authentication Layer, and Connection Layer.
+
+## Transport Layer
+
+The Transport Layer provides encryption, integrity, and data protection to ensure secure communication between the client and server.
+
+## Authentication Layer
+
+The Authentication Layer verifies the identity of the client to ensure that only authorized users can access the server.
+
+## Connection Layer
+
+The Connection Layer multiplexes the encrypted and authenticated communication into multiple logical channels.
diff --git a/data/guides/how-does-terraform-turn-code-into-cloud.md b/data/guides/how-does-terraform-turn-code-into-cloud.md
new file mode 100644
index 0000000..43a6555
--- /dev/null
+++ b/data/guides/how-does-terraform-turn-code-into-cloud.md
@@ -0,0 +1,44 @@
+---
+title: "How does Terraform turn Code into Cloud?"
+description: "Explore how Terraform transforms code into cloud infrastructure."
+image: "https://assets.bytebytego.com/diagrams/0225-how-terraform-creates-infra-at-scale.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Terraform"
+ - "Infrastructure as Code"
+---
+
+
+
+There are multiple stages in a Terraform workflow:
+
+## Write Infrastructure as Code
+
+* Define resources, providers, and configurations in Terraform configuration files.
+
+* Use variables, modules, and functions to make the code reusable and maintainable.
+
+* Integrate with Terraform community registries for ready-to-use modules.
+
+## Terraform Plan
+
+Preview the changes Terraform will make to the infrastructure by running “terraform plan”. It can be triggered as part of a CI/CD pipeline.
+
+Terraform compares the desired state defined in the configuration file with the current state in the state file.
+
+## Terraform Apply
+
+Run “terraform apply” to create, update, or delete resources based on the plan.
+
+Terraform makes API calls to the specified providers (AWS, Azure, GCP, Kubernetes, etc) to provision the resources.
+
+The state file is updated to reflect the new state of the infrastructure.
+
+## Infrastructure Ready
+
+Terraform state file acts as a single source of truth for the current state of the infrastructure.
+
+State file enables version control and collaboration between team members for future changes.
diff --git a/data/guides/how-does-the-browser-render-a-web-page.md b/data/guides/how-does-the-browser-render-a-web-page.md
new file mode 100644
index 0000000..4ff1f63
--- /dev/null
+++ b/data/guides/how-does-the-browser-render-a-web-page.md
@@ -0,0 +1,36 @@
+---
+title: 'How Browsers Render Web Pages'
+description: 'Explore how browsers render web pages: from HTML parsing to display.'
+image: 'https://assets.bytebytego.com/diagrams/0090-browser-render-page.jpg'
+createdAt: '2024-02-01'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - browsers
+ - rendering
+---
+
+
+
+* **Parse HTML and generate a Document Object Model (DOM) tree.**
+
+ When the browser receives the HTML data from the server, it immediately parses it and converts it into a DOM tree.
+
+* **Parse CSS and generate CSSOM tree.**
+
+ The styles (CSS files) are loaded and parsed to the CSSOM (CSS Object Model).
+
+* **Combine DOM tree and CSSOM tree to construct the Render Tree.** The render tree maps all DOM structures except invisible elements (such as `` or tags with `display:none;`). In other words, the render tree is a visual representation of the DOM.
+
+* **Layout**
+
+ The content in each element of the rendering tree will be calculated to get the geometric information (position, size), which is called layout.
+
+* **Painting**
+
+ After the layout is complete, the rendering tree is transformed into the actual content on the screen. This step is called painting. The browser gets the absolute pixels of the content.
+
+* **Display**
+
+ Finally, the browser sends the absolute pixels to the GPU and displays them on the page.
diff --git a/data/guides/how-does-the-domain-name-system-dns-lookup-work.md b/data/guides/how-does-the-domain-name-system-dns-lookup-work.md
new file mode 100644
index 0000000..b59e73f
--- /dev/null
+++ b/data/guides/how-does-the-domain-name-system-dns-lookup-work.md
@@ -0,0 +1,46 @@
+---
+title: "How Does the Domain Name System (DNS) Lookup Work?"
+description: "Learn how DNS translates domain names to IP addresses for web access."
+image: "https://assets.bytebytego.com/diagrams/0176-dns-look-up.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "DNS"
+ - "Networking"
+---
+
+
+
+DNS acts as an address book. It translates human-readable domain names ([google.com](http://google.com/)) to machine-readable IP addresses ([142.251.46.238](http://142.251.46.238/)).
+
+To achieve better scalability, the DNS servers are organized in a hierarchical tree structure.
+
+There are 3 basic levels of DNS servers:
+
+* Root name server (.). It stores the IP addresses of Top Level Domain (TLD) name servers. There are 13 logical root name servers globally.
+
+* TLD name server. It stores the IP addresses of authoritative name servers. There are several types of TLD names. For example, generic TLD (.com, .org), country code TLD (.us), test TLD (.test).
+
+* Authoritative name server. It provides actual answers to the DNS query. You can register authoritative name servers with domain name registrar such as GoDaddy, Namecheap, etc.
+
+The diagram below illustrates how DNS lookup works under the hood:
+
+1. [google.com](http://google.com/) is typed into the browser, and the browser sends the domain name to the DNS resolver.
+
+2. The resolver queries a DNS root name server.
+
+3. The root server responds to the resolver with the address of a TLD DNS server. In this case, it is .com.
+
+4. The resolver then makes a request to the .com TLD.
+
+5. The TLD server responds with the IP address of the domain’s name server, [google.com](http://google.com/) (authoritative name server).
+
+6. The DNS resolver sends a query to the domain’s nameserver.
+
+7. The IP address for [google.com](http://google.com/) is then returned to the resolver from the nameserver.
+
+8. The DNS resolver responds to the web browser with the IP address ([142.251.46.238](http://142.251.46.238/)) of the domain requested initially.
+
+DNS lookups on average take between 20-120 milliseconds to complete (according to YSlow).
diff --git a/data/guides/how-does-twitter-recommend-tweets.md b/data/guides/how-does-twitter-recommend-tweets.md
new file mode 100644
index 0000000..b6203b6
--- /dev/null
+++ b/data/guides/how-does-twitter-recommend-tweets.md
@@ -0,0 +1,30 @@
+---
+title: How does Twitter recommend “For You” Timeline in 1.5 seconds?
+description: Twitter's "For You" timeline recommendation system explained.
+image: 'https://assets.bytebytego.com/diagrams/0121-twitter-serving-pipeline.jpeg'
+createdAt: '2024-02-22'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Recommendation Systems
+---
+
+
+
+We spent a few days analyzing it.
+
+The diagram above shows the detailed pipeline based on the open-sourced algorithm.
+
+The process involves 5 stages:
+
+* **Candidate Sourcing** ~ start with 500 million Tweets
+* **Global Filtering** ~ down to 1500 candidates
+* **Scoring & Ranking** ~ 48M parameter neural network, Twitter Blue boost
+* **Filtering** ~ to achieve author and content diversity
+* **Mixing** ~ with Ads recommendation and Who to Follow
+
+The post was jointly created by ByteByteGo and [Mem](https://www.linkedin.com/company/memdotai/). Special thanks [Scott Mackie](https://www.linkedin.com/in/ACoAABLDe9kBSK7DsORQHK2G1srZCmM1isaUun8), founding engineer at Mem, for putting this together.
+
+Mem is building the world’s first knowledge assistant. In next week’s ByteByteGo guest newsletter, Mem will be sharing lessons they’ve learned from their extensive work with large language models and building AI-native infrastructure.
diff --git a/data/guides/how-does-visa-make-money.md b/data/guides/how-does-visa-make-money.md
new file mode 100644
index 0000000..32d72b7
--- /dev/null
+++ b/data/guides/how-does-visa-make-money.md
@@ -0,0 +1,38 @@
+---
+title: "How does Visa make money?"
+description: "Explore Visa's revenue streams and credit card payment flow economics."
+image: "https://assets.bytebytego.com/diagrams/0041-how-does-visa-make-money.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Fintech"
+ - "Visa"
+---
+
+
+
+Why is the credit card called “the most profitable product in banks”? How does VISA/Mastercard make money?
+
+The diagram above shows the economics of the credit card payment flow.
+
+- **Step 1.** The cardholder pays a merchant $100 to buy a product.
+
+- **Step 2.** The merchant benefits from the use of the credit card with higher sales volume and needs to compensate the issuer and the card network for providing the payment service. The acquiring bank sets a fee with the merchant, called the "**merchant discount fee**."
+
+- **Step 3 - 4.** The acquiring bank keeps $0.25 as the **acquiring markup**, and $1.75 is paid to the issuing bank as the **interchange fee**. The merchant discount fee should cover the interchange fee. The interchange fee is set by the card network because it is less efficient for each issuing bank to negotiate fees with each merchant.
+
+- **Step 5.** The card network sets up the **network assessments and fees** with each bank, which pays the card network for its services every month. For example, VISA charges a 0.11% assessment, plus a $0.0195 usage fee, for every swipe.
+
+- **Step 6.** The cardholder pays the issuing bank for its services.
+
+## Why should the issuing bank be compensated?
+
+* The issuer pays the merchant even if the cardholder fails to pay the issuer.
+
+* The issuer pays the merchant before the cardholder pays the issuer.
+
+* The issuer has other operating costs, including managing customer accounts, providing statements, fraud detection, risk management, clearing & settlement, etc.
+
+Over to you: Does the card network charge the same interchange fee for big merchants as for small merchants?
diff --git a/data/guides/how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchant's-shop.md b/data/guides/how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchant's-shop.md
new file mode 100644
index 0000000..a225295
--- /dev/null
+++ b/data/guides/how-does-visa-work-when-we-swipe-a-credit-card-at-a-merchant's-shop.md
@@ -0,0 +1,44 @@
+---
+title: "How VISA Works When Swiping a Credit Card"
+description: "Explore the VISA payment process from authorization to settlement."
+image: "https://assets.bytebytego.com/diagrams/0403-visa-payment.jpg"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "VISA"
+ - "Payment Processing"
+---
+
+
+
+VISA, Mastercard, and American Express act as card networks for clearing and settling funds. The card acquiring bank and the card issuing bank can be – and often are – different. If banks were to settle transactions one by one without an intermediary, each bank would have to settle the transactions with all the other banks. This is quite inefficient.
+
+The diagram shows VISA’s role in the credit card payment process. There are two flows involved. Authorization flow happens when the customer swipes the credit card. Capture and settlement flow occurs when the merchant wants to get the money at the end of the day.
+
+## Authorization Flow
+
+* Step 0: The card issuing bank issues credit cards to its customers.
+
+* Step 1: The cardholder wants to buy a product and swipes the credit card at the Point of Sale (POS) terminal in the merchant’s shop.
+
+* Step 2: The POS terminal sends the transaction to the acquiring bank, which has provided the POS terminal.
+
+* Steps 3 and 4: The acquiring bank sends the transaction to the card network, also called the card scheme. The card network sends the transaction to the issuing bank for approval.
+
+* Steps 4.1, 4.2, and 4.3: The issuing bank freezes the money if the transaction is approved. The approval or rejection is sent back to the acquirer, as well as the POS terminal.
+
+## Capture and Settlement Flow
+
+* Steps 1 and 2: The merchant wants to collect the money at the end of the day, so they hit ”capture” on the POS terminal. The transactions are sent to the acquirer in batches. The acquirer sends the batch file with transactions to the card network.
+
+* Step 3: The card network performs clearing for the transactions collected from different acquirers, and sends the clearing files to different issuing banks.
+
+* Step 4: The issuing banks confirm the correctness of the clearing files, and transfer money to the relevant acquiring banks.
+
+* Step 5: The acquiring bank then transfers money to the merchant’s bank.
+
+* Step 4: The card network clears the transactions from different acquiring banks. Clearing is a process in which mutual offset transactions are netted, so the number of total transactions is reduced.
+
+In the process, the card network takes on the burden of talking to each bank and receives service fees in return.
diff --git a/data/guides/how-does-youtube-handle-massive-video-content-upload.md b/data/guides/how-does-youtube-handle-massive-video-content-upload.md
new file mode 100644
index 0000000..f8a7635
--- /dev/null
+++ b/data/guides/how-does-youtube-handle-massive-video-content-upload.md
@@ -0,0 +1,34 @@
+---
+title: 'How YouTube Handles Massive Video Uploads'
+description: "Explore YouTube's architecture for handling massive video uploads."
+image: 'https://assets.bytebytego.com/diagrams/0425-yt-massive-upload.png'
+createdAt: '2024-02-23'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Scalability
+---
+
+
+
+YouTube handles 500+ hours of video content uploads every minute on average. How does it manage this?
+
+The diagram above shows YouTube’s innovative hardware encoding published in 2021.
+
+* **Traditional Software Encoding**
+
+YouTube’s mission is to transcode raw video into different compression rates to adapt to different viewing devices - mobile(720p), laptop(1080p), or high-resolution TV(4k).
+
+Creators upload a massive amount of video content on YouTube every minute. Especially during the COVID-19 pandemic, video consumption is greatly increased as people are sheltered at home. Software-based encoding became slow and costly. This means there was a need for a specialized processing brain tailored made for video encoding/decoding.
+
+* **YouTube’s Transcoding Brain - VCU**
+
+Like GPU or TPU was used for graphics or machine learning calculations, YouTube developed VCU (Video transCoding Unit) for warehouse-scale video processing.
+
+Each cluster has a number of VCU accelerated servers. Each server has multiple accelerator trays, each containing multiple VCU cards. Each card has encoders, decoders, etc.
+
+VCU cluster generates video content with different resolutions and stores it in cloud storage.
+
+This new design brought 20-33x improvements in computing efficiency compared to the previous optimized system.
diff --git a/data/guides/how-is-a-sql-statement-executed-in-the-database.md b/data/guides/how-is-a-sql-statement-executed-in-the-database.md
new file mode 100644
index 0000000..f52d62a
--- /dev/null
+++ b/data/guides/how-is-a-sql-statement-executed-in-the-database.md
@@ -0,0 +1,48 @@
+---
+title: "SQL Statement Execution in Database"
+description: "Explore the steps of SQL statement execution within a database system."
+image: "https://assets.bytebytego.com/diagrams/0340-sql-execution-order-in-db.jpeg"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - SQL
+ - Database Internals
+---
+
+
+
+The diagram above shows the process. Note that the architectures for different databases are different, the diagram demonstrates some common designs.
+
+## Step 1 - Transport Layer
+
+A SQL statement is sent to the database via a transport layer protocol (e.g. TCP).
+
+## Step 2 - Command Parser
+
+The SQL statement is sent to the command parser, where it goes through syntactic and semantic analysis, and a query tree is generated afterward.
+
+## Step 3 - Optimizer
+
+The query tree is sent to the optimizer. The optimizer creates an execution plan.
+
+## Step 4 - Executor
+
+The execution plan is sent to the executor. The executor retrieves data from the execution.
+
+## Step 5 - Access Methods
+
+Access methods provide the data fetching logic required for execution, retrieving data from the storage engine.
+
+## Step 6 - Buffer Manager (Read-Only Queries)
+
+Access methods decide whether the SQL statement is read-only. If the query is read-only (SELECT statement), it is passed to the buffer manager for further processing. The buffer manager looks for the data in the cache or data files.
+
+## Step 7 - Transaction Manager (Update/Insert)
+
+If the statement is an UPDATE or INSERT, it is passed to the transaction manager for further processing.
+
+## Step 8 - Lock Manager
+
+During a transaction, the data is in lock mode. This is guaranteed by the lock manager. It also ensures the transaction’s ACID properties.
diff --git a/data/guides/how-is-data-transmitted-between-applications.md b/data/guides/how-is-data-transmitted-between-applications.md
new file mode 100644
index 0000000..6b4b44f
--- /dev/null
+++ b/data/guides/how-is-data-transmitted-between-applications.md
@@ -0,0 +1,22 @@
+---
+title: "Data Transmission Between Applications"
+description: "Explore how data travels between applications in detail."
+image: "https://assets.bytebytego.com/diagrams/0159-data-transfer-between-apps.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - software-development
+tags:
+ - networking
+ - data-transfer
+---
+
+
+
+The diagram below shows how a server sends data to another server.
+
+Assume a chat application running in the user space sends out a chat message. The message is sent to the send buffer in the kernel space. The data then goes through the network stack and is wrapped with a TCP header, an IP header, and a MAC header. The data also goes through qdisc (Queueing Disciplines) for flow control. Then the data is sent to the NIC (Network Interface Card) via a ring buffer.
+
+The data is sent to the internet via NIC. After many hops among routers and switches, the data arrives at the NIC of the receiving server.
+
+The NIC of the receiving server puts the data in the ring buffer and sends a hard interrupt to the CPU. The CPU sends a soft interrupt so that ksoftirqd receives data from the ring buffer. Then the data is unwrapped through the data link layer, network layer and transport layer. Eventually, the data (chat message) is copied to the user space and reaches the chat application on the receiving side.
diff --git a/data/guides/how-is-email-delivered.md b/data/guides/how-is-email-delivered.md
new file mode 100644
index 0000000..1a7b300
--- /dev/null
+++ b/data/guides/how-is-email-delivered.md
@@ -0,0 +1,28 @@
+---
+title: "How is Email Delivered?"
+description: "Explore the journey of an email, from sender to receiver, step by step."
+image: "https://assets.bytebytego.com/diagrams/0185-email-deliver.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - EmailProtocols
+ - EmailDelivery
+---
+
+Do you know how an email is delivered?
+
+When I first learned how similar email is to traditional ‘snail’ mail, I was surprised. Maybe you will be, too. Allow me to explain.
+
+
+
+In the physical world, if I want to send a postcard to a friend, I would put it in a nearby mailbox. The postal office collects the mail regularly and relays it to the destination postal office. This postal office then puts the postcard in my friend’s mailbox. This process usually takes a few days and my friend receives my gratitude in paper form.
+
+Email functions in a similar way. The terminology changes because it is an internet-based solution, but the fundamentals are the same:
+
+* Instead of putting mail in a mailbox, the sender pushes an email to the Sender Mail Server using MUA (mail user agent,) such as Outlook or Gmail.
+
+* Instead of using postal offices to relay mail, MTA (mail transmission agent) relays the email. It communicates via the SMTP protocol.
+
+The email is received by the Receiver Mail Server. It stores the email to the Mailbox by using MDA (mail delivery agent.) The receiver uses MUA to retrieve the email using the POP3/IMAP protocol.
diff --git a/data/guides/how-levelsfyi-scaled-to-millions-of-users-with-google-sheets.md b/data/guides/how-levelsfyi-scaled-to-millions-of-users-with-google-sheets.md
new file mode 100644
index 0000000..1c4dde8
--- /dev/null
+++ b/data/guides/how-levelsfyi-scaled-to-millions-of-users-with-google-sheets.md
@@ -0,0 +1,22 @@
+---
+title: 'How Levelsfyi Scaled to Millions of Users with Google Sheets'
+description: 'Learn how Levelsfyi scaled to millions of users using Google Sheets.'
+image: 'https://assets.bytebytego.com/diagrams/0255-levels-fyi.jpg'
+createdAt: '2024-02-17'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Scalability
+ - Google Sheets
+---
+
+
+
+I read something unbelievable today: Levelsfyi scaled to millions of users using Google Sheets as a backend!
+
+They started off on Google Forms and Sheets, which helped them reach millions of monthly active users before switching to a proper backend.
+
+To be fair, they do use serverless computing, but using Google Sheets as the database is an interesting choice.
+
+Why do they use Google Sheets as a backend? Using their own words: "It seems like a pretty counterintuitive idea for a site with our traffic volume to not have a backend or any fancy infrastructure, but our philosophy to building products has always been, start simple and iterate. This allows us to move fast and focus on what’s important".
diff --git a/data/guides/how-nat-made-the-growth-of-the-internet-possible.md b/data/guides/how-nat-made-the-growth-of-the-internet-possible.md
new file mode 100644
index 0000000..ee73767
--- /dev/null
+++ b/data/guides/how-nat-made-the-growth-of-the-internet-possible.md
@@ -0,0 +1,31 @@
+---
+title: 'How NAT Enabled the Internet'
+description: 'Explore how NAT facilitated the expansion of the internet.'
+image: 'https://assets.bytebytego.com/diagrams/0231-http-header.png'
+createdAt: '2024-01-29'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - NAT
+ - Networking
+---
+
+
+
+Network Address Translation (NAT) is the process that has made the growth of the Internet possible.
+
+But how does it work?
+
+1. In a corporate or home setting, multiple devices (phones, computers, etc.) share one router with a single public IP address.
+2. When a device wants to access the internet, it sends a request to your router. The request contains the device's private IP address.
+3. The router’s NAT process replaces the private IP with the router’s public IP.
+4. The modified request is sent to the internet.
+5. When the response comes back, NAT checks its record and replaces the public IP with the correct private IP. It sends the response to the right device.
+
+NAT has several important uses:
+
+* **Conserves public IP addresses:** Without NAT, IPv4 addresses would have been depleted much faster, severely limiting the growth of the Internet.
+* **Allows sharing:** It allows sharing a single public IP address across multiple devices.
+* **Acts as a basic firewall:** NAT acts as a basic firewall that hides internal IP addresses.
+* **Eases network management:** NAT also makes it easy to manage large networks.
diff --git a/data/guides/how-netflix-really-uses-java.md b/data/guides/how-netflix-really-uses-java.md
new file mode 100644
index 0000000..e5fbb2d
--- /dev/null
+++ b/data/guides/how-netflix-really-uses-java.md
@@ -0,0 +1,36 @@
+---
+title: How Netflix Really Uses Java
+description: Explore Netflix's extensive use of Java in its microservices architecture.
+image: 'https://assets.bytebytego.com/diagrams/0102-how-netflix-really-uses-java.png'
+createdAt: '2024-03-04'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Java
+ - Microservices
+---
+
+
+
+Netflix is predominantly a Java shop.
+
+Every backend application (including internal apps, streaming, and movie production apps) at Netflix is a Java application.
+
+However, the Java stack is not static and has gone through multiple iterations over the years.
+
+Here are the details of those iterations:
+
+* **API Gateway**
+
+ Netflix follows a microservices architecture. Every piece of functionality and data is owned by a microservice built using Java (initially version 8)
+
+* **BFFs with Groovy & RxJava**
+
+ Using a single gateway for multiple clients was a problem for Netflix because each client (such as TV, mobile apps, or web browser) had subtle differences.
+
+ To handle this, Netflix used the Backend-for-Frontend (BFF) pattern. Zuul was moved to the role of a proxy
+
+* **GraphQL Federation**
+
+ The Groovy and RxJava approach required more work from the UI developers in creating the Groovy scripts. Also, reactive programming is generally hard.
diff --git a/data/guides/how-redis-architecture-evolve.md b/data/guides/how-redis-architecture-evolve.md
new file mode 100644
index 0000000..cd08e0f
--- /dev/null
+++ b/data/guides/how-redis-architecture-evolve.md
@@ -0,0 +1,48 @@
+---
+title: "How Redis Architecture Evolved"
+description: "Explore the evolution of Redis architecture, from standalone to cluster."
+image: "https://assets.bytebytego.com/diagrams/0223-how-redis-architecture-evolve.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Redis
+ - Architecture
+---
+
+
+
+Redis is a popular in-memory cache. How did it evolve to the architecture it is today?
+
+## 2010 - Standalone Redis
+
+When Redis 1.0 was released in 2010, the architecture was quite simple. It is usually used as a cache to the business application.
+
+However, Redis stores data in memory. When we restart Redis, we will lose all the data and the traffic directly hits the database.
+
+## 2013 - Persistence
+
+When Redis 2.8 was released in 2013, it addressed the previous restrictions. Redis introduced RDB in-memory snapshots to persist data. It also supports AOF (Append-Only-File), where each write command is written to an AOF file.
+
+## 2013 - Replication
+
+Redis 2.8 also added replication to increase availability. The primary instance handles real-time read and write requests, while replica synchronizes the primary's data.
+
+## 2013 - Sentinel
+
+Redis 2.8 introduced Sentinel to monitor the Redis instances in real time. is a system designed to help managing Redis instances. It performs the following four tasks: monitoring, notification, automatic failover and configuration provider.
+
+## 2015 - Cluster
+
+In 2015, Redis 3.0 was released. It added Redis clusters.
+
+A Redis cluster is a distributed database solution that manages data through sharding. The data is divided into 16384 slots, and each node is responsible for a portion of the slot.
+
+## Looking Ahead
+
+Redis is popular because of its high performance and rich data structures that dramatically reduce the complexity of developing a business application.
+
+In 2017, Redis 5.0 was released, adding the stream data type.
+
+In 2020, Redis 6.0 was released, introducing the multi-threaded I/O in the network module. Redis model is divided into the network module and the main processing module. The Redis developers the network module tends to become a bottleneck in the system.
diff --git a/data/guides/how-tiktok-manages-a-200k-file-frontend-monorepo.md b/data/guides/how-tiktok-manages-a-200k-file-frontend-monorepo.md
new file mode 100644
index 0000000..2efcd71
--- /dev/null
+++ b/data/guides/how-tiktok-manages-a-200k-file-frontend-monorepo.md
@@ -0,0 +1,35 @@
+---
+title: How TikTok Manages a 200K File Frontend MonoRepo
+description: TikTok's strategy for managing a large frontend MonoRepo with 200K files.
+image: 'https://assets.bytebytego.com/diagrams/0226-how-tiktok-manages-a-200k-file-frontend-monorepo.png'
+createdAt: '2024-03-03'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Monorepo
+ - Performance
+---
+
+
+
+A MonoRepo, short for a monolithic repository, is a software development strategy where a single repository contains multiple projects, libraries, and services.
+
+The good parts of a MonoRepo are:
+
+* **Better code sharing**
+* **Simplified dependency management**
+* **A unified view of the code base**
+
+However, the bigger the MonoRepo gets, the slower the various Git operations.
+
+TikTok faced a similar change with its frontend TypeScript MonoRepo with 200K files.
+
+To deal with this, TikTok built a tool named Sparo that optimizes the performance of Git operations for large frontend MonoRepos.
+
+Sparo dramatically improved the performance of Git operations. Some stats are as follows
+
+* Git clone time went from 40 mins to just 2 mins.
+* Checkout went from 1.5 minutes to 30 seconds.
+* Status went from 7 seconds to 1 second.
+* Git commit time went from 15 seconds to 11 seconds.
diff --git a/data/guides/how-to-ace-system-design-interviews-like-a-boss.md b/data/guides/how-to-ace-system-design-interviews-like-a-boss.md
new file mode 100644
index 0000000..9de9027
--- /dev/null
+++ b/data/guides/how-to-ace-system-design-interviews-like-a-boss.md
@@ -0,0 +1,46 @@
+---
+title: "How to Ace System Design Interviews"
+description: "A 7-step process to excel in system design interviews."
+image: "https://assets.bytebytego.com/diagrams/0104-how-to-ace-system-design-interviews-like-a-boss.png"
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "System Design"
+ - "Interview Preparation"
+---
+
+
+
+Follow this 7-step process to do well in a System Design Round
+
+## 1. Requirements Clarification
+
+In the first step, clarify functional and non-functional requirements. Ask questions to understand the core features of the system as well as non-functional aspects such as data volume, availability, scale, etc.
+
+## 2. Capacity Estimation
+
+Next, estimate the capacity of the system. Focus on attributes like the number of users, traffic, storage/memory needs, and compute and networking requirements.
+
+## 3. Create High-Level Design
+
+Break down the system into components such as client apps, servers, load balancers, databases, etc.
+
+Start with drawing a simple block diagram that shows these components and their potential interaction with each other. Focus on the data flow.
+
+## 4. Database Design
+
+Model the data and choose the right database type for the system. Once done, focus on the database schema.
+
+## 5. Interface Design
+
+Next, focus on the interfaces to the system. This could be API endpoints or event models exchanged between the various components of the system. Also, choose a communication approach such as REST, GraphQL, gRPC, or an event-driven
+
+## 6. Scalability and Performance
+
+Address the scalability, performance, and latency aspects of the system by suggesting techniques that will be used. For example, vertical and horizontal scaling, caching, indexing, denormalizing, sharding, replication, CDNs, etc.
+
+## 7. Reliability and Resiliency
+
+Lastly, address the reliability and resiliency of the design. Identify single points of failure and mitigate their impact.
diff --git a/data/guides/how-to-avoid-crawling-duplicate-urls-at-google-scale.md b/data/guides/how-to-avoid-crawling-duplicate-urls-at-google-scale.md
new file mode 100644
index 0000000..fea2fb0
--- /dev/null
+++ b/data/guides/how-to-avoid-crawling-duplicate-urls-at-google-scale.md
@@ -0,0 +1,39 @@
+---
+title: "How to Avoid Crawling Duplicate URLs at Google Scale?"
+description: "Learn how to avoid crawling duplicate URLs at Google scale."
+image: "https://assets.bytebytego.com/diagrams/0089-bloomfilter.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Bloom Filter"
+ - "Web Crawling"
+---
+
+
+
+Option 1: Use a Set data structure to check if a URL already exists or not. Set is fast, but it is not space-efficient.
+
+Option 2: Store URLs in a database and check if a new URL is in the database. This can work but the load to the database will be very high.
+
+### Option 3: Bloom Filter
+
+This option is preferred. Bloom filter was proposed by Burton Howard Bloom in 1970. It is a probabilistic data structure that is used to test whether an element is a member of a set.
+
+* false: the element is definitely not in the set.
+* true: the element is probably in the set.
+
+False-positive matches are possible, but false negatives are not.
+
+The diagram below illustrates how the Bloom filter works. The basic data structure for the Bloom filter is Bit Vector. Each bit represents a hashed value.
+
+### Step 1
+
+To add an element to the bloom filter, we feed it to 3 different hash functions (A, B, and C) and set the bits at the resulting positions. Note that both “[www.myweb1.com](http://www.myweb1.com/)” and “[www.myweb2.com](http://www.myweb2.com/)” mark the same bit with 1 at index 5. False positives are possible because a bit might be set by another element.
+
+### Step 2
+
+When testing the existence of a URL string, the same hash functions A, B, and C are applied to the URL string. If all three bits are 1, then the URL may exist in the dataset; if any of the bits is 0, then the URL definitely does not exist in the dataset.
+
+Hash function choices are important. They must be uniformly distributed and fast. For example, RedisBloom and Apache Spark use murmur, and InfluxDB uses xxhash.
diff --git a/data/guides/how-to-avoid-double-payment.md b/data/guides/how-to-avoid-double-payment.md
new file mode 100644
index 0000000..ad01016
--- /dev/null
+++ b/data/guides/how-to-avoid-double-payment.md
@@ -0,0 +1,33 @@
+---
+title: "How to Avoid Double Payment"
+description: "Learn how to prevent double payments in your payment system."
+image: "https://assets.bytebytego.com/diagrams/0178-double-charge.jpg"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - Payment Systems
+ - Idempotency
+---
+
+
+
+One of the most serious problems a payment system can have is to **double charge** a customer. When we design the payment system, it is important to guarantee that the payment system executes a payment order exactly-once.
+
+At the first glance, exactly-once delivery seems very hard to tackle, but if we divide the problem into two parts, it is much easier to solve. Mathematically, an operation is executed exactly-once if:
+
+* It is executed at least once.
+* At the same time, it is executed at most once.
+
+We now explain how to implement at least once using retry and at most once using idempotency check.
+
+## Retry
+
+Occasionally, we need to retry a payment transaction due to network errors or timeout. Retry provides the at-least-once guarantee. For example, as shown in Figure 10, the client tries to make a $10 payment, but the payment keeps failing due to a poor network connection. Considering the network condition might get better, the client retries the request and this payment finally succeeds at the fourth attempt.
+
+## Idempotency
+
+From an API standpoint, idempotency means clients can make the same call repeatedly and produce the same result.
+
+For communication between clients (web and mobile applications) and servers, an idempotency key is usually a unique value that is generated by clients and expires after a certain period of time. A UUID is commonly used as an idempotency key and it is recommended by many tech companies such as Stripe and PayPal. To perform an idempotent payment request, an idempotency key is added to the HTTP header: .
diff --git a/data/guides/how-to-choose-the-right-database.md b/data/guides/how-to-choose-the-right-database.md
new file mode 100644
index 0000000..1aeb5d5
--- /dev/null
+++ b/data/guides/how-to-choose-the-right-database.md
@@ -0,0 +1,30 @@
+---
+title: "How to Choose the Right Database"
+description: "A guide to selecting the optimal database for your specific needs."
+image: "https://assets.bytebytego.com/diagrams/0227-how-to-choose-the-right-database.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "database selection"
+ - "data storage"
+---
+
+
+
+* OLTP: For transactional systems requiring strong consistency
+
+* OLAP: Optimized for complex queries and data analysis
+
+* Full-Text Search: Fast, flexible text search capabilities
+
+* Document Stores: JSON-like document storage and querying
+
+* Key-Value Stores: High-speed, simple data models
+
+* Graph Databases: Managing highly connected data
+
+* Embeddings: Efficient storage and retrieval of vector representations
+
+* Geospatial: Specialized for location-based data and queries
diff --git a/data/guides/how-to-deploy-services.md b/data/guides/how-to-deploy-services.md
new file mode 100644
index 0000000..627eae9
--- /dev/null
+++ b/data/guides/how-to-deploy-services.md
@@ -0,0 +1,32 @@
+---
+title: "Deployment Strategies"
+description: "Explore risk mitigation strategies for deploying and upgrading services."
+image: "https://assets.bytebytego.com/diagrams/0166-deployment-strategies.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Deployment"
+ - "DevOps"
+---
+
+
+
+Deploying or upgrading services is risky. In this post, we explore risk mitigation strategies.
+
+## Multi-Service Deployment
+
+In this model, we deploy new changes to multiple services simultaneously. This approach is easy to implement. But since all the services are upgraded at the same time, it is hard to manage and test dependencies. It’s also hard to rollback safely.
+
+## Blue-Green Deployment
+
+With blue-green deployment, we have two identical environments: one is staging (blue) and the other is production (green). The staging environment is one version ahead of production. Once testing is done in the staging environment, user traffic is switched to the staging environment, and the staging becomes the production. This deployment strategy is simple to perform rollback, but having two identical production quality environments could be expensive.
+
+## Canary Deployment
+
+A canary deployment upgrades services gradually, each time to a subset of users. It is cheaper than blue-green deployment and easy to perform rollback. However, since there is no staging environment, we have to test on production. This process is more complicated because we need to monitor the canary while gradually migrating more and more users away from the old version.
+
+## A/B Test
+
+In the A/B test, different versions of services run in production simultaneously. Each version runs an “experiment” for a subset of users. A/B test is a cheap method to test new features in production. We need to control the deployment process in case some features are pushed to users by accident.
diff --git a/data/guides/how-to-design-google-docs.md b/data/guides/how-to-design-google-docs.md
new file mode 100644
index 0000000..2337abf
--- /dev/null
+++ b/data/guides/how-to-design-google-docs.md
@@ -0,0 +1,32 @@
+---
+title: "How to Design Google Docs"
+description: "Learn how to design Google Docs with this detailed guide."
+image: "https://assets.bytebytego.com/diagrams/0206-google-doc.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "System Design"
+ - "Real-time Collaboration"
+---
+
+
+
+1. Clients send document editing operations to the WebSocket Server.
+
+2. The real-time communication is handled by the WebSocket Server.
+
+3. Documents operations are persisted in the Message Queue.
+
+4. The File Operation Server consumes operations produced by clients and generates transformed operations using collaboration algorithms.
+
+5. Three types of data are stored: file metadata, file content, and operations.
+
+One of the biggest challenges is real-time conflict resolution. Common algorithms include:
+
+* Operational transformation (OT)
+* Differential Synchronization (DS)
+* Conflict-free replicated data type (CRDT)
+
+Google Doc uses OT according to its Wikipedia page and CRDT is an active area of research for real-time concurrent editing.
diff --git a/data/guides/how-to-design-secure-web-api-access-for-your-website.md b/data/guides/how-to-design-secure-web-api-access-for-your-website.md
new file mode 100644
index 0000000..29a98ae
--- /dev/null
+++ b/data/guides/how-to-design-secure-web-api-access-for-your-website.md
@@ -0,0 +1,45 @@
+---
+title: How to Design Secure Web API Access
+description: Learn how to design secure web API access for your website.
+image: 'https://assets.bytebytego.com/diagrams/0325-secure-api.png'
+createdAt: '2024-03-06'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Security
+ - Authentication
+---
+
+
+
+When we open web API access to users, we need to make sure each API call is authenticated. This means the user must be who they claim to be.
+
+In this post, we explore two common ways:
+
+* Token based authentication
+* HMAC (Hash-based Message Authentication Code) authentication
+
+The diagram above illustrates how they work.
+
+**Token based**
+
+Step 1 - the user enters their password into the client, and the client sends the password to the Authentication Server.
+
+Step 2 - the Authentication Server authenticates the credentials and generates a token with an expiry time.
+
+Steps 3 and 4 - now the client can send requests to access server resources with the token in the HTTP header. This access is valid until the token expires.
+
+**HMAC based**
+
+This mechanism generates a Message Authentication Code (signature) by using a hash function (SHA256 or MD5).
+
+Steps 1 and 2 - the server generates two keys, one is Public APP ID (public key) and the other one is API Key (private key).
+
+Step 3 - we now generate a HMAC signature on the client side (hmac A). This signature is generated with a set of attributes listed in the diagram.
+
+Step 4 - the client sends requests to access server resources with hmac A in the HTTP header.
+
+Step 5 - the server receives the request which contains the request data and the authentication header. It extracts the necessary attributes from the request and uses the API key that’s stored on the server side to generate a signature (hmac B.)
+
+Steps 6 and 7 - the server compares hmac A (generated on the client side) and hmac B (generated on the server side). If they are matched, the requested resource will be returned to the client.
diff --git a/data/guides/how-to-handle-web-request-error.md b/data/guides/how-to-handle-web-request-error.md
new file mode 100644
index 0000000..e3c8533
--- /dev/null
+++ b/data/guides/how-to-handle-web-request-error.md
@@ -0,0 +1,36 @@
+---
+title: "How to Handle Web Request Errors"
+description: "Learn how to handle HTTP errors on both the client and server sides."
+image: "https://assets.bytebytego.com/diagrams/0144-client-handle-error.png"
+createdAt: "2024-02-13"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Error Handling"
+ - "Web Requests"
+---
+
+
+
+How do we properly deal with HTTP errors on the browser side? And how do we handle them correctly on the server side when the client side is at fault?
+
+From the browser's point of view, the easiest thing to do is to try again and hope the error just goes away. This is a good idea in a distributed network, but we also have to be very careful not to make things worse. Here’s two general rules:
+
+* For 4XX HTTP error code, do not retry.
+
+* For 5XX HTTP error code, try again carefully.
+
+So which things should we do carefully in the browser? We definitely should not overwhelm the server with retried requests. An algorithm named exponential backoff might be able to help. It controls two things:
+
+* The latency between two retries. The latency will increase exponentially.
+
+* The number of retries is usually capped.
+
+Will all browsers handle their retry logic in a graceful way? Most likely not. So the server has to take care of its own safety. A common way to control the flow of HTTP requests is to set up a flow control gateway in front of the server. This provides two useful tools:
+
+* **Rate limiter:** which limits how often a request can be made. It has two slightly different choices; the token bucket and the leaky bucket.
+
+* **Circuit breaker:** This will stop the HTTP flow immediately when the error threshold is exceeded. After a set amount of time, it will only let a limited amount of HTTP traffic through. If everything works well, it will slowly let all HTTP traffic through.
+
+We should be able to handle intermittent errors effectively with exponential backoff in the browser and with a flow control gateway on the server side. Any remaining issues are real errors that need to be fixed carefully.
diff --git a/data/guides/how-to-implement-read-replica-pattern.md b/data/guides/how-to-implement-read-replica-pattern.md
new file mode 100644
index 0000000..bc9522e
--- /dev/null
+++ b/data/guides/how-to-implement-read-replica-pattern.md
@@ -0,0 +1,43 @@
+---
+title: "How to Implement Read Replica Pattern"
+description: "Learn how to implement the read replica pattern using database middleware."
+image: "https://assets.bytebytego.com/diagrams/0162-database-middleware.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - Database
+ - Read Replicas
+---
+
+
+
+There are two common ways to implement the read replica pattern:
+
+* Embed the routing logic in the application code (explained in the last post).
+* Use database middleware.
+
+We focus on option 2 here. The middleware provides transparent routing between the application and database servers. We can customize the routing logic based on difficult rules such as user, schema, statement, etc.
+
+The diagram above illustrates the setup:
+
+1. When Alice places an order on amazon, the request is sent to Order Service.
+2. Order Service does not directly interact with the database. Instead, it sends database queries to the database middleware.
+3. The database middleware routes writes to the primary database. Data is replicated to two replicas.
+4. Alice views the order details (read). The request is sent through the middleware.
+5. Alice views the recent order history (read). The request is sent through the middleware.
+
+The database middleware acts as a proxy between the application and databases. It uses standard MySQL network protocol for communication.
+
+## Pros
+
+* Simplified application code. The application doesn’t need to be aware of the database topology and manage access to the database directly.
+
+* Better compatibility. The middleware uses the MySQL network protocol. Any MySQL compatible client can connect to the middleware easily. This makes database migration easier.
+
+## Cons
+
+* Increased system complexity. A database middleware is a complex system. Since all database queries go through the middleware, it usually requires a high availability setup to avoid a single point of failure.
+
+* Additional middleware layer means additional network latency. Therefore, this layer requires excellent performance.
diff --git a/data/guides/how-to-learn-payments.md b/data/guides/how-to-learn-payments.md
new file mode 100644
index 0000000..78cfdc2
--- /dev/null
+++ b/data/guides/how-to-learn-payments.md
@@ -0,0 +1,48 @@
+---
+title: "How to Learn Payments"
+description: "A guide to understanding the payment industry and its key components."
+image: "https://assets.bytebytego.com/diagrams/0254-learn-payment.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Fintech"
+---
+
+
+
+The mind map below shows an extensive outline of payment knowledge.
+
+This gives us 𝐚 𝐭𝐨𝐩-𝐝𝐨𝐰𝐧 𝐯𝐢𝐞𝐰 𝐨𝐟 𝐭𝐡𝐞 𝐢𝐧𝐝𝐮𝐬𝐭𝐫𝐲 and an overview of how the payment systems work.
+
+Notice that different countries have different payment frameworks. But in general, the payment industry is composed of below parts:
+
+* Regulatory Authority
+
+* Central Bank
+
+* Commercial Banks
+
+* Non-Bank Payment Companies
+
+* Payment Systems
+
+* Clearing Networks
+
+* Settlement Systems
+
+## More Useful Materials
+
+Here are some useful materials for your reference:
+
+* Payment Systems in the U.S. by GlenBrook
+
+* BIS (Bank for International Settlements) Website
+
+* PayPal documents
+
+* Stripe documents
+
+* SWIFT documents
diff --git a/data/guides/how-to-load-your-websites-at-lightning-speed.md b/data/guides/how-to-load-your-websites-at-lightning-speed.md
new file mode 100644
index 0000000..df4e378
--- /dev/null
+++ b/data/guides/how-to-load-your-websites-at-lightning-speed.md
@@ -0,0 +1,32 @@
+---
+title: "Frontend Performance Optimization"
+description: "Boost your website's speed with these frontend optimization tips."
+image: "https://assets.bytebytego.com/diagrams/0198-frontend-performance-cheatsheet.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "frontend"
+ - "performance"
+---
+
+
+
+Check out these 8 tips to boost frontend performance:
+
+* **Compression** Compress files and minimize data size before transmission to reduce network load.
+
+* **Selective Rendering/Windowing** Display only visible elements to optimize rendering performance. For example, in a dynamic list, only render visible items.
+
+* **Modular Architecture with Code Splitting** Split a bigger application bundle into multiple smaller bundles for efficient loading.
+
+* **Priority-Based Loading** Prioritize essential resources and visible (or above-the-fold) content for a better user experience.
+
+* **Pre-loading** Fetch resources in advance before they are requested to improve loading speed.
+
+* **Tree Shaking or Dead Code Removal** Optimize the final JS bundle by removing dead code that will never be used.
+
+* **Pre-fetching** Proactively fetch or cache resources that are likely to be needed soon.
+
+* **Dynamic Imports** Load code modules dynamically based on user actions to optimize the initial loading times.
diff --git a/data/guides/how-to-release-a-mobile-app.md b/data/guides/how-to-release-a-mobile-app.md
new file mode 100644
index 0000000..068648e
--- /dev/null
+++ b/data/guides/how-to-release-a-mobile-app.md
@@ -0,0 +1,53 @@
+---
+title: "How To Release A Mobile App"
+description: "A simplified guide to the mobile app release process."
+image: "https://assets.bytebytego.com/diagrams/0228-how-to-release-a-mobile-app.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Mobile Development"
+ - "App Release"
+---
+
+
+
+The mobile app release process differs from conventional methods. This illustration simplifies the journey to help you understand.
+
+### 1. Registration & Development (iOS & Android):
+
+- Enroll in Apple's Developer Program and Google Play Console as iOS and Android developer
+- Code using platform-specific tools: Swift/Obj-C for iOS, and Java/Kotlin for Android
+
+### 2. Build & Test (iOS & Android):
+
+Compile the app's binary, run extensive tests on both platforms to ensure functionality and performance. Create a release candidate build.
+
+### 3. QA:
+
+- Internally test the app for issue identification (dogfooding)
+- Beta test with external users to collect feedback
+- Conduct regression testing to maintain feature stability
+
+### 4. Internal Approvals:
+
+- Obtain approval from stakeholders and key team members.
+- Comply with app store guidelines and industry regulations
+- Obtain security approvals to safeguard user data and privacy
+
+### 5. App Store Optimization (ASO):
+
+- Optimize metadata, including titles, descriptions, and keywords, for better search visibility
+- Design captivating screenshots and icons to entice users
+- Prepare engaging release notes to inform users about new features and updates
+
+### 6. App Submission To Store:
+
+- Submit the iOS app via App Store Connect following Apple's guidelines
+- Submit the Android app via Google Play Console, adhering to Google's policies
+- Both platforms may request issues resolution for approval
+
+### 7. Release:
+
+- Upon approval, set a release date to coordinate the launch on both iOS and Android platforms
diff --git a/data/guides/how-to-scale-a-website-to-support-millions-of-users.md b/data/guides/how-to-scale-a-website-to-support-millions-of-users.md
new file mode 100644
index 0000000..9f00569
--- /dev/null
+++ b/data/guides/how-to-scale-a-website-to-support-millions-of-users.md
@@ -0,0 +1,46 @@
+---
+title: "Scaling Websites for Millions of Users"
+description: "Learn how to scale your website architecture to support millions of users."
+image: "https://assets.bytebytego.com/diagrams/0322-scale-to-million.jpg"
+createdAt: "2024-02-07"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - scalability
+ - architecture
+---
+
+
+
+The diagram below illustrates the evolution of a simplified eCommerce website. It goes from a monolithic design on one single server, to a service-oriented/microservice architecture.
+
+Suppose we have two services: inventory service (handles product descriptions and inventory management) and user service (handles user information, registration, login, etc.).
+
+## Step 1
+
+With the growth of the user base, one single application server cannot handle the traffic anymore. We put the application server and the database server into two separate servers.
+
+## Step 2
+
+The business continues to grow, and a single application server is no longer enough. So we deploy a cluster of application servers.
+
+## Step 3
+
+Now the incoming requests have to be routed to multiple application servers, how can we ensure each application server gets an even load? The load balancer handles this nicely.
+
+## Step 4
+
+With the business continuing to grow, the database might become the bottleneck. To mitigate this, we separate reads and writes in a way that frequent read queries go to read replicas. With this setup, the throughput for the database writes can be greatly increased.
+
+## Step 5
+
+Suppose the business continues to grow. One single database cannot handle the load on both the inventory table and user table. We have a few options:
+
+* **Vertical partition.** Adding more power (CPU, RAM, etc.) to the database server. It has a hard limit.
+* **Horizontal partition** by adding more database servers.
+* Adding a caching layer to offload read requests.
+
+## Step 6
+
+Now we can modularize the functions into different services. The architecture becomes service-oriented / microservice.
diff --git a/data/guides/how-to-store-passwords-in-the-database.md b/data/guides/how-to-store-passwords-in-the-database.md
new file mode 100644
index 0000000..c1afc3b
--- /dev/null
+++ b/data/guides/how-to-store-passwords-in-the-database.md
@@ -0,0 +1,44 @@
+---
+title: "Storing Passwords Safely: A Comprehensive Guide"
+description: "Learn how to securely store and validate passwords in your database."
+image: "https://assets.bytebytego.com/diagrams/0321-salt.png"
+createdAt: "2024-02-12"
+draft: false
+categories:
+ - security
+tags:
+ - "password security"
+ - "data protection"
+---
+
+
+
+## Things NOT to do
+
+* Storing passwords in plain text is not a good idea because anyone with internal access can see them.
+
+* Storing password hashes directly is not sufficient because it is prone to precomputation attacks, such as rainbow tables.
+
+* To mitigate precomputation attacks, we salt the passwords.
+
+## What is salt?
+
+According to OWASP guidelines, “a salt is a unique, randomly generated string that is added to each password as part of the hashing process”.
+
+## How to store a password and salt?
+
+1. A salt is not meant to be secret and it can be stored in plain text in the database. It is used to ensure the hash result is unique to each password.
+
+2. The password can be stored in the database using the following format: 𝘩𝘢𝘴𝘩( 𝘱𝘢𝘴𝘴𝘸𝘰𝘳𝘥 + 𝘴𝘢𝘭𝘵).
+
+## How to validate a password?
+
+To validate a password, it can go through the following process:
+
+1. A client enters the password.
+
+2. The system fetches the corresponding salt from the database.
+
+3. The system appends the salt to the password and hashes it. Let’s call the hashed value H1.
+
+4. The system compares H1 and H2, where H2 is the hash stored in the database. If they are the same, the password is valid.
diff --git a/data/guides/how-to-upload-a-large-file-to-s3.md b/data/guides/how-to-upload-a-large-file-to-s3.md
new file mode 100644
index 0000000..08ea66e
--- /dev/null
+++ b/data/guides/how-to-upload-a-large-file-to-s3.md
@@ -0,0 +1,32 @@
+---
+title: "How to Upload a Large File to S3"
+description: "Optimize performance when uploading large files to object storage like S3."
+image: "https://assets.bytebytego.com/diagrams/0284-multipart-upload.png"
+createdAt: "2024-01-30"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "S3"
+ - "Object Storage"
+---
+
+
+
+How can we optimize performance when we **upload large files** to object storage service such as S3?
+
+Before we answer this question, let's take a look at why we need to optimize this process. Some files might be larger than a few GBs. It is possible to upload such a large object file directly, but it could take a long time. If the network connection fails in the middle of the upload, we have to start over. A better solution is to slice a large object into smaller parts and upload them independently. After all the parts are uploaded, the object store re-assembles the object from the parts. This process is called **multipart upload**.
+
+The diagram above illustrates how multipart upload works:
+
+1. The client calls the object storage to initiate a multipart upload.
+
+2. The data store returns an uploadID, which uniquely identifies the upload.
+
+3. The client splits the large file into small objects and starts uploading. Let’s assume the size of the file is 1.6GB and the client splits it into 8 parts, so each part is 200 MB in size. The client uploads the first part to the data store together with the uploadID it received in step 2.
+
+4. When a part is uploaded, the data store returns an ETag, which is essentially the md5 checksum of that part. It is used to verify multipart uploads.
+
+5. After all parts are uploaded, the client sends a complete multipart upload request, which includes the uploadID, part numbers, and ETags.
+
+6. The data store reassembles the object from its parts based on the part number. Since the object is really large, this process may take a few minutes. After reassembly is complete, it returns a success message to the client.
diff --git a/data/guides/how-will-you-design-the-stack-overflow-website.md b/data/guides/how-will-you-design-the-stack-overflow-website.md
new file mode 100644
index 0000000..cfce3f8
--- /dev/null
+++ b/data/guides/how-will-you-design-the-stack-overflow-website.md
@@ -0,0 +1,31 @@
+---
+title: 'How to Design Stack Overflow'
+description: 'Explore the architecture of Stack Overflow and its design considerations.'
+image: 'https://assets.bytebytego.com/diagrams/0343-stack-overflow-architecture.png'
+createdAt: '2024-02-20'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Architecture
+---
+
+
+
+If your answer is on-premise servers and monolith, you would likely fail the interview, but that's how it is built in reality!
+
+**What people think it should look like**
+The interviewer is probably expecting something on the left side.
+
+* Microservice is used to decompose the system into small components.
+* Each service has its own database. Use cache heavily.
+* The service is sharded.
+* The services talk to each other asynchronously through message queues.
+* The service is implemented using Event Sourcing with CQRS.
+* Showing off knowledge in distributed systems such as eventual consistency, CAP theorem, etc.
+
+**What it actually is**
+Stack Overflow serves all the traffic with only 9 on-premise web servers, and it’s on monolith! It has its own servers and does not run on the cloud.
+
+This is contrary to all our popular beliefs these days.
diff --git a/data/guides/http-cookies-explained-with-a-simple-diagram.md b/data/guides/http-cookies-explained-with-a-simple-diagram.md
new file mode 100644
index 0000000..87b4fac
--- /dev/null
+++ b/data/guides/http-cookies-explained-with-a-simple-diagram.md
@@ -0,0 +1,26 @@
+---
+title: "HTTP Cookies Explained With a Simple Diagram"
+description: "Understand HTTP cookies with a simple diagram and clear explanations."
+image: "https://assets.bytebytego.com/diagrams/0153-cookies.png"
+createdAt: "2024-02-18"
+draft: false
+categories:
+ - security
+tags:
+ - HTTP
+ - Web Development
+---
+
+
+
+HTTP, the language of the web, is naturally "stateless." But hey, we all want that seamless, continuous browsing experience, right? Enter the unsung heroes - Cookies!
+
+So, here's the scoop in this cookie flyer:
+
+* HTTP is like a goldfish with no memory - it forgets you instantly! But cookies swoop in to the rescue, adding that "session secret sauce" to your web interactions.
+
+* Cookies? Think of them as little notes you pass to the web server, saying, "Remember me, please!" And yes, they're stored there, like cherished mementos.
+
+* Browsers are like cookie bouncers, making sure your cookies don't party crash at the wrong website.
+
+* Finally, meet the cookie celebrities - SameSite, Name, Value, Secure, Domain, and HttpOnly. They're the cool kids setting the rules in the cookie jar!
diff --git a/data/guides/http-status-code-you-should-know.md b/data/guides/http-status-code-you-should-know.md
new file mode 100644
index 0000000..965b216
--- /dev/null
+++ b/data/guides/http-status-code-you-should-know.md
@@ -0,0 +1,22 @@
+---
+title: 'HTTP Status Codes You Should Know'
+description: 'Understand HTTP status codes: categories and common examples.'
+image: 'https://assets.bytebytego.com/diagrams/0233-http-status-code.png'
+createdAt: '2024-02-24'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - API
+---
+
+
+
+The response codes for HTTP are divided into five categories:
+
+* **Informational (100-199)**
+* **Success (200-299)**
+* **Redirection (300-399)**
+* **Client Error (400-499)**
+* **Server Error (500-599)**
diff --git a/data/guides/http1-http2-http3.md b/data/guides/http1-http2-http3.md
new file mode 100644
index 0000000..ffa9adc
--- /dev/null
+++ b/data/guides/http1-http2-http3.md
@@ -0,0 +1,22 @@
+---
+title: 'HTTP/1 -> HTTP/2 -> HTTP/3'
+description: 'Explore the evolution of HTTP: from HTTP/1 to the latest HTTP/3.'
+image: 'https://assets.bytebytego.com/diagrams/0101-http-1-http-2-http-3.png'
+createdAt: '2024-03-02'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - Protocols
+---
+
+
+
+HTTP 1 started in 1996 followed by HTTP 1.1 the very next year. In 2015, HTTP 2 came about and in 2019 we got HTTP 3.
+
+With each iteration, the protocol has evolved in new and interesting ways.
+
+* **HTTP 1** (and its sub-versions) introduced features like persistent connections, pipelining, and the concept of headers. The protocol was built on top of TCP and provided a reliable way of communication over the World Wide Web. It is still used despite being over 25 years old.
+* **HTTP 2** brought new features such as multiplexing, stream prioritization, server push, and HPACK compression. However, it still used TCP as the underlying protocol.
+* **HTTP 3** uses Google’s QUIC, which is built on top of UDP. In other words, HTTP 3 has moved away from TCP.
diff --git a/data/guides/https-ssl-handshake-and-data-encryption-explained-to-kids.md b/data/guides/https-ssl-handshake-and-data-encryption-explained-to-kids.md
new file mode 100644
index 0000000..e1ec9ad
--- /dev/null
+++ b/data/guides/https-ssl-handshake-and-data-encryption-explained-to-kids.md
@@ -0,0 +1,22 @@
+---
+title: "HTTPS, SSL Handshake, and Data Encryption Explained"
+description: "Learn about HTTPS, SSL handshake, and data encryption in simple terms."
+image: "https://assets.bytebytego.com/diagrams/0409-https-ssl-handshake-and-data-encryption-explained-to-kids.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - security
+tags:
+ - "HTTPS"
+ - "Encryption"
+---
+
+
+
+HTTPS: Safeguards your data from eavesdroppers and breaches. Understand how encryption and digital certificates create an impregnable shield.
+
+SSL Handshake: Behind the Scenes — Witness the cryptographic protocols that establish a secure connection. Experience the intricate exchange of keys and negotiation.
+
+Secure Data Transmission: Navigating the Tunnel — Journey through the encrypted tunnel forged by HTTPS. Learn how your information travels while shielded from cyber threats.
+
+HTML's Role: Peek into HTML's role in structuring the web. Uncover how hyperlinks and content come together seamlessly. And why is it called HYPER TEXT.
diff --git a/data/guides/imperative-vs-functional-vs-object-oriented-programming.md b/data/guides/imperative-vs-functional-vs-object-oriented-programming.md
new file mode 100644
index 0000000..1e8e2fd
--- /dev/null
+++ b/data/guides/imperative-vs-functional-vs-object-oriented-programming.md
@@ -0,0 +1,46 @@
+---
+title: "Imperative vs Functional vs Object-oriented Programming"
+description: "Explore imperative, functional, and object-oriented programming paradigms."
+image: "https://assets.bytebytego.com/diagrams/0035-imperative-vs-functional-vs-oop.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - software-development
+tags:
+ - Programming Paradigms
+ - Software Design
+---
+
+
+
+In software development, different programming paradigms offer unique ways to structure code. Three main paradigms are Imperative, Functional, and Object-oriented programming, each with distinct approaches to problem-solving.
+
+## Imperative Programming
+
+* Works by changing program state through a sequence of commands.
+
+* Uses control structures like loops and conditional statements for execution flow.
+
+* Emphasizes mutable data and explicit steps for task completion.
+
+* Examples: C, Python, and most procedural languages.
+
+## Functional Programming
+
+* Relies on pure functions, emphasizing computation without side effects.
+
+* Promotes immutability and the avoidance of mutable state.
+
+* Supports higher-order functions, recursion, and declarative programming.
+
+* Examples: Haskell, Lisp, Scala, and functional features in languages like JavaScript.
+
+## Object-oriented Programming
+
+* Focuses on modeling real-world entities as objects, containing data and methods.
+
+* Encourages concepts such as inheritance, encapsulation, and polymorphism.
+
+* Utilizes classes, objects, and interfaces to structure code.
+
+* Examples: Java, C++, Python, and Ruby.
diff --git a/data/guides/important-things-about-http-headers-you-may-not-know.md b/data/guides/important-things-about-http-headers-you-may-not-know.md
new file mode 100644
index 0000000..9000212
--- /dev/null
+++ b/data/guides/important-things-about-http-headers-you-may-not-know.md
@@ -0,0 +1,20 @@
+---
+title: 'Important Things About HTTP Headers'
+description: 'Learn about essential HTTP headers for client-server communication.'
+image: 'https://assets.bytebytego.com/diagrams/0231-http-header.png'
+createdAt: '2024-01-30'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - Headers
+---
+
+
+
+HTTP requests are like asking for something from a server, and HTTP responses are the server's replies. It's like sending a message and receiving a reply.
+
+An HTTP request header is an extra piece of information you include when making a request, such as what kind of data you are sending or who you are. In response headers, the server provides information about the response it is sending you, such as what type of data you're receiving or if you have special instructions.
+
+A header serves a vital role in enabling client-server communication when building RESTful applications. In order to send the right information with their requests and interpret the server's responses correctly, you need to understand these headers.
diff --git a/data/guides/internet-traffic-routing-policies.md b/data/guides/internet-traffic-routing-policies.md
new file mode 100644
index 0000000..ad8b1c2
--- /dev/null
+++ b/data/guides/internet-traffic-routing-policies.md
@@ -0,0 +1,23 @@
+---
+title: 'Internet Traffic Routing Policies'
+description: 'Explore internet traffic routing policies for efficient network management.'
+image: 'https://assets.bytebytego.com/diagrams/0106-internet-traffic-routing-policies.png'
+createdAt: '2024-01-31'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Networking
+ - Routing
+---
+
+
+
+Internet traffic routing policies (DNS policies) play a crucial role in efficiently managing and directing network traffic. Let's discuss the different types of policies.
+
+* **Simple:** Directs all traffic to a single endpoint based on a standard DNS query without any special conditions or requirements.
+* **Failover:** Routes traffic to a primary endpoint but automatically switches to a secondary endpoint if the primary is unavailable.
+* **Geolocation:** Distributes traffic based on the geographic location of the requester, aiming to provide localized content or services.
+* **Latency:** Directs traffic to the endpoint that provides the lowest latency for the requester, enhancing user experience with faster response times.
+* **Multivalue Answer:** Responds to DNS queries with multiple IP addresses, allowing the client to select an endpoint. However, it should not be considered a replacement for a load balancer.
+* **Weighted Routing Policy:** Distributes traffic across multiple endpoints with assigned weights, allowing for proportional traffic distribution based on these weights.
diff --git a/data/guides/ipv4-vs-ipv6.md b/data/guides/ipv4-vs-ipv6.md
new file mode 100644
index 0000000..ec5164b
--- /dev/null
+++ b/data/guides/ipv4-vs-ipv6.md
@@ -0,0 +1,34 @@
+---
+title: "IPv4 vs. IPv6: Differences"
+description: "Explore the key differences between IPv4 and IPv6 protocols."
+image: "https://assets.bytebytego.com/diagrams/0236-ipv4-vs-ipv6.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Networking"
+ - "Protocols"
+---
+
+
+
+The transition from Internet Protocol version 4 (IPv4) to Internet Protocol version 6 (IPv6) is primarily driven by the need for more internet addresses, alongside the desire to streamline certain aspects of network management.
+
+## Format and Length
+
+IPv4 uses a 32-bit address format, which is typically displayed as four decimal numbers separated by dots (e.g., 192.168.0.12). The 32-bit format allows for approximately 4.3 billion unique addresses, a number that is rapidly proving insufficient due to the explosion of internet-connected devices.
+
+In contrast, IPv6 utilizes a 128-bit address format, represented by eight groups of four hexadecimal digits separated by colons (e.g., 50B3:F200:0211:AB00:0123:4321:6571:B000). This expansion allows for approximately much more addresses, ensuring the internet's growth can continue unabated.
+
+## Header
+
+The IPv4 header is more complex and includes fields such as the header length, service type, total length, identification, flags, fragment offset, time to live (TTL), protocol, header checksum, source and destination IP addresses, and options.
+
+IPv6 headers are designed to be simpler and more efficient. The fixed header size is 40 bytes and includes less frequently used fields in optional extension headers. The main fields include version, traffic class, flow label, payload length, next header, hop limit, and source and destination addresses. This simplification helps improve packet processing speeds.
+
+## Translation between IPv4 and IPv6
+
+As the internet transitions from IPv4 to IPv6, mechanisms to allow these protocols to coexist have become essential:
+
+* **Dual Stack:** This technique involves running IPv4 and IPv6 simultaneously on the same network devices. It allows seamless communication in both protocols, depending on the destination address availability and compatibility. The dual stack is considered one of the best approaches for the smooth transition from IPv4 to IPv6.
diff --git a/data/guides/iqiyi-database-selection-trees.md b/data/guides/iqiyi-database-selection-trees.md
new file mode 100644
index 0000000..62fbb9b
--- /dev/null
+++ b/data/guides/iqiyi-database-selection-trees.md
@@ -0,0 +1,30 @@
+---
+title: "iQIYI Database Selection Trees"
+description: "Explore iQIYI's database selection process for relational and NoSQL."
+image: "https://assets.bytebytego.com/diagrams/0215-how-to-choose-db.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - database selection
+ - iQIYI
+---
+
+
+
+One picture is worth a thousand words.
+
+iQIYI is one of the largest online video sites in the world, with over 500 million monthly active users. Let's look at how they choose relational and NoSQL databases.
+
+The following databases are used at iQIYI:
+
+* MySQL
+* Redis
+* TiDB: a hybrid transactional/analytical processing (HTAP) distributed database
+* Couchbase: distributed multi-model NoSQL document-oriented database
+* TokuDB: open-source storage engine for MySQL and MariaDB.
+* Big data analytical systems, like Hive and Impala
+* Other databases, like MongoDB, HiGraph, and TiKV
+
+The database selection trees below explain how they choose a database.
diff --git a/data/guides/is-https-safe.md b/data/guides/is-https-safe.md
new file mode 100644
index 0000000..19a954b
--- /dev/null
+++ b/data/guides/is-https-safe.md
@@ -0,0 +1,36 @@
+---
+title: "Is HTTPS Safe?"
+description: "Explore HTTPS security, vulnerabilities, and how tools capture packets."
+image: "https://assets.bytebytego.com/diagrams/0238-is-https-reliable.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - security
+tags:
+ - "HTTPS"
+ - "Security"
+---
+
+
+
+If HTTPS is safe, how can tools like Fiddler capture network packets sent via HTTPS?
+
+The diagram below shows a scenario where a malicious intermediate hijacks the packets.
+
+Prerequisite: root certificate of the intermediate server is present in the trust-store.
+
+## How Packets are Hijacked
+
+**Step 1** - The client requests to establish a TCP connection with the server. The request is maliciously routed to an intermediate server, instead of the real backend server. Then, a TCP connection is established between the client and the intermediate server.
+
+**Step 2** - The intermediate server establishes a TCP connection with the actual server.
+
+**Step 3** - The intermediate server sends the SSL certificate to the client. The certificate contains the public key, hostname, expiry dates, etc. The client validates the certificate.
+
+**Step 4** - The legitimate server sends its certificate to the intermediate server. The intermediate server validates the certificate.
+
+**Step 5** - The client generates a session key and encrypts it using the public key from the intermediate server. The intermediate server receives the encrypted session key and decrypts it with the private key.
+
+**Step 6** - The intermediate server encrypts the session key using the public key from the actual server and then sends it there. The legitimate server decrypts the session key with the private key.
+
+**Steps 7 and 8** - Now, the client and the server can communicate using the session key (symmetric encryption.) The encrypted data is transmitted in a secure bi-directional channel. The intermediate server can always decrypt the data.
diff --git a/data/guides/is-it-possible-to-run-c-c++-or-rust-on-a-web-browser.md b/data/guides/is-it-possible-to-run-c-c++-or-rust-on-a-web-browser.md
new file mode 100644
index 0000000..eb2cb25
--- /dev/null
+++ b/data/guides/is-it-possible-to-run-c-c++-or-rust-on-a-web-browser.md
@@ -0,0 +1,26 @@
+---
+title: "Running C, C++, or Rust in a Web Browser"
+description: "Explore running C, C++, and Rust code in web browsers using WASM."
+image: "https://assets.bytebytego.com/diagrams/0406-how-wasm-work.jpeg"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - software-development
+tags:
+ - "WebAssembly"
+ - "Performance"
+---
+
+
+
+What is **web assembly** (WASM)? Why does it attract so much attention?
+
+The diagram shows how we can run native C/C++/Rust code inside a web browser with WASM.
+
+Traditionally, we can only work with Javascript in the web browser, and the performance cannot compare with native code like C/C++ because it is interpreted.
+
+However, with WASM, we can **reuse** existing native code libraries developed in C/C++/Rust, etc to run in the web browser. These web applications have near-native performance.
+
+For example, we can run the **video encoding/decoding** library (written in C++) in the web browser.
+
+This opens a lot of possibilities for cloud computing and **edge computing**. We can run serverless applications with fewer resources and instant startup time.
diff --git a/data/guides/is-microservice-architecture-the-silver-bullet.md b/data/guides/is-microservice-architecture-the-silver-bullet.md
new file mode 100644
index 0000000..2ba5d2a
--- /dev/null
+++ b/data/guides/is-microservice-architecture-the-silver-bullet.md
@@ -0,0 +1,26 @@
+---
+title: "Is Microservice Architecture the Silver Bullet?"
+description: "Explore when microservices aren't the best choice for your architecture."
+image: "https://assets.bytebytego.com/diagrams/0278-monolithic-arch-use-cases.jpg"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "microservices"
+ - "architecture patterns"
+---
+
+The diagram above shows why **real-time gaming** and **low-latency trading** applications should not use microservice architecture.
+
+
+
+There are some common features of these applications, which make them choose monolithic architecture:
+
+* These applications are very **latency-sensitive**. For real-time gaming, the latency should be at the milli-second level; for low-latency trading, the latency should be at the micro-second level. We cannot separate the services into different processes because the network latency is unbearable.
+
+* Microservice architecture is usually **stateless**, and the states are persisted in the database. Real-time gaming and low-latency trading need to **store the states in memory** for quick updates. For example, when a character is injured in a game, we don’t want to see the update 3 seconds later. This kind of user experience can kill a game.
+
+* Real-time gaming and low-latency trading need to talk to the server in high frequency, and the requests need to go to the same running instance. So **web socket** connections and **sticky routing** are needed.
+
+So microservice architecture is designed to solve problems for certain domains. We need to think about “why” when designing applications.
diff --git a/data/guides/is-passkey-shaping-a-passwordless-future.md b/data/guides/is-passkey-shaping-a-passwordless-future.md
new file mode 100644
index 0000000..f3071e9
--- /dev/null
+++ b/data/guides/is-passkey-shaping-a-passwordless-future.md
@@ -0,0 +1,34 @@
+---
+title: "Is PassKey Shaping a Passwordless Future?"
+description: "Exploring PassKey's potential to revolutionize online security."
+image: "https://assets.bytebytego.com/diagrams/0296-is-passkey-shaping-a-passwordless-future.png"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Passkeys"
+---
+
+
+
+Google recently announced PassKey support for both Android and Chrome.
+
+Passkey, also backed by Apple and Microsoft, is claimed to be a significantly **safer replacement** for passwords.
+
+## How PassKeys Work
+
+* **Step 1 - Create PassKeys**
+
+ The end-user needs to confirm the account information and present their credentials (face ID, touch ID, etc.).
+
+ A private key is generated based on the public key provided by the website. The private key is stored on the device.
+
+* **Step 2 - Sign in with PassKeys on devices**
+
+ When the user tries to sign in to a website, they use the generated private key. Just select the account information and present the credentials to unlock the private key.
+
+Consequently, there is no risk of password leakage since no passwords are stored in the websites' databases.
+
+Passkeys are built on **industry standards**, and it works across different platforms and browsers - including Windows, macOS and iOS, and ChromeOS, with a **uniform user experience**.
diff --git a/data/guides/is-postgresql-eating-the-database-world.md b/data/guides/is-postgresql-eating-the-database-world.md
new file mode 100644
index 0000000..4c19df7
--- /dev/null
+++ b/data/guides/is-postgresql-eating-the-database-world.md
@@ -0,0 +1,50 @@
+---
+title: "Is PostgreSQL Eating the Database World?"
+description: "Explore PostgreSQL's versatility and its impact on the database landscape."
+image: "https://assets.bytebytego.com/diagrams/0237-is-postgresql-eating-the-database-world.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "PostgreSQL"
+ - "Databases"
+---
+
+
+
+It seems that no matter what the use case, PostgreSQL supports it. When in doubt, you can simply use PostgreSQL.
+
+## PostgreSQL Capabilities
+
+* **TimeSeries**
+
+ PostgreSQL embraces Timescale, a powerful time-series database extension for efficient handling of time-stamped data.
+
+* **Machine Learning**
+
+ With pgVector and PostgresML, Postgres can support machine learning capabilities and vector similarity searches.
+
+* **OLAP**
+
+ Postgres can support OLAP with tools such as Hydra, Citus, and pg\_analytics.
+
+* **Derived**
+
+ Even derived databases such as DuckDB, FerretDB, CockroachDB, AlloyDB, YugaByte DB, Supabase, etc provide PostgreSQL.
+
+* **GeoSpatial**
+
+ PostGIS extends PostgreSQL with geospatial capabilities, enabling you to easily store, query, and analyze geographic data.
+
+* **Search**
+
+ Postgres extensions like pgroonga, ParadeDB, and ZomboDB provide full-text search, text indexing, and data parsing capabilities.
+
+* **Federated**
+
+ Postgres seamlessly integrates with various data sources such as MongoDB, MySQL, Redis, Oracle, ParquetDB, SQLite, etc, enabling federated querying and data access.
+
+* **Graph**
+
+ Apache AGE and EdgeDB are graph databases built on top of PostgreSQL. Also, pg\_graphql is an extension that provides GraphQL support for Postgres.
diff --git a/data/guides/is-telegram-secure.md b/data/guides/is-telegram-secure.md
new file mode 100644
index 0000000..6599b75
--- /dev/null
+++ b/data/guides/is-telegram-secure.md
@@ -0,0 +1,32 @@
+---
+title: Is Telegram Secure?
+description: Exploring Telegram's security features and encryption methods.
+image: 'https://assets.bytebytego.com/diagrams/0354-is-telegram-secure.jpg'
+createdAt: '2024-02-15'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Security
+ - Encryption
+---
+
+
+
+Let’s first define what “secure” means. A “secure” chat in a messaging App generally means the message is encrypted at the sender side and is only decryptable at the receiver side. It is also called “E2EE” (end-to-end encryption).
+
+𝐓𝐞𝐥𝐞𝐠𝐫𝐚𝐦'𝐬 𝐮𝐬𝐮𝐚𝐥 𝐩𝐫𝐢𝐯𝐚𝐭𝐞 𝐚𝐧𝐝 𝐠𝐫𝐨𝐮𝐩 𝐜𝐡𝐚𝐭𝐬 𝐚𝐫𝐞𝐧'𝐭 𝐞𝐧𝐝-𝐭𝐨-𝐞𝐧𝐝 𝐞𝐧𝐜𝐫𝐲𝐩𝐭𝐞𝐝
+
+It generally means third parties can intercept and read your messages. Telegram uses the following approach for security:
+
+* The encrypted message is stored in Telegram servers, but split into several pieces and stored in different countries.
+* The decryption keys are also split and saved in different countries.
+
+This means the hacker needs to get message chunks and keys from all places. It is possible but extremely difficult.
+
+𝐒𝐞𝐜𝐫𝐞𝐭 𝐜𝐡𝐚𝐭𝐬 𝐚𝐫𝐞 𝐞𝐧𝐝-𝐭𝐨-𝐞𝐧𝐝 𝐞𝐧𝐜𝐫𝐲𝐩𝐭𝐞𝐝
+
+If you choose the “secret chat” option, it is end-to-end encrypted. It has several limitations:
+
+* It doesn’t support group chat or normal one-to-one chat.
+* It is only enabled for mobile devices.
diff --git a/data/guides/java-collection-hierarchy.md b/data/guides/java-collection-hierarchy.md
new file mode 100644
index 0000000..fff5806
--- /dev/null
+++ b/data/guides/java-collection-hierarchy.md
@@ -0,0 +1,30 @@
+---
+title: "Java Collection Hierarchy"
+description: "Explore the Java Collection Framework: interfaces, classes, and usage."
+image: "https://assets.bytebytego.com/diagrams/0240-java-collection.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Java"
+ - "Data Structures"
+---
+
+
+
+Are you familiar with the Java Collection Framework?
+
+Every Java engineer has encountered the Java Collections Framework (JCF) at some point in their career. It has enabled us to solve complex problems in an efficient and standardized manner.
+
+JCF is built upon a set of interfaces that define the basic operations for common data structures such as lists, sets, and maps. Each data structure is implemented by several concrete classes, which provide specific functionality.
+
+Java Collections are based on the Collection interface. A collection class should support basic operations such as adding, removing, and querying elements.
+
+Through the enhanced for-loop or iterators, the Collection interface extends the Iterable interface, making it convenient to iterate over the elements.
+
+The Collection interface has three main subinterfaces: List, Set, and Queue. Each of these interfaces has its unique characteristics and use cases.
+
+Java engineers need to be familiar with the Java Collection hierarchy to make informed decisions when choosing the right data structure for a particular problem.
+
+We can write more efficient and maintainable code by familiarizing ourselves with the key interfaces and their implementations. We will undoubtedly benefit from mastering the JCF as it is a versatile and powerful tool in our Java arsenal.
diff --git a/data/guides/json-files.md b/data/guides/json-files.md
new file mode 100644
index 0000000..e2e53ec
--- /dev/null
+++ b/data/guides/json-files.md
@@ -0,0 +1,20 @@
+---
+title: "JSON Crack: Visualize JSON Files"
+description: "Visualize and understand complex JSON data with JSON Crack."
+image: "https://assets.bytebytego.com/diagrams/0242-json-crack.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "JSON"
+ - "Visualization"
+---
+
+
+
+If you use JSON files, you'll probably like this tool 👇
+
+Nested JSON files are hard to read.
+
+JsonCrack generates graph diagrams from JSON files and makes them easy to read.
diff --git a/data/guides/jwt-101-key-to-stateless-authentication.md b/data/guides/jwt-101-key-to-stateless-authentication.md
new file mode 100644
index 0000000..1d17742
--- /dev/null
+++ b/data/guides/jwt-101-key-to-stateless-authentication.md
@@ -0,0 +1,40 @@
+---
+title: "JWT 101: Key to Stateless Authentication"
+description: "Learn about JSON Web Tokens (JWT) for secure, stateless authentication."
+image: "https://assets.bytebytego.com/diagrams/0244-jwt-101-key-to-stateless-authentication.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - security
+tags:
+ - "authentication"
+ - "jwt"
+---
+
+
+
+JWT or JSON Web Tokens is an open standard for securely transmitting information between two parties. They are widely used for authentication and authorization.
+
+A JWT consists of three main components:
+
+1. Header
+
+Every JWT carries a header specifying the algorithms for signing the JWT. It’s written in JSON format.
+
+2. Payload
+
+The payload consists of the claims and the user data. There are different types of claims such as registered, public, and private claims.
+
+3. Signature
+
+The signature is what makes the JWT secure. It is created by taking the encoded header, encoded payload, secret key, and the algorithm and signing it.
+
+JWTs can be signed in two different ways:
+
+* **Symmetric Signatures**
+
+ It uses a single secret key for both signing the token and verifying it. The same key must be shared between the server that signs the JWT and the system that verifies it.
+
+* **Asymmetric Signatures**
+
+ In this case, a private key is used to sign the token, and a public key to verify it. The private key is kept secure on the server, while the public key can be distributed to anyone who needs to verify the token.
diff --git a/data/guides/key-concepts-to-understand-database-sharding.md b/data/guides/key-concepts-to-understand-database-sharding.md
new file mode 100644
index 0000000..15a9c87
--- /dev/null
+++ b/data/guides/key-concepts-to-understand-database-sharding.md
@@ -0,0 +1,28 @@
+---
+title: "Key Concepts to Understand Database Sharding"
+description: "Explore key concepts of database sharding with vertical/horizontal strategies."
+image: "https://assets.bytebytego.com/diagrams/0096-dbshards.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Sharding"
+ - "Database Design"
+---
+
+
+
+In this concise and visually engaging resource, we break down the key concepts of database partitioning, explaining both vertical and horizontal strategies.
+
+## Range-Based Sharding
+
+Splitting your data into distinct ranges. Think of it as organizing your books by genre on separate shelves.
+
+## Key-Based Sharding (with a dash of %3 hash)
+
+Imagine each piece of data having a unique key, and we distribute them based on a specific rule. It's like sorting your playing cards by suit and number.
+
+## Directory-Based Sharding
+
+A directory, like a phone book, helps you quickly find the information you need. Similarly, this technique uses a directory to route data efficiently.
diff --git a/data/guides/key-data-terms.md b/data/guides/key-data-terms.md
new file mode 100644
index 0000000..5ddcfd6
--- /dev/null
+++ b/data/guides/key-data-terms.md
@@ -0,0 +1,23 @@
+---
+title: 'Key Data Terms'
+description: 'Understand essential data terminology for effective data management.'
+image: 'https://assets.bytebytego.com/diagrams/0158-data-terms.png'
+createdAt: '2024-03-09'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - Data Warehousing
+ - Data Lakes
+---
+
+Data is used everywhere, but do you know all the commonly used data terms?
+
+
+
+- **Data Warehouse:** A large, structured repository of integrated data from various sources, used for complex querying and historical analysis.
+- **Data Mart:** A more focused, department-specific subset of a data warehouse providing quick data retrieval and analysis.
+- **Data Lake:** A vast pool of raw, unstructured data stored in its native format until it's needed for use.
+- **Delta Lake:** An open-source storage layer that brings reliability and ACID transactions to data lakes, unifying batch, and streaming data processing.
+- **Data Pipeline:** A process that moves and transforms data from one system to another, often used to populate data warehouses and data lakes.
+- **Data Mesh:** An architectural and organizational approach where data ownership and delivery are decentralized across domain-specific, cross-functional teams.
diff --git a/data/guides/key-terms-in-domain-driven-design.md b/data/guides/key-terms-in-domain-driven-design.md
new file mode 100644
index 0000000..8829af5
--- /dev/null
+++ b/data/guides/key-terms-in-domain-driven-design.md
@@ -0,0 +1,38 @@
+---
+title: "Key Terms in Domain-Driven Design"
+description: "Understand key concepts in Domain-Driven Design for better software."
+image: "https://assets.bytebytego.com/diagrams/0163-ddd.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Domain-Driven Design"
+ - "Software Design"
+---
+
+Have you heard of Domain-Driven Design (DDD), a major software design approach?
+
+
+
+DDD was introduced in Eric Evans’ classic book “Domain-Driven Design: Tackling Complexity in the Heart of Software”. It explained a methodology to model a complex business. In this book, there is a lot of content, so I'll summarize the basics.
+
+## The composition of domain objects:
+
+* **Entity:** a domain object that has ID and life cycle.
+
+* **Value Object:** a domain object without ID. It is used to describe the property of Entity.
+
+* **Aggregate:** a collection of Entities that are bounded together by Aggregate Root (which is also an entity). It is the unit of storage.
+
+## The life cycle of domain objects:
+
+* **Repository:** storing and loading the Aggregate.
+
+* **Factory:** handling the creation of the Aggregate.
+
+## Behavior of domain objects:
+
+* **Domain Service:** orchestrate multiple Aggregate.
+
+* **Domain Event:** a description of what has happened to the Aggregate. The publication is made public so others can consume and reconstruct it.
diff --git a/data/guides/key-use-cases-for-load-balancers.md b/data/guides/key-use-cases-for-load-balancers.md
new file mode 100644
index 0000000..5610ac7
--- /dev/null
+++ b/data/guides/key-use-cases-for-load-balancers.md
@@ -0,0 +1,34 @@
+---
+title: 'Key Use Cases for Load Balancers'
+description: 'Explore key use cases for load balancers in modern architectures.'
+image: 'https://assets.bytebytego.com/diagrams/0046-top-6-load-balancer-use-cases.png'
+createdAt: '2024-02-04'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Load Balancing
+ - Scalability
+---
+
+
+
+The diagram above shows the top 6 use cases where we use a load balancer.
+
+* **Traffic Distribution**
+ Load balancers evenly distribute incoming traffic among multiple servers, preventing any single server from becoming overwhelmed. This helps maintain optimal performance, scalability, and reliability of applications or websites.
+
+* **High Availability**
+ Load balancers enhance system availability by rerouting traffic away from failed or unhealthy servers to healthy ones. This ensures uninterrupted service even if certain servers experience issues.
+
+* **SSL Termination**
+ Load balancers can offload SSL/TLS encryption and decryption tasks from backend servers, reducing their workload and improving overall performance.
+
+* **Session Persistence**
+ For applications that require maintaining a user's session on a specific server, load balancers can ensure that subsequent requests from a user are sent to the same server.
+
+* **Scalability**
+ Load balancers facilitate horizontal scaling by effectively managing increased traffic. Additional servers can be easily added to the pool, and the load balancer will distribute traffic across all servers.
+
+* **Health Monitoring**
+ Load balancers continuously monitor the health and performance of servers, removing failed or unhealthy servers from the pool to maintain optimal performance.
diff --git a/data/guides/kubernetes-deployment-strategies.md b/data/guides/kubernetes-deployment-strategies.md
new file mode 100644
index 0000000..1b5457d
--- /dev/null
+++ b/data/guides/kubernetes-deployment-strategies.md
@@ -0,0 +1,61 @@
+---
+title: "Kubernetes Deployment Strategies"
+description: "Explore Kubernetes deployment strategies for seamless application updates."
+image: "https://assets.bytebytego.com/diagrams/0247-kubernates-deployment-strategy.jpeg"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Kubernetes"
+ - "Deployment"
+---
+
+
+
+Each strategy offers a unique approach to manage updates.
+
+## Recreate
+
+All existing instances are terminated at once, and new instances with the updated version are created.
+
+* Downtime: Yes
+* Use case: Non-critical applications or during initial development stages
+
+## Rolling Update
+
+Application instances are updated one by one, ensuring high availability during the process.
+
+* Downtime: No
+* Use case: Periodic releases
+
+## Shadow
+
+A copy of the live traffic is redirected to the new version for testing without affecting production users.
+
+This is the most complex deployment strategy and involves establishing mock services to interact with the new version of the deployment.
+
+* Downtime: No
+* Use case: Validating new version performance and behavior in a real environment
+
+## Canary
+
+The new version is released to a subset of users or servers for testing before broader deployment.
+
+* Downtime: No
+* Use case: Impact validation on a subset of users
+
+## Blue-Green
+
+* Two identical environments are maintained: one with the current version (blue) and the other with the updated version (green).
+* Traffic starts with blue, then switches to the prepared green environment for the updated version.
+
+* Downtime: No
+* Use case: High-stake updates
+
+## A/B Testing
+
+Multiple versions are concurrently tested on different users to compare performance or user experience.
+
+* Downtime: Not directly applicable
+* Use case: Optimizing user experience
diff --git a/data/guides/kubernetes-periodic-table.md b/data/guides/kubernetes-periodic-table.md
new file mode 100644
index 0000000..062c4df
--- /dev/null
+++ b/data/guides/kubernetes-periodic-table.md
@@ -0,0 +1,20 @@
+---
+title: "Kubernetes Periodic Table"
+description: "A visual guide to Kubernetes key components and their relationships."
+image: "https://assets.bytebytego.com/diagrams/0108-kubernetes-periodic-table.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - Orchestration
+---
+
+
+
+A comprehensive visual guide that demystifies the key building blocks of this powerful container orchestration platform.
+
+This Kubernetes Periodic Table sheds light on the 120 crucial components that make up the Kubernetes ecosystem.
+
+Whether you're a developer, system administrator, or cloud enthusiast, this handy resource will help you navigate the complex Kubernetes landscape.
diff --git a/data/guides/kubernetes-tools-ecosystem.md b/data/guides/kubernetes-tools-ecosystem.md
new file mode 100644
index 0000000..f71207e
--- /dev/null
+++ b/data/guides/kubernetes-tools-ecosystem.md
@@ -0,0 +1,27 @@
+---
+title: "Kubernetes Tools Ecosystem"
+description: "Explore the Kubernetes tools ecosystem for efficient container management."
+image: "https://assets.bytebytego.com/diagrams/0109-kubernetes-tools-ecosystem.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - DevOps
+---
+
+
+
+Kubernetes, the leading container orchestration platform, boasts a vast ecosystem of tools and components that collectively empower organizations to efficiently deploy, manage, and scale containerized applications.
+
+Kubernetes practitioners need to be well-versed in these tools to ensure the reliability, security, and performance of containerized applications within Kubernetes clusters.
+
+To introduce a holistic view of the Kubernetes ecosystem, we've created an illustration covering the aspects of:
+
+* Security
+* Networking
+* Container Runtime
+* Cluster Management
+* Monitoring and Observability
+* Infrastructure Orchestration
diff --git a/data/guides/kubernetes-tools-stack-wheel.md b/data/guides/kubernetes-tools-stack-wheel.md
new file mode 100644
index 0000000..e99f954
--- /dev/null
+++ b/data/guides/kubernetes-tools-stack-wheel.md
@@ -0,0 +1,20 @@
+---
+title: "Kubernetes Tools Stack Wheel"
+description: "Explore the Kubernetes tools stack wheel for efficient container orchestration."
+image: "https://assets.bytebytego.com/diagrams/0110-kubernetes-tools-stack-wheel.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - DevOps
+---
+
+
+
+Kubernetes tools continually evolve, offering enhanced capabilities and simplifying container orchestration. The innumerable choice of tools speaks about the vastness and the scope of this dynamic ecosystem, catering to diverse needs in the world of containerization.
+
+In fact, getting to know about the existing tools themselves can be a significant endeavor. With new tools and updates being introduced regularly, staying informed about their features, compatibility, and best practices becomes essential for Kubernetes practitioners, ensuring they can make informed decisions and adapt to the ever-changing landscape effectively.
+
+This tool stack streamlines the decision-making process and keeps up with that evolution, ultimately helping you to choose the right combination of tools for your use cases.
diff --git a/data/guides/learn-cache.md b/data/guides/learn-cache.md
new file mode 100644
index 0000000..ddcaef7
--- /dev/null
+++ b/data/guides/learn-cache.md
@@ -0,0 +1,26 @@
+---
+title: "Learn Cache"
+description: "A visual guide to understanding caching systems and their key considerations."
+image: "https://assets.bytebytego.com/diagrams/0004-learn-cache.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "System Design"
+---
+
+Made a simple visual guide to help everyone understand the key considerations when designing or using caching systems.
+
+
+
+* What is a cache
+* Why do we need cache
+* Where is cache used
+* Cache deployment
+* Distributed cache
+* Cache replacement and invalidation
+* Cache strategies
+* Caching challenges
+* And more.
diff --git a/data/guides/life-is-short-use-dev-tools.md b/data/guides/life-is-short-use-dev-tools.md
new file mode 100644
index 0000000..63f31a0
--- /dev/null
+++ b/data/guides/life-is-short-use-dev-tools.md
@@ -0,0 +1,50 @@
+---
+title: "Life is Short, Use Dev Tools"
+description: "Discover essential dev tools to save time and boost productivity."
+image: "https://assets.bytebytego.com/diagrams/0256-life-is-short-use-dev-tools.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Productivity"
+ - "Dev Tools"
+---
+
+
+
+The right dev tool can save you precious time, energy, and perhaps the weekend as well.
+
+Here are our favorite dev tools:
+
+* **Development Environment**
+
+ A good local dev environment is a force multiplier. Powerful IDEs like VSCode, IntelliJ IDEA, Notepad++, Vim, PyCharm & Jupyter Notebook can make your life easy.
+
+* **Diagramming**
+
+ Showcase your ideas visually with diagramming tools like DrawIO, Excalidraw, mindmap, Mermaid, PlantUML, Microsoft Visio, and Miro.
+
+* **AI Tools**
+
+ AI can boost your productivity. Don’t ignore tools like ChatGPT, GitHub Copilot, Tabnine, Claude, Ollama, Midjourney, and Stable Diffusion.
+
+* **Hosting and Deployment**
+
+ For hosting your applications, explore solutions like AWS, Cloudflare, GitHub, Fly, Heroku, and Digital Ocean.
+
+* **Code Quality**
+
+ Quality code is a great differentiator. Leverage tools like Jest, ESLint, Selenium, SonarQube, FindBugs, and Checkstyle to ensure top-notch quality.
+
+* **Security**
+
+ Don’t ignore the security aspects and use solutions like 1Password, LastPass, OWASP, Snyk, and Nmap.
+
+* **Note-taking**
+
+ Your notes are a reflection of your knowledge. Streamline your note-taking with Notion, Markdown, Obsidian, Roam, Logseq, and Tiddly Wiki.
+
+* **Design**
+
+ Elevate your visual game with design tools like Figma, Sketch, Adobe Illustrator, Canva, and Adobe Photoshop.
diff --git a/data/guides/linux-boot-process-explained.md b/data/guides/linux-boot-process-explained.md
new file mode 100644
index 0000000..afd3a88
--- /dev/null
+++ b/data/guides/linux-boot-process-explained.md
@@ -0,0 +1,49 @@
+---
+title: "Linux Boot Process Explained"
+description: "Explore the Linux boot process, from BIOS/UEFI to user login."
+image: "https://assets.bytebytego.com/diagrams/0213-linux-boot-process-explained.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - software-architecture
+ - software-development
+tags:
+ - "Linux"
+ - "Operating Systems"
+---
+
+
+
+Almost every software engineer has used Linux before, but only a handful know how its Boot Process works. Let's dive in.
+
+## Step 1
+
+When we turn on the power, BIOS (Basic Input/Output System) or UEFI (Unified Extensible Firmware Interface) firmware is loaded from non-volatile memory and executes POST (Power On Self Test).
+
+## Step 2
+
+BIOS/UEFI detects the devices connected to the system, including CPU, RAM, and storage.
+
+## Step 3
+
+Choose a booting device to boot the OS from. This can be the hard drive, the network server, or CD ROM.
+
+## Step 4
+
+BIOS/UEFI runs the boot loader (GRUB), which provides a menu to choose the OS or the kernel functions.
+
+## Step 5
+
+After the kernel is ready, we now switch to the user space. The kernel starts up systemd as the first user-space process, which manages the processes and services, probes all remaining hardware, mounts filesystems, and runs a desktop environment.
+
+## Step 6
+
+systemd activates the default. target unit by default when the system boots. Other analysis units are executed as well.
+
+## Step 7
+
+The system runs a set of startup scripts and configure the environment.
+
+## Step 8
+
+The users are presented with a login window. The system is now ready.
diff --git a/data/guides/linux-file-permission-illustrated.md b/data/guides/linux-file-permission-illustrated.md
new file mode 100644
index 0000000..85bd847
--- /dev/null
+++ b/data/guides/linux-file-permission-illustrated.md
@@ -0,0 +1,34 @@
+---
+title: "Linux File Permissions Illustrated"
+description: "Understand Linux file permissions: owner, group, and others."
+image: "https://assets.bytebytego.com/diagrams/0259-linux-permissions-copy.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Linux"
+ - "File Management"
+---
+
+
+
+## Ownership
+
+Every file or directory is assigned 3 types of owner:
+
+* **Owner**: the owner is the user who created the file or directory.
+
+* **Group**: a group can have multiple users. All users in the group have the same permissions to access the file or directory.
+
+* **Other**: other means those users who are not owners or members of the group.
+
+## Permission
+
+There are only three types of permissions for a file or directory.
+
+* **Read (r)**: the read permission allows the user to read a file.
+
+* **Write (w)**: the write permission allows the user to change the content of the file.
+
+* **Execute (x)**: the execute permission allows a file to be executed.
diff --git a/data/guides/linux-file-system-explained.md b/data/guides/linux-file-system-explained.md
new file mode 100644
index 0000000..37a0e75
--- /dev/null
+++ b/data/guides/linux-file-system-explained.md
@@ -0,0 +1,20 @@
+---
+title: "Linux File System Explained"
+description: "Understanding the Linux file system hierarchy and its importance."
+image: "https://assets.bytebytego.com/diagrams/0258-linux-file-system-explained.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Linux"
+ - "Filesystem"
+---
+
+
+
+The Linux file system used to resemble an unorganized town where individuals constructed their houses wherever they pleased. However, in 1994, the Filesystem Hierarchy Standard (FHS) was introduced to bring order to the Linux file system.
+
+By implementing a standard like the FHS, software can ensure a consistent layout across various Linux distributions. Nonetheless, not all Linux distributions strictly adhere to this standard. They often incorporate their own unique elements or cater to specific requirements.
+
+To become proficient in this standard, you can begin by exploring. Utilize commands such as "cd" for navigation and "ls" for listing directory contents. Imagine the file system as a tree, starting from the root (/). With time, it will become second nature to you, transforming you into a skilled Linux administrator.
diff --git a/data/guides/live-streaming-explained.md b/data/guides/live-streaming-explained.md
new file mode 100644
index 0000000..711925f
--- /dev/null
+++ b/data/guides/live-streaming-explained.md
@@ -0,0 +1,46 @@
+---
+title: "Live Streaming Explained"
+description: "Learn how live streaming works on platforms like YouTube and Twitch."
+image: "https://assets.bytebytego.com/diagrams/0260-live-streaming-updated.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Live Streaming"
+ - "Video Streaming"
+---
+
+
+
+How do video live streamings work on YouTube, TikTok live, or Twitch? The technique is called live streaming.
+
+Livestreaming differs from regular streaming because the video content is sent via the internet in real-time, usually with a latency of just a few seconds.
+
+The diagram below explains what happens behind the scenes to make this possible.
+
+## Live Streaming Steps
+
+**Step 1**: The raw video data is captured by a microphone and camera. The data is sent to the server side.
+
+**Step 2**: The video data is compressed and encoded. For example, the compressing algorithm separates the background and other video elements. After compression, the video is encoded to standards such as H.264. The size of the video data is much smaller after this step.
+
+**Step 3**: The encoded data is divided into smaller segments, usually seconds in length, so it takes much less time to download or stream.
+
+**Step 4**: The segmented data is sent to the streaming server. The streaming server needs to support different devices and network conditions. This is called ‘Adaptive Bitrate Streaming.’ This means we need to produce multiple files at different bitrates in steps 2 and 3.
+
+**Step 5**: The live streaming data is pushed to edge servers supported by CDN (Content Delivery Network.) Millions of viewers can watch the video from an edge server nearby. CDN significantly lowers data transmission latency.
+
+**Step 6**: The viewers’ devices decode and decompress the video data and play the video in a video player.
+
+**Steps 7 and 8**: If the video needs to be stored for replay, the encoded data is sent to a storage server, and viewers can request a replay from it later.
+
+## Standard Protocols for Live Streaming
+
+Standard protocols for live streaming include:
+
+* **RTMP (Real-Time Messaging Protocol)**: This was originally developed by Macromedia to transmit data between a Flash player and a server. Now it is used for streaming video data over the internet. Note that video conferencing applications like Skype use RTC (Real-Time Communication) protocol for lower latency.
+* **HLS (HTTP Live Streaming)**: It requires the H.264 or H.265 encoding. Apple devices accept only HLS format.
+* **DASH (Dynamic Adaptive Streaming over HTTP)**: DASH does not support Apple devices.
+
+Both HLS and DASH support adaptive bitrate streaming.
diff --git a/data/guides/load-balancer-realistic-use-cases-you-may-not-know.md b/data/guides/load-balancer-realistic-use-cases-you-may-not-know.md
new file mode 100644
index 0000000..7c1a3c6
--- /dev/null
+++ b/data/guides/load-balancer-realistic-use-cases-you-may-not-know.md
@@ -0,0 +1,25 @@
+---
+title: 'Load Balancer Realistic Use Cases'
+description: 'Explore load balancer use cases for efficient network traffic management.'
+image: 'https://assets.bytebytego.com/diagrams/0232-http-status-code-shouldnt-exist.png'
+createdAt: '2024-01-26'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Load Balancing
+ - Scalability
+---
+
+Load balancers are inherently dynamic and adaptable, designed to efficiently address multiple purposes and use cases in network traffic and server workload management.
+
+
+
+Let's explore some of the use cases:
+
+* **Failure Handling:** Automatically redirects traffic away from malfunctioning elements to maintain continuous service and reduce service interruptions.
+* **Instance Health Checks:** Continuously evaluates the functionality of instances, directing incoming requests exclusively to those that are fully operational and efficient.
+* **Platform Specific Routing:** Routes requests from different device types (like mobiles, desktops) to specialized backend systems, providing customized responses based on platform.
+* **SSL Termination:** Handles the encryption and decryption of SSL traffic, reducing the processing burden on backend infrastructure.
+* **Cross Zone Load Balancing:** Distributes incoming traffic across various geographic or network zones, increasing the system's resilience and capacity for handling large volumes of requests.
+* **User Stickiness:** Maintains user session integrity and tailored user interactions by consistently directing requests from specific users to designated backend servers.
diff --git a/data/guides/log-parsing-cheat-sheet.md b/data/guides/log-parsing-cheat-sheet.md
new file mode 100644
index 0000000..1822c28
--- /dev/null
+++ b/data/guides/log-parsing-cheat-sheet.md
@@ -0,0 +1,48 @@
+---
+title: "Log Parsing Cheat Sheet"
+description: "A handy guide to log parsing commands for efficient log analysis."
+image: "https://assets.bytebytego.com/diagrams/0263-log-parsing.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Log Analysis"
+ - "Command Line"
+---
+
+
+
+The diagram below lists the top 6 log parsing commands.
+
+## Log Parsing Commands
+
+* **GREP**
+
+ GREP searches any given input files, selecting lines that match one or more patterns.
+
+* **CUT**
+
+ CUT cuts out selected portions of each line from each file and writes them to the standard output.
+
+* **SED**
+
+ SED reads the specified files, modifying the input as specified by a list of commands.
+
+* **AWK**
+
+ AWK scans each input file for lines that match any of a set of patterns.
+
+* **SORT**
+
+ SORT sorts text and binary files by lines.
+
+* **UNIQ**
+
+ UNIQ reads the specified input file comparing adjacent lines and writes a copy of each unique input line to the output file.
+
+These commands are often used in combination to quickly find useful information from the log files. For example, the below commands list the timestamps (column 2) when there is an exception happening for xxService.
+
+```bash
+grep “xxService” service.log | grep “Exception” | cut -d” “ -f 2
+```
diff --git a/data/guides/logging-tracing-metrics.md b/data/guides/logging-tracing-metrics.md
new file mode 100644
index 0000000..acb7749
--- /dev/null
+++ b/data/guides/logging-tracing-metrics.md
@@ -0,0 +1,28 @@
+---
+title: "Logging, Tracing, and Metrics"
+description: "Understand logging, tracing, and metrics for system observability."
+image: "https://assets.bytebytego.com/diagrams/0264-logging-tracing-metrics.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "observability"
+ - "monitoring"
+---
+
+Logging, tracing, and metrics are 3 pillars of system observability. The diagram below shows their definitions and typical architectures.
+
+
+
+## Logging
+
+Logging records discrete events in the system. For example, we can record an incoming request or a visit to databases as events. It has the highest volume. ELK (Elastic-Logstash-Kibana) stack is often used to build a log analysis platform. We often define a standardized logging format for different teams to implement, so that we can leverage keywords when searching among massive amounts of logs.
+
+## Tracing
+
+Tracing is usually request-scoped. For example, a user request goes through the API gateway, load balancer, service A, service B, and database, which can be visualized in the tracing systems. This is useful when we are trying to identify the bottlenecks in the system. We use OpenTelemetry to showcase the typical architecture, which unifies the 3 pillars in a single framework.
+
+## Metrics
+
+Metrics are usually aggregatable information from the system. For example, service QPS, API responsiveness, service latency, etc. The raw data is recorded in time-series databases like InfluxDB. Prometheus pulls the data and transforms the data based on pre-defined alerting rules. Then the data is sent to Grafana for display or to the alert manager which then sends out email, SMS, or Slack notifications or alerts.
diff --git a/data/guides/low-latency-stock-exchange.md b/data/guides/low-latency-stock-exchange.md
new file mode 100644
index 0000000..ed3d229
--- /dev/null
+++ b/data/guides/low-latency-stock-exchange.md
@@ -0,0 +1,50 @@
+---
+title: "Low Latency Stock Exchange"
+description: "Explore the architecture of a low-latency stock exchange system."
+image: "https://assets.bytebytego.com/diagrams/0265-low-latency-stock-exchange.jpg"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Low Latency"
+ - "Stock Exchange"
+---
+
+
+
+How does a modern stock exchange achieve **microsecond latency**? The principal is:
+
+**Do less on the critical path**
+
+* Fewer tasks on the critical path
+
+* Less time on each task
+
+* Fewer network hops
+
+* Less disk usage
+
+For the stock exchange, the critical path is:
+
+* **start**: an order comes into the order manager
+
+* mandatory risk checks
+
+* the order gets matched and the execution is sent back
+
+* **end**: the execution comes out of the order manager
+
+Other non-critical tasks should be removed from the critical path.
+
+We put together a design as shown in the diagram:
+
+* deploy all the components in a single giant server (no containers)
+
+* use shared memory as an event bus to communicate among the components, no hard disk
+
+* key components like Order Manager and Matching Engine are single-threaded on the critical path, and each pinned to a CPU so that there is **no context switch** and **no locks**
+
+* the single-threaded application loop executes tasks one by one in sequence
+
+* other components listen on the event bus and react accordingly
diff --git a/data/guides/making-sense-of-search-engine-optimization.md b/data/guides/making-sense-of-search-engine-optimization.md
new file mode 100644
index 0000000..5b5dfba
--- /dev/null
+++ b/data/guides/making-sense-of-search-engine-optimization.md
@@ -0,0 +1,54 @@
+---
+title: "Making Sense of Search Engine Optimization"
+description: "Understand how search engines rank websites and optimize your website."
+image: "https://assets.bytebytego.com/diagrams/0326-seo.jpg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "SEO"
+ - "Web Development"
+---
+
+
+
+You have just developed a new website. What does it take to be ranked at the top?
+
+We need to understand how search engines rank websites and optimize our website to be search engine-friendly. This is called SEO (Search Engine Optimization).
+
+A search engine works in 3 stages:
+
+* The crawler reads the page content (HTML code) and follows the hyperlink to read more web pages.
+
+* The preprocessor also works in 3 steps:
+
+ * It removes HTML tags and ‘Stop’ words, which are words like ‘a’ or ‘an’ or ‘the.’ It also removes other noise that is not relevant to the web page's content, for example, the disclaimer.
+
+ * Then the keywords form structured indices, called forward indices and inverted indices.
+
+ * The preprocessor calculates the hyperlink relationships, for example, how many hyperlinks are on the web page and how many hyperlinks point to it.
+
+* When a user types in a search term, the search engine uses the indices and ranking algorithms to rank the web pages and presents the search results to the user.
+
+How do we make our website rank higher in search results? The diagram below shows some ways to do this.
+
+## Optimize website structure:
+
+We need to make it easier for the crawler to crawl our website. Remove anything the crawler cannot read, including flash, frames, and dynamic URLs. Make the website hierarchy less deep, so the web pages are less distant from the main home page.
+
+The URLs must be short and descriptive. Try to include keywords in the URLs, as well. It will also help to use HTTPS. But don’t use underscore in the URL because that will screw up the tokenization.
+
+## Choose the keywords to optimize for:
+
+Keywords must be relevant to what the website is selling, and they must have business values. For example, a keyword is considered valuable if it’s a popular search, but has fewer search results.
+
+## Optimize the web page
+
+The crawler crawls the HTML contents. Therefore the title and description should be optimized to include keywords and be concise. The body of the web page should include relevant keywords.
+
+Another aspect is the user experience. In May 2020, Google published Core Web Vitals, officially listing user experience as an important factor of page ranking algorithms.
+
+## External link
+
+If our website is referenced by a highly-ranked website, it will increase our website’s ranking. So carefully building external links is important. Publishing high-quality content on your website which is useful to other users, is a good way to attract external links.
diff --git a/data/guides/mcdonald's-event-driven-architecture.md b/data/guides/mcdonald's-event-driven-architecture.md
new file mode 100644
index 0000000..01c92e9
--- /dev/null
+++ b/data/guides/mcdonald's-event-driven-architecture.md
@@ -0,0 +1,27 @@
+---
+title: 'McDonald’s Event-Driven Architecture'
+description: 'Explore McDonald’s event-driven architecture for scalability and efficiency.'
+image: 'https://assets.bytebytego.com/diagrams/0266-mcdonald-s-event-driven-architecture.png'
+createdAt: '2024-02-18'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Event-Driven Architecture
+ - Case Study
+---
+
+
+
+Think you know everything about McDonald's? What about its event-driven architecture?
+
+McDonald's standardizes events using the following components:
+
+* **Event Registry:** An event registry to define a standardized schema.
+* **Custom SDKs:** Custom software development kits (SDKs) to process events and handle errors.
+* **Event Gateway:** An event gateway that performs identity authentication and authorization.
+* **Utilities and Tools:** Utilities and tools to fix events, keep the cluster healthy, and perform administrative tasks.
+
+To scale event processing, McDonald uses a regional architecture that provides global availability based on AWS. Within a region, producers shard events by domains, and each domain is processed by an MSK cluster. The cluster auto-scales based on MSK metrics (e.g., CPU usage), and the auto-scale workflow is based on step-functions and re-assignment tasks.
+
+Reference: Behind the scenes: [McDonald’s event-driven architecture](https://medium.com/mcdonalds-technical-blog/behind-the-scenes-mcdonalds-event-driven-architecture-51a6542c0d86)
diff --git a/data/guides/memcached-vs-redis.md b/data/guides/memcached-vs-redis.md
new file mode 100644
index 0000000..cedcae4
--- /dev/null
+++ b/data/guides/memcached-vs-redis.md
@@ -0,0 +1,26 @@
+---
+title: "Memcached vs Redis"
+description: "Explore the key differences between Memcached and Redis for caching."
+image: "https://assets.bytebytego.com/diagrams/0267-memcached-redis.jpg"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "memcached"
+ - "redis"
+---
+
+
+
+Popular interview question - what are the differences between Redis and Memcached?
+
+The diagram above illustrates the key differences. The advantages of data structures make Redis a good choice for:
+
+* Recording the number of clicks and comments for each post (hash)
+
+* Sorting the commented user list and deduping the users (zset)
+
+* Caching user behavior history and filtering malicious behaviors (zset, hash)
+
+* Storing boolean information of extremely large data into small space. For example, login status, membership status. (bitmap)
diff --git a/data/guides/money-movement.md b/data/guides/money-movement.md
new file mode 100644
index 0000000..32dd5b5
--- /dev/null
+++ b/data/guides/money-movement.md
@@ -0,0 +1,58 @@
+---
+title: "Money Movement"
+description: "Understanding the flow of money during online transactions."
+image: "https://assets.bytebytego.com/diagrams/0127-buy-something-money-movement.jpg"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Fintech"
+---
+
+One picture is worth more than a thousand words. This is what happens when you buy a product using Paypal/bank card under the hood.
+
+
+
+To understand this, we need to digest two concepts: **clearing & settlement**. Clearing is a process that calculates who should pay whom with how much money; while settlement is a process where real money moves between reserves in the settlement bank.
+
+Let’s say Bob wants to buy an SDI book from Claire’s shop on Amazon.
+
+### Pay-in flow (Bob pays Amazon money):
+
+* Bob buys a book on Amazon using Paypal.
+
+* Amazon issues a money transfer request to Paypal.
+
+* Since the payment token of Bob’s debit card is stored in Paypal, Paypal can transfer money, on Bob’s behalf, to Amazon’s bank account in Bank A.
+
+* Both Bank A and Bank B send transaction statements to the clearing institution. It reduces the transactions that need to be settled. Let’s assume Bank A owes Bank B $100 and Bank B owes bank A $500 at the end of the day. When they settle, the net position is that Bank B pays Bank A $400.
+
+* 1. 5 & 1.6 The clearing institution sends clearing and settlement information to the settlement bank. Both Bank A and Bank B have pre-deposited funds in the settlement bank as money reserves, so actual money movement happens between two reserve accounts in the settlement bank.
+
+### Pay-out flow (Amazon pays the money to the seller: Claire):
+
+* Amazon informs the seller (Claire) that she will get paid soon.
+
+* Amazon issues a money transfer request from its owe bank (Bank A) to the seller bank (bank C). Here both banks record the transactions, but no real money is moved.
+
+* Both Bank A and Bank C send transaction statements to the clearing institution.
+
+* 2. 4 & 2.5 The clearing institution sends clearing and settlement information to the settlement bank. Money is transferred from Bank A’s reserve to Bank C’s reserve.
+
+Notice that we have three layers:
+
+* Transaction layer: where the online purchases happen
+
+* Payment and clearing layer: where the payment instructions and transaction netting happen
+
+* Settlement layer: where the actual money movement happen
+
+The first two layers are called information flow, and the settlement layer is called fund flow.
+
+You can see the **information flow and fund flow are separated**. In the info flow, the money seems to be deducted from one bank account and added to another bank account, but the actual money movement happens in the settlement bank at the end of the day.
+
+Because of the asynchronous nature of the info flow and the fund flow, reconciliation is very important for data consistency in the systems along with the flow.
+
+It makes things even more interesting when Bob wants to buy a book in the Indian market, where Bob pays USD but the seller can only receive INR.
diff --git a/data/guides/monorepo-vs.md b/data/guides/monorepo-vs.md
new file mode 100644
index 0000000..1d52b68
--- /dev/null
+++ b/data/guides/monorepo-vs.md
@@ -0,0 +1,40 @@
+---
+title: "Monorepo vs. Microrepo: Which is Best?"
+description: "Explore the monorepo vs. microrepo approach to code management."
+image: "https://assets.bytebytego.com/diagrams/0279-monorepo-microrepo.png"
+createdAt: "2024-02-12"
+draft: false
+categories:
+ - "cloud-distributed-systems"
+tags:
+ - "Monorepo"
+ - "Microservices"
+---
+
+
+
+Why do different companies choose different options?
+
+## Do you believe that Google, Meta, Uber, and Airbnb put almost all of their code in one repository?
+
+This practice is called a monorepo. Guest post by [Xiong Wang](https://www.linkedin.com/in/wangxiong/).
+
+Monorepo isn't new; Linux and Windows were both created using Monorepo. To improve scalability and build speed, Google developed its internal dedicated toolchain to scale it faster and strict coding quality standards to keep it consistent.
+
+Amazon and Netflix are major ambassadors of the Microservice philosophy. This approach naturally separates the service code into separate repositories. It scales faster but can lead to governance pain points later on.
+
+Within Monorepo, each service is a folder, and every folder has a BUILD config and OWNERS permission control. Every service member is responsible for their own folder.
+
+On the other hand, in Microrepo, each service is responsible for its repository, with the build config and permissions typically set for the entire repository.
+
+In Monorepo, dependencies are shared across the entire codebase regardless of your business, so when there's a version upgrade, every codebase upgrades their version.
+
+In Microrepo, dependencies are controlled within each repository. Businesses choose when to upgrade their versions based on their own schedules.
+
+Monorepo has a standard for check-ins. Google's code review process is famously known for setting a high bar, ensuring a coherent quality standard for Monorepo, regardless of the business.
+
+Microrepo can either set their own standard or adopt a shared standard by incorporating best practices. It can scale faster for business, but the code quality might be a bit different.
+
+Google engineers built Bazel, and Meta built Buck. There are other open-source tools available, including Nix, Lerna, and others.
+
+Over the years, Microrepo has had more supported tools, including Maven and Gradle for Java, NPM for NodeJS, and CMake for C/C++, among others.
diff --git a/data/guides/most-popular-cache-eviction.md b/data/guides/most-popular-cache-eviction.md
new file mode 100644
index 0000000..4340ed1
--- /dev/null
+++ b/data/guides/most-popular-cache-eviction.md
@@ -0,0 +1,48 @@
+---
+title: "Cache Eviction Policies"
+description: "Explore popular cache eviction strategies and their impact on performance."
+image: "https://assets.bytebytego.com/diagrams/0281-most-popular-cache-eviction.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Algorithms"
+---
+
+
+
+What are the most popular Cache Eviction strategies? And how do they work?
+
+Caching can provide a boost to your application’s performance by storing data in memory for faster access.
+
+But when the cache gets full, you need to evict some data to make room for new stuff.
+
+This is where cache eviction strategies come into play.
+
+The strategy you choose can have a significant impact on your system's performance, memory usage, and hit rates. Here are five popular strategies to consider:
+
+## Time-to-Live (TTL)
+
+Items are evicted after a predetermined time period, regardless of access patterns. It’s simple to implement but can lead to premature eviction of frequently used data. TTL is suitable for data that is only valid for a certain period of time such as session information. It is also used as a default fallback strategy.
+
+## Least-Recently Used (LRU)
+
+Evicts the least recently accessed items first. This strategy works well when access patterns exhibit temporal locality, i.e., recently accessed items are likely to be accessed again soon.
+
+## Least Frequently Used (LFU)
+
+Evicts the least frequently accessed items first. Suitable when some items are accessed more often than others, and you want to keep only the most popular items in the cache. However, you also need a mechanism to maintain a count of the number of times an item is accessed.
+
+## Most Recently Used (MRU)
+
+Evicts the most recently accessed items first. Counterintuitive but useful in specific scenarios like operating system buffer caches, where recently evicted items are unlikely to be needed again soon. Also useful in streaming or batch-processing requirements.
+
+## Segmented LRU (SLRU)
+
+Divides the cache into probationary and protected segments, applying LRU separately to each. Newly added items go into the probationary segment, and frequently accessed items are promoted to the protected segment, shielding them from being evicted too soon.
+
+The best caching strategy depends on the context of your system requirements and constraints. But having a broad understanding of them can help make the right choice.
+
+Over to you: have you used any other cache eviction strategy?
diff --git a/data/guides/most-used-linux-commands-map.md b/data/guides/most-used-linux-commands-map.md
new file mode 100644
index 0000000..1245916
--- /dev/null
+++ b/data/guides/most-used-linux-commands-map.md
@@ -0,0 +1,30 @@
+---
+title: "Most Used Linux Commands Map"
+description: "A concise guide to the most used Linux commands."
+image: "https://assets.bytebytego.com/diagrams/0283-most-used-linux.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "linux"
+ - "commands"
+---
+
+
+
+This map provides a concise overview of the most commonly used Linux commands, categorized by their primary function.
+
+## File and Directory Management
+
+## File Viewing and Editing
+
+## Process Management
+
+## System Information
+
+## User and Group Management
+
+## Network Configuration and Monitoring
+
+## Package Management
diff --git a/data/guides/must-know-system-design-building-blocks.md b/data/guides/must-know-system-design-building-blocks.md
new file mode 100644
index 0000000..9983706
--- /dev/null
+++ b/data/guides/must-know-system-design-building-blocks.md
@@ -0,0 +1,58 @@
+---
+title: "Must Know System Design Building Blocks"
+description: "Essential system design components for building scalable applications."
+image: "https://assets.bytebytego.com/diagrams/0285-must-know-system-design-building-blocks.png"
+createdAt: "2024-02-11"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "scalability"
+---
+
+
+
+These are divided into 6 broad categories
+
+## Distributed Computing
+
+* Distributed message queues facilitate async communication and decouple services
+
+* Distributed caching improves performance by storing frequently accessed data in memory
+
+* A Distributed task scheduler manages and coordinates the execution of tasks
+
+## Scalability and Performance
+
+* Scaling services help adjust the capacity of services to handle changes in demand
+
+* CDNs serve content from geographically closer locations to improve performance and reduce latency.
+
+* Consistent hashing minimizes the remapping of keys when nodes are added or removed
+
+## Service Management
+
+* Service discovery enables services to find and communicate with each other without hard-coding network locations
+
+## Networking and Communication
+
+* DNS translates human-readable domain names into IP addresses
+
+* Load Balancer distributes incoming network traffic across multiple servers
+
+* API Gateway acts as a single entry point for a group of microservices
+
+## Data Storage and Management
+
+* Databases store and manage structured data
+
+* Object storage helps store complex objects like images, videos, and documents
+
+* Sharding helps horizontally partition data across multiple nodes
+
+* Replication helps horizontally scale the database by copying data to multiple nodes
+
+## Observability and Resiliency
+
+Gain insights into the system's internal state through metrics, logging, and tracing.
diff --git a/data/guides/mvc-mvp-mvvm-viper-patterns.md b/data/guides/mvc-mvp-mvvm-viper-patterns.md
new file mode 100644
index 0000000..634f337
--- /dev/null
+++ b/data/guides/mvc-mvp-mvvm-viper-patterns.md
@@ -0,0 +1,28 @@
+---
+title: "MVC, MVP, MVVM, VIPER Patterns"
+description: "Comparing MVC, MVP, MVVM, and VIPER architectural patterns."
+image: "https://assets.bytebytego.com/diagrams/0143-client-arch-patterns.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "architectural patterns"
+ - "software design"
+---
+
+
+
+What distinguishes MVC, MVP, MVVM, MVVM-C, and VIPER architecture patterns from each other?
+
+These architecture patterns are among the most commonly used in app development, whether on iOS or Android platforms. Developers have introduced them to overcome the limitations of earlier patterns. So, how do they differ?
+
+* MVC, the oldest pattern, dates back almost 50 years
+
+* Every pattern has a "view" (V) responsible for displaying content and receiving user input
+
+* Most patterns include a "model" (M) to manage business data
+
+* "Controller," "presenter," and "view-model" are translators that mediate between the view and the model ("entity" in the VIPER pattern)
+
+* These translators can be quite complex to write, so various patterns have been proposed to make them more maintainable
diff --git a/data/guides/my-recommended-materials-for-cracking-your-next-technical-interview.md b/data/guides/my-recommended-materials-for-cracking-your-next-technical-interview.md
new file mode 100644
index 0000000..7066b04
--- /dev/null
+++ b/data/guides/my-recommended-materials-for-cracking-your-next-technical-interview.md
@@ -0,0 +1,50 @@
+---
+title: "Recommended Materials for Technical Interviews"
+description: "Ace your technical interviews with these recommended resources."
+image: "https://assets.bytebytego.com/diagrams/0353-my-recommended-materials-for-cracking-your-next-technical-interview.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "interview preparation"
+ - "system design"
+---
+
+
+
+## Coding
+
+* Leetcode
+* Cracking the coding interview book
+* Neetcode
+
+## System Design Interview
+
+* System Design Interview Book 1, 2 by Alex Xu, Sahn Lam
+* Grokking the system design by Design Guru
+* Design Data-intensive Application book
+
+## Behavioral interview
+
+* Tech Interview Handbook (Github repo)
+* A Life Engineered (YT)
+* STAR method (general method)
+
+## OOD Interview
+
+* Interviewready
+* OOD by educative
+* Head First Design Patterns Book
+
+## Mock interviews
+
+* Interviewingio
+* Pramp
+* Meetapro
+
+## Apply for Jobs
+
+* Linkedin
+* Monster
+* Indeed
diff --git a/data/guides/netflix-tech-stack-cicd-pipeline.md b/data/guides/netflix-tech-stack-cicd-pipeline.md
new file mode 100644
index 0000000..e6c6e99
--- /dev/null
+++ b/data/guides/netflix-tech-stack-cicd-pipeline.md
@@ -0,0 +1,31 @@
+---
+title: 'Netflix Tech Stack - CI/CD Pipeline'
+description: "Netflix's CI/CD pipeline: from planning to incident reporting."
+image: 'https://assets.bytebytego.com/diagrams/0287-netflix-ci-cd.png'
+createdAt: '2024-03-02'
+draft: false
+categories:
+ - real-world-case-studies
+ - devops-cicd
+tags:
+ - CI/CD
+ - Streaming
+---
+
+
+
+* **Planning:** Netflix Engineering uses JIRA for planning and Confluence for documentation.
+
+* **Coding:** Java is the primary programming language for the backend service, while other languages are used for different use cases.
+
+* **Build:** Gradle is mainly used for building, and Gradle plugins are built to support various use cases.
+
+* **Packaging:** Package and dependencies are packed into an Amazon Machine Image (AMI) for release.
+
+* **Testing:** Testing emphasizes the production culture's focus on building chaos tools.
+
+* **Deployment:** Netflix uses its self-built Spinnaker for canary rollout deployment.
+
+* **Monitoring:** The monitoring metrics are centralized in Atlas, and Kayenta is used to detect anomalies.
+
+* **Incident report:** Incidents are dispatched according to priority, and PagerDuty is used for incident handling.
diff --git a/data/guides/netflix-tech-stack-databases.md b/data/guides/netflix-tech-stack-databases.md
new file mode 100644
index 0000000..e985f83
--- /dev/null
+++ b/data/guides/netflix-tech-stack-databases.md
@@ -0,0 +1,30 @@
+---
+title: Netflix Tech Stack - Databases
+description: Netflix uses a variety of databases to power streaming at scale.
+image: 'https://assets.bytebytego.com/diagrams/0098-databases-used-in-netflix.jpg'
+createdAt: '2024-02-26'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Databases
+ - Tech Stack
+---
+
+
+
+The Netflix Engineering team selects a variety of databases to empower streaming at scale.
+
+* **Relational databases:** Netflix chooses MySql for billing transactions, subscriptions, taxes, and revenue. They also use CockroachDB to support a multi-region active-active architecture, global transactions, and data pipeline workflows.
+
+* **Columnar databases:** Netflix primarily uses them for analytics purposes. They utilize Redshift and Druid for structured data storage, Spark and data pipeline processing, and Tableau for data visualization.
+
+* **Key-value databases:** Netflix mainly uses EVCache built on top of Memcached. EVCache has been with Netflix for over 10 years and is used for most services, caching various data such as the Netflix Homepage and Personal Recommendations.
+
+* **Wide-column databases:** Cassandra is usually the default choice at Netflix. They use it for almost everything, including Video/Actor information, User Data, Device information, and Viewing History.
+
+* **Time-series databases:** Netflix built an open-source in-memory database called Atlas for metrics storage and aggregation.
+
+* **Unstructured data:** S3 is the default choice and stores almost everything related to Image/Video/Metrics/Log files. Apache Iceberg is also used with S3 for big data storage.
+
+If you work for a large company and wish to discuss your company's technology stack, feel free to get in touch with me. By default, all communications will be treated as anonymous.
diff --git a/data/guides/netflixs-overall-architecture.md b/data/guides/netflixs-overall-architecture.md
new file mode 100644
index 0000000..ad57206
--- /dev/null
+++ b/data/guides/netflixs-overall-architecture.md
@@ -0,0 +1,32 @@
+---
+title: "Netflix's Overall Architecture"
+description: "Explore Netflix's architecture: from frontend to backend services."
+image: 'https://assets.bytebytego.com/diagrams/0288-netflix-overal-arch.png'
+createdAt: '2024-03-01'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Streaming
+---
+
+
+
+This post is based on research from many Netflix engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us.
+
+Mobile and web: Netflix has adopted Swift and Kotlin to build native mobile apps. For its web application, it uses React.
+
+Frontend/server communication: Netflix uses GraphQL.
+
+Backend services: Netflix relies on ZUUL, Eureka, the Spring Boot framework, and other technologies.
+
+Databases: Netflix utilizes EV cache, Cassandra, CockroachDB, and other databases.
+
+Messaging/streaming: Netflix employs Apache Kafka and Fink for messaging and streaming purposes.
+
+Video storage: Netflix uses S3 and Open Connect for video storage.
+
+Data processing: Netflix utilizes Flink and Spark for data processing, which is then visualized using Tableau. Redshift is used for processing structured data warehouse information.
+
+CI/CD: Netflix employs various tools such as JIRA, Confluence, PagerDuty, Jenkins, Gradle, Chaos Monkey, Spinnaker, Altas, and more for CI/CD processes.
diff --git a/data/guides/netflixs-tech-stack.md b/data/guides/netflixs-tech-stack.md
new file mode 100644
index 0000000..bcb14a6
--- /dev/null
+++ b/data/guides/netflixs-tech-stack.md
@@ -0,0 +1,32 @@
+---
+title: Netflix's Tech Stack
+description: Explore the technologies behind Netflix's streaming infrastructure.
+image: 'https://assets.bytebytego.com/diagrams/0286-netflix-tech-stack.png'
+createdAt: '2024-03-15'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Streaming
+---
+
+This post is based on research from many Netflix engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us.
+
+
+
+* Mobile and web: Netflix has adopted Swift and Kotlin to build native mobile apps. For its web application, it uses React.
+
+* Frontend/server communication: GraphQL.
+
+* Backend services: Netflix relies on ZUUL, Eureka, the Spring Boot framework, and other technologies.
+
+* Databases: Netflix utilizes EV cache, Cassandra, CockroachDB, and other databases.
+
+* Messaging/streaming: Netflix employs Apache Kafka and Fink for messaging and streaming purposes.
+
+* Video storage: Netflix uses S3 and Open Connect for video storage.
+
+* Data processing: Netflix utilizes Flink and Spark for data processing, which is then visualized using Tableau. Redshift is used for processing structured data warehouse information.
+
+* CI/CD: Netflix employs various tools such as JIRA, Confluence, PagerDuty, Jenkins, Gradle, Chaos Monkey, Spinnaker, Altas, and more for CI/CD processes.
diff --git a/data/guides/oauth-2-explained-with-siple-terms.md b/data/guides/oauth-2-explained-with-siple-terms.md
new file mode 100644
index 0000000..6596c86
--- /dev/null
+++ b/data/guides/oauth-2-explained-with-siple-terms.md
@@ -0,0 +1,30 @@
+---
+title: "OAuth 2.0 Explained With Simple Terms"
+description: "Learn about OAuth 2.0, a secure framework for app interactions."
+image: "https://assets.bytebytego.com/diagrams/0111-what-is-oauth.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - security
+tags:
+ - "OAuth 2.0"
+ - "Authentication"
+---
+
+
+
+OAuth 2.0 is a powerful and secure framework that allows different applications to securely interact with each other on behalf of users without sharing sensitive credentials.
+
+The entities involved in OAuth are the User, the Server, and the Identity Provider (IDP).
+
+## What Can an OAuth Token Do?
+
+When you use OAuth, you get an OAuth token that represents your identity and permissions. This token can do a few important things:
+
+* Single Sign-On (SSO): With an OAuth token, you can log into multiple services or apps using just one login, making life easier and safer.
+
+* Authorization Across Systems: The OAuth token allows you to share your authorization or access rights across various systems, so you don't have to log in separately everywhere.
+
+* Accessing User Profile: Apps with an OAuth token can access certain parts of your user profile that you allow, but they won't see everything.
+
+Remember, OAuth 2.0 is all about keeping you and your data safe while making your online experiences seamless and hassle-free across different applications and services.
diff --git a/data/guides/oauth-20-flows.md b/data/guides/oauth-20-flows.md
new file mode 100644
index 0000000..932df53
--- /dev/null
+++ b/data/guides/oauth-20-flows.md
@@ -0,0 +1,30 @@
+---
+title: "OAuth 2.0 Flows"
+description: "Explore OAuth 2.0 flows: Authorization Code, Client Credentials, and more."
+image: "https://assets.bytebytego.com/diagrams/0112-oauth-flows.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - security
+tags:
+ - "OAuth 2.0"
+ - "Authorization"
+---
+
+
+
+## Authorization Code Flow
+
+The most common OAuth flow. After user authentication, the client receives an authorization code and exchanges it for an access token and refresh token.
+
+## Client Credentials Flow
+
+Designed for single-page applications. The access token is returned directly to the client without an intermediate authorization code.
+
+## Implicit Code Flow
+
+Designed for single-page applications. The access token is returned directly to the client without an intermediate authorization code.
+
+## Resource Owner Password Grant Flow
+
+Allows users to provide their username and password directly to the client, which then exchanges them for an access token.
diff --git a/data/guides/orchestration-vs-choreography-microservices.md b/data/guides/orchestration-vs-choreography-microservices.md
new file mode 100644
index 0000000..7d7306e
--- /dev/null
+++ b/data/guides/orchestration-vs-choreography-microservices.md
@@ -0,0 +1,36 @@
+---
+title: "Orchestration vs. Choreography in Microservices"
+description: "Explore orchestration vs. choreography for microservice collaboration."
+image: "https://assets.bytebytego.com/diagrams/0113-orchestration-vs-choreography-microservices.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Microservices
+ - Architecture
+---
+
+
+
+How do microservices collaborate and interact with each other?
+
+There are two ways: 𝐨𝐫𝐜𝐡𝐞𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧 and 𝐜𝐡𝐨𝐫𝐞𝐨𝐠𝐫𝐚𝐩𝐡𝐲.
+
+Choreography is like having a choreographer set all the rules. Then the dancers on stage (the microservices) interact according to them. Service choreography describes this exchange of messages and the rules by which the microservices interact.
+
+Orchestration is different. The orchestrator acts as a center of authority. It is responsible for invoking and combining the services. It describes the interactions between all the participating services. It is just like a conductor leading the musicians in a musical symphony. The orchestration pattern also includes the transaction management among different services.
+
+## The benefits of orchestration:
+
+* **Reliability** - orchestration has built-in transaction management and error handling, while choreography is point-to-point communications and the fault tolerance scenarios are much more complicated.
+
+* **Scalability** - when adding a new service into orchestration, only the orchestrator needs to modify the interaction rules, while in choreography all the interacting services need to be modified.
+
+## Some limitations of orchestration:
+
+* **Performance** - all the services talk via a centralized orchestrator, so latency is higher than it is with choreography. Also, the throughput is bound to the capacity of the orchestrator.
+
+* **Single point of failure** - if the orchestrator goes down, no services can talk to each other. To mitigate this, the orchestrator must be highly available.
+
+Real-world use case: Netflix Conductor is a microservice orchestrator and you can read more details on the orchestrator design.
diff --git a/data/guides/paradigm-shift-how-developer-to-tester-ratio-changed-from-11-to-1001.md b/data/guides/paradigm-shift-how-developer-to-tester-ratio-changed-from-11-to-1001.md
new file mode 100644
index 0000000..0f55a65
--- /dev/null
+++ b/data/guides/paradigm-shift-how-developer-to-tester-ratio-changed-from-11-to-1001.md
@@ -0,0 +1,40 @@
+---
+title: "Paradigm Shift: Developer to Tester Ratio"
+description: "Explore the paradigm shift in developer to tester ratios over the years."
+image: "https://assets.bytebytego.com/diagrams/0170-dev-tester-ratio.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Software Testing"
+ - "DevOps"
+---
+
+
+
+This post is inspired by the article "The Paradigm Shifts with Different Dev:Test Ratios" by [Carlos Arguelles](https://www.linkedin.com/in/ACoAAABj60kByWwNDRyWLdeCCmaKZYUHd4LynqQ). I highly recommend that you read the original article [here](https://lnkd.in/ehbZzZck).
+
+## 1:1 ratio (~1997)
+
+Software used to be burned onto physical CDs and delivered to customers. The development process was waterfall-style, builds were certified, and versions were released roughly every three years.
+
+If you had a bug, that bug would live forever. It wasn’t until years later that companies added the ability for software to ping the internet for updates and automatically install them.
+
+## 10:1 ratio (~2009)
+
+Around 2009, the release-to-production speed increased significantly. Patches could be installed within weeks, and the agile movement, along with iteration-driven development, changed the development process.
+
+For example, at Amazon, the web services are mainly developed and tested by the developers. They are also responsible for dealing with production issues, and testing resources are stretched thin (10:1 ratio).
+
+## 100:1 ratio (~2020)
+
+Around 2015, big tech companies like Google and Microsoft removed SDET or SETI titles, and Amazon slowed down the hiring of SDETs.
+
+But how is this going to work for big tech in terms of testing?
+
+Firstly, the testing aspect of the software has shifted towards highly scalable, standardized testing tools. These tools have been widely adopted by developers for building their own automated tests.
+
+Secondly, testing knowledge is disseminated through education and consulting.
+
+Together, these factors have facilitated a smooth transition to the 100:1 testing ratio we see today.
diff --git a/data/guides/payment-system.md b/data/guides/payment-system.md
new file mode 100644
index 0000000..d6c825d
--- /dev/null
+++ b/data/guides/payment-system.md
@@ -0,0 +1,39 @@
+---
+title: "Payment System"
+description: "Explore the architecture and flow of a typical payment system."
+image: "https://assets.bytebytego.com/diagrams/0299-payment-system.jpeg"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - payment-and-fintech
+ - how-it-works
+tags:
+ - "Payment Processing"
+ - "System Design"
+---
+
+
+
+Here is how money moves when you click the Buy button on Amazon or any of your favorite shopping websites.
+
+## Payment Flow
+
+* When a user clicks the “Buy” button, a payment event is generated and sent to the payment service.
+
+* The payment service stores the payment event in the database.
+
+* Sometimes a single payment event may contain several payment orders. For example, you may select products from multiple sellers in a single checkout process. The payment service will call the payment executor for each payment order.
+
+* The payment executor stores the payment order in the database.
+
+* The payment executor calls an external PSP to finish the credit card payment.
+
+* After the payment executor has successfully executed the payment, the payment service will update the wallet to record how much money a given seller has.
+
+* The wallet server stores the updated balance information in the database.
+
+* After the wallet service has successfully updated the seller’s balance information, the payment service will call the ledger to update it.
+
+* The ledger service appends the new ledger information to the database.
+
+* Every night the PSP or banks send settlement files to their clients. The settlement file contains the balance of the bank account, together with all the transactions that took place on this bank account during the day.
diff --git a/data/guides/pessimistic-vs-optimistic-locking.md b/data/guides/pessimistic-vs-optimistic-locking.md
new file mode 100644
index 0000000..7a5c4a5
--- /dev/null
+++ b/data/guides/pessimistic-vs-optimistic-locking.md
@@ -0,0 +1,30 @@
+---
+title: "Pessimistic vs Optimistic Locking"
+description: "Explore pessimistic and optimistic locking strategies for data consistency."
+image: "https://assets.bytebytego.com/diagrams/0301-pessimistic-vs-optimistic-locking.png"
+createdAt: "2024-01-29"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Concurrency Control"
+ - "Database Transactions"
+---
+
+
+
+Locks are essential to maintain data consistency and integrity in multi-user environments. They prevent simultaneous modifications that can lead to data inconsistencies.
+
+Pessimistic locking assumes conflicts will occur and locks the data before any changes are made. It prevents other users from accessing and updating the data until the lock is released.
+
+Optimistic locking assumes conflicts are rare. It allows multiple users to access data simultaneously and checks for conflicts when changes are committed. If a conflict is detected, the operation is rolled back.
+
+## Best Practices
+
+Here are some best practices to consider:
+
+* Hold locks for the minimum possible time to reduce contention.
+* Apply locks at the most granular level such as rows rather than tables.
+* Implement retry logic for transactions that fail due to conflicts.
+* Pessimistic locking is better for data integrity but can impact performance.
+* Optimistic locking is better for efficiency and performance.
diff --git a/data/guides/polling-vs-webhooks.md b/data/guides/polling-vs-webhooks.md
new file mode 100644
index 0000000..7074f33
--- /dev/null
+++ b/data/guides/polling-vs-webhooks.md
@@ -0,0 +1,44 @@
+---
+title: "Polling vs Webhooks"
+description: "Polling vs webhooks: a detailed comparison of two data retrieval methods."
+image: 'https://assets.bytebytego.com/diagrams/0057-pooling-vs-webhook.png'
+createdAt: '2024-03-03'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - APIs
+ - Webhooks
+---
+
+
+
+## Polling
+
+Polling involves repeatedly checking the external service or endpoint at fixed intervals to retrieve updated information.
+
+It’s like constantly asking, “Do you have something new for me?” even where there might not be any update.
+
+This approach is resource-intensive and inefficient.
+
+Also, you get updates only when you ask for it, thereby missing any real-time information.
+
+However, developers have more control over when and how the data is fetched.
+
+## Webhooks
+
+Webhooks are like having a built-in notification system.
+
+You don’t continuously ask for information.
+
+Instead you create an endpoint in your application server and provide it as a callback to the external service (such as a payment processor or a shipping vendor)
+
+Every time something interesting happens, the external service calls the endpoint and provides the information.
+
+This makes webhooks ideal for dealing with real-time updates because data is pushed to your application as soon as it’s available.
+
+So, when to use Polling or Webhook?
+
+Polling is a solid option when there is some infrastructural limitation that prevents the use of webhooks. Also, with webhooks there is a risk of missed notifications due to network issues, hence proper retry mechanisms are needed.
+
+Webhooks are recommended for applications that need instant data delivery. Also, webhooks are efficient in terms of resource utilization especially in high throughput environments.
diff --git a/data/guides/possible-experiment-platform-architecture.md b/data/guides/possible-experiment-platform-architecture.md
new file mode 100644
index 0000000..6f316a8
--- /dev/null
+++ b/data/guides/possible-experiment-platform-architecture.md
@@ -0,0 +1,26 @@
+---
+title: "Experiment Platform Architecture"
+description: "Explore the architecture of an experiment platform with key components."
+image: "https://assets.bytebytego.com/diagrams/0189-experiment-framework.jpg"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "A/B Testing"
+ - "Experimentation"
+---
+
+[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd79ea50e-e386-41c9-9f66-e28006ed1115_1677x1536.jpeg)
+
+The architecture of a potential experiment platform is depicted in the diagram below. This content of the visual is from the book: "Trustworthy Online Controlled Experiments" (redrawn by me). The platform contains 4 high-level components.
+
+## Key Components
+
+* **Experiment definition, setup, and management via a UI.** They are stored in the experiment system configuration.
+
+* **Experiment deployment** to both the server and client-side (covers variant assignment and parameterization as well).
+
+* **Experiment instrumentation.**
+
+* **Experiment analysis.**
diff --git a/data/guides/proximity-service.md b/data/guides/proximity-service.md
new file mode 100644
index 0000000..aae7ae3
--- /dev/null
+++ b/data/guides/proximity-service.md
@@ -0,0 +1,48 @@
+---
+title: "Proximity Service"
+description: "Explore the design of proximity services for finding nearby locations."
+image: "https://assets.bytebytego.com/diagrams/0306-proximity-service-design.jpg"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Location Services"
+ - "Geospatial Data"
+---
+
+
+
+How do we find nearby restaurants on Yelp or Google Maps? Here are some design details behind the scenes.
+
+There are two key services (see the diagram below):
+
+## Business Service
+
+* Add/delete/update restaurant information
+* Customers view restaurant details
+
+## Location-based Service
+
+* Given a radius and location, return a list of nearby restaurants
+
+How are the restaurant locations stored in the database so that LBS can return nearby restaurants efficiently?
+
+Store the latitude and longitude of restaurants in the database? The query will be very inefficient when you need to calculate the distance between you and every restaurant.
+
+One way to speed up the search is using the geohash algorithm.
+
+First, divide the planet into four quadrants along with the prime meridian and equator:
+
+* Latitude range \[-90, 0] is represented by 0
+* Latitude range \[0, 90] is represented by 1
+* Longitude range \[-180, 0] is represented by 0
+* Longitude range \[0, 180] is represented by 1
+
+Second, divide each grid into four smaller grids. Each grid can be represented by alternating between longitude bit and latitude bit.
+
+So when you want to search for the nearby restaurants in the red-highlighted grid, you can write SQL like:
+
+SELECT \* FROM geohash\_index WHERE geohash LIKE \`01%\`
+
+Geohash has some limitations. There can be a lot of restaurants in one grid (downtown New York), but none in another grid (ocean). So there are other more complicated algorithms to optimize the process. Let me know if you are interested in the details.
diff --git a/data/guides/proxy-vs-reverse-proxy.md b/data/guides/proxy-vs-reverse-proxy.md
new file mode 100644
index 0000000..f25a285
--- /dev/null
+++ b/data/guides/proxy-vs-reverse-proxy.md
@@ -0,0 +1,27 @@
+---
+title: 'Proxy vs Reverse Proxy'
+description: 'Understanding the differences between forward and reverse proxies.'
+image: 'https://assets.bytebytego.com/diagrams/0196-forward-proxy-vs-reverse-proxy.png'
+createdAt: '2024-03-01'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Networking
+ - Security
+---
+
+
+
+A forward proxy is a server that sits between user devices and the internet. A forward proxy is commonly used for:
+
+* **Protect clients**
+* **Avoid browsing restrictions**
+* **Block access to certain content**
+
+A reverse proxy is a server that accepts a request from the client, forwards the request to web servers, and returns the results to the client as if the proxy server had processed the request. A reverse proxy is good for:
+
+* **Protect servers**
+* **Load balancing**
+* **Cache static contents**
+* **Encrypt and decrypt SSL communications**
diff --git a/data/guides/push-vs-pull-in-metrics-collecting-systems.md b/data/guides/push-vs-pull-in-metrics-collecting-systems.md
new file mode 100644
index 0000000..41cf2e1
--- /dev/null
+++ b/data/guides/push-vs-pull-in-metrics-collecting-systems.md
@@ -0,0 +1,32 @@
+---
+title: "Push vs Pull in Metrics Collection Systems"
+description: "Explore push vs pull models in metrics collection systems."
+image: "https://assets.bytebytego.com/diagrams/0274-metrics-push-pull.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "metrics"
+ - "monitoring"
+---
+
+[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F197e300b-7e29-40b4-ac0e-8e9280133bf0_1514x1999.png)
+
+There are two ways metrics data can be collected, pull or push. It is a routine debate as to which one is better and there is no clear answer. In this post, we will take a look at the pull model.
+
+Figure 1 shows data collection with a pull model over HTTP. We have dedicated metric collectors which pull metrics values from the running applications periodically.
+
+In this approach, the metrics collector needs to know the complete list of service endpoints to pull data from. One naive approach is to use a file to hold DNS/IP information for every service endpoint on the “metric collector” servers. While the idea is simple, this approach is hard to maintain in a large-scale environment where servers are added or removed frequently, and we want to ensure that metric collectors don’t miss out on collecting metrics from any new servers.
+
+The good news is that we have a reliable, scalable, and maintainable solution available through Service Discovery, provided by Kubernetes, Zookeeper, etc., wherein services register their availability and the metrics collector can be notified by the Service Discovery component whenever the list of service endpoints changes. Service discovery contains configuration rules about when and where to collect metrics as shown in Figure 2.
+
+Figure 3 explains the pull model in detail.
+
+### Pull Model Details
+
+* The metrics collector fetches configuration metadata of service endpoints from Service Discovery. Metadata include pulling interval, IP addresses, timeout and retries parameters, etc.
+
+* The metrics collector pulls metrics data via a pre-defined HTTP endpoint (for example, /metrics). To expose the endpoint, a client library usually needs to be added to the service. In Figure 3, the service is Web Servers.
+
+* Optionally, the metrics collector registers a change event notification with Service Discovery to receive an update whenever the service endpoints change. Alternatively, the metrics collector can poll for endpoint changes periodically.
diff --git a/data/guides/quadtree.md b/data/guides/quadtree.md
new file mode 100644
index 0000000..765b5d5
--- /dev/null
+++ b/data/guides/quadtree.md
@@ -0,0 +1,38 @@
+---
+title: "Quadtree"
+description: "Explore the quadtree data structure for spatial data partitioning."
+image: "https://assets.bytebytego.com/diagrams/0311-quadtree.jpg"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Data Structures"
+ - "Algorithms"
+---
+
+
+
+Let's explore another data structure to find nearby restaurants on Yelp or Google Maps.
+
+A quadtree is a data structure that is commonly used to partition a two-dimensional space by recursively subdividing it into four quadrants (grids) until the contents of the grids meet certain criteria.
+
+A quadtree is an **in-memory data structure** and it is not a database solution. It runs on each LBS (Location-Based Service, see last week’s post) server, and the data structure is built at server start-up time.
+
+The second diagram explains the quadtree building process in more detail. The root node represents the whole world map. The root node is recursively broken down into 4 quadrants until no nodes are left with more than 100 businesses.
+
+## How to get nearby businesses with quadtree?
+
+* Build the quadtree in memory.
+
+* After the quadtree is built, start searching from the root and traverse the tree, until we find the leaf node where the search origin is.
+
+* If that leaf node has 100 businesses, return the node. Otherwise, add businesses from its neighbors until enough businesses are returned.
+
+## Update LBS server and rebuild quadtree
+
+* It may take a few minutes to build a quadtree in memory with 200 million businesses at the server start-up time.
+
+* While the quadtree is being built, the server cannot serve traffic.
+
+* Therefore, we should roll out a new release of the server incrementally to a small subset of servers at a time. This avoids taking a large swathe of the server cluster offline and causes service brownout.
diff --git a/data/guides/read-replica-pattern.md b/data/guides/read-replica-pattern.md
new file mode 100644
index 0000000..246b80b
--- /dev/null
+++ b/data/guides/read-replica-pattern.md
@@ -0,0 +1,37 @@
+---
+title: "Read Replica Pattern"
+description: "Explore the read replica pattern for database design and optimization."
+image: "https://assets.bytebytego.com/diagrams/0312-read-replica-pattern.png"
+createdAt: "2024-01-28"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Replication"
+ - "Read Scalability"
+---
+
+
+
+In this post, we talk about a simple yet commonly used database design pattern (setup): **Read replica pattern**.
+
+In this setup, all data-modifying commands like insert, delete, or update are sent to the primary DB and reads are sent to read replicas.
+
+The diagram above illustrates the setup:
+
+1. When Alice places an order on amazon.com, the request is sent to Order Service.
+2. Order Service creates a record about the order in the primary DB (write). Data is replicated to two replicas.
+3. Alice views the order details. Data is served from a replica (read).
+4. Alice views the recent order history. Data is served from a replica (read).
+
+There is one major problem in this setup: **replication lag**.
+
+Under certain circumstances (network delay, server overload, etc.), data in replicas might be seconds or even minutes behind. In this case, if Alice immediately checks the order status (query is served by the replica) after the order is placed, she might not see the order at all. This leaves Alice confused. In this case, we need “read-after-write” consistency.
+
+## Possible solutions to mitigate this problem:
+
+* Latency sensitive reads are sent to the primary database.
+
+* Reads that immediately follow writes are routed to the primary database.
+
+* A relational DB generally provides a way to check if a replica is caught up with the primary. If data is up to date, query the replica. Otherwise fail the read request or read from the primary.
diff --git a/data/guides/reconciliation-in-payment.md b/data/guides/reconciliation-in-payment.md
new file mode 100644
index 0000000..e3c217f
--- /dev/null
+++ b/data/guides/reconciliation-in-payment.md
@@ -0,0 +1,50 @@
+---
+title: "Reconciliation in Payment"
+description: "Explore payment reconciliation: challenges, solutions, and its importance."
+image: "https://assets.bytebytego.com/diagrams/0298-payment-reconciliation.jpg"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payment Systems"
+ - "Data Reconciliation"
+---
+
+
+
+Reconciliation might be the most painful process in a payment system. It is the process of comparing records in different systems to make sure the amounts match each other.
+
+For example, if you pay $200 to buy a watch with Paypal:
+
+* The eCommerce website should have a record of the $200 purchase order.
+
+* There should be a transaction record of $200 in Paypal (marked with 2 in the diagram).
+
+* The Ledger should record a debit of $200 dollars for the buyer, and a credit of $200 for the seller. This is called double-entry bookkeeping (see the table below).
+
+Let’s take a look at some pain points and how we can address them:
+
+## Problem 1: Data normalization
+
+When comparing records in different systems, they come in different formats. For example, the timestamp can be “2022/01/01” in one system and “Jan 1, 2022” in another.
+
+### Possible solution
+
+We can add a layer to transform different formats into the same format.
+
+## Problem 2: Massive data volume
+
+### Possible solution
+
+We can use big data processing techniques to speed up data comparisons. If we need near real-time reconciliation, a streaming platform such as Flink is used; otherwise, end-of-day batch processing such as Hadoop is enough.
+
+## Problem 3: Cut-off time issue
+
+For example, if we choose 00:00:00 as the daily cut-off time, one record is stamped with 23:59:55 in the internal system, but might be stamped 00:00:30 in the external system (Paypal), which is the next day. In this case, we couldn’t find this record in today’s Paypal records. It causes a discrepancy.
+
+### Possible solution
+
+We need to categorize this break as a “temporary break” and run it later against the next day’s Paypal records. If we find a match in the next day’s Paypal records, the break is cleared, and no more action is needed.
+
+You may argue that if we have exactly-once semantics in the system, there shouldn’t be any discrepancies. But the truth is, there are so many places that can go wrong. Having a reconciliation system is always necessary. It is like having a safety net to keep you sleeping well at night.
diff --git a/data/guides/reddit's-core-architecture.md b/data/guides/reddit's-core-architecture.md
new file mode 100644
index 0000000..68fd96c
--- /dev/null
+++ b/data/guides/reddit's-core-architecture.md
@@ -0,0 +1,30 @@
+---
+title: Reddit's Core Architecture
+description: Overview of Reddit's architecture for serving millions of users.
+image: 'https://assets.bytebytego.com/diagrams/0356-the-core-reddit-architecture.png'
+createdAt: '2024-03-06'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Social Media
+---
+
+
+A quick look at Reddit’s Core Architecture that helps it serve over 1 billion users every month.
+
+This information is based on research from many Reddit engineering blogs. But since architecture is ever-evolving, things might have changed in some aspects.
+
+The main points of Reddit’s architecture are as follows:
+
+* Reddit uses a Content Delivery Network (CDN) from Fastly as a front for the application.
+* Reddit started using jQuery in early 2009. Later on, they started using Typescript and have now moved to modern Node.js frameworks. Over the years, Reddit has also built mobile apps for Android and iOS.
+* Within the application stack, the load balancer sits in front and routes incoming requests to the appropriate services.
+* Reddit started as a Python-based monolithic application but has since started moving to microservices built using Go.
+* Reddit heavily uses GraphQL for its API layer. In early 2021, they started moving to GraphQL Federation, which is a way to combine multiple smaller GraphQL APIs known as Domain Graph Services (DGS). In 2022, the GraphQL team at Reddit added several new Go subgraphs for core Reddit entities thereby splitting the GraphQL monolith.
+* From a data storage point of view, Reddit relies on Postgres for its core data model. To reduce the load on the database, they use memcached in front of Postgres. Also, they use Cassandra quite heavily for new features mainly because of its resiliency and availability properties.
+* To support data replication and maintain cache consistency, Reddit uses Debezium to run a Change Data Capture process.
+* Expensive operations such as a user voting or submitting a link are deferred to an async job queue via RabbitMQ and processed by job workers. For content safety checks and moderation, they use Kafka to transfer data in real-time to run rules over them.
+* Reddit uses AWS and Kubernetes as the hosting platform for its various apps and internal services.
+* For deployment and infrastructure, they use Spinnaker, Drone CI, and Terraform.
diff --git a/data/guides/resiliency-patterns.md b/data/guides/resiliency-patterns.md
new file mode 100644
index 0000000..df61c78
--- /dev/null
+++ b/data/guides/resiliency-patterns.md
@@ -0,0 +1,31 @@
+---
+title: "Resiliency Patterns"
+description: "Explore cloud design patterns for building resilient systems."
+image: "https://assets.bytebytego.com/diagrams/0316-reliciency-patterns.jpg"
+createdAt: "2024-02-08"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Resilience"
+ - "Design Patterns"
+---
+
+Have you noticed that the largest incidents are usually caused by something very small?
+
+
+
+A minor error starts the snowball effect that keeps building up. Suddenly, everything is down.
+
+Here are 8 cloud design patterns to reduce the damage done by failures.
+
+* Timeout
+* Retry
+* Circuit breaker
+* Rate limiting
+* Load shedding
+* Bulkhead
+* Back pressure
+* Let it crash
+
+These patterns are usually not used alone. To apply them effectively, we need to understand why we need them, how they work, and their limitations.
diff --git a/data/guides/rest-api-cheatsheet.md b/data/guides/rest-api-cheatsheet.md
new file mode 100644
index 0000000..0a19ca2
--- /dev/null
+++ b/data/guides/rest-api-cheatsheet.md
@@ -0,0 +1,24 @@
+---
+title: 'REST API Cheatsheet'
+description: 'A concise guide to REST API principles, components, and best practices.'
+image: 'https://assets.bytebytego.com/diagrams/0040-rest-api-cheatsheet.png'
+createdAt: '2024-03-13'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - REST
+---
+
+
+
+This guide is designed to help you understand the world of RESTful APIs in a clear and engaging way.
+
+What's inside:
+
+* An exploration of the six fundamental principles of REST API design.
+* Insights into key components such as HTTP methods, protocols, versioning, and more.
+* A special focus on practical aspects like pagination, filtering, and endpoint design.
+
+Whether you're beginning your API journey or looking to refresh your knowledge, this blog and cheat sheet combo is the perfect toolkit for success.
diff --git a/data/guides/rest-api-vs-graphql.md b/data/guides/rest-api-vs-graphql.md
new file mode 100644
index 0000000..bd207f1
--- /dev/null
+++ b/data/guides/rest-api-vs-graphql.md
@@ -0,0 +1,34 @@
+---
+title: 'REST API vs. GraphQL'
+description: 'Explore the differences between REST API and GraphQL for API design.'
+image: 'https://assets.bytebytego.com/diagrams/0036-rest-vs-graphql.png'
+createdAt: '2024-03-11'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - GraphQL
+---
+
+
+
+When it comes to API design, REST and GraphQL each have their own strengths and weaknesses.
+
+**REST**
+
+* Uses standard HTTP methods like GET, POST, PUT, DELETE for CRUD operations.
+* Works well when you need simple, uniform interfaces between separate services/applications.
+* Caching strategies are straightforward to implement.
+* The downside is it may require multiple roundtrips to assemble related data from separate endpoints.
+
+**GraphQL**
+
+* Provides a single endpoint for clients to query for precisely the data they need.
+* Clients specify the exact fields required in nested queries, and the server returns optimized payloads containing just those fields.
+* Supports Mutations for modifying data and Subscriptions for real-time notifications.
+* Great for aggregating data from multiple sources and works well with rapidly evolving frontend requirements.
+* However, it shifts complexity to the client side and can allow abusive queries if not properly safeguarded.
+* Caching strategies can be more complicated than REST.
+
+The best choice between REST and GraphQL depends on the specific requirements of the application and development team. GraphQL is a good fit for complex or frequently changing frontend needs, while REST suits applications where simple and consistent contracts are preferred.
diff --git a/data/guides/reverse-proxy-vs-api-gateway-vs-load-balancer.md b/data/guides/reverse-proxy-vs-api-gateway-vs-load-balancer.md
new file mode 100644
index 0000000..be4677b
--- /dev/null
+++ b/data/guides/reverse-proxy-vs-api-gateway-vs-load-balancer.md
@@ -0,0 +1,28 @@
+---
+title: 'Reverse Proxy vs. API Gateway vs. Load Balancer'
+description: 'Understand the differences between reverse proxy, API gateway, and load balancer.'
+image: 'https://assets.bytebytego.com/diagrams/0320-reverse-gateway-lb.png'
+createdAt: '2024-02-09'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Load Balancing
+---
+
+
+
+As modern websites and applications are like busy beehives, we use a variety of tools to manage the buzz. Here we'll explore three superheroes: Reverse Proxy, API Gateway, and Load Balancer.
+
+* **Reverse Proxy:** change identity
+ * Fetching data secretly, keeping servers hidden.
+ * Perfect for shielding sensitive websites from cyber-attacks and prying eyes.
+* **API Gateway:** postman
+ * Delivers requests to the right services.
+ * Ideal for bustling applications with numerous intercommunicating services.
+* **Load Balancer:** traffic cop
+ * Directs traffic evenly across servers, preventing bottlenecks
+ * Essential for popular websites with heavy traffic and high demand.
+
+In a nutshell, choose a Reverse Proxy for stealth, an API Gateway for organized communications, and a Load Balancer for traffic control. Sometimes, it's wise to have all three - they make a super team that keeps your digital kingdom safe and efficient.
diff --git a/data/guides/session-cookie-jwt-token-sso-and-oauth-2.md b/data/guides/session-cookie-jwt-token-sso-and-oauth-2.md
new file mode 100644
index 0000000..097058c
--- /dev/null
+++ b/data/guides/session-cookie-jwt-token-sso-and-oauth-2.md
@@ -0,0 +1,28 @@
+---
+title: "Session, Cookie, JWT, Token, SSO, and OAuth 2.0 Explained"
+description: "Understanding sessions, cookies, JWT, SSO, and OAuth 2.0 in one diagram."
+image: "https://assets.bytebytego.com/diagrams/0152-cookies-session-jwt.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Authorization"
+---
+
+
+
+When you login to a website, your identity needs to be managed. Here is how different solutions work:
+
+* **Session** - The server stores your identity and gives the browser a session ID cookie. This allows the server to track login state. But cookies don't work well across devices.
+
+* **Token** - Your identity is encoded into a token sent to the browser. The browser sends this token on future requests for authentication. No server session storage is required. But tokens need encryption/decryption.
+
+* **JWT** - JSON Web Tokens standardize identity tokens using digital signatures for trust. The signature is contained in the token so no server session is needed.
+
+* **SSO** - Single Sign On uses a central authentication service. This allows a single login to work across multiple sites.
+
+* **OAuth2** - Allows limited access to your data on one site by another site, without giving away passwords.
+
+* **QR Code** - Encodes a random token into a QR code for mobile login. Scanning the code logs you in without typing a password.
diff --git a/data/guides/shortlong-polling-sse-websocket.md b/data/guides/shortlong-polling-sse-websocket.md
new file mode 100644
index 0000000..a0aaac9
--- /dev/null
+++ b/data/guides/shortlong-polling-sse-websocket.md
@@ -0,0 +1,21 @@
+---
+title: 'Short/long polling, SSE, WebSocket'
+description: 'Explore real-time web updates: polling, SSE, and WebSockets.'
+image: 'https://assets.bytebytego.com/diagrams/0337-short-long-polling-sse-websocket.jpeg'
+createdAt: '2024-01-25'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - WebSockets
+ - SSE
+---
+
+
+
+An HTTP server cannot automatically initiate a connection to a browser. As a result, the web browser is the initiator. What should we do next to get real-time updates from the HTTP server?
+
+Both the web browser and the HTTP server could be responsible for this task.
+
+* **Web browsers do the heavy lifting**: short polling or long polling. With short polling, the browser will retry until it gets the latest data. With long polling, the HTTP server doesn’t return results until new data has arrived.
+* **HTTP server and web browser cooperate**: WebSocket or SSE (server-sent event). In both cases, the HTTP server could directly send the latest data to the browser after the connection is established. The difference is that SSE is uni-directional, so the browser cannot send a new request to the server, while WebSocket is fully-duplex, so the browser can keep sending new requests.
diff --git a/data/guides/smooth-data-migration-with-avro.md b/data/guides/smooth-data-migration-with-avro.md
new file mode 100644
index 0000000..6c3a746
--- /dev/null
+++ b/data/guides/smooth-data-migration-with-avro.md
@@ -0,0 +1,25 @@
+---
+title: "Smooth Data Migration with Avro"
+description: "Learn how Apache Avro facilitates smooth data migration with schema evolution."
+image: "https://assets.bytebytego.com/diagrams/0080-avro.png"
+createdAt: "2024-02-01"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Migration"
+ - "Apache Avro"
+---
+
+
+
+How do we ensure when performing data migration? The diagram above shows how Apache Avro manages the schema evolution during data migration.
+
+Avro was started in 2009, initially as a subproject of Apache Hadoop to address Thrift’s limitation in Hadoop use cases. Avro is mainly used for two things: Data serialization and RPC.
+
+Key points in the diagram:
+
+* We can export the data to **object container files**, where schema sits together with the data blocks. Avro **dynamically** generates the schemas based on the columns, so if the schema is changed, a new schema is generated and stored with new data.
+
+* When the exported files are loaded into another data storage (for example, teradata), anyone can read the schema and know how to read the data. The old data and new data can be successfully migrated to the new database.
+ Unlike gRPC or Thrift, which statically generate schemas, Avro makes the data migration process easier.
diff --git a/data/guides/soap-vs-rest-vs-graphql-vs-rpc.md b/data/guides/soap-vs-rest-vs-graphql-vs-rpc.md
new file mode 100644
index 0000000..b9cdeaf
--- /dev/null
+++ b/data/guides/soap-vs-rest-vs-graphql-vs-rpc.md
@@ -0,0 +1,20 @@
+---
+title: 'SOAP vs REST vs GraphQL vs RPC'
+description: 'A comparison of API styles: SOAP, REST, GraphQL, and RPC.'
+image: 'https://assets.bytebytego.com/diagrams/0126-api-style-compare.jpg'
+createdAt: '2024-02-25'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Architecture
+---
+
+The diagram above illustrates the API timeline and API styles comparison.
+
+
+
+Over time, different API architectural styles are released. Each of them has its own patterns of standardizing data exchange.
+
+You can check out the use cases of each style in the diagram.
diff --git a/data/guides/some-devops-books-i-find-enlightening.md b/data/guides/some-devops-books-i-find-enlightening.md
new file mode 100644
index 0000000..90e7712
--- /dev/null
+++ b/data/guides/some-devops-books-i-find-enlightening.md
@@ -0,0 +1,28 @@
+---
+title: "Some DevOps Books I Find Enlightening"
+description: "A list of enlightening DevOps books covering SRE, delivery, and more."
+image: "https://assets.bytebytego.com/diagrams/0171-dev-ops-books.jpg"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - DevOps
+ - SRE
+---
+
+
+
+## DevOps Books
+
+* **Accelerate** - presents both the findings and the science behind measuring software delivery performance.
+
+* **Continuous Delivery** - introduces automated architecture management and data migration. It also pointed out key problems and optimal solutions in each area.
+
+* **Site Reliability Engineering** - famous Google SRE book. It explains the whole life cycle of Google’s development, deployment, and monitoring, and how to manage the world’s biggest software systems.
+
+* **Effective DevOps** - provides effective ways to improve team coordination.
+
+* **The Phoenix Project** - a classic novel about effectiveness and communications. IT work is like manufacturing plant work, and a system must be established to streamline the workflow. Very interesting read!
+
+* **The DevOps Handbook** - introduces product development, quality assurance, IT operations, and information security.
diff --git a/data/guides/storage-systems-overview.md b/data/guides/storage-systems-overview.md
new file mode 100644
index 0000000..66755c8
--- /dev/null
+++ b/data/guides/storage-systems-overview.md
@@ -0,0 +1,42 @@
+---
+title: "Storage Systems Overview"
+description: "A detailed overview of block, file, and object storage systems."
+image: "https://assets.bytebytego.com/diagrams/0346-storage-system.png"
+createdAt: "2024-02-13"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Storage Systems"
+ - "Data Storage"
+---
+
+
+
+# **Storage systems overview**
+
+Let's review the storage systems in general.
+
+Storage systems fall into three broad categories:
+
+* Block storage
+* File storage
+* Object storage
+
+The diagram above illustrates the comparison of different storage systems.
+
+## Block Storage
+
+Block storage came first, in the 1960s. Common storage devices like hard disk drives (HDD) and solid-state drives (SSD) that are physically attached to servers are all considered as block storage.
+
+Block storage presents the raw blocks to the server as a volume. This is the most flexible and versatile form of storage. The server can format the raw blocks and use them as a file system, or it can hand control of those blocks to an application. Some applications like a database or a virtual machine engine manage these blocks directly in order to squeeze every drop of performance out of them.
+
+Block storage is not limited to physically attached storage. Block storage could be connected to a server over a high-speed network or over industry-standard connectivity protocols like Fibre Channel (FC) and iSCSI. Conceptually, the network-attached block storage still presents raw blocks. To the servers, it works the same as physically attached block storage. Whether to a network or physically attached, block storage is fully owned by a single server. It is not a shared resource.
+
+## File storage
+
+File storage is built on top of block storage. It provides a higher-level abstraction to make it easier to handle files and directories. Data is stored as files under a hierarchical directory structure. File storage is the most common general-purpose storage solution. File storage could be made accessible by a large number of servers using common file-level network protocols like SMB/CIFS and NFS. The servers accessing file storage do not need to deal with the complexity of managing the blocks, formatting volume, etc. The simplicity of file storage makes it a great solution for sharing a large number of files and folders within an organization.
+
+## Object storage
+
+Object storage is new. It makes a very deliberate tradeoff to sacrifice performance for high durability, vast scale, and low cost. It targets relatively “cold” data and is mainly used for archival and backup. Object storage stores all data as objects in a flat structure. There is no hierarchical directory structure. Data access is normally provided via a RESTful API. It is relatively slow compared to other storage types. Most public cloud service providers have an object storage offering, such as AWS S3, Google block storage, and Azure blob storage.
diff --git a/data/guides/swift-payment-messaging-system.md b/data/guides/swift-payment-messaging-system.md
new file mode 100644
index 0000000..22cd975
--- /dev/null
+++ b/data/guides/swift-payment-messaging-system.md
@@ -0,0 +1,54 @@
+---
+title: "SWIFT Payment Messaging System"
+description: "Explore the SWIFT system, its role in secure, cross-border payments."
+image: "https://assets.bytebytego.com/diagrams/0348-swift-payment-messaging-system.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Payments"
+ - "Finance"
+---
+
+
+
+You probably heard about SWIFT. What is SWIFT? What role does it play in cross-border payments? You can find answers to those questions in this post.
+
+The Society for Worldwide Interbank Financial Telecommunication (SWIFT) is the main secure **messaging system** that links the world’s banks.
+
+The Belgium-based system is run by its member banks and handles millions of payment messages per day. The diagram above illustrates how payment messages are transmitted from Bank A (in New York) to Bank B (in London).
+
+## SWIFT Message Flow
+
+Step 1: Bank A sends a message with transfer details to Regional Processor A in New York. The destination is Bank B.
+
+Step 2: Regional processor validates the format and sends it to Slice Processor A. The Regional Processor is responsible for input message validation and output message queuing. The Slice Processor is responsible for storing and routing messages safely.
+
+Step 3: Slice Processor A stores the message.
+
+Step 4: Slice Processor A informs Regional Processor A the message is stored.
+
+Step 5: Regional Processor A sends ACK/NAK to Bank A. ACK means a message will be sent to Bank B. NAK means the message will NOT be sent to Bank B.
+
+Step 6: Slice Processor A sends the message to Regional Processor B in London.
+
+Step 7: Regional Processor B stores the message temporarily.
+
+Step 8: Regional Processor B assigns a unique ID MON (Message Output Number) to the message and sends it to Slice Processor B
+
+Step 9: Slice Processor B validates MON.
+
+Step 10: Slice Processor B authorizes Regional Processor B to send the message to Bank B.
+
+Step 11: Regional Processor B sends the message to Bank B.
+
+Step 12: Bank B receives the message and stores it.
+
+Step 13: Bank B sends UAK/UNK to Regional Processor B. UAK (user positive acknowledgment) means Bank B received the message without error; UNK (user negative acknowledgment) means Bank B received checksum failure.
+
+Step 14: Regional Processor B creates a report based on Bank B’s response, and sends it to Slice Processor B.
+
+Step 15: Slice Processor B stores the report.
+
+Step 16 - 17: Slice Processor B sends a copy of the report to Slice Processor A. Slice Processor A stores the report.
diff --git a/data/guides/symmetric-encryption-vs-asymmetric-encryption.md b/data/guides/symmetric-encryption-vs-asymmetric-encryption.md
new file mode 100644
index 0000000..4d37e83
--- /dev/null
+++ b/data/guides/symmetric-encryption-vs-asymmetric-encryption.md
@@ -0,0 +1,20 @@
+---
+title: "Symmetric vs Asymmetric Encryption"
+description: "Explore symmetric vs asymmetric encryption: methods, security, and use cases."
+image: "https://assets.bytebytego.com/diagrams/0349-symmetric-encryption-vs-asymmetric-encryption.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - security
+tags:
+ - "Encryption"
+ - "Cryptography"
+---
+
+
+
+Symmetric encryption and asymmetric encryption are two types of cryptographic techniques used to secure data and communications, but they differ in their methods of encryption and decryption.
+
+* In symmetric encryption, a single key is used for both encryption and decryption of data. It is faster and can be applied to bulk data encryption/decryption. For example, we can use it to encrypt massive amounts of PII (Personally Identifiable Information) data. It poses challenges in key management because the sender and receiver share the same key.
+
+* Asymmetric encryption uses a pair of keys: a public key and a private key. The public key is freely distributed and used to encrypt data, while the private key is kept secret and used to decrypt the data. It is more secure than symmetric encryption because the private key is never shared. However, asymmetric encryption is slower because of the complexity of key generation and maths computations. For example, HTTPS uses asymmetric encryption to exchange session keys during TLS handshake, and after that, HTTPS uses symmetric encryption for subsequent communications.
diff --git a/data/guides/system-design-blueprint-the-ultimate-guide.md b/data/guides/system-design-blueprint-the-ultimate-guide.md
new file mode 100644
index 0000000..fa2bf18
--- /dev/null
+++ b/data/guides/system-design-blueprint-the-ultimate-guide.md
@@ -0,0 +1,35 @@
+---
+title: "System Design Blueprint: The Ultimate Guide"
+description: "A system design blueprint to tackle various system design problems."
+image: "https://assets.bytebytego.com/diagrams/0324-system-design-blueprint.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system-design"
+ - "interview-preparation"
+---
+
+We've created a template to tackle various system design problems in interviews.
+
+
+
+Hope this checklist is useful to guide your discussions during the interview process.
+
+This briefly touches on the following discussion points:
+
+* Load Balancing
+* API Gateway
+* Communication Protocols
+* Content Delivery Network (CDN)
+* Database
+* Cache
+* Message Queue
+* Unique ID Generation
+* Scalability
+* Availability
+* Performance
+* Security
+* Fault Tolerance and Resilience
+* And more
diff --git a/data/guides/system-design-cheat-sheet.md b/data/guides/system-design-cheat-sheet.md
new file mode 100644
index 0000000..675f5ea
--- /dev/null
+++ b/data/guides/system-design-cheat-sheet.md
@@ -0,0 +1,39 @@
+---
+title: "System Design Cheat Sheet"
+description: "A system design cheat sheet with common solutions for system architects."
+image: "https://assets.bytebytego.com/diagrams/0351-system-design-cheat-sheet.png"
+createdAt: "2024-01-28"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "System Design"
+ - "Scalability"
+---
+
+
+
+We are often asked to design for high availability, high scalability, and high throughput. What do they mean exactly?
+
+The diagram below is a system design cheat sheet with common solutions.
+
+## High Availability
+
+This means we need to ensure a high agreed level of uptime. We often describe the design target as “3 nines” or “4 nines”. “4 nines”, 99.99% uptime, means the service can only be down 8.64 seconds per day.
+
+To achieve high availability, we need to design redundancy in the system. There are several ways to do this:
+
+* Hot-hot: two instances receive the same input and send the output to the downstream service. In case one side is down, the other side can immediately take over. Since both sides send output to the downstream, the downstream system needs to dedupe.
+* Hot-warm: two instances receive the same input and only the hot side sends the output to the downstream service. In case the hot side is down, the warm side takes over and starts to send output to the downstream service.
+* Single-leader cluster: one leader instance receives data from the upstream system and replicates to other replicas.
+* Leaderless cluster: there is no leader in this type of cluster. Any write will get replicated to other instances. As long as the number of write instances plus the number of read instances are larger than the total number of instances, we should get valid data.
+
+## High Throughput
+
+This means the service needs to handle a high number of requests given a period of time. Commonly used metrics are QPS (query per second) or TPS (transaction per second).
+
+To achieve high throughput, we often add caches to the architecture so that the request can return without hitting slower I/O devices like databases or disks. We can also increase the number of threads for computation-intensive tasks. However, adding too many threads can deteriorate the performance. We then need to identify the bottlenecks in the system and increase its throughput. Using asynchronous processing can often effectively isolate heavy-lifting components.
+
+## High Scalability
+
+This means a system can quickly and easily extend to accommodate more volume (horizontal scalability) or more functionalities (vertical scalability). Normally we watch the response time to decide if we need to scale the system.
diff --git a/data/guides/the-12-factor-app.md b/data/guides/the-12-factor-app.md
new file mode 100644
index 0000000..d63d29f
--- /dev/null
+++ b/data/guides/the-12-factor-app.md
@@ -0,0 +1,66 @@
+---
+title: "The 12-Factor App"
+description: "Best practices for building modern, scalable, and reliable applications."
+image: "https://assets.bytebytego.com/diagrams/0028-12-factor-app.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Application Architecture"
+ - "Best Practices"
+---
+
+
+
+The "12 Factor App" offers a set of best practices for building modern software applications. Following these 12 principles can help developers and teams in building reliable, scalable, and manageable applications.
+
+Here's a brief overview of each principle:
+
+## I. Codebase
+
+Have one place to keep all your code, and manage it using version control like Git.
+
+## II. Dependencies
+
+List all the things your app needs to work properly, and make sure they're easy to install.
+
+## III. Config
+
+Keep important settings like database credentials separate from your code, so you can change them without rewriting code.
+
+## IV. Backing Services
+
+Use other services (like databases or payment processors) as separate components that your app connects to.
+
+## V. Build, Release, Run
+
+Make a clear distinction between preparing your app, releasing it, and running it in production.
+
+## VI. Processes
+
+Design your app so that each part doesn't rely on a specific computer or memory. It's like making LEGO blocks that fit together.
+
+## VII. Port Binding
+
+Let your app be accessible through a network port, and make sure it doesn't store critical information on a single computer.
+
+## VIII. Concurrency
+
+Make your app able to handle more work by adding more copies of the same thing, like hiring more workers for a busy restaurant.
+
+## IX. Disposability
+
+Your app should start quickly and shut down gracefully, like turning off a light switch instead of yanking out the power cord.
+
+## X. Dev/Prod Parity
+
+Ensure that what you use for developing your app is very similar to what you use in production, to avoid surprises.
+
+## XI. Logs
+
+Keep a record of what happens in your app so you can understand and fix issues, like a diary for your software.
+
+## XII. Admin Processes
+
+Run special tasks separately from your app, like doing maintenance work in a workshop instead of on the factory floor.
diff --git a/data/guides/the-9-algorithms-that-dominate-our-world.md b/data/guides/the-9-algorithms-that-dominate-our-world.md
new file mode 100644
index 0000000..40e6385
--- /dev/null
+++ b/data/guides/the-9-algorithms-that-dominate-our-world.md
@@ -0,0 +1,34 @@
+---
+title: "The 9 Algorithms That Dominate Our World"
+description: "Explore the 9 algorithms that power our daily digital experiences."
+image: "https://assets.bytebytego.com/diagrams/0018-9-algorithms-that-dominate-our-world.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Algorithms"
+ - "Data Science"
+---
+
+
+
+The diagram below shows the most commonly used algorithms in our daily lives. They are used in internet search engines, social networks, WiFi, cell phones, and even satellites.
+
+## 1. Sorting
+
+## 2. Dijkstra’s Algorithm
+
+## 3. Transformers
+
+## 4. Link Analysis
+
+## 5. RSA Algorithm
+
+## 6. Integer Factorization
+
+## 7. Convolutional Neural Networks
+
+## 8. Huffman Coding
+
+## 9. Secure Hash Algorithm
diff --git a/data/guides/the-evolving-landscape-of-api-protocols-in-2023.md b/data/guides/the-evolving-landscape-of-api-protocols-in-2023.md
new file mode 100644
index 0000000..12f5a34
--- /dev/null
+++ b/data/guides/the-evolving-landscape-of-api-protocols-in-2023.md
@@ -0,0 +1,20 @@
+---
+title: 'The Evolving Landscape of API Protocols in 2023'
+description: 'Explore the evolving landscape of API protocols in 2023.'
+image: 'https://assets.bytebytego.com/diagrams/0077-api-protocols.png'
+createdAt: '2024-03-15'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Protocols
+---
+
+This is a brief summary of the blog post I wrote for Postman.
+
+
+
+In this blog post, I cover the six most popular API protocols: REST, Webhooks, GraphQL, SOAP, WebSocket, and gRPC. The discussion includes the benefits and challenges associated with each protocol.
+
+You can read the [full blog post here](https://blog.postman.com/api-protocols-in-2023/).
diff --git a/data/guides/the-fundamental-pillars-of-object-oriented-programming.md b/data/guides/the-fundamental-pillars-of-object-oriented-programming.md
new file mode 100644
index 0000000..5afa6ba
--- /dev/null
+++ b/data/guides/the-fundamental-pillars-of-object-oriented-programming.md
@@ -0,0 +1,32 @@
+---
+title: "The Fundamental Pillars of Object-Oriented Programming"
+description: "Explore the core principles of object-oriented programming (OOP)."
+image: "https://assets.bytebytego.com/diagrams/0197-4-fundamental-pillars-of-object-oriented-programming.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - software-development
+tags:
+ - OOP
+ - Principles
+---
+
+
+
+Abstraction, Encapsulation, Inheritance, and Polymorphism are the four pillars of object-oriented programming. What do they mean?
+
+## Abstraction
+
+This is the process of hiding implementation details and showing only the essential features of an object. For example, a Vehicle class with an abstract stop method.
+
+## Encapsulation
+
+It involves wrapping data (fields) and methods in a single unit (class) and restricting direct access using access modifiers. For example, private fields with public getters and setters.
+
+## Inheritance
+
+The process of creating a new class (child) that inherits attributes and methods from an existing class (parent), thereby promoting code reuse. For example, a Car class inherits from a Vehicle class.
+
+## Polymorphism
+
+It allows methods to perform differently based on the object they are invoked on. When two types share an inheritance chain, they can be used interchangeably with no errors.
diff --git a/data/guides/the-one-line-change-that-reduced-clone-times-by-a-whopping-99-says-pinterest.md b/data/guides/the-one-line-change-that-reduced-clone-times-by-a-whopping-99-says-pinterest.md
new file mode 100644
index 0000000..309564b
--- /dev/null
+++ b/data/guides/the-one-line-change-that-reduced-clone-times-by-a-whopping-99-says-pinterest.md
@@ -0,0 +1,46 @@
+---
+title: 'The one-line change that reduced clone times by 99% at Pinterest'
+description: 'A one-line change reduced clone times by 99% at Pinterest.'
+image: 'https://assets.bytebytego.com/diagrams/0302-pinterest-one-line-change.png'
+createdAt: '2024-02-14'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - DevOps
+ - Git
+---
+
+
+
+While it may sound cliché, small changes can definitely create a big impact.
+
+The Engineering Productivity team at Pinterest witnessed this first-hand.
+
+They made a small change in the Jenkins build pipeline of their monorepo codebase called Pinboard.
+
+And it brought down clone times from 40 minutes to a staggering 30 seconds.
+
+For reference, Pinboard is the oldest and largest monorepo at Pinterest. Some facts about it:
+
+* **350K commits**
+* **20 GB in size when cloned fully**
+* **60K git pulls on every business day**
+
+Cloning monorepos having a lot of code and history is time consuming. This was exactly what was happening with Pinboard.
+
+The build pipeline (written in Groovy) started with a “Checkout” stage where the repository was cloned for the build and test steps.
+
+The clone options were set to shallow clone, no fetching of tags and only fetching the last 50 commits.
+
+But it missed a vital piece of optimization.
+
+The Checkout step didn’t use the Git refspec option.
+
+This meant that Git was effectively fetching all refspecs for every build. For the Pinboard monorepo, it meant fetching more than 2500 branches.
+
+𝐒𝐨 - 𝐰𝐡𝐚𝐭 𝐰𝐚𝐬 𝐭𝐡𝐞 𝐟𝐢𝐱?
+
+The team simply added the refspec option and specified which ref they cared about. It was the “master” branch in this case.
+
+This single change allowed Git clone to deal with only one branch and significantly reduced the overall build time of the monorepo.
diff --git a/data/guides/the-open-source-ai-stack.md b/data/guides/the-open-source-ai-stack.md
new file mode 100644
index 0000000..d8727c0
--- /dev/null
+++ b/data/guides/the-open-source-ai-stack.md
@@ -0,0 +1,39 @@
+---
+title: 'The Open Source AI Stack'
+description: 'Explore the open-source AI stack: tools and frameworks for AI development.'
+image: 'https://assets.bytebytego.com/diagrams/0359-the-open-source-ai-stack.png'
+createdAt: '2024-03-12'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI
+ - Open Source
+---
+
+
+
+You don’t need to spend a fortune to build an AI application. The best AI developer tools are open-source, and an excellent ecosystem is evolving that can make AI accessible to everyone.
+
+The key components of this open-source AI stack are as follows:
+
+## Frontend
+
+To build beautiful AI UIs, frameworks like NextJS and Streamlit are extremely useful. Also, Vercel can help with deployment.
+
+## Embeddings and RAG libraries
+
+Embedding models and RAG libraries like Nomic, JinaAI, Cognito, and LLMAware help developers build accurate search and RAG features.
+
+## Backend and Model Access
+
+For backend development, developers can rely on frameworks like FastAPI, Langchain, and Netflix Metaflow. Options like Ollama and Huggingface are available
+for model access.
+## Data and Retrieval
+
+For data storage and retrieval, several options like Postgres, Milvus, Weaviate, PGVector, and FAISS are available.
+
+## Large-Language Models
+
+Based on performance benchmarks, open-source models like Llama, Mistral, Qwen, Phi, and Gemma are great alternatives to proprietary LLMs like GPT and Claude.
+
diff --git a/data/guides/the-payments-ecosystem.md b/data/guides/the-payments-ecosystem.md
new file mode 100644
index 0000000..f8488a7
--- /dev/null
+++ b/data/guides/the-payments-ecosystem.md
@@ -0,0 +1,34 @@
+---
+title: "The Payments Ecosystem"
+description: "Explore the key players and processes in the payments ecosystem."
+image: "https://assets.bytebytego.com/diagrams/0360-the-payments-ecosystem.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - Fintech
+ - Payments
+---
+
+How do fintech startups find new opportunities among so many payment companies? What do PayPal, Stripe, and Square do exactly?!
+
+
+
+## Steps 0-1
+
+The cardholder opens an account in the issuing bank and gets the debit/credit card. The merchant registers with ISO (Independent Sales Organization) or MSP (Member Service Provider) for in-store sales. ISO/MSP partners with payment processors to open merchant accounts.
+
+## Steps 2-5
+
+The acquiring process.
+
+The payment gateway accepts the purchase transaction and collects payment information. It is then sent to a payment processor, which uses customer information to collect payments. The acquiring processor sends the transaction to the card network. It also owns and operates the merchant’s account during settlement, which doesn’t happen in real-time.
+
+## Steps 6-8
+
+The issuing process.
+
+The issuing processor talks to the card network on the issuing bank’s behalf. It validates and operates the customer’s account.
+
+I’ve listed some companies in different verticals in the diagram. Notice payment companies usually start from one vertical, but later expand to multiple verticals.
diff --git a/data/guides/the-ultimate-api-learning-roadmap.md b/data/guides/the-ultimate-api-learning-roadmap.md
new file mode 100644
index 0000000..578d2f7
--- /dev/null
+++ b/data/guides/the-ultimate-api-learning-roadmap.md
@@ -0,0 +1,37 @@
+---
+title: The Ultimate API Learning Roadmap
+description: "Your guide to mastering APIs: from basics to advanced techniques."
+image: 'https://assets.bytebytego.com/diagrams/0361-the-ultimate-api-learning-roadmap.png'
+createdAt: '2024-03-14'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API
+ - Roadmap
+---
+
+
+
+APIs are the backbone of communication over the Internet. Every developer needs to learn about APIs. Here’s a roadmap that covers the most important topics:
+
+* **Introduction to APIs**
+ * API is a set of protocols and tools for building applications. Different types of APIs exist, such as public, private, and partner.
+* **API Terminologies**
+ * Various API terminologies, such as HTTP versions, cookies, and caching, need to be understood.
+* **API Styles**
+ * The most common API styles are REST, SOAP, GraphQL, gRPC, and WebSockets
+* **API Authentication**
+ * API Authentication techniques like Basic Auth, Token, JWTs, OAuth, and Session Auth
+* **API Documentation**
+ * A good API is understandable. API Documentation tools like Swagger, Postman, Redoc, and DapperDox make it possible.
+* **API Features**
+ * Key API features include pagination, parameters, idempotency, API versioning, HATEOAS, and content negotiation
+* **API Performance Techniques**
+ * Common API performance techniques are caching, rate limiting, load balancing, pagination, DB indexing, scaling, and performance testing.
+* **API Gateways**
+ * Learn about API Gateways such as Amazon API Gateway, Azure API Services, Kong, Nginx, etc.
+* **API Implementation Frameworks**
+ * The most popular API development frameworks are Node.js, Spring, Flask, Django, and FastAPI
+* **API Integration Patterns**
+ * Learn about various API integration patterns such as gateways, event-driven, webhook, polling, and batch processing.
diff --git a/data/guides/the-ultimate-kafka-101-you-cannot-miss.md b/data/guides/the-ultimate-kafka-101-you-cannot-miss.md
new file mode 100644
index 0000000..28c76b2
--- /dev/null
+++ b/data/guides/the-ultimate-kafka-101-you-cannot-miss.md
@@ -0,0 +1,50 @@
+---
+title: "The Ultimate Kafka 101 You Cannot Miss"
+description: "Learn the fundamentals of Kafka in 8 simple steps."
+image: "https://assets.bytebytego.com/diagrams/0246-kafka-101-8-steps-to-learn-the-fundamentals-of-kafka.png"
+createdAt: "2024-02-02"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Kafka"
+ - "Distributed Systems"
+---
+
+
+
+Kafka is super-popular but can be overwhelming in the beginning.
+
+Here are 8 simple steps that can help you understand the fundamentals of Kafka.
+
+## What is Kafka?
+
+Kafka is a distributed event store and a streaming platform. It began as an internal project at LinkedIn and now powers some of the largest data pipelines in the world in orgs like Netflix, Uber, etc.
+
+## Kafka Messages
+
+Message is the basic unit of data in Kafka. It’s like a record in a table consisting of headers, key, and value.
+
+## Kafka Topics and Partitions
+
+Every message goes to a particular Topic. Think of the topic as a folder on your computer. Topics also have multiple partitions.
+
+## Advantages of Kafka
+
+Kafka can handle multiple producers and consumers, while providing disk-based data retention and high scalability.
+
+## Kafka Producer
+
+Producers in Kafka create new messages, batch them, and send them to a Kafka topic. They also take care of balancing messages across different partitions.
+
+## Kafka Consumer
+
+Kafka consumers work together as a consumer group to read messages from the broker.
+
+## Kafka Cluster
+
+A Kafka cluster consists of several brokers where each partition is replicated across multiple brokers to ensure high availability and redundancy.
+
+## Use Cases of Kafka
+
+Kafka can be used for log analysis, data streaming, change data capture, and system monitoring.
diff --git a/data/guides/the-ultimate-kubernetes-command-cheatsheet.md b/data/guides/the-ultimate-kubernetes-command-cheatsheet.md
new file mode 100644
index 0000000..b7bb19e
--- /dev/null
+++ b/data/guides/the-ultimate-kubernetes-command-cheatsheet.md
@@ -0,0 +1,32 @@
+---
+title: "Kubernetes Command Cheatsheet"
+description: "Your go-to guide for essential Kubernetes commands."
+image: "https://assets.bytebytego.com/diagrams/0248-kubernetes-command-cheatsheet.png"
+createdAt: "2024-03-06"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - DevOps
+---
+
+
+
+Kubernetes is an open-source container orchestration platform. It automates the deployment, scaling, and management of containerized applications.
+
+Initially developed by Google, Kubernetes is now maintained by CNCF (Cloud Native Computing Foundation).
+
+This cheat sheet contains the most important Kubernetes commands for different purposes:
+
+* Kubernetes Setup
+
+* General Cluster Management
+
+* Kubernetes Deployments
+
+* Kubernetes Pod Inspection
+
+* Troubleshooting and Configuration
+
+* Miscellaneous commands related to services, config maps, and managing ingresses.
diff --git a/data/guides/the-ultimate-redis-101.md b/data/guides/the-ultimate-redis-101.md
new file mode 100644
index 0000000..e870a29
--- /dev/null
+++ b/data/guides/the-ultimate-redis-101.md
@@ -0,0 +1,50 @@
+---
+title: "The Ultimate Redis 101"
+description: "Learn the fundamentals of Redis with these simple steps."
+image: "https://assets.bytebytego.com/diagrams/0009-steps-to-learn-the-fundamentals-of-redis-101.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Database"
+---
+
+
+
+Redis is one of the most popular data stores in the world and is packed with features.
+
+Here are 8 simple steps that can help you understand the fundamentals of Redis.
+
+## What is Redis?
+
+Redis (Remote Dictionary Server) is a multi-modal database that provides sub-millisecond latency. The core idea behind Redis is that a cache can also act as a full-fledged database.
+
+## Redis Adoption
+
+High-traffic internet websites like Airbnb, Uber, Slack, and many others have adopted Redis in their technology stack.
+
+## How Redis Changed the Database Game?
+
+Redis supports main memory read/writes while still supporting fully durable storage. Read and writes are served from the main memory but the data is also persisted to the disk. This is done using snapshots (RDB) and AOF.
+
+## Redis Data Structures
+
+Redis stores data in key-value format. It supports various data structures such as strings, bitmaps, lists, sets, sorted sets, hash, JSON, etc.
+
+## Basic Redis Commands
+
+Some of the most used Redis commands are SET, GET, DELETE, INCR, HSET, etc. There are many more commands available.
+
+## Redis Modules
+
+Redis modules are add-ons that extend Redis functionality beyond its core features. Some prominent modules are RediSearch, RedisJSON, RedisGraph, RedisBloom, RedisAI, RedisTimeSeries, RedisGears, RedisML, and so on.
+
+## Redis Pub/Sub
+
+Redis also supports even-driven architecture using a publish-subscribe communication model.
+
+## Redis Use Cases
+
+Top Redis use cases are Distributed Caching, Session Storage, Message Queue, Rate Limiting, High-Speed Database, etc.
diff --git a/data/guides/the-ultimate-software-architect-knowledge-map.md b/data/guides/the-ultimate-software-architect-knowledge-map.md
new file mode 100644
index 0000000..5764460
--- /dev/null
+++ b/data/guides/the-ultimate-software-architect-knowledge-map.md
@@ -0,0 +1,52 @@
+---
+title: "The Ultimate Software Architect Knowledge Map"
+description: "A guide to the essential knowledge for software architects."
+image: "https://assets.bytebytego.com/diagrams/0118-the-ultimate-software-architect-knowledge-map.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Software Architecture
+ - Career Development
+---
+
+
+
+Becoming a Software Architect is a journey where you are always learning. But there are some things you must definitely strive to know.
+
+## Essential Skills for Software Architects
+
+* **Master a Programming Language**
+
+ Look to master 1-2 programming languages such as Java, Python, Golang, JavaScript, etc.
+
+* **Tools**
+
+ Build proficiency with key tools such as GitHub, Jenkins, Jira, ELK, Sonar, etc.
+
+* **Design Principles**
+
+ Learn about important design principles such as OOPS, Clean Code, TDD, DDD, CAP Theorem, MVC Pattern, ACID, and GOF.
+
+* **Architectural Principles**
+
+ Become proficient in multiple architectural patterns such as Microservices, Publish-Subscribe, Layered, Event-Driven, Client-Server, Hexagonal, etc.
+
+* **Platform Knowledge**
+
+ Get to know about several platforms such as containers, orchestration, cloud, serverless, CDN, API Gateways, Distributed Systems, and CI/CD
+
+* **Data Analytics**
+
+ Build a solid knowledge of data and analytics components like SQL and NoSQL databases, data streaming solutions with Kafka, object storage, data migration, OLAP, and so on.
+
+* **Networking and Security**
+
+ Learn about networking and security concepts such as DNS, TCP, TLS, HTTPS, Encryption, JWT, OAuth, and Credential Management.
+
+* **Supporting Skills**
+
+ Apart from technical, software architects also need several supporting skills such as decision-making, technology knowledge, stakeholder management, communication, estimation, leadership, etc.
+
+Over to you - What else would you add to the roadmap?
diff --git a/data/guides/things-to-consider-when-using-cache.md b/data/guides/things-to-consider-when-using-cache.md
new file mode 100644
index 0000000..2a84c38
--- /dev/null
+++ b/data/guides/things-to-consider-when-using-cache.md
@@ -0,0 +1,70 @@
+---
+title: "Things to Consider When Using Cache"
+description: "Top 5 things to consider when using cache to build fast online systems."
+image: "https://assets.bytebytego.com/diagrams/0362-things-to-consider-when-using-cache.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Performance"
+---
+
+
+
+Caching is one of the 𝐦𝐨𝐬𝐭 𝐜𝐨𝐦𝐦𝐨𝐧𝐥𝐲 used techniques when building fast online systems. When using a cache, here are the top 5 things to consider:
+
+The first version of the cheatsheet was written by guest author [Love Sharma](https://twitter.com/Zonito87).
+
+## Suitable Scenarios
+
+* In-memory solution
+
+* Read heavy system
+
+* Data is not frequently updated
+
+## Caching Techniques
+
+* Cache aside
+
+* Write-through
+
+* Read-through
+
+* Write-around
+
+* Write-back
+
+## Cache Eviction Algorithms
+
+* Least Recently Used (LRU)
+
+* Least Frequently Used (LFU)
+
+* First-in First-out (FIFO)
+
+* Random Replacement (RR)
+
+## Key Metrics
+
+* Cache Hit Ratio
+
+* Latency
+
+* Throughput
+
+* Invalidation Rate
+
+* Memory Usage
+
+* CPU usage
+
+* Network usage
+
+## Other Issues
+
+* Thunder herd on cold start
+
+* Time-to-live (TTL)
diff --git a/data/guides/time-series-db-tsdb-in-20-lines.md b/data/guides/time-series-db-tsdb-in-20-lines.md
new file mode 100644
index 0000000..6454a3f
--- /dev/null
+++ b/data/guides/time-series-db-tsdb-in-20-lines.md
@@ -0,0 +1,34 @@
+---
+title: "Time Series DB (TSDB) in 20 Lines"
+description: "Learn about Time Series Databases (TSDB) and their applications."
+image: "https://assets.bytebytego.com/diagrams/0364-time-series-db-tsdb-in-20-lines.jpeg"
+createdAt: "2024-02-07"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database"
+ - "TimeSeries"
+---
+
+
+
+What is **Time-Series DB** (TSDB)? How is it different from Relational DB?
+
+The diagram above shows the **internal data model** of a typical Time-Series DB.
+
+A TSDB is a database optimized for time series data.
+
+* From the users’ perspective, the data looks similar to the relational DB table. But behind the scenes, the weather table is stored in 4 TSMs (Time-Structured Merge Trees) in the format of \[Measurement, Tag, Field Name].
+
+* In this way, we can quickly aggregate and analyze data based on time and tags.
+
+* Typical usage:
+
+ * Trades and market data updates in a market
+ * Server metrics
+ * Application performance monitoring
+ * Network data
+ * Sensor data
+ * Events
+ * Clicks streams
diff --git a/data/guides/token-cookie-session.md b/data/guides/token-cookie-session.md
new file mode 100644
index 0000000..7f97f0c
--- /dev/null
+++ b/data/guides/token-cookie-session.md
@@ -0,0 +1,44 @@
+---
+title: "Token, Cookie, Session"
+description: "Understanding tokens, cookies, and sessions for user identity management."
+image: "https://assets.bytebytego.com/diagrams/0331-session-cookie-jwt.jpg"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Authorization"
+---
+
+
+
+Session, cookie, JWT, token, SSO, and OAuth 2.0 - what are they?!
+
+These terms are all related to user identity management. When you log into a website, you declare who you are (identification). Your identity is verified (authentication), and you are granted the necessary permissions (authorization). Many solutions have been proposed in the past, and the list keeps growing.
+
+From simple to complex, here is my understanding of user identity management:
+
+## WWW-Authenticate
+
+WWW-Authenticate is the most basic method. You are asked for the username and password by the browser. As a result of the inability to control the login life cycle, it is seldom used today.
+
+## Session-Cookie
+
+A finer control over the login life cycle is session-cookie. The server maintains session storage, and the browser keeps the ID of the session. A cookie usually only works with browsers and is not mobile app friendly.
+
+## Token
+
+To address the compatibility issue, the token can be used. The client sends the token to the server, and the server validates the token. The downside is that the token needs to be encrypted and decrypted, which may be time-consuming.
+
+## JWT
+
+JWT is a standard way of representing tokens. This information can be verified and trusted because it is digitally signed. Since JWT contains the signature, there is no need to save session information on the server side.
+
+## SSO (Single Sign-On)
+
+By using SSO (single sign-on), you can sign on only once and log in to multiple websites. It uses CAS (central authentication service) to maintain cross-site information
+
+## OAuth 2.0
+
+By using OAuth 2.0, you can authorize one website to access your information on another website
diff --git a/data/guides/top-10-k8s-design-patterns.md b/data/guides/top-10-k8s-design-patterns.md
new file mode 100644
index 0000000..208f7be
--- /dev/null
+++ b/data/guides/top-10-k8s-design-patterns.md
@@ -0,0 +1,70 @@
+---
+title: "Top 10 Kubernetes Design Patterns"
+description: "Explore the top 10 Kubernetes design patterns with detailed explanations."
+image: "https://assets.bytebytego.com/diagrams/0372-top-10-k8s-design-patterns.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Kubernetes"
+ - "Design Patterns"
+---
+
+
+
+## Foundational Patterns
+
+These patterns are the fundamental principles for applications to be automated on k8s, regardless of the application's nature.
+
+* **Health Probe Pattern**
+
+ This pattern requires that every container must implement observable APIs for the platform to manage the application.
+
+* **Predictable Demands Pattern**
+
+ This pattern requires that we should declare application requirements and runtime dependencies. Every container should declare its resource profile.
+
+* **Automated Placement Pattern**
+
+ This pattern describes the principles of Kubernetes’ scheduling algorithm.
+
+## Structural Patterns
+
+These patterns focus on structuring and organizing containers in a Pod.
+
+* **Init Container Pattern**
+
+ This pattern has a separate life cycle for initialization-releated tasks.
+
+* **Sidecar Pattern**
+
+ This pattern extends a container’s functionalities without changing it.
+
+## Behavioral Patterns
+
+These patterns describe the life cycle management of a Pod. Depending on the type of the workload, it can run as a service or a batch job.
+
+* **Batch Job Pattern**
+
+ This pattern is used to manage isolated atomic units of work.
+
+* **Stateful Service Pattern**
+
+ This pattern creates distributed stateful applications.
+
+* **Service Discovery Pattern**
+
+ This pattern describes how clients discover the services.
+
+## Higher-Level Patterns
+
+These patterns focus on higher-level application management.
+
+* **Controller Pattern**
+
+ This pattern monitors the current state and reconciles with the declared target state.
+
+* **Operator Pattern**
+
+ This pattern defines operational knowledge in an algorithmic and automated form.
diff --git a/data/guides/top-10-most-popular-open-source-databases.md b/data/guides/top-10-most-popular-open-source-databases.md
new file mode 100644
index 0000000..05bf9f8
--- /dev/null
+++ b/data/guides/top-10-most-popular-open-source-databases.md
@@ -0,0 +1,29 @@
+---
+title: "Top 10 Most Popular Open-Source Databases"
+description: "Explore the top 10 open-source databases and their impact."
+image: "https://assets.bytebytego.com/diagrams/0282-top-10-most-popular-open-source-databases.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Databases"
+ - "Open Source"
+---
+
+
+
+This list is based on factors like adoption, industry impact, and the general awareness of the database among the developer community.
+
+## Top 10 Most Popular Open-Source Databases
+
+* MySQL
+* PostgreSQL
+* MariaDB
+* Apache Cassandra
+* Neo4j
+* SQLite
+* CockroachDB
+* Redis
+* MongoDB
+* Couchbase
diff --git a/data/guides/top-12-tips-for-api-security.md b/data/guides/top-12-tips-for-api-security.md
new file mode 100644
index 0000000..307dda0
--- /dev/null
+++ b/data/guides/top-12-tips-for-api-security.md
@@ -0,0 +1,27 @@
+---
+title: 'Top 12 Tips for API Security'
+description: 'Enhance API security with these top 12 essential tips.'
+image: 'https://assets.bytebytego.com/diagrams/0027-12-tips-for-api-security.png'
+createdAt: '2024-03-09'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Security
+ - Web Security
+---
+
+
+
+* Use HTTPS
+* Use OAuth2
+* Use WebAuthn
+* Use Leveled API Keys
+* Authorization
+* Rate Limiting
+* API Versioning
+* Whitelisting
+* Check OWASP API Security Risks
+* Use API Gateway
+* Error Handling
+* Input Validation
diff --git a/data/guides/top-3-api-gateway-use-cases.md b/data/guides/top-3-api-gateway-use-cases.md
new file mode 100644
index 0000000..3bcbf0e
--- /dev/null
+++ b/data/guides/top-3-api-gateway-use-cases.md
@@ -0,0 +1,23 @@
+---
+title: 'Top 3 API Gateway Use Cases'
+description: 'Explore the top 3 use cases for API gateways in modern architectures.'
+image: 'https://assets.bytebytego.com/diagrams/0073-top-3-api-gateway-use-cases.png'
+createdAt: '2024-02-16'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Microservices
+---
+
+
+
+API gateway sits between the clients and services, providing API communications between them.
+
+* **API gateway helps build an ecosystem.**
+ The users can leverage an API gateway to access a wider set of tools. The partners in the ecosystem collaborate with each other to provide better integrations for the users.
+* **API gateway builds API marketplace**
+ The API marketplace hosts fundamental functionalities for everyone. The developers and businesses can easily develop or innovate in this ecosystem and sell APIs on the marketplace.
+* **API gateway provides compatibility with multiple platforms**
+ When dealing with multiple platforms, an API gateway can help work across multiple complex architectures.
diff --git a/data/guides/top-4-data-sharding-algorithms-explained.md b/data/guides/top-4-data-sharding-algorithms-explained.md
new file mode 100644
index 0000000..d91b057
--- /dev/null
+++ b/data/guides/top-4-data-sharding-algorithms-explained.md
@@ -0,0 +1,34 @@
+---
+title: "Top 4 Data Sharding Algorithms Explained"
+description: "Explore the top data sharding algorithms for efficient data management."
+image: "https://assets.bytebytego.com/diagrams/0373-top-4-data-sharding-algorithms-explained.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Data Sharding"
+ - "Algorithms"
+---
+
+
+
+We are dealing with massive amounts of data. Often we need to split data into smaller, more manageable pieces, or “shards”. Here are some of the top data sharding algorithms commonly used:
+
+## Range-Based Sharding
+
+This involves partitioning data based on a range of values. For example, customer data can be sharded based on alphabetical order of last names, or transaction data can be sharded based on date ranges.
+
+## Hash-Based Sharding
+
+In this method, a hash function is applied to a shard key chosen from the data (like a customer ID or transaction ID).
+
+This tends to distribute data more evenly across shards compared to range-based sharding. However, we need to choose a proper hash function to avoid hash collisions.
+
+## Consistent Hashing
+
+This is an extension of hash-based sharding that reduces the impact of adding or removing shards. It distributes data more evenly and minimizes the amount of data that needs to be relocated when shards are added or removed.
+
+## Virtual Bucket Sharding
+
+Data is mapped into virtual buckets, and these buckets are then mapped to physical shards. This two-level mapping allows for more flexible shard management and rebalancing without significant data movement.
diff --git a/data/guides/top-4-forms-of-authentication-mechanisms.md b/data/guides/top-4-forms-of-authentication-mechanisms.md
new file mode 100644
index 0000000..3ef146e
--- /dev/null
+++ b/data/guides/top-4-forms-of-authentication-mechanisms.md
@@ -0,0 +1,34 @@
+---
+title: "Top 4 Authentication Mechanisms"
+description: "Explore the top 4 authentication mechanisms for secure access."
+image: "https://assets.bytebytego.com/diagrams/0078-authentication-mechanisms.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "Security"
+---
+
+
+
+## 1. SSH Keys
+
+Cryptographic keys are used to access remote systems and servers securely.
+
+## 2. OAuth Tokens
+
+Tokens that provide limited access to user data on third-party applications.
+
+## 3. SSL Certificates
+
+Digital certificates ensure secure and encrypted communication between servers and clients.
+
+## 4. Credentials
+
+User authentication information is used to verify and grant access to various systems and services.
+
+Over to you: How do you manage those security keys? Is it a good idea to put them in a GitHub repository?
+
+Guest post by [Govardhana Miriyala Kannaiah](https://www.linkedin.com/in/govardhana-miriyala-kannaiah/?lipi=urn%3Ali%3Apage%3Ad_flagship3_profile_view_base_recent_activity_content_view%3B453ttTK1RbaZ6dUsydRz9Q%3D%3D).
diff --git a/data/guides/top-4-kubernetes-service-types-in-one-diagram.md b/data/guides/top-4-kubernetes-service-types-in-one-diagram.md
new file mode 100644
index 0000000..9a5bac4
--- /dev/null
+++ b/data/guides/top-4-kubernetes-service-types-in-one-diagram.md
@@ -0,0 +1,38 @@
+---
+title: "Top 4 Kubernetes Service Types"
+description: "Explore the top 4 Kubernetes service types with a helpful diagram."
+image: "https://assets.bytebytego.com/diagrams/0005-4-k8s-service-types.png"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - Kubernetes
+ - Networking
+---
+
+
+
+The diagram below shows 4 ways to expose a Service.
+
+In Kubernetes, a Service is a method for exposing a network application in the cluster. We use a Service to make that set of Pods available on the network so that users can interact with it.
+
+There are 4 types of Kubernetes services: ClusterIP, NodePort, LoadBalancer and ExternalName. The “type” property in the Service's specification determines how the service is exposed to the network.
+
+## Kubernetes Service Types
+
+* **ClusterIP**
+
+ ClusterIP is the default and most common service type. Kubernetes will assign a cluster-internal IP address to ClusterIP service. This makes the service only reachable within the cluster.
+
+* **NodePort**
+
+ This exposes the service outside of the cluster by adding a cluster-wide port on top of ClusterIP. We can request the service by NodeIP:NodePort.
+
+* **LoadBalancer**
+
+ This exposes the Service externally using a cloud provider’s load balancer.
+
+* **ExternalName**
+
+ This maps a Service to a domain name. This is commonly used to create a service within Kubernetes to represent an external database.
diff --git a/data/guides/top-4-most-popular-use-cases-for-udp.md b/data/guides/top-4-most-popular-use-cases-for-udp.md
new file mode 100644
index 0000000..7aecbf6
--- /dev/null
+++ b/data/guides/top-4-most-popular-use-cases-for-udp.md
@@ -0,0 +1,32 @@
+---
+title: "Top 4 Most Popular Use Cases for UDP"
+description: "Explore the top 4 use cases for UDP: streaming, DNS, multicast, and IoT."
+image: "https://assets.bytebytego.com/diagrams/0044-top-4-udp-use-cases.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "UDP"
+ - "Networking"
+---
+
+
+
+### UDP (User Datagram Protocol) is used in various software architectures for its simplicity, speed, and low overhead compared to other protocols like TCP.
+
+## Live Video Streaming
+
+Many VoIP and video conferencing applications leverage UDP due to its lower overhead and ability to tolerate packet loss. Real-time communication benefits from UDP's reduced latency compared to TCP.
+
+## DNS
+
+DNS (Domain Name Service) queries typically use UDP for their fast and lightweight nature. Although DNS can also use TCP for large responses or zone transfers, most queries are handled via UDP.
+
+## Market Data Multicast
+
+In low-latency trading, UDP is utilized for efficient market data delivery to multiple recipients simultaneously.
+
+## IoT
+
+UDP is often used in IoT devices for communications, sending small packets of data between devices.
diff --git a/data/guides/top-5-caching-strategies.md b/data/guides/top-5-caching-strategies.md
new file mode 100644
index 0000000..180d44a
--- /dev/null
+++ b/data/guides/top-5-caching-strategies.md
@@ -0,0 +1,31 @@
+---
+title: "Top 5 Caching Strategies"
+description: "Explore the top 5 caching strategies to optimize data synchronization."
+image: "https://assets.bytebytego.com/diagrams/0374-top-5-caching-strategies.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Data Synchronization"
+---
+
+
+
+When we introduce a cache into the architecture, synchronization between the cache and the database becomes inevitable.
+
+Let’s look at 5 common strategies for how we keep the data in sync.
+
+## Read Strategies
+
+* Cache aside
+* Read through
+
+## Write Strategies
+
+* Write around
+* Write back
+* Write through
+
+The caching strategies are often used in combination. For example, write-around is often used together with cache-aside to make sure the cache is up-to-date.
diff --git a/data/guides/top-5-common-ways-to-improve-api-performance.md b/data/guides/top-5-common-ways-to-improve-api-performance.md
new file mode 100644
index 0000000..d593ecc
--- /dev/null
+++ b/data/guides/top-5-common-ways-to-improve-api-performance.md
@@ -0,0 +1,34 @@
+---
+title: "Top 5 Common Ways to Improve API Performance"
+description: "Explore 5 common ways to boost your API's performance effectively."
+image: "https://assets.bytebytego.com/diagrams/0001-how-to-improve-api-performance.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - api performance
+ - optimization
+---
+
+
+
+## 1. Result Pagination:
+
+This method is used to optimize large result sets by streaming them back to the client, enhancing service responsiveness and user experience.
+
+## 2. Asynchronous Logging:
+
+This approach involves sending logs to a lock-free buffer and returning immediately, rather than dealing with the disk on every call. Logs are periodically flushed to the disk, significantly reducing I/O overhead.
+
+## 3. Data Caching:
+
+Frequently accessed data can be stored in a cache to speed up retrieval. Clients check the cache before querying the database, with data storage solutions like Redis offering faster access due to in-memory storage.
+
+## 4. Payload Compression:
+
+To reduce data transmission time, requests and responses can be compressed (e.g., using gzip), making the upload and download processes quicker.
+
+## 5. Connection Pooling:
+
+This technique involves using a pool of open connections to manage database interaction, which reduces the overhead associated with opening and closing connections each time data needs to be loaded. The pool manages the lifecycle of connections for efficient resource use.
diff --git a/data/guides/top-5-kafka-use-cases.md b/data/guides/top-5-kafka-use-cases.md
new file mode 100644
index 0000000..7575ba2
--- /dev/null
+++ b/data/guides/top-5-kafka-use-cases.md
@@ -0,0 +1,28 @@
+---
+title: "Top 5 Kafka Use Cases"
+description: "Explore the top 5 Kafka use cases for data streaming and processing."
+image: "https://assets.bytebytego.com/diagrams/0368-top-5-kafka-use-cases.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Kafka"
+ - "Data Streaming"
+---
+
+
+
+Kafka was originally built for massive log processing. It retains messages until expiration and lets consumers pull messages at their own pace.
+
+Let’s review the popular Kafka use cases.
+
+* Log processing and analysis
+
+* Data streaming in recommendations
+
+* System monitoring and alerting
+
+* CDC (Change data capture)
+
+* System migration
diff --git a/data/guides/top-5-most-used-deployment-strategies.md b/data/guides/top-5-most-used-deployment-strategies.md
new file mode 100644
index 0000000..6231515
--- /dev/null
+++ b/data/guides/top-5-most-used-deployment-strategies.md
@@ -0,0 +1,26 @@
+---
+title: "Top 5 Most-Used Deployment Strategies"
+description: "Explore the top 5 deployment strategies for efficient software releases."
+image: "https://assets.bytebytego.com/diagrams/0358-the-most-popular-deployment-strategies.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "deployment strategies"
+ - "software deployment"
+---
+
+
+
+Here are the top 5 most-used deployment strategies:
+
+* **Big Bang Deployment**
+
+* **Rolling Deployment**
+
+* **Blue-Green Deployment**
+
+* **Canary Deployment**
+
+* **Feature Toggle**
diff --git a/data/guides/top-5-software-architectural-patterns.md b/data/guides/top-5-software-architectural-patterns.md
new file mode 100644
index 0000000..c82dfc4
--- /dev/null
+++ b/data/guides/top-5-software-architectural-patterns.md
@@ -0,0 +1,20 @@
+---
+title: "Top 5 Software Architectural Patterns"
+description: "Explore the top 5 software architectural patterns for system design."
+image: "https://assets.bytebytego.com/diagrams/0339-software-architecture-styles.png"
+createdAt: "2024-03-15"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - "Software Architecture"
+ - "Design Patterns"
+---
+
+
+
+In software development, architecture plays a crucial role in shaping the structure and behavior of software systems. It provides a blueprint for system design, detailing how components interact with each other to deliver specific functionality. They also offer solutions to common problems, saving time and effort and leading to more robust and maintainable systems.
+
+However, with the vast array of architectural styles and patterns available, it can take time to discern which approach best suits a particular project or system. Aims to shed light on these concepts, helping you make informed decisions in your architectural endeavors.
+
+To help you navigate the vast landscape of architectural styles and patterns, there is a cheat sheet that encapsulates all. This cheat sheet is a handy reference guide that you can use to quickly recall the main characteristics of each architectural style and pattern.
diff --git a/data/guides/top-5-strategies-to-reduce-latency.md b/data/guides/top-5-strategies-to-reduce-latency.md
new file mode 100644
index 0000000..f71fabe
--- /dev/null
+++ b/data/guides/top-5-strategies-to-reduce-latency.md
@@ -0,0 +1,27 @@
+---
+title: "Top 5 Strategies to Reduce Latency"
+description: "Explore top strategies to minimize latency in high-scale systems."
+image: "https://assets.bytebytego.com/diagrams/0375-top-5-strategies-to-reduce-latency.png"
+createdAt: "2024-02-21"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Latency"
+ - "Optimization"
+---
+
+
+
+10 years ago, Amazon found that every 100ms of latency cost them 1% in sales. That’s a staggering $5.7 billion in today’s terms.
+
+For high-scale user-facing systems, high latency is a big loss of revenue.
+
+Here are the top strategies to reduce latency:
+
+* **Database Indexing**
+* **Caching**
+* **Load Balancing**
+* **Content Delivery Network**
+* **Async Processing**
+* **Data Compression**
diff --git a/data/guides/top-5-trade-offs-in-system-designs.md b/data/guides/top-5-trade-offs-in-system-designs.md
new file mode 100644
index 0000000..a36d319
--- /dev/null
+++ b/data/guides/top-5-trade-offs-in-system-designs.md
@@ -0,0 +1,24 @@
+---
+title: "Top 5 Trade-offs in System Designs"
+description: "Explore the top 5 trade-offs in system design for optimal solutions."
+image: "https://assets.bytebytego.com/diagrams/0376-top-5-trade-offs-in-system-designs.png"
+createdAt: "2024-02-02"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "trade-offs"
+---
+
+
+
+Everything is a trade-off. Everything is a compromise. There is no right or wrong design.
+
+The diagram below shows some of the most important trade-offs.
+
+* **Cost vs. Performance**
+* **Reliability vs. Scalability**
+* **Performance vs. Consistency**
+* **Security vs. Flexibility**
+* **Development Speed vs. Quality**
diff --git a/data/guides/top-6-cases-to-apply-idempotency.md b/data/guides/top-6-cases-to-apply-idempotency.md
new file mode 100644
index 0000000..4d15ce4
--- /dev/null
+++ b/data/guides/top-6-cases-to-apply-idempotency.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Cases to Apply Idempotency"
+description: "Explore 6 key use cases where idempotency is crucial for reliable systems."
+image: "https://assets.bytebytego.com/diagrams/0377-top-6-cases-of-leveraging-idempotency.png"
+createdAt: "2024-02-01"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Idempotency"
+ - "Distributed Systems"
+---
+
+
+
+Idempotency is essential in various scenarios, particularly where operations might be retried or executed multiple times. Here are the top 6 use cases where idempotency is crucial:
+
+## 1. RESTful API Requests
+
+We need to ensure that retrying an API request does not lead to multiple executions of the same operation. Implement idempotent methods (like PUT and DELETE) to maintain consistent resource states.
+
+## 2. Payment Processing
+
+We need to ensure that customers are not charged multiple times due to retries or network issues. Payment gateways often need to retry transactions; idempotency ensures only one charge is made.
+
+## 3. Order Management Systems
+
+We need to ensure that submitting an order multiple times results in only one order being placed. We design a safe mechanism to prevent duplicate inventory deductions or updates.
+
+## 4. Database Operations
+
+We need to ensure that reapplying a transaction does not change the database state beyond the initial application.
+
+## 5. User Account Management
+
+We need to ensure that retrying a registration request does not create multiple user accounts. Also, we need to ensure that multiple password reset requests result in a single reset action.
+
+## 6. Distributed Systems and Messaging
+
+We need to ensure that reprocessing messages from a queue does not result in duplicate processing. We Implement handlers that can process the same message multiple times without side effects.
diff --git a/data/guides/top-6-cloud-messaging-patterns.md b/data/guides/top-6-cloud-messaging-patterns.md
new file mode 100644
index 0000000..0974125
--- /dev/null
+++ b/data/guides/top-6-cloud-messaging-patterns.md
@@ -0,0 +1,44 @@
+---
+title: "Top 6 Cloud Messaging Patterns"
+description: "Explore 6 key cloud messaging patterns for distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0378-top-6-cloud-messaging-patterns.png"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Cloud Messaging"
+ - "Design Patterns"
+---
+
+How do services communicate with each other? The diagram below shows 6 cloud messaging patterns.
+
+
+
+## Asynchronous Request-Reply
+
+This pattern aims at providing determinism for long-running backend tasks. It decouples backend processing from frontend clients.
+
+In the diagram below, the client makes a synchronous call to the API, triggering a long-running operation on the backend. The API returns an HTTP 202 (Accepted) status code, acknowledging that the request has been received for processing.
+
+## Publisher-Subscriber
+
+This pattern targets decoupling senders from consumers, and avoiding blocking the sender to wait for a response.
+
+## Claim Check
+
+This pattern solves the transmision of large messages. It stores the whole message payload into a database and transmits only the reference to the message, which will be used later to retrieve the payload from the database.
+
+## Priority Queue
+
+This pattern prioritizes requests sent to services so that requests with a higher priority are received and processed more quickly than those with a lower priority.
+
+## Saga
+
+Saga is used to manage data consistency across multiple services in distributed systems, especially in microservices architectures where each service manages its own database.
+
+The saga pattern addresses the challenge of maintaining data consistency without relying on distributed transactions, which are difficult to scale and can negatively impact system performance.
+
+## Competing Consumers
+
+This pattern enables multiple concurrent consumers to process messages received on the same messaging channel. There is no need to configure complex coordination between the consumers. However, this pattern cannot guarantee message ordering.
diff --git a/data/guides/top-6-database-models.md b/data/guides/top-6-database-models.md
new file mode 100644
index 0000000..8e652e2
--- /dev/null
+++ b/data/guides/top-6-database-models.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Database Models"
+description: "Explore the top 6 database models and their unique characteristics."
+image: "https://assets.bytebytego.com/diagrams/0369-top-6-database-models.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Models"
+ - "Data Structures"
+---
+
+
+
+The diagram above shows top 6 data models.
+
+* **Flat Model**
+
+ The flat data model is one of the simplest forms of database models. It organizes data into a single table where each row represents a record and each column represents an attribute. This model is similar to a spreadsheet and is straightforward to understand and implement. However, it lacks the ability to efficiently handle complex relationships between data entities.
+
+* **Hierarchical Model**
+
+ The hierarchical data model organizes data into a tree-like structure, where each record has a single parent but can have multiple children. This model is efficient for scenarios with a clear "parent-child" relationship among data entities. However, it struggles with many-to-many relationships and can become complex and rigid.
+
+* **Relational Model**
+
+ Introduced by E.F. Codd in 1970, the relational model represents data in tables (relations), consisting of rows (tuples) and columns (attributes). It supports data integrity and avoids redundancy through the use of keys and normalization. The relational model's strength lies in its flexibility and the simplicity of its query language, SQL (Structured Query Language), making it the most widely used data model for traditional database systems. It efficiently handles many-to-many relationships and supports complex queries and transactions.
+
+* **Star Schema**
+
+ The star schema is a specialized data model used in data warehousing for OLAP (Online Analytical Processing) applications. It features a central fact table that contains measurable, quantitative data, surrounded by dimension tables that contain descriptive attributes related to the fact data. This model is optimized for query performance in analytical applications, offering simplicity and fast data retrieval by minimizing the number of joins needed for queries.
+
+* **Snowflake Model**
+
+ The snowflake model is a variation of the star schema where the dimension tables are normalized into multiple related tables, reducing redundancy and improving data integrity. This results in a structure that resembles a snowflake. While the snowflake model can lead to more complex queries due to the increased number of joins, it offers benefits in terms of storage efficiency and can be advantageous in scenarios where dimension tables are large or frequently updated.
+
+* **Network Model**
+
+ The network data model allows each record to have multiple parents and children, forming a graph structure that can represent complex relationships between data entities. This model overcomes some of the hierarchical model's limitations by efficiently handling many-to-many relationships.
diff --git a/data/guides/top-6-elasticsearch-use-cases.md b/data/guides/top-6-elasticsearch-use-cases.md
new file mode 100644
index 0000000..76a7c1d
--- /dev/null
+++ b/data/guides/top-6-elasticsearch-use-cases.md
@@ -0,0 +1,40 @@
+---
+title: "Top 6 Elasticsearch Use Cases"
+description: "Explore the top 6 use cases of Elasticsearch in various applications."
+image: "https://assets.bytebytego.com/diagrams/0380-top-6-elasticsearch-use-cases.png"
+createdAt: "2024-03-02"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - Search
+ - Analytics
+---
+
+
+
+Elasticsearch is widely used for its powerful and versatile search capabilities. The diagram above shows the top 6 use cases:
+
+## Full-Text Search
+
+Elasticsearch excels in full-text search scenarios due to its robust, scalable, and fast search capabilities. It allows users to perform complex queries with near real-time responses.
+
+## Real-Time Analytics
+
+Elasticsearch's ability to perform analytics in real-time makes it suitable for dashboards that track live data, such as user activity, transactions, or sensor outputs.
+
+## Machine Learning
+
+With the addition of the machine learning feature in X-Pack, Elasticsearch can automatically detect anomalies, patterns, and trends in the data.
+
+## Geo-Data Applications
+
+Elasticsearch supports geo-data through geospatial indexing and searching capabilities. This is useful for applications that need to manage and visualize geographical information, such as mapping and location-based services.
+
+## Log and Event Data Analysis
+
+Organizations use Elasticsearch to aggregate, monitor, and analyze logs and event data from various sources. It's a key component of the ELK stack (Elasticsearch, Logstash, Kibana), which is popular for managing system and application logs to identify issues and monitor system health.
+
+## Security Information and Event Management (SIEM)
+
+Elasticsearch can be used as a tool for SIEM, helping organizations to analyze security events in real time.
diff --git a/data/guides/top-6-firewall-use-cases.md b/data/guides/top-6-firewall-use-cases.md
new file mode 100644
index 0000000..cea917e
--- /dev/null
+++ b/data/guides/top-6-firewall-use-cases.md
@@ -0,0 +1,38 @@
+---
+title: "Top 6 Firewall Use Cases"
+description: "Explore the top 6 firewall use cases for enhanced network security."
+image: "https://assets.bytebytego.com/diagrams/0047-top-6-firewall-use-cases.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - security
+tags:
+ - "Network Security"
+ - "Firewall"
+---
+
+
+
+## Port-Based Rules
+
+Firewall rules can be set to allow or block traffic based on specific ports. For example, allowing only traffic on ports 80 (HTTP) and 443 (HTTPS) for web browsing.
+
+## IP Address Filtering
+
+Rules can be configured to allow or deny traffic based on source or destination IP addresses. This can include whitelisting trusted IP addresses or blacklisting known malicious ones.
+
+## Protocol-Based Rules
+
+Firewalls can be configured to allow or block traffic based on specific network protocols such as TCP, UDP, ICMP, etc. For instance, allowing only TCP traffic on port 22 (SSH).
+
+## Time-Based Rules
+
+Firewalls can be configured to enforce rules based on specific times or schedules. This can be useful for setting different access rules during business hours versus after-hours.
+
+## Stateful Inspection
+
+**Stateful Inspection:** Stateful firewalls monitor the state of active connections and allow traffic only if it matches an established connection, preventing unauthorized access from the outside.
+
+## Application-Based Rules
+
+Some firewalls offer application-level control by allowing or blocking traffic based on specific applications or services. For instance, allowing or restricting access to certain applications like Skype, BitTorrent, etc.
diff --git a/data/guides/top-6-load-balancing-algorithms.md b/data/guides/top-6-load-balancing-algorithms.md
new file mode 100644
index 0000000..2c5e463
--- /dev/null
+++ b/data/guides/top-6-load-balancing-algorithms.md
@@ -0,0 +1,44 @@
+---
+title: "Top 6 Load Balancing Algorithms"
+description: "Explore the top 6 load balancing algorithms in detail."
+image: "https://assets.bytebytego.com/diagrams/0251-lb-algorithms.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Load Balancing"
+ - "Algorithms"
+---
+
+
+
+## Top 6 Load Balancing Algorithms
+
+* **Static Algorithms**
+
+ * Round robin
+
+ The client requests are sent to different service instances in sequential order. The services are usually required to be stateless.
+
+ * Sticky round-robin
+
+ This is an improvement of the round-robin algorithm. If Alice’s first request goes to service A, the following requests go to service A as well.
+
+ * Weighted round-robin
+
+ The admin can specify the weight for each service. The ones with a higher weight handle more requests than others.
+
+ * Hash
+
+ This algorithm applies a hash function on the incoming requests’ IP or URL. The requests are routed to relevant instances based on the hash function result.
+
+* **Dynamic Algorithms**
+
+ * Least connections
+
+ A new request is sent to the service instance with the least concurrent connections.
+
+ * Least response time
+
+ A new request is sent to the service instance with the fastest response time.
diff --git a/data/guides/top-6-most-commonly-used-server-types.md b/data/guides/top-6-most-commonly-used-server-types.md
new file mode 100644
index 0000000..7829d42
--- /dev/null
+++ b/data/guides/top-6-most-commonly-used-server-types.md
@@ -0,0 +1,38 @@
+---
+title: "Top 6 Most Commonly Used Server Types"
+description: "Explore the top 6 most commonly used server types in modern infrastructure."
+image: "https://assets.bytebytego.com/diagrams/0327-server-types.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - software-development
+tags:
+ - "servers"
+ - "networking"
+---
+
+
+
+## 1. Web Server
+
+Hosts websites and delivers web content to clients over the internet.
+
+## 2. Mail Server
+
+Handles the sending, receiving, and routing of emails across networks.
+
+## 3. DNS Server
+
+Translates domain names (like bytebytego.com) into IP addresses, enabling users to access websites by their human-readable names.
+
+## 4. Proxy Server
+
+An intermediary server that acts as a gateway between clients and other servers, providing additional security, performance optimization, and anonymity.
+
+## 5. FTP Server
+
+Facilitates the transfer of files between clients and servers over a network.
+
+## 6. Origin Server
+
+Hosts central source of content that is cached and distributed to edge servers for faster delivery to end users.
diff --git a/data/guides/top-6-multithreading-design-patterns-you-must-know.md b/data/guides/top-6-multithreading-design-patterns-you-must-know.md
new file mode 100644
index 0000000..b5e3121
--- /dev/null
+++ b/data/guides/top-6-multithreading-design-patterns-you-must-know.md
@@ -0,0 +1,42 @@
+---
+title: "Top 6 Multithreading Design Patterns You Must Know"
+description: "Explore essential multithreading design patterns for concurrent programming."
+image: "https://assets.bytebytego.com/diagrams/0381-top-6-multithreading-design-patterns-you-must-know.png"
+createdAt: "2024-02-23"
+draft: false
+categories:
+ - software-development
+tags:
+ - Concurrency
+ - Design Patterns
+---
+
+
+
+Multithreading enables a single program or process to execute multiple tasks concurrently. Each task is a thread. Think of threads as lightweight units of execution that share the resources of the process such as memory space.
+
+However, multithreading also introduces complexities like synchronization, communication, and potential race conditions. This is where patterns help.
+
+## Producer-Consumer Pattern
+
+This pattern involves two types of threads: producers generating data and consumers processing that data. A blocking queue acts as a buffer between the two.
+
+## Thread Pool Pattern
+
+In this pattern, there is a pool of worker threads that can be reused for executing tasks. Using a pool removes the overhead of creating and destroying threads. Great for executing a large number of short-lived tasks.
+
+## Futures and Promises Pattern
+
+In this pattern, the promise is an object that holds the eventual results and the future provides a way to access the result. This is great for executing long-running operations concurrently without blocking the main thread.
+
+## Monitor Object Pattern
+
+Ensures that only one thread can access or modify a shared resource within an object at a time. This helps prevent race conditions. The pattern is required when you need to protect shared data or resources from concurrent access.
+
+## Barrier Pattern
+
+Synchronizes a group of threads. Each thread executes until it reaches a barrier point in the code and blocks until all threads have reached the same barrier. Ideal for parallel tasks that need to reach a specific stage before starting the next stage.
+
+## Read-Write Lock Pattern
+
+It allows multiple threads to read from a shared resource but only allows one thread to write to it at a time. Ideal for managing shared resources where reads are more frequent than writes.
diff --git a/data/guides/top-6-tools-to-turn-code-into-beautiful-diagrams.md b/data/guides/top-6-tools-to-turn-code-into-beautiful-diagrams.md
new file mode 100644
index 0000000..bf138f3
--- /dev/null
+++ b/data/guides/top-6-tools-to-turn-code-into-beautiful-diagrams.md
@@ -0,0 +1,23 @@
+---
+title: "Top 6 Tools to Turn Code into Beautiful Diagrams"
+description: "Explore the best tools for transforming code into stunning diagrams."
+image: "https://assets.bytebytego.com/diagrams/0382-top-6-tools-to-turn-code-into-beautiful-diagrams.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "Diagramming"
+ - "Code Visualization"
+---
+
+
+
+Here are the top tools to turn code into diagrams:
+
+* Diagrams
+* Go Diagrams
+* Mermaid
+* PlantUML
+* ASCII diagrams
+* Markmap
diff --git a/data/guides/top-7-most-used-distributed-system-patterns.md b/data/guides/top-7-most-used-distributed-system-patterns.md
new file mode 100644
index 0000000..576252e
--- /dev/null
+++ b/data/guides/top-7-most-used-distributed-system-patterns.md
@@ -0,0 +1,22 @@
+---
+title: "Top 7 Most-Used Distributed System Patterns"
+description: "Explore the top 7 most-used patterns in distributed system design."
+image: "https://assets.bytebytego.com/diagrams/0119-top-7-most-used-distributed-system-patterns.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "distributed systems"
+ - "system design"
+---
+
+
+
+* Ambassador
+* Circuit Breaker
+* CQRS
+* Event Sourcing
+* Leader Election
+* Publisher/Subscriber
+* Sharding
diff --git a/data/guides/top-8-c++-use-cases.md b/data/guides/top-8-c++-use-cases.md
new file mode 100644
index 0000000..0a4c317
--- /dev/null
+++ b/data/guides/top-8-c++-use-cases.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 C++ Use Cases"
+description: "Explore the top use cases for C++ in various industries."
+image: "https://assets.bytebytego.com/diagrams/0384-top-8-c-use-cases.png"
+createdAt: "2024-02-22"
+draft: false
+categories:
+ - software-development
+tags:
+ - "C++"
+ - "Use Cases"
+---
+
+
+
+C++ is a highly versatile programming language that is suitable for a wide range of applications.
+
+## Embedded Systems
+
+* The language's efficiency and fine control over hardware resources make it excellent for embedded systems development.
+
+## Game Development
+
+* C++ is a staple in the game development industry due to its performance and efficiency.
+
+## Operating Systems
+
+* C++ provides extensive control over system resources and memory, making it ideal for developing operating systems and low-level system utilities.
+
+## Databases
+
+* Many high-performance database systems are implemented in C++ to manage memory efficiently and ensure fast execution of queries.
+
+## Financial Applications
+
+## Web Browsers
+
+* C++ is used in the development of web browsers and their components, such as rendering engines.
+
+## Networking
+
+* C++ is often used for developing network devices and simulation tools.
+
+## Scientific Computing
+
+* C++ finds extensive use in scientific computing and engineering applications that require high performance and precise control over computational resources.
diff --git a/data/guides/top-8-cache-eviction-strategies.md b/data/guides/top-8-cache-eviction-strategies.md
new file mode 100644
index 0000000..ea95ea9
--- /dev/null
+++ b/data/guides/top-8-cache-eviction-strategies.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 Cache Eviction Strategies"
+description: "Explore 8 key cache eviction strategies to optimize performance."
+image: "https://assets.bytebytego.com/diagrams/0059-top-8-cache-eviction-strategies.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Caching"
+ - "Algorithms"
+---
+
+
+
+## LRU (Least Recently Used)
+
+LRU eviction strategy removes the least recently accessed items first. This approach is based on the principle that items accessed recently are more likely to be accessed again in the near future.
+
+## MRU (Most Recently Used)
+
+Contrary to LRU, the MRU algorithm removes the most recently used items first. This strategy can be useful in scenarios where the most recently accessed items are less likely to be accessed again soon.
+
+## SLRU (Segmented LRU)
+
+SLRU divides the cache into two segments: a probationary segment and a protected segment. New items are initially placed into the probationary segment. If an item in the probationary segment is accessed again, it is promoted to the protected segment.
+
+## LFU (Least Frequently Used)
+
+LFU algorithm evicts the items with the lowest access frequency.
+
+## FIFO (First In First Out)
+
+FIFO is one of the simplest caching strategies, where the cache behaves in a queue-like manner, evicting the oldest items first, regardless of their access patterns or frequency.
+
+## TTL (Time-to-Live)
+
+While not strictly an eviction algorithm, TTL is a strategy where each cache item is given a specific lifespan.
+
+## Two-Tiered Caching
+
+In Two-Tiered Caching strategy, we use an in-memory cache for the first layer and a distributed cache for the second layer.
+
+## RR (Random Replacement)
+
+Random Replacement algorithm randomly selects a cache item and evicts it to make space for new items. This method is also simple to implement and does not require tracking access patterns or frequencies.
diff --git a/data/guides/top-8-must-know-docker-concepts.md b/data/guides/top-8-must-know-docker-concepts.md
new file mode 100644
index 0000000..edb8adc
--- /dev/null
+++ b/data/guides/top-8-must-know-docker-concepts.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 Must-Know Docker Concepts"
+description: "Learn the essential Docker concepts for efficient application deployment."
+image: "https://assets.bytebytego.com/diagrams/0012-8-must-know-docker-concepts.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Docker"
+ - "Containers"
+---
+
+
+
+## Dockerfile
+
+It contains the instructions to build a Docker image by specifying the base image, dependencies, and run command.
+
+## Docker Image
+
+A lightweight, standalone package that includes everything (code, libraries, and dependencies) needed to run your application. Images are built from a Dockerfile and can be versioned.
+
+## Docker Container
+
+A running instance of a Docker image. Containers are isolated from each other and the host system, providing a secure and reproducible environment for running your apps.
+
+## Docker Registry
+
+A centralized repository for storing and distributing Docker images. For example, Docker Hub is the default public registry but you can also set up private registries.
+
+## Docker Volumes
+
+A way to persist data generated by containers. Volumes are outside the container’s file system and can be shared between multiple containers.
+
+## Docker Compose
+
+A tool for defining and running multi-container Docker applications, making it easy to manage the entire stack.
+
+## Docker Networks
+
+Used to enable communication between containers and the host system. Custom networks can isolate containers or enable selective communication.
+
+## Docker CLI
+
+The primary way to interact with Docker, providing commands for building images, running containers, managing volumes, and performing other operations.
diff --git a/data/guides/top-8-programming-paradigms.md b/data/guides/top-8-programming-paradigms.md
new file mode 100644
index 0000000..85421a2
--- /dev/null
+++ b/data/guides/top-8-programming-paradigms.md
@@ -0,0 +1,46 @@
+---
+title: "Top 8 Programming Paradigms"
+description: "Explore the top 8 programming paradigms shaping modern software development."
+image: "https://assets.bytebytego.com/diagrams/0120-top-8-programming-paradigms-2.png"
+createdAt: "2024-03-07"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Programming Paradigms"
+ - "Software Development"
+---
+
+
+
+## Imperative Programming
+
+Imperative programming describes a sequence of steps that change the program’s state. Languages like C, C++, Java, Python (to an extent), and many others support imperative programming styles.
+
+## Declarative Programming
+
+Declarative programming emphasizes expressing logic and functionalities without describing the control flow explicitly. Functional programming is a popular form of declarative programming.
+
+## Object-Oriented Programming (OOP)
+
+Object-oriented programming (OOP) revolves around the concept of objects, which encapsulate data (attributes) and behavior (methods or functions). Common object-oriented programming languages include Java, C++, Python, Ruby, and C#.
+
+## Aspect-Oriented Programming (AOP)
+
+Aspect-oriented programming (AOP) aims to modularize concerns that cut across multiple parts of a software system. AspectJ is one of the most well-known AOP frameworks that extends Java with AOP capabilities.
+
+## Functional Programming
+
+Functional Programming (FP) treats computation as the evaluation of mathematical functions and emphasizes the use of immutable data and declarative expressions. Languages like Haskell, Lisp, Erlang, and some features in languages like JavaScript, Python, and Scala support functional programming paradigms.
+
+## Reactive Programming
+
+Reactive Programming deals with asynchronous data streams and the propagation of changes. Event-driven applications, and streaming data processing applications benefit from reactive programming.
+
+## Generic Programming
+
+Generic Programming aims at creating reusable, flexible, and type-independent code by allowing algorithms and data structures to be written without specifying the types they will operate on. Generic programming is extensively used in libraries and frameworks to create data structures like lists, stacks, queues, and algorithms like sorting, searching.
+
+## Concurrent Programming
+
+Concurrent Programming deals with the execution of multiple tasks or processes simultaneously, improving performance and resource utilization. Concurrent programming is utilized in various applications, including multi-threaded servers, parallel processing, concurrent web servers, and high-performance computing.
diff --git a/data/guides/top-8-standards-every-developer-should-know.md b/data/guides/top-8-standards-every-developer-should-know.md
new file mode 100644
index 0000000..be97438
--- /dev/null
+++ b/data/guides/top-8-standards-every-developer-should-know.md
@@ -0,0 +1,48 @@
+---
+title: "Top 8 Standards Every Developer Should Know"
+description: "Explore the top 8 essential standards every developer should know."
+image: "https://assets.bytebytego.com/diagrams/0015-8-standards-developers-should-know.png"
+createdAt: "2024-03-01"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Software Standards"
+ - "Web Development"
+---
+
+
+
+## TCP/IP
+
+Developed by the IETF organization, the TCP/IP protocol is the foundation of the Internet and one of the best-known networking standards.
+
+## HTTP
+
+The IETF has also developed the HTTP protocol, which is essential for all web developers.
+
+## SQL
+
+Structured Query Language (SQL) is a domain-specific language used to manage data.
+
+## OAuth
+
+OAuth (Open Authorization) is an open standard for access delegation commonly used to grant websites or applications limited access to user information without exposing their passwords.
+
+## HTML/CSS
+
+With HTML, web pages are rendered uniformly across browsers, which reduces development effort spent on compatibility issues.HTML tags.
+
+CSS standards are often used in conjunction with HTML.
+
+## ECMAScript
+
+ECMAScript is a standardized scripting language specification that serves as the foundation for several programming languages, the most well-known being JavaScript.
+
+## ISO Date
+
+It is common for developers to have problems with inconsistent time formats on a daily basis. ISO 8601 is a date and time format standard developed by the ISO (International Organization for Standardization) to provide a common format for exchanging date and time data across borders, cultures, and industries.
+
+## OpenAPI
+
+OpenAPI, also known as the OpenAPI Specification (OAS), is a standardized format for describing and documenting RESTful APIs.
diff --git a/data/guides/top-9-architectural-patterns-for-data-and-communication-flow.md b/data/guides/top-9-architectural-patterns-for-data-and-communication-flow.md
new file mode 100644
index 0000000..9f70931
--- /dev/null
+++ b/data/guides/top-9-architectural-patterns-for-data-and-communication-flow.md
@@ -0,0 +1,50 @@
+---
+title: "Top 9 Architectural Patterns for Data and Communication Flow"
+description: "Explore 9 key architectural patterns for efficient data and communication."
+image: "https://assets.bytebytego.com/diagrams/0387-top-9-system-integrations.png"
+createdAt: "2024-01-31"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Architecture"
+ - "Data Flow"
+---
+
+
+
+* **Peer-to-Peer**
+
+ The Peer-to-Peer pattern involves direct communication between two components without the need for a central coordinator.
+
+* **API Gateway**
+
+ An API Gateway acts as a single entry point for all client requests to the backend services of an application.
+
+* **Pub-Sub**
+
+ The Pub-Sub pattern decouples the producers of messages (publishers) from the consumers of messages (subscribers) through a message broker.
+
+* **Request-Response**
+
+ This is one of the most fundamental integration patterns, where a client sends a request to a server and waits for a response.
+
+* **Event Sourcing**
+
+ Event Sourcing involves storing the state changes of an application as a sequence of events.
+
+* **ETL**
+
+ ETL is a data integration pattern used to gather data from multiple sources, transform it into a structured format, and load it into a destination database.
+
+* **Batching**
+
+ Batching involves accumulating data over a period or until a certain threshold is met before processing it as a single group.
+
+* **Streaming Processing**
+
+ Streaming Processing allows for the continuous ingestion, processing, and analysis of data streams in real-time.
+
+* **Orchestration**
+
+ Orchestration involves a central coordinator (an orchestrator) managing the interactions between distributed components or services to achieve a workflow or business process.
diff --git a/data/guides/top-9-cases-behind-100-cpu-usage.md b/data/guides/top-9-cases-behind-100-cpu-usage.md
new file mode 100644
index 0000000..772cd78
--- /dev/null
+++ b/data/guides/top-9-cases-behind-100-cpu-usage.md
@@ -0,0 +1,28 @@
+---
+title: "Top 9 Causes of 100% CPU Usage"
+description: "Explore the top causes behind 100% CPU usage and how to resolve them."
+image: "https://assets.bytebytego.com/diagrams/0386-top-9-cases-behind-100-cpu-usage.png"
+createdAt: "2024-03-03"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - "CPU Usage"
+ - "Troubleshooting"
+---
+
+
+
+The diagram below shows common culprits that can lead to 100% CPU usage. Understanding these can help in diagnosing problems and improving system efficiency.
+
+## Top 9 Causes of 100% CPU Usage
+
+* Infinite Loops
+* Background Processes
+* High Traffic Volume
+* Resource-Intensive Applications
+* Insufficient Memory
+* Concurrent Processes
+* Busy Waiting
+* Regular Expression Matching
+* Malware and Viruses
diff --git a/data/guides/top-9-engineering-blog-favorites.md b/data/guides/top-9-engineering-blog-favorites.md
new file mode 100644
index 0000000..f527d3f
--- /dev/null
+++ b/data/guides/top-9-engineering-blog-favorites.md
@@ -0,0 +1,26 @@
+---
+title: 'Top 9 Engineering Blogs'
+description: 'My favorite engineering blogs to stay up-to-date with the industry.'
+image: 'https://assets.bytebytego.com/diagrams/0190-9-of-my-favorite-engg-blogs.png'
+createdAt: '2024-03-09'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Engineering Blogs
+ - Software Development
+---
+
+
+
+There are over 1,000 engineering blogs. Here are my top 9 favorites:
+
+* Netflix TechBlog
+* Uber Blog
+* Cloudflare Blog
+* Engineering at Meta
+* LinkedIn Engineering
+* Discord Blog
+* AWS Architecture
+* Slack Engineering
+* Stripe Blog
diff --git a/data/guides/top-9-http-request-methods.md b/data/guides/top-9-http-request-methods.md
new file mode 100644
index 0000000..9b70e9f
--- /dev/null
+++ b/data/guides/top-9-http-request-methods.md
@@ -0,0 +1,44 @@
+---
+title: 'Top 9 HTTP Request Methods'
+description: 'Explore the top 9 HTTP request methods with clear explanations.'
+image: 'https://assets.bytebytego.com/diagrams/0371-top-9-http-request-methods.png'
+createdAt: '2024-02-27'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP
+ - API
+---
+
+
+
+GET, POST, PUT... Common HTTP “verbs” in one figure.
+
+* **HTTP GET**
+
+ This retrieves a resource from the server. It is idempotent. Multiple identical requests return the same result.
+* **HTTP PUT**
+
+ This updates or Creates a resource. It is idempotent. Multiple identical requests will update the same resource.
+* **HTTP POST**
+
+ This is used to create new resources. It is not idempotent, making two identical POST will duplicate the resource creation.
+* **HTTP DELETE**
+
+ This is used to delete a resource. It is idempotent. Multiple identical requests will delete the same resource.
+* **HTTP PATCH**
+
+ The PATCH method applies partial modifications to a resource.
+* **HTTP HEAD**
+
+ The HEAD method asks for a response identical to a GET request but without the response body.
+* **HTTP CONNECT**
+
+ The CONNECT method establishes a tunnel to the server identified by the target resource.
+* **HTTP OPTIONS**
+
+ This describes the communication options for the target resource.
+* **HTTP TRACE**
+
+ This performs a message loop-back test along the path to the target resource.
diff --git a/data/guides/top-9-website-performance-metrics-you-cannot-ignore.md b/data/guides/top-9-website-performance-metrics-you-cannot-ignore.md
new file mode 100644
index 0000000..5e683db
--- /dev/null
+++ b/data/guides/top-9-website-performance-metrics-you-cannot-ignore.md
@@ -0,0 +1,50 @@
+---
+title: "Top 9 Website Performance Metrics You Cannot Ignore"
+description: "Explore the top website performance metrics for optimal user experience."
+image: "https://assets.bytebytego.com/diagrams/0021-must-know-website-performance-metrics.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - web-performance
+ - metrics
+---
+
+
+
+## Load Time
+
+This is the time taken by the web browser to download and display the webpage. It’s measured in milliseconds.
+
+## Time to First Byte (TTFB)
+
+It’s the time taken by the browser to receive the first byte of data from the web server. TTFB is crucial because it indicates the general ability of the server to handle traffic.
+
+## Request Count
+
+The number of HTTP requests a browser has to make to fully load the page. The lower this count, the faster a website will feel to the user.
+
+## DOMContentLoaded (DCL)
+
+This is the time it takes for the full HTML code of a webpage to be loaded. The faster this happens, the faster users can see useful functionality. This time doesn’t include loading CSS and other assets
+
+## Time to Above-the-Fold Load
+
+“Above the fold” is the area of a webpage that fits in a browser window without a user having to scroll down. This is the content that is first seen by the user and often dictates whether they’ll continue reading the webpage.
+
+## First Contentful Paint (FCP)
+
+This is the time at which content first begins to be “painted” by the browser. It can be a text, image, or even background color.
+
+## Page Size
+
+This is the total file size of all content and assets that appear on the page. Over the last several years, the page size of websites has been growing constantly. The bigger the size of a webpage, the longer it will take to load
+
+## Round Trip Time (RTT)
+
+This is the amount of time a round trip takes. A round trip constitutes a request traveling from the browser to the origin server and the response from the server going to the browser. Reducing RTT is one of the key approaches to improving a website’s performance.
+
+## Render Blocking Resources
+
+Some resources block other parts of the page from being loaded. It’s important to track the number of such resources. The more render-blocking resources a webpage has, the greater the delay for the browser to load the page.
diff --git a/data/guides/top-eventual-consistency-patterns-you-must-know.md b/data/guides/top-eventual-consistency-patterns-you-must-know.md
new file mode 100644
index 0000000..8057512
--- /dev/null
+++ b/data/guides/top-eventual-consistency-patterns-you-must-know.md
@@ -0,0 +1,34 @@
+---
+title: "Top Eventual Consistency Patterns You Must Know"
+description: "Explore eventual consistency patterns for distributed database design."
+image: "https://assets.bytebytego.com/diagrams/0100-eventual-consistency-patterns-you-must-know.png"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Consistency"
+ - "Databases"
+---
+
+
+
+Eventual consistency is a data consistency model that ensures that updates to a distributed database are eventually reflected across all nodes. Techniques like async replication help achieve eventual consistency.
+
+However, eventual consistency can also result in data inconsistency. Here are 4 patterns that can help you design applications.
+
+## Event-based Eventual Consistency
+
+Services emit events and other services listen to these events to update their database instances. This makes services loosely coupled but delays data consistency.
+
+## Background Sync Eventual Consistency
+
+In this pattern, a background job makes the data across databases consistent. It results in slower eventual consistency since the background job runs on a specific schedule.
+
+## Saga-based Eventual Consistency
+
+Saga is a sequence of local transactions where each transaction updates data with a single service. It is used to manage long-lived transactions that are eventually consistent.
+
+## CQRS-based Eventual Consistency
+
+Separate read and write operations into different databases that are eventually consistent. Read and write models can be optimized for specific requirements.
diff --git a/data/guides/top-network-security-cheatsheet.md b/data/guides/top-network-security-cheatsheet.md
new file mode 100644
index 0000000..a492bc0
--- /dev/null
+++ b/data/guides/top-network-security-cheatsheet.md
@@ -0,0 +1,57 @@
+---
+title: "Top Network Security Cheatsheet"
+description: "A concise guide to network security threats across OSI layers."
+image: "https://assets.bytebytego.com/diagrams/0049-top-network-security-cheatsheet.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - security
+tags:
+ - "Network Security"
+ - "Cybersecurity"
+---
+
+The diagram below shows some possible network attacks in 7 OSI model layers.
+
+
+
+## Application Layer
+
+* Pushing
+* Malware injection
+* DDoS attacks
+
+## Presentation Layer
+
+* Encoding/decoding vulnerabilities
+* Format string attacks
+* Malicious code injection
+
+## Session Layer
+
+* Session hijacking
+* Session fixation attacks
+* Brute force attacks
+
+## Transport Layer
+
+* Man-in-the-middle attacks
+* SYN/ACK flood
+
+## Network Layer
+
+* IP spoofing
+* Route table manipulation
+* DDoS attacks
+
+## Data Link Layer
+
+* MAC address spoofing
+* ARP spoofing
+* VLAN hopping
+
+## Physical Layer
+
+* Wiretapping
+* Physical tampering
+* Electromagnetic interference
diff --git a/data/guides/twitter-10-tech-stack.md b/data/guides/twitter-10-tech-stack.md
new file mode 100644
index 0000000..f9aa2a7
--- /dev/null
+++ b/data/guides/twitter-10-tech-stack.md
@@ -0,0 +1,20 @@
+---
+title: 'Twitter 1.0 Tech Stack'
+description: 'Explore the tech stack behind Twitter 1.0: a deep dive into its architecture.'
+image: 'https://assets.bytebytego.com/diagrams/0122-twitter1-0-tech-stack.jpg'
+createdAt: '2024-02-21'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Social Media
+---
+
+
+
+* **Mobile:** Swift, Kotlin, PWA
+* **Web:** JS, React, Redux
+* **Services:** Mesos, Finagle
+* **Caching:** Pelikan Cache, Redis
+* **Databases:** Manhattan, MySQL, PostgreSQL
diff --git a/data/guides/twitter-architecture-2022-vs-2012.md b/data/guides/twitter-architecture-2022-vs-2012.md
new file mode 100644
index 0000000..73730ab
--- /dev/null
+++ b/data/guides/twitter-architecture-2022-vs-2012.md
@@ -0,0 +1,16 @@
+---
+title: 'Twitter Architecture 2022 vs. 2012'
+description: "A look at how Twitter's architecture evolved over the past decade."
+image: 'https://assets.bytebytego.com/diagrams/0392-twitter-architecture-2022-vs-2012.jpeg'
+createdAt: '2024-03-13'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Scalability
+---
+
+
+
+What’s changed over the past 10 years?!
diff --git a/data/guides/types-of-databases.md b/data/guides/types-of-databases.md
new file mode 100644
index 0000000..69860e7
--- /dev/null
+++ b/data/guides/types-of-databases.md
@@ -0,0 +1,38 @@
+---
+title: "Types of Databases"
+description: "Explore common database types: relational, OLAP, NoSQL, and more."
+image: "https://assets.bytebytego.com/diagrams/0097-dbtypes.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - Database
+ - NoSQL
+---
+
+What is a database? What are some common types of databases?
+
+
+
+First off, what's a database? Think of it as a digital playground where we organize and store loads of information in a structured manner. Now, let's shake things up and look at the main types of databases.
+
+## Relational DB
+
+Imagine it's like organizing data in neat tables. Think of it as the well-behaved sibling, keeping everything in order.
+
+## OLAP DB
+
+Online Analytical Processing (OLAP) is a technology optimized for reporting and analysis purposes.
+
+## NoSQL DBs
+
+These rebels have their own cool club, saying "No" to traditional SQL ways. NoSQL databases come in four exciting flavors:
+
+* **Graph DB:** Think of social networks, where relationships between people matter most. It's like mapping who's friends with whom.
+
+* **Key-value Store DB:** It's like a treasure chest, with each item having its unique key. Finding what you need is a piece of cake.
+
+* **Document DB:** A document database is a kind of database that stores information in a format similar to JSON. It's different from traditional databases and is made for working with documents instead of tables.
+
+* **Column DB:** Imagine slicing and dicing your data like a chef prepping ingredients. It's efficient and speedy.
diff --git a/data/guides/types-of-memory-and-storage.md b/data/guides/types-of-memory-and-storage.md
new file mode 100644
index 0000000..021127e
--- /dev/null
+++ b/data/guides/types-of-memory-and-storage.md
@@ -0,0 +1,23 @@
+---
+title: "Types of Memory and Storage"
+description: "Explore computer memory and storage: RAM, ROM, HDD, SSD, and more."
+image: "https://assets.bytebytego.com/diagrams/0268-memory-storage.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "memory"
+ - "storage"
+---
+
+
+
+Diving into the world of computer memory and storage.
+
+* The fundamental duo: RAM and ROM
+* DDR4 and DDR5
+* Firmware and BIOS
+* SRAM and DRAM
+* HDD, SSD, USB Drive, SD Card
+* and more
diff --git a/data/guides/types-of-memory.md b/data/guides/types-of-memory.md
new file mode 100644
index 0000000..e34db46
--- /dev/null
+++ b/data/guides/types-of-memory.md
@@ -0,0 +1,32 @@
+---
+title: "Types of Memory"
+description: "Explore the hierarchy of memory types, from registers to remote storage."
+image: "https://assets.bytebytego.com/diagrams/0045-memory-types.png"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Memory Management"
+ - "System Architecture"
+---
+
+
+
+Memory types vary by speed, size, and function, creating a multi-layered architecture that balances cost with the need for rapid data access.
+
+By grasping the roles and capabilities of each memory type, developers and system architects can design systems that effectively leverage the strengths of each storage layer, leading to improved overall system performance and user experience.
+
+Some of the common Memory types are:
+
+* **Registers:** Tiny, ultra-fast storage within the CPU for immediate data access.
+
+* **Caches:** Small, quick memory located close to the CPU to speed up data retrieval.
+
+* **Main Memory (RAM):** Larger, primary storage for currently executing programs and data.
+
+* **Solid-State Drives (SSDs):** Fast, reliable storage with no moving parts, used for persistent data.
+
+* **Hard Disk Drives (HDDs):** Mechanical drives with large capacities for long-term storage.
+
+* **Remote Secondary Storage:** Offsite storage for data backup and archiving, accessible over a network.
diff --git a/data/guides/types-of-message-queue.md b/data/guides/types-of-message-queue.md
new file mode 100644
index 0000000..2e3e91f
--- /dev/null
+++ b/data/guides/types-of-message-queue.md
@@ -0,0 +1,36 @@
+---
+title: "Types of Message Queues"
+description: "Explore different types of message queues and their key features."
+image: "https://assets.bytebytego.com/diagrams/0272-message-queues.png"
+createdAt: "2024-01-31"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Message Queue"
+ - "Messaging Systems"
+---
+
+
+
+### How many message queues do you know?
+
+Like a post office, a message queue helps computer programs communicate in an organized manner. Imagine little digital envelopes being passed around to keep everything on track. There are a few key features to consider when selecting message queues:
+
+* Speed: How fast messages are sent and received
+
+* Scalability: Can it grow with more messages
+
+* Reliability: Will it make sure messages don’t get lost
+
+* Durability: Can it keep messages safe over time
+
+* Ease of Use: Is it simple to set up and manage
+
+* Ecosystem: Are there helpful tools available
+
+* Integration: Can it play nice with other software
+
+* Protocol Support: What languages can it speak
+
+Try out a message queue and practice sending and receiving messages until you're comfortable. Choose an easy one like Kafka and experiment with sending and receiving messages. Read books or take online courses as you get more comfortable. Build little projects and learn from those who have already been there. Soon, you'll know everything about message queues.
diff --git a/data/guides/types-of-vpns.md b/data/guides/types-of-vpns.md
new file mode 100644
index 0000000..efba417
--- /dev/null
+++ b/data/guides/types-of-vpns.md
@@ -0,0 +1,16 @@
+---
+title: "Types of VPNs"
+description: "Explore different VPN types and their use cases for secure connections."
+image: "https://assets.bytebytego.com/diagrams/0404-vpns.png"
+createdAt: "2024-03-08"
+draft: false
+categories:
+ - security
+tags:
+ - VPN
+ - Security
+---
+
+
+
+Think you know how VPNs work? Think again! 😳 It's so complex.
diff --git a/data/guides/typical-aws-network-architecture-in-one-diagram.md b/data/guides/typical-aws-network-architecture-in-one-diagram.md
new file mode 100644
index 0000000..4778730
--- /dev/null
+++ b/data/guides/typical-aws-network-architecture-in-one-diagram.md
@@ -0,0 +1,62 @@
+---
+title: "Typical AWS Network Architecture"
+description: "Explore a typical AWS network architecture with key components."
+image: "https://assets.bytebytego.com/diagrams/0123-typical-aws-network-architecture.png"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - AWS Networking
+ - Cloud Architecture
+---
+
+
+
+Amazon Web Services (AWS) offers a comprehensive suite of networking services designed to provide businesses with secure, scalable, and highly available network infrastructure. AWS's network architecture components enable seamless connectivity between the internet, remote workers, corporate data centers, and within the AWS ecosystem itself.
+
+## Key Components
+
+* **VPC (Virtual Private Cloud)**
+
+ At the heart of AWS's networking services is the Amazon VPC, which allows users to provision a logically isolated section of the AWS Cloud. Within this isolated environment, users can launch AWS resources in a virtual network that they define.
+
+* **AZ (Availability Zone)**
+
+ An AZ in AWS refers to one or more discrete data centers with redundant power, networking, and connectivity in an AWS Region.
+
+Now let’s go through the network connectivity one by one:
+
+## Network Connectivity
+
+### 1. Connect to the Internet - Internet Gateway (IGW)
+
+An IGW serves as the doorway between your AWS VPC and the internet, facilitating bidirectional communication.
+
+### 2. Remote Workers - Client VPN Endpoint
+
+AWS offers a Client VPN service that enables remote workers to access AWS resources or an on-premises network securely over the internet. It provides a secure and easy-to-manage VPN solution.
+
+### 3. Corporate Data Center Connection - Virtual Gateway (VGW)
+
+A VGW is the VPN concentrator on the Amazon side of the Site-to-Site VPN connection between your network and your VPC.
+
+### 4. VPC Peering
+
+VPC Peering allows you to connect two VPCs, enabling you to route traffic between them using private IPv4 or IPv6 addresses.
+
+### 5. Transit Gateway
+
+AWS Transit Gateway acts as a network transit hub, enabling you to connect multiple VPCs, VPNs, and AWS accounts together.
+
+### 6. VPC Endpoint (Gateway)
+
+A VPC Endpoint (Gateway type) allows you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, VPN.
+
+### 7. VPC Endpoint (Interface)
+
+An Interface VPC Endpoint (powered by AWS PrivateLink) enables private connections between your VPC and supported AWS services, other VPCs, or AWS Marketplace services, without requiring an IGW, VGW, or NAT device.
+
+### 8. SaaS Private Link Connection
+
+AWS PrivateLink provides private connectivity between VPCs and services hosted on AWS or on-premises, ideal for accessing SaaS applications securely.
diff --git a/data/guides/uber-tech-stack-cicd.md b/data/guides/uber-tech-stack-cicd.md
new file mode 100644
index 0000000..e86f04e
--- /dev/null
+++ b/data/guides/uber-tech-stack-cicd.md
@@ -0,0 +1,38 @@
+---
+title: Uber Tech Stack - CI/CD
+description: "Uber's CI/CD tech stack: Tools and platforms for efficient delivery."
+image: 'https://assets.bytebytego.com/diagrams/0398-uber-tech-stack-ci-cd.png'
+createdAt: '2024-02-19'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - CI/CD
+ - Uber
+---
+
+Uber is one of the most innovative companies in the engineering field. Let’s take a look at their CI/CD tech stacks.
+
+
+
+Note: This post is based on research on Uber engineering blogs. If you spot any inaccuracies, please let us know.
+
+* **Project planning:** JIRA
+
+* **Backend services:** Spring Boot to develop their backend services. And to make things even faster, they've created a nifty configuration system called Flipr that allows for speedy configuration releases.
+
+* **Code issues:** They developed NullAway to tackle NullPointer problems and NEAL to lint the code. Plus, they built Piranha to clean out-dated feature flags.
+
+* **Repository:** They believe in Monorepo. It uses Bazel on a large scale.
+
+* **Testing:** They use SLATE to manage short-lived testing environments and rely on Shadower for load testing by replaying production traffic. They even developed Ballast to ensure a smooth user experience.
+
+* **Experiment platform:** it is based on deep learning and they've generously open-sourced parts of it, like Pyro.
+
+* **Build:** Uber packages their services into containers using uBuild. It's their go-to tool, powered by Buildkite, for all the packaging tasks.
+
+* **Deploying applications:** Netflix Spinnaker. It's their trusted tool for getting things into production smoothly and efficiently.
+
+* **Monitoring:** Uber built their own monitoring systems. They use the uMetric platform, built on Cassandra, to keep things consistent.
+
+* **Special tooling:** Uber relies on Peloton for capacity planning, scheduling, and operations. Crane builds a multi-cloud infrastructure to optimize costs. And with uAct and the OnCall dashboard, they've got event tracing and on-call duty management covered.
diff --git a/data/guides/uber-tech-stack.md b/data/guides/uber-tech-stack.md
new file mode 100644
index 0000000..f911324
--- /dev/null
+++ b/data/guides/uber-tech-stack.md
@@ -0,0 +1,32 @@
+---
+title: Uber Tech Stack
+description: Explore the tech stack that powers Uber's real-time transportation network.
+image: 'https://assets.bytebytego.com/diagrams/0124-uber-tech-stack-overall.png'
+createdAt: '2024-03-10'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - Architecture
+ - Scalability
+---
+
+
+
+This post is based on research from many Uber engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us. The corresponding links are added in the comment section.
+
+**Web frontend:** Uber builds Fusion.js as a modern React framework to create robust web applications. They also develop visualization.js for geospatial visualization scenarios.
+
+**Mobile side:** Uber builds the RIB cross-platform with the VIPER architecture instead of MVC. This architecture can work with different languages: Swift for iOS, and Java for Android.
+
+**Service mesh:** Uber built Uber Gateway as a dynamic configuration on top of NGINX. The service uses gRPC and QUIC for client-server communication, and Apache Thrift for API definition.
+
+**Service side:** Uber built a unified configuration store named Flipr (later changed to UCDP), H3 as a location-index store library. They use Spring Boot for Java-based services, uAct for event-driven architecture, and Cadence for async workflow orchestration.
+
+**Database end:** the OLTP mainly uses the strongly-consistent DocStore, which employs MySQL and PostgreSQL, along with the RocksDB database engine.
+
+**Big data:** managed through the Hadoop family. Hudi and Parquet are used as file formats, and Alluxio serves as cache. Time-series data is stored in Pinot and AresDB.
+
+**Data processing:** Hive, Spark, and the open-source data ingestion framework Marmaray. Messaging and streaming middleware include Apache Kafka and Apache Flink.
+
+**DevOps side:** Uber utilizes a Monorepo, with a simplified development environment called devpod. Continuous delivery is managed through Netflix Spinnaker, metrics are emitted to uMetric, alarms on uMonitor, and a consistent observability database M3.
diff --git a/data/guides/understanding-database-types.md b/data/guides/understanding-database-types.md
new file mode 100644
index 0000000..cc9fe36
--- /dev/null
+++ b/data/guides/understanding-database-types.md
@@ -0,0 +1,16 @@
+---
+title: "Understanding Database Types"
+description: "Explore different database types and their use cases."
+image: "https://assets.bytebytego.com/diagrams/0394-understanding-database-types.png"
+createdAt: "2024-02-20"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "databases"
+ - "data management"
+---
+
+
+
+To make the best decision for our projects, it is essential to understand the various types of databases available in the market. We need to consider key characteristics of different database types, including popular options for each, and compare their use cases.
diff --git a/data/guides/unicast-vs-broadcast-vs-multicast-vs-anycast.md b/data/guides/unicast-vs-broadcast-vs-multicast-vs-anycast.md
new file mode 100644
index 0000000..7b1649e
--- /dev/null
+++ b/data/guides/unicast-vs-broadcast-vs-multicast-vs-anycast.md
@@ -0,0 +1,48 @@
+---
+title: 'Unicast vs Broadcast vs Multicast vs Anycast'
+description: 'Understand the differences between unicast, broadcast, multicast, and anycast.'
+image: 'https://assets.bytebytego.com/diagrams/0125-unicast-vs-broadcast-vs-multicast-vs-anycast.png'
+createdAt: '2024-02-19'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Network Communication
+ - Protocols
+---
+
+
+
+These are 4 network communication methods you must know.
+
+* **Unicast**
+
+ Unique sender and a single receiver.
+
+ For example, communication between two people in a party.
+
+ Used in protocols such as HTTP, FTP, and SMTP.
+
+* **Broadcast**
+
+ Single sender and multiple receivers.
+
+ For example, a person at a party stands up on a podium and shouts a message to everyone. However, it doesn’t mean that every receiver gets the message.
+
+ Used in Address Resolution Protocol, DHCP, and NTP
+
+* **Multicast**
+
+ Sender to a specific group of devices in a network. This is a specialized case of broadcast routing.
+
+ For example, a member of the group talks and listens to other members of the group within a party.
+
+ Used in IPTV and video conference applications.
+
+* **Anycast**
+
+ Sender to a single device or a specific group of devices.
+
+ For example, saying thank you to one host out of a group of hosts organizing a party. All other hosts also expected to receive the thank you note.
+
+ Used in DNS querying and CDNs.
diff --git a/data/guides/unified-payments-interface-upi-in-india.md b/data/guides/unified-payments-interface-upi-in-india.md
new file mode 100644
index 0000000..7780b10
--- /dev/null
+++ b/data/guides/unified-payments-interface-upi-in-india.md
@@ -0,0 +1,62 @@
+---
+title: "Unified Payments Interface (UPI)"
+description: "Explore the architecture and workings of India's UPI payment system."
+image: "https://assets.bytebytego.com/diagrams/0400-upi-2.png"
+createdAt: "2024-03-04"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Fintech"
+ - "UPI"
+---
+
+
+
+The Unified Payments Interface (UPI) for real-time transactions in India is a good case study for other nations in the payment space.
+
+## What’s UPI?
+
+UPI is an instant real-time payment system developed by the National Payments Corporation of India.
+
+It accounts for 60% of digital retail transactions in India today and is still growing.
+
+UPI = payment markup language + standard for interoperable payments
+
+Let's take a look at how it works.
+
+## Registration
+
+* Bob wants to open an account and provides his phone number +91 12345678
+
+* Bob performs OTP (One-Time Password) phone verification
+
+* Bob sets up VPA (Virtual Payment Address) bobaxis
+
+* Bob’s payment app creates VPA with the acquiring bank
+
+* The acquiring bank returns with VPA
+
+* The payment app returns VPA to Bob
+
+## Link to Bank Account
+
+* Bob wants to link his SBI bank account with VPA bob at the axis. The request is forwarded to NPCI (National Payments Corporation of India).
+
+* NPCI acts as a switch between acquiring banks and issuing banks. It resolves the account detail from VPA with different issuing banks.
+
+* Bob authenticates with account details and sets the PIN, which is used for 2FA. This goes all the way to the issuing bank.
+
+## Direct payment
+
+1. Alice enters Bob’s UPI ID bob and the amount INR 100
+
+2. PhonePe verifies and forwards the request to NPCI via ICICI bank
+
+3. NPCI requests Axis Bank to resolve detail for bob at axis
+
+4. NPCI deducts Alice’s HDFC bank account by INR 100
+
+5. NPCI sends an instruction to SBI bank and add INR 100 to Bob’s account in SBI bank.
+
+6. Upon success, NPCI notifies the payment apps via acquiring banks.
diff --git a/data/guides/unique-id-generator.md b/data/guides/unique-id-generator.md
new file mode 100644
index 0000000..692c334
--- /dev/null
+++ b/data/guides/unique-id-generator.md
@@ -0,0 +1,32 @@
+---
+title: "Unique ID Generator"
+description: "Explore unique ID generation for scalable backend systems."
+image: "https://assets.bytebytego.com/diagrams/0105-id-generator.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "ID Generation"
+ - "System Design"
+---
+
+
+
+IDs are very important for the backend. Do you know how to generate globally unique IDs?
+
+In this post, we explore common requirements for IDs that are used in social media such as Facebook, Twitter, and LinkedIn.
+
+## Requirements:
+
+* Globally unique
+
+* Roughly sorted by time
+
+* Numerical values only
+
+* 64 bits
+
+* Highly scalable, low latency
+
+The implementation details of the algorithms can be found online so we will not go into detail here.
diff --git a/data/guides/url-uri-urn-do-you-know-the-differences.md b/data/guides/url-uri-urn-do-you-know-the-differences.md
new file mode 100644
index 0000000..ecb8513
--- /dev/null
+++ b/data/guides/url-uri-urn-do-you-know-the-differences.md
@@ -0,0 +1,33 @@
+---
+title: 'URL, URI, URN - Differences Explained'
+description: 'Understand the differences between URL, URI, and URN with clear examples.'
+image: 'https://assets.bytebytego.com/diagrams/0401-url-uri-urn.png'
+createdAt: '2024-02-21'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Networking
+ - Web
+---
+
+
+
+The diagram above shows a comparison of URL, URI, and URN.
+
+* **URI**
+
+ URI stands for Uniform Resource Identifier. It identifies a logical or physical resource on the web. URL and URN are subtypes of URI. URL locates a resource, while URN names a resource.
+
+A URI is composed of the following parts:
+
+```
+scheme:[//authority]path[?query][#fragment]
+```
+
+* **URL**
+
+ URL stands for Uniform Resource Locator, the key concept of HTTP. It is the address of a unique resource on the web. It can be used with other protocols like FTP and JDBC.
+* **URN**
+
+ URN stands for Uniform Resource Name. It uses the urn scheme. URNs cannot be used to locate a resource. A simple example given in the diagram is composed of a namespace and a namespace-specific string.
diff --git a/data/guides/v1what-is-sso-single-sign-on.md b/data/guides/v1what-is-sso-single-sign-on.md
new file mode 100644
index 0000000..f2f4841
--- /dev/null
+++ b/data/guides/v1what-is-sso-single-sign-on.md
@@ -0,0 +1,36 @@
+---
+title: "What is SSO (Single Sign-On)?"
+description: "Learn about Single Sign-On (SSO) and how it simplifies user authentication."
+image: "https://assets.bytebytego.com/diagrams/0342-how-does-sso-work.jpeg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - security
+tags:
+ - "authentication"
+ - "SSO"
+---
+
+
+
+A friend recently went through the irksome experience of being signed out from a number of websites they use daily. This event will be familiar to millions of web users, and it is a tedious process to fix. It can involve trying to remember multiple long-forgotten passwords, or typing in the names of pets from childhood to answer security questions. SSO removes this inconvenience and makes life online better. But how does it work?
+
+Basically, Single Sign-On (SSO) is an authentication scheme. It allows a user to log in to different systems using a single ID.
+
+The diagram below illustrates how SSO works.
+
+## How SSO Works
+
+Step 1: A user visits Gmail, or any email service. Gmail finds the user is not logged in and so redirects them to the SSO authentication server, which also finds the user is not logged in. As a result, the user is redirected to the SSO login page, where they enter their login credentials.
+
+Steps 2-3: The SSO authentication server validates the credentials, creates the global session for the user, and creates a token.
+
+Steps 4-7: Gmail validates the token in the SSO authentication server. The authentication server registers the Gmail system, and returns “valid.” Gmail returns the protected resource to the user.
+
+Step 8: From Gmail, the user navigates to another Google-owned website, for example, YouTube.
+
+Steps 9-10: YouTube finds the user is not logged in, and then requests authentication. The SSO authentication server finds the user is already logged in and returns the token.
+
+Steps 11-14: YouTube validates the token in the SSO authentication server. The authentication server registers the YouTube system, and returns “valid.” YouTube returns the protected resource to the user.
+
+The process is complete and the user gets back access to their account.
diff --git a/data/guides/vertical-partitioning-vs-horizontal-partitioning.md b/data/guides/vertical-partitioning-vs-horizontal-partitioning.md
new file mode 100644
index 0000000..f5ac2b6
--- /dev/null
+++ b/data/guides/vertical-partitioning-vs-horizontal-partitioning.md
@@ -0,0 +1,42 @@
+---
+title: "Vertical vs Horizontal Partitioning"
+description: "Explore vertical vs horizontal partitioning strategies in databases."
+image: "https://assets.bytebytego.com/diagrams/0402-vertical-partitioning-vs-horizontal-partitioning.png"
+createdAt: "2024-01-30"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "Database Partitioning"
+ - "Sharding"
+---
+
+
+
+In many large-scale applications, data is divided into partitions that can be accessed separately. There are two typical strategies for partitioning data.
+
+* Vertical partitioning: it means some columns are moved to new tables. Each table contains the same number of rows but fewer columns (see diagram below).
+
+* Horizontal partitioning (often called sharding): it divides a table into multiple smaller tables. Each table is a separate data store, and it contains the same number of columns, but fewer rows (see diagram below).
+
+Horizontal partitioning is widely used so let’s take a closer look.
+
+## Routing algorithm
+
+The routing algorithm decides which partition (shard) stores the data.
+
+* Range-based sharding. This algorithm uses ordered columns, such as integers, longs, timestamps, to separate the rows. For example, the diagram below uses the User ID column for range partition: User IDs 1 and 2 are in shard 1, User IDs 3 and 4 are in shard 2.
+
+* Hash-based sharding. This algorithm applies a hash function to one column or several columns to decide which row goes to which table. For example, the diagram below uses **User ID mod 2** as a hash function. User IDs 1 and 3 are in shard 1, User IDs 2 and 4 are in shard 2.
+
+## Benefits
+
+* Facilitate horizontal scaling. Sharding facilitates the possibility of adding more machines to spread out the load.
+
+* Shorten response time. By sharding one table into multiple tables, queries go over fewer rows, and results are returned much more quickly.
+
+## Drawbacks
+
+* The order by operation is more complicated. Usually, we need to fetch data from different shards and sort the data in the application's code.
+
+* Uneven distribution. Some shards may contain more data than others (this is also called the hotspot).
diff --git a/data/guides/visualizing-a-sql-query.md b/data/guides/visualizing-a-sql-query.md
new file mode 100644
index 0000000..7f8c105
--- /dev/null
+++ b/data/guides/visualizing-a-sql-query.md
@@ -0,0 +1,24 @@
+---
+title: "Visualizing a SQL Query"
+description: "Understand the logical order of operations in a SQL query."
+image: "https://assets.bytebytego.com/diagrams/0114-sql-query-logical-order.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "SQL"
+ - "Databases"
+---
+
+
+
+SQL statements are executed by the database system in several steps, including:
+
+* Parsing the SQL statement and checking its validity
+
+* Transforming the SQL into an internal representation, such as relational algebra
+
+* Optimizing the internal representation and creating an execution plan that utilizes index information
+
+* Executing the plan and returning the results
diff --git a/data/guides/what's-the-difference-between-session-based-authentication-and-jwts.md b/data/guides/what's-the-difference-between-session-based-authentication-and-jwts.md
new file mode 100644
index 0000000..8341bab
--- /dev/null
+++ b/data/guides/what's-the-difference-between-session-based-authentication-and-jwts.md
@@ -0,0 +1,46 @@
+---
+title: "Session-based Authentication vs. JWT"
+description: "Understand the key differences between session and JWT authentication."
+image: "https://assets.bytebytego.com/diagrams/0333-what-s-the-difference-between-session-based-authentication-and-jwts.png"
+createdAt: "2024-02-28"
+draft: false
+categories:
+ - security
+tags:
+ - "Authentication"
+ - "JWT"
+---
+
+
+
+Here’s a simple breakdown for both approaches:
+
+## Session-Based Authentication
+
+In this approach, you store the session information in a database or session store and hand over a session ID to the user.
+
+Think of it like a passenger getting just the Ticket ID of their flight while all other details are stored in the airline’s database.
+
+Here’s how it works:
+
+* The user makes a login request and the frontend app sends the request to the backend server.
+* The backend creates a session using a secret key and stores the data in session storage.
+* The server sends a cookie back to the client with the unique session ID.
+* The user makes a new request and the browser sends the session ID along with the request.
+* The server authenticates the user using the session ID.
+
+## JWT-Based Authentication
+
+In the JWT-based approach, you don’t store the session information in the session store.
+
+The entire information is available within the token.
+
+Think of it like getting the flight ticket along with all the details available on the ticket but encoded.
+
+Here’s how it works:
+
+* The user makes a login request and it goes to the backend server.
+* The server verifies the credentials and issues a JWT. The JWT is signed using a private key and no session storage is involved.
+* The JWT is passed to the client, either as a cookie or in the response body. Both approaches have their pros and cons but we’ve gone with the cookie approach.
+* For every subsequent request, the browser sends the cookie with the JWT.
+* The server verifies the JWT using the secret private key and extracts the user info.
diff --git a/data/guides/what-are-database-isolation-levels.md b/data/guides/what-are-database-isolation-levels.md
new file mode 100644
index 0000000..ad1867b
--- /dev/null
+++ b/data/guides/what-are-database-isolation-levels.md
@@ -0,0 +1,42 @@
+---
+title: "Database Isolation Levels"
+description: "Explore database isolation levels and their impact on transaction concurrency."
+image: "https://assets.bytebytego.com/diagrams/0239-isolation-level.png"
+createdAt: "2024-02-03"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Databases"
+ - "Transactions"
+---
+
+
+
+## What are they used for?
+
+Database isolation allows a transaction to execute as if there are no other concurrently running transactions.
+
+The diagram above illustrates four isolation levels.
+
+## Isolation Levels
+
+* **Serializable:** This is the highest isolation level. Concurrent transactions are guaranteed to be executed in sequence.
+
+* **Repeatable Read:** Data read during the transaction stays the same as the transaction starts.
+
+* **Read Committed:** Data modification can only be read after the transaction is committed.
+
+* **Read Uncommitted:** The data modification can be read by other transactions before a transaction is committed.
+
+The isolation is guaranteed by MVCC (Multi-Version Consistency Control) and locks.
+
+## MVCC Example
+
+The diagram takes Repeatable Read as an example to demonstrate how MVCC works:
+
+There are two hidden columns for each row: transaction\_id and roll\_pointer. When transaction A starts, a new Read View with transaction\_id=201 is created. Shortly afterward, transaction B starts, and a new Read View with transaction\_id=202 is created.
+
+Now transaction A modifies the balance to 200, a new row of the log is created, and the roll\_pointer points to the old row. Before transaction A commits, transaction B reads the balance data. Transaction B finds that transaction\_id 201 is not committed, it reads the next committed record(transaction\_id=200).
+
+Even when transaction A commits, transaction B still reads data based on the Read View created when transaction B starts. So transaction B always reads the data with balance=100.
diff --git a/data/guides/what-are-the-differences-among-database-locks.md b/data/guides/what-are-the-differences-among-database-locks.md
new file mode 100644
index 0000000..7760057
--- /dev/null
+++ b/data/guides/what-are-the-differences-among-database-locks.md
@@ -0,0 +1,56 @@
+---
+title: "Database Locks Explained"
+description: "Explore the different types of database locks and their functionalities."
+image: "https://assets.bytebytego.com/diagrams/0022-9-types-of-database-locks.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Database Locking"
+ - "Concurrency Control"
+---
+
+
+
+In database management, locks are mechanisms that prevent concurrent access to data to ensure data integrity and consistency.
+
+## Common Types of Locks
+
+Here are the common types of locks used in databases:
+
+* **Shared Lock (S Lock)**
+
+ It allows multiple transactions to read a resource simultaneously but not modify it. Other transactions can also acquire a shared lock on the same resource.
+
+* **Exclusive Lock (X Lock)**
+
+ It allows a transaction to both read and modify a resource. No other transaction can acquire any type of lock on the same resource while an exclusive lock is held.
+
+* **Update Lock (U Lock)**
+
+ It is used to prevent a deadlock scenario when a transaction intends to update a resource.
+
+* **Schema Lock**
+
+ It is used to protect the structure of database objects.
+
+* **Bulk Update Lock (BU Lock)**
+
+ It is used during bulk insert operations to improve performance by reducing the number of locks required.
+
+* **Key-Range Lock**
+
+ It is used in indexed data to prevent phantom reads (inserting new rows into a range that a transaction has already read).
+
+* **Row-Level Lock**
+
+ It locks a specific row in a table, allowing other rows to be accessed concurrently.
+
+* **Page-Level Lock**
+
+ It locks a specific page (a fixed-size block of data) in the database.
+
+* **Table-Level Lock**
+
+ It locks an entire table. This is simple to implement but can reduce concurrency significantly.
diff --git a/data/guides/what-are-the-differences-between-a-load-balancer-and-an-api-gateway.md b/data/guides/what-are-the-differences-between-a-load-balancer-and-an-api-gateway.md
new file mode 100644
index 0000000..755a17e
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-a-load-balancer-and-an-api-gateway.md
@@ -0,0 +1,26 @@
+---
+title: 'Load Balancer vs. API Gateway'
+description: 'Explore the key differences between load balancers and API gateways.'
+image: 'https://assets.bytebytego.com/diagrams/0252-lb-api-gateway.png'
+createdAt: '2024-02-11'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Load Balancer
+---
+
+
+
+First, let's clarify some concepts before discussing the differences.
+
+* NLB (Network Load Balancer) is usually deployed before the API gateway, handling traffic routing based on IP. It does not parse the HTTP requests.
+* ALB (Application Load Balancer) routes requests based on HTTP header or URL and thus can provide richer routing rules. We can choose the load balancer based on routing requirements. For simple services with a smaller scale, one load balancer is enough.
+* The API gateway performs tasks more on the application level. So it has different responsibilities from the load balancer.
+
+The diagram above shows the detail. Often, they are used in combination to provide a scalable and secure architecture for modern web apps.
+
+Option a: ALB is used to distribute requests among different services. Due to the fact that the services implement their own rating limitation, authentication, etc., this approach is more flexible but requires more work at the service level.
+
+Option b: An API gateway takes care of authentication, rate limiting, caching, etc., so there is less work at the service level. However, this option is less flexible compared with the ALB approach.
diff --git a/data/guides/what-are-the-differences-between-cookies-and-sessions.md b/data/guides/what-are-the-differences-between-cookies-and-sessions.md
new file mode 100644
index 0000000..178de35
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-cookies-and-sessions.md
@@ -0,0 +1,24 @@
+---
+title: "Cookies vs Sessions"
+description: "Explore the key differences between cookies and sessions in web development."
+image: "https://assets.bytebytego.com/diagrams/0154-cookies-vs-session.png"
+createdAt: "2024-02-17"
+draft: false
+categories:
+ - security
+tags:
+ - "cookies"
+ - "sessions"
+---
+
+
+
+Cookies and sessions are both used to carry user information over HTTP requests, including user login status, user permissions, etc.
+
+## Cookies
+
+Cookies typically have size limits (4KB). They carry small pieces of information and are stored on the users’ devices. Cookies are sent with each subsequent user request. Users can choose to ban cookies in their browsers.
+
+## Sessions
+
+Unlike cookies, sessions are created and stored on the server side. There is usually a unique session ID generated on the server, which is attached to a specific user session. This session ID is returned to the client side in a cookie. Sessions can hold larger amounts of data. Since the session data is not directly accessed by the client, the session offers more security.
diff --git a/data/guides/what-are-the-differences-between-paging-and-segmentation.md b/data/guides/what-are-the-differences-between-paging-and-segmentation.md
new file mode 100644
index 0000000..65f5fff
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-paging-and-segmentation.md
@@ -0,0 +1,46 @@
+---
+title: "Paging vs Segmentation"
+description: "Explore paging vs segmentation: memory management techniques."
+image: "https://assets.bytebytego.com/diagrams/0269-memory-allocation-paging-vs-segmentation.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Memory Management"
+ - "Operating Systems"
+---
+
+
+
+## Paging
+
+Paging is a memory management scheme that eliminates the need for contiguous allocation of physical memory. The process's address space is divided into fixed-size blocks called pages, while physical memory is divided into fixed-size blocks called frames.
+
+The address translation process works in 3 steps:
+
+* Logical Address Space: The logical address (generated by the CPU) is divided into a page number and a page offset.
+* Page Table Lookup: The page number is used as an index into the page table to find the corresponding frame number.
+* Physical Address Formation: The frame number is combined with the page offset to form the physical address in memory.
+
+### Advantages:
+
+* Eliminates external fragmentation.
+* Simplifies memory allocation.
+* Supports efficient swapping and virtual memory.
+
+## Segmentation
+
+Segmentation is a memory management technique where the memory is divided into variable-sized segments based on the logical divisions of a program, such as functions, objects, or data arrays.
+
+The address tranlation process works in 3 steps:
+
+* Logical Address Space: The logical address consists of a segment number and an offset within that segment.
+* Segment Table Lookup: The segment number is used as an index into the segment table to find the base address of the segment.
+* Physical Address Formation: The base address is added to the offset to form the physical address in memory.
+
+### Advantages:
+
+* Provides logical separation of different parts of a program.
+* Facilitates protection and sharing of segments.
+* Simplifies management of growing data structures.
diff --git a/data/guides/what-are-the-differences-between-wan-lan-pan-and-man.md b/data/guides/what-are-the-differences-between-wan-lan-pan-and-man.md
new file mode 100644
index 0000000..f2c0bc5
--- /dev/null
+++ b/data/guides/what-are-the-differences-between-wan-lan-pan-and-man.md
@@ -0,0 +1,56 @@
+---
+title: 'What are the differences between WAN, LAN, PAN and MAN?'
+description: 'Explore the key differences between WAN, LAN, PAN, and MAN networks.'
+image: 'https://assets.bytebytego.com/diagrams/0405-wan-lan-pan-man-explained.png'
+createdAt: '2024-02-06'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - network types
+ - network architecture
+---
+
+
+
+In the world of networking, different types of networks are defined based on their size, range, and purpose. The most common types of networks are WAN (Wide Area Network), MAN (Metropolitan Area Network), LAN (Local Area Network), and PAN (Personal Area Network).
+
+* **Personal Area Network (PAN)**
+
+ A PAN is a network used for communication among devices close to one person, typically within a range of a few meters.
+
+ Use Cases:
+
+ * Connecting personal devices like smartphones, tablets, and wearables.
+ * Enabling hands-free communication through Bluetooth headsets.
+ * Synchronizing data between a computer and a smartphone.
+
+* **Local Area Network (LAN)**
+
+ A LAN is a network that connects computers and devices within a limited area such as a home, office, or building.
+
+ Use Cases:
+
+ * Sharing resources like printers and file servers within an office.
+ * Facilitating communication and collaboration among employees.
+ * Providing internet access within a home or small business.
+
+* **Metropolitan Area Network (MAN)**
+
+ A MAN covers a larger geographic area than a LAN but smaller than a WAN, typically spanning a city or a large campus.
+
+ Use Cases:
+
+ * Connecting multiple campuses of a university.
+ * Providing high-speed internet access across a city.
+ * Linking local government offices within a metropolitan area.
+
+* **Wide Area Network (WAN)**
+
+ A WAN spans a large geographic area, often a country or continent. The most prominent example of a WAN is the Internet.
+
+ Use Cases:
+
+ * Connecting branch offices of multinational companies.
+ * Facilitating global communication and data exchange.
+ * Enabling remote access to central resources.
diff --git a/data/guides/what-are-the-greenest-programming-languages.md b/data/guides/what-are-the-greenest-programming-languages.md
new file mode 100644
index 0000000..6b4a765
--- /dev/null
+++ b/data/guides/what-are-the-greenest-programming-languages.md
@@ -0,0 +1,18 @@
+---
+title: "What Are the Greenest Programming Languages?"
+description: "Explore energy efficiency in programming languages and their impact."
+image: "https://assets.bytebytego.com/diagrams/0186-energy-efficient-language.jpg"
+createdAt: "2024-02-19"
+draft: false
+categories:
+ - software-development
+tags:
+ - "Programming Languages"
+ - "Energy Efficiency"
+---
+
+
+
+The study below runs 10 benchmark problems in 28 languages. It measures the runtime, memory usage, and energy consumption of each language. This take might be controversial.
+
+“This paper presents a study of the runtime, memory usage, and energy consumption of twenty-seven well-known software languages. We monitor the performance of such languages using ten different programming problems, expressed in each of the languages. Our results show interesting findings, such as slower/faster languages consuming less/more energy, and how memory usage influences energy consumption. We show how to use our results to provide software engineers support to decide which language to use when energy efficiency is a concern”.
diff --git a/data/guides/what-are-the-most-important-aws-services-to-learn.md b/data/guides/what-are-the-most-important-aws-services-to-learn.md
new file mode 100644
index 0000000..07b837b
--- /dev/null
+++ b/data/guides/what-are-the-most-important-aws-services-to-learn.md
@@ -0,0 +1,28 @@
+---
+title: "Most Important AWS Services to Learn"
+description: "Explore essential AWS services for cloud computing and architecture."
+image: "https://assets.bytebytego.com/diagrams/0280-most-important-aws-services.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - AWS
+ - Cloud Computing
+---
+
+
+
+Since its inception in 2006, AWS has rapidly evolved from simple offerings like S3 and EC2 to an expansive, versatile cloud ecosystem.
+
+Today, AWS provides a highly reliable, scalable infrastructure platform with over 200 services in the cloud, powering hundreds of thousands of businesses in 190 countries around the world.
+
+For both newcomers and seasoned professionals, navigating the broad set of AWS services is no small feat.
+
+From computing power, storage options, and networking capabilities to database management, analytics, and machine learning, AWS provides a wide array of tools that can be daunting to understand and master.
+
+Each service is tailored to specific needs and use cases, requiring a deep understanding of not just the services themselves, but also how they interact and integrate within an IT ecosystem.
+
+This attached illustration can serve as both a starting point and a quick reference for anyone looking to demystify AWS and focus their efforts on the services that matter most.
+
+It provides a visual roadmap, outlining the foundational services that underpin cloud computing essentials, as well as advanced services catering to specific needs like serverless architectures, DevOps, and machine learning.
diff --git a/data/guides/what-are-the-top-caching-strategies.md b/data/guides/what-are-the-top-caching-strategies.md
new file mode 100644
index 0000000..1f4f546
--- /dev/null
+++ b/data/guides/what-are-the-top-caching-strategies.md
@@ -0,0 +1,31 @@
+---
+title: "Top Caching Strategies"
+description: "Explore the top caching strategies to optimize system performance."
+image: "https://assets.bytebytego.com/diagrams/0129-caching-strategy.jpg"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "caching"
+ - "performance"
+---
+
+
+
+Read data from the system:
+
+* **Cache aside**
+* **Read through**
+
+Write data to the system:
+
+* **Write around**
+* **Write back**
+* **Write through**
+
+The diagram above illustrates how those 5 strategies work. Some of the caching strategies can be used together.
+
+I left out a lot of details as that will make the post very long.
+
+Feel free to leave a comment so we can learn from each other.
diff --git a/data/guides/what-do-version-numbers-mean.md b/data/guides/what-do-version-numbers-mean.md
new file mode 100644
index 0000000..0a59847
--- /dev/null
+++ b/data/guides/what-do-version-numbers-mean.md
@@ -0,0 +1,33 @@
+---
+title: What do version numbers mean?
+description: "Understand version numbers: MAJOR, MINOR, PATCH and Semantic Versioning."
+image: 'https://assets.bytebytego.com/diagrams/0415-what-do-version-numbers-mean.png'
+createdAt: '2024-02-17'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Versioning
+ - SemVer
+---
+
+
+
+Semantic Versioning (SemVer) is a versioning scheme for software that aims to convey meaning about the underlying changes in a release.
+
+* SemVer uses a three-part version number: MAJOR.MINOR.PATCH.
+ * **MAJOR version**: Incremented when there are incompatible API changes.
+ * **MINOR version**: Incremented when functionality is added in a backward-compatible manner.
+ * **PATCH version**: Incremented when backward-compatible bug fixes are made.
+* **Example Workflow**
+ * **Initial Development Phase**
+ * Start with version 0.1.0.
+ * **First Stable Release**
+ * Reach a stable release: 1.0.0.
+ * **Subsequent Changes**
+ * **Patch Release**: A bug fix is needed for 1.0.0. Update to 1.0.1.
+ * **Minor Release**: A new, backward-compatible feature is added to 1.0.3. Update to 1.1.0.
+ * **Major Release**: A significant change that is not backward-compatible is introduced in 1.2.2. Update to 2.0.0.
+ * **Special Versions and Pre-releases**
+ * **Pre-release Versions**: 1.0.0-alpha, 1.0.0-beta, 1.0.0-rc.1.
+ * **Build Metadata**: 1.0.0+20130313144700.
diff --git a/data/guides/what-does-a-typical-microservice-architecture-look-like.md b/data/guides/what-does-a-typical-microservice-architecture-look-like.md
new file mode 100644
index 0000000..a84ae6f
--- /dev/null
+++ b/data/guides/what-does-a-typical-microservice-architecture-look-like.md
@@ -0,0 +1,32 @@
+---
+title: "Typical Microservice Architecture"
+description: "Explore a typical microservice architecture with key components."
+image: "https://assets.bytebytego.com/diagrams/0396-typical-microservice-architecture.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - software-architecture
+tags:
+ - Microservices
+ - Architecture
+---
+
+
+
+The diagram above shows a typical microservice architecture.
+
+## Key Components
+
+* **Load Balancer:** This distributes incoming traffic across multiple backend services.
+
+* **CDN (Content Delivery Network):** CDN is a group of geographically distributed servers that hold static content for faster delivery. The clients look for content in CDN first, then progress to backend services.
+
+* **API Gateway:** This handles incoming requests and routes them to the relevant services. It talks to the identity provider and service discovery.
+
+* **Identity Provider:** This handles authentication and authorization for users.
+
+* **Service Registry & Discovery:** Microservice registration and discovery happen in this component, and the API gateway looks for relevant services in this component to talk to.
+
+* **Management:** This component is responsible for monitoring the services.
+
+* **Microservices:** Microservices are designed and deployed in different domains. Each domain has its database.
diff --git a/data/guides/what-does-acid-mean.md b/data/guides/what-does-acid-mean.md
new file mode 100644
index 0000000..c3250b4
--- /dev/null
+++ b/data/guides/what-does-acid-mean.md
@@ -0,0 +1,34 @@
+---
+title: "What does ACID mean?"
+description: "Understand the ACID properties of database transactions."
+image: "https://assets.bytebytego.com/diagrams/0407-what-does-acid-mean.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Databases"
+ - "ACID"
+---
+
+The diagram above explains what ACID means in the context of a database transaction.
+
+
+
+## Atomicity
+
+The writes in a transaction are executed all at once and cannot be broken into smaller parts. If there are faults when executing the transaction, the writes in the transaction are rolled back.
+
+So atomicity means “all or nothing”.
+
+## Consistency
+
+Unlike “consistency” in CAP theorem, which means every read receives the most recent write or an error, here consistency means preserving database invariants. Any data written by a transaction must be valid according to all defined rules and maintain the database in a good state.
+
+## Isolation
+
+When there are concurrent writes from two different transactions, the two transactions are isolated from each other. The most strict isolation is “serializability”, where each transaction acts like it is the only transaction running in the database. However, this is hard to implement in reality, so we often adopt loser isolation level.
+
+## Durability
+
+Data is persisted after a transaction is committed even in a system failure. In a distributed system, this means the data is replicated to some other nodes.
diff --git a/data/guides/what-does-api-gateway-do.md b/data/guides/what-does-api-gateway-do.md
new file mode 100644
index 0000000..e96f8da
--- /dev/null
+++ b/data/guides/what-does-api-gateway-do.md
@@ -0,0 +1,32 @@
+---
+title: 'What Does an API Gateway Do?'
+description: 'Explore the functions and benefits of using an API gateway in microservices.'
+image: 'https://assets.bytebytego.com/diagrams/0072-what-does-api-gateway-do.png'
+createdAt: '2024-03-07'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - API Gateway
+ - Microservices
+---
+
+
+
+The diagram above shows the details.
+
+**Step 1** - The client sends an HTTP request to the API gateway.
+
+**Step 2** - The API gateway parses and validates the attributes in the HTTP request.
+
+**Step 3** - The API gateway performs allow-list/deny-list checks.
+
+**Step 4** - The API gateway talks to an identity provider for authentication and authorization.
+
+**Step 5** - The rate limiting rules are applied to the request. If it is over the limit, the request is rejected.
+
+**Steps 6 and 7** - Now that the request has passed basic checks, the API gateway finds the relevant service to route to by path matching.
+
+**Step 8** - The API gateway transforms the request into the appropriate protocol and sends it to backend microservices.
+
+**Steps 9-12** - The API gateway can handle errors properly and deals with faults if the error takes a longer time to recover (circuit break). It can also leverage ELK (Elastic-Logstash-Kibana) stack for logging and monitoring. We sometimes cache data in the API gateway.
diff --git a/data/guides/what-happens-when-you-type-a-url-into-your-browser.md b/data/guides/what-happens-when-you-type-a-url-into-your-browser.md
new file mode 100644
index 0000000..f365d41
--- /dev/null
+++ b/data/guides/what-happens-when-you-type-a-url-into-your-browser.md
@@ -0,0 +1,50 @@
+---
+title: "What Happens When You Type a URL Into Your Browser?"
+description: "Explore the journey of a URL from browser input to webpage display."
+image: "https://assets.bytebytego.com/diagrams/0393-type-a-url-into-your-browser.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "Networking"
+ - "Browsers"
+---
+
+
+
+The diagram above illustrates the steps.
+
+- Bob enters a URL into the browser and hits Enter. In this example, the URL is composed of 4 parts:
+ - **scheme** - *http://*. This tells the browser to send a connection to the server using HTTP.
+ - **domain** - *example.com*. This is the domain name of the site.
+ - **path** - *product/electric*. It is the path on the server to the requested resource: phone.
+ - **resource** - *phone*. It is the name of the resource Bob wants to visit.
+
+- The browser looks up the IP address for the domain with a domain name system (DNS) lookup. To make the lookup process fast, data is cached at different layers: browser cache, OS cache, local network cache, and ISP cache.
+ - If the IP address cannot be found at any of the caches, the browser goes to DNS servers to do a recursive DNS lookup until the IP address is found (this will be covered in another post).
+
+- Now that we have the IP address of the server, the browser establishes a TCP connection with the server.
+
+- The browser sends an HTTP request to the server. The request looks like this:
+
+ ```
+ 𝘎𝘌𝘛 /𝘱𝘩𝘰𝘯𝘦 𝘏𝘛𝘛𝘗/1.1
+ 𝘏𝘰𝘴𝘵: 𝘦𝘹𝘢𝘮𝘱𝘭𝘦.𝘤𝘰𝘮
+ ```
+
+- The server processes the request and sends back the response. For a successful response (the status code is 200). The HTML response might look like this:
+
+ ```
+ 𝘏𝘛𝘛𝘗/1.1 200 𝘖𝘒
+ 𝘋𝘢𝘵𝘦: 𝘚𝘶𝘯, 30 𝘑𝘢𝘯 2022 00:01:01 𝘎𝘔𝘛
+ 𝘚𝘦𝘳𝘷𝘦𝘳: 𝘈𝘱𝘢𝘤𝘩𝘦
+ 𝘊𝘰𝘯𝘵𝘦𝘯𝘵-𝘛𝘺𝘱𝘦: 𝘵𝘦𝘹𝘵/𝘩𝘵𝘮𝘭; 𝘤𝘩𝘢𝘳𝘴𝘦𝘵=𝘶𝘵𝘧-8
+
+ <**!𝘋𝘖𝘊𝘛𝘠𝘗𝘌** 𝘩𝘵𝘮𝘭>
+ <**𝘩𝘵𝘮𝘭** 𝘭𝘢𝘯𝘨="𝘦𝘯">
+ 𝘏𝘦𝘭𝘭𝘰 𝘸𝘰𝘳𝘭𝘥
+
+ ```
+
+- The browser renders the HTML content.
diff --git a/data/guides/what-happens-when-you-type-google.md b/data/guides/what-happens-when-you-type-google.md
new file mode 100644
index 0000000..9f60699
--- /dev/null
+++ b/data/guides/what-happens-when-you-type-google.md
@@ -0,0 +1,30 @@
+---
+title: "What Happens When You Type google.com Into a Browser?"
+description: "Explore the journey of typing google.com into a browser."
+image: "https://assets.bytebytego.com/diagrams/0410-what-happens-when-you-type-google-in-your-browser.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - technical-interviews
+tags:
+ - "Networking"
+ - "Web Browsers"
+---
+
+
+
+1. First up, you type the website address in the browser’s address bar.
+
+2. The browser checks its cache first. If there’s a cache miss, it must find the IP address.
+
+3. DNS lookup begins (think of it as looking up a phone number). The request goes through different DNS servers (root, TLD, and authoritative). Finally, the IP address is retrieved.
+
+4. Next, your browser initiates a TCP connection like a handshake. For example, in the case of HTTP 1.1, the client and server perform a TCP three-way handshake with SYN, SYN-ACK, and ACK messages.
+
+5. Once the handshake is successful, the browser makes an HTTP request to the server and the server responds with HTML, CSS, and JS files.
+
+6. Finally, the browser processes everything. It parses the HTML document and creates DOM and CSSOM trees.
+
+7. The browser executes the JavaScript and renders the page through various steps (tokenizer, parser, render tree, layout, and painting).
+
+8. Finally, the webpage appears on your screen.
diff --git a/data/guides/what-happens-when-you-upload-a-file-to-amazon-s3.md b/data/guides/what-happens-when-you-upload-a-file-to-amazon-s3.md
new file mode 100644
index 0000000..5fabaa3
--- /dev/null
+++ b/data/guides/what-happens-when-you-upload-a-file-to-amazon-s3.md
@@ -0,0 +1,43 @@
+---
+title: "What Happens When You Upload a File to Amazon S3?"
+description: "Explore the process of uploading a file to Amazon S3 in detail."
+image: "https://assets.bytebytego.com/diagrams/0169-design-s3.jpg"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - how-it-works
+tags:
+ - "Amazon S3"
+ - "Cloud Storage"
+---
+
+
+
+Before we dive into the design, let’s define some terms.
+
+**Bucket**. A logical container for objects. The bucket name is globally unique. To upload data to S3, we must first create a bucket.
+
+**Object**. An object is an individual piece of data we store in a bucket. It contains object data (also called payload) and metadata. Object data can be any sequence of bytes we want to store. The metadata is a set of name-value pairs that describe the object.
+
+An S3 object consists of (Figure 1):
+
+* Metadata. It is mutable and contains attributes such as ID, bucket name, object name, etc.
+* Object data. It is immutable and contains the actual data.
+
+In S3, an object resides in a bucket. The path looks like this: /bucket-to-share/script.txt. The bucket only has metadata. The object has metadata and the actual data.
+
+The diagram below (Figure 2) illustrates how file uploading works. In this example, we first create a bucket named “bucket-to-share” and then upload a file named “script.txt” to the bucket.
+
+1. The client sends an HTTP PUT request to create a bucket named “bucket-to-share.” The request is forwarded to the API service.
+
+2. The API service calls Identity and Access Management (IAM) to ensure the user is authorized and has WRITE permission.
+
+3. The API service calls the metadata store to create an entry with the bucket info in the metadata database. Once the entry is created, a success message is returned to the client.
+
+4. After the bucket is created, the client sends an HTTP PUT request to create an object named “script.txt”.
+
+5. The API service verifies the user’s identity and ensures the user has WRITE permission on the bucket.
+
+6. Once validation succeeds, the API service sends the object data in the HTTP PUT payload to the data store. The data store persists the payload as an object and returns the UUID of the object.
+
+7. The API service calls the metadata store to create a new entry in the metadata database. It contains important metadata such as the object\_id (UUID), bucket\_id (which bucket the object belongs to), object\_name, etc.
diff --git a/data/guides/what-is-a-cookie.md b/data/guides/what-is-a-cookie.md
new file mode 100644
index 0000000..23d04eb
--- /dev/null
+++ b/data/guides/what-is-a-cookie.md
@@ -0,0 +1,20 @@
+---
+title: "What is a Cookie?"
+description: "Learn about cookies, how they work, and their role in web browsing."
+image: "https://assets.bytebytego.com/diagrams/0043-what-is-a-cookie.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - security
+tags:
+ - "Web Security"
+ - "Cookies"
+---
+
+
+
+Imagine Bob goes to a coffee shop for the first time, orders a medium-sized espresso with two sugars. The cashier records Bob’s identity and preferences on a card and hands it over to Bob with a cup of coffee.
+
+The next time Bob goes to the cafe, he shows the cashier the preference card. The cashier immediately knows who the customer is and what kind of coffee he likes.
+
+A cookie acts as the preference card. When we log in to a website, the server issues a cookie to us with a small amount of data. The cookie is stored on the client side, so the next time we send a request to the server with the cookie, the server knows our identity and preferences immediately without looking into the database.
diff --git a/data/guides/what-is-a-deadlock.md b/data/guides/what-is-a-deadlock.md
new file mode 100644
index 0000000..97baedf
--- /dev/null
+++ b/data/guides/what-is-a-deadlock.md
@@ -0,0 +1,39 @@
+---
+title: "What is a Deadlock?"
+description: "Explore deadlocks: conditions, prevention, and recovery strategies."
+image: "https://assets.bytebytego.com/diagrams/0411-what-is-a-deadlock.png"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Concurrency"
+ - "Databases"
+---
+
+A deadlock occurs when two or more transactions are waiting for each other to release locks on resources they need to continue processing. This results in a situation where neither transaction can proceed, and they end up waiting indefinitely.
+
+
+
+## Coffman Conditions
+
+The Coffman conditions, named after Edward G. Coffman, Jr., who first outlined them in 1971, describe four necessary conditions that must be present simultaneously for a deadlock to occur:
+
+* Mutual Exclusion
+* Hold and Wait
+* No Preemption
+* Circular Wait
+
+## Deadlock Prevention
+
+* Resource ordering: impose a total ordering of all resource types, and require that each process requests resources in a strictly increasing order.
+
+* Timeouts: A process that holds resources for too long can be rolled back.
+
+* Banker’s Algorithm: A deadlock avoidance algorithm that simulates the allocation of resources to processes and helps in deciding whether it is safe to grant a resource request based on the future availability of resources, thus avoiding unsafe states.
+
+## Deadlock Recovery
+
+* Selecting a victim: Most modern Database Management Systems (DBMS) and Operating Systems implement sophisticated algorithms for detecting deadlocks and selecting victims, often allowing customization of the victim selection criteria via configuration settings. The selection can be based on resource utilization, transaction priority, cost of rollback etc.
+
+* Rollback: The database may roll back the entire transaction or just enough of it to break the deadlock. Rolled-back transactions can be restarted automatically by the database management system.
diff --git a/data/guides/what-is-a-load-balancer.md b/data/guides/what-is-a-load-balancer.md
new file mode 100644
index 0000000..98268f5
--- /dev/null
+++ b/data/guides/what-is-a-load-balancer.md
@@ -0,0 +1,32 @@
+---
+title: What is a Load Balancer?
+description: Distributes network traffic across multiple servers to optimize resources.
+image: 'https://assets.bytebytego.com/diagrams/0261-what-is-a-load-balancer.png'
+createdAt: '2024-02-28'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - Load Balancing
+ - Networking
+---
+
+
+
+A load balancer is a device or software application that distributes network or application traffic across multiple servers.
+
+* **What Does a Load Balancer Do?**
+
+ * Distributes Traffic
+ * Ensures Availability and Reliability
+ * Improves Performance
+ * Scales Applications
+
+* **Types of Load Balancers**
+
+ * Hardware Load Balancers: These are physical devices designed to distribute traffic across servers.
+ * Software Load Balancers: These are applications that can be installed on standard hardware or virtual machines.
+ * Cloud-based Load Balancers: Provided by cloud service providers, these load balancers are integrated into the cloud infrastructure. Examples include AWS Elastic Load Balancer, Google Cloud Load Balancing, and Azure Load Balancer.
+ * Layer 4 Load Balancers (Transport Layer): Operate at the transport layer (OSI Layer 4) and make forwarding decisions based on IP address and TCP/UDP ports.
+ * Layer 7 Load Balancers (Application Layer): Operate at the application layer (OSI Layer 7).
+ * Global Server Load Balancing (GSLB): Distributes traffic across multiple geographical locations to improve redundancy and performance on a global scale.
diff --git a/data/guides/what-is-a-stop-loss-order-and-how-does-it-work.md b/data/guides/what-is-a-stop-loss-order-and-how-does-it-work.md
new file mode 100644
index 0000000..9dbb435
--- /dev/null
+++ b/data/guides/what-is-a-stop-loss-order-and-how-does-it-work.md
@@ -0,0 +1,36 @@
+---
+title: "What is a Stop-Loss Order and How Does it Work?"
+description: "Learn about stop-loss orders and how they help minimize investment losses."
+image: "https://assets.bytebytego.com/diagrams/0345-stop-loss.jpg"
+createdAt: "2024-02-26"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Trading"
+ - "Risk Management"
+---
+
+
+
+A stop-loss order allows us to set a price called the ‘stop-loss price’ of a stock or a share. This is a value the investor chooses, at which they will sell it to minimize their loss on the investment.
+
+When the price of the stock hits the stop-loss point, the stop-loss order is triggered and it turns into a market order to sell at the current market price.
+
+For example, let's say an investor has 100 shares in ABC Inc., and the current price is $40 per share. The investor wants to sell the stock if the market price falls to or below $36, in order to limit their loss.
+
+The diagram above illustrates how a stop-loss order is executed by a trading system.
+
+## Stop-Loss Order Execution
+
+* The investor submits a stop-loss order to the trading system with 100 shares, to sell for $36.
+
+* Upon receiving the order request, the trading engine creates the stop-loss order.
+
+* The trading engine subscribes to the market data of ABC Inc. from the exchange and monitors its real-time market price.
+
+* If the trading engine detects that the market price of ABC Inc. falls to, say, $35, it immediately creates a market order and then submits it to the exchange to sell the 100 shares for the current best market price.
+
+* The order is filled (i.e. matched to the best buy orders in the market,) usually instantaneously. Then the trading engine receives from the exchange a ‘fill report’ stating the shares have been sold for, say, $35.5 per share.
+
+* The trading system notifies the investor that the 100 shares have been sold for $35.5 per share.
diff --git a/data/guides/what-is-an-ai-agent.md b/data/guides/what-is-an-ai-agent.md
new file mode 100644
index 0000000..2523a05
--- /dev/null
+++ b/data/guides/what-is-an-ai-agent.md
@@ -0,0 +1,32 @@
+---
+title: 'What is an AI Agent?'
+description: 'Explore the concept of AI agents, their characteristics, and applications.'
+image: 'https://assets.bytebytego.com/diagrams/0412-what-is-an-ai-agent.png'
+createdAt: '2024-03-13'
+draft: false
+categories:
+ - ai-machine-learning
+tags:
+ - AI Agents
+ - Machine Learning
+---
+
+[]()
+
+An AI agent is a software program that can interact with its environment, gather data, and use that data to achieve predetermined goals. AI agents can choose the best actions to perform to meet those goals.
+
+Key characteristics of AI agents are as follows:
+
+* An agent can perform autonomous actions without constant human intervention. Also, they can have a human in the loop to maintain control.
+* Agents have a memory to store individual preferences and allow for personalization. It can also store knowledge. An LLM can undertake information processing and decision-making functions.
+* Agents must be able to perceive and process the information available from their environment.
+* Agents can also use tools such as accessing the internet, using code interpreters and making API calls.
+* Agents can also collaborate with other agents or humans.
+
+Multiple types of AI agents are available such as learning agents, simple reflex agents, model-based reflex agents, goal-based agents, and utility-based agents.
+
+A system with AI agents can be built with different architectural approaches.
+
+1. **Single Agent**: Agents can serve as personal assistants.
+2. **Multi-Agent**: Agents can interact with each other in collaborative or competitive ways.
+3. **Human Machine**: Agents can interact with humans to execute tasks more efficiently.
diff --git a/data/guides/what-is-cdn-content-delivery-network.md b/data/guides/what-is-cdn-content-delivery-network.md
new file mode 100644
index 0000000..c9d68b4
--- /dev/null
+++ b/data/guides/what-is-cdn-content-delivery-network.md
@@ -0,0 +1,30 @@
+---
+title: "What is CDN (Content Delivery Network)?"
+description: "Learn how CDNs accelerate content delivery and improve website security."
+image: "https://assets.bytebytego.com/diagrams/0132-cdn.png"
+createdAt: "2024-03-09"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "CDN"
+ - "Content Delivery"
+---
+
+How does CDN make content delivery faster? The diagram above shows why.
+
+
+
+A CDN refers to geographically distributed servers (also called edge servers) that provide fast delivery of **static and dynamic content**.
+
+With CDN, users don’t need to retrieve content (music, video, files, pictures, etc.) from the origin server. Instead, the content is cached at CDN nodes around the globe, and users can retrieve the content from nearby CDN nodes.
+
+## The benefits of CDN are:
+
+* Reducing latency
+
+* Reducing bandwidth
+
+* Improving website security, especially protecting against DDoS (Distributed Denial-of-Service) attack
+
+* Increasing content availability
diff --git a/data/guides/what-is-cloud-native.md b/data/guides/what-is-cloud-native.md
new file mode 100644
index 0000000..36abd8f
--- /dev/null
+++ b/data/guides/what-is-cloud-native.md
@@ -0,0 +1,38 @@
+---
+title: "What is Cloud Native?"
+description: "Explore cloud native technologies and their impact on application architecture."
+image: "https://assets.bytebytego.com/diagrams/0413-what-is-cloud-native.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - Cloud Computing
+ - Microservices
+---
+
+Below is a diagram showing the evolution of architecture and processes since the 1980s.
+
+
+
+Organizations can build and run scalable applications on public, private, and hybrid clouds using cloud native technologies.
+
+This means the applications are designed to leverage cloud features, so they are resilient to load and easy to scale.
+
+Cloud native includes 4 aspects:
+
+* **Development process**
+
+ This has progressed from waterfall to agile to DevOps.
+
+* **Application Architecture**
+
+ The architecture has gone from monolithic to microservices. Each service is designed to be small, and adaptive to the limited resources in cloud containers.
+
+* **Deployment & packaging**
+
+ The applications used to be deployed on physical servers. Then around 2000, the applications that were not sensitive to latency were usually deployed on virtual servers. With cloud native applications, they are packaged into docker images and deployed in containers.
+
+* **Application infrastructure**
+
+ The applications are massively deployed on cloud infrastructure instead of self-hosted servers.
diff --git a/data/guides/what-is-css-cascading-style-sheets.md b/data/guides/what-is-css-cascading-style-sheets.md
new file mode 100644
index 0000000..b9d6e76
--- /dev/null
+++ b/data/guides/what-is-css-cascading-style-sheets.md
@@ -0,0 +1,41 @@
+---
+title: What is CSS (Cascading Style Sheets)?
+description: CSS is a markup language for describing the presentation of web pages.
+image: 'https://assets.bytebytego.com/diagrams/0408-what-is-css-cascading-style-sheets.png'
+createdAt: '2024-02-03'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - CSS
+ - Web Development
+---
+
+
+
+Front-end development requires not only content presentation, but also good-looking. CSS is a markup language used to describe how elements on a web page should be rendered.
+
+* **What CSS does**
+ CSS separates the content and presentation of a document. In the early days of web development, HTML acted as both content and style.
+
+ CSS divides structure (HTML) and style (CSS). This has many benefits, for example, when we change the color scheme of a web page, all we need to do is to tweak the CSS file.
+* **How CSS works**
+ CSS consists of a selector and a set of properties, which can be thought of as individual rules. Selectors are used to locate HTML elements that we want to change the style of, and properties are the specific style descriptions for those elements, such as color, size, position, etc.
+
+ For example, if we want to make all the text in a paragraph blue, we write CSS code like this:
+ p { color: blue; }
+ Here “p” is the selector and “color: blue” is the attribute that declares the color of the paragraph text to be blue.
+* **Cascading in CSS**
+ The concept of cascading is crucial to understanding CSS.
+
+ When multiple style rules conflict, the browser needs to decide which rule to use based on a specific prioritization rule. The one with the highest weight wins. The weight can be determined by a variety of factors, including selector type and the order of the source.
+* **Powerful Layout Capabilities of CSS**
+ In the past, CSS was only used for simple visual effects such as text colors, font styles, or backgrounds. Today, CSS has evolved into a powerful layout tool capable of handling complex design layouts.
+
+ The “Flexbox” and “Grid” layout modules are two popular CSS layout modules that make it easy to create responsive designs and precise placement of web elements, so web developers no longer have to rely on complex tables or floating layouts.
+* **CSS Animation**
+ Animation and interactive elements can greatly enhance the user experience.
+
+ CSS3 introduces animation features that allow us to transform and animate elements without using JavaScript. For example, “@keyframes” rule defines animation sequences, and the `transition` property can be used to set animated transitions from one state to another.
+* **Responsive Design**
+ CSS allows the layout and style of a website to be adapted to different screen sizes and resolutions, so that we can provide an optimized browsing experience for different devices such as cell phones, tablets and computers.
diff --git a/data/guides/what-is-devsecops.md b/data/guides/what-is-devsecops.md
new file mode 100644
index 0000000..562f213
--- /dev/null
+++ b/data/guides/what-is-devsecops.md
@@ -0,0 +1,40 @@
+---
+title: "What is DevSecOps?"
+description: "Explore DevSecOps: integrating security into the DevOps lifecycle."
+image: "https://assets.bytebytego.com/diagrams/0060-what-is-devsecops.png"
+createdAt: "2024-02-10"
+draft: false
+categories:
+ - security
+tags:
+ - "DevOps"
+ - "Security"
+---
+
+
+
+DevSecOps emerged as a natural evolution of DevOps practices with a focus on integrating security into the software development and deployment process. The term "DevSecOps" represents the convergence of Development (Dev), Security (Sec), and Operations (Ops) practices, emphasizing the importance of security throughout the software development lifecycle.
+
+The diagram below shows the important concepts in DevSecOps.
+
+## Key Concepts in DevSecOps
+
+* Automated Security Checks
+
+* Continuous Monitoring
+
+* CI/CD Automation
+
+* Infrastructure as Code (IaC)
+
+* Container Security
+
+* Secret Management
+
+* Threat Modeling
+
+* Quality Assurance (QA) Integration
+
+* Collaboration and Communication
+
+* Vulnerability Management
diff --git a/data/guides/what-is-elk-stack-and-why-is-it-so-popular-for-log-management.md b/data/guides/what-is-elk-stack-and-why-is-it-so-popular-for-log-management.md
new file mode 100644
index 0000000..b434f0b
--- /dev/null
+++ b/data/guides/what-is-elk-stack-and-why-is-it-so-popular-for-log-management.md
@@ -0,0 +1,38 @@
+---
+title: "What is ELK Stack and Why is it Popular?"
+description: "Learn about the ELK Stack: Elasticsearch, Logstash, and Kibana."
+image: "https://assets.bytebytego.com/diagrams/0183-elk.jpg"
+createdAt: "2024-02-15"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "ELK Stack"
+ - "Log Management"
+---
+
+
+
+The ELK Stack is composed of three open-source products. ELK stands for Elasticsearch, Logstash, and Kibana.
+
+* Elasticsearch is a full-text search and analysis engine, leveraging Apache Lucene search engine as its core component.
+
+* Logstash collects data from all kinds of edge collectors, then transforms that data and sends it to various destinations for further processing or visualization.
+
+In order to scale the edge data ingestion, a new product Beats is later developed as lightweight agents installed on edge hosts to collect and ship logs to Logstash.
+
+* Kibana is a visualization layer with which users analyze and visualize the data.
+
+The diagram above shows how ELK Stack works:
+
+## ELK Stack Workflow
+
+Step 1 - Beats collects data from various data sources. For example, Filebeat and Winlogbeat work with logs, and Packetbeat works with network traffic.
+
+Step 2 - Beats sends data to Logstash for aggregation and transformation. If we work with massive data, we can add a message queue (Kafka) to decouple the data producers and consumers.
+
+Step 3 - Logstash writes data into Elasticsearch for data indexing and storage.
+
+Step 4 - Kibana builds on top of Elasticsearch and provides users with various search tools and dashboards with which to visualize the data.
+
+ELK Stack is pretty convenient for troubleshooting and monitoring. It became popular by providing a simple and robust suite in the log analytics space, for a reasonable price.
diff --git a/data/guides/what-is-graphql.md b/data/guides/what-is-graphql.md
new file mode 100644
index 0000000..14c0962
--- /dev/null
+++ b/data/guides/what-is-graphql.md
@@ -0,0 +1,37 @@
+---
+title: What is GraphQL?
+description: "GraphQL explained: a query language for APIs."
+image: 'https://assets.bytebytego.com/diagrams/0055-what-is-graphql.png'
+createdAt: '2024-03-12'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - GraphQL
+ - API
+---
+
+
+
+### Is it a replacement for the REST API?
+
+GraphQL is a query language for APIs and a runtime for executing those queries by using a type system you define for your data. It was developed internally by Meta in 2012 before being publicly released in 2015.
+
+Unlike the more traditional REST API, GraphQL allows clients to request exactly the data they need, making it possible to fetch data from multiple sources with a single query. This efficiency in data retrieval can lead to improved performance for web and mobile applications.
+
+GraphQL servers sit in between the client and the backend services. It can aggregate multiple REST requests into one query. GraphQL server organizes the resources in a graph.
+
+GraphQL supports queries, mutations (applying data modifications to resources), and subscriptions (receiving notifications on schema modifications).
+
+**Benefits of GraphQL:**
+
+* GraphQL is more efficient in data fetching.
+* GraphQL returns more accurate results.
+* GraphQL has a strong type system to manage the structure of entities, reducing errors.
+* GraphQL is suitable for managing complex microservices.
+
+**Disadvantages of GraphQL**
+
+* Increased complexity.
+* Over fetching by design
+* Caching complexity
diff --git a/data/guides/what-is-grpc.md b/data/guides/what-is-grpc.md
new file mode 100644
index 0000000..5cf07b5
--- /dev/null
+++ b/data/guides/what-is-grpc.md
@@ -0,0 +1,25 @@
+---
+title: What is gRPC?
+description: Learn about gRPC, a high-performance RPC framework by Google.
+image: 'https://assets.bytebytego.com/diagrams/0054-what-is-grpc.png'
+createdAt: '2024-03-08'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - gRPC
+ - Microservices
+---
+
+
+
+gRPC is a high-performance, open-source universal RPC (Remote Procedure Call) framework initially developed by Google. It leverages HTTP/2 for transport, Protocol Buffers as the interface description language, and provides features such as authentication, load balancing, and more.
+
+gRPC is designed to enable efficient and robust communication between services in a microservices architecture, making it a popular choice for building distributed systems and APIs.
+
+**Key Features of gRPC:**
+
+* **Protocol Buffers:** By default, gRPC uses Protocol Buffers (proto files) as its interface definition language (IDL). This makes gRPC messages smaller and faster compared to JSON or XML.
+* **HTTP/2 Based Transport:** gRPC uses HTTP/2 for transport, which allows for many improvements over HTTP/1.x.
+* **Multiple Language Support:** gRPC supports a wide range of programming languages.
+* **Bi-Directional Streaming:** gRPC supports streaming requests and responses, allowing for the development of sophisticated real-time applications with bidirectional communication like chat services.
diff --git a/data/guides/what-is-k8s-kubernetes.md b/data/guides/what-is-k8s-kubernetes.md
new file mode 100644
index 0000000..59e6c6a
--- /dev/null
+++ b/data/guides/what-is-k8s-kubernetes.md
@@ -0,0 +1,52 @@
+---
+title: "What is Kubernetes (k8s)?"
+description: "Learn about Kubernetes, a container orchestration system for deployment."
+image: "https://assets.bytebytego.com/diagrams/0245-k8s.png"
+createdAt: "2024-03-14"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Kubernetes"
+ - "Containers"
+---
+
+[](https://assets.bytebytego.com/diagrams/0245-k8s.png)
+
+k8s is a container orchestration system. It is used for container deployment and management. Its design is greatly impacted by Google’s internal system Borg.
+
+A k8s cluster consists of a set of worker machines, called nodes, that run containerized applications. Every cluster has at least one worker node. \[1]
+
+The worker node(s) host the Pods that are the components of the application workload. The control plane manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers and a cluster usually runs multiple nodes, providing fault tolerance and high availability. \[1]
+
+## Control Plane Components
+
+* **API Server**
+
+ The API server talks to all the components in the k8s cluster. All the operations on pods are executed by talking to the API server.
+
+* **Scheduler**
+
+ The scheduler watches the workloads on pods and assigns loads on newly created pods.
+
+* **Controller Manager**
+
+ The controller manager runs the controllers, including Node Controller, Job Controller, EndpointSlice Controller, and ServiceAccount Controller.
+
+* **etcd**
+
+ etcd is a key-value store used as Kubernetes' backing store for all cluster data.
+
+## Nodes
+
+* **Pods**
+
+ A pod is a group of containers and is the smallest unit that k8s administers. Pods have a single IP address applied to every container within the pod.
+
+* **Kubelet**
+
+ An agent that runs on each node in the cluster. It ensures containers are running in a Pod. \[1]
+
+* **Kube Proxy**
+
+ kube-proxy is a network proxy that runs on each node in your cluster. It routes traffic coming into a node from the service. It forwards requests for work to the correct containers.
diff --git a/data/guides/what-is-osi-model.md b/data/guides/what-is-osi-model.md
new file mode 100644
index 0000000..a136eb8
--- /dev/null
+++ b/data/guides/what-is-osi-model.md
@@ -0,0 +1,32 @@
+---
+title: "OSI Model Explained"
+description: "Learn about the OSI model and how data is transmitted over a network."
+image: "https://assets.bytebytego.com/diagrams/0295-osi-model.jpeg"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Networking"
+ - "OSI Model"
+---
+
+
+
+How is data sent over the network? Why do we need so many layers in the OSI model?
+
+The diagram below shows how data is encapsulated and de-encapsulated when transmitting over the network.
+
+* Step 1: When Device A sends data to Device B over the network via the HTTP protocol, it is first added an HTTP header at the application layer.
+
+* Step 2: Then a TCP or a UDP header is added to the data. It is encapsulated into TCP segments at the transport layer. The header contains the source port, destination port, and sequence number.
+
+* Step 3: The segments are then encapsulated with an IP header at the network layer. The IP header contains the source/destination IP addresses.
+
+* Step 4: The IP datagram is added a MAC header at the data link layer, with source/destination MAC addresses.
+
+* Step 5: The encapsulated frames are sent to the physical layer and sent over the network in binary bits.
+
+* Steps 6-10: When Device B receives the bits from the network, it performs the de-encapsulation process, which is a reverse processing of the encapsulation process. The headers are removed layer by layer, and eventually, Device B can read the data.
+
+We need layers in the network model because each layer focuses on its own responsibilities. Each layer can rely on the headers for processing instructions and does not need to know the meaning of the data from the last layer.
diff --git a/data/guides/what-is-serverless-db.md b/data/guides/what-is-serverless-db.md
new file mode 100644
index 0000000..8f39dc7
--- /dev/null
+++ b/data/guides/what-is-serverless-db.md
@@ -0,0 +1,24 @@
+---
+title: "What is Serverless DB?"
+description: "Explore serverless databases, their benefits, and how they differ."
+image: "https://assets.bytebytego.com/diagrams/0329-serverlessdb.jpeg"
+createdAt: "2024-02-24"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Serverless"
+ - "Database"
+---
+
+
+
+Are serverless databases the future? How do serverless databases differ from traditional cloud databases?
+
+Amazon Aurora Serverless, depicted in the diagram above, is a configuration that is auto-scaling and available on-demand for Amazon Aurora.
+
+## Key Features of Aurora Serverless
+
+* Aurora Serverless has the ability to scale capacity automatically up or down as per business requirements. For example, an eCommerce website preparing for a major promotion can scale the load to multiple databases within a few milliseconds. In comparison to regular cloud databases, which necessitate the provision and administration of database instances, Aurora Serverless can automatically start up and shut down.
+
+* By decoupling the compute layer from the data storage layer, Aurora Serverless is able to charge fees in a more precise manner. Additionally, Aurora Serverless can be a combination of provisioned and serverless instances, enabling existing provisioned databases to become a part of the serverless pool.
diff --git a/data/guides/what-is-the-best-way-to-learn-sql.md b/data/guides/what-is-the-best-way-to-learn-sql.md
new file mode 100644
index 0000000..79a576c
--- /dev/null
+++ b/data/guides/what-is-the-best-way-to-learn-sql.md
@@ -0,0 +1,32 @@
+---
+title: "What is the Best Way to Learn SQL?"
+description: "A guide to efficiently learn SQL and its components for different roles."
+image: "https://assets.bytebytego.com/diagrams/0031-how-to-learn-sql.png"
+createdAt: "2024-03-16"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "SQL"
+ - "Databases"
+---
+
+
+
+In 1986, SQL (Structured Query Language) became a standard. Over the next 40 years, it became the dominant language for relational database management systems. Reading the latest standard (ANSI SQL 2016) can be time-consuming. How can I learn it?
+
+## SQL Components
+
+There are 5 components of the SQL language:
+
+* **DDL**: data definition language, such as CREATE, ALTER, DROP
+
+* **DQL**: data query language, such as SELECT
+
+* **DML**: data manipulation language, such as INSERT, UPDATE, DELETE
+
+* **DCL**: data control language, such as GRANT, REVOKE
+
+* **TCL**: transaction control language, such as COMMIT, ROLLBACK
+
+For a backend engineer, you may need to know most of it. As a data analyst, you may need to have a good understanding of DQL. Select the topics that are most relevant to you.
diff --git a/data/guides/what-is-the-difference-between-process-and-thread.md b/data/guides/what-is-the-difference-between-process-and-thread.md
new file mode 100644
index 0000000..99619e0
--- /dev/null
+++ b/data/guides/what-is-the-difference-between-process-and-thread.md
@@ -0,0 +1,40 @@
+---
+title: "Process vs Thread: Key Differences"
+description: "Understand the core differences between processes and threads."
+image: "https://assets.bytebytego.com/diagrams/0304-program-process-thread.png"
+createdAt: "2024-03-12"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - "Operating Systems"
+ - "Concurrency"
+---
+
+
+
+To better understand this question, let’s first take a look at what a Program is. A Program is an executable file containing a set of instructions and passively stored on disk. One program can have multiple processes. For example, the Chrome browser creates a different process for every single tab.
+
+A Process means a program is in execution. When a program is loaded into the memory and becomes active, the program becomes a process. The process requires some essential resources such as registers, program counter, and stack.
+
+A Thread is the smallest unit of execution within a process.
+
+The following process explains the relationship between program, process, and thread.
+
+1. The program contains a set of instructions.
+
+2. The program is loaded into memory. It becomes one or more running processes.
+
+3. When a process starts, it is assigned memory and resources. A process can have one or more threads. For example, in the Microsoft Word app, a thread might be responsible for spelling checking and the other thread for inserting text into the doc.
+
+## Main differences between process and thread:
+
+* Processes are usually independent, while threads exist as subsets of a process.
+
+* Each process has its own memory space. Threads that belong to the same process share the same memory.
+
+* A process is a heavyweight operation. It takes more time to create and terminate.
+
+* Context switching is more expensive between processes.
+
+* Inter-thread communication is faster for threads.
diff --git a/data/guides/what-is-the-journey-of-a-slack-message.md b/data/guides/what-is-the-journey-of-a-slack-message.md
new file mode 100644
index 0000000..2f7b6eb
--- /dev/null
+++ b/data/guides/what-is-the-journey-of-a-slack-message.md
@@ -0,0 +1,29 @@
+---
+title: 'What is the Journey of a Slack Message?'
+description: 'Explore the journey of a Slack message from sender to receiver.'
+image: 'https://assets.bytebytego.com/diagrams/0338-slack-message-journey.jpg'
+createdAt: '2024-03-08'
+draft: false
+categories:
+ - real-world-case-studies
+tags:
+ - System Design
+ - Messaging
+---
+
+
+
+In a recent technical article, Slack explains how its real-time messaging framework works. Here is my short summary:
+
+A Slack message travels through five important servers:
+
+* **WebApp:** defines the API that a Slack client could use
+* **Admin Server (AS):** finds the correct Channel Server using channel ID
+* **Channel Server (CS):** maintains the history of message channel
+* **Gateway Server (GS):** deployed in each geographic region. Maintain WebSocket channel subscription
+* **Envoy:** service proxy for cloud-native applications
+
+* Because there are too many channels, the Channel Server (CS) uses consistent hashing to allocate millions of channels to many channel servers.
+* Slack messages are delivered through WebApp and Admin Server to the correct Channel Server.
+* Through Gate Server and Envoy (a proxy), the Channel Server will push messages to message receivers.
+* Message receivers use WebSocket, which is a bi-directional messaging mechanism, so they are able to receive updates in real-time.
diff --git a/data/guides/what-is-web-3.md b/data/guides/what-is-web-3.md
new file mode 100644
index 0000000..94100bf
--- /dev/null
+++ b/data/guides/what-is-web-3.md
@@ -0,0 +1,36 @@
+---
+title: "What is Web 3.0? Why doesn't it have ads?"
+description: "Explore Web 3.0: ownership, decentralization, and ad-free potential."
+image: "https://assets.bytebytego.com/diagrams/0416-what-is-web-3.png"
+createdAt: "2024-02-27"
+draft: false
+categories:
+ - payment-and-fintech
+tags:
+ - "Web3"
+ - "Decentralization"
+---
+
+The diagram above shows Web 1.0/Web 2.0/Web 3.0 from a bird's-eye view.
+
+
+
+* Web 1.0 - Read Only
+
+Between 1991 and 2004, the internet was like a **catalog of static pages**. We can browse the content by jumping from one hyperlink to another. It doesn’t provide any interactions with the content.
+
+* Web 2.0 - Read Write
+
+From 2004 to now, the internet has evolved to have search engines, social media apps, and recommendation algorithms backed apps.
+
+Because the apps digitalize human behaviors and persist user data when users interact with these apps, big companies leverage user data for advertisements, which becomes **one of the main business models** in Web 2.0.
+
+That’s why people say the apps know you better than your friends, family, or even yourself.
+
+* Web 3.0 - Read Write Own
+
+The idea has been discussed a lot recently due to the development of blockchain and decentralized apps. The creators’ content is stored on IPFS (InterPlanetary File System) and **owned by the users**.
+
+If apps want to access the data, they need to get **authorization** from the users and **pay** for it.
+
+In Web 3.0, the ownership change may lead to some major innovations.
diff --git a/data/guides/what-makes-aws-lambda-so-fast.md b/data/guides/what-makes-aws-lambda-so-fast.md
new file mode 100644
index 0000000..1817f48
--- /dev/null
+++ b/data/guides/what-makes-aws-lambda-so-fast.md
@@ -0,0 +1,48 @@
+---
+title: "What makes AWS Lambda so fast?"
+description: "Explore the key factors behind AWS Lambda's impressive speed."
+image: "https://assets.bytebytego.com/diagrams/0417-what-makes-aws-lambda-so-fast.png"
+createdAt: "2024-02-06"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "AWS Lambda"
+ - "Serverless"
+---
+
+
+
+There are 4 main pillars:
+
+## Function Invocation
+
+AWS Lambda supports synchronous and asynchronous invocation.
+
+In synchronous invocation, the caller directly calls the Lambda function using AWS CLI, SDK, or other services.
+
+In asynchronous invocation, the caller doesn’t wait for the function’s response. The request is authorized and an event is placed in an internal SQS queue. Pollers read messages from the queue and send them for processing.
+
+## Assignment Service
+
+The Assignment Service manages the execution environments.
+
+The service is written in Rust for high performance and is divided into multiple partitions with a leader-follower approach for high availability.
+
+The state of execution environments is written to an external journal log.
+
+## Firecracker MicroVM
+
+Firecracker is a lightweight virtual machine manager designed for running serverless workloads such as AWS Lambda and AWS Fargate.
+
+It uses Linux’s Kernel-based virtual machine to create and manage secure, fast-booting microVMs.
+
+## Component Storage
+
+AWS Lambda also has to manage the state consisting of input data and function code.
+
+To make it efficient, it uses multiple techniques:
+
+* Chunking to store the container images more efficiently.
+* Using convergent encryption to secure the shared data. This involves appending additional data to the chunk to compute a more robust hash.
+* SnapStart feature to reduce cold start latency by pre-initializing the execution environment
diff --git a/data/guides/what-makes-http2-faster-than-http1.md b/data/guides/what-makes-http2-faster-than-http1.md
new file mode 100644
index 0000000..2271f5a
--- /dev/null
+++ b/data/guides/what-makes-http2-faster-than-http1.md
@@ -0,0 +1,31 @@
+---
+title: What makes HTTP2 faster than HTTP1?
+description: Discover the key features that make HTTP2 faster than HTTP1.
+image: 'https://assets.bytebytego.com/diagrams/0421-why-http2-is-faster-than-http1.png'
+createdAt: '2024-02-02'
+draft: false
+categories:
+ - api-web-development
+tags:
+ - HTTP2
+ - Performance
+---
+
+
+
+The key features of HTTP2 play a big role in this. Let’s look at them:
+
+* **Binary Framing Layer**
+ HTTP2 encodes the messages into binary format.
+ This allows the messages into smaller units called frames, which are then sent over the TCP connection, resulting in more efficient processing.
+* **Multiplexing**
+ The Binary Framing allows full request and response multiplexing.
+ Clients and servers can interleave frames during transmissions and reassemble them on the other side.
+* **Stream Prioritization**
+ With stream prioritization, developers can customize the relative weight of requests or streams to make the server send more frames for higher-priority requests.
+* **Server Push**
+ Since HTTP2 allows multiple concurrent responses to a client’s request, a server can send additional resources along with the requested page to the client.
+* **HPACK Header Compression**
+ HTTP2 uses a special compression algorithm called HPACK to make the headers smaller for multiple requests, thereby saving bandwidth.
+
+Of course, despite these features, HTTP2 can also be slow depending on the exact technical scenario. Therefore, developers need to test and optimize things to maximize the benefits of HTTP2.
diff --git a/data/guides/what-protocol-does-online-gaming-use-to-transmit-data.md b/data/guides/what-protocol-does-online-gaming-use-to-transmit-data.md
new file mode 100644
index 0000000..0fa77db
--- /dev/null
+++ b/data/guides/what-protocol-does-online-gaming-use-to-transmit-data.md
@@ -0,0 +1,28 @@
+---
+title: "TCP vs UDP for Online Gaming"
+description: "Explore TCP and UDP protocols in online gaming for data transmission."
+image: "https://assets.bytebytego.com/diagrams/0315-reliable-udp.png"
+createdAt: "2024-03-10"
+draft: false
+categories:
+ - computer-fundamentals
+tags:
+ - Networking
+ - Protocols
+---
+
+
+
+A common practice is to use RUDP (Reliable UDP). It adds a **reliable** mechanism on top of UDP to provide **much lower latency** than TCP and guarantee accuracy.
+
+The diagram below shows how reliable data delivery is implemented in online gaming to get eventually-synchronized states.
+
+Suppose there is a big fight in a simulation shooter game. Characters A, B, and C open fires in sequence. How does the game server transmit the states from the game server to the game client?
+
+* **Steps 1 and 2** - Character A opens fires. The packet (packet 0) is sent to the client. The client acknowledges the server.
+
+* **Step 3** - Character B opens fire. The packet is lost during transmission.
+
+* **Steps 4 and 5** - Character C opens fire. The packet (packet 2) is sent to the client. Since the last successfully delivered packet is packet 0, the client knows that packet 1 is lost, so packet 2 is **buffered** on the client side. The client acknowledges the server for the reception of packet 2.
+
+* **Steps 6 and 7** - The server doesn’t receive the ack for packet 1 for a while, so it resends packet 1. When the client receives packet 1, all the subsequent packets become effective, so packets 1 and 2 become “**delivered**”. The client then acknowledges the server for the reception of packet 1. No packets are buffered at this point.
diff --git a/data/guides/what-tools-does-your-team-use-to-ship-code-to-production-and-ensure-code-quality.md b/data/guides/what-tools-does-your-team-use-to-ship-code-to-production-and-ensure-code-quality.md
new file mode 100644
index 0000000..1509390
--- /dev/null
+++ b/data/guides/what-tools-does-your-team-use-to-ship-code-to-production-and-ensure-code-quality.md
@@ -0,0 +1,32 @@
+---
+title: "Tools for Shipping Code to Production"
+description: "Explore tools for shipping code to production and ensuring code quality."
+image: "https://assets.bytebytego.com/diagrams/0335-ship-to-prod-tools.png"
+createdAt: "2024-03-05"
+draft: false
+categories:
+ - devtools-productivity
+tags:
+ - DevOps
+ - Software Delivery
+---
+
+
+
+The approach generally depends on the size of the company. There is no one-size-fits-all solution, but we try to provide a general overview.
+
+## 1-10 employees
+
+In the early stages of a company, the focus is on finding a product-market fit. The emphasis is primarily on delivery and experimentation. Utilizing existing free or low-cost tools, developers handle testing and deployment. They also pay close attention to customer feedback and reports.
+
+## 10-100 employees
+
+Once the product-market fit is found, companies strive to scale. They are able to invest more in quality for critical functionalities and can create rapid evolution processes, such as scheduled deployments and testing procedures. Companies also proactively establish customer support processes to handle customer issues and provide proactive alerts.
+
+## 100-1,000 employees
+
+When a company's go-to-market strategy proves successful, and the product scales and grows rapidly, it starts to optimize its engineering efficiency. More commercial tools can be purchased, such as Atlassian products. A certain level of standardization across tools is introduced, and automation comes into play.
+
+## 1,000-10,000+ employees
+
+Large tech companies build experimental tooling and automation to ensure quality and gather customer feedback at scale. Netflix, for example, is well known for its "Test in Production" strategy, which conducts everything through experiments.
diff --git a/data/guides/which-latency-numbers-should-you-know.md b/data/guides/which-latency-numbers-should-you-know.md
new file mode 100644
index 0000000..4efa155
--- /dev/null
+++ b/data/guides/which-latency-numbers-should-you-know.md
@@ -0,0 +1,50 @@
+---
+title: "Which Latency Numbers Should You Know?"
+description: "Essential latency benchmarks for developers and system designers."
+image: "https://assets.bytebytego.com/diagrams/0250-latency-numbers.jpg"
+createdAt: "2024-03-11"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "latency"
+ - "performance"
+---
+
+Please note those are not accurate numbers. They are based on some online benchmarks (Jeff Dean’s latency numbers + some other sources).
+
+
+
+* **L1 and L2 caches: 1 ns, 10 ns**
+
+ E.g.: They are usually built onto the microprocessor chip. Unless you work with hardware directly, you probably don’t need to worry about them.
+
+* **RAM access: 100 ns**
+
+ E.g.: It takes around 100 ns to read data from memory. Redis is an in-memory data store, so it takes about 100 ns to read data from Redis.
+
+* **Send 1K bytes over 1 Gbps network: 10 us**
+
+ E.g.: It takes around 10 us to send 1KB of data from Memcached through the network.
+
+* **Read from SSD: 100 us**
+
+ E.g.: RocksDB is a disk-based K/V store, so the read latency is around 100 us on SSD.
+
+* **Database insert operation: 1 ms**
+
+ E.g.: Postgresql commit might take 1ms. The database needs to store the data, create the index, and flush logs. All these actions take time.
+
+* **Send packet CA->Netherlands->CA: 100 ms**
+
+ E.g.: If we have a long-distance Zoom call, the latency might be around 100 ms.
+
+* **Retry/refresh internal: 1-10s**
+
+ E.g: In a monitoring system, the refresh interval is usually set to 5~10 seconds (default value on Grafana).
+
+## Notes
+
+1 ns = 10^-9 seconds
+1 us = 10^-6 seconds = 1,000 ns
+1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
diff --git a/data/guides/who-are-the-fantastic-four-of-system-design.md b/data/guides/who-are-the-fantastic-four-of-system-design.md
new file mode 100644
index 0000000..cc8ff44
--- /dev/null
+++ b/data/guides/who-are-the-fantastic-four-of-system-design.md
@@ -0,0 +1,34 @@
+---
+title: "The Fantastic Four of System Design"
+description: "Explore the core principles of system design: scalability, availability..."
+image: 'https://assets.bytebytego.com/diagrams/0357-who-are-the-fantastic-four-of-system-design.png'
+createdAt: '2024-02-05'
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "system design"
+ - "scalability"
+---
+
+
+
+Scalability, Availability, Reliability, and Performance. They are the most critical components to crafting successful software systems.
+
+Let’s look at each of them with implementation techniques:
+
+* **Scalability**
+
+ Scalability ensures that your application can handle more load without compromising performance.
+
+* **Availability**
+
+ Availability makes sure that your application is always ready to serve the users and downtime is minimal.
+
+* **Reliability**
+
+ Reliability is about building software that consistently delivers correct results.
+
+* **Performance**
+
+ Performance is the ability of a system to carry out its tasks at an expected rate under peak load using available resources.
diff --git a/data/guides/why-are-content-delivery-networks-cdn-so-popular.md b/data/guides/why-are-content-delivery-networks-cdn-so-popular.md
new file mode 100644
index 0000000..cd9f39f
--- /dev/null
+++ b/data/guides/why-are-content-delivery-networks-cdn-so-popular.md
@@ -0,0 +1,54 @@
+---
+title: "Why are Content Delivery Networks (CDN) so Popular?"
+description: "Explore the popularity of CDNs and their impact on performance."
+image: "https://assets.bytebytego.com/diagrams/0420-why-cdns-are-so-popular.png"
+createdAt: "2024-02-16"
+draft: false
+categories:
+ - caching-performance
+tags:
+ - CDN
+ - Performance
+---
+
+
+
+The CDN market is expected to reach nearly $38 billion by 2028. Companies like Akamai, Cloudflare, and Amazon CloudFront are investing heavily in this area.
+
+## The Impact of CDN
+
+CDNs improve performance, increase availability, and enhance bandwidth costs. With the use of CDN, there is a significant reduction in latency.
+
+## CDN Request Flow
+
+After DNS resolution, the user’s device sends the content request to the CDN edge server.
+
+* The edge server checks its local cache for the content. If found, the edge server serves the content to the user.
+
+* If not found, the edge server forwards the request to the origin server.
+
+* After receiving the content from the origin server, the edge server stores a copy in its cache and delivers it to the user.
+
+## The Architecture of CDN
+
+There are multiple components in a CDN’s architecture:
+
+* **Origin Server:** This is the primary source of content.
+
+* **Edge Servers:** They cache and server content to the users and are distributed across the world.
+
+* **DNS:** The DNS resolves the domain name to the IP address of the nearest edge server
+
+* **Control Plane:** Responsible for configuring and managing the edge servers.
+
+## CDN Request Routing
+
+* **GSLB:** Routes user requests to the server based on factors like geographic proximity, server load, network conditions
+
+* **Anycast DNS:** Allows multiple servers to share the same IP address. It helps route incoming traffic to the nearest data center.
+
+* **Internet Exchange Points:** CDN providers establish a presence at major IXPs, allowing them to exchange traffic directly with ISPs and other networks.
+
+## Best Practices
+
+Some key best practices to optimize CDN performance are related to security aspects, caching optimizations, and content optimizations.
diff --git a/data/guides/why-do-we-need-to-use-a-distributed-lock.md b/data/guides/why-do-we-need-to-use-a-distributed-lock.md
new file mode 100644
index 0000000..2c857ad
--- /dev/null
+++ b/data/guides/why-do-we-need-to-use-a-distributed-lock.md
@@ -0,0 +1,42 @@
+---
+title: "Why Use a Distributed Lock?"
+description: "Explore the top use cases for distributed locks in distributed systems."
+image: "https://assets.bytebytego.com/diagrams/0383-top-6-use-cases-of-distributed-lock.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - cloud-distributed-systems
+tags:
+ - "distributed systems"
+ - "concurrency"
+---
+
+
+
+A distributed lock is a mechanism that ensures mutual exclusion across a distributed system.
+
+## Top 6 Use Cases for Distributed Locks
+
+* **Leader Election**
+
+ Distributed locks can be used to ensure that only one node becomes the leader at any given time.
+
+* **Task Scheduling**
+
+ In a distributed task scheduler, distributed locks ensure that a scheduled task is executed by only one worker node, preventing duplicate execution.
+
+* **Resource Allocation**
+
+ When managing shared resources like file systems, network sockets, or hardware devices, distributed locks ensure that only one process can access the resource at a time.
+
+* **Microservices Coordination**
+
+ When multiple microservices need to perform coordinated operations, such as updating related data in different databases, distributed locks ensure that these operations are performed in a controlled and orderly manner.
+
+* **Inventory Management**
+
+ In e-commerce platforms, distributed locks can manage inventory updates to ensure that stock levels are accurately maintained when multiple users attempt to purchase the same item simultaneously.
+
+* **Session Management**
+
+ When handling user sessions in a distributed environment, distributed locks can ensure that a user session is only modified by one server at a time, preventing inconsistencies.
diff --git a/data/guides/why-is-kafka-fast.md b/data/guides/why-is-kafka-fast.md
new file mode 100644
index 0000000..a0f105a
--- /dev/null
+++ b/data/guides/why-is-kafka-fast.md
@@ -0,0 +1,40 @@
+---
+title: "Why is Kafka Fast?"
+description: "Explore the key design choices behind Kafka's high performance."
+image: "https://assets.bytebytego.com/diagrams/0424-why-is-kafka-fast.jpg"
+createdAt: "2024-02-05"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "Kafka"
+ - "Performance"
+---
+
+
+
+There are many design decisions that contributed to Kafka’s performance. In this post, we’ll focus on two. We think these two carried the most weight.
+
+## Sequential I/O
+
+The first one is Kafka’s reliance on Sequential I/O.
+
+## Zero Copy
+
+The second design choice that gives Kafka its performance advantage is its focus on efficiency: zero copy principle.
+
+The diagram above illustrates how the data is transmitted between producer and consumer, and what zero-copy means.
+
+* Step 1.1 - 1.3: Producer writes data to the disk
+* Step 2: Consumer reads data without zero-copy
+ * 2.1: The data is loaded from disk to OS cache
+ * 2.2 The data is copied from OS cache to Kafka application
+ * 2.3 Kafka application copies the data into the socket buffer
+ * 2.4 The data is copied from socket buffer to network card
+ * 2.5 The network card sends data out to the consumer
+* Step 3: Consumer reads data with zero-copy
+ * 3.1: The data is loaded from disk to OS cache
+ * 3.2 OS cache directly copies the data to the network card via sendfile() command
+ * 3.3 The network card sends data out to the consumer
+
+Zero copy is a shortcut to save multiple data copies between the application context and kernel context.
diff --git a/data/guides/why-is-nginx-so-popular.md b/data/guides/why-is-nginx-so-popular.md
new file mode 100644
index 0000000..2b73cf0
--- /dev/null
+++ b/data/guides/why-is-nginx-so-popular.md
@@ -0,0 +1,27 @@
+---
+title: "Why is Nginx so Popular?"
+description: "Explore the reasons behind Nginx's widespread popularity and usage."
+image: "https://assets.bytebytego.com/diagrams/0423-why-is-nginx-so-popular.png"
+createdAt: "2024-03-13"
+draft: false
+categories:
+ - devops-cicd
+tags:
+ - "Nginx"
+ - "Web Servers"
+---
+
+
+
+Nginx is a high-performance web server and reverse proxy.
+
+It follows a master-worker process model that contributes to its stability, scalability, and efficient resource utilization.
+
+The master process is responsible for reading the configuration and managing worker processes. Worker processes handle incoming connections using an event-driven non-blocking I/O model.
+
+Due to its architecture, Nginx excels in supporting multiple features such as:
+
+* **High-Performance Web Server**
+* **Reverse Proxy and Load Balancing**
+* **Content Cache**
+* **SSL Termination**
diff --git a/data/guides/why-is-postgresql-voted-as-the-most-loved-database-by-stackoverflow-2022-developer-survey.md b/data/guides/why-is-postgresql-voted-as-the-most-loved-database-by-stackoverflow-2022-developer-survey.md
new file mode 100644
index 0000000..2357038
--- /dev/null
+++ b/data/guides/why-is-postgresql-voted-as-the-most-loved-database-by-stackoverflow-2022-developer-survey.md
@@ -0,0 +1,46 @@
+---
+title: "Why PostgreSQL is the Most Loved Database"
+description: "Explore why PostgreSQL was voted the most loved database in the 2022 survey."
+image: "https://assets.bytebytego.com/diagrams/0303-postgres.png"
+createdAt: "2024-02-25"
+draft: false
+categories:
+ - database-and-storage
+tags:
+ - "PostgreSQL"
+ - "Database"
+---
+
+
+
+The diagram shows the many use cases of PostgreSQL - one database that includes almost **all the use cases** developers need.
+
+## Use Cases of PostgreSQL
+
+* **OLTP (Online Transaction Processing)**
+
+ We can use PostgreSQL for CRUD (Create-Read-Update-Delete) operations.
+
+* **OLAP (Online Analytical Processing)**
+
+ We can use PostgreSQL for analytical processing. PostgreSQL is based on **HTAP**(Hybrid transactional/analytical processing) architecture, so it can handle both OLTP and OLAP well.
+
+* **FDW (Foreign Data Wrapper)**
+
+ A FDW is an extension available in PostgreSQL that allows us to access a table or schema in one database from another.
+
+* **Streaming**
+
+ PipelineDB is a PostgreSQL extension for high-performance time-series aggregation, designed to power real-time reporting and analytics applications.
+
+* **Geospatial**
+
+ PostGIS is a spatial database extender for PostgreSQL object-relational database. It adds support for geographic objects, allowing location queries to be run in SQL.
+
+* **Time Series**
+
+ Timescale extends PostgreSQL for time series and analytics. For example, developers can combine relentless streams of financial and tick data with other business data to build new apps and uncover unique insights.
+
+* **Distributed Tables**
+
+ CitusData scales Postgres by distributing data & queries.
diff --git a/data/guides/why-is-redis-so-fast.md b/data/guides/why-is-redis-so-fast.md
new file mode 100644
index 0000000..a4ce7f9
--- /dev/null
+++ b/data/guides/why-is-redis-so-fast.md
@@ -0,0 +1,22 @@
+---
+title: "Why is Redis so Fast?"
+description: "Explore the key factors behind Redis's exceptional speed."
+image: "https://assets.bytebytego.com/diagrams/0422-why-is-redis-so-fast.png"
+createdAt: '2024-03-07'
+draft: false
+categories:
+ - caching-performance
+tags:
+ - "Redis"
+ - "Performance"
+---
+
+
+
+There are 3 main reasons as shown in the diagram above.
+
+* Redis is a RAM-based database. RAM access is at least 1000 times faster than random disk access.
+
+* Redis leverages IO multiplexing and single-threaded execution loop for execution efficiency.
+
+* Redis leverages several efficient lower-level data structures.
diff --git a/images/18 Most-Used Linux Commands You Should Know-01.jpeg b/images/18 Most-Used Linux Commands You Should Know-01.jpeg
deleted file mode 100644
index cb3f15a..0000000
Binary files a/images/18 Most-Used Linux Commands You Should Know-01.jpeg and /dev/null differ
diff --git a/images/18-oo-patterns.png b/images/18-oo-patterns.png
deleted file mode 100644
index f257d6f..0000000
Binary files a/images/18-oo-patterns.png and /dev/null differ
diff --git a/images/8-ds-db.jpg b/images/8-ds-db.jpg
deleted file mode 100644
index 6a5ff99..0000000
Binary files a/images/8-ds-db.jpg and /dev/null differ
diff --git a/images/Forward Proxy v.s. Reverse Proxy2x.jpg b/images/Forward Proxy v.s. Reverse Proxy2x.jpg
deleted file mode 100644
index 89f6eda..0000000
Binary files a/images/Forward Proxy v.s. Reverse Proxy2x.jpg and /dev/null differ
diff --git a/images/SOAP vs REST vs GraphQL vs RPC.jpeg b/images/SOAP vs REST vs GraphQL vs RPC.jpeg
deleted file mode 100644
index 9bd3e04..0000000
Binary files a/images/SOAP vs REST vs GraphQL vs RPC.jpeg and /dev/null differ
diff --git a/images/Types_of_Memory_and_Storage.jpeg b/images/Types_of_Memory_and_Storage.jpeg
deleted file mode 100644
index f0182e0..0000000
Binary files a/images/Types_of_Memory_and_Storage.jpeg and /dev/null differ
diff --git a/images/airbnb_arch.jpeg b/images/airbnb_arch.jpeg
deleted file mode 100644
index 3b49450..0000000
Binary files a/images/airbnb_arch.jpeg and /dev/null differ
diff --git a/images/api-architecture-styles.png b/images/api-architecture-styles.png
deleted file mode 100644
index 0878f9d..0000000
Binary files a/images/api-architecture-styles.png and /dev/null differ
diff --git a/images/api-performance.jpg b/images/api-performance.jpg
deleted file mode 100644
index f2be80d..0000000
Binary files a/images/api-performance.jpg and /dev/null differ
diff --git a/images/api_first.jpg b/images/api_first.jpg
deleted file mode 100644
index 479efdf..0000000
Binary files a/images/api_first.jpg and /dev/null differ
diff --git a/images/api_gateway.jpg b/images/api_gateway.jpg
deleted file mode 100644
index 97eec07..0000000
Binary files a/images/api_gateway.jpg and /dev/null differ
diff --git a/images/bytebytego.png b/images/bytebytego.png
deleted file mode 100644
index 0117392..0000000
Binary files a/images/bytebytego.png and /dev/null differ
diff --git a/images/cap theorem.jpeg b/images/cap theorem.jpeg
deleted file mode 100644
index d87a977..0000000
Binary files a/images/cap theorem.jpeg and /dev/null differ
diff --git a/images/ci-cd-pipeline.jpg b/images/ci-cd-pipeline.jpg
deleted file mode 100644
index ce97c26..0000000
Binary files a/images/ci-cd-pipeline.jpg and /dev/null differ
diff --git a/images/client arch patterns.png b/images/client arch patterns.png
deleted file mode 100644
index faa9973..0000000
Binary files a/images/client arch patterns.png and /dev/null differ
diff --git a/images/cloud-compare.jpg b/images/cloud-compare.jpg
deleted file mode 100644
index 87f5879..0000000
Binary files a/images/cloud-compare.jpg and /dev/null differ
diff --git a/images/cloud-dbs2.png b/images/cloud-dbs2.png
deleted file mode 100644
index c15b8a7..0000000
Binary files a/images/cloud-dbs2.png and /dev/null differ
diff --git a/images/cloud-native.jpeg b/images/cloud-native.jpeg
deleted file mode 100644
index bac9239..0000000
Binary files a/images/cloud-native.jpeg and /dev/null differ
diff --git a/images/devops-sre-platform.jpg b/images/devops-sre-platform.jpg
deleted file mode 100644
index e01a1f9..0000000
Binary files a/images/devops-sre-platform.jpg and /dev/null differ
diff --git a/images/diagrams_as_code.jpeg b/images/diagrams_as_code.jpeg
deleted file mode 100644
index 4c2190d..0000000
Binary files a/images/diagrams_as_code.jpeg and /dev/null differ
diff --git a/images/discord-store-messages.jpg b/images/discord-store-messages.jpg
deleted file mode 100644
index c826add..0000000
Binary files a/images/discord-store-messages.jpg and /dev/null differ
diff --git a/images/docker-vs-k8s.jpg b/images/docker-vs-k8s.jpg
deleted file mode 100644
index 5f12a51..0000000
Binary files a/images/docker-vs-k8s.jpg and /dev/null differ
diff --git a/images/docker.jpg b/images/docker.jpg
deleted file mode 100644
index e299ad7..0000000
Binary files a/images/docker.jpg and /dev/null differ
diff --git a/images/git-commands.png b/images/git-commands.png
deleted file mode 100644
index a19032f..0000000
Binary files a/images/git-commands.png and /dev/null differ
diff --git a/images/git-merge-git-rebase.jpeg b/images/git-merge-git-rebase.jpeg
deleted file mode 100644
index 35521bb..0000000
Binary files a/images/git-merge-git-rebase.jpeg and /dev/null differ
diff --git a/images/git-workflow.jpeg b/images/git-workflow.jpeg
deleted file mode 100644
index 82f6034..0000000
Binary files a/images/git-workflow.jpeg and /dev/null differ
diff --git a/images/google_authenticate.jpeg b/images/google_authenticate.jpeg
deleted file mode 100644
index 0650686..0000000
Binary files a/images/google_authenticate.jpeg and /dev/null differ
diff --git a/images/graphQL.jpg b/images/graphQL.jpg
deleted file mode 100644
index de9d183..0000000
Binary files a/images/graphQL.jpg and /dev/null differ
diff --git a/images/grpc.jpg b/images/grpc.jpg
deleted file mode 100644
index e7b9ac9..0000000
Binary files a/images/grpc.jpg and /dev/null differ
diff --git a/images/hotstar_emojis.jpeg b/images/hotstar_emojis.jpeg
deleted file mode 100644
index 5025172..0000000
Binary files a/images/hotstar_emojis.jpeg and /dev/null differ
diff --git a/images/how does visa makes money.jpg b/images/how does visa makes money.jpg
deleted file mode 100644
index 4bac278..0000000
Binary files a/images/how does visa makes money.jpg and /dev/null differ
diff --git a/images/how-does-upi-work.png b/images/how-does-upi-work.png
deleted file mode 100644
index 5e2b8cb..0000000
Binary files a/images/how-does-upi-work.png and /dev/null differ
diff --git a/images/how-to-learn-sql.jpg b/images/how-to-learn-sql.jpg
deleted file mode 100644
index 33cb28f..0000000
Binary files a/images/how-to-learn-sql.jpg and /dev/null differ
diff --git a/images/http-status-code.jpg b/images/http-status-code.jpg
deleted file mode 100644
index f856f75..0000000
Binary files a/images/http-status-code.jpg and /dev/null differ
diff --git a/images/http3.jpg b/images/http3.jpg
deleted file mode 100644
index e761ab7..0000000
Binary files a/images/http3.jpg and /dev/null differ
diff --git a/images/https.jpg b/images/https.jpg
deleted file mode 100644
index 62100e8..0000000
Binary files a/images/https.jpg and /dev/null differ
diff --git a/images/json-cracker.jpeg b/images/json-cracker.jpeg
deleted file mode 100644
index 4933924..0000000
Binary files a/images/json-cracker.jpeg and /dev/null differ
diff --git a/images/jwt.jpg b/images/jwt.jpg
deleted file mode 100644
index 05f4f5f..0000000
Binary files a/images/jwt.jpg and /dev/null differ
diff --git a/images/k8s.jpeg b/images/k8s.jpeg
deleted file mode 100644
index 568dc71..0000000
Binary files a/images/k8s.jpeg and /dev/null differ
diff --git a/images/lb-algorithms.jpg b/images/lb-algorithms.jpg
deleted file mode 100644
index 0463e49..0000000
Binary files a/images/lb-algorithms.jpg and /dev/null differ
diff --git a/images/learn-payments.jpg b/images/learn-payments.jpg
deleted file mode 100644
index 4abdee5..0000000
Binary files a/images/learn-payments.jpg and /dev/null differ
diff --git a/images/linux-file-systems.jpg b/images/linux-file-systems.jpg
deleted file mode 100644
index c247db9..0000000
Binary files a/images/linux-file-systems.jpg and /dev/null differ
diff --git a/images/live_streaming_updated.jpg b/images/live_streaming_updated.jpg
deleted file mode 100644
index 99a90cf..0000000
Binary files a/images/live_streaming_updated.jpg and /dev/null differ
diff --git a/images/microservice-best-practices.jpeg b/images/microservice-best-practices.jpeg
deleted file mode 100644
index a08b89c..0000000
Binary files a/images/microservice-best-practices.jpeg and /dev/null differ
diff --git a/images/microservice-tech.jpeg b/images/microservice-tech.jpeg
deleted file mode 100644
index 653be78..0000000
Binary files a/images/microservice-tech.jpeg and /dev/null differ
diff --git a/images/monorepo-microrepo.jpg b/images/monorepo-microrepo.jpg
deleted file mode 100644
index 4692f79..0000000
Binary files a/images/monorepo-microrepo.jpg and /dev/null differ
diff --git a/images/netflix tech stack.png b/images/netflix tech stack.png
deleted file mode 100644
index a7d7e81..0000000
Binary files a/images/netflix tech stack.png and /dev/null differ
diff --git a/images/netflix-ci-cd.jpg b/images/netflix-ci-cd.jpg
deleted file mode 100644
index e023d29..0000000
Binary files a/images/netflix-ci-cd.jpg and /dev/null differ
diff --git a/images/network-protocols.gif b/images/network-protocols.gif
deleted file mode 100644
index 22bf691..0000000
Binary files a/images/network-protocols.gif and /dev/null differ
diff --git a/images/oAuth2.jpg b/images/oAuth2.jpg
deleted file mode 100644
index 0f6c37d..0000000
Binary files a/images/oAuth2.jpg and /dev/null differ
diff --git a/images/osi model.jpeg b/images/osi model.jpeg
deleted file mode 100644
index d2946fb..0000000
Binary files a/images/osi model.jpeg and /dev/null differ
diff --git a/images/safe-apis.jpg b/images/safe-apis.jpg
deleted file mode 100644
index b6d8bc2..0000000
Binary files a/images/safe-apis.jpg and /dev/null differ
diff --git a/images/salt.jpg b/images/salt.jpg
deleted file mode 100644
index ff3cd10..0000000
Binary files a/images/salt.jpg and /dev/null differ
diff --git a/images/serverless-to-monolithic.jpeg b/images/serverless-to-monolithic.jpeg
deleted file mode 100644
index 6b49615..0000000
Binary files a/images/serverless-to-monolithic.jpeg and /dev/null differ
diff --git a/images/session.jpeg b/images/session.jpeg
deleted file mode 100644
index f217471..0000000
Binary files a/images/session.jpeg and /dev/null differ
diff --git a/images/sql execution order in db.jpeg b/images/sql execution order in db.jpeg
deleted file mode 100644
index a41c99b..0000000
Binary files a/images/sql execution order in db.jpeg and /dev/null differ
diff --git a/images/sql-execution-order.jpg b/images/sql-execution-order.jpg
deleted file mode 100644
index 1e768ef..0000000
Binary files a/images/sql-execution-order.jpg and /dev/null differ
diff --git a/images/stackoverflow.jpg b/images/stackoverflow.jpg
deleted file mode 100644
index 2ccdd0c..0000000
Binary files a/images/stackoverflow.jpg and /dev/null differ
diff --git a/images/top-redis-use-cases.jpg b/images/top-redis-use-cases.jpg
deleted file mode 100644
index 77db6dd..0000000
Binary files a/images/top-redis-use-cases.jpg and /dev/null differ
diff --git a/images/top4-most-used-auth.jpg b/images/top4-most-used-auth.jpg
deleted file mode 100644
index b5c7dd1..0000000
Binary files a/images/top4-most-used-auth.jpg and /dev/null differ
diff --git a/images/top_caching_strategy.jpeg b/images/top_caching_strategy.jpeg
deleted file mode 100644
index a63a429..0000000
Binary files a/images/top_caching_strategy.jpeg and /dev/null differ
diff --git a/images/twitter-arch.jpeg b/images/twitter-arch.jpeg
deleted file mode 100644
index 7c31bb5..0000000
Binary files a/images/twitter-arch.jpeg and /dev/null differ
diff --git a/images/typical-microservice-arch.jpg b/images/typical-microservice-arch.jpg
deleted file mode 100644
index 4b98e9f..0000000
Binary files a/images/typical-microservice-arch.jpg and /dev/null differ
diff --git a/images/url-uri-urn.jpg b/images/url-uri-urn.jpg
deleted file mode 100644
index a78183f..0000000
Binary files a/images/url-uri-urn.jpg and /dev/null differ
diff --git a/images/visa_payment.jpeg b/images/visa_payment.jpeg
deleted file mode 100644
index b879f64..0000000
Binary files a/images/visa_payment.jpeg and /dev/null differ
diff --git a/images/webhook.jpeg b/images/webhook.jpeg
deleted file mode 100644
index 79279cb..0000000
Binary files a/images/webhook.jpeg and /dev/null differ
diff --git a/images/where do we cache data.jpeg b/images/where do we cache data.jpeg
deleted file mode 100644
index 9ad7e34..0000000
Binary files a/images/where do we cache data.jpeg and /dev/null differ
diff --git a/images/why_is_kafka_fast.jpeg b/images/why_is_kafka_fast.jpeg
deleted file mode 100644
index 6c40f7a..0000000
Binary files a/images/why_is_kafka_fast.jpeg and /dev/null differ
diff --git a/images/why_redis_fast.jpeg b/images/why_redis_fast.jpeg
deleted file mode 100644
index 0b4b882..0000000
Binary files a/images/why_redis_fast.jpeg and /dev/null differ
diff --git a/images/youtube.png b/images/youtube.png
deleted file mode 100644
index 48e3ca4..0000000
Binary files a/images/youtube.png and /dev/null differ
diff --git a/package.json b/package.json
new file mode 100644
index 0000000..2b8d9ec
--- /dev/null
+++ b/package.json
@@ -0,0 +1,15 @@
+{
+ "name": "system-design-101",
+ "version": "1.0.0",
+ "description": "Explain complex systems using visuals and simple terms.",
+ "scripts": {
+ "update-readme": "tsx scripts/readme.ts"
+ },
+ "author": "",
+ "license": "cc-by-nc-sd-4.0",
+ "devDependencies": {
+ "@types/node": "^22.13.14",
+ "gray-matter": "^4.0.3",
+ "tsx": "^4.19.3"
+ }
+}
diff --git a/pnpm-lock.yaml b/pnpm-lock.yaml
new file mode 100644
index 0000000..025effe
--- /dev/null
+++ b/pnpm-lock.yaml
@@ -0,0 +1,399 @@
+lockfileVersion: '9.0'
+
+settings:
+ autoInstallPeers: true
+ excludeLinksFromLockfile: false
+
+importers:
+
+ .:
+ devDependencies:
+ '@types/node':
+ specifier: ^22.13.14
+ version: 22.13.14
+ gray-matter:
+ specifier: ^4.0.3
+ version: 4.0.3
+ tsx:
+ specifier: ^4.19.3
+ version: 4.19.3
+
+packages:
+
+ '@esbuild/aix-ppc64@0.25.2':
+ resolution: {integrity: sha512-wCIboOL2yXZym2cgm6mlA742s9QeJ8DjGVaL39dLN4rRwrOgOyYSnOaFPhKZGLb2ngj4EyfAFjsNJwPXZvseag==}
+ engines: {node: '>=18'}
+ cpu: [ppc64]
+ os: [aix]
+
+ '@esbuild/android-arm64@0.25.2':
+ resolution: {integrity: sha512-5ZAX5xOmTligeBaeNEPnPaeEuah53Id2tX4c2CVP3JaROTH+j4fnfHCkr1PjXMd78hMst+TlkfKcW/DlTq0i4w==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [android]
+
+ '@esbuild/android-arm@0.25.2':
+ resolution: {integrity: sha512-NQhH7jFstVY5x8CKbcfa166GoV0EFkaPkCKBQkdPJFvo5u+nGXLEH/ooniLb3QI8Fk58YAx7nsPLozUWfCBOJA==}
+ engines: {node: '>=18'}
+ cpu: [arm]
+ os: [android]
+
+ '@esbuild/android-x64@0.25.2':
+ resolution: {integrity: sha512-Ffcx+nnma8Sge4jzddPHCZVRvIfQ0kMsUsCMcJRHkGJ1cDmhe4SsrYIjLUKn1xpHZybmOqCWwB0zQvsjdEHtkg==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [android]
+
+ '@esbuild/darwin-arm64@0.25.2':
+ resolution: {integrity: sha512-MpM6LUVTXAzOvN4KbjzU/q5smzryuoNjlriAIx+06RpecwCkL9JpenNzpKd2YMzLJFOdPqBpuub6eVRP5IgiSA==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [darwin]
+
+ '@esbuild/darwin-x64@0.25.2':
+ resolution: {integrity: sha512-5eRPrTX7wFyuWe8FqEFPG2cU0+butQQVNcT4sVipqjLYQjjh8a8+vUTfgBKM88ObB85ahsnTwF7PSIt6PG+QkA==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [darwin]
+
+ '@esbuild/freebsd-arm64@0.25.2':
+ resolution: {integrity: sha512-mLwm4vXKiQ2UTSX4+ImyiPdiHjiZhIaE9QvC7sw0tZ6HoNMjYAqQpGyui5VRIi5sGd+uWq940gdCbY3VLvsO1w==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [freebsd]
+
+ '@esbuild/freebsd-x64@0.25.2':
+ resolution: {integrity: sha512-6qyyn6TjayJSwGpm8J9QYYGQcRgc90nmfdUb0O7pp1s4lTY+9D0H9O02v5JqGApUyiHOtkz6+1hZNvNtEhbwRQ==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [freebsd]
+
+ '@esbuild/linux-arm64@0.25.2':
+ resolution: {integrity: sha512-gq/sjLsOyMT19I8obBISvhoYiZIAaGF8JpeXu1u8yPv8BE5HlWYobmlsfijFIZ9hIVGYkbdFhEqC0NvM4kNO0g==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [linux]
+
+ '@esbuild/linux-arm@0.25.2':
+ resolution: {integrity: sha512-UHBRgJcmjJv5oeQF8EpTRZs/1knq6loLxTsjc3nxO9eXAPDLcWW55flrMVc97qFPbmZP31ta1AZVUKQzKTzb0g==}
+ engines: {node: '>=18'}
+ cpu: [arm]
+ os: [linux]
+
+ '@esbuild/linux-ia32@0.25.2':
+ resolution: {integrity: sha512-bBYCv9obgW2cBP+2ZWfjYTU+f5cxRoGGQ5SeDbYdFCAZpYWrfjjfYwvUpP8MlKbP0nwZ5gyOU/0aUzZ5HWPuvQ==}
+ engines: {node: '>=18'}
+ cpu: [ia32]
+ os: [linux]
+
+ '@esbuild/linux-loong64@0.25.2':
+ resolution: {integrity: sha512-SHNGiKtvnU2dBlM5D8CXRFdd+6etgZ9dXfaPCeJtz+37PIUlixvlIhI23L5khKXs3DIzAn9V8v+qb1TRKrgT5w==}
+ engines: {node: '>=18'}
+ cpu: [loong64]
+ os: [linux]
+
+ '@esbuild/linux-mips64el@0.25.2':
+ resolution: {integrity: sha512-hDDRlzE6rPeoj+5fsADqdUZl1OzqDYow4TB4Y/3PlKBD0ph1e6uPHzIQcv2Z65u2K0kpeByIyAjCmjn1hJgG0Q==}
+ engines: {node: '>=18'}
+ cpu: [mips64el]
+ os: [linux]
+
+ '@esbuild/linux-ppc64@0.25.2':
+ resolution: {integrity: sha512-tsHu2RRSWzipmUi9UBDEzc0nLc4HtpZEI5Ba+Omms5456x5WaNuiG3u7xh5AO6sipnJ9r4cRWQB2tUjPyIkc6g==}
+ engines: {node: '>=18'}
+ cpu: [ppc64]
+ os: [linux]
+
+ '@esbuild/linux-riscv64@0.25.2':
+ resolution: {integrity: sha512-k4LtpgV7NJQOml/10uPU0s4SAXGnowi5qBSjaLWMojNCUICNu7TshqHLAEbkBdAszL5TabfvQ48kK84hyFzjnw==}
+ engines: {node: '>=18'}
+ cpu: [riscv64]
+ os: [linux]
+
+ '@esbuild/linux-s390x@0.25.2':
+ resolution: {integrity: sha512-GRa4IshOdvKY7M/rDpRR3gkiTNp34M0eLTaC1a08gNrh4u488aPhuZOCpkF6+2wl3zAN7L7XIpOFBhnaE3/Q8Q==}
+ engines: {node: '>=18'}
+ cpu: [s390x]
+ os: [linux]
+
+ '@esbuild/linux-x64@0.25.2':
+ resolution: {integrity: sha512-QInHERlqpTTZ4FRB0fROQWXcYRD64lAoiegezDunLpalZMjcUcld3YzZmVJ2H/Cp0wJRZ8Xtjtj0cEHhYc/uUg==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [linux]
+
+ '@esbuild/netbsd-arm64@0.25.2':
+ resolution: {integrity: sha512-talAIBoY5M8vHc6EeI2WW9d/CkiO9MQJ0IOWX8hrLhxGbro/vBXJvaQXefW2cP0z0nQVTdQ/eNyGFV1GSKrxfw==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [netbsd]
+
+ '@esbuild/netbsd-x64@0.25.2':
+ resolution: {integrity: sha512-voZT9Z+tpOxrvfKFyfDYPc4DO4rk06qamv1a/fkuzHpiVBMOhpjK+vBmWM8J1eiB3OLSMFYNaOaBNLXGChf5tg==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [netbsd]
+
+ '@esbuild/openbsd-arm64@0.25.2':
+ resolution: {integrity: sha512-dcXYOC6NXOqcykeDlwId9kB6OkPUxOEqU+rkrYVqJbK2hagWOMrsTGsMr8+rW02M+d5Op5NNlgMmjzecaRf7Tg==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [openbsd]
+
+ '@esbuild/openbsd-x64@0.25.2':
+ resolution: {integrity: sha512-t/TkWwahkH0Tsgoq1Ju7QfgGhArkGLkF1uYz8nQS/PPFlXbP5YgRpqQR3ARRiC2iXoLTWFxc6DJMSK10dVXluw==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [openbsd]
+
+ '@esbuild/sunos-x64@0.25.2':
+ resolution: {integrity: sha512-cfZH1co2+imVdWCjd+D1gf9NjkchVhhdpgb1q5y6Hcv9TP6Zi9ZG/beI3ig8TvwT9lH9dlxLq5MQBBgwuj4xvA==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [sunos]
+
+ '@esbuild/win32-arm64@0.25.2':
+ resolution: {integrity: sha512-7Loyjh+D/Nx/sOTzV8vfbB3GJuHdOQyrOryFdZvPHLf42Tk9ivBU5Aedi7iyX+x6rbn2Mh68T4qq1SDqJBQO5Q==}
+ engines: {node: '>=18'}
+ cpu: [arm64]
+ os: [win32]
+
+ '@esbuild/win32-ia32@0.25.2':
+ resolution: {integrity: sha512-WRJgsz9un0nqZJ4MfhabxaD9Ft8KioqU3JMinOTvobbX6MOSUigSBlogP8QB3uxpJDsFS6yN+3FDBdqE5lg9kg==}
+ engines: {node: '>=18'}
+ cpu: [ia32]
+ os: [win32]
+
+ '@esbuild/win32-x64@0.25.2':
+ resolution: {integrity: sha512-kM3HKb16VIXZyIeVrM1ygYmZBKybX8N4p754bw390wGO3Tf2j4L2/WYL+4suWujpgf6GBYs3jv7TyUivdd05JA==}
+ engines: {node: '>=18'}
+ cpu: [x64]
+ os: [win32]
+
+ '@types/node@22.13.14':
+ resolution: {integrity: sha512-Zs/Ollc1SJ8nKUAgc7ivOEdIBM8JAKgrqqUYi2J997JuKO7/tpQC+WCetQ1sypiKCQWHdvdg9wBNpUPEWZae7w==}
+
+ argparse@1.0.10:
+ resolution: {integrity: sha512-o5Roy6tNG4SL/FOkCAN6RzjiakZS25RLYFrcMttJqbdd8BWrnA+fGz57iN5Pb06pvBGvl5gQ0B48dJlslXvoTg==}
+
+ esbuild@0.25.2:
+ resolution: {integrity: sha512-16854zccKPnC+toMywC+uKNeYSv+/eXkevRAfwRD/G9Cleq66m8XFIrigkbvauLLlCfDL45Q2cWegSg53gGBnQ==}
+ engines: {node: '>=18'}
+ hasBin: true
+
+ esprima@4.0.1:
+ resolution: {integrity: sha512-eGuFFw7Upda+g4p+QHvnW0RyTX/SVeJBDM/gCtMARO0cLuT2HcEKnTPvhjV6aGeqrCB/sbNop0Kszm0jsaWU4A==}
+ engines: {node: '>=4'}
+ hasBin: true
+
+ extend-shallow@2.0.1:
+ resolution: {integrity: sha512-zCnTtlxNoAiDc3gqY2aYAWFx7XWWiasuF2K8Me5WbN8otHKTUKBwjPtNpRs/rbUZm7KxWAaNj7P1a/p52GbVug==}
+ engines: {node: '>=0.10.0'}
+
+ fsevents@2.3.3:
+ resolution: {integrity: sha512-5xoDfX+fL7faATnagmWPpbFtwh/R77WmMMqqHGS65C3vvB0YHrgF+B1YmZ3441tMj5n63k0212XNoJwzlhffQw==}
+ engines: {node: ^8.16.0 || ^10.6.0 || >=11.0.0}
+ os: [darwin]
+
+ get-tsconfig@4.10.0:
+ resolution: {integrity: sha512-kGzZ3LWWQcGIAmg6iWvXn0ei6WDtV26wzHRMwDSzmAbcXrTEXxHy6IehI6/4eT6VRKyMP1eF1VqwrVUmE/LR7A==}
+
+ gray-matter@4.0.3:
+ resolution: {integrity: sha512-5v6yZd4JK3eMI3FqqCouswVqwugaA9r4dNZB1wwcmrD02QkV5H0y7XBQW8QwQqEaZY1pM9aqORSORhJRdNK44Q==}
+ engines: {node: '>=6.0'}
+
+ is-extendable@0.1.1:
+ resolution: {integrity: sha512-5BMULNob1vgFX6EjQw5izWDxrecWK9AM72rugNr0TFldMOi0fj6Jk+zeKIt0xGj4cEfQIJth4w3OKWOJ4f+AFw==}
+ engines: {node: '>=0.10.0'}
+
+ js-yaml@3.14.1:
+ resolution: {integrity: sha512-okMH7OXXJ7YrN9Ok3/SXrnu4iX9yOk+25nqX4imS2npuvTYDmo/QEZoqwZkYaIDk3jVvBOTOIEgEhaLOynBS9g==}
+ hasBin: true
+
+ kind-of@6.0.3:
+ resolution: {integrity: sha512-dcS1ul+9tmeD95T+x28/ehLgd9mENa3LsvDTtzm3vyBEO7RPptvAD+t44WVXaUjTBRcrpFeFlC8WCruUR456hw==}
+ engines: {node: '>=0.10.0'}
+
+ resolve-pkg-maps@1.0.0:
+ resolution: {integrity: sha512-seS2Tj26TBVOC2NIc2rOe2y2ZO7efxITtLZcGSOnHHNOQ7CkiUBfw0Iw2ck6xkIhPwLhKNLS8BO+hEpngQlqzw==}
+
+ section-matter@1.0.0:
+ resolution: {integrity: sha512-vfD3pmTzGpufjScBh50YHKzEu2lxBWhVEHsNGoEXmCmn2hKGfeNLYMzCJpe8cD7gqX7TJluOVpBkAequ6dgMmA==}
+ engines: {node: '>=4'}
+
+ sprintf-js@1.0.3:
+ resolution: {integrity: sha512-D9cPgkvLlV3t3IzL0D0YLvGA9Ahk4PcvVwUbN0dSGr1aP0Nrt4AEnTUbuGvquEC0mA64Gqt1fzirlRs5ibXx8g==}
+
+ strip-bom-string@1.0.0:
+ resolution: {integrity: sha512-uCC2VHvQRYu+lMh4My/sFNmF2klFymLX1wHJeXnbEJERpV/ZsVuonzerjfrGpIGF7LBVa1O7i9kjiWvJiFck8g==}
+ engines: {node: '>=0.10.0'}
+
+ tsx@4.19.3:
+ resolution: {integrity: sha512-4H8vUNGNjQ4V2EOoGw005+c+dGuPSnhpPBPHBtsZdGZBk/iJb4kguGlPWaZTZ3q5nMtFOEsY0nRDlh9PJyd6SQ==}
+ engines: {node: '>=18.0.0'}
+ hasBin: true
+
+ undici-types@6.20.0:
+ resolution: {integrity: sha512-Ny6QZ2Nju20vw1SRHe3d9jVu6gJ+4e3+MMpqu7pqE5HT6WsTSlce++GQmK5UXS8mzV8DSYHrQH+Xrf2jVcuKNg==}
+
+snapshots:
+
+ '@esbuild/aix-ppc64@0.25.2':
+ optional: true
+
+ '@esbuild/android-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/android-arm@0.25.2':
+ optional: true
+
+ '@esbuild/android-x64@0.25.2':
+ optional: true
+
+ '@esbuild/darwin-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/darwin-x64@0.25.2':
+ optional: true
+
+ '@esbuild/freebsd-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/freebsd-x64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-arm@0.25.2':
+ optional: true
+
+ '@esbuild/linux-ia32@0.25.2':
+ optional: true
+
+ '@esbuild/linux-loong64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-mips64el@0.25.2':
+ optional: true
+
+ '@esbuild/linux-ppc64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-riscv64@0.25.2':
+ optional: true
+
+ '@esbuild/linux-s390x@0.25.2':
+ optional: true
+
+ '@esbuild/linux-x64@0.25.2':
+ optional: true
+
+ '@esbuild/netbsd-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/netbsd-x64@0.25.2':
+ optional: true
+
+ '@esbuild/openbsd-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/openbsd-x64@0.25.2':
+ optional: true
+
+ '@esbuild/sunos-x64@0.25.2':
+ optional: true
+
+ '@esbuild/win32-arm64@0.25.2':
+ optional: true
+
+ '@esbuild/win32-ia32@0.25.2':
+ optional: true
+
+ '@esbuild/win32-x64@0.25.2':
+ optional: true
+
+ '@types/node@22.13.14':
+ dependencies:
+ undici-types: 6.20.0
+
+ argparse@1.0.10:
+ dependencies:
+ sprintf-js: 1.0.3
+
+ esbuild@0.25.2:
+ optionalDependencies:
+ '@esbuild/aix-ppc64': 0.25.2
+ '@esbuild/android-arm': 0.25.2
+ '@esbuild/android-arm64': 0.25.2
+ '@esbuild/android-x64': 0.25.2
+ '@esbuild/darwin-arm64': 0.25.2
+ '@esbuild/darwin-x64': 0.25.2
+ '@esbuild/freebsd-arm64': 0.25.2
+ '@esbuild/freebsd-x64': 0.25.2
+ '@esbuild/linux-arm': 0.25.2
+ '@esbuild/linux-arm64': 0.25.2
+ '@esbuild/linux-ia32': 0.25.2
+ '@esbuild/linux-loong64': 0.25.2
+ '@esbuild/linux-mips64el': 0.25.2
+ '@esbuild/linux-ppc64': 0.25.2
+ '@esbuild/linux-riscv64': 0.25.2
+ '@esbuild/linux-s390x': 0.25.2
+ '@esbuild/linux-x64': 0.25.2
+ '@esbuild/netbsd-arm64': 0.25.2
+ '@esbuild/netbsd-x64': 0.25.2
+ '@esbuild/openbsd-arm64': 0.25.2
+ '@esbuild/openbsd-x64': 0.25.2
+ '@esbuild/sunos-x64': 0.25.2
+ '@esbuild/win32-arm64': 0.25.2
+ '@esbuild/win32-ia32': 0.25.2
+ '@esbuild/win32-x64': 0.25.2
+
+ esprima@4.0.1: {}
+
+ extend-shallow@2.0.1:
+ dependencies:
+ is-extendable: 0.1.1
+
+ fsevents@2.3.3:
+ optional: true
+
+ get-tsconfig@4.10.0:
+ dependencies:
+ resolve-pkg-maps: 1.0.0
+
+ gray-matter@4.0.3:
+ dependencies:
+ js-yaml: 3.14.1
+ kind-of: 6.0.3
+ section-matter: 1.0.0
+ strip-bom-string: 1.0.0
+
+ is-extendable@0.1.1: {}
+
+ js-yaml@3.14.1:
+ dependencies:
+ argparse: 1.0.10
+ esprima: 4.0.1
+
+ kind-of@6.0.3: {}
+
+ resolve-pkg-maps@1.0.0: {}
+
+ section-matter@1.0.0:
+ dependencies:
+ extend-shallow: 2.0.1
+ kind-of: 6.0.3
+
+ sprintf-js@1.0.3: {}
+
+ strip-bom-string@1.0.0: {}
+
+ tsx@4.19.3:
+ dependencies:
+ esbuild: 0.25.2
+ get-tsconfig: 4.10.0
+ optionalDependencies:
+ fsevents: 2.3.3
+
+ undici-types@6.20.0: {}
diff --git a/scripts/readme.ts b/scripts/readme.ts
new file mode 100644
index 0000000..0b8bfe9
--- /dev/null
+++ b/scripts/readme.ts
@@ -0,0 +1,82 @@
+import fs from 'fs'
+import path from 'path'
+import matter from 'gray-matter'
+
+interface Category {
+ id: string
+ title: string
+ sort: number
+}
+
+interface Guide {
+ id: string
+ title: string
+ createdAt: string
+ categories: string[]
+}
+
+const CATEGORIES_DIR = path.join(process.cwd(), 'data/categories')
+const GUIDES_DIR = path.join(process.cwd(), 'data/guides')
+const README_PATH = path.join(process.cwd(), 'README.md')
+
+function getCategories(): Category[] {
+ const files = fs.readdirSync(CATEGORIES_DIR)
+ return files
+ .map(file => {
+ const content = fs.readFileSync(path.join(CATEGORIES_DIR, file), 'utf8')
+ const { data } = matter(content)
+ return {
+ id: file.replace('.md', ''),
+ title: data.title,
+ sort: data.sort
+ }
+ })
+ .sort((a, b) => a.sort - b.sort)
+}
+
+function getGuides(): Guide[] {
+ const files = fs.readdirSync(GUIDES_DIR)
+ return files
+ .map(file => {
+ const content = fs.readFileSync(path.join(GUIDES_DIR, file), 'utf8')
+ const { data } = matter(content)
+ return {
+ id: file.replace('.md', ''),
+ title: data.title,
+ createdAt: data.createdAt,
+ categories: data.categories || []
+ }
+ })
+ .sort((a, b) => new Date(a.createdAt).getTime() - new Date(b.createdAt).getTime())
+}
+
+function generateMarkdownList() {
+ const categories = getCategories()
+ const guides = getGuides()
+
+ let markdown = ''
+
+ categories.forEach(category => {
+ markdown += `* [${category.title}](https://bytebytego.com/guides/${category.id})\n`
+
+ const categoryGuides = guides.filter(guide => guide.categories.includes(category.id))
+ if (categoryGuides.length > 0) {
+ categoryGuides.forEach(guide => {
+ markdown += ` * [${guide.title}](https://bytebytego.com/guides/${guide.id})\n`
+ })
+ }
+ })
+
+ return markdown
+}
+
+function updateReadmeToc() {
+ const readmeContent = fs.readFileSync(README_PATH, 'utf8')
+ const tocRegex = /\n([\s\S]*?)\n/
+ const newToc = `\n\n${generateMarkdownList()}\n\n`
+ const updatedContent = readmeContent.replace(tocRegex, newToc)
+ fs.writeFileSync(README_PATH, updatedContent)
+ console.log('TOC updated successfully!')
+}
+
+updateReadmeToc()
diff --git a/translations/TRANSLATIONS.md b/translations/TRANSLATIONS.md
deleted file mode 100644
index d3a3f0a..0000000
--- a/translations/TRANSLATIONS.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# Translations
-
-We'd like for the repo to be available in many languages. Here is the process for maintaining translations:
-
-* Please put new translation README files here.
-* We'll migrate the existing translations when they are ready.
-* All diagrams are maintained in English and will not be translated.
-* To start a new translation, please:
- 1. Make an issue (for collaboration with other translators)
- 2. Make a pull request to collaborate and commit to.
- 3. Let us know when it's ready to merge.
-
-### Translation template credits
-
-Thanks to [coding-interview-university](https://github.com/jwasham/coding-interview-university/blob/main/translations/how-to.md) for the translation template.