This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
1.6 KiB
title, description, image, createdAt, draft, categories, tags
| title | description | image | createdAt | draft | categories | tags | |||
|---|---|---|---|---|---|---|---|---|---|
| 100X Postgres Scaling at Figma | Learn how Figma scaled its Postgres database by 100x. | https://assets.bytebytego.com/diagrams/0048-100x-postgres-scaling-at-figma.png | 2024-02-12 | false |
|
|
With 3 million monthly users, Figma’s user base has increased by 200% since 2018.
As a result, its Postgres database witnessed a whopping 100X growth.
-
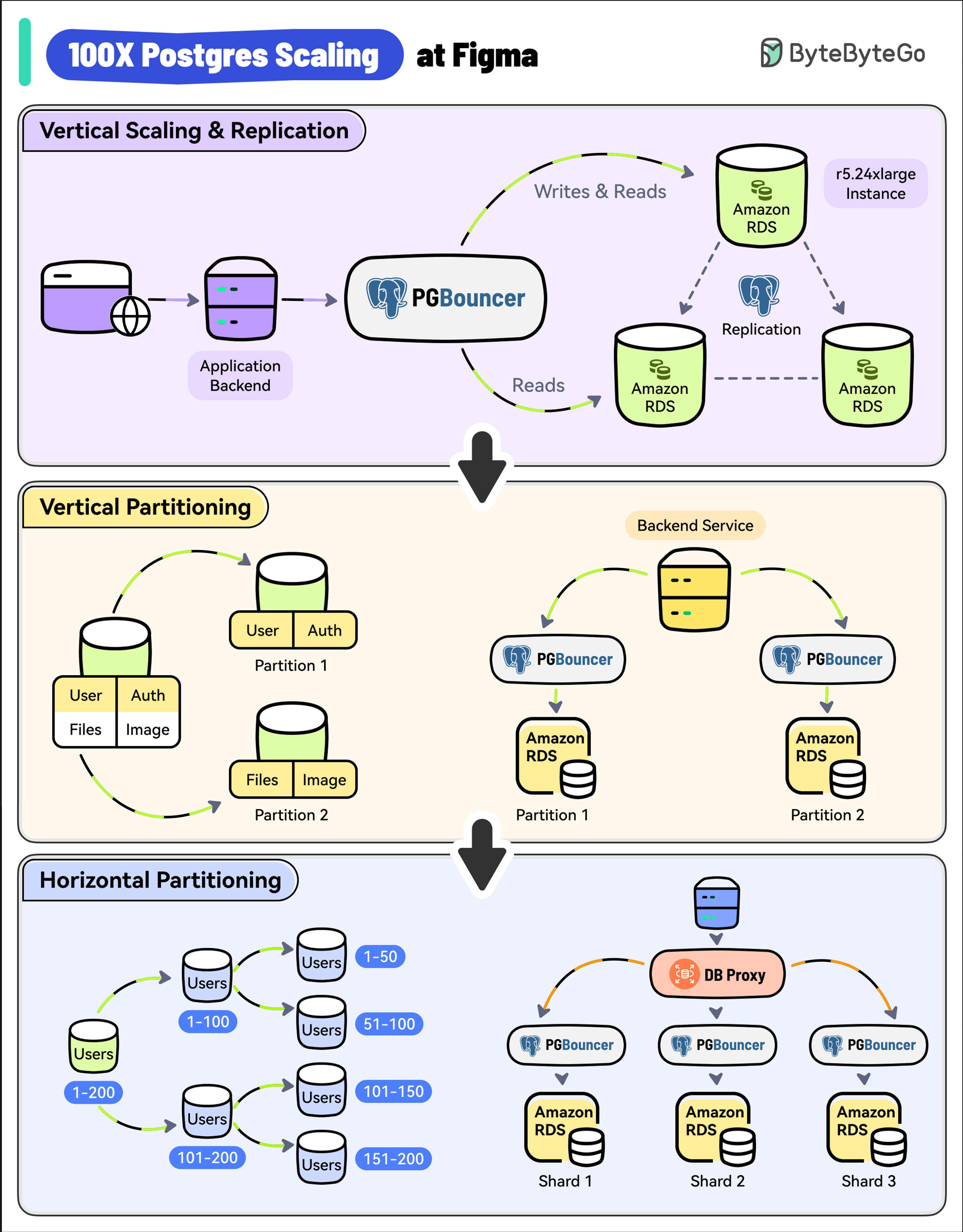
Vertical Scaling and Replication
Figma used a single, large Amazon RDS database.
As a first step, they upgraded to the largest instance available (from r5.12xlarge to r5.24xlarge).
They also created multiple read replicas to scale read traffic and added PgBouncer as a connection pooler to limit the impact of a growing number of connections.
-
Vertical Partitioning
The next step was vertical partitioning.
They migrated high-traffic tables like “Figma Files” and “Organizations” into their separate databases.
Multiple PgBouncer instances were used to manage the connections for these separate databases.
-
Horizontal Partitioning
Over time, some tables crossed several terabytes of data and billions of rows.
Postgres Vacuum became an issue and max IOPS exceeded the limits of Amazon RDS at the time.
To solve this, Figma implemented horizontal partitioning by splitting large tables across multiple physical databases.
A new DBProxy service was built to handle routing and query execution.