This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
2.5 KiB
title, description, image, createdAt, draft, categories, tags
| title | description | image | createdAt | draft | categories | tags | |||
|---|---|---|---|---|---|---|---|---|---|
| Consistent Hashing Explained | Explore consistent hashing: its benefits, and real-world applications. | https://assets.bytebytego.com/diagrams/0151-consistent-hashing.png | 2024-03-07 | false |
|
|
Algorithm 1: Consistent Hashing
What do Amazon DynamoDB, Apache Cassandra, Discord, and Akamai CDN have in common?
They all use consistent hashing. Let’s dive right in.
What’s the issue with simple hashing?
In a large-scale distributed system, data does not fit on a single server. They are “distributed” across many machines. This is called horizontal scaling.
To build such a system with predictable performance, it is important to distribute the data evenly across those servers.
Simple hashing: serverIndex = hash(key) % N, where N is the size of the server pool
This approach works well when the size of the cluster is fixed, and the data distribution is even. But when new servers get added to meet new demand, or when existing servers get removed, it triggers a storm of misses and a lot of objects to be moved.
Consistent hashing
Consistent hashing is an effective technique to mitigate this issue.
The goal of consistent hashing is simple. We want almost all objects to stay assigned to the same server even as the number of servers changes.
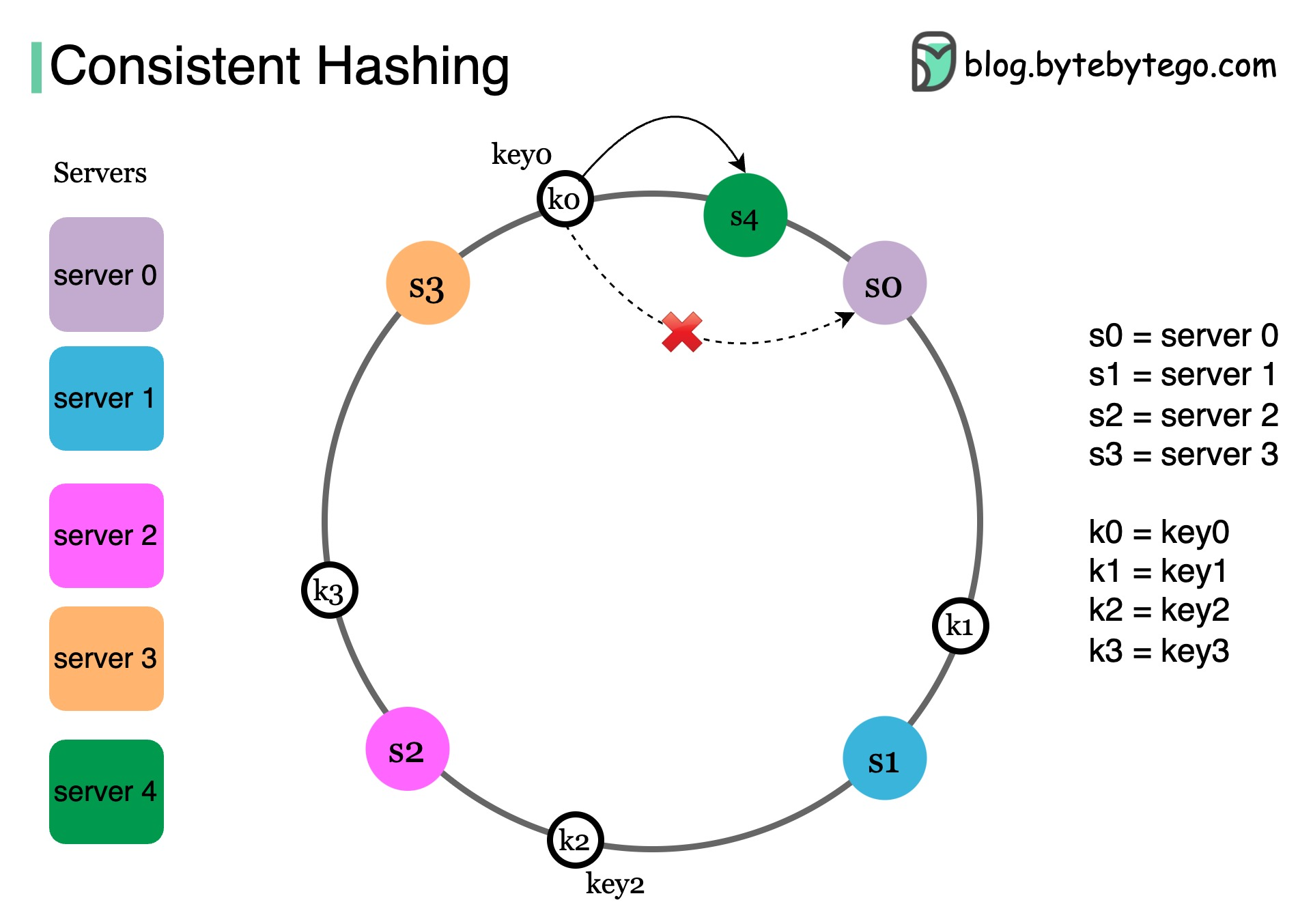
As shown in the diagram, using a hash function, we hash each server by its name or IP address, and place the server onto the ring. Next, we hash each object by its key with the same hashing function.
To locate the server for a particular object, we go clockwise from the location of the object key on the ring until a server is found. Continue with our example, key 0 is on server 0, key 1 is on server 1.
Now let’s take a look at what happens when we add a server.
Here we insert a new server s4 to the left of s0 on the ring. Note that only k0 needs to be moved from s0 to s4. This is because s4 is the first server k0 encounters by going clockwise from k0’s position on the ring. Keys k1, k2, and k3 are not affected.
How consistent hashing is used in the real world
-
Amazon DynamoDB and Apache Cassandra: minimize data movement during rebalancing
-
Content delivery networks like Akamai: distribute web contents evenly among the edge servers
-
Load balancers like Google Network Load Balancer: distribute persistent connections evenly across backend servers