This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
1.4 KiB
title, description, image, createdAt, draft, categories, tags
| title | description | image | createdAt | draft | categories | tags | |||
|---|---|---|---|---|---|---|---|---|---|
| A Cheat Sheet for Designing Fault-Tolerant Systems | Top principles for designing robust, fault-tolerant systems. | https://assets.bytebytego.com/diagrams/0139-cheat-sheet-for-fault-tolerant-systems.png | 2024-02-14 | false |
|
|
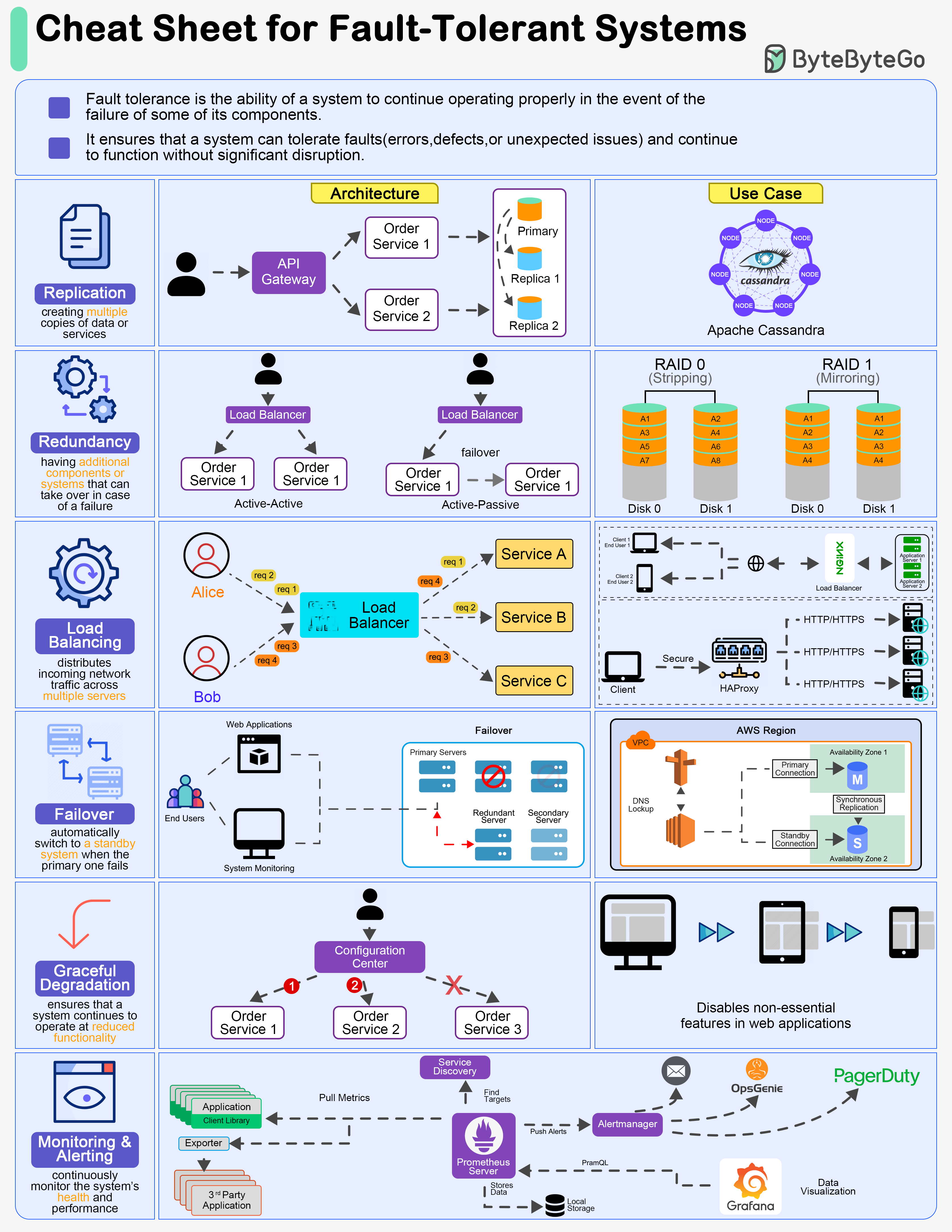
Designing fault-tolerant systems is crucial for ensuring high availability and reliability in various applications. Here are six top principles of designing fault-tolerant systems:
Replication
Replication involves creating multiple copies of data or services across different nodes or locations.
Redundancy
Redundancy refers to having additional components or systems that can take over in case of a failure.
Load Balancing
Load balancing distributes incoming network traffic across multiple servers to ensure no single server becomes a point of failure.
Failover Mechanisms
Failover mechanisms automatically switch to a standby system or component when the primary one fails.
Graceful Degradation
Graceful degradation ensures that a system continues to operate at reduced functionality rather than completely failing when some components fail.
Monitoring and Alerting
Continuously monitor the system's health and performance, and set up alerts for any anomalies or failures.