mirror of
https://github.com/ByteByteGoHq/system-design-101.git
synced 2026-04-01 16:57:23 -04:00
This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
33 lines
1.3 KiB
Markdown
33 lines
1.3 KiB
Markdown
---
|
||
title: "Big Data Pipeline Cheatsheet for AWS, Azure, and Google Cloud"
|
||
description: "Big data pipeline cheatsheet for AWS, Azure, and Google Cloud."
|
||
image: "https://assets.bytebytego.com/diagrams/0086-big-data-pipeline-cheatsheet-for-aws-azure-and-gcp.png"
|
||
createdAt: "2024-03-14"
|
||
draft: false
|
||
categories:
|
||
- cloud-distributed-systems
|
||
tags:
|
||
- "Big Data"
|
||
- "Cloud Computing"
|
||
---
|
||
|
||
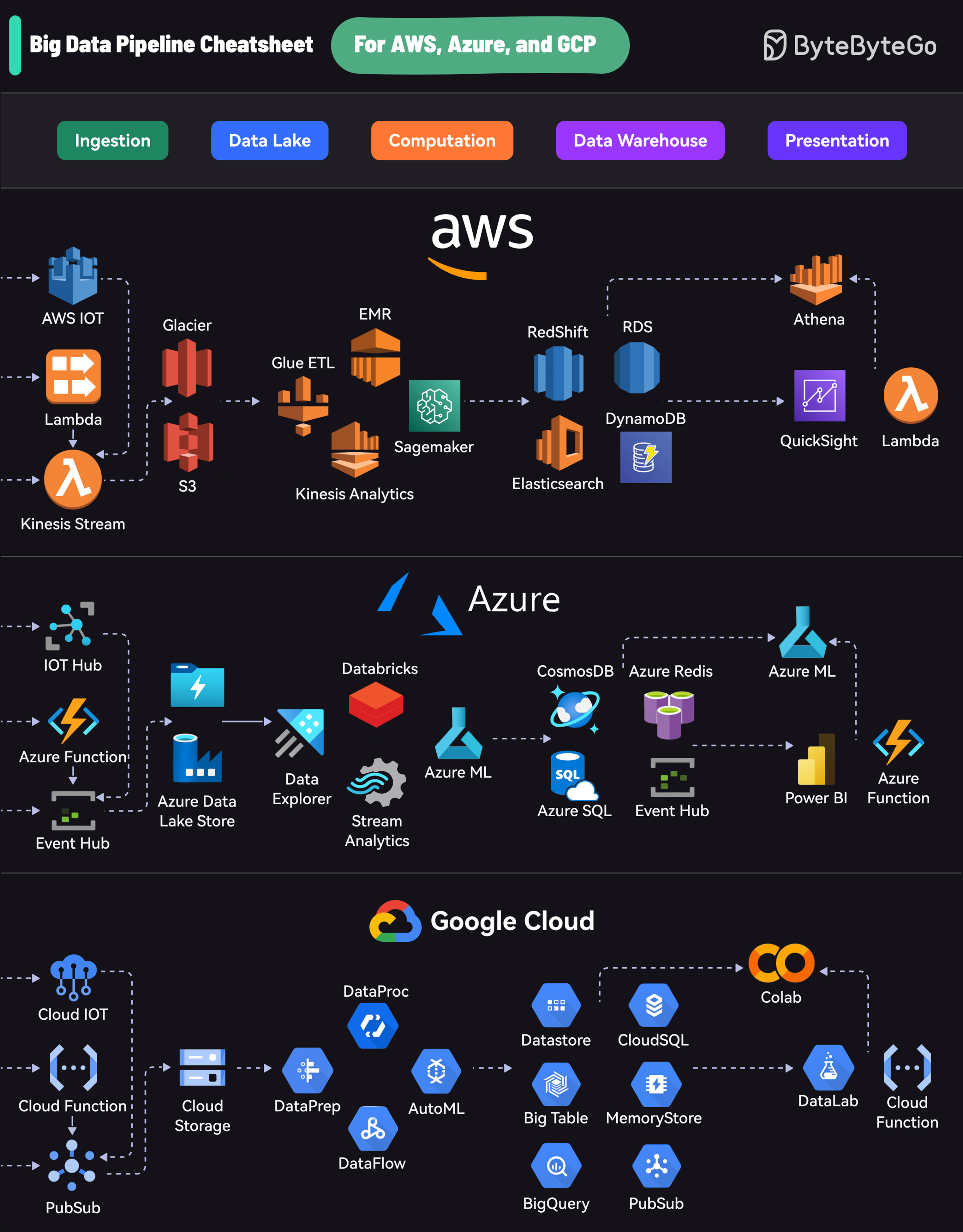
|
||
|
||
Each platform offers a comprehensive suite of services that cover the entire lifecycle:
|
||
|
||
* Ingestion: Collecting data from various sources
|
||
|
||
* Data Lake: Storing raw data
|
||
|
||
* Computation: Processing and analyzing data
|
||
|
||
* Data Warehouse: Storing structured data
|
||
|
||
* Presentation: Visualizing and reporting insights
|
||
|
||
AWS uses services like Kinesis for data streaming, S3 for storage, EMR for processing, RedShift for warehousing, and QuickSight for visualization.
|
||
|
||
Azure’s pipeline includes Event Hubs for ingestion, Data Lake Store for storage, Databricks for processing, Cosmos DB for warehousing, and Power BI for presentation.
|
||
|
||
GCP offers PubSub for data streaming, Cloud Storage for data lakes, DataProc and DataFlow for processing, BigQuery for warehousing, and Data Studio for visualization.
|