mirror of
https://github.com/ByteByteGoHq/system-design-101.git
synced 2026-04-01 16:57:23 -04:00
This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
51 lines
1.5 KiB
Markdown
51 lines
1.5 KiB
Markdown
---
|
||
title: "8 Must-Know Scalability Strategies"
|
||
description: "Explore 8 essential strategies to effectively scale your system."
|
||
image: "https://assets.bytebytego.com/diagrams/0013-8-must-know-strategies-to-scale-your-system.png"
|
||
createdAt: "2024-01-27"
|
||
draft: false
|
||
categories:
|
||
- cloud-distributed-systems
|
||
tags:
|
||
- "Scalability"
|
||
- "System Design"
|
||
---
|
||
|
||
What do Amazon, Netflix, and Uber have in common? They are extremely good at scaling their system whenever needed.
|
||
|
||
|
||
|
||
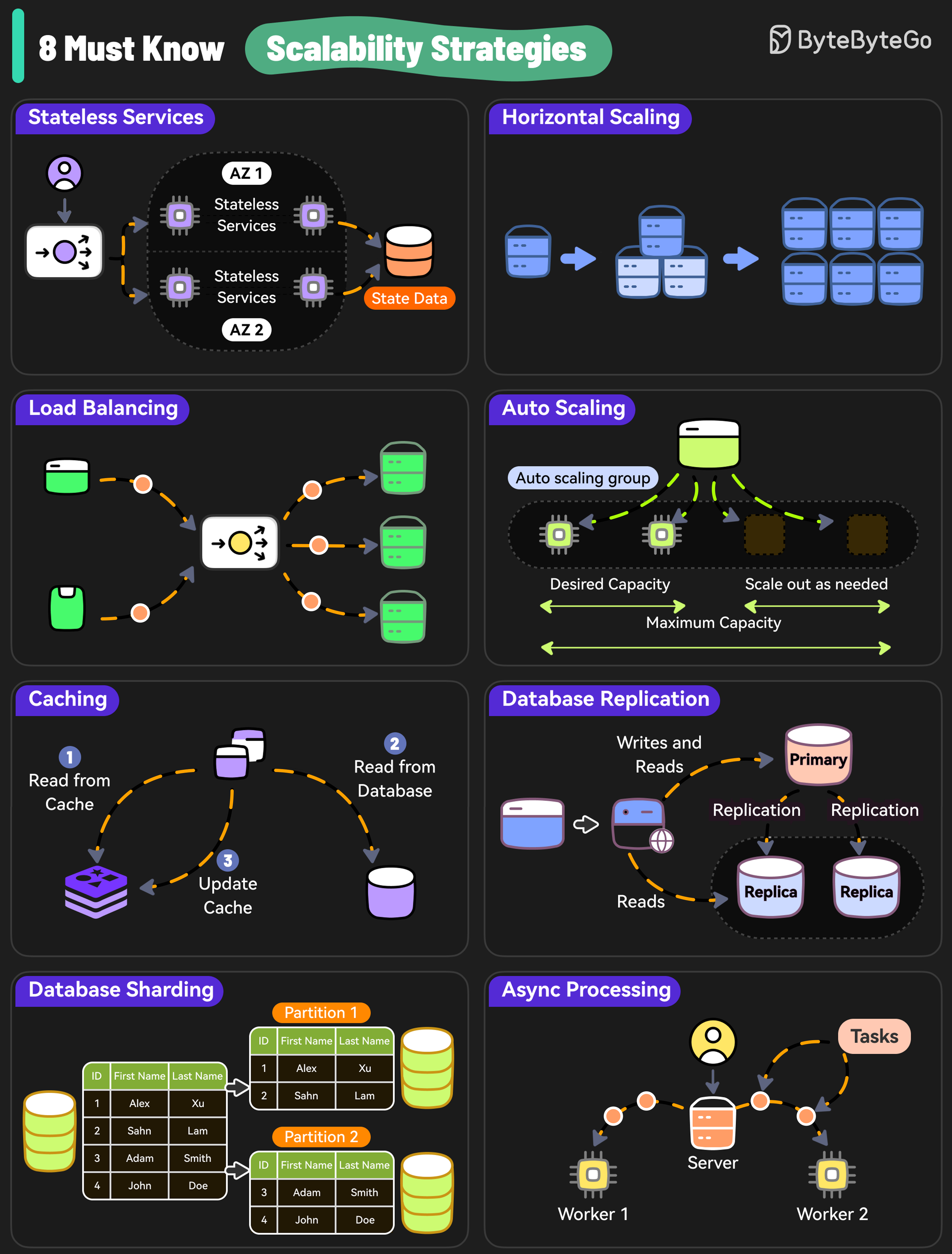
Here are 8 must-know strategies to scale your system.
|
||
|
||
* Stateless Services
|
||
|
||
Design stateless services because they don’t rely on server-specific data and are easier to scale.
|
||
|
||
* Horizontal Scaling
|
||
|
||
Add more servers so that the workload can be shared.
|
||
|
||
* Load Balancing
|
||
|
||
Use a load balancer to distribute incoming requests evenly across multiple servers.
|
||
|
||
* Auto Scaling
|
||
|
||
Implement auto-scaling policies to adjust resources based on real-time traffic.
|
||
|
||
* Caching
|
||
|
||
Use caching to reduce the load on the database and handle repetitive requests at scale.
|
||
|
||
* Database Replication
|
||
|
||
Replicate data across multiple nodes to scale the read operations while improving redundancy.
|
||
|
||
* Database Sharding
|
||
|
||
Distribute data across multiple instances to scale the writes as well as reads.
|
||
|
||
* Async Processing
|
||
|
||
Move time-consuming and resource-intensive tasks to background workers using async processing to scale out new requests.
|