This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
2.4 KiB
title, description, image, createdAt, draft, categories, tags
| title | description | image | createdAt | draft | categories | tags | |||
|---|---|---|---|---|---|---|---|---|---|
| What Happens When You Upload a File to Amazon S3? | Explore the process of uploading a file to Amazon S3 in detail. | https://assets.bytebytego.com/diagrams/0169-design-s3.jpg | 2024-03-13 | false |
|
|
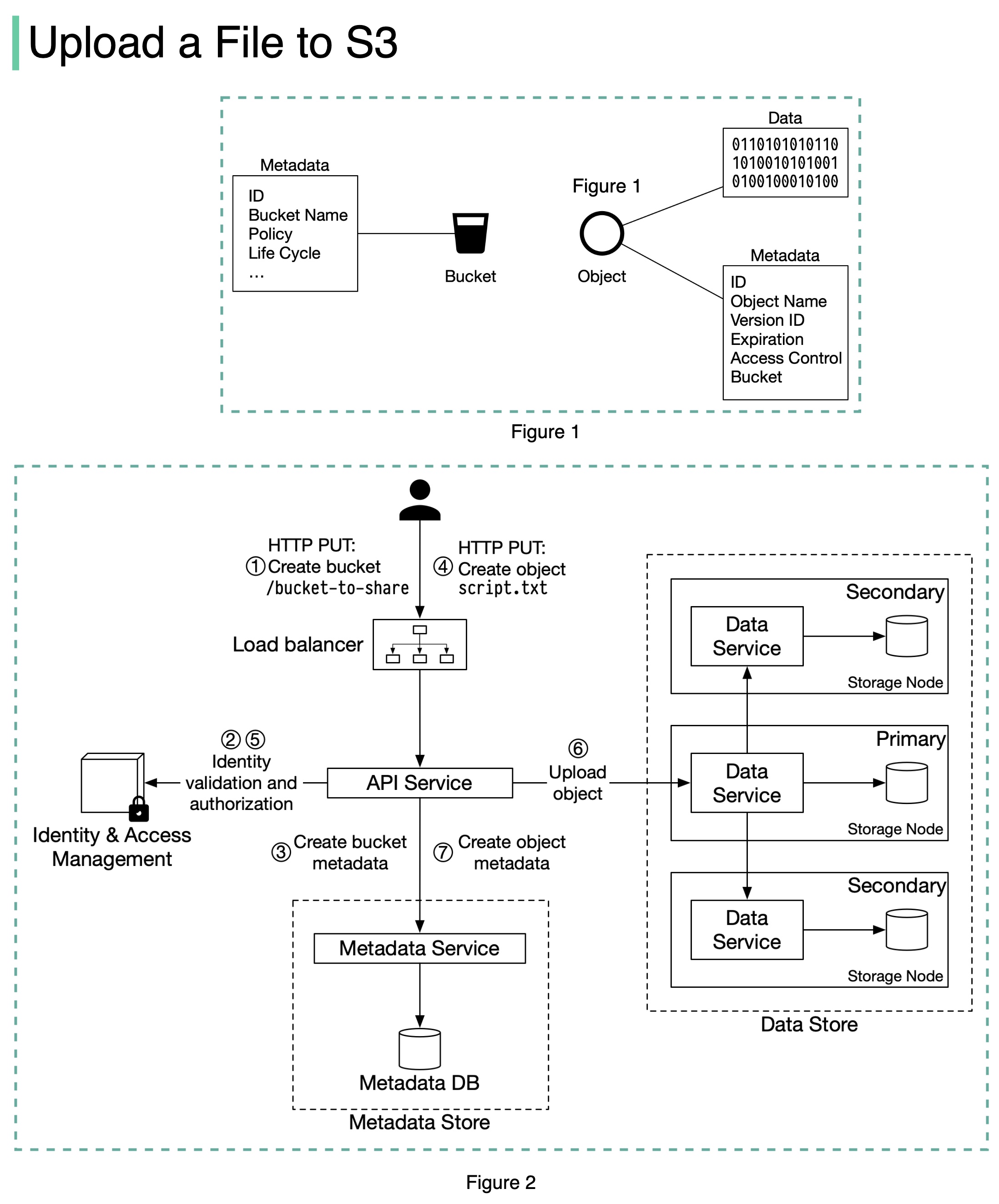
Before we dive into the design, let’s define some terms.
Bucket. A logical container for objects. The bucket name is globally unique. To upload data to S3, we must first create a bucket.
Object. An object is an individual piece of data we store in a bucket. It contains object data (also called payload) and metadata. Object data can be any sequence of bytes we want to store. The metadata is a set of name-value pairs that describe the object.
An S3 object consists of (Figure 1):
- Metadata. It is mutable and contains attributes such as ID, bucket name, object name, etc.
- Object data. It is immutable and contains the actual data.
In S3, an object resides in a bucket. The path looks like this: /bucket-to-share/script.txt. The bucket only has metadata. The object has metadata and the actual data.
The diagram below (Figure 2) illustrates how file uploading works. In this example, we first create a bucket named “bucket-to-share” and then upload a file named “script.txt” to the bucket.
-
The client sends an HTTP PUT request to create a bucket named “bucket-to-share.” The request is forwarded to the API service.
-
The API service calls Identity and Access Management (IAM) to ensure the user is authorized and has WRITE permission.
-
The API service calls the metadata store to create an entry with the bucket info in the metadata database. Once the entry is created, a success message is returned to the client.
-
After the bucket is created, the client sends an HTTP PUT request to create an object named “script.txt”.
-
The API service verifies the user’s identity and ensures the user has WRITE permission on the bucket.
-
Once validation succeeds, the API service sends the object data in the HTTP PUT payload to the data store. The data store persists the payload as an object and returns the UUID of the object.
-
The API service calls the metadata store to create a new entry in the metadata database. It contains important metadata such as the object_id (UUID), bucket_id (which bucket the object belongs to), object_name, etc.