This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
1.6 KiB
title, description, image, createdAt, draft, categories, tags
| title | description | image | createdAt | draft | categories | tags | |||
|---|---|---|---|---|---|---|---|---|---|
| Top 4 Data Sharding Algorithms Explained | Explore the top data sharding algorithms for efficient data management. | https://assets.bytebytego.com/diagrams/0373-top-4-data-sharding-algorithms-explained.png | 2024-02-21 | false |
|
|
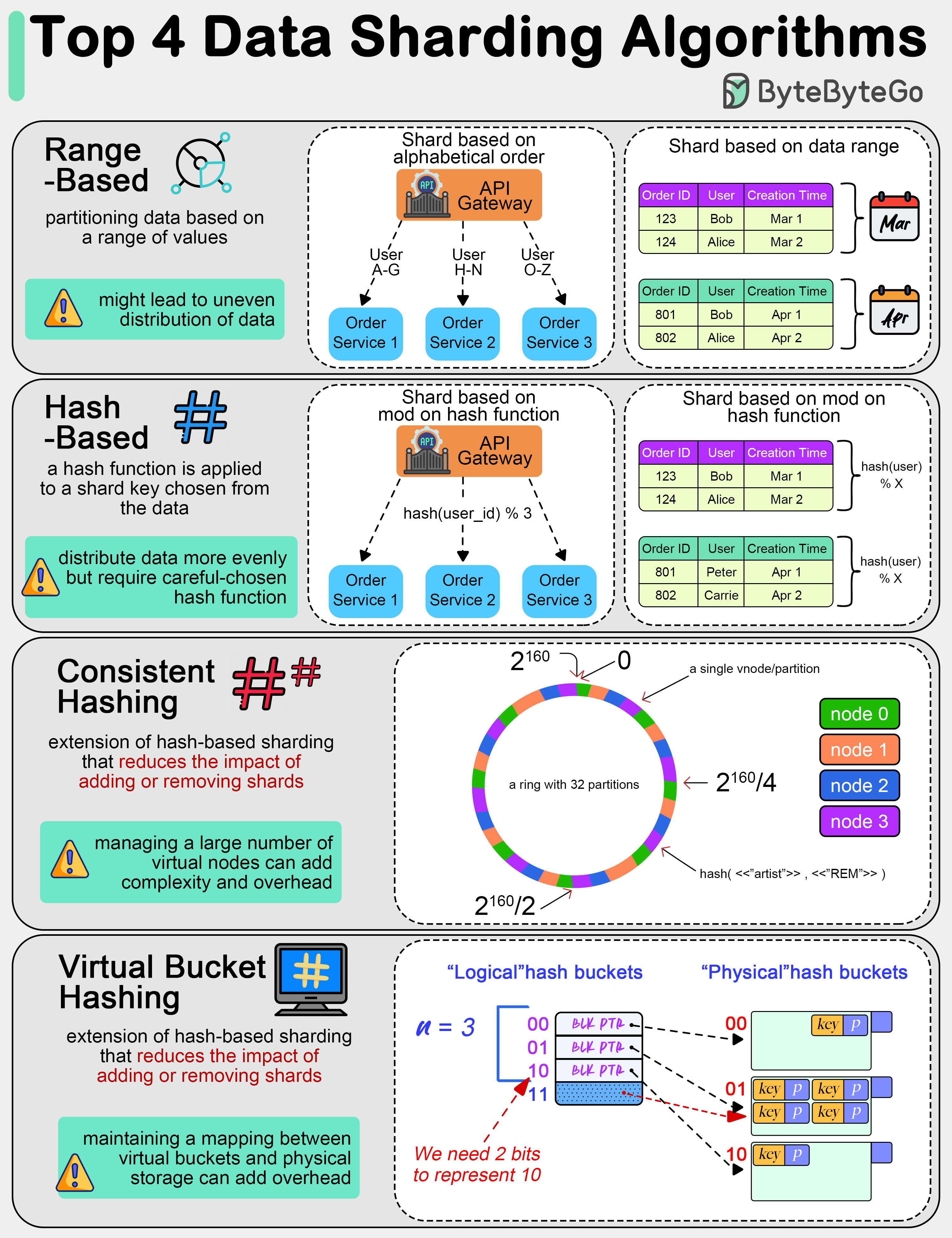
We are dealing with massive amounts of data. Often we need to split data into smaller, more manageable pieces, or “shards”. Here are some of the top data sharding algorithms commonly used:
Range-Based Sharding
This involves partitioning data based on a range of values. For example, customer data can be sharded based on alphabetical order of last names, or transaction data can be sharded based on date ranges.
Hash-Based Sharding
In this method, a hash function is applied to a shard key chosen from the data (like a customer ID or transaction ID).
This tends to distribute data more evenly across shards compared to range-based sharding. However, we need to choose a proper hash function to avoid hash collisions.
Consistent Hashing
This is an extension of hash-based sharding that reduces the impact of adding or removing shards. It distributes data more evenly and minimizes the amount of data that needs to be relocated when shards are added or removed.
Virtual Bucket Sharding
Data is mapped into virtual buckets, and these buckets are then mapped to physical shards. This two-level mapping allows for more flexible shard management and rebalancing without significant data movement.