This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
2.0 KiB
title, description, image, createdAt, draft, categories, tags
| title | description | image | createdAt | draft | categories | tags | |||
|---|---|---|---|---|---|---|---|---|---|
| Scaling Websites for Millions of Users | Learn how to scale your website architecture to support millions of users. | https://assets.bytebytego.com/diagrams/0322-scale-to-million.jpg | 2024-02-07 | false |
|
|
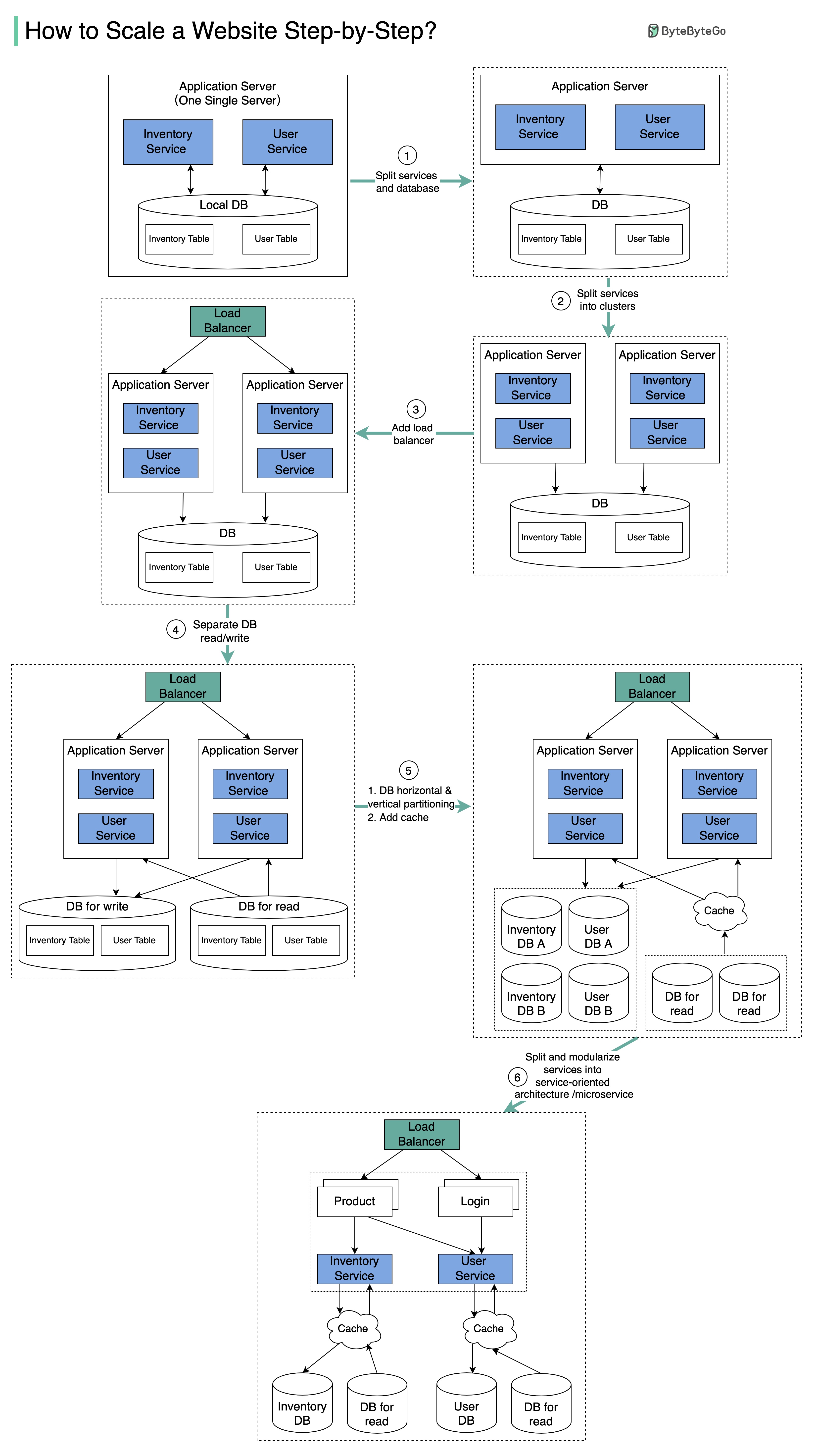
The diagram below illustrates the evolution of a simplified eCommerce website. It goes from a monolithic design on one single server, to a service-oriented/microservice architecture.
Suppose we have two services: inventory service (handles product descriptions and inventory management) and user service (handles user information, registration, login, etc.).
Step 1
With the growth of the user base, one single application server cannot handle the traffic anymore. We put the application server and the database server into two separate servers.
Step 2
The business continues to grow, and a single application server is no longer enough. So we deploy a cluster of application servers.
Step 3
Now the incoming requests have to be routed to multiple application servers, how can we ensure each application server gets an even load? The load balancer handles this nicely.
Step 4
With the business continuing to grow, the database might become the bottleneck. To mitigate this, we separate reads and writes in a way that frequent read queries go to read replicas. With this setup, the throughput for the database writes can be greatly increased.
Step 5
Suppose the business continues to grow. One single database cannot handle the load on both the inventory table and user table. We have a few options:
- Vertical partition. Adding more power (CPU, RAM, etc.) to the database server. It has a hard limit.
- Horizontal partition by adding more database servers.
- Adding a caching layer to offload read requests.
Step 6
Now we can modularize the functions into different services. The architecture becomes service-oriented / microservice.