mirror of
https://github.com/ByteByteGoHq/system-design-101.git
synced 2026-04-04 17:37:23 -04:00
This PR adds all the guides from [Visual Guides](https://bytebytego.com/guides/) section on bytebytego to the repository with proper links. - [x] Markdown files for guides and categories are placed inside `data/guides` and `data/categories` - [x] Guide links in readme are auto-generated using `scripts/readme.ts`. Everytime you run the script `npm run update-readme`, it reads the categories and guides from the above mentioned folders, generate production links for guides and categories and populate the table of content in the readme. This ensures that any future guides and categories will automatically get added to the readme. - [x] Sorting inside the readme matches the actual category and guides sorting on production
1.4 KiB
1.4 KiB
title, description, image, createdAt, draft, categories, tags
| title | description | image | createdAt | draft | categories | tags | |||
|---|---|---|---|---|---|---|---|---|---|
| How does Twitter recommend “For You” Timeline in 1.5 seconds? | Twitter's "For You" timeline recommendation system explained. | https://assets.bytebytego.com/diagrams/0121-twitter-serving-pipeline.jpeg | 2024-02-22 | false |
|
|
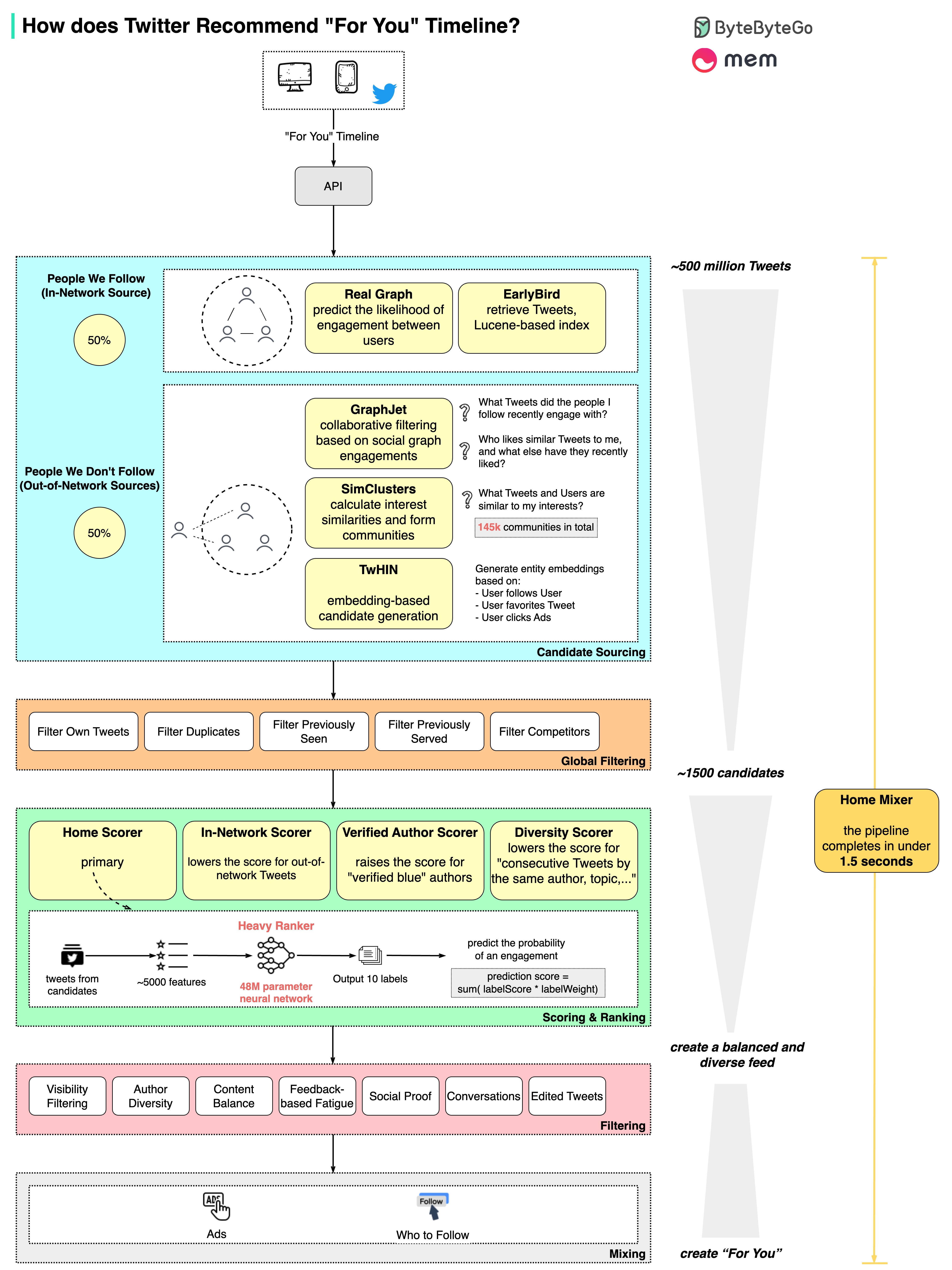
We spent a few days analyzing it.
The diagram above shows the detailed pipeline based on the open-sourced algorithm.
The process involves 5 stages:
- Candidate Sourcing ~ start with 500 million Tweets
- Global Filtering ~ down to 1500 candidates
- Scoring & Ranking ~ 48M parameter neural network, Twitter Blue boost
- Filtering ~ to achieve author and content diversity
- Mixing ~ with Ads recommendation and Who to Follow
The post was jointly created by ByteByteGo and Mem. Special thanks Scott Mackie, founding engineer at Mem, for putting this together.
Mem is building the world’s first knowledge assistant. In next week’s ByteByteGo guest newsletter, Mem will be sharing lessons they’ve learned from their extensive work with large language models and building AI-native infrastructure.